13 DESCRIPTORES DE ACCESO
13.1 Indexación
Cada uno de los elementos dentro de una estructura de datos se encuentra indexado. Esto permite referenciarlo a través del correspondiente índice. Para tal efecto, R cuenta con tres descriptores de acceso: los corchetes sencillos [], los corchetes dobles [[]] y el símbolo $.
El descriptor de acceso [] permite referenciar el elemento que ocupa una posición específica dentro de una estructura. Así, datos[7] se refiere al elemento que ocupa la séptima posición dentro del objeto datos.
Para los objetos unidimensionales (vectores y listas), la indexación es directa, asignándosele a cada elemento el índice correspondiente a su posición.
a <- c(3, 8, 21, 7, 14)
a[2]
#> [1] 8Puesto que las listas también son objetos unidimensionales (vectores genéricos), el índice hace referencia en estos casos a la posición ocupada por los elementos de mayor jerarquía. En la lista lis2, definida en la sección 8.5, la instrucción lis2[1] hará referencia al primer elemento de dicha lista, es decir, al vector nombre:
lis2[1]
#> [[1]]
#> [1] "Iván" "Rosa" "Diana"La referencia a un elemento particular dentro de un objeto multidimensional (matrices, arreglos o data frames) puede realizarse de varias formas, la más intuitiva de las cuales consiste en separar con comas los correspondientes índices de posición en cada una de las dimensiones.
Considérese el arreglo tridimensional letras, generado anteriormente, el cual se esquematizaba de la siguiente manera:
| Tiempo1 | |||
| v1 | v2 | v3 | |
| unidad1 | a | x | d |
| unidad2 | c | m | b |
| unidad3 | f | j | u |
| unidad4 | d | l | y |
| Tiempo2 | |||
| v1 | v2 | v3 | |
| unidad1 | b | h | r |
| unidad2 | j | o | s |
| unidad3 | h | w | n |
| unidad4 | l | p | q |
Para referenciar el elemento de la unidad4, v1, tiempo2, se escribe:
letras[4, 1, 2]
#> [1] "i"La designación de todos los elementos de un componente dimensional determinado se realiza omitiendo la referencia al índice de las demás dimensiones, manteniendo, sin embargo, la(s) correspondiente(s) coma(s) de separación. Considérese la matriz m2 (cf. sección 8.2):
\[ m2 = \begin{pmatrix} 2 & 0 & 5\\ -1 & 9 & 1 \end{pmatrix} \]
Para referenciar todos los elementos de la segunda fila, se omite el índice de las columnas así: m2[2, ]. Nemotécnicamente, esto puede leerse como fila 2 con todas las columnas.
#> [1] -1 9 1Análogamente, la referencia a todos los elementos de la tercera columna se realiza con la instrucción m2[, 3] (todas las filas de la columna 3).
#> [1] 5 1En el arreglo letras (cf. sección 8.3), la referencia a todas las lecturas del tiempo1 se realiza con la instrucción letras[, , 1].
#> [,1] [,2] [,3]
#> [1,] "a" "x" "d"
#> [2,] "c" "m" "b"
#> [3,] "f" "j" "u"
#> [4,] "d" "l" "y"Nótese que la salida de la anterior instrucción es un arreglo bidimensional, en el cual cada una de sus filas y columnas se encabeza con base en la nomenclatura expuesta. En caso de que se hubieran asignado nombres a los diferentes componentes dimensionales, se mostrarían estos en lugar de la nomenclatura descrita.
#> v1 v2 v3
#> unidad1 "a" "x" "d"
#> unidad2 "c" "m" "b"
#> unidad3 "f" "j" "u"
#> unidad4 "d" "l" "y"En el mismo arreglo letras, la referencia a todas las lecturas de v3, en el tiempo2 se realiza con la instrucción letras[, 3, 2].
letras[, 3, 2]
#> unidad1 unidad2 unidad3 unidad4
#> "r" "s" "n" "q"Cuando los componentes dimensionales tienen nombres, estos pueden usarse entrecomillados en lugar de los índices numéricos. Así, el resultado anterior podría obtenerse igualmente mediante la instrucción: letras[, "v3", "tiempo2"].
