Construcción y cálculo del IMTM
Ilustración propiedad del Banco Interamericano de Desarrollo, en su Guía de transformación digital del gobierno bajo la licencia Creative Commons IGO 3.0 Reconocimiento-NoComercial-SinObrasDerivadas (CC-IGO 3.0 BY-NCND).
El siguiente apartado busca compartir la metodología utilizada para obtener los resultados en esta investigación, permitiendo replicar el proceso de construcción y transformación de los datos, así como el cálculo del índice. El código escrito no es perfecto porque está muy lejos de estar optimizado y simplificado, pero es lo que surgió en este continuo proceso de aprendizaje y que espero sirva como ejemplo del uso del lenguaje R y RStudio en la carrera de Administración Pública y Ciencia Política.
El script de R, encuestas aplicadas, planillas en formato Excel (xlsx), junto a otros documentos se encuentra disponibles en el siguiente enlace en GitHub
Espero que sea de ayuda :-)
print(“Hello World”)
## [1] “Hello World”
Actualizaciones
Actualización 1
Durante marzo de 2023 recibí las respuestas faltantes de San Rosendo, Tirúa y Alto Biobío, los cuales fueron incluidos en esta última versión del documento. Se aplicaron cambios necesarios para que algunos bloques de código sean calculados con 33 que son los municipios actuales y no los 30 de la versión de Diciembre de 2022.
Actualización 2
Durante mayo de 2023 apliqué los cálculos de estadística descriptiva mediante una función, que busca simplificar y disminuir la cantidad de lineas de código utilizadas.
Actualización 3
Durante junio de 2023 incorporé este apartado que originalmente era un Markdown que estaba en el repositorio en mi GitHub, pero que no tenía un formato de presentación mejor que el PDF. Ahora ha sido incorporado correctamente al Bookdown de mi memoria de título permitiendo una clara conexión entre ambos documentos.
Script de R
En este R script fueron utilizadas los siguientes paquetes:
library("readxl")
library("car")
library("dplyr")
library("tidyverse")
library("knitr")
library("modeest")
library("summarytools")
library("psych")
library("sjPlot")
library("ggplot2")Base
Se importará el archivo base.xlsx con el libro investigación_1 correspondiente a la base de datos con municipios, provincias, código FIGEM, variable IMTM 2015 y las que conforman las variables requeridas para la construcción del índice de madurez tecnológica municipal en las dimensiones infraestructura tecnológica, recursos humanos, gestión tecnológica municipal y servicios municipales en línea. Los subindices correspondientes a investigacion_2, investigacion_3 e investigacion_4 corresponden a seg_info, procesos y tramites.
# Archivo cargado con la libreria "readxl", libros separados
cuestionarios <- read_excel("docs/Base.xlsx", sheet = 1)
medidas_seguridad <- read_excel("docs/Base.xlsx", sheet = 2)
procesos <- read_excel("docs/Base.xlsx", sheet = 3)
tramites <- read_excel("docs/Base.xlsx", sheet = 4)
IMTM_2015 <- read_excel("docs/Base.xlsx", sheet = 5)Creación Indice IMTM 2022
Construcción Dataframe
# Sumar filas de variables subindices
medidas_seguridad <- medidas_seguridad %>% mutate(num_seg = rowSums(.[4:7]))
procesos <- procesos %>% mutate(num_procesos = rowSums(.[4:21]))
