20 Day 20 (April 3)
20.1 Announcements
Remember that next lecture on Tuesday is a work day.
April check-in is worth 5% of your grade. Please send email to both Aidan and I to plan your April check in.
Selected questions/clarifications from journals
- Where is the line between “statistical models” and “machine learning models”?
- Review expoential growth model from last lecture and why this is statistics
- Machine learning applied to whooping crane data (Download here)
- MS defense in Room 302 Dickens Hall Tomorrow
- Project related question. Build my own software for model fitting, use a specialized R package (like TGP), or use something like JAGs?
- Where is the line between “statistical models” and “machine learning models”?
20.2 Data fusion
- See Ch. 25 in BBM2L
- Formative story (math and people working together) and publication
- Many different names
- Integrated modeling
- Data reconciliation
- Data fusion
- Why use Bayesian statistics for data fusion?
- The probability someone has crafted the model you need (and criticism of my own work)?
- Use of the hierarchical modeling framework
- Recursive use of Bayes theorem (see here)
- Example where it is time consuming to get precise data
- Age vs. height
- Abundance vs. presence/absence data
- Disease status of plants (see pgs 407-424 in BBM2L)
- Percent cover data
- Ad-hoc approaches
- Simple pooling
- Transform high quality into low quality data and then pool
- Example: Konza percent grass cover
- Exact cover data
url <- "https://www.dropbox.com/s/8ohtahx99jox9a5/konza_grass_exact.csv?dl=1" df.grass.exact <- read.csv(url) head(df.grass.exact)## percgrass elev ## 1 13 420.860 ## 2 45 399.306 ## 3 72 412.792 ## 4 9 422.606 ## 5 21 381.152 ## 6 37 397.789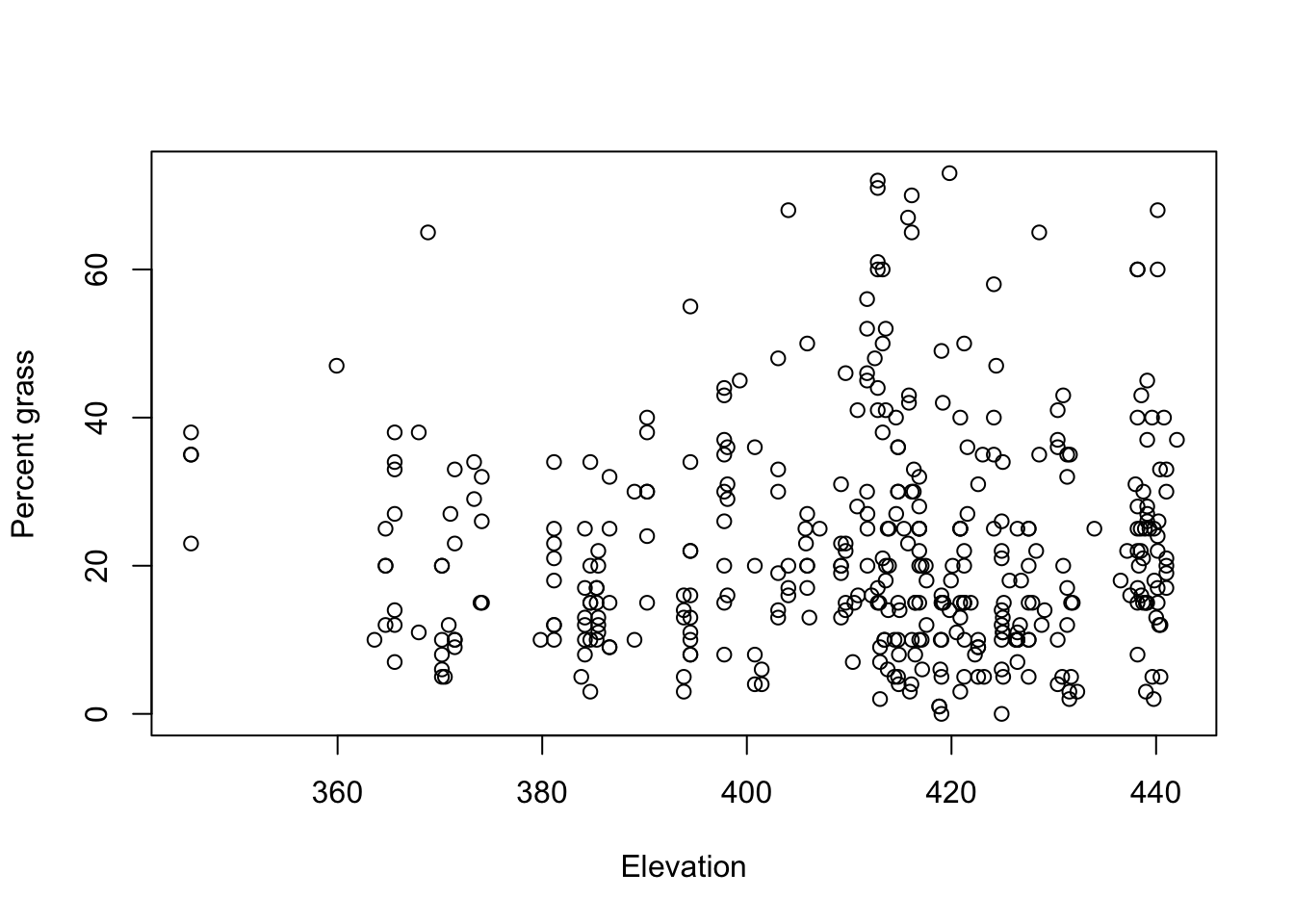
- Cheap cover data
url <- "https://www.dropbox.com/s/eef5hy8geyi73ke/konza_grass_cheap.csv?dl=1" df.grass.cheap <- read.csv(url) head(df.grass.cheap)## percgrass elev ## 1 <50% 430.380 ## 2 <50% 430.380 ## 3 <50% 430.380 ## 4 <50% 430.380 ## 5 <50% 425.015 ## 6 <50% 425.015- Model formulation (go over on white board)
- Model implementation (go over on white board)
- Live example (Download here)