1 Motivação e Introdução
Neste capítulo será feita uma contextualização do curso e apresentados os primeiros conceitos e nomenclaturas da literatura de Machine Learning, que em português se diz Aprendizado de Máquinas.
1.1 Inteligência Artificial, Machine Learning e Deep Learning.
O termo Deep Learning representa um subconjunto de Machine Learning, que por sua vez é um subconjunto da Inteligência Artificial (Figura Figure 1.1) .

A Inteligência Artificial é caracterizada por qualquer programa que pode sentir, raciocinar, agir ou se adaptar, habilidades estas tipicamente humanas. Veja alguns exemplos:
Internet das Coisas (Internet of Things ou IoT);
Reconhecimento de imagens;
Reconhecimento de voz;
Mineração de texto;
Sistemas de Recomendação;
Tradução de um idioma para outro.
O Aprendizado de Máquinas é uma área da Inteligência Artificial caracterizada por algoritmos que melhoram o seu desempenho quando expostos a mais dados de entrada. Por exemplo, reconhecimento de imagens; reconhecimento de voz; algoritmos de previsão; recomendação. Já Deep Learning é um subconjunto do Aprendizado de Máquinas, isto é, também são algoritmos que melhoram o seu desempenho com o aumento dos dados de entrada, criados a partir de redes neurais multicamadas. Esses tipos de algoritmos são muito usados para problemas complexos com muitas variáveis de entradas, problemas de identificação em imagens ou tradução de idiomas.
1.2 Aprendizado de Máquinas
Em Aprendizado de Máquinas existem vários tipos de problemas. Para cada um deles, diversas maneiras de solucioná-los. A Figura Figure 1.2 apresenta uma divisão usual dos tipos de problemas em Aprendizado de Máquinas.
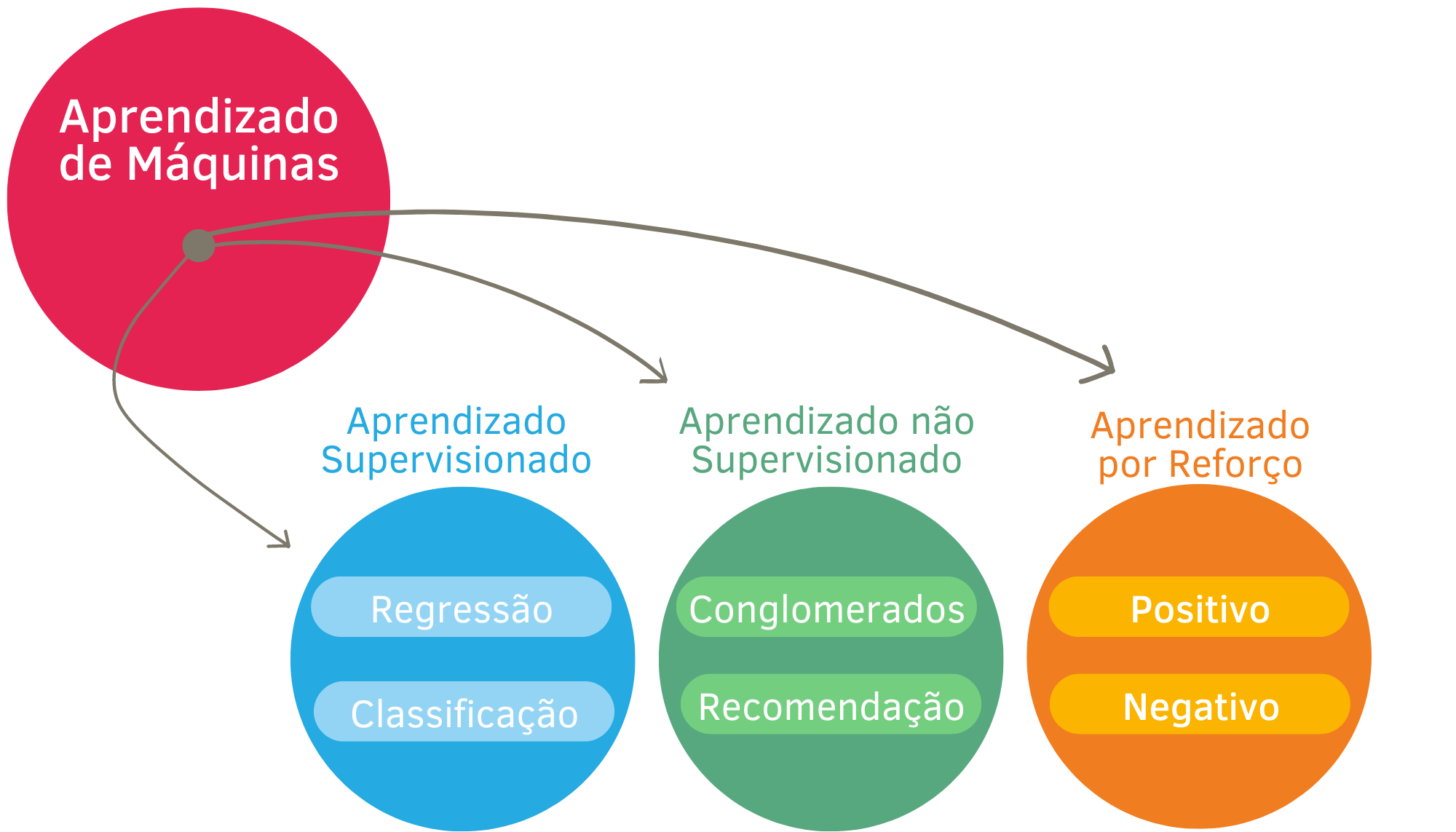
1.2.1 Aprendizado supervisionado
