getwd()2 Leitura, limpeza e organização dos dados
Neste capítulo os conceitos serão abordados através de exemplos práticos. Para isso usaremos a base de dados do ENEM 2015, disponível pelo site do INEP 1. Esta base contém informações por escola.
Questões interessantes que podemos tentar responder a partir desta base de dados:
Quais as principais características das escolas que influenciam, positivamente ou negativamente, no resultado dos seus alunos no ENEM?
Quais as características das escolas que indicam menor taxa de participação no ENEM?
Dada uma escola qualquer, qual a probabilidade da nota média dos seus alunos em todas as provas ser maior que 500?
Responder essas perguntas pode ser importante para tomadas de decisão sobre como usar os recursos nas escolas, tanto recursos públicos quanto particulares.
2.1 Leitura de dados no R
Para começar a trabalhar com dados no R sempre primeiro devemos verificar se o diretório corrente é aquele em que estamos trabalhando, onde foi salvo o arquivo com dados a serem lidos. Para isso, o comando getwd() verifica o diretório corrente.
Caso queira alterar o diretório corrente, use setwd()
setwd("D:/Jessica/Trabalho/IMDS/CURSO ML/Material")É preciso que o diretório corrente do R seja o mesmo onde estão salvos o script.R e a base de dados.
A base de dados está salva no formato csv no arquivo MICRODADOS_ENEM_ESCOLA_2015.csv. O primeiro passo é a leitura desta base dentro do Programa R (R Core Team 2022). Para trabalhar com os dados, vamos instalar o pacote tidyverse (Wickham et al. 2019), que na sua instalação também instala os pacotes dplyr(Wickham et al. 2022) e readr(Wickham, Hester, and Bryan 2022).

library(tidyverse)Para leitura da base pode-se usar as funções read_csv, read_csv2 ou read_delim , todas retornam um objeto fo tipo tibble. Em particupar, a última delas possibilita escolher o caractere para separação das colunas, com a definição do argumento delim, e para separação de casas decimais, a partir do decimal_mark. Como a base está com as colunas separadas por ; e a casa decimal por ,, será usada a função read_csv2para a sua leitura.
base = read_csv2(file="MICRODADOS_ENEM_ESCOLA_2015.csv")É importante ressaltar que, geralmente, junto com uma base pública é disponibilizado um arquivo de dicionário. É nele que estão as explicações de cada variável da base. Para a base MICRODADOS_ENEM_ESCOLA_2015.csv o arquivo dicionário é Dicionário_Microdados_Enem_Escola.xlsx.
2.2 Classificação das variáveis da base
2.2.1 Quanto ao seu tipo
O primeiro passo, em qualquer análise de dados, é entender cada variável da base. Para isso elas serão classificadas entre as seguintes possibilidades:
| Classificação | Descrição |
|---|---|
| Identificação | Aquelas cuja única função é identificar a unidade amostral (linha). Esta variável assume um valor diferente para cada linha da base. |
| Quantitativa | Aquelas que atribuem à cada unidade amostral uma característica de quantidade. |
| Qualitativa | Aquelas que atribuem a cada unidade amostral uma característica, que pode ser de diferentes naturezas: textual, lógica ou até mesmo numérica. Mas sempre indica uma categoria e não uma quantidade. |
Vejamos uma rápida apresentação de cada variável a partir da função glimpse.
glimpse(base)Rows: 15,598
Columns: 27
$ NU_ANO <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 20…
$ CO_UF_ESCOLA <dbl> 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, …
$ SG_UF_ESCOLA <chr> "RO", "RO", "RO", "RO", "RO", "RO", "RO", "R…
$ CO_MUNICIPIO_ESCOLA <dbl> 1100205, 1100205, 1100205, 1100205, 1100205,…
$ NO_MUNICIPIO_ESCOLA <chr> "Porto Velho", "Porto Velho", "Porto Velho",…
$ CO_ESCOLA_EDUCACENSO <dbl> 11000058, 11000171, 11000198, 11000244, 1100…
$ NO_ESCOLA_EDUCACENSO <chr> "CENTRO DE ENSINO CLASSE A", "CENTRO EDUCACI…
$ TP_DEPENDENCIA_ADM_ESCOLA <dbl> 4, 4, 4, 4, 4, 2, 2, 4, 2, 2, 2, 2, 2, 2, 4,…
$ TP_LOCALIZACAO_ESCOLA <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1,…
$ NU_MATRICULAS <dbl> 137, 20, 39, 55, 26, 97, 44, 34, 75, 41, 24,…
$ NU_PARTICIPANTES_NEC_ESP <dbl> 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,…
$ NU_PARTICIPANTES <dbl> 130, 17, 37, 49, 23, 96, 38, 29, 59, 22, 21,…
$ NU_TAXA_PARTICIPACAO <dbl> 94.89, 85.00, 94.87, 89.09, 88.46, 98.97, 86…
$ NU_MEDIA_CN <dbl> 591.64, 458.46, 529.05, 508.74, 523.38, 505.…
$ NU_MEDIA_CH <dbl> 652.34, 533.51, 583.87, 586.45, 591.66, 582.…
$ NU_MEDIA_LP <dbl> 604.53, 472.62, 547.11, 531.35, 563.45, 527.…
$ NU_MEDIA_MT <dbl> 627.66, 459.72, 507.22, 529.87, 528.93, 492.…
$ NU_MEDIA_RED <dbl> 732.00, 507.82, 652.43, 591.84, 583.48, 580.…
$ NU_MEDIA_OBJ <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ NU_MEDIA_TOT <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ INSE <chr> "Grupo 6", "Grupo 4", "Grupo 5", "Grupo 5", …
$ PC_FORMACAO_DOCENTE <dbl> 67.5, 58.3, 67.7, 56.0, 72.7, 53.6, 73.9, 46…
$ NU_TAXA_PERMANENCIA <dbl> 78.46, 70.59, 40.54, 81.63, 52.17, 85.42, 63…
$ NU_TAXA_APROVACAO <dbl> 96.1, 94.6, 90.1, 88.7, 84.5, 89.2, 73.9, 88…
$ NU_TAXA_REPROVACAO <dbl> 3.9, 5.4, 9.9, 10.5, 13.1, 10.8, 22.2, 9.9, …
$ NU_TAXA_ABANDONO <dbl> 0.0, 0.0, 0.0, 0.8, 2.4, 0.0, 3.9, 1.4, 0.3,…
$ PORTE_ESCOLA <chr> "Maior que 90 alunos", "De 1 a 30 alunos", "…Nesta base as variáveis podem ser identificadas de acordo com a tabela a seguir.
| Classificação | Variáveis |
| Identificação | CO_ESCOLA_EDUCACENSO , NO_ESCOLA_EDUCACENSO |
| Quantitativas | NU_MATRICULAS , NU_PARTICIPANTES_NEC_ESP , NU_PARTICIPANTES , NU_TAXA_PERMANENCIA , NU_TAXA_APROVACAO , NU_TAXA_REPROVACAO , NU_TAXA_ABANDONO , PC_FORMACAO_DOCENTE , NU_TAXA_PARTICIPACAO , NU_MEDIA_CN , NU_MEDIA_CH , NU_MEDIA_LP , NU_MEDIA_MT , NU_MEDIA_RED , NU_MEDIA_OBJ , NU_MEDIA_TOT |
| Qualitativas | NU_MATRICULAS , NU_PARTICIPANTES_NEC_ESP , NU_PARTICIPANTES , NU_TAXA_PERMANENCIA , NU_TAXA_APROVACAO , NU_TAXA_REPROVACAO , NU_TAXA_ABANDONO , C_FORMACAO_DOCENTE , NU_TAXA_PARTICIPACAO , NU_MEDIA_CN , NU_MEDIA_OBJ , NU_MEDIA_TOT , NU_MEDIA_CH , NU_MEDIA_LP , NU_MEDIA_MT , NU_MEDIA_RED |
O CO_ESCOLA_EDUCACENSO, apesar de ser representada por um número, é uma variável que indica uma identidade e não uma quantidade. Por isso é importante que o R não reconheça esta variável como um número. Veja na segunda coluna da saída da função glimpse, na linha referente à variável CO_ESCOLA_EDUCACENSO, aparece <dbl>, o que indica que o R entendeu que esta variável como um double. Em breve este problema será resolvido.
As variáveis quantitativas foram todas corretamente lidas como double. Já as variáveis qualitativa, algumas delas, como TP_DEPENDENCIA_ADM_ESCOLA , por exemplo, por terem a sua categoria representada por um número foram erradamente lidas pelo R como um double.
Veja mais um problema na base.
base$NO_MUNICIPIO_ESCOLA[1:50] [1] "Porto Velho" "Porto Velho" "Porto Velho"
[4] "Porto Velho" "Porto Velho" "Porto Velho"
[7] "Porto Velho" "Porto Velho" "Porto Velho"
[10] "Porto Velho" "Porto Velho" "Porto Velho"
[13] "Porto Velho" "Porto Velho" "Porto Velho"
[16] "Porto Velho" "Porto Velho" "Porto Velho"
[19] "Porto Velho" "Porto Velho" "Porto Velho"
[22] "Porto Velho" "Porto Velho" "Porto Velho"
[25] "Porto Velho" "Porto Velho" "Porto Velho"
[28] "Porto Velho" "Porto Velho" "Porto Velho"
[31] "Porto Velho" "Porto Velho" "Porto Velho"
[34] "Porto Velho" "Porto Velho" "Nova Mamor\xe9"
[37] "Nova Mamor\xe9" "Buritis" "Candeias do Jamari"
[40] "Itapu\xe3 do Oeste" "Costa Marques" "Guajar\xe1-Mirim"
[43] "Guajar\xe1-Mirim" "Guajar\xe1-Mirim" "Guajar\xe1-Mirim"
[46] "Guajar\xe1-Mirim" "Guajar\xe1-Mirim" "Guajar\xe1-Mirim"
[49] "Ariquemes" "Ariquemes" Variáveis com texto em protuguês muitas vezes têm acentos e caracteres especiais, precisamos verificar se estes foram lidos corretamente. Caso não tenha sido lido, mudamos o encoding na função de leitura da base e este problema será resolvido.
base = read_csv2(file="MICRODADOS_ENEM_ESCOLA_2015.csv",
locale = locale(encoding = "latin1"))
base$NO_MUNICIPIO_ESCOLA[1:50]Agora só falta corrigir o tipo das variáveis. Vamos fazer com que todas as variáveis de identificação sejam do tipo "character" e todas as variáveis qualitativas para o tipo factor.
base$CO_ESCOLA_EDUCACENSO = as.character(base$CO_ESCOLA_EDUCACENSO)base$NU_ANO = factor(base$NU_ANO)
base$CO_UF_ESCOLA = factor(base$CO_UF_ESCOLA)
base$SG_UF_ESCOLA = factor(base$SG_UF_ESCOLA)
base$CO_MUNICIPIO_ESCOLA = factor(base$CO_MUNICIPIO_ESCOLA)
base$NO_MUNICIPIO_ESCOLA = factor(base$NO_MUNICIPIO_ESCOLA)
base$TP_DEPENDENCIA_ADM_ESCOLA = factor(base$TP_DEPENDENCIA_ADM_ESCOLA,
levels = c(1,2,3,4),
labels = c("Federal", "Estadual" ,"Municipal","Privada")
)
base$TP_LOCALIZACAO_ESCOLA = factor(base$TP_LOCALIZACAO_ESCOLA,
levels = c(1,2),
labels = c("Urbana", "Rural")
)
base$INSE = factor(base$INSE)
base$PORTE_ESCOLA = factor(base$PORTE_ESCOLA)getwd()2.2.2 Quanto ao seu objetivo
Outra classificação interessante de ser feita entre as variáveis, diferentes das de identificação, é definir quais variáveis são determinísticas e quais são aleatórias. Veja que algumas das variáveis são facilmente observadas antes mesmo da prova do ENEM, por exemplo, o número de alunos matriculados ("NU_MATRICULAS") e o porte da escola ("PORTE_ESCOLA"). Estas são variáveis que de alguma maneira caracterizam as escolas.
Outras variáveis já são aleatórias, que depende do desempenho dos alunos no ENEM, como as notas das escolas no ENEM. Estas são aquelas que pretendemos explicar em termos das que conhecemos. Será que uma escola grande tem mais chance de ter uma boa nota no ENEM quando comparada com uma escola pequena, ou seria o contrário? Como será a influência da taxa de abandono de uma escola com o seu desempenho no ENEM?
Costumamos chamar as variáveis determinísticas de covariáveis, ou variáveis independentes. Já as aleatórias, chamamos de variável de interesse, variável alvo ou desfecho.
| Classificação | Variáveis |
|---|---|
| Covariáveis | “NU_ANO”, “NU_MATRICULAS”, “NU_PARTICIPANTES_NEC_ESP”, “NU_TAXA_PERMANENCIA”, “NU_TAXA_APROVACAO”, “NU_TAXA_REPROVACAO”, “NU_TAXA_ABANDONO”, “PC_FORMACAO_DOCENTE”, “CO_UF_ESCOLA”, “SG_UF_ESCOLA”, “CO_MUNICIPIO_ESCOLA”, “NO_MUNICIPIO_ESCOLA”, “TP_DEPENDENCIA_ADM_ESCOLA”, “TP_LOCALIZACAO_ESCOLA”, “INSE” e “PORTE_ESCOLA” |
| Variáveis alvo | “NU_PARTICIPANTES”, “NU_TAXA_PARTICIPACAO”, “NU_MEDIA_CN”, “NU_MEDIA_LP”, “NU_MEDIA_MT”, “NU_MEDIA_RED”, “NU_MEDIA_OBJ” e “NU_MEDIA_TOT” |
2.3 Separação da base em treino e de teste
Em qualquer problema de Aprendizado de Máquinas é adequado separar a base de dados em duas partes: base de treino e base de teste. A base de treino é composta pela maioria das linhas da base original, geralmente em torno de 70% ou 80%, e é a partir dela que faremos todas as análises estatísticas. A base de teste , a menor parte, em torno de 20% ou 30%, será usada apenas para avaliar o desempenho dos modelos fora da base de treinamento. Dessa maneira é possível mensurar se o modelo está de fato aprendendo ou se está ocorrendo sobreajuste.
No pacote caret Kuhn (2008) existe a função createDataPartition que realiza a partição da base. Essa função retorna uma seleção aleatória dos índices da base de tamanho indicada pelo argumento de entrada p.
library(caret)
set.seed(123456789)O código acima somente carrega o pacote e define o valor da semente pelo comendo set.seed. Isso é recomendado fazer sempre que o código tiver alguma seleção aleatória, pois assim é possível replicar o código como da primeira vez se for necessário.
N = nrow(base) #numero de linhas da base
indices_treino = createDataPartition(1:N,p=0.75)[[1]]
base_treino = base |> slice(indices_treino)
base_teste = base |> slice(-indices_treino)Vamos verificar se a partição realizada respeitou 75% para base de treino e 25% para a base de teste.
n_treino = dim(base_treino)[1]
n_teste = dim(base_teste)[1]
#verificando a proporcao entre as bases
(n_treino/(n_treino+n_teste))[1] 0.7500962(n_teste/(n_treino+n_teste))[1] 0.2499038Toda análise realizada a partir de agora será feita considerando os dados da base de treino.
2.4 Limpeza da base de dados
Antes de ajustar/treinar qualquer modelo precisamos analisar com cuidado a base de dados para garantir que não teremos problemas futuros. Os principais passos dessa análise de dados são:
breve análise a partir da função
summary;procurar dados faltantes;
procurar covariáveis com variância quase zero (ou zero);
procurar covariáveis com alta correlação.
2.4.1 Dados faltantes
É preciso verificar se a base possui dados faltantes. Caso afirmativo, teremos que tomar uma decisão: eliminar a linha (escola), eliminar a coluna (variável) ou imputar valores para as entradas com dados faltantes.
A função summary mostra se alguma variável está toda preenchida com `NA.
summary(base_treino) NU_ANO CO_UF_ESCOLA SG_UF_ESCOLA CO_MUNICIPIO_ESCOLA
2015:11700 35 :2495 SP :2495 3550308: 510
31 :1279 MG :1279 3304557: 362
33 :1076 RJ :1076 2304400: 219
43 : 858 RS : 858 5300108: 149
23 : 632 CE : 632 3106200: 136
41 : 524 PR : 524 2927408: 121
(Other):4836 (Other):4836 (Other):10203
NO_MUNICIPIO_ESCOLA CO_ESCOLA_EDUCACENSO NO_ESCOLA_EDUCACENSO
São Paulo : 510 Length:11700 Length:11700
Rio de Janeiro: 362 Class :character Class :character
Fortaleza : 219 Mode :character Mode :character
Brasília : 149
Belo Horizonte: 136
Salvador : 121
(Other) :10203
TP_DEPENDENCIA_ADM_ESCOLA TP_LOCALIZACAO_ESCOLA NU_MATRICULAS
Federal : 247 Urbana:11277 Min. : 10.00
Estadual :6629 Rural : 423 1st Qu.: 29.00
Municipal: 79 Median : 58.00
Privada :4745 Mean : 85.92
3rd Qu.:113.00
Max. :835.00
NU_PARTICIPANTES_NEC_ESP NU_PARTICIPANTES NU_TAXA_PARTICIPACAO NU_MEDIA_CN
Min. : 0.0000 Min. : 10.00 Min. : 50.00 Min. :388.6
1st Qu.: 0.0000 1st Qu.: 23.00 1st Qu.: 62.31 1st Qu.:456.5
Median : 0.0000 Median : 42.00 Median : 76.92 Median :476.6
Mean : 0.5626 Mean : 62.84 Mean : 76.16 Mean :490.8
3rd Qu.: 1.0000 3rd Qu.: 80.00 3rd Qu.: 90.38 3rd Qu.:519.0
Max. :27.0000 Max. :658.00 Max. :100.00 Max. :720.4
NU_MEDIA_CH NU_MEDIA_LP NU_MEDIA_MT NU_MEDIA_RED NU_MEDIA_OBJ
Min. :460.9 Min. :397.1 Min. :372.4 Min. :345.0 Mode:logical
1st Qu.:537.3 1st Qu.:484.4 1st Qu.:442.9 1st Qu.:508.4 NA's:11700
Median :559.0 Median :509.7 Median :471.3 Median :547.2
Mean :566.8 Mean :515.4 Mean :492.4 Mean :564.0
3rd Qu.:594.1 3rd Qu.:545.3 3rd Qu.:527.8 3rd Qu.:609.6
Max. :709.2 Max. :649.9 Max. :845.7 Max. :920.0
NU_MEDIA_TOT INSE PC_FORMACAO_DOCENTE NU_TAXA_PERMANENCIA
Mode:logical Grupo 1: 753 Min. : 0.00 Min. : 0.00
NA's:11700 Grupo 2:1030 1st Qu.: 49.70 1st Qu.: 69.23
Grupo 3:3578 Median : 62.00 Median : 80.47
Grupo 4:2856 Mean : 60.44 Mean : 75.98
Grupo 5:2464 3rd Qu.: 73.10 3rd Qu.: 88.89
Grupo 6:1018 Max. :100.00 Max. :100.00
NA's : 1 NA's :14
NU_TAXA_APROVACAO NU_TAXA_REPROVACAO NU_TAXA_ABANDONO
Min. : 38.9 Min. : 0.000 Min. : 0.000
1st Qu.: 80.8 1st Qu.: 2.800 1st Qu.: 0.000
Median : 90.5 Median : 6.700 Median : 0.900
Mean : 87.4 Mean : 8.822 Mean : 3.776
3rd Qu.: 96.2 3rd Qu.:12.700 3rd Qu.: 6.000
Max. :100.0 Max. :60.200 Max. :51.600
NA's :65 NA's :65 NA's :65
PORTE_ESCOLA
De 1 a 30 alunos :3147
De 31 a 60 alunos :2893
De 61 a 90 alunos :1827
Maior que 90 alunos:3833
Podemos identificar que as variábeis NU_MEDIA_OBJ e NU_MEDIA_TOT estão com todos os valores como NA. Nesse, as duas variáveis serão retiradas da base.
base_treino = base_treino |> select(-c(NU_MEDIA_OBJ, NU_MEDIA_TOT))Mas será aque ainda existem dados faltantes?
