18 Metric Predicted Variable with Multiple Metric Predictors
We will consider models in which the predicted variable is an additive combination of predictors, all of which have proportional influence on the prediction. This kind of model is called multiple linear regression. We will also consider nonadditive combinations of predictors, which are called interactions. (Kruschke, 2015, p. 509, emphasis in the original)
18.1 Multiple linear regression
Say we have one criterion y and two predictors, x1 and x2. If y∼Normal(μ,σ) and μ=β0+β1x1+β2x2, then it’s also the case that we can rewrite the formula for y as
y∼Normal(β0+β1x1+β2x2,σ).
As Kruschke pointed out, the basic model “assumes homogeneity of variance, which means that at all values of x1 and x2, the variance σ2 of y is the same” (p. 510).
If we presume the data for the two x variables are uniformly distributed within 0 and 10, we can make the data for Figure 18.1 like this.
library(tidyverse)
n <- 300
set.seed(18)
d <-
tibble(x_1 = runif(n = n, min = 0, max = 10),
x_2 = runif(n = n, min = 0, max = 10)) %>%
mutate(y = rnorm(n = n, mean = 10 + x_1 + 2 * x_2, sd = 2))
head(d) ## # A tibble: 6 × 3
## x_1 x_2 y
## <dbl> <dbl> <dbl>
## 1 8.23 8.62 38.4
## 2 7.10 1.33 20.8
## 3 9.66 1.08 17.1
## 4 0.786 7.09 25.2
## 5 0.536 6.67 27.3
## 6 5.75 4.72 26.1Before we plot those d data, we’ll want to make a data object containing the information necessary to make the grid lines for Kruschke’s 3D regression plane. To my mind, this will be easier to do in stages. If you look at the top upper panel of Figure 18.1 as a reference, our first step will be to make the vertical lines. Save them as d1.
theme_set(
theme_linedraw() +
theme(panel.grid = element_blank())
)
d1 <-
tibble(index = 1:21,
x_1 = seq(from = 0, to = 10, length.out = 21)) %>%
expand_grid(x_2 = c(0, 10)) %>%
mutate(y = 10 + 1 * x_1 + 2 * x_2)
d1 %>%
ggplot(aes(x = x_1, y = y, group = index)) +
geom_path(color = "grey85") +
ylim(0, 50)
You may have noticed our theme_set() lines at the top. Though we’ll be using a different default theme later in the project, this is the best theme to use for these initial few plots. Okay, now let’s make the more horizontally-oriented grid lines and save them as d2.
d2 <-
tibble(index = 1:21 + 21,
x_2 = seq(from = 0, to = 10, length.out = 21)) %>%
expand_grid(x_1 = c(0, 10)) %>%
mutate(y = 10 + 1 * x_1 + 2 * x_2)
d2 %>%
ggplot(aes(x = x_1, y = y, group = index)) +
geom_path(color = "grey85") +
ylim(0, 50)
Now combine the two and save them as grid.
grid <-
bind_rows(d1, d2)
grid %>%
ggplot(aes(x = x_1, y = y, group = index)) +
geom_path(color = "grey85") +
ylim(0, 50)
grid %>%
ggplot(aes(x = x_2, y = y, group = index)) +
geom_path(color = "grey85") +
ylim(0, 50)
grid %>%
ggplot(aes(x = x_1, y = x_2, group = index)) +
geom_path(color = "grey85")
We’re finally ready combine d and grid to make the three 2D scatter plots from Figure 18.1.
d %>%
ggplot(aes(x = x_1, y = y)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_segment(aes(xend = x_1,
yend = 10 + x_1 + 2 * x_2),
linewidth = 1/4, linetype = 3) +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2) +
scale_y_continuous(limits = c(0, 50), expand = c(0, 0))
d %>%
ggplot(aes(x = x_2, y = y)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_segment(aes(xend = x_2,
yend = 10 + x_1 + 2 * x_2),
linewidth = 1/4, linetype = 3) +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2) +
scale_y_continuous(limits = c(0, 50), expand = c(0, 0))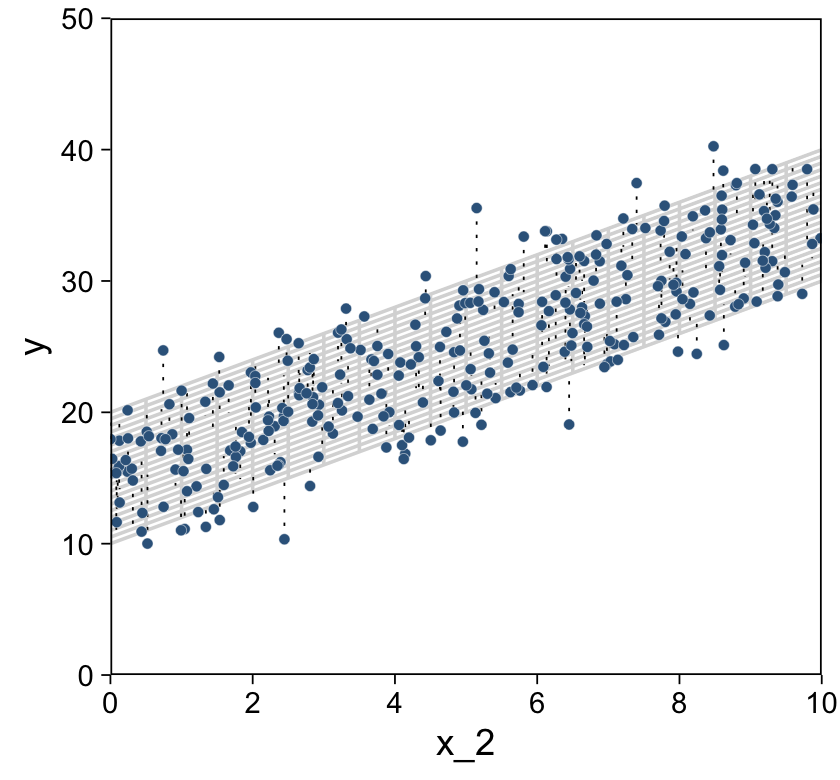
d %>%
ggplot(aes(x = x_1, y = x_2)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2) +
scale_y_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2)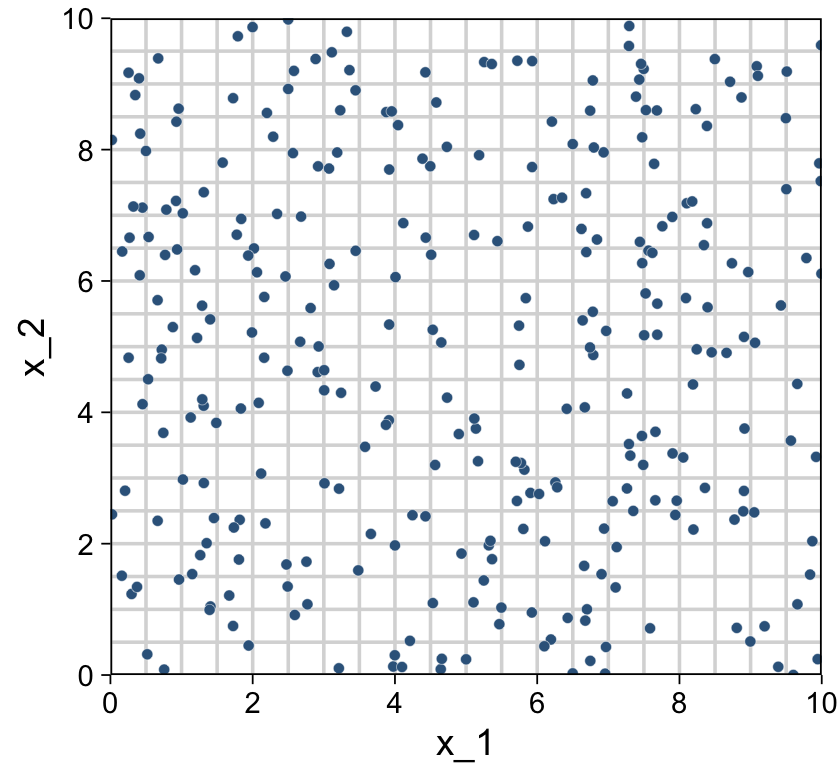
As in previous chapters, I’m not aware that ggplot2 allows for three-dimensional wireframe plots of the kind in the upper left panel. If you’d like to make one in base R, have at it.
For Figure 18.2, the x variables look to be multivariate normal with a correlation of about -.95. We can simulate such data with help from the MASS package (Ripley, 2022; Venables & Ripley, 2002).
Sven Hohenstein’s answer to this stats.stackexchange.com question provides the steps for simulating the data. First, we’ll need to specify the desired means and standard deviations for our variables. Then we’ll make a correlation matrix with 1s on the diagonal and the desired correlation coefficient, ρ on the off-diagonal. Since the correlation matrix is symmetric, both off-diagonal positions are the same. Then we convert the correlation matrix to a covariance matrix.
mus <- c(5, 5)
sds <- c(2, 2)
cors <- matrix(c(1, -.95,
-.95, 1),
ncol = 2)
cors## [,1] [,2]
## [1,] 1.00 -0.95
## [2,] -0.95 1.00covs <- sds %*% t(sds) * cors
covs## [,1] [,2]
## [1,] 4.0 -3.8
## [2,] -3.8 4.0Now we’ve defined our means, standard deviations, and covariance matrix, we’re ready to simulate the data with the MASS::mvrnorm() function.
# how many data points would you like to simulate?
n <- 300
set.seed(18.2)
d <-
MASS::mvrnorm(n = n,
mu = mus,
Sigma = covs,
empirical = T) %>%
as_tibble() %>%
set_names("x_1", "x_2") %>%
mutate(y = rnorm(n = n, mean = 10 + x_1 + 2 * x_2, sd = 2))Now we have our simulated data in hand, we’re ready for three of the four panels of Figure 18.2.
p1 <-
d %>%
ggplot(aes(x = x_1, y = y)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_segment(aes(xend = x_1,
yend = 10 + x_1 + 2 * x_2),
linewidth = 1/4, linetype = 3) +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2) +
scale_y_continuous(limits = c(0, 50), expand = c(0, 0))
p2 <-
d %>%
ggplot(aes(x = x_2, y = y)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_segment(aes(xend = x_2,
yend = 10 + x_1 + 2 * x_2),
linewidth = 1/4, linetype = 3) +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2) +
scale_y_continuous(limits = c(0, 50), expand = c(0, 0))
p3 <-
d %>%
ggplot(aes(x = x_1, y = x_2)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2) +
scale_y_continuous(limits = c(0, 10), expand = c(0, 0), breaks = 0:5 * 2)
# bind them together with patchwork
library(patchwork)
plot_spacer() + p1 + p2 + p3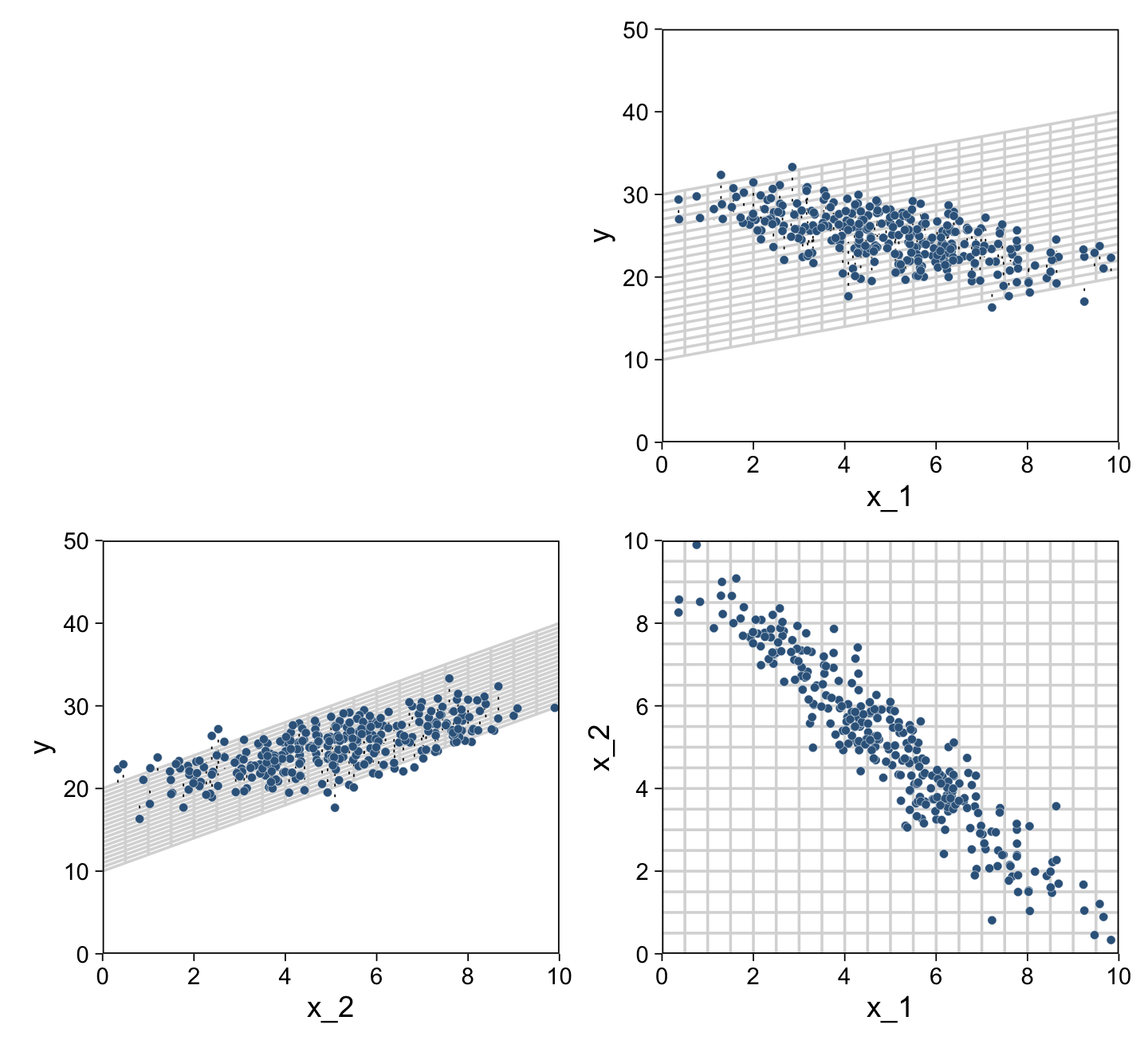
We came pretty close.
18.1.1 The perils of correlated predictors.
Figures 18.1 and 18.2 show data generated from the same model. In both figures, σ=2, β0=10, β1=1, β2=2. All that differs between the two figures is the distribution of the ⟨x1,x2⟩ values, which is not specified by the model. In Figure 18.1, the ⟨x1,x2⟩ values are distributed independently. In Figure 18.2, the ⟨x1,x2⟩ values are negatively correlated: When x1 is small, x2 tends to be large, and when x1 is large, x2 tends to be small. (p. 510)
If you look closely at our simulation code from above, you’ll see we have done so, too.
Real data often have correlated predictors. For example, consider trying to predict a state’s average high-school SAT score on the basis of the amount of money the state spends per pupil. If you plot only mean SAT against money spent, there is actually a decreasing trend… (p. 513, emphasis in the original)
Before we remake Figure 18.3 to examine that decreasing trend, we’ll need to load the data from (Guber, 1999).
my_data <- read_csv("data.R/Guber1999data.csv")
glimpse(my_data)## Rows: 50
## Columns: 8
## $ State <chr> "Alabama", "Alaska", "Arizona", "Arkansas", "California", "C…
## $ Spend <dbl> 4.405, 8.963, 4.778, 4.459, 4.992, 5.443, 8.817, 7.030, 5.71…
## $ StuTeaRat <dbl> 17.2, 17.6, 19.3, 17.1, 24.0, 18.4, 14.4, 16.6, 19.1, 16.3, …
## $ Salary <dbl> 31.144, 47.951, 32.175, 28.934, 41.078, 34.571, 50.045, 39.0…
## $ PrcntTake <dbl> 8, 47, 27, 6, 45, 29, 81, 68, 48, 65, 57, 15, 13, 58, 5, 9, …
## $ SATV <dbl> 491, 445, 448, 482, 417, 462, 431, 429, 420, 406, 407, 468, …
## $ SATM <dbl> 538, 489, 496, 523, 485, 518, 477, 468, 469, 448, 482, 511, …
## $ SATT <dbl> 1029, 934, 944, 1005, 902, 980, 908, 897, 889, 854, 889, 979…Before we get all excited and try to plot those data as in Figure 18.3, we’ll need to redefine the 3D grid of our regression plane, this time based on the equation at the top of Figure 18.3.
d1 <-
tibble(index = 1:21,
Spend = seq(from = 3.4, to = 10.1, length.out = 21)) %>%
expand_grid(PrcntTake = c(0, 85))
d2 <-
tibble(index = 1:21 + 21,
PrcntTake = seq(from = 0, to = 85, length.out = 21)) %>%
expand_grid(Spend = c(3.4, 10.1))
grid <-
bind_rows(d1, d2) %>%
mutate(SATT = 993.8 + -2.9 * PrcntTake + 12.3 * Spend)
grid %>% glimpse()## Rows: 84
## Columns: 4
## $ index <dbl> 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10…
## $ Spend <dbl> 3.400, 3.400, 3.735, 3.735, 4.070, 4.070, 4.405, 4.405, 4.74…
## $ PrcntTake <dbl> 0, 85, 0, 85, 0, 85, 0, 85, 0, 85, 0, 85, 0, 85, 0, 85, 0, 8…
## $ SATT <dbl> 1035.6200, 789.1200, 1039.7405, 793.2405, 1043.8610, 797.361…Now we have our updated grid object, we’re ready to plot the data in our version of Figure 18.3.
p1 <-
my_data %>%
ggplot(aes(x = Spend, y = SATT)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_segment(aes(xend = Spend,
yend = 993.8 + -2.9 * PrcntTake + 12.3 * Spend),
linewidth = 1/4, linetype = 3) +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous(limits = c(3.4, 10.1), expand = c(0, 0), breaks = 2:5 * 2) +
scale_y_continuous(limits = c(785, 1120))
p2 <-
my_data %>%
ggplot(aes(x = PrcntTake, y = SATT)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_segment(aes(xend = PrcntTake,
yend = 993.8 + -2.9 * PrcntTake + 12.3 * Spend),
linewidth = 1/4, linetype = 3) +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous("% Take", limits = c(0, 85), expand = c(0, 0)) +
scale_y_continuous(limits = c(785, 1120))
p3 <-
my_data %>%
ggplot(aes(x = PrcntTake, y = Spend)) +
geom_path(data = grid,
aes(group = index),
color = "grey85") +
geom_point(shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
scale_x_continuous("% Take", limits = c(0, 85), expand = c(0, 0)) +
scale_y_continuous(limits = c(3.4, 10.1), expand = c(0, 0))
# bind them together and add a title
wrap_elements(grid::textGrob('No 3D wireframe plots for us')) +
p1 + p2 + p3 +
plot_annotation(title = "SATT ~ N(m,sd=31.5), m = 993.8 + −2.9 %Take + 12.3 Spend")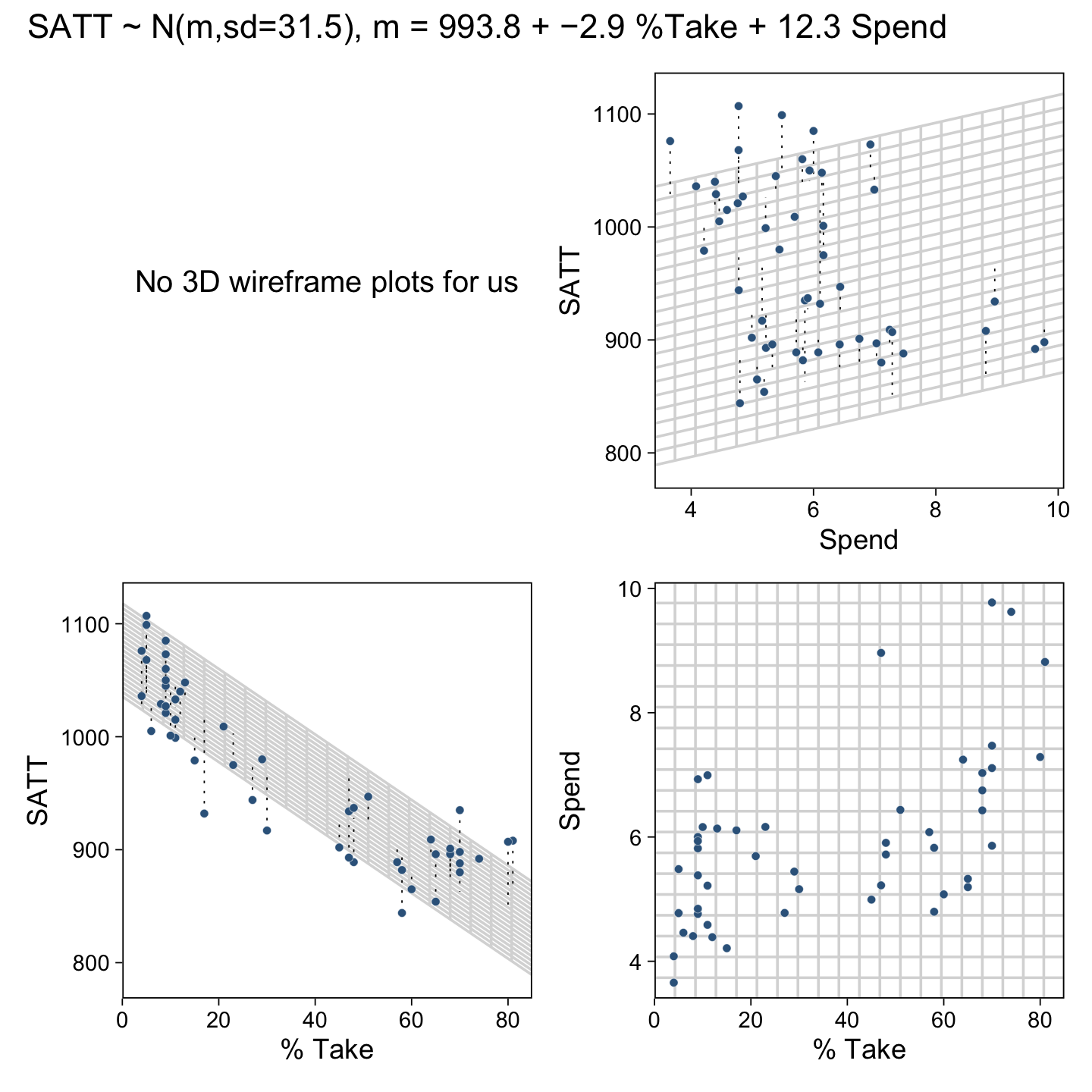
You can learn more about how we added that title to our plot ensemble from Pedersen’s (2020a) vignette, Adding annotation and style, and more about how we added that text in place of a wireframe plot from another of his (2020b) vignettes, Plot assembly.
The separate influences of the two predictors could be assessed in this example because the predictors had only mild correlation with each other. There was enough independent variation of the two predictors that their distinct relationships to the outcome variable could be detected. In some situations, however, the predictors are so tightly correlated that their distinct effects are difficult to tease apart. Correlation of predictors causes the estimates of their regression coefficients to trade-off, as we will see when we examine the posterior distribution. (p. 514)
18.1.2 The model and implementation.
Let’s make our version of the model diagram in Figure 18.4 to get a sense of where we’re going. If you look back to Section 17.2, you’ll see this is just a minor reworking of the code from Figure 17.2.