Os algoritmos de aprendizado supervisionado são aqueles que buscam prever uma variável alvo, que também pode ser chamada de desfecho, variável resposta ou variável de interesse. Nesse grupo de algoritmos um conjunto de covariáveis é usado para prever a variável alvo, que pode ser quantitativa ou qualitativa (categórica).
Quando a variável alvo for quantitativa, dizemos que o problema é de regressão. Quando a variável alvo for qualitativa, dizemos que o problema é de classificação.
Alguns métodos de aprendizado supervisionado: Modelos de Regressão Linear, Modelos Lineares Generalizados, Métodos Baseados em Árvores de Decisão (Floresta Aleatória e Boosting), Redes Neurais.
1.2.2 Aprendizado não supervisionado
Os algoritmos de aprendizado não supervisionado são aqueles que extraem informações de um conjunto de covariáveis, sem que haja uma variável de interesse a ser estimada. Como por exemplo, os problemas de análise de conglomerado, mapas-auto-organizáveis e os problemas de recomendação.
1.2.3 Aprendizado por reforço
Os algoritmos de aprendizado por reforço são aqueles que são aprimorados a partir de um esquema de punição e recompensa. Esses algoritmos também podem ser usados para resolver problemas de recomendação, por exemplo.
1.3 Problemas de regressão
Os problemas de regressão são aqueles que buscam uma relação entre uma variável alvo quantitativa, geralmente contínua, e diversas covariáveis. O método retorna uma estimativa para a variável alvo dada uma observação das covariáveis.
Predição do consumo de energia
Prever gastos previne surpresas e permite que o provedor se prepare para as despesas futuras. A previsão do consumo de energia em edifícios, em particular, é um problema desafiador uma vez que o consumo nos edifícios tem uma relação complexa com várias covariáveis.