library(naniar)base_treino |> gg_miss_var()
base_treino |> vis_miss()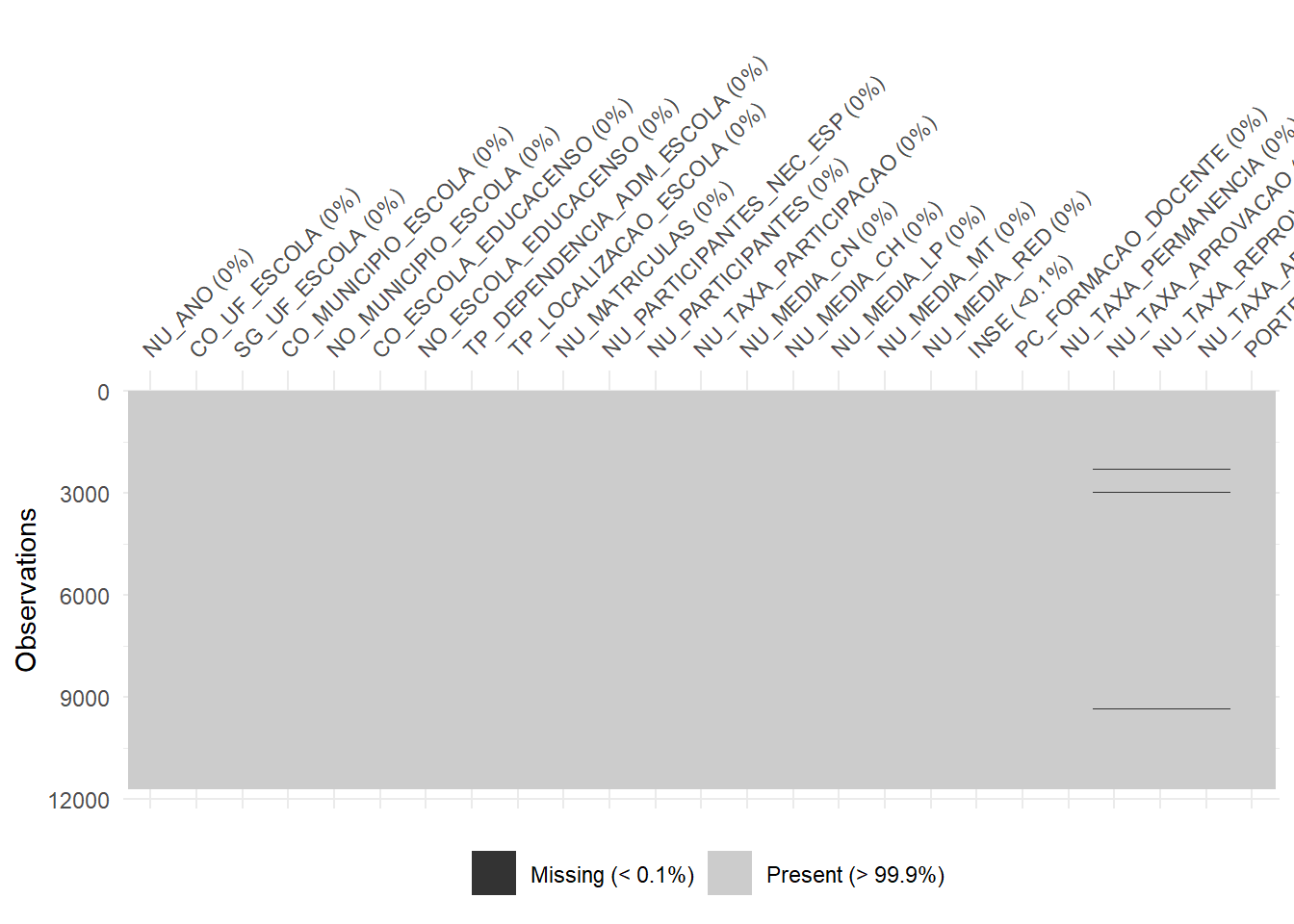
base_treino |> miss_var_summary()# A tibble: 25 × 3
variable n_miss pct_miss
<chr> <int> <dbl>
1 NU_TAXA_APROVACAO 65 0.556
2 NU_TAXA_REPROVACAO 65 0.556
3 NU_TAXA_ABANDONO 65 0.556
4 PC_FORMACAO_DOCENTE 14 0.120
5 INSE 1 0.00855
6 NU_ANO 0 0
7 CO_UF_ESCOLA 0 0
8 SG_UF_ESCOLA 0 0
9 CO_MUNICIPIO_ESCOLA 0 0
10 NO_MUNICIPIO_ESCOLA 0 0
# ℹ 15 more rows2.4.1.1 Dados faltantes para a variável de interesse
Caso seja encontrada alguma linha da base, para o nosso exemplo alguma escola, com dados faltantes para uma das varáveis de interesse, as linhas correspondentes devem ser eliminadas, uma vez que não pode-se imputar valores para ela.
Observando novamente a saída do comando summarypercebemos que as únicas variáveis de interesse com dados faltantes eram NU_MEDIA_OBJ e NU_MEDIA_TOT, que já foram retiradas da base. Assim não temos dados faltantes em nenhuma variável de interesse depois da última alteração.
2.4.1.2 Dados faltantes para as covariáveis
Analisando os gráficos apresentados nesta seção podemos perceber que as variáveis NU_TAXA_APROVACAO, NU_TAXA_REPROVACAO e nem para NU_TAXA_ABANDONO têm valores faltantes para as mesmas linhas da base de dados, ou seja, para as mesmas escolas. Se excluirmos essas escolas da base de treino, o método criado não terá capacidade de analisar outras escolas, da base de teste, com as mesmas informações faltantes.
Uma alternativa, que pouco muda o ajuste do modelo e permite que ele seja usado mesmo quando existem valores faltantes na base, é imputar valores para os dados faltantes. Em geral usa-se a média, no caso das variáveis quantitativas, ou a moda, no caso das variáveis qualitativas. Se fosse uma variável qualitativa com muitos valores faltantes, ainda existe a possibilidade de se criar uma nova categoria, como por exemplo "não respondeu".
Segue as linhas de comando para imputação dos valores faltantes. Primeiro as variáveis quantitativas e por último a única variável qualitativa com valores faltantes, INSE.
base_treino = base_treino |>
mutate(NU_TAXA_APROVACAO = replace_na(NU_TAXA_APROVACAO, mean(NU_TAXA_APROVACAO, na.rm = TRUE)),
NU_TAXA_REPROVACAO = replace_na(NU_TAXA_REPROVACAO, mean(NU_TAXA_REPROVACAO, na.rm = TRUE)),
NU_TAXA_ABANDONO = replace_na(NU_TAXA_ABANDONO, mean(NU_TAXA_ABANDONO, na.rm = TRUE)),
PC_FORMACAO_DOCENTE = replace_na(PC_FORMACAO_DOCENTE, mean(PC_FORMACAO_DOCENTE, na.rm = TRUE))
)moda = names(table(base_treino$INSE))[which.max(table(base_treino$INSE))]
base_treino = base_treino |> mutate(INSE = replace_na(INSE,moda))Verificando que não há mais dados faltantes.
base_treino |> miss_var_summary()# A tibble: 25 × 3
variable n_miss pct_miss
<chr> <int> <dbl>
1 NU_ANO 0 0
2 CO_UF_ESCOLA 0 0
3 SG_UF_ESCOLA 0 0
4 CO_MUNICIPIO_ESCOLA 0 0
5 NO_MUNICIPIO_ESCOLA 0 0
6 CO_ESCOLA_EDUCACENSO 0 0
7 NO_ESCOLA_EDUCACENSO 0 0
8 TP_DEPENDENCIA_ADM_ESCOLA 0 0
9 TP_LOCALIZACAO_ESCOLA 0 0
10 NU_MATRICULAS 0 0
# ℹ 15 more rows2.4.2 Covariáveis com variância (quase) zero
Para procurar as variáveis com variância (quase) zero vamos analisar a variabilidade de cada variável. Nesse momento é importante tratar de forma diferente as variáveis quantitativas das qualitativas, por isso foram criados os objetos qualitativas e quantitativas, que guardam os nomes das covariáveis quantitativas e qualitativas. Ele facilitará o código a seguir.
A variabilidade das variáveis quantitativas será dada pela variância amostral, que pode ser encontrada a partir do comando var.
diag(var(base_treino |> select(where(is.numeric)) )) NU_MATRICULAS NU_PARTICIPANTES_NEC_ESP NU_PARTICIPANTES
7118.322823 1.829308 3858.560551
NU_TAXA_PARTICIPACAO NU_MEDIA_CN NU_MEDIA_CH
236.777373 2227.860448 1595.884448
NU_MEDIA_LP NU_MEDIA_MT NU_MEDIA_RED
1732.500132 4716.964468 6029.947170
PC_FORMACAO_DOCENTE NU_TAXA_PERMANENCIA NU_TAXA_APROVACAO
297.007113 390.706286 119.106033
