2 Introduction: Credibility, Models, and Parameters
The goal of this chapter is to introduce the conceptual framework of Bayesian data analysis. Bayesian data analysis has two foundational ideas. The first idea is that Bayesian inference is reallocation of credibility across possibilities. The second foundational idea is that the possibilities, over which we allocate credibility, are parameter values in meaningful mathematical models. (Kruschke, 2015, p. 15)
2.1 Bayesian inference is reallocation of credibility across possibilities
The first step toward making Figure 2.1 is putting together a data object. To help with that, we’ll open up the tidyverse.
library(tidyverse)
d <-
crossing(iteration = 1:3,
stage = factor(c("Prior", "Posterior"),
levels = c("Prior", "Posterior"))) %>%
expand_grid(Possibilities = LETTERS[1:4]) %>%
mutate(Credibility = c(rep(.25, times = 4),
0, rep(1/3, times = 3),
0, rep(1/3, times = 3),
rep(c(0, .5), each = 2),
rep(c(0, .5), each = 2),
rep(0, times = 3), 1))When making data with many repetitions in the rows, it’s good to have the tidyr::expand_grid() function up your sleeve. Go here to learn more.
We can take a look at the top few rows of the data with the head() function.
head(d)## # A tibble: 6 × 4
## iteration stage Possibilities Credibility
## <int> <fct> <chr> <dbl>
## 1 1 Prior A 0.25
## 2 1 Prior B 0.25
## 3 1 Prior C 0.25
## 4 1 Prior D 0.25
## 5 1 Posterior A 0
## 6 1 Posterior B 0.333Before we attempt Figure 2.1, we’ll need two supplemental data frames. The first one, text, will supply the coordinates for the annotation in the plot. The second, arrow, will supply the coordinates for the arrows.
text <-
tibble(Possibilities = "B",
Credibility = .75,
label = str_c(LETTERS[1:3], " is\nimpossible"),
iteration = 1:3,
stage = factor("Posterior",
levels = c("Prior", "Posterior")))
arrow <-
tibble(Possibilities = LETTERS[1:3],
iteration = 1:3) %>%
expand_grid(Credibility = c(0.01, 0.6)) %>%
mutate(stage = factor("Posterior", levels = c("Prior", "Posterior")))Now we’re ready to code our version of Figure 2.1.
d %>%
ggplot(aes(x = Possibilities, y = Credibility)) +
geom_col(color = "grey30", fill = "grey30") +
# annotation in the bottom row
geom_text(data = text,
aes(label = label)) +
# arrows in the bottom row
geom_line(data = arrow,
arrow = arrow(length = unit(0.30, "cm"),
ends = "first", type = "closed")) +
facet_grid(stage ~ iteration) +
theme(axis.ticks.x = element_blank(),
panel.grid = element_blank(),
strip.text.x = element_blank())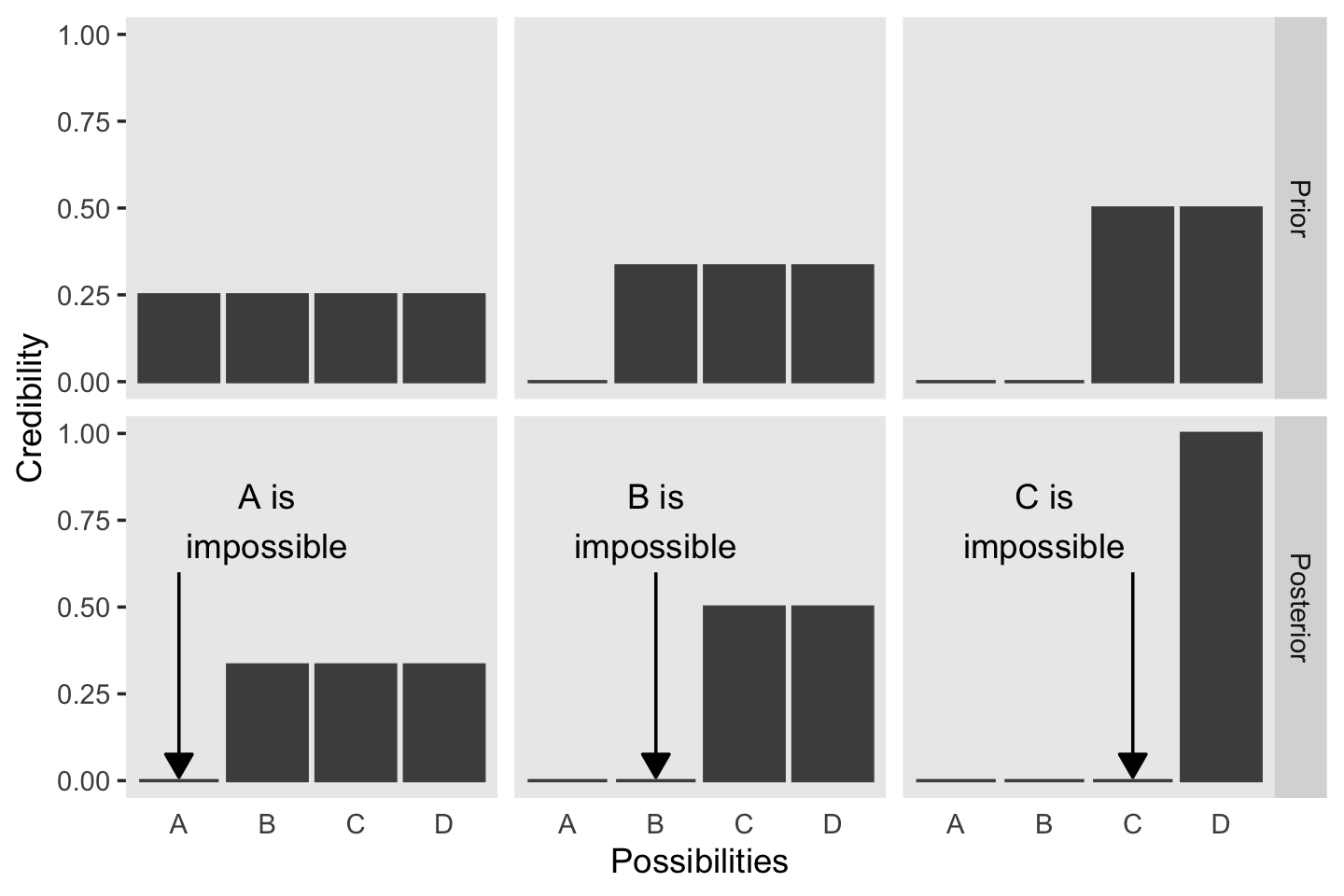
We will take a similar approach to make our version of Figure 2.2. But this time, we’ll define our supplemental data sets directly in geom_text() and geom_line(). It’s good to have both methods up your sleeve. Also notice how we simply fed our primary data set directly into ggplot() without saving it, either.
