n <- 50
x <- rnorm(n, mean=5, sd=2)9 Stichproben
In diesem Kapitel schlagen wir eine Brücke von der rein theoretischen Wahrscheinlichkeitsrechnung zur Empirie. Ein großer Vorteil der Wahrscheinlichkeitstheorie besteht nämlich darin, dass sie es uns erlaubt, Aussagen über Zufallsvariablen oder Populationen zu machen, von denen wir keine vollständigen Informationen haben, sondern nur einen Teil beobachten können. Man sagt, dass man von einer Stichprobe auf die Population schließt, und spricht daher auch von statistischer Inferenz (engl. statistical inference). Leider entspricht die Definition einer Stichprobe nicht dem umgangssprachlichen Gebrauch des Worts. Tatsächlich ist es nicht leicht - aber wichtig -, die formale Definition einer Stichprobe tief zu verstehen. In diesem Kurs beschränken wir uns auf den einfachsten Fall, die sogenannte einfache Stichprobe.
9.1 Einfache Stichproben
Ausgangspunkt unserer Überlegungen ist eine Zufallsvariable \(X\). Es kann sich dabei um eine beliebige Zufallsvariable mit einer beliebigen Verteilung handeln. Die Zufallsvariable \(X\) steht für die Population.
Zu der Zufallsvariable \(X\) gehört eine Stichprobe \(X_1,X_2,\ldots,X_n\) des Umfangs \(n\).
Neben dem englischen Terminus “simple random sample” spricht man auch von einem “i.i.d. sample”, wobei die Abkürzung für “identical and independently distributed” steht.
 Achtung: Im Gegensatz zur umgangssprachlichen Bedeutung des Worts “Stichprobe” handelt es sich nicht um tatsächlich beobachtete Daten! Eine Stichprobe im Sinne der formalen Definition besteht aus Zufallsvariablen. Man kann sich eine Stichprobe vorstellen als die erhobenen Daten, bevor sie tatsächlich erhoben wurden. Sobald die Stichprobe (also die Zufallsvariablen) realisiert wurde, erhält man die tatsächlich erhobenen Daten. Um sie von der Stichprobe zu unterscheiden, schreibt man sie meist mit Kleinbuchstaben, \(x_1,x_2,\ldots,x_n\), und man spricht von der konkreten Stichprobe (oder realisierten Stichprobe).
Achtung: Im Gegensatz zur umgangssprachlichen Bedeutung des Worts “Stichprobe” handelt es sich nicht um tatsächlich beobachtete Daten! Eine Stichprobe im Sinne der formalen Definition besteht aus Zufallsvariablen. Man kann sich eine Stichprobe vorstellen als die erhobenen Daten, bevor sie tatsächlich erhoben wurden. Sobald die Stichprobe (also die Zufallsvariablen) realisiert wurde, erhält man die tatsächlich erhobenen Daten. Um sie von der Stichprobe zu unterscheiden, schreibt man sie meist mit Kleinbuchstaben, \(x_1,x_2,\ldots,x_n\), und man spricht von der konkreten Stichprobe (oder realisierten Stichprobe).
Beim Blick auf die tatsächlich vorliegenden Daten sollte man sich immer klar machen:
Es hätte auch anders kommen können.
Würde man die Stichprobe erneut ziehen, erhielte man eine andere konkrete Stichprobe. Der Zufall spielt immer eine Rolle, sei es weil der Prozess inhärent zufällig ist wie ein Würfelwurf, sei es weil wir nicht ganz genau wissen, warum es zu einer bestimmten Realisation kommt, wie beispielsweise bei der Entwicklung von Aktienkursen.
9.2 Statistiken
Als Vorbereitung auf die eigentliche statistische Inferenz dient die folgende Definition.
