10 Model Comparison and Hierarchical Modeling
There are situations in which different models compete to describe the same set of data…
…Bayesian inference is reallocation of credibility over possibilities. In model comparison, the focal possibilities are the models, and Bayesian model comparison reallocates credibility across the models, given the data. In this chapter, we explore examples and methods of Bayesian inference about the relative credibilities of models. (Kruschke, 2015, pp. 265–266)
In the text, the emphasis is on the Bayes Factor paradigm. While we will discuss that, we will also present the alternatives available with information criteria, model averaging, and model stacking.
10.1 General formula and the Bayes factor
So far we have spoken of
- the data, denoted by \(D\) or \(y\);
- the model parameters, generically denoted \(\theta\);
- the likelihood function, denoted \(p(D | \theta)\); and
- the prior distribution, denoted \(p(\theta)\).
Now we add \(m\), which is a model index where \(m = 1\) stands for the first model, \(m = 2\) stands for the second model, and so on. So when we have more than one model in play, we might refer to the likelihood as \(p_m(y | \theta_m, m)\) and the prior as \(p_m(\theta_m | m)\). It’s also the case, then, that each model can be given a prior probability \(p(m)\).
“The Bayes factor (BF) is the ratio of the probabilities of the data in models 1 and 2” (p. 268).
This can be expressed simply as
\[\text{BF} = \frac{p(D | m = 1)}{p(D | m = 2)}.\]
Kruschke further explained that
one convention for converting the magnitude of the BF to a discrete decision about the models is that there is “substantial” evidence for model \(m = 1\) when the BF exceeds \(3.0\) and, equivalently, “substantial” evidence for model \(m = 2\) when the BF is less than \(1/3\) (Jeffreys, 1961; Kass & Raftery, 1995; Wetzels et al., 2011). (p. 268)
However, as with \(p\)-values, effect sizes, and so on, BF values exist within continua and might should be evaluated in terms of degree more so than as ordered kinds.
10.2 Example: Two factories of coins
Kruschke considered the coin bias of two factories, each described by the beta distribution. We can organize how to derive the \(\alpha\) and \(\beta\) parameters from \(\omega\) and \(\kappa\) with a tibble.
library(tidyverse)
d <-
tibble(factory = 1:2,
omega = c(.25, .75),
kappa = 12) %>%
mutate(alpha = omega * (kappa - 2) + 1,
beta = (1 - omega) * (kappa - 2) + 1)
d %>%
knitr::kable()| factory | omega | kappa | alpha | beta |
|---|---|---|---|---|
| 1 | 0.25 | 12 | 3.5 | 8.5 |
| 2 | 0.75 | 12 | 8.5 | 3.5 |
Thus given \(\omega_1 = .25\), \(\omega_2 = .75\) and \(\kappa = 12\), we can describe the bias of the two coin factories as \(\operatorname{Beta}(\theta_{[m = 1]} | 3.5, 8.5)\) and \(\operatorname{Beta}(\theta_{[m = 2]} | 8.5, 3.5)\). With a little wrangling, we can use our d tibble to make the densities of Figure 10.2. But before we do, we should discuss plotting.
In the past few chapters, we have explored different plotting conventions using themes from Wilke’s cowplot package, such as theme_cowplot() and theme_minimal_grid(). We also modified some of our plots using principles from Wilke’s (2019) text, Fundamentals of data visualization, and his (2020a) Themes vignette. To further build on those principles, each chapter from here onward will have its own color scheme. The scheme in this chapter is based on Katsushika Hokusai’s (1820–1831) woodblock print, The great wave off Kanagawa. We can get a prearranged color palette based on The great wave off Kanagawa from Tyler Littlefield’s lisa package (Littlefield, 2020).
library(lisa)
lisa_palette("KatsushikaHokusai")## * Work: The Great Wave off Kanagawa
## * Author: KatsushikaHokusai
## * Colors: #1F284C #2D4472 #6E6352 #D9CCAC #ECE2C6plot(lisa_palette("KatsushikaHokusai"))
The "KatsushikaHokusai" palette comes out of the box with five colors. However, we can use the lisa_palette() function to expand the palette by setting type = "continuous" and then increasing the n argument to a value larger than five. Here’s what happens when you set n = 9 and n = 1000.
plot(lisa_palette("KatsushikaHokusai", n = 9, type = "continuous"))
plot(lisa_palette("KatsushikaHokusai", n = 1000, type = "continuous"))
Next, we will use the five base colors from "KatsushikaHokusai" to adjust the global theme default for all ggplots in this chapter. We can accomplish this with the ggplot2::theme_set() function. First, we start with the default theme_grey() as our base and then modify several of the settings with arguments within the theme() function.
theme_set(
theme_grey() +
theme(text = element_text(color = lisa_palette("KatsushikaHokusai")[1]),
axis.text = element_text(color = lisa_palette("KatsushikaHokusai")[1]),
axis.ticks = element_line(color = lisa_palette("KatsushikaHokusai")[1]),
legend.background = element_blank(),
legend.box.background = element_blank(),
legend.key = element_rect(fill = lisa_palette("KatsushikaHokusai")[5]),
panel.background = element_rect(fill = lisa_palette("KatsushikaHokusai")[5],
color = lisa_palette("KatsushikaHokusai")[1]),
panel.grid = element_blank(),
plot.background = element_rect(fill = lisa_palette("KatsushikaHokusai")[5],
color = lisa_palette("KatsushikaHokusai")[5]),
strip.background = element_rect(fill = lisa_palette("KatsushikaHokusai")[4]),
strip.text = element_text(color = lisa_palette("KatsushikaHokusai")[1]))
)You can undo this by executing theme_set(theme_grey()). Next we’ll save the color names from a 9-color version of "KatsushikaHokusai" as a conveniently-named object, kh. We’ll use kh to adjust the fill and color settings within our plots on the fly.
kh <- lisa_palette("KatsushikaHokusai", 9, "continuous")
kh## * Work: The Great Wave off Kanagawa
## * Author: KatsushikaHokusai
## * Colors: #1F284C #26365F #2D4472 #4D5362 #6E6352 ... and 4 moreOkay, it’s time to get a sense of what we’ve done by making our version of Figure 10.2.
length <- 101
d %>%
expand_grid(theta = seq(from = 0, to = 1, length.out = length)) %>%
mutate(label = str_c("factory ", factory)) %>%
ggplot(aes(x = theta, y = dbeta(x = theta, shape1 = alpha, shape2 = beta))) +
geom_area(fill = kh[6]) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
xlab(expression(theta)) +
facet_wrap(~ label)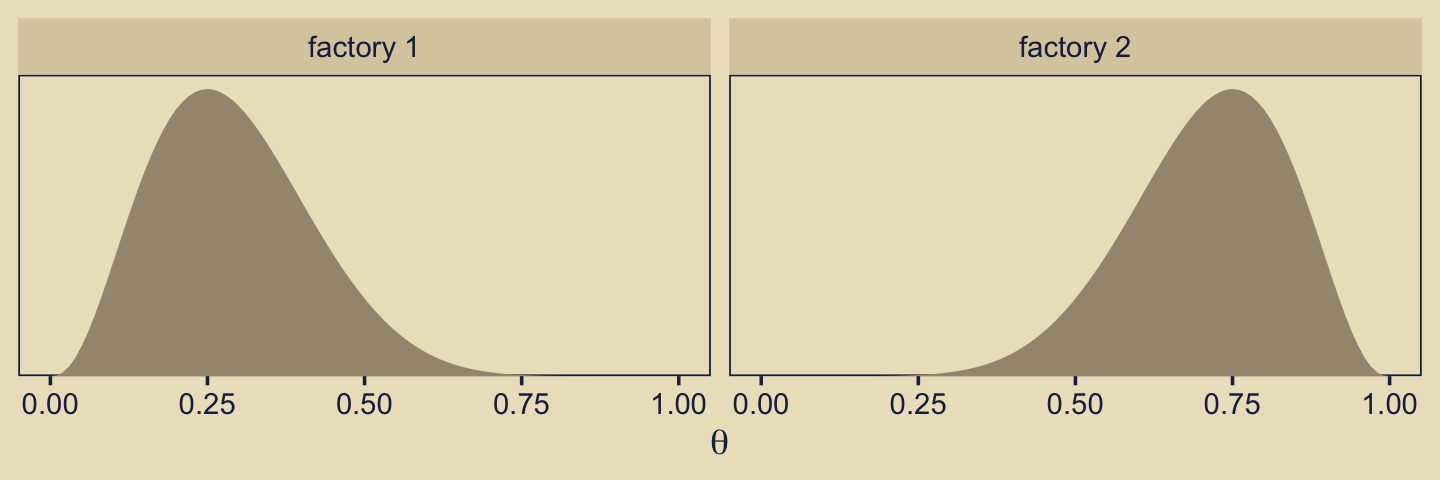
We might recreate the top panel with geom_col().
tibble(Model = c("1", "2"), y = 1) %>%
ggplot(aes(x = Model, y = y)) +
geom_col(width = .75, fill = kh[5]) +
scale_y_continuous(expand = expansion(mult = c(0, 0.05)))
Consider the Bernoulli bar plots in the bottom panels of Figure 10.2. The heights of the bars are arbitrary and just intended to give a sense of the Bernoulli distribution. If we wanted the heights to correspond to the Beta distributions above them, we might do so like this.
crossing(factory = str_c("factory ", 1:2),
flip = factor(c("tails", "heads"), levels = c("tails", "heads"))) %>%
mutate(prob = c(.75, .25, .25, .75)) %>%
ggplot(aes(x = flip, y = prob)) +
geom_col(width = .75, fill = kh[4]) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
xlab(NULL) +
theme(axis.ticks.x = element_blank(),
panel.grid = element_blank()) +
facet_wrap(~ factory)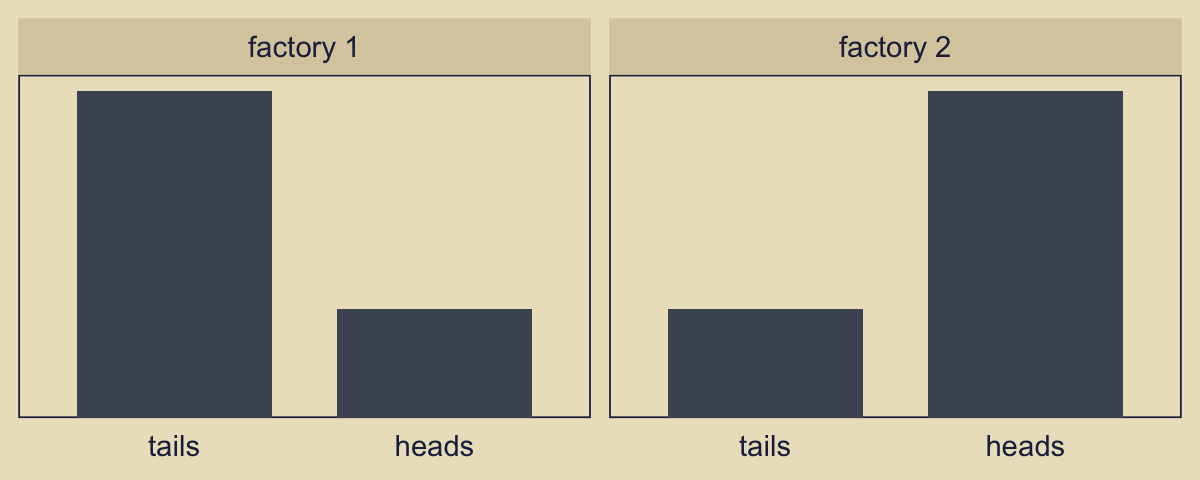
But now
suppose we flip the coin nine times and get six heads. Given those data, what are the posterior probabilities of the coin coming from the head-biased or tail-biased factories? We will pursue the answer three ways: via formal analysis, grid approximation, and MCMC. (p. 270)
Before we move on to a formal analysis, here’s a more faithful version of Kruschke’s Figure 10.2 based on the method from my blog post, Make model diagrams, Kruschke style.
library(patchwork)
library(ggforce)
p1 <-
tibble(x = 1:2,
d = c(.75, .75)) %>%
ggplot(aes(x = x, y = d)) +
geom_col(fill = alpha(kh[5], .9), width = .45) +
annotate(geom = "text",
x = 1.5, y = .2,
label = "categorical",
size = 5, color = kh[1]) +
annotate(geom = "text",
x = 1.5, y = .85,
label = "italic(P[m])",
size = 5, color = kh[1], family = "Times", parse = TRUE) +
coord_cartesian(xlim = c(-.5, 3.5),
ylim = 0:1) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5, color = kh[1]))
## an annotated arrow
# save our custom arrow settings
my_arrow <- arrow(angle = 20, length = unit(0.35, "cm"), type = "closed")
p2 <-
tibble(x = .5,
y = 1,
xend = .5,
yend = 0) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow, color = kh[1]) +
annotate(geom = "text",
x = .375, y = 1/3,
label = "'~'",
size = 10, color = kh[1], family = "Times", parse = T) +
xlim(0, 1) +
theme_void()
p3 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 5, 10) / max(dbeta(x, 5, 10)))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = alpha(kh[4], .85)) +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 5, color = kh[1]) +
annotate(geom = "text",
x = .5, y = .6,
label = "list(italic(A)[1], italic(B)[1])",
size = 5, color = kh[1], family = "Times", parse = TRUE) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5, color = kh[1]))
p4 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 10, 5) / max(dbeta(x, 10, 5)))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = kh[6]) +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 5, color = kh[1]) +
annotate(geom = "text",
x = .5, y = .6,
label = "list(italic(A)[2], italic(B)[2])",
size = 5, color = kh[1], family = "Times", parse = TRUE) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5, color = kh[1]))
# bar plot of Bernoulli data
p5 <-
tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = 1/3)) / max(dbinom(x, size = 1, prob = 1/3))) %>%
ggplot(aes(x = x, y = d)) +
geom_col(fill = alpha(kh[4], .85), width = .4) +
annotate(geom = "text",
x = .5, y = .2,
label = "Bernoulli",
size = 7, color = kh[1]) +
annotate(geom = "text",
x = .5, y = .94,
label = "theta",
size = 7, color = kh[1], family = "Times", parse = T) +
xlim(-.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5, color = kh[1]))
# another bar plot of Bernoulli data
p6 <-
tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = 2/3)) / max(dbinom(x, size = 1, prob = 2/3))) %>%
ggplot(aes(x = x, y = d)) +
geom_col(fill = kh[6], width = .4) +
annotate(geom = "text",
x = .5, y = .2,
label = "Bernoulli",
size = 7, color = kh[1]) +
annotate(geom = "text",
x = .5, y = .94,
label = "theta",
size = 7, color = kh[1], family = "Times", parse = T) +
xlim(-.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5, color = kh[1]))
# another annotated arrow
p7 <-
tibble(x = c(.375, .625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow, color = kh[1]) +
xlim(0, 1) +
theme_void()
# some text
p8 <-
tibble(x = 1,
y = .5,
label = "italic(y[i])") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, color = kh[1], parse = T, family = "Times") +
xlim(0, 2) +
theme_void()
# dashed borders
p9 <-
tibble(x = c(0, 0.999, 0.999, 0, 1.001, 2, 2, 1.001),
y = c(0, 0, 1, 1, 0, 0, 1, 1),
z = rep(letters[1:2], each = 4)) %>%
ggplot(aes(x = x, y = y, group = z)) +
geom_shape(fill = "transparent", color = kh[1], linetype = 2,
radius = unit(1, 'cm')) +
scale_x_continuous(NULL, breaks = NULL, expand=c(0,0)) +
scale_y_continuous(NULL, breaks = NULL, expand=c(0,0)) +
theme_void()
# define the layout
layout <- c(
# cat
area(t = 1, b = 5, l = 5, r = 9),
area(t = 6, b = 8, l = 5, r = 9),
# beta
area(t = 9, b = 13, l = 2, r = 6),
area(t = 9, b = 13, l = 8, r = 12),
# arrow
area(t = 14, b = 16, l = 2, r = 6),
area(t = 14, b = 16, l = 8, r = 12),
# bern
area(t = 17, b = 21, l = 2, r = 6),
area(t = 17, b = 21, l = 8, r = 12),
area(t = 23, b = 25, l = 5, r = 9),
area(t = 26, b = 27, l = 5, r = 9),
area(t = 8, b = 23, l = 1, r = 13)
)
