9 Hierarchical Models
As Kruschke put it, “There are many realistic situations that involve meaningful hierarchical structure. Bayesian modeling software makes it straightforward to specify and analyze complex hierarchical models” (2015, p. 221). IMO, brms makes it even easier than JAGS. Further down, we read:
The parameters at different levels in a hierarchical model are all merely parameters that coexist in a joint parameter space. We simply apply Bayes’ rule to the joint parameter space, as we did for example when estimating two coin biases back in Figure 7.5, p. 167. To say it a little more formally with our parameters θ and ω, Bayes’ rule applies to the joint parameter space: p(θ,ω|D)∝p(D|θ,ω)p(θ,ω). What is special to hierarchical models is that the terms on the right-hand side can be factored into a chain of dependencies, like this:
p(θ,ω|D)∝p(D|θ,ω)p(θ,ω)=p(D|θ)p(θ|ω)p(ω)
The refactoring in the second line means that the data depend only on the value of θ, in the sense that when the value θ is set then the data are independent of all other parameter values. Moreover, the value of θ depends on the value of ω and the value of θ is conditionally independent of all other parameters. Any model that can be factored into a chain of dependencies like [this] is a hierarchical model. (pp. 222–223)
9.1 A single coin from a single mint
Recall from the last chapter that our likelihood is the Bernoulli distribution,
yi∼Bernoulli(θ).
We’ll use the beta density for our prior distribution for θ,
θ∼Beta(α,β).
And we can re-express α and β in terms of the mode ω and concentration κ, such that
α=ω(κ−2)+1andβ=(1−ω)(κ−2)+1.
As a consequence, we can re-express θ as
θ∼Beta(ω(κ−2)+1,(1−ω)(κ−2)+1).
On page 224, Kruschke wrote: “The value of κ governs how near θ is to ω, with larger values of κ generating values of θ more concentrated near ω.” To give a sense of that, we’ll simulate 20 beta distributions, all with ω=.25 but with θ increasing from 10 to 200, by 10. We’ll then plot them with a little help from the ggridges package (Wilke, 2021).
library(tidyverse)
library(cowplot)
library(ggridges)
beta_by_k <- function(k) {
w <- .25
tibble(x = seq(from = 0, to = 1, length.out = 1000)) %>%
mutate(theta = dbeta(x = x,
shape1 = w * (k - 2) + 1,
shape2 = (1 - w) * (k - 2) + 1))
}
tibble(k = seq(from = 10, to = 200, by = 10)) %>%
mutate(theta = map(k, beta_by_k)) %>%
unnest(theta) %>%
ggplot(aes(x = x, y = k,
height = theta,
group = k, fill = k)) +
geom_vline(xintercept = .25, color = "grey85", linewidth = 1/2) +
geom_ridgeline(size = 1/5, color = "grey92", scale = 2) +
scale_fill_viridis_c(expression(kappa), option = "A") +
scale_y_continuous(expression(kappa), breaks = seq(from = 10, to = 200, by = 10)) +
xlab(expression(theta)) +
theme_minimal_hgrid()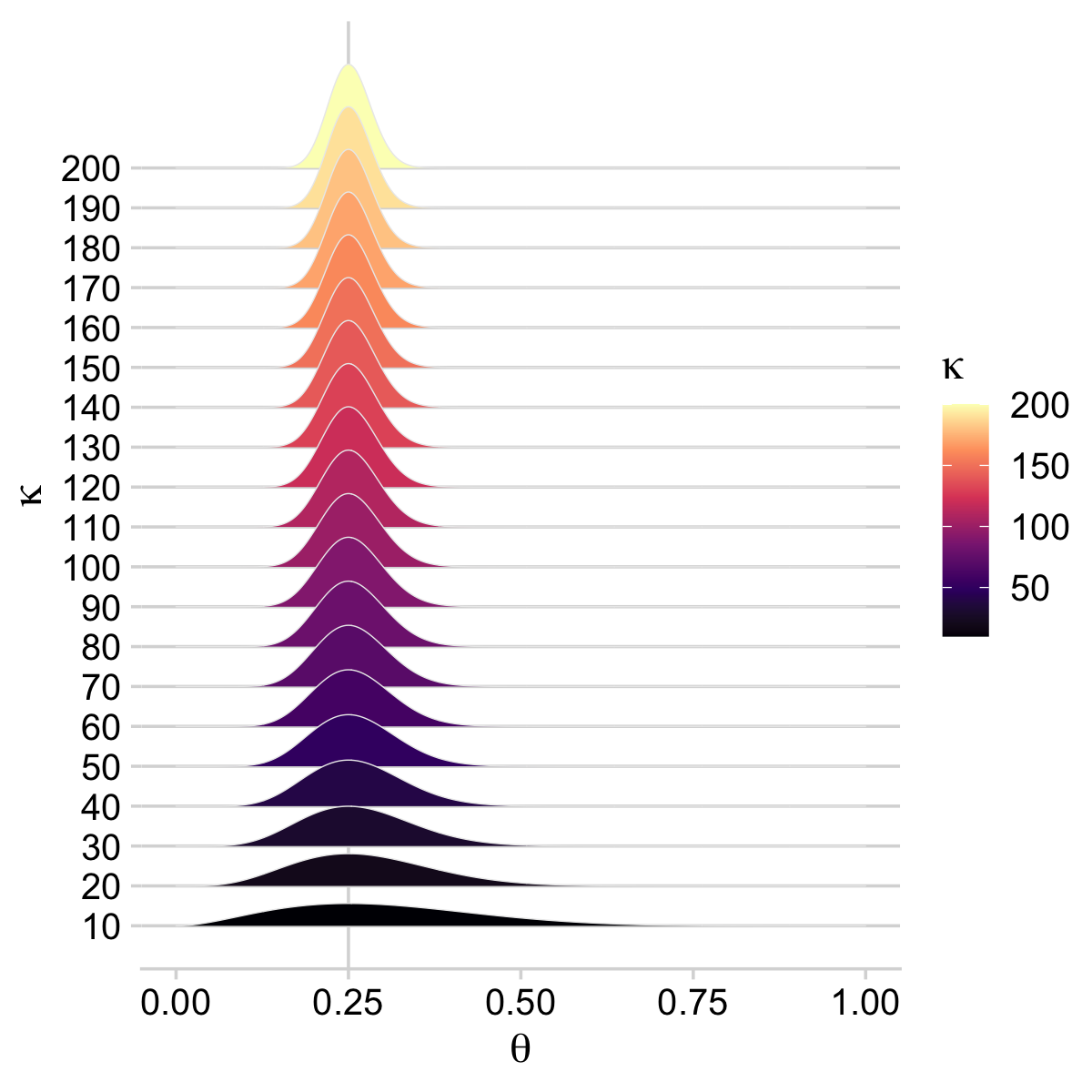
Holding ω constant, the density gets more concentrated around ω as κ increases. But back to the text: “Now we make the essential expansion of our scenario into the realm of hierarchical models. Instead of thinking of ω as fixed by prior knowledge, we think of it as another parameter to be estimated” (p. 224). In the hierarchical model diagram of Figure 9.1, Kruschke depicted how we might treat ω as a parameter controlled by the prior distribution, Beta(Aω,Bω). Here’s our version of the diagram.
library(ggforce)
library(patchwork)
p1 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 2, 2)) / max(dbeta(x, 2, 2))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = "grey67") +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 7) +
annotate(geom = "text",
x = .5, y = .6,
label = "italic(A[omega])*', '*italic(B[omega])",
size = 7, family = "Times", parse = TRUE) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
p2 <-
tibble(x = c(.5, .475, .26, .08, .06,
.5, .55, .85, 1.15, 1.2),
y = c(1, .7, .6, .5, .2,
1, .7, .6, .5, .2),
line = rep(letters[2:1], each = 5)) %>%
ggplot(aes(x = x, y = y)) +
geom_bspline(aes(color = line),
linewidth = 2/3, show.legend = F) +
annotate(geom = "text",
x = 0, y = .125,
label = "omega(italic(K)-2)+1*', '*(1-omega)(italic(K)-2)+1",
size = 7, parse = T, family = "Times", hjust = 0) +
annotate(geom = "text",
x = 1/3, y = .7,
label = "'~'",
size = 10, parse = T, family = "Times") +
scale_color_manual(values = c("grey75", "black")) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 2)) +
ylim(0, 1) +
theme_void()
p3 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 2, 2)) / max(dbeta(x, 2, 2))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = "grey67") +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
## an annotated arrow
# save our custom arrow settings
my_arrow <- arrow(angle = 20, length = unit(0.35, "cm"), type = "closed")
p4 <-
tibble(x = .5,
y = 1,
xend = .5,
yend = 0) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = .375, y = 1/3,
label = "'~'",
size = 10, family = "Times", parse = T) +
xlim(0, 1) +
theme_void()
# bar plot of Bernoulli data
p5 <-
tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = .6)) / max(dbinom(x, size = 1, prob = .6))) %>%
ggplot(aes(x = x, y = d)) +
geom_col(fill = "grey67", width = .4) +
annotate(geom = "text",
x = .5, y = .2,
label = "Bernoulli",
size = 7) +
annotate(geom = "text",
x = .5, y = .94,
label = "theta",
size = 7, family = "Times", parse = T) +
xlim(-.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# another annotated arrow
p6 <-
tibble(x = c(.375, .625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# some text
p7 <-
tibble(x = .5,
y = .5,
label = "italic(y[i])") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
xlim(0, 1) +
theme_void()
# define the layout
layout <- c(
area(t = 1, b = 2, l = 1, r = 1),
area(t = 4, b = 5, l = 1, r = 1),
area(t = 3, b = 4, l = 1, r = 2),
area(t = 6, b = 6, l = 1, r = 1),
area(t = 7, b = 8, l = 1, r = 1),
area(t = 9, b = 9, l = 1, r = 1),
area(t = 10, b = 10, l = 1, r = 1)
)
# combine and plot!
(p1 + p3 + p2 + p4 + p5 + p6 + p7) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))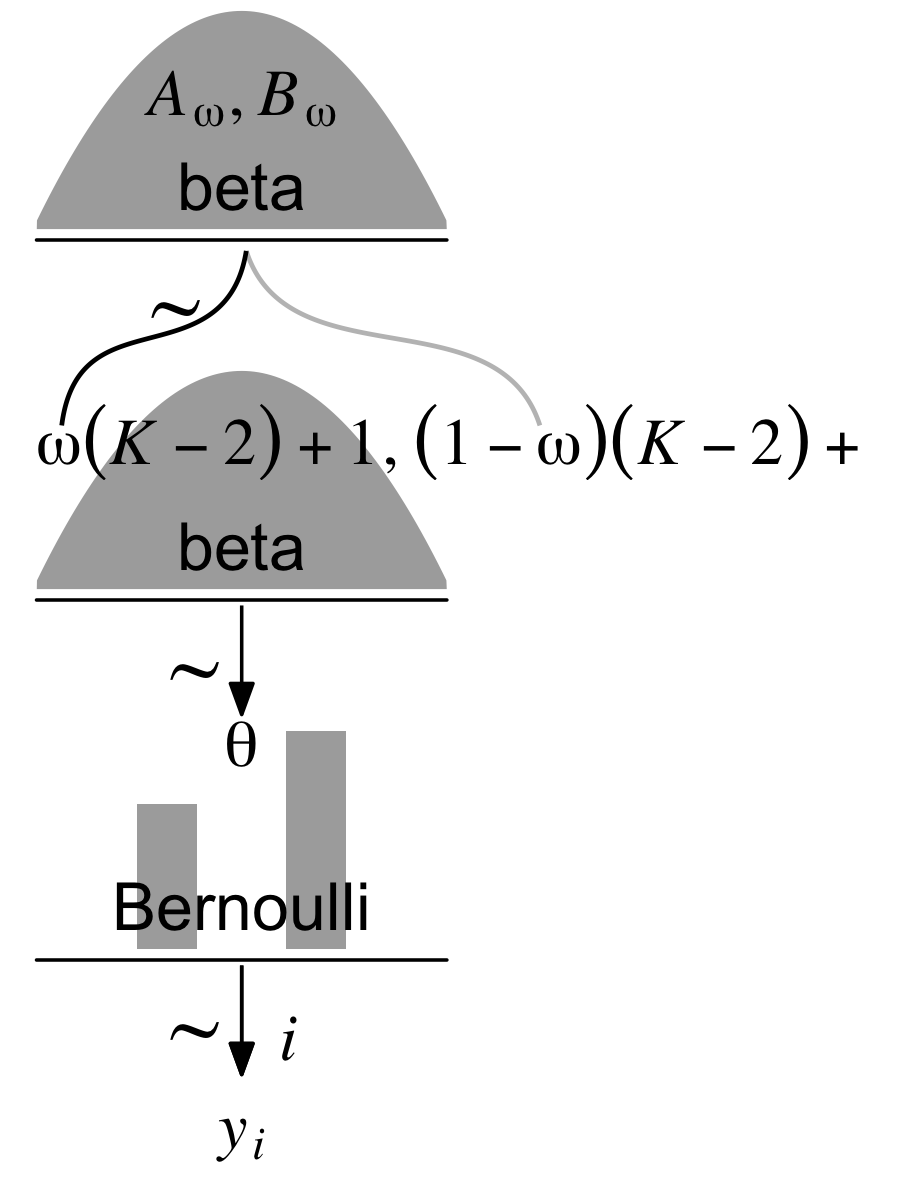
Note that whereas this model includes a hierarchical prior for ω, the hyperparameter K is fixed across cases.
9.1.1 Posterior via grid approximation.
When the parameters extend over a finite domain, and there are not too many of them, then we can approximate the posterior via grid approximation. In our present situation, we have the parameters θ and ω that both have finite domains, namely the interval [0,1]. Therefore, a grid approximation is tractable and the distributions can be readily graphed. (p. 226)
Given α and β, we can compute the corresponding mode ω. To foreshadow, consider beta(2,2).
alpha <- 2
beta <- 2
(alpha - 1) / (alpha + beta - 2)## [1] 0.5That is, the mode of Beta(2,2) is .5.
We won’t be able to make the wireframe plots on the left of Figure 9.2, but we can make the others. We’ll make the initial data following Kruschke’s (p. 226) formulas.
p(θ,ω)=p(θ|ω)p(ω)=Beta(θ|ω(100−2)+1,(1−ω)(100−2)+1)Beta(ω|2,2)
First, we’ll make a custom function, make_prior() based on the formulas.
make_prior <- function(theta, omega, alpha, beta, kappa) {
# p(theta | omega)
t <- dbeta(x = theta,
shape1 = omega * (kappa - 2) + 1,
shape2 = (1 - omega) * (kappa - 2) + 1)
# p(omega)
o <- dbeta(x = omega,
shape1 = alpha,
shape2 = beta)
# p(theta, omega) = p(theta | omega) * p(omega)
return(t * o)
}Next we’ll define the parameter space as a tightly-spaced sequence of values ranging from 0 to 1.
parameter_space <- seq(from = 0, to = 1, by = .01)Now we’ll use parameter_space to define the ranges for the two variables, theta and omega, which we’ll save in a tibble. We’ll then sequentially feed those theta and omega values into our make_prior() while manually specifying the desired values for alpha, beta, and kappa.
d <-
# here we define the grid for our grid approximation
crossing(theta = parameter_space,
omega = parameter_space) %>%
# compute the joint prior
mutate(prior = make_prior(theta, omega, alpha = 2, beta = 2, kappa = 100)) %>%
# convert the prior from the density metric to the probability metric
mutate(prior = prior / sum(prior))
head(d)## # A tibble: 6 × 3
## theta omega prior
## <dbl> <dbl> <dbl>
## 1 0 0 0
## 2 0 0.01 0
## 3 0 0.02 0
## 4 0 0.03 0
## 5 0 0.04 0
## 6 0 0.05 0Now we’re ready to plot the top middle panel of Figure 9.2.
d %>%
ggplot(aes(x = theta, y = omega, fill = prior)) +
geom_raster(interpolate = T) +
scale_fill_viridis_c(option = "A") +
labs(x = expression(theta),
y = expression(omega)) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
scale_y_continuous(expand = c(0, 0), limits = c(0, 1)) +
coord_equal() +
theme_minimal_grid() +
theme(legend.position = "none")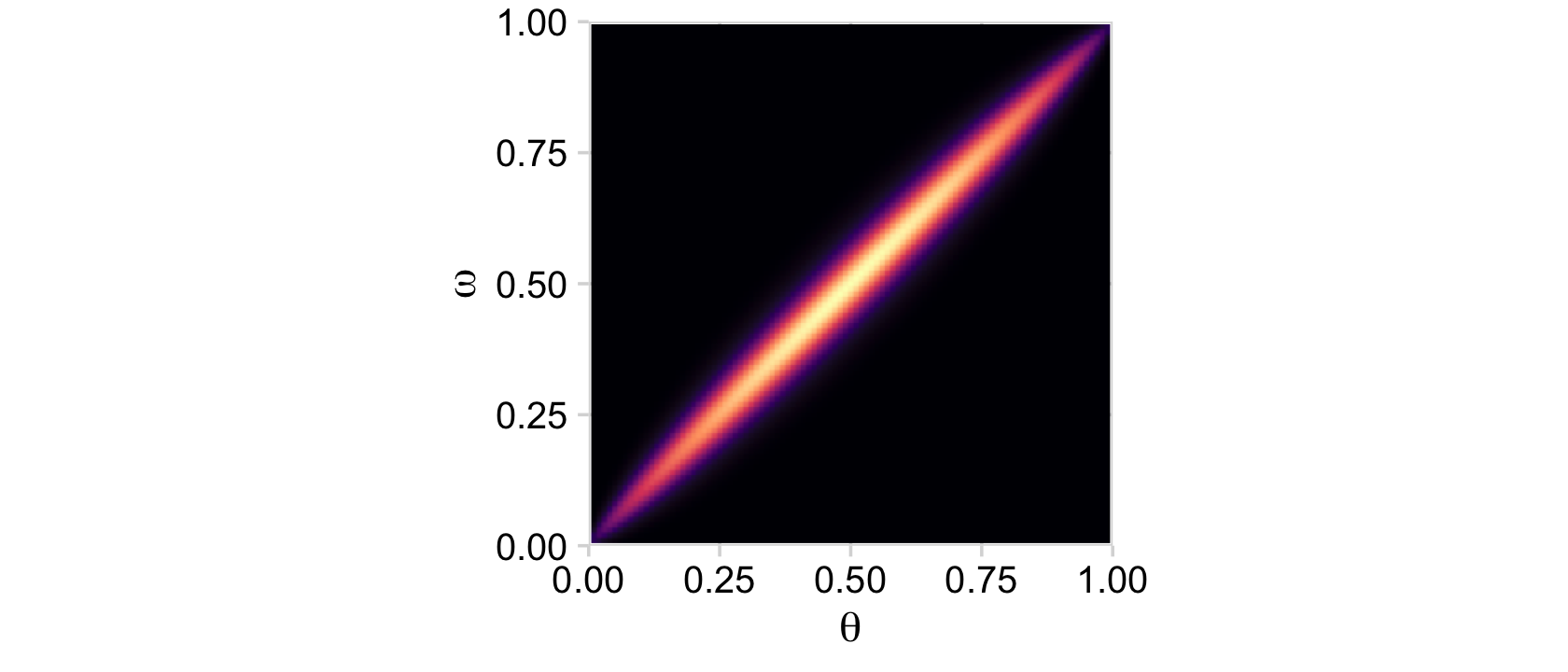
You could also make this with geom_tile(), but geom_raster() with interpolate = TRUE smooths the color transitions. Since we are going to be making a lot of plots like this in this chapter, we should consider streamlining our plotting code. In Chapter 19 of Wichkam’s (2016) ggplot2: Elegant graphics for data analysis, we learn how to make a custom geom. Here we’ll use those skills to wrap the bulk of the plot code from above into a single geom we’ll call geom_2dd(), for 2D-density plots.
geom_2dd <- function(...) {
list(
geom_raster(interpolate = T),
scale_fill_viridis_c(option = "A"),
scale_x_continuous(expand = c(0, 0), limits = c(0, 1), breaks = 0:5 / 5),
scale_y_continuous(expand = c(0, 0), limits = c(0, 1), breaks = 0:5 / 5),
coord_equal(),
theme_minimal_grid(...),
theme(legend.position = "none")
)
}Try it out.
d %>%
ggplot(aes(x = theta, y = omega, fill = prior)) +
geom_2dd() +
labs(x = expression(theta),
y = expression(omega))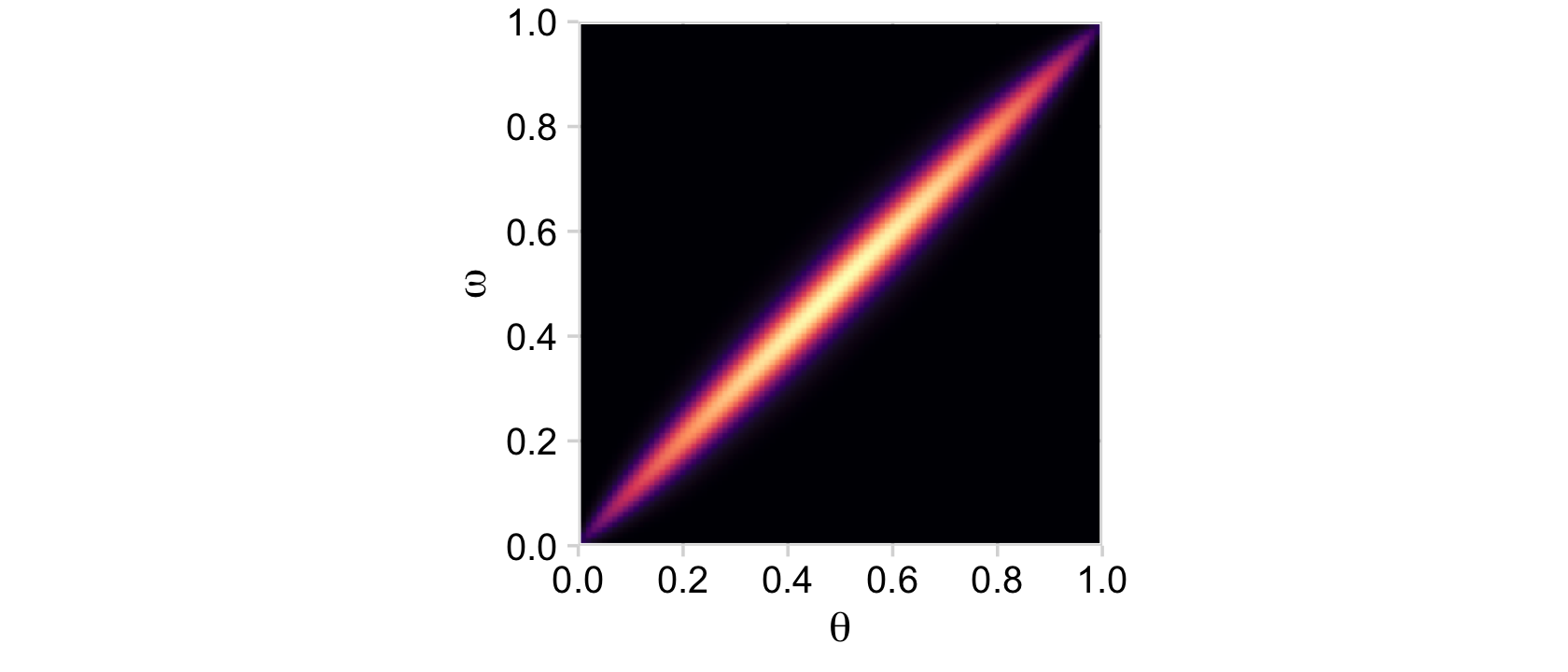
If we collapse “the joint prior across θ” (i.e., group_by(omega) and then sum(prior)), we plot the marginal distribution for p(ω) as seen in the top right panel.
library(viridis)
a_purple <- viridis_pal(option = "A")(9)[4]
d %>%
group_by(omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = omega, y = prior)) +
geom_area(fill = a_purple) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1), breaks = 0:5 / 5) +
scale_y_continuous(expand = c(0, 0), limits = c(0, 0.035)) +
labs(x = expression(omega),
y = expression(Marginal~p(omega))) +
coord_flip() +
theme_cowplot() +
panel_border() +
theme(axis.line = element_blank())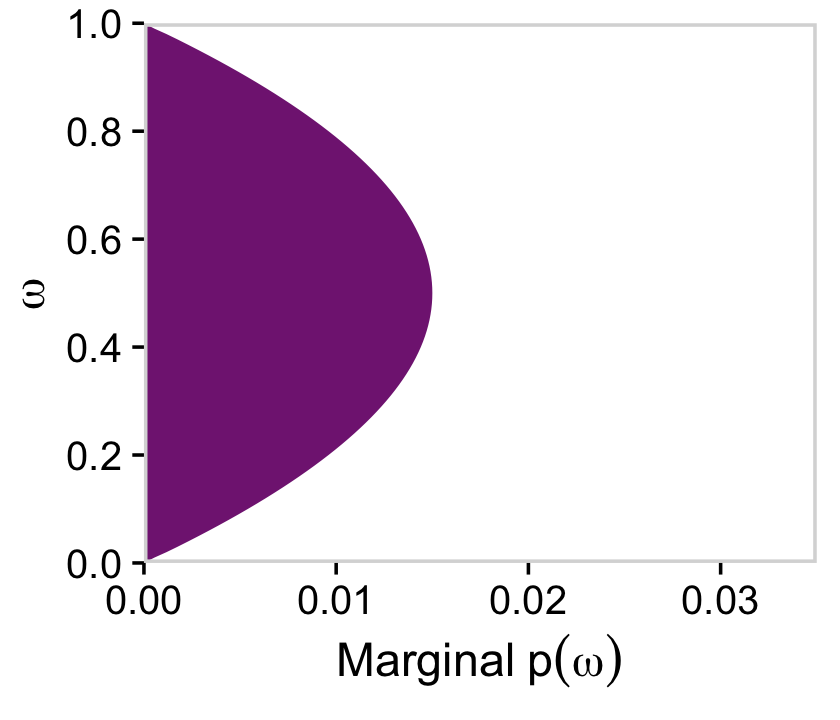
Note how we loaded the viridis package (Garnier, 2021). That gave us access to the viridis_pal() function, which will allow us to discretize the viridis palettes and save the color names as objects. In our case, we discretized the "A" palette into nine colors and saved the fourth as a_purple. Here’s the color name.
a_purple## [1] "#822681FF"We’ll use that color in many of the plots to follow. It’ll be something of a signature color for this chapter.
Anyway, since we are going to be making a lot of plots like this in this chapter, we’ll make another custom geom called geom_marginal().
geom_marginal <- function(ul, ...) {
list(
geom_area(fill = viridis_pal(option = "A")(9)[4]),
scale_x_continuous(expand = c(0, 0), limits = c(0, 1), breaks = 0:5 / 5),
scale_y_continuous(expand = c(0, 0), limits = c(0, ul)),
theme_cowplot(...),
panel_border(),
theme(axis.line = element_blank())
)
}Try it out.
d %>%
group_by(omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = omega, y = prior)) +
geom_marginal(ul = 0.035) +
labs(x = expression(omega),
y = expression(Marginal~p(omega))) +
coord_flip()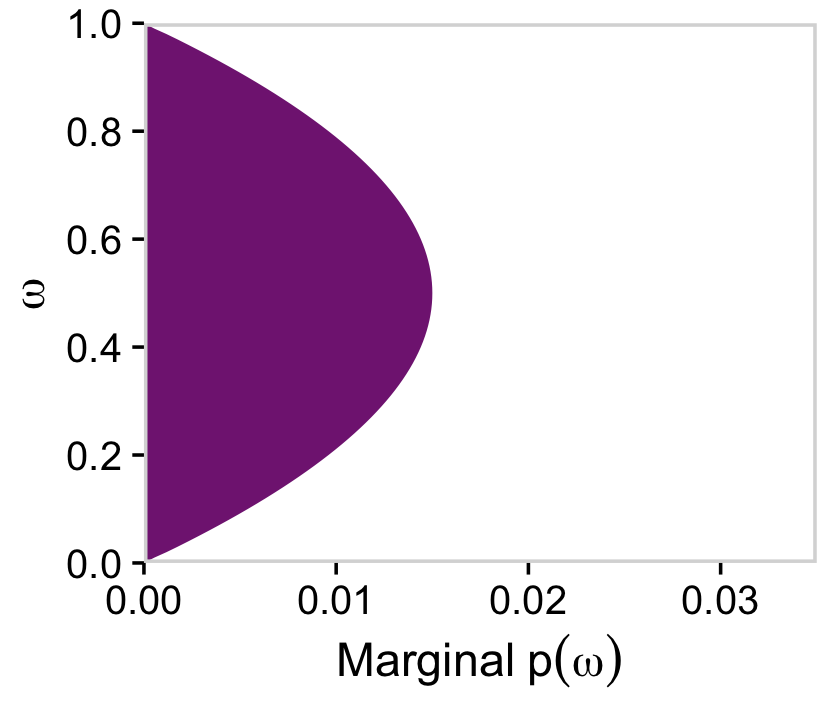
We’ll follow a similar procedure to get the marginal probability distribution for theta.
d %>%
group_by(theta) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta, y = prior)) +
geom_marginal(ul = 0.035) +
labs(x = expression(theta),
y = expression(Marginal~p(theta)))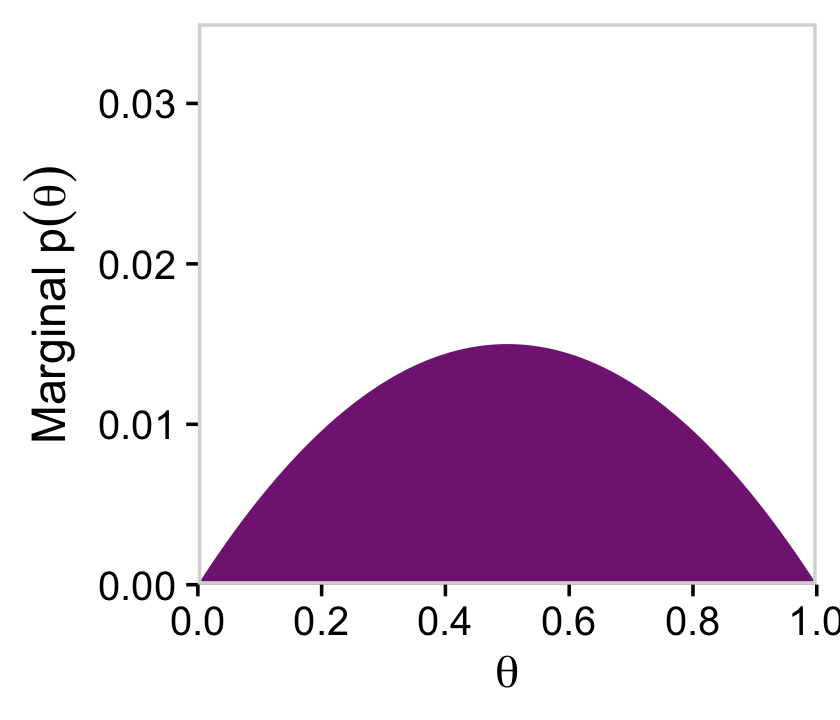
We’ll use the filter() function to take the two slices from the posterior grid. Since we’re taking slices, we’re no longer working with the joint probability distribution. As such, our two marginal prior distributions for theta no longer sum to 1, which means they’re no longer in a probability metric. No worries. After we group by omega, we can simply divide prior by the sum() of prior which renormalizes the two slices “so that they are individually proper probability densities that sum to 1.0 over θ” (p. 226).
d %>%
filter(omega %in% c(.25, .75)) %>%
group_by(omega) %>%
mutate(prior = prior / sum(prior)) %>%
mutate(label = factor(str_c("omega==", omega),
levels = c("omega==0.75", "omega==0.25"))) %>%
ggplot(aes(x = theta, y = prior)) +
geom_marginal(ul = 0.095) +
labs(x = expression(theta),
y = expression(p(theta*"|"*omega))) +
facet_wrap(~ label, ncol = 1, labeller = label_parsed)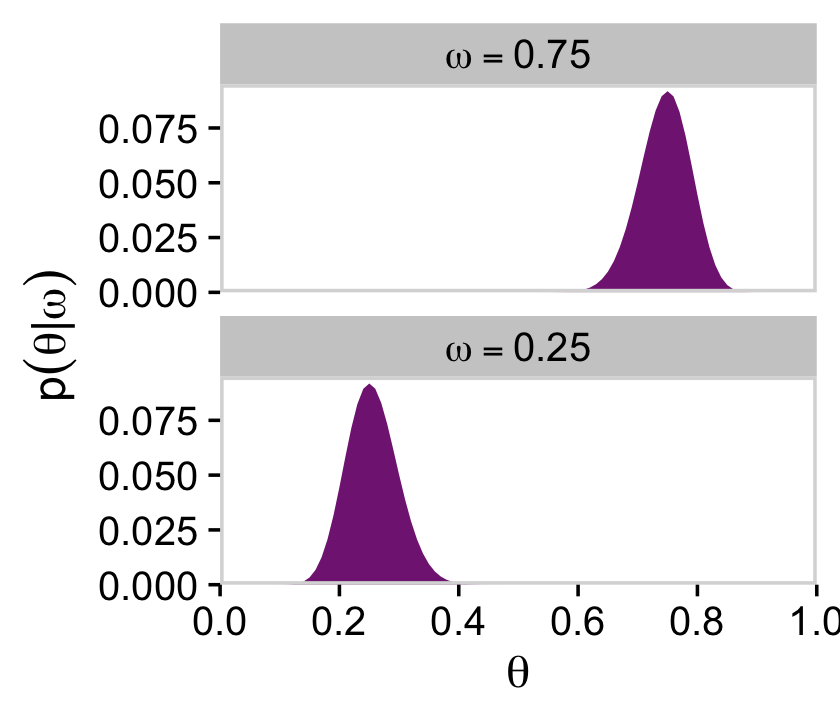
As Kruschke pointed out at the top of page 228, these are indeed beta densities. Here’s proof.
# we'll want this for the annotation
text <-
tibble(theta = c(.75, .25),
y = 10,
label = c("Beta(74.5, 25.5)", "Beta(25.5, 74.5)"),
omega = letters[1:2])
# here's the primary data for the plot
tibble(theta = rep(parameter_space, times = 2),
alpha = rep(c(74.5, 25.5), each = 101),
beta = rep(c(25.5, 74.5), each = 101),
omega = rep(letters[1:2], each = 101)) %>%
# the plot
ggplot(aes(x = theta, fill = omega)) +
geom_area(aes(y = dbeta(x = theta, shape1 = alpha, shape2 = beta))) +
geom_text(data = text,
aes(y = y, label = label, color = omega)) +
scale_fill_viridis_d(option = "A", begin = 2/9, end = 6/9) +
scale_color_viridis_d(option = "A", begin = 2/9, end = 6/9) +
scale_x_continuous(expression(theta), expand = c(0, 0), limits = c(0, 1),
breaks = 0:5 / 5) +
scale_y_continuous("density", expand = c(0, 0), limits = c(0, 11)) +
theme_cowplot() +
panel_border() +
theme(axis.line = element_blank(),
legend.position = "none")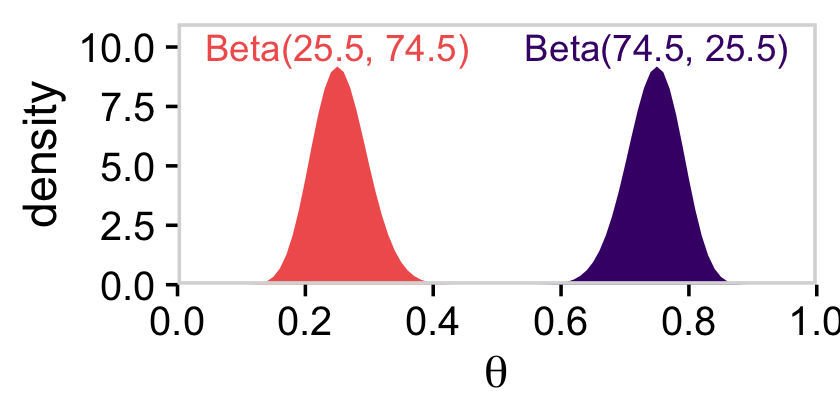
But back on track, we need the Bernoulli likelihood function for the lower three rows of Figure 9.2.
bernoulli_likelihood <- function(theta, data) {
n <- length(data)
z <- sum(data)
return(theta^z * (1 - theta)^(n - sum(data)))
}Time to feed theta and our data into the bernoulli_likelihood() function, which will allow us to make the 2-dimensional density plot in the middle of Figure 9.2.
# define the data
n <- 12
z <- 9
trial_data <- rep(0:1, times = c(n - z, z))
# compute the likelihood
d <-
d %>%
mutate(likelihood = bernoulli_likelihood(theta = theta,
data = trial_data))
# plot
d %>%
ggplot(aes(x = theta, y = omega, fill = likelihood)) +
geom_2dd() +
labs(x = expression(theta),
y = expression(omega))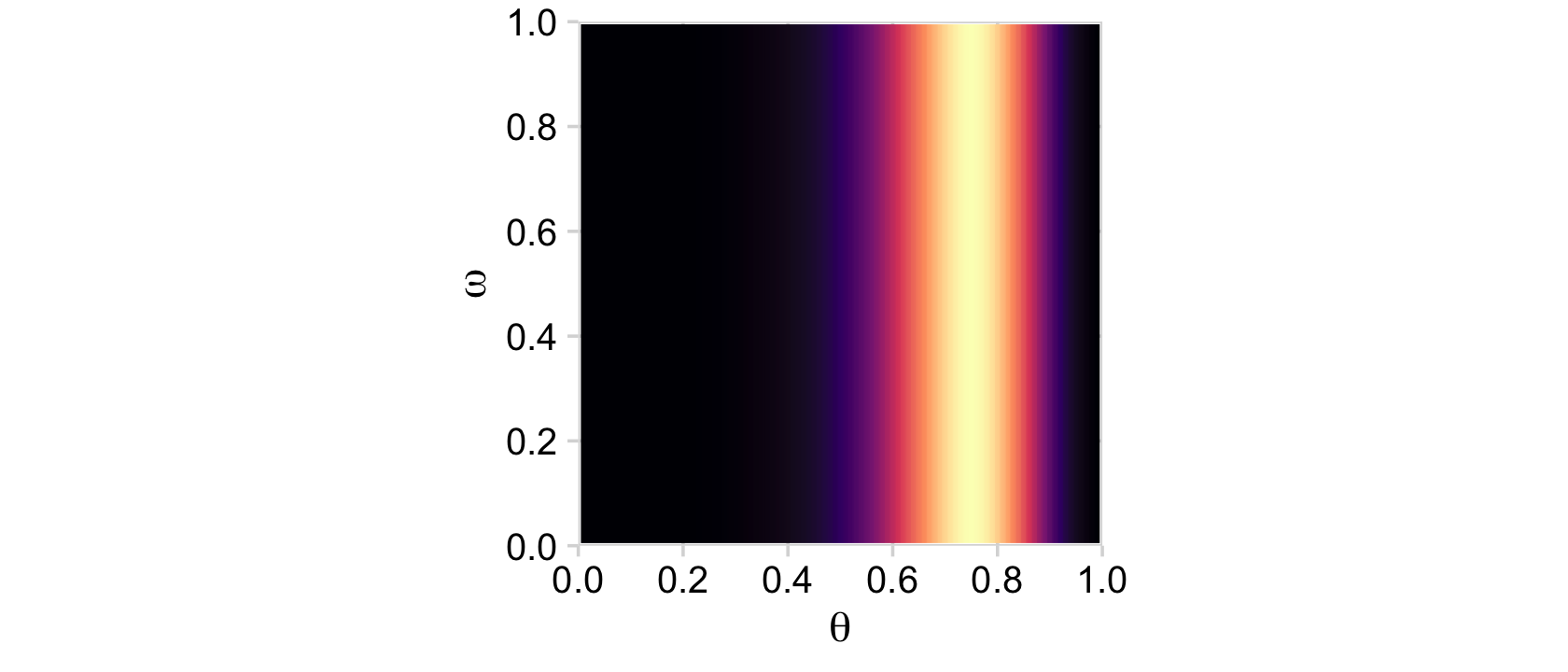
Note how this plot demonstrates how the likelihood is solely dependent on θ; it’s orthogonal to ω. This is the visual consequence of Kruschke’s Formula 9.6,
p(θ,ω|y)=p(y|θ,ω)p(θ,ω)p(y)=p(y|θ)p(θ|ω)p(ω)p(y).
