Anexo D Formateo de data frames
Aunque el uso de las dos funciones ilustradas en el Anexo B resulta suficiente para generar objetos funcionales para la mayoría de las situaciones, hay casos en los que se requiere realizar algún formateo adicional. La función formatData facilita dicho proceso, realizando las siguientes acciones:
- Llevar un objeto multiclase —como los que se generan al importar con la función
read_excel— a la clasedata.frame. - Adecuar nombres de variables y eliminar puntos innecesarios.
- Convertir vectores en factores.
- Eliminación de espacios en los niveles de los factores.
En el Anexo B se menciona que los objetos multiclase pueden generar conflictos y errores cuando se usan con las funciones tradicionales. En consecuencia, es deseable eliminar las clases que no van a usarse, llevando tales objetos a la clase data.frame. La función formatData realiza este proceso.
En el Anexo B se hace referencia a los nombres de las variables en los data frames, indicando que estos no deben contener ni espacios ni caracteres especiales (cf. capítulo 12). En ocasiones sucede que el proceso de adecuación, al remplazar los espacios y los caracteres especiales por puntos, genera nombres con muchos puntos, dando lugar a nombres que, aunque funcionales, no resultan estéticos.
Un nombre como ‘log..Crecimiento..UFC..’ podría verse mejor así: ‘log.Crecimiento.UFC’.
La función formatData verifica los nombres de todas las variables y realiza las adecuaciones necesarias, eliminando espacios y caracteres especiales, y dejando únicamente un punto de separación entre palabras.
Muchas funciones exigen que sus argumentos sean vectores de la clase factor, la cual se utiliza para caracterizar variables categóricas con base en un conjunto de niveles (cf. sección 10.4). Esta clase de objetos no se genera automáticamente en los procesos de importación, siendo necesario realizar la definición específica para los vectores que así lo requieran.
La función formatData convierte en factores todos los vectores de la clase character (los que contenían cadenas de caracteres en el archivo Excel desde el cual fueron importados). Asimismo, de manera opcional, convierte en factores todos los demás vectores especificados por el usuario, a través del argumento factors, mediante el cual se indica, por medio de un vector numérico, cuáles columnas del data frame deben convertirse en factores.
En adición a lo anterior, en ocasiones sucede que las etiquetas que definen los niveles de los factores no se han ingresado de manera homogénea en el archivo Excel, pudiendo existir espacios antes o después de la etiqueta que, aunque no se visualicen en el archivo de Excel, se importan como diferentes etiquetas . Así, cada una de las siguientes etiquetas representa un nivel diferente del factor:
" a1" " a1" "a1" "a1 " "a1 " " a1 " La función formatData elimina los espacios que pudieran existir antes y después de estas. Así, las 6 etiquetas ilustradas anteriormente quedarían unificadas en un único nivel: “a1”, lo cual, sin lugar a dudas, es lo que el usuario tenía en mente.
A continuación se presenta la función formatData, con comentarios al inicio de cada sección, para mejor comprensión:
formatData <- function (data = NULL, factors = NULL)
{
# Adecúa clase, nombres y niveles de los factores
# Args:
# data : Data frame con los datos (def: data)
# factors : Convierte y revisa todos los vectores de las
# clases factor y character (por defecto)
# Adicionalmente, pueden definirse otros
# factores, usando un vector con los
# correspondientes números de columna
# Lectura de la base de datos -------------------------------
if (is.null(data))
data <- .GlobalEnv$data
# Conversión a data frame -----------------------------------
data <- data.frame(data)
# Adecuación de nombres de variables ------------------------
n0 <- names (data)
names(data) <- sub("^+[.]", "", (sub("[.]+$", "",
(gsub("[.]+", ".", n0)))))
# Vector indicador de factores ------------------------------
f <- rep(F, ncol(data))
if(!is.null(factors))
f[factors] <- T # Factores especificados por el usuario
for (j in 1:ncol(data))
if(is.factor(data[, j]) | is.character(data[, j]))
f[j] <- T
# Eliminación de espacios en niveles de los factores -------
for (j in 1:ncol(data))
if (f[j]) {
data[, j] <- as.character(data[, j])
for (i in 1:nrow(data))
data[i, j] <- trimws((data[i, j]), white = "[\\h\\v]")
data[, j] <- factor(data[, j])
}
output <- data
}\[ \]
La función formatData no requiere ningún argumento. Por defecto, lee un data frame llamado data (si el data frame tuviera otro nombre, se indicaría explícitamente) y el resultado se sobrescribe en el data frame.
Así, para realizar la adecuación de un data frame llamado data, que se encuentre ubicado en el ‘Global Environment’, basta con escribir la siguiente instrucción:
data <- formatData()Consideremos ahora la siguiente información de un archivo Excel.
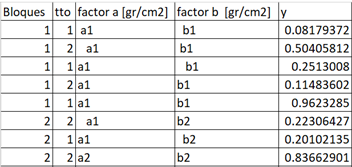
Con el fin de ilustrar las adecuaciones que pueden realizarse mediante la función formatData, supongamos que se realiza el proceso de importación mediante las siguientes instrucciones.
library(openxl)
data6 <- read.xlsx ("Anexo 4.xlsx"))Los nombres de las columnas del objeto data6 no se ajustan a un formato estándar que pueda usarse de manera directa en las funciones (cf. capítulo 12). Los dos primeros vectores del data frame son de la clase numeric, mientras que el tercero y el cuarto son de la clase character. Adicionalmente, se observa que las etiquetas de las columnas 3 y 4 no están escritas de manera uniforme, lo que da lugar a una definición errónea de los niveles de los factores .
names(data6)
#> [1] "Bloques" "tto" "factor.a.[gr/cm2]" "factor.b.[gr/cm2]" "y"
class(data6$Bloques)
#> [1] "numeric"class(data6$`factor.a.[gr/cm2]`)
#> [1] "character"levels(factor(data6$`factor.a.[gr/cm2]`))
#> [1] " a1" " a1 " " a3 " " a1" " a2" " a3" "a1" "a1 "
#> [9] "a1 " "a2" "a2 " "a3" "a4"
Supóngase que, para el proceso que va a aplicarse sobre estos datos, se requiere que las 4 primeras columnas sean factores. Puesto que la función formatData automáticamente convierte en factores aquellos vectores de la clase character (tercera y cuarta columna), basta con especificar los 2 primeros.
data6 <- formatData(data6, f = c(1, 2))Puede verificarse que el nuevo data frame ha sido formateado adecuadamente:
names(data6)
#> [1] "Bloques" "tto" "factor.a.gr.cm2" "factor.b.gr.cm2" "y"class(data6$Bloques)
#> [1] "factor"class(data6$tto)
#> [1] "factor"class(data6$factor.a.gr.cm2)
#> [1] "factor"class(data6$factor.b.gr.cm2)
#> [1] "factor"levels(data6$factor.a.gr.cm2)
#> [1] "a1" "a2" "a3" "a4"levels(data6$factor.b.gr.cm2)
#> [1] "b1" "b2" "b3" "b4"