# combine and plot!
(p1 + p2 + p3 + p4 + p2 + p2 + p5 + p6 + p7 + p8 + p9) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))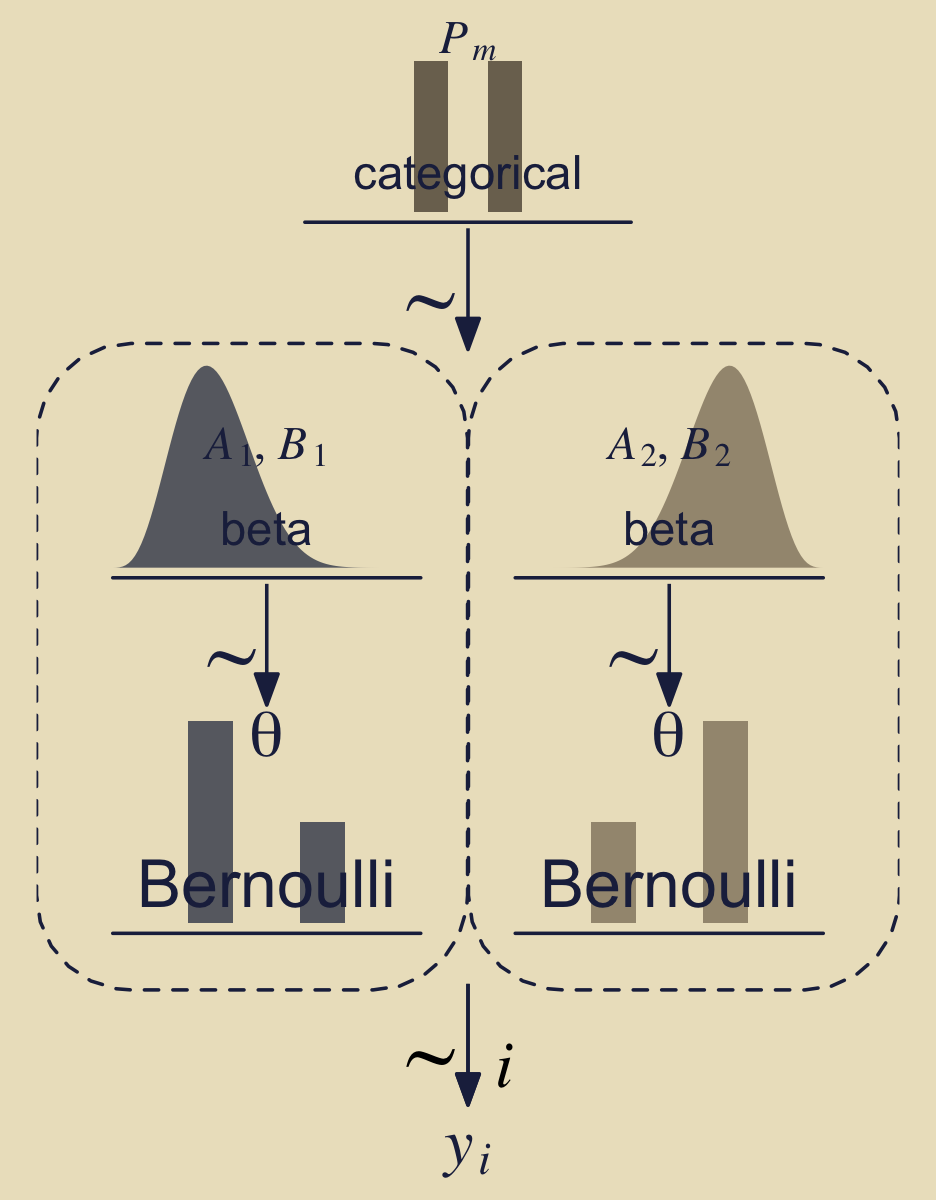
Note how we used the geom_shape() function from the ggforce package (Thomas Lin Pedersen, 2021) to make the two dashed borders with the rounded edges. You can learn more from Pedersen’s (n.d.) vignette, Draw polygons with expansion/contraction and/or rounded corners — geom_shape.
10.2.1 Solution by formal analysis.
Here we rehearse if we have a \(\operatorname{Beta}(\theta, a, b)\) prior for \(\theta\) of the Bernoulli likelihood function, then the analytic solution for the posterior is \(\operatorname{Beta}(\theta | z + a, N – z + b)\). Within this paradigm, if you would like to compute \(p(D | m)\), don’t use the following function. If suffers from underflow with large values.
p_d <- function(z, n, a, b) {
beta(z + a, n - z + b) / beta(a, b)
}This version is more robust.
p_d <- function(z, n, a, b) {
exp(lbeta(z + a, n - z + b) - lbeta(a, b))
}You’d use it like this to compute \(p(D|m_1)\).
p_d(z = 6, n = 9, a = 3.5, b = 8.5)## [1] 0.0004993439So to compute our BF, \(\frac{p(D|m_1)}{p(D|m_2)}\), you might use the p_d() function like this.
p_d_1 <- p_d(z = 6, n = 9, a = 3.5, b = 8.5)
p_d_2 <- p_d(z = 6, n = 9, a = 8.5, b = 3.5)
p_d_1 / p_d_2## [1] 0.2135266And if we computed the BF the other way, it’d look like this.
p_d_2 / p_d_1## [1] 4.683258Since the BF itself is only \(\text{BF} = \frac{p(D | m = 1)}{p(D | m = 2)}\), we’d need to bring in the priors for the models themselves to get the posterior probabilities, which follows the form
\[\frac{p(m = 1 | D)}{p(m = 2 | D)} = \left (\frac{p(D | m = 1)}{p(D | m = 2)} \right ) \left ( \frac{p(m = 1)}{p(m = 2)} \right).\]
If for both our models \(p(m) = .5\), then the BF is the same it was, before.
(p_d_1 * .5) / (p_d_2 * .5)## [1] 0.2135266As Kruschke pointed out, because we’re working in the probability metric, the sum of \(p(m = 1 | D )\) and \(p(m = 2 | D )\) must be 1. By simple algebra then,
\[p(m = 2 | D ) = 1 - p(m = 1 | D ).\]
Therefore, it’s also the case that
\[\frac{p(m = 1 | D)}{1 - p(m = 1 | D)} = 0.2135266.\]
Thus, 0.2135266 is in an odds metric. If you want to convert odds to a probability, you follow the formula
\[\text{odds} = \frac{\text{probability}}{1 - \text{probability}}.\]
And with more algebraic manipulation, you can solve for the probability.
\[\begin{align*} \text{odds} & = \frac{\text{probability}}{1 - \text{probability}} \\ \text{odds} - \text{odds} \cdot \text{probability} & = \text{probability} \\ \text{odds} & = \text{probability} + \text{odds} \cdot \text{probability} \\ \text{odds} & = \text{probability} (1 + \text{odds}) \\ \frac{\text{odds}}{1 + \text{odds}} & = \text{probability} \end{align*}\]
Thus, the posterior probability for \(m = 1\) is
\[p(m = 1 | D) = \frac{0.2135266}{1 + 0.2135266}.\]
We can express that in code like so.
odds <- (p_d_1 * .5) / (p_d_2 * .5)
odds / (1 + odds)## [1] 0.1759554Relative to \(m = 2\), our posterior probability for \(m = 1\) is about .18. Therefore the posterior probability of \(m = 2\) is 1 minus that.
1 - (odds / (1 + odds))## [1] 0.8240446Given the data, the two models and the prior assumption they were equally credible, we conclude \(m = 2\) is .82 probable.
10.2.2 Solution by grid approximation.
As in earlier chapters, we won’t be able to make the wireframe plots on the left of Figure 10.3. But we can do some of the others. Here’s the upper right panel.
p13 <-
tibble(omega = seq(from = 0, to = 1, length.out = length)) %>%
mutate(m_p = ifelse(omega %in% c(.25, .75), 15, 0)) %>%
ggplot(aes(xmin = 0, xmax = m_p, y = omega)) +
geom_ribbon(fill = kh[4], color = kh[4]) +
scale_x_continuous(expand = expansion(mult = c(0.002, 0.05)), limits = c(0, 25)) +
scale_y_continuous(expand = expansion(mult = c(0, 0))) +
labs(x = expression(Marginal~p(omega)),
y = expression(omega))
p13 + labs(subtitle = "Remember, the scale on the x is arbitrary.")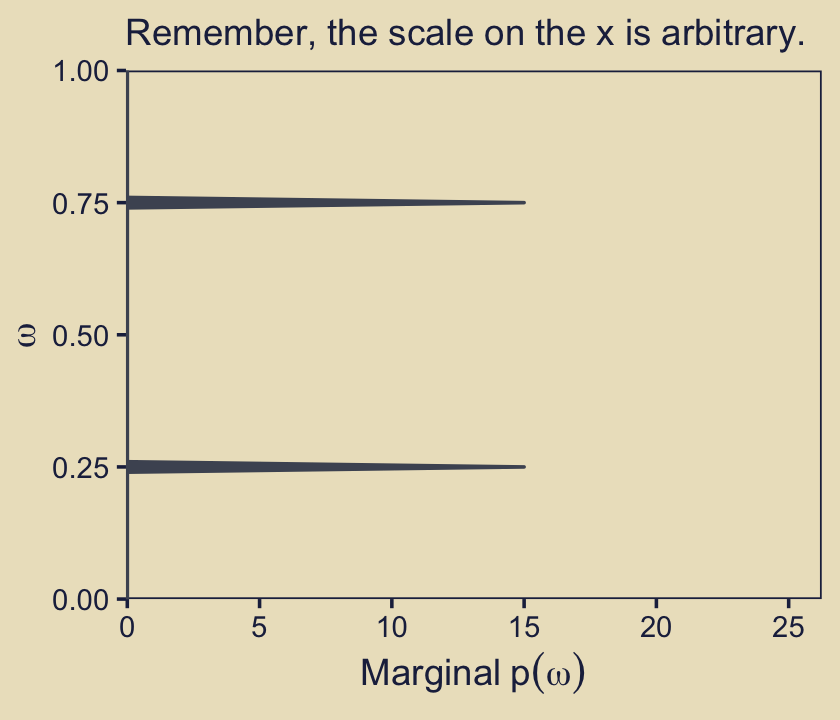
Building on that, here’s the upper middle panel of the “two [prior] dorsal fins” (p. 271).
d <-
crossing(omega = seq(from = 0, to = 1, length.out = length),
theta = seq(from = 0, to = 1, length.out = length)) %>%
mutate(prior = ifelse(omega == .25, dbeta(theta, 3.5, 8.5),
ifelse(omega == .75, dbeta(theta, 8.5, 3.5),
0)))
p12 <-
d %>%
ggplot(aes(x = theta, y = omega, fill = prior)) +
geom_raster(interpolate = T) +
scale_fill_gradient(low = kh[1], high = kh[9], breaks = NULL) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5, expand = c(0, 0)) +
scale_y_continuous(expression(omega), breaks = 0:5 / 5, expand = c(0, 0))
p12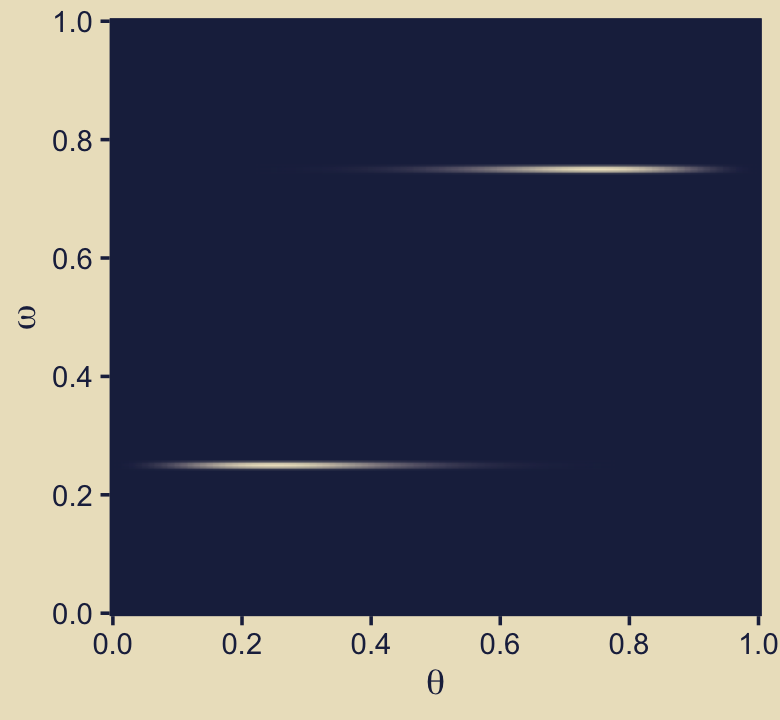
This time we’ll separate \(p_{m = 1}(\theta)\) and \(p_{m = 2}(\theta)\) into the two short plots on the right of the next row down.
p23 <-
d %>%
filter(omega %in% c(.25, .75)) %>%
mutate(omega = factor(str_c("omega == ", omega),
levels = str_c("omega == ", c(.75, .25)))) %>%
ggplot(aes(x = theta, y = prior)) +
geom_area(fill = kh[4]) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5,
expand = expansion(mult = c(0, 0))) +
scale_y_continuous(expression(Marginal~p(theta*"|"*omega)),
expand = expansion(mult = c(0, 0.05)), limits = c(0, NA)) +
facet_wrap(~ omega, ncol = 1, scales = "free", labeller = label_parsed)
p23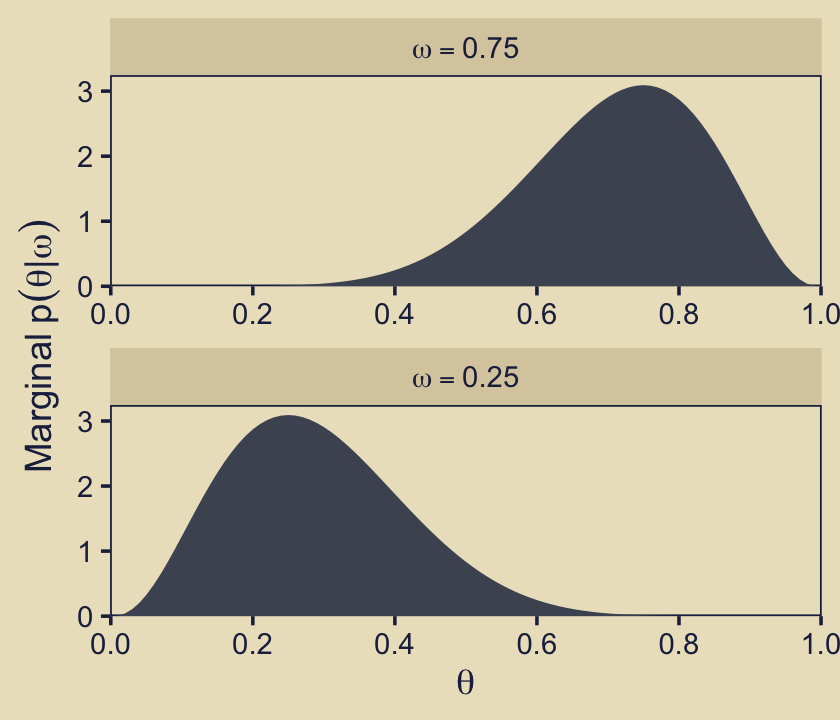
We can continue to build on those sensibilities for the middle panel of the same row. Here we’re literally adding \(p_{m = 1}(\theta)\) to \(p_{m = 2}(\theta)\) and taking their average.