# normal density
p1 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 0, y = .2,
label = "normal",
size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = .6,
label = c("italic(M)[0]", "italic(S)[0]"),
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# a second normal density
p2 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 0, y = .2,
label = "normal",
size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = .6,
label = c("italic(M)[italic(j)]", "italic(S)[italic(j)]"),
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
## two annotated arrows
# save our custom arrow settings
my_arrow <- arrow(angle = 20, length = unit(0.35, "cm"), type = "closed")
p3 <-
tibble(x = c(.33, 1.67),
y = c(1, 1),
xend = c(.67, 1.2),
yend = c(0, 0)) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = c(.35, 1.3), y = .5,
label = "'~'",
size = 10, family = "Times", parse = T) +
xlim(0, 2) +
theme_void()
# exponential density
p4 <-
tibble(x = seq(from = 0, to = 1, by = .01)) %>%
ggplot(aes(x = x, y = (dexp(x, 2) / max(dexp(x, 2))))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = .5, y = .2,
label = "exp",
size = 7) +
annotate(geom = "text",
x = .5, y = .6,
label = "italic(K)",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# likelihood formula
p5 <-
tibble(x = .5,
y = .25,
label = "beta[0]+sum()[italic(j)]*beta[italic(j)]*italic(x)[italic(ji)]") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# half-normal density
p6 <-
tibble(x = seq(from = 0, to = 3, by = .01)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 1.5, y = .2,
label = "half-normal",
size = 7) +
annotate(geom = "text",
x = 1.5, y = .6,
label = "0*','*~italic(S)[sigma]",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# four annotated arrows
p7 <-
tibble(x = c(.43, .43, 1.5, 2.5),
y = c(1, .55, 1, 1),
xend = c(.43, 1.225, 1.5, 1.75),
yend = c(.8, .15, .2, .2)) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = c(.3, .7, 1.38, 2), y = c(.92, .22, .65, .6),
label = c("'~'", "'='", "'='", "'~'"),
size = 10, family = "Times", parse = T) +
annotate(geom = "text",
x = .43, y = .7,
label = "nu*minute+1",
size = 7, family = "Times", parse = T) +
xlim(0, 3) +
theme_void()
# student-t density
p8 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dt(x, 3) / max(dt(x, 3))))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 0, y = .2,
label = "student t",
size = 7) +
annotate(geom = "text",
x = 0, y = .6,
label = "nu~~~mu[italic(i)]~~~sigma",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# the final annotated arrow
p9 <-
tibble(x = c(.375, .625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# some text
p10 <-
tibble(x = .5,
y = .5,
label = "italic(y[i])") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
xlim(0, 1) +
theme_void()
# define the layout
layout <- c(
area(t = 1, b = 2, l = 3, r = 5),
area(t = 1, b = 2, l = 7, r = 9),
area(t = 4, b = 5, l = 1, r = 3),
area(t = 4, b = 5, l = 5, r = 7),
area(t = 4, b = 5, l = 9, r = 11),
area(t = 3, b = 4, l = 3, r = 9),
area(t = 7, b = 8, l = 5, r = 7),
area(t = 6, b = 7, l = 1, r = 11),
area(t = 9, b = 9, l = 5, r = 7),
area(t = 10, b = 10, l = 5, r = 7)
)
# combine and plot!
(p1 + p2 + p4 + p5 + p6 + p3 + p8 + p7 + p9 + p10) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))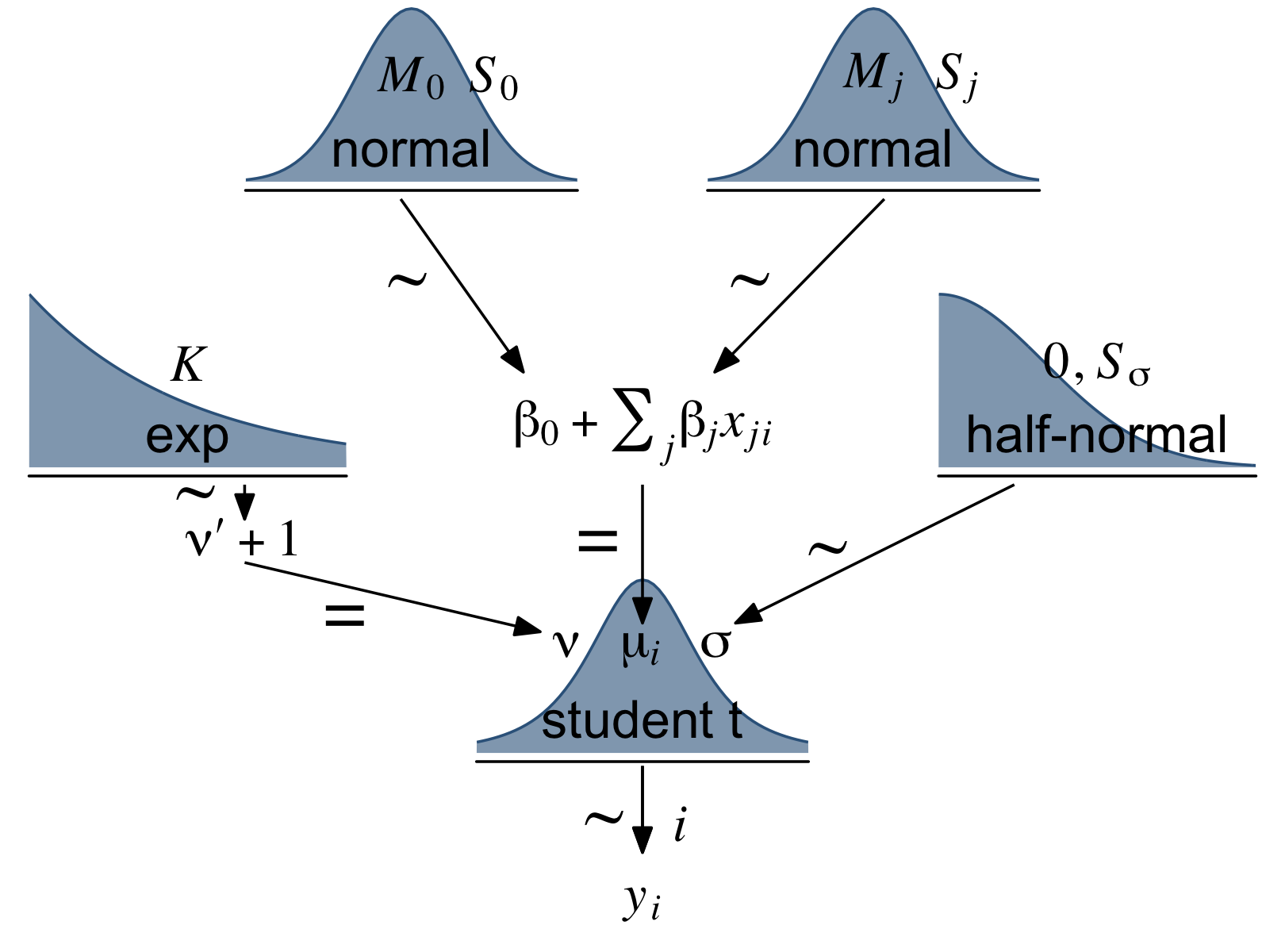
“As with the model for simple linear regression, the Markov Chain Monte Carlo (MCMC) sampling can be more efficient if the data are mean-centered or standardized” (p. 515). We’ll make a custom function to standardize the criterion and predictor values.
standardize <- function(x) {
(x - mean(x)) / sd(x)
}
my_data <-
my_data %>%
mutate(prcnt_take_z = standardize(PrcntTake),
spend_z = standardize(Spend),
satt_z = standardize(SATT))Let’s open brms.
library(brms)Now we’re ready to fit the model. As Kruschke pointed out, the priors on the standardized predictors are set with
an arbitrary standard deviation of 2.0. This value was chosen because standardized regression coefficients are algebraically constrained to fall between −1 and +1 in least-squares regression6, and therefore, the regression coefficients will not exceed those limits by much. A normal distribution with standard deviation of 2.0 is reasonably flat over the range from −1 to +1. (p. 516)
With data like this, even a prior(normal(0, 1), class = b) would be only mildly regularizing.
This is a good place to emphasize how priors in brms are given classes. If you’d like all parameters within a given class to have the prior, you can just specify one prior argument within that class. For our fit8.1, both parameters of class = b have a normal(0, 2) prior. So we can just include one statement to handle both. Had we wanted different priors for the coefficients for spend_z and prcnt_take_z, we’d need to include two prior() arguments with at least one including a coef argument.
fit18.1 <-
brm(data = my_data,
family = student,
satt_z ~ 1 + spend_z + prcnt_take_z,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
chains = 4, cores = 4,
stanvars = stanvar(1/29, name = "one_over_twentynine"),
seed = 18,
file = "fits/fit18.01")Check the model summary.
print(fit18.1)## Family: student
## Links: mu = identity; sigma = identity; nu = identity
## Formula: satt_z ~ 1 + spend_z + prcnt_take_z
## Data: my_data (Number of observations: 50)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -0.00 0.06 -0.13 0.12 1.00 3960 2676
## spend_z 0.24 0.08 0.09 0.40 1.00 3135 3103
## prcnt_take_z -1.03 0.08 -1.19 -0.88 1.00 3231 3156
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sigma 0.42 0.05 0.32 0.53 1.00 3243 2544
## nu 32.66 28.46 4.25 108.83 1.00 3133 2672
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).So when we use a multivariable model, increases in spending now appear associated with increases in SAT scores.
18.1.3 The posterior distribution.
Based on Equation 18.1, we can convert the standardized coefficients from our multivariable model back to their original metric as follows:
β0=SDyζ0+My−SDy∑jζjMxjSDxjandβj=SDyζjSDxj.
To use them, we’ll first extract the posterior draws
draws <- as_draws_df(fit18.1)
head(draws)## # A draws_df: 6 iterations, 1 chains, and 7 variables
## b_Intercept b_spend_z b_prcnt_take_z sigma nu lprior lp__
## 1 -0.0027 0.265 -1.05 0.41 15.1 -9.1 -35
## 2 0.0420 0.118 -0.95 0.45 98.4 -12.0 -37
## 3 0.1076 0.250 -1.01 0.44 16.1 -9.2 -37
## 4 0.0997 0.168 -0.96 0.41 10.3 -9.0 -37
## 5 -0.0577 0.099 -0.93 0.44 120.0 -12.7 -38
## 6 0.1263 0.209 -0.99 0.41 6.9 -8.8 -38
## # ... hidden reserved variables {'.chain', '.iteration', '.draw'}Like we did in Chapter 17, let’s wrap the consequences of Equation 18.1 into two functions.
make_beta_0 <- function(zeta_0, zeta_1, zeta_2, sd_x_1, sd_x_2, sd_y, m_x_1, m_x_2, m_y) {
sd_y * zeta_0 + m_y - sd_y * ((zeta_1 * m_x_1 / sd_x_1) + (zeta_2 * m_x_2 / sd_x_2))
}
make_beta_j <- function(zeta_j, sd_j, sd_y) {
sd_y * zeta_j / sd_j
}After saving a few values, we’re ready to use our custom functions.
sd_x_1 <- sd(my_data$Spend)
sd_x_2 <- sd(my_data$PrcntTake)
sd_y <- sd(my_data$SATT)
m_x_1 <- mean(my_data$Spend)
m_x_2 <- mean(my_data$PrcntTake)
m_y <- mean(my_data$SATT)
draws <-
draws %>%
mutate(b_0 = make_beta_0(zeta_0 = b_Intercept,
zeta_1 = b_spend_z,
zeta_2 = b_prcnt_take_z,
sd_x_1 = sd_x_1,
sd_x_2 = sd_x_2,
sd_y = sd_y,
m_x_1 = m_x_1,
m_x_2 = m_x_2,
m_y = m_y),
b_1 = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
b_2 = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y))
glimpse(draws)## Rows: 4,000
## Columns: 13
## $ b_Intercept <dbl> -0.002697924, 0.042041763, 0.107571901, 0.099739103, -0…
## $ b_spend_z <dbl> 0.26475590, 0.11795547, 0.24994698, 0.16762745, 0.09880…
## $ b_prcnt_take_z <dbl> -1.0502024, -0.9532420, -1.0056834, -0.9577257, -0.9265…
## $ sigma <dbl> 0.4095773, 0.4518504, 0.4420941, 0.4108245, 0.4441622, …
## $ nu <dbl> 15.105647, 98.430670, 16.097243, 10.343269, 119.990594,…
## $ lprior <dbl> -9.146251, -12.006651, -9.183343, -8.955325, -12.740062…
## $ lp__ <dbl> -35.12580, -37.26377, -36.94507, -37.32173, -38.33067, …
## $ .chain <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ .iteration <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, …
## $ .draw <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, …
## $ b_0 <dbl> 983.3494, 1024.7382, 992.0149, 1013.3928, 1020.8516, 10…
## $ b_1 <dbl> 14.535580, 6.475970, 13.722544, 9.203052, 5.424804, 11.…
## $ b_2 <dbl> -2.936085, -2.665010, -2.811622, -2.677545, -2.590445, …Before we make the figure, we’ll update our overall plot theme to cowplot::theme_minimal_grid(). Our overall color scheme and plot aesthetic will be based on some of the plots in Chapter 16, Visualizing uncertainty, of Wilke (2019). As we’ll be making a lot of customized density plots in this chapter, we may as well save those settings, here. We’ll call the function with those settings stat_wilke().
library(tidybayes)
library(ggdist)
library(cowplot)
# update the default theme setting
theme_set(theme_minimal_grid())
# define the function
stat_wilke <- function(height = 1.25, point_size = 5, ...) {
list(
# for the graded fill
stat_slab(aes(fill_ramp = stat(
cut_cdf_qi(cdf,
.width = c(.8, .95, .99),
labels = scales::percent_format(accuracy = 1)))),
height = height, slab_alpha = .75, fill = "steelblue4",
...),
# for the top outline and the mode dot
stat_halfeye(.width = 0, point_interval = mode_qi,
height = height, size = point_size, slab_size = 1/3,
slab_color = "steelblue4", fill = NA, color = "chocolate3",
...),
# fill settings
scale_fill_ramp_discrete(range = c(1, .4), na.translate = F),
# adjust the guide_legend() settings
guides(fill_ramp =
guide_legend(
direction = "horizontal",
keywidth = unit(0.925, "cm"),
label.hjust = 0.5,
label.position = "bottom",
title = "posterior prob.",
title.hjust = 0.5,
title.position = "top")),
# ensure we're using `cowplot::theme_minimal_hgrid()` as a base theme
theme_minimal_hgrid(),
# adjust the legend settings
theme(legend.background = element_rect(fill = "white"),
legend.text = element_text(margin = margin(-0.2, 0, -0.2, 0, "cm")),
legend.title = element_text(margin = margin(-0.2, 0, -0.2, 0, "cm")))
)
}Here’s the top panel of Figure 18.5.
# here are the primary data
draws %>%
transmute(Intercept = b_0,
Spend = b_1,
`Percent Take` = b_2,
Scale = sigma * sd_y,
Normality = nu %>% log10()) %>%
pivot_longer(everything()) %>%
# the plot
ggplot(aes(x = value)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(legend.position = c(.72, .2)) +
facet_wrap(~ name, scales = "free", ncol = 3)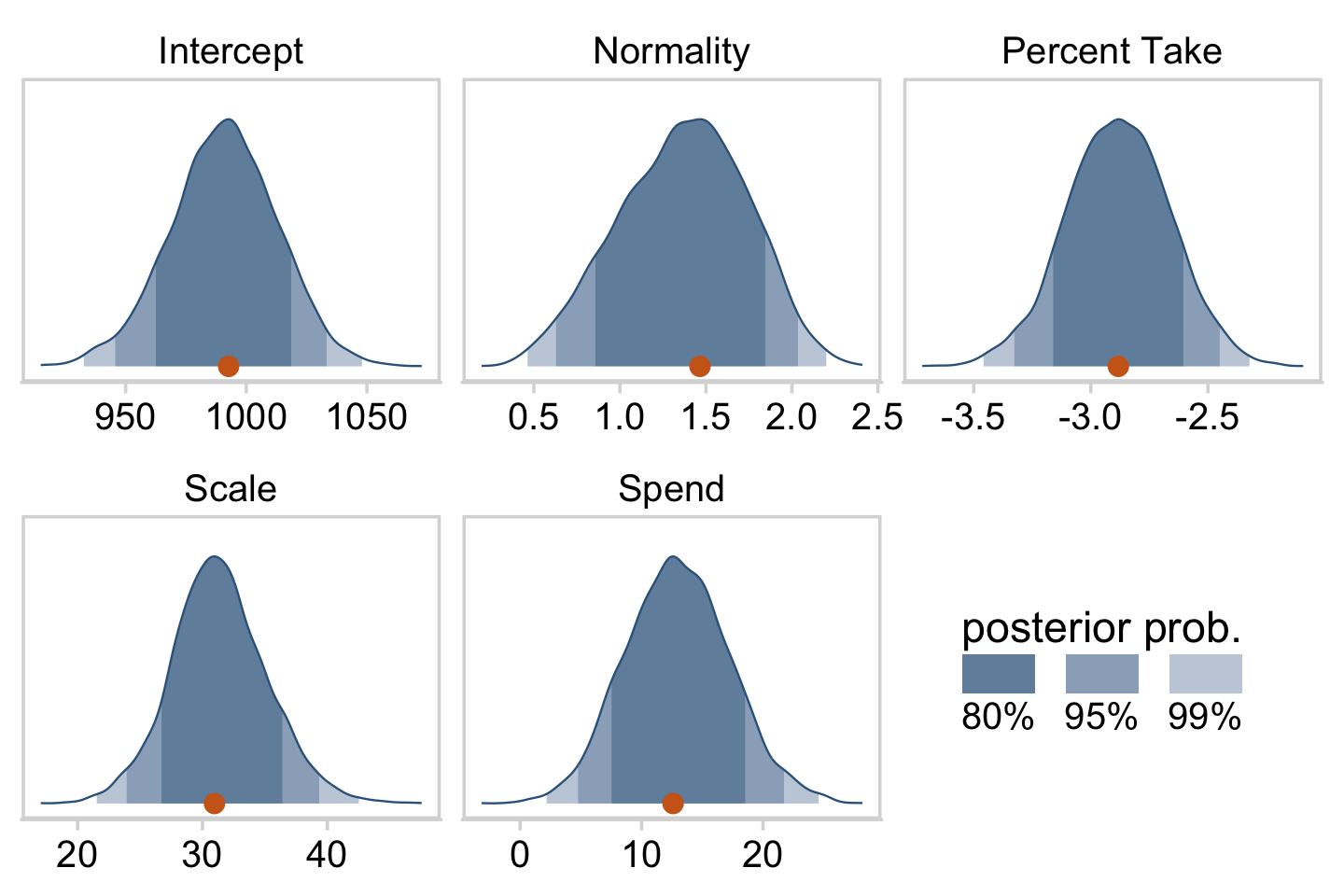
The slope on spending has a mode of about 13, which suggests that SAT scores rise by about 13 points for every extra $1000 spent per pupil. The slope on percentage taking the exam (PrcntTake) is also credibly non-zero, with a mode around −2.8, which suggests that SAT scores fall by about 2.8 points for every additional 1% of students who take the test. (p. 517)
If you want those exact modes and, say, 50% intervals around them, you can just use tidybayes::mode_hdi().
draws %>%
transmute(Spend = b_1,
`Percent Take` = b_2) %>%
pivot_longer(everything()) %>%
group_by(name) %>%
mode_hdi(value, .width = .5)## # A tibble: 2 × 7
## name value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 Percent Take -2.88 -3.04 -2.74 0.5 mode hdi
## 2 Spend 12.6 9.81 15.6 0.5 mode hdiThe brms::bayes_R2() function makes it easy to compute a Bayesian R2. Simply feed a brm() fit object into bayes_R2() and you’ll get back the posterior mean, SD, and 95% intervals.
bayes_R2(fit18.1)## Estimate Est.Error Q2.5 Q97.5
## R2 0.8138893 0.02282763 0.7575688 0.8431136I’m not going to go into the technical details here, but you should be aware that the Bayeisan R2 returned from the bayes_R2() function is not calculated the same as it is with OLS. If you want to dive in, check out the paper by Gelman et al. (2019), R-squared for Bayesian regression models. Anyway, if you’d like to view the Bayesian R2 distribution rather than just get the summaries, specify summary = F, convert the output to a tibble, and plot as usual.
bayes_R2(fit18.1, summary = F) %>%
as_tibble() %>%
ggplot(aes(x = R2, y = 0)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
labs(subtitle = expression(paste("Bayesian ", italic(R)^2)),
x = NULL) +
coord_cartesian(xlim = c(0, 1),
ylim = c(-0.01, NA)) +
theme(legend.position = c(.01, .8))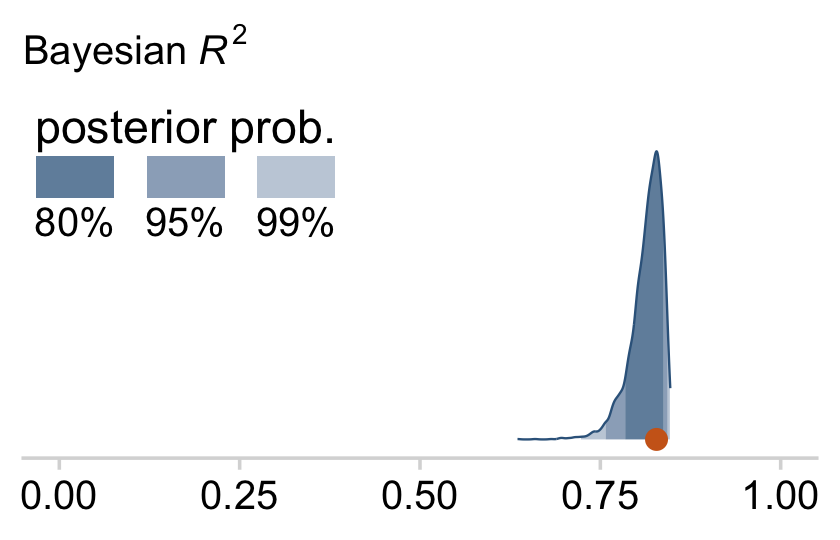
Since the brms::bayes_R2() function is not identical with Kruschke’s method in the text, the results might differ a bit.
We can get a sense of the scatter plots with bayesplot::mcmc_pairs().
library(bayesplot)
color_scheme_set(c("steelblue4", "steelblue4", "steelblue4", "steelblue4", "steelblue4", "steelblue4"))
draws %>%
transmute(Intercept = b_0,
Spend = b_1,
`Percent Take` = b_2,
Scale = sigma * sd_y,
Normality = nu %>% log10()) %>%
mcmc_pairs(diag_fun = "dens",
off_diag_args = list(size = 1/8, alpha = 1/8))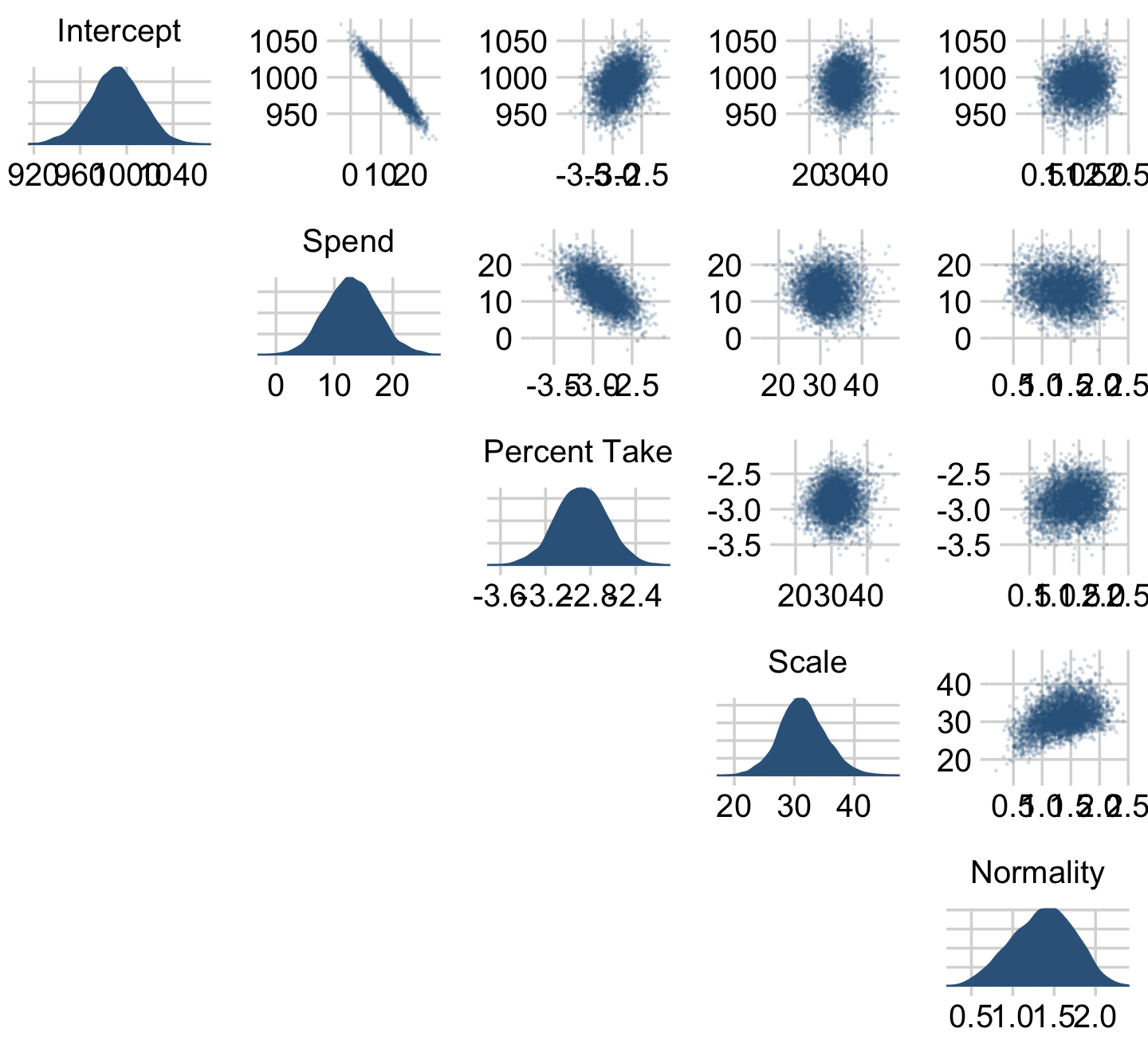
One way to get the Pearson’s correlation coefficients among the parameters is with psych::lowerCor().
draws %>%
transmute(Intercept = b_0,
Spend = b_1,
`Percent Take` = b_2,
Scale = sigma * sd_y,
Normality = nu %>% log10()) %>%
psych::lowerCor(digits = 3)## Intrc Spend PrcnT Scale Nrmlt
## Intercept 1.000
## Spend -0.936 1.000
## Percent Take 0.335 -0.597 1.000
## Scale 0.036 -0.051 0.080 1.000
## Normality 0.099 -0.125 0.137 0.384 1.000If you like more control for customizing your pairs plots, you’ll find a friend in the ggpairs() function from the GGally package (Schloerke et al., 2021). We’re going to blow past the default settings and customize the format for the plots in the upper triangle, the diagonal, and the lower triangle.
library(GGally)
my_upper <- function(data, mapping, ...) {
ggplot(data = data, mapping = mapping) +
geom_point(size = 1/2, shape = 21, stroke = 1/10,
color = "white", fill = "steelblue4") +
panel_border()
}
my_diag <- function(data, mapping, ...) {
ggplot(data = data, mapping = mapping) +
stat_wilke(point_size = 2) +
scale_x_continuous(NULL, breaks = NULL) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border()
}
my_lower <- function(data, mapping, ...) {
# get the x and y data to use the other code
x <- eval_data_col(data, mapping$x)
y <- eval_data_col(data, mapping$y)
# compute the correlations
corr <- cor(x, y, method = "p", use = "pairwise")
# plot the cor value
ggally_text(
label = formatC(corr, digits = 2, format = "f") %>% str_replace(., "0\\.", "."),
mapping = aes(),
color = "black",
size = 4) +
scale_x_continuous(NULL, breaks = NULL) +
scale_y_continuous(NULL, breaks = NULL) +
panel_border()
}Let’s see what we’ve done.
draws %>%
transmute(`Intercept~(beta[0])` = b_0,
`Spend~(beta[1])` = b_1,
`Percent~Take~(beta[2])` = b_2,
sigma = sigma * sd_y,
`log10(nu)` = nu %>% log10()) %>%
ggpairs(upper = list(continuous = my_upper),
diag = list(continuous = my_diag),
lower = list(continuous = my_lower),
labeller = label_parsed) +
theme(strip.text = element_text(size = 8))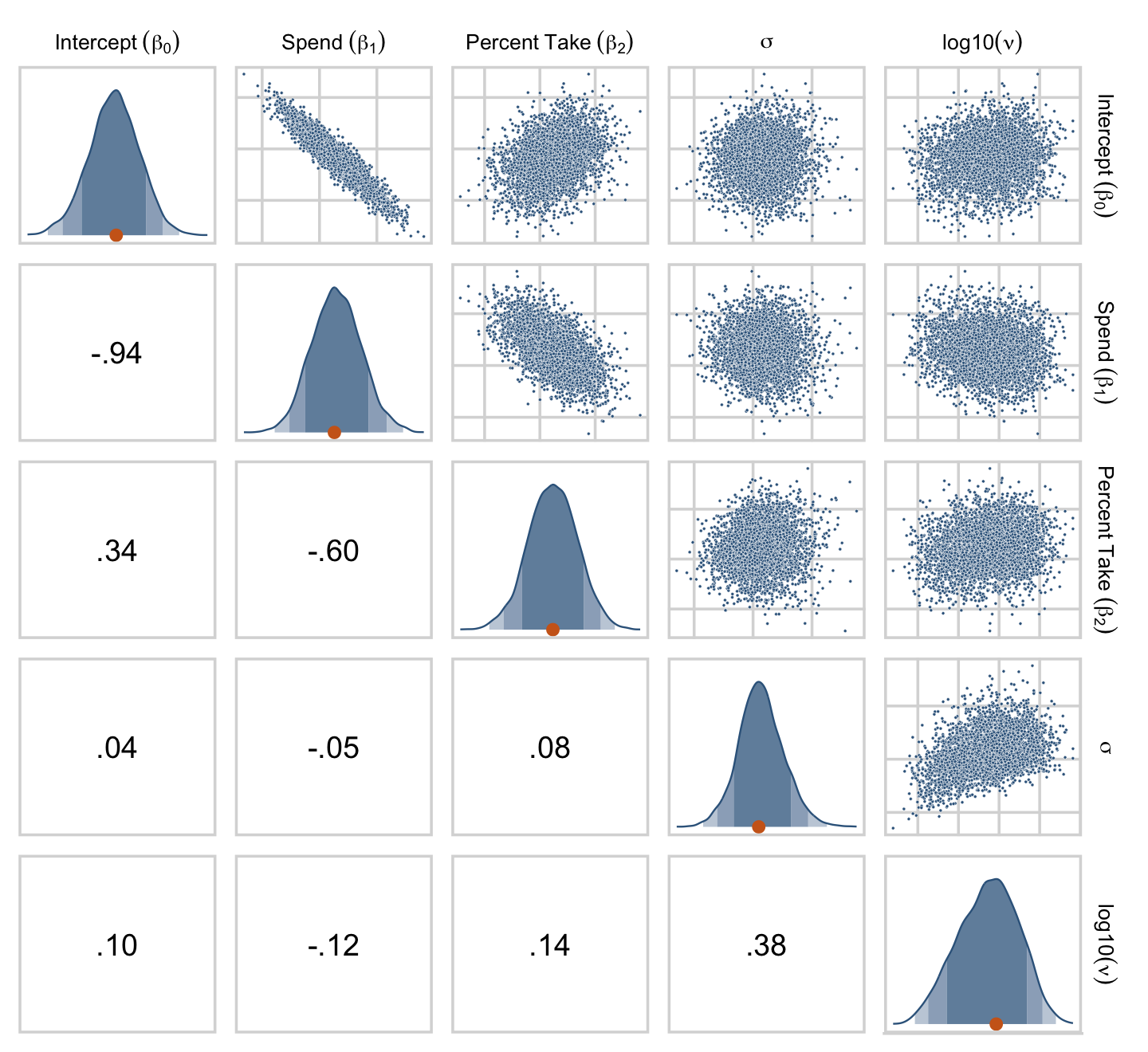
For more ideas on customizing a ggpairs() plot, go here or here or here.