# primary data
crossing(stage = factor(c("Prior", "Posterior"),
levels = c("Prior", "Posterior")),
Possibilities = LETTERS[1:4]) %>%
mutate(Credibility = c(rep(0.25, times = 4),
rep(0, times = 3),
1)) %>%
# plot!
ggplot(aes(x = Possibilities, y = Credibility)) +
geom_col(color = "grey30", fill = "grey30") +
# annotation in the bottom panel
geom_text(data = tibble(
Possibilities = "B",
Credibility = .8,
label = "D is\nresponsible",
stage = factor("Posterior", levels = c("Prior", "Posterior"))
), aes(label = label)
) +
# the arrow
geom_line(data = tibble(
Possibilities = LETTERS[c(4, 4)],
Credibility = c(.25, .99),
stage = factor("Posterior", levels = c("Prior", "Posterior"))
),
arrow = arrow(length = unit(0.30, "cm"), ends = "last", type = "closed"),
color = "grey92") +
facet_wrap(~ stage, ncol = 1) +
theme(axis.ticks.x = element_blank(),
panel.grid = element_blank())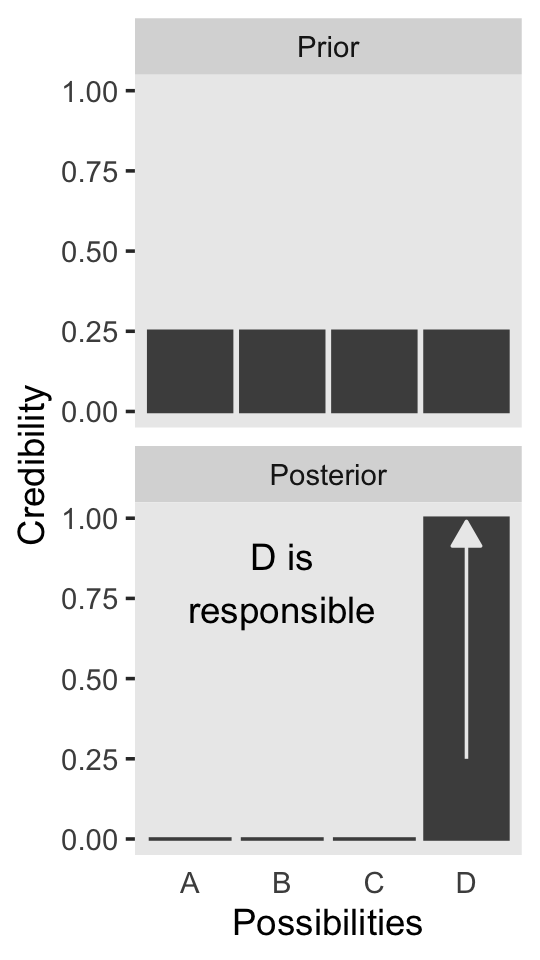
2.1.1 Data are noisy and inferences are probabilistic.
Now on to Figure 2.3. I’m pretty sure the curves in the plot are Gaussian, which we’ll make with the dnorm() function. After a little trial and error, their standard deviations look to be 1.2. However, it’s tricky placing those curves in along with the probabilities, because the probabilities for the four discrete sizes (i.e., 1 through 4) are in a different metric than the Gaussian density curves. Since the probability metric for the four discrete sizes are the primary metric of the plot, we need to rescale the curves using a little algebra, which we do in the data code below. After that, the code for the plot is relatively simple.