p22 <-
tibble(theta = seq(from = 0, to = 1, length.out = length)) %>%
mutate(d_75 = dbeta(x = theta, shape1 = 8.5, shape2 = 3.5),
d_25 = dbeta(x = theta, shape1 = 3.5, shape2 = 8.5)) %>%
mutate(mean_prior = (d_75 + d_25) / 2) %>%
ggplot(aes(x = theta, y = mean_prior)) +
geom_area(fill = kh[4]) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5,
expand = expansion(mult = c(0, 0))) +
scale_y_continuous(expression(Marginal~p(theta)),
expand = expansion(mult = c(0, 0.05)), limits = c(0, 3))
p22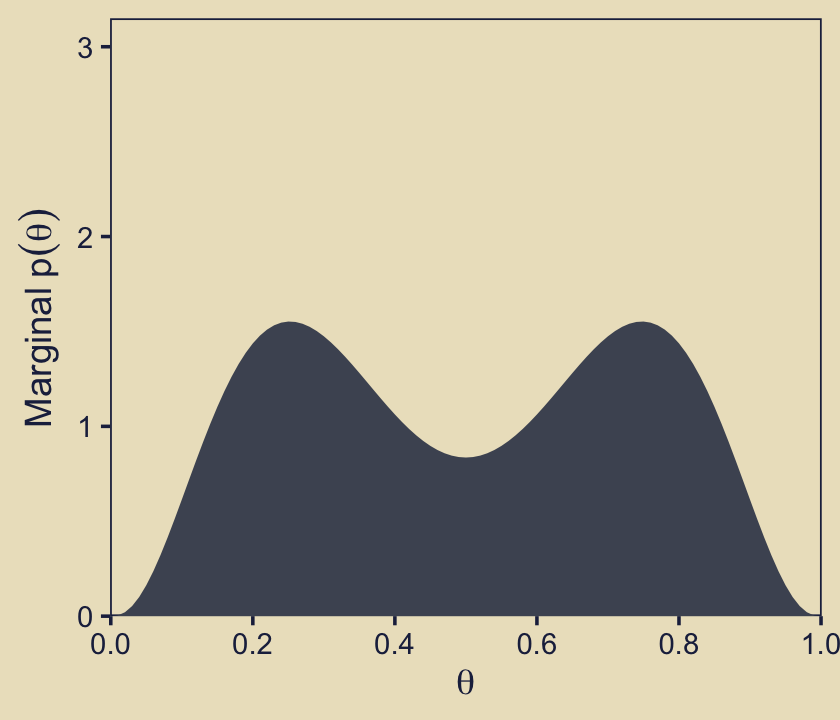
We need the Bernoulli likelihood function for the next step.
bernoulli_likelihood <- function(theta, data) {
n <- length(data)
z <- sum(data)
return(theta^z * (1 - theta)^(n - sum(data)))
}Time to feed our data and the parameter space into bernoulli_likelihood(), which will allow us to make the 2-dimensional density plot at the heart of Figure 10.3.
n <- 9
z <- 6
trial_data <- rep(0:1, times = c(n - z, z))
d <-
d %>%
mutate(likelihood = bernoulli_likelihood(theta = theta, data = trial_data))
p32 <-
d %>%
ggplot(aes(x = theta, y = omega, fill = likelihood)) +
geom_raster(interpolate = T) +
scale_fill_gradient(low = kh[1], high = kh[9], breaks = NULL) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5, expand = c(0, 0)) +
scale_y_continuous(expression(omega), breaks = 0:5 / 5, expand = c(0, 0))
p32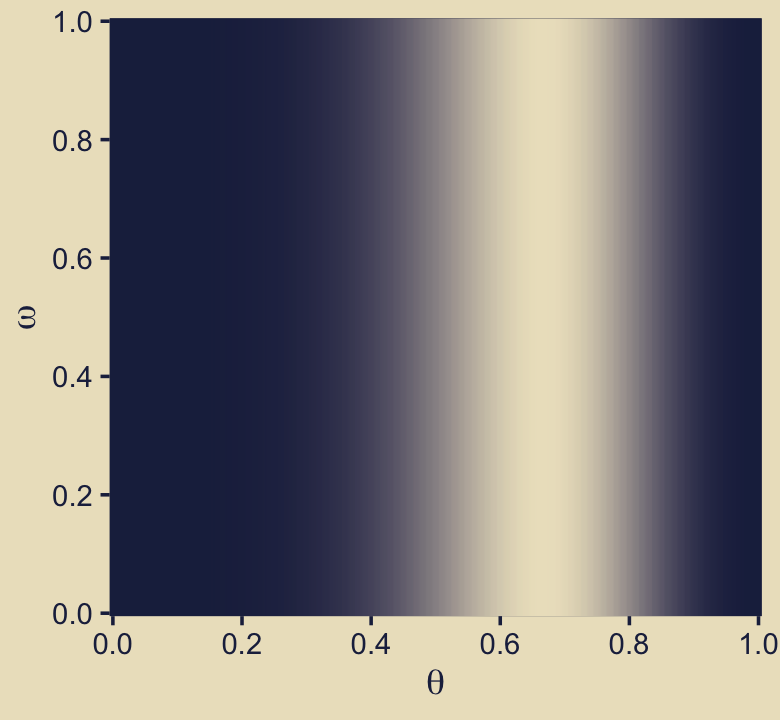
Now we just need the marginal likelihood, \(p(D)\), to compute the posterior. Our first depiction will be the middle panel of the second row from the bottom–the panel with the uneven dolphin fins.
d <-
d %>%
mutate(marginal_likelihood = sum(prior * likelihood)) %>%
mutate(posterior = (prior * likelihood) / marginal_likelihood)
p42 <-
d %>%
ggplot(aes(x = theta, y = omega, fill = posterior)) +
geom_raster(interpolate = T) +
scale_fill_gradient(low = kh[1], high = kh[9], breaks = NULL) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5, expand = c(0, 0)) +
scale_y_continuous(expression(omega), breaks = 0:5 / 5, expand = c(0, 0))
p42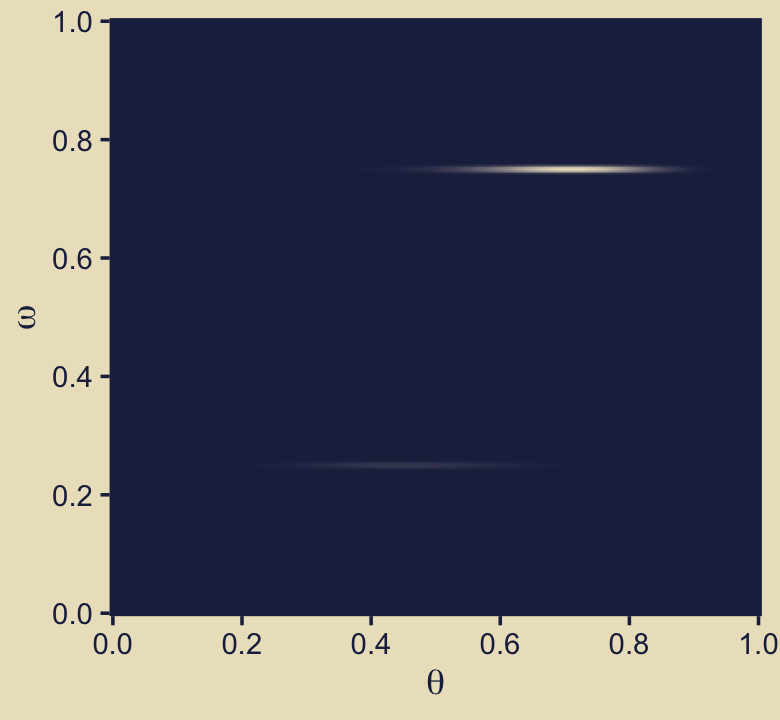
Here, then, is a way to get the panel in on the right of the second row from the bottom.
p43 <-
d %>%
mutate(marginal = (posterior / max(posterior)) * 25) %>%
ggplot(aes(xmin = 0, xmax = marginal, y = omega)) +
geom_ribbon(fill = kh[6], color = kh[6]) +
scale_x_continuous(expression(omega),
expand = expansion(mult = c(0.002, 0.05)), limits = c(0, 25)) +
scale_y_continuous(expression(Marginal~p(omega*"|"*D)),
expand = expansion(mult = c(0, 0)))
p43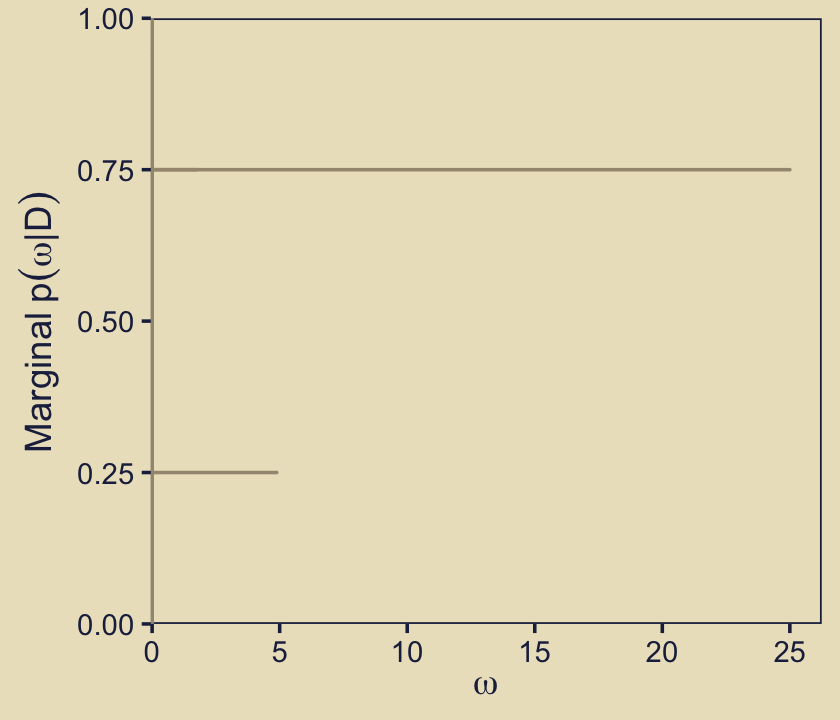
To make the middle bottom panel of Figure 10.3, we have to average the posterior values of \(\theta\) over the grid of \(\omega\) values. That is, we have to marginalize.
p52 <-
d %>%
group_by(theta) %>%
summarise(marginal_theta = mean(posterior)) %>%
ggplot(aes(x = theta, y = marginal_theta)) +
geom_area(fill = kh[6]) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5,
expand = expansion(mult = c(0, 0))) +
scale_y_continuous(expression(Marginal~p(theta*"|"*D)),
expand = expansion(mult = c(0, 0.05)), limits = c(0, NA))
p52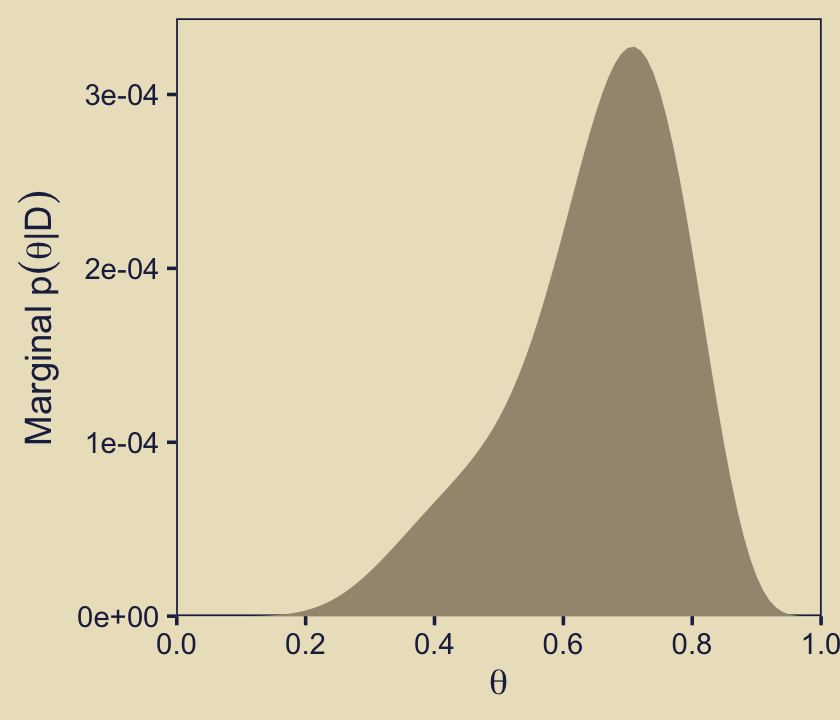
For the lower right panel of Figure 10.3, we’ll filter() to our two focal values of \(\omega\) and then facet by them.
p53 <-
d %>%
filter(omega %in% c(.25, .75)) %>%
mutate(omega = factor(str_c("omega == ", omega),
levels = str_c("omega == ", c(.75, .25)))) %>%
ggplot(aes(x = theta, y = posterior)) +
geom_area(fill = kh[6]) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5,
expand = expansion(mult = c(0, 0))) +
scale_y_continuous(expression(Marginal~p(theta*"|"*omega*", "*D)),
expand = expansion(mult = c(0, 0.05)), limits = c(0, NA)) +
facet_wrap(~ omega, ncol = 1, scales = "free", labeller = label_parsed)
p53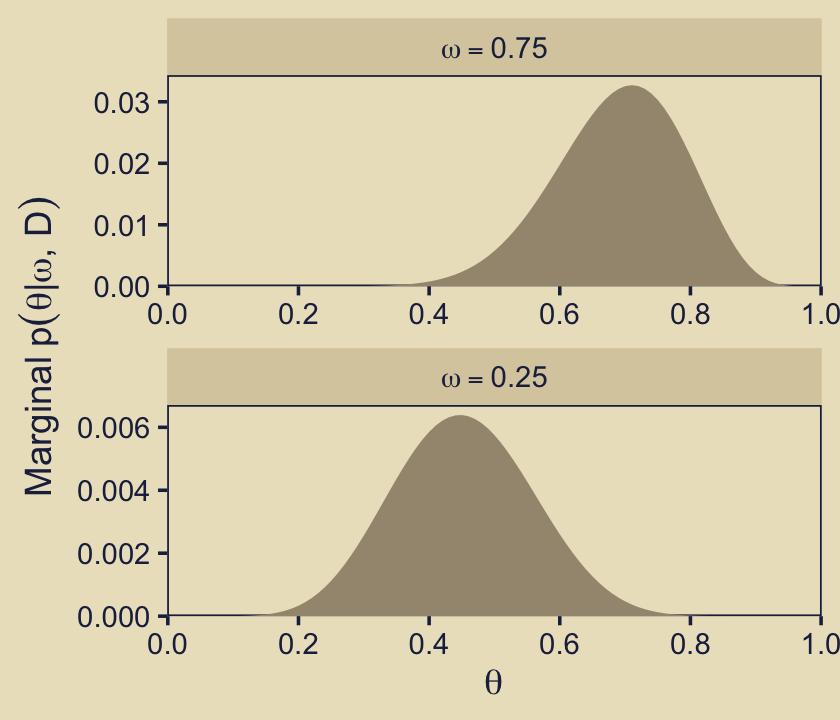
Do note the different scales on the \(y\). Here’s what they’d look like on the same scale.
d %>%
filter(omega %in% c(.25, .75)) %>%
mutate(omega = str_c("omega == ", omega)) %>%
ggplot(aes(x = theta, y = posterior)) +
geom_area(fill = kh[6]) +
scale_x_continuous(expression(theta), breaks = 0:5 / 5,
expand = expansion(mult = c(0, 0))) +
scale_y_continuous(expression(Marginal~p(theta*"|"*omega)),
expand = expansion(mult = c(0, 0.05)), limits = c(0, NA)) +
facet_wrap(~ omega, ncol = 1, labeller = label_parsed)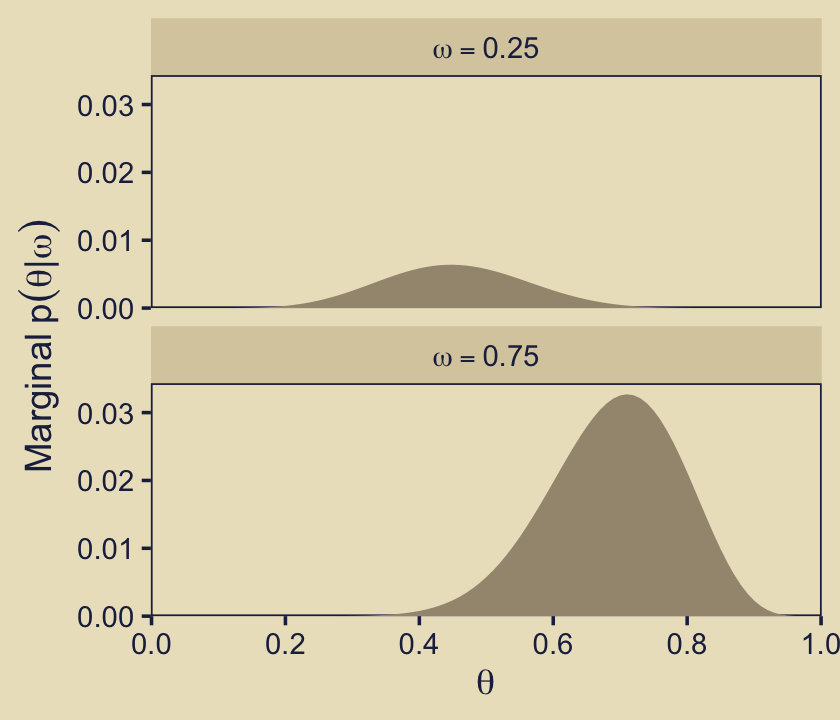
Hopefully that helps build the intuition of what Kruschke meant when he wrote “visual inspection suggests that the ratio of the heights is about 5 to 1, which matches the Bayes factor of 4.68 that we computed exactly in the previous section” (p. 273, emphasis in the original).