tramites <- tramites %>% mutate(num_tramites = rowSums(.[4:26]))
# Calcular indicador con fórmula lineal
medidas_seguridad <- mutate(medidas_seguridad, seg_info = (num_seg)/4)
procesos <- mutate(procesos, procesos = (num_procesos)/18)
tramites <- mutate(tramites, tramites = (num_tramites)/18)
# Limitar valor máximo a 1 según fórmula
tramites$tramites <- ifelse(tramites$tramites > 1,1, tramites$tramites)
# Agregar variables transformadas
cuestionarios$seg_info <- medidas_seguridad$seg_info
cuestionarios$procesos <- procesos$procesos
cuestionarios$tramites <- tramites$tramites
# Conversión a valores numericos
cuestionarios <- cuestionarios %>% mutate_at(c('seg_info', 'num_serv', 'area_info',
'educ_info', 'org_info', 'org_info_dep', 'procesos', 'tramites'), as.numeric)# Creación de las dimensiones
cuestionarios <- mutate(cuestionarios, IT = (seg_info + num_serv)/2) %>%
mutate(cuestionarios, RRHH = (area_info + educ_info + org_info)/3) %>%
mutate(cuestionarios, GTM = (intranet + procesos + estrategia_servicios)/3) %>%
mutate(cuestionarios, SML = (tramites)) %>%
mutate(cuestionarios, IMTM_2022= (IT + RRHH + GTM + SML)/4) # Creación Dataframe IMTM 2022
IMTM_2022 <- select(cuestionarios, Provincia, Municipio, FIGEM, IMTM_2022)Objetivo general
El objetivo planteado fue Analizar el nivel de madurez digital en los municipios de la región del Biobío al año 2022
# Resultados como ranking
IMTM_2022_rank <- IMTM_2022 %>% arrange(desc(IMTM_2022))
Ranking <- c(1:33)
IMTM_2022_rank <- cbind(Ranking, IMTM_2022_rank) kable(IMTM_2022_rank, digits= 2, caption = "IMTM Region del Biobío", align =
'r', col.names = c("Ranking", "Provincia", "Municipalidades", "Tipología", "IMTM"))| Ranking | Provincia | Municipalidades | Tipología | IMTM |
|---|---|---|---|---|
| 1 | Concepción | Concepción | 1 | 0.89 |
| 2 | Concepción | Hualpén | 1 | 0.81 |
| 3 | Concepción | San Pedro de la Paz | 1 | 0.79 |
| 4 | Biobío | Los Ángeles | 2 | 0.78 |
| 5 | Concepción | Talcahuano | 1 | 0.73 |
| 6 | Concepción | Chiguayante | 1 | 0.73 |
| 7 | Biobío | Nacimiento | 3 | 0.65 |
| 8 | Concepción | Coronel | 2 | 0.63 |
| 9 | Concepción | Tomé | 2 | 0.62 |
| 10 | Biobío | Quilleco | 5 | 0.57 |
| 11 | Biobío | Mulchén | 3 | 0.56 |
| 12 | Biobío | Santa Barbara | 3 | 0.56 |
| 13 | Concepción | Santa Juana | 5 | 0.55 |
| 14 | Arauco | Los Álamos | 3 | 0.53 |
| 15 | Concepción | Penco | 2 | 0.50 |
| 16 | Biobío | Laja | 4 | 0.49 |
| 17 | Concepción | Florida | 5 | 0.45 |
| 18 | Biobío | Tucapel | 5 | 0.45 |
| 19 | Concepción | Hualqui | 5 | 0.42 |
| 20 | Arauco | Curanilahue | 3 | 0.42 |
| 21 | Concepción | Lota | 2 | 0.39 |
| 22 | Arauco | Lebu | 3 | 0.39 |
| 23 | Biobío | Cabrero | 3 | 0.34 |
| 24 | Arauco | Contulmo | 5 | 0.33 |
| 25 | Arauco | Tirúa | 5 | 0.33 |
| 26 | Arauco | Cañete | 3 | 0.31 |
| 27 | Arauco | Arauco | 4 | 0.31 |
| 28 | Biobío | Antuco | 5 | 0.31 |
| 29 | Biobío | Alto Biobío | 5 | 0.26 |
| 30 | Biobío | San Rosendo | 3 | 0.26 |
| 31 | Biobío | Yumbel | 5 | 0.25 |
| 32 | Biobío | Quilaco | 5 | 0.24 |
| 33 | Biobío | Negrete | 5 | 0.20 |
Objetivo 4: Contrastar
Para Contrastar el IMTM 2015 y el IMTM 2022 se realizará una tabla de datos que incluya la diferencia entre ambas variables. También estadística descriptiva y gráficos de caja.
