13 Portfolio Theory with Short Sales Constraints
Updated: June 29, 2021
Copyright © Eric Zivot 2015, 2016, 2020, 2021
The portfolio theory described in Chapters 11 and 12 assumed that investors can freely short sell all assets. In many situation, however, investors may not be allowed to short sell some or all assets and/or there may be restrictions on when short sales may occur. In particular, certain types of assets (e.g., mutual funds) cannot be sold short. This has implications for asset allocation in individual retirement accounts. Some institutions, such as pension funds, are prevented from directly short selling assets. Government regulations may prevent certain assets from being sold short, or prevent short sales from occurring at certain times. For example, during the 2008 financial crisis the Securities and Exchange Commission temporarily blocked the short sale of financial stocks. Because of these practical limitations on short sales, it is important to be able to incorporate short sales restrictions into mean-variance portfolio theory and this chapter describes how to do it.
This chapter is organized as follows. Section 13.2 describes the impact of short sales constraints, on risky assets, on efficient portfolios in the simplified two risk asset setting presented in Chapter 11. Section 13.3 discusses the computation of mean-variance efficient portfolios when there are short sales constraints in the general case of \(N\) risky assets as described in Chapter 12. Section 13.5 gives a real-world application of the theory to asset allocation among Vanguard mutual funds.
The examples in this chapter use the IntroCompFinR, PerformanceAnalytics, and quadprog packages. Make sure these packages are installed and loaded in R before replicating the chapter examples.
suppressPackageStartupMessages(library(IntroCompFinR))
suppressPackageStartupMessages(library(PerformanceAnalytics))
suppressPackageStartupMessages(library(quadprog))
options(digits=3)13.1 Overview of Short Selling
Most investments involve purchases of assets that you believe will increase in value over time. When you buy an asset you establish a long position in the asset. You profit from the long position by selling the asset in the future at a price higher than the original purchase price. However, sometimes you may believe that an asset will decrease in value over time. To profit on an investment in which the asset price is lower in the future requires short selling the asset. In general, short selling involves selling an asset you borrow from someone else today and repurchasing the asset in the future and returning it to its owner. You profit on the short sale if you repurchase the asset for a lower price than you initially sold it. Because short selling involves borrowing it is a type of leveraged investment and so risk increases with the size of the short position.
In practice, a short sale of an asset works as follows. Suppose you have an investment account at some brokerage firm and you are interested in short selling one share of an individual stock, such as Microsoft, that you do not currently own. Because the brokerage firm has so many clients, one of the clients will own Microsoft. The brokerage firm will allow you to borrow Microsoft, sell it and add the proceeds of the short sale to your investment account. Doing so establishes a short position in Microsoft which is a liability to return the borrowed share sometime in the future. You close the short position in the future by repurchasing one share of Microsoft through the brokerage firm who returns the share to the original owner. However, borrowing is not free. You will have to pay interest on the amount borrowed. You will also need sufficient capital in your account to cover any potential losses from the short sale. In addition, if the price of the short sold asset rises substantially during the short sale period then the brokerage firm may require you to add additional margin capital to your account. If you cannot do this then the brokerage firm will force you to close the short position immediately.
13.2 Portfolio Theory with Short Sales Constraints in a Simplified Setting
In this section, we illustrate the impact of short sales constraints on risky assets on portfolios in the simplified setting described in Chapter 11. We first look at simple portfolios of two risky assets, then consider portfolios of a risky asset plus a risk-free asset, and finish with portfolios of two risky assets plus a risk-free asset.
13.2.1 Two Risky Assets
Consider the two risky asset example data from Chapter 11:
mu.A = 0.175
sig.A = 0.258
sig2.A = sig.A^2
mu.B = 0.055
sig.B = 0.115
sig2.B = sig.B^2
rho.AB = -0.164
sig.AB = rho.AB*sig.A*sig.B
assetNames = c("Asset A", "Asset B")
mu.vals = c(mu.A, mu.B)
names(mu.vals) = assetNames
Sigma = matrix(c(sig2.A, sig.AB, sig.AB, sig2.B), 2, 2)
colnames(Sigma) = rownames(Sigma) = assetNamesAsset A is the high average return and high risk asset, and asset B is the low average return and low risk asset. Consider the following set of 19 portfolios:
x.A = seq(from=-0.4, to=1.4, by=0.1)
x.B = 1 - x.A
n.port = length(x.A)
names(x.A) = names(x.B) = paste("p", 1:n.port, sep=".")
mu.p = x.A*mu.A + x.B*mu.B
sig2.p = x.A^2 * sig2.A + x.B^2 * sig2.B + 2*x.A*x.B*sig.AB
sig.p = sqrt(sig2.p)Figure 13.1 shows the risky asset only portfolio frontier created using:
cex.val = 1.5
plot(sig.p, mu.p, type="b", pch=16, cex = cex.val,
ylim=c(0, max(mu.p)), xlim=c(0, max(sig.p)),
xlab=expression(sigma[p]), ylab=expression(mu[p]), cex.lab=cex.val,
col=c(rep("lightblue", 4), rep("black", 11), rep("lightblue", 4)))
text(x=sig.A, y=mu.A, labels="Asset A", pos=4, cex = cex.val)
text(x=sig.B, y=mu.B, labels="Asset B", pos=4, cex = cex.val)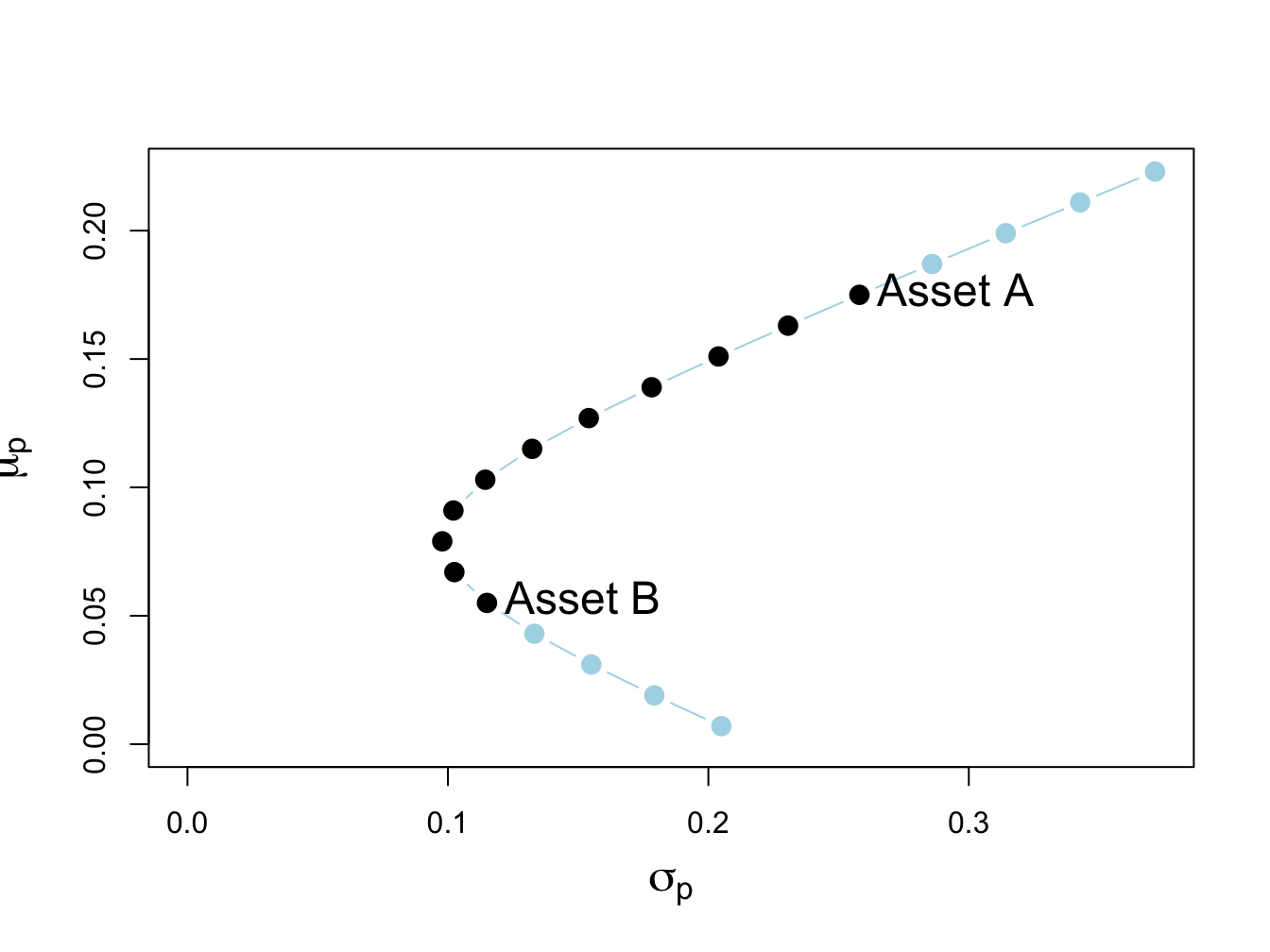
Figure 13.1: Two-risky asset portfolio frontier. Long-only portfolios are in black (between Asset B and Asset A), and long-short portfolios are in blue (below Asset B and above Asset A).
The long only (no short sale) portfolios, shown in black dots between the points labeled “Asset B” and “Asset A”, are portfolios 5 to 15. The asset weights on these portfolios are:
## p.5 p.6 p.7 p.8 p.9 p.10 p.11 p.12 p.13 p.14 p.15
## Asset A 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
## Asset B 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0The long-short portfolios, shown in blue dots below the point labeled “Asset B” and above the point labeled “Asset A”, are portfolios 1 to 4 and portfolios 16 to 19:
longShort = rbind(x.A[c(1:4, 16:19)], x.B[c(1:4, 16:19)])
rownames(longShort) = assetNames
longShort## p.1 p.2 p.3 p.4 p.16 p.17 p.18 p.19
## Asset A -0.4 -0.3 -0.2 -0.1 1.1 1.2 1.3 1.4
## Asset B 1.4 1.3 1.2 1.1 -0.1 -0.2 -0.3 -0.4Not allowing short sales for asset A eliminates the inefficient portfolios 1 to 4 (blue dots below the label “Asset B” ), and not allowing short sales for asset B eliminates the efficient portfolios 16 to 19 (blue dots above the label “Asset A” ). We make the following remarks:
- Not allowing short sales in both assets limits the set of feasible portfolios.
- It is not possible to invest in a portfolio with a higher expected return than asset A.
- It is not possible to invest in a portfolio with a lower expected return than asset B.
13.2.1.1 Short sales constraints and the global minimum variance portfolio
Recall, the two risky asset global minimum variance portfolio solves the unconstrained optimization problem: \[\begin{align*} &\underset{m_{A},m_{B}}{\min}\sigma_{p}^{2} =m_{A}^{2}\sigma_{A}^{2}+m_{B}^{2}\sigma_{B}^{2}+2m_{A}m_{B}\sigma_{AB}\\ &s.t.~m_{A}+m_{B} =1. \end{align*}\]
From Chapter 11, the two risky asset unconstrained global minimum variance portfolio weights are:
\[\begin{equation} m_{A}=\frac{\sigma_{B}^{2}-\sigma_{AB}}{\sigma_{A}^{2}+\sigma_{B}^{2}-2\sigma_{AB}},~m_{B}=1-m_{A}.\tag{13.1} \end{equation}\]
For the example data, the unconstrained global minimum variance portfolio weights are both positive:
## Call:
## globalMin.portfolio(er = mu.vals, cov.mat = Sigma)
##
## Portfolio expected return: 0.0793
## Portfolio standard deviation: 0.0978
## Portfolio weights:
## Asset A Asset B
## 0.202 0.798This means that if we disallow short-sales in both assets we still get the same global minimum variance portfolio weights. In this case, we say that the no short sales constraints are not binding (have no effect) on the solution for the unconstrained optimization problem (13.1). However, it is possible for one of the weights in the global minimum variance portfolio to be negative if correlation between the returns on assets A and B is sufficiently positive. To see this, the numerator in the formula for the global minimum variance weight for asset A can be re-written as:87
\[ \sigma_{B}^{2}-\sigma_{AB}=\sigma_{B}^{2}-\rho_{AB}\sigma_{A}\sigma_{B}=\sigma_{B}^{2}\left(1-\rho_{AB}\frac{\sigma_{A}}{\sigma_{B}}\right). \]
Hence, the weight in asset A in the global minimum variance portfolio will be negative if:
\[\begin{eqnarray*} 1-\rho_{AB}\frac{\sigma_{A}}{\sigma_{B}} & <0 & \Rightarrow\rho_{AB}>\frac{\sigma_{B}}{\sigma_{A}}. \end{eqnarray*}\]
For the example data, this cut-off value for the correlation is:
## [1] 0.446Figure 13.2 shows the two risky asset portfolio frontier computed with \(\rho_{AB}=0.8\). Here, the global minimum variance portfolio is:
rho.AB = 0.8
sig.AB = rho.AB*sig.A*sig.B
Sigma = matrix(c(sig2.A, sig.AB, sig.AB, sig2.B), 2, 2)
gmin.port = globalMin.portfolio(mu.vals, Sigma)
gmin.port## Call:
## globalMin.portfolio(er = mu.vals, cov.mat = Sigma)
##
## Portfolio expected return: 0.016
## Portfolio standard deviation: 0.099
## Portfolio weights:
## Asset A Asset B
## -0.325 1.325and contains a negative weight in asset A. This portfolio is shown as the green dot in Figure 13.2, and plots below the point labeled “Asset B” . Here, the no-short sales constraint on asset A is a binding constraint: it is not possible to invest in the global minimum variance portfolio without shorting asset A. Visually, we can see that the feasible long-only portfolio with the smallest variance is 100% invested in asset B. This is the no short sales constrained global minimum variance portfolio. Notice that the variance of this portfolio is larger than the variance of the global minimum variance portfolio. This is the cost, in terms of variance, of imposing the no-short sales constraint.
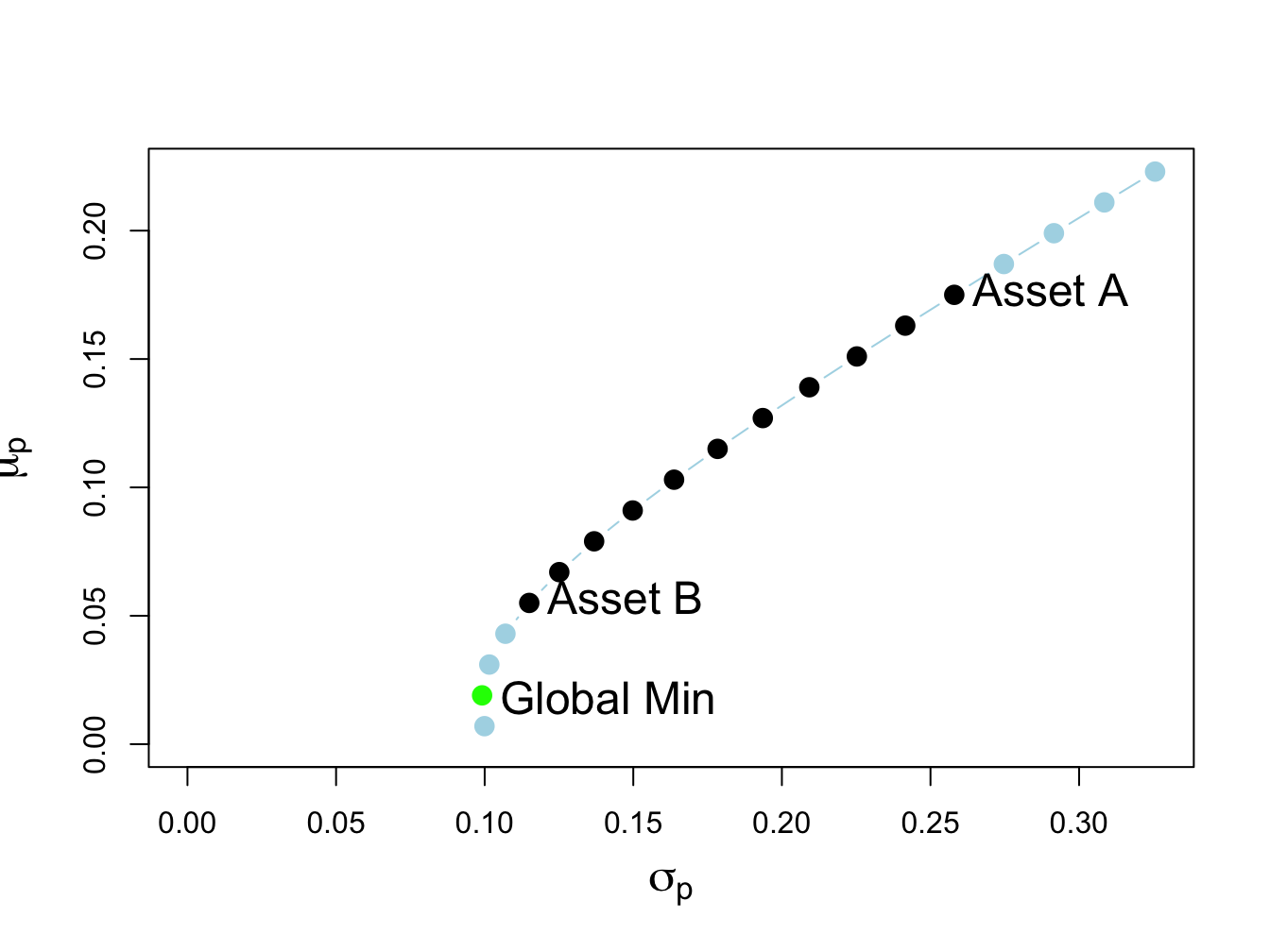
Figure 13.2: Two risky asset portfolio frontier with short sale in Asset A in the global minimum variance portfolio.