Before we move on to the BF, let’s save a few more ggplots and combine them with the previous bunch to make the full version of Figure 10.3.
p21 <-
tibble(x = 1,
y = 8:7,
label = c("Prior", "K==12"),
size = c(2, 1)) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(aes(size = size),
color = kh[1], parse = T, hjust = 0, show.legend = F) +
scale_size_continuous(range = c(3.5, 5.5)) +
coord_cartesian(xlim = c(1, 2),
ylim = c(4, 11)) +
theme(axis.text = element_text(color = kh[9]),
axis.ticks = element_blank(),
panel.background = element_rect(color = kh[9]),
text = element_text(color = kh[9]))
p33 <-
tibble(x = 1,
y = 8:7,
label = c("Likelihood", "D = 6 heads, 3 tails"),
size = c(2, 1)) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(aes(size = size),
hjust = 0, show.legend = F, color = kh[1]) +
scale_size_continuous(range = c(3.5, 5.5)) +
coord_cartesian(xlim = c(1, 2),
ylim = c(4, 11)) +
theme(axis.text = element_text(color = kh[9]),
axis.ticks = element_blank(),
panel.background = element_rect(color = kh[9]),
text = element_text(color = kh[9]))
p51 <-
ggplot() +
annotate(geom = "text", x = 1, y = 8,
label = "Posterior", size = 6, hjust = 0, color = kh[1]) +
coord_cartesian(xlim = c(1, 2),
ylim = c(3, 11)) +
theme(axis.text = element_text(color = kh[9]),
axis.ticks = element_blank(),
panel.background = element_rect(color = kh[9]),
text = element_text(color = kh[9]))
p11 <- plot_spacer()
# combine and plot!
(p11 / p21 / p11 / p11 / p51) | (p12 / p22 / p32 / p42 / p52) | (p13 / p23 / p33 / p43 / p53)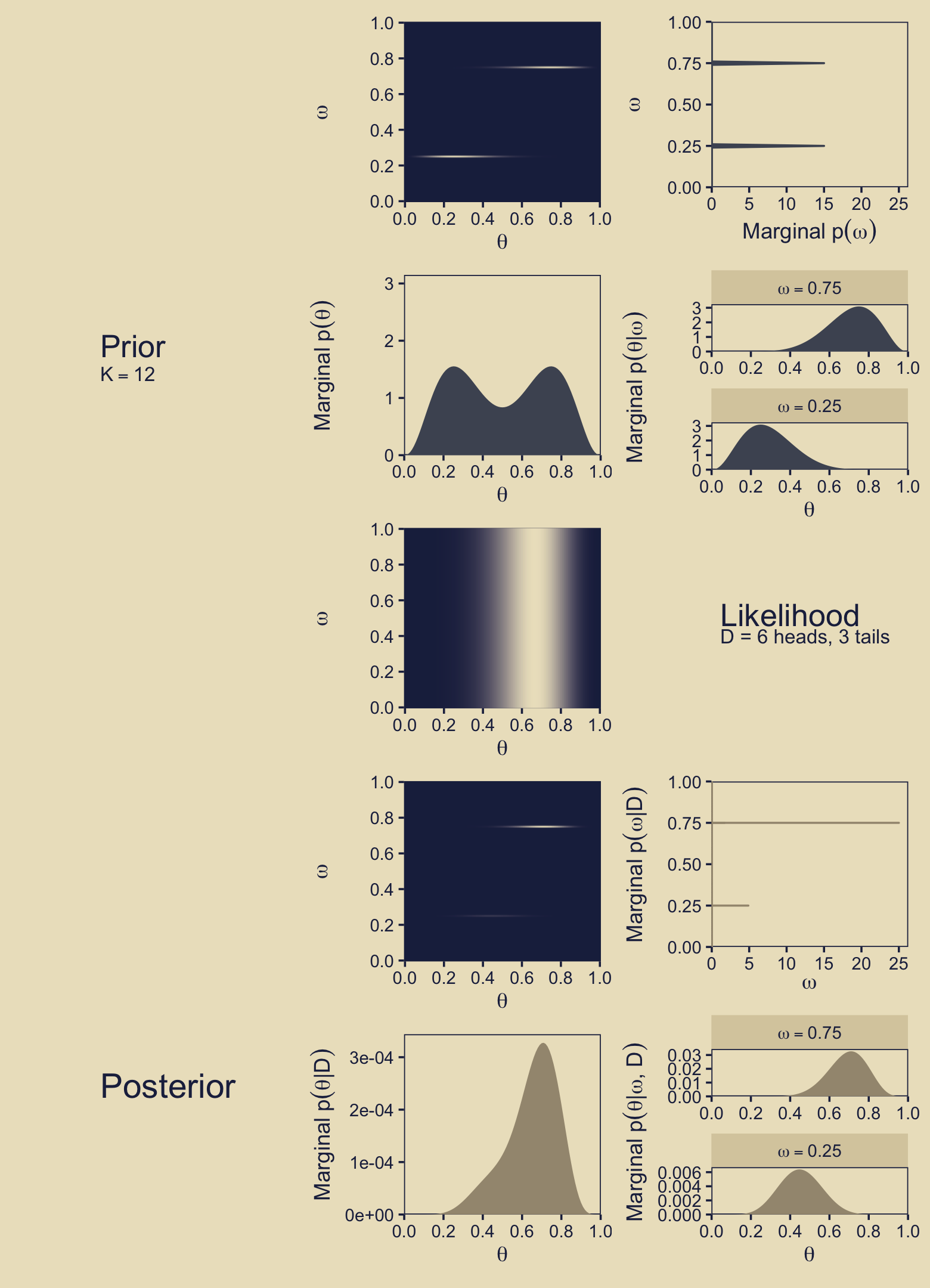
Oh mamma! Using the grid, you might compute that BF like this.
d %>%
filter(omega %in% c(.25, .75)) %>%
group_by(omega) %>%
summarise(sum_posterior = sum(posterior)) %>%
mutate(model = c("model_1", "model_2")) %>%
pivot_wider(-omega,
names_from = model,
values_from = sum_posterior) %>%
mutate(BF = model_2 / model_1)## # A tibble: 1 × 3
## model_1 model_2 BF
## <dbl> <dbl> <dbl>
## 1 0.176 0.824 4.68Please note4 how, in the previous section, Kruschke computed the BF as
\[\frac{p(m = 1 | D)}{p(m = 2 | D)} = .213,\]
which we achieved with this code:
p_d_1 / p_d_2## [1] 0.2135266Here, we’re flipping the ratio to
\[\frac{p(m = 2 | D)}{p(m = 1 | D)},\]
which is why we now have a BF near 5.
p_d_2 / p_d_1## [1] 4.683258But anyway, both the posterior distributions in the figure and the BF indicate \(\omega = .75\) is a better representation of the data than \(\omega = .25\).
10.3 Solution by MCMC
Kruschke started with: “For large, complex models, we cannot derive \(p(D | m)\) analytically or with grid approximation, and therefore we will approximate the posterior probabilities using MCMC methods” (p. 274). He’s not kidding. Welcome to modern Bayes.
10.3.1 Nonhierarchical MCMC computation of each model’s marginal likelihood.
Before you get excited, Kruschke warned: “For complex models, this method might not be tractable. [But] for the simple application here, however, the method works well, as demonstrated in the next section” (p. 277).
10.3.1.1 Implementation with JAGS brms.
Load brms.
library(brms)Let’s save the trial_data as a tibble.
trial_data <-
tibble(y = trial_data)Time to learn a new brms skill. When you want to enter variables into the parameters defining priors in brms::brm(), you need to specify them using the stanvar() function. Since we want to do this for two variables, we’ll use stanvar() twice and save the results as an object, conveniently named stanvars.
omega <- .75
kappa <- 12
stanvars <-
stanvar( omega * (kappa - 2) + 1, name = "my_alpha") +
stanvar((1 - omega) * (kappa - 2) + 1, name = "my_beta")Now we have our stanvars object, we are ready to fit the first model (i.e., the model for which \(\omega = .75\)).
fit10.1 <-
brm(data = trial_data,
family = bernoulli(link = identity),
y ~ 1,
# stanvars lets us do this
prior(beta(my_alpha, my_beta), class = Intercept, lb = 0, ub = 1),
iter = 11000, warmup = 1000, chains = 4, cores = 4,
seed = 10,
stanvars = stanvars,
file = "fits/fit10.01")Note how we fed our stanvars object into the stanvars function.
Anyway, let’s inspect the chains.
plot(fit10.1, widths = c(2, 3))
They look great. Now we glance at the model summary.
print(fit10.1)## Family: bernoulli
## Links: mu = identity
## Formula: y ~ 1
## Data: trial_data (Number of observations: 9)
## Draws: 4 chains, each with iter = 11000; warmup = 1000; thin = 1;
## total post-warmup draws = 40000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept 0.69 0.10 0.48 0.86 1.00 14225 17083
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Next we’ll follow Kruschke and extract the posterior draws, saving them as theta.
theta <- as_draws_df(fit10.1)
head(theta)## # A draws_df: 6 iterations, 1 chains, and 3 variables
## b_Intercept lprior lp__
## 1 0.68 1.025 -6.2
## 2 0.75 1.129 -6.4
## 3 0.52 0.016 -7.5
## 4 0.56 0.337 -7.0
## 5 0.75 1.128 -6.5
## 6 0.73 1.113 -6.3
## # ... hidden reserved variables {'.chain', '.iteration', '.draw'}The fixef() function will return the posterior summaries for the model intercept (i.e., \(\theta\)). We can then index and save the desired summaries.
fixef(fit10.1)## Estimate Est.Error Q2.5 Q97.5
## Intercept 0.6889111 0.09827117 0.4827282 0.8631757(mean_theta <- fixef(fit10.1)[1])## [1] 0.6889111(sd_theta <- fixef(fit10.1)[2])## [1] 0.09827117Now we’ll convert them to the \(\alpha\) and \(\beta\) parameters, a_post and b_post, respectively.
a_post <- mean_theta * ( mean_theta * (1 - mean_theta) / sd_theta^2 - 1)
b_post <- (1 - mean_theta) * ( mean_theta * (1 - mean_theta) / sd_theta^2 - 1)Recall we’ve already defined several values.
n <- 9
z <- 6
omega <- .75
kappa <- 12The reason we’re saving all these values is we’re aiming to compute \(p(D)\), the probability of the data (i.e., the marginal likelihood), given the model. But our intermediary step will be computing its reciprocal, \(\frac{1}{p(D)}\). Here we’ll express Kruschke’s oneOverPD as a function, one_over_pd().
one_over_pd <- function(theta) {
mean(dbeta(theta, a_post, b_post ) /
(theta^z * (1 - theta)^(n - z) *
dbeta(theta, omega * (kappa - 2) + 1, (1 - omega) * (kappa - 2) + 1 )))
}We’re ready to use one_over_pd() to help compute \(p(D)\).
theta %>%
summarise(pd = 1 / one_over_pd(theta = b_Intercept))## # A tibble: 1 × 1
## pd
## <dbl>
## 1 0.00234That matches up nicely with Kruschke’s value at the top of page 278! Let’s rinse, wash, and repeat for \(\omega = .25\). First, we’ll need to redefine omega and our stanvars.
omega <- .25
stanvars <-
stanvar( omega * (kappa - 2) + 1, name = "my_alpha") +
stanvar((1 - omega) * (kappa - 2) + 1, name = "my_beta")Fit the model.
fit10.2 <-
brm(data = trial_data,
family = bernoulli(link = identity),
y ~ 1,
prior(beta(my_alpha, my_beta), class = Intercept, lb = 0, ub = 1),
iter = 11000, warmup = 1000, chains = 4, cores = 4,
seed = 10,
stanvars = stanvars,
file = "fits/fit10.02")We’ll do the rest in bulk.
theta <- as_draws_df(fit10.2)
mean_theta <- fixef(fit10.2)[1]
sd_theta <- fixef(fit10.2)[2]
a_post <- mean_theta * (mean_theta * (1 - mean_theta) / sd_theta^2 - 1)
b_post <- (1 - mean_theta) * (mean_theta * (1 - mean_theta) / sd_theta^2 - 1)
theta %>%
summarise(pd = 1 / one_over_pd(theta = b_Intercept))## # A tibble: 1 × 1
## pd
## <dbl>
## 1 0.000499Boom!
10.3.2 Hierarchical MCMC computation of relative model probability is not available in brms: We’ll cover information criteria instead.
I’m not aware of a way to specify a model “in which the top-level parameter is the index across models” in brms (p. 278). If you know of a way, share your code.
However, we do have options. We can compare and weight models using information criteria, about which you can learn more here or here. The LOO and WAIC are two primary information criteria available for brms. You can compute them for a given model with the loo() and waic() functions, respectively. Here’s a quick example of how to use the waic() function.
waic(fit10.1)##
## Computed from 40000 by 9 log-likelihood matrix
##
## Estimate SE
## elpd_waic -6.2 1.3
## p_waic 0.5 0.1
## waic 12.4 2.7We’ll explain that output in a bit. Before we do, you should know the current recommended workflow for information criteria with brms models is to use the add_criterion() function, which will allow us to compute information-criterion-related output and save it to our brms fit objects. Here’s how to do that with both our fits.
fit10.1 <- add_criterion(fit10.1, criterion = c("loo", "waic"))
fit10.2 <- add_criterion(fit10.2, criterion = c("loo", "waic"))You can extract the same WAIC output for fit10.1 we saw above by executing fit10.1$criteria$waic. Here we look at the LOO summary for fit10.2, instead.
fit10.2$criteria$loo##
## Computed from 40000 by 9 log-likelihood matrix
##
## Estimate SE
## elpd_loo -7.1 0.3
## p_loo 0.5 0.0
## looic 14.1 0.6
## ------
## Monte Carlo SE of elpd_loo is 0.0.
##
## All Pareto k estimates are good (k < 0.5).
## See help('pareto-k-diagnostic') for details.You get a wealth of output, more of which can be seen by executing str(fit10.1$criteria$loo). First, notice the message “All Pareto k estimates are good (k < 0.5).” Pareto \(k\) values can be used for diagnostics (Vehtari & Gabry, 2022a, Plotting Pareto \(k\) diagnostics). Each case in the data gets its own \(k\) value and we like it when those \(k\)’s are low. The makers of the loo package (Vehtari et al., 2017; Vehtari et al., 2022) get worried when \(k\) values exceed 0.7 and, as a result, we will get warning messages when they do. Happily, we have no such warning messages in this example.
In the main section, we get estimates for the expected log predictive density (elpd_loo), the estimated effective number of parameters (p_loo), and the Pareto smoothed importance-sampling leave-one-out cross-validation (PSIS-LOO; looic). Each estimate comes with a standard error (i.e., SE). Like other information criteria, the LOO values aren’t of interest in and of themselves. However, the estimate of one model’s LOO relative to that of another can be of great interest. We generally prefer models with lower information criteria. With the loo_compare() function, we can compute a formal difference score between two models.
loo_compare(fit10.1, fit10.2, criterion = "loo")## elpd_diff se_diff
## fit10.1 0.0 0.0
## fit10.2 -0.8 1.6The loo_compare() output rank orders the models such that the best fitting model appears on top. All models receive a difference score relative to the best model. Here the best fitting model is fit10.1 and since the LOO for fit10.1 minus itself is zero, the values in the top row are all zero.