# data
tibble(mu = 1:4,
p = .25) %>%
expand_grid(x = seq(from = -2, to = 6, by = .1)) %>%
mutate(density = dnorm(x, mean = mu, sd = 1.2)) %>%
mutate(d_max = max(density)) %>%
mutate(rescale = p / d_max) %>%
mutate(density = density * rescale) %>%
# plot!
ggplot(aes(x = x)) +
geom_col(data = . %>% distinct(mu, p),
aes(x = mu, y = p),
fill = "grey67", width = 1/3) +
geom_line(aes(y = density, group = mu)) +
scale_x_continuous(breaks = 1:4) +
scale_y_continuous(breaks = 0:5 / 5) +
coord_cartesian(xlim = c(0, 5),
ylim = c(0, 1)) +
labs(title = "Prior",
x = "Possibilities",
y = "Credibility") +
theme(axis.ticks.x = element_blank(),
panel.grid = element_blank())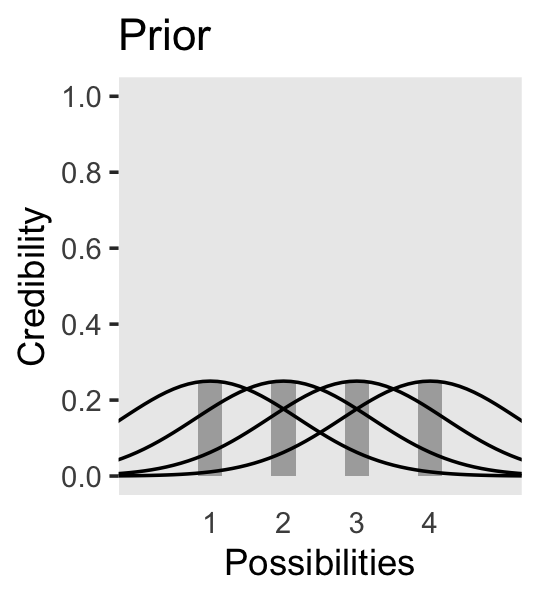
We can use the same basic method to make the bottom panel of Figure 2.3. Kruschke gave the relative probability values on page 21. Notice that they sum perfectly to 1. The only other notable change from the previous plot is our addition of a geom_point() section, the data in which we defined on the fly.
tibble(mu = 1:4,
p = c(.11, .56, .31, .02)) %>%
expand_grid(x = seq(from = -2, to = 6, by = .1)) %>%
mutate(density = dnorm(x, mean = mu, sd = 1.2)) %>%
mutate(d_max = max(density)) %>%
mutate(rescale = p / d_max) %>%
mutate(density = density * rescale) %>%
# plot!
ggplot() +
geom_col(data = . %>% distinct(mu, p),
aes(x = mu, y = p),
fill = "grey67", width = 1/3) +
geom_line(aes(x = x, y = density, group = mu)) +
geom_point(data = tibble(x = c(1.75, 2.25, 2.75), y = 0),
aes(x = x, y = y),
size = 3, color = "grey33", alpha = 3/4) +
scale_x_continuous(breaks = 1:4) +
scale_y_continuous(breaks = 0:5 / 5) +
coord_cartesian(xlim = c(0, 5),
ylim = c(0, 1)) +
labs(title = "Posterior",
x = "Possibilities",
y = "Credibility") +
theme(axis.ticks.x = element_blank(),
panel.grid = element_blank())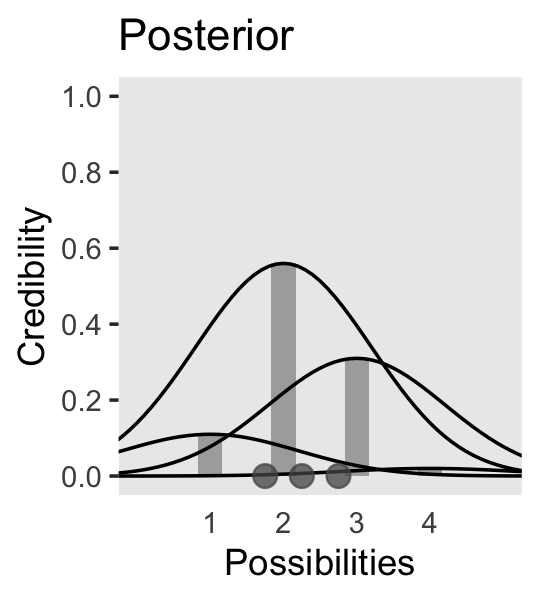
In summary, the essence of Bayesian inference is reallocation of credibility across possibilities. The distribution of credibility initially reflects prior knowledge about the possibilities, which can be quite vague. Then new data are observed, and the credibility is re-allocated. Possibilities that are consistent with the data garner more credibility, while possibilities that are not consistent with the data lose credibility. Bayesian analysis is the mathematics of re-allocating credibility in a logically coherent and precise way. (p. 22)
2.2 Possibilities are parameter values in descriptive models
“A key step in Bayesian analysis is defining the set of possibilities over which credibility is allocated. This is not a trivial step, because there might always be possibilities beyond the ones we include in the initial set” (p. 22, emphasis added).
In the last section, we used the dnorm() function to make curves following the normal distribution (a.k.a. the Gaussian distribution). Here we’ll do that again, but also use the rnorm() function to simulate actual data from that same normal distribution. Behold Figure 2.4.a.