13.2.2 One risky asset and a risk-free asset
Now consider portfolios of a risky asset (e.g., asset A) and a risk-free asset (e.g., U.S. T-Bill) with risk-free rate \(r_{f}>0\). Let \(x\) denote the portfolio weight in the risky asset. Then \(1-x\) gives the weight in the risk-free asset. From Chapter 11, the expected return and volatility of portfolios of one risky asset and one risk-free asset are: \[\begin{eqnarray*} \mu_{p} & = & r_{f}+x(\mu-r_{f}),\\ \sigma_{p} & = & |x|\sigma, \end{eqnarray*}\] where \(\mu\) and \(\sigma\) are the expected return and volatility of the risky asset, respectively. For example, Figure 13.3 shows 29 portfolios of asset A and the risk-free asset with \(r_{f}=0.03\) created with:
r.f = 0.03
x.A = seq(from=-1.4, to=1.4, by=0.1)
mu.p.A = r.f + x.A*(mu.A - r.f)
sig.p.A = abs(x.A)*sig.A
plot(sig.p.A, mu.p.A, type="b", ylim=c(min(mu.p.A), max(mu.p.A)),
xlim=c(-0.01, max(sig.p.A)), pch=16, cex = cex.val,
xlab=expression(sigma[p]), ylab=expression(mu[p]), cex.lab = cex.val,
col=c(rep("lightblue", 14), rep("black", 11), rep("lightblue", 4)))
abline(h=0)
text(x=sig.A, y=mu.A, labels="Asset A", pos=4, cex = cex.val)
text(x=0, y=r.f, labels=expression(r[f]), pos=2, cex = cex.val)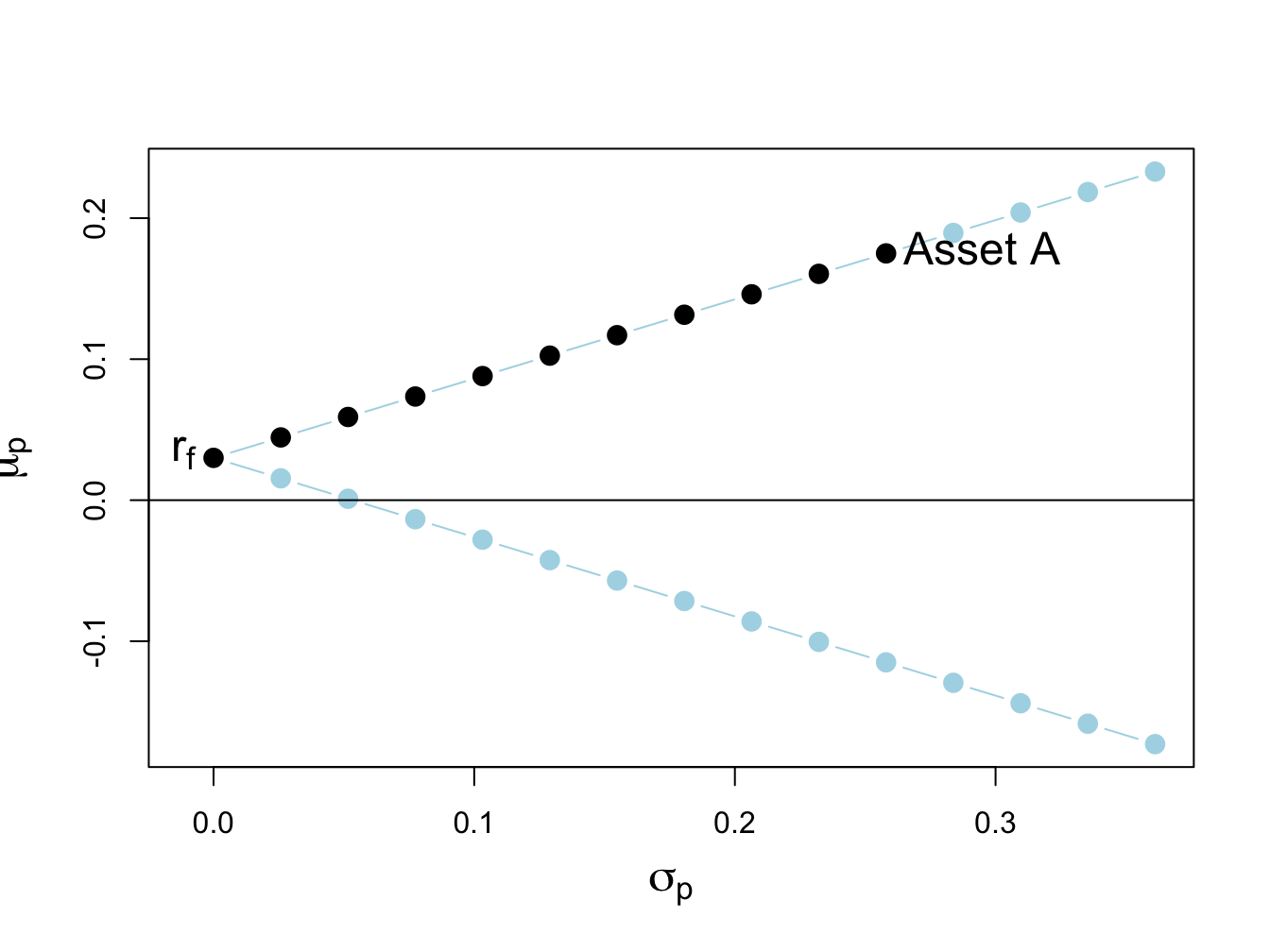
Figure 13.3: Return-risk characteristics of portfolios of asset A and a risk-free asset with \(r_{f}=0.03\). Long-only portfolios are in black (between \(\mathrm{r}_{f}\) and Asset A), and long-short portfolios are in blue (below \(\mathrm{r}_{f}\) and above Asset A).
The portfolios (blue dots) above the point labeled “Asset A” are short the risk-free asset and long more than 100% of asset A. The portfolios (blue dots) below \(r_{f}=0.03\) are short the risky asset and long more than 100% in the risk-free asset.
Here, we assume that the short sales constraint only applies to the risky asset and not the risk-free asset. That is, we assume that we can borrow and lend at the risk-free rate \(r_{f}\) without constraints. In this situation, the no short sales constraint on the risky asset eliminates the inefficient portfolios (blue dots) below the risk-free rate \(r_{f}\).
13.2.3 Two risky assets and risk-free asset
As discussed in Chapter 11, in the case of two risky assets (with no short sales restrictions) plus a risk-free asset the set of efficient portfolios is a combination of the tangency portfolio (i.e., the maximum Sharpe ratio portfolio of two risky assets) and the risk-free asset. For the example data with \(\rho_{AB}=-0.164\) and \(r_{f}=0.03\), the tangency portfolio is:
rho.AB = -0.164
sig.AB = rho.AB*sig.A*sig.B
Sigma = matrix(c(sig2.A, sig.AB, sig.AB, sig2.B), 2, 2)
r.f = 0.03
tan.port = tangency.portfolio(mu.vals, Sigma, r.f)
summary(tan.port, r.f)## Call:
## tangency.portfolio(er = mu.vals, cov.mat = Sigma, risk.free = r.f)
##
## Portfolio expected return: 0.111
## Portfolio standard deviation: 0.125
## Portfolio Sharpe Ratio: 0.644
## Portfolio weights:
## Asset A Asset B
## 0.463 0.537No asset is sold short in the unconstrained tangency portfolio, and so this is also the short-sales constrained tangency portfolio. The set of efficient portfolios is illustrated in Figure 13.4, created with:
# risky asset only portfolios
x.A = seq(from=0, to=1, by=0.1)
x.B = 1 - x.A
mu.p = x.A*mu.A + x.B*mu.B
sig2.p = x.A^2 * sig2.A + x.B^2 * sig2.B + 2*x.A*x.B*sig.AB
sig.p = sqrt(sig2.p)
# T-bills plus tangency
x.tan = seq(from=0, to=2.4, by=0.1)
mu.p.tan.tbill = r.f + x.tan*(tan.port$er - r.f)
sig.p.tan.tbill = x.tan*tan.port$sd
# global minimum variance portfolio
gmin.port = globalMin.portfolio(mu.vals, Sigma)
# plot efficient portfolios
plot(sig.p, mu.p, type="b", pch=16, cex = cex.val,
ylim=c(0, 0.20), xlim=c(-0.01, 0.35),
xlab=expression(sigma[p]), ylab=expression(mu[p]), cex.lab = cex.val)
text(x=sig.A, y=mu.A, labels="Asset A", pos=4, cex = cex.val)
text(x=sig.B, y=mu.B, labels="Asset B", pos=4, cex = cex.val)
text(x=0, y=r.f, labels=expression(r[f]), pos=2, cex = cex.val)
text(x=tan.port$sd, y=tan.port$er, labels="Tangency", pos=2, cex = cex.val)
text(gmin.port$sd, gmin.port$er, labels="Global Min", pos = 4,
cex = cex.val)
points(sig.p.tan.tbill, mu.p.tan.tbill, type="l", col="green",
lwd=2, cex = cex.val)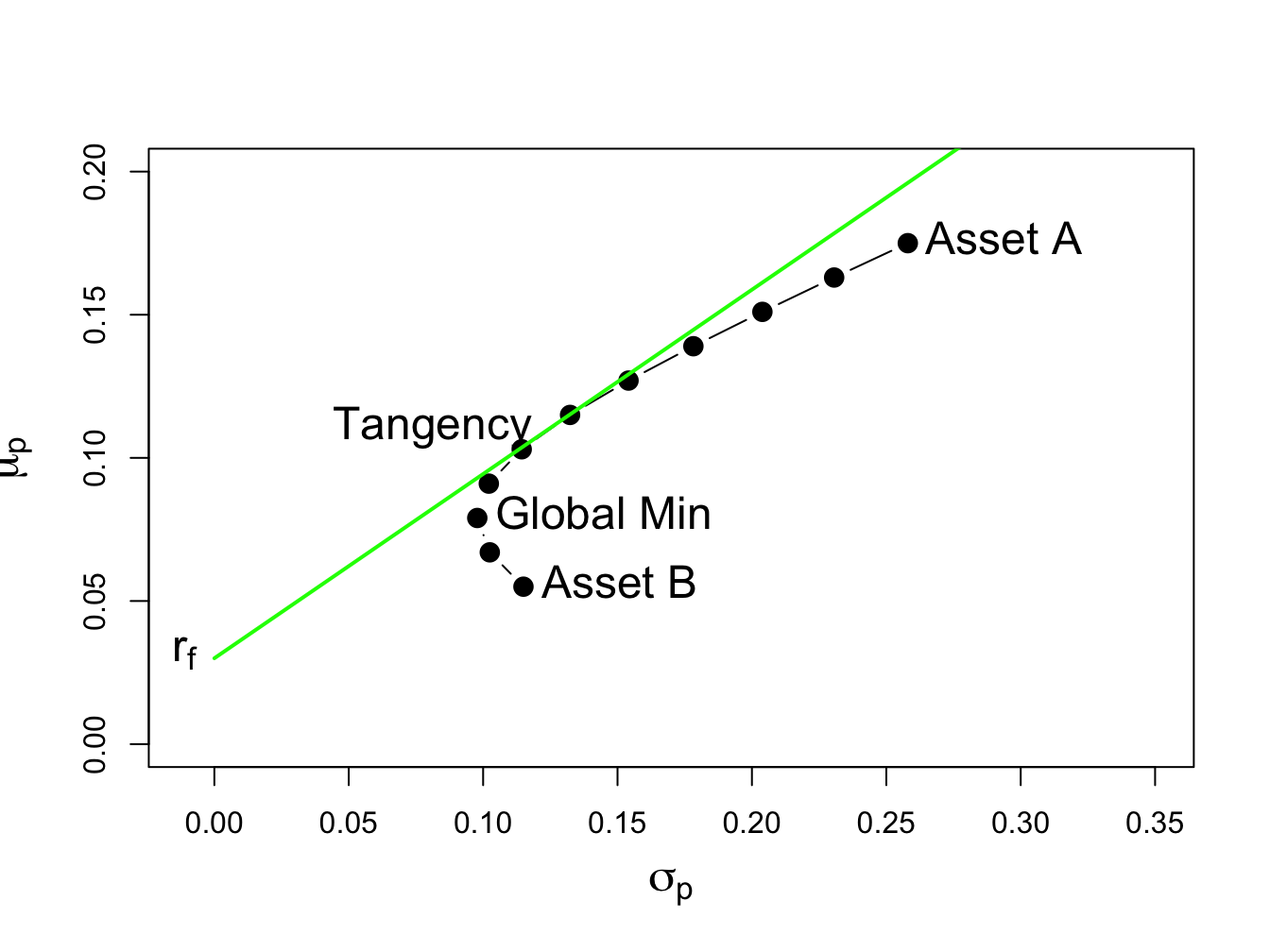
Figure 13.4: Efficient portfolios of two risky assets plus a risk-free asset: \(\rho_{AB}=-0.164\) and \(r_{f}=0.03\). No short sales in unconstrained tangency portfolio.
Figure 13.4 shows that when the tangency portfolio is located between the global minimum variance portfolio (tip of the Markowitz bullet) and asset A, there will be no short sales in the tangency portfolio. However, if the correlation between assets A and B is sufficiently positive (and the risk-free rate is adjusted so that it is less than the expected return on the global minimum variance portfolio) then asset B can be sold short in the unconstrained tangency portfolio. For example, if \(\rho_{AB}=0.7\) and \(r_{f}=0.01\) the unconstrained tangency portfolio becomes:
rho.AB = 0.7
sig.AB = rho.AB*sig.A*sig.B
Sigma = matrix(c(sig2.A, sig.AB, sig.AB, sig2.B), 2, 2)
r.f = 0.01
tan.port = tangency.portfolio(mu.vals, Sigma, r.f)
summary(tan.port, r.f)## Call:
## tangency.portfolio(er = mu.vals, cov.mat = Sigma, risk.free = r.f)
##
## Portfolio expected return: 0.238
## Portfolio standard deviation: 0.355
## Portfolio Sharpe Ratio: 0.644
## Portfolio weights:
## Asset A Asset B
## 1.529 -0.529Now, asset B is sold short in the tangency portfolio. The set of efficient portfolios in this case is illustrated in Figure 13.5. Notice that the tangency portfolio is located on the set of risky asset only portfolios above the point labeled “Asset A”, which indicates that asset B is sold short and more than 100% is invested in asset A.88
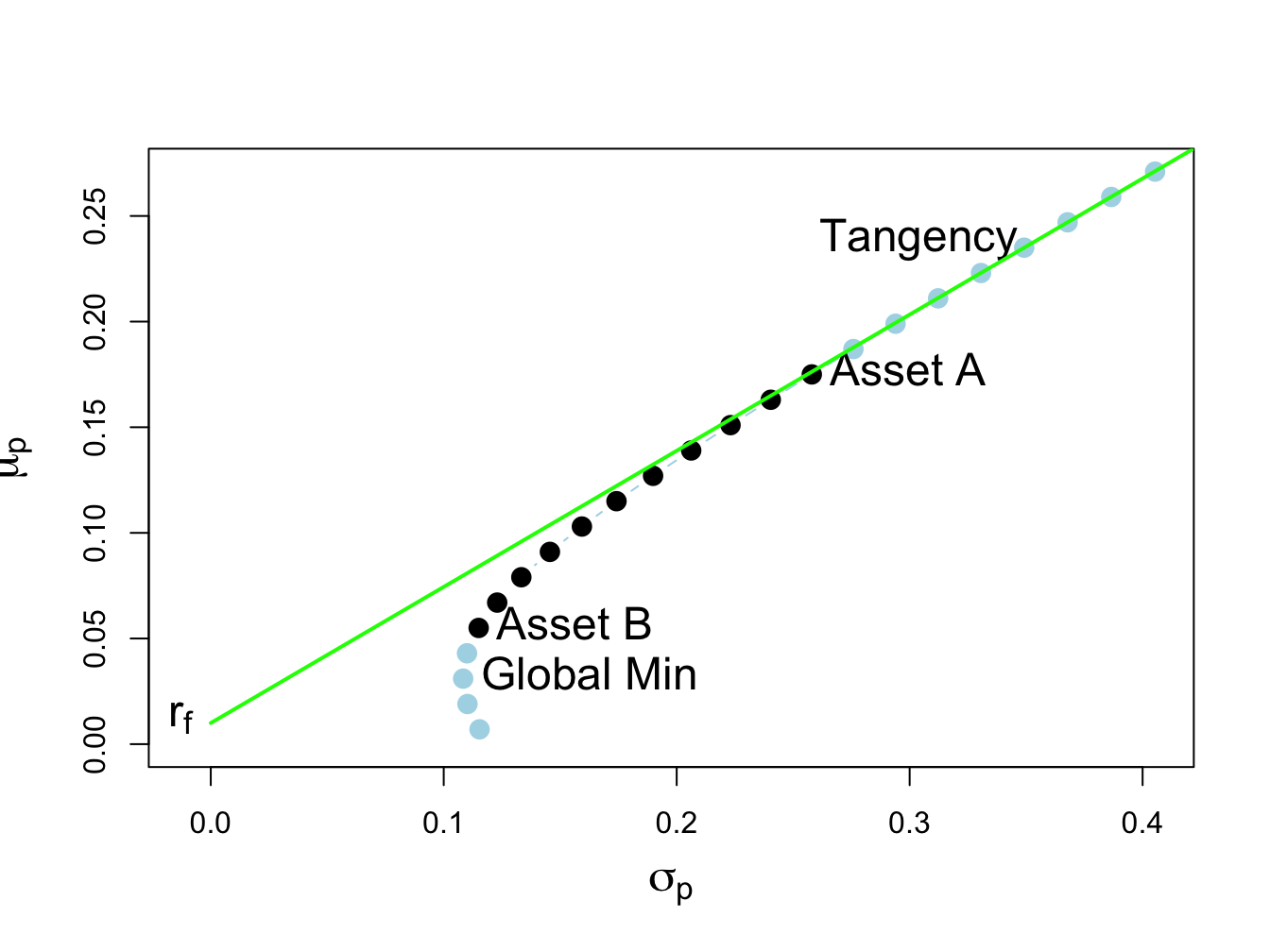
Figure 13.5: Efficient portfolios of two risky assets plus a risk free asset: \(\rho_{AB}=0.7\) and \(r_{f}=0.01\). Asset B sold short in unconstrained tangency portfolio. The short sale constrained tangency portfolio is the point labeled “Asset A”.
When shorts sales of risky assets are not allowed, the unconstrained tangency portfolio is infeasible. In this case, the constrained tangency portfolio is not the tangency portfolio but is 100% invested in asset A. This portfolio is located at the tangency point of a straight line drawn from the risk-free rate to the long-only risky asset frontier. Here, the cost of the no-short sales constraint is the reduction in the Sharpe ratio of the tangency portfolio. The Sharpe ratio of the constrained tangency portfolio is the Sharpe ratio of asset A:
## [1] 0.64Hence, the cost of the no short sales constraint in this example is very small.
13.3 Portfolio Theory with Short Sales Constraints in a General Setting
In this section we extend the analysis of the previous section to the more general setting of \(N\) risky assets plus a risk free asset.
13.3.1 Multiple risky assets
The example data on Microsoft, Nordstrom and Starbucks from Chapter 12 is used to illustrate the computation of mean-variance efficient portfolios with short sales constraints. These data are created using:
asset.names <- c("MSFT", "NORD", "SBUX")
mu.vec = c(0.0427, 0.0015, 0.0285)
names(mu.vec) = asset.names
sigma.mat = matrix(c(0.0100, 0.0018, 0.0011,
0.0018, 0.0109, 0.0026,
0.0011, 0.0026, 0.0199),
nrow=3, ncol=3)
dimnames(sigma.mat) = list(asset.names, asset.names)
sd.vec = sqrt(diag(sigma.mat))
r.f=0.005The impact of the no short sales restrictions on the risk-return characteristics of feasible portfolios is nicely illustrated by constructing random long-only portfolios of these three assets:
set.seed(123)
x.msft = runif(400, min=0, max=1)
x.nord = runif(400, min=0, max=1)
x.sbux = 1 - x.msft - x.nord
long.only = which(x.sbux > 0)
x.msft = x.msft[long.only]
x.nord = x.nord[long.only]
x.sbux = x.sbux[long.only]
length(long.only)## [1] 191Here we first create 400 random weights for Microsoft and Nordstrom that lie between zero and one, respectively. Then, we determine the weight on Starbucks and throw out portfolios for which the weight on Starbucks is negative. The remaining 191 portfolios are then long-only portfolios. To be sure, these weights are illustrated in Figure 13.6 created using:
library(PerformanceAnalytics)
chart.StackedBar(cbind(x.msft, x.nord, x.sbux),
main="Random long-only portfolio weight vectors", xlab = "portfolio", ylab = "weights",
xaxis.labels=as.character(1:length(long.only)))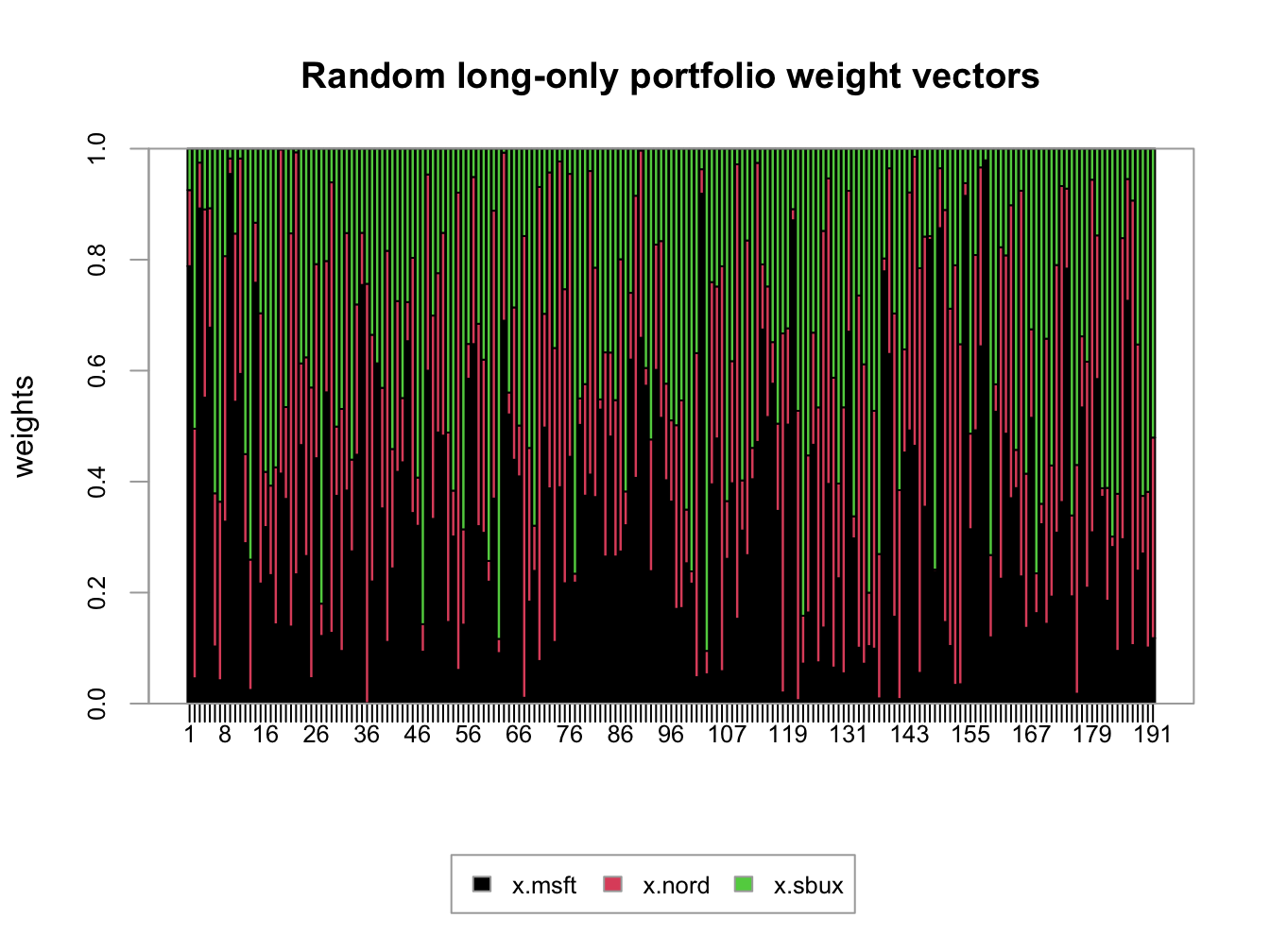
Figure 13.6: Weights on 191 random long-only portfolios of Microsoft, Nordstrom and Starbucks.