That is, in the second line of the equation, the probability of y was only conditional on θ. But the reason we call this a hierarchical model is because the probability of θ itself is conditioned on ω. The prior itself had a prior.
From Formula 9.1, the posterior p(θ,ω|D) is proportional to p(D|θ)p(θ|ω)p(ω). Divide that by the normalizing constant and we’ll have it in a proper probability metric. Recall that we’ve already saved the results of p(θ|ω)p(ω) in the prior column. So we just need to multiply prior by likelihood and divide by their sum.
Our first depiction will be the middle panel of the second row from the bottom.
d <-
d %>%
mutate(posterior = (likelihood * prior) / sum(likelihood * prior))
d %>%
ggplot(aes(x = theta, y = omega, fill = posterior)) +
geom_2dd() +
labs(x = expression(theta),
y = expression(omega))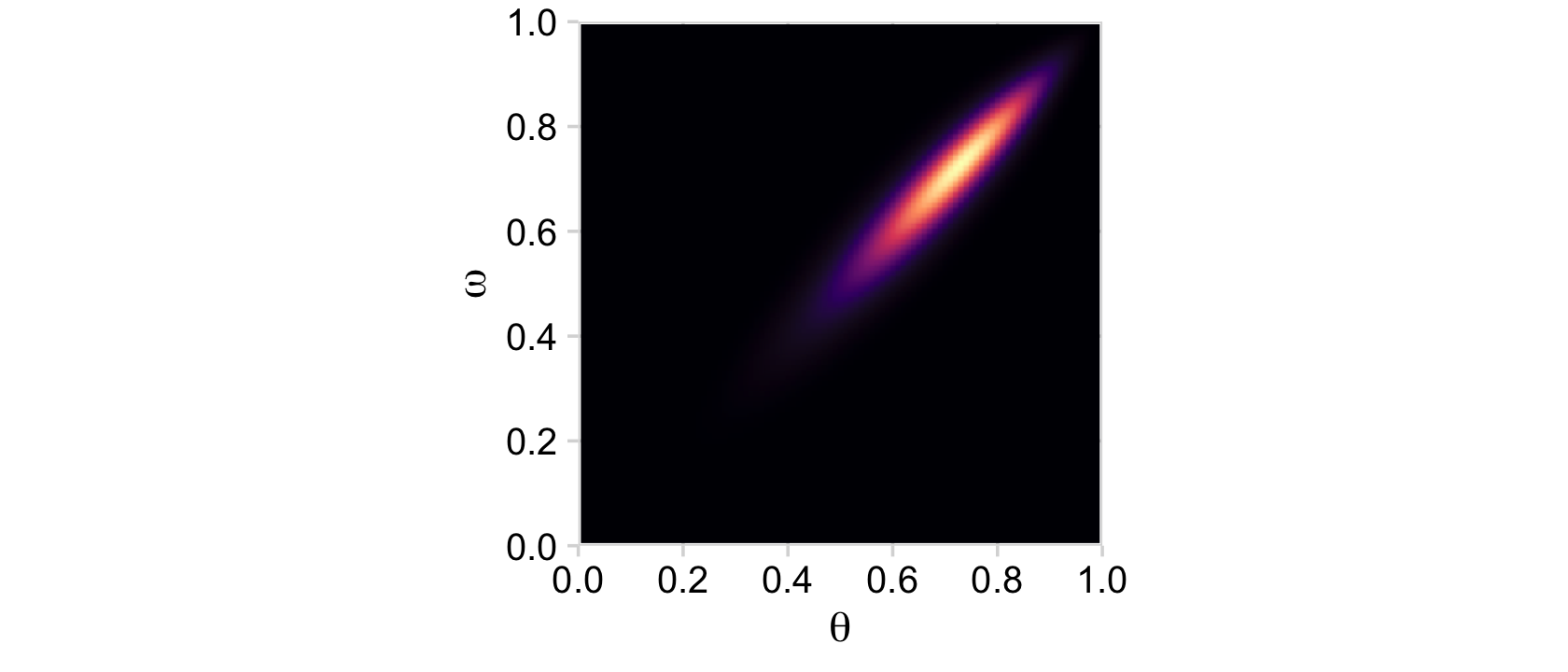
Although the likelihood was orthogonal to ω, conditioning the prior for θ on ω resulted in a posterior that was conditioned on both θ and ω.
Making the marginal plots for posterior is much like when making them for prior, above.
# for omega
d %>%
group_by(omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = omega, y = posterior)) +
geom_marginal(ul = 0.035) +
labs(x = expression(omega),
y = expression(Marginal~p(omega*"|"*D))) +
coord_flip()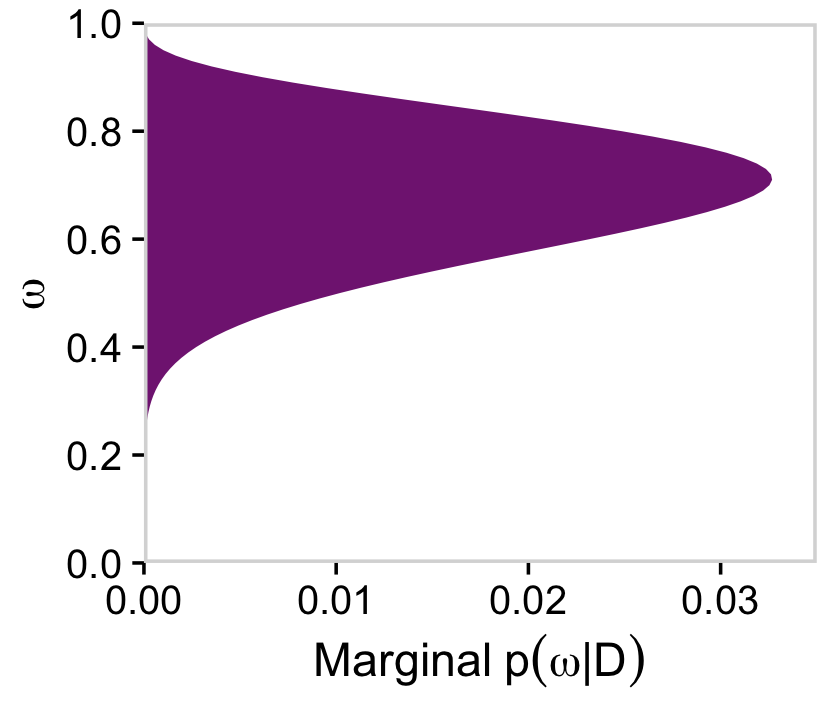
# for theta
d %>%
group_by(theta) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta, y = posterior)) +
geom_marginal(ul = 0.035) +
labs(x = expression(theta),
y = expression(Marginal~p(theta*"|"*D))) +
coord_cartesian()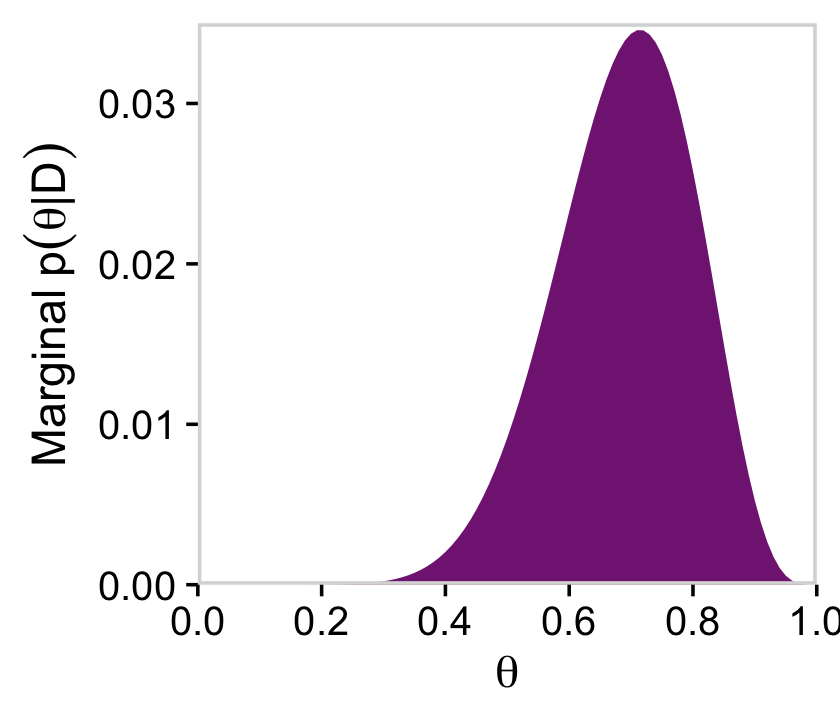
Note that after we slice with filter(), the next two wrangling lines renormalize those posterior slices into probability metrics. That is, when we take a slice through the joint posterior at a particular value of ω, and renormalize by dividing the sum of discrete probability masses in that slice, we get the conditional distribution p(θ|ω,D).
d %>%
filter(omega %in% c(.25, .75)) %>%
group_by(omega) %>%
mutate(posterior = posterior / sum(posterior)) %>%
mutate(label = factor(str_c("omega==", omega),
levels = c("omega==0.75", "omega==0.25"))) %>%
ggplot(aes(x = theta, y = posterior)) +
geom_marginal(ul = 0.1) +
labs(x = expression(theta),
y = expression(p(theta*"|"*omega))) +
facet_wrap(~ label, ncol = 1, labeller = label_parsed, scales = "free")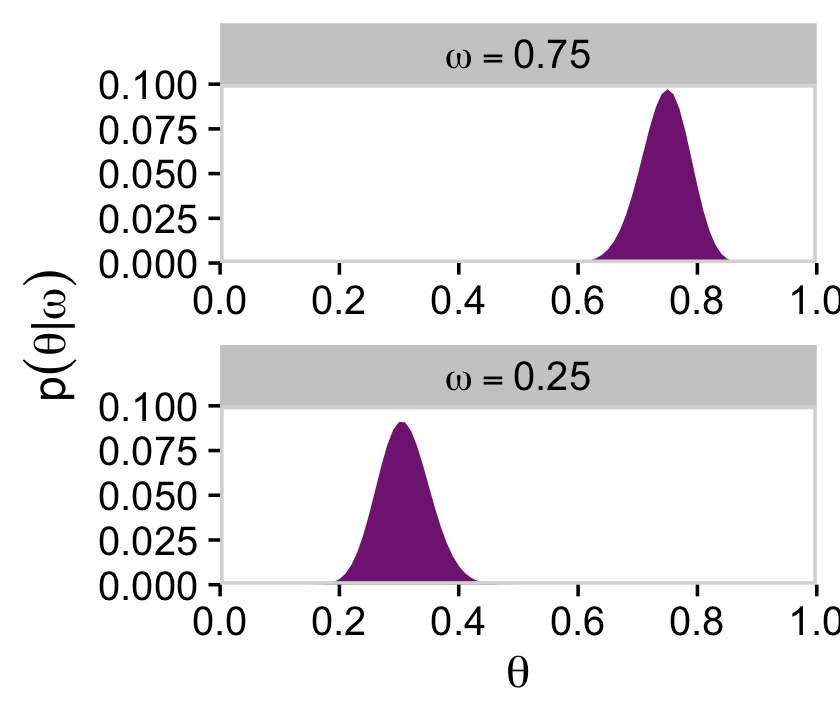
In the next example depicted in Figure 9.3, we consider what happens when we combine the same data of 9 heads out of 12 trials to the same Bernoulli likelihood p(y|θ), but his time with a much lower K values expressing greater uncertainty in the Beta(θ|ω(6−2)+1,(1−ω)(6−2)+1) portion of the joint prior and with a more certain hyperprior for ω, Beta(ω|20,20).
To repeat the process for Figure 9.3, we’ll first compute the new joint prior.
d <-
crossing(theta = parameter_space,
omega = parameter_space) %>%
mutate(prior = make_prior(theta, omega, alpha = 20, beta = 20, kappa = 6)) %>%
mutate(prior = prior / sum(prior))Here’s the initial data and the 2-dimensional density plot for the prior, the middle plot in the top row of Figure 9.3.
d %>%
ggplot(aes(x = theta, y = omega, fill = prior)) +
geom_2dd() +
labs(x = expression(theta),
y = expression(omega))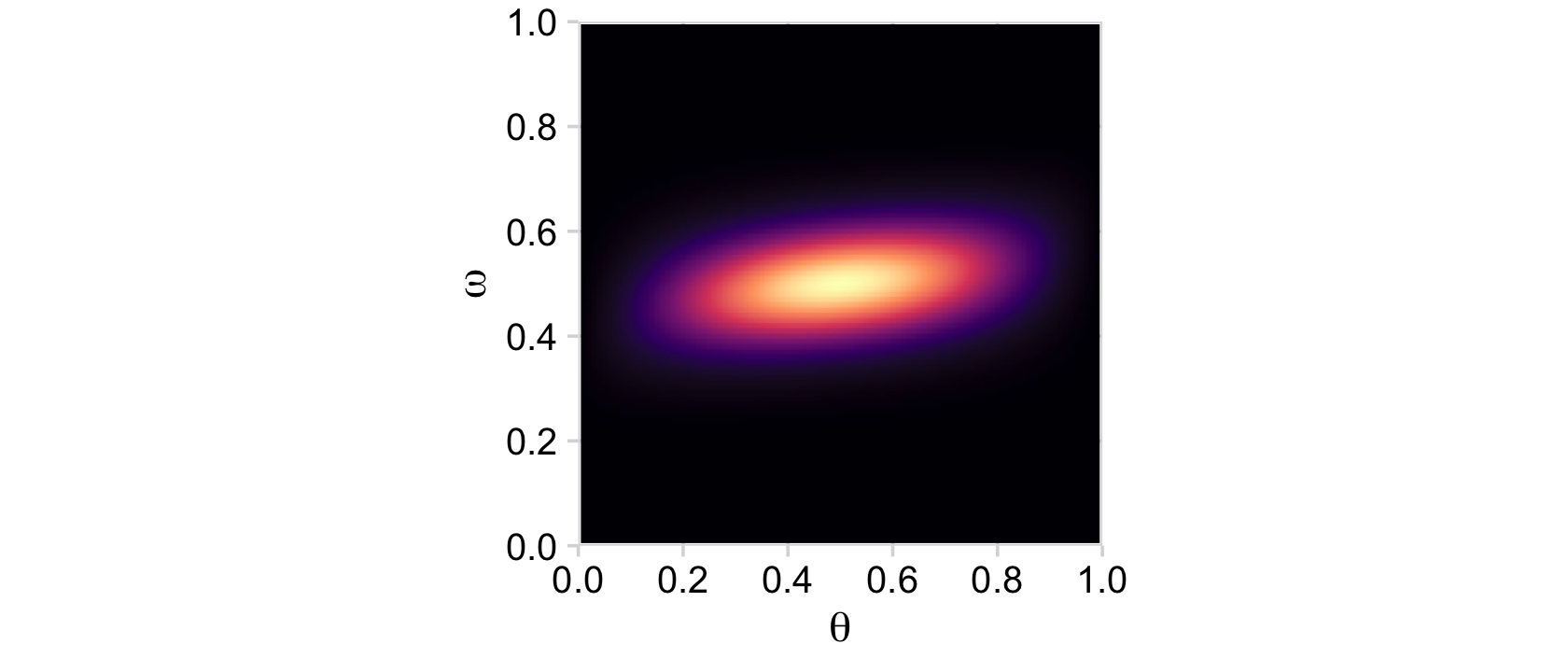
That higher certainty in ω resulted in a two-dimensional density plot where the values on the y-axis were concentrated near .5. This will have down-the-road consequences for the posterior. But before we get there, we’ll average over omega and theta to plot their marginal prior distributions.
# for omega
d %>%
group_by(omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = omega, y = prior)) +
geom_marginal(ul = 0.052) +
labs(x = expression(omega),
y = expression(Marginal~p(omega))) +
coord_flip()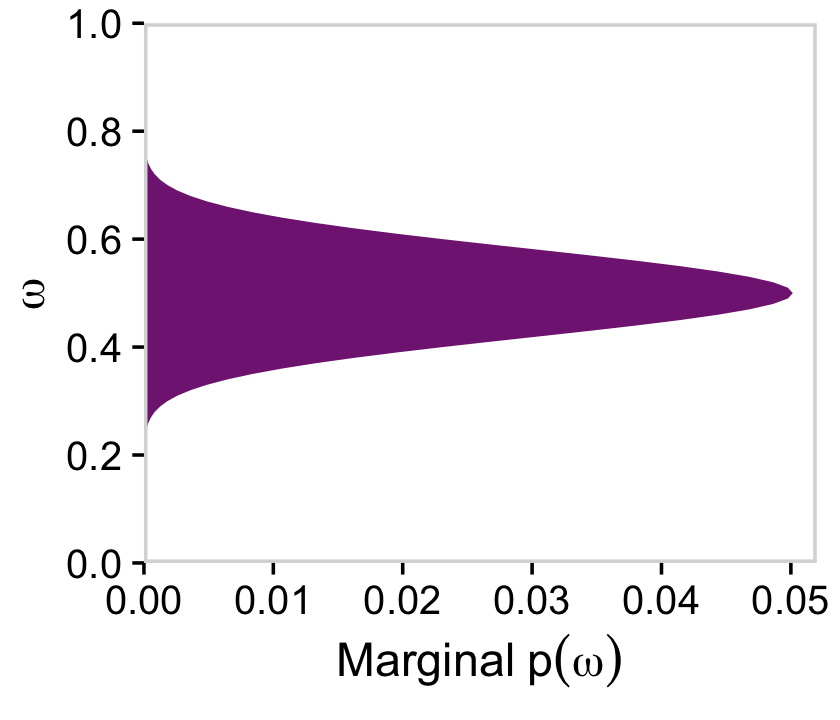
# for theta
d %>%
group_by(theta) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta, y = prior)) +
geom_marginal(ul = 0.039) +
labs(x = expression(theta),
y = expression(Marginal~p(theta)))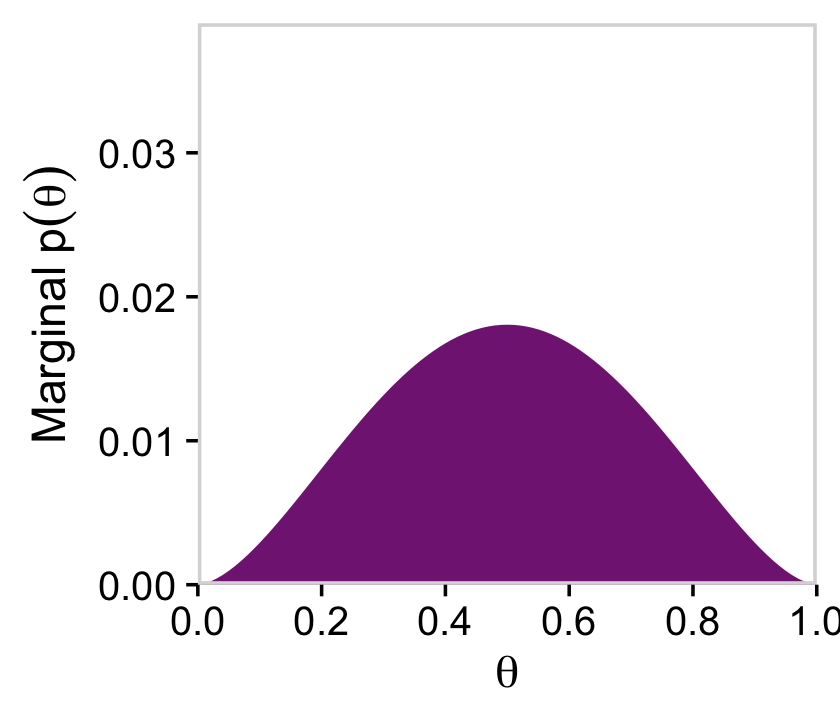
Here are the two short plots in the right panel of the second row from the top of Figure 9.3.
d %>%
filter(omega %in% c(.25, .75)) %>%
group_by(omega) %>%
mutate(prior = prior / sum(prior)) %>%
mutate(label = factor(str_c("omega == ", omega),
levels = c("omega == 0.75", "omega == 0.25"))) %>%
ggplot(aes(x = theta, y = prior)) +
geom_marginal(ul = 0.039) +
labs(x = expression(theta),
y = expression(p(theta*"|"*omega))) +
facet_wrap(~ label, ncol = 1, labeller = label_parsed)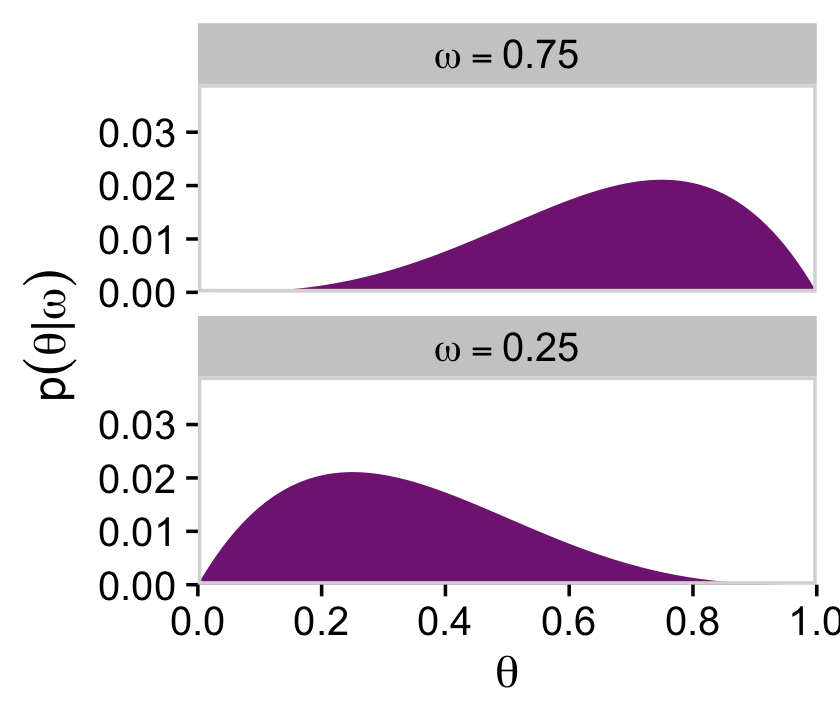
Now we’re ready for the likelihood.
# compute
d <-
d %>%
mutate(likelihood = bernoulli_likelihood(theta = theta,
data = trial_data))
# plot
d %>%
ggplot(aes(x = theta, y = omega, fill = likelihood)) +
geom_2dd() +
labs(x = expression(theta),
y = expression(omega))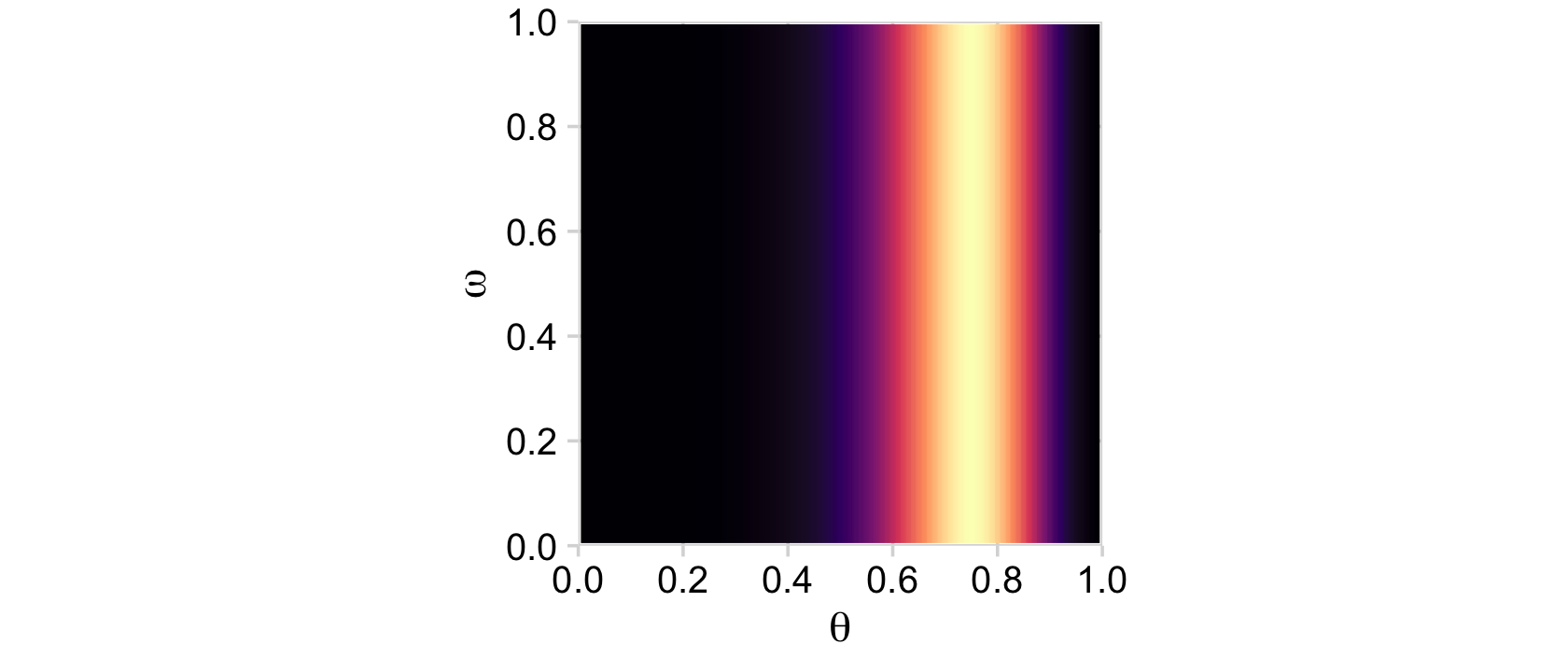
Now on to the posterior. Our first depiction will be the middle panel of the second row from the bottom of Figure 9.3. This will be p(θ,ω|y).
# compute the posterior
d <-
d %>%
mutate(posterior = (likelihood * prior) / sum(likelihood * prior))
# plot
d %>%
ggplot(aes(x = theta, y = omega, fill = posterior)) +
geom_2dd() +
labs(x = expression(theta),
y = expression(omega))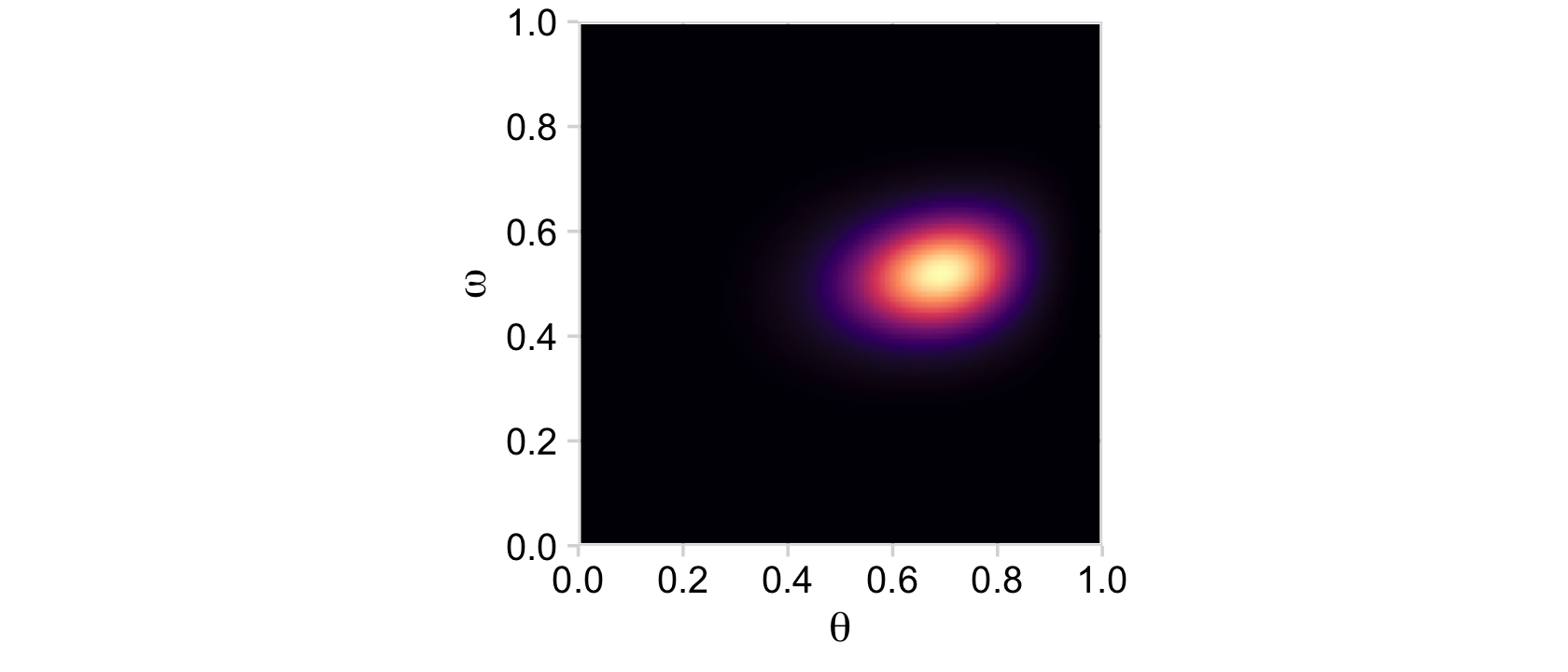
Here are the marginal plots for the two dimensions in our posterior.
# for omega
d %>%
group_by(omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = omega, y = posterior)) +
geom_marginal(ul = 0.052) +
labs(x = expression(omega),
y = expression(Marginal~p(omega*"|"*D))) +
coord_flip()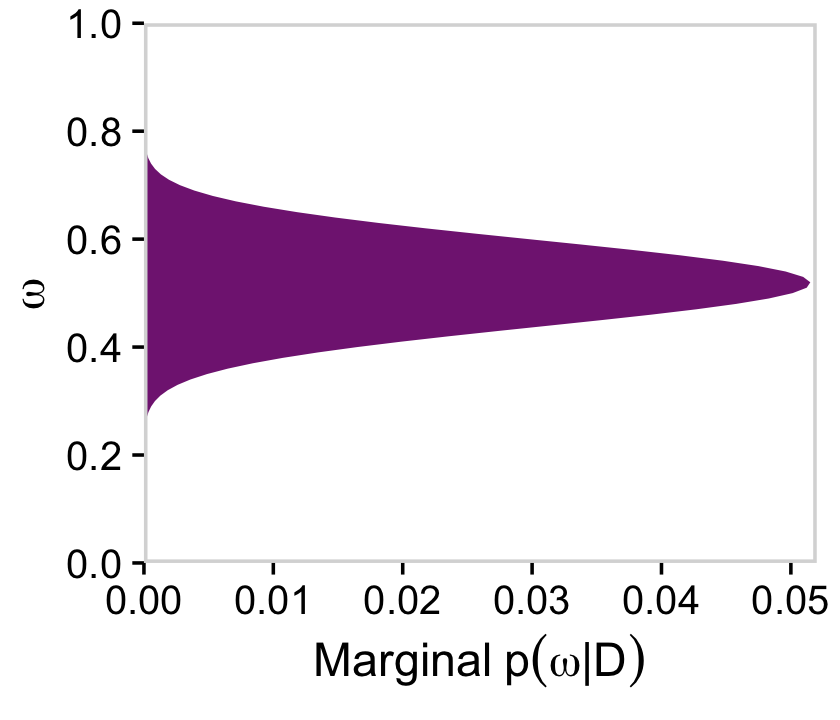
# for theta
d %>%
group_by(theta) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta, y = posterior)) +
geom_marginal(ul = 0.039) +
labs(x = expression(theta),
y = expression(Marginal~p(theta*"|"*D)))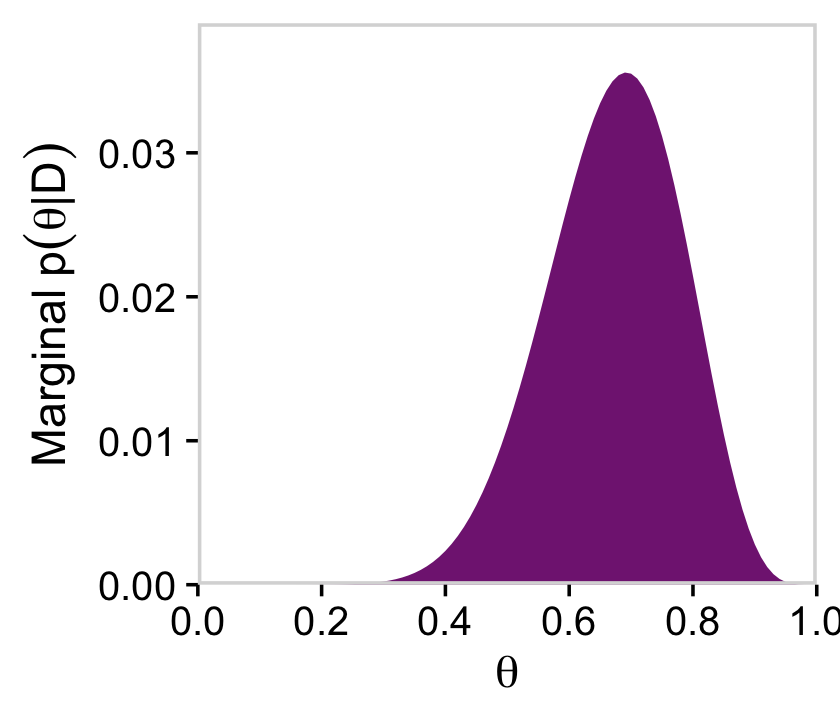
And we’ll finish off with the plots of Figure 9.3’s lower right panel.
d %>%
filter(omega %in% c(.25, .75)) %>%
group_by(omega) %>%
mutate(posterior = posterior / sum(posterior)) %>%
mutate(label = factor(str_c("omega==", omega),
levels = c("omega==0.75", "omega==0.25"))) %>%
ggplot(aes(x = theta, y = posterior)) +
geom_marginal(ul = 0.039) +
labs(x = expression(theta),
y = expression(p(theta*"|"*omega))) +
facet_wrap(~ label, ncol = 1, labeller = label_parsed, scales = "free")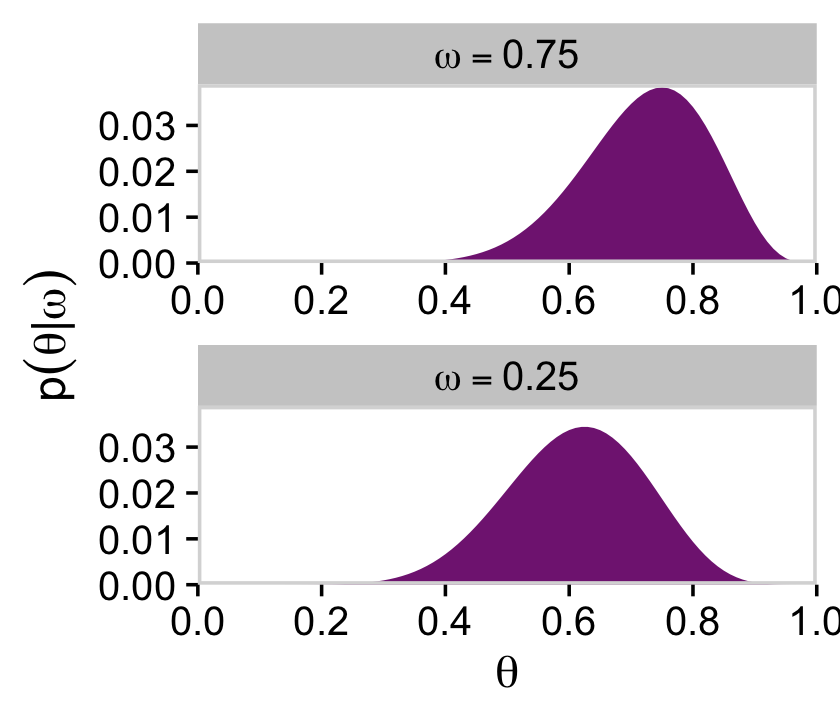
In summary, Bayesian inference in a hierarchical model is merely Bayesian inference on a joint parameter space, but we look at the joint distribution (e.g., p(θ,ω)) in terms of its marginal on a subset of parameters (e.g., p(ω)) and its conditional distribution for other parameters (e.g., p(θ|ω)). We do this primarily because it is meaningful in the context of particular models. (p. 230)
9.2 Multiple coins from a single mint
What if we collect data from more than one coin created by the mint? If each coin has its own distinct bias θs, then we are estimating a distinct parameter value for each coin, and using all the data to estimate ω. (p. 230)
Kruschke broke down a model of this form with his diagram in Figure 9.4. Here’s our version of that figure.
p1 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 2, 2)) / max(dbeta(x, 2, 2))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 7) +
annotate(geom = "text",
x = .5, y = .6,
label = "italic(A[omega])*', '*italic(B[omega])",
size = 7, family = "Times", parse = TRUE) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
p2 <-
tibble(x = c(.5, .475, .26, .08, .06,
.5, .55, .85, 1.15, 1.2),
y = c(1, .7, .6, .5, .2,
1, .7, .6, .5, .2),
line = rep(letters[2:1], each = 5)) %>%
ggplot(aes(x = x, y = y)) +
geom_bspline(aes(color = line),
linewidth = 2/3, show.legend = F) +
annotate(geom = "text",
x = 0, y = .125,
label = "omega(italic(K)-2)+1*', '*(1-omega)(italic(K)-2)+1",
size = 7, parse = T, family = "Times", hjust = 0) +
annotate(geom = "text",
x = 1/3, y = .7,
label = "'~'",
size = 10, parse = T, family = "Times") +
scale_color_manual(values = c("grey75", "black")) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 2)) +
ylim(0, 1) +
theme_void()
p3 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 2, 2)) / max(dbeta(x, 2, 2))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# an annotated arrow
p4 <-
tibble(x = c(.35, .65),
y = c(1/3, 1/3),
label = c("'~'", "italic(s)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# bar plot of Bernoulli data
p5 <-
tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = .6)) / max(dbinom(x, size = 1, prob = .6))) %>%
ggplot(aes(x = x, y = d)) +
geom_col(fill = a_purple, width = .4) +
annotate(geom = "text",
x = .5, y = .2,
label = "Bernoulli",
size = 7) +
annotate(geom = "text",
x = .5, y = .92,
label = "theta[italic(s)]",
size = 7, family = "Times", parse = T) +
xlim(-.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# another annotated arrow
p6 <-
tibble(x = c(.35, .65),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)*'|'*italic(s)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# some text
p7 <-
tibble(x = 1,
y = .5,
label = "italic(y)[italic(i)*'|'*italic(s)]") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
xlim(0, 2) +
theme_void()
# define the layout
layout <- c(
area(t = 1, b = 2, l = 1, r = 1),
area(t = 4, b = 5, l = 1, r = 1),
area(t = 3, b = 4, l = 1, r = 2),
area(t = 6, b = 6, l = 1, r = 1),
area(t = 7, b = 8, l = 1, r = 1),
area(t = 9, b = 9, l = 1, r = 1),
area(t = 10, b = 10, l = 1, r = 1)
)
# plot!
(p1 + p3 + p2 + p4 + p5 + p6 + p7) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))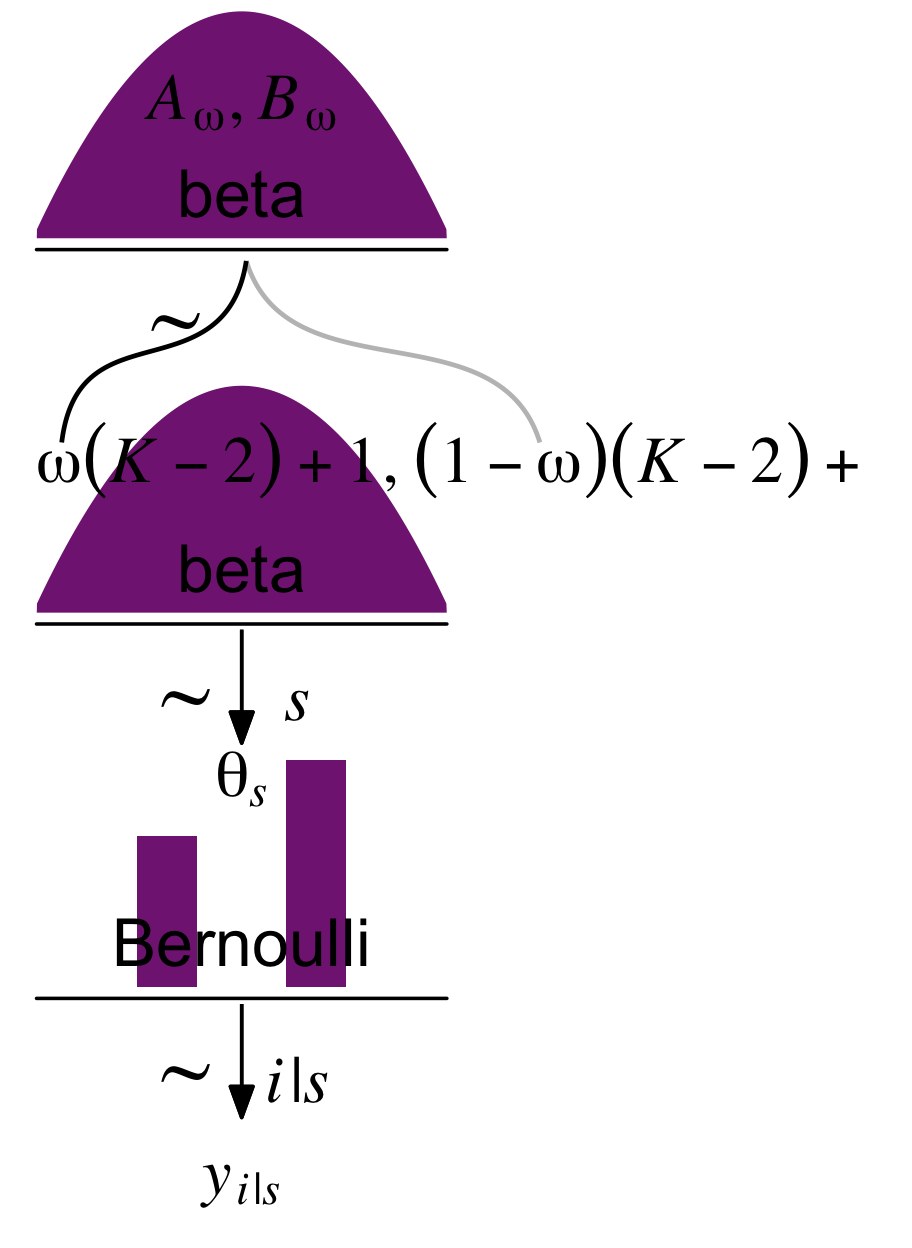
The diagram accounts for multiple coins with the s index.