También es posible referenciar cualquier elemento de una matriz o arreglo con base en un único índice. En tales casos, el índice corresponde con la posición del elemento, contabilizando de manera continua y ordenada a través de las diferentes dimensiones, empezando con la primera.
Considérese nuevamente la matriz m1 definida anteriormente (sección 8.2):
#> [,1] [,2] [,3]
#> [1,] 2 5 9
#> [2,] 0 -1 1Las siguientes instrucciones son equivalentes:
m1[1, 3]
#> [1] 9
m1[5]
#> [1] 9Nótese que en este caso el conteo se realiza haciendo variar inicialmente las filas (primera dimensión) y luego las columnas (segunda dimensión).
En el arreglo letras, las siguientes instrucciones son equivalentes:
letras[2, 1, 2]
letras[14]
#> [1] "j"En este caso el conteo se realiza inicialmente a través de las unidades (primera dimensión), luego a través de las variables (segunda dimensión) y finalmente a través de los tiempos (tercera dimensión).
Para seleccionar un grupo de elementos, basta con enumerar sus correspondientes posiciones. Si las posiciones de los elementos son contiguas, podrá usarse el operador de secuencia (cf. sección 2.7); en caso contrario, deberá usarse un vector.
Para seleccionar en el arreglo letras las unidades 2, 3 y 4, para todas las variables, en el primer tiempo, se usa la siguiente instrucción:
letras[2:4, , 1]
#> v1 v2 v3
#> unidad2 "c" "m" "b"
#> unidad3 "f" "j" "u"
#> unidad4 "d" "l" "y"Para elegir las unidades 1 y 4 de las variables 1 y 3, en el tiempo 2, se usa la siguiente instrucción:
Cuando se usa un único índice en un data frame, este hace referencia a la correspondiente columna. Así, df[2] es equivalente a df[, 2]. En ambos casos se selecciona la segunda columna.
Una de las maneras más usuales de hacer referencia a una columna específica de un data frame es por su nombre, usando el descriptor de acceso $. El formato general es nombre.data.frame$nombre.columna. Considérese el data frame df, que se ejemplificó en la sección de estructuras de datos (8.4. Para hacer referencia a su primera columna, puede escribirse df$id, df[, 1], df[, "id"], df[1] o df["id"].
Es importante anotar que, aunque las cinco instrucciones anteriores hacen referencia a la misma información (la primera columna del data frame df), no todas dan lugar a objetos de la misma clase. Las tres primeras instrucciones generan objetos de la clase correspondiente al vector atómico al que se hace referencia (en este caso, factor); las dos últimas instrucciones generan objetos de la clase data frame (sin importar que tenga una sola columna).
El descriptor de acceso $ también puede usarse para referenciar objetos que forman parte de una lista, siempre que les haya sido asignado un nombre a los mismos. Supóngase que a la lista lis2 que se usó como ejemplo anteriormente (sección 8.5)se le asignan nombres.
Ahora puede invocarse el primer elemento de mayor jerarquía de dicha lista, mediante la siguiente instrucción:
lis2$nombre
#> [1] "Iván" "Rosa" "Diana"Es posible combinar este descriptor de acceso $ con el descriptor [] para acceder a los elementos dentro del elemento de mayor jerarquía. Así, para recuperar el tercer nombre, se usa la siguiente instrucción.
lis2$nombre[3]
#> [1] "Diana"Para acceder a todos los elementos ubicados en la fila 1 de la matriz m1, que constituye el cuarto elemento de la lista lis2, se usa la siguiente instrucción.
lis2$m1[1, ]
#> [1] 2 5 9Cuando los subelementos de una lista también tienen nombre, pueden encadenarse varios descriptores de acceso $ para referenciar subelementos en un nivel más interno.
Considérense los siguientes nombres para los elementos de la lista lis1 que constituye el quinto elemento de la lista lis2.
Para referenciar el objeto de la fila 2, columna 2, de la matriz m1 que aparece como cuarto elemento de la lista lis1, se usa el siguiente comando.
lis2$lis1$m1_1[2, 2]
#> [1] -1El descriptor de acceso [[]] tiene un uso análogo al del descriptor de acceso $: permite elegir un elemento específico de una estructura recursiva, bien sea, a partir de su nombre o de su posición. Los elementos en cuestión, para el caso de los data frames son sus columnas; para las listas, son los elementos de mayor jerarquía. Cuando se usan los nombres de tales elementos, estos deben ir entrecomillados23.