# set the seed to make the simulation reproducible
set.seed(2)
# simulate the data with `rnorm()`
d <- tibble(x = rnorm(2000, mean = 10, sd = 5))
# plot!
ggplot(data = d, aes(x = x)) +
geom_histogram(aes(y = after_stat(density)),
binwidth = 1, fill = "grey67",
color = "grey92", linewidth = 1/10) +
geom_line(data = tibble(x = seq(from = -6, to = 26, by = .01)),
aes(x = x, y = dnorm(x, mean = 10, sd = 5)),
color = "grey33") +
coord_cartesian(xlim = c(-5, 25)) +
labs(subtitle = "The candidate normal distribution\nhas a mean of 10 and SD of 5.",
x = "Data Values",
y = "Data Probability") +
theme(panel.grid = element_blank())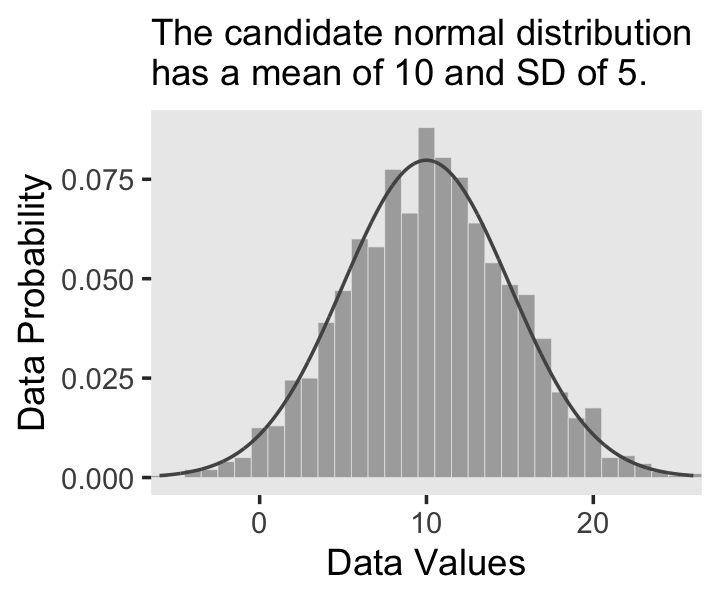
Did you notice how we made the data for the density curve within geom_line()? That’s one way to do it, and in our next plot we’ll take a more elegant approach with the stat_function() function. Here’s our Figure 2.4.b.
ggplot(data = d, aes(x = x)) +
geom_histogram(aes(y = after_stat(density)),
binwidth = 1, fill = "grey67",
color = "grey92", linewidth = 1/8) +
stat_function(fun = dnorm, n = 101, args = list(mean = 8, sd = 6),
color = "grey33", linetype = 2) +
coord_cartesian(xlim = c(-5, 25)) +
labs(subtitle = "The candidate normal distribution\nhas a mean of 8 and SD of 6.",
x = "Data Values",
y = "Data Probability") +
theme(panel.grid = element_blank())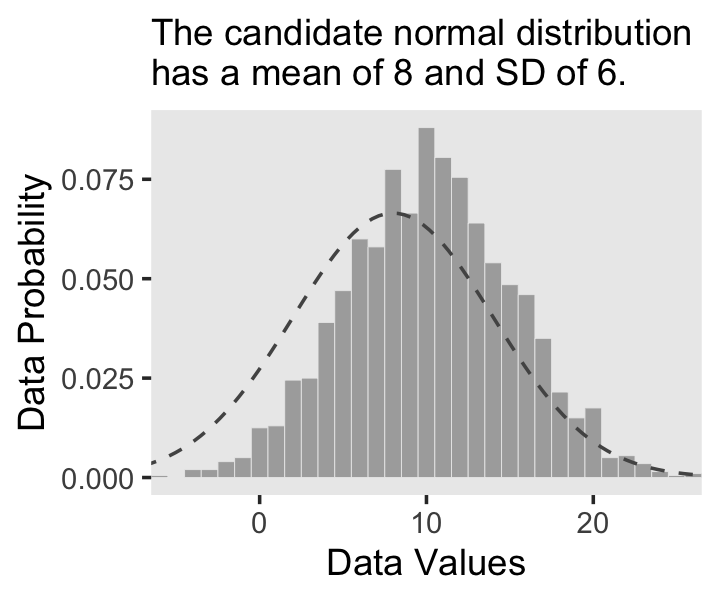
2.3 The steps of Bayesian data analysis
In general, Bayesian analysis of data follows these steps:
- Identify the data relevant to the research questions. What are the measurement scales of the data? Which data variables are to be predicted, and which data variables are supposed to act as predictors?
- Define a descriptive model for the relevant data. The mathematical form and its parameters should be meaningful and appropriate to the theoretical purposes of the analysis.
- Specify a prior distribution on the parameters. The prior must pass muster with the audience of the analysis, such as skeptical scientists.
- Use Bayesian inference to re-allocate credibility across parameter values. Interpret the posterior distribution with respect to theoretically meaningful issues (assuming that the model is a reasonable description of the data; see next step).
- Check that the posterior predictions mimic the data with reasonable accuracy (i.e., conduct a “posterior predictive check”). If not, then consider a different descriptive model.
Perhaps the best way to explain these steps is with a realistic example of Bayesian data analysis. The discussion that follows is abbreviated for purposes of this introductory chapter, with many technical details suppressed. (p. 25)
I will show you a few more details than Kruschke did in the text. But just has he did, we’ll cover this workflow in much more detail in the chapters to come.