NU_TAXA_REPROVACAO NU_TAXA_ABANDONO
62.774436 30.303195 Nenhuma variável quantitativa com variância nula.
Agora o caso das variáveis qualitativas. Para medir a variabilidade destas variáveis vamos contar a quantidade de categorias que cada uma delas apresenta. Só será descartada aquelas que apresentarem apenas uma categoria.
summary(base_treino |> select(where(is.factor))) NU_ANO CO_UF_ESCOLA SG_UF_ESCOLA CO_MUNICIPIO_ESCOLA
2015:11700 35 :2495 SP :2495 3550308: 510
31 :1279 MG :1279 3304557: 362
33 :1076 RJ :1076 2304400: 219
43 : 858 RS : 858 5300108: 149
23 : 632 CE : 632 3106200: 136
41 : 524 PR : 524 2927408: 121
(Other):4836 (Other):4836 (Other):10203
NO_MUNICIPIO_ESCOLA TP_DEPENDENCIA_ADM_ESCOLA TP_LOCALIZACAO_ESCOLA
São Paulo : 510 Federal : 247 Urbana:11277
Rio de Janeiro: 362 Estadual :6629 Rural : 423
Fortaleza : 219 Municipal: 79
Brasília : 149 Privada :4745
Belo Horizonte: 136
Salvador : 121
(Other) :10203
INSE PORTE_ESCOLA
Grupo 1: 753 De 1 a 30 alunos :3147
Grupo 2:1030 De 31 a 60 alunos :2893
Grupo 3:3579 De 61 a 90 alunos :1827
Grupo 4:2856 Maior que 90 alunos:3833
Grupo 5:2464
Grupo 6:1018
Veja que a variável NU_ANO apresenta uma única categoria. Todas as observações são referentes ao mesmo ano. Dessa forma esta variável não agrega informação e será retirada da base.
base_treino = base_treino |> select(-NU_ANO)2.4.3 Análise de Multicolinearidade
A Análise de Multicolinearidade é o processo de seleção de variáveis para garantir que as covariáveis da base não apresentam alta correlação entre si. Esse processo consiste em procurar variáveis altamente correlacionadas e, no caso destas existirem, escolher algumas para ficarem na base e outras para saírem, de forma que a base final não contenha covariáveis com correlação maior que 80%.
Para isso faremos o cálculo da correlação amostral, a partir da função cor do R. Mas só faz sentido esta conta entre variáveis quantitativas.
Primeiro a análise das associações entre as variáveis quantitativas, duas a duas. A medida de associação utilizada será a correlação, a partir da função cor. As variáveis de interesse não serão consideradas nesta etapa.
mat_cor = base_treino |>
select(where(is.numeric)) |>
select(-c(NU_TAXA_PARTICIPACAO,
NU_PARTICIPANTES,
NU_MEDIA_CN,
NU_MEDIA_LP,
NU_MEDIA_MT,
NU_MEDIA_RED,
NU_MEDIA_CH)) |>
cor()
mat_cor NU_MATRICULAS NU_PARTICIPANTES_NEC_ESP
NU_MATRICULAS 1.000000000 0.40071034
NU_PARTICIPANTES_NEC_ESP 0.400710336 1.00000000
PC_FORMACAO_DOCENTE 0.152880742 0.06447547
NU_TAXA_PERMANENCIA -0.006362418 0.01192405
NU_TAXA_APROVACAO -0.283616144 -0.18180816
NU_TAXA_REPROVACAO 0.228583994 0.15421657
NU_TAXA_ABANDONO 0.233283453 0.13848074
PC_FORMACAO_DOCENTE NU_TAXA_PERMANENCIA
NU_MATRICULAS 0.152880742 -0.0063624179
NU_PARTICIPANTES_NEC_ESP 0.064475474 0.0119240509
PC_FORMACAO_DOCENTE 1.000000000 0.0290660572
NU_TAXA_PERMANENCIA 0.029066057 1.0000000000
NU_TAXA_APROVACAO -0.005119007 0.0050907666
NU_TAXA_REPROVACAO 0.048549624 -0.0063308905
NU_TAXA_ABANDONO -0.059728155 -0.0009807009
NU_TAXA_APROVACAO NU_TAXA_REPROVACAO NU_TAXA_ABANDONO
NU_MATRICULAS -0.283616144 0.22858399 0.2332834533
NU_PARTICIPANTES_NEC_ESP -0.181808162 0.15421657 0.1384807443
PC_FORMACAO_DOCENTE -0.005119007 0.04854962 -0.0597281554
NU_TAXA_PERMANENCIA 0.005090767 -0.00633089 -0.0009807009
NU_TAXA_APROVACAO 1.000000000 -0.87648766 -0.7210265409
NU_TAXA_REPROVACAO -0.876487660 1.00000000 0.2983883659
NU_TAXA_ABANDONO -0.721026541 0.29838837 1.0000000000Uma maneira gráfica de visualizar essas correlações, e ainda ganhar uma análise descritiva de brinde, é a partir do comando ggpairs.
library(GGally)
base_treino |>
select(where(is.numeric)) |>
select(-c(NU_TAXA_PARTICIPACAO,
NU_PARTICIPANTES,
NU_MEDIA_CN,
NU_MEDIA_LP,
NU_MEDIA_MT,
NU_MEDIA_RED,
NU_MEDIA_CH)) |>