Each difference score also comes with a standard error. In this case, even though fit10.1 has the lower estimates, the standard error is twice the magnitude of the difference score. So the LOO difference score puts the two models on similar footing. You can do a similar analysis with the WAIC estimates.
In addition to difference-score comparisons, you can also use the LOO or WAIC for AIC-type model weighting. In brms, you do this with the model_weights() function.
(mw <- model_weights(fit10.1, fit10.2))## fit10.1 fit10.2
## 0.8399257 0.1600743I don’t know that I’d call these weights probabilities, but they do sum to one. In this case, the analysis suggests we put about five times more weight to fit10.1 relative to fit10.2.
mw[1] / mw[2]## fit10.1
## 5.247101With brms::model_weights(), we have a variety of weighting schemes available to us. Since we didn’t specify any in the weights argument, we used the default "stacking"method, which is described in Yao et al. (2018). Vehtari has written about the paper on Gelman’s blog, too. But anyway, the point is that different weighting schemes might not produce the same results. For example, here’s the result from weighting using the WAIC.
model_weights(fit10.1, fit10.2, weights = "waic")## fit10.1 fit10.2
## 0.698708 0.301292The results are similar, for sure. But they’re not the same. The stacking method via the brms default weights = "stacking" is the current preferred method by the folks on the Stan team (e.g., the authors of the above linked paper).
For more on stacking and other weighting schemes, see Vehtari and Gabry’s (2022b) vignette, Bayesian Stacking and Pseudo-BMA weights using the loo package, or Vehtari’s modelselection_tutorial GitHub repository. But don’t worry. We will have more opportunities to practice with information criteria, model weights, and such later in this ebook.
10.3.2.1 Using [No need to use] pseudo-priors to reduce autocorrelation.
Since we didn’t use Kruschke’s method from the last subsection, we don’t have the same worry about autocorrelation. For example, here are the autocorrelation plots for fit10.1.
library(bayesplot)
color_scheme_set(
scheme = c(lisa_palette("KatsushikaHokusai", n = 9, type = "continuous")[6:1])
)
theta %>%
mutate(chain = .chain) %>%
mcmc_acf(pars = "b_Intercept",
lags = 35)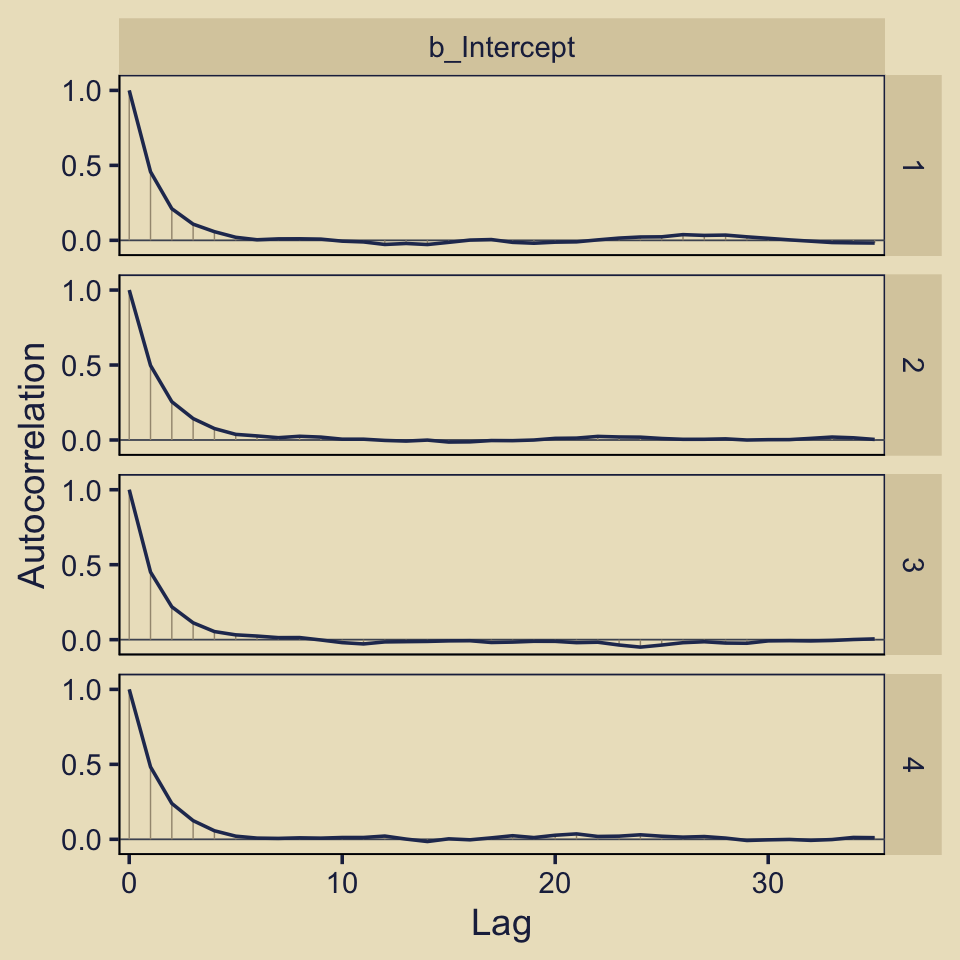
Our autocorrelations were a little high for HMC, but nowhere near pathological. The results for fit10.2 were similar. Before we move on, note our use of bayesplot::color_scheme_set(), which allowed us to customize the color scheme bayesplot used within the plot. Based on that code, here is our new color scheme for all plots made by bayesplot.
color_scheme_view()
color_scheme_get()## custom
## 1 #A3977F
## 2 #6E6352
## 3 #4D5362
## 4 #2D4472
## 5 #26365F
## 6 #1F284CIn case you were curious, here is the default.
color_scheme_view(scheme = "blue")
Anyway, as you might imagine from the moderate autocorrelations, the \(N_{eff}/N\) ratio for b_Intercept wasn’t great.
neff_ratio(fit10.1)[1] %>%
mcmc_neff() +
yaxis_text(hjust = 0)
But we specified a lot of post-warmup draws, so we’re still in good shape. Plus, the \(\widehat R\) was fine.
rhat(fit10.1)[1]## b_Intercept
## 1.0002710.3.3 Models with different “noise” distributions in JAGS brms.
Probability distribution[s are] sometimes [called “noise”] distribution[s] because [they describe] the random variability of the data values around the underlying trend. In more general applications, different models can have different noise distributions. For example, one model might describe the data as log-normal distributed, while another model might describe the data as gamma distributed. (p. 288)
If there are more than one plausible noise distributions for our data, we might want to compare the models. Kruschke then gave us a general trick in the form of this JAGS code:
data {
C <- 10000 # JAGS does not warn if too small!
for (i in 1:N) {
ones[i] <- 1 }
} model {
for (i in 1:N) {
spy1[i] <- pdf1(y[i], parameters1) / C # where pdf1 is a formula
spy2[i] <- pdf2(y[i], parameters2) / C # where pdf2 is a formula
spy[i] <- equals(m,1) * spy1[i] + equals(m, 2) * spy2[i]
ones[i] ~ dbern(spy[i])
}
parameters1 ~ dprior1...
parameters2 ~ dprior2...
m ~ dcat(mPriorProb[])
mPriorProb[1] <- .5
mPriorProb[2] <- .5
}I’m not aware that we can do this within the Stan/brms framework. If I’m in error and you know how, please share your code. However, we do have options. In anticipation of Chapter 16, let’s consider Gaussian-like data with thick tails. We might generate some like this.
# how many draws would you like?
n <- 1e3
set.seed(10)
(d <- tibble(y = rt(n, df = 7)))## # A tibble: 1,000 × 1
## y
## <dbl>
## 1 0.0214
## 2 -0.987
## 3 0.646
## 4 -0.237
## 5 0.977
## 6 -0.200
## 7 0.781
## 8 -1.09
## 9 1.83
## 10 -0.682
## # … with 990 more rowsThe resulting data look like this.
d %>%
ggplot(aes(x = y)) +
geom_histogram(color = kh[9], fill = kh[3],
linewidth = 0.1, bins = 30) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
theme(panel.grid = element_blank())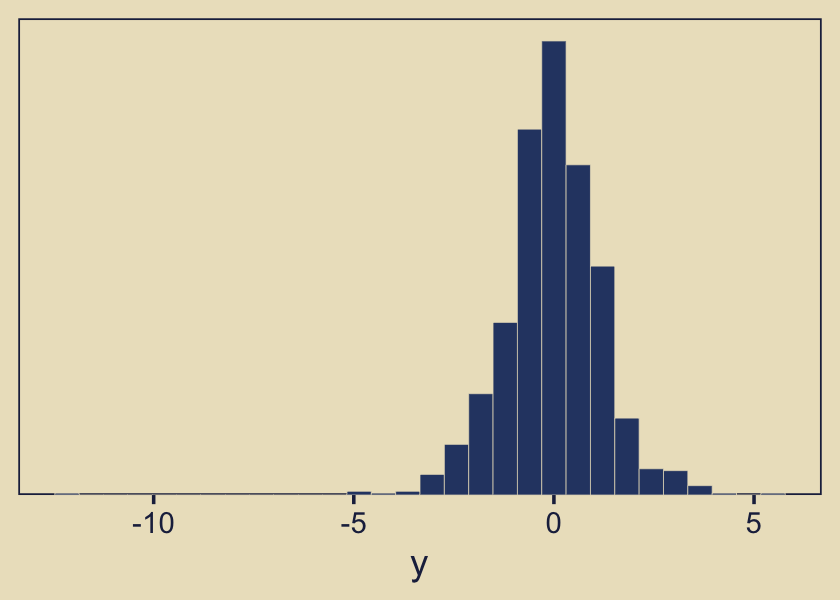
As you’d expect with a small-\(\nu\) Student’s \(t\), some of our values are far from the central clump. If you don’t recall, Student’s \(t\)-distribution has three parameters: \(\nu\), \(\mu\), and \(\sigma\). The Gaussian is a special case of Student’s \(t\) where \(\nu = \infty\). As \(\nu\) gets small, the distribution allocates more mass in the tails. From a Gaussian perspective, the small-\(\nu\) Student’s \(t\) expects more outliers–though it’s a little odd calling them outliers from a small-\(\nu\) Student’s \(t\) perspective.
Let’s see how well the Gaussian versus the Student’s \(t\) likelihoods handle the data. Here we’ll use fairly liberal priors.
fit10.3 <-
brm(data = d,
family = gaussian,
y ~ 1,
prior = c(prior(normal(0, 5), class = Intercept),
# by default, this has a lower bound of 0
prior(normal(0, 5), class = sigma)),
chains = 4, cores = 4,
seed = 10,
file = "fits/fit10.03")
fit10.4 <-
brm(data = d,
family = student,
y ~ 1,
prior = c(prior(normal(0, 5), class = Intercept),
prior(normal(0, 5), class = sigma),
# this is the brms default prior for nu
prior(gamma(2, 0.1), class = nu)),
chains = 4, cores = 4,
seed = 10,
file = "fits/fit10.04")In case you were curious, here’s what that default gamma(2, 0.1) prior on nu looks like.
tibble(x = seq(from = 1, to = 100, by = 1)) %>%
ggplot(aes(x = x, y = dgamma(x, 2, 0.1))) +
geom_area(fill = kh[5]) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
scale_x_continuous(expression(italic(p)(nu)), expand = expansion(mult = c(0, 0.01)), limits = c(0, 100))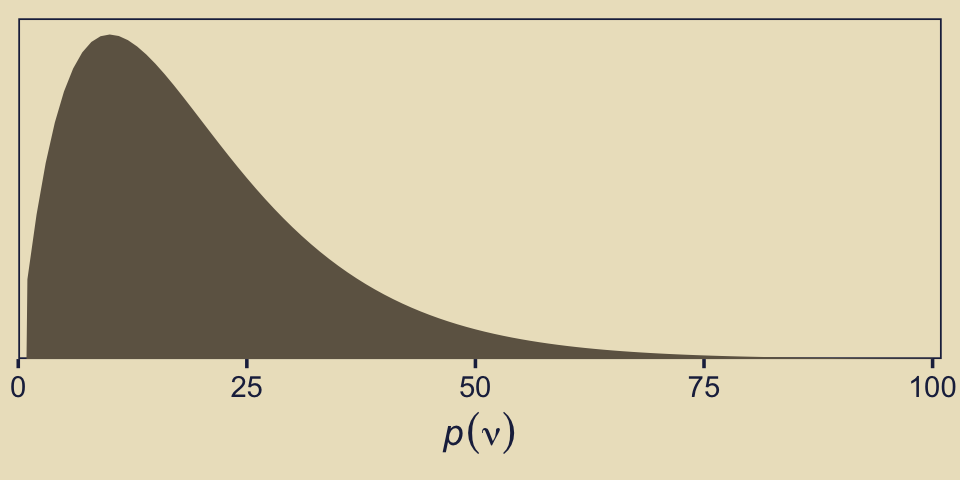
That prior puts most of the probability mass below 50, but the right tail gently fades off into the triple digits, allowing for the possibility of larger estimates.
We can use the posterior_summary() function to get a compact look at the parameter summaries.
posterior_summary(fit10.3)[1:2, ] %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept -0.03 0.04 -0.11 0.05
## sigma 1.25 0.03 1.20 1.31posterior_summary(fit10.4)[1:3, ] %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept -0.01 0.04 -0.08 0.06
## sigma 0.98 0.04 0.91 1.05
## nu 5.74 1.00 4.18 8.09Now we can compare the two approaches using information criteria. For kicks, we’ll use the WAIC.
fit10.3 <- add_criterion(fit10.3, criterion = c("loo", "waic"))
fit10.4 <- add_criterion(fit10.4, criterion = c("loo", "waic"))
loo_compare(fit10.3, fit10.4, criterion = "waic")## elpd_diff se_diff
## fit10.4 0.0 0.0
## fit10.3 -60.7 40.3Based on the WAIC difference, we have some support for preferring the Student’s \(t\), but do notice how wide that SE was. We can also compare the models using model weights. Here we’ll use the default weighting scheme.
model_weights(fit10.3, fit10.4)## fit10.3 fit10.4
## 0.02873619 0.97126381Virtually all of the stacking weight was placed on the Student’s-\(t\) model, fit10.4.
Remember what that \(p(\nu)\) looked like? Here’s our posterior distribution for \(\nu\).
as_draws_df(fit10.4) %>%
ggplot(aes(x = nu)) +
geom_histogram(color = kh[9], fill = kh[3],
linewidth = 0.1, bins = 30) +
scale_x_continuous(expression(italic(p)(nu*"|"*italic(D))),
expand = c(0, 0)) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
coord_cartesian(xlim = c(0, 21)) +
labs(subtitle = expression("Recall that for the Gaussian, "*nu==infinity.))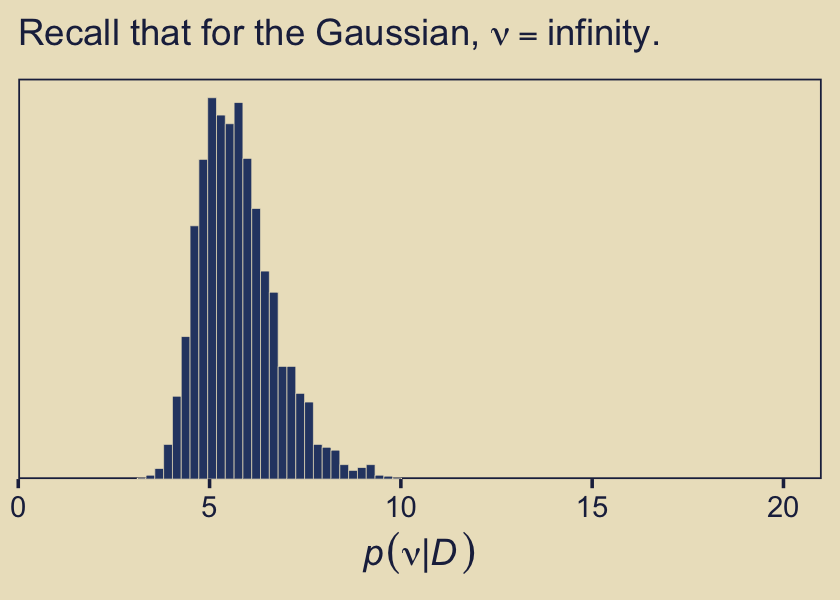
Even though our prior for \(\nu\) was relatively weak, the posterior ended up concentrated on values in the middle-single-digit range. Recall the data-generating value was 7.