In order to recreate Figure 2.5, we need to generate the data and fit a model to those data. In his HtWtDataDenerator.R script, Kruschke provided the code for a function that will generate height/weight data of the kind in his text. Here is the code in full:
HtWtDataGenerator <- function(nSubj, rndsd = NULL, maleProb = 0.50) {
# Random height, weight generator for males and females. Uses parameters from
# Brainard, J. & Burmaster, D. E. (1992). Bivariate distributions for height and
# weight of men and women in the United States. Risk Analysis, 12(2), 267-275.
# Kruschke, J. K. (2011). Doing Bayesian data analysis:
# A Tutorial with R and BUGS. Academic Press / Elsevier.
# Kruschke, J. K. (2014). Doing Bayesian data analysis, 2nd Edition:
# A Tutorial with R, JAGS and Stan. Academic Press / Elsevier.
# require(MASS)
# Specify parameters of multivariate normal (MVN) distributions.
# Men:
HtMmu <- 69.18
HtMsd <- 2.87
lnWtMmu <- 5.14
lnWtMsd <- 0.17
Mrho <- 0.42
Mmean <- c(HtMmu, lnWtMmu)
Msigma <- matrix(c(HtMsd^2, Mrho * HtMsd * lnWtMsd,
Mrho * HtMsd * lnWtMsd, lnWtMsd^2), nrow = 2)
# Women cluster 1:
HtFmu1 <- 63.11
HtFsd1 <- 2.76
lnWtFmu1 <- 5.06
lnWtFsd1 <- 0.24
Frho1 <- 0.41
prop1 <- 0.46
Fmean1 <- c(HtFmu1, lnWtFmu1)
Fsigma1 <- matrix(c(HtFsd1^2, Frho1 * HtFsd1 * lnWtFsd1,
Frho1 * HtFsd1 * lnWtFsd1, lnWtFsd1^2), nrow = 2)
# Women cluster 2:
HtFmu2 <- 64.36
HtFsd2 <- 2.49
lnWtFmu2 <- 4.86
lnWtFsd2 <- 0.14
Frho2 <- 0.44
prop2 <- 1 - prop1
Fmean2 <- c(HtFmu2, lnWtFmu2)
Fsigma2 <- matrix(c(HtFsd2^2, Frho2 * HtFsd2 * lnWtFsd2,
Frho2 * HtFsd2 * lnWtFsd2, lnWtFsd2^2), nrow = 2)
# Randomly generate data values from those MVN distributions.
if (!is.null(rndsd)) {set.seed(rndsd)}
datamatrix <- matrix(0, nrow = nSubj, ncol = 3)
colnames(datamatrix) <- c("male", "height", "weight")
maleval <- 1; femaleval <- 0 # arbitrary coding values
for (i in 1:nSubj) {
# Flip coin to decide sex
sex <- sample(c(maleval, femaleval), size = 1, replace = TRUE,
prob = c(maleProb, 1 - maleProb))
if (sex == maleval) {datum = MASS::mvrnorm(n = 1, mu = Mmean, Sigma = Msigma)}
if (sex == femaleval) {
Fclust = sample(c(1, 2), size = 1, replace = TRUE, prob = c(prop1, prop2))
if (Fclust == 1) {datum = MASS::mvrnorm(n = 1, mu = Fmean1, Sigma = Fsigma1)}
if (Fclust == 2) {datum = MASS::mvrnorm(n = 1, mu = Fmean2, Sigma = Fsigma2)}
}
datamatrix[i, ] = c(sex, round(c(datum[1], exp(datum[2])), 1))
}
return(datamatrix)
} # end functionNow we have the HtWtDataGenerator() function, all we need to do is determine how many values to generate and how probable we want the values to be based on those from men. These are controlled by the nSubj and maleProb parameters.
# set your seed to make the data generation reproducible
set.seed(2)
d <-
HtWtDataGenerator(nSubj = 57, maleProb = .5) %>%
as_tibble()
d %>%
head()## # A tibble: 6 × 3
## male height weight
## <dbl> <dbl> <dbl>
## 1 0 62.6 109.
## 2 0 63.3 154.
## 3 1 71.8 155
## 4 0 67.9 146.
## 5 0 64.4 135.
## 6 0 66.8 119We’re about ready for the model, which we will fit it with the Hamiltonian Monte Carlo (HMC) method via the brms package. We’ll introduce brms more fully in Chapter 8 and you can go here for an introduction, too. In the meantime, let’s just load the package and see what happens.
library(brms)The traditional use of diffuse and noninformative priors is discouraged with HMC, as is the uniform distribution for sigma. Instead, we’ll use weakly-regularizing priors for the intercept and slope and a half Cauchy with a fairly large scale parameter for σ.
fit2.1 <-
brm(data = d,
family = gaussian,
weight ~ 1 + height,
prior = c(prior(normal(0, 100), class = Intercept),
prior(normal(0, 100), class = b),
prior(cauchy(0, 10), class = sigma)),
chains = 4, cores = 4, iter = 2000, warmup = 1000,
seed = 2,
file = "fits/fit02.01")If you wanted a quick model summary, you could execute print(fit1). Again, we’ll walk through that and other diagnostics in greater detail starting in Chapter 8. For now, here’s how we might make Figure 2.5.a.