La instrucción lis2$lis1$m1_1[2, 2] puede escribirse equivalentemente así:
lis2[["lis1"]][["m1_1"]][2, 2]O así:
lis2[[5]][[4]][2, 2]La anterior expresión puede leerse de derecha a izquierda o viceversa. La lectura de derecha a izquierda da lugar a una descripción más compacta: “el elemento de la segunda fila, segunda columna del cuarto objeto (matriz m1_1) del quinto objeto (lista lis1) de la lista lis2”. La lectura de izquierda a derecha, aunque no genera una expresión tan compacta, ayuda a entender mejor a cuál elemento se hace referencia: “Dentro del objeto lis2, se toma su quinto elemento, que es lis1; luego, dentro de lis1, se toma el cuarto elemento, que es m1_1; luego, dentro de m1_1, se toma el elemento de la fila 2, columna 2”.
Es importante aclarar que lo indicado con respecto a la forma de leer la expresión solo se refiere a la nemotecnia que podría utilizar el usuario para entender la lógica de la nomenclatura y a cuál elemento se está haciendo referencia. Desde luego esto no tiene nada que ver con la forma en que R decodifica la instrucción. En cualquier caso, la instrucción anterior se refiere al mismo objeto.
#> [1] -1Es posible eludir la restricción del entrecomillamiento de los nombres que van entre los corchetes dobles, usando la cadena de caracteres correspondiente al nombre, en lugar del nombre mismo. Aunque esta solución normalmente resulta mucho más dispendiosa que el entrecomillamiento del nombre, eventualmente puede ser útil al interior de alguna función personalizada.
Así para referenciar el segundo elemento lis2 puede usarse lis2[[2]] o lis2[["edad"]], pero también puede usarse la siguiente estrategia:
age <- "edad"
lis2[[age]]En la sección 10.2, se indicó que existía la posibilidad de evaluar el tipo de objetos que conformaban un contenedor recursivo, mediante el uso de descriptores adecuados. Así, para averiguar, por ejemplo, de qué tipo es el primer elemento de la lista lis2, se usa la siguiente instrucción.
typeof(lis2[[1]])
#> [1] "character"Si se consulta de qué tipo de objeto es el quinto elemento de lis2, se obtiene como resultado list, puesto que ese objeto es la lista lis1. No obstante, puede averiguarse el tipo de cualquiera de los componentes atómicos de lis1. Así, por ejemplo, para averiguar de qué tipo es el tercer elemento de lis1, que se encuentra alojada dentro de lis2, se usa la siguiente instrucción.
typeof(lis2[[5]][[3]])
#> [1] "logical"En este caso, en el que los objetos de la lista tienen nombres, también podría haberse usado el descriptor $.
typeof(lis2$lis1$aprobado)
#> [1] "logical"En resumen, el descriptor de acceso $ se utiliza únicamente con nombres —nunca con posiciones— para seleccionar columnas de un data frame o elementos con nombre de una lista.
El descriptor de acceso [[]] siempre elige un único elemento; no es posible utilizarlo para seleccionar rangos de elementos. Cuando se usa con un data frame elige la columna indicada:
df[[1]]O equivalentemente:
df[["id"]]Los descriptores de acceso [] y [[]] admiten nombres y posiciones. Cuando se usan nombres, estos deben entrecomillarse. Pueden utilizarse con cualquiera de las estructuras contenedoras de datos.
El descriptor de acceso [] selecciona el elemento, pero lo mantiene dentro de la estructura contenedora global (lista o data frame); el descriptor de acceso [[]], por el contrario, extrae el elemento de la estructura contenedora. Para ilustrarlo, se reproduce a continuación una explicación genial que nos presentan Wickham y Grolemund (2017)24.
Considérese un pimientero atípico que contiene sobres de pimienta. El pimientero puede pensarse como una lista (contenedor de objetos) que contiene otras listas (sobres), que a su vez contienen pimienta:

Si el pimientero es la lista x, entonces x[1] representa el primer sobre del pimientero. No obstante, acorde con lo indicado anteriormente, el sobre se mantiene dentro del pimientero.