Kruschke finished the subsection with the observation: “Sometimes we are interested in using the linear model to predict y values for x values of interest. It is straight forward to generate a large sample of credible y values for specified x values” (p. 519).
Like we practiced with in the last chapter, the simplest way to do so in brms is with the fitted() function. For a quick example, say we wanted to know what the model would predict if we were to have a standard-score increase in spending and a simultaneous standard-score decrease in the percent taking the exam. We’d just specify those values in a tibble and feed that tibble into fitted() along with the model.
nd <-
tibble(prcnt_take_z = -1,
spend_z = 1)
fitted(fit18.1,
newdata = nd)## Estimate Est.Error Q2.5 Q97.5
## [1,] 1.266984 0.1543101 0.9738981 1.56456118.1.4 Redundant predictors.
As a simplified example of correlated predictors, think of just two data points: Suppose y=1 for ⟨x1,x2⟩=⟨1,1⟩ and y=2 for ⟨x1,x2⟩=⟨2,2⟩. The linear model, y=β1x1+β2x2 is supposed to satisfy both data points, and in this case both are satisfied by 1=β1+β2. Therefore, many different combinations of β1 and β2 satisfy the data. For example, it could be that β1=2 and β2=−1, or β1=0.5 and β2=0.5, or β1=0 and β2=1. In other words, the credible values of β1 and β2 are anticorrelated and trade-off to fit the data. (p. 519)
Here are what those data look like. You would not want to fit a regression model with these data.
tibble(x_1 = 1:2,
x_2 = 1:2,
y = 1:2)## # A tibble: 2 × 3
## x_1 x_2 y
## <int> <int> <int>
## 1 1 1 1
## 2 2 2 2We can take percentages and turn them into their inverse re-expressed as a proportion.
percent_take <- 37
(100 - percent_take) / 100## [1] 0.63Let’s make a redundant predictor and then standardize() it.
my_data <-
my_data %>%
mutate(prop_not_take = (100 - PrcntTake) / 100) %>%
mutate(prop_not_take_z = standardize(prop_not_take))
glimpse(my_data)## Rows: 50
## Columns: 13
## $ State <chr> "Alabama", "Alaska", "Arizona", "Arkansas", "Californi…
## $ Spend <dbl> 4.405, 8.963, 4.778, 4.459, 4.992, 5.443, 8.817, 7.030…
## $ StuTeaRat <dbl> 17.2, 17.6, 19.3, 17.1, 24.0, 18.4, 14.4, 16.6, 19.1, …
## $ Salary <dbl> 31.144, 47.951, 32.175, 28.934, 41.078, 34.571, 50.045…
## $ PrcntTake <dbl> 8, 47, 27, 6, 45, 29, 81, 68, 48, 65, 57, 15, 13, 58, …
## $ SATV <dbl> 491, 445, 448, 482, 417, 462, 431, 429, 420, 406, 407,…
## $ SATM <dbl> 538, 489, 496, 523, 485, 518, 477, 468, 469, 448, 482,…
## $ SATT <dbl> 1029, 934, 944, 1005, 902, 980, 908, 897, 889, 854, 88…
## $ prcnt_take_z <dbl> -1.0178453, 0.4394222, -0.3078945, -1.0925770, 0.36469…
## $ spend_z <dbl> -1.10086058, 2.24370805, -0.82716069, -1.06123647, -0.…
## $ satt_z <dbl> 0.8430838, -0.4266207, -0.2929676, 0.5223163, -0.85431…
## $ prop_not_take <dbl> 0.92, 0.53, 0.73, 0.94, 0.55, 0.71, 0.19, 0.32, 0.52, …
## $ prop_not_take_z <dbl> 1.0178453, -0.4394222, 0.3078945, 1.0925770, -0.364690…Here’s the correlation matrix for Spend, PrcntTake and prop_not_take, as seen on page 520.
my_data %>%
select(Spend, PrcntTake, prop_not_take) %>%
cor()## Spend PrcntTake prop_not_take
## Spend 1.0000000 0.5926274 -0.5926274
## PrcntTake 0.5926274 1.0000000 -1.0000000
## prop_not_take -0.5926274 -1.0000000 1.0000000We’re ready to fit the redundant-predictor model.
fit18.2 <-
brm(data = my_data,
family = student,
satt_z ~ 0 + Intercept + spend_z + prcnt_take_z + prop_not_take_z,
prior = c(prior(normal(0, 2), class = b, coef = "Intercept"),
prior(normal(0, 2), class = b, coef = "spend_z"),
prior(normal(0, 2), class = b, coef = "prcnt_take_z"),
prior(normal(0, 2), class = b, coef = "prop_not_take_z"),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
chains = 4, cores = 4,
stanvars = stanvar(1/29, name = "one_over_twentynine"),
seed = 18,
# this will let us use `prior_samples()` later on
sample_prior = "yes",
file = "fits/fit18.02")You might notice a few things about the brm() code. First, we have used the ~ 0 + Intercept + ... syntax instead of the default syntax for intercepts. In normal situations, we would have been in good shape using the typical ~ 1 + ... syntax for the intercept, especially given our use of standardized data. However, since brms version 2.5.0, using the sample_prior argument to draw samples from the prior distribution will no longer allow us to return samples from the typical brms intercept. Bürkner addressed the issue on the Stan forums. As he pointed out, if you want to get prior samples from an intercept, you’ll have to use the alternative syntax. The other thing to point out is that even though we used the same prior on all the predictors, including the intercept, we still explicitly spelled each out with the coef argument. If we hadn’t been explicit like this, we would only get a single b vector from the prior_samples() function. But since we want separate vectors for each of our predictors, we used the verbose code. If you’re having a difficult time understanding these two points, experiment. Fit the model in a few different ways with either the typical or the alternative intercept syntax and with either the verbose prior code or the simplified prior(normal(0, 2), class = b) code. And after each, execute prior_samples(fit18.2). You’ll see.
Let’s move on. Kruschke mentioned high autocorrelations in the prose. Here are the autocorrelation plots for our β’s.
color_scheme_set(c("steelblue4", "steelblue4", "chocolate3", "steelblue4", "steelblue4", "steelblue4"))
draws <- as_draws_df(fit18.2)
draws %>%
mutate(chain = .chain) %>%
mcmc_acf(pars = vars(b_Intercept:b_prop_not_take_z),
lags = 10)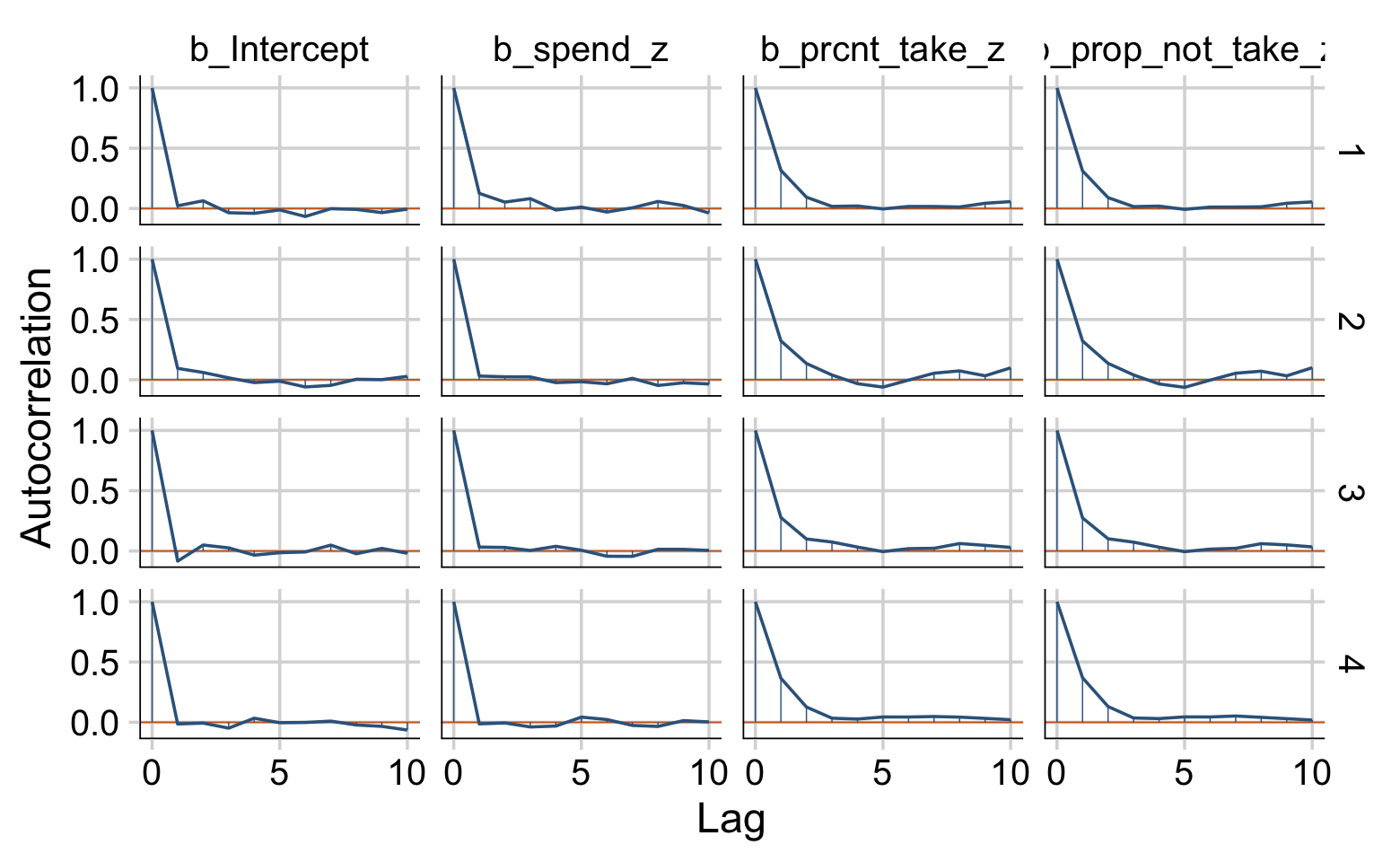
Looks like HMC made a big difference. The Neff/N ratios weren’t terrible, either.
color_scheme_set(c("steelblue4", "steelblue4", "chocolate3", "steelblue4", "chocolate3", "chocolate3"))
neff_ratio(fit18.2)[1:6] %>%
mcmc_neff() +
yaxis_text(hjust = 0)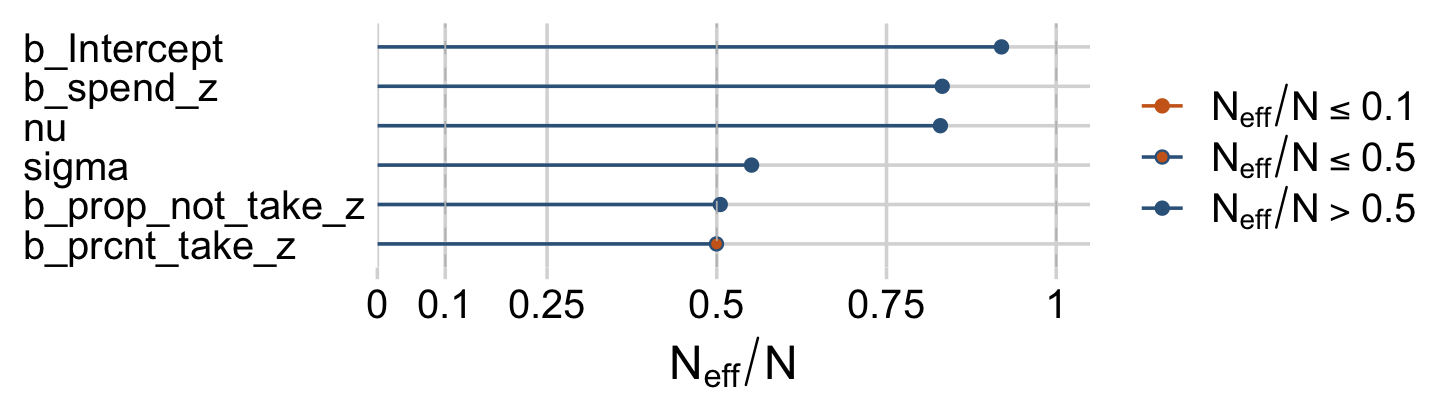
Earlier we computed the correlations among the correlation matrix for the predictors, as Kruschke displayed on page 520. Here we’ll compute the correlations among their coefficients in the model. The brms::vcov() function returns a variance/covariance matrix–or a correlation matrix when you set correlation = T–of the population-level parameters (i.e., the fixed effects). It returns the values to a decadent level of precision, so we’ll simplify the output with round().
vcov(fit18.2, correlation = T) %>%
round(digits = 3)## Intercept spend_z prcnt_take_z prop_not_take_z
## Intercept 1.000 -0.033 -0.002 -0.002
## spend_z -0.033 1.000 -0.013 0.022
## prcnt_take_z -0.002 -0.013 1.000 0.998
## prop_not_take_z -0.002 0.022 0.998 1.000The correlations among the redundant predictors were still very high.
If any of the nondiagonal correlations are high (i.e., close to +1 or close to −1), be careful when interpreting the posterior distribution. Here, we can see that the correlation of PrcntTake and PropNotTake is −1.0, which is an immediate sign of redundant predictors. (p. 520)
You can really get a sense of the silliness of the parameters if you plot them. We’ll use stat_wilke() to get a sense of densities and summaries of the β’s.
draws %>%
pivot_longer(b_Intercept:b_prop_not_take_z) %>%
# this line isn't necessary, but it does allow us to arrange the parameters on the y-axis
mutate(name = factor(name,
levels = c("b_prop_not_take_z", "b_prcnt_take_z", "b_spend_z", "b_Intercept"))) %>%
ggplot(aes(x = value, y = name)) +
geom_vline(xintercept = 0, color = "white") +
stat_wilke(normalize = "xy", point_size = 3) +
labs(x = NULL,
y = NULL) +
coord_cartesian(xlim = c(-5, 5),
ylim = c(1.4, NA)) +
theme(axis.text.y = element_text(hjust = 0),
legend.position = c(.76, .8))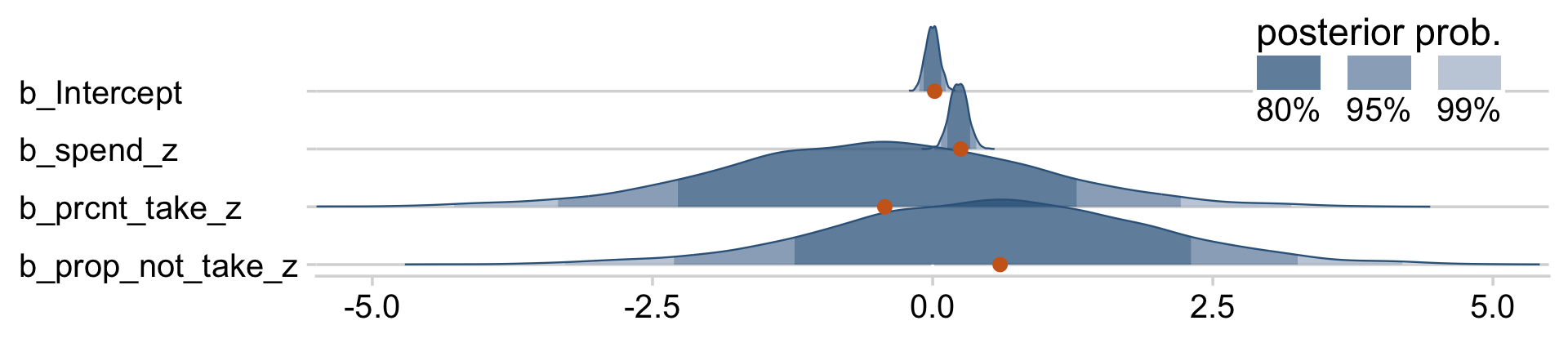
Yeah, on the standardized scale those are some ridiculous estimates. Let’s update our make_beta_0() function.
make_beta_0 <- function(zeta_0, zeta_1, zeta_2, zeta_3, sd_x_1, sd_x_2, sd_x_3, sd_y, m_x_1, m_x_2, m_x_3, m_y) {
sd_y * zeta_0 + m_y - sd_y * ((zeta_1 * m_x_1 / sd_x_1) + (zeta_2 * m_x_2 / sd_x_2) + (zeta_3 * m_x_3 / sd_x_3))
}sd_x_1 <- sd(my_data$Spend)
sd_x_2 <- sd(my_data$PrcntTake)
sd_x_3 <- sd(my_data$prop_not_take)
sd_y <- sd(my_data$SATT)
m_x_1 <- mean(my_data$Spend)
m_x_2 <- mean(my_data$PrcntTake)
m_x_3 <- mean(my_data$prop_not_take)
m_y <- mean(my_data$SATT)
draws <-
draws %>%
transmute(Intercept = make_beta_0(zeta_0 = b_Intercept,
zeta_1 = b_spend_z,
zeta_2 = b_prcnt_take_z,
zeta_3 = b_prop_not_take_z,
sd_x_1 = sd_x_1,
sd_x_2 = sd_x_2,
sd_x_3 = sd_x_3,
sd_y = sd_y,
m_x_1 = m_x_1,
m_x_2 = m_x_2,
m_x_3 = m_x_3,
m_y = m_y),
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
`Percent Take` = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
`Proportion not Take` = make_beta_j(zeta_j = b_prop_not_take_z,
sd_j = sd_x_3,
sd_y = sd_y),
Scale = sigma * sd_y,
Normality = nu %>% log10())
glimpse(draws)## Rows: 4,000
## Columns: 6
## $ Intercept <dbl> 1286.0814, 676.4512, 1027.5406, 1050.0106, 870.6…
## $ Spend <dbl> 13.245560, 15.358896, 15.489605, 6.154676, 8.823…
## $ `Percent Take` <dbl> -6.01820783, 0.08713037, -3.65264566, -3.1232467…
## $ `Proportion not Take` <dbl> -298.694047, 313.684035, -47.605008, -9.001090, …
## $ Scale <dbl> 28.00306, 27.52761, 35.59712, 30.65278, 32.54666…
## $ Normality <dbl> 0.9288994, 1.1999304, 1.6110071, 1.4414806, 1.05…Now we’ve done the conversions, here are the histograms of Figure 18.6.
draws %>%
pivot_longer(everything()) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(axis.text.x = element_text(size = 8),
legend.position = "none") +
facet_wrap(~ name, scales = "free", ncol = 3)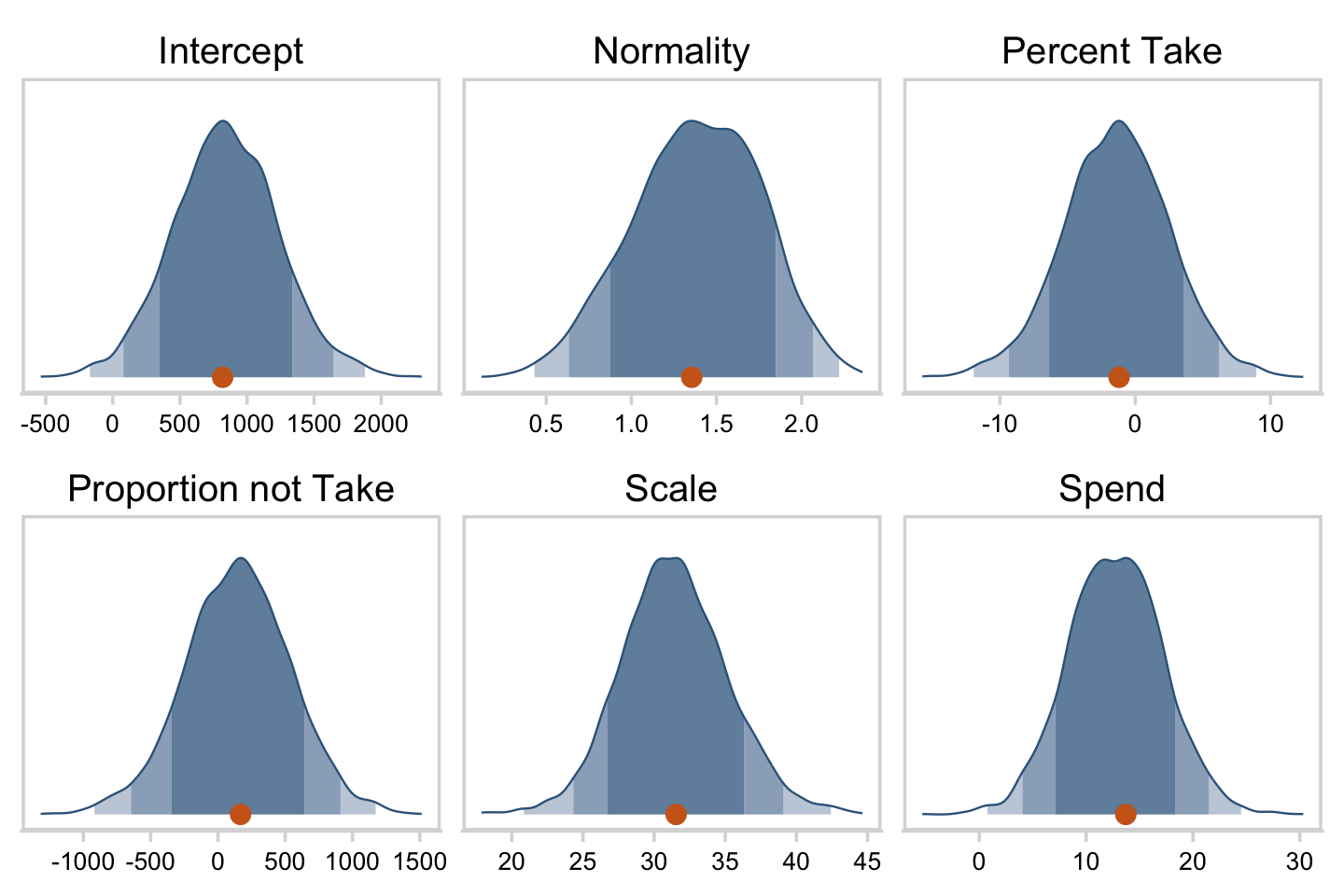
Their scatter plots are as follows.
draws %>%
set_names("Intercept~(beta[0])", "Spend~(beta[1])", "Percent~Take~(beta[2])", "Percent~Not~Take~(beta[3])", "sigma", "log10(nu)") %>%
ggpairs(upper = list(continuous = my_upper),
diag = list(continuous = my_diag),
lower = list(continuous = my_lower),
labeller = label_parsed) +
theme(strip.text = element_text(size = 7))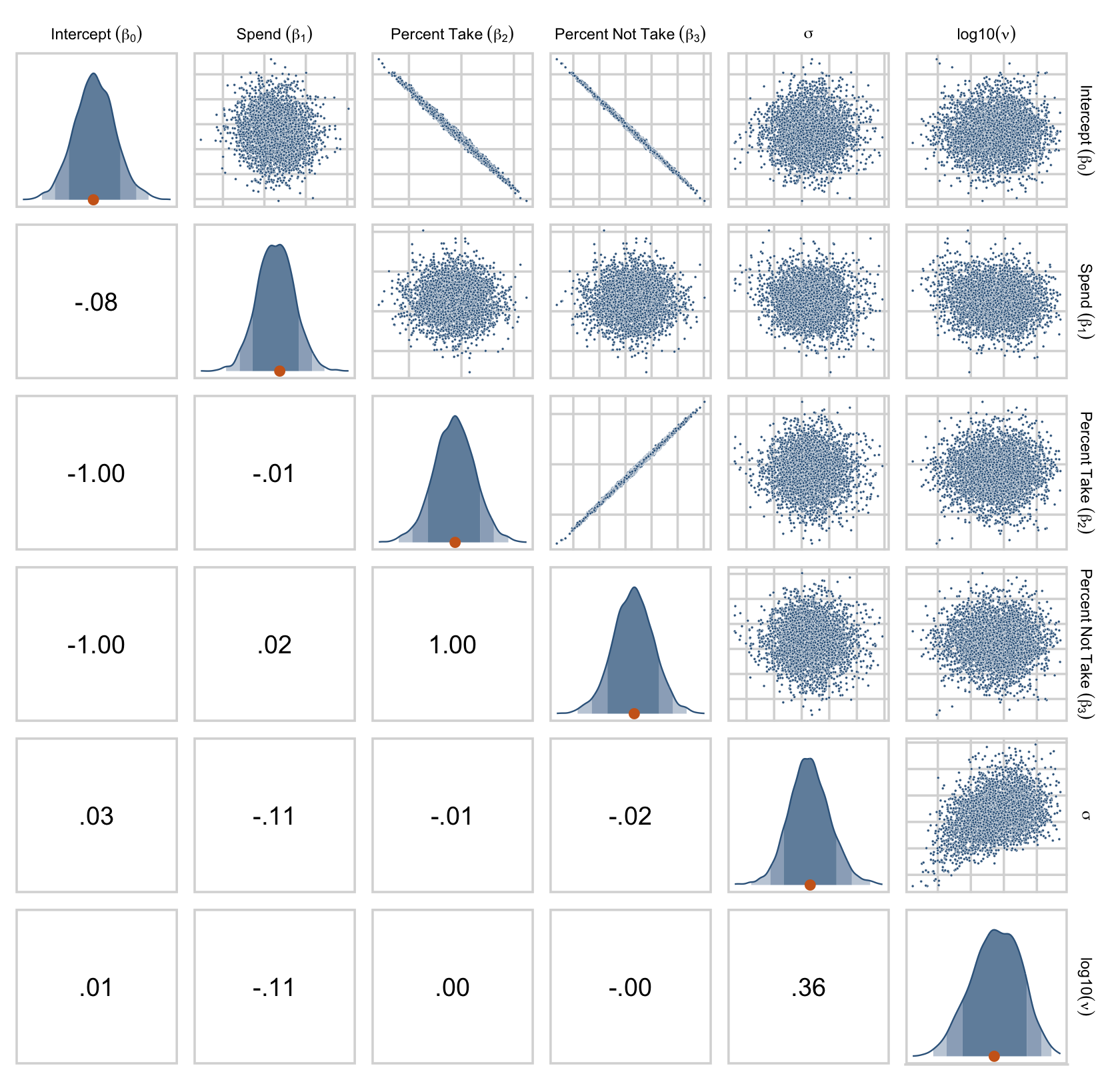
Figure 18.7 is all about the prior predictive distribution. Here we’ll extract the priors with prior_samples() and wrangle all in one step.