ggpairs()O resultado indica uma forte correlação entre NU_TAXA_APROVACAO e NU_TAXA_REPROVACAO, NU_TAXA_APROVACAO e NU_TAXA_ABANDONO. veja queNU_TAXA_REPROVACAO e NU_TAXA_ABANDONO não apresentam grande correlação entre elas. Por esse motivo será descartada da base a variávei NU_TAXA_APROVACAO.
base_treino = base_treino |> select(-NU_TAXA_APROVACAO)Entre variáveis qualitativas podemos fazer uma análise mais manual e pontual. Começamos com aquelas que obviamente são correlacionadas: CO_UF_ESCOLA, SG_UF_ESCOLA, CO_MUNICIPIO_ESCOLA e NO_MUNICIPIO_ESCOLA. Manter os dados dos municípios significa optar por trabalhar com uma variável com mais de 3500 categorias. Isso gera um custo computacional bem grande. Por esse motivo aqui será mantida apenas uma informação sobre o UF e excluída as informações sobre os municípios.
base_treino = base_treino |> select(-c(CO_UF_ESCOLA,CO_MUNICIPIO_ESCOLA,NO_MUNICIPIO_ESCOLA))Nesse momento as demais variáveis qualitativas da base são: TP_DEPENDENCIA_ADM_ESCOLA, TP_LOCALIZACAO_ESCOLA, INSE e PORTE_ESCOLA. Se quisermos é possível fazer uma análise gráfica sobre a associação entre elas.
cores = c("gold","orange","red3","pink","purple","blue","skyblue","springgreen","darkgreen","gray")
x = base_treino$TP_DEPENDENCIA_ADM_ESCOLA
y = base_treino$TP_LOCALIZACAO_ESCOLA
tabela = table(x,y)
tabela1 = prop.table(tabela,margin = 2)
barplot(tabela1,col=cores,legend.text = row.names(tabela1))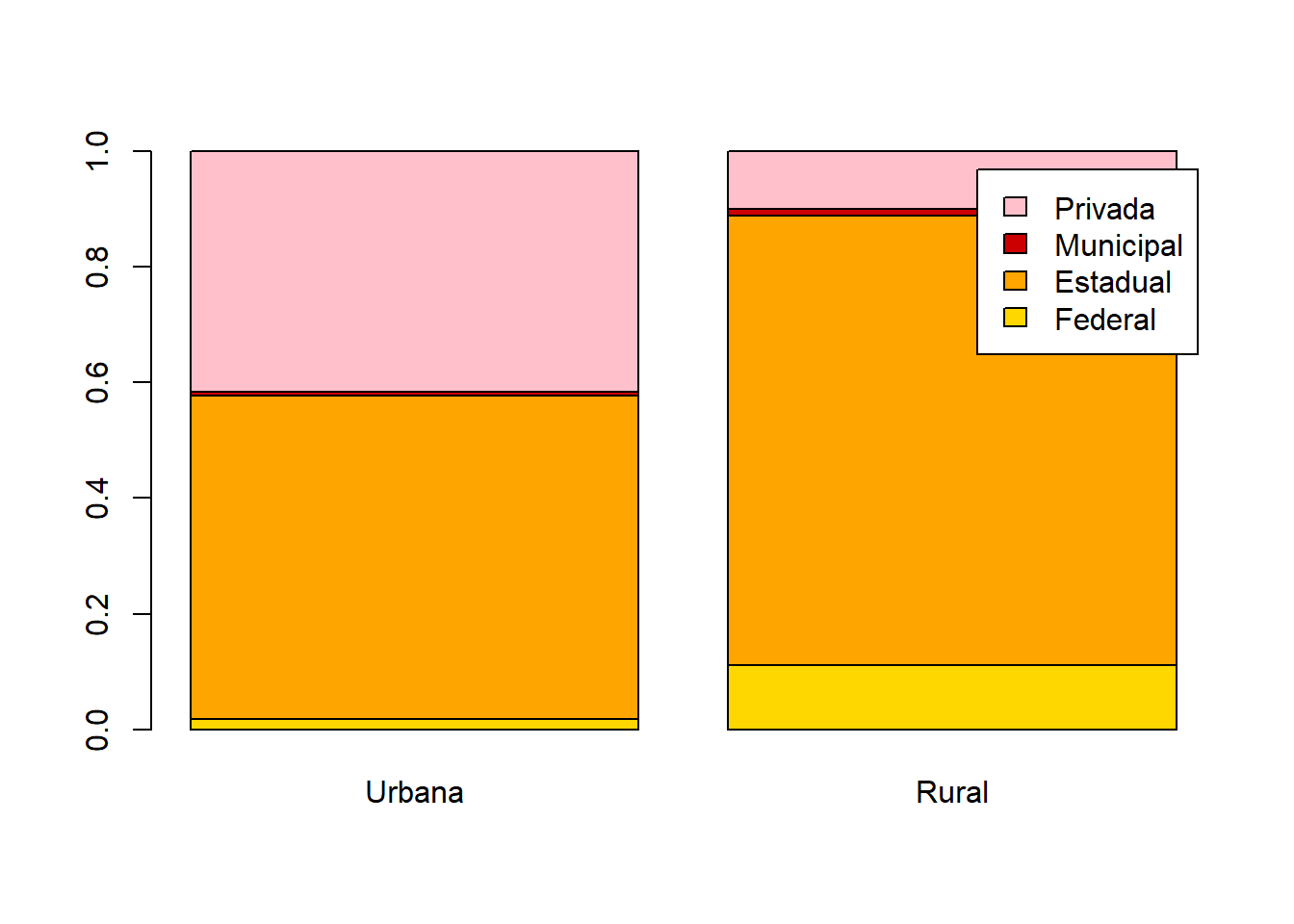
tabela2 = t(prop.table(tabela,margin = 1))
barplot(tabela2,col=cores,legend.text = row.names(tabela2))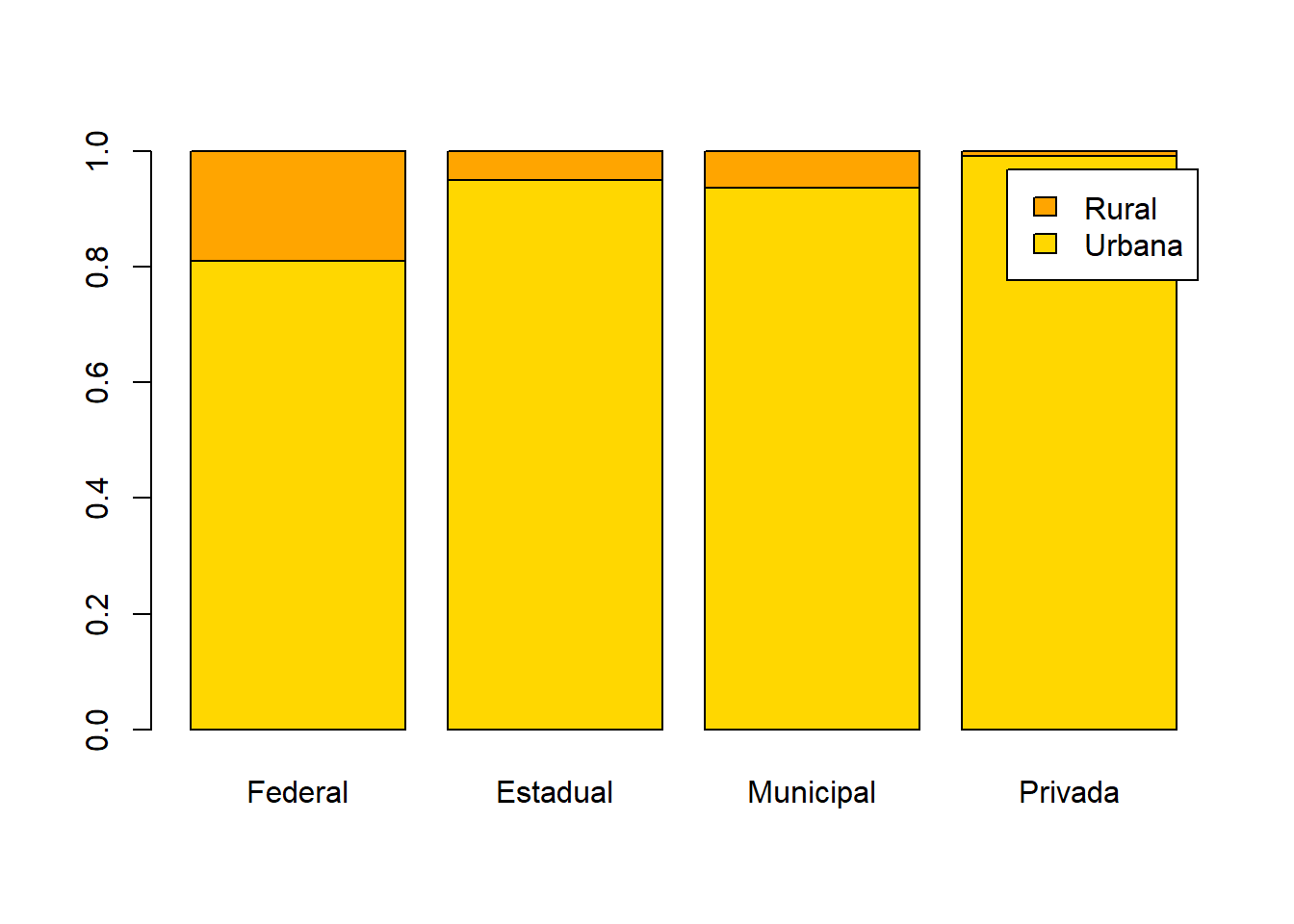
x = base_treino$TP_DEPENDENCIA_ADM_ESCOLA
y = base_treino$INSE
tabela = table(x,y)
tabela1 = prop.table(tabela,margin = 2)
barplot(tabela1,col=cores,legend.text = row.names(tabela1))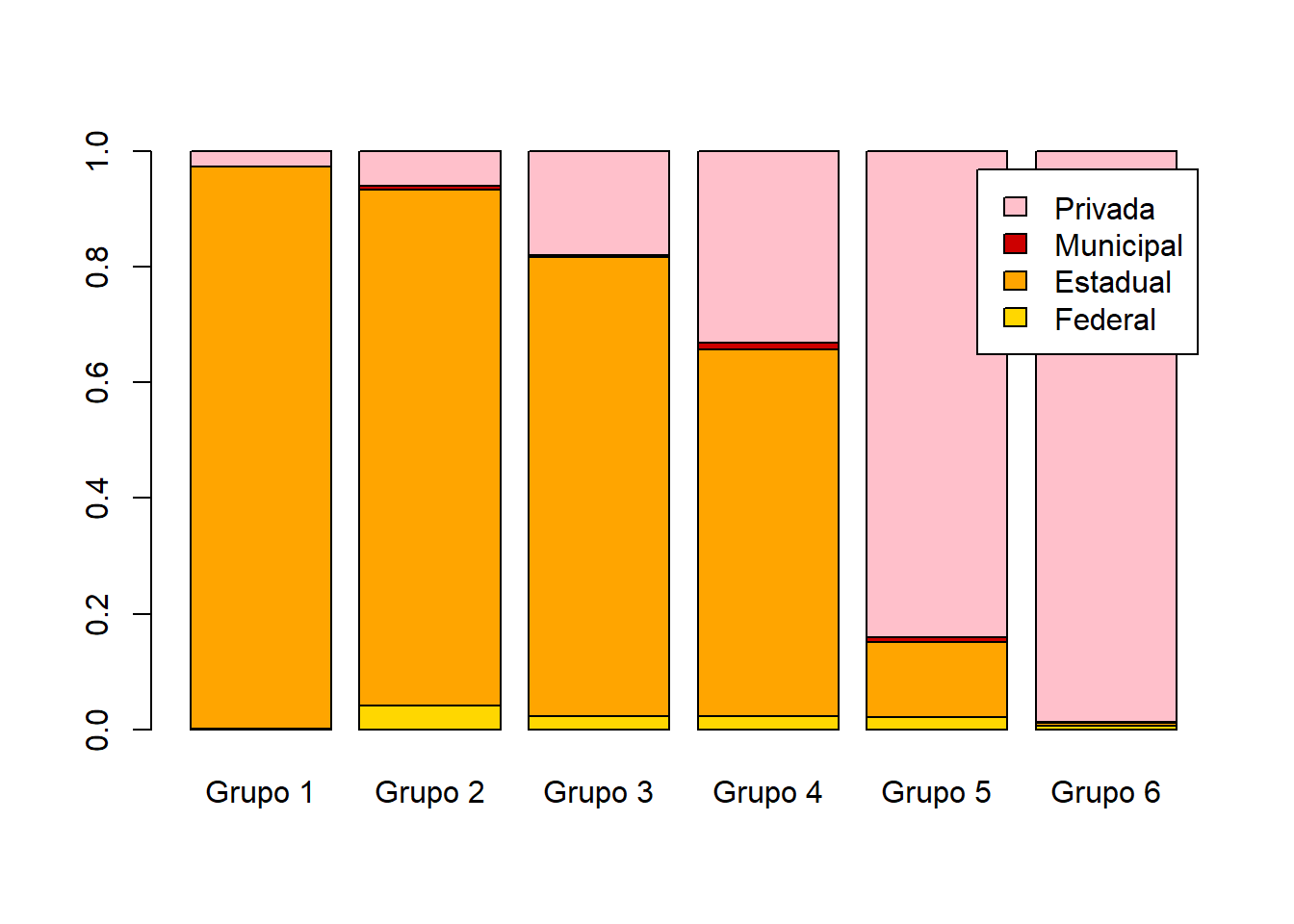
tabela2 = t(prop.table(tabela,margin = 1))
barplot(tabela2,col=cores,legend.text = row.names(tabela2))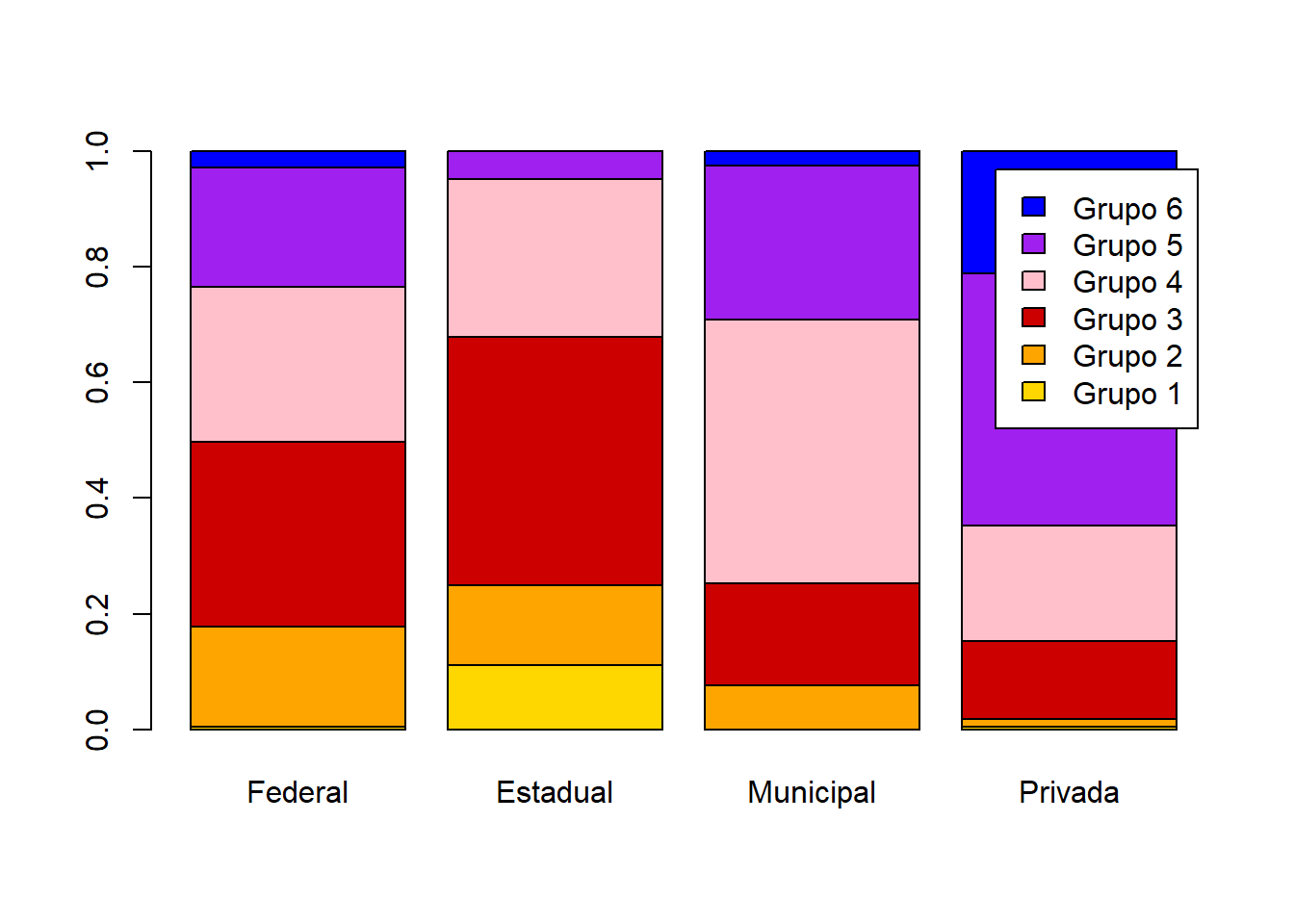
x = base_treino$TP_DEPENDENCIA_ADM_ESCOLA
y = base_treino$PORTE_ESCOLA
tabela = table(x,y)
tabela1 = prop.table(tabela,margin = 2)
barplot(tabela1,col=cores,legend.text = row.names(tabela1))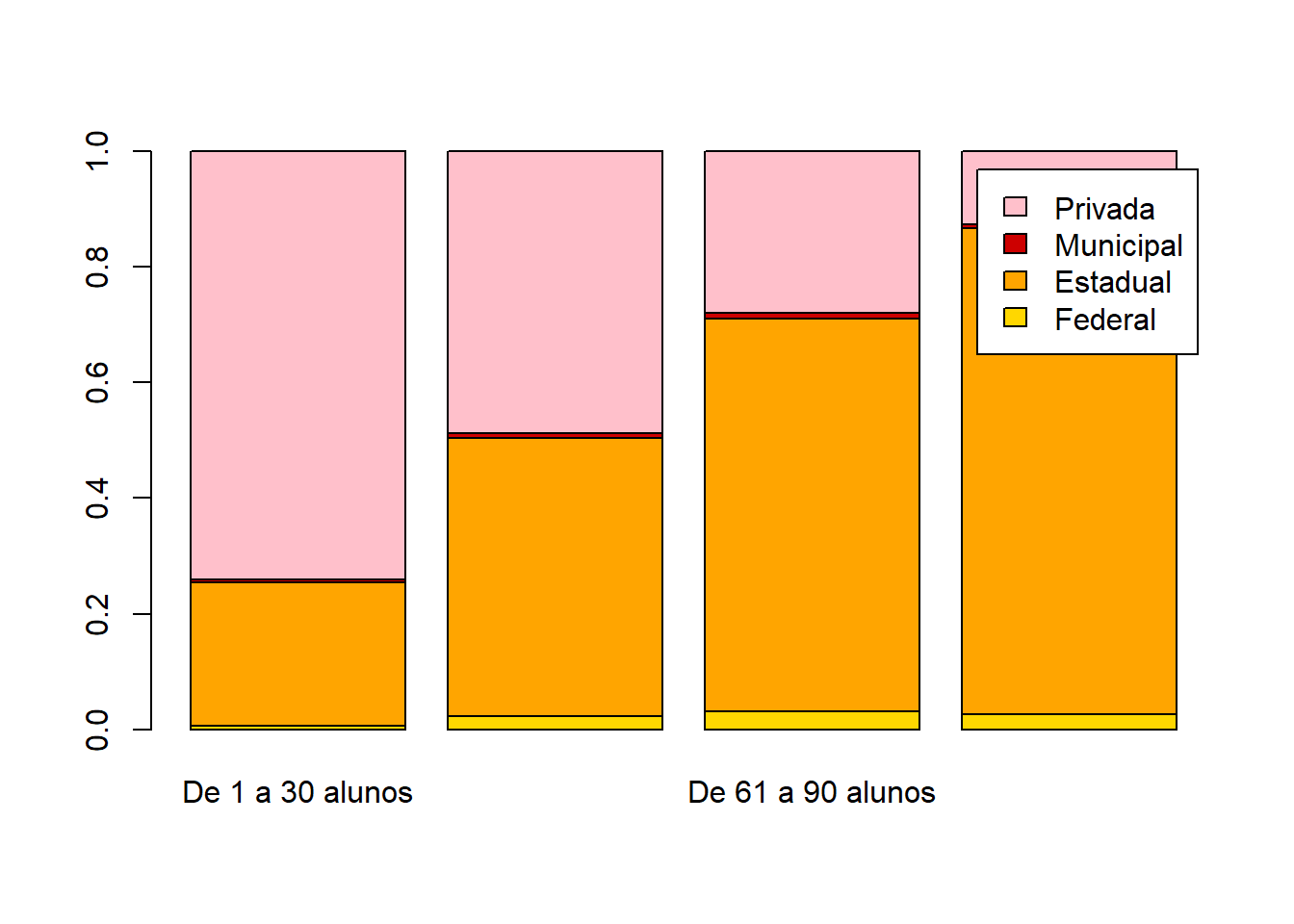
tabela2 = t(prop.table(tabela,margin = 1))
barplot(tabela2,col=cores,legend.text = row.names(tabela2))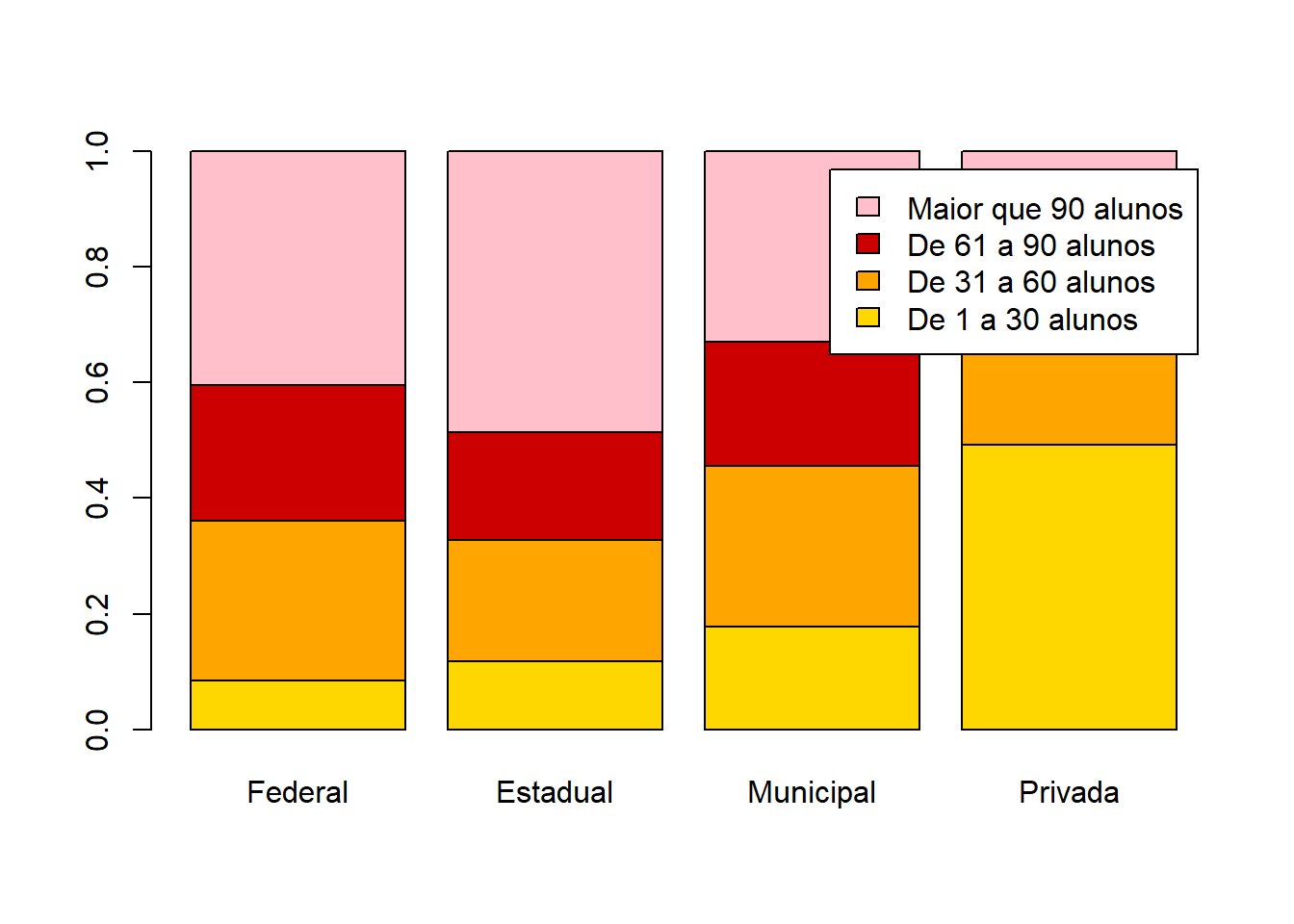
x = base_treino$TP_LOCALIZACAO_ESCOLA
y = base_treino$INSE
tabela = table(x,y)
tabela1 = prop.table(tabela,margin = 2)
barplot(tabela1,col=cores,legend.text = row.names(tabela1))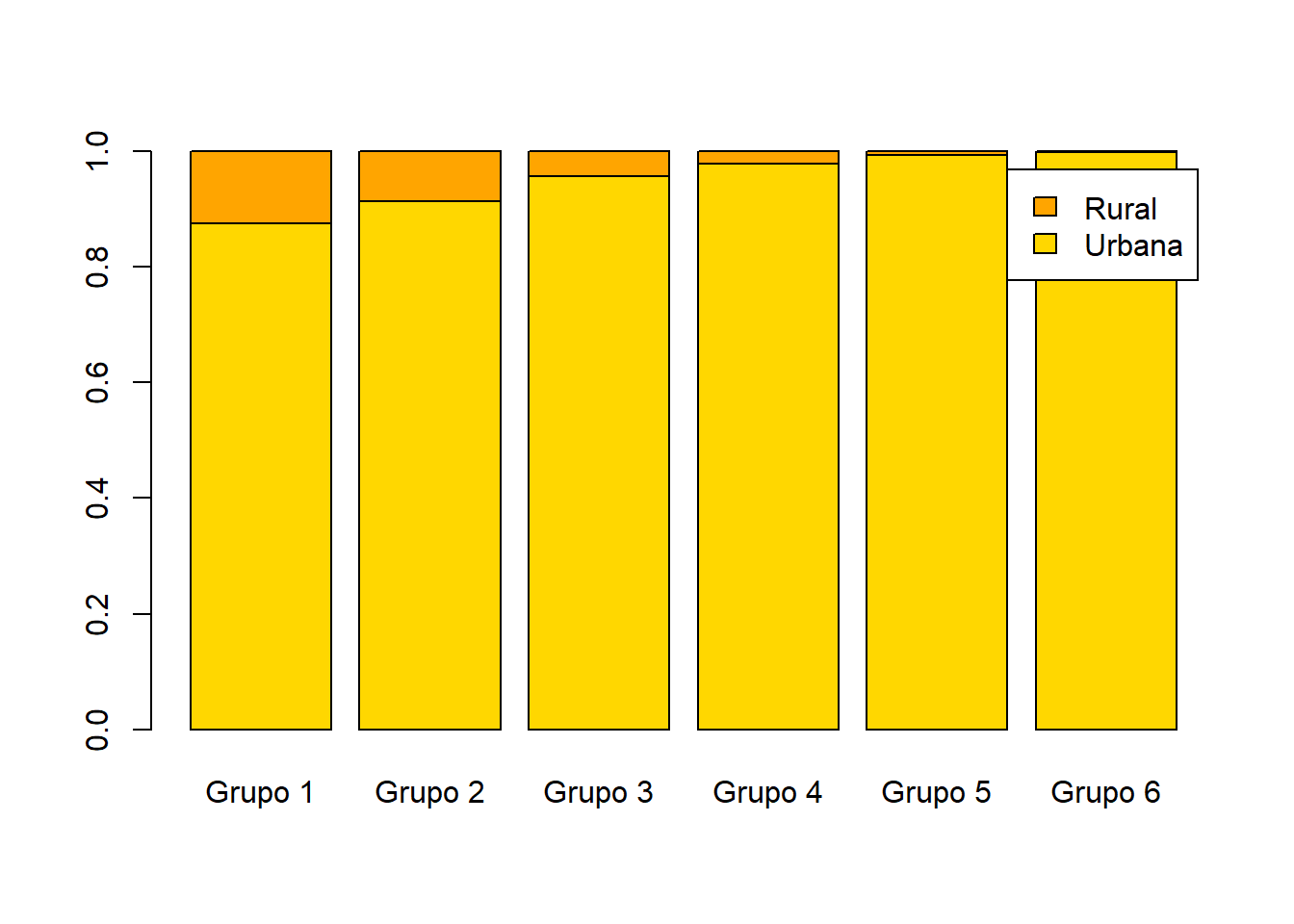
tabela2 = t(prop.table(tabela,margin = 1))
barplot(tabela2,col=cores,legend.text = row.names(tabela2))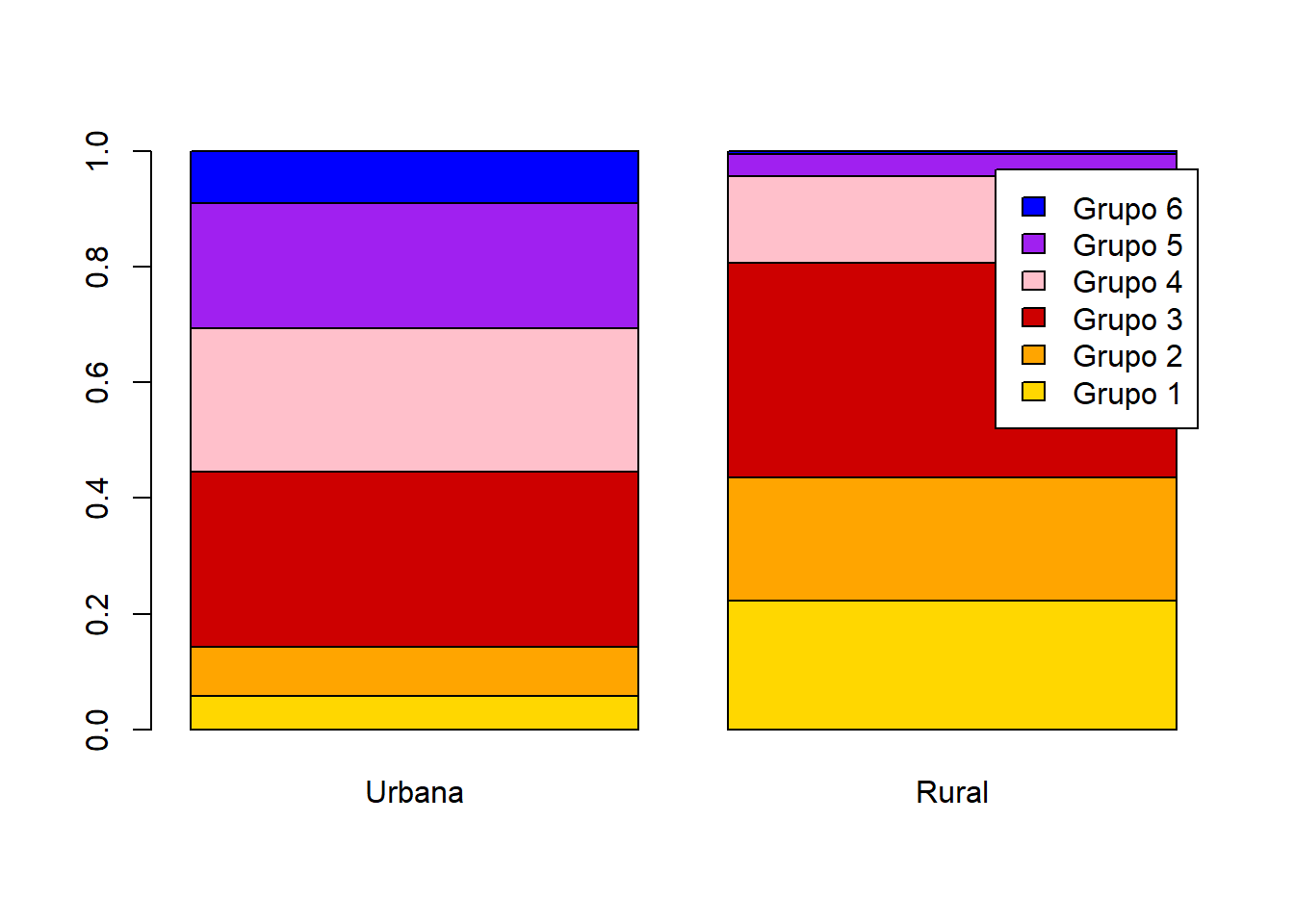
x = base_treino$TP_DEPENDENCIA_ADM_ESCOLA
y = base_treino$PORTE_ESCOLA
tabela = table(x,y)
tabela1 = prop.table(tabela,margin = 2)
barplot(tabela1,col=cores,legend.text = row.names(tabela1))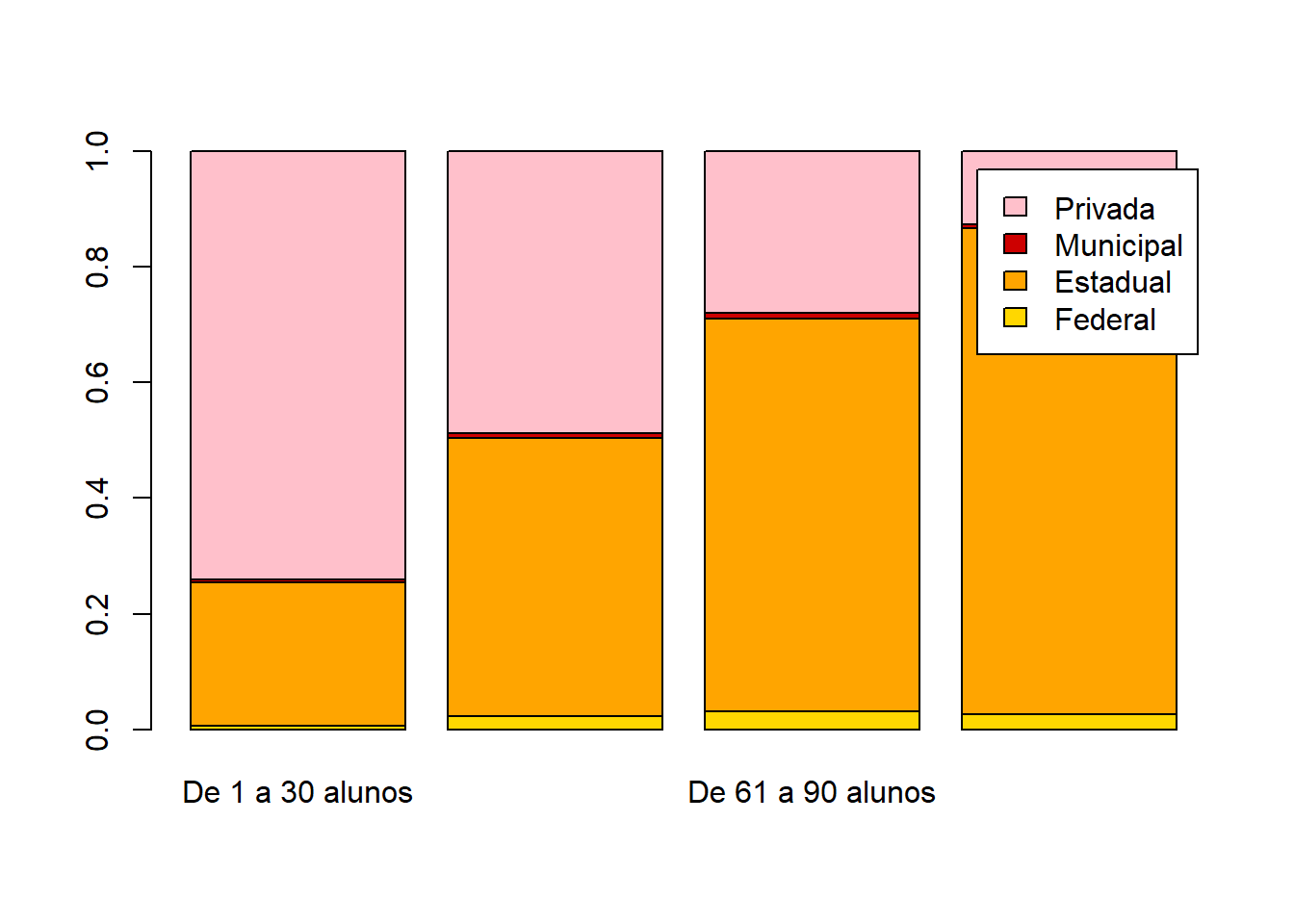
tabela2 = t(prop.table(tabela,margin = 1))
barplot(tabela2,col=cores,legend.text = row.names(tabela2))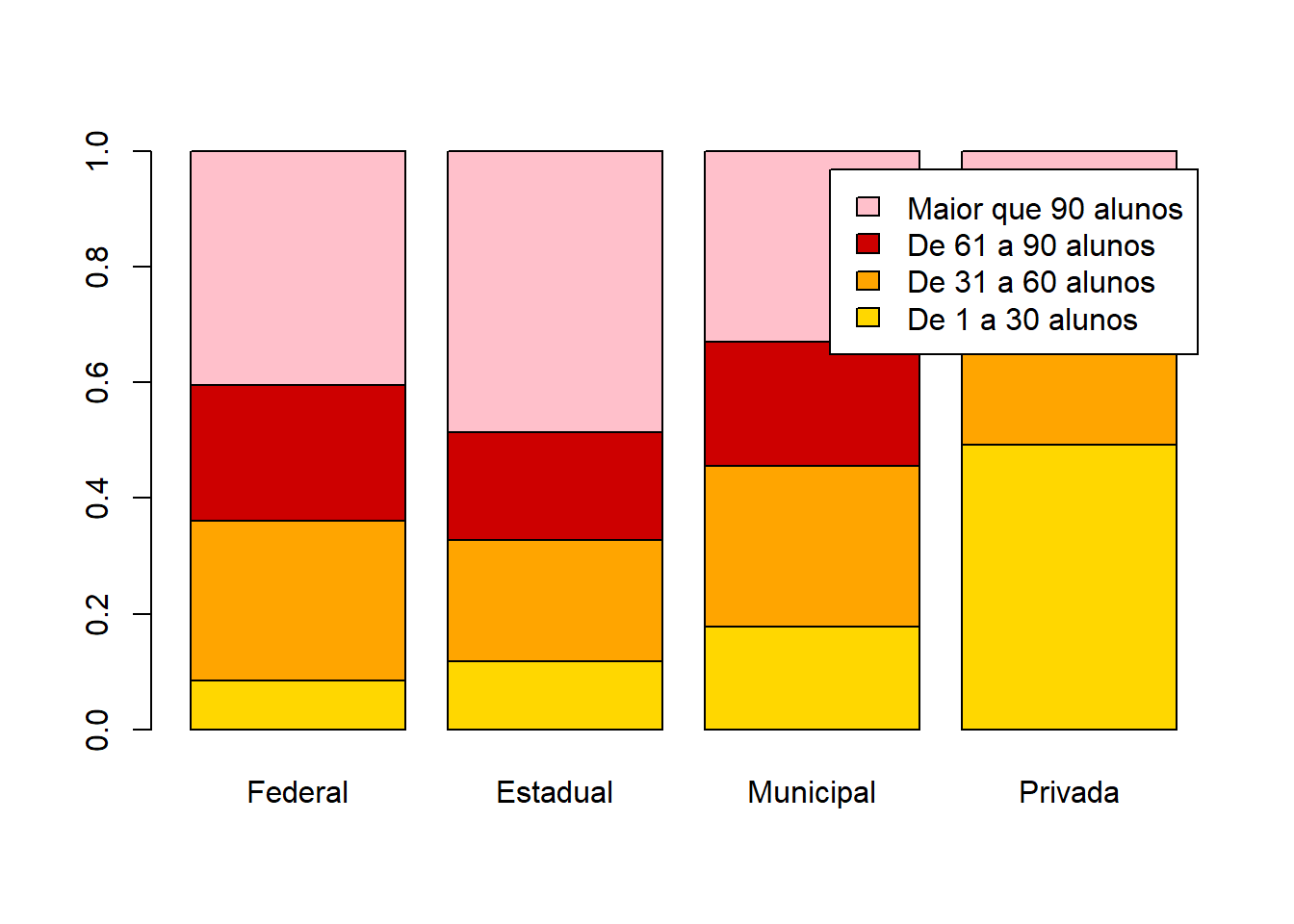
x = base_treino$INSE
y = base_treino$PORTE_ESCOLA
tabela = table(x,y)
tabela1 = prop.table(tabela,margin = 2)
barplot(tabela1,col=cores,legend.text = row.names(tabela1))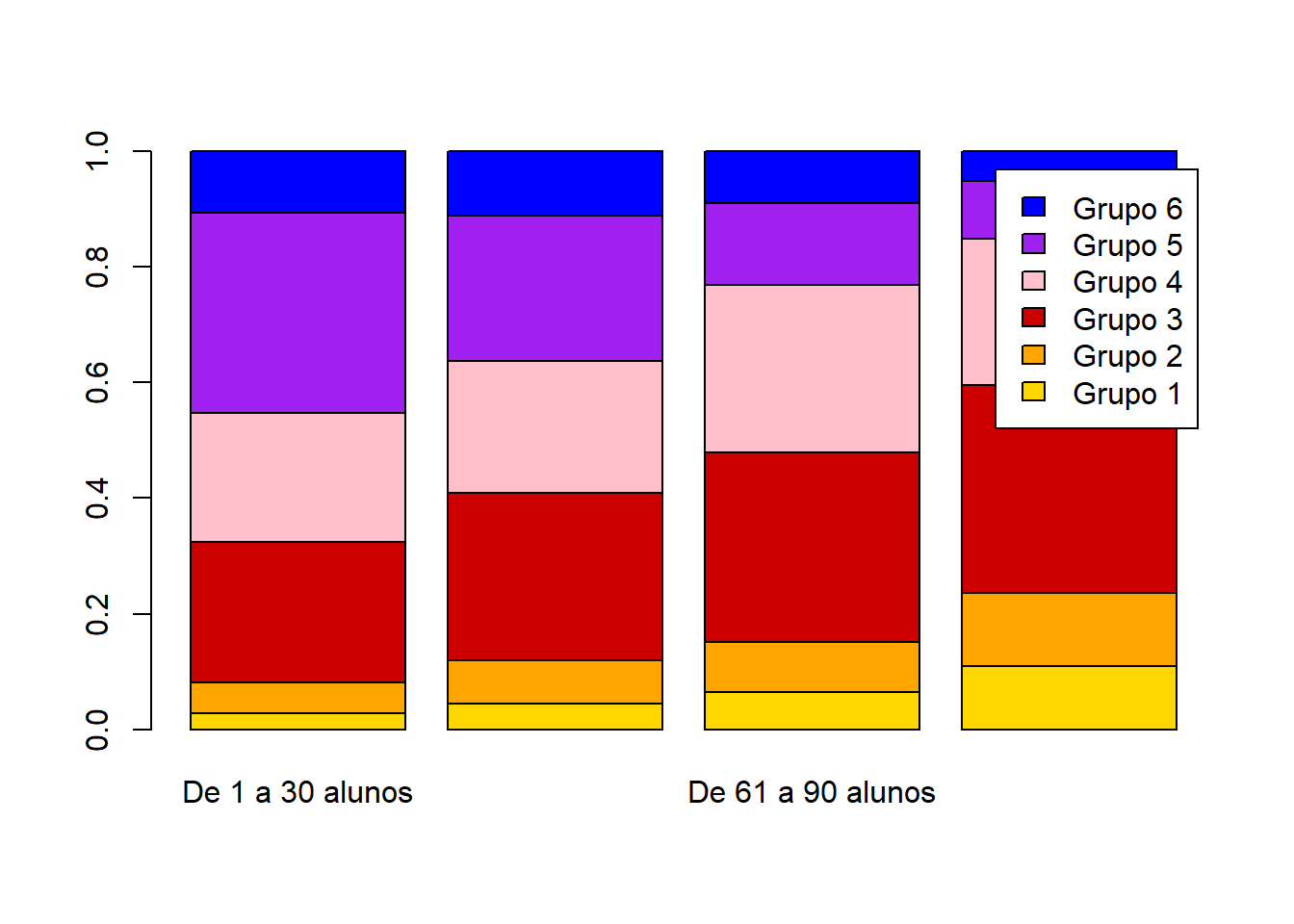
tabela2 = t(prop.table(tabela,margin = 1))
barplot(tabela2,col=cores,legend.text = row.names(tabela2))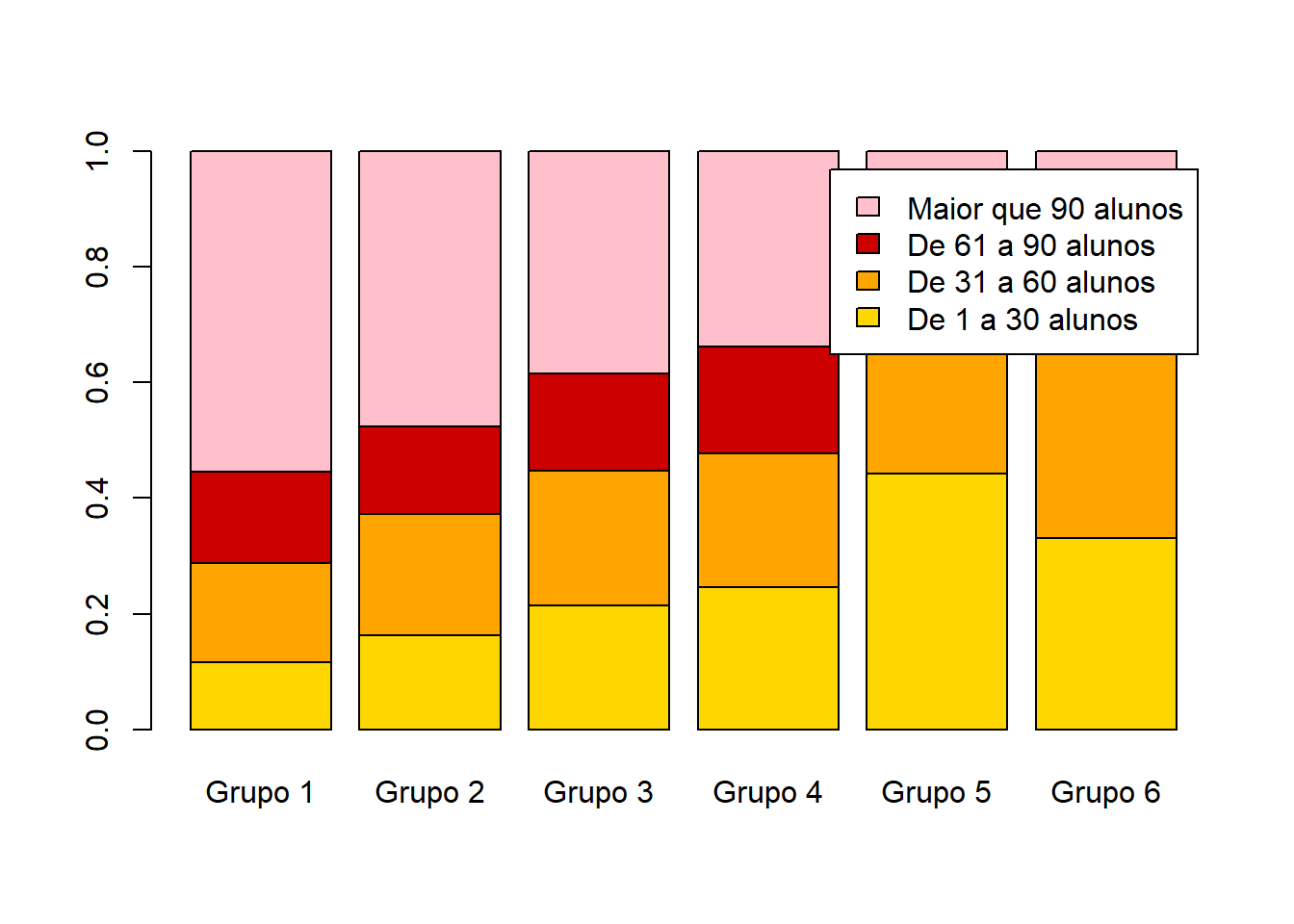
2.5 Uma breve Análise Descritiva
Antes de salvar a base de treino final vale fazer uma breve análise descritiva. A ideia aqui é já buscar alguma informação sobre quais covariáveis melhor explicam a variável de interesse. Nesse momento é preciso definir qual ou quais serão as variáveis de interesse do projeto.
Para exemplificar um problema de regressão e outro de classificação vamos usar como variável de interesse a nota média da escola na prova de matemática, NU_MEDIA_MT. Já para exemplificar os problemas de classificação podemos usar a variável NU_TAXA_PARTICIPACAO categorizada em três faixas: alta, média e baixa.