# Crear una función que realice todos los cálculos de estadística descriptiva
stats_descr <- function(x) {
c(Mínimo = min (x, na.rm = TRUE),
Primer_Cuartil = quantile(x, probs = 0.25, na.rm = TRUE),
Media = mean(x, na.rm = TRUE), Máximo = max(x, na.rm = TRUE),
Mediana = median.default(x, na.rm = TRUE),
Variación = var(x, na.rm = TRUE), Desviación_estandar = sd(x, na.rm = TRUE),
Tercer_Cuartil = quantile(x, probs = 0.75, na.rm = TRUE),
Rango = max(x, na.rm = TRUE) - min(x, na.rm = TRUE), Rango_Intercuartil =
quantile(x, probs = 0.75, na.rm = TRUE) -
quantile(x, probs = 0.25, na.rm = TRUE),
Asimetria = skew((x)/sqrt(6/1401)),
Curtosis = kurtosi((x)/sqrt(6/1401)))
} # Convertir valores en character a numeric
IMTM_2015 <- IMTM_2015 %>% mutate_at(c('IMTM_2015'), as.numeric)
# Apicar la función al dataframe y variables del IMTM 2015 y 2022
Descr_IMTM_2015 <- stats_descr(IMTM_2015$IMTM_2015)
Descr_IMTM_2022 <- stats_descr(IMTM_2022$IMTM_2022)
# Crear un dataframe con los valores de estadística descriptiva de ambos IMTM
Diferenciar <- data.frame(Descr_IMTM_2015, Descr_IMTM_2022)
# Aplicar mutate para agregar una columna que sea la sustracción entre los IMTM
Diferenciar <- mutate(Diferenciar, Diferencia = (Descr_IMTM_2015 - Descr_IMTM_2022)) kable(Diferenciar , digits = 2, align = 'r',
caption = "Diferencia estadística descriptiva IMTM 2015 y 2022",
col.names = c("IMTM 2015", "IMTM 2022", "Diferencia"))| IMTM 2015 | IMTM 2022 | Diferencia | |
|---|---|---|---|
| Mínimo | 0.21 | 0.20 | 0.01 |
| Primer_Cuartil.25% | 0.29 | 0.33 | -0.04 |
| Media | 0.44 | 0.49 | -0.04 |