prior_draws <-
prior_draws(fit18.2) %>%
transmute(Intercept = make_beta_0(zeta_0 = b_Intercept,
zeta_1 = b_spend_z,
zeta_2 = b_prcnt_take_z,
zeta_3 = b_prop_not_take_z,
sd_x_1 = sd_x_1,
sd_x_2 = sd_x_2,
sd_x_3 = sd_x_3,
sd_y = sd_y,
m_x_1 = m_x_1,
m_x_2 = m_x_2,
m_x_3 = m_x_3,
m_y = m_y),
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
`Percent Take` = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
`Proportion not Take` = make_beta_j(zeta_j = b_prop_not_take_z,
sd_j = sd_x_3,
sd_y = sd_y),
Scale = sigma * sd_y,
Normality = nu %>% log10())
glimpse(prior_draws)## Rows: 4,000
## Columns: 6
## $ Intercept <dbl> 1357.56702, 2162.89345, 2399.94017, -180.89588, …
## $ Spend <dbl> -76.87285, -198.75804, -132.41235, 163.27256, -9…
## $ `Percent Take` <dbl> -6.0704337, 1.2110818, -2.9404931, 4.3357744, -8…
## $ `Proportion not Take` <dbl> 601.4546878, 77.7307853, -788.2675110, -189.2042…
## $ Scale <dbl> 27.211411, 2.214812, 196.404525, 71.740578, 66.8…
## $ Normality <dbl> 1.7340393, 1.5508948, 1.4500064, 1.7267028, 0.76…Now we’ve wrangled the priors, we’re ready to make the histograms at the top of Figure 18.7.
prior_draws %>%
pivot_longer(everything()) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(axis.text.x = element_text(size = 8),
legend.position = "none") +
facet_wrap(~ name, scales = "free", ncol = 3)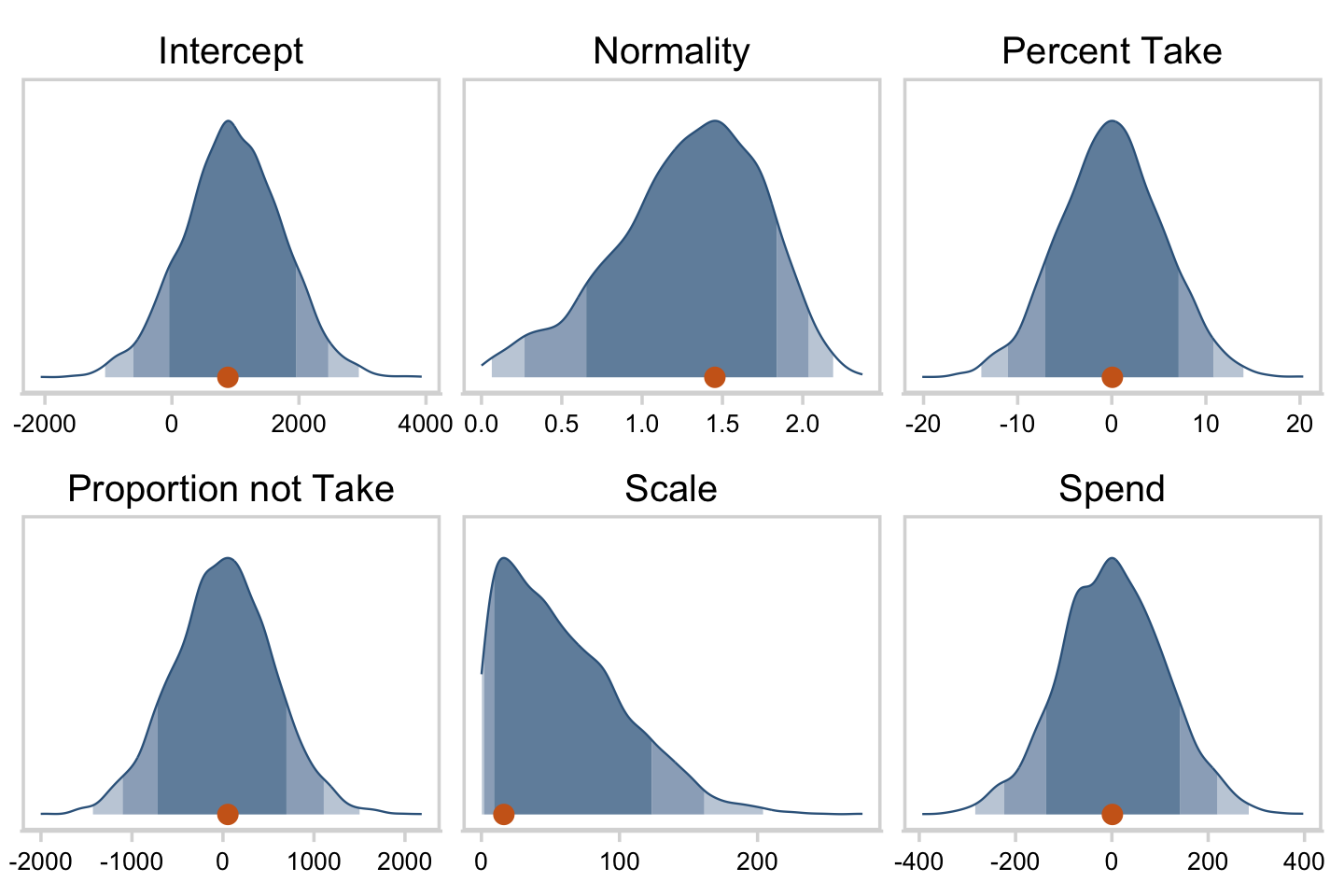
Since we used the half-Gaussian prior for our σ, our Scale histogram looks different from Kruschke’s. Otherwise, everything’s on the up and up. Here are the pairs plots at the bottom of Figure 18.7.
prior_draws %>%
set_names("Intercept~(beta[0])", "Spend~(beta[1])", "Percent~Take~(beta[2])", "Percent~Not~Take~(beta[3])", "sigma", "log10(nu)") %>%
ggpairs(upper = list(continuous = my_upper),
diag = list(continuous = my_diag),
lower = list(continuous = my_lower),
labeller = label_parsed) +
theme(strip.text = element_text(size = 7))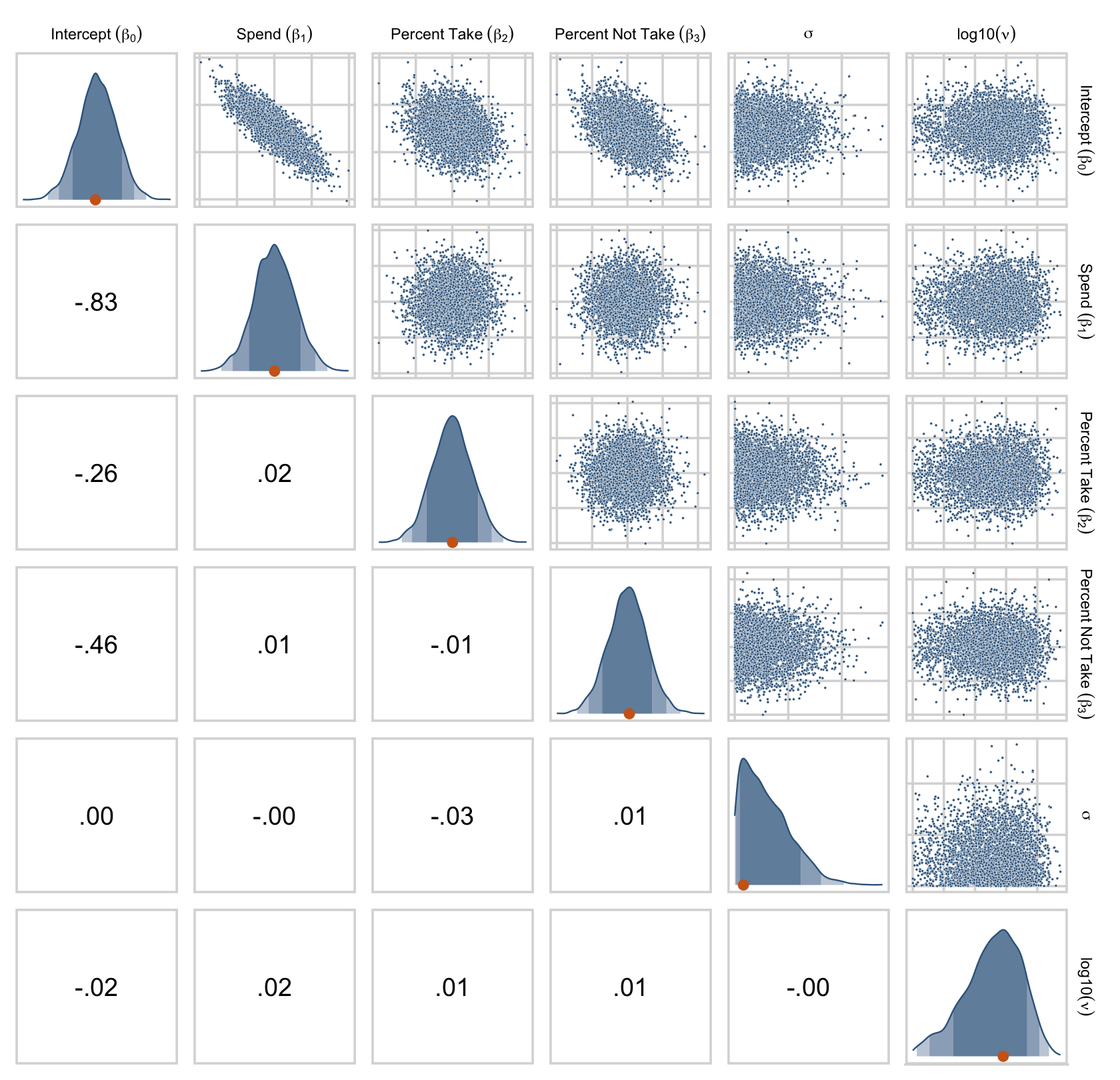
At the top of page 523, Kruschke asked us to “notice that the posterior distribution in Figure 18.6 has ranges for the redundant parameters that are only a little smaller than their priors.” With a little wrangling, we can compare the prior/posterior distributions for our redundant parameters more directly.
draws %>%
pivot_longer(everything(),
names_to = "parameter",
values_to = "posterior") %>%
bind_cols(
prior_draws %>%
pivot_longer(everything()) %>%
transmute(prior = value)
) %>%
pivot_longer(-parameter) %>%
filter(parameter %in% c("Percent Take", "Proportion not Take")) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_fill_viridis_d(option = "D", begin = .35, end = .65) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(legend.position = "none") +
facet_grid(name ~ parameter, scales = "free")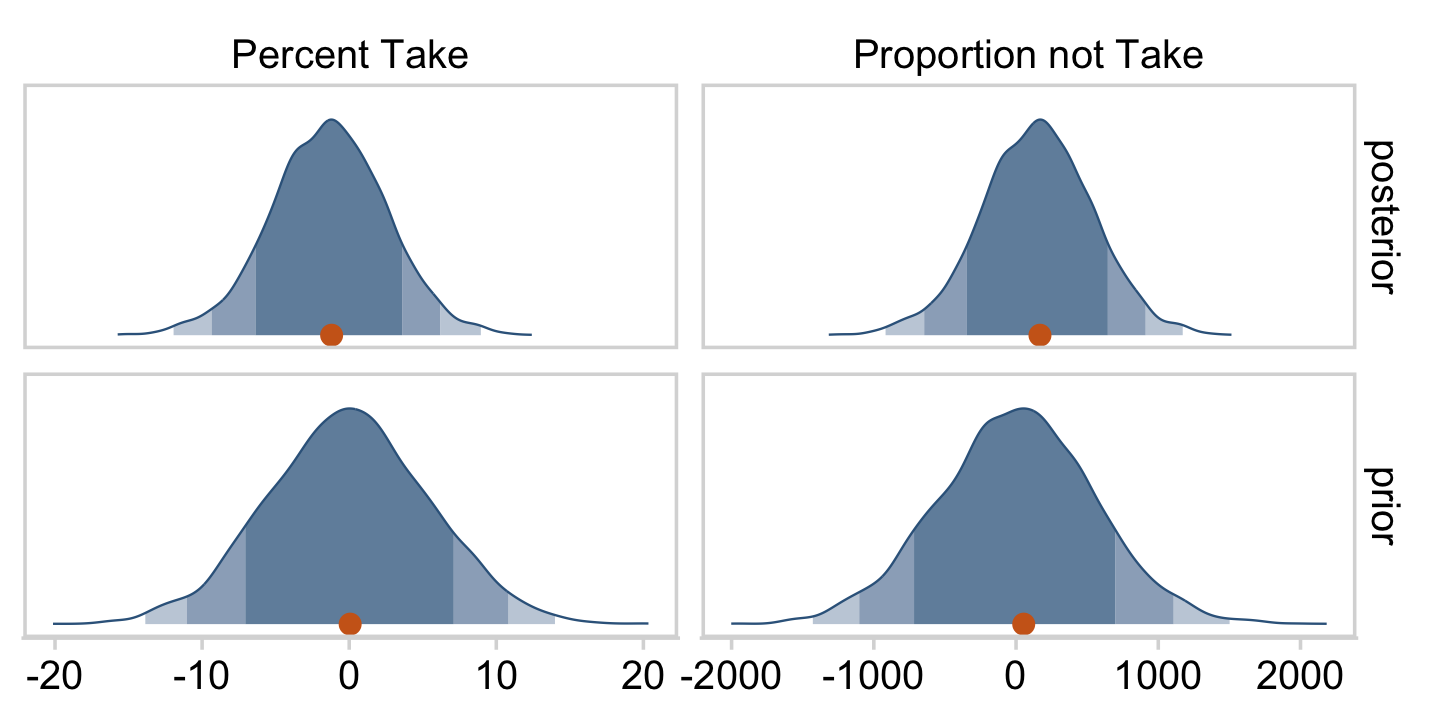
Kruschke was right. The posterior distributions are only slightly narrower than the priors for those two. With our combination of data and model, we learned virtually nothing beyond the knowledge we encoded in those priors.
Kruschke mentioned SEM as a possible solution to multicollinearity. brms isn’t fully capable of SEM, at the moment (see issue #304), but its multivariate syntax (Bürkner, 2022b) does allow for path analysis and IRT models. However, you can currently fit a variety of Bayesian SEMs with the blavaan package (Merkle et al., 2022; Merkle & Rosseel, 2018). I’m not aware of any textbooks highlighting blavaan. If you know of any, please share.
18.2 Multiplicative interaction of metric predictors
From page 526:
Formally, interactions can have many different specific functional forms. We will consider multiplicative interaction. This means that the nonadditive interaction is expressed by multiplying the predictors. The predicted value is a weighted combination of the individual predictors and, additionally, the multiplicative product of the predictors. For two metric predictors, regression with multiplicative interaction has these algebraically equivalent expressions:
μ=β0+β1x1+β2x2+β1×2x1x2=β0+(β1+β1×2x2)⏟slope of x1x1+β2x2=β0+β1x1+(β2+β1×2x1)⏟slope of x2x2.
We can’t quite reproduce Figure 18.8 with our ggplot2 repertoire. But we can capture some of Figure 18.8 with the geom_raster() approach we used in Chapter 15.
d <-
crossing(x1 = seq(from = 0, to = 10, by = 0.5),
x2 = seq(from = 0, to = 10, by = 0.5)) %>%
mutate(y = 10 + -1 * x1 + 2 * x2 + (0.2) * x1 * x2)
p1 <- d %>%
ggplot(aes(x = x1, y = x2)) +
geom_raster(aes(fill = y)) +
# these are all variants of steelblue4
scale_fill_gradient2(low = "#0a141b", mid = "#36648B", high = "#d6e0e7",
midpoint = 20, limits = c(0, 40)) +
scale_x_continuous(expression(x[1]), expand = c(0, 0),
breaks = 0:5 * 2) +
scale_y_continuous(expression(x[2]), expand = c(0, 0),
breaks = 0:5 * 2,
position = "right") +
labs(subtitle = expression(y==10+-1*x[1]+2*x[2]+(0.2)*x[1]*x[2])) +
coord_equal() +
theme(legend.position = "left",
plot.subtitle = element_text(size = 8))
p2 <- d %>%
ggplot(aes(x = x1, y = x2)) +
geom_raster(aes(fill = y)) +
geom_hline(yintercept = c(0:5 * 2), linewidth = 1, color = "chocolate3") +
# these are all variants of steelblue4
scale_fill_gradient2(low = "#0a141b", mid = "#36648B", high = "#d6e0e7",
midpoint = 20, limits = c(0, 40)) +
scale_x_continuous(expression(x[1]), expand = c(0, 0),
breaks = 0:5 * 2) +
scale_y_continuous(expression(x[2]), expand = c(0, 0),
breaks = 0:5 * 2,
position = "right") +
labs(subtitle = expression(y==10+(-1+0.2*x[2])*x[1]+2*x[2])) +
coord_equal() +
theme(legend.position = "none",
plot.subtitle = element_text(size = 8))
p3 <- d %>%
ggplot(aes(x = x1, y = x2)) +
geom_raster(aes(fill = y)) +
geom_vline(xintercept = c(0:5 * 2), linewidth = 1, color = "chocolate3") +
# these are all variants of steelblue4
scale_fill_gradient2(low = "#0a141b", mid = "#36648B", high = "#d6e0e7",
midpoint = 20, limits = c(0, 40)) +
scale_x_continuous(expression(x[1]), expand = c(0, 0),
breaks = 0:5 * 2) +
scale_y_continuous(expression(x[2]), expand = c(0, 0),
breaks = 0:5 * 2,
position = "right") +
labs(subtitle = expression(y==10+-1*x[1]+(2+0.2*x[1])*x[2])) +
coord_equal() +
theme(legend.position = "none",
plot.subtitle = element_text(size = 8))
p1 + p2 + p3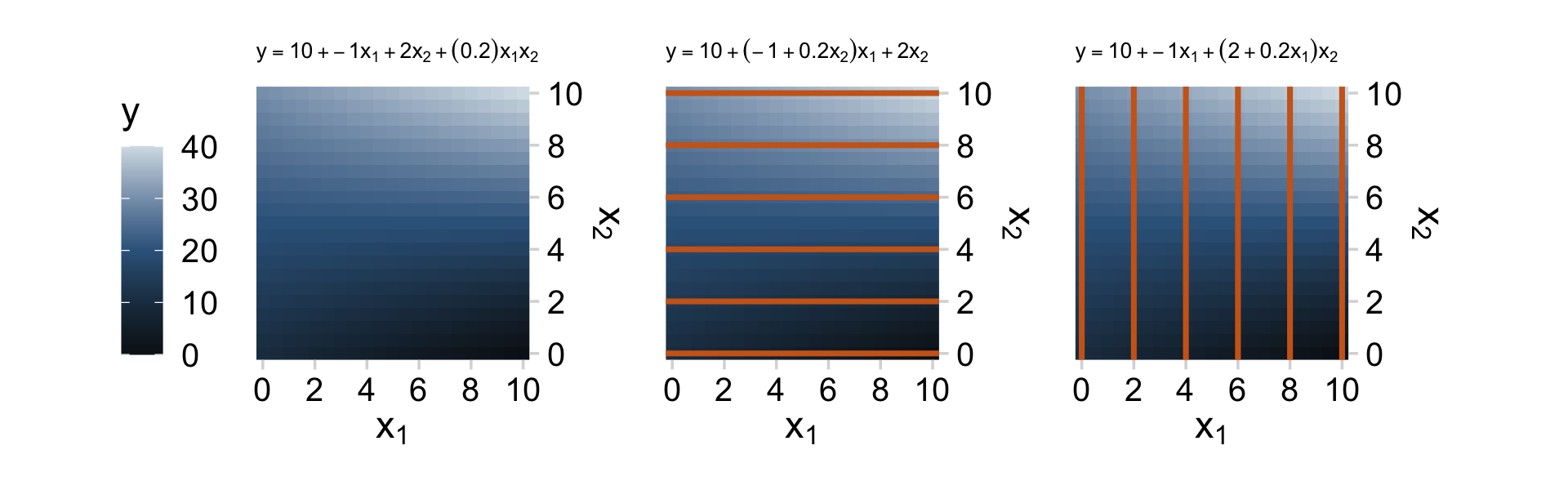
As Kruschke wrote: “Great care must be taken when interpreting the coefficients of a model that includes interaction terms (Braumoeller, 2004). In particular, low-order terms are especially difficult to interpret when higher-order interactions are present” (p. 526). When in doubt, plot.
18.2.1 An example.
Presuming we’re still just modeling μ with two predictors, we can express the formula with the interaction term as
μ=β0+β1+β2x2+β1×2⏟β3x2x1⏟x3.
With brms, you can specify an interaction with either the x_i*x_j syntax or the x_i:x_j syntax. I typically use x_i:x_j. It’s often the case that you can just make the interaction term right in the model formula. But since we’re fitting the model with standardized predictors and then using Kruschke’s equations to convert the parameters back to the unstandardized metric, it seems easier to make the interaction term in the data, first.
my_data <-
my_data %>%
# make x_3
mutate(interaction = Spend * PrcntTake) %>%
mutate(interaction_z = standardize(interaction))Now we’ll fit the model.
fit18.3 <-
brm(data = my_data,
family = student,
satt_z ~ 1 + spend_z + prcnt_take_z + interaction_z,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
chains = 4, cores = 4,
stanvars = stanvar(1/29, name = "one_over_twentynine"),
seed = 18,
file = "fits/fit18.03")Note that even though an interaction term might seem different kind from other regression terms, it’s just another coefficient of class = b as far as the prior() statements are concerned. Anyway, let’s inspect the summary().
summary(fit18.3)## Family: student
## Links: mu = identity; sigma = identity; nu = identity
## Formula: satt_z ~ 1 + spend_z + prcnt_take_z + interaction_z
## Data: my_data (Number of observations: 50)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept 0.00 0.06 -0.11 0.12 1.00 2834 2360
## spend_z 0.04 0.14 -0.23 0.33 1.00 1928 2436
## prcnt_take_z -1.46 0.29 -2.01 -0.88 1.00 1719 2147
## interaction_z 0.57 0.37 -0.16 1.28 1.00 1625 1955
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sigma 0.41 0.05 0.32 0.52 1.00 2509 2045
## nu 35.69 30.43 4.63 115.70 1.00 2371 2168
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Like Kruschke reported on page 528, here’s the correlation matrix for the (unstandardized) predictors.
my_data %>%
select(Spend, PrcntTake, interaction) %>%
cor()## Spend PrcntTake interaction
## Spend 1.0000000 0.5926274 0.7750251
## PrcntTake 0.5926274 1.0000000 0.9511463
## interaction 0.7750251 0.9511463 1.0000000The correlations among the ζ coefficients are about as severe.
vcov(fit18.3, correlation = T) %>%
round(digits = 3)## Intercept spend_z prcnt_take_z interaction_z
## Intercept 1.000 0.058 0.041 -0.052
## spend_z 0.058 1.000 0.706 -0.829
## prcnt_take_z 0.041 0.706 1.000 -0.963
## interaction_z -0.052 -0.829 -0.963 1.000We can see that the interaction variable is strongly correlated with both predictors. Therefore, we know that there will be strong trade-offs among the regression coefficients, and the marginal distributions of single regression coefficients might be much wider than when there was no interaction included. (p. 528)
Let’s convert the posterior draws to the unstandardized metric.
sd_x_3 <- sd(my_data$interaction)
m_x_3 <- mean(my_data$interaction)
draws <-
as_draws_df(fit18.3) %>%
transmute(Intercept = make_beta_0(zeta_0 = b_Intercept,
zeta_1 = b_spend_z,
zeta_2 = b_prcnt_take_z,
zeta_3 = b_interaction_z,
sd_x_1 = sd_x_1,
sd_x_2 = sd_x_2,
sd_x_3 = sd_x_3,
sd_y = sd_y,
m_x_1 = m_x_1,
m_x_2 = m_x_2,
m_x_3 = m_x_3,
m_y = m_y),
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
`Percent Take` = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
`Spend : Percent Take` = make_beta_j(zeta_j = b_interaction_z,
sd_j = sd_x_3,
sd_y = sd_y),
Scale = sigma * sd_y,
Normality = nu %>% log10())
glimpse(draws)## Rows: 4,000
## Columns: 6
## $ Intercept <dbl> 1052.8407, 1089.7440, 1014.5478, 1065.8655, 108…
## $ Spend <dbl> -0.2380493, -4.4463594, 8.0726366, -0.7320065, …
## $ `Percent Take` <dbl> -4.235056, -4.348027, -4.017688, -3.967700, -3.…
## $ `Spend : Percent Take` <dbl> 0.271935765, 0.245176318, 0.160051920, 0.193318…
## $ Scale <dbl> 32.21732, 30.62781, 31.34580, 25.56230, 24.6994…
## $ Normality <dbl> 1.6576920, 1.2469875, 1.3987112, 1.7882973, 1.4…Now we’ve done the conversions, here are our versions of the histograms of Figure 18.9.
draws %>%
pivot_longer(everything()) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(legend.position = "none") +
facet_wrap(~ name, scales = "free", ncol = 3)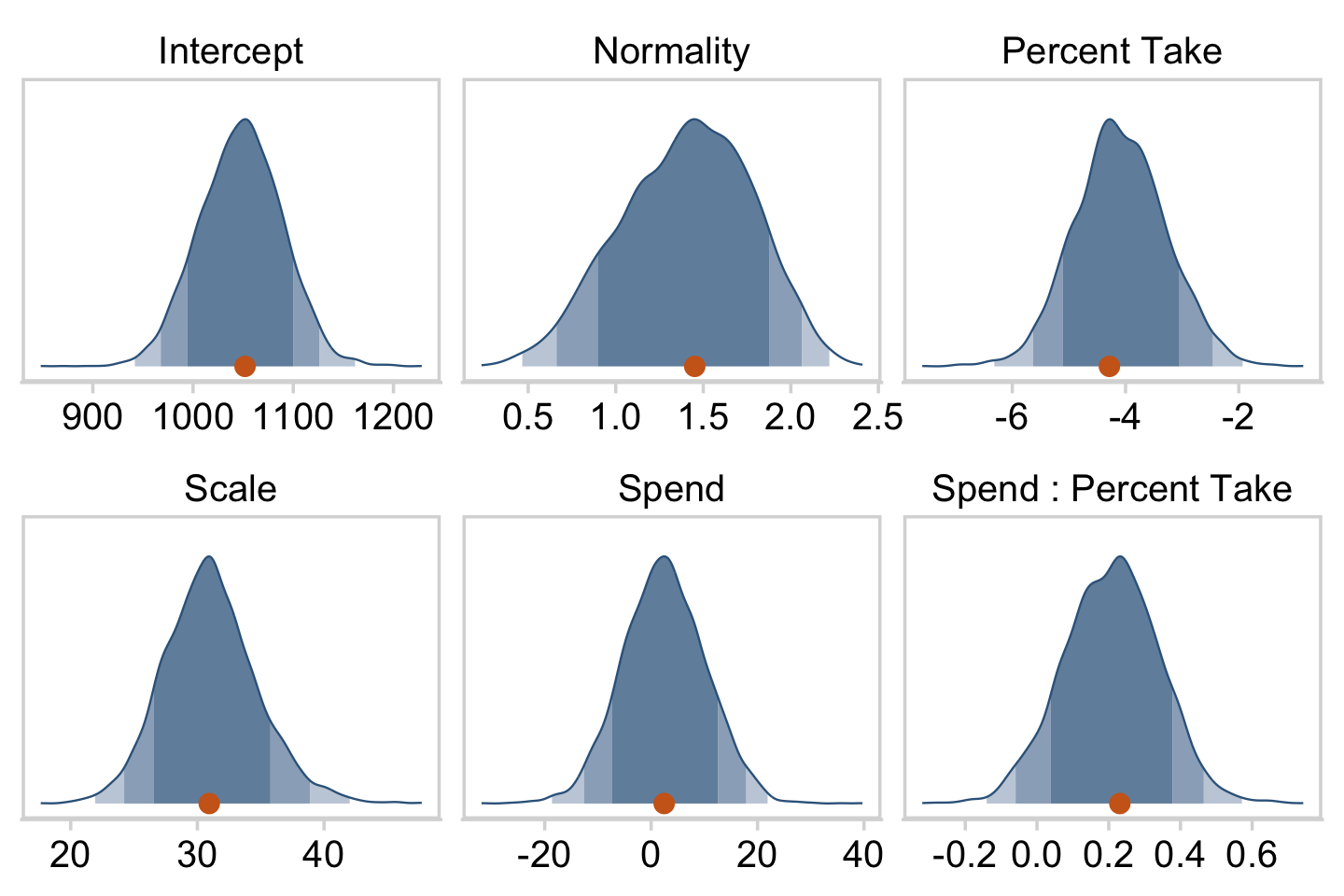
“To properly understand the credible slopes on the two predictors, we must consider the credible slopes on each predictor as a function of the value of the other predictor” (p. 528). This is our motivation for the middle panel of Figure 18.9. To make it, we’ll need to expand our post with expand_grid(), wrangle a bit, and plot with geom_pointrange().