Eine Statistik im Sinne dieser Definition ist also eine Funktion einer Stichprobe. Da die Stichprobenelemente Zufallsvariablen sind, ist auch die Statistik \(Z\) eine Zufallsvariable. Daher hat die Statistik - wie jede Zufallsvariable - eine Verteilung, einen Erwartungswert, eine Varianz etc. Um die Verteilung der Statistik herzuleiten, muss man die Verteilung der Population bzw. der Stichprobenelemente kennen. In realen Anwendungen kennt man die Verteilung der Population natürlich nicht, sonst würde man ja keine statistische Inferenz betreiben wollen! Trotzdem ist es für das tiefere Verständnis der Inferenzverfahren sinnvoll, sich zu überlegen, wie eine Statistik verteilt ist, wenn die Populationsverteilung (also die Verteilung von \(X\)) bekannt ist. In einigen Spezialfällen kann man das analytisch tun Wenn eine analytische Lösung nicht möglich oder zu umständlich ist, bieten sich Monte-Carlo-Simulationen (Abschnitt 8.2) an. Sie sind praktisch immer relativ leicht umzusetzen, sie haben nur den Nachteil, dass sie für eine hohe Genauigkeit sehr viele Simulationsdurchläufe brauchen und daher relativ langsam sind.
Beispiel: Stichprobenstandardabweichung einer Paretoverteilung
Die Stichprobenstandardabweichung \[
S=\sqrt{\frac{1}{n-1}\sum_{i=1}^n (X_i-\bar X)^2}
\] ist eine Statistik, da sie aus den \(n\) Stichprobenelementen errechnet wird. Es handelt sich bei \(S\) folglich um eine Zufallsvariable. Wie ist \(S\) verteilt, wenn die Population \(X\) einer Paretoverteilung mit den Parametern \(x_{min}=1\) und \(k=5\) folgt und wenn eine Stichprobe vom Umfang \(n=50\) gezogen wird? Das lässt sich leicht durch eine Monte-Carlo-Simulation herausfinden. Die Dichte von \(S\) kann durch ein Histogramm sehr vieler Realisationen von \(S\) ermittelt werden, z.B. \(R=10000\). In jedem Simulationsdurchlauf wird eine Stichprobe x vom Umfang \(n=50\) aus der Paretoverteilung (mit den gegebenen Parametern) gezogen und die