plot(sd.vec, mu.vec, ylim=c(0, 0.05), xlim=c(0, 0.2),
ylab=expression(mu[p]),
xlab=expression(sigma[p]), type="n", cex.lab=1.5)
for (i in 1:length(long.only)) {
z.vec = c(x.msft[i], x.nord[i], x.sbux[i])
mu.p = crossprod(z.vec,mu.vec)
sig.p = sqrt(t(z.vec)%*%sigma.mat%*%z.vec)
points(sig.p, mu.p, pch=16, col="grey", cex=1.5)
}
points(sd.vec, mu.vec, pch=16, col="black", cex=2.5, cex.lab=1.75)
text(sd.vec, mu.vec, labels=asset.names, pos=4, cex = cex.val)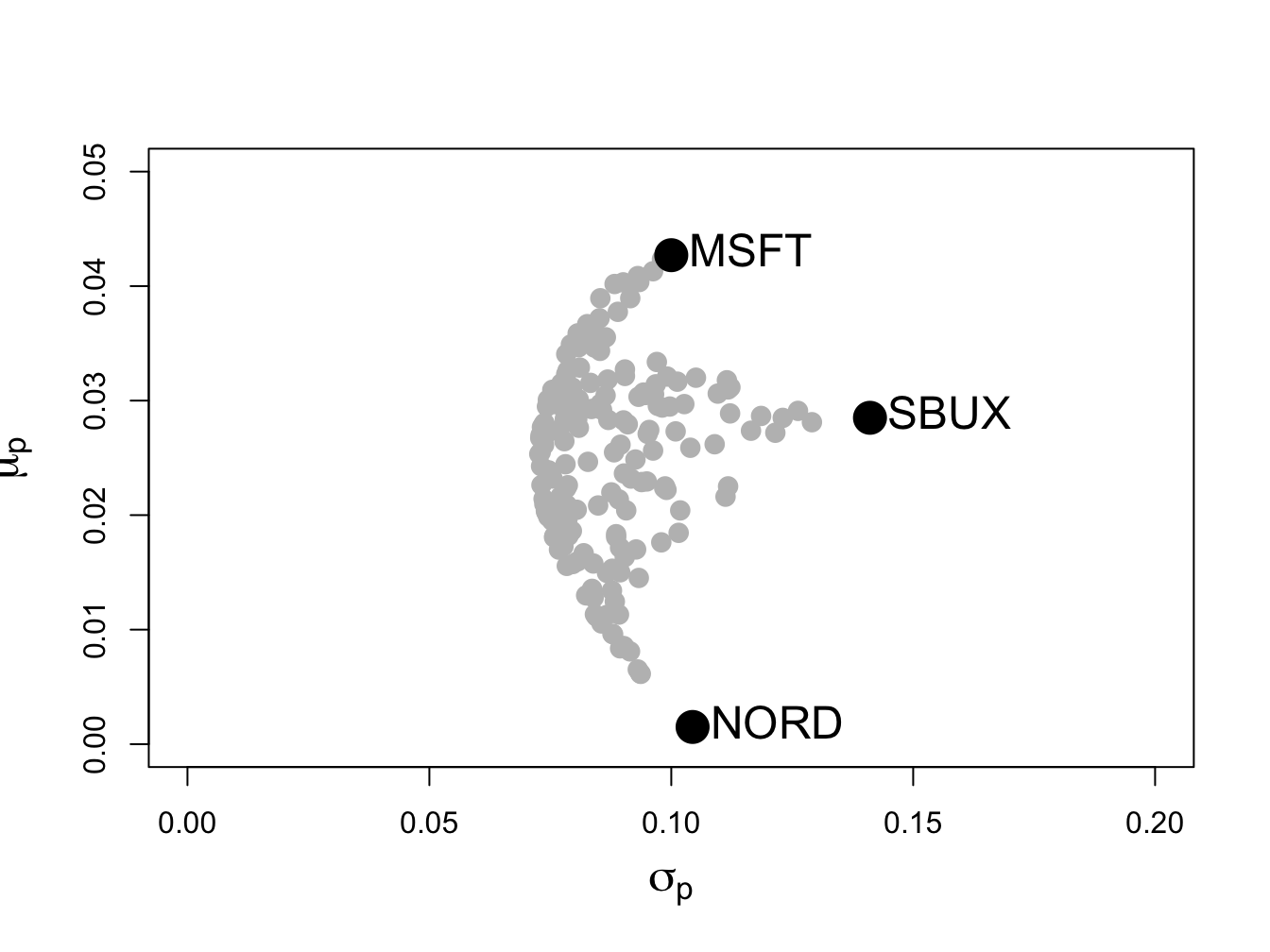
Figure 13.7: Risk-return characteristics of 191 random long-only portfolios of Microsoft, Nordstrom and Starbucks.
The shape of the risk-return scatter is revealing. No random long-only portfolio has an expected return higher than the expected return on Microsoft, which is the asset with the highest expected return. Similarly, no random portfolio has an expected return lower than the expected return on Nordstrom - which is the asset with the lowest expected return. Finally, no random portfolio has a volatility higher than the volatility on Starbucks, the asset with the highest volatility. The scatter of points has a convex (to the origin) parabolic-shaped outer boundary with endpoints at Microsoft and Nordstrom, respectively. The points inside the boundary taper outward from Starbucks towards the outer boundary. The entire risk-return scatter resembles an umbrella tipped on its side with spires extending from the outer boundary to the individual assets.
13.3.2 Portfolio optimization imposing no-short sales constraints
Consider an investment universe with \(N\) risky assets whose simple returns are described by the GWN model with expected return vector \(\mu\) and covariance matrix \(\Sigma\). The optimization problem to solve for the global minimum variance portfolio \(\mathbf{m}\) with no-short sales constraints on all assets is a straightforward extension of the problem that allows short sales. We simply add the \(N\) no-short sales inequality constraints \(m_{i}\geq0\,(i=1,\ldots,N)\). The optimization problem is: \[\begin{align} \min_{\mathbf{m}}\sigma_{p,m}^{2} & =\mathbf{m}^{\prime}\Sigma \mathbf{m}\tag{13.2}\\ \text{s.t. } \mathbf{m}^{\prime}\mathbf{1} & =1,\nonumber \\ m_{i} & \geq0\text{ }(i=1,\ldots,N).\nonumber \end{align}\] Here, there is one equality constraint, \(\mathbf{m}^{\prime}\mathbf{1}=1\), and \(N\) inequality constraints, \(m_{i}\geq0\text{ }(i=1,\ldots,N)\).
Similarly, the optimization problem to solve for a minimum variance portfolio \(\mathbf{x}\) with target expected return \(\mu_{p}^{0}\) and no short sales allowed for any asset becomes: \[\begin{align} \min_{\mathbf{x}}\sigma_{p,x}^{2} & =\mathbf{x}^{\prime}\Sigma \mathbf{x} \tag{13.3}\\ \text{s.t. }\mu_{p,x} & =\mathbf{x}^{\prime}\mu=\mu_{p}^{0},\nonumber \\ \mathbf{x}^{\prime}\mathbf{1} & =1,\nonumber \\ x_{i} & \geq0\text{ }(i=1,\ldots,N).\nonumber \end{align}\] Here there are two equality constraints, \(\mathbf{x}^{\prime}\mu=\mu_{p}^{0}\) and \(\mathbf{x}^{\prime}\mathbf{1}=1\), and \(N\) inequality constraints, \(x_{i}\geq0\text{ }(i=1,\ldots,N)\)
Remarks:
- The optimization problems (13.2) and (13.3), unfortunately, cannot be analytically solved using the method of Lagrange multipliers due to the inequality constraints. They must be solved numerically using an optimization algorithm. Fortunately, the optimization problems (13.2) and (13.3) are special cases of a more general quadratic programming problem for which there is a specialized optimization algorithm that is fast and efficient and available in R in the package quadprog.89
- There may not be a feasible solution to (13.3). That is, there may not exist a no-short sale portfolio \(\mathbf{x}\) that reaches the target return \(\mu_{p}^{0}.\) For example, in Figure 13.7 there is no efficient portfolio that has target expected return higher than the expected return on Microsoft. In general, with \(N\) assets there is no feasible solution to (13.3) for target expected returns higher than the maximum expected return among the \(N\) assets. If you try to solve (13.3) for an infeasible target expected return, the numerical optimizer will return an error message that indicates no solution is found.
- The portfolio variances associated with the solutions to (13.2) and (13.3), respectively, must be at least as large as the variances associated with the solutions that do not impose the short sales restrictions. Intuitively this makes sense. Adding additional constraints to a minimization problem will lead to a higher minimum at the solution if the additional constraints are binding. If the constraints are not binding, then the solution with and without the additional constraints are the same.
- The entire frontier of minimum variance portfolios without short sales exists only for target expected returns between the expected return on the global minimum variance portfolio with no short sales that solves (13.2) and the target expected return equal to the maximum expected return among the \(N\) assets. For these target returns, the no-short sales frontier will lie inside and to the right of the frontier that allows short sales if the no-short sales restrictions are binding for some asset.
- The entire frontier of minimum variance portfolios without short sales can no longer be constructed from any two frontier portfolios. It has to be computed by brute force for each portfolio solving (13.3) with target expected return \(\mu_{p}^{0}\) above the expected return on the the global minimum variance portfolio that solves (13.2) and below the target return equal to the maximum expected return among the \(N\) assets.
13.4 Quadratic Programming Problems
In this Section, we show that the inequality constrained portfolio
optimization problems (13.2) and (13.3)
are special cases of more general quadratic programming problems and
we show how to use the function solve.QP() from the R package
quadprog to numerically solve these problems.
Quadratic programming (QP) problems are of the form: \[\begin{align} \min_{\mathbf{x}}&\text{ }\frac{1}{2}\mathbf{x}^{\prime}\mathbf{Dx}-\mathbf{d}^{\prime}\mathbf{x},\tag{13.4}\\ \text{s.t. }& \mathbf{A}_{eq}^{\prime}\mathbf{x} \geq\mathbf{b}_{eq}\text{ for }l\text{ equality constraints,}\tag{13.5}\\ & \mathbf{A}_{neq}^{\prime}\mathbf{x} =\mathbf{b}_{neq}\text{ for }m\text{ inequality constraints},\tag{13.6} \end{align}\] where \(\mathbf{D}\) is an \(N\times N\) matrix, \(\mathbf{x}\) and \(\mathbf{d}\) are \(N\times1\) vectors, \(\mathbf{A}_{neq}^{\prime}\) is an \(m\times N\) matrix, \(\mathbf{b}_{neq}\) is an \(m\times1\) vector, \(\mathbf{A}_{eq}^{\prime}\) is an \(l\times N\) matrix, and \(\mathbf{b}_{eq}\) is an \(l\times1\) vector.
The solve.QP() function from the R package quadprog
can be used to solve QP functions of the form (13.4)
- (13.6). The function solve.QP()
takes as input the matrices and vectors \(\mathbf{D}\), \(\mathbf{d}\),
\(\mathbf{A}_{eq}\), \(\mathbf{b}_{eq},\) \(\mathbf{A}_{neq}\) and \(\mathbf{b}_{neq}\):
## function (Dmat, dvec, Amat, bvec, meq = 0, factorized = FALSE)
## NULLwhere the arguments Dmat and dvec correspond to
the matrix \(\mathbf{D}\) and the vector \(\mathbf{d}\), respectively.
The function solve.QP(), however, assumes that the equality
and inequality matrices (\(\mathbf{A}_{eq},\,\mathbf{A}_{neq}\)) and
vectors (\(\mathbf{b}_{eq},\,\mathbf{b}_{neq}\)) are combined into
a single \((l+m)\times N\) matrix \(\mathbf{A}^{\prime}\) and a single
\((l+m)\)\(\times1\) vector \(\mathbf{b}\) of the form:
\[
\mathbf{A}^{\prime}=\left[\begin{array}{c}
\mathbf{A}_{eq}^{\prime}\\
\mathbf{A}_{neq}^{\prime}
\end{array}\right],\,\mathbf{b}=\left(\begin{array}{c}
\mathbf{b}_{eq}\\
\mathbf{b}_{neq}
\end{array}\right).
\]
In solve.QP(), the argument Amat represents the
matrix \(\mathbf{A}\) (not \(\mathbf{A}^{\prime})\) and the argument
bmat represents the vector \(\mathbf{b}\). The argument meq
determines the number of linear equality constraints (i.e., the number
of rows \(l\) of \(\mathbf{A}_{eq}^{\prime}\)) so that \(\mathbf{A}^{\prime}\)
can be separated into \(\mathbf{A}_{eq}^{\prime}\) and \(\mathbf{A}_{neq}^{\prime}\),
respectively.
13.4.1 No short sales global minimum variance portfolio
The portfolio optimization problems (13.2) and (13.3) are special cases of the general QP problem (13.4) - (13.6). Consider first the problem to find the global minimum variance portfolio (13.2). The objective function \(\sigma_{p,m}^{2}=\mathbf{m}^{\prime}\Sigma \mathbf{m}\) can be recovered from (13.4) by setting \(\mathbf{x}=\mathbf{m}\), \(\mathbf{D}=2\times\mathbf{\varSigma}\) and \(\mathbf{d}=(0,\ldots,0)^{\prime}.\) Then, \[ \frac{1}{2}\mathbf{x}^{\prime}\mathbf{Dx}-\mathbf{d}^{\prime}\mathbf{x}=\mathbf{m^{\prime}\varSigma m}=\sigma_{p,m}^{2}. \] Here, there is one equality constraint, \(\mathbf{m}^{\prime}\mathbf{1}=1\), and \(N\) inequality constraints, \(m_{i}\geq0\text{ }(i=1,\ldots,N)\), which can be expressed compactly as \(\mathbf{m}\geq\mathbf{0}\). These constraints can be expressed in the form (13.5) and (13.6) by defining the restriction matrices: \[\begin{align*} \underset{(1\times N)}{\mathbf{A}_{eq}^{\prime}} & =\mathbf{1}^{\prime},\text{ }\underset{(1\times1)}{\mathbf{b}_{eq}}=1\\ \underset{(N\times N)}{\mathbf{A}_{neq}^{\prime}} & =\mathbf{I}_{N},\underset{(N\times1)}{\mathbf{b}_{neq}}=(0,\ldots,0)^{\prime}=\mathbf{0}, \end{align*}\] so that \[ \mathbf{A}^{\prime}=\left[\begin{array}{c} \mathbf{1}^{\prime}\\ \mathbf{I}_{N} \end{array}\right],\,\mathbf{b}=\left(\begin{array}{c} 1\\ \mathbf{0} \end{array}\right). \] Here, \[\begin{eqnarray*} \mathbf{A}_{eq}^{\prime}\mathbf{m} & = & \mathbf{1^{\prime}m}=1=b_{eq},\\ \mathbf{A}_{neq}^{\prime}\mathbf{m} & = & \mathbf{I}_{N}\mathbf{m}=\mathbf{m}\geq\mathbf{0}=\mathbf{b}_{neq}. \end{eqnarray*}\]
The unconstrained global minimum variance portfolio of Microsoft, Nordstrom and Starbucks is:
## Call:
## globalMin.portfolio(er = mu.vec, cov.mat = sigma.mat)
##
## Portfolio expected return: 0.0249
## Portfolio standard deviation: 0.0727
## Portfolio weights:
## MSFT NORD SBUX
## 0.441 0.366 0.193This portfolio does not have any negative weights and so the no-short sales restriction is not binding. Hence, the short sales constrained global minimum variance is the same as the unconstrained global minimum variance portfolio.
The restriction matrices and vectors required by solve.QP()
to compute the short sales constrained global minimum variance portfolio
are:
## MSFT NORD SBUX
## MSFT 0.0200 0.0036 0.0022
## NORD 0.0036 0.0218 0.0052
## SBUX 0.0022 0.0052 0.0398## [1] 0 0 0## [,1] [,2] [,3]
## [1,] 1 1 1
## [2,] 1 0 0
## [3,] 0 1 0
## [4,] 0 0 1## [1] 1 0 0 0To find the short sales constrained global minimum variance portfolio,
call solve.QP() with the above inputs and set meq=1
to indicate one equality constraint:
## [1] "list"## [1] "solution" "value"
## [3] "unconstrained.solution" "iterations"
## [5] "Lagrangian" "iact"The returned object, qp.out, is a list with the following
components:
## $solution
## [1] 0.441 0.366 0.193
##
## $value
## [1] 0.00528
##
## $unconstrained.solution
## [1] 0 0 0
##
## $iterations
## [1] 2 0
##
## $Lagrangian
## [1] 0.0106 0.0000 0.0000 0.0000
##
## $iact
## [1] 1The portfolio weights are in the solution component, which
match the global minimum variance weights allowing short sales, and
satisfy the required constraints (weights sum to one and all weights
are positive). The minimized value of the objective function (portfolio
variance) is in the value component. See the help file for
solve.QP() for explanations of the other components.