# this will come in handy in `expand_grid()`
bounds <- range(my_data$PrcntTake)
p1 <-
# wrangle
draws %>%
expand_grid(PrcntTake = seq(from = bounds[1], to = bounds[2], length.out = 20)) %>%
mutate(slope = Spend + `Spend : Percent Take` * PrcntTake) %>%
group_by(PrcntTake) %>%
median_hdi(slope) %>%
# plot
ggplot(aes(x = PrcntTake, y = slope,
ymin = .lower, ymax = .upper)) +
geom_hline(yintercept = 0, color = "grey25", linetype = 2) +
geom_pointrange(shape = 21, stroke = 1/10, fatten = 6,
color = "steelblue4", fill = "chocolate3") +
labs(title = expression("Slope on spend is "~beta[1]+beta[3]%.%prcnt_take),
x = "Value of prcnt_take",
y = "Slope on spend")We’ll follow the same basic order of operations for the final panel and then bind them together with patchwork.
# this will come in handy in `expand_grid()`
bounds <- range(my_data$Spend)
p2 <-
# wrangle
draws %>%
select(`Percent Take`, `Spend : Percent Take`) %>%
expand_grid(Spend = seq(from = bounds[1], to = bounds[2], length.out = 20)) %>%
mutate(slope = `Percent Take` + `Spend : Percent Take` * Spend) %>%
group_by(Spend) %>%
median_hdi(slope) %>%
# plot
ggplot(aes(x = Spend, y = slope,
ymin = .lower, ymax = .upper)) +
geom_pointrange(shape = 21, stroke = 1/10, fatten = 6,
color = "steelblue4", fill = "chocolate3") +
labs(title = expression("Slope on prcnt_take is "~beta[2]+beta[3]%.%spend),
x = "Value of spend",
y = "Slope on prcnt_take")
p1 / p2
Kruschke outlined all this in the opening paragraphs of page 530. His parting words of this subsection warrant repeating: “if you include an interaction term, you cannot ignore it even if its marginal posterior distribution includes zero” (p. 530).
18.3 Shrinkage of regression coefficients
In some research, there are many candidate predictors which we suspect could possibly be informative about the predicted variable. For example, when predicting college GPA, we might include high-school GPA, high-school SAT score, income of student, income of parents, years of education of the parents, spending per pupil at the student’s high school, student IQ, student height, weight, shoe size, hours of sleep per night, distance from home to school, amount of caffeine consumed, hours spent studying, hours spent earning a wage, blood pressure, etc. We can include all the candidate predictors in the model, with a regression coefficient for every predictor. And this is not even considering interactions, which we will ignore for now.
With so many candidate predictors of noisy data, there may be some regression coefficients that are spuriously estimated to be non-zero. We would like some protection against accidentally nonzero regression coefficients. (p. 530)
That’s what this section is all about. Figure 18.10 will give us a sense of what a model like this might look like.
# brackets
p1 <-
tibble(x = .5,
y = .5,
label = "{_} {_}") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 10, family = "Times") +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# two annotated arrows
p2 <-
tibble(x = c(.15, .85),
y = c(1, 1),
xend = c(.25, .75),
yend = c(.2, .2)) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# normal density
p3 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 0, y = .2,
label = "normal",
size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = .6,
label = c("italic(M)[0]", "italic(S)[0]"),
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# a student-t density
p4 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dt(x, 3) / max(dt(x, 3))))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 0, y = .2,
label = "student t",
size = 7) +
annotate(geom = "text",
x = 0, y = .6,
label = "nu[beta]~~~0~~~sigma[beta]",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# two more annotated arrows
p5 <-
tibble(x = c(.33, 1.67),
y = c(1, 1),
xend = c(.63, 1.2),
yend = c(0, 0)) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = c(.35, 1.35, 1.54), y = .5,
label = c("'~'", "'~'", "italic(j)"),
size = c(10, 10, 7), family = "Times", parse = T) +
xlim(0, 2) +
theme_void()
# exponential density
p6 <-
tibble(x = seq(from = 0, to = 1, by = .01)) %>%
ggplot(aes(x = x, y = (dexp(x, 2) / max(dexp(x, 2))))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = .5, y = .2,
label = "exp",
size = 7) +
annotate(geom = "text",
x = .5, y = .6,
label = "italic(K)",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# likelihood formula
p7 <-
tibble(x = .5,
y = .25,
label = "beta[0]+sum()[italic(j)]*beta[italic(j)]*italic(x)[italic(ji)]") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# half-normal density
p8 <-
tibble(x = seq(from = 0, to = 3, by = .01)) %>%
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 1.5, y = .2,
label = "half-normal",
size = 7) +
annotate(geom = "text",
x = 1.5, y = .6,
label = "0*','*~italic(S)[sigma]",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# four annotated arrows
p9 <-
tibble(x = c(.43, .43, 1.5, 2.5),
y = c(1, .55, 1, 1),
xend = c(.43, 1.225, 1.5, 1.75),
yend = c(.8, .15, .2, .2)) %>%
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow) +
annotate(geom = "text",
x = c(.3, .7, 1.38, 2), y = c(.92, .22, .65, .6),
label = c("'~'", "'='", "'='", "'~'"),
size = 10, family = "Times", parse = T) +
annotate(geom = "text",
x = .43, y = .7,
label = "nu*minute+1",
size = 7, family = "Times", parse = T) +
xlim(0, 3) +
theme_void()
# a second student-t density
p10 <-
tibble(x = seq(from = -3, to = 3, by = .1)) %>%
ggplot(aes(x = x, y = (dt(x, 3) / max(dt(x, 3))))) +
geom_area(fill = "steelblue4", color = "steelblue4", alpha = .6) +
annotate(geom = "text",
x = 0, y = .2,
label = "student t",
size = 7) +
annotate(geom = "text",
x = 0, y = .6,
label = "nu~~~mu[italic(i)]~~~sigma",
size = 7, family = "Times", parse = T) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5))
# the final annotated arrow
p11 <-
tibble(x = c(.375, .625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)")) %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = c(10, 7), parse = T, family = "Times") +
geom_segment(x = .5, xend = .5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# some text
p12 <-
tibble(x = .5,
y = .5,
label = "italic(y[i])") %>%
ggplot(aes(x = x, y = y, label = label)) +
geom_text(size = 7, parse = T, family = "Times") +
xlim(0, 1) +
theme_void()
# define the layout
layout <- c(
area(t = 1, b = 1, l = 7, r = 9),
area(t = 3, b = 4, l = 3, r = 5),
area(t = 3, b = 4, l = 7, r = 9),
area(t = 2, b = 3, l = 7, r = 9),
area(t = 6, b = 7, l = 1, r = 3),
area(t = 6, b = 7, l = 5, r = 7),
area(t = 6, b = 7, l = 9, r = 11),
area(t = 5, b = 6, l = 3, r = 9),
area(t = 9, b = 10, l = 5, r = 7),
area(t = 8, b = 9, l = 1, r = 11),
area(t = 11, b = 11, l = 5, r = 7),
area(t = 12, b = 12, l = 5, r = 7)
)
# combine and plot!
(p1 + p3 + p4 + p2 + p6 + p7 + p8 + p5 + p10 + p9 + p11 + p12) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))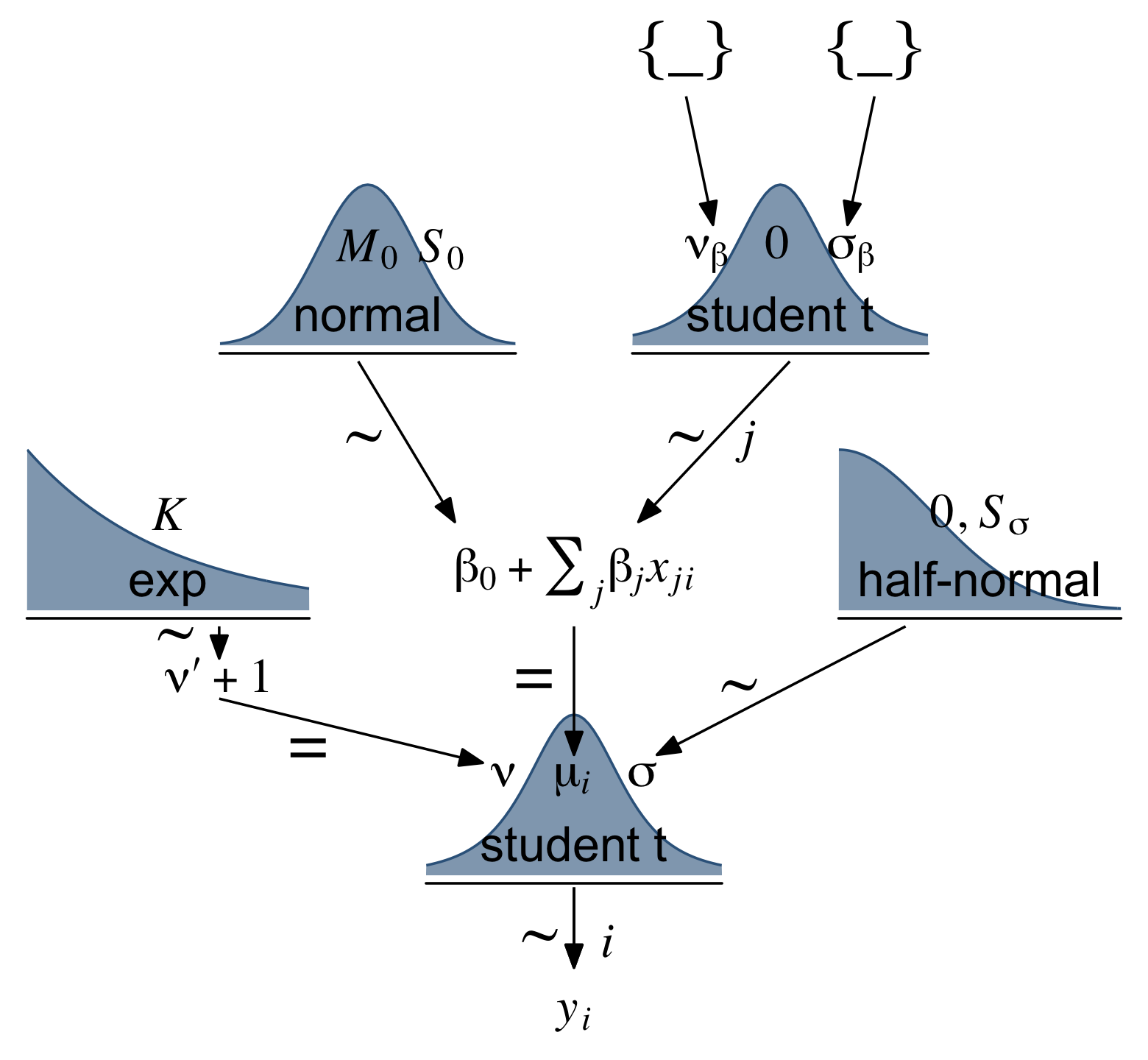
Make our random noise predictors with rnorm().
set.seed(18)
my_data <-
my_data %>%
mutate(x_rand_1 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_2 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_3 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_4 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_5 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_6 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_7 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_8 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_9 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_10 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_11 = rnorm(n = n(), mean = 0, sd = 1),
x_rand_12 = rnorm(n = n(), mean = 0, sd = 1))
glimpse(my_data)## Rows: 50
## Columns: 27
## $ State <chr> "Alabama", "Alaska", "Arizona", "Arkansas", "Californi…
## $ Spend <dbl> 4.405, 8.963, 4.778, 4.459, 4.992, 5.443, 8.817, 7.030…
## $ StuTeaRat <dbl> 17.2, 17.6, 19.3, 17.1, 24.0, 18.4, 14.4, 16.6, 19.1, …
## $ Salary <dbl> 31.144, 47.951, 32.175, 28.934, 41.078, 34.571, 50.045…
## $ PrcntTake <dbl> 8, 47, 27, 6, 45, 29, 81, 68, 48, 65, 57, 15, 13, 58, …
## $ SATV <dbl> 491, 445, 448, 482, 417, 462, 431, 429, 420, 406, 407,…
## $ SATM <dbl> 538, 489, 496, 523, 485, 518, 477, 468, 469, 448, 482,…
## $ SATT <dbl> 1029, 934, 944, 1005, 902, 980, 908, 897, 889, 854, 88…
## $ prcnt_take_z <dbl> -1.0178453, 0.4394222, -0.3078945, -1.0925770, 0.36469…
## $ spend_z <dbl> -1.10086058, 2.24370805, -0.82716069, -1.06123647, -0.…
## $ satt_z <dbl> 0.8430838, -0.4266207, -0.2929676, 0.5223163, -0.85431…
## $ prop_not_take <dbl> 0.92, 0.53, 0.73, 0.94, 0.55, 0.71, 0.19, 0.32, 0.52, …
## $ prop_not_take_z <dbl> 1.0178453, -0.4394222, 0.3078945, 1.0925770, -0.364690…
## $ interaction <dbl> 35.240, 421.261, 129.006, 26.754, 224.640, 157.847, 71…
## $ interaction_z <dbl> -0.94113720, 0.93111798, -0.48635915, -0.98229547, -0.…
## $ x_rand_1 <dbl> 0.92645924, 1.82282117, -1.61056690, -0.28510975, -0.3…
## $ x_rand_2 <dbl> -0.90258025, -1.13163679, 0.49708131, -0.54771876, -0.…
## $ x_rand_3 <dbl> 0.51576102, 0.30710965, 0.66199996, 2.21990655, -2.041…
## $ x_rand_4 <dbl> 1.08730491, -1.23909473, 0.43161390, 1.06733141, -0.78…
## $ x_rand_5 <dbl> -0.23846777, 0.15702031, -1.02132795, 0.75395217, -2.3…
## $ x_rand_6 <dbl> 0.06014956, 1.00555800, 1.47981871, -0.82827890, -0.58…
## $ x_rand_7 <dbl> 1.46961709, 0.51790320, -2.33110353, 0.11339996, 1.726…
## $ x_rand_8 <dbl> 0.03463437, -1.48737599, -0.01528284, 0.48480309, 0.20…
## $ x_rand_9 <dbl> -0.4556078, -0.7035475, -0.5001913, -0.6526022, 0.7742…
## $ x_rand_10 <dbl> 1.2858586, -0.7474640, -0.3107255, -1.1037468, 0.33136…
## $ x_rand_11 <dbl> 0.17236599, -0.37956084, 0.31982301, 0.29678108, 1.220…
## $ x_rand_12 <dbl> -0.53048519, 0.92465424, 0.66876661, 0.30935146, 1.474…Here’s how to fit the naïve model, which does not impose shrinkage on the coefficients.
fit18.4 <-
update(fit18.1,
newdata = my_data,
formula = satt_z ~ 1 + prcnt_take_z + spend_z + x_rand_1 + x_rand_2 + x_rand_3 + x_rand_4 + x_rand_5 + x_rand_6 + x_rand_7 + x_rand_8 + x_rand_9 + x_rand_10 + x_rand_11 + x_rand_12,
seed = 18,
file = "fits/fit18.04")Examine the posterior with posterior_summary().
posterior_summary(fit18.4)[1:17, ] %>%
round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept -0.03 0.07 -0.16 0.11
## b_prcnt_take_z -1.12 0.09 -1.28 -0.94
## b_spend_z 0.32 0.09 0.16 0.50
## b_x_rand_1 0.03 0.06 -0.08 0.15
## b_x_rand_2 0.02 0.09 -0.16 0.20
## b_x_rand_3 0.09 0.07 -0.05 0.23
## b_x_rand_4 -0.09 0.07 -0.23 0.05
## b_x_rand_5 0.00 0.06 -0.12 0.13
## b_x_rand_6 -0.02 0.08 -0.17 0.13
## b_x_rand_7 -0.03 0.07 -0.17 0.12
## b_x_rand_8 -0.18 0.07 -0.32 -0.04
## b_x_rand_9 0.13 0.06 0.02 0.25
## b_x_rand_10 0.00 0.05 -0.10 0.10
## b_x_rand_11 0.05 0.09 -0.14 0.22
## b_x_rand_12 -0.08 0.06 -0.20 0.04
## sigma 0.38 0.07 0.23 0.52
## nu 25.02 26.94 2.08 99.25Before we can make Figure 18.11, we’ll need to update our make_beta_0() function to accommodate this model.
make_beta_0 <-
function(zeta_0, zeta_1, zeta_2, zeta_3, zeta_4, zeta_5, zeta_6, zeta_7, zeta_8, zeta_9, zeta_10, zeta_11, zeta_12, zeta_13, zeta_14,
sd_x_1, sd_x_2, sd_x_3, sd_x_4, sd_x_5, sd_x_6, sd_x_7, sd_x_8, sd_x_9, sd_x_10, sd_x_11, sd_x_12, sd_x_13, sd_x_14, sd_y,
m_x_1, m_x_2, m_x_3, m_x_4, m_x_5, m_x_6, m_x_7, m_x_8, m_x_9, m_x_10, m_x_11, m_x_12, m_x_13, m_x_14, m_y) {
sd_y * zeta_0 + m_y - sd_y * ((zeta_1 * m_x_1 / sd_x_1) +
(zeta_2 * m_x_2 / sd_x_2) +
(zeta_3 * m_x_3 / sd_x_3) +
(zeta_4 * m_x_4 / sd_x_4) +
(zeta_5 * m_x_5 / sd_x_5) +
(zeta_6 * m_x_6 / sd_x_6) +
(zeta_7 * m_x_7 / sd_x_7) +
(zeta_8 * m_x_8 / sd_x_8) +
(zeta_9 * m_x_9 / sd_x_9) +
(zeta_10 * m_x_10 / sd_x_10) +
(zeta_11 * m_x_11 / sd_x_11) +
(zeta_12 * m_x_12 / sd_x_12) +
(zeta_13 * m_x_13 / sd_x_13) +
(zeta_14 * m_x_14 / sd_x_14))
}Sigh, our poor make_beta_0() and make_beta_1() code is getting obscene. I don’t have the energy to think of how to wrap this into a simpler function. Someone probably should. If that ends up as you, do share your code.
sd_x_1 <- sd(my_data$Spend)
sd_x_2 <- sd(my_data$PrcntTake)
sd_x_3 <- sd(my_data$x_rand_1)
sd_x_4 <- sd(my_data$x_rand_2)
sd_x_5 <- sd(my_data$x_rand_3)
sd_x_6 <- sd(my_data$x_rand_4)
sd_x_7 <- sd(my_data$x_rand_5)
sd_x_8 <- sd(my_data$x_rand_6)
sd_x_9 <- sd(my_data$x_rand_7)
sd_x_10 <- sd(my_data$x_rand_8)
sd_x_11 <- sd(my_data$x_rand_9)
sd_x_12 <- sd(my_data$x_rand_10)
sd_x_13 <- sd(my_data$x_rand_11)
sd_x_14 <- sd(my_data$x_rand_12)
sd_y <- sd(my_data$SATT)
m_x_1 <- mean(my_data$Spend)
m_x_2 <- mean(my_data$PrcntTake)
m_x_3 <- mean(my_data$x_rand_1)
m_x_4 <- mean(my_data$x_rand_2)
m_x_5 <- mean(my_data$x_rand_3)
m_x_6 <- mean(my_data$x_rand_4)
m_x_7 <- mean(my_data$x_rand_5)
m_x_8 <- mean(my_data$x_rand_6)
m_x_9 <- mean(my_data$x_rand_7)
m_x_10 <- mean(my_data$x_rand_8)
m_x_11 <- mean(my_data$x_rand_9)
m_x_12 <- mean(my_data$x_rand_10)
m_x_13 <- mean(my_data$x_rand_11)
m_x_14 <- mean(my_data$x_rand_12)
m_y <- mean(my_data$SATT)
draws <-
as_draws_df(fit18.4) %>%
transmute(Intercept = make_beta_0(zeta_0 = b_Intercept,
zeta_1 = b_spend_z,
zeta_2 = b_prcnt_take_z,
zeta_3 = b_x_rand_1,
zeta_4 = b_x_rand_2,
zeta_5 = b_x_rand_3,
zeta_6 = b_x_rand_4,
zeta_7 = b_x_rand_5,
zeta_8 = b_x_rand_6,
zeta_9 = b_x_rand_7,
zeta_10 = b_x_rand_8,
zeta_11 = b_x_rand_9,
zeta_12 = b_x_rand_10,
zeta_13 = b_x_rand_11,
zeta_14 = b_x_rand_12,
sd_x_1 = sd_x_1,
sd_x_2 = sd_x_2,
sd_x_3 = sd_x_3,
sd_x_4 = sd_x_4,
sd_x_5 = sd_x_5,
sd_x_6 = sd_x_6,
sd_x_7 = sd_x_7,
sd_x_8 = sd_x_8,
sd_x_9 = sd_x_9,
sd_x_10 = sd_x_10,
sd_x_11 = sd_x_11,
sd_x_12 = sd_x_12,
sd_x_13 = sd_x_13,
sd_x_14 = sd_x_14,
sd_y = sd_y,
m_x_1 = m_x_1,
m_x_2 = m_x_2,
m_x_3 = m_x_3,
m_x_4 = m_x_4,
m_x_5 = m_x_5,
m_x_6 = m_x_6,
m_x_7 = m_x_7,
m_x_8 = m_x_8,
m_x_9 = m_x_9,
m_x_10 = m_x_10,
m_x_11 = m_x_11,
m_x_12 = m_x_12,
m_x_13 = m_x_13,
m_x_14 = m_x_14,
m_y = m_y),
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
`Percent Take` = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
x_rand_1 = make_beta_j(zeta_j = b_x_rand_1,
sd_j = sd_x_3,
sd_y = sd_y),
x_rand_2 = make_beta_j(zeta_j = b_x_rand_2,
sd_j = sd_x_4,
sd_y = sd_y),
x_rand_3 = make_beta_j(zeta_j = b_x_rand_3,
sd_j = sd_x_5,
sd_y = sd_y),
x_rand_4 = make_beta_j(zeta_j = b_x_rand_4,
sd_j = sd_x_6,
sd_y = sd_y),
x_rand_5 = make_beta_j(zeta_j = b_x_rand_5,
sd_j = sd_x_7,
sd_y = sd_y),
x_rand_6 = make_beta_j(zeta_j = b_x_rand_6,
sd_j = sd_x_8,
sd_y = sd_y),
x_rand_7 = make_beta_j(zeta_j = b_x_rand_7,
sd_j = sd_x_9,
sd_y = sd_y),
x_rand_8 = make_beta_j(zeta_j = b_x_rand_8,
sd_j = sd_x_10,
sd_y = sd_y),
x_rand_9 = make_beta_j(zeta_j = b_x_rand_9,
sd_j = sd_x_11,
sd_y = sd_y),
x_rand_10 = make_beta_j(zeta_j = b_x_rand_10,
sd_j = sd_x_12,
sd_y = sd_y),
x_rand_11 = make_beta_j(zeta_j = b_x_rand_11,
sd_j = sd_x_13,
sd_y = sd_y),
x_rand_12 = make_beta_j(zeta_j = b_x_rand_12,
sd_j = sd_x_14,
sd_y = sd_y),
Scale = sigma * sd_y,
Normality = nu %>% log10())
glimpse(draws)## Rows: 4,000
## Columns: 17
## $ Intercept <dbl> 950.7077, 969.4177, 955.6650, 957.3323, 979.0691, 904.1…
## $ Spend <dbl> 21.337416, 19.647029, 19.676473, 20.433890, 14.925248, …
## $ `Percent Take` <dbl> -3.286047, -3.473662, -3.293917, -3.168405, -3.199506, …
## $ x_rand_1 <dbl> -0.7750959, 1.2345310, 2.2533082, 7.9075852, -6.3989120…
## $ x_rand_2 <dbl> 4.3716598, 5.3214159, 0.2139152, -2.3934613, 0.9786895,…
## $ x_rand_3 <dbl> 13.9225315, 8.7596922, 12.3683049, 1.9136425, 1.9405810…
## $ x_rand_4 <dbl> -8.833918, -4.325065, -5.970432, -1.095080, -8.476883, …
## $ x_rand_5 <dbl> 0.2862657, 0.0327725, -1.8087232, 7.4595729, -2.4899133…
## $ x_rand_6 <dbl> -7.58014923, -10.39285061, -10.38175497, -1.85296607, -…
## $ x_rand_7 <dbl> -8.1876266, 6.9171116, 3.1819146, -6.7840152, -1.746752…
## $ x_rand_8 <dbl> -10.748734, -20.558489, -24.303320, -9.397539, -13.0822…
## $ x_rand_9 <dbl> 10.897684, 10.371134, 7.273580, 9.937170, 2.848720, 5.1…
## $ x_rand_10 <dbl> 4.36641286, 1.51521683, -1.71910237, 2.30166117, -0.417…
## $ x_rand_11 <dbl> -2.1425651, -6.5159347, 0.9490695, -2.5980596, 9.091885…
## $ x_rand_12 <dbl> -6.0867734, -3.1446508, -8.0939326, -2.2343898, 0.70466…
## $ Scale <dbl> 22.81950, 26.20729, 29.09542, 24.65083, 20.92236, 27.80…
## $ Normality <dbl> 0.6783691, 0.6442554, 1.4320776, 0.8167508, 0.5223094, …Okay, here are our versions of the histograms of Figure 18.11.