Ding et. al. (Ding, Fan, and Liu 2021) realizaram um estudo que comparou o desempenho de diversos métodos de aprendizado de máquinas para previsão do gasto de energia de um prédio. O banco de dados utilizado, depois de um processo de limpeza, continha informações sobre 2.370 prédios. Foram ajustados seis modelos de regressão: Regressão Linear, Ridge Regression, SVR, Árvores de Decisão, Floresta Aleatória e XGBoost. Em particular, o método XGBoost apresentou o modelo mais adequado para a previsão do consumo de energia em um prédio. Analisando as variáveis importantes para todos os modelos pode-se concluir que o tipo principal de equipamento de refrigeração e a principal atividade do prédio foram as mais representativas para a previsão do consumo de energia.
Previsão de popularidade em redes sociais
Hoje em dia muitas pessoas usam as redes sociais como forma de trabalho, são os chamados influenciadores. Em geral, boa parte da fonte de renda deles vem de anúncios ou propagandas no seu perfil. O que faz uma marca se interessar em anunciar no perfil de um influenciador, é a sua popularidade. Então este é um indicador importante para se fazer negócios neste meio.

No trabalho de Purba et. al. (Purba, Asirvatham, and Murugesan 2020) o objetivo principal é prever a popularidade de usuários do Instagram. A variável alvo utilizada foi um índice de popularidade que combina a taxa de engajamento e a taxa de crescimento dos seguidores. Foram consideradas 14 covariáveis, entre elas: número de postagens, tamanho da descrição do perfil, número médio de hashtags utilizadas, entre outras. Os métodos utilizados para realizar essa previsão foram a Regressão Linear, Árvores de Regressão, Redes Neurais, XGBoost, Floresta Aleatória e SVR. Para a comparação dos modelos foi realizado uma validação cruzada e comparados os valores de \(R^2\), \(MAE\), \(RSME\) e \(RAE\). O Método de Floresta Aleatória apresentou o melhor resultado: \(R^2 = 0,852\) e o número de seguidores foi a variável mais relevante para a predição.
1.3.1 Previsão do aumento no custo de vida com a COVID
Durante a pandemia do coronavírus (COVID-19) vivemos um período de incertezas. Um fator relevante neste período foi a instabilidade no orçamento das famílias, muitas delas tiveram diminuição de renda com a política de isolamento social.

Lotfy (Lotfy 2021) realizou um estudo durante o período pandêmico cujo objetivo era prever o valor médio dos custos extras nos gastos dos lares egípcios com a pandemia da COVID-19. Um questionário estruturado pré-desenhado foi criado para medir o impacto da situação da COVID-19 sobre a economia dos lares. A maioria dos entrevistados eram mulheres (81%) e tinham entre 30 e 40 anos de idade (56,3%). Cerca de 63,1% das famílias mantiveram a mesma renda mensal enquanto 35,4% tiveram diminuição na renda mensal. Um modelo de Árvore de Regressão foi ajustado e detectou que o gasto extra em mercearia foi o item dominante em comparação com outros itens. Quanto à árvore de regressão, a média máxima dos custos extras devidos à pandemia de COVID-19 foi cerca de 88,56$/mês, enquanto a média mínima dos custos extras foi de 13,86$/mês. Concluiu-se que O efeito da pandemia da COVID-19 nos gastos domésticos varia muito entre as famílias, depende do que elas fazem para prevenir a COVID-19.
1.3.2 Previsão do desempenho escolar
Os estudantes enfrentam problemas que podem atrapalhar sua busca acadêmica pelo sucesso, problemas que vão desde questões triviais, como a condição da sala de aula e o estado emocional do estudante, até questões graves, como ruptura familiar, motivos econômicos e muitos outros. Os professores estão buscando uma maneira eficaz de encontrar a melhor solução para resolver certos problemas, uma vez que cada estudante pode enfrentar problemas diferentes, e resolver um de cada vez não é possível com o número de estudantes a cada ano.