| Máximo | 0.80 | 0.89 | -0.09 |
| Mediana | 0.45 | 0.45 | 0.00 |
| Variación | 0.02 | 0.04 | -0.01 |
| Desviación_estandar | 0.15 | 0.19 | -0.04 |
| Tercer_Cuartil.75% | 0.54 | 0.62 | -0.08 |
| Rango | 0.59 | 0.69 | -0.10 |
| Rango_Intercuartil.75% | 0.25 | 0.29 | -0.04 |
| Asimetria | 0.27 | 0.40 | -0.14 |
| Curtosis | -0.74 | -0.98 | 0.24 |
# Seleccionar columnas
Diferenciar <- select(cuestionarios, Provincia, Municipio, IMTM_2022)
# Agregar IMTM del 2015
Diferenciar$IMTM_2015 <- IMTM_2015$IMTM_2015
# Calcular la diferencia
Diferenciar <- mutate(Diferenciar, Diferencia = (IMTM_2022-IMTM_2015))
kable(Diferenciar, digits = 2, align = 'r', caption = "Diferencia IMTM 2015 y 2022",
col.names = c("Provincia", "Municipio", "IMTM 2022", "IMTM 2015", "Diferencia"))| Provincia | Municipio | IMTM 2022 | IMTM 2015 | Diferencia |
|---|---|---|---|---|
| Concepción | Chiguayante | 0.73 | NA | NA |
| Concepción | Concepción | 0.89 | 0.23 | 0.66 |
| Concepción | Coronel | 0.63 | 0.48 | 0.15 |
| Concepción | Florida | 0.45 | 0.53 | -0.08 |
| Concepción | Hualpén | 0.81 | NA | NA |
| Concepción | Hualqui | 0.42 | 0.66 | -0.24 |
| Concepción | Lota | 0.39 | 0.80 | -0.41 |
| Concepción | Penco | 0.50 | 0.54 | -0.04 |
| Concepción | San Pedro de la Paz | 0.79 | 0.50 | 0.29 |
| Concepción | Santa Juana | 0.55 | 0.49 | 0.06 |
| Concepción | Talcahuano | 0.73 | 0.49 | 0.24 |
| Concepción | Tomé | 0.62 | NA | NA |
| Biobío | Alto Biobío | 0.26 | 0.29 | -0.03 |
| Biobío | Antuco | 0.31 | 0.29 | 0.02 |
| Biobío | Cabrero | 0.34 | 0.36 | -0.02 |