draws %>%
pivot_longer(cols = c(Intercept:x_rand_3, x_rand_10:Normality)) %>%
mutate(name = factor(name,
levels = c("Intercept", "Spend", "Percent Take",
"x_rand_1", "x_rand_2", "x_rand_3",
"x_rand_10", "x_rand_11", "x_rand_12",
"Scale", "Normality"))) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(axis.text.x = element_text(size = 9),
legend.position = c(.74, .09)) +
facet_wrap(~ name, scales = "free", ncol = 3)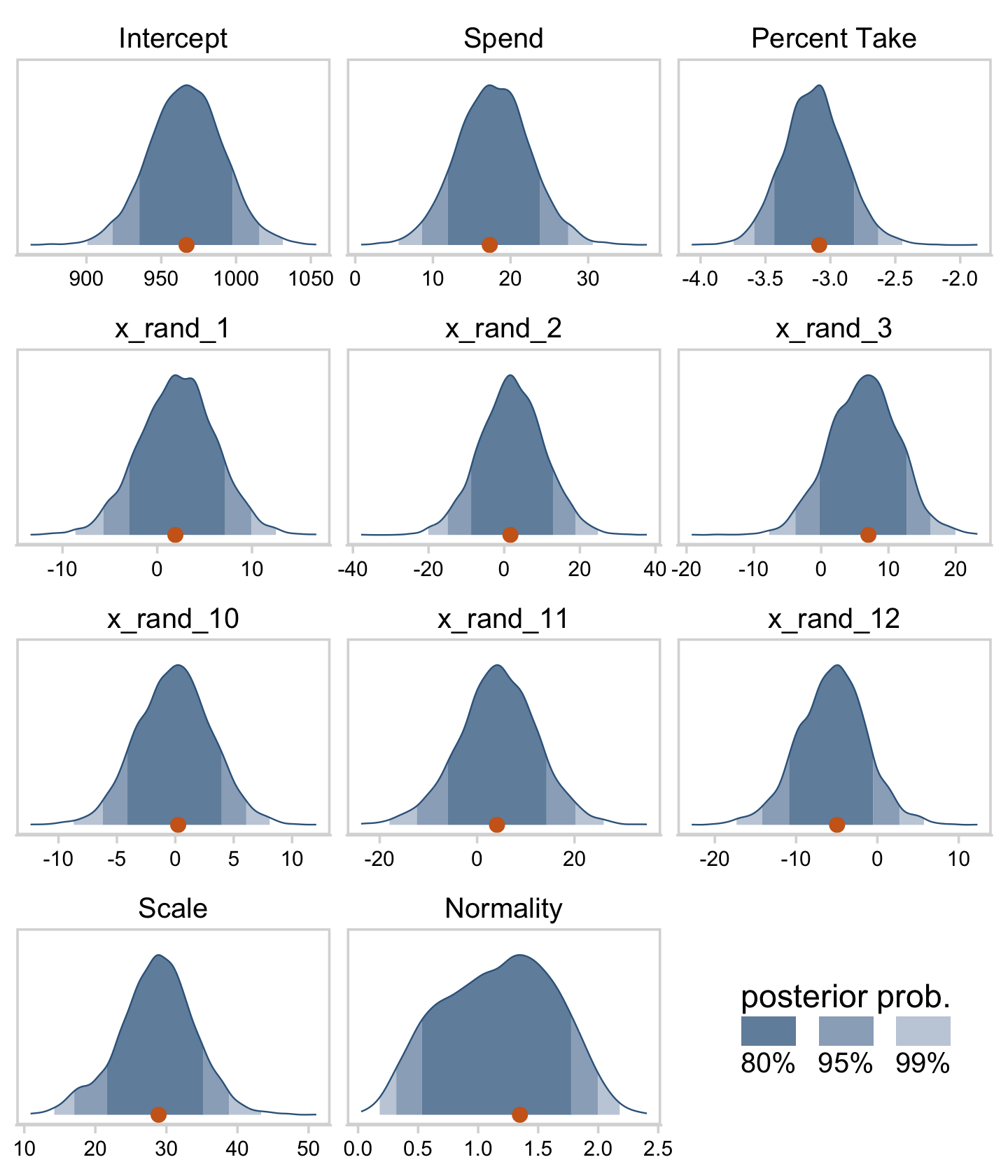
And here’s the final density plot depicting the Bayesian R2.
bayes_R2(fit18.4, summary = F) %>%
as_tibble() %>%
ggplot(aes(x = R2, y = 0)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
labs(subtitle = expression(paste("Bayesian ", italic(R)^2)),
x = NULL) +
coord_cartesian(xlim = c(0, 1),
ylim = c(-0.01, NA)) +
theme(legend.position = c(.01, .8))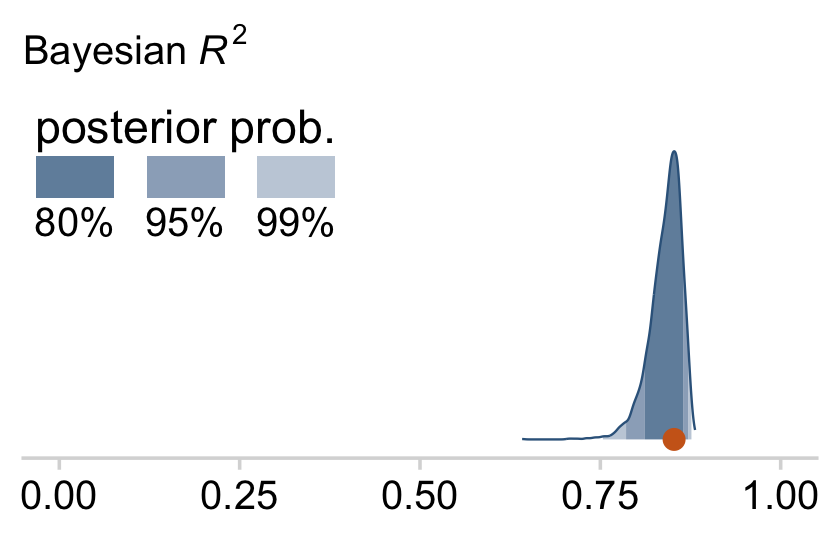
Note that unlike the one Kruschke displayed in the text, our brms::bayes_R2()-based R2 distribution did not exceed the logical right bound of 1.
Sometimes when you have this many parameters you’d like to compare, it’s better to display their summaries with an ordered coefficient plot.
draws %>%
pivot_longer(Spend:x_rand_12) %>%
mutate(name = fct_reorder(name, value)) %>%
ggplot(aes(x = value, y = name)) +
geom_vline(xintercept = 0, color = "grey25", linetype = 2) +
stat_pointinterval(point_interval = mode_hdi, .width = .95, point_size = 4,
color = "steelblue4", point_color = "chocolate3") +
labs(x = NULL,
y = NULL) +
theme(axis.text.y = element_text(hjust = 0))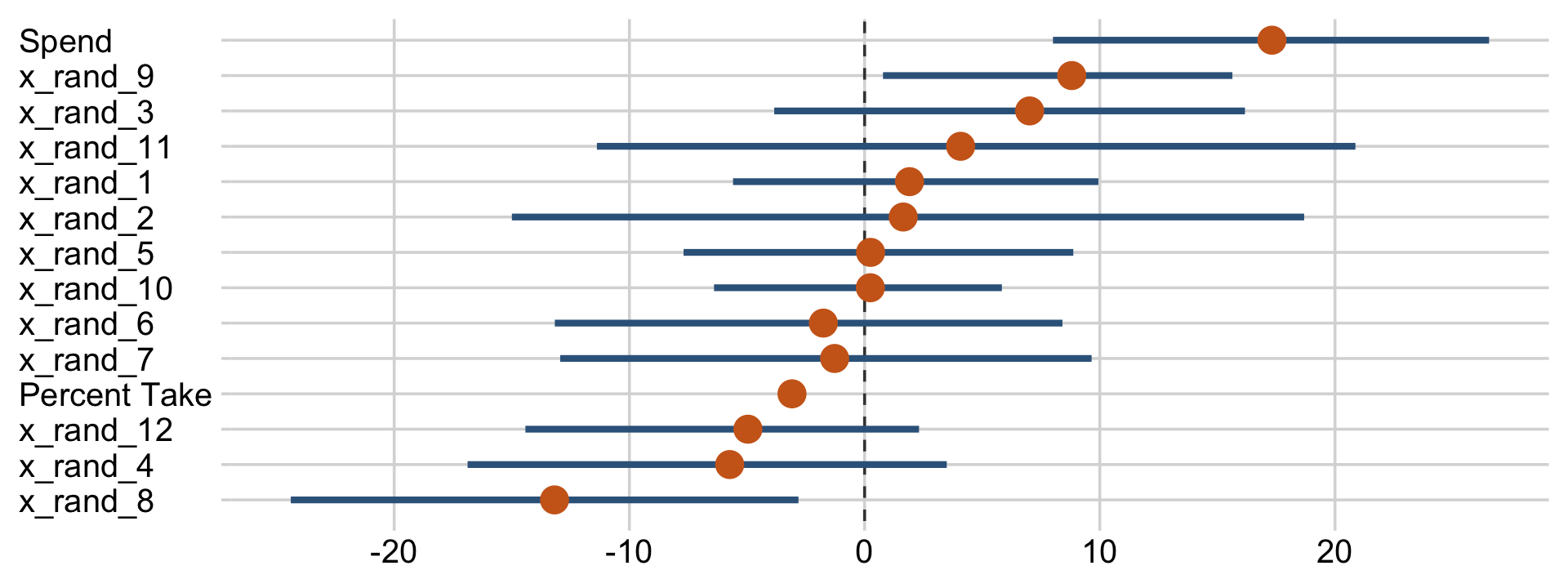
Now we can see that by chance alone, the coefficients for x_rand_8 and x_rand_9 are clearly distinct from zero. Our stat_wilke() function can be informative, too.
draws %>%
pivot_longer(Spend:x_rand_12) %>%
ggplot(aes(x = value, y = reorder(name, value), group = reorder(name, value))) +
geom_vline(xintercept = 0, color = "grey25", linetype = 2) +
stat_wilke(height = 10, point_size = 3) +
labs(x = NULL,
y = NULL) +
coord_cartesian(ylim = c(1.25, 14.5)) +
theme(axis.text.y = element_text(hjust = 0),
legend.position = c(.785, .13)) 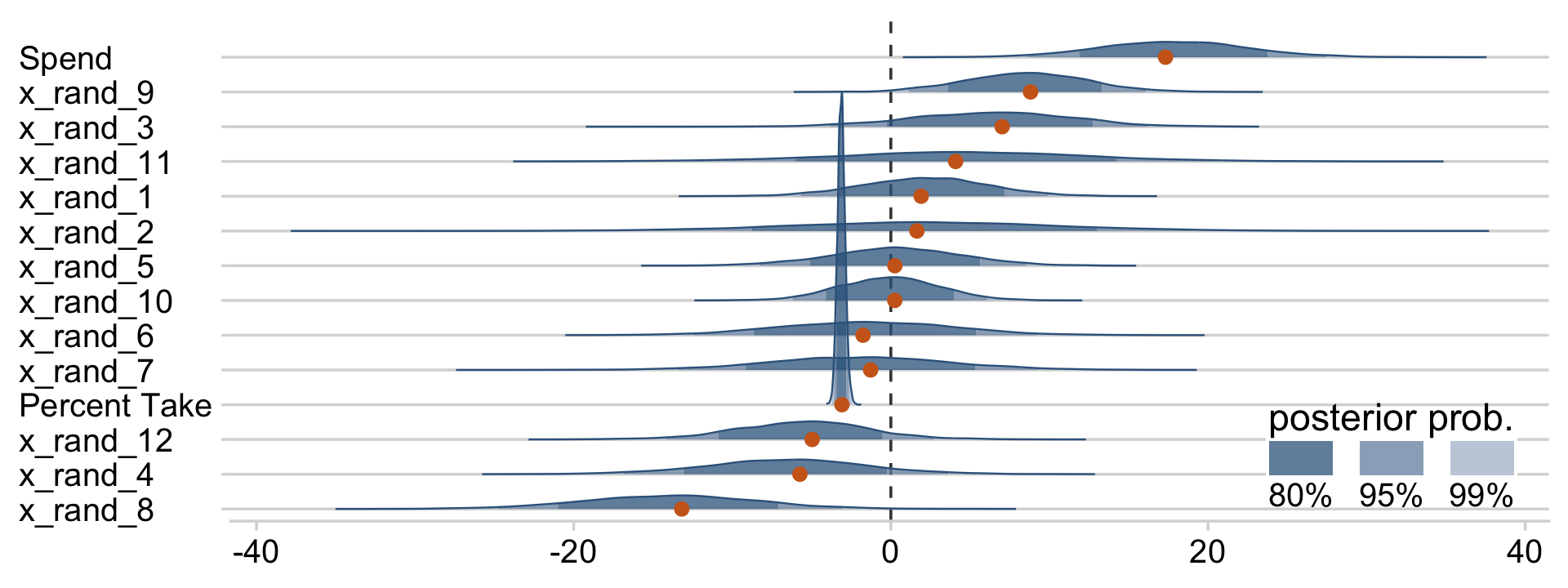
With brms, we can fit something like the model Kruschke displayed in Figure 18.12 with the horseshoe() prior. From the horseshoe section of the brms reference manual:
The horseshoe prior is a special shrinkage prior initially proposed by (Carvalho et al., 2009). It is symmetric around zero with fat tails and an infinitely large spike at zero. This makes it ideal for sparse models that have many regression coefficients, although only a minority of them is non-zero. The horseshoe prior can be applied on all population-level effects at once (excluding the intercept) by using
set_prior("horseshoe(1)"). The1implies that the student-t prior of the local shrinkage parameters has 1 degrees of freedom (Bürkner, 2022f, p. 105)
Based on the quote, here’s how to fit our horseshoe-prior model with brm().
fit18.5 <-
update(fit18.4,
newdata = my_data,
formula = satt_z ~ 1 + prcnt_take_z + spend_z + x_rand_1 + x_rand_2 + x_rand_3 + x_rand_4 + x_rand_5 + x_rand_6 + x_rand_7 + x_rand_8 + x_rand_9 + x_rand_10 + x_rand_11 + x_rand_12,
prior = c(prior(normal(0, 2), class = Intercept),
prior(horseshoe(1), class = b),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
seed = 18,
control = list(adapt_delta = .9),
file = "fits/fit18.05")Check the parameter summary.
posterior_summary(fit18.5)[1:17, ] %>%
round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept -0.02 0.06 -0.14 0.11
## b_prcnt_take_z -1.02 0.10 -1.20 -0.82
## b_spend_z 0.20 0.11 0.00 0.39
## b_x_rand_1 0.01 0.04 -0.05 0.10
## b_x_rand_2 0.01 0.04 -0.09 0.11
## b_x_rand_3 0.02 0.04 -0.05 0.13
## b_x_rand_4 -0.03 0.05 -0.15 0.04
## b_x_rand_5 0.00 0.03 -0.07 0.08
## b_x_rand_6 -0.02 0.04 -0.12 0.06
## b_x_rand_7 -0.01 0.04 -0.10 0.07
## b_x_rand_8 -0.09 0.07 -0.23 0.01
## b_x_rand_9 0.05 0.06 -0.02 0.18
## b_x_rand_10 0.00 0.03 -0.06 0.07
## b_x_rand_11 0.01 0.05 -0.08 0.12
## b_x_rand_12 -0.02 0.04 -0.12 0.05
## sigma 0.40 0.06 0.25 0.52
## nu 30.92 28.58 2.99 109.39Our make_beta_0() and make_beta_1() code remains obscene.
draws <-
as_draws_df(fit18.5) %>%
transmute(Intercept = make_beta_0(zeta_0 = b_Intercept,
zeta_1 = b_spend_z,
zeta_2 = b_prcnt_take_z,
zeta_3 = b_x_rand_1,
zeta_4 = b_x_rand_2,
zeta_5 = b_x_rand_3,
zeta_6 = b_x_rand_4,
zeta_7 = b_x_rand_5,
zeta_8 = b_x_rand_6,
zeta_9 = b_x_rand_7,
zeta_10 = b_x_rand_8,
zeta_11 = b_x_rand_9,
zeta_12 = b_x_rand_10,
zeta_13 = b_x_rand_11,
zeta_14 = b_x_rand_12,
sd_x_1 = sd_x_1,
sd_x_2 = sd_x_2,
sd_x_3 = sd_x_3,
sd_x_4 = sd_x_4,
sd_x_5 = sd_x_5,
sd_x_6 = sd_x_6,
sd_x_7 = sd_x_7,
sd_x_8 = sd_x_8,
sd_x_9 = sd_x_9,
sd_x_10 = sd_x_10,
sd_x_11 = sd_x_11,
sd_x_12 = sd_x_12,
sd_x_13 = sd_x_13,
sd_x_14 = sd_x_14,
sd_y = sd_y,
m_x_1 = m_x_1,
m_x_2 = m_x_2,
m_x_3 = m_x_3,
m_x_4 = m_x_4,
m_x_5 = m_x_5,
m_x_6 = m_x_6,
m_x_7 = m_x_7,
m_x_8 = m_x_8,
m_x_9 = m_x_9,
m_x_10 = m_x_10,
m_x_11 = m_x_11,
m_x_12 = m_x_12,
m_x_13 = m_x_13,
m_x_14 = m_x_14,
m_y = m_y),
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
`Percent Take` = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
x_rand_1 = make_beta_j(zeta_j = b_x_rand_1,
sd_j = sd_x_3,
sd_y = sd_y),
x_rand_2 = make_beta_j(zeta_j = b_x_rand_2,
sd_j = sd_x_4,
sd_y = sd_y),
x_rand_3 = make_beta_j(zeta_j = b_x_rand_3,
sd_j = sd_x_5,
sd_y = sd_y),
x_rand_4 = make_beta_j(zeta_j = b_x_rand_4,
sd_j = sd_x_6,
sd_y = sd_y),
x_rand_5 = make_beta_j(zeta_j = b_x_rand_5,
sd_j = sd_x_7,
sd_y = sd_y),
x_rand_6 = make_beta_j(zeta_j = b_x_rand_6,
sd_j = sd_x_8,
sd_y = sd_y),
x_rand_7 = make_beta_j(zeta_j = b_x_rand_7,
sd_j = sd_x_9,
sd_y = sd_y),
x_rand_8 = make_beta_j(zeta_j = b_x_rand_8,
sd_j = sd_x_10,
sd_y = sd_y),
x_rand_9 = make_beta_j(zeta_j = b_x_rand_9,
sd_j = sd_x_11,
sd_y = sd_y),
x_rand_10 = make_beta_j(zeta_j = b_x_rand_10,
sd_j = sd_x_12,
sd_y = sd_y),
x_rand_11 = make_beta_j(zeta_j = b_x_rand_11,
sd_j = sd_x_13,
sd_y = sd_y),
x_rand_12 = make_beta_j(zeta_j = b_x_rand_12,
sd_j = sd_x_14,
sd_y = sd_y),
Scale = sigma * sd_y,
Normality = nu %>% log10())
glimpse(draws)## Rows: 4,000
## Columns: 17
## $ Intercept <dbl> 1043.4842, 955.1105, 997.7826, 960.3109, 1009.5597, 990…
## $ Spend <dbl> 3.466299, 18.465108, 9.246108, 16.303882, 11.150742, 14…
## $ `Percent Take` <dbl> -2.637569, -2.876726, -2.489912, -2.703482, -3.139547, …
## $ x_rand_1 <dbl> 2.72503654, -0.48380911, -1.21854153, 0.26639377, 3.568…
## $ x_rand_2 <dbl> -2.138543765, 5.538560141, 0.332987840, 0.219574019, 0.…
## $ x_rand_3 <dbl> 1.75638920, 1.60000395, 3.24765170, -1.43170057, 1.0854…
## $ x_rand_4 <dbl> -0.222482772, 0.200751027, -0.116239310, 1.779126024, -…
## $ x_rand_5 <dbl> -0.36486960, 1.13923859, -1.08890670, -2.20912245, 0.02…
## $ x_rand_6 <dbl> -0.09521246, -2.04746521, -5.59629491, -0.08087280, -1.…
## $ x_rand_7 <dbl> -3.208171846, 2.454125289, 1.809477083, -0.171674689, -…
## $ x_rand_8 <dbl> 0.6524765, -11.3271844, -6.8373678, -14.3736269, -1.623…
## $ x_rand_9 <dbl> 3.75898992, 4.45866480, 2.13479111, 5.58475417, 2.51534…
## $ x_rand_10 <dbl> -0.38315913, -0.53013225, -2.26906586, 0.13986268, 0.79…
## $ x_rand_11 <dbl> 0.03762051, -1.99494054, 3.81382431, 0.39868220, -8.240…
## $ x_rand_12 <dbl> -1.45354785, -1.09171882, -2.94307027, 1.72021426, 0.04…
## $ Scale <dbl> 36.03939, 27.98800, 36.53762, 27.37404, 32.54841, 33.36…
## $ Normality <dbl> 1.3218879, 1.3955561, 1.6572943, 1.4741560, 1.0952938, …And here are our stat_wilke() plot versions of the majority of the histograms of Figure 18.12.
draws %>%
pivot_longer(cols = c(Intercept:x_rand_3, x_rand_10:Normality)) %>%
mutate(name = factor(name,
levels = c("Intercept", "Spend", "Percent Take",
"x_rand_1", "x_rand_2", "x_rand_3",
"x_rand_10", "x_rand_11", "x_rand_12",
"Scale", "Normality"))) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(axis.text.x = element_text(size = 10),
legend.position = c(.74, .09)) +
facet_wrap(~ name, scales = "free", ncol = 3)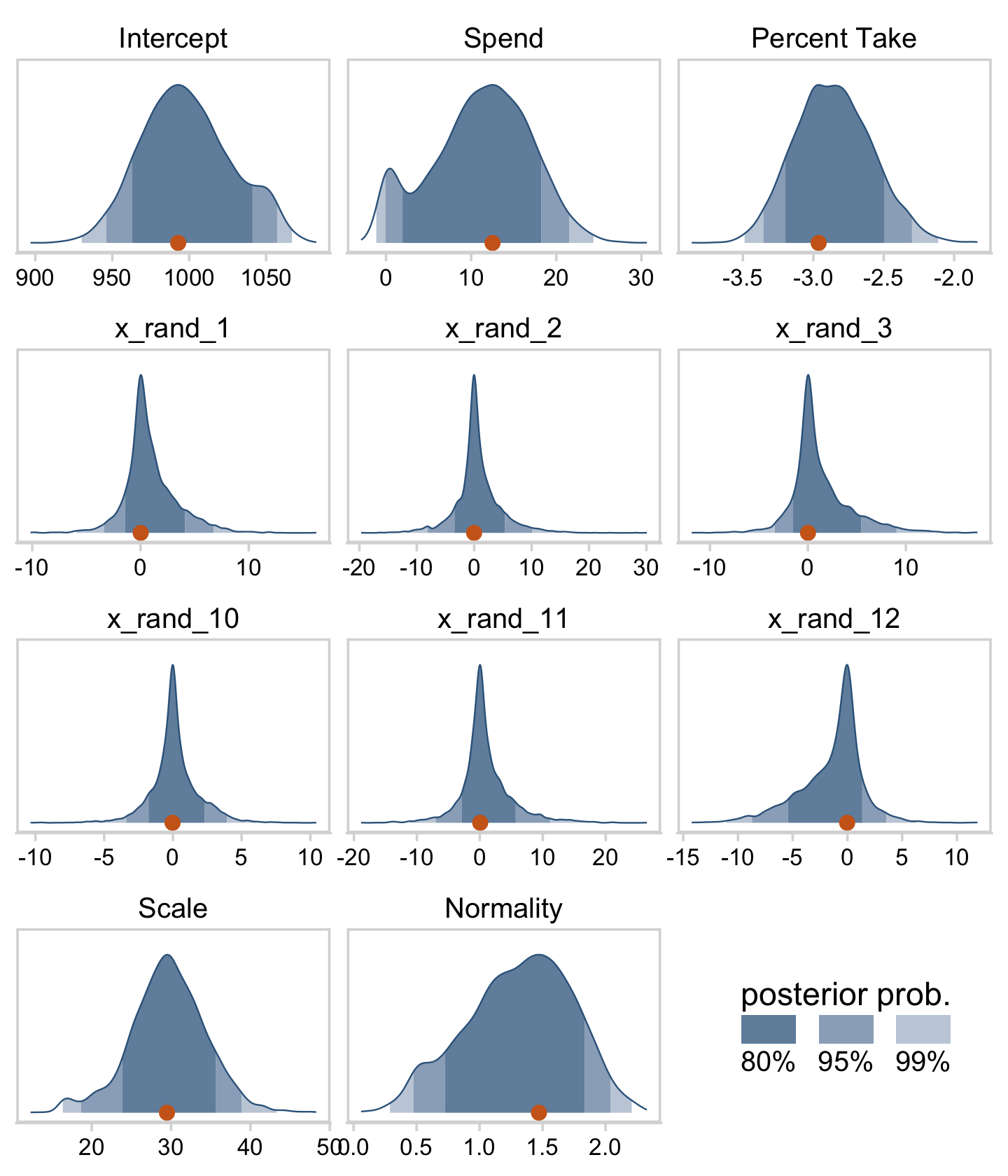
Based on the distributions for the random predictors, it looks like our brms horseshoe prior regularized more aggressively than Kruschke’s hierarchical prior in the text. And interestingly, look how our marginal posterior for Spend is bimodal.