A variável NU_TAXA_PARTICIPACAO categorizada não existe e por isso vamos criá-la.
base_treino = base_treino |>
mutate(TAXA_PART_CAT = ifelse(NU_TAXA_PARTICIPACAO >= 86, "alta", ifelse(NU_TAXA_PARTICIPACAO <= 67, "baixa","media")))
table(base_treino$TAXA_PART_CAT)
alta baixa media
3981 3963 3756 glimpse(base_treino) Rows: 11,700
Columns: 21
$ SG_UF_ESCOLA <fct> RO, RO, RO, RO, RO, RO, RO, RO, RO, RO, RO, …
$ CO_ESCOLA_EDUCACENSO <chr> "11000058", "11000244", "11000260", "1100031…
$ NO_ESCOLA_EDUCACENSO <chr> "CENTRO DE ENSINO CLASSE A", "COLEGIO DOM BO…
$ TP_DEPENDENCIA_ADM_ESCOLA <fct> Privada, Privada, Estadual, Estadual, Privad…
$ TP_LOCALIZACAO_ESCOLA <fct> Urbana, Urbana, Urbana, Urbana, Urbana, Rura…
$ NU_MATRICULAS <dbl> 137, 55, 97, 44, 34, 41, 24, 33, 28, 72, 61,…
$ NU_PARTICIPANTES_NEC_ESP <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2,…
$ NU_PARTICIPANTES <dbl> 130, 49, 96, 38, 29, 22, 21, 24, 19, 57, 55,…
$ NU_TAXA_PARTICIPACAO <dbl> 94.89, 89.09, 98.97, 86.36, 85.29, 53.66, 87…
$ NU_MEDIA_CN <dbl> 591.64, 508.74, 505.77, 484.43, 480.60, 443.…
$ NU_MEDIA_CH <dbl> 652.34, 586.45, 582.16, 540.06, 591.92, 483.…
$ NU_MEDIA_LP <dbl> 604.53, 531.35, 527.39, 489.87, 532.11, 452.…
$ NU_MEDIA_MT <dbl> 627.66, 529.87, 492.85, 456.92, 486.22, 429.…
$ NU_MEDIA_RED <dbl> 732.00, 591.84, 580.83, 543.68, 602.07, 415.…
$ INSE <fct> Grupo 6, Grupo 5, Grupo 5, Grupo 4, Grupo 4,…
$ PC_FORMACAO_DOCENTE <dbl> 67.5, 56.0, 53.6, 73.9, 46.2, 34.6, 63.3, 48…
$ NU_TAXA_PERMANENCIA <dbl> 78.46, 81.63, 85.42, 63.16, 58.62, 72.73, 76…
$ NU_TAXA_REPROVACAO <dbl> 3.9, 10.5, 10.8, 22.2, 9.9, 6.5, 35.1, 11.4,…
$ NU_TAXA_ABANDONO <dbl> 0.0, 0.8, 0.0, 3.9, 1.4, 18.0, 0.0, 7.0, 13.…