| Biobío | Laja | 0.49 | 0.21 | 0.28 |
| Biobío | Los Ángeles | 0.78 | 0.59 | 0.19 |
| Biobío | Mulchén | 0.56 | 0.26 | 0.30 |
| Biobío | Nacimiento | 0.65 | 0.29 | 0.36 |
| Biobío | Negrete | 0.20 | 0.45 | -0.25 |
| Biobío | Quilaco | 0.24 | 0.44 | -0.20 |
| Biobío | Quilleco | 0.57 | 0.54 | 0.03 |
| Biobío | San Rosendo | 0.26 | 0.23 | 0.03 |
| Biobío | Santa Barbara | 0.56 | 0.45 | 0.11 |
| Biobío | Tucapel | 0.45 | 0.40 | 0.05 |
| Biobío | Yumbel | 0.25 | 0.25 | 0.00 |
| Arauco | Arauco | 0.31 | 0.63 | -0.32 |
| Arauco | Cañete | 0.31 | NA | NA |
| Arauco | Contulmo | 0.33 | 0.69 | -0.36 |
| Arauco | Curanilahue | 0.42 | 0.37 | 0.05 |
| Arauco | Lebu | 0.39 | 0.45 | -0.06 |
| Arauco | Los Álamos | 0.53 | 0.37 | 0.16 |
| Arauco | Tirúa | 0.33 | 0.59 | -0.26 |
## Boxplot IMTM 2015 y 2022
# Apilar valores IMTM como factor
Diferenciar <- cbind(Diferenciar[1:2:5], stack(Diferenciar[3:4]))
Diferenciar <- rename(Diferenciar, Valores = values, Índice = ind)
qplot(data = Diferenciar, x = Índice, y = Valores, fill = Índice,
geom = "boxplot", main = "Gráfico de caja IMTM 2015 y 2022") +
scale_fill_brewer(palette = "Dark2")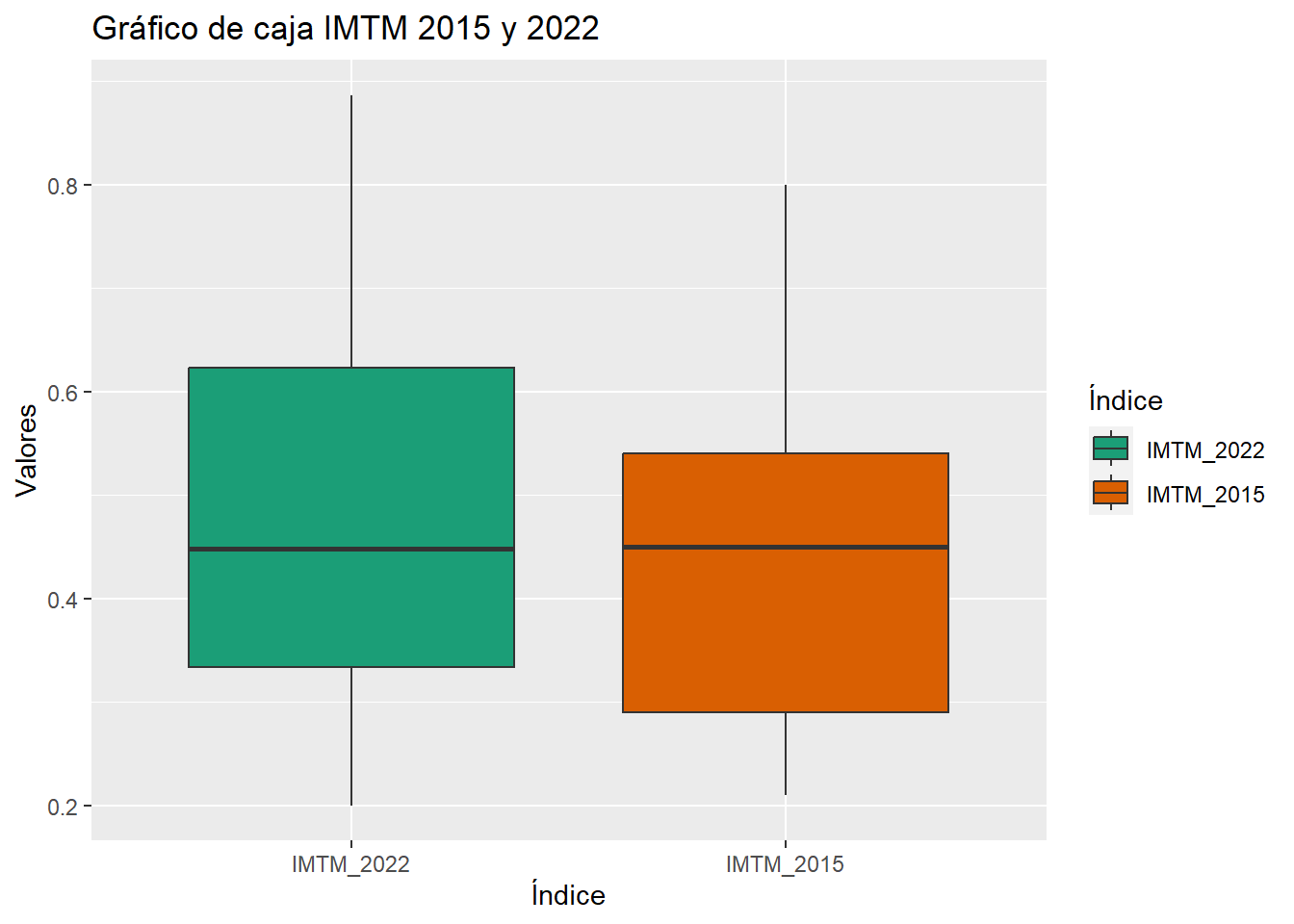
Objetivo 1: Caracterizar
Para Caracterizar la madurez digital de los municipios de la región del Biobio al año 2022 según el Índice de madurez tecnológica Municipal se construirán dataframes para luego realizar tablas con los valores obtenidos en cada dimensión, correlaciones entre dimensión e índice, estadística descriptiva y por último gráficos de caja que permitan apreciar la distribución de estos valores.