Stichprobenstandardabweichung sd(x) für diese Stichprobe berechnet und in einen Vektor S geschrieben. Der Vektor wird vor dem Schleifenstart initialisiert, z.B. durch die rep-Funktion. Für die Ziehung einer Stichprobe aus der Paretoverteilung aktivieren wir das Paket distributionsrd. Das Paket stellt die Funktion rpareto zur Vefügung.
library(distributionsrd)
R <- 10000
S <- rep(0,R)
n <- 50
xmin <- 1
k <- 5
for(r in 1:R){
x <- rpareto(n, xmin=xmin, k=k)
S[r] <- sd(x)
}
hist(S, breaks=50, xlim=c(0,2),
main="Verteilung der Stichproben-Standardabweichung")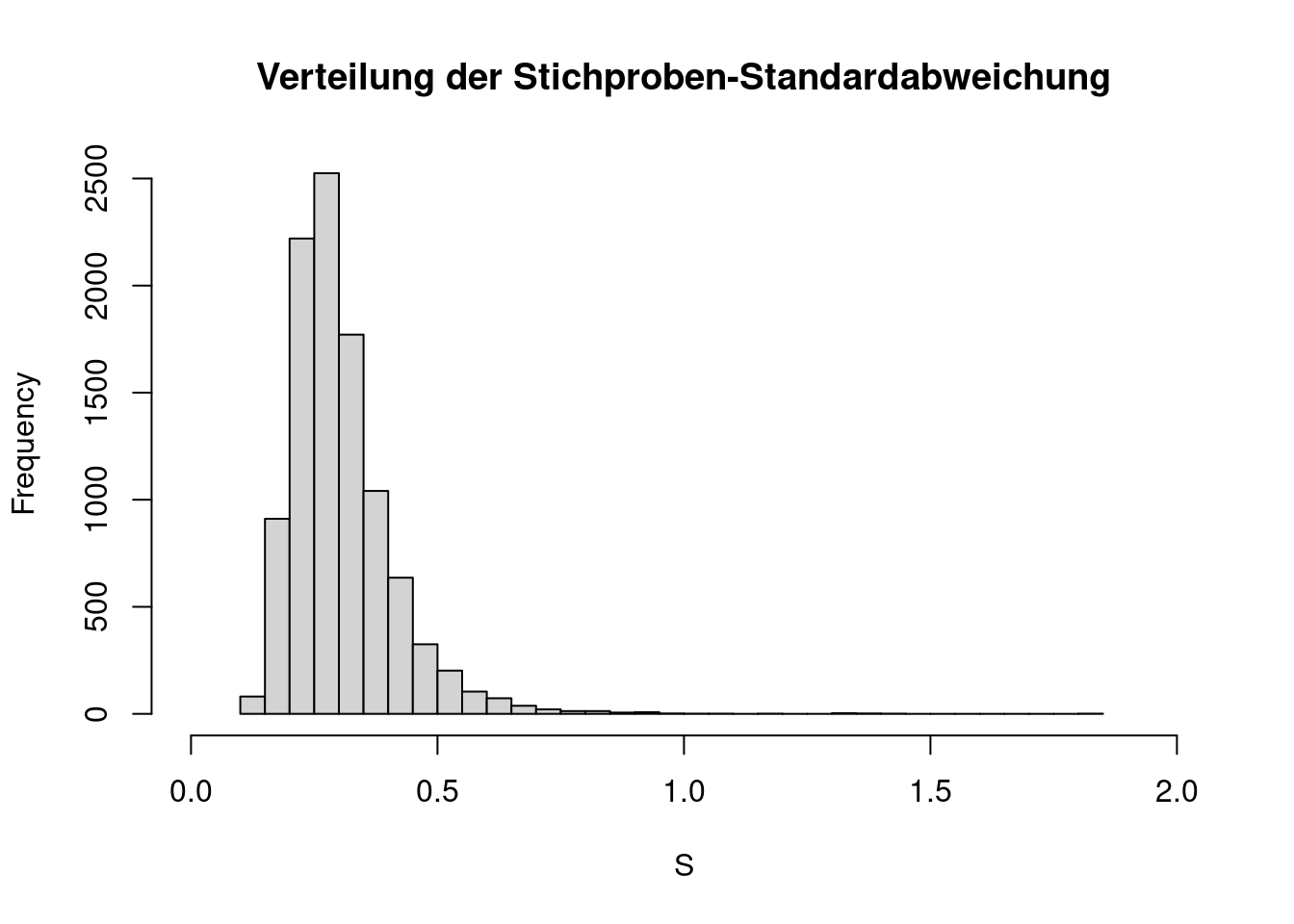
Die Stichprobenstandardabweichung liegt also in den allermeisten Fällen unterhalb von 0.5, es gibt aber Ausreißer, die teilweise deutlich größer sind. Das 0.999-Quantil ist
quantile(S, prob=0.999) 99.9%
0.995449 Als Mittelwert des Vektors smpl_sd ergibt sich
mean(S)[1] 0.3035819Der Erwartungswert \(E(S)\) der Stichprobenstandardabweichung einer Stichprobe vom Umfang \(n=50\) aus einer Paretoverteilung mit den Parametern \(x_{min}=1\) und \(k=5\) beträgt also (ungefähr) 0.304.
Im restlichen Verlauf dieses Kurses lernen Sie die drei wichtigsten Arten von Statistiken kennen:
Statistiken, die dazu dienen aus der Stichprobe eine Schätzung für einen Parameter der Population zu gewinnen. Zum Beispiel kann man den Erwartungswert durch das Stichprobenmittel schätzen oder die Standardabweichung durch die Stichprobenstandardabweichung. Solche Statistiken nennt man Punktschätzer. Sie werden in Kapitel 10 behandelt.
Statistiken, die eine Unter- oder Obergrenze für ein Intervall darstellen, in dem ein unbekannter Parameter einer Population mit großer Wahrscheinlichkeit liegt. Solche Intervalle nennt man Konfidenzintervalle. Sie werden in Kapitel 11 behandelt.
Statistiken, die als Entscheidungsgrundlage für eine empirische Überprüfung von Hypothesen über Populationsparameter dienen. Sie heißen Teststatistik und werden in Kapitel 12 bis Kapitel 15 behandelt.