# extract the posterior draws
draws <- as_draws_df(fit2.1)
# this will subset the output
n_lines <- 150
# plot!
draws %>%
slice(1:n_lines) %>%
ggplot() +
geom_abline(aes(intercept = b_Intercept, slope = b_height, group = .draw),
color = "grey50", linewidth = 1/4, alpha = .3) +
geom_point(data = d,
aes(x = height, y = weight),
shape = 1) +
# the `eval(substitute(paste()))` trick came from: https://www.r-bloggers.com/value-of-an-r-object-in-an-expression/
labs(subtitle = eval(substitute(paste("Data with", n_lines, "credible regression lines"))),
x = "Height in inches",
y = "Weight in pounds") +
coord_cartesian(xlim = c(55, 80),
ylim = c(50, 250)) +
theme(panel.grid = element_blank())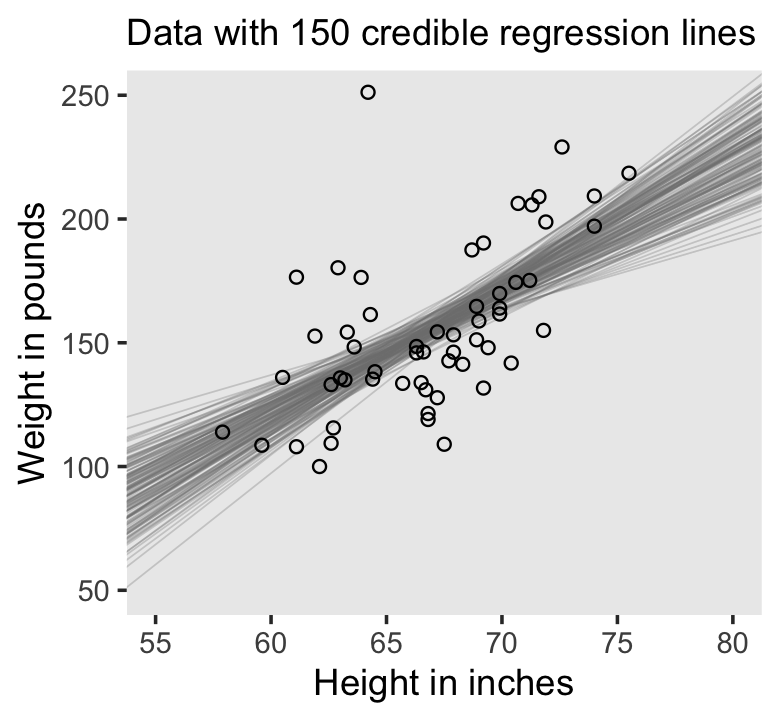
For Figure 2.5.b., we’ll mark off the mode and 95% highest density interval (HDI) with help from the handy stat_histinterval() function, provided by the tidybayes package (Kay, 2022b).
library(tidybayes)
draws %>%
ggplot(aes(x = b_height, y = 0)) +
stat_histinterval(point_interval = mode_hdi, .width = .95,
fill = "grey67", slab_color = "grey92",
breaks = 40, slab_size = .2, outline_bars = T) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(0, 8)) +
labs(title = "The posterior distribution",
subtitle = "The mode and 95% HPD intervals are\nthe dot and horizontal line at the bottom.",
x = expression(beta[1]~(slope))) +
theme(panel.grid = element_blank())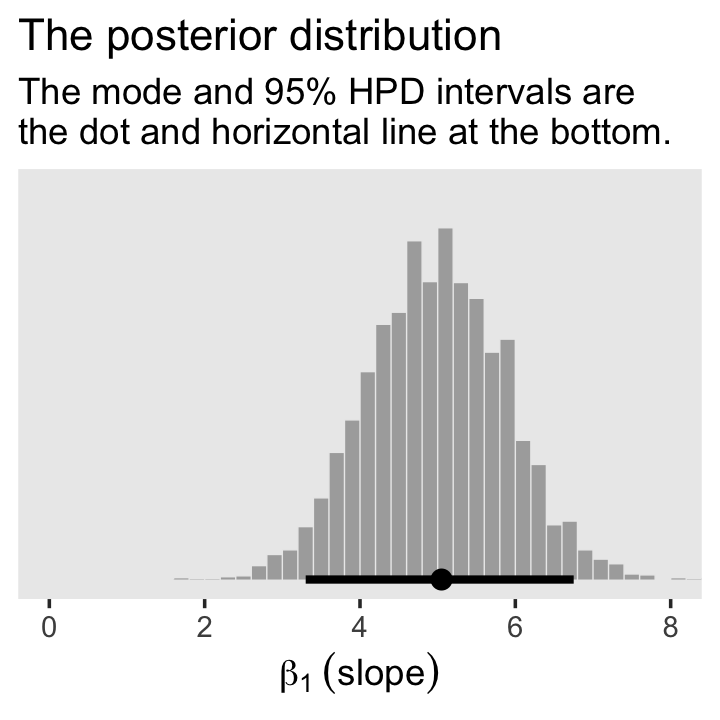
To make Figure 2.6, we use the brms::predict() function, which we’ll cover more fully in the pages to come.