$ PORTE_ESCOLA <fct> Maior que 90 alunos, De 31 a 60 alunos, Maio…
$ TAXA_PART_CAT <chr> "alta", "alta", "alta", "alta", "media", "ba…base_treino$TAXA_PART_CAT = as.factor(base_treino$TAXA_PART_CAT)Vejamos a relação entre a variável resposta NU_MEDIA_MT e as demais. Primeiro a sua relação com as covariáveis quantitativas.
plot(base_treino$NU_MATRICULAS,base_treino$NU_MEDIA_MT)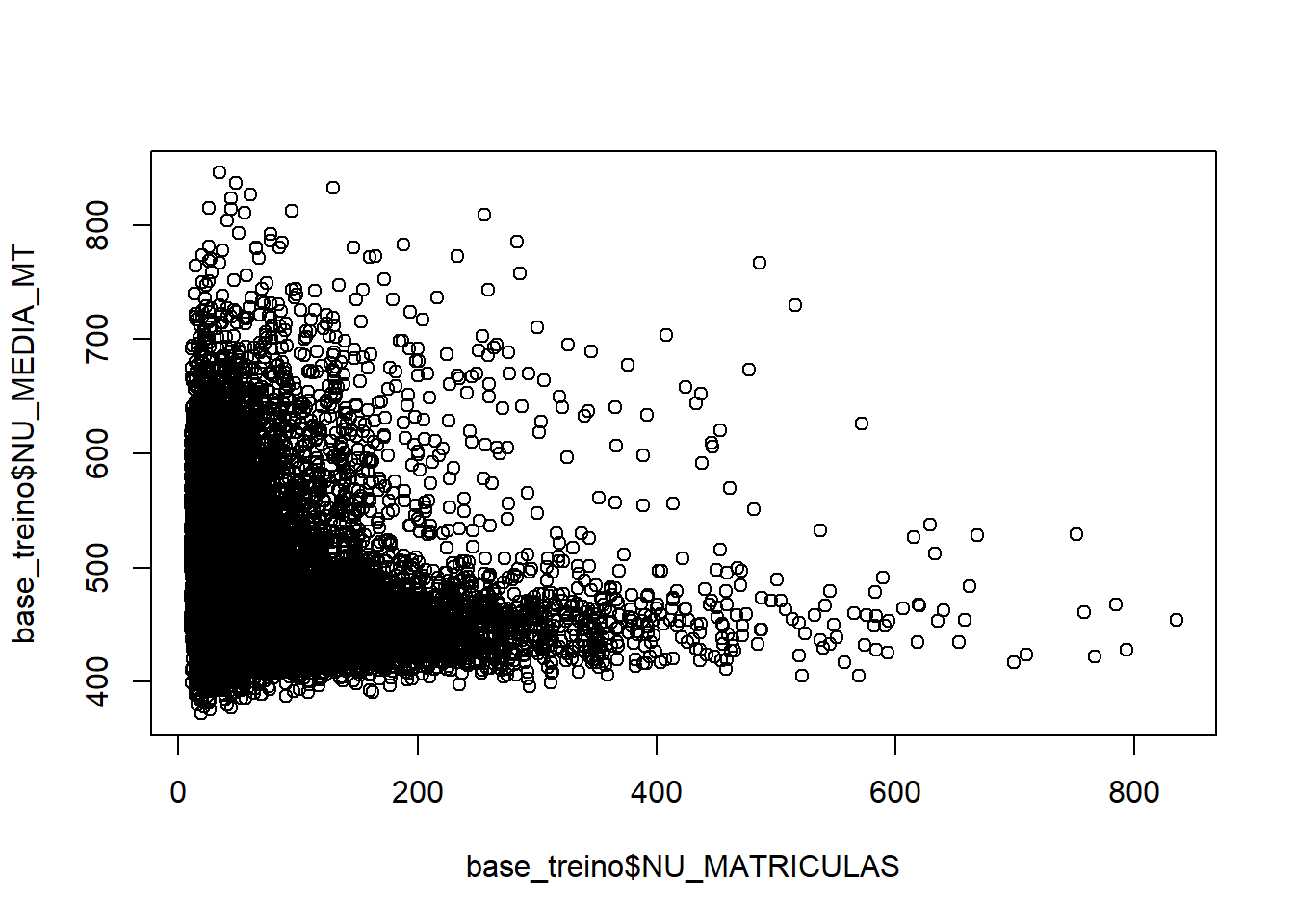
plot(base_treino$NU_PARTICIPANTES_NEC_ESP,base_treino$NU_MEDIA_MT)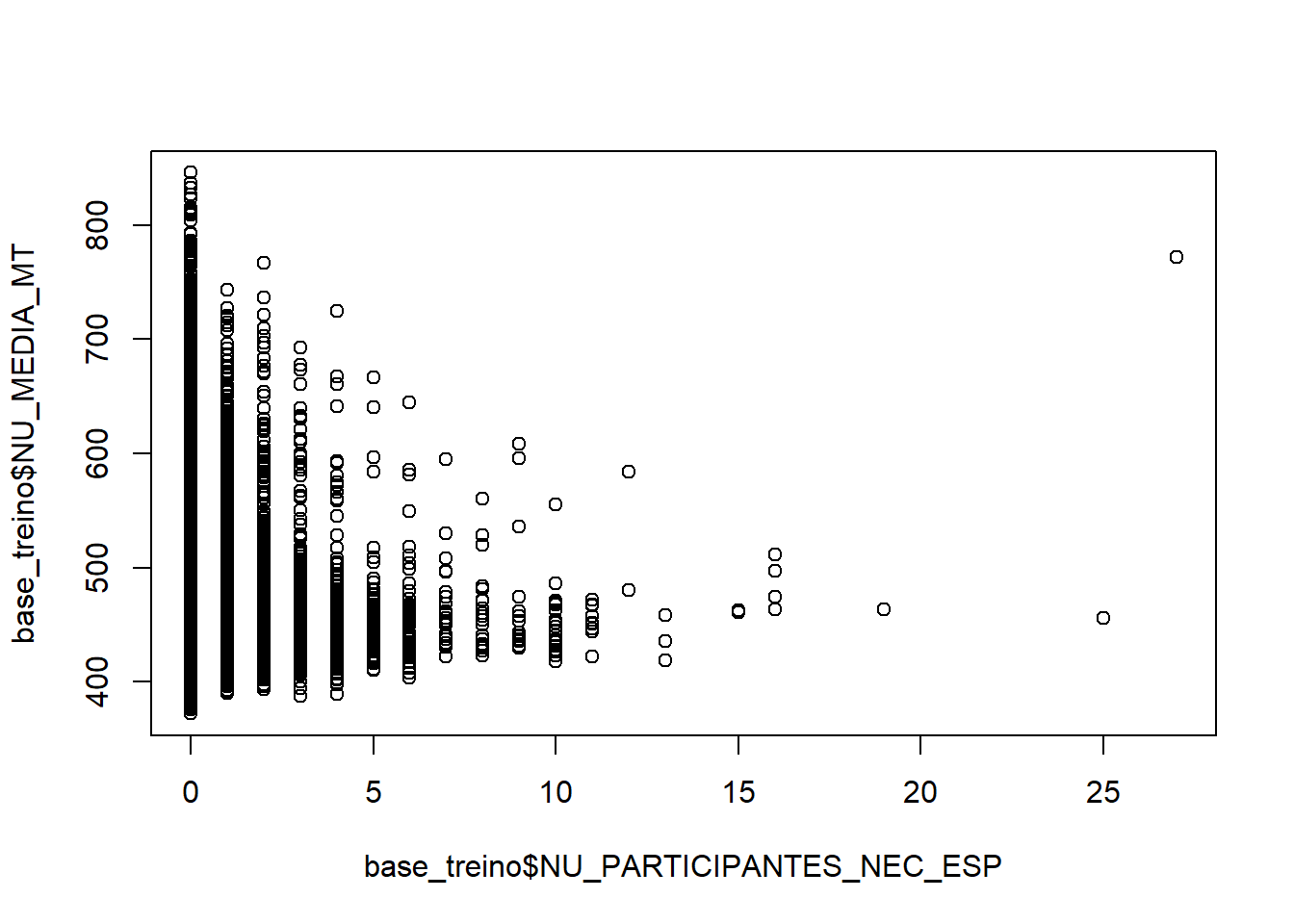
plot(base_treino$NU_PARTICIPANTES,base_treino$NU_MEDIA_MT)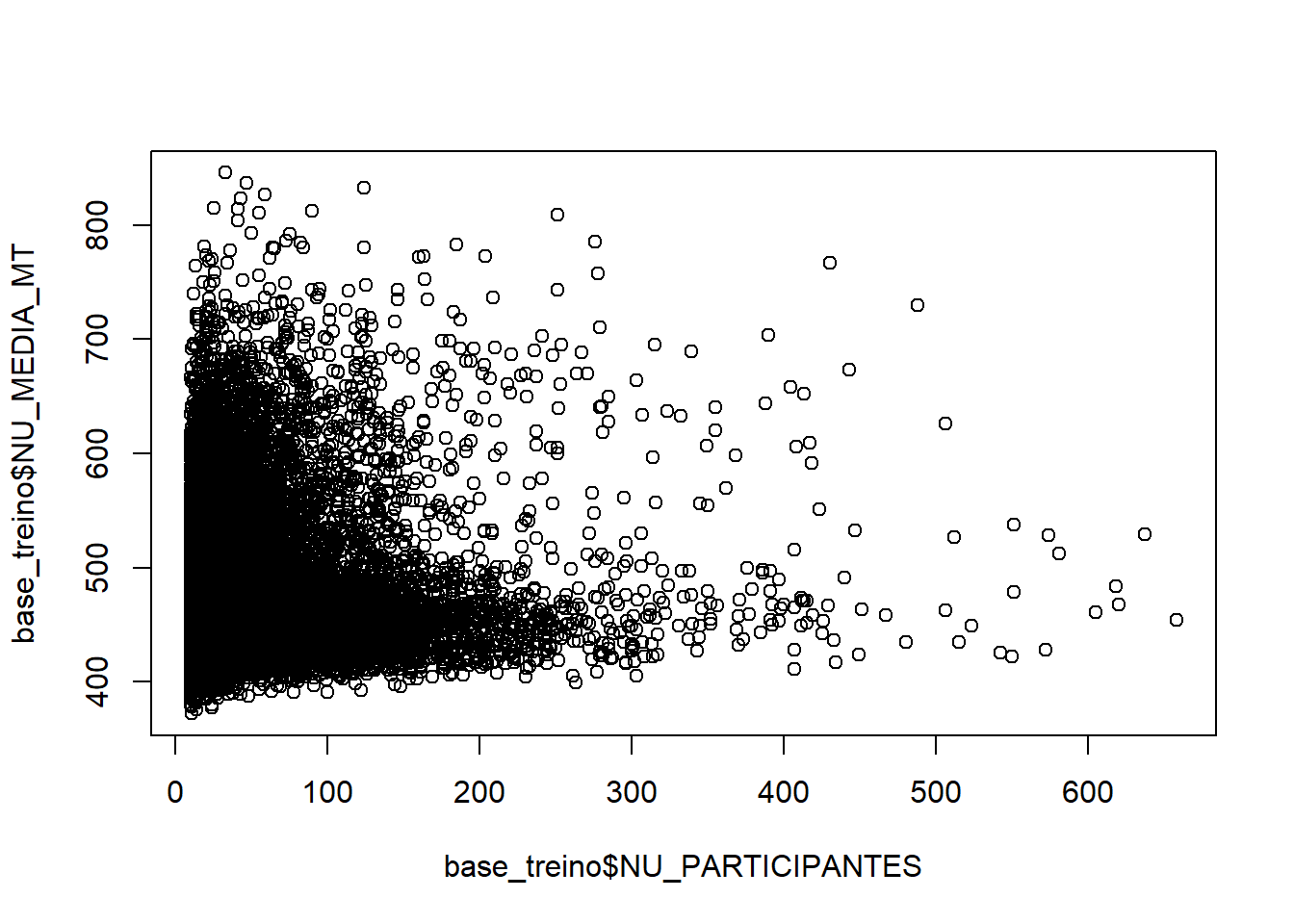
plot(base_treino$NU_TAXA_PERMANENCIA,base_treino$NU_MEDIA_MT)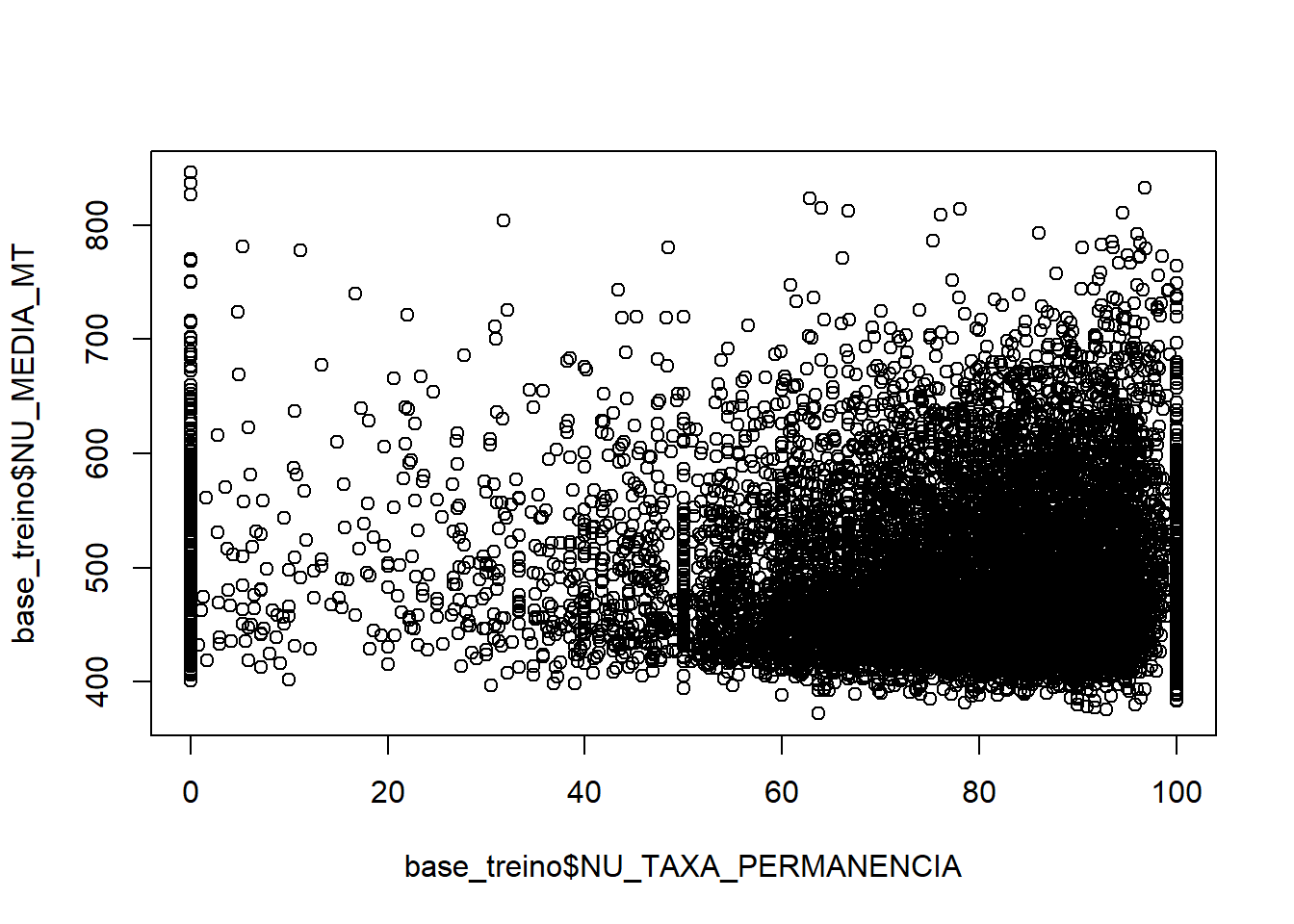
plot(base_treino$NU_TAXA_REPROVACAO,base_treino$NU_MEDIA_MT)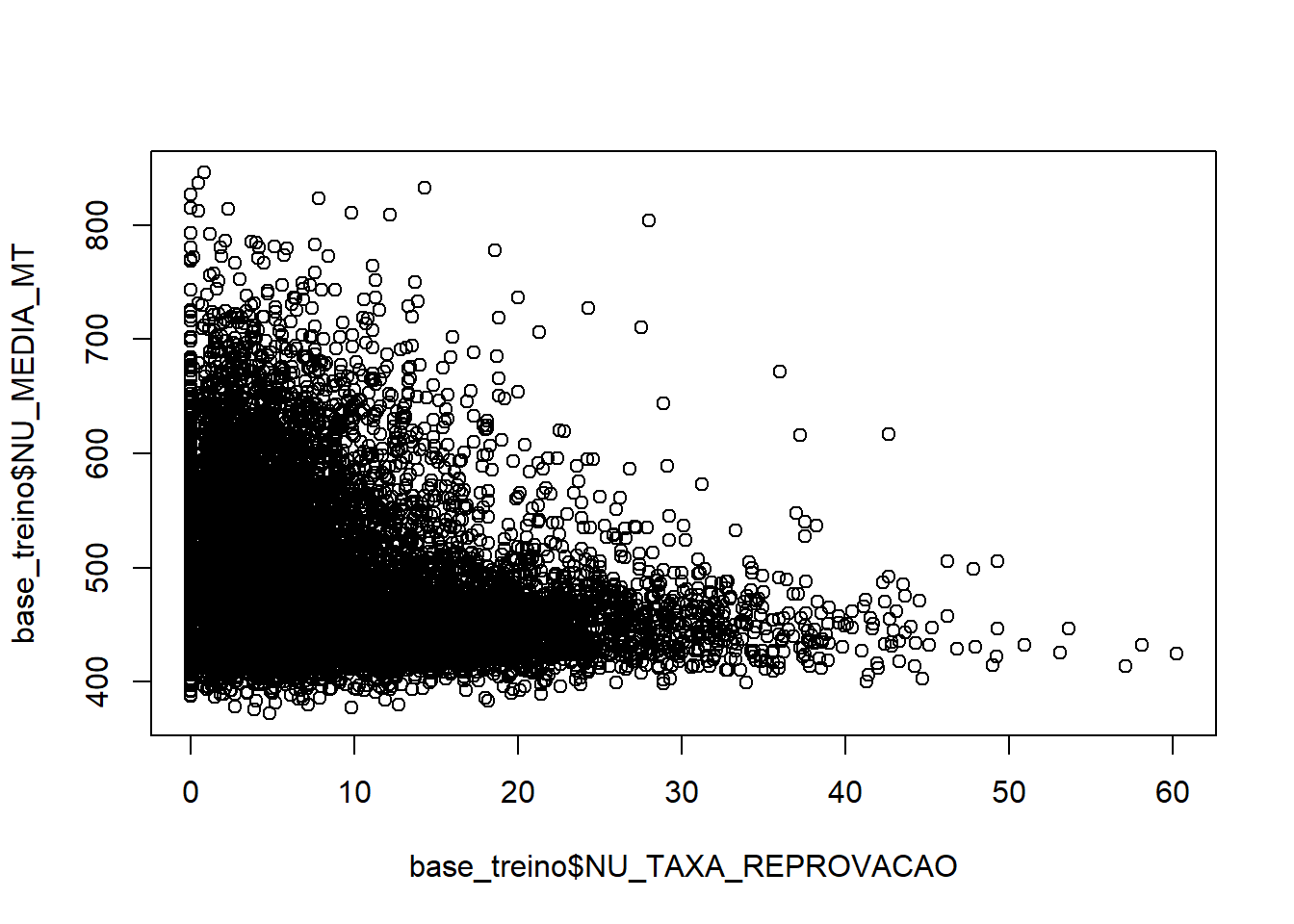
plot(base_treino$NU_TAXA_ABANDONO,base_treino$NU_MEDIA_MT)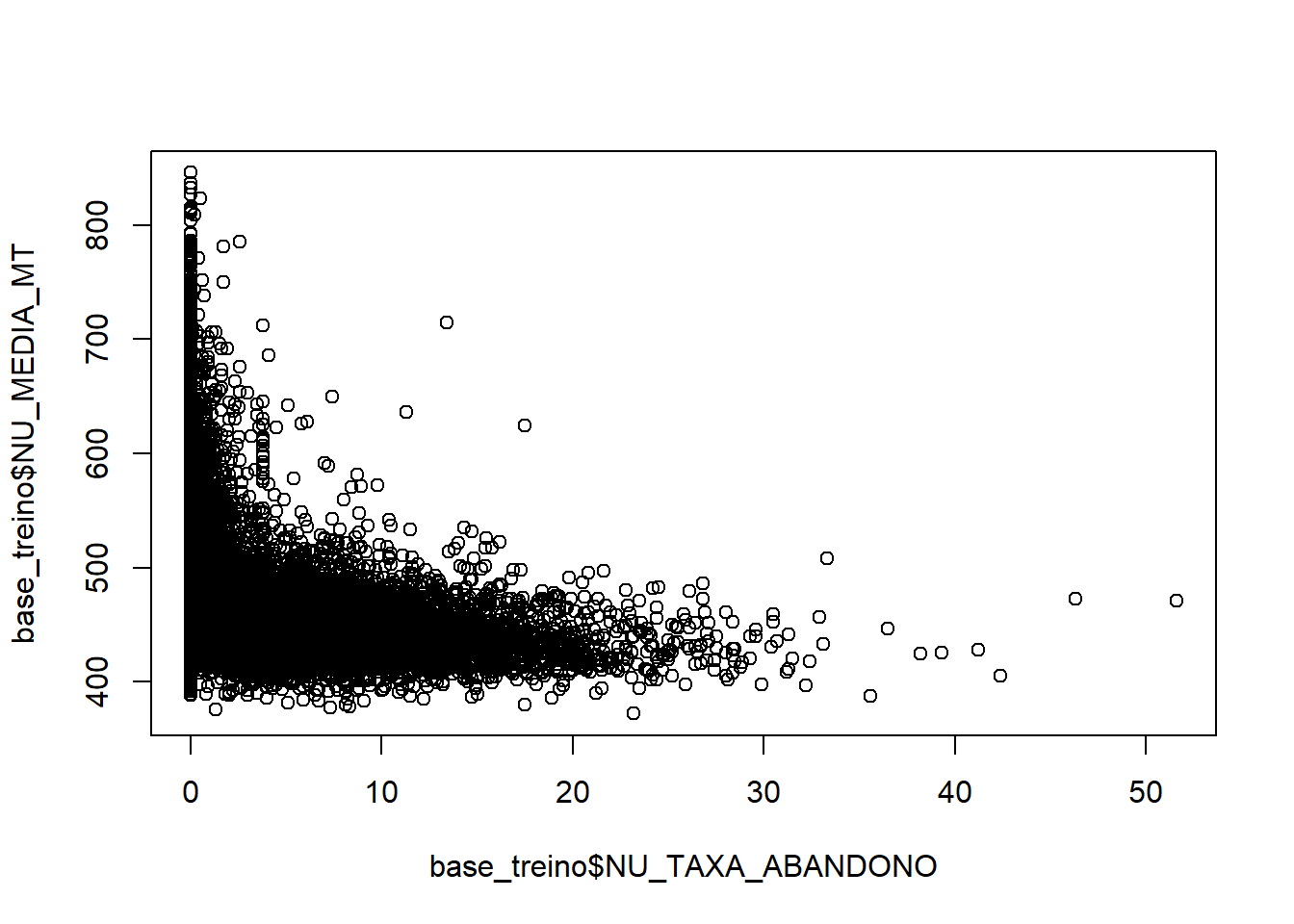
plot(base_treino$PC_FORMACAO_DOCENTE,base_treino$NU_MEDIA_MT)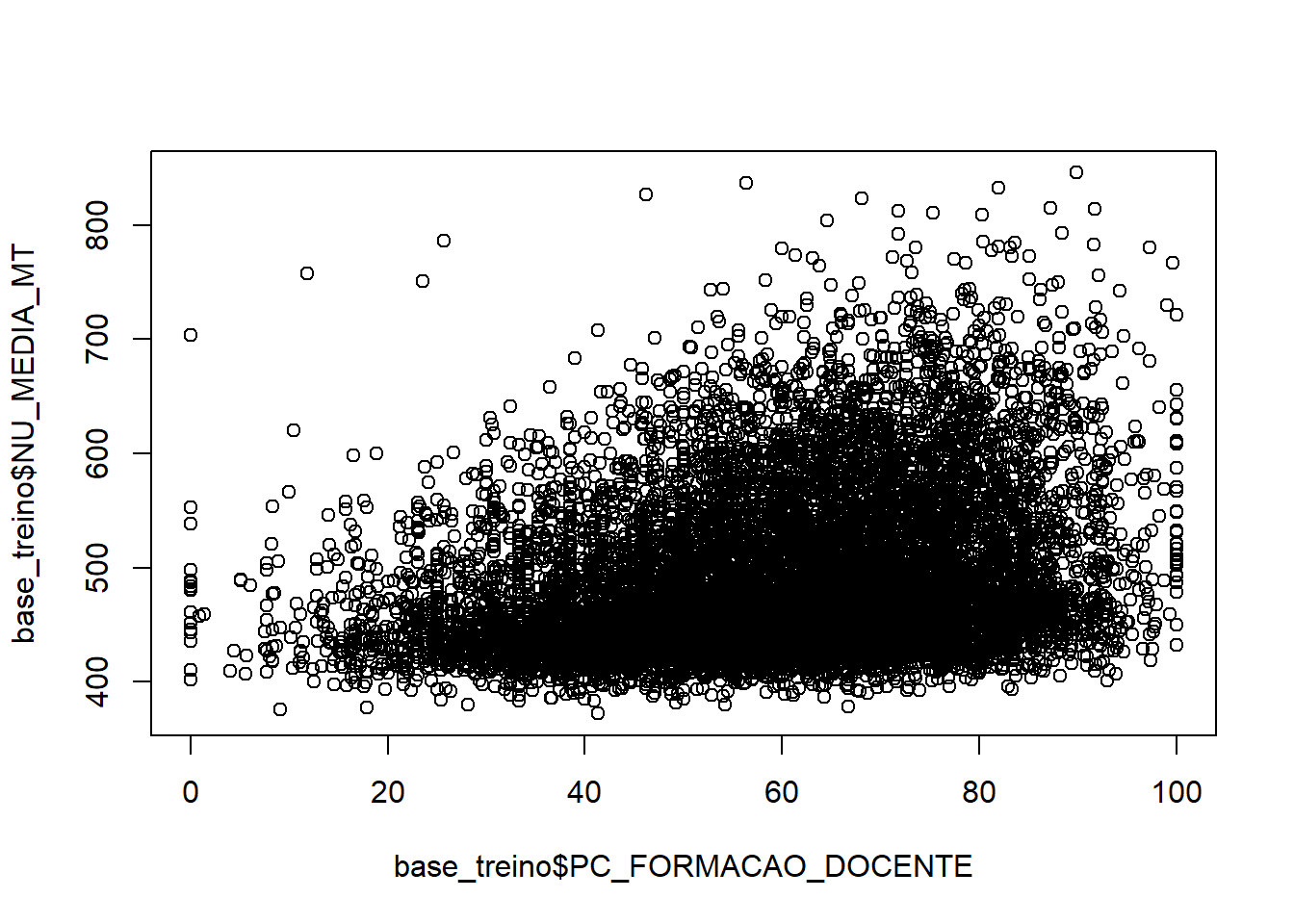
Agora a sua relação com as covariáveis qualitativas.
boxplot(base_treino$NU_MEDIA_MT ~ base_treino$TP_DEPENDENCIA_ADM_ESCOLA)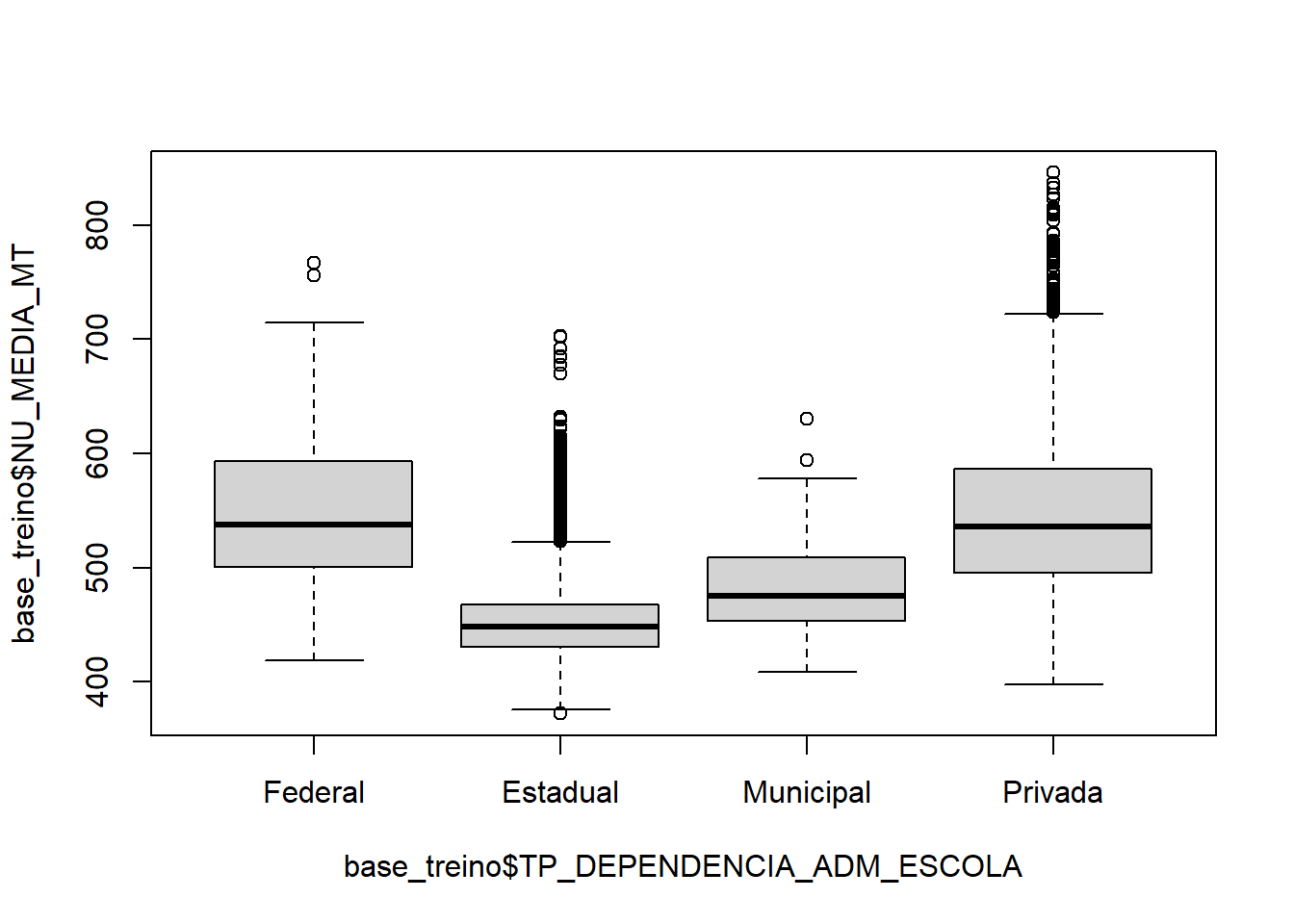
boxplot(base_treino$NU_MEDIA_MT ~ base_treino$TP_LOCALIZACAO_ESCOLA)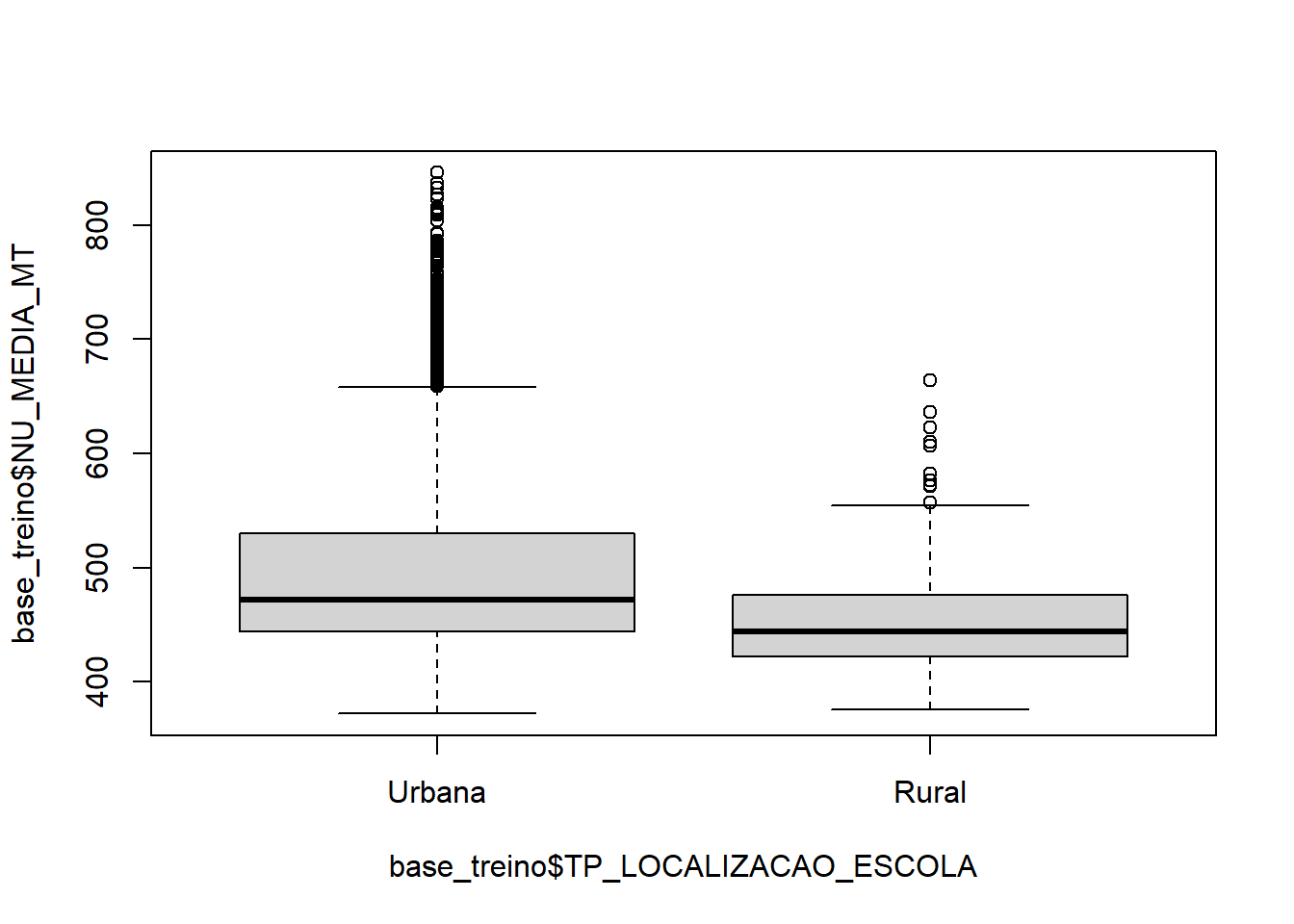
boxplot(base_treino$NU_MEDIA_MT ~ base_treino$INSE)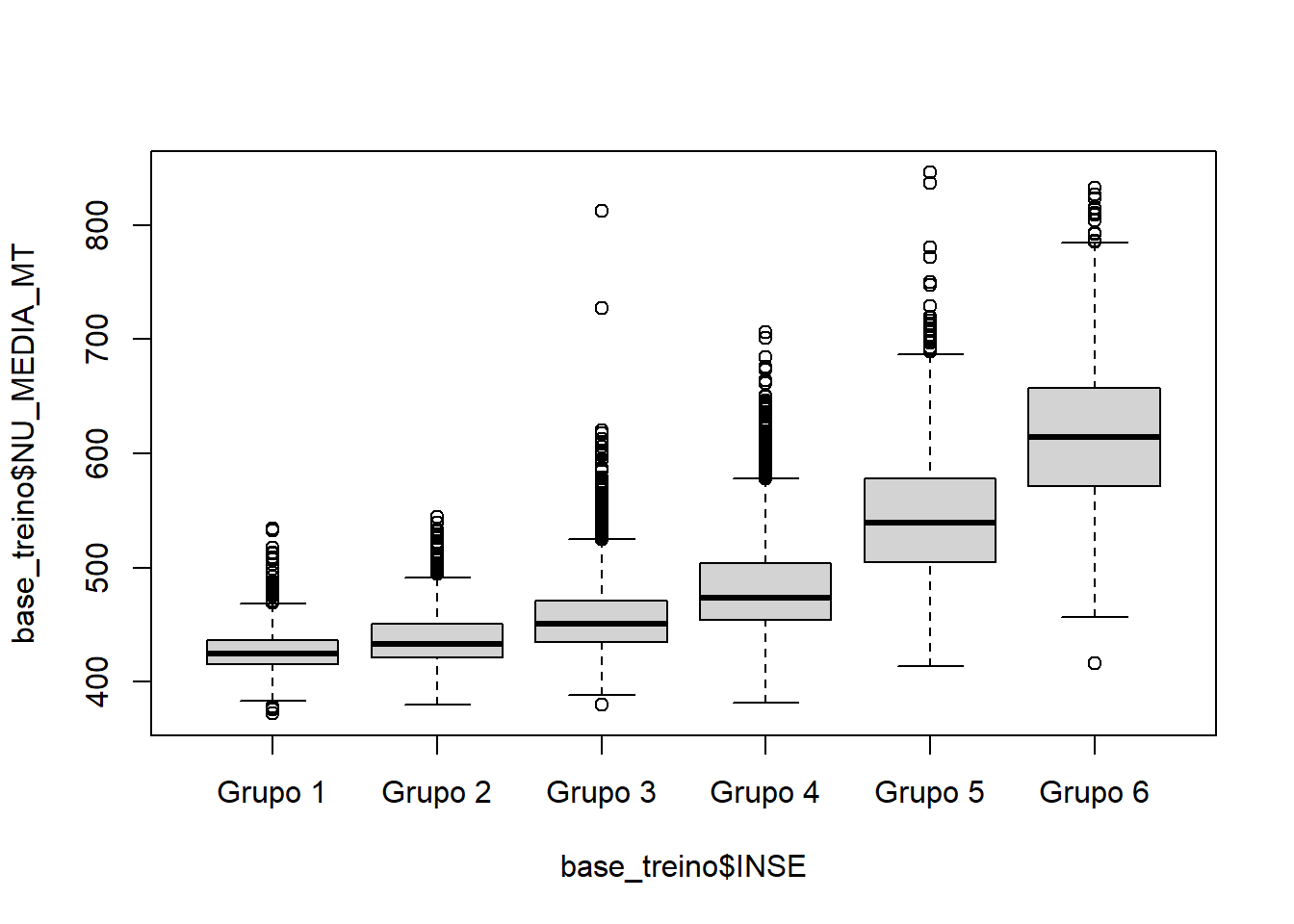
boxplot(base_treino$NU_MEDIA_MT ~ base_treino$PORTE_ESCOLA)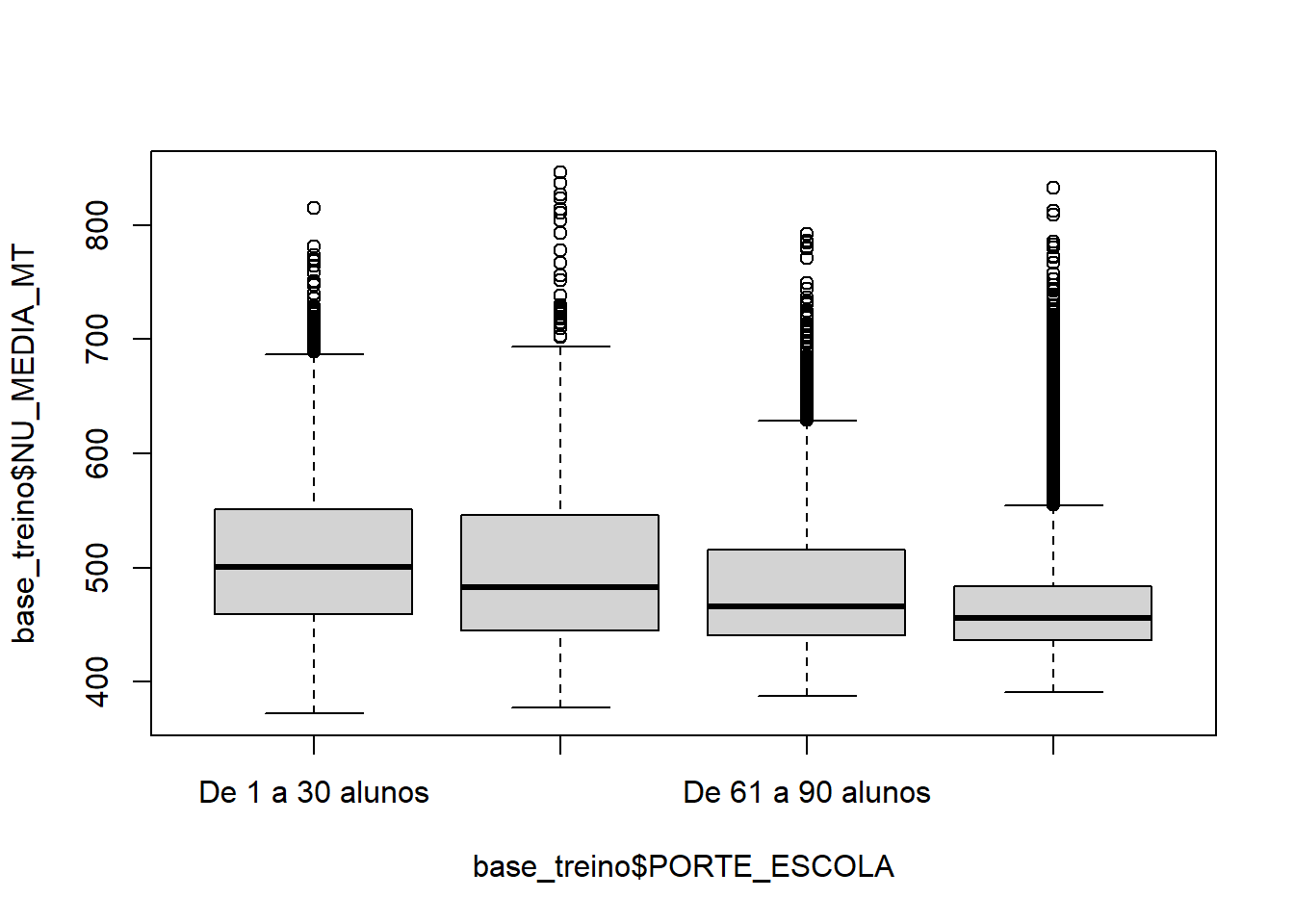
Para terminar a breve análise descritiva vejamos a relação da variável resposta qualitativa TAXA_PART_CAT e as demais covariáveis. Primeiro a sua relação com as covariáveis quantitativas.