For kicks and giggles, here’s the corresponding coefficient plot for β1 through β14.
draws %>%
pivot_longer(Spend:x_rand_12) %>%
ggplot(aes(x = value, y = reorder(name, value))) +
geom_vline(xintercept = 0, color = "grey25", linetype = 2) +
stat_pointinterval(point_interval = mode_hdi, .width = .95, point_size = 4,
color = "steelblue4", point_color = "chocolate3") +
labs(x = NULL,
y = NULL) +
theme(axis.text.y = element_text(hjust = 0))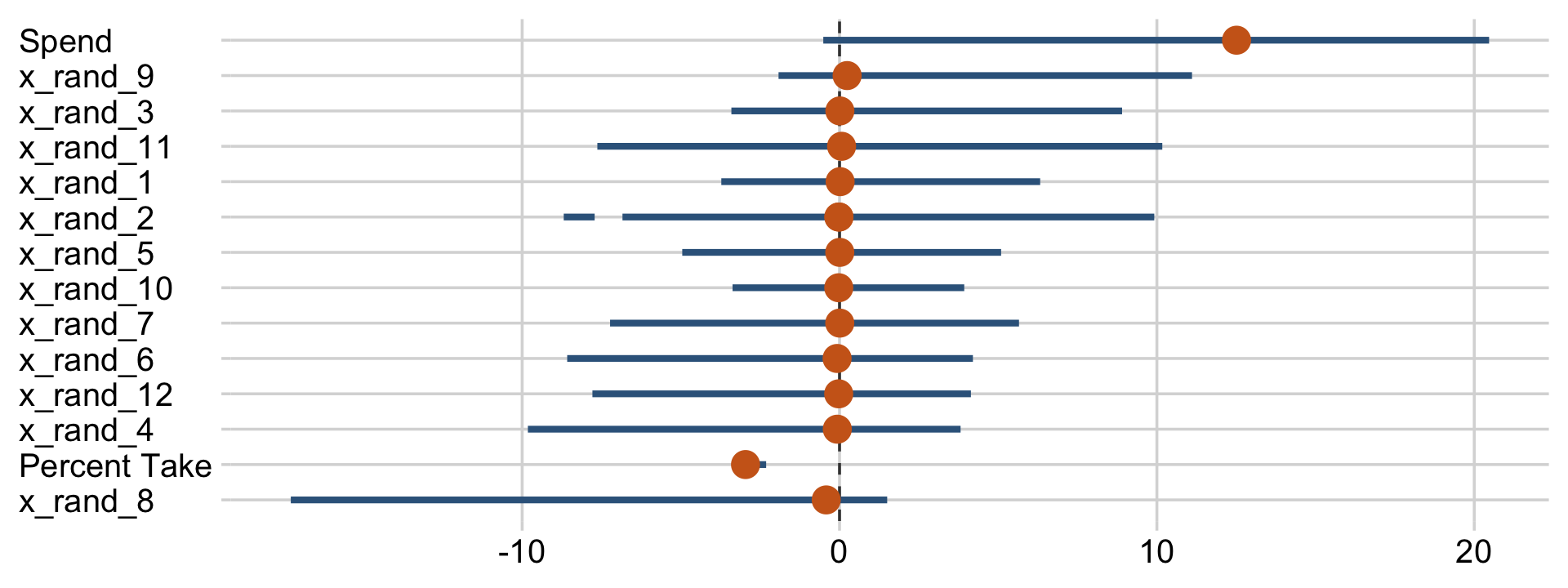
But anyways, here’s that final Bayesian R2 density for Figure 18.12.
bayes_R2(fit18.5, summary = F) %>%
as_tibble() %>%
ggplot(aes(x = R2, y = 0)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
labs(subtitle = expression(paste("Bayesian ", italic(R)^2)),
x = NULL) +
coord_cartesian(xlim = c(0, 1),
ylim = c(-0.01, NA)) +
theme(legend.position = c(.01, .8))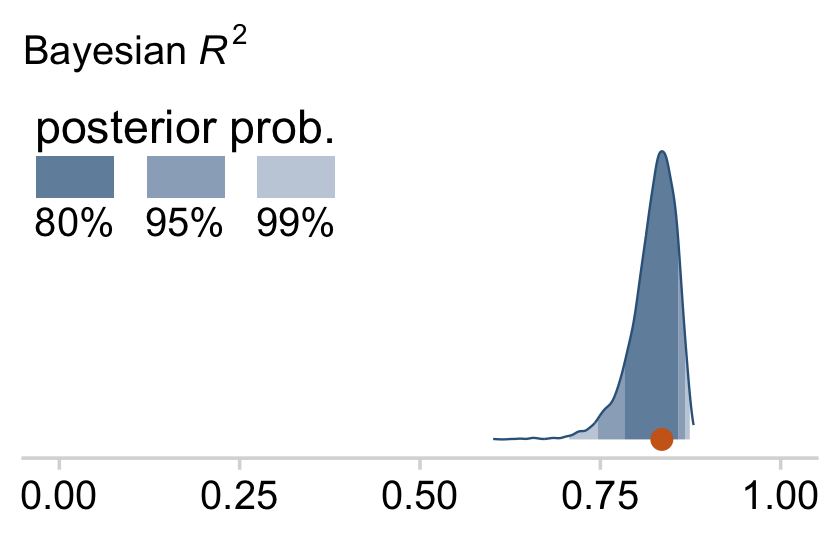
Just recall, though, that our fit18.5 was not exactly like Kruschke’s model. Whereas we hard coded the scale of our Student-t horseshoe prior to be 1, Kruschke estimated it with help from the gamma distribution. I’m not aware that’s currently possible in brms. If I’m at fault and you know how to do it, please share your code.
18.4 Variable selection
We can rewrite the linear regression model to accommodate whether it includes a predictor as
μi=β0+∑jδjβjxj,i,
where δ is a dummy for which 0 = not included 1 = included. I’m not aware of a way to use δ as an inclusion indicator in brms the way Kruschke implemented it in JAGS. And in fact, it appears this might be unfeasible within the Stan framework. But if you know of a way, please share your code. However, this issue can lead to a similar approach: information criteria. To do so, let’s follow Kruschke’s basic flow and use the first model from way back in Section 18.1.1 as a starting point. The model formula was as follows.
fit18.1$formula## satt_z ~ 1 + spend_z + prcnt_take_zTaking interactions off the table for a moment, we can specify four model types with various combinations of the two predictors, prcnt_take_z and spend_z. fit18.1 was the first, which we might denote as ⟨1,1⟩. That leads to the remaining possibilities as
- ⟨1,0⟩:
satt_z ~ 1 + spend_z - ⟨0,1⟩:
satt_z ~ 1 + prcnt_take_z - ⟨0,0⟩:
satt_z ~ 1
Let’s fit those models.
fit18.6 <-
update(fit18.1,
formula = satt_z ~ 1 + spend_z,
seed = 18,
file = "fits/fit18.06")
fit18.7 <-
update(fit18.1,
formula = satt_z ~ 1 + prcnt_take_z,
seed = 18,
file = "fits/fit18.07")
fit18.8 <-
brm(data = my_data,
family = student,
satt_z ~ 1,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
chains = 4, cores = 4,
stanvars = stanvar(1/29, name = "one_over_twentynine"),
seed = 18,
file = "fits/fit18.08")We’ll compare our models with the LOO information criterion. Like other information criteria, the LOO values aren’t of interest in and of themselves. However, the values of one model’s LOO relative to that of another is of great interest. We generally prefer models with lower estimates.
fit18.1 <- add_criterion(fit18.1, "loo")
fit18.6 <- add_criterion(fit18.6, "loo")
fit18.7 <- add_criterion(fit18.7, "loo")
fit18.8 <- add_criterion(fit18.8, "loo")
loo_compare(fit18.1, fit18.6, fit18.7, fit18.8) %>%
print(simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## fit18.1 0.0 0.0 -31.9 5.4 4.0 0.7 63.8 10.7
## fit18.7 -3.2 2.9 -35.1 4.4 2.7 0.5 70.3 8.8
## fit18.6 -37.7 6.3 -69.6 4.0 2.1 0.3 139.2 8.1
## fit18.8 -40.8 5.7 -72.7 3.1 1.3 0.2 145.4 6.1In this case, fit18.1 and fit18.7 clearly have the lowest estimates, but the standard error of their difference score is about the same size as their difference. So the LOO difference score puts them on similar footing. Recall that you can do a similar analysis with the waic() function.
Let’s compare that with the insights from the model_weights() function.
(mw <- model_weights(fit18.1, fit18.6, fit18.7, fit18.8))## fit18.1 fit18.6 fit18.7 fit18.8
## 8.858096e-01 1.308897e-08 1.141904e-01 4.281579e-08If you don’t like scientific notation, you can always wrangle and plot.
mw %>%
as.data.frame() %>%
rownames_to_column() %>%
set_names("fit", "estimate") %>%
ggplot(aes(x = estimate, y = reorder(fit, estimate))) +
geom_text(aes(label = estimate %>% round(3) %>% as.character())) +
scale_x_continuous("stacking weight", limits = c(0, 1)) +
ylab(NULL)
Based on this weighting scheme, almost all the weight went to the full model, fit18.1. But note, in the intro of their vignette on the topic, Vehtari & Gabry (2022b) opined:
Ideally, we would avoid the Bayesian model combination problem by extending the model to include the separate models as special cases, and preferably as a continuous expansion of the model space. For example, instead of model averaging over different covariate combinations, all potentially relevant covariates should be included in a predictive model (for causal analysis more care is needed) and a prior assumption that only some of the covariates are relevant can be presented with regularized horseshoe prior (Piironen & Vehtari, 2017). For variable selection we recommend projective predictive variable selection (Piironen and Vehtari, 2017; projpred package).
Perhaps unsurprisingly, their thoughts on the topic are similar with the Gelman et al quotation Kruschke provided on page 536:
Some prominent authors eschew the variable-selection approach for typical applications in their fields. For example, (Gelman et al., 2013, p. 369) said, “For the regressions we typically see, we do not believe any coefficients to be truly zero and we do not generally consider it a conceptual (as opposed to computational) advantage to get point estimates of zero—but regularized estimates such as obtained by lasso can be much better than those resulting from simple least squares and flat prior distributions …we are not comfortable with an underlying model in which the coefficients can be exactly zero.”
For more on some of these methods, check out Vehtari’s GitHub repository, Tutorial on model assessment, model selection and inference after model selection.
But anyways, our model weighting methods cohered with Kruschke’s δ-inclusion-indicator method in that both suggested the full model, fit1, and the model with prcnt_take as the sole predictor, fit7, were given the greatest weight. I’m not aware that our information criteria weighting/model stacking methods provide probability distributions of the type Kruschke displayed in the left portions of Figure 18.13. But we can at least recreate the plots in the other panels.
# first we'll get the posterior draws from `fit18.1` and wrangle them
as_draws_df(fit18.1) %>%
transmute(Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
# within `bind_rows()`, we extract and wrangle the posterior draws from `fit18.7` and them insert them below those from `fit18.1`
bind_rows(
as_draws_df(fit18.7) %>%
mutate(value = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
name = "PrcntTake") %>%
select(name, value)
) %>%
# now we just need a little indexing and factor ordering
mutate(model = rep(c("fit18.1", "fit18.7"), times = c(8000, 4000)),
name = factor(name, levels = c("Spend", "PrcntTake"))) %>%
# we finally plot!
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(legend.position = c(.13, .23)) +
facet_grid(model ~ name, scales = "free")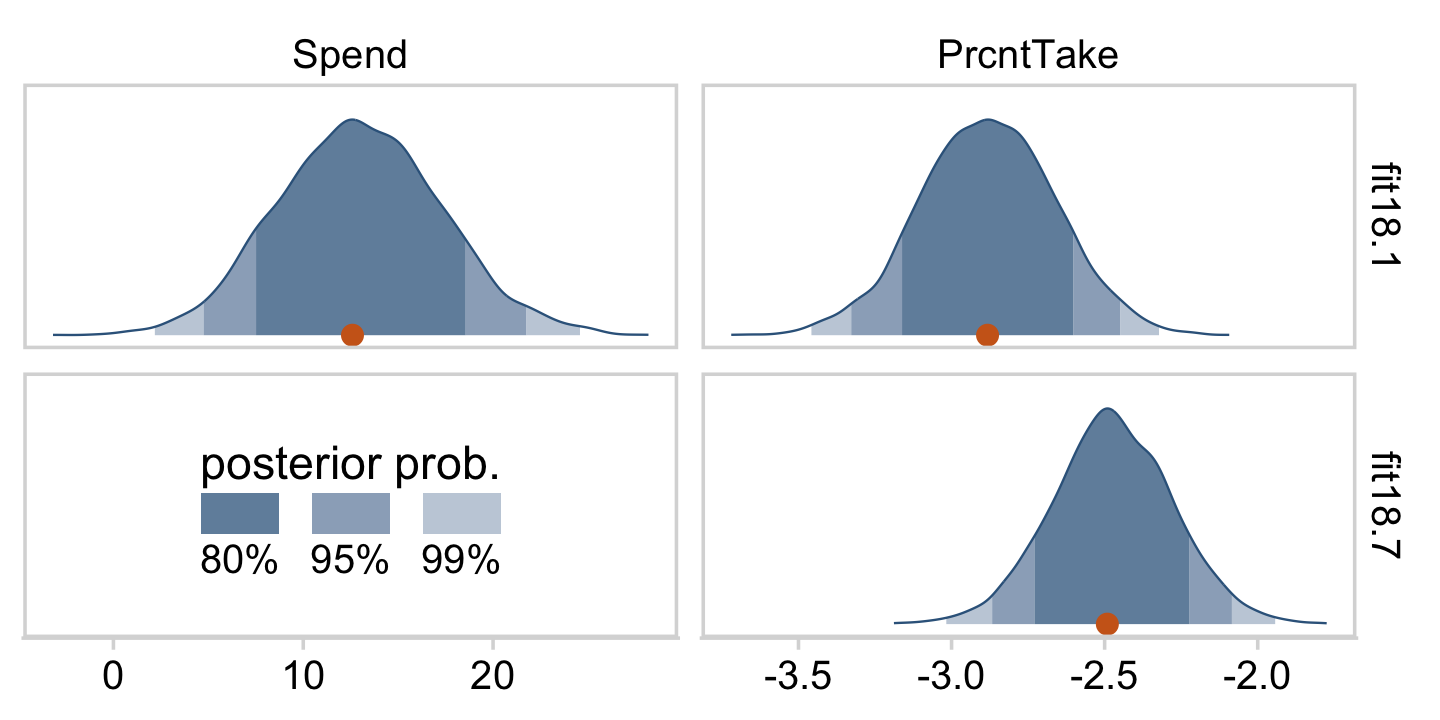
18.4.1 Inclusion probability is strongly affected by vagueness of prior.
To follow along, let’s fit the models with the updated SD=1 on the β1+ priors code.
fit18.9 <-
update(fit18.1,
prior = c(prior(normal(0, 1), class = Intercept),
prior(normal(0, 1), class = b),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
chains = 4, cores = 4,
stanvars = stanvar(1/29, name = "one_over_twentynine"),
seed = 18,
file = "fits/fit18.09")
fit18.10 <-
update(fit18.9,
formula = satt_z ~ 1 + spend_z,
seed = 18,
file = "fits/fit18.10")
fit18.11 <-
update(fit18.9,
formula = satt_z ~ 1 + prcnt_take_z,
seed = 18,
file = "fits/fit18.11")
fit18.12 <-
update(fit18.8,
prior = c(prior(normal(0, 1), class = Intercept),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
seed = 18,
file = "fits/fit18.12")And now we’ll fit the models with the updated SD=10.
fit18.13 <-
update(fit18.9,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = b),
prior(normal(0, 10), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
seed = 18,
file = "fits/fit18.13")
fit18.14 <-
update(fit18.13,
formula = satt_z ~ 1 + spend_z,
seed = 18,
file = "fits/fit18.14")
fit18.15 <-
update(fit18.13,
formula = satt_z ~ 1 + prcnt_take_z,
seed = 18,
file = "fits/fit18.15")
fit18.16 <-
update(fit18.12,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
seed = 18,
file = "fits/fit18.16")Now we’ve fit the models, we’re ready to examine how altering the SD’s on the βj priors influenced the model comparisons via model_weights(). Here we’ll use the default stacking method.
mw %>%
rbind(model_weights(fit18.9, fit18.10, fit18.11, fit18.12),
model_weights(fit18.13, fit18.14, fit18.15, fit18.16)) %>%
as_tibble() %>%
set_names("1, 1", "1, 0", "0, 1", "0, 0") %>%
pivot_longer(everything()) %>%
mutate(prior = rep(str_c("SD = ", c(10, 2, 1)), times = 4) %>%
factor(., levels = str_c("SD = ", c(10, 2, 1)))) %>%
ggplot(aes(x = value, y = reorder(name, value))) +
geom_text(aes(label = value %>% round(3) %>% as.character())) +
labs(x = "Stacking weight",
y = expression(paste("Models defined by Kruschke's ", delta, " notation"))) +
coord_cartesian(xlim = c(0, 1)) +
theme(panel.grid = element_blank()) +
panel_border() +
facet_grid(prior ~ .)
So unlike in the depictions in Figure 18.14, the stacking method was insensitive to the SD’s on our βj priors. We might compare LOO difference scores, too.
fit18.9 <- add_criterion(fit18.9, "loo")
fit18.10 <- add_criterion(fit18.10, "loo")
fit18.11 <- add_criterion(fit18.11, "loo")
fit18.12 <- add_criterion(fit18.12, "loo")
fit18.13 <- add_criterion(fit18.13, "loo")
fit18.14 <- add_criterion(fit18.14, "loo")
fit18.15 <- add_criterion(fit18.15, "loo")
fit18.16 <- add_criterion(fit18.16, "loo")
loo_compare(fit18.1, fit18.6, fit18.7, fit18.8) %>%
print(simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## fit18.1 0.0 0.0 -31.9 5.4 4.0 0.7 63.8 10.7
## fit18.7 -3.2 2.9 -35.1 4.4 2.7 0.5 70.3 8.8
## fit18.6 -37.7 6.3 -69.6 4.0 2.1 0.3 139.2 8.1
## fit18.8 -40.8 5.7 -72.7 3.1 1.3 0.2 145.4 6.1loo_compare(fit18.9, fit18.10, fit18.11, fit18.12) %>%
print(simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## fit18.9 0.0 0.0 -32.0 5.4 4.0 0.8 63.9 10.7
## fit18.11 -3.2 2.8 -35.1 4.4 2.7 0.5 70.3 8.8
## fit18.10 -37.6 6.3 -69.6 4.0 2.1 0.3 139.1 8.1
## fit18.12 -40.7 5.7 -72.7 3.0 1.4 0.2 145.4 6.1loo_compare(fit18.13, fit18.14, fit18.15, fit18.16) %>%
print(simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## fit18.13 0.0 0.0 -32.0 5.4 4.1 0.8 64.1 10.7
## fit18.15 -3.1 2.9 -35.2 4.4 2.7 0.5 70.3 8.7
## fit18.14 -37.5 6.3 -69.6 4.0 2.0 0.3 139.1 8.0
## fit18.16 -40.7 5.7 -72.8 3.0 1.4 0.2 145.5 6.0The LOO difference score patterns were also about the same across the SD’s on our βj priors. Let’s finish up with our version of the histograms comparing the model predictors. Here’s the code for those in the top portion of Figure 18.14.
# first we'll get the posterior draws from `fit18.9` and wrangle them
as_draws_df(fit18.9) %>%
transmute(Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
# within `bind_rows()`, we extract and wrangle the posterior draws from `fit18.11` and
# then insert them below those from `fit18.9`
bind_rows(
as_draws_df(fit18.11) %>%
transmute(value = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
name = "PrcntTake") %>%
select(name, value)
) %>%
# now we just need a little indexing and factor ordering
mutate(model = rep(c("fit18.9", "fit18.11"), times = c(8000, 4000)) %>%
factor(., levels = c("fit18.9", "fit18.11")),
name = factor(name, levels = c("Spend", "PrcntTake"))) %>%
# we finally plot!
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(legend.position = c(.13, .23)) +
facet_grid(model ~ name, scales = "free")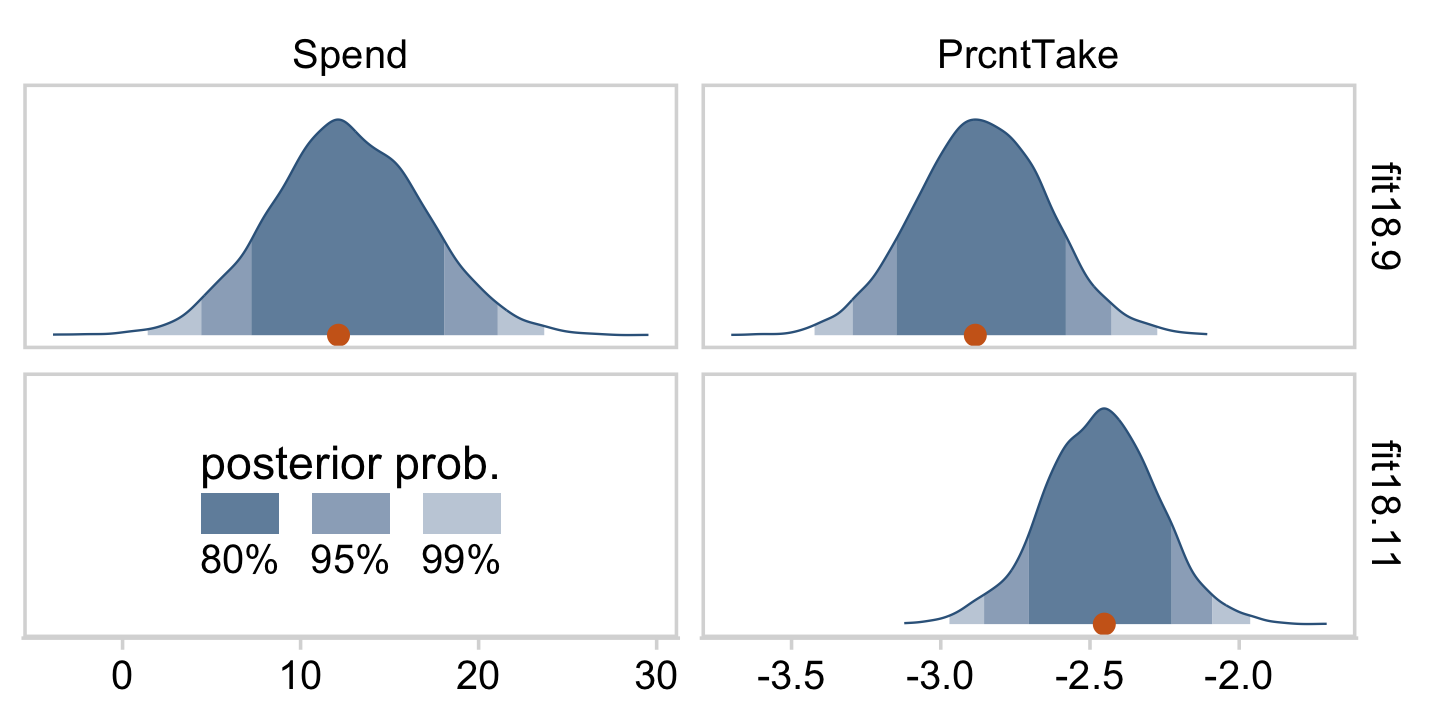
And now we’ll do our version of the histograms for the bottom portion of Figure 18.14.
as_draws_df(fit18.13) %>%
transmute(Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
bind_rows(
as_draws_df(fit18.15) %>%
transmute(value = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
name = "PrcntTake") %>%
select(name, value)
) %>%
mutate(model = rep(c("fit18.13", "fit18.15"), times = c(8000, 4000)) %>%
factor(., levels = c("fit18.13", "fit18.15")),
name = factor(name, levels = c("Spend", "PrcntTake"))) %>%
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels") +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
theme(legend.position = c(.13, .23)) +
panel_border() +
facet_grid(model ~ name, scales = "free")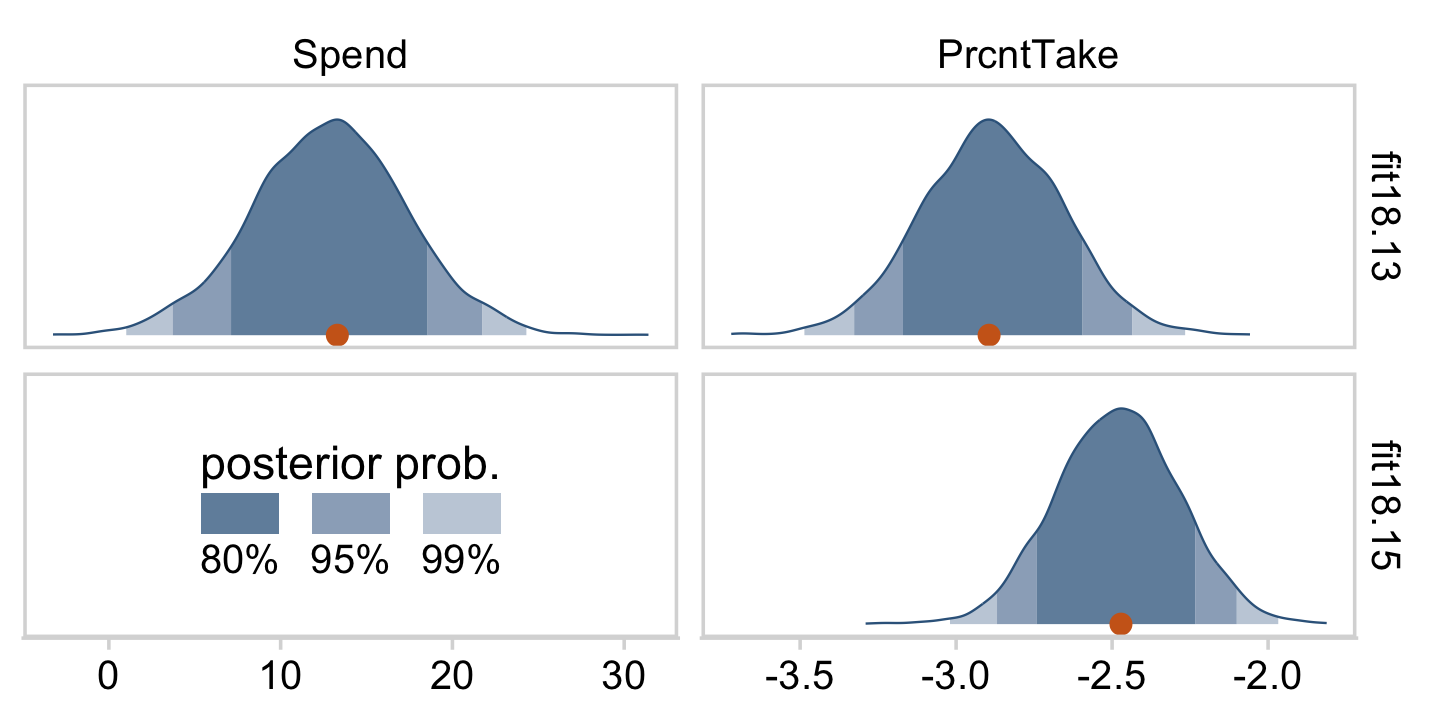
Kruschke concluded this subsection with
Bayesian model comparison can be strongly affected by the degree of vagueness in the priors, even though explicit estimates of the parameter values may be minimally affected. Therefore, be very cautious when interpreting the results of Bayesian variable selection. The next section discusses a way to inform the prior by using concurrent data instead of previous data. (p. 542)
We should note that while the method in text was “strongly affected by the degree of vagueness in the priors”, the information-criteria and model weighting methods, above, were not. If you’re interested in comparing models within the Bayesian paradigm, choose your method with care.