You can also use the IntroCompFinR function globalmin.portfolio()
to compute the global minimum variance portfolio subject to short-sales
constraints by specifying the optional argument shorts=FALSE:
## Call:
## globalMin.portfolio(er = mu.vec, cov.mat = sigma.mat, shorts = FALSE)
##
## Portfolio expected return: 0.0249
## Portfolio standard deviation: 0.0727
## Portfolio weights:
## MSFT NORD SBUX
## 0.441 0.366 0.193When shorts=FALSE, globalmin.portfolio() uses solve.QP() as described above to do the optimization.
\(\blacksquare\)
13.4.2 No short sales minimum variance portfolio with target expected return
Next, consider the problem (13.3) to find a minimum variance portfolio with a given target expected return. The objective function (13.4) has \(\mathbf{D}=2\times\mathbf{\varSigma}\) and \(\mathbf{d}=(0,\ldots,0)^{\prime}.\) The two linear equality constraints, \(\mathbf{x}^{\prime}\mu=\mu_{p}^{0}\) and \(\mathbf{x}^{\prime}\mathbf{1}=1\), and \(N\) inequality constraints \(\mathbf{x}\geq\mathbf{0}\) have restriction matrices and vectors: \[\begin{align*} \underset{(2\times N)}{\mathbf{A}_{eq}^{\prime}} & =\left(\begin{array}{c} \mu^{\prime}\\ \mathbf{1}^{\prime} \end{array}\right),\,\underset{(2\times1)}{\mathbf{b}_{eq}}=\left(\begin{array}{c} \mu_{p}^{0}\\ 1 \end{array}\right).\text{ }\\ \underset{(N\times N)}{\mathbf{A}_{neq}^{\prime}} & =\mathbf{I}_{N},\,\underset{(N\times1)}{\mathbf{b}_{neq}}=(0,\ldots,0)^{\prime}. \end{align*}\] so that \[ \mathbf{A}^{\prime}=\left(\begin{array}{c} \mu^{\prime}\\ \mathbf{1}^{\prime}\\ \mathbf{I}_{N} \end{array}\right),\text{ }\mathbf{b}=\left(\begin{array}{c} \mu_{p}^{0}\\ 1\\ \mathbf{0} \end{array}\right). \] Here, \[\begin{eqnarray*} \mathbf{A}_{eq}^{\prime}\mathbf{x} & = & \left(\begin{array}{c} \mu^{\prime}\\ \mathbf{1}^{\prime} \end{array}\right)\mathbf{x=}\left(\begin{array}{c} \mu^{\prime}\mathbf{x}\\ \mathbf{1}^{\prime}\mathbf{x} \end{array}\right)=\left(\begin{array}{c} \mu_{p}^{0}\\ 1 \end{array}\right)=\mathbf{b}_{eq},\\ \mathbf{A}_{neq}^{\prime}\mathbf{x} & = & \mathbf{I}_{N}\mathbf{x}=\mathbf{x}\geq0. \end{eqnarray*}\]
Now, we consider finding the minimum variance portfolio that has the
same mean as Microsoft but does not allow short sales. First, we find
the minimum variance portfolio allowing for short sales using the
IntroCompFinR function efficient.portfolio():
## Call:
## efficient.portfolio(er = mu.vec, cov.mat = sigma.mat, target.return = mu.vec["MSFT"])
##
## Portfolio expected return: 0.0427
## Portfolio standard deviation: 0.0917
## Portfolio weights:
## MSFT NORD SBUX
## 0.8275 -0.0907 0.2633This portfolio has a short sale (negative weight) in Nordstrom. Hence,
when the short sales restriction is imposed it will be binding. Next,
we set up the restriction matrices and vectors required by solve.QP()
to compute the minimum variance portfolio with no-short sales:
D.mat = 2*sigma.mat
d.vec = rep(0, 3)
A.mat = cbind(mu.vec, rep(1,3), diag(3))
b.vec = c(mu.vec["MSFT"], 1, rep(0,3))
t(A.mat)## MSFT NORD SBUX
## mu.vec 0.0427 0.0015 0.0285
## 1.0000 1.0000 1.0000
## 1.0000 0.0000 0.0000
## 0.0000 1.0000 0.0000
## 0.0000 0.0000 1.0000## MSFT
## 0.0427 1.0000 0.0000 0.0000 0.0000Then we call solve.QP() with meq=2 to indicate two equality constraints:
qp.out = solve.QP(Dmat=D.mat, dvec=d.vec,
Amat=A.mat, bvec=b.vec, meq=2)
names(qp.out$solution) = names(mu.vec)
round(qp.out$solution, digits=3)## MSFT NORD SBUX
## 1 0 0With short sales not allowed, the minimum variance portfolio with the same mean as Microsoft is 100% invested in Microsoft. This is consistent with what we see in Figure 13.7. The volatility of this portfolio is slightly higher than the volatility of the portfolio that allows short sales:
## [1] 0.1## [1] 0.0917You can also use the IntroCompFinR function efficient.portfolio()
to compute a minimum variance portfolio with target expected return
subject to short-sales constraints by specifying the optional argument
shorts=FALSE:
## Call:
## efficient.portfolio(er = mu.vec, cov.mat = sigma.mat, target.return = mu.vec["MSFT"],
## shorts = FALSE)
##
## Portfolio expected return: 0.0427
## Portfolio standard deviation: 0.1
## Portfolio weights:
## MSFT NORD SBUX
## 1 0 0Suppose you try to find a minimum variance portfolio with target return higher than the mean of Microsoft while imposing no short sales:
# efficient.portfolio(mu.vec, sigma.mat,
# target.return = mu.vec["MSFT"]+0.01,
# shorts = FALSE)
# uncomment this line to see the resultsHere, solve.QP() reports the error “constraints are inconsistent,
no solution!” This agrees with what we see in Figure 13.7.
\(\blacksquare\)
In this example we compare the efficient frontier portfolios computed
with and without short sales. This can be easily done using the IntroCompFinR
function efficient.frontier(). First, we compute the efficient
frontier allowing short sales for target returns between the mean
of the global minimum variance portfolio and the mean of Microsoft:
## MSFT NORD SBUX
## port 1 0.827 -0.0907 0.263
## port 2 0.785 -0.0400 0.256
## port 3 0.742 0.0107 0.248
## port 4 0.699 0.0614 0.240
## port 5 0.656 0.1121 0.232
## port 6 0.613 0.1628 0.224
## port 7 0.570 0.2135 0.217
## port 8 0.527 0.2642 0.209
## port 9 0.484 0.3149 0.201
## port 10 0.441 0.3656 0.193Here, portfolio 1 is the global minimum variance portfolio and portfolio 10 is the efficient portfolio with the same mean as Microsoft. Notice that portfolios 9 and 10 have negative weights in Nordstrom. Next, we compute the efficient frontier not allowing short sales for the same range of target returns:
ef.ns = efficient.frontier(mu.vec, sigma.mat, alpha.min=0,
alpha.max=1, nport=10, shorts=FALSE)
ef.ns$weights## MSFT NORD SBUX
## port 1 0.441 0.3656 0.193
## port 2 0.484 0.3149 0.201
## port 3 0.527 0.2642 0.209
## port 4 0.570 0.2135 0.217
## port 5 0.613 0.1628 0.224
## port 6 0.656 0.1121 0.232
## port 7 0.699 0.0614 0.240
## port 8 0.742 0.0107 0.248
## port 9 0.861 0.0000 0.139
## port 10 1.000 0.0000 0.000Portfolios 1 - 8 have all positive weights and are the same as portfolios 1 - 8 when short sales are allowed. However, for portfolios 9 and 10 the short sales constraint is binding. For portfolio 9, the weight in Nordstrom is forced to zero and the weight in Starbucks is reduced. For portfolio 10, the weights on Nordstrom and Starbucks are forced to zero. The two frontiers are illustrated in Figure 13.8. For portfolios 1-8, the two frontiers coincide. For portfolios 9 and 10, the no-shorts frontier lies inside and to the right of the short-sales frontier. The cost of the short sales constraint is the increase in the volatility of minimum variance portfolios for target returns near the expected return on Microsoft.
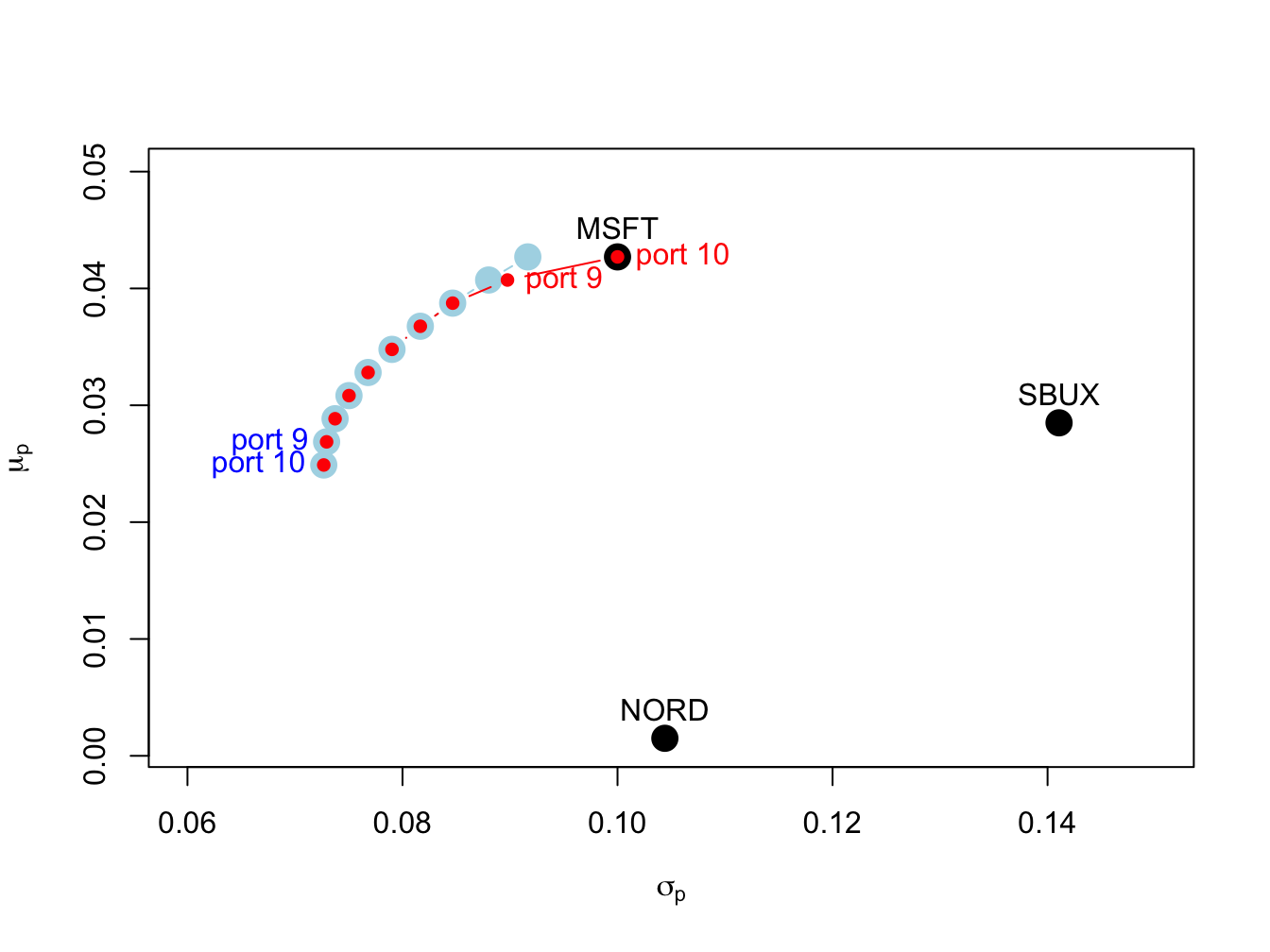
Figure 13.8: Efficient frontier portfolios with and without short sales. The unconstrained efficient frontier portfolios are in blue, and the short sales constrained efficient portfolios are in red. The unconstrained portfolios labeled “port 9” and “port 10” have short sales in Nordstrom. The constrained portfolio labeled “port 9” has zero weight in Nordstrom, and the constrained portfolio labeled "port 10align has zero weights in Nordstrom and Starbucks.
13.4.3 No short sales tangency portfolio
Consider an investment universe with \(N\) risky assets and a single risk-free asset. We assume that short sales constraints only apply to the \(N\) risky assets, and that investors can borrow and lend at the risk-free rate \(r_{f}\). As shown in Chapter 12, with short sales allowed, mean-variance efficient portfolios are combinations of the risk-free asset and the tangency portfolio. The tangency portfolio is the maximum Sharpe ratio portfolio of risky assets and is the solution to the maximization problem: \[\begin{eqnarray*} \underset{\mathbf{t}}{\max}\,\frac{\mu_{t}-r_{f}}{\sigma_{t}} & = & \frac{\mathbf{t}^{\prime}\mu-r_{f}}{(\mathbf{t}^{\prime}\Sigma\mathbf{t})^{1/2}}\,s.t.\\ \mathbf{t}^{\prime}\mathbf{1} & = & 1. \end{eqnarray*}\]
Assuming a risk-free rate \(r_{f}=0.005\), we can compute the unconstrained
tangency portfolio for the three asset example data using the IntroCompFinR
function tangency.portfolio():
## Call:
## tangency.portfolio(er = mu.vec, cov.mat = sigma.mat, risk.free = r.f)
##
## Portfolio expected return: 0.0519
## Portfolio standard deviation: 0.112
## Portfolio Sharpe Ratio: 0.42
## Portfolio weights:
## MSFT NORD SBUX
## 1.027 -0.326 0.299Here, the unconstrained tangency portfolio has a negative weight in Nordstrom so that the short sales constraint on the risky assets will be binding. The unconstrained set of efficient portfolios, that are combinations of the risk-free asset and the unconstrained tangency portfolio, is illustrated in Figure 13.9.
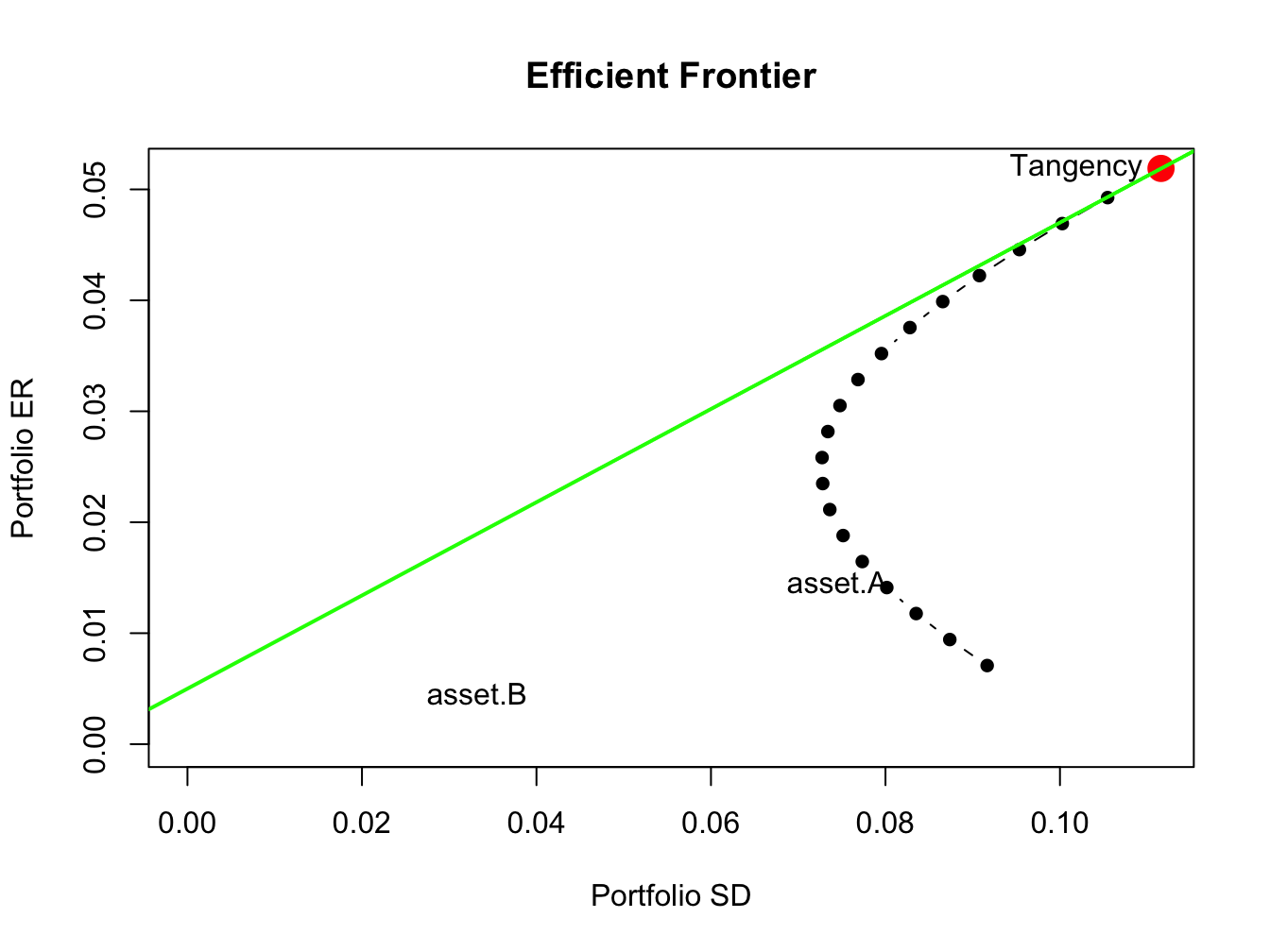
Figure 13.9: Efficient portfolios of three risky assets and a risk-free asset allowing short sales. Nordstrom is sold short in the unconstrained tangency portfolio.
Here, we see that the unconstrained tangency portfolio is located on the frontier of risky asset portfolios above the point labeled “MSFT”. The green line represents portfolios of the risk-free asset and the unconstrained tangency portfolio.
\(\blacksquare\)
Under short sales constraints on the risky assets, the maximum Sharpe
ratio portfolio solves:
\[\begin{eqnarray*}
\max_{\mathbf{t}}\,\frac{\mu_{t}-r_{f}}{\sigma_{t}} & = & \frac{\mathbf{t}^{\prime}\mu-r_{f}}{(\mathbf{t}^{\prime}\Sigma\mathbf{t})^{1/2}}\,s.t.\\
\mathbf{t}^{\prime}\mathbf{1} & = & 1,\\
t_{i} & \geq & 0,\,i=1,\ldots,N.
\end{eqnarray*}\]
This optimization problem cannot be written as a QP optimization as
expressed in (13.4) - (13.6).
Hence, it looks like we cannot use the function solve.QP()
to find the short sales constrained tangency portfolio. However, it
turns out we can use solve.QP() to find the short sales constrained
tangency portfolio. To do this we utilize the alternative derivation
of the tangency portfolio presented in Chapter 12.
The alternative way to compute the tangency portfolio is to first
find a minimum variance portfolio of risky assets and a risk-free
asset whose excess expected return, \(\tilde{\mu}_{p,x}=\mu^{\prime}\mathbf{x}-r_{f}\mathbf{1}\),
achieves a target excess return \(\tilde{\mu}_{p,0}=\mu_{p,0}-r_{f}>0\).
This portfolio solves the minimization problem:
\[
\min_{\mathbf{x}}~\sigma_{p,x}^{2}=\mathbf{x}^{\prime}\Sigma \mathbf{x}\textrm{ s.t. }\tilde{\mu}_{p,x}=\tilde{\mu}_{p,0},
\]
where the weight vector \(\mathbf{x}\) is not constrained to satisfy
\(\mathbf{x}^{\prime}\mathbf{1}=\mathbf{1}\). The tangency portfolio
is then determined by normalizing the weight vector \(\mathbf{x}\)
so that its elements sum to one:90
\[
\mathbf{t}=\frac{\mathbf{x}}{\mathbf{x}^{\prime}\mathbf{1}}=\frac{\Sigma^{-1}(\mu-r_{f}\cdot\mathbf{1})}{\mathbf{1}^{\prime}\Sigma^{-1}(\mu-r_{f}\cdot\mathbf{1})}.
\]
An interesting feature of this result is that it does not depend on
the value of the target excess return value \(\tilde{\mu}_{p,0}=\mu_{p,0}-r_{f}>0\).