boxplot(base_treino$NU_MATRICULAS ~ base_treino$TAXA_PART_CAT,horizontal = T)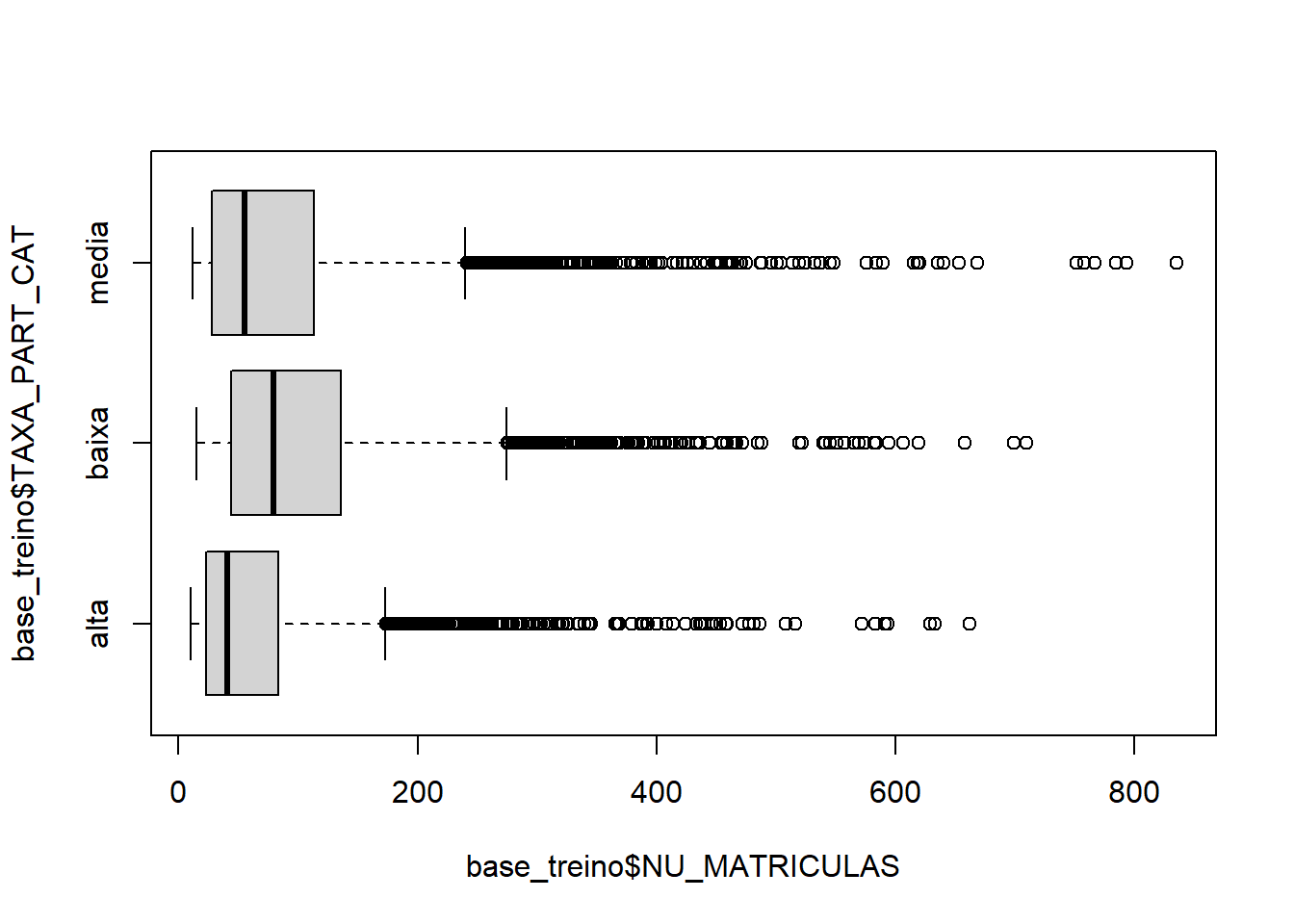
boxplot(base_treino$NU_PARTICIPANTES_NEC_ESP ~ base_treino$TAXA_PART_CAT,horizontal = T)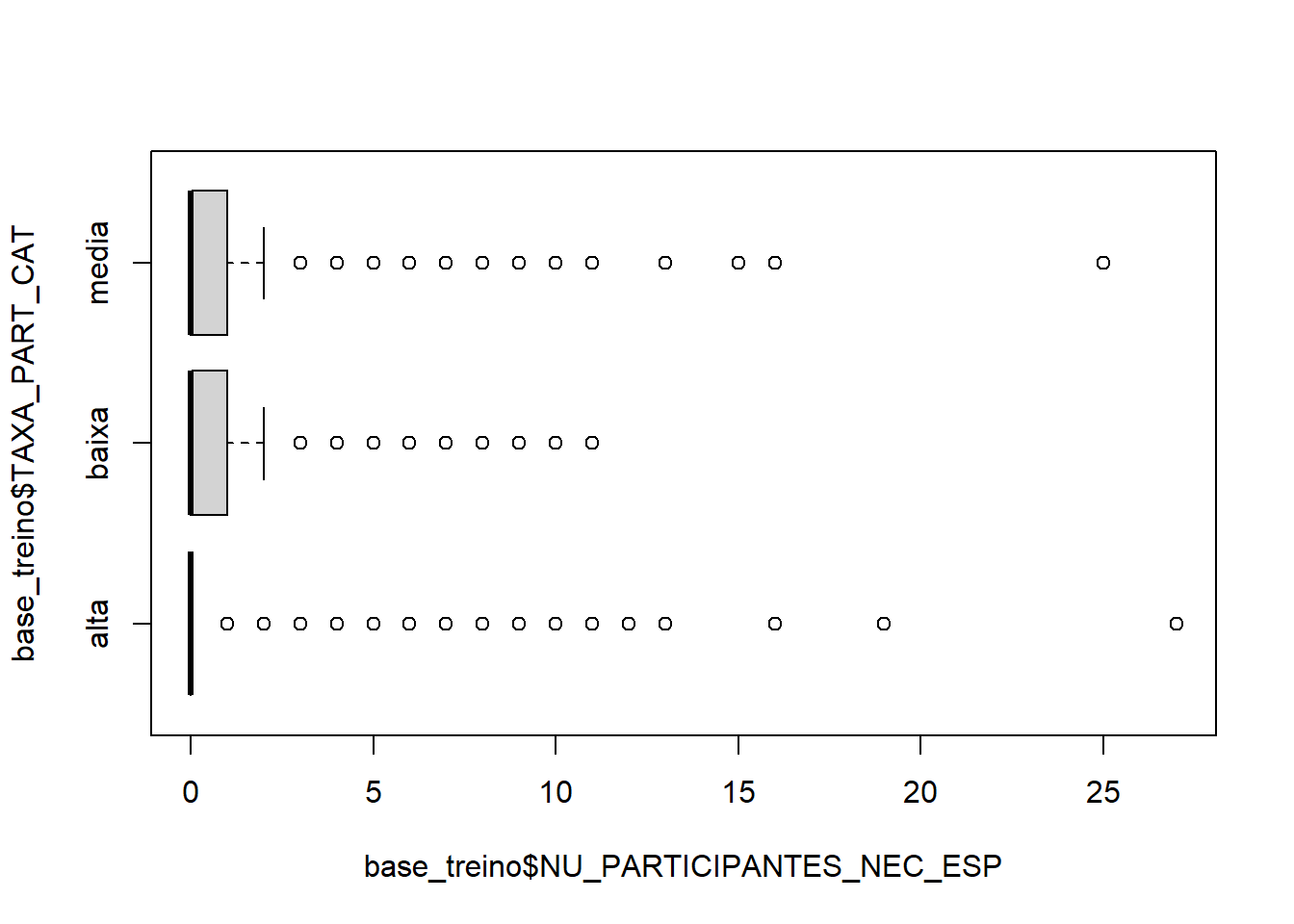
boxplot(base_treino$NU_PARTICIPANTES ~ base_treino$TAXA_PART_CAT,horizontal = T)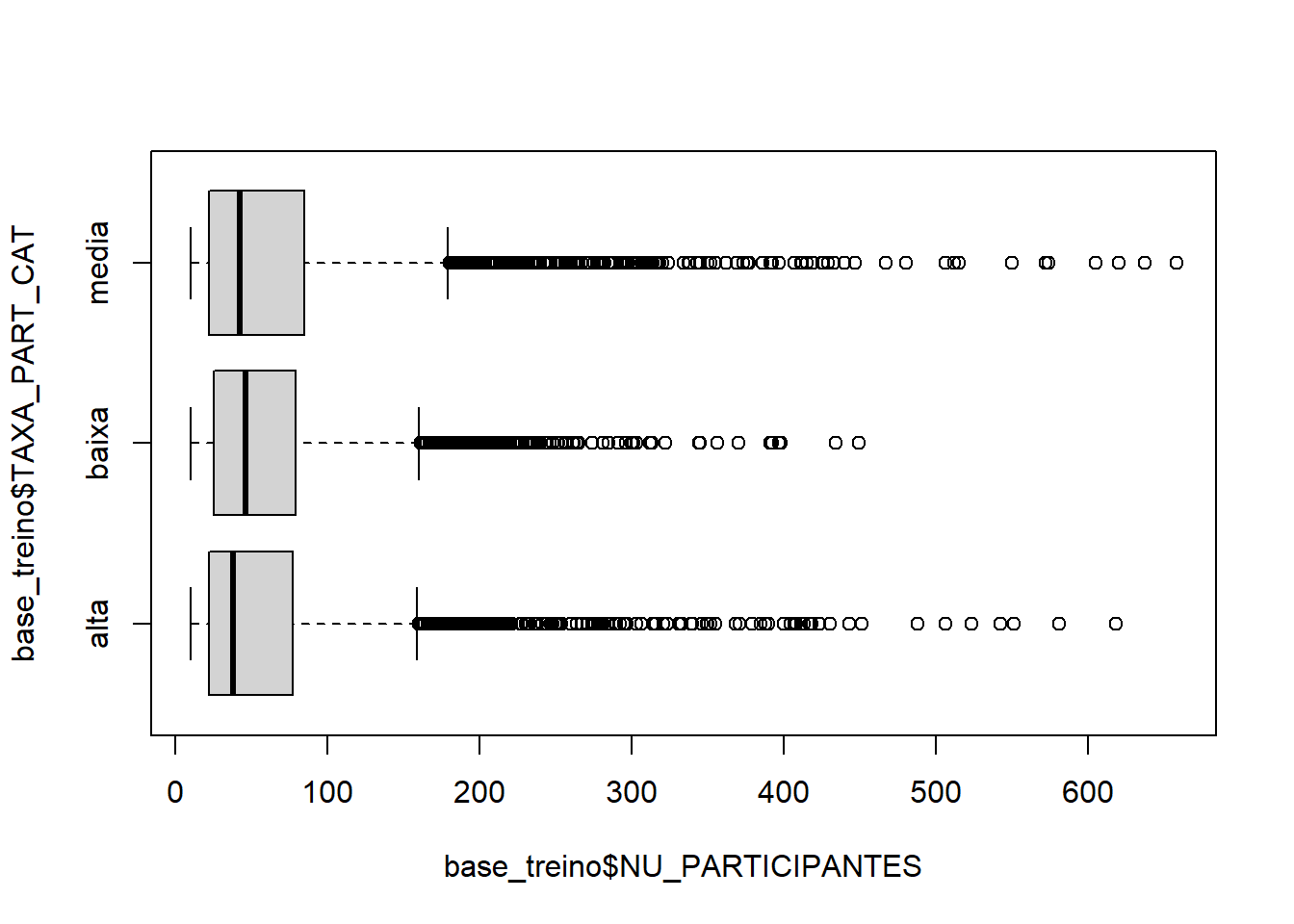
boxplot(base_treino$NU_TAXA_PERMANENCIA ~ base_treino$TAXA_PART_CAT,horizontal = T)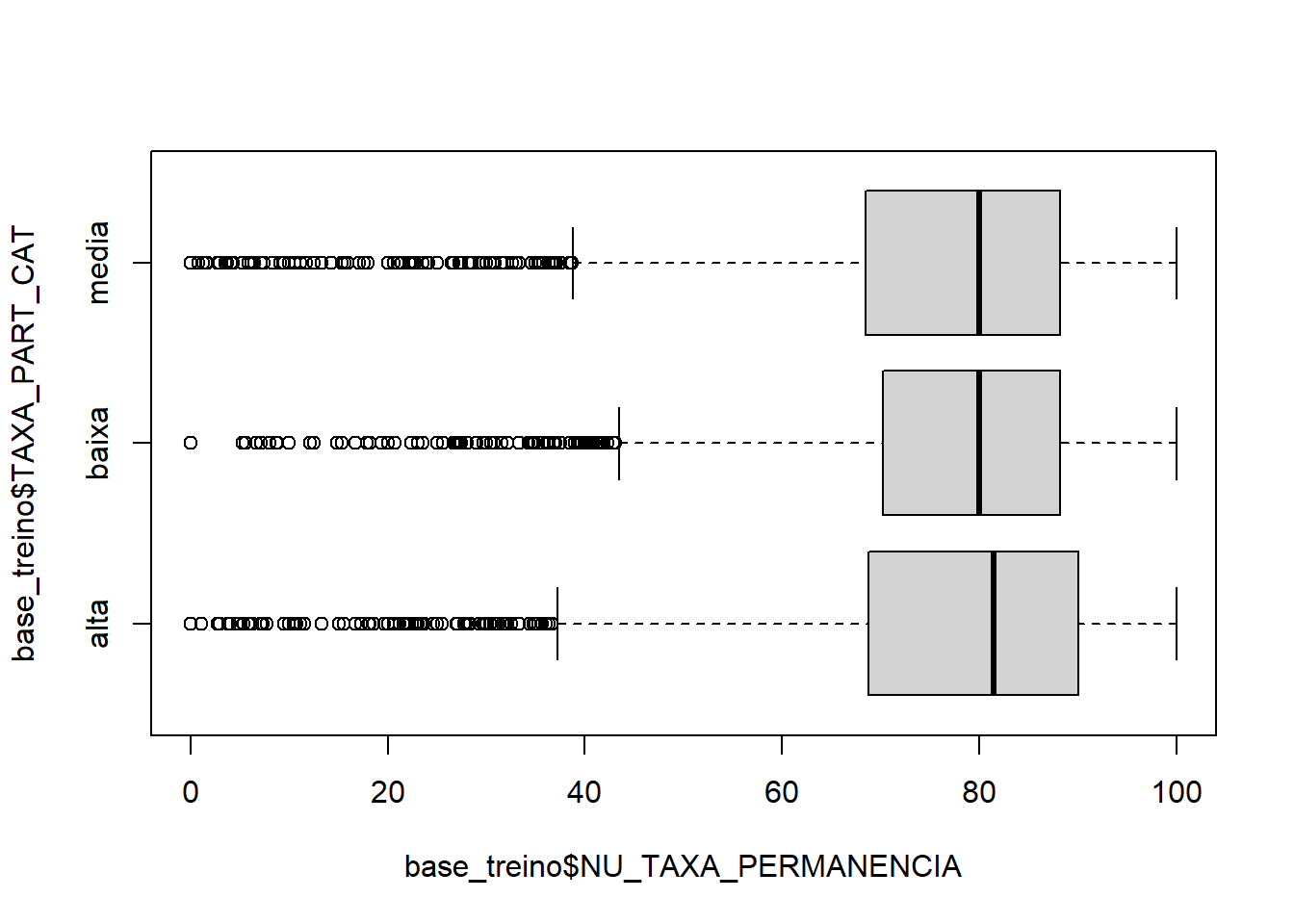
boxplot(base_treino$NU_TAXA_REPROVACAO ~ base_treino$TAXA_PART_CAT,horizontal = T)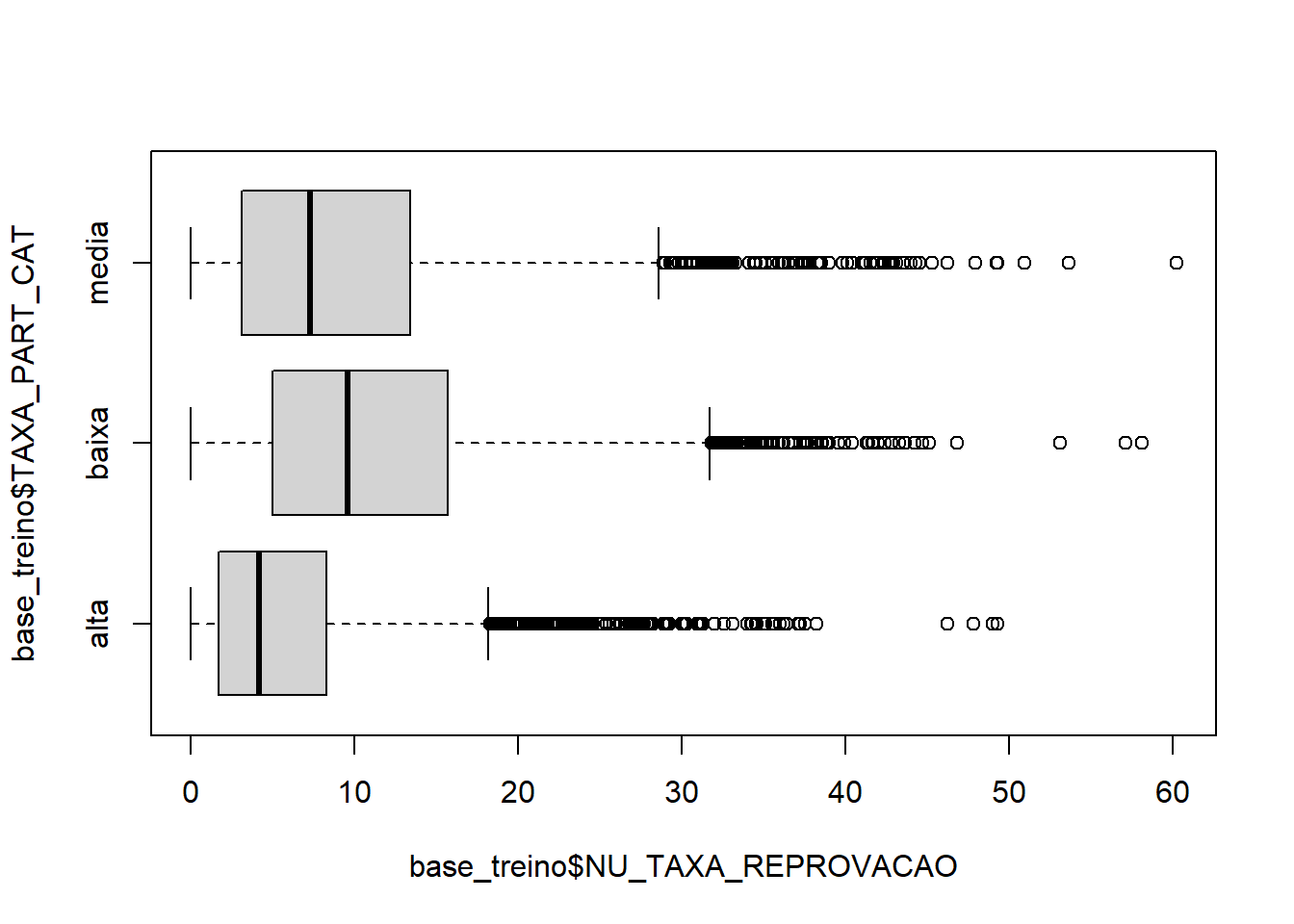
boxplot(base_treino$NU_TAXA_ABANDONO ~ base_treino$TAXA_PART_CAT,horizontal = T)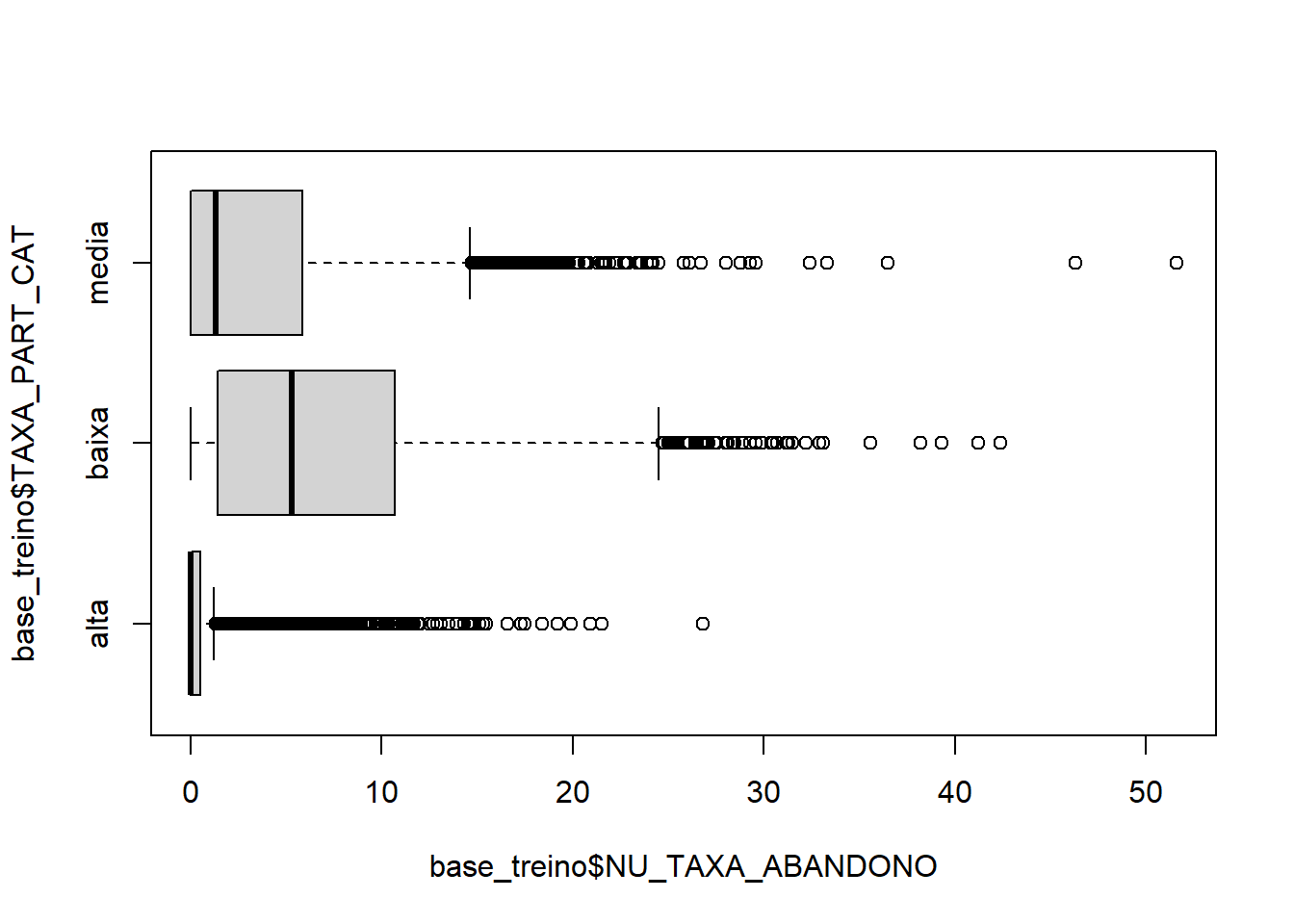
boxplot(base_treino$PC_FORMACAO_DOCENTE ~ base_treino$TAXA_PART_CAT,horizontal = T)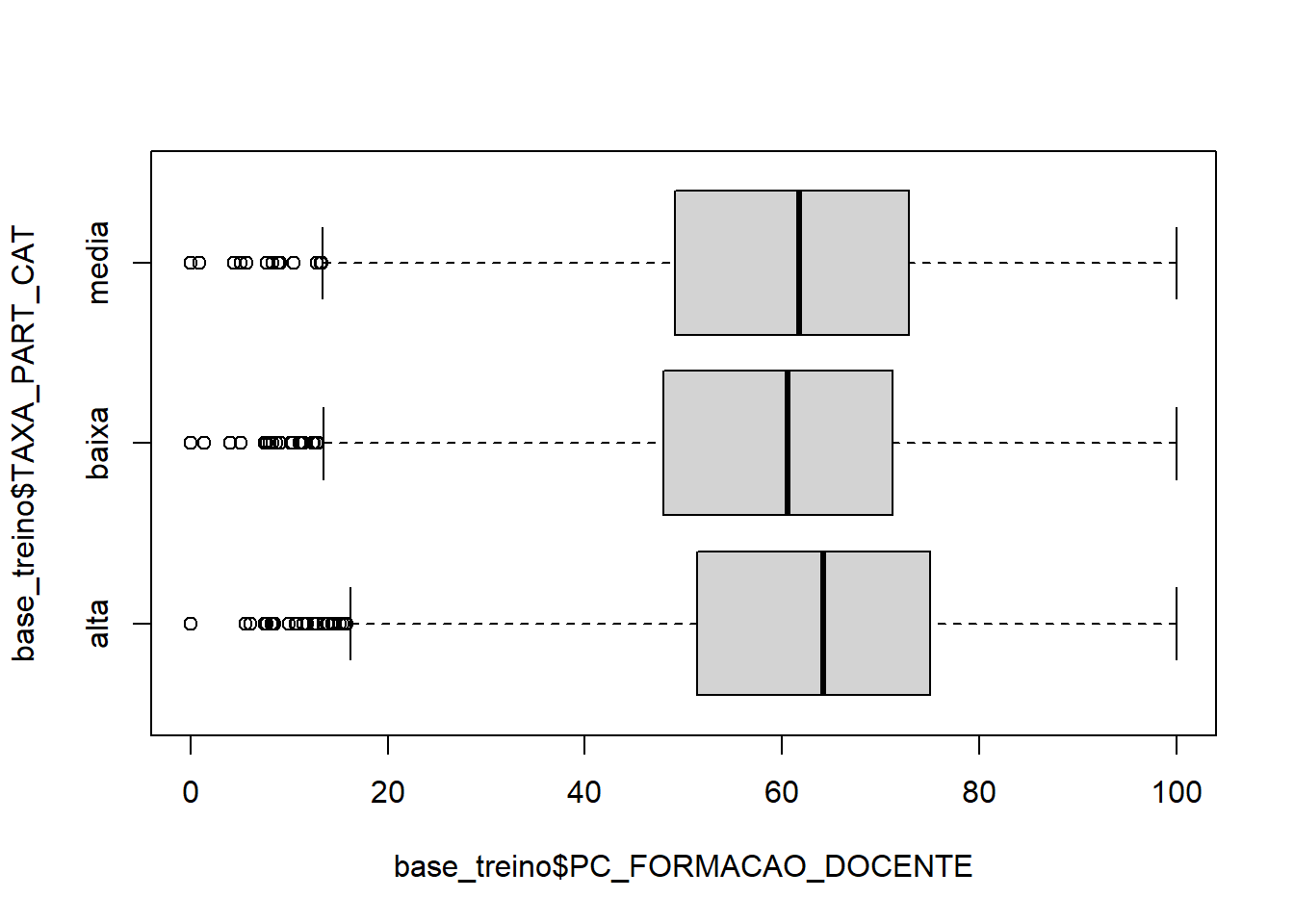
Agora a sua relação com as covariáveis qualitativas.
tabela = prop.table(table(base_treino$TAXA_PART_CAT,base_treino$TP_DEPENDENCIA_ADM_ESCOLA),2)
barplot(tabela,legend.text = row.names(tabela))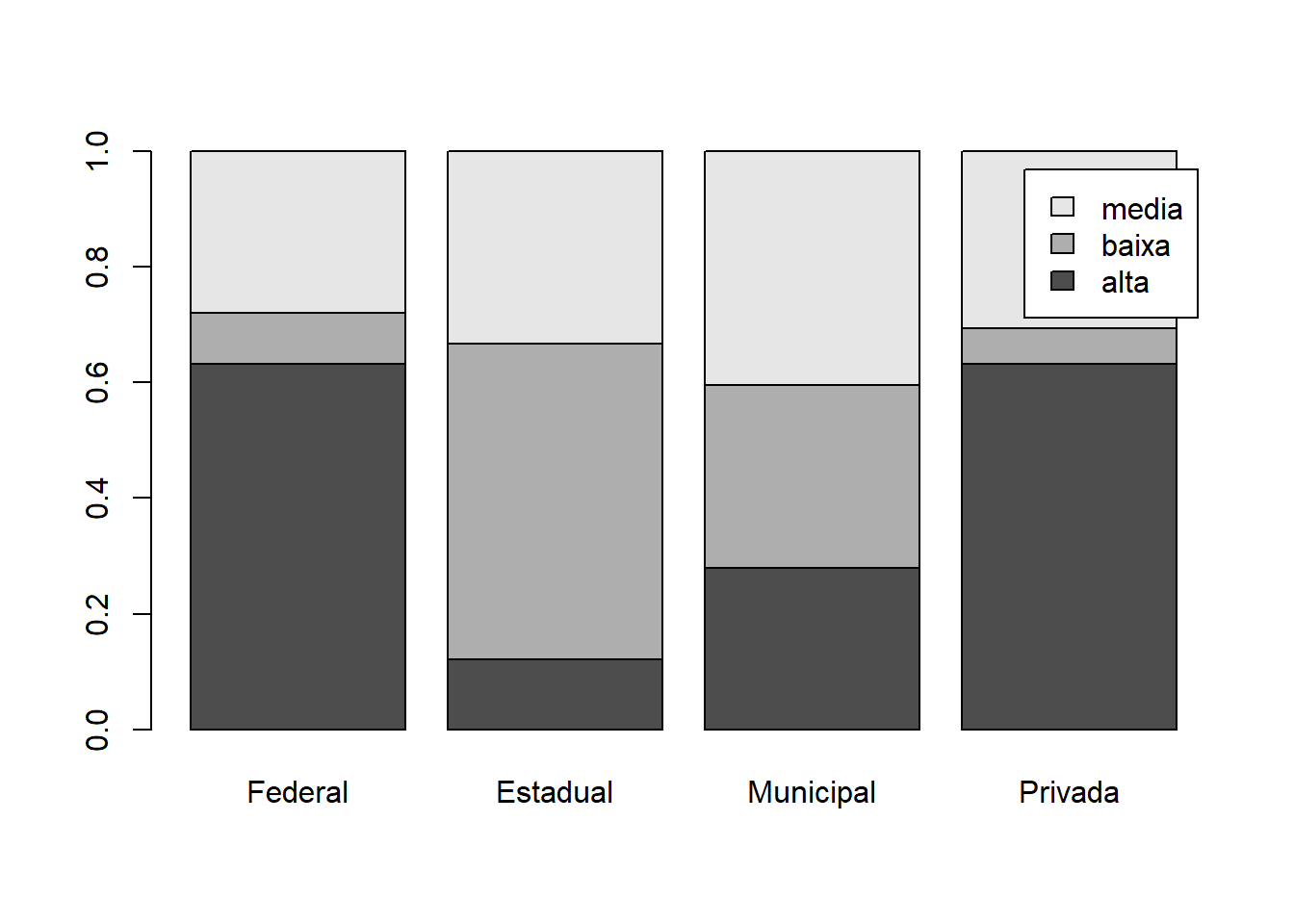