9.2.1 Posterior via grid approximation.
Now we have two coins,
the full prior distribution is a joint distribution over three parameters: ω, θ1, and θ2. In a grid approximation, the prior is specified as a three-dimensional (3D) array that holds the prior probability at various grid points in the 3D space. (p. 233)
The biases for both coins, θ1, and θ2, have the same prior Beta(θj|ω(5−2)+1,(1−ω)(5−2)+1), which, if it’s not apparent, is marked by the rather uncertain K=5. As in our first example depicted in Figure 9.2, we have a gentle hyperprior Beta(ω|2,2), which centers the posterior mode for ω at .5. To express this in plots, we’re going to have to update our make_prior() function. It was originally designed to handle two dimensions, θ and ω. But now we have to update it to handle our three dimensions.
make_prior <- function(theta1, theta2, omega, alpha, beta, kappa) {
# p(theta_1 | omega)
t1 <- dbeta(x = theta1,
shape1 = omega * (kappa - 2) + 1,
shape2 = (1 - omega) * (kappa - 2) + 1)
# p(theta_2 | omega)
t2 <- dbeta(x = theta2,
shape1 = omega * (kappa - 2) + 1,
shape2 = (1 - omega) * (kappa - 2) + 1)
# p(omega)
o <- dbeta(x = omega,
shape1 = alpha,
shape2 = beta)
# p(theta1, theta2, omega) = p(theta1 | omega) * p(theta2 | omega) * p(omega)
return(t1 * t2 * o)
} Let’s make our new data object, d.
d <-
crossing(theta_1 = parameter_space,
theta_2 = parameter_space,
omega = parameter_space) %>%
mutate(prior = make_prior(theta_1, theta_2, omega, alpha = 2, beta = 2, kappa = 5)) %>%
# here we normalize
mutate(prior = prior / sum(prior))
glimpse(d)## Rows: 1,030,301
## Columns: 4
## $ theta_1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ theta_2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ omega <dbl> 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.…
## $ prior <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…Unlike what Kruschke said in the text (p. 233), we’re not using a 3D data array. Rather, we’re just using a tibble with which prior has been expanded across all possible dimensions of the three indexing variables: theta_1, theta_2, and omega. As you can see from the ‘Rows’ count, above, this makes for a very long tibble.
“Because the parameter space is 3D, a distribution on it cannot easily be displayed on a 2D page. Instead, Figure 9.5 shows various marginal distributions” (p. 234). The consequence of that is when we marginalize, we’ll have to group by the two variables we’d like to retain for the plot. For example, the plots in the left and middle columns of the top row are the same save for their indices. So let’s just do the plot for theta_1. In order to marginalize over theta_2, we’ll need to group_by(theta_1, omega) and then summarise(prior = sum(prior)).
d %>%
group_by(theta_1, omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta_1, y = omega, fill = prior)) +
geom_2dd() +
labs(x = expression(theta[1]),
y = expression(omega))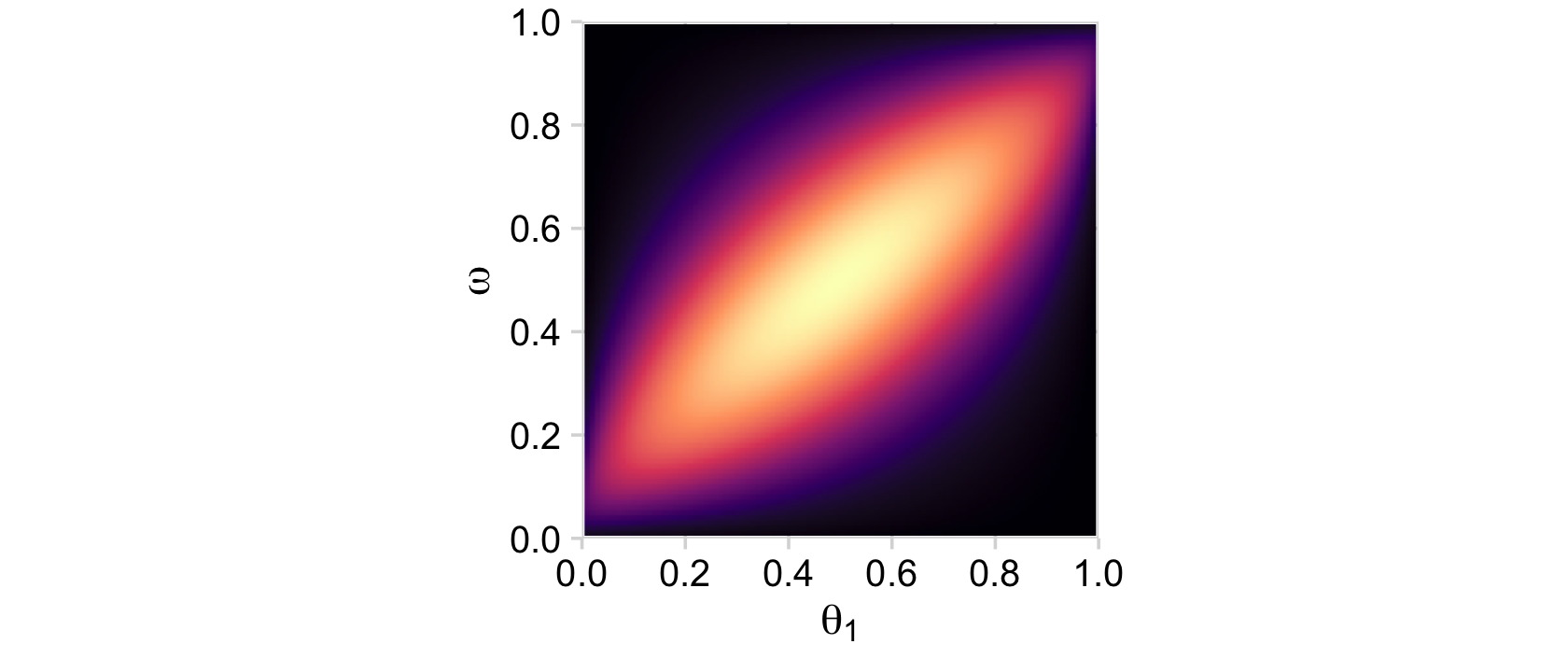
But we just have to average over omega and theta_1 to plot their marginal prior distributions.
# for omega
d %>%
group_by(omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = omega, y = prior)) +
geom_marginal(ul = 0.041) +
labs(x = expression(omega),
y = expression(p(omega))) +
coord_flip()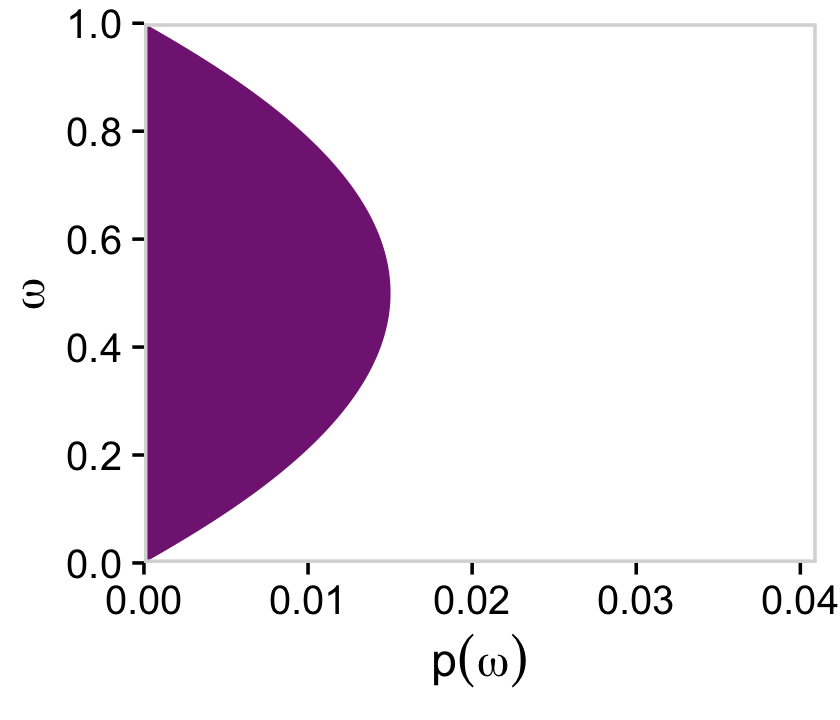
# for theta
d %>%
group_by(theta_1) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta_1, y = prior)) +
geom_marginal(ul = 0.041) +
labs(x = expression(theta[1]),
y = expression(p(theta[1])))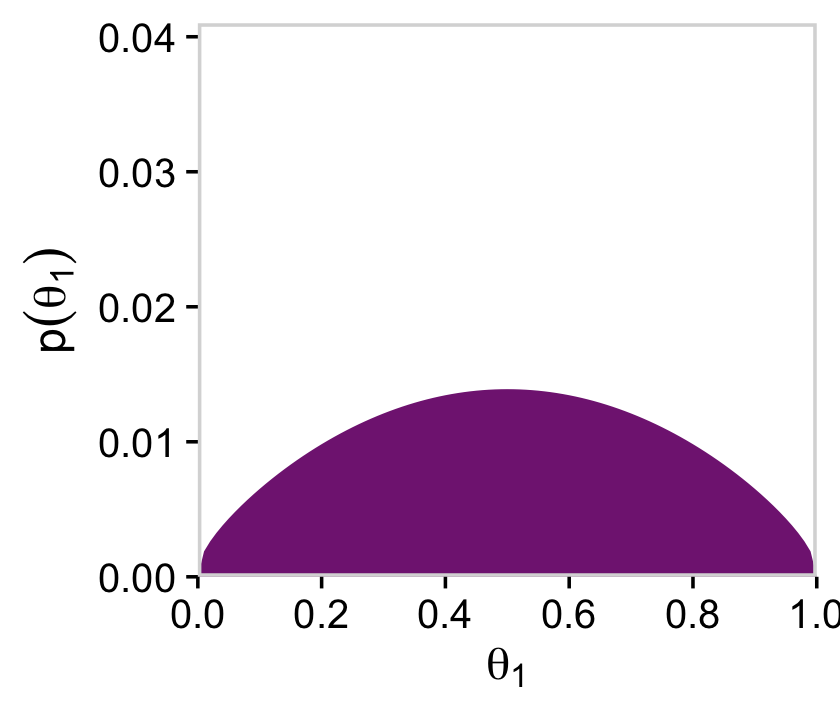
Before we make the plots in the middle row of Figure 9.5, we need to add the likelihoods. Recall that we’re presuming the coin flips contained in D1 and D2 are independent. Kruschke explained in Section 7.4.1, that
independence of the data across the two coins means that the data from coin 1 depend only on the bias in coin 1, and the data from coin 2 depend only on the bias in coin 2, which can be expressed formally as p(y1|θ1,θ2)=p(y1|θ1) and p(y2|θ1,θ2)=p(y2|θ2). (p. 164)
The likelihood function for our two series of coin flips is then
p(D|θ1,θ2)=(θz11(1−θ1)N1−z1)(θz22(1−θ2)N2−z2).
The upshot is we can compute the likelihoods for D1 and D2 separately and just multiply them together.
# D1: 3 heads, 12 tails
n <- 15
z <- 3
trial_data_1 <- rep(0:1, times = c(n - z, z))
# D2: 4 heads, 1 tail
n <- 5
z <- 4
trial_data_2 <- rep(0:1, times = c(n - z, z))
d <-
d %>%
mutate(likelihood_1 = bernoulli_likelihood(theta = theta_1, data = trial_data_1),
likelihood_2 = bernoulli_likelihood(theta = theta_2, data = trial_data_2)) %>%
mutate(likelihood = likelihood_1 * likelihood_2)
head(d)## # A tibble: 6 × 7
## theta_1 theta_2 omega prior likelihood_1 likelihood_2 likelihood
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0 0 0 0 0 0 0
## 2 0 0 0.01 0 0 0 0
## 3 0 0 0.02 0 0 0 0
## 4 0 0 0.03 0 0 0 0
## 5 0 0 0.04 0 0 0 0
## 6 0 0 0.05 0 0 0 0Now after a little group_by() followed by summarise() we can plot the two marginal likelihoods, the two plots in the middle row of Figure 9.5.
# likelihood_1
d %>%
group_by(theta_1, omega) %>%
summarise(likelihood = sum(likelihood)) %>%
ggplot(aes(x = theta_1, y = omega, fill = likelihood)) +
geom_2dd() +
labs(x = expression(theta[1]),
y = expression(omega))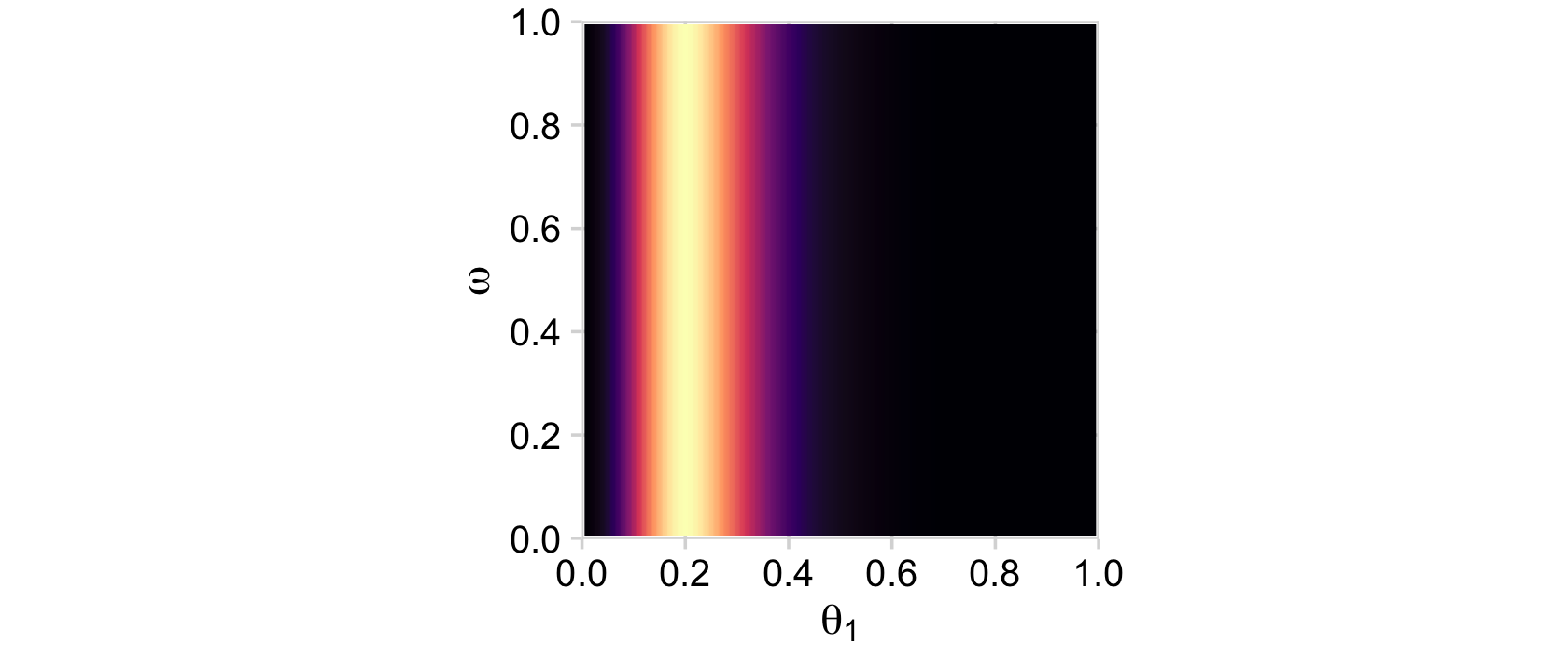
# likelihood_2
d %>%
group_by(theta_2, omega) %>%
summarise(likelihood = sum(likelihood)) %>%
ggplot(aes(x = theta_2, y = omega, fill = likelihood)) +
geom_2dd() +
labs(x = expression(theta[2]),
y = expression(omega))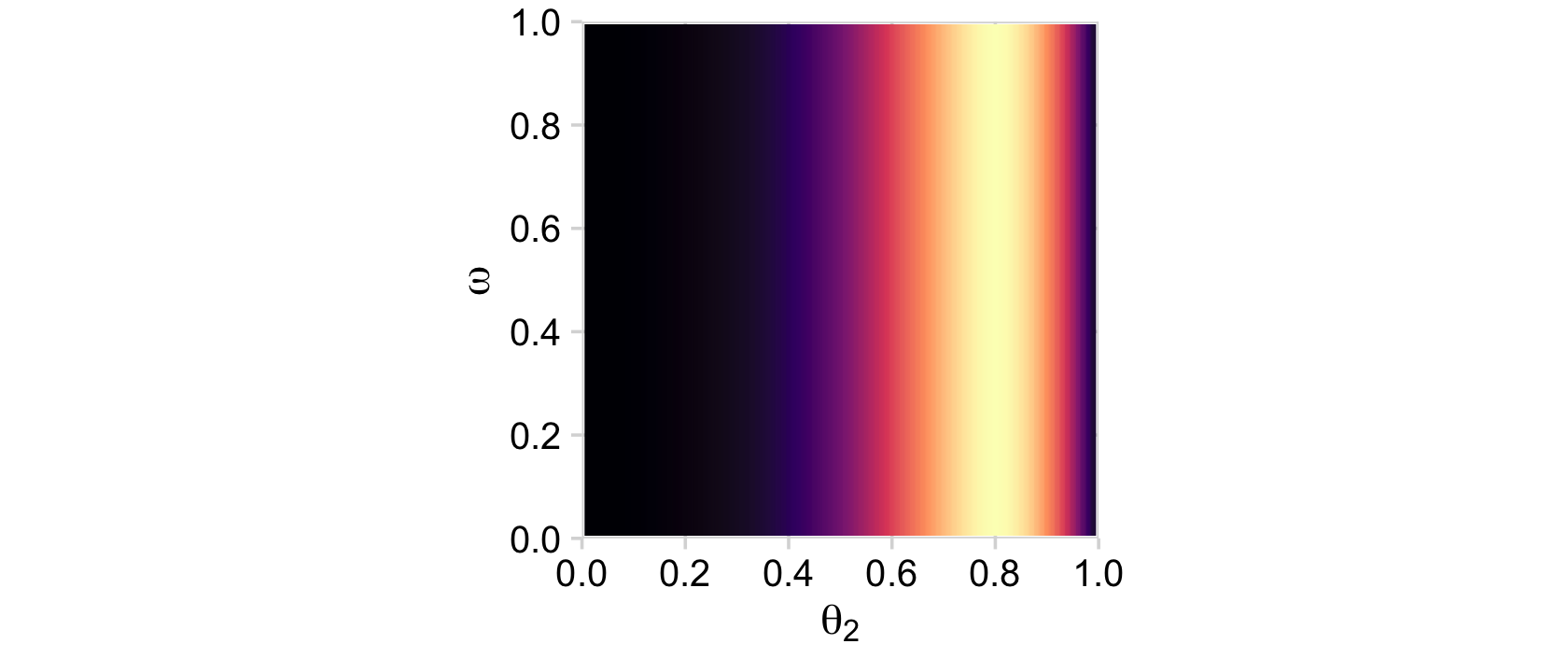
The likelihoods look good. Next we compute the posterior in the same way we’ve done before: multiply the prior and the likelihood and then divide by their sum in order to convert the results to a probability metric.
# compute
d <-
d %>%
mutate(posterior = (prior * likelihood) / sum(prior * likelihood))
# posterior_1
d %>%
group_by(theta_1, omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_1, y = omega, fill = posterior)) +
geom_2dd() +
labs(x = expression(theta[1]),
y = expression(omega))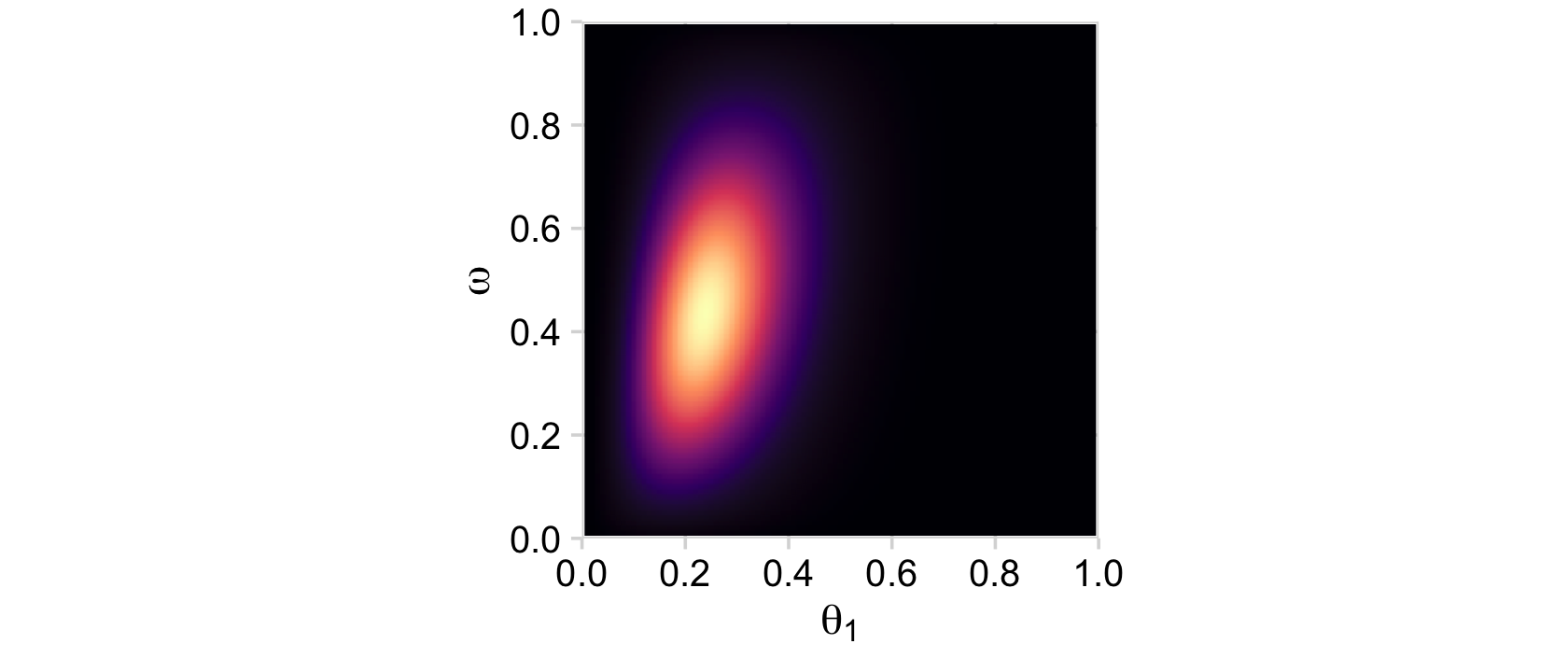
# posterior_2
d %>%
group_by(theta_2, omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_2, y = omega, fill = posterior)) +
geom_2dd() +
labs(x = expression(theta[2]),
y = expression(omega))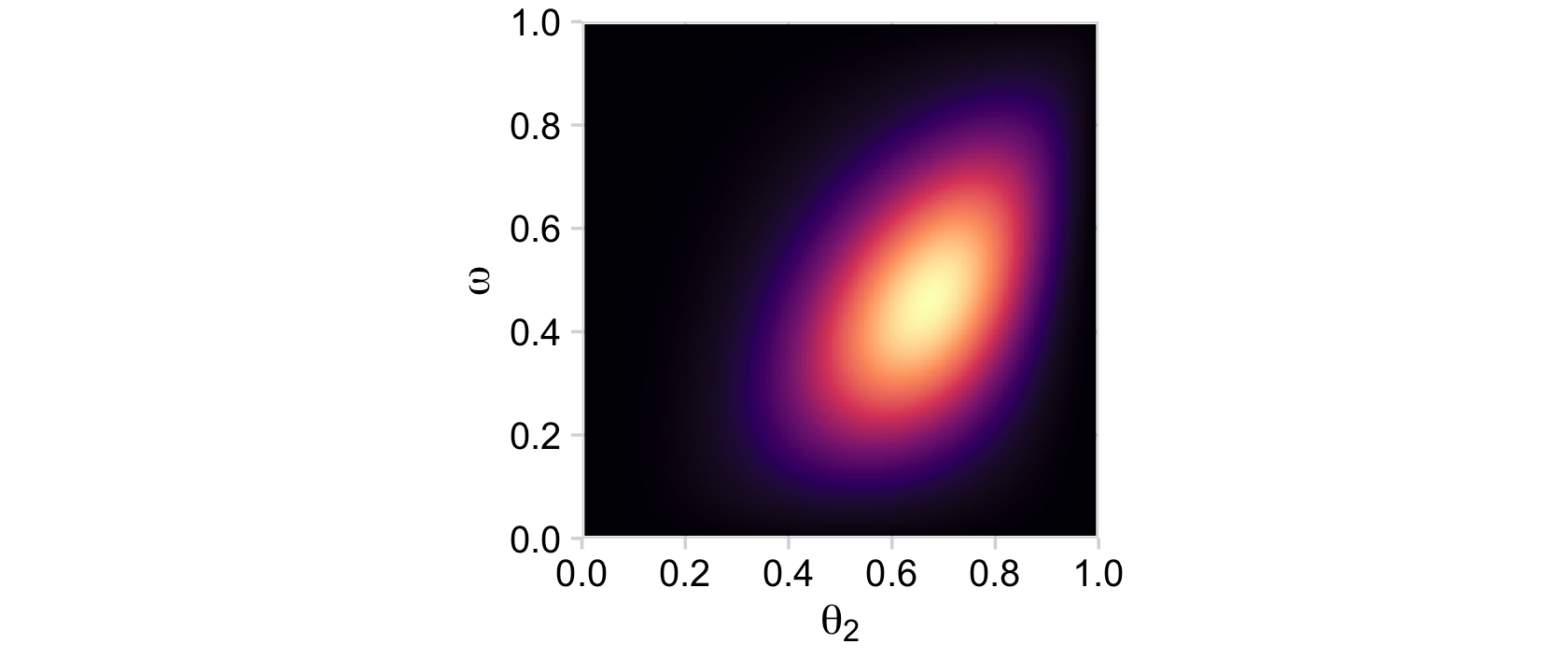
Here’s the right plot on the second row from the bottom, the posterior distribution for ω.
# for omega
d %>%
group_by(omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = omega, y = posterior)) +
geom_marginal(ul = 0.041) +
labs(x = expression(omega),
y = expression(p(omega*"|"*D))) +
coord_flip()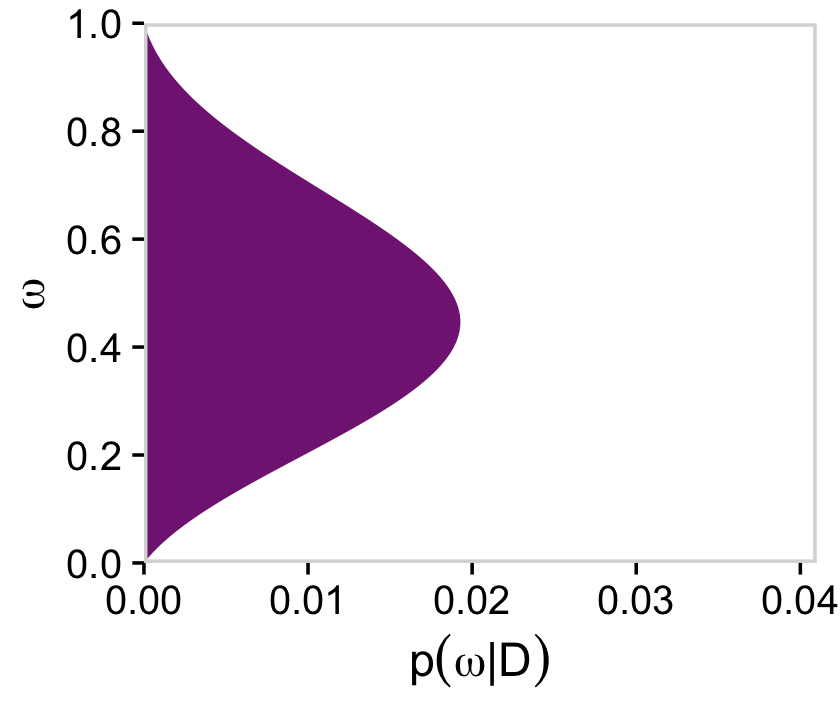
Now here are the marginal posterior plots on the bottom row of Figure 9.5.
# for theta_1
d %>%
group_by(theta_1) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_1, y = posterior)) +
geom_marginal(ul = 0.041) +
labs(x = expression(theta[1]),
y = expression(p(theta[1]*"|"*D)))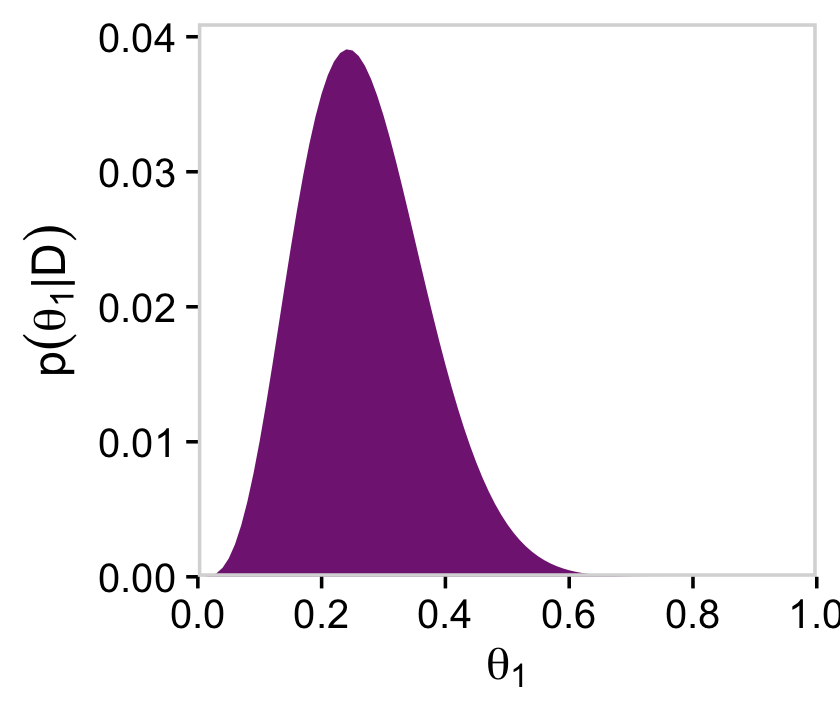
# for theta_2
d %>%
group_by(theta_2) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_2, y = posterior)) +
geom_marginal(ul = 0.041) +
labs(x = expression(theta[2]),
y = expression(p(theta[2]*"|"*D)))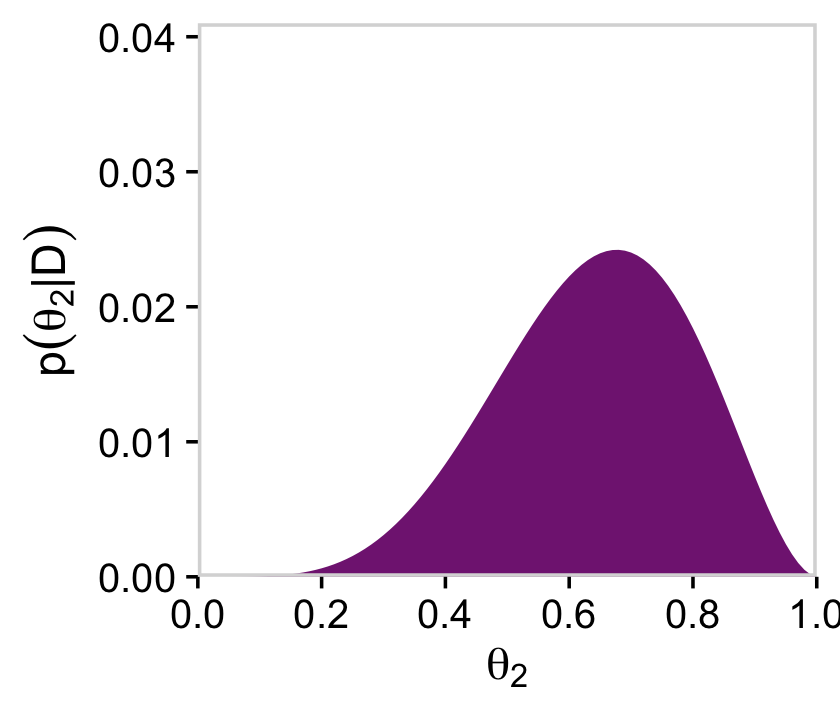
We’ll do this dog and pony one more time for Figure 9.6. Keeping the data and likelihood constant, we now set K=75 and but retain both Aω=2 and Bω=2. First, we make our new data object, d.
d <-
crossing(theta_1 = parameter_space,
theta_2 = parameter_space,
omega = parameter_space) %>%
mutate(prior = make_prior(theta_1, theta_2, omega, alpha = 2, beta = 2, kappa = 75)) %>%
mutate(prior = prior / sum(prior))Again, note how the only thing we changed from the last time was increasing kappa to 75. Also like last time, the plots in the left and middle columns of the top row are the same save for their indices. But unlike last time, we’ll make both in preparation for a grand plotting finale. You’ll see.