Beckham et. al. (Beckham et al. 2023) realizaram um estudo que buscou identificar fatores que podem prejudicar ou melhorar o desempenho dos estudantes a partir da correlação de Pearson. Com base no resultado, falhas anteriores afetarão negativamente as notas dos estudantes, enquanto a Educação da Mãe afetará positivamente as notas dos estudantes. Em seguida foi feita a previsão das notas dos estudantes usando modelos de aprendizado de máquina: Perceptron multi-camadas, Árvores de Decisão e Floresta Aleatória. O modelo perceptron com 12 neurônios apresentou melhor desempenho, com um valor de RMSE de 4,32, seguido pelo Random Forest com um valor de RMSE de 4,52, e finalmente a Árvore de Decisão com um valor de RMSE de 5,69.
1.4 Problemas de classificação
Os problemas de classificação são aqueles que buscam uma relação entre uma variável alvo qualitativa (categórica) e diversas covariáveis. Em geral o método retorna um vetor de números entre 0 e 1, que indica a probabilidade de pertencer a cada categoria. Seguem dois exemplos.
Identificação de transação fraudulenta em cartão de crédito
O objetivo deste problema é determinar se uma certa operação no cartão de crédito representa uma fraude ou não. Em outras palavras, queremos observar características da transação e a partir desta informação decidir entre: fraude ou legítima. Para isso precisamos de uma amostra de dados sobre diversas transações, sendo algumas fraudulentas e outras não.
As covariáveis do problema são as informações possíveis de serem observadas até o instante da compra, como por exemplo, o valor da transação, a localização do estabelecimento de compra, a hora da operação, dados do cliente, entre outras. A variável de interesse é aquela que queremos prever, que não conseguimos identificar no momento da compra, que é uma variável categórica que indica se a operação em questão é uma fraude ou é legítima.

Dubey et al. (Dubey, Mundhe, and Kadam 2020) comparam diferentes métodos de classificação, como Redes Neurais, Árvores de Decisão, SVM, Regressão Logística e Floresta Aleatória, para identificar se uma transação é ou não fraudulenta. Todos os métodos deste estudo apresentaram acurácia maior que 95%, com destaque para a Rede Neural e a Floresta Aleatória, com acurácia superior a 99%.
Identificação de spam
O objetivo deste problema é identificar se uma mensagem (de email ou SMS) trata-se ou não de um spam observando as características dela. As características possíveis de serem observadas são as covariáveis do problema: o texto no assunto da mensagem, o texto no corpo da mensagem, o número de remetentes, o provedor de origem da mensagem, entre outras. A variável de interesse é aquela que queremos prever, que não conseguimos identificar no momento do recebimento da mensagem, que é uma variável categórica que indica se a mensagem é ou não um spam.
Este é um problema que tem mais um complicador: boa parte da informação é fornecida em formato de texto.
Goswami et al (Goswami, Malviya, and Sharma 2020) e Navaney et al. (Navaney, Dubey, and Rana 2018) comparam, em duas pesquisas diferentes, o desempenho de alguns métodos de classificação para a identificação de spam em mensagens de SMS. Os dois artigos trabalham com o mesmo conjunto de dados, que foi retirado do UC Irvine Machine Learning Repository1. Goswami et al (Goswami, Malviya, and Sharma 2020) compara o desempenho dos métodos de Floresta Aleatória, Naive Bayes (NB) e Support Vector Machine (SVM); já Navaney et al. (Navaney, Dubey, and Rana 2018) compara o desempenho do NB e SVM. A medida de comparação adotada foi a acurácia. Os resultados de Goswami et al (Goswami, Malviya, and Sharma 2020) apresentam valores de acurácia de 97.11%, 99.49% e 86.35% para os métodos de Floresta Aleatória, Naive Bayes e Support Vector Machine, respectivamente. Já o estudo de Navaney et al. (Navaney, Dubey, and Rana 2018) obteve uma acurácia melhor para o SVM quando comparado com o NB.
1.4.1 Identificação de risco para Diabetes
Na área de saúde é de grande interesse identificar fatores de riscos para doenças. Dessa forma é possível identificar os indivíduos com maior chance de desenvolver a doença e realizar um acompanhamento preventivo a fim de identificar a doença em seu estágio inciail.