We can also compare the models using posterior-predictive checks. There are a variety of ways we might do this, but the most convenient way is with brms::pp_check(), which is itself a wrapper for the family of ppc functions from the bayesplot package.
pp_check(fit10.3, ndraws = 50) +
coord_cartesian(xlim = c(-10, 10)) +
ggtitle("Gaussian model")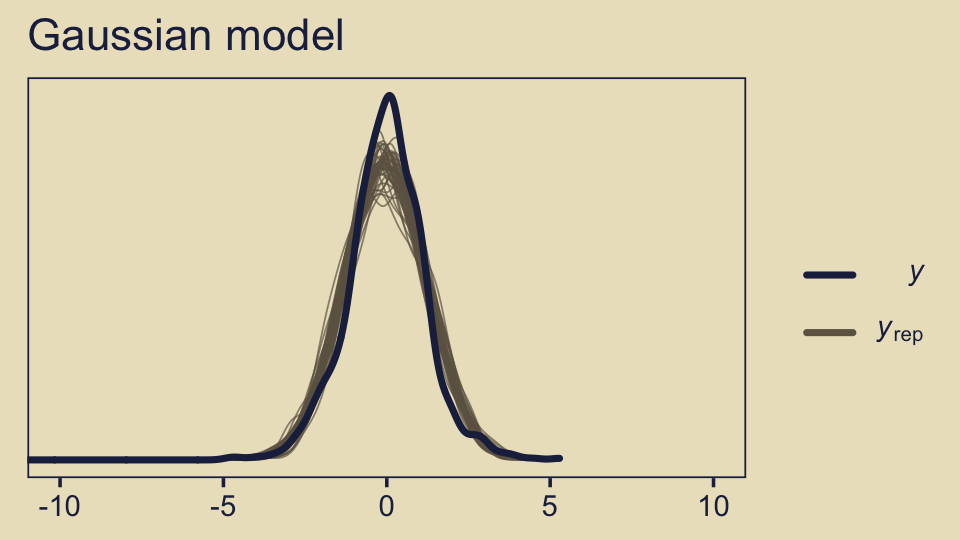
pp_check(fit10.4, ndraws = 50) +
coord_cartesian(xlim = c(-10, 10)) +
ggtitle("Student-t model")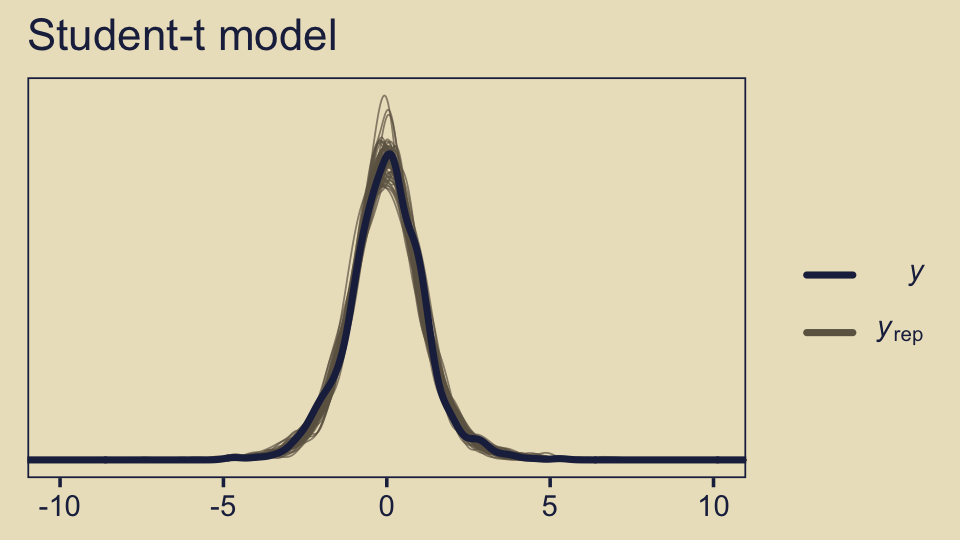
The default pp_check() setting allows us to compare the density of the data \(y\) (i.e., the dark blue) with 10 densities simulated from the posterior \(y_\text{rep}\) (i.e., the light blue). By ndraws = 50, we adjusted that default to 50 simulated densities. We prefer models that produce \(y_\text{rep}\) distributions resembling \(y\). Though the results from both models were similar, the simulated distributions from fit10.4 mimicked the original data a little more convincingly. To learn more about this approach to posterior predictive checks, check out Gabry’s (2022) vignette, Graphical posterior predictive checks using the bayesplot package.
10.4 Prediction: Model averaging
In many applications of model comparison, the analyst wants to identify the best model and then base predictions of future data on that single best model, denoted with index \(b\). In this case, predictions of future \(\hat y\) are based exclusively on the likelihood function \(p_b(\hat y | \theta_b, m = b)\) and the posterior distribution \(p_b(\theta_b | D, m = b)\) of the winning model:
\[p(\hat y | D, m = b) = \int \text d \theta_b \; p_b (\hat y | \theta_b, m = b) p_b(\theta_b | D, m = b)\]
But the full model of the data is actually the complete hierarchical structure that spans all the models being compared, as indicated in Figure 10.1 (p. 267). Therefore, if the hierarchical structure really expresses our prior beliefs, then the most complete prediction of future data takes into account all the models, weighted by their posterior credibilities. In other words, we take a weighted average across the models, with the weights being the posterior probabilities of the models. Instead of conditionalizing on the winning model, we have
\[\begin{align*} p (\hat y | D) & = \sum_m p (\hat y | D, m) p (m | D) \\ & = \sum_m \int \text d \theta_m \; p_m (\hat y | \theta_m, m) p_m(\theta_m | D, m) p (m | D) \end{align*}\]
This is called model averaging. (p. 289)
Okay, while the concept of model averaging is of great interest, we aren’t going to be able to follow this approach to it within the Stan/brms paradigm. This, recall, is because our paradigm doesn’t allow for a hierarchical organization of models in the same way JAGS does. However, we can still play the model averaging game with extensions of our model weighting paradigm, above. Before we get into the details,
recall that there were two models of mints that created the coin, with one mint being tail-biased with mode \(\omega = 0.25\) and one mint being head-biased with mode \(\omega = 0.75\) The two subpanels in the lower-right [of Figure 10.3] illustrate the posterior distributions on \(\omega\) within each model, \(p(\theta | D, \omega = 0.25)\) and \(p(\theta | D, \omega = 0.75)\) The winning model was \(\omega = 0.75\), and therefore the predicted value of future data, based on the winning model alone, would use \(p(\theta | D, \omega = 0.75)\). (p. 289)
Here’s the histogram for \(p(\theta | D, \omega = 0.75)\), which we generate from our fit10.1.
library(tidybayes)
as_draws_df(fit10.1) %>%
ggplot(aes(x = b_Intercept, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = c(.95, .5),
fill = kh[6], slab_color = kh[5], color = kh[2],
breaks = 40, slab_size = .25, outline_bars = T) +
scale_x_continuous(expression(italic(p)(theta*"|"*italic(D)*", "*omega==.75)),
expand = expansion(mult = c(0, 0)),
breaks = 0:5 / 5, limits = c(0, 1)) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0.02, 0.05))) +
labs(subtitle = "The posterior for the probability, given fit10.1") 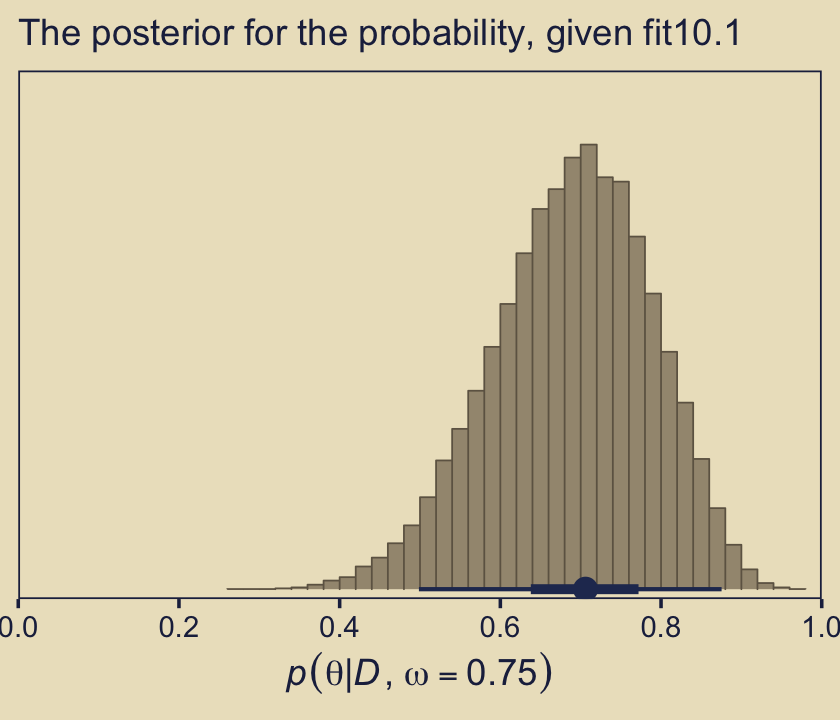
But the overall model included \(\omega = 0.75\), and if we use the overall model, then the predicted value of future data should be based on the complete posterior summed across values of \(\omega\). The complete posterior distribution [is] \(p(\theta | D)\) (p. 289).
The cool thing about the model weighting stuff we learned about earlier is that you can use those model weights to average across models. Again, we’re not weighting the models by posterior probabilities the way Kruschke discussed in text, but the spirit is similar. We can use the brms::pp_average() function to make posterior predictive prediction with mixtures of the models, weighted by our chosen weighting scheme. Here, we’ll go with the default stacking weights.
nd <- tibble(y = 1)
pp_a <-
pp_average(fit10.1, fit10.2,
newdata = nd,
# this line is not necessary,
# but you should see how to choose weighing methods
weights = "stacking",
method = "fitted",
summary = F) %>%
as_tibble() %>%
set_names("theta")
# what does this produce?
head(pp_a) ## # A tibble: 6 × 1
## theta
## <dbl>
## 1 0.751
## 2 0.520
## 3 0.558
## 4 0.755
## 5 0.725
## 6 0.818We can plot our model-averaged \(\theta\) with a little help from good old tidybayes::stat_histinterval().
pp_a %>%
ggplot(aes(x = theta, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = c(.95, .5),
fill = kh[6], slab_color = kh[5], color = kh[2],
breaks = 40, slab_size = .25, outline_bars = T) +
scale_x_continuous(expression(italic(p)(theta*"|"*italic(D))),
expand = expansion(mult = c(0, 0)),
breaks = 0:5 / 5, limits = c(0, 1)) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0.02, 0.05))) +
labs(subtitle = "The posterior for the probability, given the\nweighted combination of fit10.1 and fit10.2")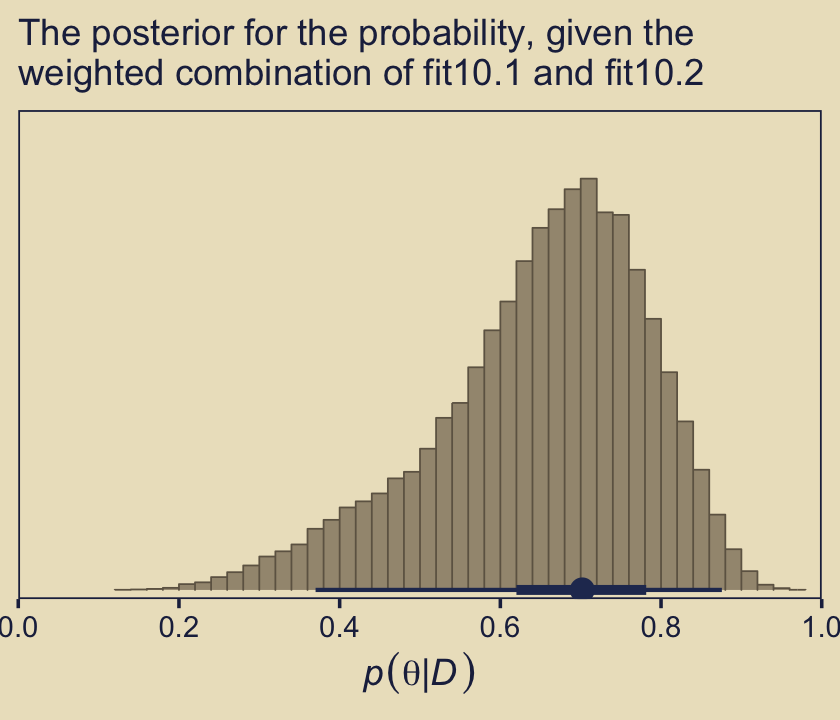
As Kruschke concluded, “you can see the contribution of \(p(\theta | D, \omega = 0.25)\) as the extended leftward tail” (p. 289). Interestingly enough, that looks a lot like the marginal density of \(p (\theta | D)\) across values of \(\omega\) we made with grid approximation in Figure 10.3, doesn’t it?
10.5 Model complexity naturally accounted for
A complex model (usually) has an inherent advantage over a simpler model because the complex model can find some combination of its parameter values that match the data better than the simpler model. There are so many more parameter options in the complex model that one of those options is likely to fit the data better than any of the fewer options in the simpler model. The problem is that data are contaminated by random noise, and we do not want to always choose the more complex model merely because it can better fit noise. Without some way of accounting for model complexity, the presence of noise in data will tend to favor the complex model.
Bayesian model comparison compensates for model complexity by the fact that each model must have a prior distribution over its parameters, and more complex models must dilute their prior distributions over larger parameter spaces than simpler models. Thus, even if a complex model has some particular combination of parameter values that fit the data well, the prior probability of that particular combination must be small because the prior is spread thinly over the broad parameter space. (pp. 289–290)
Now our two models are:
- the “must-be-fair” model \(p(\theta | D, \kappa = 1{,}000)\), and
- the “anything’s-possible” model \(p(\theta | D, \kappa = 2)\).
They look like this.