One more step: for the 2D density plots in this section, we’ll omit the coord_equal() line from our custom geom_2dd() geom. This will help us with the formatting of our final plot.
geom_2dd <- function(...) {
list(
geom_raster(interpolate = T),
scale_fill_viridis_c(option = "A"),
scale_x_continuous(expand = c(0, 0), limits = c(0, 1), breaks = 0:5 / 5),
scale_y_continuous(expand = c(0, 0), limits = c(0, 1), breaks = 0:5 / 5),
# coord_equal(),
theme_minimal_grid(...),
theme(legend.position = "none")
)
}Okay, here are our two 2D prior density plots.
p11 <-
d %>%
group_by(theta_1, omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta_1, y = omega, fill = prior)) +
geom_2dd(font_size = 10) +
annotate(geom = "text", x = .05, y = .925,
label = "p(list(theta[1], omega))",
parse = T, color = "white", hjust = 0) +
labs(x = expression(theta[1]),
y = expression(omega))
p12 <-
d %>%
group_by(theta_2, omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta_2, y = omega, fill = prior)) +
geom_2dd(font_size = 10) +
annotate(geom = "text", x = .05, y = .925,
label = "p(list(theta[2], omega))",
parse = T, color = "white", hjust = 0) +
labs(x = expression(theta[2]),
y = expression(omega))
p11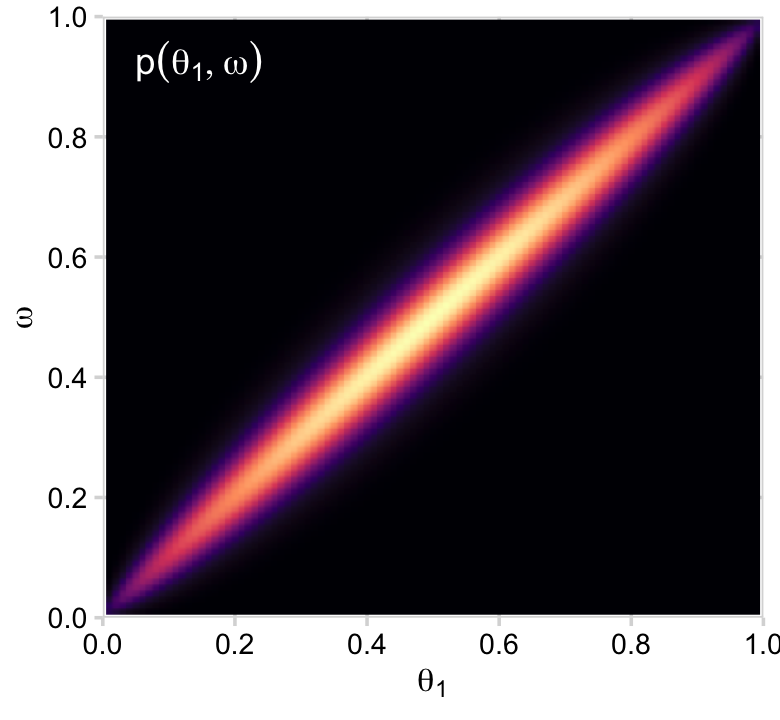
p12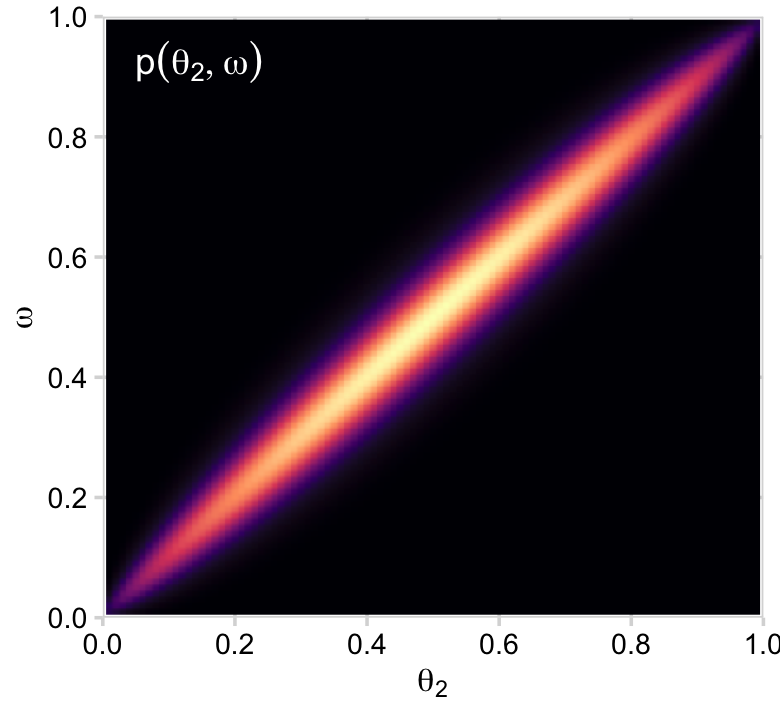
Now we’ll average over omega and theta to plot their marginal prior distributions.
# for omega
p13 <-
d %>%
group_by(omega) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = omega, y = prior)) +
geom_marginal(ul = 0.041, font_size = 10) +
labs(x = expression(omega),
y = expression(p(omega))) +
coord_flip()
# for theta_1
p21 <-
d %>%
group_by(theta_1) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta_1, y = prior)) +
geom_marginal(ul = 0.041, font_size = 10) +
labs(x = expression(theta[1]),
y = expression(p(theta[1])))
# for theta_2
p22 <-
d %>%
group_by(theta_2) %>%
summarise(prior = sum(prior)) %>%
ggplot(aes(x = theta_2, y = prior)) +
geom_marginal(ul = 0.041, font_size = 10) +
labs(x = expression(theta[2]),
y = expression(p(theta[2])))
p13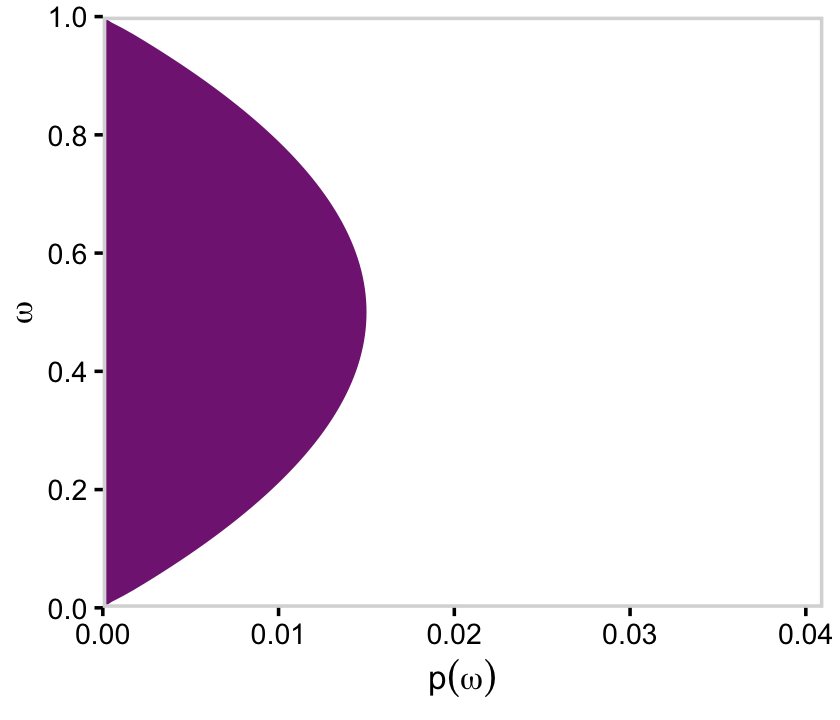
p21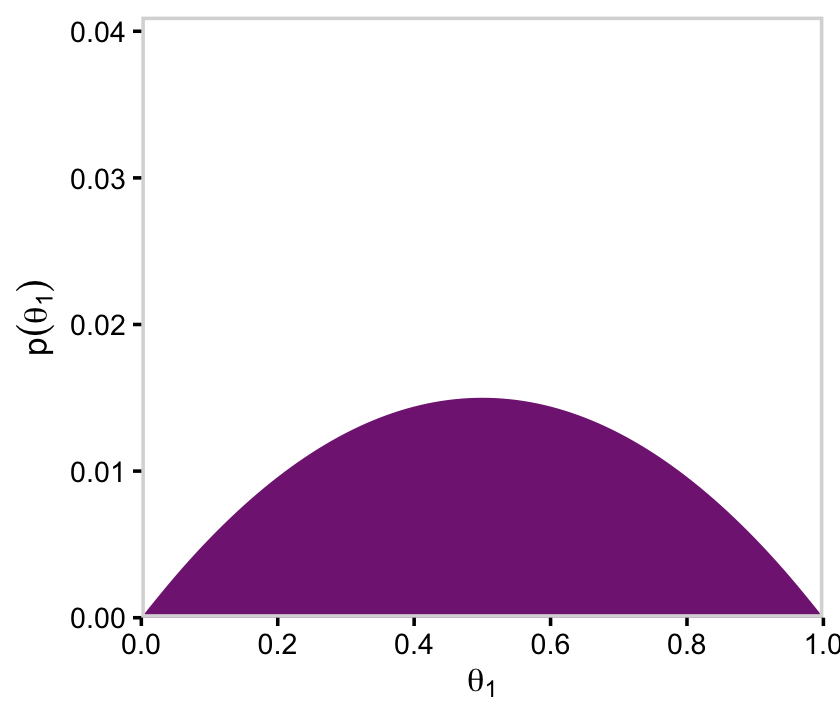
p22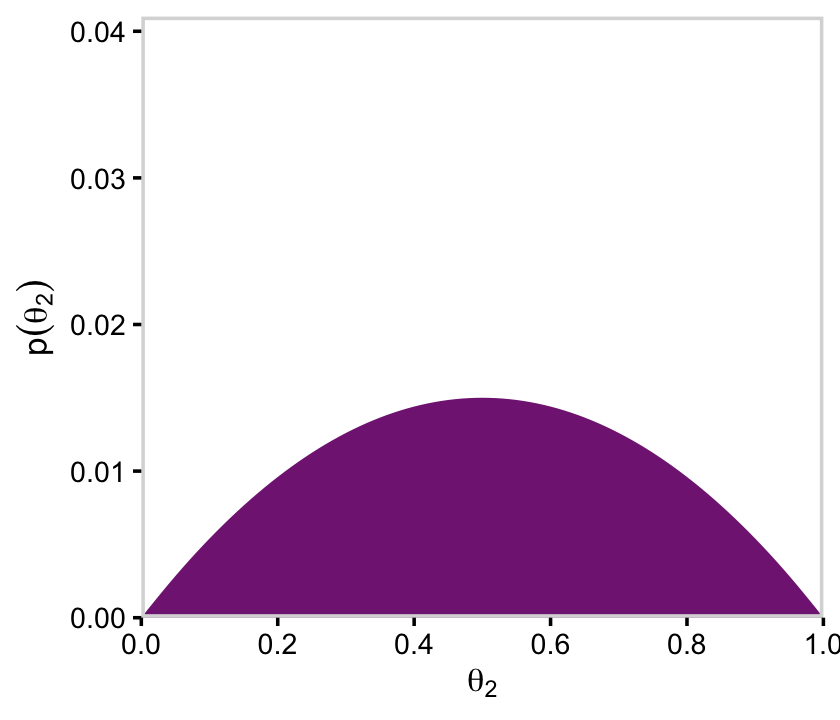
Let’s get those likelihoods in there and plot.
# D1: 3 heads, 12 tails
n <- 15
z <- 3
trial_data_1 <- rep(0:1, times = c(n - z, z))
# D2: 4 heads, 1 tail
n <- 5
z <- 4
trial_data_2 <- rep(0:1, times = c(n - z, z))
# compute the likelihoods
d <-
d %>%
mutate(likelihood_1 = bernoulli_likelihood(theta = theta_1, data = trial_data_1),
likelihood_2 = bernoulli_likelihood(theta = theta_2, data = trial_data_2)) %>%
mutate(likelihood = likelihood_1 * likelihood_2)
# plot likelihood_1
p31 <-
d %>%
group_by(theta_1, omega) %>%
summarise(likelihood = sum(likelihood)) %>%
ggplot(aes(x = theta_1, y = omega, fill = likelihood)) +
geom_2dd(font_size = 10) +
labs(x = expression(theta[1]),
y = expression(omega))
# plot likelihood_2
p32 <-
d %>%
group_by(theta_2, omega) %>%
summarise(likelihood = sum(likelihood)) %>%
ggplot(aes(x = theta_2, y = omega, fill = likelihood)) +
geom_2dd(font_size = 10) +
labs(x = expression(theta[2]),
y = expression(omega))
p31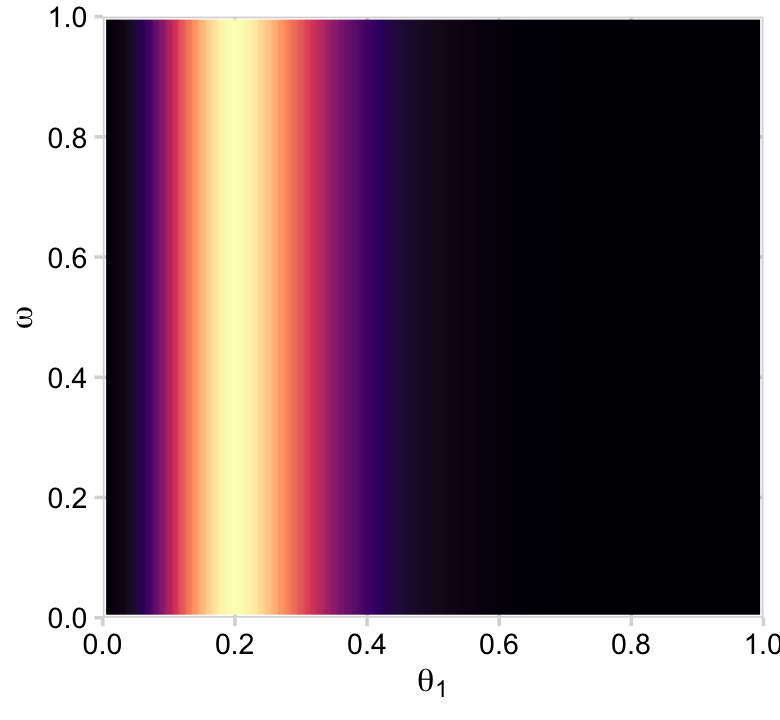
p32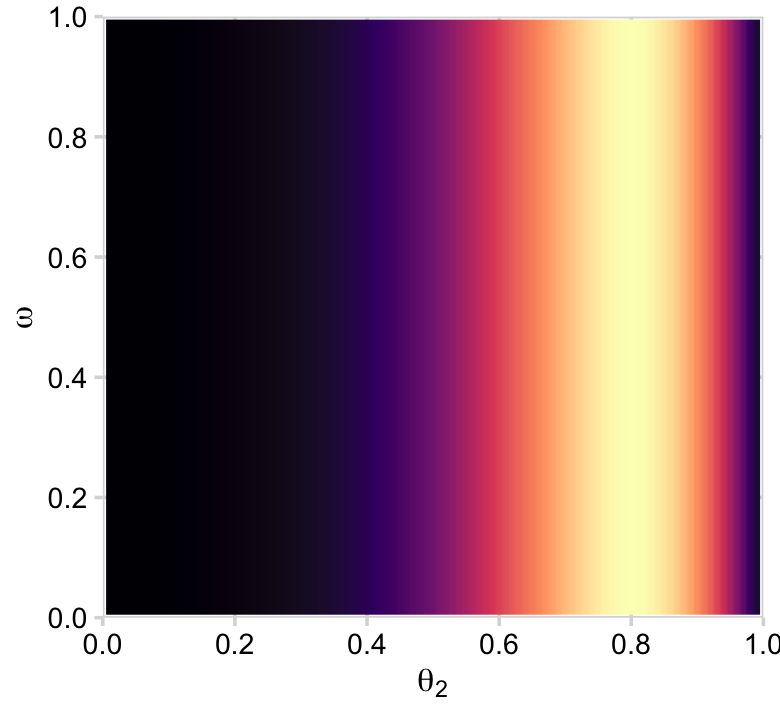
Compute the posterior and make the left and middle plots of the second row to the bottom of Figure 9.6.
d <-
d %>%
mutate(posterior = (prior * likelihood) / sum(prior * likelihood))
# posterior_1
p41 <-
d %>%
group_by(theta_1, omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_1, y = omega, fill = posterior)) +
geom_2dd(font_size = 10) +
annotate(geom = "text", x = .05, y = .925,
label = expression(p(list(theta[1], omega)*"|"*D)),
parse = T, color = "white", hjust = 0) +
labs(x = expression(theta[1]),
y = expression(omega))
# posterior_2
p42 <-
d %>%
group_by(theta_2, omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_2, y = omega, fill = posterior)) +
geom_2dd(font_size = 10) +
annotate(geom = "text", x = .05, y = .925,
label = expression(p(list(theta[2], omega)*"|"*D)),
parse = T, color = "white", hjust = 0) +
labs(x = expression(theta[2]),
y = expression(omega))
p41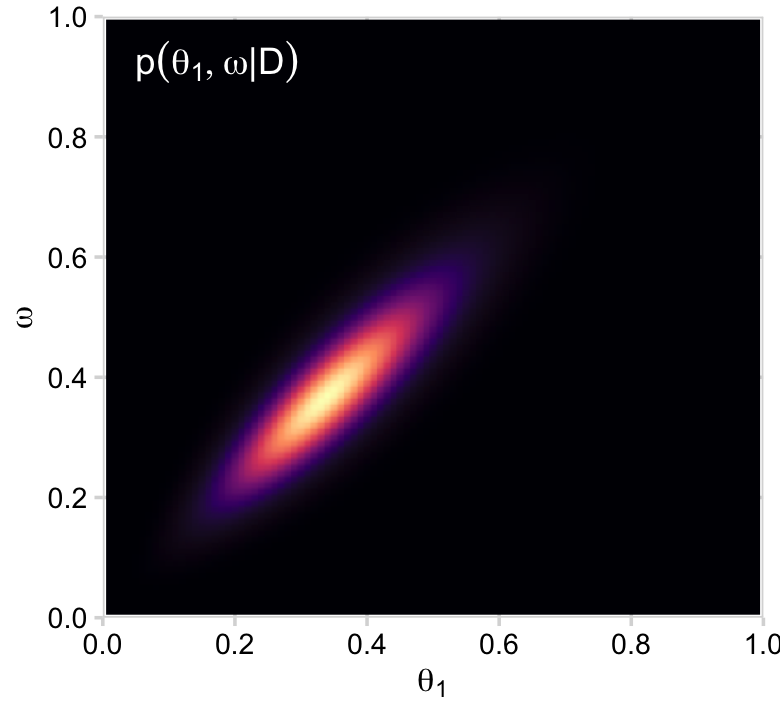
p42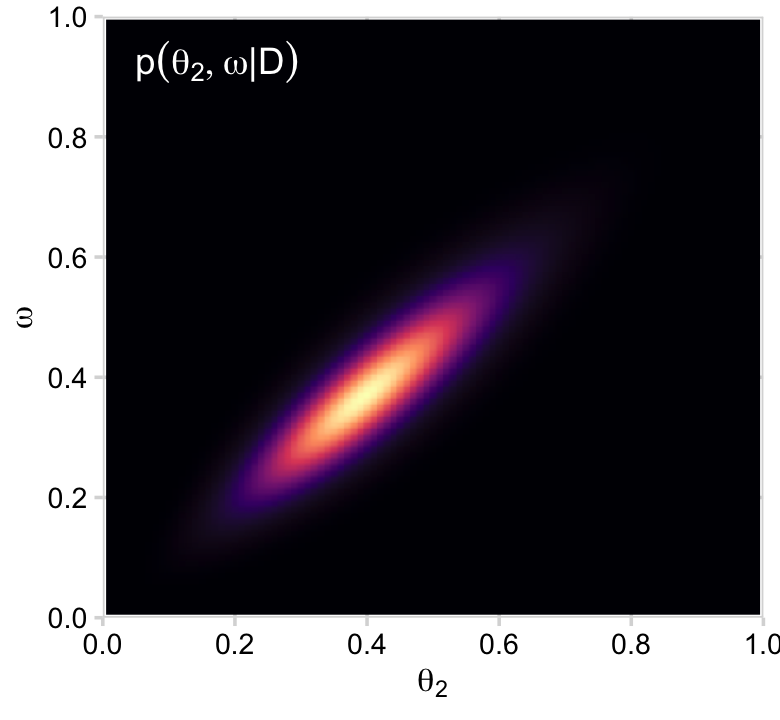
Here’s the right plot on the same row, the posterior distribution for ω.
# for omega
p43 <-
d %>%
group_by(omega) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = omega, y = posterior)) +
geom_marginal(ul = 0.041, font_size = 10) +
labs(x = expression(omega),
y = expression(p(omega*"|"*D))) +
coord_flip()
p43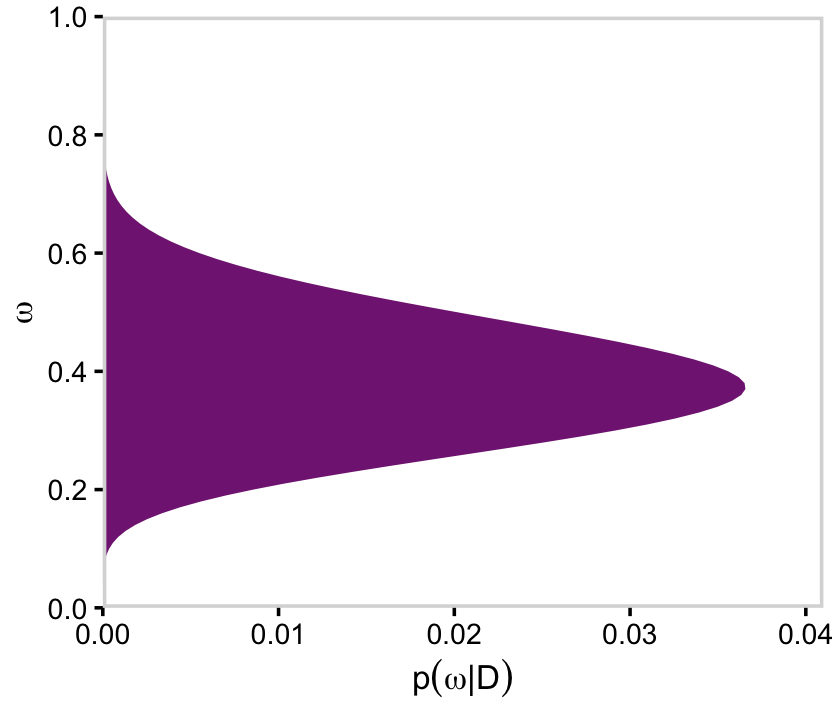
Finally, here are the marginal posterior plots on the bottom row of Figure 9.6.
# for theta_1
p51 <-
d %>%
group_by(theta_1) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_1, y = posterior)) +
geom_marginal(ul = 0.041, font_size = 10) +
labs(x = expression(theta[1]),
y = expression(p(theta[1]*"|"*D)))
# for theta_2
p52 <-
d %>%
group_by(theta_2) %>%
summarise(posterior = sum(posterior)) %>%
ggplot(aes(x = theta_2, y = posterior)) +
geom_marginal(ul = 0.041, font_size = 10) +
labs(x = expression(theta[2]),
y = expression(p(theta[2]*"|"*D)))
p51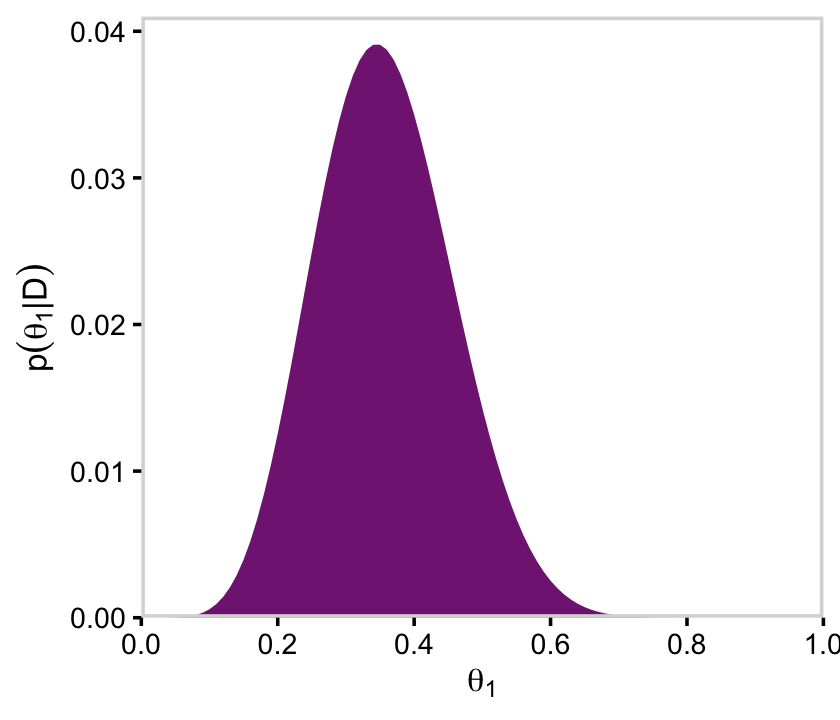
p52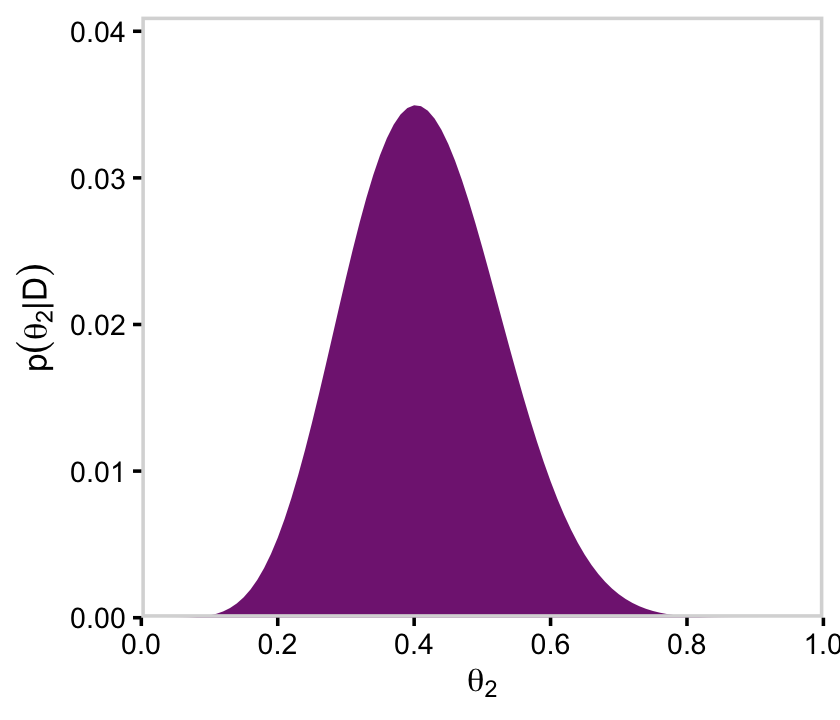
Did you notice how we saved each of plot from this last batch as objects? For the grand finale of this subsection, we’ll be stitching all those subplots together using syntax from the patchwork package. But before we do, we need to define three more subplots: the subplots with the annotation.
text <-
tibble(x = 1,
y = 10:8,
label = c("Prior", "list(A[omega]==2, B[omega]==2)", "K==75"),
size = c(2, 1, 1))
p23 <-
text %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(aes(size = size),
parse = T, hjust = 0, show.legend = F) +
scale_size_continuous(range = c(3.5, 5.5)) +
coord_cartesian(xlim = c(1, 2),
ylim = c(4, 11)) +
theme_cowplot(font_size = 10) +
theme(axis.line = element_blank(),
axis.text = element_text(color = "white"),
axis.ticks = element_blank(),
text = element_text(color = "white"))
text <-
tibble(x = 1,
y = 10:8,
label = c("Likelihood", "D1: 3 heads, 12 tails", "D2: 4 heads, 1 tail"),
size = c(2, 1, 1))
p33 <-
text %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(aes(size = size),
hjust = 0, show.legend = F) +
scale_size_continuous(range = c(3.5, 5.5)) +
coord_cartesian(xlim = c(1, 2),
ylim = c(4, 11)) +
theme_cowplot(font_size = 10) +
theme(axis.line = element_blank(),
axis.text = element_text(color = "white"),
axis.ticks = element_blank(),
text = element_text(color = "white"))
p53 <-
ggplot() +
annotate(geom = "text", x = 1, y = 10,
label = "Posterior", size = 6, hjust = 0) +
coord_cartesian(xlim = c(1, 2),
ylim = c(3, 11)) +
theme_cowplot(font_size = 10) +
theme(axis.line = element_blank(),
axis.text = element_text(color = "white"),
axis.ticks = element_blank(),
text = element_text(color = "white"))Okay, let’s make the full version of Figure 9.6.
(p11 / p21 / p31 / p41 / p51) | (p12 / p22 / p32 / p42 / p52) | (p13 / p23 / p33 / p43 / p53)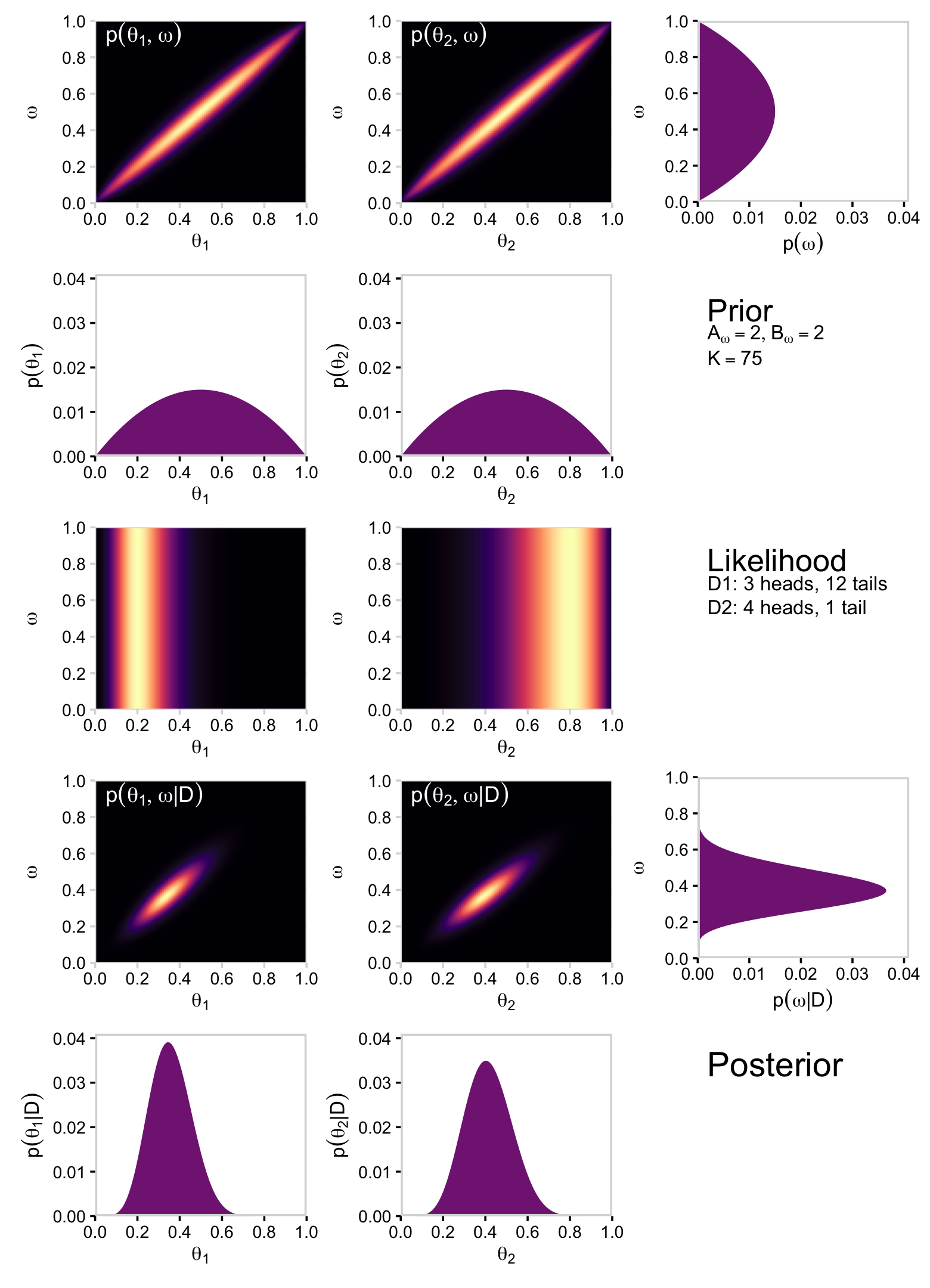
Oh mamma!
The grid approximation displayed in Figures 9.5 and 9.6 used combs of only [101] points on each parameter (ω, θ1, and θ2). This means that the 3D grid had [1013=1,030,301] points, which is a size that can be handled easily on an ordinary desktop computer of the early 21st century. It is interesting to remind ourselves that the grid approximation displayed in Figures 9.5 and 9.6 would have been on the edge of computability 50 years ago, and would have been impossible 100 years ago. The number of points in a grid approximation can get hefty in a hurry. If we were to expand the example by including a third coin, with its parameter θ3, then the grid would have [1014=104,060,401] points, which already strains small computers. Include a fourth coin, and the grid contains over [10 billion] points. Grid approximation is not a viable approach to even modestly large problems, which we encounter next. (p. 235)
In case you didn’t catch it, we used different numbers of points to evaluate each parameter. Whereas Kruschke indicated in the text he only used 50, we used 101. That value of 101 came from how we defined our parameter_space with the code seq(from = 0, to = 1, by = .01). The reason we used a more densely-packed parameter space was to get smoother-looking 2D density plots.
9.2.2 A realistic model with MCMC.
In this section, Kruschke freed up the previously fixed value of K, now letting κ vary hierarchically with a gamma prior. He depicted the model in Figure 9.7. Here’s our version of the figure.
# a beta density
p1 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 2, 2)) / max(dbeta(x, 2, 2))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 7) +
annotate(geom = "text",
x = .5, y = .6,
label = "italic(A[omega])*', '*italic(B[omega])",
size = 7, family = "Times", parse = TRUE) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# a gamma density
p2 <-
tibble(x = seq(from = 0, to = 5, by = .01),
d = (dgamma(x, 1.75, .85) / max(dgamma(x, 1.75, .85)))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = 2.5, y = .2,
label = "gamma",
size = 7) +
annotate(geom = "text",
x = 2.5, y = .6,
label = "list(italic(S)[kappa], italic(R)[kappa])",
size = 7, family = "Times", parse = TRUE) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
p3 <-
tibble(x = c(.5, .475, .26, .08, .06,
.5, .55, .85, 1.15, 1.175,
1.5, 1.4, 1, .25, .2,
1.5, 1.49, 1.445, 1.4, 1.39),
y = c(1, .7, .6, .5, .2,
1, .7, .6, .5, .2,
1, .7, .6, .5, .2,
1, .75, .6, .45, .2),
line = rep(letters[2:1], each = 5) %>% rep(., times = 2),
plot = rep(1:2, each = 10)) %>%
ggplot(aes(x = x, y = y, group = interaction(plot, line))) +
geom_bspline(aes(color = line),
linewidth = 2/3, show.legend = F) +
annotate(geom = "text",
x = 0, y = .1,
label = "omega(kappa-2)+1*', '*(1-omega)(kappa-2)+1",
size = 7, parse = T, family = "Times", hjust = 0) +
annotate(geom = "text",
x = c(1/3, 1.15), y = .7,
label = "'~'",
size = 10, parse = T, family = "Times") +
scale_color_manual(values = c("grey75", "black")) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 2)) +
ylim(0, 1) +
theme_void()
# another beta density
p4 <-
tibble(x = seq(from = .01, to = .99, by = .01),
d = (dbeta(x, 2, 2)) / max(dbeta(x, 2, 2))) %>%
ggplot(aes(x = x, y = d)) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = .5, y = .2,
label = "beta",
size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# an annotated arrow
p5 <-
tibble(x = c(.375, .625),
y = c(1/3, 1/3),
label = c("'~'", "italic(s)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# bar plot of Bernoulli data
p6 <-
tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = .6)) / max(dbinom(x, size = 1, prob = .6))) %>%
ggplot(aes(x = x, y = d)) +
geom_col(fill = a_purple, width = .4) +
annotate(geom = "text",
x = .5, y = .2,
label = "Bernoulli",
size = 7) +
annotate(geom = "text",
x = .5, y = .94,
label = "theta",
size = 7, family = "Times", parse = T) +
xlim(-.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# another annotated arrow
p7 <-
tibble(x = c(.35, .65),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)*'|'*italic(s)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# some text
p8 <-
tibble(x = .5,
y = .5,
label = "italic(y[i])['|'][italic(s)]") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
xlim(0, 1) +
theme_void()
# define the layout
layout <- c(
area(t = 1, b = 2, l = 1, r = 1),
area(t = 1, b = 2, l = 2, r = 2),
area(t = 4, b = 5, l = 1, r = 1),
area(t = 3, b = 4, l = 1, r = 2),
area(t = 6, b = 6, l = 1, r = 1),
area(t = 7, b = 8, l = 1, r = 1),
area(t = 9, b = 9, l = 1, r = 1),
area(t = 10, b = 10, l = 1, r = 1)
)
# plot!
(p1 + p2 + p4 + p3 + p5 + p6 + p7 + p8) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))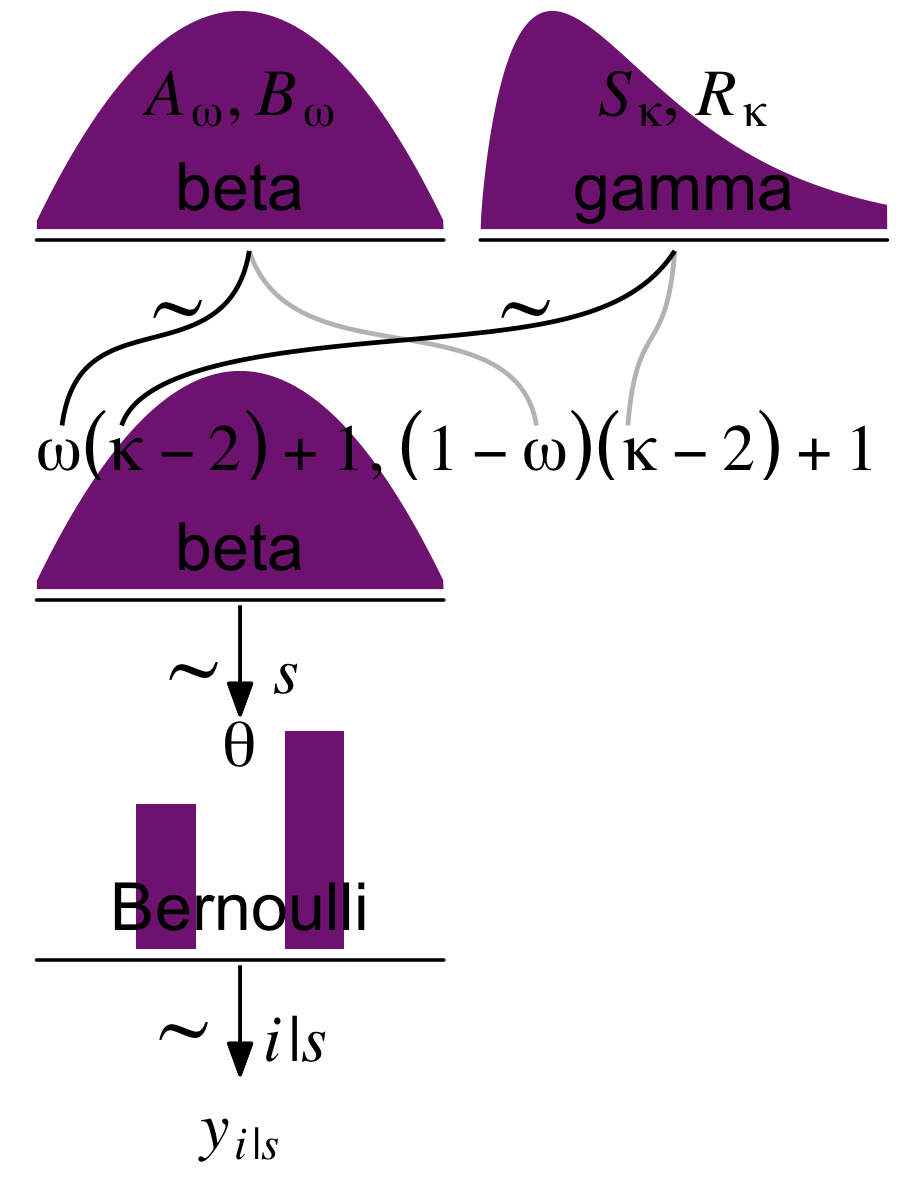
“Because the value of κ−2 must be non-negative, the prior distribution on κ−2 must not allow negative values” (p. 237). Gamma is one of the distributions with that property. The gamma distribution is defined by two parameters, its shape and rate. To get a sense of how those play out, here’ a look at the gamma densities of Figure 9.8.