nd <- tibble(height = seq(from = 53, to = 81, length.out = 20))
predict(fit2.1, newdata = nd) %>%
data.frame() %>%
bind_cols(nd) %>%
ggplot(aes(x = height)) +
geom_pointrange(aes(y = Estimate, ymin = Q2.5, ymax = Q97.5),
color = "grey67", shape = 20) +
geom_point(data = d,
aes(y = weight),
alpha = 2/3) +
labs(subtitle = "Data with the percentile-based 95% intervals and\nthe means of the posterior predictions",
x = "Height in inches",
y = "Weight in inches") +
theme(panel.grid = element_blank())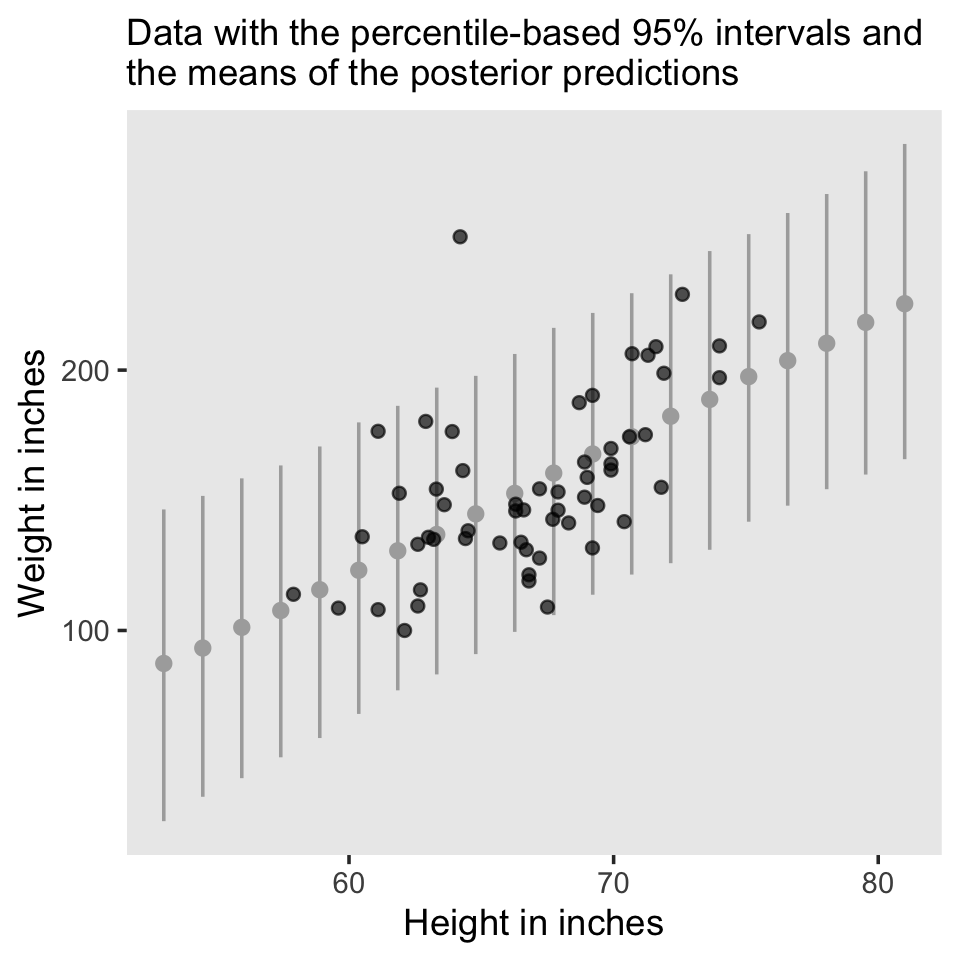
The posterior predictions might be easier to depict with a ribbon and line, instead.
nd <- tibble(height = seq(from = 53, to = 81, length.out = 30))
predict(fit2.1, newdata = nd) %>%
data.frame() %>%
bind_cols(nd) %>%
ggplot(aes(x = height)) +
geom_ribbon(aes(ymin = Q2.5, ymax = Q97.5), fill = "grey75") +
geom_line(aes(y = Estimate),
color = "grey92") +
geom_point(data = d,
aes(y = weight),
alpha = 2/3) +
labs(subtitle = "Data with the percentile-based 95% intervals and\nthe means of the posterior predictions",
x = "Height in inches",
y = "Weight in inches") +
theme(panel.grid = element_blank())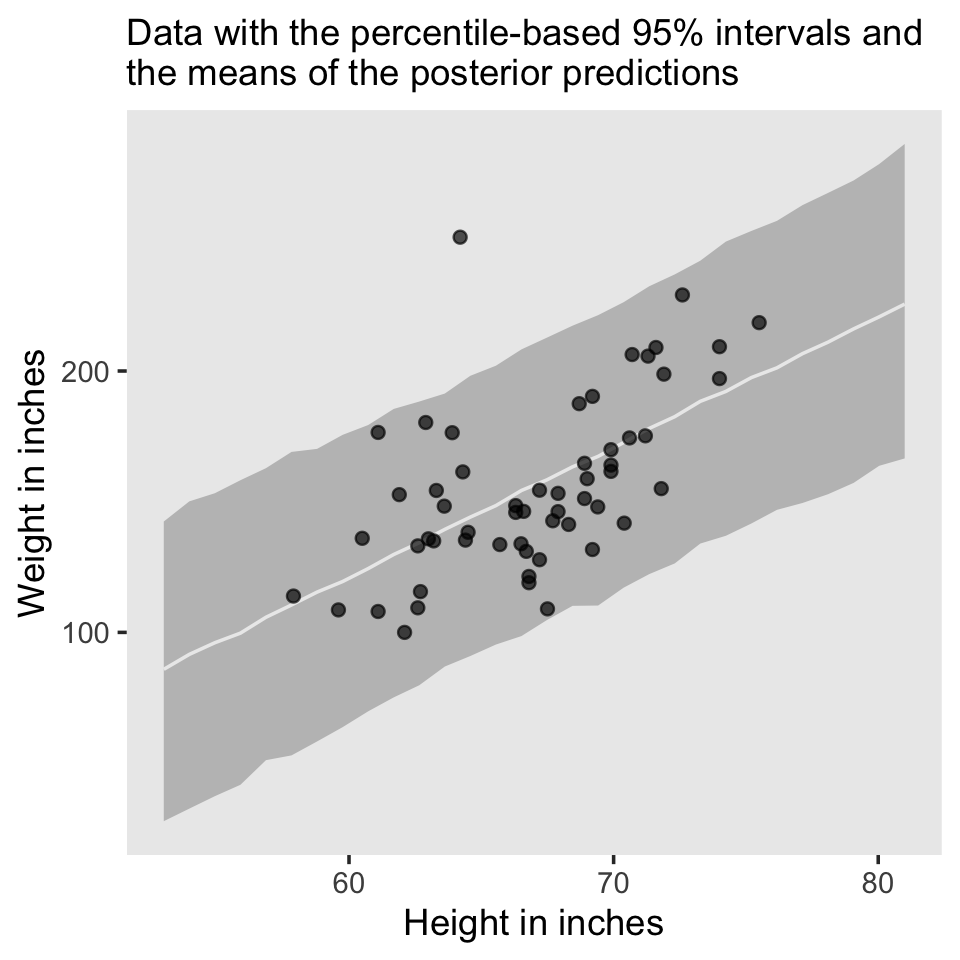
“We have seen the five steps of Bayesian analysis in a fairly realistic example. This book explains how to do this sort of analysis for many different applications and types of descriptive models” (p. 30). Are you intrigued and excited? You should be. Welcome to Bayes, friends!