# how granular to you want the theta sequence?
n <- 1e3
# simulate the data
tibble(omega = .5,
kappa = c(1000, 2),
model = c("The must-be-fair model", "The anything's-possible model")) %>%
expand_grid(theta = seq(from = 0, to = 1, length.out = n)) %>%
mutate(density = dbeta(theta,
shape1 = omega * (kappa - 2) + 1,
shape2 = (1 - omega) * (kappa - 2) + 1)) %>%
# plot
ggplot(aes(x = theta, y = density)) +
geom_area(fill = kh[5]) +
scale_x_continuous(expression(theta), expand = expansion(mult = c(0, 0)),
breaks = 0:5 / 5, labels = c("0", ".2", ".4", ".6", ".8", "1"),
limits = c(0, 1)) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
labs(subtitle = "Note that in this case, their y-axes are on the same scale.") +
facet_wrap(~ model)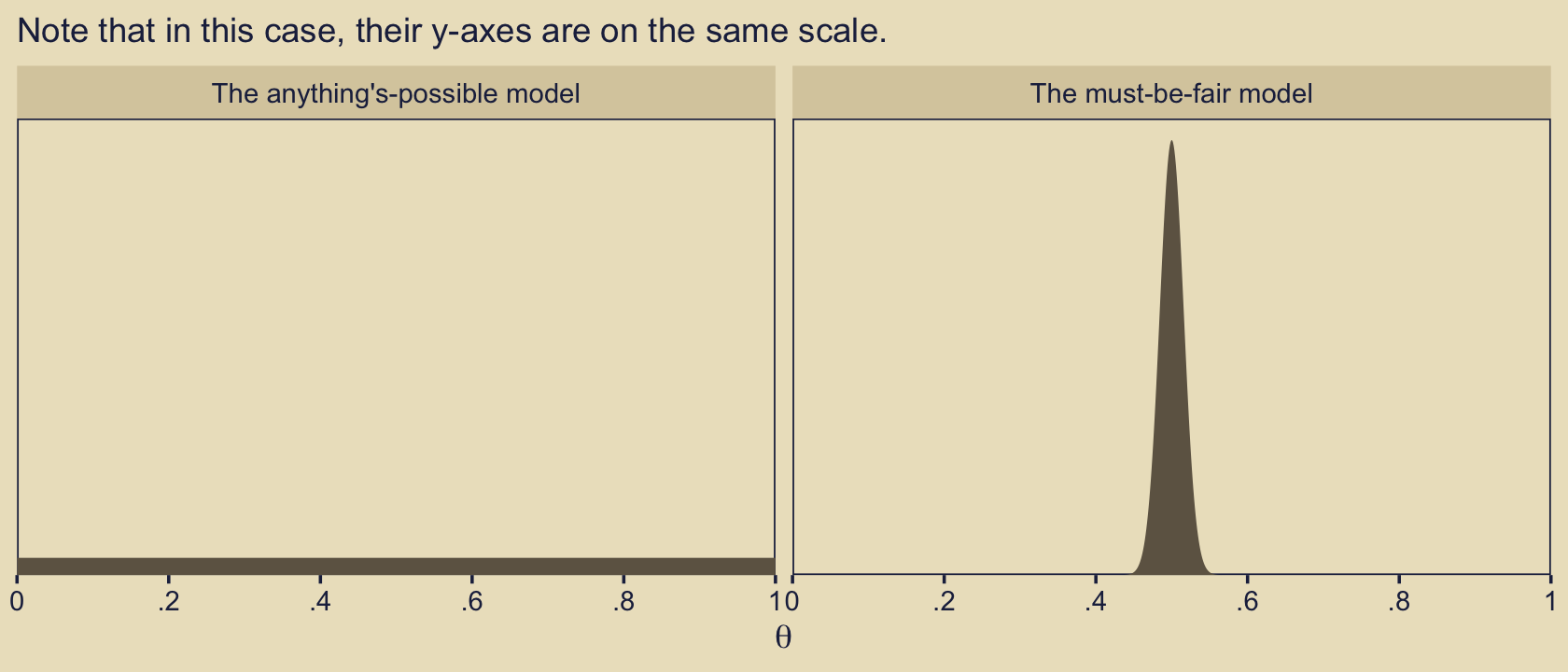
Here’s how you might compute the \(\alpha\) and \(\beta\) values for the corresponding beta distributions.
tibble(omega = .5,
kappa = c(1000, 2),
model = c("The must-be-fair model", "The anything's-possible model")) %>%
mutate(alpha = omega * (kappa - 2) + 1,
beta = (1 - omega) * (kappa - 2) + 1)## # A tibble: 2 × 5
## omega kappa model alpha beta
## <dbl> <dbl> <chr> <dbl> <dbl>
## 1 0.5 1000 The must-be-fair model 500 500
## 2 0.5 2 The anything's-possible model 1 1With those in hand, we can use our p_d() function to compute the Bayes factor based on flipping a coin \(N = 20\) times and observing \(z = 15\) heads.
# the data summaries
z <- 15
n <- 20
p_d(z, n, a = 500, b = 500) / p_d(z, n, a = 1, b = 1)## [1] 0.3229023Let’s try again, this time supposing we observe \(z = 15\) heads out of \(N = 20\) coin flips.
z <- 11
p_d(z, n, a = 500, b = 500) / p_d(z, n, a = 1, b = 1)## [1] 3.337148The anything’s-possible model loses because it pays the price of having a small prior probability on the values of \(\theta\) near the data proportion, while the must-be-fair model has large prior probability on \(\theta\) values sufficiently near the data proportion to be credible. Thus, in Bayesian model comparison, a simpler model can win if the data are consistent with it, even if the complex model fits just as well. The complex model pays the price of having small prior probability on parameter values that describe simple data. (p. 291)
10.5.1 Caveats regarding nested model comparison.
A frequently encountered special case of comparing models of different complexity occurs when one model is “nested” within the other. Consider a model that implements all the meaningful parameters we can contemplate for the particular application. We call that the full model. We might consider various restrictions of those parameters, such as setting some of them to zero, or forcing some to be equal to each other. A model with such a restriction is said to be nested within the full model. (p. 291)
Kruschke didn’t walk out the examples in this section. But for the sake of practice, let’s work through the first one. “Recall the hierarchical model of baseball batting abilities” from Chapter 9 (p. 291). Let’s reload those data.
my_data <- read_csv("data.R/BattingAverage.csv")
glimpse(my_data)## Rows: 948
## Columns: 6
## $ Player <chr> "Fernando Abad", "Bobby Abreu", "Tony Abreu", "Dustin Ack…
## $ PriPos <chr> "Pitcher", "Left Field", "2nd Base", "2nd Base", "1st Bas…
## $ Hits <dbl> 1, 53, 18, 137, 21, 0, 0, 2, 150, 167, 0, 128, 66, 3, 1, …
## $ AtBats <dbl> 7, 219, 70, 607, 86, 1, 1, 20, 549, 576, 1, 525, 275, 12,…
## $ PlayerNumber <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
## $ PriPosNumber <dbl> 1, 7, 4, 4, 3, 1, 1, 3, 3, 4, 1, 5, 4, 2, 7, 4, 6, 8, 9, …“The full model has a distinct modal batting ability, \(\omega_c\) , for each of the nine fielding positions. The full model also has distinct concentration parameters for each of the nine positions” (p. 291). Let’s fit that model again.
fit9.2 <-
brm(data = my_data,
family = binomial(link = logit),
Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 3500, warmup = 500, chains = 3, cores = 3,
control = list(adapt_delta = .99),
seed = 9,
file = "fits/fit09.02")Next we’ll consider a restricted version of fit9.2 “in which all infielders (first base, second base, etc.) are grouped together versus all outfielders (right field, center field, and left field). In this restricted model, we are forcing the modal batting abilities of all the outfielders to be the same, that is, \(\omega_\text{left field} = \omega_\text{center field} = \omega_\text{right field}\)” (p. 291). To fit that model, we’ll need to make a new variable PriPos_small which is identical to its parent variable PriPos except that it collapses those three positions into our new category Outfield.
my_data <-
my_data %>%
mutate(PriPos_small = if_else(PriPos %in% c("Center Field", "Left Field", "Right Field"),
"Outfield", PriPos))Now use update() to fit the restricted model.
fit10.5 <-
update(fit9.2,
newdata = my_data,
formula = Hits | trials(AtBats) ~ 1 + (1 | PriPos_small) + (1 | PriPos_small:Player),
iter = 3500, warmup = 500, chains = 3, cores = 3,
control = list(adapt_delta = .99),
seed = 10,
file = "fits/fit10.05")Unlike with what Kruschke alluded to in the prose, here we’ll compare the two models with the WAIC.
fit9.2 <- add_criterion(fit9.2, criterion = "waic")
fit10.5 <- add_criterion(fit10.5, criterion = "waic")
loo_compare(fit9.2, fit10.5, criterion = "waic")## elpd_diff se_diff
## fit9.2 0.0 0.0
## fit10.5 -0.1 1.2Based on the WAIC difference score, they’re near equivalent. Now let’s see how their WAIC weights shake out.
model_weights(fit9.2, fit10.5, weights = "waic") %>% round(2)## fit9.2 fit10.5
## 0.53 0.47In this case, just a little more of the weight went to the full model, fit9.2. The overall pattern between the WAIC difference and the WAIC weights was uncertainty. Make sure to use good substantive reasoning when comparing models.
10.6 Extreme sensitivity to prior distribution
In many realistic applications of Bayesian model comparison, the theoretical emphasis is on the difference between the models’ likelihood functions. For example, one theory predicts planetary motions based on elliptical orbits around the sun, and another theory predicts planetary motions based on circular cycles and epicycles around the earth. The two models involve very different parameters. In these sorts of models, the form of the prior distribution on the parameters is not a focus, and is often an afterthought. But, when doing Bayesian model comparison, the form of the prior is crucial because the Bayes factor integrates the likelihood function weighted by the prior distribution. (p. 292)
However, “the sensitivity of Bayes factors to prior distributions is well known in the literature (e.g., Kass & Raftery, 1995; Liu & Aitkin, 2008; Vanpaemel, 2010),” and furthermore, when comparing Bayesian models using the methods Kruschke outlined in this chapter of the text, “different forms of vague priors can yield very different Bayes factors” (p. 293).
In the two BFs to follow, we compare the must-be-fair model and the anything’s-possible models from Section 10.5 to new data: \(z = 65, N = 100\).
z <- 65
n <- 100
p_d(z, n, a = 500, b = 500) / p_d(z, n, a = 1, b = 1)## [1] 0.125287The resulting 0.13 favored the anything’s-possible model.
Another way to express the anything’s-possible model is with the Haldane prior, which sets the two parameters within the beta distribution to be a) equivalent and b) quite small (i.e., 0.01 in this case).
p_d(z, n, a = 500, b = 500) / p_d(z, n, a = .01, b = .01)## [1] 5.728066Now we flipped to favoring the must-be-fair model. You might be asking, Wait, kind of distribution did that Haldane prior produce? Here we compare it to the \(\operatorname{Beta}(1, 1)\).
# save this text for later
text <- c("Uninformative prior, Beta(1, 1)", "Haldane prior, Beta(0.01, 0.01)")
# how granular to you want the theta sequence?
length <- 1e3
# simulate the data
tibble(alpha = c(1, .01),
beta = c(1, .01),
model = factor(text, levels = text)) %>%
expand_grid(theta = seq(from = 0, to = 1, length.out = length)) %>%
mutate(density = dbeta(theta, shape1 = alpha, shape2 = beta)) %>%
# plot
ggplot(aes(x = theta, y = density)) +
geom_area(fill = kh[3]) +
scale_x_continuous(expression(theta), expand = expansion(mult = c(0, 0)),
breaks = 0:5 / 5, labels = c("0", ".2", ".4", ".6", ".8", "1"),
limits = c(0, 1)) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0, 0.05))) +
labs(title = "We have two anything’s-possible models!",
subtitle = "These y-axes are on the same scale.") +
facet_wrap(~ model)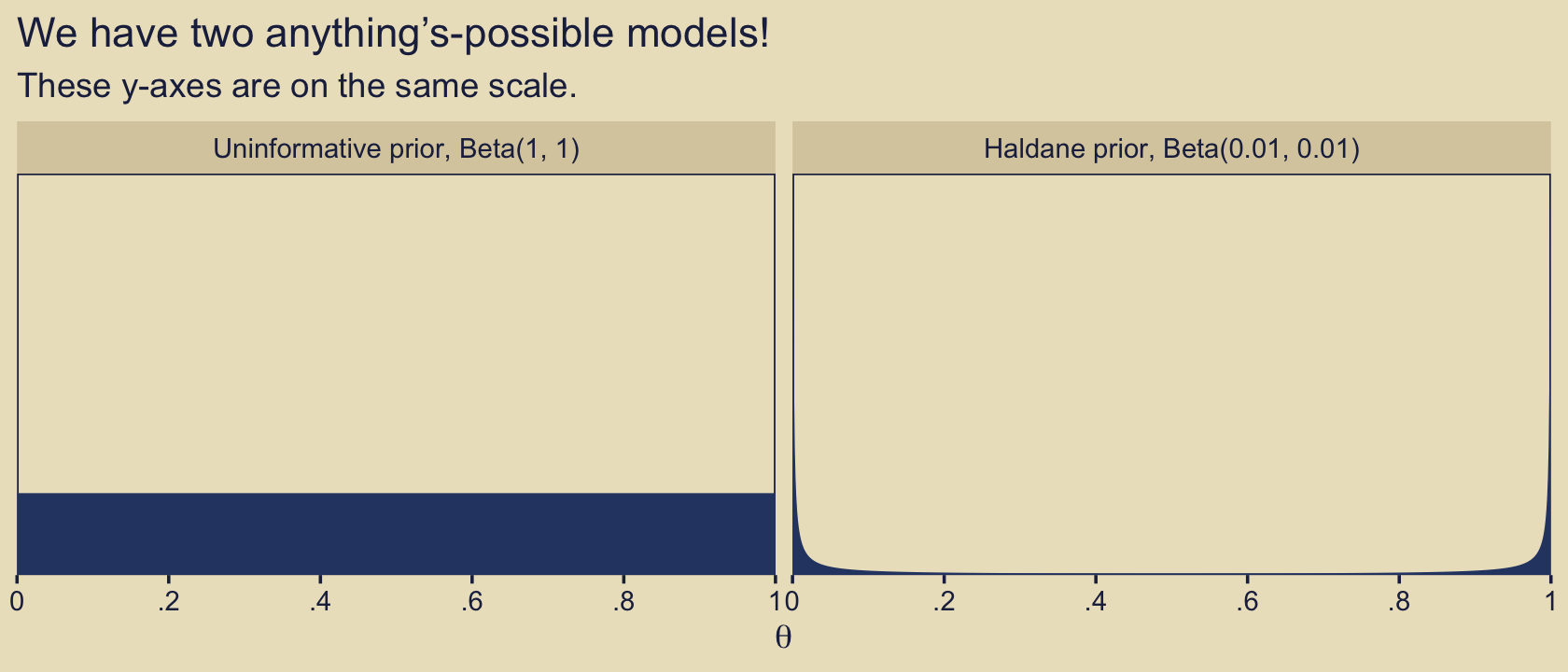
Before we can complete the analyses of this subsection, we’ll need to define our version of Kruschke’s HDIofICDF function(), hdi_of_icdf(). Like we’ve done in previous chapters, here we mildly reformat the function.
hdi_of_icdf <- function(name, width = .95, tol = 1e-8, ... ) {
incredible_mass <- 1.0 - width
interval_width <- function(low_tail_prob, name, width, ...) {
name(width + low_tail_prob, ...) - name(low_tail_prob, ...)
}
opt_info <- optimize(interval_width, c(0, incredible_mass),
name = name, width = width,
tol = tol, ...)
hdi_lower_tail_prob <- opt_info$minimum
return(c(name(hdi_lower_tail_prob, ...),
name(width + hdi_lower_tail_prob, ...)))
}And here we’ll make a custom variant to be more useful within the context of the map2() function.
hdi_of_qbeta <- function(shape1, shape2) {
hdi_of_icdf(name = qbeta,
shape1 = shape1,
shape2 = shape2) %>%
data.frame() %>%
mutate(level = c("ll", "ul")) %>%
spread(key = level, value = ".")
}Recall that when we combine a \(\operatorname{Beta}(\theta | \alpha, \beta)\) prior with the results of a Bernoulli likelihood, we get a posterior defined by \(\operatorname{Beta}(\theta | z + \alpha, N - z + \beta)\).
d <-
tibble(model = c("Uniform", "Haldane"),
prior_a = c(1, .01),
prior_b = c(1, .01)) %>%
mutate(posterior_a = z + prior_a,
posterior_b = n - z + prior_b)
d## # A tibble: 2 × 5
## model prior_a prior_b posterior_a posterior_b
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Uniform 1 1 66 36
## 2 Haldane 0.01 0.01 65.0 35.0Now we’ll use our custom hdi_of_qbeta() to compute the HDIs.
(
d <-
d %>%
mutate(levels = map2(posterior_a, posterior_b, hdi_of_qbeta)) %>%
unnest(levels)
)## # A tibble: 2 × 7
## model prior_a prior_b posterior_a posterior_b ll ul
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Uniform 1 1 66 36 0.554 0.738
## 2 Haldane 0.01 0.01 65.0 35.0 0.556 0.742Let’s compare those HDIs in a plot.
d %>%
ggplot(aes(x = ll, xend = ul,
y = model, yend = model)) +
geom_segment(linewidth = 1, color = kh[2]) +
scale_x_continuous(expression(theta), expand = expansion(mult = c(0, 0)),
breaks = 0:5 / 5, labels = c("0", ".2", ".4", ".6", ".8", "1"),
limits = c(0, 1)) +
labs(subtitle = "Those two sets of HDIs are quite similar.\nIt almost seems silly their respective BFs\nare so different.",
y = NULL) +
theme(axis.text.y = element_text(hjust = 0),
axis.ticks.y = element_blank())
“The HDIs are virtually identical. In particular, for either prior, the posterior distribution rules out \(\theta = 0.5\), which is to say that the must-be-fair hypothesis is not among the credible values” (p. 294).