# how many points do you want in your sequence of x values?
length <- 150
# wrangle
tibble(shape = c(.01, 1.56, 1, 6.25),
rate = c(.01, .0312, .02, .125)) %>%
expand_grid(x = seq(from = 0, to = 200, length.out = length)) %>%
mutate(mean = shape * 1 / rate,
sd = sqrt(shape * (1 / rate)^2)) %>%
mutate(label = str_c("shape = ", shape, ", rate = ", rate,
"\nmean = ", mean, ", sd = ", round(sd, 4))) %>%
# plot
ggplot(aes(x = x, y = dgamma(x = x, shape = shape, rate = rate))) +
geom_area(aes(fill = label)) +
scale_fill_viridis_d(option = "A", end = .9, breaks = NULL) +
scale_x_continuous(expression(kappa), expand = expansion(mult = c(0, 0.05))) +
scale_y_continuous(expression(p(kappa*"|"*s*","*r)), breaks = c(0, .01, .02),
expand = expansion(mult = c(0, 0.05))) +
coord_cartesian(xlim = c(0, 150)) +
theme_cowplot(line_size = 0) +
panel_border() +
facet_wrap(~ label)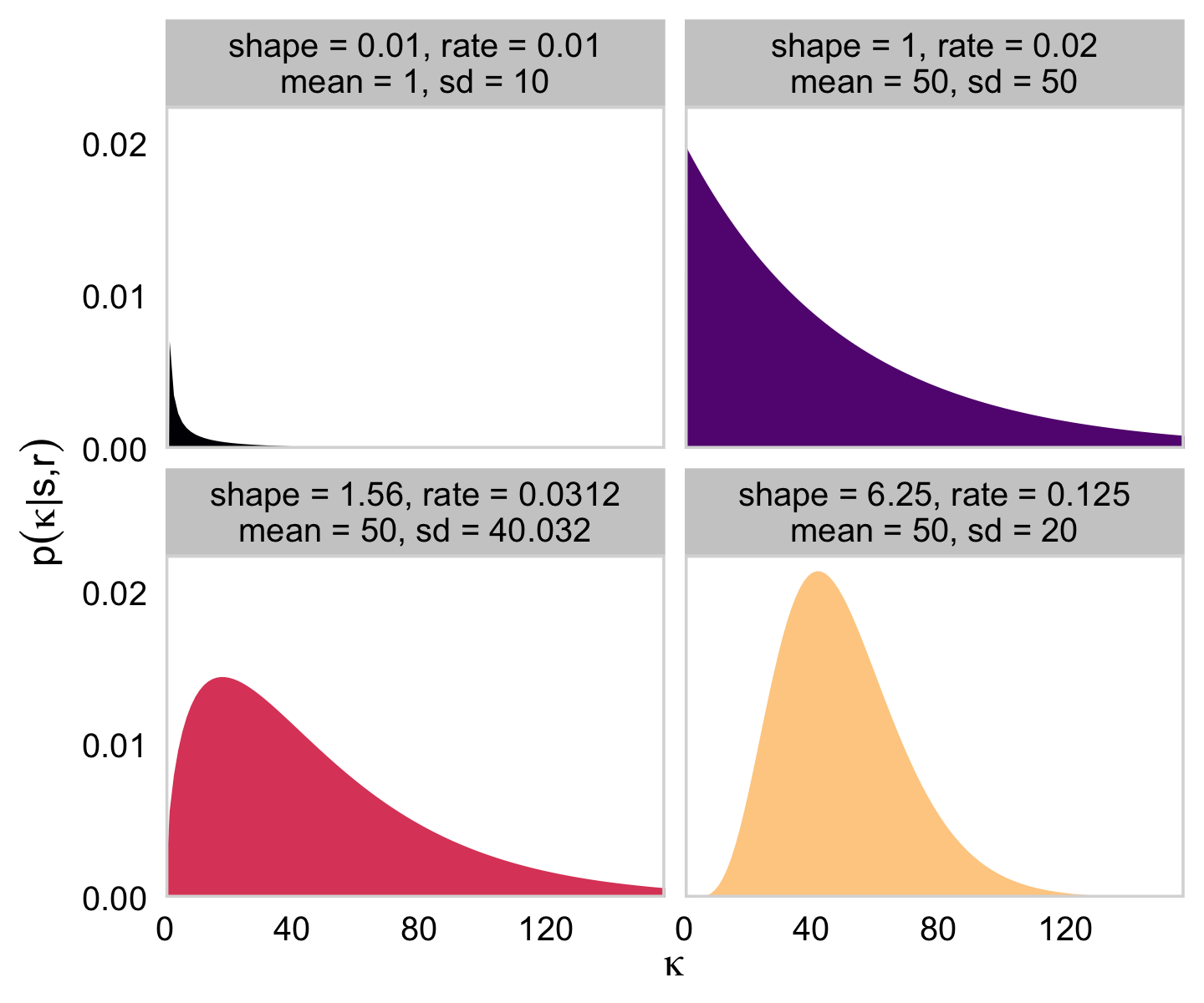
You can find the formulas for the mean and SD for a given gamma distribution here. We used those formulas in the second mutate() statement for the data-prep stage of that last figure.
Using s for shape and r for rate, Kruschke’s Equations 9.7 and 9.8 are as follows:
s=μ2σ2andr=μσ2for meanμ>0s=1+ωrwherer=ω+√ω2+4σ22σ2for modeω>0.
With those in hand, we can follow Kruschke’s DBDA2E-utilities.R file to make a couple convenience functions.
gamma_s_and_r_from_mean_sd <- function(mean, sd) {
if (mean <= 0) stop("mean must be > 0")
if (sd <= 0) stop("sd must be > 0")
shape <- mean^2 / sd^2
rate <- mean / sd^2
return(list(shape = shape, rate = rate))
}
gamma_s_and_r_from_mode_sd <- function(mode, sd) {
if (mode <= 0) stop("mode must be > 0")
if (sd <= 0) stop("sd must be > 0")
rate <- (mode + sqrt(mode^2 + 4 * sd^2)) / (2 * sd^2)
shape <- 1 + mode * rate
return(list(shape = shape, rate = rate))
}They’re easy to put to use:
gamma_s_and_r_from_mean_sd(mean = 10, sd = 100)## $shape
## [1] 0.01
##
## $rate
## [1] 0.001gamma_s_and_r_from_mode_sd(mode = 10, sd = 100)## $shape
## [1] 1.105125
##
## $rate
## [1] 0.01051249Here’s a more detailed look at the structure of their output.
gamma_param <- gamma_s_and_r_from_mode_sd(mode = 10, sd = 100)
str(gamma_param)## List of 2
## $ shape: num 1.11
## $ rate : num 0.01059.2.3 Doing it with JAGS brms.
Unlike JAGS, the brms formula will not correspond as closely to the schematic in Figure 9.7. You’ll see in just a bit.
9.2.4 Example: Therapeutic touch.
Load the data from the TherapeuticTouchData.csv file (see Rosa et al., 1998).
my_data <- read_csv("data.R/TherapeuticTouchData.csv")
glimpse(my_data)## Rows: 280
## Columns: 2
## $ y <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0,…
## $ s <chr> "S01", "S01", "S01", "S01", "S01", "S01", "S01", "S01", "S01", "S01"…Here are what the data look like.
my_data %>%
mutate(y = y %>% as.character()) %>%
ggplot(aes(y = y)) +
geom_bar(aes(fill = after_stat(count))) +
scale_fill_viridis_c(option = "A", end = .7, breaks = NULL) +
scale_x_continuous(breaks = 0:4 * 2, expand = c(0, NA), limits = c(0, 9)) +
theme_minimal_vgrid() +
panel_border() +
facet_wrap(~ s, ncol = 7)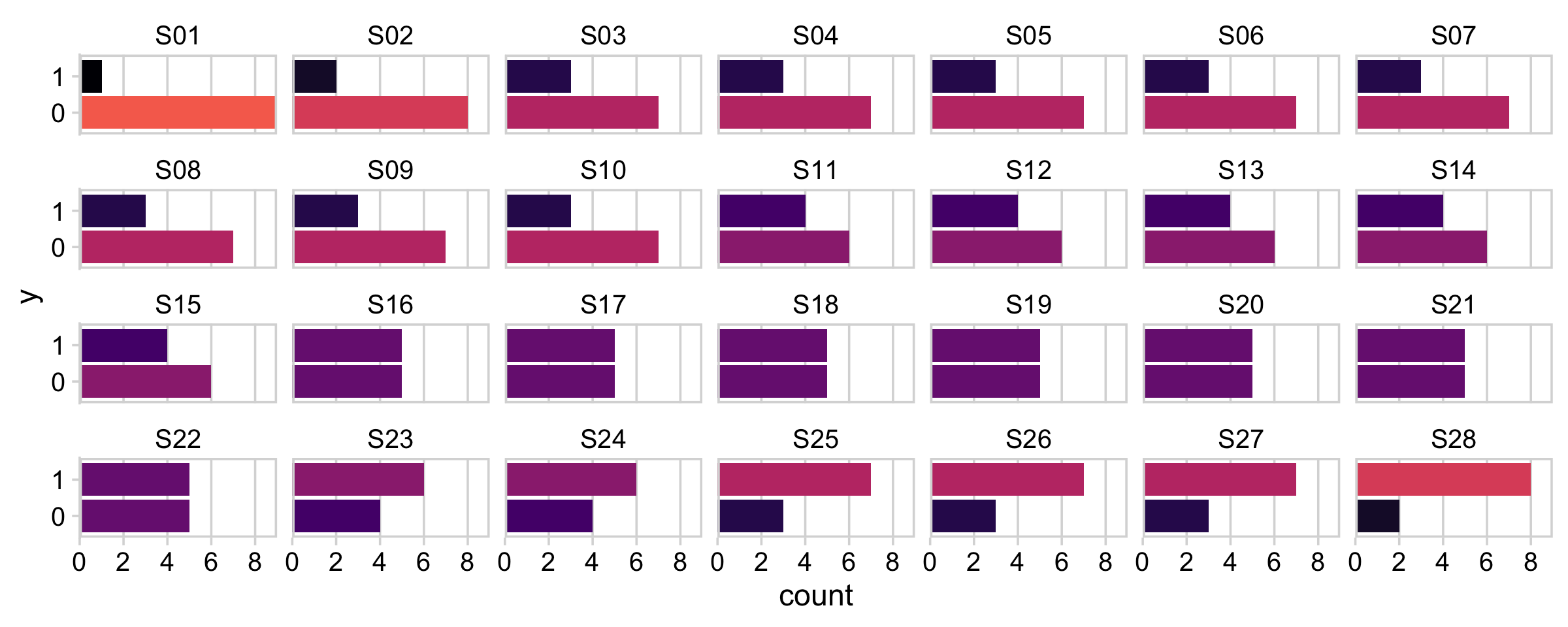
And here’s our Figure 9.9.
my_data %>%
group_by(s) %>%
summarize(mean = mean(y)) %>%
ggplot(aes(x = mean)) +
geom_histogram(color = "white", fill = a_purple,
linewidth = .2, binwidth = .1) +
scale_x_continuous("Proportion Correct", limits = c(0, 1)) +
scale_y_continuous("# Practitioners", expand = c(0, NA)) +
theme_minimal_hgrid()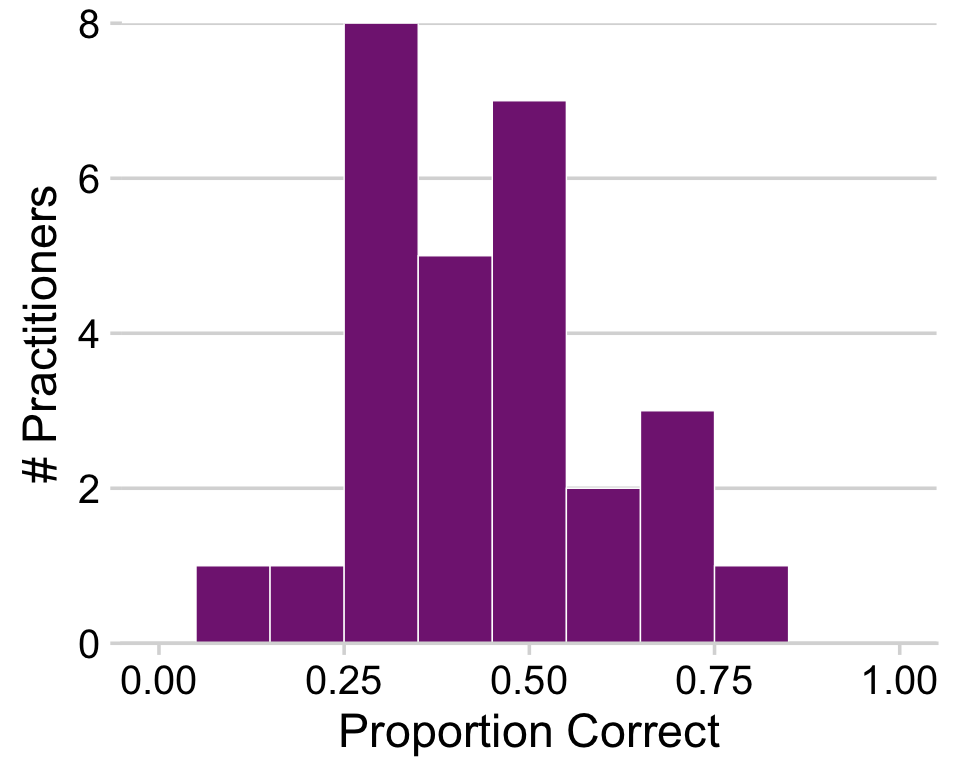
Let’s open brms.
library(brms)In applied statistics, the typical way to model a Bernoulli variable is with logistic regression. Instead of going through the pain of setting up a model in brms that mirrors the one in the text, I’m going to set up a hierarchical logistic regression model, instead.
Note the family = bernoulli(link = logit) argument. In work-a-day regression with vanilla Gaussian variables, the prediction space is unbounded. But when we want to model the probability of a success for a Bernoulli variable (i.e., θ), we need to constrain the model to only produce predictions between 0 and 1. With logistic regression, we use a link function to do just that. The consequence is that instead of modeling the probability, θ, we’re modeling the logit probability.
In case you’re curious, the logit of θ follows the formula
logit(θ)=log(θ/[1−θ]).
But anyway, we’ll be doing logistic regression using the logit link. Kruschke covered this in detail in Chapter 21.
The next new part of our syntax is (1 | s). As in the popular frequentist lme4 package (Bates et al., 2015, 2022), you specify random effects or group-level parameters with the (|) syntax in brms. On the left side of the |, you tell brms what parameters you’d like to make random (i.e., vary by group). On the right side of the |, you tell brms what variable you want to group the parameters by. In our case, we want the intercepts to vary over the grouping variable s.
fit9.1 <-
brm(data = my_data,
family = bernoulli(link = logit),
y ~ 1 + (1 | s),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 20000, warmup = 1000, thin = 10, chains = 4, cores = 4,
seed = 9,
file = "fits/fit09.01")As it turns out, the N(0,1.5) prior is flat in the probability space for the intercept in a logistic regression model. We’ll explore that a little further down. The N(0,1) prior for the random effect is actually a half Normal. That’s because brms defaults to bound SD parameters to zero and above. The half Normal prior for a hierarchical SD parameter in a logistic regression model is weakly regularizing and is conservative in the sense that it presumes some pooling is preferable to no pooling. If you wanted to take a lighter approach, you might use something like a cauchy(0, 5), instead. See the prior wiki by the Stan team for more ideas on priors.
Here are the trace plots and posterior densities of the main parameters.
plot(fit9.1, widths = c(2, 3))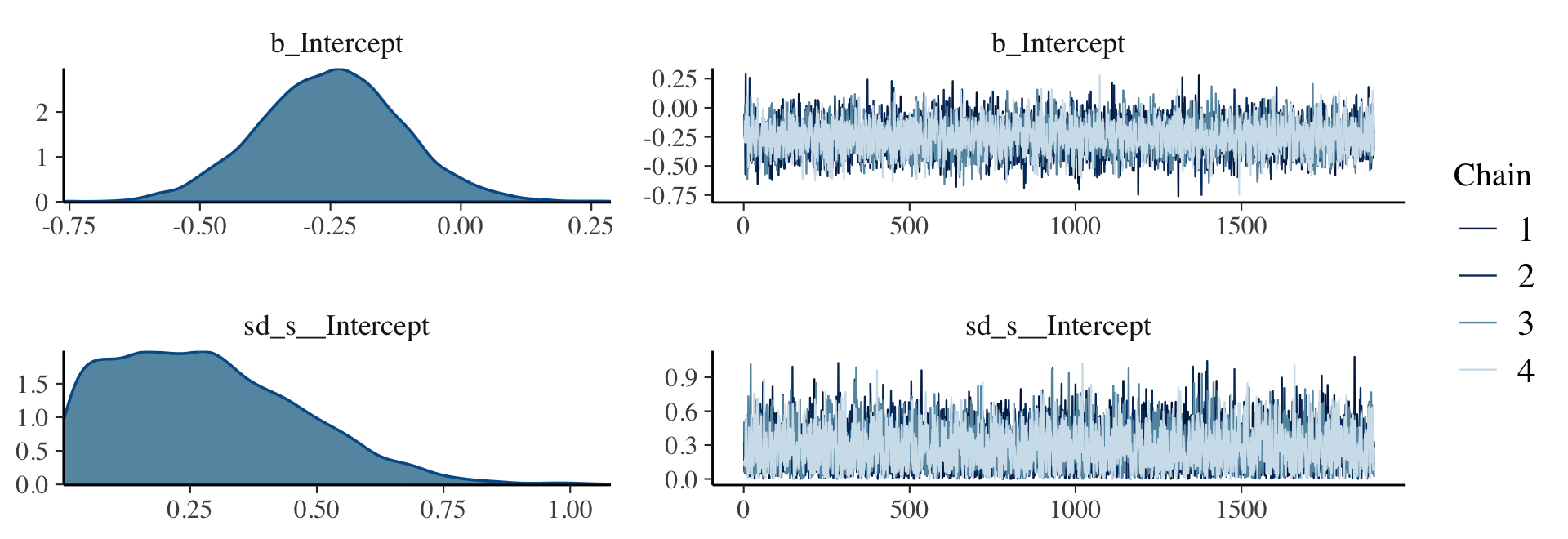
The trace plots indicate no problems with convergence. We’ll need to extract the posterior draws with as_draws_df() and open the bayesplot package before we can examine the autocorrelations.
draws <- as_draws_df(fit9.1)
library(bayesplot)One of the nice things about bayesplot is it returns ggplot2 objects. As such, we can amend their theme settings to be consistent with our other ggplot2 plots. Here we’ll amend bayesplot::mcmc_acf() to the theme_cowplot() theme.
draws %>%
mutate(chain = .chain) %>%
mcmc_acf(pars = vars(b_Intercept, sd_s__Intercept), lags = 10) +
theme_cowplot()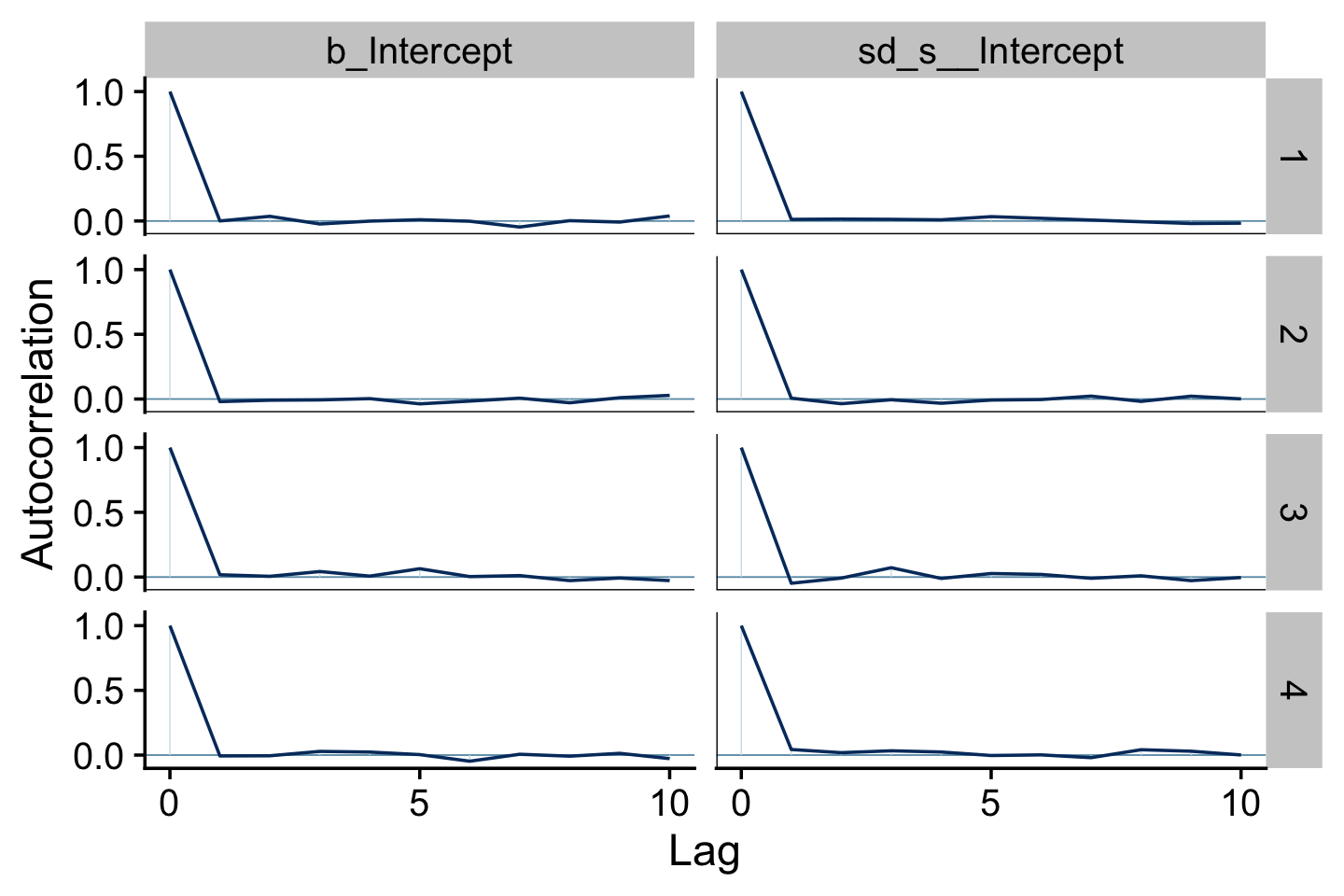
It appears fit9.1 had very low autocorrelations. Here we’ll examine the Neff/N ratio.
neff_ratio(fit9.1) %>%
mcmc_neff() +
theme_cowplot(font_size = 12)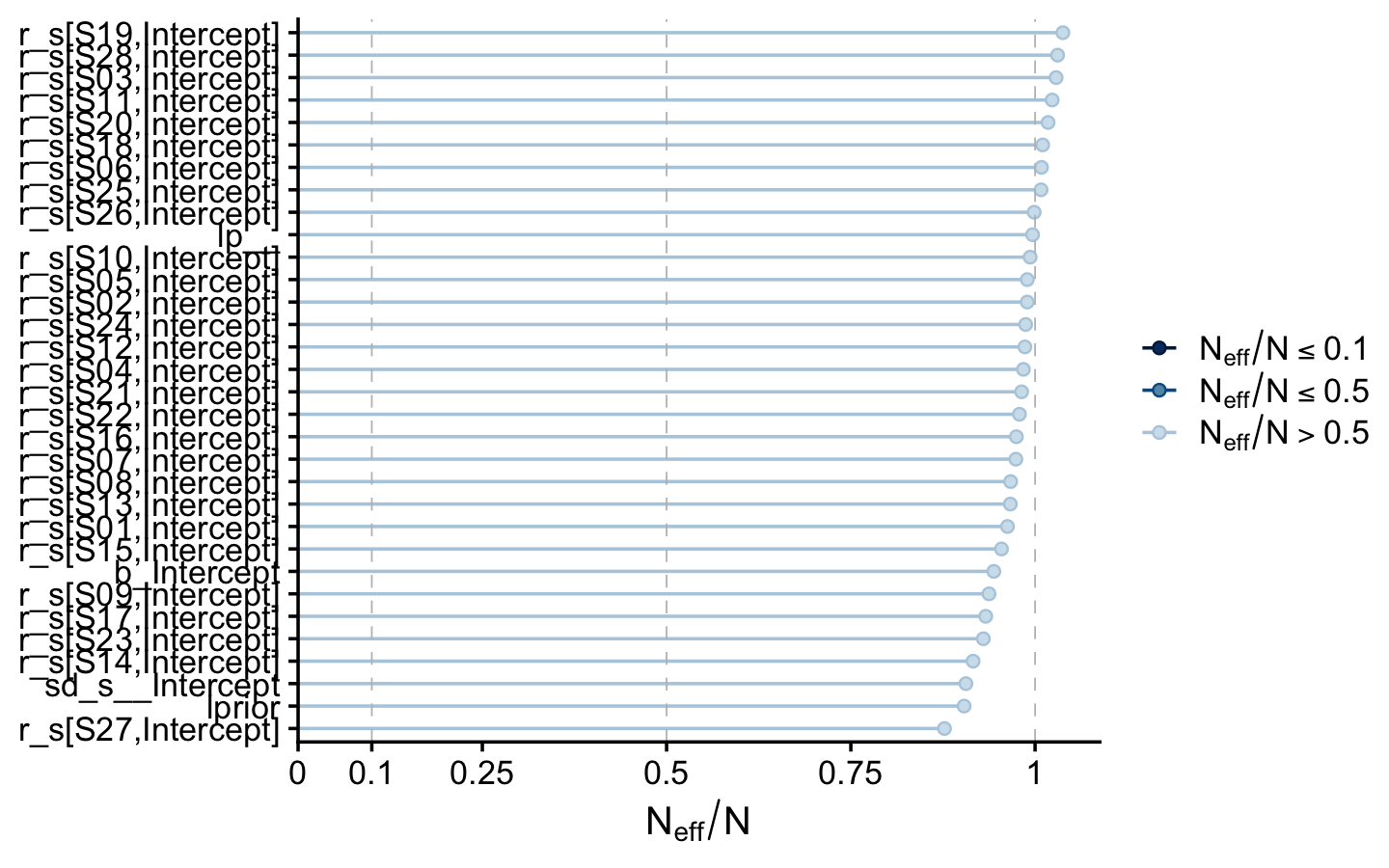
The Neff/N ratio values for our model parameters were excellent. Here’s a numeric summary of the model.
print(fit9.1)## Family: bernoulli
## Links: mu = logit
## Formula: y ~ 1 + (1 | s)
## Data: my_data (Number of observations: 280)
## Draws: 4 chains, each with iter = 20000; warmup = 1000; thin = 10;
## total post-warmup draws = 7600
##
## Group-Level Effects:
## ~s (Number of levels: 28)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 0.28 0.18 0.01 0.68 1.00 7170 7051
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -0.25 0.14 -0.52 0.02 1.00 7205 6715
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).We’ll need brms::inv_logit_scaled() to convert the model parameters to predict θ rather than logit(θ). After the conversions, we’ll be ready to make the histograms in the lower portion of Figure 9.10.
# load
library(tidybayes)
# wrangle
draws_small <-
draws %>%
# convert the linear model parameters to the probability space with `inv_logit_scaled()`
mutate(`theta[1]` = (b_Intercept + `r_s[S01,Intercept]`) %>% inv_logit_scaled(),
`theta[14]` = (b_Intercept + `r_s[S14,Intercept]`) %>% inv_logit_scaled(),
`theta[28]` = (b_Intercept + `r_s[S28,Intercept]`) %>% inv_logit_scaled()) %>%
# make the difference distributions
mutate(`theta[1] - theta[14]` = `theta[1]` - `theta[14]`,
`theta[1] - theta[28]` = `theta[1]` - `theta[28]`,
`theta[14] - theta[28]` = `theta[14]` - `theta[28]`) %>%
select(starts_with("theta"))
draws_small %>%
pivot_longer(everything()) %>%
# this line is unnecessary, but will help order the plots
mutate(name = factor(name, levels = c("theta[1]", "theta[14]", "theta[28]",
"theta[1] - theta[14]", "theta[1] - theta[28]", "theta[14] - theta[28]"))) %>%
ggplot(aes(x = value, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95,
fill = a_purple, breaks = 40, normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
theme_minimal_hgrid() +
facet_wrap(~ name, scales = "free", ncol = 3)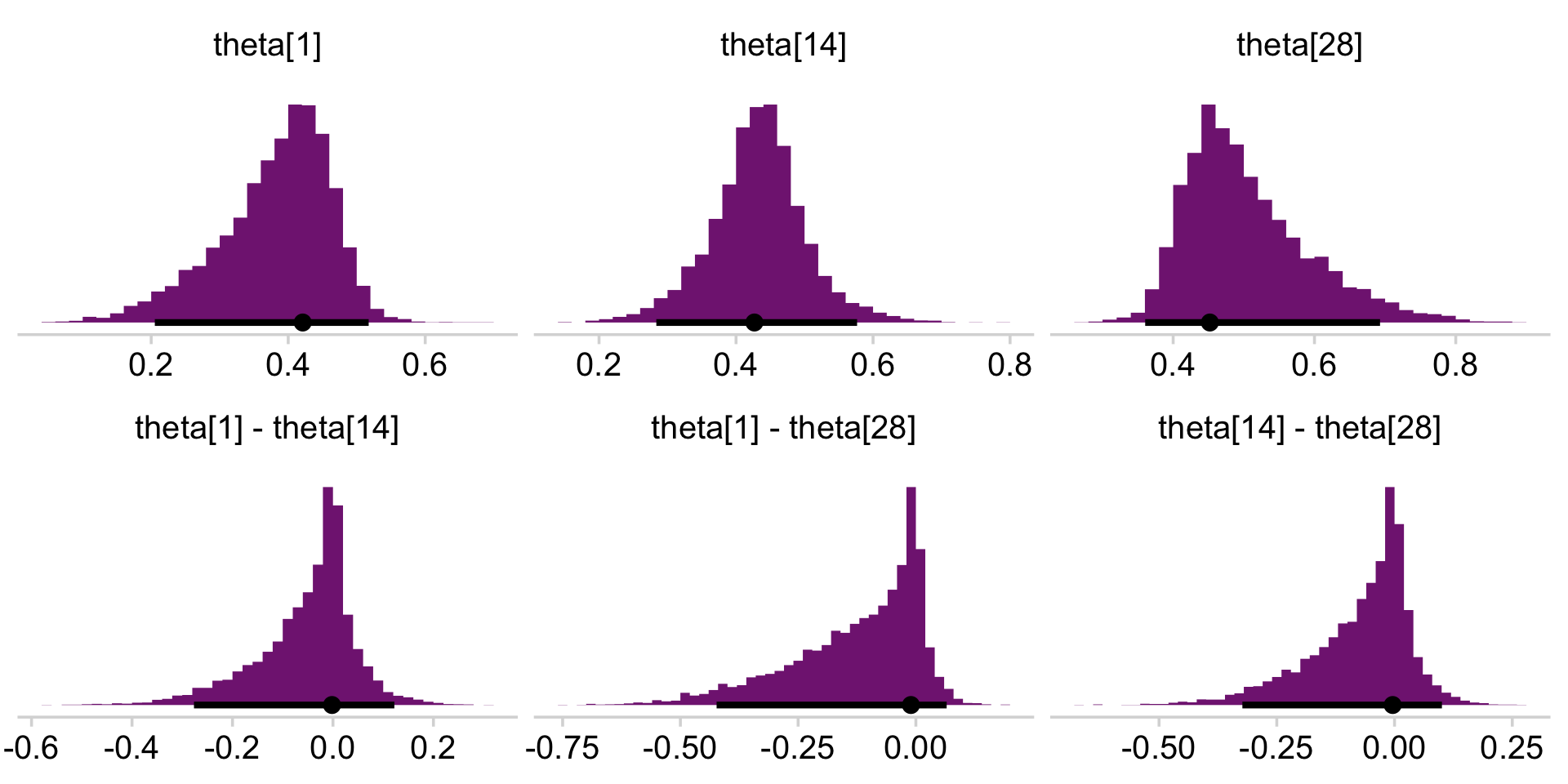
If you wanted the specific values of the posterior modes and 95% HDIs, you could execute this.
draws_small %>%
pivot_longer(everything()) %>%
group_by(name) %>%
mode_hdi(value) %>%
mutate_if(is.double, round, digits = 3)## # A tibble: 6 × 7
## name value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 theta[1] 0.421 0.205 0.517 0.95 mode hdi
## 2 theta[1] - theta[14] -0.002 -0.277 0.122 0.95 mode hdi
## 3 theta[1] - theta[28] -0.01 -0.423 0.065 0.95 mode hdi
## 4 theta[14] 0.427 0.284 0.577 0.95 mode hdi
## 5 theta[14] - theta[28] -0.004 -0.323 0.101 0.95 mode hdi
## 6 theta[28] 0.452 0.36 0.693 0.95 mode hdiAnd here are the Figure 9.10 scatter plots.
p1 <-
draws_small %>%
ggplot(aes(x = `theta[1]`, y = `theta[14]`)) +
geom_abline(linetype = 2) +
geom_point(color = a_purple, size = 1/8, alpha = 1/8)
p2 <-
draws_small %>%
ggplot(aes(x = `theta[1]`, y = `theta[28]`)) +
geom_abline(linetype = 2) +
geom_point(color = a_purple, size = 1/8, alpha = 1/8)
p3 <-
draws_small %>%
ggplot(aes(x = `theta[14]`, y = `theta[28]`)) +
geom_abline(linetype = 2) +
geom_point(color = a_purple, size = 1/8, alpha = 1/8)
(p1 + p2 + p3) &
coord_cartesian(xlim = c(0, 1),
ylim = c(0, 1)) &
theme_minimal_grid()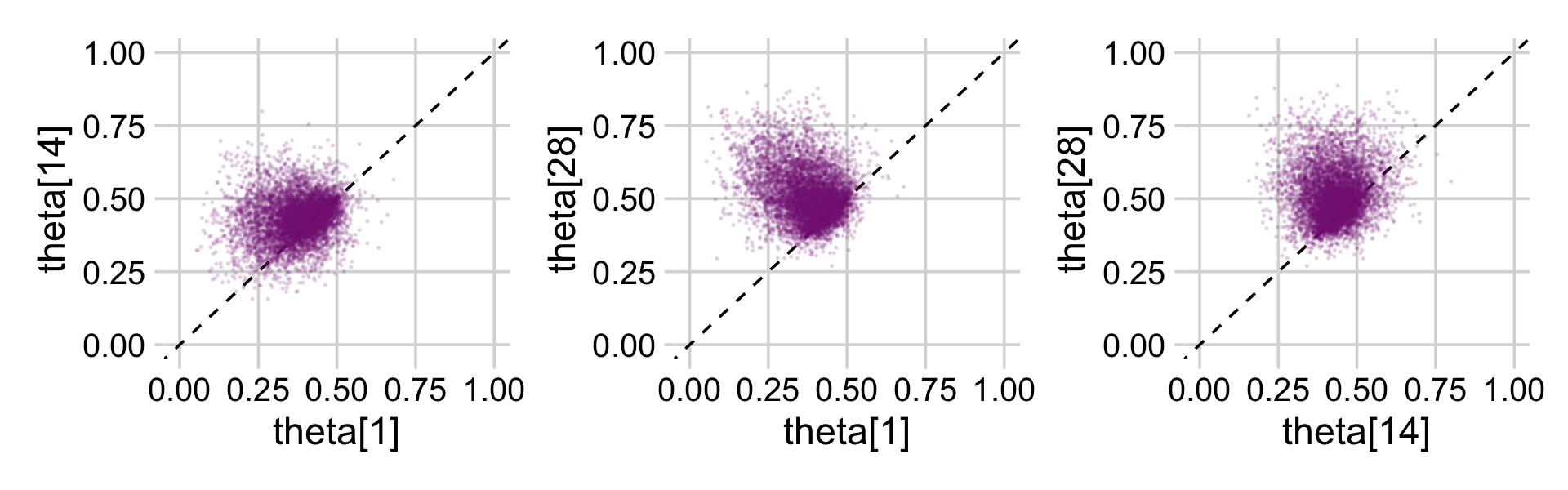
This is posterior distribution for the population estimate for θ, which roughly corresponds to the upper right histogram of ω in Figure 9.10.