18.4.2 Variable selection with hierarchical shrinkage.
Kruschke opened the subsection with a few good points:
If you have strong previous research that can inform the prior, then it should be used. But if previous knowledge is weak, then the uncertainty should be expressed in the prior. This is an underlying mantra of the Bayesian approach: Any uncertainty should be expressed in the prior. (p. 543)
Here we’ll standardize our new predictors, StuTeaRat and Salary.
my_data <-
my_data %>%
mutate(stu_tea_rat_z = standardize(StuTeaRat),
salary_z = standardize(Salary))We can use Kruschke’s gamma_s_and_r_from_mode_sd() function to return the exact shape and rate parameters to make a gamma with a mode of 1 and an SD of 10.
gamma_s_and_r_from_mode_sd <- function(mode, sd) {
if (mode <= 0) stop("mode must be > 0")
if (sd <= 0) stop("sd must be > 0")
rate <- (mode + sqrt(mode^2 + 4 * sd^2)) / (2 * sd^2)
shape <- 1 + mode * rate
return(list(shape = shape, rate = rate))
}Here are the values.
(p <- gamma_s_and_r_from_mode_sd(mode = 1, sd = 10) %>% as.numeric())## [1] 1.1051249 0.1051249That gamma distribution looks like this.
tibble(x = seq(from = 0, to = 65, length.out = 1e3)) %>%
ggplot(aes(x = x, y = dgamma(x, shape = p[1], rate = p[2]))) +
geom_area(color = "steelblue4", fill = "steelblue4", alpha = .6) +
scale_y_continuous(NULL, breaks = NULL) +
xlab("Our gamma prior") +
coord_cartesian(xlim = c(0, 60))
We can code those values in with arbitrary precision with the stanvar() function.
stanvars <-
stanvar(1/29, name = "one_over_twentynine") +
stanvar(p[1], name = "my_shape") +
stanvar(p[2], name = "my_rate") +
stanvar(scode = " real<lower=0> tau;", block = "parameters")Note that last stanvar() line. Bürkner recently posted an exemplar of how to set a hierarchical prior on a regression coefficient in a brm() model:
# define a hierarchical prior on the regression coefficients
bprior <- set_prior("normal(0, tau)", class = "b") +
set_prior("target += normal_lpdf(tau | 0, 10)", check = FALSE)
stanvars <- stanvar(scode = " real<lower=0> tau;", block = "parameters")
make_stancode(count ~ Trt + log_Base4_c, epilepsy,
prior = bprior, stanvars = stanvars)Following the method, we tell brm() we’d like to estimate the SD of our β1+ priors with prior(normal(0, tau), class = b), where the tau is a stand-in for the SD. In the next line, set_prior("target += gamma_lpdf(tau | my_shape, my_rate)", check = FALSE), we tell brm() we’d like to estimate tau with a gamma(my_shape, my_rate), the values for which were saved in our stanvars object, above. And it’s that stanvar() line in that code wherein we told brm() we’d like that parameter to have a lower bound of 0. Let’s put it to use.
fit18.1111 <-
brm(data = my_data,
family = student,
satt_z ~ 1 + spend_z + prcnt_take_z + stu_tea_rat_z + salary_z,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, tau), class = b),
set_prior("target += gamma_lpdf(tau | my_shape, my_rate)", check = FALSE),
prior(normal(0, 1), class = sigma),
prior(exponential(one_over_twentynine), class = nu)),
chains = 4, cores = 4,
control = list(adapt_delta = .99),
stanvars = stanvars,
seed = 18,
file = "fits/fit18.1111")
fit18.0111 <-
update(fit18.1111,
formula = satt_z ~ 1 + prcnt_take_z + stu_tea_rat_z + salary_z,
file = "fits/fit18.0111")
fit18.1011 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z + stu_tea_rat_z + salary_z,
file = "fits/fit18.1011")
fit18.1101 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z + prcnt_take_z + salary_z,
file = "fits/fit18.1101")
fit18.1110 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z + prcnt_take_z + stu_tea_rat_z ,
file = "fits/fit18.1110")
fit18.0011 <-
update(fit18.1111,
formula = satt_z ~ 1 + stu_tea_rat_z + salary_z,
file = "fits/fit18.0011")
fit18.0101 <-
update(fit18.1111,
formula = satt_z ~ 1 + prcnt_take_z + salary_z,
file = "fits/fit18.0101")
fit18.0110 <-
update(fit18.1111,
formula = satt_z ~ 1 + prcnt_take_z + stu_tea_rat_z ,
file = "fits/fit18.0110")
fit18.1001 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z + salary_z,
file = "fits/fit18.1001")
fit18.1010 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z + stu_tea_rat_z ,
file = "fits/fit18.1010")
fit18.1100 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z + prcnt_take_z ,
file = "fits/fit18.1100")
fit18.0001 <-
update(fit18.1111,
formula = satt_z ~ 1 + salary_z,
file = "fits/fit18.0001")
fit18.0010 <-
update(fit18.1111,
formula = satt_z ~ 1 + stu_tea_rat_z ,
control = list(adapt_delta = .99999),
seed = 18,
file = "fits/fit18.0010")
fit18.0100 <-
update(fit18.1111,
formula = satt_z ~ 1 + prcnt_take_z ,
file = "fits/fit18.0100")
fit18.1000 <-
update(fit18.1111,
formula = satt_z ~ 1 + spend_z ,
file = "fits/fit18.1000")
fit18.0000 <-
update(fit18.1111,
formula = satt_z ~ 1 ,
file = "fits/fit18.0000")In order to keep track of the next 16 models, we switched our usual naming convention. Instead of continuing on keeping on calling them fit18.17 through fit18.33, we used Kruschke’s δ 0/1 convention. If we set the formula for the full model as satt_z ~ 1 + spend_z + prcnt_take_z + stu_tea_rat_z + salary_z, the name becomes fit18.1111. Accordingly, we called the model omitting spend_z, the first predictor, fit18.0111, and so on.
Before we go any further, here are the correlations among the predictor variables in the full model, fit18.1111.
my_data %>%
select(Spend, PrcntTake, StuTeaRat, Salary) %>%
cor() %>%
round(digits = 3)## Spend PrcntTake StuTeaRat Salary
## Spend 1.000 0.593 -0.371 0.870
## PrcntTake 0.593 1.000 -0.213 0.617
## StuTeaRat -0.371 -0.213 1.000 -0.001
## Salary 0.870 0.617 -0.001 1.000Notice above that Salary is strongly correlated with Spend, and therefore, a model that includes both Salary and Spend will show a strong trade-off between those predictors and consequently will show inflated uncertainty in the regression coefficients for either one. Should only one or the other be included, or both, or neither? (p. 544)
Behold the model weights.
(
mw <-
model_weights(fit18.1111,
fit18.0111, fit18.1011, fit18.1101, fit18.1110,
fit18.0011, fit18.0101, fit18.0110, fit18.1001, fit18.1010, fit18.1100,
fit18.0001, fit18.0010, fit18.0100, fit18.1000,
fit18.0000)
)## fit18.1111 fit18.0111 fit18.1011 fit18.1101 fit18.1110 fit18.0011
## 2.964385e-06 2.535276e-01 3.007985e-05 4.983780e-06 3.880511e-06 3.467826e-05
## fit18.0101 fit18.0110 fit18.1001 fit18.1010 fit18.1100 fit18.0001
## 6.332967e-03 2.317225e-02 4.617908e-07 6.120252e-07 2.250000e-01 7.676098e-02
## fit18.0010 fit18.0100 fit18.1000 fit18.0000
## 2.407980e-07 3.302637e-01 8.486454e-02 5.330482e-09We’ll plot our model weights like before.
mw %>%
data.frame() %>%
rownames_to_column() %>%
set_names("fit", "weight") %>%
mutate(fit = str_remove(fit, "fit18.")) %>%
ggplot(aes(x = weight, y = reorder(fit, weight))) +
geom_text(aes(label = weight %>% round(3) %>% as.character()),
size = 3) +
coord_cartesian(xlim = c(0, 1)) +
labs(x = "Stacking weight",
y = "fit18.[xxxx]") +
theme(panel.grid = element_blank()) +
panel_border()
As you might notice, pattern among model weights is similar with but not identical to the one among the model probabilities Kruschke displayed in Figure 18.15. Here we’ll plot the histograms for our top six.
# first, we need to redefine `sd_x_3` and `sd_x_4` in terms of our two new predictors
sd_x_3 <- sd(my_data$StuTeaRat)
sd_x_4 <- sd(my_data$Salary)
## Now we'll start extracting our posterior draws and wrangling them, by model
# fit18.0100
as_draws_df(fit18.0100) %>%
transmute(Intercept = b_Intercept,
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
mutate(fit = "fit18.0100") %>%
# fit18.0111
bind_rows(
as_draws_df(fit18.0111) %>%
transmute(Intercept = b_Intercept,
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
StuTeaRat = make_beta_j(zeta_j = b_stu_tea_rat_z,
sd_j = sd_x_3,
sd_y = sd_y),
Salary = make_beta_j(zeta_j = b_salary_z,
sd_j = sd_x_4,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
mutate(fit = "fit18.0111")
) %>%
# fit18.1100
bind_rows(
as_draws_df(fit18.1100) %>%
transmute(Intercept = b_Intercept,
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y),
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
mutate(fit = "fit18.1100")
) %>%
# fit18.1000
bind_rows(
as_draws_df(fit18.1000) %>%
transmute(Intercept = b_Intercept,
Spend = make_beta_j(zeta_j = b_spend_z,
sd_j = sd_x_1,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
mutate(fit = "fit18.1000")
) %>%
# fit18.0001
bind_rows(
as_draws_df(fit18.0001) %>%
transmute(Intercept = b_Intercept,
Salary = make_beta_j(zeta_j = b_salary_z,
sd_j = sd_x_4,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
mutate(fit = "fit18.0001")
) %>%
# fit18.0110 # spend_z + prcnt_take_z + stu_tea_rat_z
bind_rows(
as_draws_df(fit18.0110) %>%
transmute(Intercept = b_Intercept,
PrcntTake = make_beta_j(zeta_j = b_prcnt_take_z,
sd_j = sd_x_2,
sd_y = sd_y),
StuTeaRat = make_beta_j(zeta_j = b_stu_tea_rat_z,
sd_j = sd_x_3,
sd_y = sd_y)) %>%
pivot_longer(everything()) %>%
mutate(fit = "fit18.0110")
) %>%
# the next two lines just help order the grid the plots appear in
mutate(name = factor(name, levels = c("Intercept", "Spend", "PrcntTake", "StuTeaRat", "Salary")),
fit = factor(fit, levels = c("fit18.0100", "fit18.0111", "fit18.1100", "fit18.1000", "fit18.0001", "fit18.0110"))) %>%
# finally, the plot!
ggplot(aes(x = value, y = 0)) +
stat_wilke(normalize = "panels", point_size = 4) +
scale_fill_viridis_d(option = "D", begin = .2, end = .8) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
coord_cartesian(ylim = c(-0.01, NA)) +
panel_border() +
theme(legend.position = "none") +
facet_grid(fit ~ name, scales = "free")
Like Kruschke’s results in the text, PrcntTake was the most prominent predictor.
18.4.3 What to report and what to conclude.
Kruschke made a great point in the opening paragraph of this subsection.
It might make sense to use the single most credible model, especially if it is notably more credible than the runner up, and if the goal is to have a parsimonious explanatory description of the data. But it is important to recognize that using the single best model, when it excludes some predictors, is concluding that the regression coefficients on the excluded predictors are exactly zero. (p. 546)
Later he added “A forthright report should state the posterior probabilities of the several top models. Additionally, it can be useful to report, for each model, the ratio of its posterior probability relative to that of the best model” (p. 546). With our information criteria and model weights approach, we don’t have posterior probabilities for the models themselves. But we can report on their information criteria comparisons and weights.
In the final paragraph of the subsection, Kruschke wrote:
When the goal is prediction of y for interesting values of the predictors, as opposed to parsimonious explanation, then it is usually not appropriate to use only the single most probable model. Instead, predictions should be based on as much information as possible, using all models to the extent that they are credible. This approach is called Bayesian model averaging (BMA). (p. 547)
It’s worth it to walk this out a bit. With brms, one can use brms::pp_average() to get the weighted posterior distributions for the model parameters. This is a natural extension of our model weights comparisons.
# how many points on the x-axis?
n_points <- 30
# what vales of the predictors would we like to evaluate the weighted posterior over?
nd <-
tibble(spend_z = seq(from = -3, to = 3, length.out = n_points),
prcnt_take_z = 0,
stu_tea_rat_z = 0,
salary_z = 0)
pp <-
# the first things we feed into `pp_average()` are the `brm()` fits we'd like to average over
pp_average(fit18.1111, fit18.0111, fit18.1011, fit18.1101, fit18.1110, fit18.0011, fit18.0101, fit18.0110, fit18.1001, fit18.1010, fit18.1100, fit18.0001, fit18.0010, fit18.0100, fit18.1000, fit18.0000,
# here we tell it to evaluate the posterior over these predictor values
newdata = nd,
# we can get the mean trends using the "fitted" method
method = "fitted",
# by `robust`, we mean we'd like the Estimate in terms of posterior medians, rather than means
robust = T)
str(pp)## num [1:30, 1:4] -0.0183 -0.0183 -0.0183 -0.0183 -0.0183 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:4] "Estimate" "Est.Error" "Q2.5" "Q97.5"
## - attr(*, "weights")= Named num [1:16] 2.96e-06 2.54e-01 3.01e-05 4.98e-06 3.88e-06 ...
## ..- attr(*, "names")= chr [1:16] "fit18.1111" "fit18.0111" "fit18.1011" "fit18.1101" ...
## - attr(*, "ndraws")= Named num [1:16] 0 1014 0 0 0 ...
## ..- attr(*, "names")= chr [1:16] "fit18.1111" "fit18.0111" "fit18.1011" "fit18.1101" ...The pp object will require a little wrangling before it’s of use for ggplot2.
pp %>%
as_tibble() %>%
bind_cols(nd) %>%
ggplot(aes(x = spend_z, y = Estimate,
ymin = Q2.5, ymax = Q97.5)) +
geom_hline(yintercept = 0, color = "grey25", linetype = 2) +
geom_pointrange(shape = 21, stroke = 1/10, fatten = 6,
color = "steelblue4", fill = "chocolate3") +
labs(x = "Value of Spend_z",
y = "Standardized SATT")
We can build on this to make a plot considering each of the four predictors. But first that requires we make a new nd tibble to feed into pp_average().
# how many points on the x-axis?
n_points <- 30
# what vales of the predictors would we like to evaluate the weighted posterior over?
nd <-
tibble(spend_z = c(seq(from = -3, to = 3, length.out = n_points),
rep(0, times = n_points * 3)),
prcnt_take_z = c(rep(0, times = n_points),
seq(from = -3, to = 3, length.out = n_points),
rep(0, times = n_points * 2)),
stu_tea_rat_z = c(rep(0, times = n_points * 2),
seq(from = -3, to = 3, length.out = n_points),
rep(0, times = n_points)),
salary_z = c(rep(0, times = n_points * 3),
seq(from = -3, to = 3, length.out = n_points)))
pp <-
pp_average(fit18.1111, fit18.0111, fit18.1011, fit18.1101, fit18.1110, fit18.0011, fit18.0101, fit18.0110, fit18.1001, fit18.1010, fit18.1100, fit18.0001, fit18.0010, fit18.0100, fit18.1000, fit18.0000,
newdata = nd,
method = "fitted",
robust = T,
# note the `probs` argument
probs = c(.025, .975, .1, .9, .25, .75))
str(pp)## num [1:120, 1:8] -0.0186 -0.0186 -0.0186 -0.0186 -0.0186 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:8] "Estimate" "Est.Error" "Q2.5" "Q97.5" ...
## - attr(*, "weights")= Named num [1:16] 2.96e-06 2.54e-01 3.01e-05 4.98e-06 3.88e-06 ...
## ..- attr(*, "names")= chr [1:16] "fit18.1111" "fit18.0111" "fit18.1011" "fit18.1101" ...
## - attr(*, "ndraws")= Named num [1:16] 0 1014 0 0 0 ...
## ..- attr(*, "names")= chr [1:16] "fit18.1111" "fit18.0111" "fit18.1011" "fit18.1101" ...In each panel of the plot, below, we focus on one predictor. For that predictor, we hold all other three at their mean, which, since they are all standardized, is zero. We consider the posterior predictions for standardized SAT scores across a range of values each focal predictor. The posterior predictions are depicted in terms of 95%, 80%, and 50% percentile-based interval bands and a line at the median.
pp %>%
as_tibble() %>%
mutate(x = seq(from = -3, to = 3, length.out = n_points) %>% rep(., times = 4),
predictor = rep(c("Spend_z", "PrcntTake_z", "StuTeaRat_z", "Salary_z"), each = n_points)) %>%
ggplot(aes(x = x)) +
geom_hline(yintercept = 0, color = "grey25", linetype = 2) +
geom_ribbon(aes(ymin = Q2.5, ymax = Q97.5),
alpha = 1/5, fill = "steelblue4") +
geom_ribbon(aes(ymin = Q10, ymax = Q90),
alpha = 1/4, fill = "steelblue4") +
geom_ribbon(aes(ymin = Q25, ymax = Q75),
alpha = 1/3, fill = "steelblue4") +
geom_line(aes(y = Estimate),
linewidth = 1, color = "chocolate3") +
labs(x = "Standardized value of the focal predictor",
y = "Standardized SATT") +
theme_minimal_vgrid() +
panel_border() +
facet_grid(predictor ~ ., scales = "free")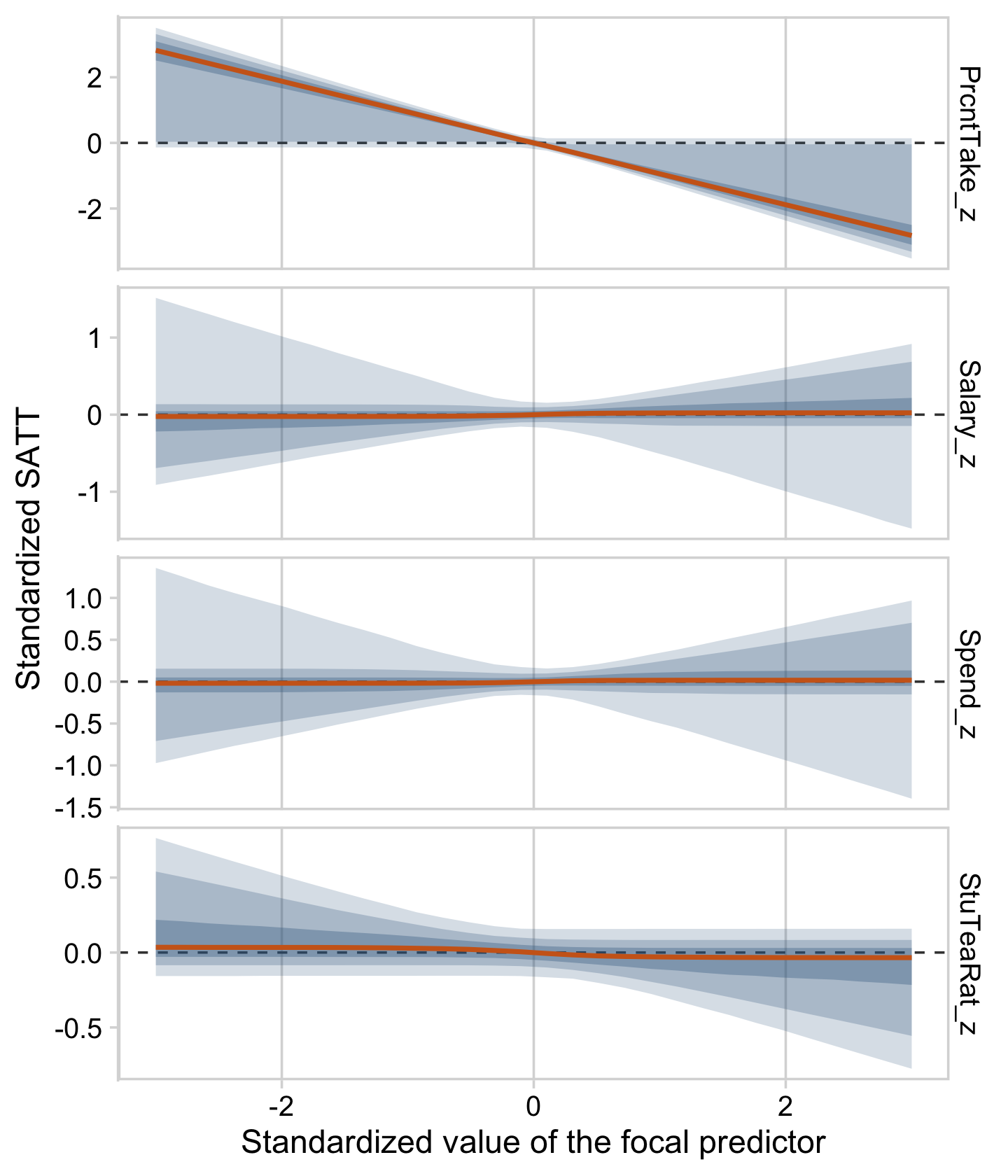
Based on the weighted average across the models, the PrcntTake_z predictor was the most potent.
18.4.4 Caution: Computational methods.
To conclude this section regarding variable selection, it is appropriate to recapitulate the considerations at the beginning of the section. Variable selection is a reasonable approach only if it is genuinely plausible and meaningful that candidate predictors have zero relation to the predicted variable. The results can be surprisingly sensitive to the seemingly innocuous choice of prior for the regression coefficients, and, of course, the prior for the inclusion probability. Because of these limitations, hierarchical shrinkage priors may be a more meaningful approach. (p. 548)
18.4.5 Caution: Interaction variables.
When interaction terms are included in a model that also has hierarchical shrinkage on regression coefficients, the interaction coefficients should not be put under the same higher-level prior distribution as the individual component coefficients, because interaction coefficients are conceptually from a different class of variables than individual components. (pp. 548–549)
Session info
sessionInfo()## R version 4.2.2 (2022-10-31)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur ... 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] GGally_2.1.2 bayesplot_1.10.0 cowplot_1.1.1 ggdist_3.2.1
## [5] tidybayes_3.0.2 brms_2.18.0 Rcpp_1.0.9 patchwork_1.1.2
## [9] forcats_0.5.1 stringr_1.4.1 dplyr_1.0.10 purrr_1.0.1
## [13] readr_2.1.2 tidyr_1.2.1 tibble_3.1.8 ggplot2_3.4.0
## [17] tidyverse_1.3.2
##
## loaded via a namespace (and not attached):
## [1] readxl_1.4.1 backports_1.4.1 plyr_1.8.7
## [4] igraph_1.3.4 svUnit_1.0.6 splines_4.2.2
## [7] crosstalk_1.2.0 TH.data_1.1-1 rstantools_2.2.0
## [10] inline_0.3.19 digest_0.6.31 htmltools_0.5.3
## [13] fansi_1.0.3 magrittr_2.0.3 checkmate_2.1.0
## [16] googlesheets4_1.0.1 tzdb_0.3.0 modelr_0.1.8
## [19] RcppParallel_5.1.5 matrixStats_0.63.0 vroom_1.5.7
## [22] xts_0.12.1 sandwich_3.0-2 prettyunits_1.1.1
## [25] colorspace_2.0-3 rvest_1.0.2 haven_2.5.1
## [28] xfun_0.35 callr_3.7.3 crayon_1.5.2
## [31] jsonlite_1.8.4 lme4_1.1-31 survival_3.4-0
## [34] zoo_1.8-10 glue_1.6.2 gtable_0.3.1
## [37] gargle_1.2.0 emmeans_1.8.0 distributional_0.3.1
## [40] pkgbuild_1.3.1 rstan_2.21.8 abind_1.4-5
## [43] scales_1.2.1 mvtnorm_1.1-3 DBI_1.1.3
## [46] miniUI_0.1.1.1 xtable_1.8-4 HDInterval_0.2.4
## [49] bit_4.0.4 stats4_4.2.2 StanHeaders_2.21.0-7
## [52] DT_0.24 htmlwidgets_1.5.4 httr_1.4.4
## [55] threejs_0.3.3 RColorBrewer_1.1-3 arrayhelpers_1.1-0
## [58] posterior_1.3.1 ellipsis_0.3.2 reshape_0.8.9
## [61] pkgconfig_2.0.3 loo_2.5.1 farver_2.1.1
## [64] sass_0.4.2 dbplyr_2.2.1 utf8_1.2.2
## [67] tidyselect_1.2.0 labeling_0.4.2 rlang_1.0.6
## [70] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
## [73] cellranger_1.1.0 tools_4.2.2 cachem_1.0.6
## [76] cli_3.6.0 generics_0.1.3 broom_1.0.2
## [79] evaluate_0.18 fastmap_1.1.0 processx_3.8.0
## [82] knitr_1.40 bit64_4.0.5 fs_1.5.2
## [85] nlme_3.1-160 projpred_2.2.1 mime_0.12
## [88] xml2_1.3.3 compiler_4.2.2 shinythemes_1.2.0
## [91] rstudioapi_0.13 gamm4_0.2-6 reprex_2.0.2
## [94] bslib_0.4.0 stringi_1.7.8 highr_0.9
## [97] ps_1.7.2 Brobdingnag_1.2-8 lattice_0.20-45
## [100] Matrix_1.5-1 psych_2.2.9 nloptr_2.0.3
## [103] markdown_1.1 shinyjs_2.1.0 tensorA_0.36.2
## [106] vctrs_0.5.1 pillar_1.8.1 lifecycle_1.0.3
## [109] jquerylib_0.1.4 bridgesampling_1.1-2 estimability_1.4.1
## [112] httpuv_1.6.5 R6_2.5.1 bookdown_0.28
## [115] promises_1.2.0.1 gridExtra_2.3 codetools_0.2-18
## [118] boot_1.3-28 colourpicker_1.1.1 MASS_7.3-58.1
## [121] gtools_3.9.4 assertthat_0.2.1 withr_2.5.0
## [124] mnormt_2.1.0 shinystan_2.6.0 multcomp_1.4-20
## [127] mgcv_1.8-41 parallel_4.2.2 hms_1.1.1
## [130] grid_4.2.2 minqa_1.2.5 coda_0.19-4
## [133] rmarkdown_2.16 googledrive_2.0.0 shiny_1.7.2
## [136] lubridate_1.8.0 base64enc_0.1-3 dygraphs_1.1.1.6References
In his Corrigenda, Kruschke further clarified: “that is true only in case there is a single predictor, not for multiple predictors. The statement could have said that ‘R^2 is algebraically constrained to fall between −1 and +1 in least-squares regression’. More relevantly, replace the statement with the following: ‘In multiple linear regression, standardized regression coefficients tend to fall between -2 and +2 unless the predictors are very strongly correlated and have strongly opposing effects. If your data have strongly correlated predictors, consider widening the prior.’”↩︎