That is, every value of \(\tilde{\mu}_{p,0}=\mu_{p,0}-r_{f}>0\) gives
the same value for the tangency portfolio.91 We can utilize this alternative derivation of the tangency portfolio
to find the tangency portfolio subject to short-sales restrictions
on risky assets. First we solve the short-sales constrained minimization
problem:
\[\begin{eqnarray}
\min_{\mathbf{x}}~\sigma_{p,x}^{2} & = & \mathbf{x}^{\prime}\Sigma \mathbf{x}\textrm{ s.t. }\tag{13.7}\\
\tilde{\mu}_{p,x} & = & \tilde{\mu}_{p,0},\tag{13.8}\\
x_{i} & \geq & 0,\,i=1,\ldots,N.\tag{13.9}
\end{eqnarray}\]
Here we can use any value for \(\tilde{\mu}_{p,0}\) so for convenience
we use \(\tilde{\mu}_{p,0}=1\). This is a QP problem with \(\mathbf{D}=2\times\mathbf{\varSigma}\)
and \(\mathbf{d}=(0,\ldots,0)^{\prime}\), one linear equality constraint,
\(\tilde{\mu}_{p,x}=\tilde{\mu}_{p,0},\) and \(N\) inequality constraints
\(\mathbf{x}\geq\mathbf{0}\). The restriction matrices and vectors
are:
\[\begin{align*}
\underset{(1\times N)}{\mathbf{A}_{eq}^{\prime}} & =(\mu-r_{f}1)^{\prime},\,\underset{(1\times1)}{\mathbf{b}_{eq}}=1,\text{ }\\
\underset{(N\times N)}{\mathbf{A}_{neq}^{\prime}} & =\mathbf{I}_{N},\,\underset{(N\times1)}{\mathbf{b}_{neq}}=(0,\ldots,0)^{\prime}.
\end{align*}\]
so that
\[
\mathbf{A}^{\prime}=\left(\begin{array}{c}
(\mu-r_{f}1)^{\prime}\\
\mathbf{I}_{N}
\end{array}\right),\text{ }\mathbf{b}=\left(\begin{array}{c}
1\\
\mathbf{0}
\end{array}\right).
\]
Here,
\[\begin{eqnarray*}
\mathbf{A}_{eq}^{\prime}\mathbf{x} & = & (\mu-r_{f}1)^{\prime}\mathbf{x=\tilde{\mu}_{p,x}}=1,\\
\mathbf{A}_{neq}^{\prime}\mathbf{x} & = & \mathbf{I}_{N}\mathbf{x}=\mathbf{x}\geq0.
\end{eqnarray*}\]
After solving the QP problem for \(\mathbf{x}\), we then determine
the short-sales constrained tangency portfolio by normalizing the
weight vector \(\mathbf{x}\) so that its elements sum to one:
\[
\mathbf{t}=\frac{\mathbf{x}}{\mathbf{x}^{\prime}\mathbf{1}}.
\]
First, we use solve.QP() to find the short sales restricted
tangency portfolio. The restriction matrices for the short sales constrained
optimization (13.7) - (13.9) are:
D.mat = 2*sigma.mat
d.vec = rep(0, 3)
A.mat = cbind(mu.vec - rep(1, 3)*r.f, diag(3))
b.vec = c(1, rep(0,3))The un-normalized portfolio \(\mathbf{x}\) is found using:
qp.out = solve.QP(Dmat=D.mat, dvec=d.vec,
Amat=A.mat, bvec=b.vec, meq=1)
x.ns = qp.out$solution
names(x.ns) = names(mu.vec)
round(x.ns, digits=3)## MSFT NORD SBUX
## 22.74 0.00 6.08The short sales constrained tangency portfolio is then:
## MSFT NORD SBUX
## 0.789 0.000 0.211In this portfolio, the allocation to Nordstrom, which was negative in the unconstrained tangency portfolio, is set to zero.
To verify that the derivation of the short sales constrained tangency portfolio does not depend on \(\tilde{\mu}_{p,0}=\mu_{p,0}-r_{f}>0\), we repeat the calculations with \(\tilde{\mu}_{p,0}=0.5\) instead of \(\tilde{\mu}_{p,0}=1\):
b.vec = c(0.5, rep(0,3))
qp.out = solve.QP(Dmat=D.mat, dvec=d.vec,
Amat=A.mat, bvec=b.vec, meq=1)
x.ns = qp.out$solution
names(x.ns) = names(mu.vec)
t.ns = x.ns/sum(x.ns)
round(t.ns, digits=3)## MSFT NORD SBUX
## 0.789 0.000 0.211You can compute the short sales restricted tangency portfolio using
the IntroCompFinR function tangency.portfolio()
with the optional argument shorts=FALSE:
## Call:
## tangency.portfolio(er = mu.vec, cov.mat = sigma.mat, risk.free = r.f,
## shorts = FALSE)
##
## Portfolio expected return: 0.0397
## Portfolio standard deviation: 0.0865
## Portfolio Sharpe Ratio: 0.401
## Portfolio weights:
## MSFT NORD SBUX
## 0.789 0.000 0.211Notice that the Sharpe ratio on the short sales restricted tangency portfolio is slightly smaller than the Sharpe ratio on the unrestricted tangency portfolio.
The set of efficient portfolios are combinations of the risk-free asset and the short sales restricted tangency portfolio. These portfolios are illustrated in Figure 13.10, created using:
ef.ns = efficient.frontier(mu.vec, sigma.mat, alpha.min=0,
alpha.max=1, nport=10, shorts=FALSE)
plot(ef.ns, plot.assets=TRUE, pch=16)
points(tan.port.ns$sd, tan.port.ns$er, col="red", pch=16, cex=2)
sr.tan.ns = (tan.port.ns$er - r.f)/tan.port.ns$sd
abline(a=r.f, b=sr.tan.ns, col="green", lwd=2)
text(tan.port$sd, tan.port$er, labels="Tangency", pos = 2)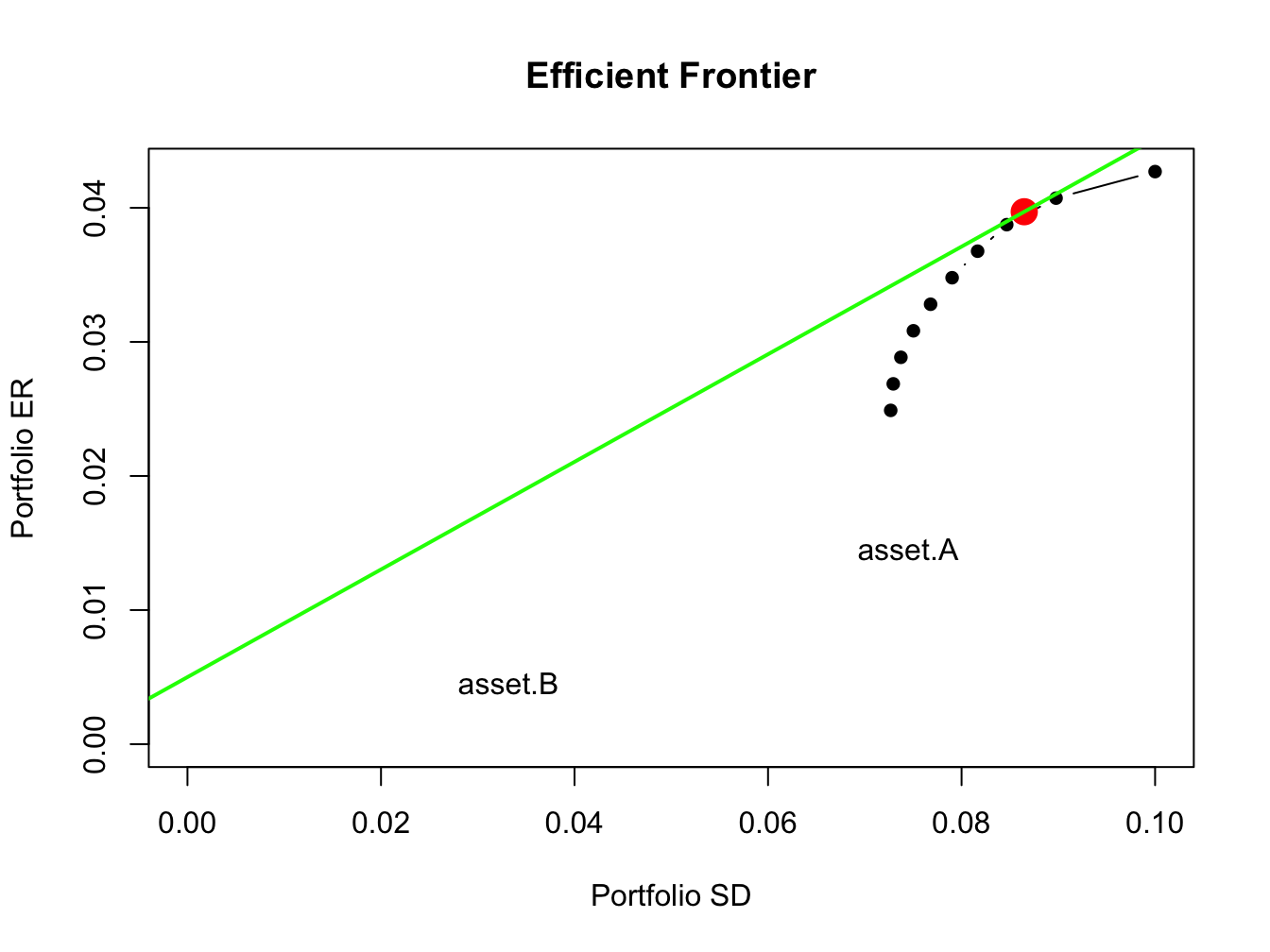
Figure 13.10: Efficient
\(\blacksquare\)
13.5 Application to Vanguard Mutual Funds
In this section, we revisit the application of mean-variance portfolio theory to the problem of asset allocation among six Vanguard mutual funds that was discussed at the end of Chapter 12. For the sub-sample January, 2010 through December, 2014 it was shown that estimated mean-variance efficient portfolios had short sales in many of the Vanguard funds. Since it is not possible to short mutual funds, we re-estimate the efficient portfolios with the additional constraints that all portfolio weights must be positive. The monthly returns and annualized GWN model estimates for the Vanguard funds are created using:
data(VanguardPrices)
VanguardPrices = as.xts(VanguardPrices)
VanguardRetS = na.omit(Return.calculate(VanguardPrices, method="simple"))
smpl = "2010-1::2014-12"
r.f = 0.001
muhat = 12*colMeans(VanguardRetS[smpl])
covhat = 12*cov(VanguardRetS[smpl])We use the IntroCompFinR portfolio functions to compute unrestricted and short-sales restricted estimates of the global minimum variance portfolio, the tangency portfolio, and the efficient frontier of risky assets:
# unrestricted (short sales allowed) portfolios
gmin.port = globalMin.portfolio(muhat, covhat)
tan.port = tangency.portfolio(muhat, covhat, r.f)
ef = efficient.frontier(muhat, covhat, alpha.min=0,
alpha.max=1.5, nport=20)
# short sales restricted portfolios
gmin.port.ns = globalMin.portfolio(muhat, covhat, shorts=FALSE)
tan.port.ns = tangency.portfolio(muhat, covhat, r.f, shorts=FALSE)
ef.ns = efficient.frontier(muhat, covhat, alpha.min=0,
alpha.max=1, nport=20, shorts=FALSE)The global minimum variance portfolios are:
## Call:
## globalMin.portfolio(er = muhat, cov.mat = covhat)
##
## Portfolio expected return: 0.0197
## Portfolio standard deviation: 0.0114
## Portfolio weights:
## vfinx veurx veiex vbltx vbisx vpacx
## 0.0581 -0.0347 -0.0214 -0.0736 1.0647 0.0069## Call:
## globalMin.portfolio(er = muhat, cov.mat = covhat, shorts = FALSE)
##
## Portfolio expected return: 0.0218
## Portfolio standard deviation: 0.0135
## Portfolio weights:
## vfinx veurx veiex vbltx vbisx vpacx
## 0.0171 0.0000 0.0000 0.0000 0.9829 0.0000In the short sales restricted global minimum variance portfolio there is 98% weight on vbisx (low volatility US short-term bond fund) and 2% weight on vfinx (S&P 500 fund). The weights on other funds are pushed to zero. The volatility of the short sales restricted portfolio is slightly higher than the volatility of the unrestricted portfolio and so the cost of the short sales restrictions is small.
The estimated tangency portfolios are:
## Call:
## tangency.portfolio(er = muhat, cov.mat = covhat, risk.free = r.f)
##
## Portfolio expected return: 0.0642
## Portfolio standard deviation: 0.0209
## Portfolio Sharpe Ratio: 3.02
## Portfolio weights:
## vfinx veurx veiex vbltx vbisx vpacx
## 0.3152 -0.0907 -0.0874 0.1159 0.7387 0.0083## Call:
## tangency.portfolio(er = muhat, cov.mat = covhat, risk.free = r.f,
## shorts = FALSE)
##
## Portfolio expected return: 0.0637
## Portfolio standard deviation: 0.0287
## Portfolio Sharpe Ratio: 2.18
## Portfolio weights:
## vfinx veurx veiex vbltx vbisx vpacx
## 0.192 0.000 0.000 0.245 0.563 0.000The short sales restricted tangency portfolio has positive weights on vfinx, vbltx, and vbisx and zero weights for the remaining assets. The Sharpe ratio of the short sales restricted tangency portfolio, however, is substantially smaller than the Sharpe ratio of the unrestricted portfolio.
Figure 13.11 shows the short sales restricted and unrestricted efficient portfolio frontiers, created using:
# unrestricted efficient frontiers
plot(ef, plot.assets=TRUE, col="blue", pch=16)
text(tan.port$sd, tan.port$er,labels = "tan", pos = 2)
sr.tan = (tan.port$er - r.f)/tan.port$sd
text(0, r.f, labels=expression(r[f]), pos = 4)
abline(a=r.f, b=sr.tan, col="green", lwd=2)
abline(h=0, v=0)
# short sales restricted frontiers
sr.tan.ns = (tan.port.ns$er - r.f)/tan.port.ns$sd
points(ef.ns$sd, ef.ns$er, type="b", pch=16, col="red")
abline(a=r.f, b=sr.tan.ns, col="green", lwd=2)
text(tan.port.ns$sd, tan.port.ns$er,labels = "tan (no shorts)", pos = 4)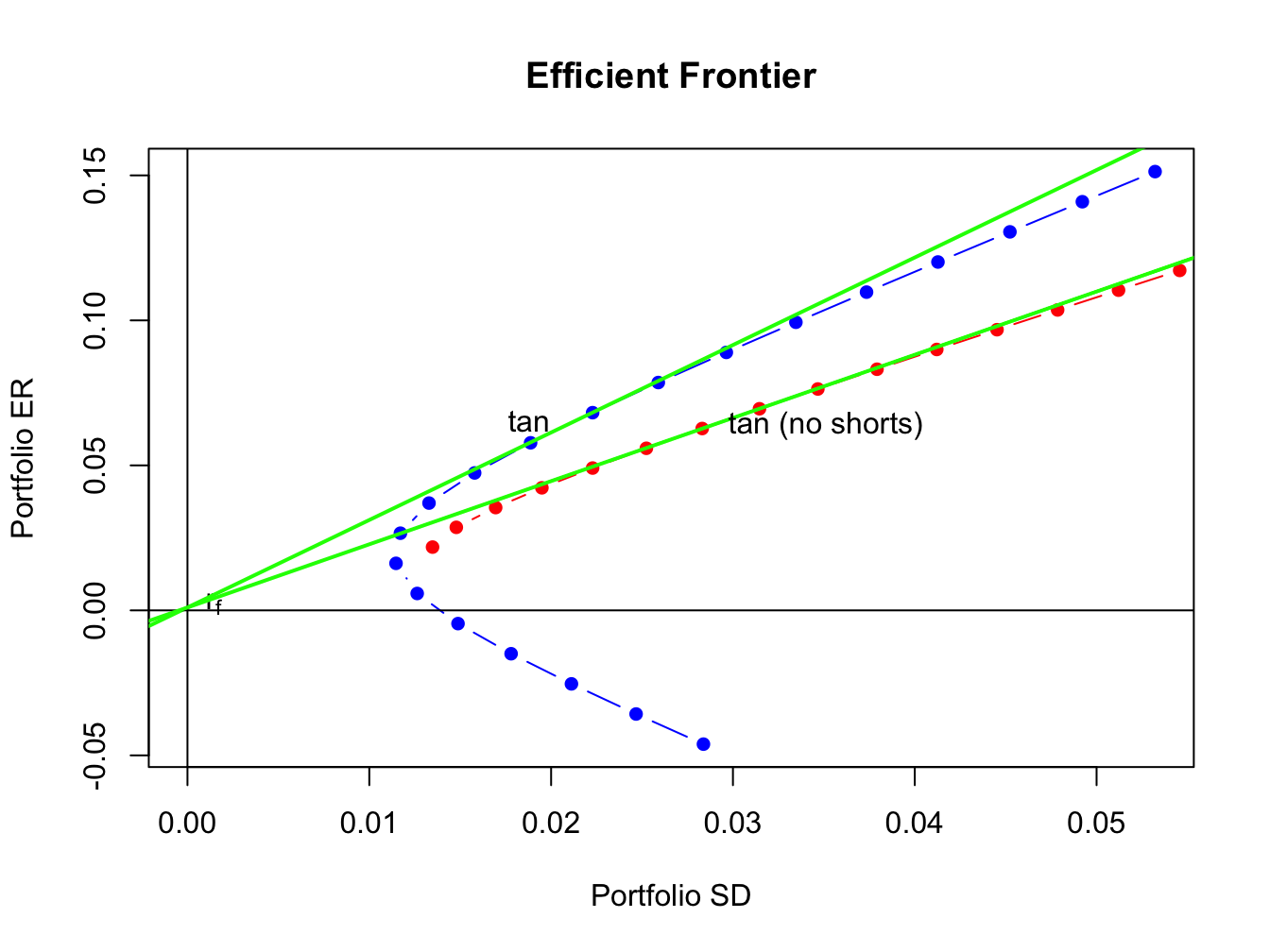
Figure 13.11: Unrestricted and short sales restricted efficient portfolio frontiers.
The short sales restricted risky asset only frontier, shown in red, lies underneath and to the right of the unrestricted risky asset frontier, shown in blue. The short sales restricted tangency portfolio has a similar expected return as the unrestricted tangency portfolio but has a higher volatility and a lower Sharpe ratio.
13.6 Further Reading: Portfolio Theory with Short Sales Constraints
- Mention other quadratic programming packages: ROI etc. See Doug’s book
- Mention Pfaff’s R book (Pfaff 2013) ??
- Mention Grilli’s book etc.
To be completed…
13.7 Problems: Portfolio Theory with Short Sales Constraints
Load packages and set options
library(IntroCompFinR)
library(corrplot)
library(PerformanceAnalytics)
library(xts)
options(digits = 3)
Sys.setenv(TZ="UTC")Loading data and computing returns
Load the daily price data from IntroCompFinR, and create monthly simple returns over the period Jan 2010 through Dec 2014:
data(amznDailyPrices, baDailyPrices, costDailyPrices, jwnDailyPrices, sbuxDailyPrices)
fiveStocks = merge(amznDailyPrices, baDailyPrices, costDailyPrices, jwnDailyPrices, sbuxDailyPrices)
fiveStocks = to.monthly(fiveStocks, OHLC=FALSE)## Warning in to.period(x, "months", indexAt = indexAt, name =
## name, ...): missing values removed from datasmpl = "2010::2014"
fiveStocksRet = na.omit(Return.calculate(fiveStocks, method = "simple"))
fiveStocksRet = fiveStocksRet[smpl]We will construct portfolios using the 5 years of simple returns from Jan 2010 - Dec 2014.