# this part makes it easier to set the break points in `scale_x_continuous()`
labels <-
draws %>%
transmute(theta = b_Intercept %>% inv_logit_scaled()) %>%
mode_hdi() %>%
pivot_longer(theta:.upper) %>%
mutate(label = value %>% round(3) %>% as.character)
draws %>%
mutate(theta = b_Intercept %>% inv_logit_scaled()) %>%
ggplot(aes(x = theta, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95,
fill = a_purple, breaks = 40) +
scale_x_continuous(expression(theta),
breaks = labels$value,
labels = labels$label) +
scale_y_continuous(NULL, breaks = NULL) +
theme_minimal_hgrid()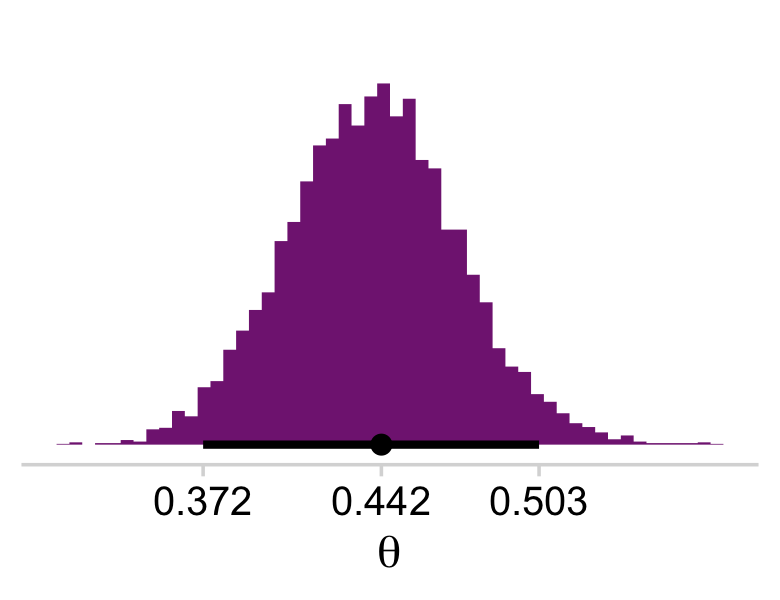
I’m not aware there’s a straight conversion to get σ in a probability metric. As far as I can tell, you have to first use coef() to “extract [the] model coefficients, which are the sum of population-level effects and corresponding group-level effects” (Bürkner, 2022f, p. 58). With the model coefficient draws in hand, you can index them by posterior iteration, group them by that index, compute the iteration-level SD’s, and then plot the distribution of the SD’s.
# the tibble of the primary data
sigmas <-
coef(fit9.1, summary = F)$s %>%
as_tibble() %>%
mutate(iter = 1:n()) %>%
group_by(iter) %>%
pivot_longer(-iter) %>%
mutate(theta = inv_logit_scaled(value)) %>%
summarise(sd = sd(theta))
# this, again, is just to customize `scale_x_continuous()`
labels <-
sigmas %>%
mode_hdi(sd) %>%
pivot_longer(sd:.upper) %>%
mutate(label = value %>% round(3) %>% as.character)
# the plot
sigmas %>%
ggplot(aes(x = sd, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95,
fill = a_purple, breaks = 40) +
scale_x_continuous(expression(paste(sigma, " of ", theta, " in a probability metric")),
breaks = labels$value,
labels = labels$label) +
scale_y_continuous(NULL, breaks = NULL) +
theme_minimal_hgrid()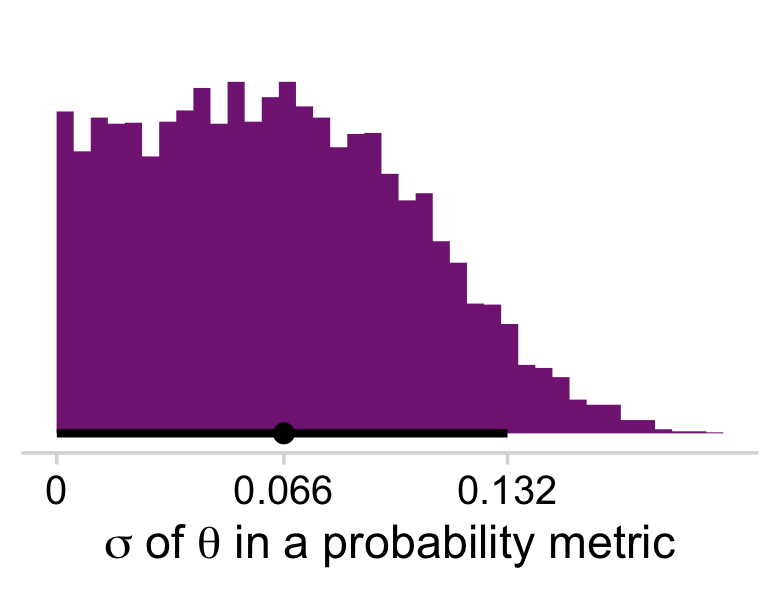
And now you have a sense of how to do all those by hand, bayesplot::mcmc_pairs() offers a fairly quick way to get a good portion of Figure 9.10.
color_scheme_set("purple")
bayesplot_theme_set(theme_default() + theme_minimal_grid())
coef(fit9.1, summary = F)$s %>%
inv_logit_scaled() %>%
data.frame() %>%
rename(`theta[1]` = S01.Intercept,
`theta[14]` = S14.Intercept,
`theta[28]` = S28.Intercept) %>%
select(`theta[1]`, `theta[14]`, `theta[28]`) %>%
mcmc_pairs(off_diag_args = list(size = 1/8, alpha = 1/8))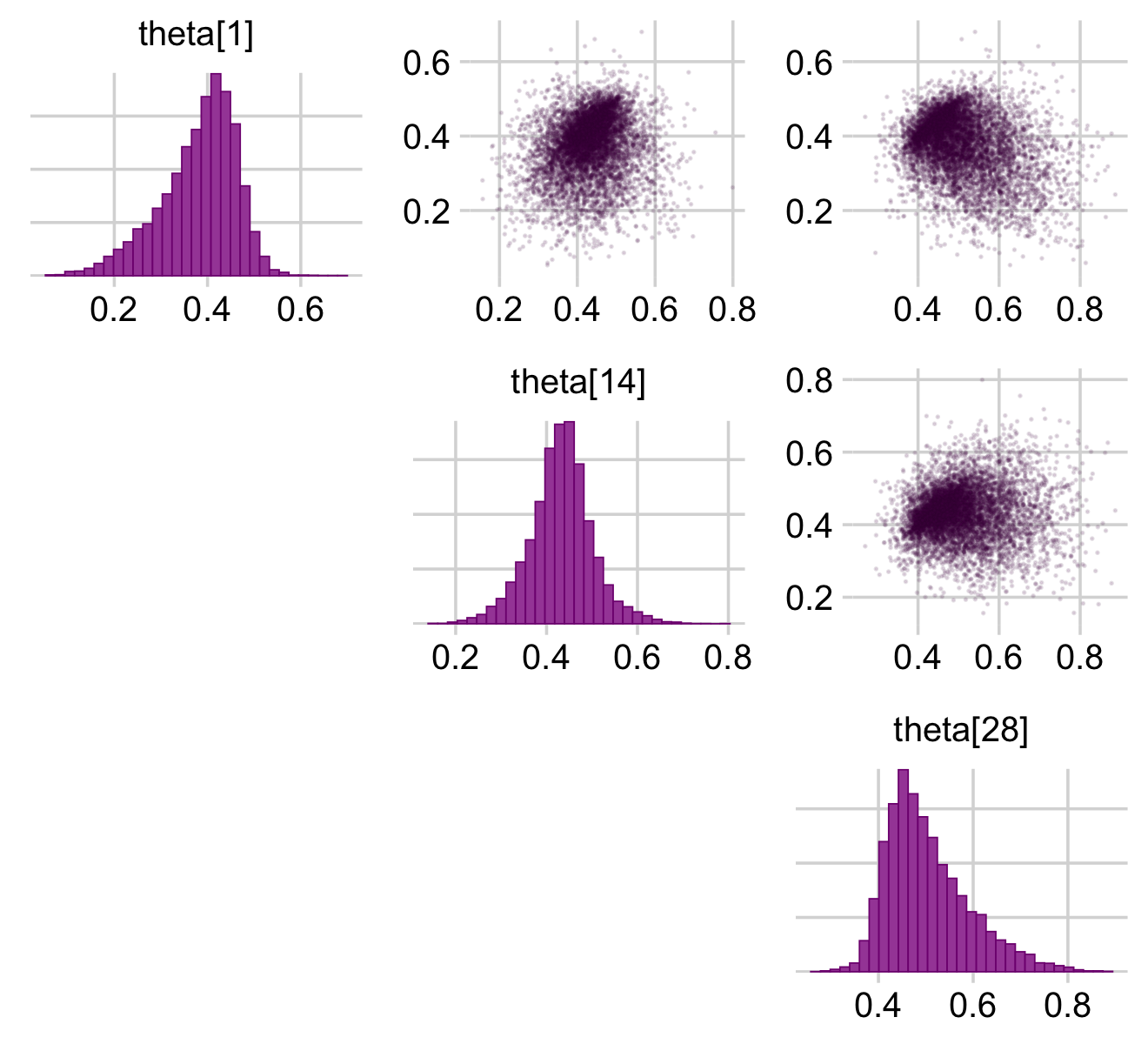
Did you see how we slipped in the color_scheme_set() and bayesplot_theme_set() lines at the top? Usually, the plots made with bayesplot are easy to modify with ggplot2 syntax. Plots made with mcmc_pairs() function are one notable exception. On the back end, these made by combining multiple ggplot into a grid, a down-the-line result of which is they are difficult to modify. Happily, one can make some modifications beforehand by altering the global settings with the color_scheme_set() and bayesplot_theme_set() functions. You can learn more in the discussion on issue #128 on the bayesplot GitHub repo.
Kruschke used a Beta(1,1) prior for ω. If you randomly draw from that prior and plot a histogram, you’ll see it was flat.
set.seed(1)
tibble(prior = rbeta(n = 1e5, 1, 1)) %>%
ggplot(aes(x = prior)) +
geom_histogram(fill = a_purple, color = "white",
linewidth = .2, binwidth = .05, boundary = 0) +
scale_x_continuous(expression(omega), labels = c("0", ".25", ".5", ".75", "1")) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(0, 1)) +
theme_minimal_hgrid()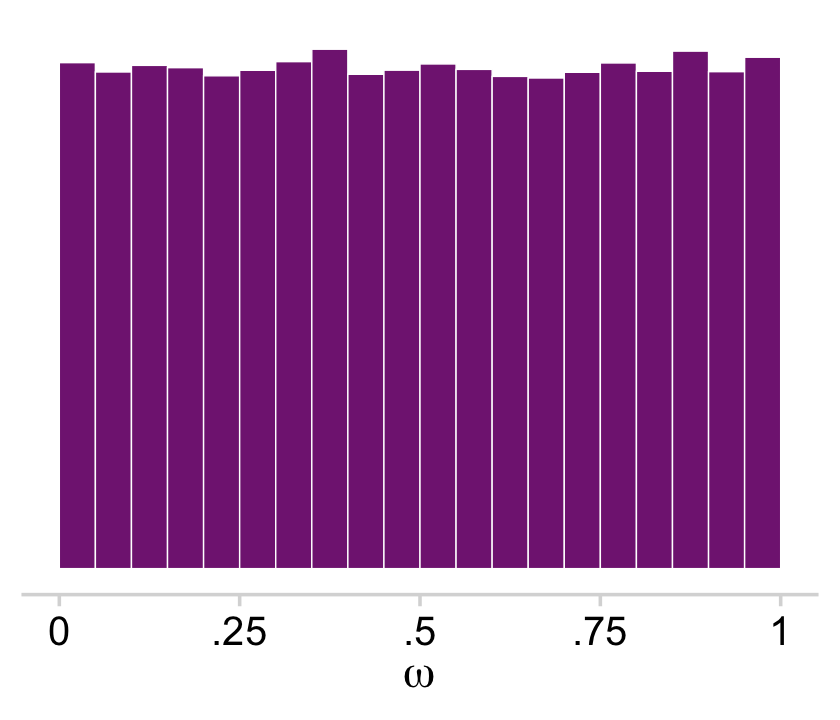
You’ll note that plot corresponds to the upper right panel of Figure 9.11.
Recall that we used a logistic regression model with a normal(0, 1.5) prior on the intercept. If you sample from normal(0, 1.5) and then convert the draws using brms::inv_logit_scaled(), you’ll discover that our normal(0, 1.5) prior was virtually flat on the probability scale. Here we’ll show the consequence of a variety of zero-mean Gaussian priors for the intercept of a logistic regression model.
# define a function
r_norm <- function(i, n = 1e4) {
set.seed(1)
rnorm(n = n, mean = 0, sd = i) %>%
inv_logit_scaled()
}
# simulate and wrangle
tibble(sd = seq(from = .25, to = 3, by = .25)) %>%
group_by(sd) %>%
mutate(prior = map(sd, r_norm)) %>%
unnest(prior) %>%
ungroup() %>%
mutate(sd = str_c("sd = ", sd)) %>%
# plot!
ggplot(aes(x = prior)) +
geom_histogram(fill = a_purple, color = "white", linewidth = .2,
binwidth = .05, boundary = 0) +
scale_x_continuous(labels = c("0", ".25", ".5", ".75", "1")) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(0, 1)) +
theme_minimal_hgrid() +
panel_border() +
facet_wrap(~ sd)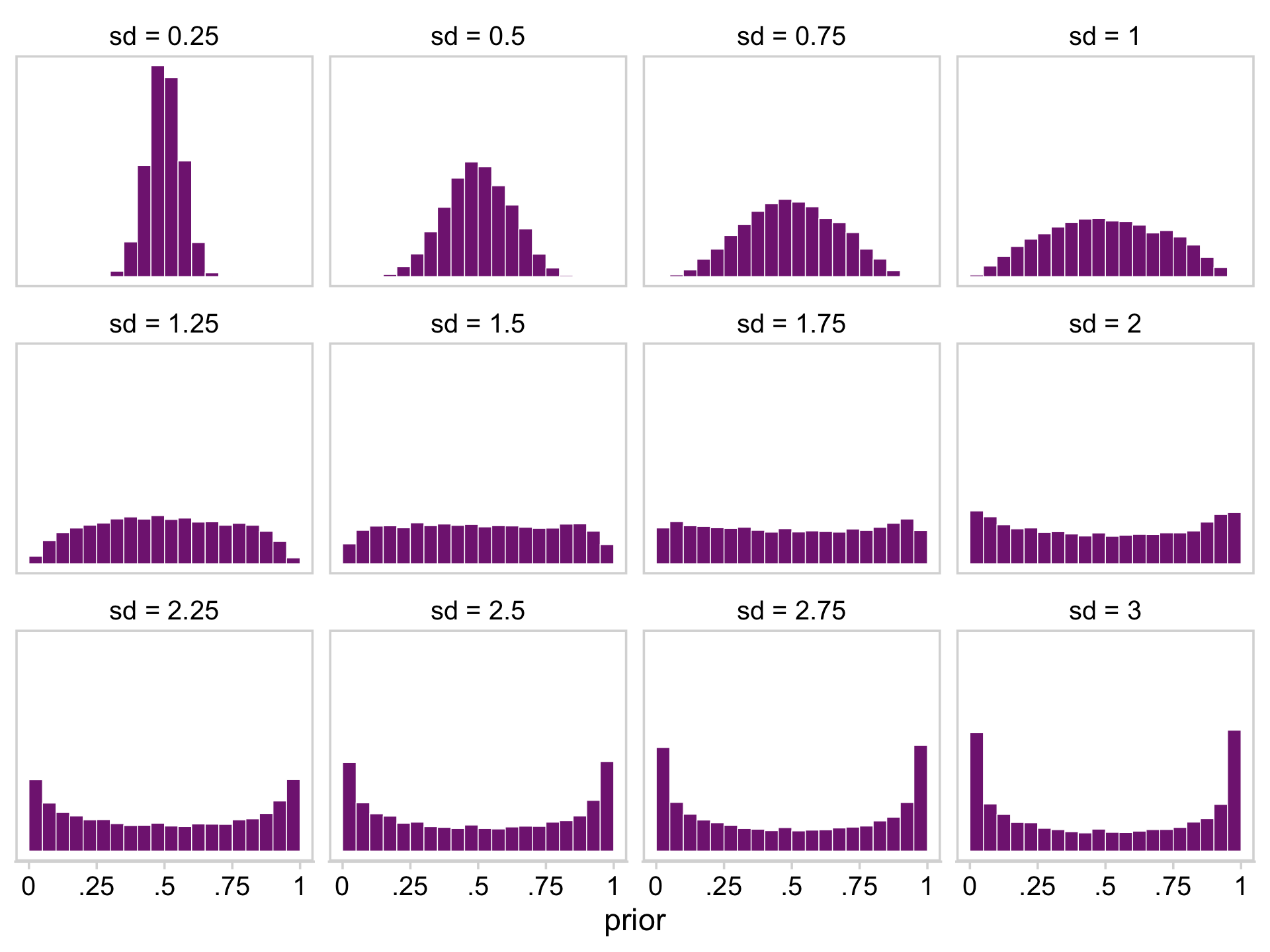
It appears that as σ goes lower than 1.25, the prior becomes increasingly regularizing, pulling the estimate for θ to a neutral .5. However, as the prior’s σ gets larger than 1.25, more and more of the probability mass ends up at extreme values.
Next, Kruschke examined the prior distribution. There are a few ways to do this. Like in the last chapter, the one we’ll explore involves adding the sample_prior = "only" argument to the brm() function. When you do so, the results of the model are just the prior. That is, brm() leaves out the likelihood. This returns a bunch of draws from the prior predictive distribution.
fit9.1_prior <-
brm(data = my_data,
family = bernoulli(link = logit),
y ~ 1 + (1 | s),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 20000, warmup = 1000, thin = 10, chains = 4, cores = 4,
seed = 9,
sample_prior = "only",
file = "fits/fit09.01_prior")If we feed fit9.1_prior into the as_draws_df() function, we’ll get back a data frame of draws from the prior, but with the same parameter names we’d get from the posterior.
prior_draws <- as_draws_df(fit9.1_prior)
head(prior_draws)## # A draws_df: 6 iterations, 1 chains, and 32 variables
## b_Intercept sd_s__Intercept r_s[S01,Intercept] r_s[S02,Intercept]
## 1 -0.74 0.021 0.013 -0.0086
## 2 -1.28 0.040 0.063 -0.0199
## 3 -1.10 0.193 -0.296 0.2139
## 4 -2.21 0.400 -0.244 -0.2008
## 5 -1.82 0.170 -0.125 -0.0132
## 6 0.59 1.246 2.077 1.4740
## r_s[S03,Intercept] r_s[S04,Intercept] r_s[S05,Intercept] r_s[S06,Intercept]
## 1 -0.0023 -0.025 -0.0038 -0.0250
## 2 -0.0229 0.025 0.0123 -0.0364
## 3 -0.1691 -0.231 -0.1658 0.0543
## 4 -0.8816 -0.802 -0.3677 -0.4067
## 5 -0.1599 0.091 -0.1417 -0.0039
## 6 -3.1299 -1.019 -0.9315 0.8389
## # ... with 24 more variables
## # ... hidden reserved variables {'.chain', '.iteration', '.draw'}And here we’ll take a subset of the columns in prior_draws, transform the results to the probability metric, and save.
prior_draws <-
prior_draws %>%
transmute(`theta[1]` = b_Intercept + `r_s[S01,Intercept]`,
`theta[14]` = b_Intercept + `r_s[S14,Intercept]`,
`theta[28]` = b_Intercept + `r_s[S28,Intercept]`) %>%
mutate_all(.funs = inv_logit_scaled)
head(prior_draws)## # A tibble: 6 × 3
## `theta[1]` `theta[14]` `theta[28]`
## <dbl> <dbl> <dbl>
## 1 0.325 0.317 0.327
## 2 0.228 0.222 0.223
## 3 0.198 0.296 0.299
## 4 0.0788 0.110 0.0687
## 5 0.126 0.158 0.162
## 6 0.935 0.803 0.874Now we can use our prior_draws object to make the diagonal of the lower grid of Figure 9.11.
prior_draws %>%
pivot_longer(everything()) %>%
ggplot(aes(x = value)) +
geom_histogram(fill = a_purple, color = "white", linewidth = .2,
binwidth = .05, boundary = 0) +
scale_x_continuous(labels = c("0", ".25", ".5", ".75", "1")) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(0, 1)) +
theme_minimal_hgrid() +
panel_border() +
facet_wrap(~ name)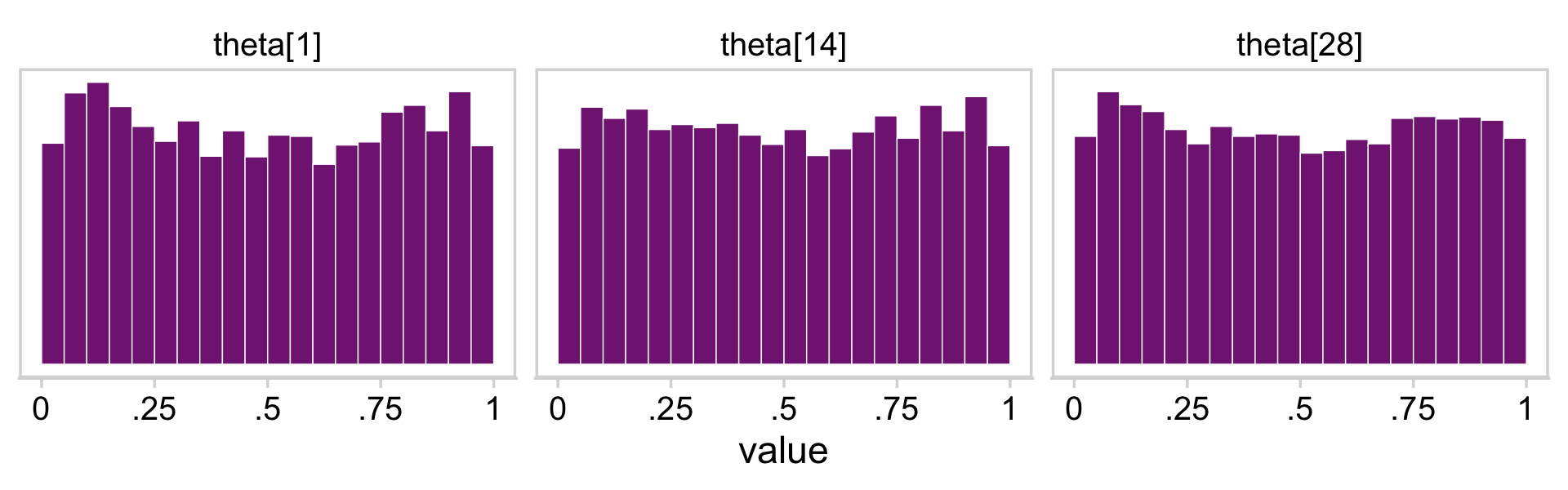
With a little subtraction, we can reproduce the plots in the upper triangle.
prior_draws %>%
mutate(`theta[1] - theta[14]` = `theta[1]` - `theta[14]`,
`theta[1] - theta[28]` = `theta[1]` - `theta[28]`,
`theta[14] - theta[28]` = `theta[14]` - `theta[28]`) %>%
pivot_longer(contains("-")) %>%
ggplot(aes(x = value)) +
geom_histogram(fill = a_purple, color = "white", linewidth = .2,
binwidth = .05, boundary = 0) +
scale_y_continuous(NULL, breaks = NULL) +
theme_minimal_hgrid() +
panel_border() +
facet_wrap(~ name)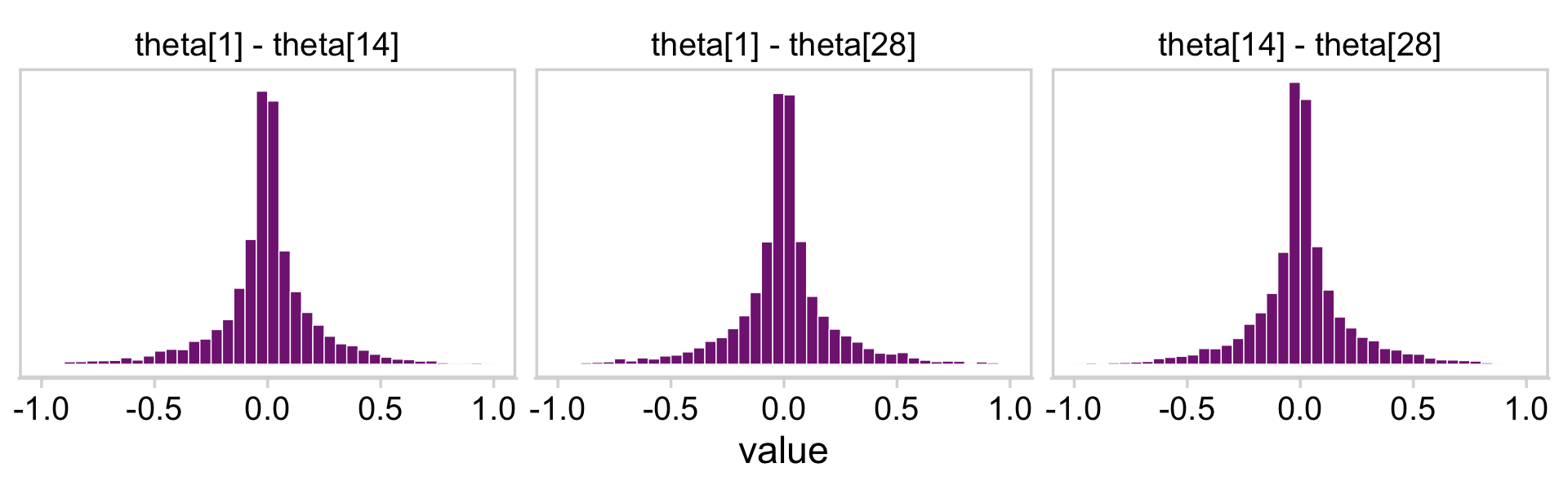
Those plots clarify our hierarchical logistic regression model was a little more regularizing than Kruschke’s. The consequence of our priors was more aggressive regularization, greater shrinkage toward zero. The prose in the next section of the text clarifies this isn’t necessarily a bad thing.
Finally, here are the plots for the lower triangle in Figure 9.11.
p1 <-
prior_draws %>%
ggplot(aes(x = `theta[1]`, y = `theta[14]`)) +
geom_point(color = a_purple, size = 1/8, alpha = 1/8)
p2 <-
prior_draws %>%
ggplot(aes(x = `theta[1]`, y = `theta[28]`)) +
geom_point(color = a_purple, size = 1/8, alpha = 1/8)
p3 <-
prior_draws %>%
ggplot(aes(x = `theta[14]`, y = `theta[28]`)) +
geom_point(color = a_purple, size = 1/8, alpha = 1/8)
(p1 + p2 + p3) &
geom_abline(linetype = 2) &
coord_cartesian(xlim = c(0, 1),
ylim = c(0, 1)) &
theme_minimal_grid()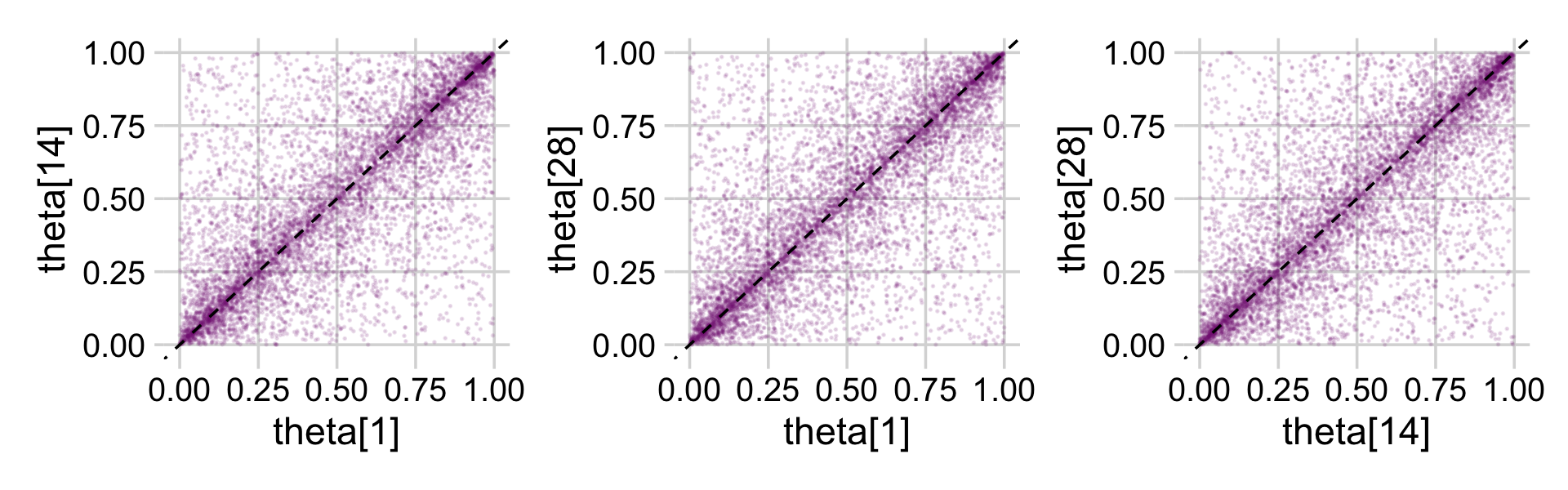
In case you were curious, here are the Pearson’s correlation coefficients among the priors.
cor(prior_draws) %>% round(digits = 2)## theta[1] theta[14] theta[28]
## theta[1] 1.00 0.73 0.72
## theta[14] 0.73 1.00 0.73
## theta[28] 0.72 0.73 1.009.3 Shrinkage in hierarchical models
“In typical hierarchical models, the estimates of low-level parameters are pulled closer together than they would be if there were not a higher-level distribution. This pulling together is called shrinkage of the estimates” (p. 245, emphasis in the original)
Further,
shrinkage is a rational implication of hierarchical model structure, and is (usually) desired by the analyst because the shrunken parameter estimates are less affected by random sampling noise than estimates derived without hierarchical structure. Intuitively, shrinkage occurs because the estimate of each low-level parameter is influenced from two sources: (1) the subset of data that are directly dependent on the low-level parameter, and (2) the higher-level parameters on which the low-level parameter depends. The higher- level parameters are affected by all the data, and therefore the estimate of a low-level parameter is affected indirectly by all the data, via their influence on the higher-level parameters. (p. 247)
Recall Formula 9.4 from page 223,
θ∼Beta(ω(κ−2)+1),(1−ω)(κ−2)+1).
With that formula, we can express dbeta()’s shape1 and shape2 in terms of ω and κ and make the shapes in Figure 9.12.
omega <- 0.5
kappa1 <- 2.1
kappa2 <- 15.8
tibble(x = seq(from = 0, to = 1, by = .001)) %>%
mutate(`kappa==2.1` = dbeta(x = x,
shape1 = omega * (kappa1 - 2) + 1,
shape2 = (1 - omega) * (kappa1 - 2) + 1),
`kappa==15.8` = dbeta(x = x,
shape1 = omega * (kappa2 - 2) + 1,
shape2 = (1 - omega) * (kappa2 - 2) + 1)) %>%
pivot_longer(-x) %>%
mutate(name = factor(name, levels = c("kappa==2.1", "kappa==15.8"))) %>%
ggplot(aes(x = x, y = value)) +
geom_area(fill = a_purple) +
scale_y_continuous(expression(dbeta(theta*"|"*omega*", "*kappa)), breaks = NULL) +
xlab(expression(Data~Proportion~or~theta~value)) +
theme_minimal_hgrid() +
panel_border() +
facet_wrap(~ name, labeller = label_parsed)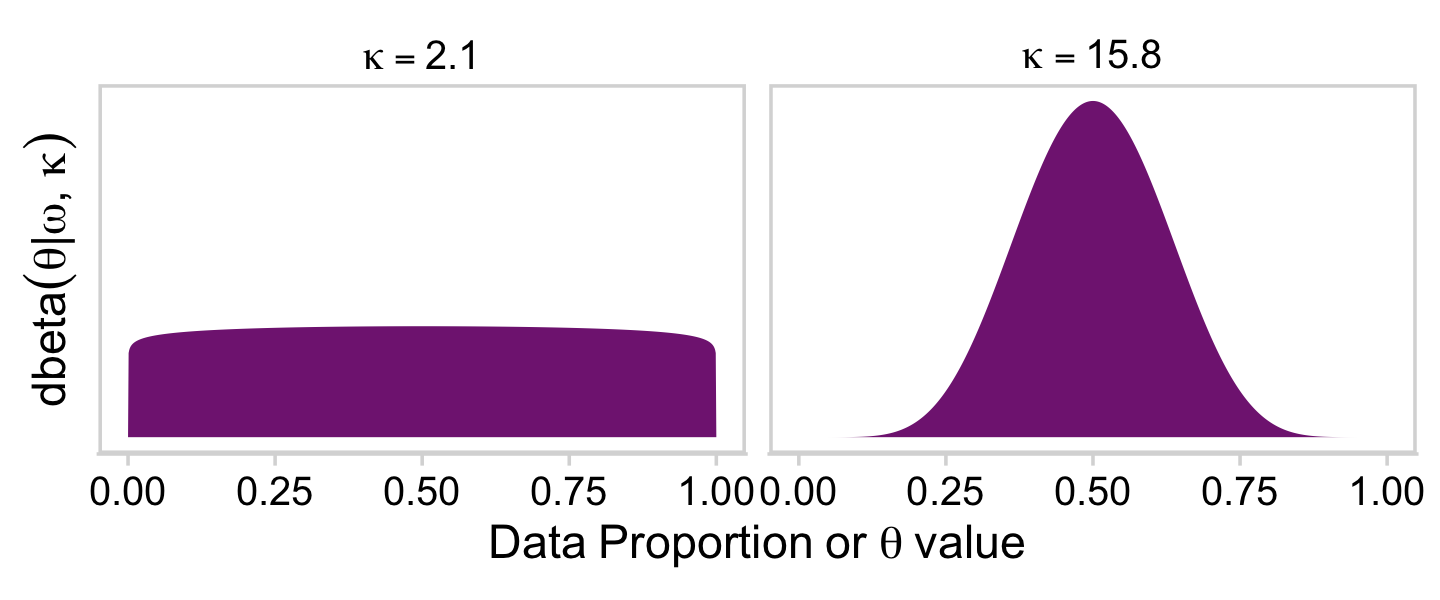
This isn’t in the text, but it might help if we gave a sense of multilevel shrinkage by plotting the phenomena using the results from our model fit9.1.
my_data %>%
group_by(s) %>%
summarise(p = mean(y)) %>%
mutate(theta = coef(fit9.1)$s[, 1, "Intercept"] %>% inv_logit_scaled()) %>%
pivot_longer(-s) %>%
# add a little jitter to reduce the overplotting
mutate(value = value + runif(n = n(), min = -0.02, max = 0.02),
name = if_else(name == "p", "italic(z/N)", "theta")) %>%
ggplot(aes(x = value, y = name, group = s)) +
geom_point(color = alpha(a_purple, 1/2)) +
geom_line(linewidth = 1/3, alpha = 1/3) +
scale_x_continuous(breaks = 0:5 / 5, expand = c(0.01, 0.01), limits = 0:1) +
scale_y_discrete(NULL, labels = ggplot2:::parse_safe) +
labs(title = "Multilevel shrinkage in fit9.1",
x = "data proportion or theta value") +
theme_minimal_hgrid() +
panel_border() 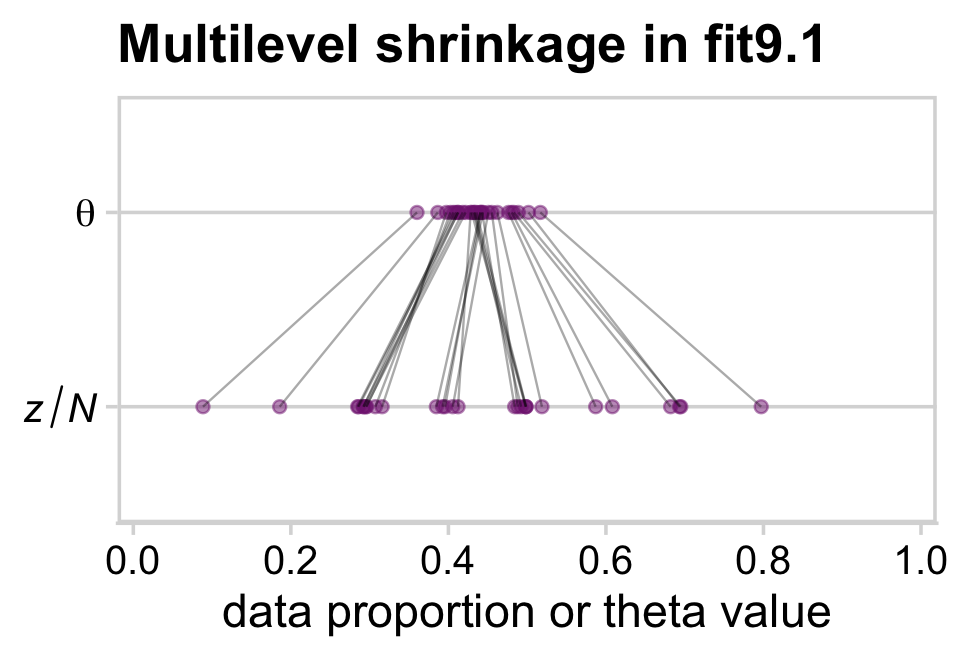
The dots in the z/N row are the sample statistics. The dots in the θ row are the posterior means for each of the levels of s, the grouping variable in the my_data data. You’ll note that we jittered the values for both within the second mutate() line to help reduce the overplotting. If you don’t understand what that means, run the code without that line or set the values within runif() closer to zero. You’ll see. Anyway, for more on multilevel shrinkage and for plots of this kind, check out Efron and Morris’s classic (1977) paper, Stein’s paradox in statistics, and my blog post walking out one of their examples in brms.
9.4 Speeding up JAGS brms
Here we’ll compare the time it takes to fit fit1 as either bernoulli(link = logit) or binomial(link = logit).
# bernoulli
start_time_bernoulli <- proc.time()
brm(data = my_data,
family = bernoulli(link = logit),
y ~ 1 + (1 | s),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 20000, warmup = 1000, thin = 10, chains = 4, cores = 4,
seed = 9)
stop_time_bernoulli <- proc.time()
# binomial
start_time_binomial <- proc.time()
brm(data = my_data,
family = binomial(link = logit),
y | trials(1) ~ 1 + (1 | s),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 20000, warmup = 1000, thin = 10, chains = 4, cores = 4,
seed = 9)
stop_time_binomial <- proc.time()See how we’re using proc.time() to record when we began and finished evaluating our brm() code? The last time we covered that was way back in Section 3.7.5. In that section, we also learned how subtracting the former from the latter yields the total elapsed time.
stop_time_bernoulli - start_time_bernoulli## user system elapsed
## 23.514 1.970 43.999stop_time_binomial - start_time_binomial## user system elapsed
## 20.497 1.463 43.058These times are based on my current laptop (a 2019 MacBook Pro). Your mileage may vary. If you wanted to be rigorous about this, you could do this multiple times in a mini simulation.