Dudkina et al. (Dudkina et al. 2021) realizaram uma pesquisa cujo objetivo é prever as chances de um indivíduo ter diabetes. Para isso foi construído um modelo de aprendizagem de máquinas com base em métodos de árvore de decisão. Os pesquisadores utilizaram a base pública The Pima Indians Diabetes DataBase, disponível pelo Kaggle*2, que contém informações sobre 768 pacientes do sexo feminino, com mais de 21 anos e de orige indígena Pima. Foram usados 9 atributos para a análise, 8 covariáveis e 1 variável alvo. As covariáveis são características das pacientes, como idade e índice de massa corporal. A variável alvo é uma variável indicadora sobre a paciente ter ou não diabetes.
1.4.2 Identificação de fatores de risco para evasão escolar
A evasão escolar de estudantes é um sério problema global. Isso afeta não apenas o indivíduo que desiste da escola, mas também a a família e a sociedade em geral. Entender os fatores que aumentam o risco de um estudante deixar os estudos permite agir com antecedência, investir recursos públicos de forma direcionada e quem sabe evitar que alguns dos estudantes largem a escola.

Em 2022 Niyogisubizo te. al. (Niyogisubizo et al. 2022) propõe um método que combina Random Forest (RF), Extreme Gradient Boosting (XGBoost), Gradient Boosting (GB) e Redes Neurais Feed-forward (FNN) para prever a evasão de estudantes em aulas universitárias. A base foi coletada entre 2016 e 2020 na Universidade Constantine the Philosopher em Nitra. O método proposto demonstrou melhor desempenho em comparação com os modelos base usando como métrica de avaliação a precisão e a área sob a curva (AUC) na base de teste.
1.4.3 Classificador Multiclasses
Ainda na área de educação, sabe-se que as notas dos alunos são um dos principais indicadores que podem ajudar os educadores a monitorar o desempenho acadêmico. Quando pensamos em avaliações conceituais, e não numéricas, o problema de prever o desempenho de um aluno passa a ser um problema de classificação e não mais de regressão. Pensando que a nota do aluno pode, por exemplo, variar entre alguns possíveis conceitos, por exemplo, A, B, C, D e E, trata-se de uma classificação multiclasses. Para aumentar ainda mais a complexidade, imagine-se que a quantidade de alunos com conceito “A” deva ser bem menor do que a quantidade de alunos com conceitos “B” ou “C”.
No entanto, existem desafios significativos na manipulação de conjuntos de dados desequilibrados para aprimorar o desempenho na previsão das notas dos alunos. O artigo de Bujang et. al. (Bujang et al. 2021) apresenta uma análise abrangente de técnicas de aprendizado de máquina para prever as notas finais dos alunos nos cursos do primeiro semestre de ciência da computação. Dois módulos serão destacados neste artigo: a comparação da precisão de seis técnicas de aprendizado de máquina (Árvore de Decisão, Máquina de Vetores de Suporte, Naïve Bayes, K-Nearest Neighbor, Regressão Logística e Floresta Aleatória); e a proposta de um novo método multiclasses para dados desequilibrados. Os resultados obtidos mostram que o modelo proposto, quando integrado com a Floresta Aleatória, oferece uma melhoria significativa, com a maior medida F de 99,5%. Esse modelo proposto indica resultados comparáveis e promissores que podem aprimorar o desempenho do modelo de previsão para multiclassificação desequilibrada na previsão das notas dos alunos.
1.5 Base de Dados
A base de dados a ser analisada pode ser construída pelos próprios pesquisadores ou pode ser retirada de algum repositório público de dados. Quando a base é de autoria dos pesquisadores, estes são responsáveis por realizar um plano amostral, de acordo com o seu problema, selecionar os indivíduos e recolher as características de interesse do estudo. Quando a base utilizada é de um repositório, os pesquisadores tentam ajustar o seu problema para a base já existente.