10.6.1 Priors of different models should be equally informed.
“We have established that seemingly innocuous changes in the vagueness of a vague prior can dramatically change a model’s marginal likelihood, and hence its Bayes factor in comparison with other models. What can be done to ameliorate the problem” (p. 294)? Kruschke posed one method might be taking a small representative portion of the data in hand and use them to make an empirically-based prior for the remaining set of data. From our previous example, “suppose that the \(10\%\) subset has \(6\) heads in \(10\) flips, so the remaining \(90\%\) of the data has \(z = 65 − 6\) and \(N = 100 − 10\)” (p. 294).
Here are the new Bayes factors based on that method.
z <- 65 - 6
n <- 100 - 10
# Peaked vs Uniform
p_d(z, n, a = 500 + 6, b = 500 + 10 - 6) / p_d(z, n, a = 1 + 6, b = 1 + 10 - 6)## [1] 0.05570509# Peaked vs Haldane
p_d(z, n, a = 500 + 6, b = 500 + 10 - 6) / p_d(z, n, a = .01 + 6, b = .01 + 10 - 6)## [1] 0.05748123Now the two Bayes Factors are nearly the same.
It’s not in the text, but let’s compare these three models using brms, information criteria, model weights, model averaging, and posterior predictive checks. First, we’ll save the \(z\) and \(N\) information as a tibble with a series of 0’s and 1’s.
z <- 65
n <- 100
trial_data <- tibble(y = rep(0:1, times = c(n - z, z)))
glimpse(trial_data)## Rows: 100
## Columns: 1
## $ y <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…Next, fit the three models with brms::brm().
fit10.6 <-
brm(data = trial_data,
family = bernoulli(link = identity),
y ~ 1,
prior(beta(500, 500), class = Intercept, lb = 0, ub = 1),
iter = 11000, warmup = 1000, chains = 4, cores = 4,
seed = 10,
file = "fits/fit10.06")
fit10.7 <-
brm(data = trial_data,
family = bernoulli(link = identity),
y ~ 1,
# Uniform
prior(beta(1, 1), class = Intercept, lb = 0, ub = 1),
iter = 11000, warmup = 1000, chains = 4, cores = 4,
seed = 10,
file = "fits/fit10.07")
fit10.8 <-
brm(data = trial_data,
family = bernoulli(link = identity),
y ~ 1,
# Haldane
prior(beta(0.01, 0.01), class = Intercept, lb = 0, ub = 1),
iter = 11000, warmup = 1000, chains = 4, cores = 4,
seed = 10,
file = "fits/fit10.08")Compare the models by the LOO.
fit10.6 <- add_criterion(fit10.6, criterion = "loo")
fit10.7 <- add_criterion(fit10.7, criterion = "loo")
fit10.8 <- add_criterion(fit10.8, criterion = "loo")
loo_compare(fit10.6, fit10.7, fit10.8)## elpd_diff se_diff
## fit10.7 0.0 0.0
## fit10.8 0.0 0.1
## fit10.6 -2.9 2.7Based on the LOO comparisons, none of the three models was a clear favorite. Although both versions of the anything’s-possible model (i.e., fit10.7 and fit10.8) had lower numeric estimates than the must-be-fair model (i.e., fit10.6), the standard errors on the difference scores were the same magnitude as the difference estimates themselves. As for comparing the two variants of the anything’s-possible model directly, their LOO estimates were almost indistinguishable.
Now let’s see what happens when we compute their model weights. Here we’ll contrast the LOO weights with the stacking weights.
mw <- model_weights(fit10.6, fit10.7, fit10.8, weights = "stacking")
mw %>%
round(digits = 2)## fit10.6 fit10.7 fit10.8
## 0.11 0.88 0.01model_weights(fit10.6, fit10.7, fit10.8, weights = "loo") %>%
round(digits = 2)## fit10.6 fit10.7 fit10.8
## 0.03 0.49 0.48The evidence varied a bit by the specific weighting scheme. Across both, the model with the uniform prior (fit10.7) did arguably the best, but the model with the Haldane prior (fit10.8) was clearly in the running. Overall, the evidence for one versus another was weak.
Like we did earlier with fit10.1 and fit10.2, we can use the pp_average() function to compute the stacking weighted posterior for \(\theta\).
pp_average(fit10.6, fit10.7, fit10.8,
newdata = nd,
weights = mw,
method = "fitted",
summary = F) %>%
as_tibble() %>%
ggplot(aes(x = V1, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = c(.95, .5),
fill = kh[6], slab_color = kh[5], color = kh[2],
breaks = 40, slab_size = .25, outline_bars = T) +
scale_x_continuous(expression(italic(p)(theta*"|"*italic(D))), expand = c(0, 0),
breaks = 0:5 / 5, labels = c("0", ".2", ".4", ".6", ".8", "1"),
limits = c(0, 1)) +
scale_y_continuous(NULL, breaks = NULL,
expand = expansion(mult = c(0.01, 0.05))) +
labs(subtitle = "The posterior for the probability, given the weighted\ncombination of fit10.6, fit10.7, and fit10.8")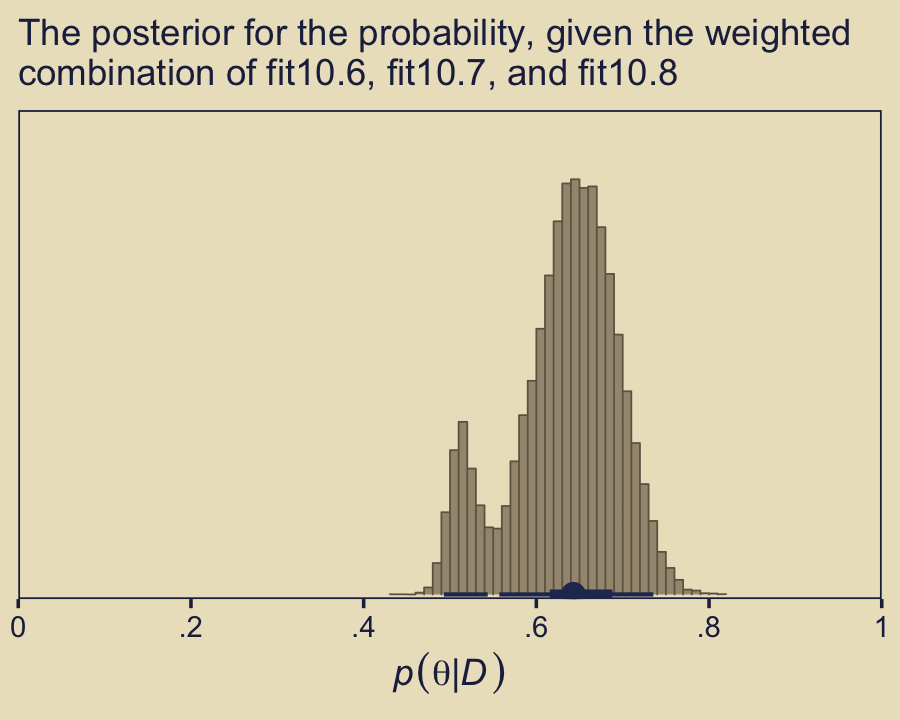
Did you notice the weights = mw argument, there? From the pp_average.brmsfit section of the brms reference manual (Bürkner, 2022f, p. 177), we read “weights may also be be a numeric vector of pre-specified weights.” Since we saved the results of model_weights() as an object mw, we were able to capitalize on that feature. If you leave out that argument, you’ll have to wait a bit for brms to compute those weights again from scratch.
Just for the sake of practice, we can also compare the models with separate posterior predictive checks using pp_check().
p1 <-
pp_check(fit10.6, type = "bars", ndraws = 1e3) +
ggtitle("fit10.6",
subtitle = expression("Beta"*(500*", "*500)))
p2 <-
pp_check(fit10.7, type = "bars", ndraws = 1e3) +
ggtitle("fit10.7",
subtitle = expression("Beta"*(1*", "*1)))
p3 <-
pp_check(fit10.8, type = "bars", ndraws = 1e3) +
ggtitle("fit10.8",
subtitle = expression("Beta"*(0.01*", "*0.01)))
((p1 + p2 + p3) &
scale_x_continuous(breaks = 0:1) &
scale_y_continuous(expand = expansion(mult = c(0, 0.05)),
limits = c(0, 80))) +
plot_layout(guides = 'collect')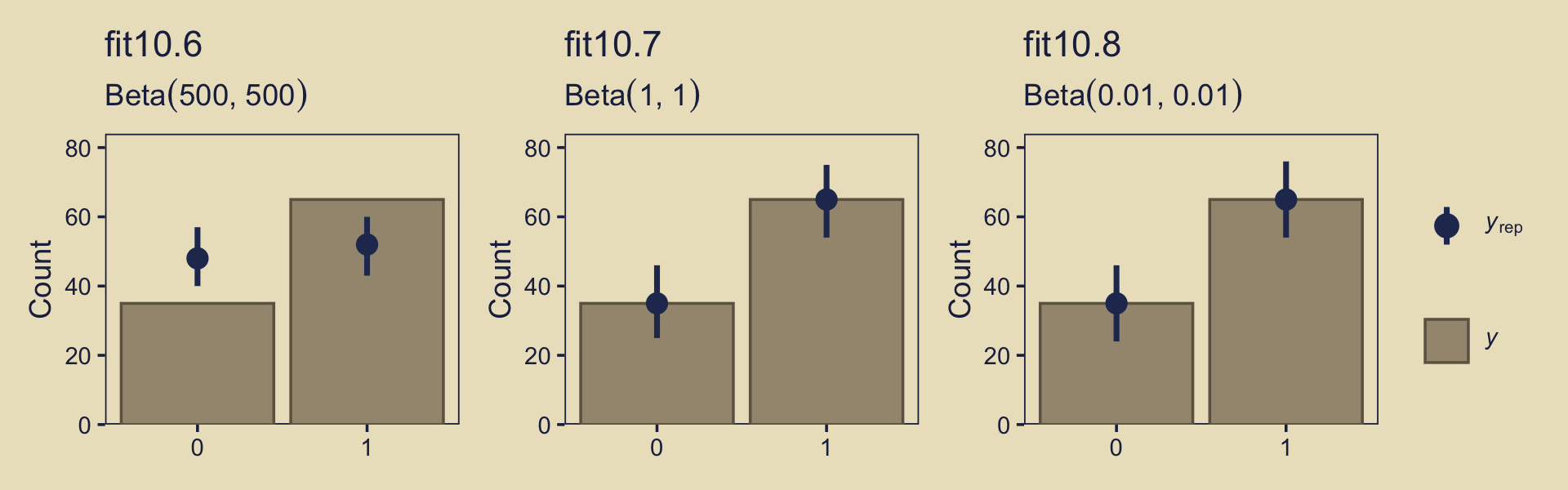
Instead of the default 10, this time we used 1,000 posterior simulations from each fit, which we summarized with dot and error bars. This method did a great job showing how little fit10.6 learned from the data. Another nice thing about this method is it reveals how similar the results are between fit10.7 and fit10.8, the two alternate versions of the anything’s-possible model. Also, did you notice how we used limits = c(0, 80) when combining the plots with patchwork? Holding the scale of the \(y\)-axis constant makes it easier to compare results across plots.
10.7 Bonus: There’s danger ahead
If you’re new to model comparison with Bayes factors, information criteria, model stacking and so on, you should know these methods are still subject to spirited debate amongst scholars. For a recent example, see Gronau and Wagenmakers’ (2019a) Limitations of Bayesian leave-one-out cross-validation for model selection, which criticized the LOO. Their paper was commented on by D. J. Navarro (2019), Chandramouli & Shiffrin (2019), and Vehtari et al. (2019). You can find Gronau and Wagenmakers’ (2019b) rejoinder here.
Session info
sessionInfo()## R version 4.2.2 (2022-10-31)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur ... 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidybayes_3.0.2 bayesplot_1.10.0 brms_2.18.0 Rcpp_1.0.9
## [5] ggforce_0.4.1 patchwork_1.1.2 lisa_0.1.2 forcats_0.5.1
## [9] stringr_1.4.1 dplyr_1.0.10 purrr_1.0.1 readr_2.1.2
## [13] tidyr_1.2.1 tibble_3.1.8 ggplot2_3.4.0 tidyverse_1.3.2
##
## loaded via a namespace (and not attached):
## [1] readxl_1.4.1 backports_1.4.1 plyr_1.8.7
## [4] igraph_1.3.4 svUnit_1.0.6 splines_4.2.2
## [7] crosstalk_1.2.0 TH.data_1.1-1 rstantools_2.2.0
## [10] inline_0.3.19 digest_0.6.31 htmltools_0.5.3
## [13] fansi_1.0.3 magrittr_2.0.3 checkmate_2.1.0
## [16] googlesheets4_1.0.1 tzdb_0.3.0 modelr_0.1.8
## [19] RcppParallel_5.1.5 matrixStats_0.63.0 vroom_1.5.7
## [22] xts_0.12.1 sandwich_3.0-2 prettyunits_1.1.1
## [25] colorspace_2.0-3 rvest_1.0.2 ggdist_3.2.1
## [28] haven_2.5.1 xfun_0.35 callr_3.7.3
## [31] crayon_1.5.2 jsonlite_1.8.4 lme4_1.1-31
## [34] survival_3.4-0 zoo_1.8-10 glue_1.6.2
## [37] polyclip_1.10-0 gtable_0.3.1 gargle_1.2.0
## [40] emmeans_1.8.0 distributional_0.3.1 pkgbuild_1.3.1
## [43] rstan_2.21.8 abind_1.4-5 scales_1.2.1
## [46] mvtnorm_1.1-3 DBI_1.1.3 miniUI_0.1.1.1
## [49] xtable_1.8-4 HDInterval_0.2.4 bit_4.0.4
## [52] stats4_4.2.2 StanHeaders_2.21.0-7 DT_0.24
## [55] htmlwidgets_1.5.4 httr_1.4.4 threejs_0.3.3
## [58] arrayhelpers_1.1-0 posterior_1.3.1 ellipsis_0.3.2
## [61] pkgconfig_2.0.3 loo_2.5.1 farver_2.1.1
## [64] sass_0.4.2 dbplyr_2.2.1 utf8_1.2.2
## [67] tidyselect_1.2.0 labeling_0.4.2 rlang_1.0.6
## [70] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
## [73] cellranger_1.1.0 tools_4.2.2 cachem_1.0.6
## [76] cli_3.6.0 generics_0.1.3 broom_1.0.2
## [79] evaluate_0.18 fastmap_1.1.0 bit64_4.0.5
## [82] processx_3.8.0 knitr_1.40 fs_1.5.2
## [85] nlme_3.1-160 mime_0.12 projpred_2.2.1
## [88] xml2_1.3.3 compiler_4.2.2 shinythemes_1.2.0
## [91] rstudioapi_0.13 gamm4_0.2-6 reprex_2.0.2
## [94] tweenr_2.0.0 bslib_0.4.0 stringi_1.7.8
## [97] highr_0.9 ps_1.7.2 Brobdingnag_1.2-8
## [100] lattice_0.20-45 Matrix_1.5-1 nloptr_2.0.3
## [103] markdown_1.1 shinyjs_2.1.0 tensorA_0.36.2
## [106] vctrs_0.5.1 pillar_1.8.1 lifecycle_1.0.3
## [109] jquerylib_0.1.4 bridgesampling_1.1-2 estimability_1.4.1
## [112] httpuv_1.6.5 R6_2.5.1 bookdown_0.28
## [115] promises_1.2.0.1 gridExtra_2.3 codetools_0.2-18
## [118] boot_1.3-28 colourpicker_1.1.1 MASS_7.3-58.1
## [121] gtools_3.9.4 assertthat_0.2.1 withr_2.5.0
## [124] shinystan_2.6.0 multcomp_1.4-20 mgcv_1.8-41
## [127] parallel_4.2.2 hms_1.1.1 grid_4.2.2
## [130] minqa_1.2.5 coda_0.19-4 rmarkdown_2.16
## [133] googledrive_2.0.0 shiny_1.7.2 lubridate_1.8.0
## [136] base64enc_0.1-3 dygraphs_1.1.1.6References
I point this out because in previous versions of this book, I accidentally flipped this order. Thankfully, Omid Ghasemi caught the mistake and kindly pointed it out in GitHub issue #34.↩︎