De igual manera, podría elegirse un conjunto de sobres, por ejemplo, el tercero y el cuarto: x[3:4], pero estos se mantendrían dentro del contenedor principal: el pimientero.
En contraste, x[[1]] también representa el primer sobre, pero extraído del pimientero.

Siguiendo la misma lógica, puede accederse al contenido del primer sobre así: x[[1]][[1]].

Finalmente, vale la pena mencionar que en ocasiones es posible referenciar una variable directamente por su nombre, sin necesidad de anteponer el nombre de la estructura contenedora y el símbolo $.
-
Cuando se liga un objeto a la ruta de búsqueda de R, mediante la función
attach.attach(dca) anova <- aov(y ~ ttos) detach(dca) -
Cuando la referencia a la variable se hace dentro de una función que incluya el argumento
data, mediante el cual se indique el nombre del data frame.anova <- aov(y ~ ttos, data = dca) -
Cuando se utiliza alguna función como
with,withinotransform, (cf. capítulo 16), las cuales crean un ambiente de trabajo dentro del cual pueden referenciarse directamente las variables.anova <- with(dca, aov(y ~ ttos))
La primera alternativa, al modificar la ruta de búsqueda, puede generar confusión y errores de ejecución, máxime si se olvida desligar la base de datos después de haberla usado. Aunque se desaconseja el uso de esta función, en caso de que el usuario decida utilizarla bajo su responsabilidad, se recomienda un desligado posterior, mediante la función detach.
El uso de la segunda alternativa, aunque es seguro, no siempre es viable. Únicamente puede usarse con funciones que consideren el argumento data.
La tercera opción, además de ser segura, siempre es viable, pudiendo usarse conjuntamente con cualquier función.
13.2 Generación de subconjuntos
Existen dos estrategias para extraer un subconjunto de elementos de un objeto, de manera que tales elementos satisfagan una condición, bien sea de posición o de cualquier otra índole. Una de tales estrategias se basa en el uso del descriptor de acceso [], presentado en la sección 13.1; la otra, en la función subset.
Para generar subconjuntos mediante el descriptor de acceso [], a partir de la posición de los elementos, se utilizan los correspondientes índices: enteros positivos, para mantener los elementos; enteros negativos, para retirarlos.
Considérese la matriz m2:
#> [,1] [,2] [,3]
#> [1,] 2 0 5
#> [2,] -1 9 1Mediante el siguiente comando, basado en el descriptor de acceso [], se seleccionan las columnas 2 y 3 de la matriz m2.
m2[, 2:3]Equivalentemente, mediante la función subset:
subset(m2, select = 2:3)
#> [,1] [,2]
#> [1,] 0 5
#> [2,] 9 1Nótese que la primera estrategia no hace uso de ninguna función (no hay paréntesis), sino que se referencian dentro de los corchetes los índices de las columnas que se mantienen en la matriz m2. En el segundo caso, se usa la función subset, con dos argumentos: el primero corresponde al objeto, mientras que el segundo (select) indica las columnas que deben mantenerse.
Usando cualquiera de las siguientes instrucciones, mediante las cuales se retira la primera columna, se llega al mismo resultado:
m2[, -1]
subset(m2, select = -1)
#> [,1] [,2]
#> [1,] 0 5
#> [2,] 9 1En los comandos trasanteriores se usó el operador de secuencia “:”, aprovechando la vecindad de las dos columnas seleccionadas. Para seleccionar columnas no adyacentes, por ejemplo, la 1 y la 3, se usa el correspondiente vector de índices, en cualquiera de las siguientes instrucciones.
m2[, c(1, 3)]Desde luego, la selección en cuestión también puede realizarse, retirando la segunda columna.
m2[, -2]
subset(m2, select = -2)
#> [,1] [,2]
#> [1,] 2 5
#> [2,] -1 1Equivalentemente, podría utilizarse un vector conformado por elementos lógicos, haciendo corresponder etiquetas TRUE (o T) con las columnas que se mantienen, y etiquetas FALSE (o F) con las que se retiran.
m2[, c(TRUE, FALSE, TRUE)]Aunque todas las variantes anteriores ilustran la selección de un subconjunto de columnas de una matriz, bien podrían usarse sobre un data frame. Considérese el data frame airquality, el cual forma parte de los datasets preinstalados en R, y cuya estructura se muestra a continuación.
str(airquality)
#> 'data.frame': 153 obs. of 6 variables:
#> $ Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
#> $ Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ...