As to the issue of parallel processing, we’ve been doing this all along. Note our chains = 4, cores = 4 arguments.
Since Kruschke wrote his text, we have other options for speeding up your brms models related to within-chain parallelization and the backend = "cmdstanr" option. For all the details, see Weber & Bürkner’s (2022) vignette, Running brms models with within-chain parallelization.
9.5 Extending the hierarchy: Subjects within categories
Many data structures invite hierarchical descriptions that may have multiple levels. Software such as
JAGS[brms] makes it easy to implement hierarchical models, and Bayesian inference makes it easy to interpret the parameter estimates, even for complex nonlinear hierarchical models. Here, we take a look at one type of extended hierarchical model. (p. 251)
As we will address below, our version of Figure 9.13 will look rather different from Kruschke’s. It’s something of a combination of the sensibilities from Figures 20.2 and 21.10. Even still, the diagram is of three-level model that shares many similarities to Kruschke’s and, as we will see, yields very similar results.
# half-normal density
p1 <-
tibble(x = seq(from = 0, to = 3, by = .01)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = 1.5, y = .2,
label = "half-normal",
size = 7) +
annotate(geom = "text",
x = 1.5, y = .6,
label = "0*','*~italic(S)[italic(s)*'|'*italic(c)]",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# second half-normal density
p2 <-
tibble(x = seq(from = 0, to = 3, by = .01)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = 1.5, y = .2,
label = "half-normal",
size = 7) +
annotate(geom = "text",
x = 1.5, y = .6,
label = "0*','*~italic(S)[italic(c)]",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# annotated arrow
p3 <-
tibble(x = .85,
y = 1,
xend = .5,
yend = .25) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = .54, y = .6, label = "'~'",
size = 10, family = "Times", parse = T) +
xlim(0, 1) +
theme_void()
# normal density
p4 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = 0, y = .2,
label = "normal",
size = 7) +
annotate(geom = "text",
x = c(0, 1.45), y = .6,
hjust = c(.5, 0),
label = c("italic(M)[0]", "italic(S)[0]"),
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# second normal density
p5 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = a_purple,) +
annotate(geom = "text",
x = 0, y = .2,
label = "normal",
size = 7) +
annotate(geom = "text",
x = c(0, 1.45), y = .6,
hjust = c(.5, 0),
label = c("0", "sigma[italic(s)*'|'*italic(c)]"),
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# third normal density
p6 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = a_purple) +
annotate(geom = "text",
x = 0, y = .2,
label = "normal",
size = 7) +
annotate(geom = "text",
x = c(0, 1.45), y = .6,
hjust = c(.5, 0),
label = c("0", "sigma[italic(c)]"),
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# three annotated arrows
p7 <-
tibble(x = c(.09, .48, .9),
y = c(1, 1, 1),
xend = c(.2, .425, .775),
yend = c(.2, .2, .2)) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = c(.10, .42, .49, .81, .87), y = .6,
label = c("'~'", "'~'", "italic(s)*'|'*italic(c)", "'~'", "italic(c)"),
size = c(10, 10, 7, 10, 7),
family = "Times", parse = T) +
xlim(0, 1) +
theme_void()
# likelihood formula
p8 <-
tibble(x = .5,
y = .5,
label = "logistic(beta[0]+sum()[italic(s)*'|'*italic(c)]*beta['['*italic(s)*'|'*italic(c)*']']*italic(x)['['*italic(s)*'|'*italic(c)*']'](italic(i))+sum()[italic(c)]*beta['['*italic(c)*']']*italic(x)['['*italic(c)*']'](italic(i)))") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# a second annotated arrow
p9 <-
tibble(x = c(.375, .5),
y = c(.75, .3),
label = c("'='", "mu[italic(i)*'|'*italic(sc)]")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = .4,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# binomial density
p10 <-
tibble(x = 0:7) %>%
ggplot(aes(x = x,
y = (dbinom(x, size = 7, prob = .625)) / max(dbinom(x, size = 7, prob = .625)))) +
geom_col(fill = a_purple, width = .4) +
annotate(geom = "text",
x = 3.5, y = .2,
label = "binomial",
size = 7) +
annotate(geom = "text",
x = 7, y = .85,
label = "italic(N)[italic(i)*'|'*italic(s)]",
size = 7, family = "Times", parse = TRUE) +
coord_cartesian(xlim = c(-1, 8),
ylim = c(0, 1.2)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# another annotated arrow
p11 <-
tibble(x = c(.375, .7),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)*'|'*italic(sc)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# some text
p12 <-
tibble(x = 1,
y = .5,
label = "italic(y)[italic(i)*'|'*italic(sc)]") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
xlim(0, 2) +
theme_void()
# define the layout
layout <- c(
area(t = 1, b = 2, l = 7, r = 9),
area(t = 1, b = 2, l = 11, r = 13),
area(t = 4, b = 5, l = 1, r = 3),
area(t = 4, b = 5, l = 5, r = 7),
area(t = 4, b = 5, l = 9, r = 11),
area(t = 3, b = 4, l = 6, r = 8),
area(t = 3, b = 4, l = 10, r = 12),
area(t = 7, b = 8, l = 1, r = 11),
area(t = 6, b = 7, l = 1, r = 11),
area(t = 11, b = 12, l = 5, r = 7),
area(t = 9, b = 11, l = 5, r = 7),
area(t = 13, b = 14, l = 5, r = 7),
area(t = 15, b = 15, l = 5, r = 7)
)
# combine and plot!
(p1 + p2 + p4 + p5 + p6 + p3 + p3 + p8 + p7 + p10 + p9 + p11 + p12) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))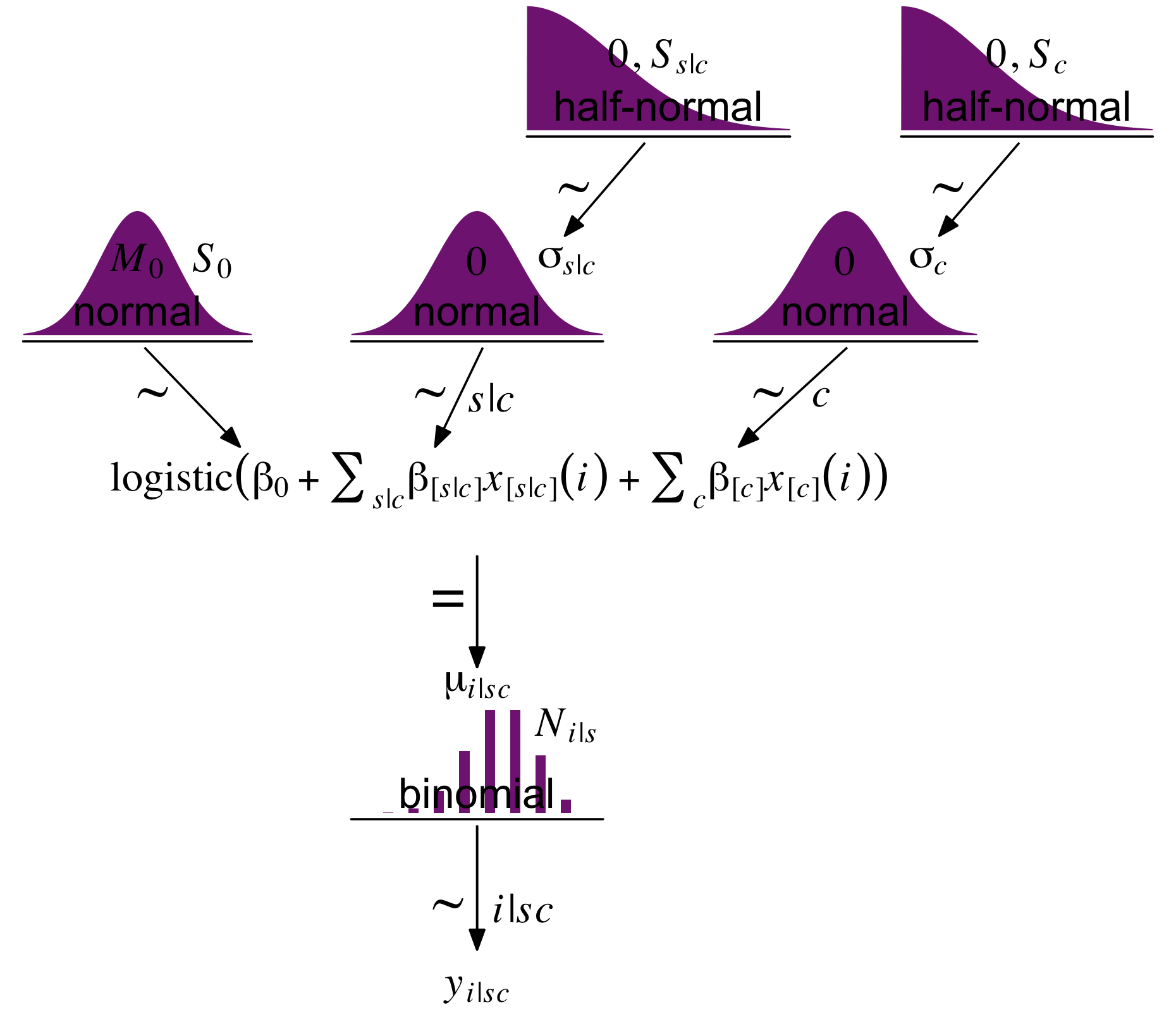
Though we will be fitting a hierarchical model with subjects s within categories c, the higher-level parameters will not be ω and κ. As we’ll go over, below, we will use the binomial distribution within a more conventional hierarchical logistic regression paradigm. In this paradigm, we have an overall intercept, often called α or β0, which will be our analogue to Kruschke’s overall ω. For the two grouping categories, s and c, we will have σ estimates, which express the variability within those grouping. You’ll see when we get there.
9.5.1 Example: Baseball batting abilities by position.
Here are the batting average data.
my_data <- read_csv("data.R/BattingAverage.csv")
glimpse(my_data)## Rows: 948
## Columns: 6
## $ Player <chr> "Fernando Abad", "Bobby Abreu", "Tony Abreu", "Dustin Ack…
## $ PriPos <chr> "Pitcher", "Left Field", "2nd Base", "2nd Base", "1st Bas…
## $ Hits <dbl> 1, 53, 18, 137, 21, 0, 0, 2, 150, 167, 0, 128, 66, 3, 1, …
## $ AtBats <dbl> 7, 219, 70, 607, 86, 1, 1, 20, 549, 576, 1, 525, 275, 12,…
## $ PlayerNumber <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
## $ PriPosNumber <dbl> 1, 7, 4, 4, 3, 1, 1, 3, 3, 4, 1, 5, 4, 2, 7, 4, 6, 8, 9, …In his footnote #6, Kruschke indicated he retrieved the data from http://www.baseball-reference.com/leagues/MLB/2012-standard-batting.shtml on December of 2012. To give a sense of the data, here are the number of occasions by primary position, PriPos, with their median at bat, AtBats, values.
my_data %>%
group_by(PriPos) %>%
summarise(n = n(),
median = median(AtBats)) %>%
arrange(desc(n))## # A tibble: 9 × 3
## PriPos n median
## <chr> <int> <dbl>
## 1 Pitcher 324 4
## 2 Catcher 103 170
## 3 Left Field 103 164
## 4 1st Base 81 265
## 5 3rd Base 75 267
## 6 2nd Base 72 228.
## 7 Center Field 67 259
## 8 Shortstop 63 205
## 9 Right Field 60 340.As these data are aggregated, we’ll fit with an aggregated binomial model. This is still logistic regression. The Bernoulli distribution is a special case of the binomial distribution when the number of trials in each data point is 1 (see Bürkner, 2022c for details). Since our data are aggregated, the information encoded in Hits is a combination of multiple trials, which requires us to jump up to the more general binomial likelihood. Note the Hits | trials(AtBats) syntax. With that bit, we instructed brms that our criterion, Hits, is an aggregate of multiple trials and the number of trials is encoded in AtBats.
Also note the (1 | PriPos) + (1 | PriPos:Player) syntax. In this model, we have two grouping factors, PriPos and Player. Thus we have two (|) arguments. But since players are themselves nested within positions, we have encoded that nesting with the (1 | PriPos:Player) syntax. For more on this style of syntax, see Kristoffer Magnusson’s handy blog post, Using R and lme/lmer to fit different two- and three-level longitudinal models. Since brms syntax is based on that from the earlier lme4 package, the basic syntax rules apply. Bürkner (2022f), of course, also covered these topics in the brmsformula subsection of the brms reference manual.
fit9.2 <-
brm(data = my_data,
family = binomial(link = logit),
Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 3500, warmup = 500, chains = 3, cores = 3,
control = list(adapt_delta = .99),
seed = 9,
file = "fits/fit09.02")The chains look good.
plot(fit9.2, widths = c(2, 3))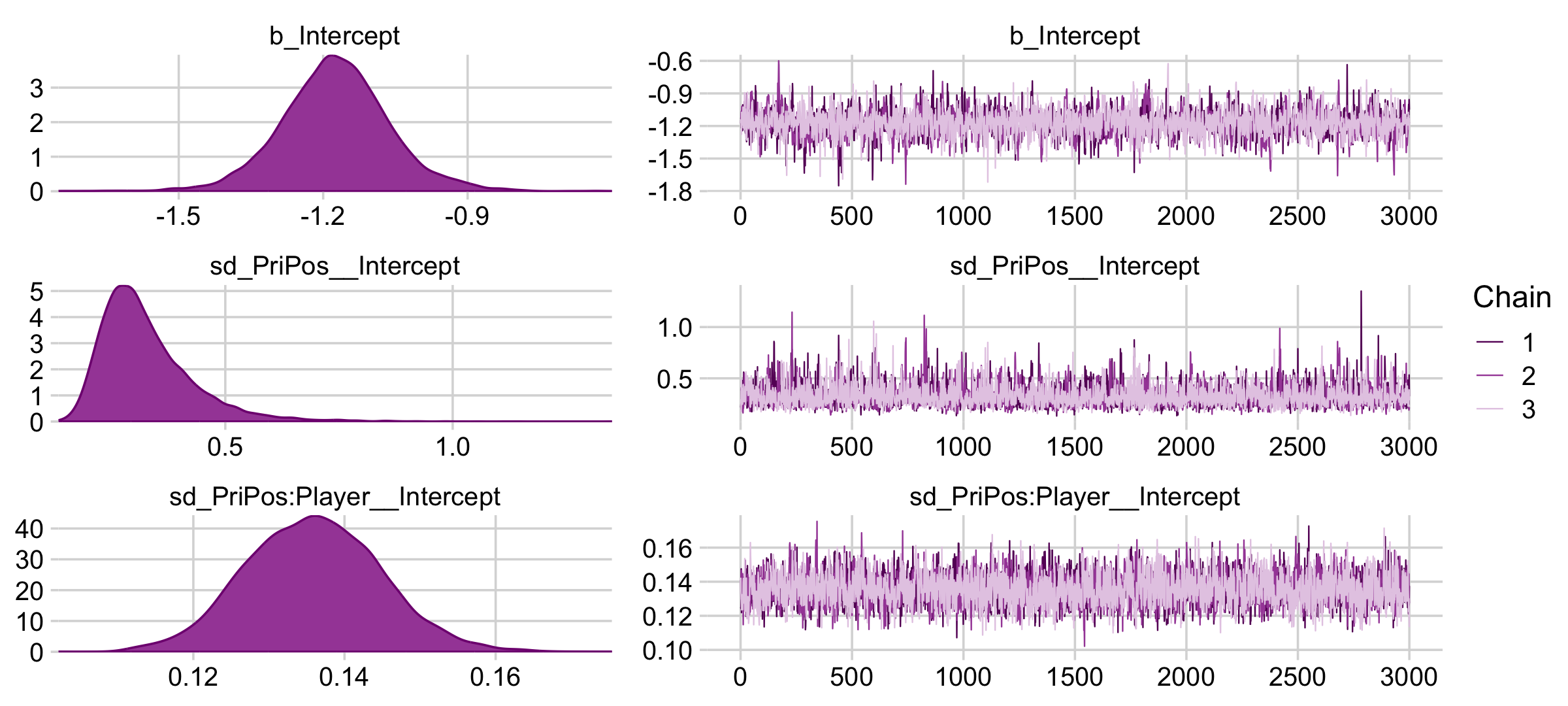
Note how our color_scheme_set("purple") line from back up in the mcmc_pairs() has effected the color scheme of brms::plot().
We might examine the autocorrelations within the chains.
draws <- as_draws_df(fit9.2)
draws %>%
mutate(chain = .chain) %>%
mcmc_acf(pars = vars(b_Intercept:`sd_PriPos:Player__Intercept`),
lags = 8) +
theme_minimal_hgrid()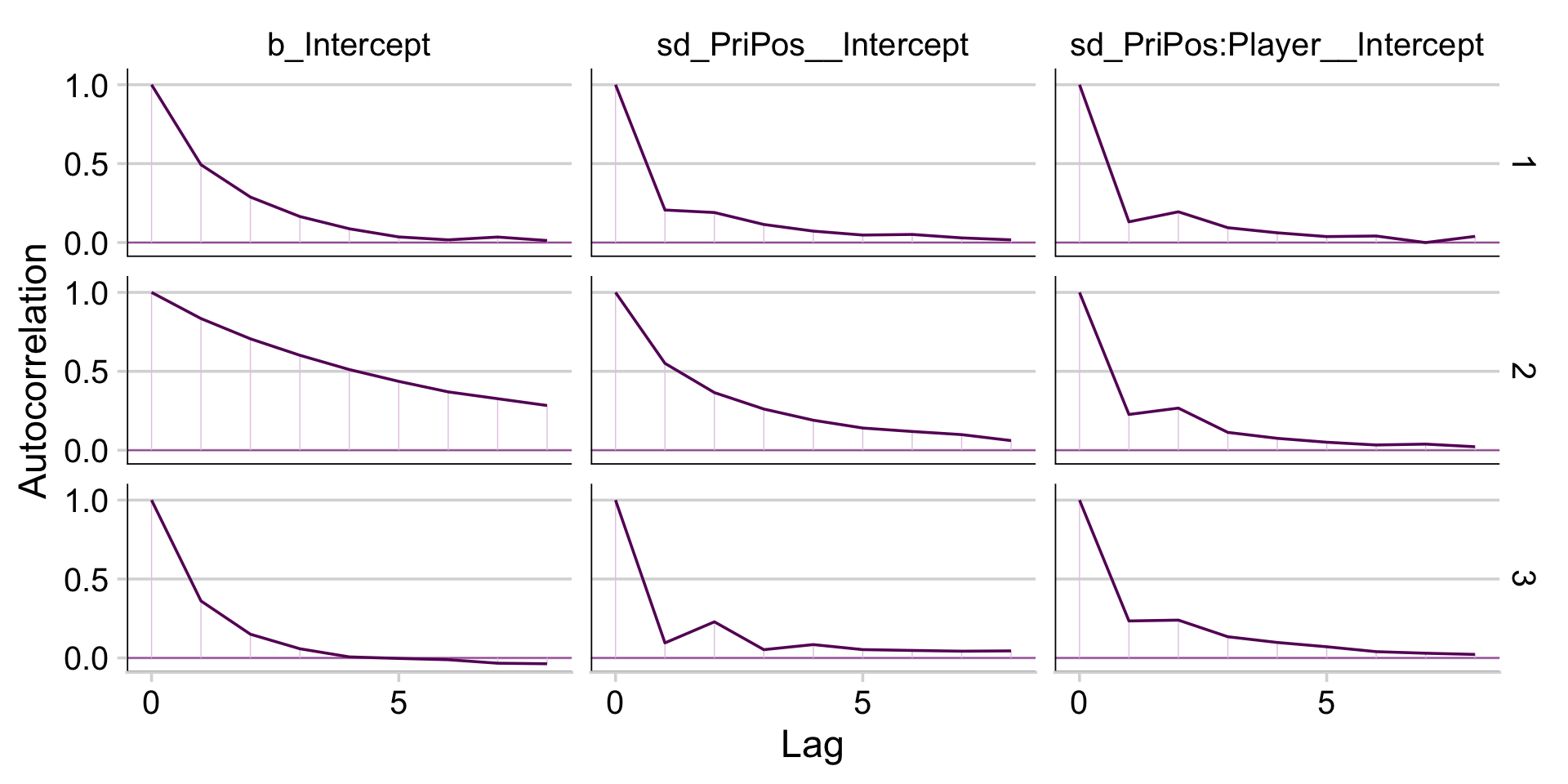
Here’s a histogram of the Neff/N ratios.
fit9.2 %>%
neff_ratio() %>%
mcmc_neff_hist(binwidth = .1) +
yaxis_text() +
theme_minimal_hgrid()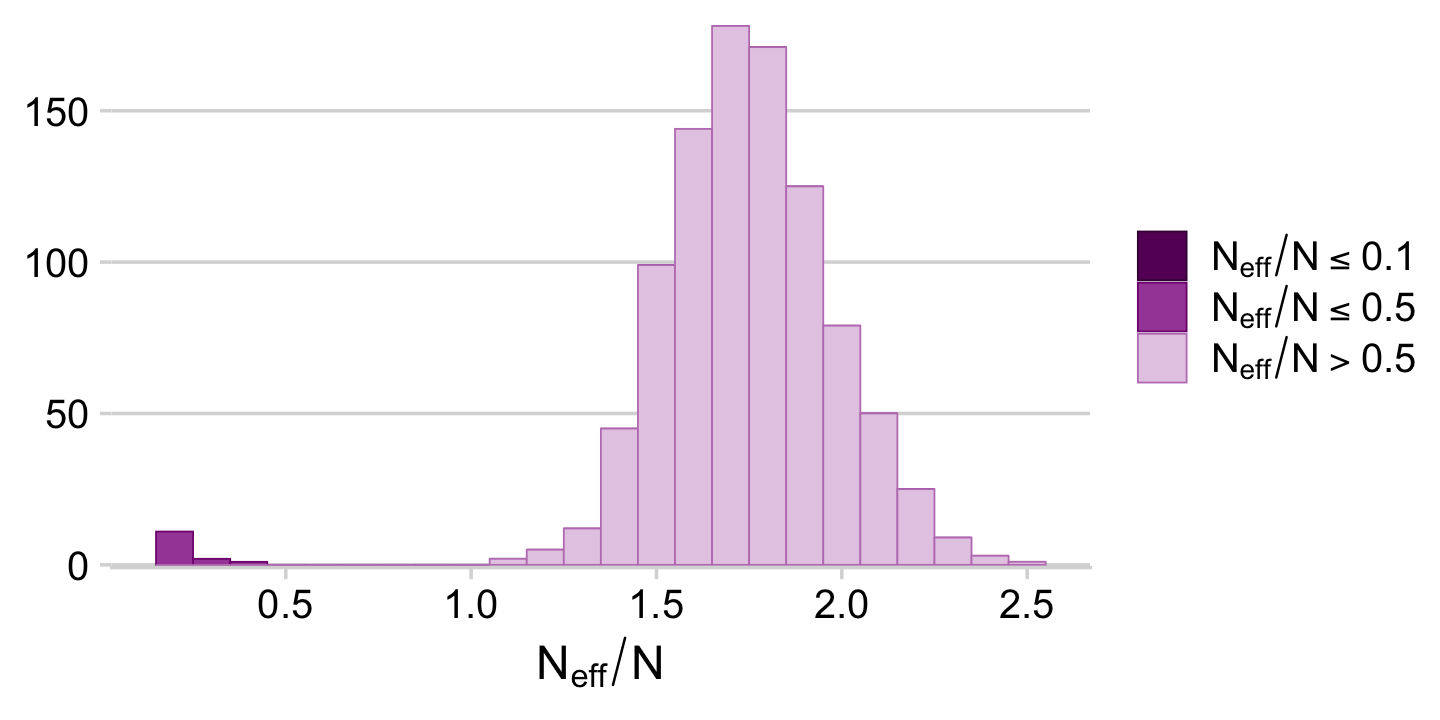
Happily, most have a very favorable ratio. Here’s a numeric summary of the primary model parameters.
print(fit9.2)## Family: binomial
## Links: mu = logit
## Formula: Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player)
## Data: my_data (Number of observations: 948)
## Draws: 3 chains, each with iter = 3500; warmup = 500; thin = 1;
## total post-warmup draws = 9000
##
## Group-Level Effects:
## ~PriPos (Number of levels: 9)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 0.33 0.10 0.19 0.58 1.00 2846 4327
##
## ~PriPos:Player (Number of levels: 948)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 0.14 0.01 0.12 0.15 1.00 3433 5479
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -1.17 0.11 -1.40 -0.94 1.00 1429 2851
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).As far as I’m aware, brms offers three major ways to get the group-level parameters for a hierarchical model: using one of the as_draws functions, coef(), or fitted(). We’ll cover each, beginning with as_draws. In order to look at the autocorrelation plots, above, we already saved the results from as_draws_df(fit9.2) as draws. Let’s look at its structure with head().
head(draws)## # A draws_df: 6 iterations, 1 chains, and 962 variables
## b_Intercept sd_PriPos__Intercept sd_PriPos:Player__Intercept
## 1 -1.1 0.22 0.13
## 2 -1.1 0.25 0.12
## 3 -1.2 0.20 0.15
## 4 -1.1 0.29 0.12
## 5 -1.1 0.22 0.13
## 6 -1.1 0.26 0.14
## r_PriPos[1st.Base,Intercept] r_PriPos[2nd.Base,Intercept]
## 1 0.074 0.068
## 2 0.037 0.063
## 3 0.156 0.101
## 4 0.043 -0.013
## 5 -0.013 0.053
## 6 0.052 -0.016
## r_PriPos[3rd.Base,Intercept] r_PriPos[Catcher,Intercept]
## 1 0.0371 -0.021
## 2 0.0907 -0.018
## 3 0.1773 0.081
## 4 0.0021 -0.062
## 5 -0.0028 -0.082
## 6 0.1030 -0.015
## r_PriPos[Center.Field,Intercept]
## 1 0.0682
## 2 0.0098
## 3 0.1379
## 4 0.0159
## 5 0.0725
## 6 0.0879
## # ... with 954 more variables
## # ... hidden reserved variables {'.chain', '.iteration', '.draw'}In the text, Kruschke described the model as having 968 parameters. Our draws data frame has one vector for each, with a couple others tacked onto the end. In the hierarchical logistic regression model, the group-specific parameters for the levels of PriPos are additive combinations of the global intercept vector, b_Intercept and each position-specific vector, r_PriPos[i.Base,Intercept], where i is a fill-in for the position of interest. And recall that since the linear model is of the logit of the criterion, we’ll need to use inv_logit_scaled() to convert that to the probability space.
draws_small <-
draws %>%
transmute(`1st Base` = (b_Intercept + `r_PriPos[1st.Base,Intercept]`),
Catcher = (b_Intercept + `r_PriPos[Catcher,Intercept]`),
Pitcher = (b_Intercept + `r_PriPos[Pitcher,Intercept]`)) %>%
mutate_all(inv_logit_scaled) %>%
# here we compute our difference distributions
mutate(`Pitcher - Catcher` = Pitcher - Catcher,
`Catcher - 1st Base` = Catcher - `1st Base`)
head(draws_small)## # A tibble: 6 × 5
## `1st Base` Catcher Pitcher `Pitcher - Catcher` `Catcher - 1st Base`
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0.257 0.240 0.130 -0.109 -0.0177
## 2 0.252 0.242 0.130 -0.112 -0.0102
## 3 0.257 0.243 0.134 -0.108 -0.0142
## 4 0.261 0.241 0.131 -0.110 -0.0197
## 5 0.249 0.237 0.132 -0.105 -0.0127
## 6 0.255 0.243 0.123 -0.120 -0.0125If you take a glance at Figures 9.14 through 9.16 in the text, we’ll be making a lot of histograms of the same basic structure. To streamline our code a bit, we can make a custom histogram plotting function.
make_histogram <- function(data, mapping, title, xlim, ...) {
ggplot(data, mapping) +
geom_histogram(fill = viridis::viridis_pal(option = "A")(9)[4],
color = "white", linewidth = .2,
bins = 30) +
stat_pointinterval(aes(y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = title,
x = expression(theta)) +
coord_cartesian(xlim = xlim) +
theme_minimal_hgrid() +
panel_border()
}We’ll do the same thing for the correlation plots.
make_point <- function(data, mapping, limits, ...) {
ggplot(data, mapping) +
geom_abline(linetype = 3, color = "grey50") +
geom_point(color = viridis::viridis_pal(option = "A")(9)[4],
size = 1/10, alpha = 1/20) +
coord_cartesian(xlim = limits,
ylim = limits) +
theme_minimal_grid(line_size = 0) +
panel_border()
}To learn more about wrapping custom plots into custom functions, check out Chapter 19 of Wickham’s (2016) ggplot2: Elegant graphics for data analysis.
Now we have our make_histogram() and make_point() functions, we’ll use grid.arrange() to paste together the left half of Figure 9.14.
p1 <-
make_histogram(data = draws_small,
aes(x = Pitcher),
title = "Pitcher",
xlim = c(.1, .25))
p2 <-
make_histogram(data = draws_small,
aes(x = `Pitcher - Catcher`),
title = "Pitcher - Catcher",
xlim = c(-.15, 0))
p3 <-
make_point(data = draws_small,
aes(x = Pitcher, y = Catcher),
limits = c(.12, .25))
p4 <-
make_histogram(data = draws_small,
aes(x = Catcher),
title = "Catcher",
xlim = c(.1, .25))
p1 + p2 + p3 + p4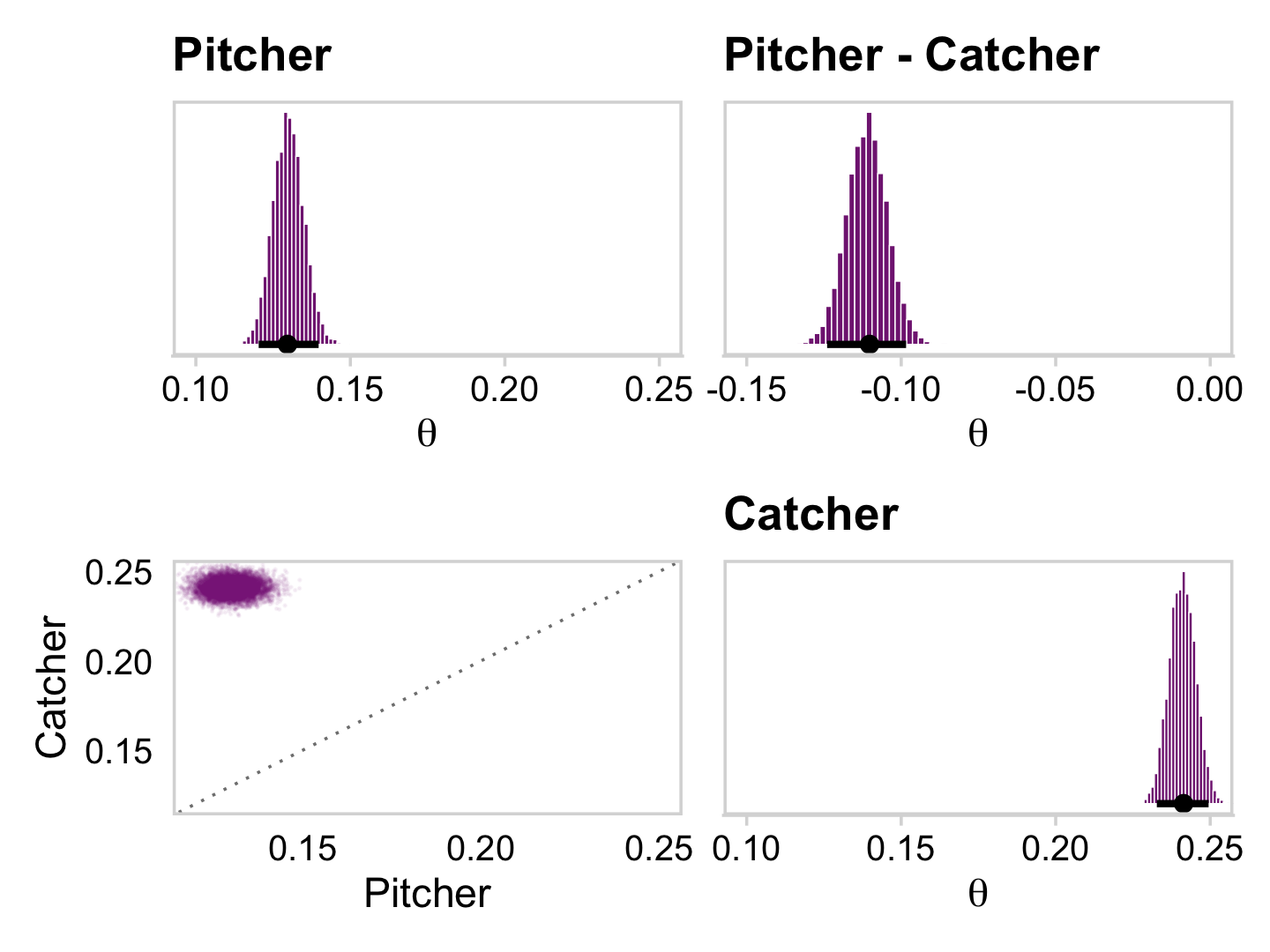
We could follow the same procedure to make the right portion of Figure 9.14. But instead, let’s switch gears and explore the second way brms affords us for plotting group-level parameters. This time, we’ll use coef().
Up in Section 9.2.4, we learned that we can use coef() to “extract [the] model coefficients, which are the sum of population-level effects and corresponding group-level effects” (Bürkner, 2022f, p. 58). The grouping level we’re interested in is PriPos, so we’ll use that to index the information returned by coef(). Since coef() returns a matrix, we’ll use as_tibble() to convert it to a tibble.
coef_primary_position <-
coef(fit9.2, summary = F)$PriPos %>%
as_tibble()
str(coef_primary_position)## tibble [9,000 × 9] (S3: tbl_df/tbl/data.frame)
## $ 1st Base.Intercept : num [1:9000] -1.06 -1.09 -1.06 -1.04 -1.1 ...
## $ 2nd Base.Intercept : num [1:9000] -1.07 -1.06 -1.12 -1.1 -1.04 ...
## $ 3rd Base.Intercept : num [1:9000] -1.1 -1.03 -1.04 -1.08 -1.09 ...
## $ Catcher.Intercept : num [1:9000] -1.15 -1.14 -1.14 -1.15 -1.17 ...
## $ Center Field.Intercept: num [1:9000] -1.06 -1.11 -1.08 -1.07 -1.02 ...
## $ Left Field.Intercept : num [1:9000] -1.09 -1.12 -1.11 -1.05 -1.1 ...
## $ Pitcher.Intercept : num [1:9000] -1.9 -1.9 -1.86 -1.89 -1.89 ...
## $ Right Field.Intercept : num [1:9000] -1.038 -1.068 -1.053 -1.083 -0.986 ...
## $ Shortstop.Intercept : num [1:9000] -1.11 -1.12 -1.08 -1.1 -1.07 ...Keep in mind that coef() returns the values in the logit scale when used for logistic regression models. So we’ll have to use brms::inv_logit_scaled() to convert the estimates to the probability metric. After we’re done converting the estimates, we’ll then make the difference distributions.
coef_small <-
coef_primary_position %>%
select(`1st Base.Intercept`, Catcher.Intercept, Pitcher.Intercept) %>%
transmute(`1st Base` = `1st Base.Intercept`,
Catcher = Catcher.Intercept,
Pitcher = Pitcher.Intercept) %>%
mutate_all(inv_logit_scaled) %>%
# here we make the difference distributions
mutate(`Pitcher - Catcher` = Pitcher - Catcher,
`Catcher - 1st Base` = Catcher - `1st Base`)
head(coef_small)## # A tibble: 6 × 5
## `1st Base` Catcher Pitcher `Pitcher - Catcher` `Catcher - 1st Base`
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0.257 0.240 0.130 -0.109 -0.0177
## 2 0.252 0.242 0.130 -0.112 -0.0102
## 3 0.257 0.243 0.134 -0.108 -0.0142
## 4 0.261 0.241 0.131 -0.110 -0.0197
## 5 0.249 0.237 0.132 -0.105 -0.0127
## 6 0.255 0.243 0.123 -0.120 -0.0125Now we’re ready for the right half of Figure 9.14.
p1 <-
make_histogram(data = coef_small,
aes(x = Catcher),
title = "Catcher",
xlim = c(.22, .27))
p2 <-
make_histogram(data = coef_small,
aes(x = `Catcher - 1st Base`),
title = "Catcher - 1st Base",
xlim = c(-.04, .01))
p3 <-
make_point(data = coef_small,
aes(x = Catcher, y = `1st Base`),
limits = c(.22, .27))
p4 <-
make_histogram(data = coef_small,
aes(x = `1st Base`),
title = "1st Base",
xlim = c(.22, .27))
p1 + p2 + p3 + p4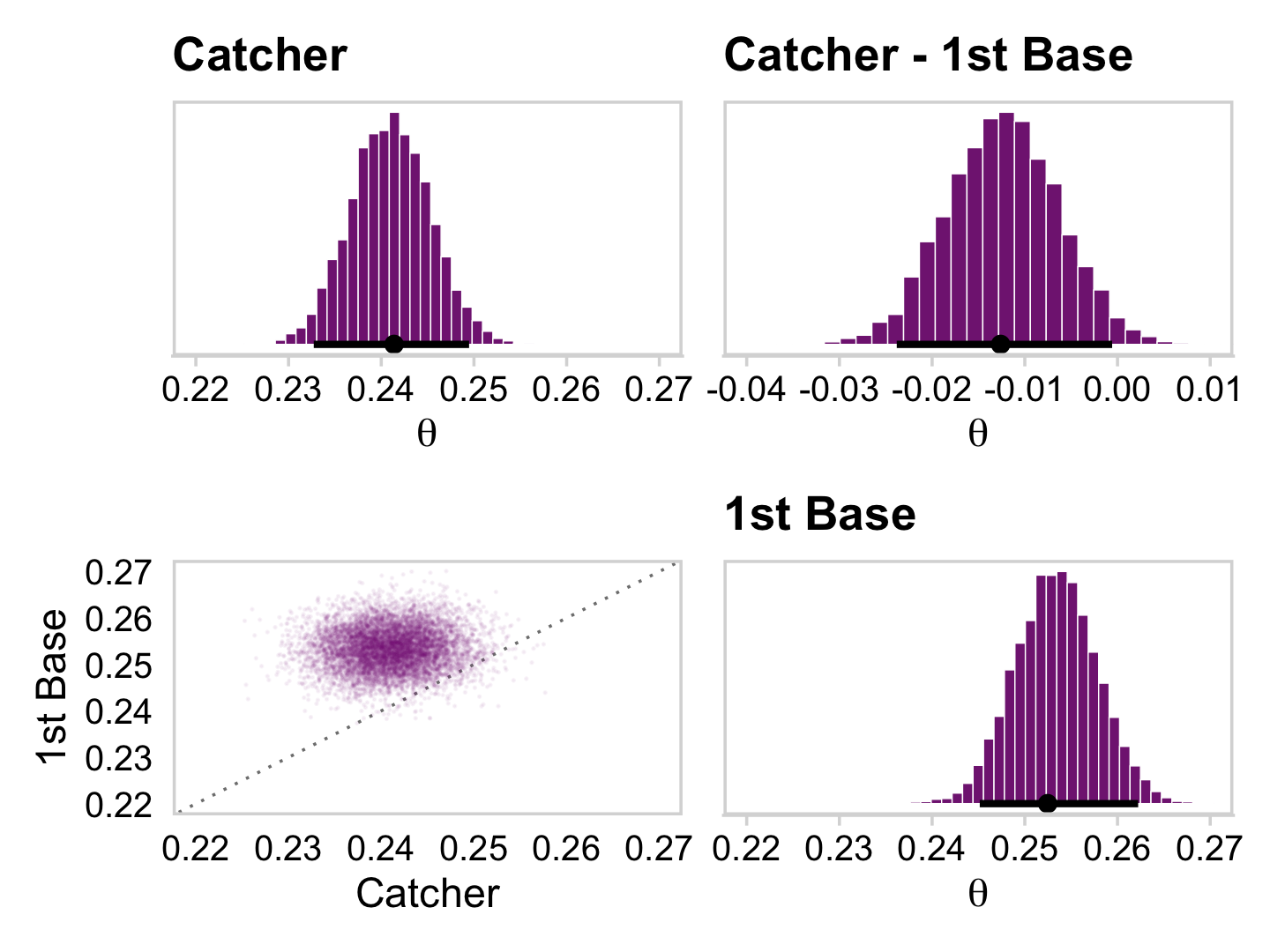
And if you wanted the posterior modes and HDIs, you’d use mode_hdi() after a little wrangling.
coef_small %>%
pivot_longer(everything()) %>%
group_by(name) %>%
mode_hdi(value) %>%
mutate_if(is.double, round, digits = 3)## # A tibble: 5 × 7
## name value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 1st Base 0.252 0.245 0.262 0.95 mode hdi
## 2 Catcher 0.241 0.233 0.249 0.95 mode hdi
## 3 Catcher - 1st Base -0.013 -0.024 -0.001 0.95 mode hdi
## 4 Pitcher 0.13 0.12 0.14 0.95 mode hdi
## 5 Pitcher - Catcher -0.11 -0.124 -0.098 0.95 mode hdiWhile we’re at it, we should capitalize on the opportunity to show how these results are the same as those derived from our as_draws_df() approach, above.
draws_small %>%
pivot_longer(everything()) %>%
group_by(name) %>%
mode_hdi(value) %>%
mutate_if(is.double, round, digits = 3)## # A tibble: 5 × 7
## name value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 1st Base 0.252 0.245 0.262 0.95 mode hdi
## 2 Catcher 0.241 0.233 0.249 0.95 mode hdi
## 3 Catcher - 1st Base -0.013 -0.024 -0.001 0.95 mode hdi
## 4 Pitcher 0.13 0.12 0.14 0.95 mode hdi
## 5 Pitcher - Catcher -0.11 -0.124 -0.098 0.95 mode hdiSuccess!
For Figures 9.15 and 9.16, Kruschke drilled down further into the posterior. To drill along with him, we’ll take the opportunity to showcase fitted(), the third way brms affords us for plotting group-level parameters.