## AMZN BA COST JWN SBUX
## Jan 2010 -0.0677 0.1195 -0.0294 -0.0808 -0.0547
## Feb 2010 -0.0559 0.0494 0.0649 0.0740 0.0509
## Mar 2010 0.1467 0.1495 -0.0208 0.1058 0.0598## AMZN BA COST JWN SBUX
## Oct 2014 -0.0527 -0.0194 0.06421 0.0620 0.00134
## Nov 2014 0.1086 0.0819 0.06835 0.0563 0.07909
## Dec 2014 -0.0835 -0.0326 -0.00255 0.0397 0.01038Part I: CER Model Estimation
Consider the CER Model for cc returns
\[\begin{align} R_{it} & = \mu_i + \epsilon_{it}, t=1,\cdots,T \\ \epsilon_{it} & \sim \text{iid } N(0, \sigma_{i}^{2}) \\ \mathrm{cov}(R_{it}, R_{jt}) & = \sigma_{i,j} \\ \mathrm{cov}(R_{it}, R_{js}) & = 0 \text{ for } s \ne t \end{align}\]
where \(R_{it}\) denotes the cc return on asset \(i\) (\(i=\mathrm{AMZN}, \cdots, \mathrm{SBUX}\)).
Using sample descriptive statistics, give estimates for the model parameters \(\mu_i, \sigma_{i}^{2}, \sigma_i, \sigma_{i,j}, \rho_{i,j}\). Put the estimated mean values in the vector
muhat.valsand put the estimated covariance matrix in the matrix objectsigma.mat.These will be inputs for the portfolio theory examples.Show the estimated risk-return tradeoff of these assets (i.e., plot the means on the y-axis and the standard deviations on the horizontal axis. Briefly comment.
- Assuming a risk free rate of 0.005 (0.5% per month or about 6% per year) compute the Sharpe ratios for each asset. Which asset has the highest Sharpe ratio?
- Using the bootstrap, compute estimated standard errors and 95% confidence intervals for the Sharpe ratios. How well are the Sharpe ratios estimated?
Compute the global minimum variance portfolio allowing short-sales. The minimization problem is
\[ \min_{\mathbf{m}}\sigma_{p,m}^{2}=\mathbf{m}^{\prime}\Sigma\mathbf{m}\text{ s.t. }\mathbf{m}^{\prime}\mathbf{1}=1 \]
where \(\mathbf{m}\) is the vector of portfolio weights and \(\Sigma\) is the covariance matrix. Briefly comment on the weights. Compute the expected return and standard deviation and add the points to the risk return graph.
- Of the five stocks, determine the stock with the largest estimated expected return. Use this maximum average return as the target return for the computation of an efficient portfolio allowing for short-sales. That is, find the minimum variance portfolio that has an expected return equal to this target return. The minimization problem is
\[\begin{align*} \min_{\mathbf{x}}\sigma_{p,x}^{2} & =\mathbf{x}^{\prime}\Sigma \mathbf{x}\text{ s.t.}\\ \mu_{p,x} & =\mathbf{x}^{\prime}\mathbf{\mu}=\mu_{p}^{0}=\text{ target return}\\ \mathbf{x}^{\prime}\mathbf{1} & =1 \end{align*}\]
where \(\mathbf{x}\) is the vector of portfolio weights, \(\mu\) is the vector of expected returns and \(\mu_{p}^{0}\) is the target expected return. Are there any negative weights in this portfolio? Compute the expected return, variance and standard deviation of this portfolio. Finally, compute the covariance between the global minimum variance portfolio and the above efficient portfolio using the formula \(\mathrm{cov}(R_{p,m}, R_{p,x})=\mathbf{m}^{\prime}\Sigma\mathbf{x}\).
Repeat question 4 but this time do not allow short sales. That is, add the following constraint: \(x_i \ge 0 \text{ for } i = AMZN,…, SBUX.\)
Using the fact that all efficient portfolios (that allow short sales) can be written as a convex combination of two efficient portfolios (that allow short sales), compute efficient portfolios as convex combinations of the global minimum variance portfolio and the efficient portfolio computed in question 4. That is, compute
\[ \mathbf{z} = \alpha \times \mathbf{m} + (1-\alpha) \times \mathbf{x} \]
for values of \(\alpha\) between \(1\) and \(-1\) (e.g., make a grid for \(\alpha = 1, 0.9, \cdots, -1\)). Compute the expected return, variance and standard deviation of these portfolios.
Plot the Markowitz bullet based on the efficient portfolios you computed in question 6. On the plot, indicate the location of the minimum variance portfolio and the location of the efficient portfolio found in question 4.
Compute the tangency portfolio assuming the risk-free rate is \(0.005\) (\(r_f = 0.5\%\)) per month. That is, solve
\[ \max_{\mathbf{t}} =\frac{\mathbf{t}^{\prime}\mathbf{\mu}-r_{f}}{\left(\mathbf{t}^{\prime}\Sigma \mathbf{t}\right)^{1/2}} \]
subject to
\[ \mathbf{t}^{\prime}\mathbf{1}=1 \]
where \(\mathbf{t}\) denotes the portfolio weights in the tangency portfolio. Are there any negative weights in the tangency portfolio? If so, interpret them.
Repeat question 8 but this time do not allow short sales. That is, add the following constraint: \(x_i \ge 0 \text{ for } i = AMZN, \cdots SBUX\). Compare the Sharpe ratio of this portfolio with the Sharpe ratio of the tangency portfolio that allows for short sales.
On the graph with the Markowitz bullet, plot the efficient portfolios that are combinations of T-bills and the tangency portfolio that allows short sales. Indicate the location of the tangency portfolio on the graph.
Find the efficient portfolio of combinations of T-bills and the tangency portfolio (that allows short sales) that has the same SD value as Starbucks. What is the expected return on this portfolio? Indicate the location of this portfolio on your graph of the Markowitz bullet.
13.8 Solutions to Selected Problems
Load packages and set options:
library(IntroCompFinR)
library(corrplot)
library(PerformanceAnalytics)
library(xts)
library(boot)
options(digits = 3, width=70)
Sys.setenv(TZ="UTC")Loading data and computing returns
Load the daily price data from IntroCompFinR, and create monthly simple returns over the period Jan 2010 through Dec 2014:
data(amznDailyPrices, baDailyPrices, costDailyPrices, jwnDailyPrices, sbuxDailyPrices)
fiveStocks = merge(amznDailyPrices, baDailyPrices, costDailyPrices, jwnDailyPrices, sbuxDailyPrices)
fiveStocks = to.monthly(fiveStocks, OHLC=FALSE)## Warning in to.period(x, "months", indexAt = indexAt, name =
## name, ...): missing values removed from datasmpl = "2010::2014"
fiveStocksRet = na.omit(Return.calculate(fiveStocks, method = "simple"))
fiveStocksRet = fiveStocksRet[smpl]We will construct portfolios using the 5 years of simple returns from Jan 2010 - Dec 2014.
## AMZN BA COST JWN SBUX
## Jan 2010 -0.0677 0.1195 -0.0294 -0.0808 -0.0547
## Feb 2010 -0.0559 0.0494 0.0649 0.0740 0.0509
## Mar 2010 0.1467 0.1495 -0.0208 0.1058 0.0598## AMZN BA COST JWN SBUX
## Oct 2014 -0.0527 -0.0194 0.06421 0.0620 0.00134
## Nov 2014 0.1086 0.0819 0.06835 0.0563 0.07909
## Dec 2014 -0.0835 -0.0326 -0.00255 0.0397 0.01038Part I: CER Model Estimation
Consider the CER Model for cc returns
\[\begin{align} R_{it} & = \mu_i + \epsilon_{it}, t=1,\cdots,T \\ \epsilon_{it} & \sim \text{iid } N(0, \sigma_{i}^{2}) \\ \mathrm{cov}(R_{it}, R_{jt}) & = \sigma_{i,j} \\ \mathrm{cov}(R_{it}, R_{js}) & = 0 \text{ for } s \ne t \end{align}\]
where \(R_{it}\) denotes the cc return on asset \(i\) (\(i=\mathrm{AMZN}, \cdots, \mathrm{SBUX}\)).
- Using sample descriptive statistics, give estimates for the model parameters \(\mu_i, \sigma_{i}^{2}, \sigma_i, \sigma_{i,j}, \rho_{i,j}\). Put the estimated mean values in the vector
muhat.valsand put the estimated covariance matrix in the matrix objectsigma.mat.These will be inputs for the portfolio theory examples.
muhat.vals = apply(fiveStocksRet, 2, mean)
sigma2hat.vals = apply(fiveStocksRet, 2, var)
sigmahat.vals = apply(fiveStocksRet, 2, sd)
sigma.mat = var(fiveStocksRet)
cor.mat = cor(fiveStocksRet)
covhat.vals = sigma.mat[lower.tri(sigma.mat)]
rhohat.vals = cor.mat[lower.tri(cor.mat)]
names(covhat.vals) <- names(rhohat.vals) <-
c("AMZN,BA","AMZN,COST","AMZN,JWN", "AMZN,SBUX",
"BA,COST", "BA,JWN", "BA,SBUX",
"COST, JWN", "COST,SBUX",
"JWN, SBUX")The estimates of \(\mu_i\) and \(\sigma_i\) are
## muhat.vals sigmahat.vals
## AMZN 0.0171 0.0802
## BA 0.0185 0.0615
## COST 0.0176 0.0415
## JWN 0.0170 0.0747
## SBUX 0.0244 0.0607Over the period 2010 - 2014, SBUX had the highest monthly mean at \(2.44\%\) and JWN (Nordstrom) and Amazon had the lowest monthly means at \(1.7\%\). COST had the lowest vol and AMZN had the highest vol.
- Show the estimated risk-return tradeoff of these assets (i.e., plot the means on the y-axis and the standard deviations on the horizontal axis. Briefly comment.
- Assuming a risk free rate of 0.005 (0.5% per month or about 6% per year) compute the Sharpe ratios for each asset. Which asset has the highest Sharpe ratio?
- Using the bootstrap, compute estimated standard errors and 95% confidence intervals for the Sharpe ratios. How well are the Sharpe ratios estimated?
The estimated risk return trade-off is
plot(sigmahat.vals, muhat.vals, ylim=c(0, 0.03), xlim=c(0, 0.20),
ylab=expression(mu[p]), xlab=expression(sigma[p]), pch=16,
col="blue", cex=2, cex.lab=1.5)
text(sigmahat.vals, muhat.vals, labels=colnames(fiveStocksRet),
pos=4, cex = 1)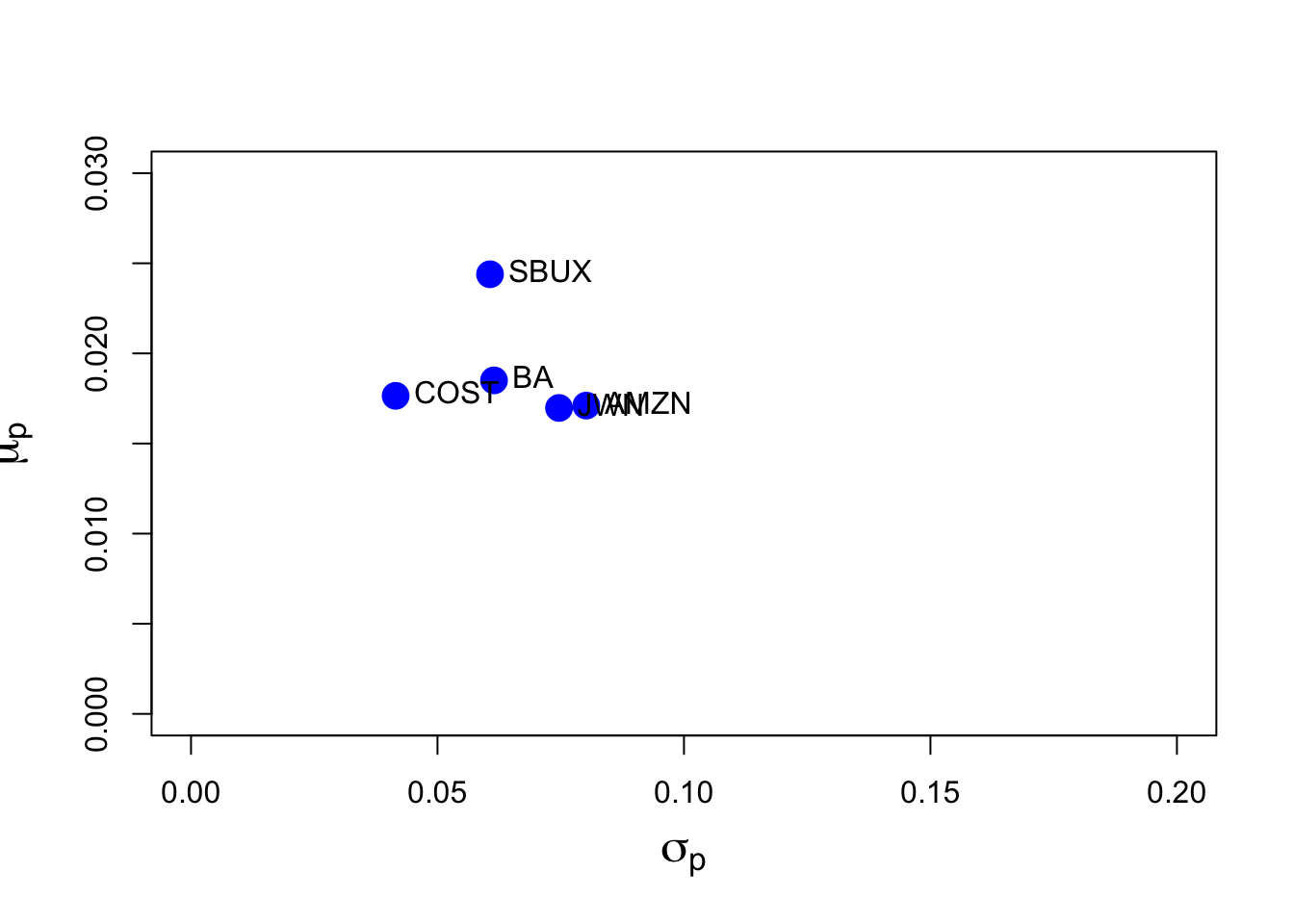
It looks like COST and SBUX have the best return-risk tradeoff and AMZN has the worst. JWN and AMZN are nearly identical in their return-risk tradeoffs.
Assuming a risk-free rate of \(0.005\), the estimated Sharpe ratios are
## AMZN BA COST JWN SBUX
## 0.151 0.220 0.305 0.160 0.320Here, SBUX has the highest SR and AMZN has the lowest.
We can use the bootstrap to get standard errors for the estimated Sharpe ratios. First, we write a function to be passed to the boot function to compute the Sharpe ratios on different bootstrap samples:
sharpeRatio.boot = function(x, idx, risk.free) {
muhat = mean(x[idx])
sigmahat = sd(x[idx])
sharpeRatio = (muhat - risk.free)/sigmahat
sharpeRatio
}Then we can bootsrap each SR estimate:
AMZN:
sharpe.AMZN.boot = boot(fiveStocksRet[, "AMZN"],
statistic=sharpeRatio.boot, R=999, risk.free=rf)
sharpe.AMZN.boot##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = fiveStocksRet[, "AMZN"], statistic = sharpeRatio.boot,
## R = 999, risk.free = rf)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 0.151 0.000516 0.129For AMZN, \(\widehat{\mathrm{SE}}_{boot}(\widehat{\mathrm{SR}}_{AMZN})=0.127\). This SE is of the same magnitude as \(\widehat{\mathrm{SR}}_{AMZN}=0.151\) which indicates that the SR is not estimated precisely at all.
BA:
sharpe.BA.boot = boot(fiveStocksRet[, "BA"],
statistic=sharpeRatio.boot, R=999, risk.free=rf)
sharpe.BA.boot##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = fiveStocksRet[, "BA"], statistic = sharpeRatio.boot,
## R = 999, risk.free = rf)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 0.22 0.00653 0.135For BA, \(\widehat{\mathrm{SE}}_{boot}(\widehat{\mathrm{SR}}_{BA})=0.134\). This SE is of the same magnitude as \(\widehat{\mathrm{SR}}_{BA}=0.22\) which indicates that the SR is not estimated precisely at all.
COST:
sharpe.COST.boot = boot(fiveStocksRet[, "COST"],
statistic=sharpeRatio.boot, R=999, risk.free=rf)
sharpe.COST.boot##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = fiveStocksRet[, "COST"], statistic = sharpeRatio.boot,
## R = 999, risk.free = rf)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 0.305 0.000859 0.127For COST, \(\widehat{\mathrm{SE}}_{boot}(\widehat{\mathrm{SR}}_{COST})=0.126\). This SE is half the size of \(\widehat{\mathrm{SR}}_{COST}=0.305\) which indicates that the SR is estimated more precisely than for AMZN and BA.
JWN
sharpe.JWN.boot = boot(fiveStocksRet[, "JWN"],
statistic=sharpeRatio.boot, R=999, risk.free=rf)
sharpe.JWN.boot##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = fiveStocksRet[, "JWN"], statistic = sharpeRatio.boot,
## R = 999, risk.free = rf)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 0.16 0.00397 0.133For JWN, \(\widehat{\mathrm{SE}}_{boot}(\widehat{\mathrm{SR}}_{JWN})=0.133\). This SE is of the same magnitude as \(\widehat{\mathrm{SR}}_{JWN}=0.16\) which indicates that the SR is not estimated precisely at all.
SBUX:
sharpe.SBUX.boot = boot(fiveStocksRet[, "SBUX"],
statistic=sharpeRatio.boot, R=999, risk.free=rf)
sharpe.SBUX.boot##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = fiveStocksRet[, "SBUX"], statistic = sharpeRatio.boot,
## R = 999, risk.free = rf)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 0.32 0.0112 0.14For SBUX, \(\widehat{\mathrm{SE}}_{boot}(\widehat{\mathrm{SR}}_{SBUX})=0.145\). This SE is half the size of \(\widehat{\mathrm{SR}}_{SBUX}=0.32\) which indicates that the SR is estimated similarly to that for COST.
- Compute the global minimum variance portfolio allowing short-sales. The minimization problem is
\[ \min_{\mathbf{m}}\sigma_{p,m}^{2}=\mathbf{m}^{\prime}\Sigma\mathbf{m}\text{ s.t. }\mathbf{m}^{\prime}\mathbf{1}=1 \]
where \(\mathbf{m}\) is the vector of portfolio weights and \(\Sigma\) is the covariance matrix. Briefly comment on the weights. Compute the expected return and standard deviation and add the points to the risk return graph.