#> $ Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
#> $ Temp : int 67 72 74 62 56 66 65 59 61 69 ...
#> $ Month : int 5 5 5 5 5 5 5 5 5 5 ...
#> $ Day : int 1 2 3 4 5 6 7 8 9 10 ...Para generar otro data frame conformado únicamente por la primera y la tercera columna de airquality, puede usarse cualquiera de las instrucciones anteriormente ilustradas, incorporando los índices 1 y 3, especificando el retiro de las columnas 2, 4, 5 y 6 o usando etiquetas lógicas. Adicionalmente, puesto que todo data frame tiene una serie de nombres asociados con sus columnas, estos pueden usarse, en lugar de los índices de posición, para la generación de los subconjuntos, así:
airquality[, c('Ozone', "Wind")]
subset(airquality, c('Ozone', 'Wind'))
subset(airquality, c(Ozone, Wind))A continuación, se resaltan varios aspectos relacionados con las instrucciones anteriores:
La generación de subconjuntos, usando el operador de acceso
[](primera instrucción) exige que los nombres estén entrecomillados.Pueden usarse comillas dobles o sencillas para encerrar los nombres.
La generación de subconjuntos, mediante la función
subsetpermite usar nombres entrecomillados o sin entrecomillar, pero no es posible mezclar unos y otros en un mismo vector.Cuando se usan nombres en lugar de índices numéricos, estos solo actúan para fines de inclusión de las correspondientes columnas; no existe un uso equivalente al de los índices negativos, para especificar la exclusión de columnas.
Para seleccionar un subconjunto de filas de una matriz o un data frame, se usa el operador de acceso [] con instrucciones análogas a las presentadas anteriormente, teniendo en cuenta que los índices de las filas van antes de la coma. Es posible incluir simultáneamente restricciones por filas y por columnas. La siguiente instrucción genera el subconjunto de los cinco primeros registros de las variables Wind y Temp del data frame airquality.
airquality[1:5, c('Wind', 'Temp')]
#> Wind Temp
#> 1 7.4 67
#> 2 8.0 72
#> 3 12.6 74
#> 4 11.5 62
#> 5 14.3 56Aunque la restricción anterior, basada en la posición, es completamente válida, la selección de filas suele estar basada en la satisfacción de alguna condición, ya sea simple o compleja.
Para seleccionar los registros con lecturas superiores a 30 en la variable Ozone, se usa la siguiente instrucción.
airquality[airquality$Ozone > 30, ]Al seleccionar mediante el operador de acceso [], no basta con escribir el nombre de la variable dentro de los corchetes (Ozone, en el presente ejemplo), sino que es necesario usar el operador de acceso $ para enlazarlo con el data frame en el que se encuentra contenido, tal y como se ilustra en la instrucción anterior.
Asimismo, es posible generar el subconjunto en cuestión, mediante la función subset, incluyendo la condición mediante el argumento homónimo subset.
subset(airquality, subset = Ozone > 30)Aunque el argumento subset también puede utilizarse para imponer una restricción por posición, permitiendo elegir, por ejemplo, las 5 primeras filas, tal y como se ilustró mediante el uso de descriptor de acceso [], la especificación, en este caso, no se realiza usando índices, sino valores lógicos.
En tal sentido, la siguiente instrucción es incorrecta:
subset(airquality, subset = 1:5)La instrucción correcta exige alimentar el argumento subset con un vector lógico que contenga valores verdaderos en las cinco primeras posiciones y falsos en las demás:
subset(airquality, subset = c(rep(T, 5), rep(F, 148)))Nótese que cuando se impone una condición como la usada anteriormente (Ozone > 30), internamente, se genera un vector de valores lógicos.