tabela = prop.table(table(base_treino$TAXA_PART_CAT,base_treino$TP_LOCALIZACAO_ESCOLA),2)
barplot(tabela,legend.text = row.names(tabela))
tabela = prop.table(table(base_treino$TAXA_PART_CAT,base_treino$INSE),2)
barplot(tabela,legend.text = row.names(tabela))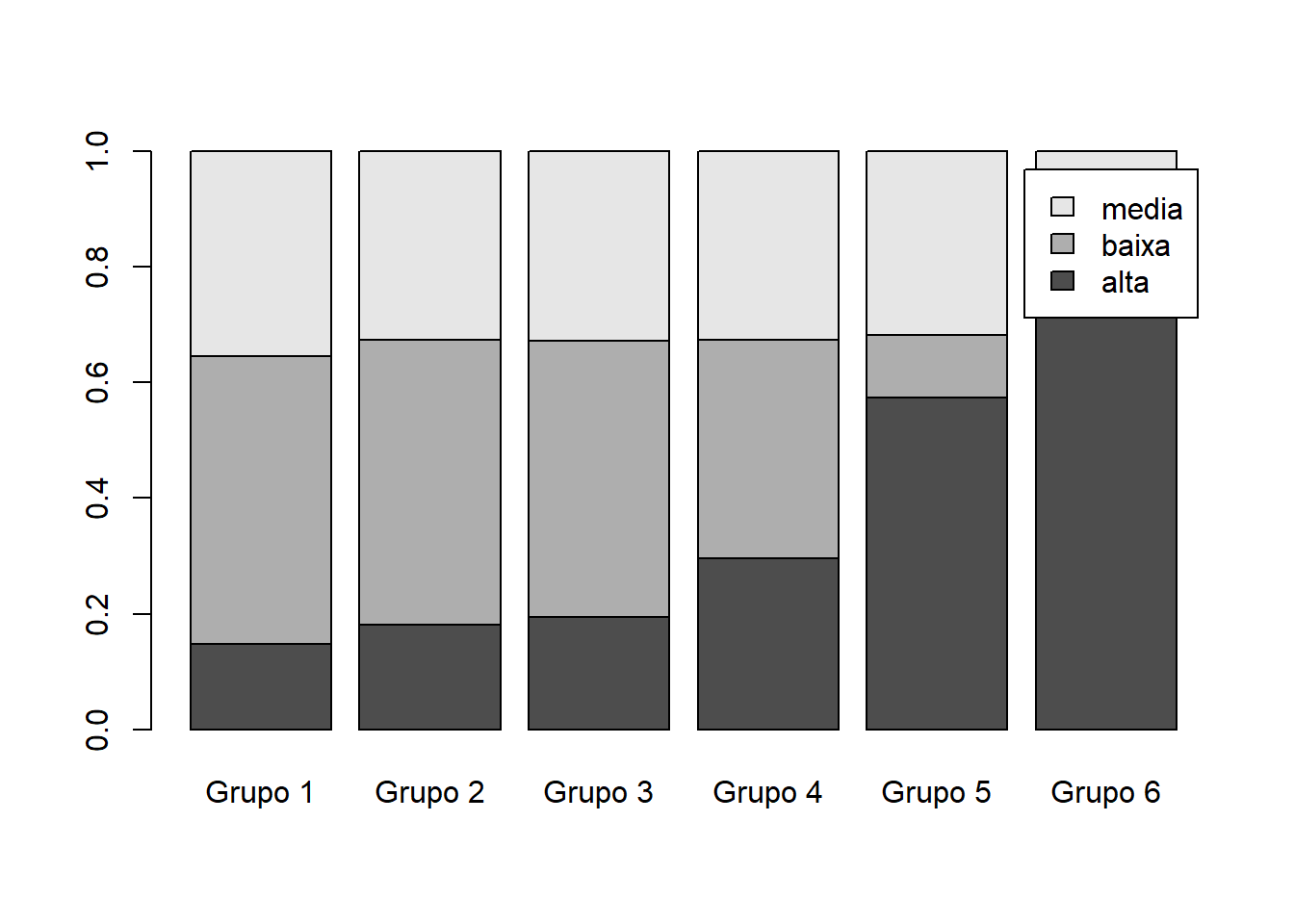
tabela = prop.table(table(base_treino$TAXA_PART_CAT,base_treino$PORTE_ESCOLA),2)
barplot(tabela,legend.text = row.names(tabela))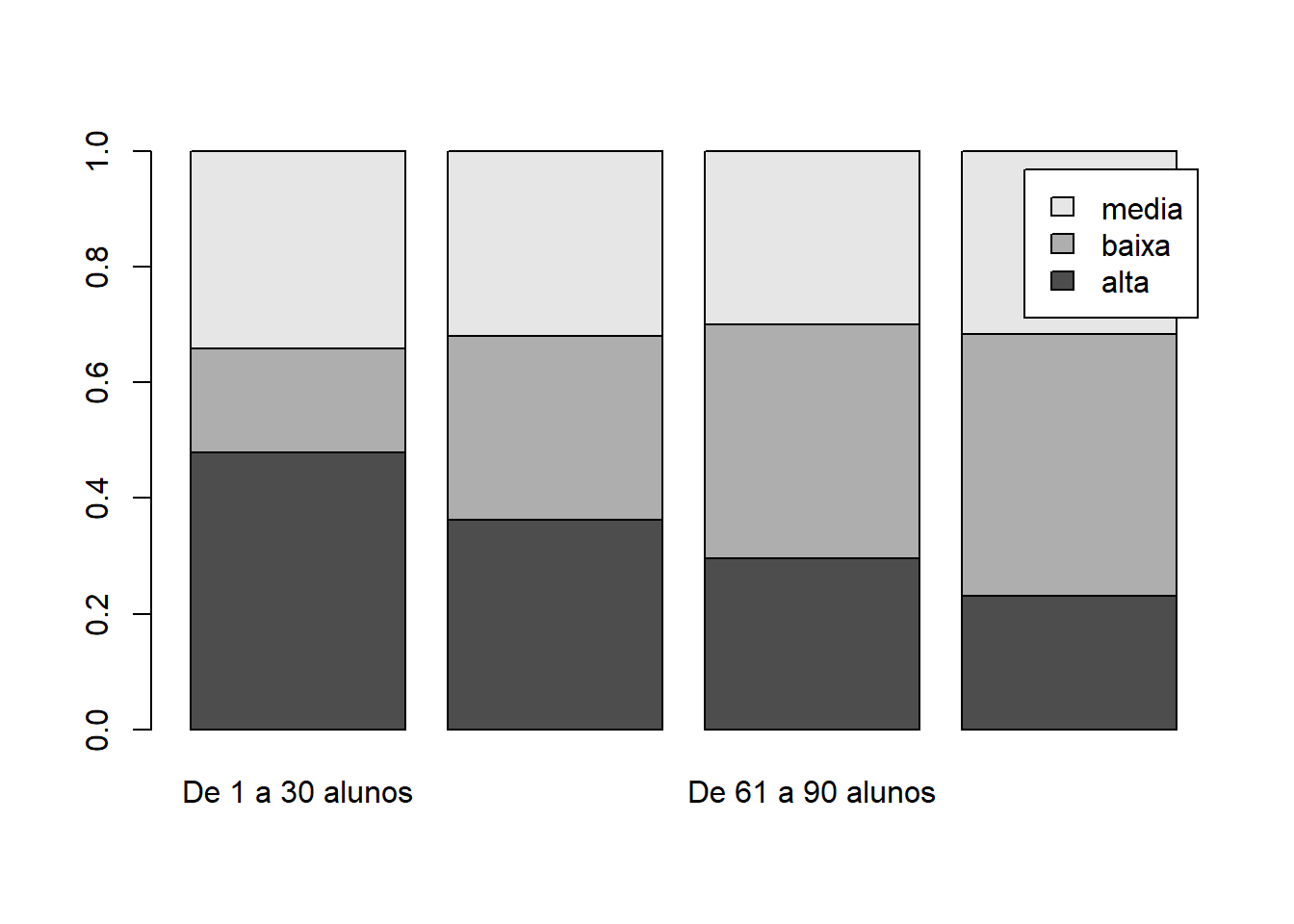
2.6 Como salvar a base final
Todo o processo realizado neste capítulo foi bem custoso e resultou em uma base de treino pronta para ser trabalhada. Para garantir que o trabalho realizado não precisará ser repetido, a base final deve ser salva. Assim, quando for necessário utilizar esta base, em algum trabalho, basta carregar a base final salva.
saveRDS(base_treino,file="salvos/base_treino_final.rds")
write_csv2(base_treino,file="salvos/base_treino_final.csv")
saveRDS(base_teste,file="salvos/base_teste.rds")
write_csv2(base_teste,file="salvos/base_teste.csv")