## Call:
## globalMin.portfolio(er = muhat.vals, cov.mat = sigma.mat)
##
## Portfolio expected return: 0.0194
## Portfolio standard deviation: 0.0359
## Portfolio weights:
## AMZN BA COST JWN SBUX
## -0.0491 0.2158 0.6901 -0.0774 0.2207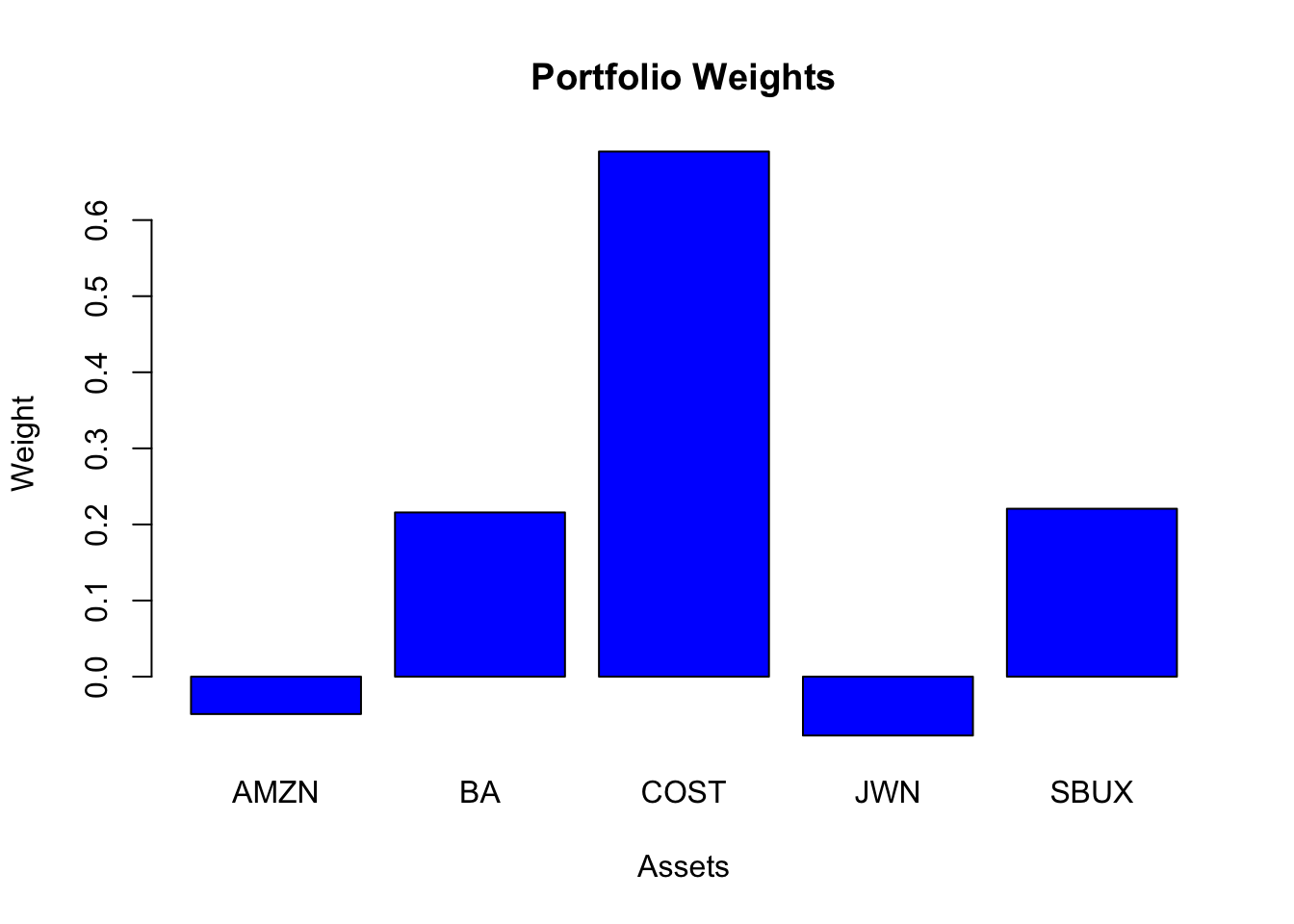
Three assets have positive weights (BA, COST, SBUX) and two assets have negative weights/shorts (AMZN, JWN). The largest weight is in COST, which has the lowest volatility.
The risk-return graph wiht the global minimum variance portfolio is
plot(sigmahat.vals, muhat.vals, ylim=c(0, 0.03), xlim=c(0, 0.20),
ylab=expression(mu[p]),
xlab=expression(sigma[p]), pch=16, col="blue", cex=2, cex.lab=1.5)
text(sigmahat.vals, muhat.vals, labels=colnames(fiveStocksRet),
pos=4, cex = 1)
points(gmin.port$sd, gmin.port$er, pch=16, col="green", cex=2)
text(gmin.port$sd, gmin.port$er, labels="GMIN", cex=1, pos=2)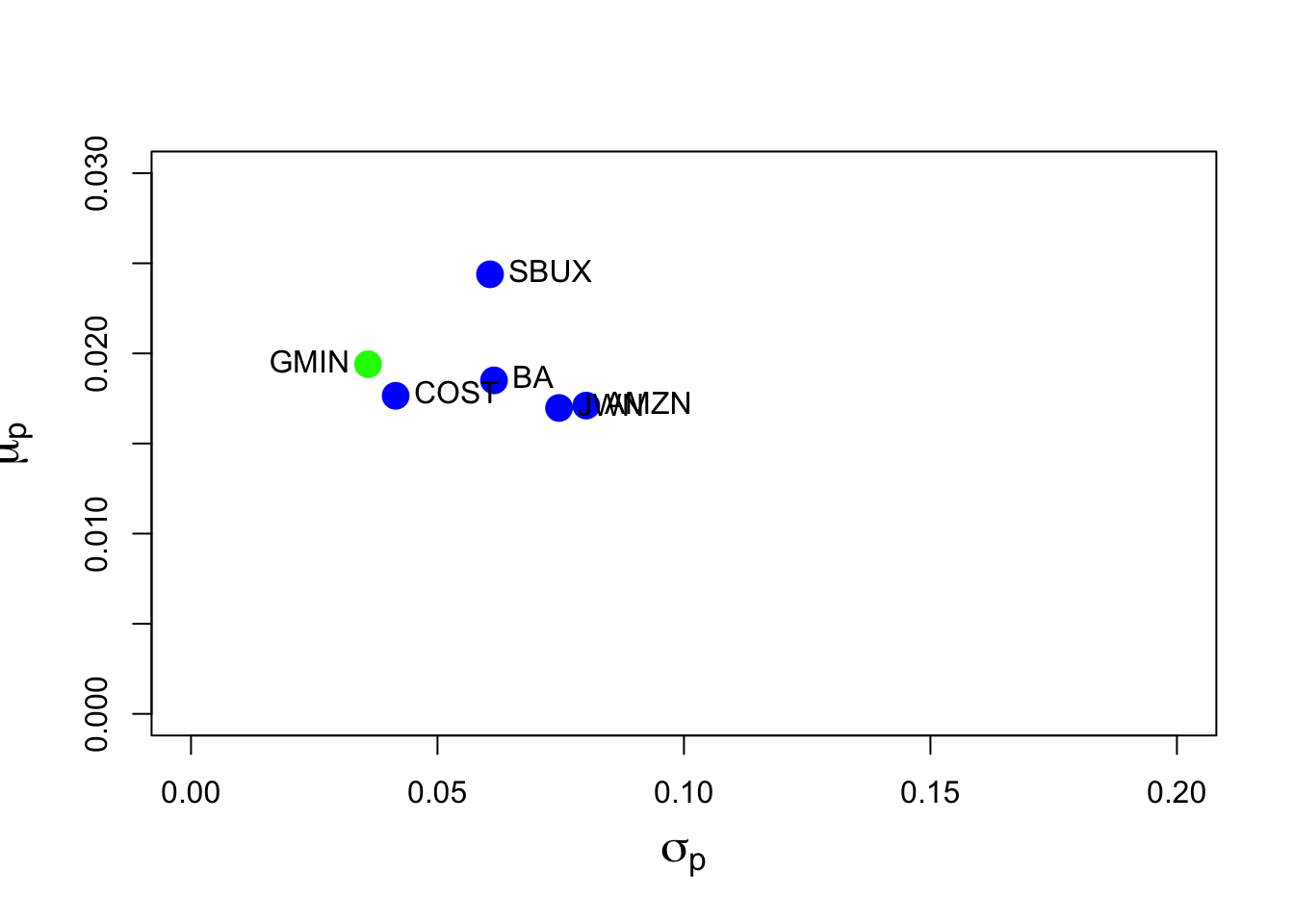
The global minimum variance portfolio not-allows for short sales is
## Call:
## globalMin.portfolio(er = muhat.vals, cov.mat = sigma.mat, shorts = FALSE)
##
## Portfolio expected return: 0.019
## Portfolio standard deviation: 0.0365
## Portfolio weights:
## AMZN BA COST JWN SBUX
## 0.000 0.193 0.628 0.000 0.180Not allowing shorts, we see that the weights in AMZN and JWN go to zero.
- Of the five stocks, determine the stock with the largest estimated expected return. Use this maximum average return as the target return for the computation of an efficient portfolio allowing for short-sales. That is, find the minimum variance portfolio that has an expected return equal to this target return. The minimization problem is
\[\begin{align*} \min_{\mathbf{x}}\sigma_{p,x}^{2} & =\mathbf{x}^{\prime}\Sigma \mathbf{x}\text{ s.t.}\\ \mu_{p,x} & =\mathbf{x}^{\prime}\mathbf{\mu}=\mu_{p}^{0}=\text{ target return}\\ \mathbf{x}^{\prime}\mathbf{1} & =1 \end{align*}\]
where \(\mathbf{x}\) is the vector of portfolio weights, \(\mu\) is the vector of expected returns and \(\mu_{p}^{0}\) is the target expected return. Are there any negative weights in this portfolio? Compute the expected return, variance and standard deviation of this portfolio. Finally, compute the covariance between the global minimum variance portfolio and the above efficient portfolio using the formula \(\mathrm{cov}(R_{p,m}, R_{p,x})=\mathbf{m}^{\prime}\Sigma\mathbf{x}\).
The stock with the highest mean return is SBUX. The efficient portfolio with the same mean as SBUX is
## Call:
## efficient.portfolio(er = muhat.vals, cov.mat = sigma.mat, target.return = mu.target)
##
## Portfolio expected return: 0.0244
## Portfolio standard deviation: 0.0532
## Portfolio weights:
## AMZN BA COST JWN SBUX
## -0.264 0.134 0.440 -0.247 0.937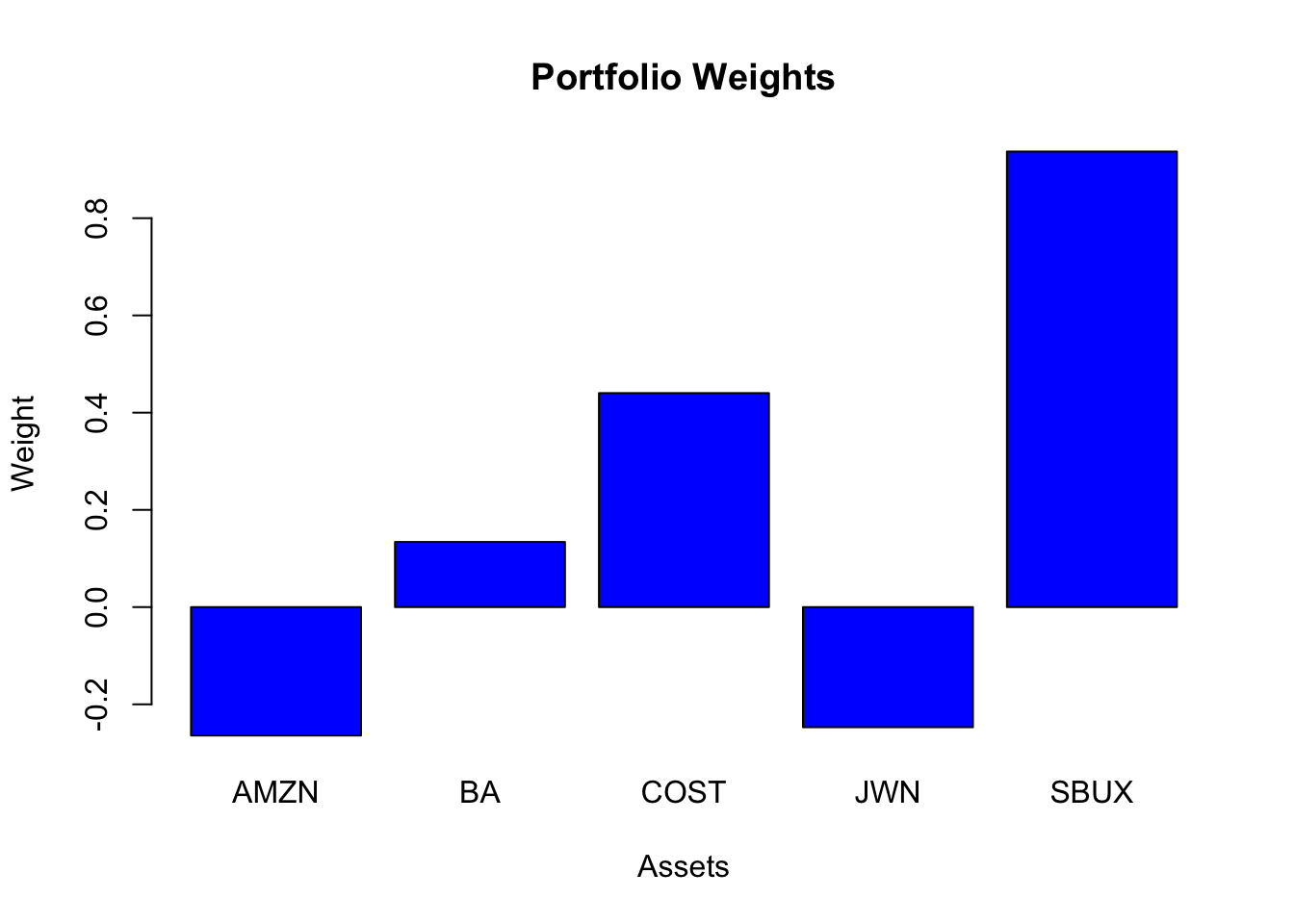
This portfolio has negative weights in AMZN and JWN (just like the global minimum variance portfolio) and the highest weight in SBUX. The mean is the same as SBUX, but its volatility is smaller at \(0.0532\) compared with the volatility of SBUX at \(0.061\).
The estimated covariance between the global minimum variance portfolio and this portfolio is
## [,1]
## [1,] 0.00129The risk-return graph with the efficient portfolio with the same mean as SBUX is
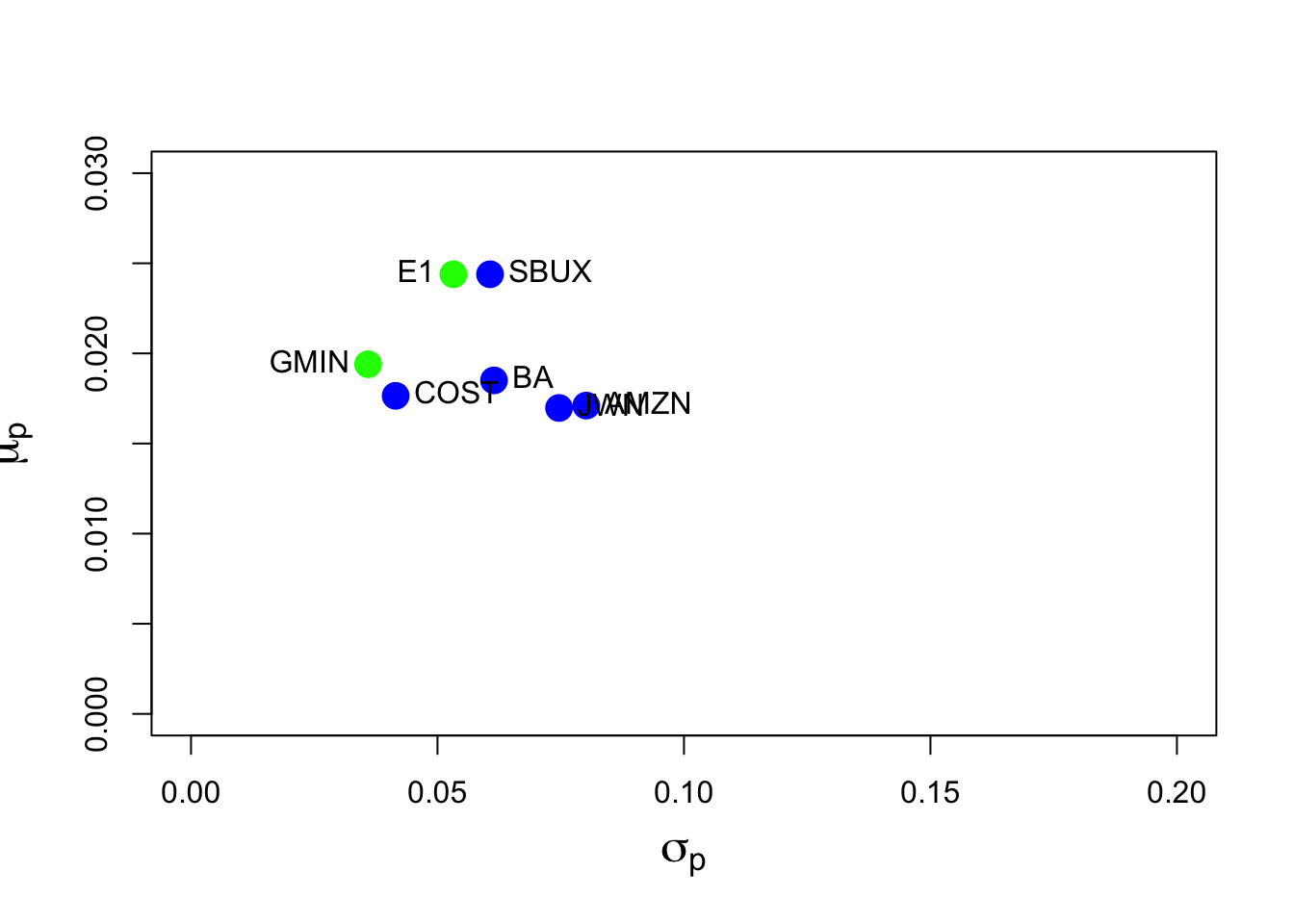
The point E1 shows the efficient portfolio with the same mean as SBUX.
- Repeat question 4 but this time do not allow short sales. That is, add the following constraint: \(x_i \ge 0 \text{ for } i = AMZN,…, SBUX.\)
The efficient portfolio with the same mean as SBUX but not allowing shorts is
## Call:
## efficient.portfolio(er = muhat.vals, cov.mat = sigma.mat, target.return = mu.target,
## shorts = FALSE)
##
## Portfolio expected return: 0.0244
## Portfolio standard deviation: 0.0607
## Portfolio weights:
## AMZN BA COST JWN SBUX
## 0 0 0 0 1This portfolio has 100% invested in SBUX.
- Using the fact that all efficient portfolios (that allow short sales) can be written as a convex combination of two efficient portfolios (that allow short sales), compute efficient portfolios as convex combinations of the global minimum variance portfolio and the efficient portfolio computed in question 4. That is, compute
\[ \mathbf{z} = \alpha \times \mathbf{m} + (1-\alpha) \times \mathbf{x} \]
for values of \(\alpha\) between \(1\) and \(-1\) (e.g., make a grid for \(\alpha = 1, 0.9, \cdots, -1\)). Compute the expected return, variance and standard deviation of these portfolios.