Pueden combinarse varias condiciones y criterios de selección en una misma instrucción. Así, por ejemplo, para generar un subconjunto con las lecturas de las variables Solar.R y Temp, que se hayan registrado durante los meses (Month) 5 o 6 y que correspondan a temperaturas (Temp) superiores a los 80 grados, puede utilizarse cualquiera de las siguientes instrucciones.
airquality[(airquality$Month == 5 | airquality$Month == 6) &
airquality$Temp > 80, c("Solar.R", "Temp")]
subset(airquality, subset = (Month == 5 | Month == 6) & Temp >
80, select = c(Solar.R, Temp))
#> Solar.R Temp
#> 29 252 81
#> 35 186 84
#> 36 220 85
#> 38 127 82
#> 39 273 87
#> 40 291 90
#> 41 323 87
#> 42 259 93
#> 43 250 92
#> 44 148 82
#> 61 138 83Cuando se usa la función subset, el argumento subset incorpora las condiciones para la selección de los registros (filas), mientras que el argumento select indica cuáles columnas quedan en el subconjunto.
El comportamiento de las dos herramientas de selección presentadas (descriptor de acceso [] y función subset) diverge cuando la variable usada para establecer el criterio de selección tiene datos perdidos (NA). Al usar el descriptor de acceso [], los registros NA se incorporan al subconjunto resultante, mientras que al usar la función subset, no. Para ejemplificarlo, considérense los siguientes subconjuntos del data frame airquality, obtenidos mediante la condición de que la radiación solar (Solar.R) sea mayor que 330.
airquality[airquality$Solar.R > 330, ]
#> Ozone Solar.R Wind Temp Month Day
#> NA NA NA NA NA NA NA
#> NA.1 NA NA NA NA NA NA
#> NA.2 NA NA NA NA NA NA
#> 16 14 334 11.5 64 5 16
#> NA.3 NA NA NA NA NA NA
#> 45 NA 332 13.8 80 6 14
#> NA.4 NA NA NA NA NA NA
#> NA.5 NA NA NA NA NA NA
#> NA.6 NA NA NA NA NA NALa instrucción anterior genera un subconjunto en el que quedan incluidos, además de los registros que satisfacen la condición (filas 16 y 45), todos aquellos con información faltante para la variable criterio (7 registros). Estos últimos aparecen identificados en el objeto resultante como NA, NA.1, …, NA.6, y la información de todas las demás variables también aparece como NA, sin importar que pudiera haber contenido valores en la base de datos original.
subset(airquality, subset = Solar.R > 330)
#> Ozone Solar.R Wind Temp Month Day
#> 16 14 334 11.5 64 5 16
#> 45 NA 332 13.8 80 6 14En contraste, al usar la función subset, se obtiene, como es de esperarse, un subconjunto que contiene únicamente los registros que satisfacen la condición (filas 16 y 45).
Otro aspecto en el que pueden diferir los resultados generados mediante las dos herramientas expuestas tiene que ver con la simplificación del objeto resultante cuando hay reducción de dimensionalidad. No obstante, este es un aspecto secundario, puesto que lo único en lo que realmente difieren las dos herramientas es en el comportamiento que manejan por defecto, pudiendo hacerlos coincidir, mediante el argumento drop.
Cuando al imponer una condición sobre una matriz o un data frame, se genera un objeto unidimensional (con una sola columna o una sola fila), bien puede suceder que tal objeto herede la clase del objeto generador (matriz o data frame) o que se simplifique hacia un vector (clase integer, character, etc.). Este comportamiento es regulado por el argumento drop (nemotécnicamente, simplificar), cuyo valor por defecto, cuando se usa el descriptor de acceso [] es TRUE (simplifica), y FALSE (no simplifica) cuando se usa la función subset.
Considérese, para el data frame airquality, la selección de los registros con vientos (Wind) mayores que 17, manteniendo únicamente los registros de dicha variable.
Usando el descriptor de acceso [], con su valor de drop por defecto (TRUE):
airquality[airquality$Wind > 17, 3]
#> [1] 20.1 18.4 20.7
class(airquality[airquality$Wind, 3])
#> [1] "numeric"El objeto resultante no ha heredado la clase del objeto original, sino que se ha simplificado a un vector numérico. Esto puede controlarse, mediante el argumento drop.
airquality[airquality$Wind > 17, 3, drop = F]
#> Wind
#> 9 20.1
#> 18 18.4
#> 48 20.7
class(airquality[airquality$Wind, 3, drop = F])
#> [1] "data.frame"Usando la función subset, con su valor de drop por defecto (FALSE):
subset(airquality, subset = Wind > 17, select = 3)
#> Wind
#> 9 20.1
#> 18 18.4
#> 48 20.7Al usar la función subset, el objeto resultante sí hereda por defecto la clase del objeto generador, sin importar que se haya reducido la dimensionalidad. No obstante, este comportamiento también puede controlarse mediante el argumento drop.