# this will make life easier. just go with it
name_list <- c("Kyle Blanks", "Bruce Chen", "ShinSoo Choo", "Ichiro Suzuki",
"Mike Leake", "Wandy Rodriguez", "Andrew McCutchen", "Brett Jackson")
# we'll define the data we'd like to feed into `fitted()`, here
nd <-
my_data %>%
filter(Player %in% name_list) %>%
# these last two lines aren't typically necessary, but they allow us to
# arrange the rows in the same order we find the names in Figures 9.15 and 9.16
mutate(Player = factor(Player, levels = name_list)) %>%
arrange(Player)
fitted_players <-
fitted(fit9.2,
newdata = nd,
scale = "linear",
summary = F) %>%
as_tibble() %>%
# rename the values as returned by `as_tibble()`
set_names(name_list) %>%
# convert the values from the logit scale to the probability scale
mutate_all(inv_logit_scaled) %>%
# in this last section, we make our difference distributions
mutate(`Kyle Blanks - Bruce Chen` = `Kyle Blanks` - `Bruce Chen`,
`ShinSoo Choo - Ichiro Suzuki` = `ShinSoo Choo` - `Ichiro Suzuki`,
`Mike Leake - Wandy Rodriguez` = `Mike Leake` - `Wandy Rodriguez`,
`Andrew McCutchen - Brett Jackson` = `Andrew McCutchen` - `Brett Jackson`)
glimpse(fitted_players)## Rows: 9,000
## Columns: 12
## $ `Kyle Blanks` <dbl> 0.2376884, 0.2748736, 0.2251325, 0.…
## $ `Bruce Chen` <dbl> 0.1347857, 0.1261347, 0.1409021, 0.…
## $ `ShinSoo Choo` <dbl> 0.3150916, 0.2539179, 0.2996450, 0.…
## $ `Ichiro Suzuki` <dbl> 0.2739827, 0.2817321, 0.2619542, 0.…
## $ `Mike Leake` <dbl> 0.1419472, 0.1854007, 0.1101245, 0.…
## $ `Wandy Rodriguez` <dbl> 0.1433120, 0.1238650, 0.1303600, 0.…
## $ `Andrew McCutchen` <dbl> 0.3249982, 0.3018530, 0.3014977, 0.…
## $ `Brett Jackson` <dbl> 0.2238559, 0.2199570, 0.2386586, 0.…
## $ `Kyle Blanks - Bruce Chen` <dbl> 0.10290271, 0.14873895, 0.08423044,…
## $ `ShinSoo Choo - Ichiro Suzuki` <dbl> 0.0411088952, -0.0278142211, 0.0376…
## $ `Mike Leake - Wandy Rodriguez` <dbl> -0.001364791, 0.061535640, -0.02023…
## $ `Andrew McCutchen - Brett Jackson` <dbl> 0.10114233, 0.08189596, 0.06283916,…Note our use of the scale = "linear" argument in the fitted() function. By default, fitted() returns predictions on the scale of the criterion. But we don’t want a list of successes and failures; we want player-level parameters. When you specify scale = "linear", you request fitted() return the values in the parameter scale.
Here’s the left portion of Figure 9.15.
p1 <-
make_histogram(data = fitted_players,
aes(x = `Kyle Blanks`),
title = "Kyle Blanks (1st Base)",
xlim = c(.05, .35))
p2 <-
make_histogram(data = fitted_players,
aes(x = `Kyle Blanks - Bruce Chen`),
title = "Kyle Blanks (1st Base) -\nBruce Chen (Pitcher)",
xlim = c(-.1, .25))
p3 <-
make_point(data = fitted_players,
aes(x = `Kyle Blanks`, y = `Bruce Chen`),
limits = c(.09, .35))
p4 <-
make_histogram(data = fitted_players,
aes(x = `Bruce Chen`),
title = "Bruce Chen (Pitcher)",
xlim = c(.05, .35))
p1 + p2 + p3 + p4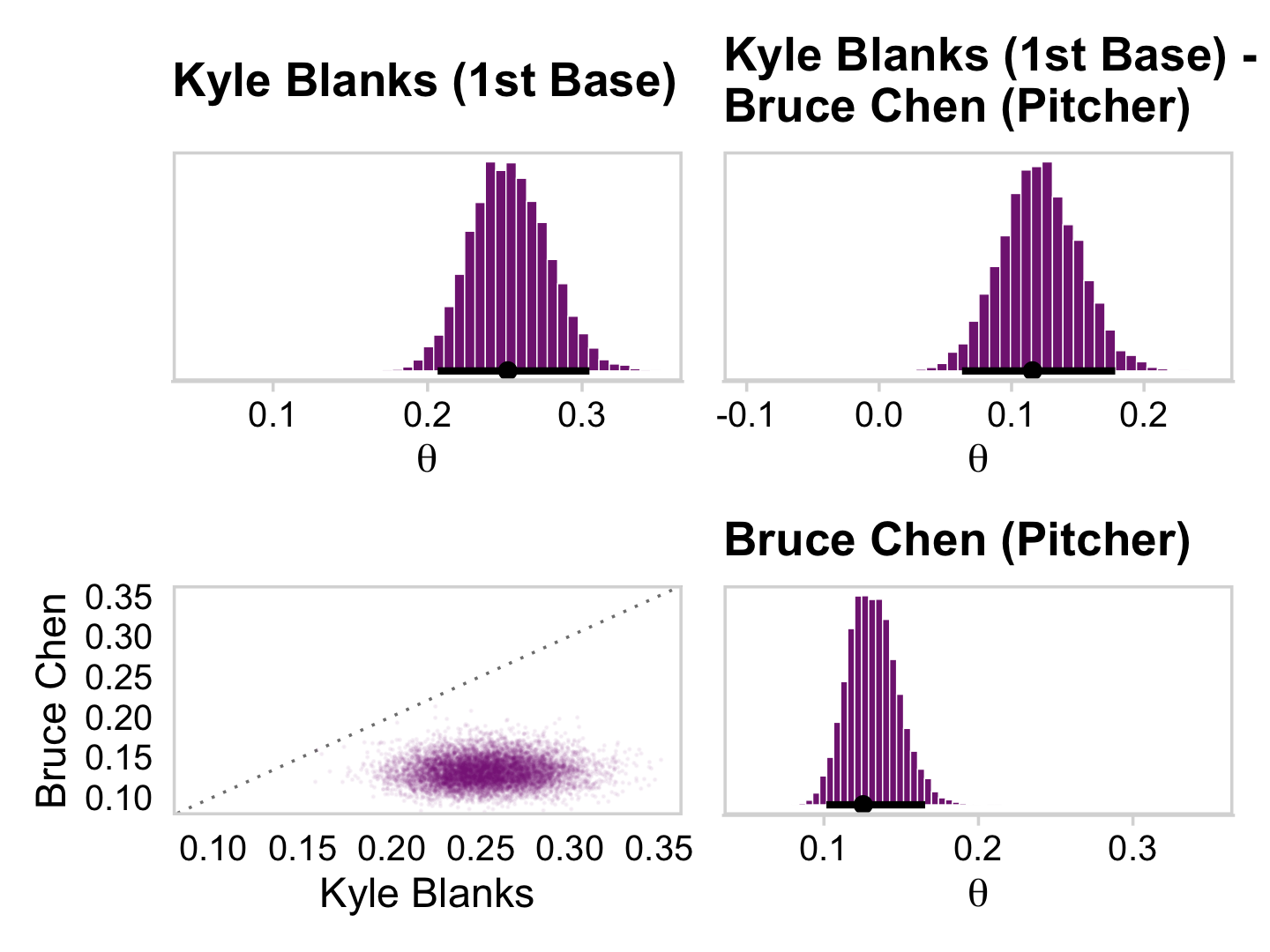
Figure 9.15, right:
p1 <-
make_histogram(data = fitted_players,
aes(x = `ShinSoo Choo`),
title = "ShinSoo Choo (Right Field)",
xlim = c(.22, .34))
p2 <-
make_histogram(data = fitted_players,
aes(x = `ShinSoo Choo - Ichiro Suzuki`),
title = "ShinSoo Choo (Right Field) -\nIchiro Suzuki (Right Field)",
xlim = c(-.07, .07))
p3 <-
make_point(data = fitted_players,
aes(x = `ShinSoo Choo`, y = `Ichiro Suzuki`),
limits = c(.23, .32))
p4 <-
make_histogram(data = fitted_players,
aes(x = `Ichiro Suzuki`),
title = "Ichiro Suzuki (Right Field)",
xlim = c(.22, .34))
(p1 + p2 + p3 + p4) &
theme(title = element_text(size = 11))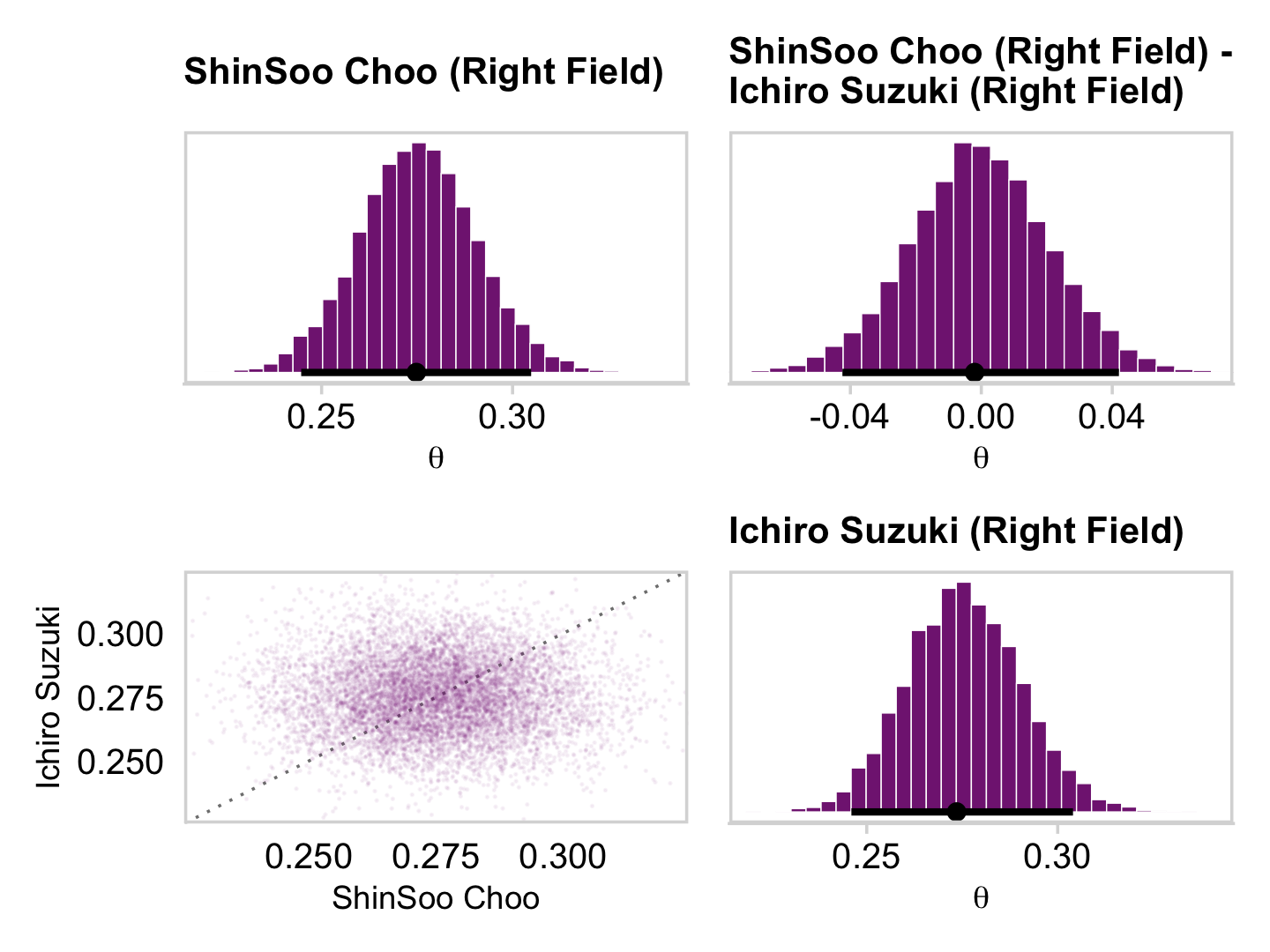
Figure 9.16, left:
p1 <-
make_histogram(data = fitted_players,
aes(x = `Mike Leake`),
title = "Mike Leake (Pitcher)",
xlim = c(.05, .35))
p2 <-
make_histogram(data = fitted_players,
aes(x = `Mike Leake - Wandy Rodriguez`),
title = "Mike Leake (Pitcher) -\nWandy Rodriguez (Pitcher)",
xlim = c(-.05, .25))
p3 <-
make_point(data = fitted_players,
aes(x = `Mike Leake`, y = `Wandy Rodriguez`),
limits = c(.07, .25))
p4 <-
make_histogram(data = fitted_players,
aes(x = `Wandy Rodriguez`),
title = "Wandy Rodriguez (Pitcher)",
xlim = c(.05, .35))
(p1 + p2 + p3 + p4) &
theme(title = element_text(size = 11))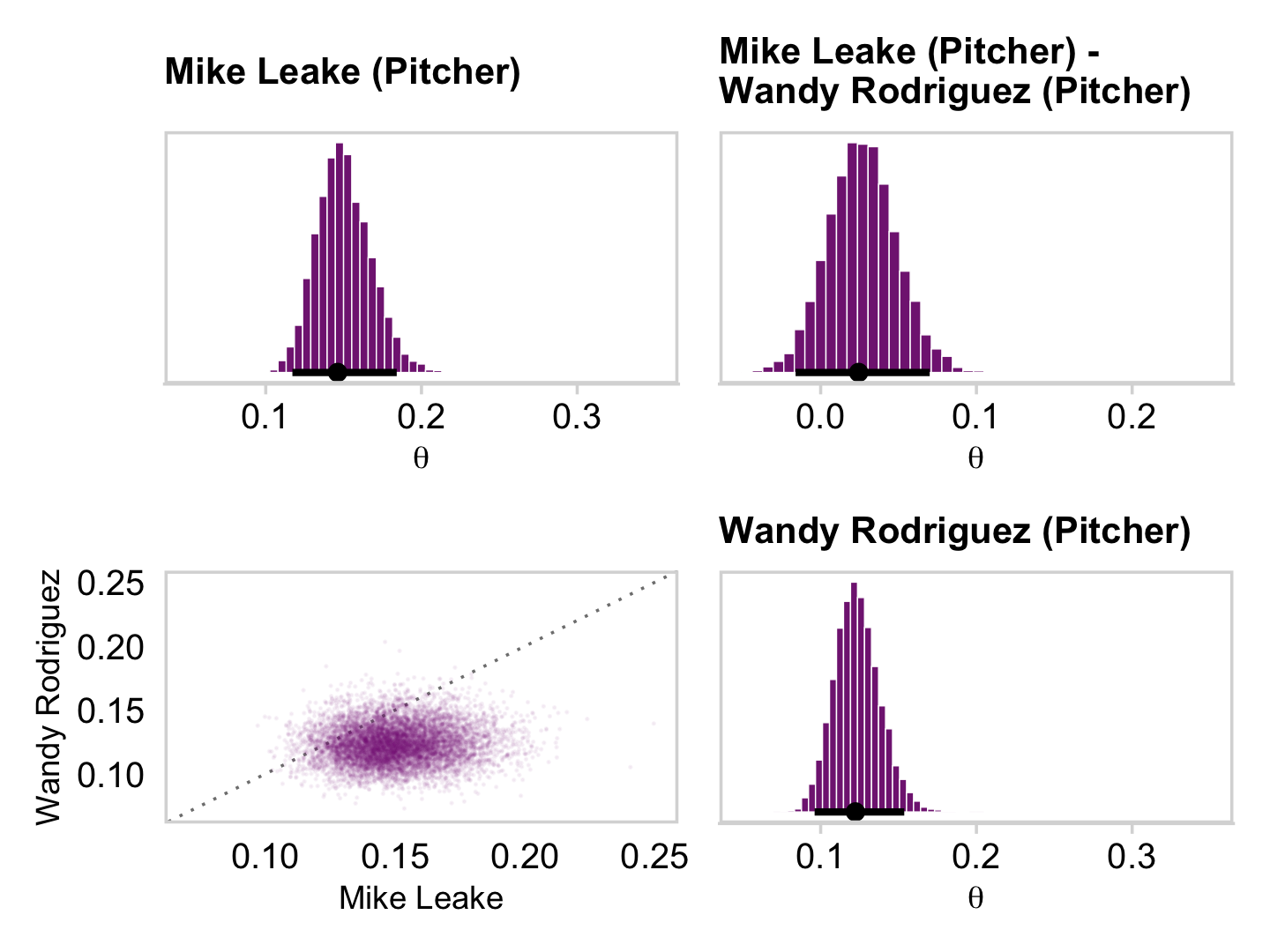
Figure 9.16, right:
p1 <-
make_histogram(data = fitted_players,
aes(x = `Andrew McCutchen`),
title = "Andrew McCutchen (Center Field)",
xlim = c(.15, .35))
p2 <-
make_histogram(data = fitted_players,
aes(x = `Andrew McCutchen - Brett Jackson`),
title = "Andrew McCutchen (Center Field) -\nBrett Jackson (Center Field)",
xlim = c(0, .20))
p3 <-
make_point(data = fitted_players,
aes(x = `Andrew McCutchen`, y = `Brett Jackson`),
limits = c(.15, .35))
p4 <-
make_histogram(data = fitted_players,
aes(x = `Brett Jackson`),
title = "Brett Jackson (Center Field)",
xlim = c(.15, .35))
(p1 + p2 + p3 + p4) &
theme(title = element_text(size = 11))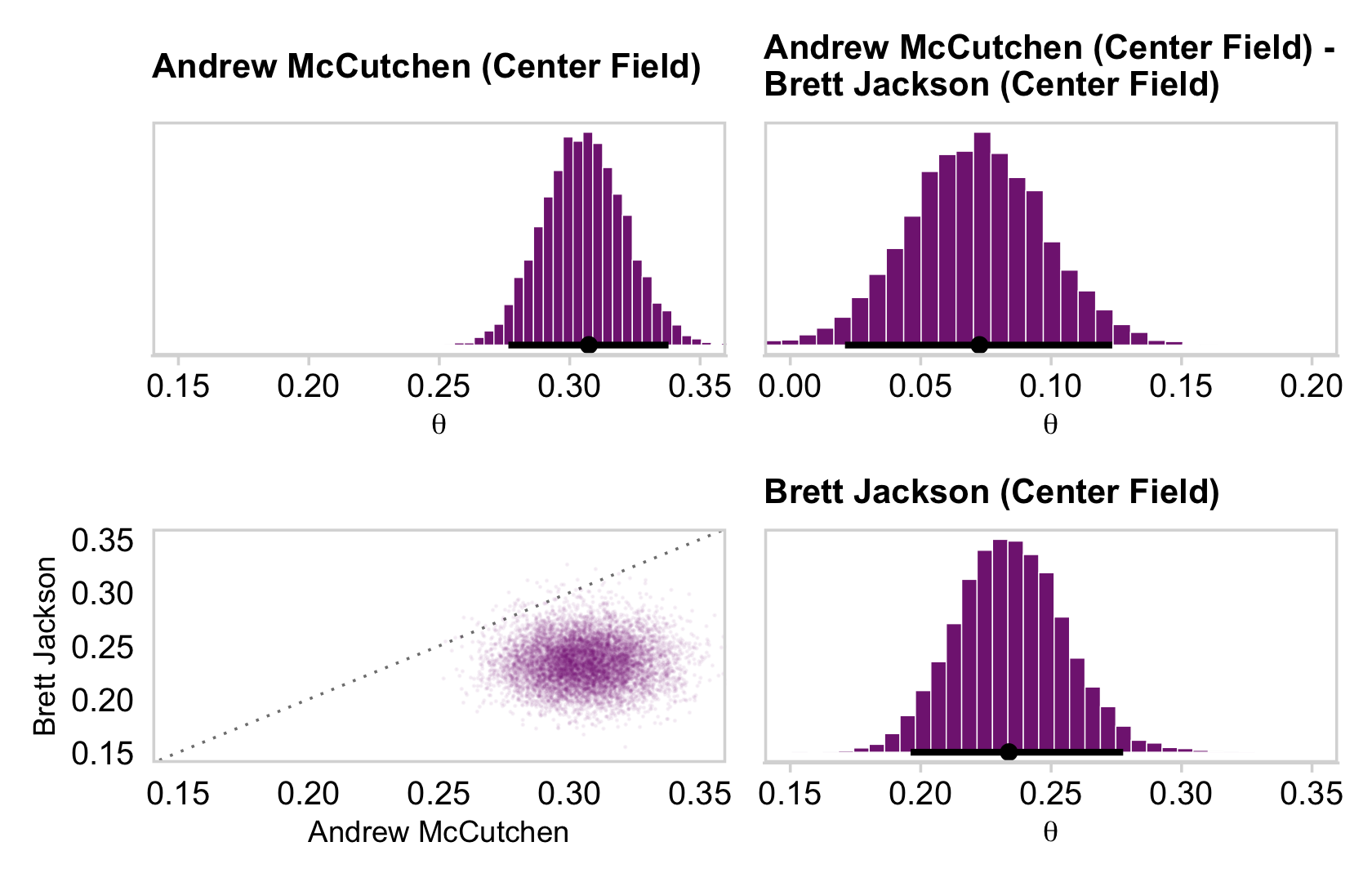
If you wanted the posterior modes and HDIs for any of the players and their contrasts, you’d use mode_hdi() after a little wrangling.
fitted_players %>%
pivot_longer(everything()) %>%
group_by(name) %>%
mode_hdi(value) %>%
mutate_if(is.double, round, digits = 3)## # A tibble: 12 × 7
## name value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 Andrew McCutchen 0.307 0.276 0.338 0.95 mode hdi
## 2 Andrew McCutchen - Brett Jackson 0.073 0.021 0.123 0.95 mode hdi
## 3 Brett Jackson 0.234 0.196 0.278 0.95 mode hdi
## 4 Bruce Chen 0.125 0.102 0.166 0.95 mode hdi
## 5 Ichiro Suzuki 0.274 0.246 0.304 0.95 mode hdi
## 6 Kyle Blanks 0.252 0.206 0.305 0.95 mode hdi
## 7 Kyle Blanks - Bruce Chen 0.116 0.063 0.178 0.95 mode hdi
## 8 Mike Leake 0.146 0.117 0.184 0.95 mode hdi
## 9 Mike Leake - Wandy Rodriguez 0.024 -0.016 0.07 0.95 mode hdi
## 10 ShinSoo Choo 0.275 0.245 0.305 0.95 mode hdi
## 11 ShinSoo Choo - Ichiro Suzuki -0.002 -0.042 0.042 0.95 mode hdi
## 12 Wandy Rodriguez 0.122 0.096 0.154 0.95 mode hdiTo make our version of Figure 9.7, we’ll have to switch gears from player-specific effects to those specific to positions averaged over individual players. The fitted() approach will probably make this the easiest. To do this, we’ll need to specify values for AtBats, which will need to be a positive integer. However, since we’re asking for fitted values of the linear predictors by setting scale = "linear", any value meeting the positive-integer criterion will return the same results. We’ll keep things simple and set AtBats = 1.
Another consideration is if we’d like to use fitted() to average across one of the hierarchical grouping parameters (i.e., (1 | PriPos:Player)), we’ll need to employ the re_formula argument. With the line re_formula = ~ (1 | PriPos), we’ll instruct fitted() to return the PriPos-specific effects after averaging across levels of Player. The rest is quire similar to our method from above.
nd <-
my_data %>%
distinct(PriPos,
AtBats = 1)
fitted_positions <-
fitted(fit9.2,
newdata = nd,
re_formula = ~ (1 | PriPos),
scale = "linear",
summary = F) %>%
as_tibble() %>%
set_names(distinct(my_data, PriPos) %>% pull()) %>%
mutate_all(inv_logit_scaled)
glimpse(fitted_positions)## Rows: 9,000
## Columns: 9
## $ Pitcher <dbl> 0.1304204, 0.1296809, 0.1344783, 0.1312847, 0.1317621, …
## $ `Left Field` <dbl> 0.2522510, 0.2461144, 0.2469496, 0.2587589, 0.2490095, …
## $ `2nd Base` <dbl> 0.2562900, 0.2572787, 0.2468012, 0.2501712, 0.2618258, …
## $ `1st Base` <dbl> 0.2574109, 0.2523072, 0.2571286, 0.2607937, 0.2493394, …
## $ `3rd Base` <dbl> 0.2505139, 0.2626069, 0.2611564, 0.2530208, 0.2512057, …
## $ Catcher <dbl> 0.2397125, 0.2420747, 0.2429536, 0.2410910, 0.2366844, …
## $ Shortstop <dbl> 0.2487001, 0.2451489, 0.2534934, 0.2503236, 0.2559054, …
## $ `Center Field` <dbl> 0.2563912, 0.2472339, 0.2536382, 0.2556327, 0.2656253, …
## $ `Right Field` <dbl> 0.2614929, 0.2557405, 0.2585578, 0.2529148, 0.2716858, …Now we make and save the nine position-specific subplots for Figure 9.17.
p1 <-
fitted_positions %>%
pivot_longer(everything(),
values_to = "theta") %>%
# though technically not needed, this line reorders the panels to match the text
mutate(name = factor(name,
levels = c("1st Base", "Catcher", "Pitcher",
"2nd Base", "Center Field", "Right Field",
"3rd Base", "Left Field", "Shortstop"))) %>%
ggplot(aes(x = theta)) +
geom_histogram(fill = a_purple, color = "white",
linewidth = .1, binwidth = .0025) +
stat_pointinterval(aes(y = 0),
point_interval = mode_hdi, .width = .95, size = 1) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(expression(theta)) +
coord_cartesian(xlim = c(.1, .28)) +
theme_minimal_hgrid() +
panel_border() +
facet_wrap(~ name, nrow = 3, scales = "free_y")In this code block, we’ll make the subplot for the overall batting average. Given the size of the model, it’s perhaps easiest to pull that information from the model with the fixef() function.
p2 <-
fixef(fit9.2, summary = F) %>%
as_tibble() %>%
transmute(theta = inv_logit_scaled(Intercept),
name = "Overall") %>%
ggplot(aes(x = theta)) +
geom_histogram(fill = a_purple, color = "white",
linewidth = .2, binwidth = .005) +
stat_pointinterval(aes(y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(expression(theta)) +
coord_cartesian(xlim = c(.1, .28)) +
theme_minimal_hgrid() +
panel_border() +
facet_wrap(~ name)Now combine the plots with a little patchwork magic.
p3 <- plot_spacer()
p1 + (p2 / p3 / p3) +
plot_layout(widths = c(3, 1))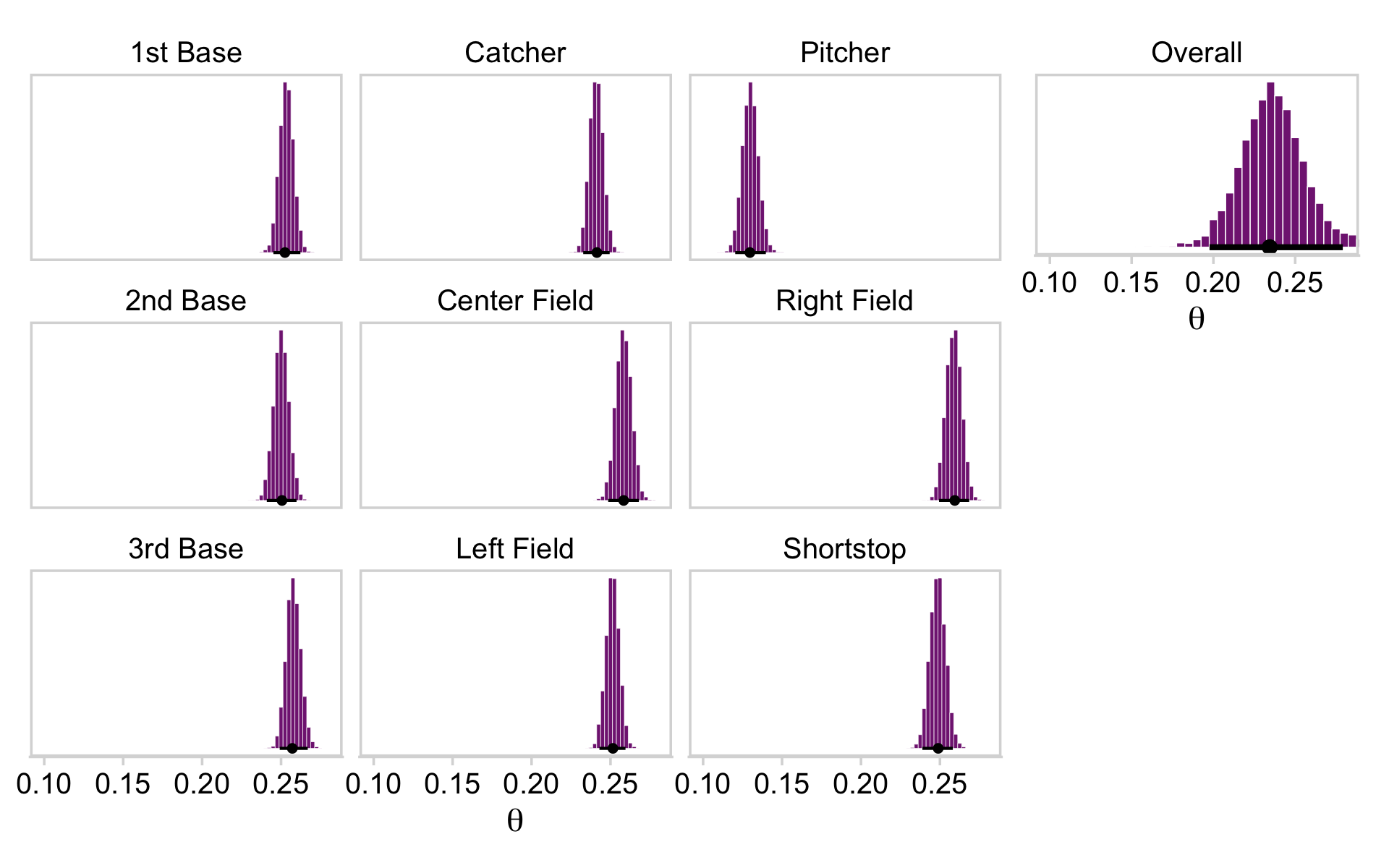
Do note that, unlike Kruschke’s Figure 9.17, our subplots are all based on θ rather than ω. This is because of our use of a hierarchical aggregated binomial, rather than the approach Kruschke took. Even so, look how similar the results are.
Finally, we have only looked at a tiny fraction of the relations among the 968 parameters. We could investigate many more comparisons among parameters if we were specifically interested. In traditional statistical testing based on p-values (which will be discussed in Chapter 11), we would pay a penalty for even intending to make more comparisons. This is because a p value depends on the space of counter-factual possibilities created from the testing intentions. In a Bayesian analysis, however, decisions are based on the posterior distribution, which is based only on the data (and the prior), not on the testing intention. More discussion of multiple comparisons can be found in Section 11.4. (pp. 259–260)
Session info
sessionInfo()## R version 4.2.2 (2022-10-31)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur ... 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidybayes_3.0.2 bayesplot_1.10.0 brms_2.18.0 Rcpp_1.0.9
## [5] viridis_0.6.2 viridisLite_0.4.1 patchwork_1.1.2 ggforce_0.4.1
## [9] ggridges_0.5.4 cowplot_1.1.1 forcats_0.5.1 stringr_1.4.1
## [13] dplyr_1.0.10 purrr_1.0.1 readr_2.1.2 tidyr_1.2.1
## [17] tibble_3.1.8 ggplot2_3.4.0 tidyverse_1.3.2
##
## loaded via a namespace (and not attached):
## [1] readxl_1.4.1 backports_1.4.1 plyr_1.8.7
## [4] igraph_1.3.4 svUnit_1.0.6 splines_4.2.2
## [7] crosstalk_1.2.0 TH.data_1.1-1 rstantools_2.2.0
## [10] inline_0.3.19 digest_0.6.31 htmltools_0.5.3
## [13] fansi_1.0.3 magrittr_2.0.3 checkmate_2.1.0
## [16] googlesheets4_1.0.1 tzdb_0.3.0 modelr_0.1.8
## [19] RcppParallel_5.1.5 matrixStats_0.63.0 vroom_1.5.7
## [22] sandwich_3.0-2 xts_0.12.1 prettyunits_1.1.1
## [25] colorspace_2.0-3 rvest_1.0.2 ggdist_3.2.1
## [28] haven_2.5.1 xfun_0.35 callr_3.7.3
## [31] crayon_1.5.2 jsonlite_1.8.4 lme4_1.1-31
## [34] survival_3.4-0 zoo_1.8-10 glue_1.6.2
## [37] polyclip_1.10-0 gtable_0.3.1 gargle_1.2.0
## [40] emmeans_1.8.0 distributional_0.3.1 pkgbuild_1.3.1
## [43] rstan_2.21.8 abind_1.4-5 scales_1.2.1
## [46] mvtnorm_1.1-3 DBI_1.1.3 miniUI_0.1.1.1
## [49] xtable_1.8-4 HDInterval_0.2.4 bit_4.0.4
## [52] stats4_4.2.2 StanHeaders_2.21.0-7 DT_0.24
## [55] htmlwidgets_1.5.4 httr_1.4.4 threejs_0.3.3
## [58] arrayhelpers_1.1-0 posterior_1.3.1 ellipsis_0.3.2
## [61] pkgconfig_2.0.3 loo_2.5.1 farver_2.1.1
## [64] sass_0.4.2 dbplyr_2.2.1 utf8_1.2.2
## [67] tidyselect_1.2.0 labeling_0.4.2 rlang_1.0.6
## [70] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
## [73] cellranger_1.1.0 tools_4.2.2 cachem_1.0.6
## [76] cli_3.6.0 generics_0.1.3 broom_1.0.2
## [79] evaluate_0.18 fastmap_1.1.0 processx_3.8.0
## [82] knitr_1.40 bit64_4.0.5 fs_1.5.2
## [85] nlme_3.1-160 projpred_2.2.1 mime_0.12
## [88] xml2_1.3.3 compiler_4.2.2 shinythemes_1.2.0
## [91] rstudioapi_0.13 gamm4_0.2-6 reprex_2.0.2
## [94] tweenr_2.0.0 bslib_0.4.0 stringi_1.7.8
## [97] highr_0.9 ps_1.7.2 Brobdingnag_1.2-8
## [100] lattice_0.20-45 Matrix_1.5-1 nloptr_2.0.3
## [103] markdown_1.1 shinyjs_2.1.0 tensorA_0.36.2
## [106] vctrs_0.5.1 pillar_1.8.1 lifecycle_1.0.3
## [109] jquerylib_0.1.4 bridgesampling_1.1-2 estimability_1.4.1
## [112] httpuv_1.6.5 R6_2.5.1 bookdown_0.28
## [115] promises_1.2.0.1 gridExtra_2.3 codetools_0.2-18
## [118] boot_1.3-28 colourpicker_1.1.1 MASS_7.3-58.1
## [121] gtools_3.9.4 assertthat_0.2.1 withr_2.5.0
## [124] shinystan_2.6.0 multcomp_1.4-20 mgcv_1.8-41
## [127] parallel_4.2.2 hms_1.1.1 grid_4.2.2
## [130] minqa_1.2.5 coda_0.19-4 rmarkdown_2.16
## [133] googledrive_2.0.0 shiny_1.7.2 lubridate_1.8.0
## [136] base64enc_0.1-3 dygraphs_1.1.1.6