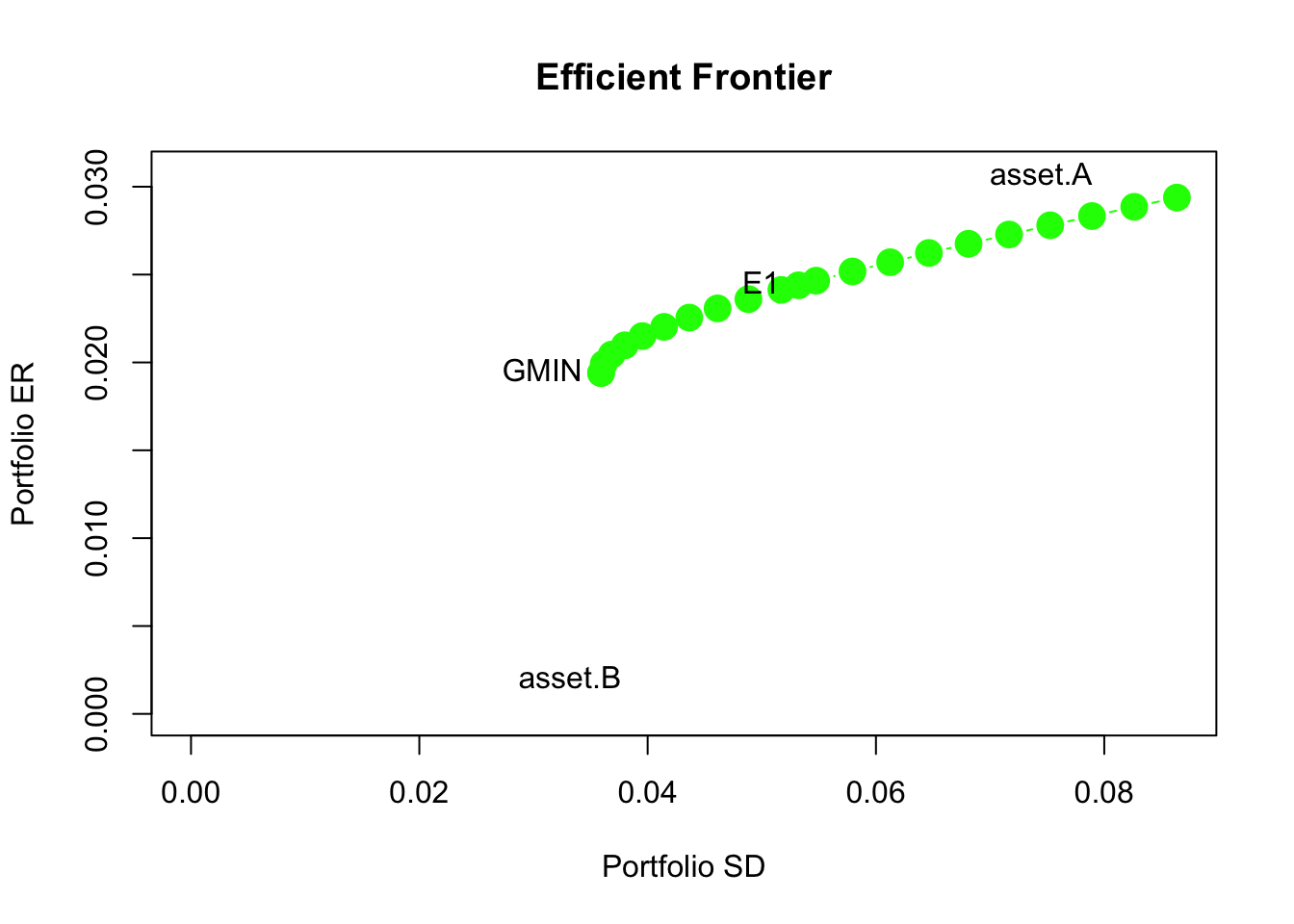
Here, we use the IntroCompFinR function efficient.frontier()
e.frontier = efficient.frontier(muhat.vals, sigma.mat, alpha.min=-1, alpha.max=1)
summary(e.frontier)## $call
## efficient.frontier(er = muhat.vals, cov.mat = sigma.mat, alpha.min = -1,
## alpha.max = 1)
##
## $er
## port 1 port 2 port 3 port 4 port 5 port 6 port 7 port 8
## 0.0294 0.0289 0.0283 0.0278 0.0273 0.0268 0.0262 0.0257
## port 9 port 10 port 11 port 12 port 13 port 14 port 15 port 16
## 0.0252 0.0247 0.0241 0.0236 0.0231 0.0226 0.0220 0.0215
## port 17 port 18 port 19 port 20
## 0.0210 0.0204 0.0199 0.0194
##
## $sd
## port 1 port 2 port 3 port 4 port 5 port 6 port 7 port 8
## 0.0864 0.0826 0.0789 0.0753 0.0717 0.0681 0.0646 0.0612
## port 9 port 10 port 11 port 12 port 13 port 14 port 15 port 16
## 0.0579 0.0548 0.0517 0.0488 0.0461 0.0437 0.0414 0.0395
## port 17 port 18 port 19 port 20
## 0.0380 0.0369 0.0362 0.0359
##
## $weights
## AMZN BA COST JWN SBUX
## port 1 -0.4791 0.0522 0.190 -0.4169 1.654
## port 2 -0.4565 0.0608 0.217 -0.3990 1.578
## port 3 -0.4338 0.0694 0.243 -0.3812 1.503
## port 4 -0.4112 0.0780 0.269 -0.3633 1.427
## port 5 -0.3886 0.0866 0.296 -0.3454 1.352
## port 6 -0.3660 0.0952 0.322 -0.3276 1.276
## port 7 -0.3433 0.1038 0.348 -0.3097 1.201
## port 8 -0.3207 0.1124 0.374 -0.2918 1.126
## port 9 -0.2981 0.1211 0.401 -0.2739 1.050
## port 10 -0.2754 0.1297 0.427 -0.2561 0.975
## port 11 -0.2528 0.1383 0.453 -0.2382 0.899
## port 12 -0.2302 0.1469 0.480 -0.2203 0.824
## port 13 -0.2076 0.1555 0.506 -0.2025 0.749
## port 14 -0.1849 0.1641 0.532 -0.1846 0.673
## port 15 -0.1623 0.1727 0.559 -0.1667 0.598
## port 16 -0.1397 0.1813 0.585 -0.1488 0.522
## port 17 -0.1170 0.1899 0.611 -0.1310 0.447
## port 18 -0.0944 0.1986 0.637 -0.1131 0.371
## port 19 -0.0718 0.2072 0.664 -0.0952 0.296
## port 20 -0.0491 0.2158 0.690 -0.0774 0.221
##
## attr(,"class")
## [1] "summary.Markowitz"- Plot the Markowitz bullet based on the efficient portfolios you computed in question 6. On the plot, indicate the location of the minimum variance portfolio and the location of the efficient portfolio found in question 4.
- Compute the tangency portfolio assuming the risk-free rate is \(0.005\) (\(r_f = 0.5\%\)) per month. That is, solve
\[ \max_{\mathbf{t}} =\frac{\mathbf{t}^{\prime}\mathbf{\mu}-r_{f}}{\left(\mathbf{t}^{\prime}\Sigma \mathbf{t}\right)^{1/2}} \]
subject to
\[ \mathbf{t}^{\prime}\mathbf{1}=1 \]
where \(\mathbf{t}\) denotes the portfolio weights in the tangency portfolio. Are there any negative weights in the tangency portfolio? If so, interpret them.
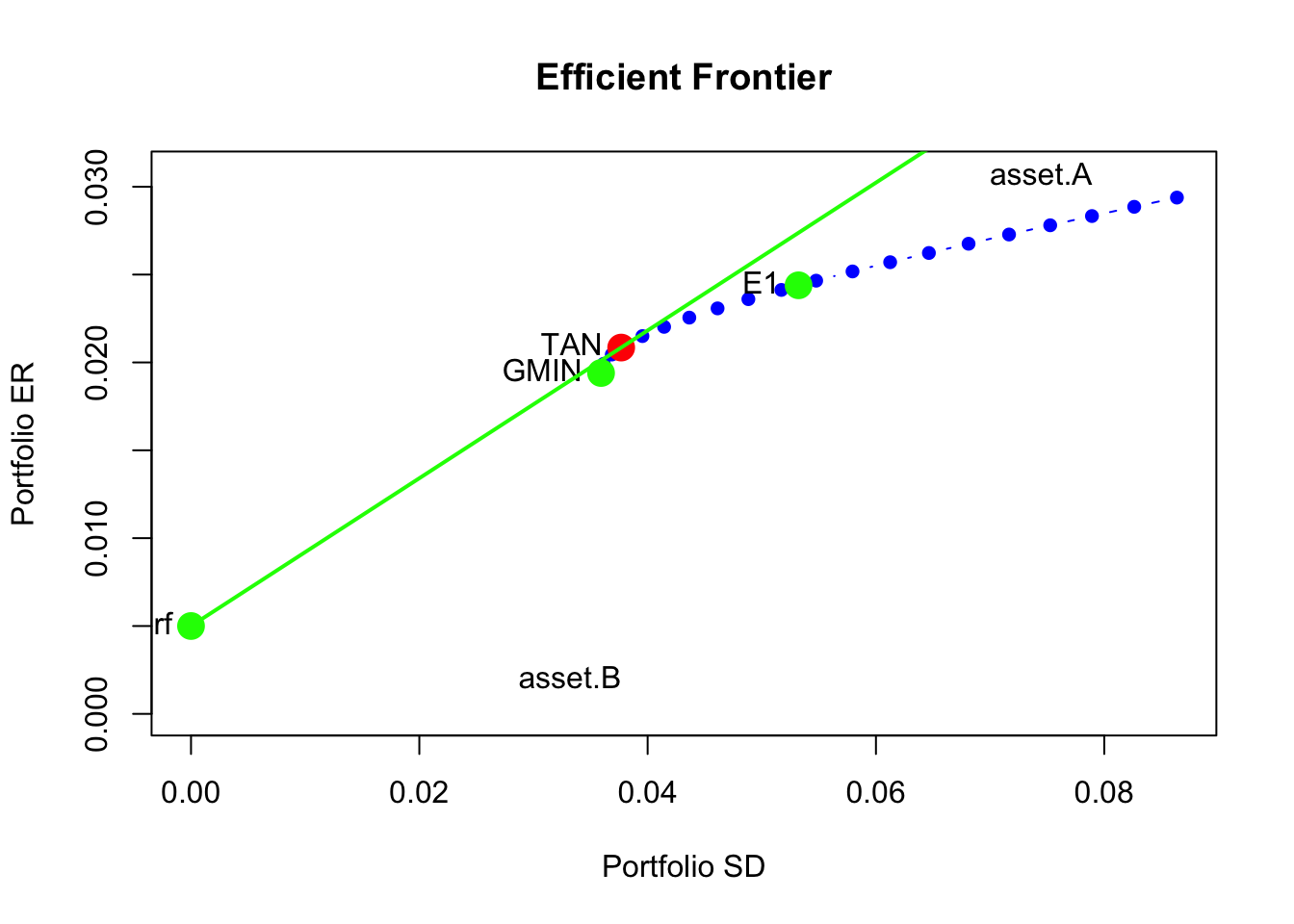
The tangency portfolio is
tan.port = tangency.portfolio(muhat.vals, sigma.mat, risk.free=rf)
summary(tan.port, risk.free = rf)## Call:
## tangency.portfolio(er = muhat.vals, cov.mat = sigma.mat, risk.free = rf)
##
## Portfolio expected return: 0.0208
## Portfolio standard deviation: 0.0377
## Portfolio Sharpe Ratio: 0.421
## Portfolio weights:
## AMZN BA COST JWN SBUX
## -0.112 0.192 0.618 -0.127 0.428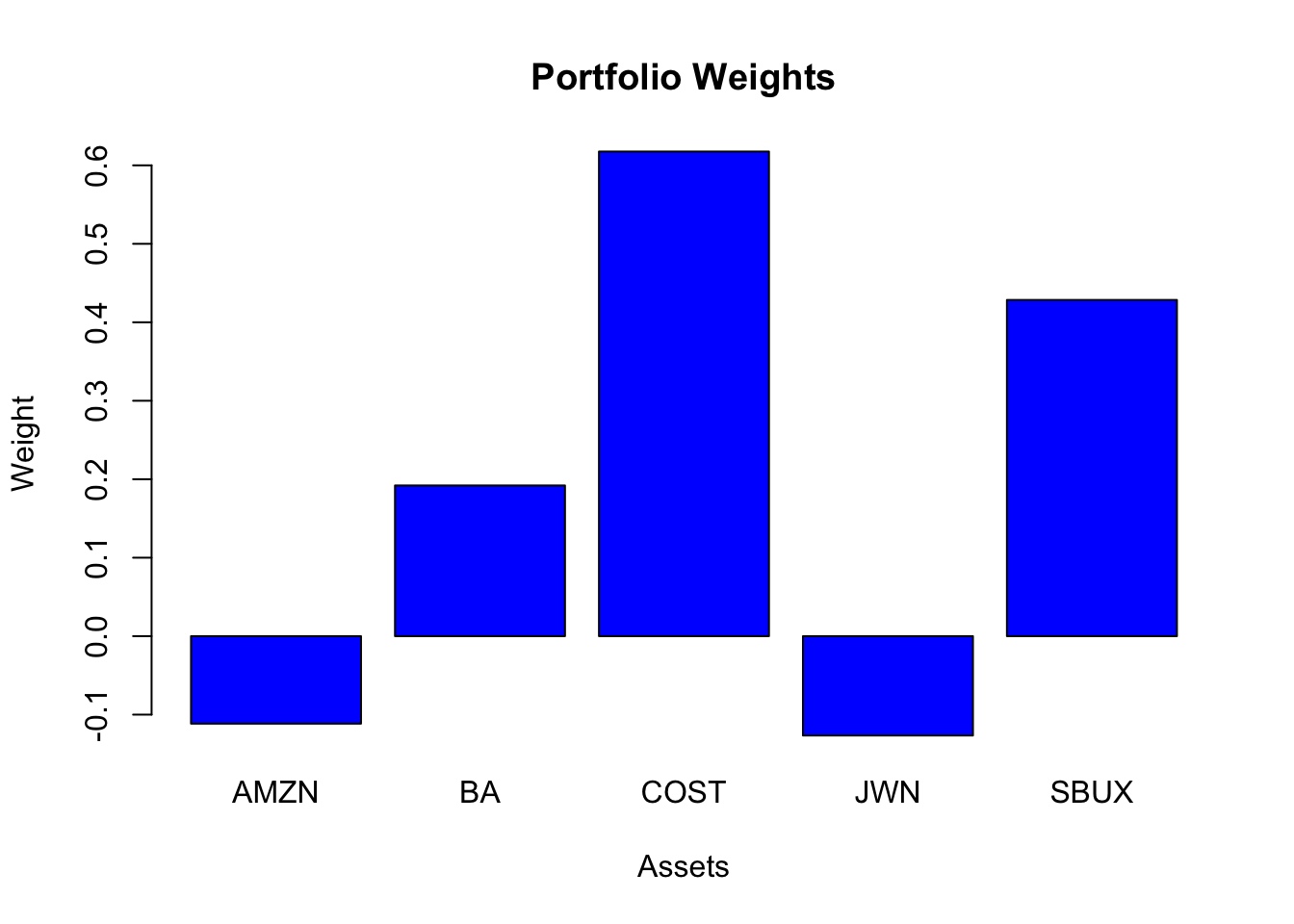
There are negative weights in the tangency portfolio (AMZN, JWN) and it is similar to the global minimum variance portfolio.
- Repeat question 8 but this time do not allow short sales. That is, add the following constraint: \(x_i \ge 0 \text{ for } i = AMZN, \cdots SBUX\). Compare the Sharpe ratio of this portfolio with the Sharpe ratio of the tangency portfolio that allows for short sales.
The tangency portfolio not allowing short sales is
tan.port.ns = tangency.portfolio(muhat.vals, sigma.mat, risk.free=rf, shorts=FALSE)
summary(tan.port.ns, risk.free = rf)## Call:
## tangency.portfolio(er = muhat.vals, cov.mat = sigma.mat, risk.free = rf,
## shorts = FALSE)
##
## Portfolio expected return: 0.0202
## Portfolio standard deviation: 0.0379
## Portfolio Sharpe Ratio: 0.4
## Portfolio weights:
## AMZN BA COST JWN SBUX
## 0.000 0.146 0.496 0.000 0.358Here, the weights in AMZN and JWN are set to zero.
- On the graph with the Markowitz bullet, plot the efficient portfolios that are combinations of T-bills and the tangency portfolio that allows short sales. Indicate the location of the tangency portfolio on the graph.
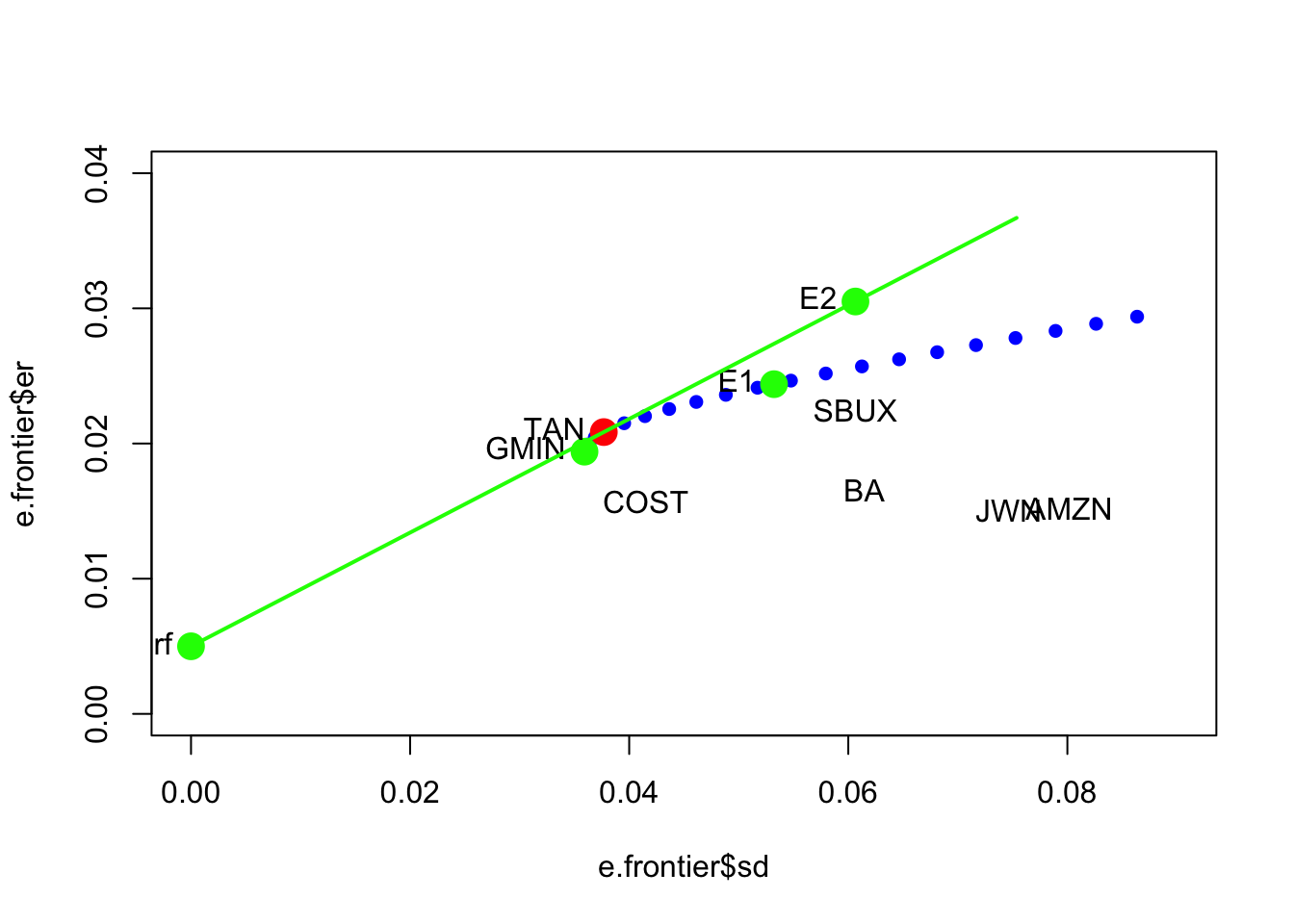
- Find the efficient portfolio of combinations of T-bills and the tangency portfolio (that allows short sales) that has the same SD value as Starbucks. What is the expected return on this portfolio? Indicate the location of this portfolio on your graph of the Markowitz bullet.
Here, we use the equation for the volatility of an efficient portfolio
\[ \sigma_p^e = x_t \times \sigma_{\mathrm{tan}} \]
where \(\sigma_{\mathrm{tan}} = 0.0377\). Setting \(\sigma_p^e = \sigma_{\mathrm{SBUX}} = 0.0607\) we can solve for \(x_t\):
## [1] 1.61Hence, the efficient portfolio with the same volatility as SBUX has \(161\%\) invested in the tangency portfoio and \(-61\%\) invested in T-Bills. The expected return on this portfolio is
## SBUX
## 0.0305We can check this soluion by putting the portfolio on the return-risk graph:
References
Pfaff, B. 2013. Financial Risk Modelling and Portfolio Optimization with R. Chichester, UK.: Wiley.
By the Cauchy-Schwarz inequality the denominator for \(m_{A}\) in (13.1) is always positive. ↩︎
Also notice that when \(\rho_{AB}=0.7\) the expected return on the global minimum variance drops (frontier of risky assets is shifted down) below \(0.03\) so we need to reduce \(r_{f}\) to \(0.01\) to ensure that the tangency portfolio has a positive slope. ↩︎
See the CRAN Optimization Task View for additional R packages that can be used to solve QP problems.↩︎
This normalization ensures that the tangency portfolio is 100% invested in the risky assets.↩︎
If \(\tilde{\mu}_{p,0}=0\) then the portfolio of risky assets and the risk-free asset has expected return equal to \(r_{f}\). In this case, \(\mathbf{x}=\mathbf{0}\) and \(x_{f}=1\). ↩︎