subset(airquality, subset = Wind > 17, select = 3, drop = T)
#> [1] 20.1 18.4 20.7En resumen, se cuenta con dos estrategias para extraer un subconjunto de elementos de un objeto: el descriptor de acceso [] y la función subset. Cuando se usa una condición basada en una variable con datos faltantes, la función subset genera resultados más adecuados, por cuanto no incluye los registros con información faltante. Los objetos que se obtienen a partir de la función subset heredan por defecto la clase del objeto generador; no obstante, dicho comportamiento podría modificarse a través del argumento drop. Para elegir una serie de elementos, con base en su posición, puede resultar más cómodo el uso del descriptor de acceso [].
13.3 Adición y sustitución de elementos
Para sustituir un elemento dentro de un objeto, basta con asignar otro valor a la correspondiente posición.
Considérese nuevamente la matriz m2:
#> [,1] [,2] [,3]
#> [1,] 2 0 5
#> [2,] -1 9 1Podría remplazarse el elemento de la segunda fila, tercera columna por 7, así:
m2[2, 3] <- 7
m2
#> [,1] [,2] [,3]
#> [1,] 2 0 5
#> [2,] -1 9 7Puede remplazarse la primera fila de la matriz m2, así:
m2[1, ] <- c(1, 2, 3)
m2
#> [,1] [,2] [,3]
#> [1,] 1 2 3
#> [2,] -1 9 7Una asignación a una posición inexistente da lugar a la ampliación del objeto. Esta estrategia puede usarse con vectores, listas y data frames, mas no con matrices o arreglos.
a <- c(2, 0, -7)
a[4] <- 5
a
#> [1] 2 0 -7 5Para el caso de vectores o listas no se requiere que los nuevos elementos estén contiguos a los existentes. Así, podría asignarse un nuevo elemento a la sexta posición del vector definido anteriormente, con lo cual se marca la quinta posición como vacía.
a[6] <- 4
a
#> [1] 2 0 -7 5 NA 4Mediante un proceso análogo al anterior, es posible agregar nuevas filas o columnas a un data frame. Las nuevas filas no necesariamente tienen que ser contiguas a las existentes; no obstante, las nuevas columnas sí tendrían que quedar a continuación de las existentes, no siendo posible dejar columnas vacías en un data frame.
13.4 Ubicación de una posición
En ocasiones es necesario averiguar la posición ocupada por un elemento que satisfaga una condición específica. Supóngase, por ejemplo, que se tiene un vector con ocho elementos y se desea conocer la posición ocupada por el máximo.
v <- c(7.9, 12.5, 19.0, 1.4, 77.7, 11.6, 12.4, 32.8)En este caso, el máximo es 77.7; este valor ocupa la sexta posición del vector v.
El máximo puede obtenerse así:
max(v)
#> [1] 77.7Si el vector es pequeño, como el del presente ejemplo, no hay ninguna dificultad en localizar el valor y determinar su posición. No obstante, si el vector es grande y/o se desea automatizar algún proceso, se recurre al comando which, el cual puede leerse nemotécnicamente como “la posición tal que…”. En este caso se quiere averiguar la posición (del vector v) tal que su valor sea máximo. El argumento de which debe ser de tipo lógico; which devolverá la posición o posiciones para las cuales la condición sea verdadera (cf. sección 20.4).
El siguiente vector, que contiene valores tanto positivos como negativos, podría representar los residuales de un modelo.
resid <- c(-2.5, 1.4, -4.3, 2.3, 0.2, 3.9, 0.4, -1.7)Para averiguar cuál es la posición del vector resid tal que su valor absoluto sea máximo, se usa la siguiente instrucción.
Nótese que en este caso es necesario incorporar el valor absoluto también en el término de la izquierda de la condición, pues de no hacerlo no se satisfaría la condición de igualdad si el máximo residual en valor absoluto correspondiera a un residual negativo, como en el presente caso.