Session info
sessionInfo()## R version 4.2.2 (2022-10-31)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur ... 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidybayes_3.0.2 brms_2.18.0 Rcpp_1.0.9 forcats_0.5.1
## [5] stringr_1.4.1 dplyr_1.0.10 purrr_1.0.1 readr_2.1.2
## [9] tidyr_1.2.1 tibble_3.1.8 ggplot2_3.4.0 tidyverse_1.3.2
##
## loaded via a namespace (and not attached):
## [1] readxl_1.4.1 backports_1.4.1 plyr_1.8.7
## [4] igraph_1.3.4 svUnit_1.0.6 splines_4.2.2
## [7] crosstalk_1.2.0 TH.data_1.1-1 rstantools_2.2.0
## [10] inline_0.3.19 digest_0.6.31 htmltools_0.5.3
## [13] fansi_1.0.3 magrittr_2.0.3 checkmate_2.1.0
## [16] googlesheets4_1.0.1 tzdb_0.3.0 modelr_0.1.8
## [19] RcppParallel_5.1.5 matrixStats_0.63.0 xts_0.12.1
## [22] sandwich_3.0-2 prettyunits_1.1.1 colorspace_2.0-3
## [25] rvest_1.0.2 ggdist_3.2.1 haven_2.5.1
## [28] xfun_0.35 callr_3.7.3 crayon_1.5.2
## [31] jsonlite_1.8.4 lme4_1.1-31 survival_3.4-0
## [34] zoo_1.8-10 glue_1.6.2 gtable_0.3.1
## [37] gargle_1.2.0 emmeans_1.8.0 distributional_0.3.1
## [40] pkgbuild_1.3.1 rstan_2.21.8 abind_1.4-5
## [43] scales_1.2.1 mvtnorm_1.1-3 DBI_1.1.3
## [46] miniUI_0.1.1.1 xtable_1.8-4 HDInterval_0.2.4
## [49] stats4_4.2.2 StanHeaders_2.21.0-7 DT_0.24
## [52] htmlwidgets_1.5.4 httr_1.4.4 threejs_0.3.3
## [55] arrayhelpers_1.1-0 posterior_1.3.1 ellipsis_0.3.2
## [58] pkgconfig_2.0.3 loo_2.5.1 farver_2.1.1
## [61] sass_0.4.2 dbplyr_2.2.1 utf8_1.2.2
## [64] tidyselect_1.2.0 labeling_0.4.2 rlang_1.0.6
## [67] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
## [70] cellranger_1.1.0 tools_4.2.2 cachem_1.0.6
## [73] cli_3.6.0 generics_0.1.3 broom_1.0.2
## [76] evaluate_0.18 fastmap_1.1.0 processx_3.8.0
## [79] knitr_1.40 fs_1.5.2 nlme_3.1-160
## [82] mime_0.12 projpred_2.2.1 xml2_1.3.3
## [85] compiler_4.2.2 bayesplot_1.10.0 shinythemes_1.2.0
## [88] rstudioapi_0.13 gamm4_0.2-6 reprex_2.0.2
## [91] bslib_0.4.0 stringi_1.7.8 highr_0.9
## [94] ps_1.7.2 Brobdingnag_1.2-8 lattice_0.20-45
## [97] Matrix_1.5-1 nloptr_2.0.3 markdown_1.1
## [100] shinyjs_2.1.0 tensorA_0.36.2 vctrs_0.5.1
## [103] pillar_1.8.1 lifecycle_1.0.3 jquerylib_0.1.4
## [106] bridgesampling_1.1-2 estimability_1.4.1 httpuv_1.6.5
## [109] R6_2.5.1 bookdown_0.28 promises_1.2.0.1
## [112] gridExtra_2.3 codetools_0.2-18 boot_1.3-28
## [115] colourpicker_1.1.1 MASS_7.3-58.1 gtools_3.9.4
## [118] assertthat_0.2.1 withr_2.5.0 shinystan_2.6.0
## [121] multcomp_1.4-20 mgcv_1.8-41 parallel_4.2.2
## [124] hms_1.1.1 grid_4.2.2 minqa_1.2.5
## [127] coda_0.19-4 rmarkdown_2.16 googledrive_2.0.0
## [130] shiny_1.7.2 lubridate_1.8.0 base64enc_0.1-3
## [133] dygraphs_1.1.1.6