Esta información podría resultar muy útil si se deseara, por ejemplo, retirar el valor correspondiente a dicha posición en otra base de datos. Suponiendo que el vector resid, contiene los residuales de un modelo ajustado con base en información contenida en un data frame llamado data, y que el usuario hubiera decidido retirar la observación correspondiente al mayor residual en valor absoluto, debería retirar la tercera observación del data frame data.
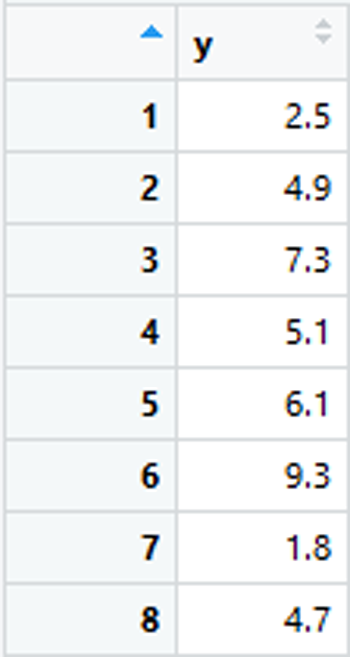
data <- data[-3, ]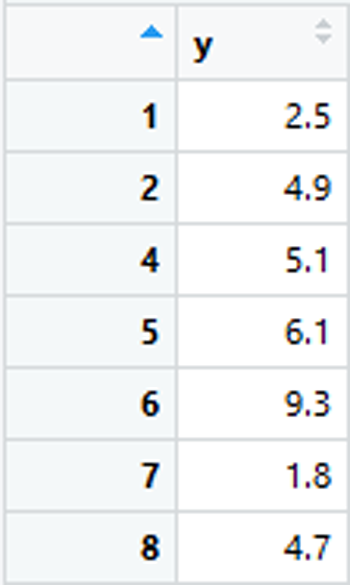
Supóngase ahora que tras retirar la observación en cuestión y correr nuevamente el modelo se obtiene el siguiente vector de residuales.
resid <- c(-2.8, 1.1, 2.0, -0.2, 3.7, 0.3, -1.5)Si de nuevo se realiza el proceso de búsqueda de la posición cuyo residual en valor absoluto sea máximo, se obtendría que este se ubica en la quinta posición. Y si nuevamente se desea retirar la correspondiente observación del data frame data, se realizaría un proceso análogo al mostrado anteriormente, con lo cual se retiraría la observación que ocupa la quinta posición, es decir, y = 9.3.
Puede resultar desconcertante que al automatizar un proceso se elimine la observación y = 9.3, cuando aparentemente la observación que debería retirarse es la correspondiente a y = 6.1. Nótese, sin embargo, que la observación que efectivamente ocupa la quinta posición es y = 9.3, a pesar de que el nombre de fila indique que esa es la observación 6. Esto se debe a que al realizar la creación o importación del data frame, el sistema automáticamente asigna a cada fila un nombre acorde con la posición ocupada, el cual no cambia cuando se modifica la posición de la observación. Nótese que en el data frame original y = 9.3 ocupa la sexta posición, por lo cual se le asigna a esa fila el nombre 6. Posteriormente, al retirar la tercera fila, aunque todas las filas siguientes se desplazan una posición, mantienen sus nombres de fila originales, con lo cual la fila llamada 4 pasa a ocupar la posición 3, la 5 pasa a la posición 4 y así sucesivamente.
Aunque este hecho no tiene por qué afectar el desempeño de algún proceso basado en las posiciones, si ello resultara perturbador, podría solucionarse fácilmente renombrando las filas en una secuencia que vaya desde 1 hasta el número de observaciones, así:
rownames(data) <- 1:nrow(data)La función which también puede dar por resultado varias posiciones que satisfagan una condición determinada. Considérese la matriz m2:
\[ m2 = \begin{pmatrix} 1 & 2 & 3\\ -1 & 9 & 7 \end{pmatrix} \]
which (m2 > 3)
#> [1] 4 6La condición indicada (que m2 sea mayor que 3) es satisfecha por los elementos que ocupan la cuarta y la quinta posición. Recuérdese que cuando se usa un único índice para referenciar los elementos contenidos en objetos atómicos dimensionales (matrices y arreglos), el conteo se realiza haciendo variar primero la primera dimensión (filas) y luego la segunda (columnas) (cf. sección 13.1).