# Crear dataframes de las dimensiones
IT <- select(cuestionarios, Municipio, seg_info, num_serv, IT)
RRHH <- select(cuestionarios, Municipio, area_info, educ_info, org_info, RRHH)
GTM <- select(cuestionarios, Municipio, intranet, procesos, estrategia_servicios, GTM)
SML <- select(cuestionarios, Municipio, tramites, SML) kable(IT, digits= 2, caption = "IT Region del Biobío", align = 'r',
col.names = c("Municipalidades", "Medidas seguridad", "Numero de servidores", "IT"))| Municipalidades | Medidas seguridad | Numero de servidores | IT |
|---|---|---|---|
| Chiguayante | 1.00 | 0.26 | 0.63 |
| Concepción | 1.00 | 0.13 | 0.56 |
| Coronel | 1.00 | 0.40 | 0.70 |
| Florida | 0.75 | 0.13 | 0.44 |
| Hualpén | 1.00 | 0.00 | 0.50 |
| Hualqui | 0.25 | 0.06 | 0.16 |
| Lota | 1.00 | 0.00 | 0.50 |
| Penco | 1.00 | 0.13 | 0.56 |
| San Pedro de la Paz | 0.75 | 0.06 | 0.41 |
| Santa Juana | 1.00 | 0.06 | 0.53 |
| Talcahuano | 1.00 | 0.66 | 0.83 |
| Tomé | 1.00 | 0.20 | 0.60 |
| Alto Biobío | 0.50 | 0.06 | 0.28 |
| Antuco | 0.00 | 0.00 | 0.00 |
| Cabrero | 1.00 | 0.26 | 0.63 |
| Laja | 0.75 | 0.06 | 0.41 |
| Los Ángeles | 1.00 | 0.40 | 0.70 |
| Mulchén | 1.00 | 0.00 | 0.50 |
| Nacimiento | 1.00 | 0.20 | 0.60 |
| Negrete | 0.00 | 0.06 | 0.03 |
| Quilaco | 0.25 | 0.13 | 0.19 |
| Quilleco | 0.75 | 0.20 | 0.48 |
| San Rosendo | 0.25 | 0.06 | 0.16 |
| Santa Barbara | 0.75 | 0.26 | 0.50 |
| Tucapel | 0.75 | 0.13 | 0.44 |
| Yumbel | 0.50 | 0.13 | 0.32 |
| Arauco | 0.50 | 0.06 | 0.28 |
| Cañete | 0.75 | 0.06 | 0.41 |
| Contulmo | 0.50 | 0.00 | 0.25 |
| Curanilahue | 0.50 | 0.20 | 0.35 |
| Lebu | 1.00 | 0.13 | 0.56 |
| Los Álamos | 0.75 | 0.06 | 0.41 |
| Tirúa | 0.00 | 0.00 | 0.00 |
# Dataframe RRHH
kable(RRHH, digits = 2, caption = "RRHH Region del Biobío", align = 'r',
col.names = c("Municipalidades", "Area informática",
"Nivel educacional encargado", "Area dependencia", "RRHH"))| Municipalidades | Area informática | Nivel educacional encargado | Area dependencia | RRHH |
|---|---|---|---|---|
| Chiguayante | 1 | 1.0 | 1.0 | 1.00 |
| Concepción | 1 | 1.0 | 1.0 | 1.00 |
| Coronel | 1 | 1.0 | 1.0 | 1.00 |
| Florida | 0 | 1.0 | 1.0 | 0.67 |
| Hualpén | 1 | 1.0 | 1.0 | 1.00 |
| Hualqui | 1 | 0.5 | 1.0 | 0.83 |
| Lota | 1 | 1.0 | 0.4 | 0.80 |
| Penco | 1 | 1.0 | 1.0 | 1.00 |
| San Pedro de la Paz | 1 | 1.0 | 0.4 | 0.80 |
| Santa Juana | 1 | 1.0 | 0.6 | 0.87 |
| Talcahuano | 1 | 1.0 | 0.6 | 0.87 |
| Tomé | 1 | 0.5 | 0.4 | 0.63 |
| Alto Biobío | 0 | 0.5 | 1.0 | 0.50 |
| Antuco | 0 | 1.0 | 1.0 | 0.67 |
| Cabrero | 0 | 1.0 | 0.6 | 0.53 |
| Laja | 1 | 0.5 | 1.0 | 0.83 |
| Los Ángeles | 1 | 0.5 | 1.0 | 0.83 |
| Mulchén | 1 | 1.0 | 0.6 | 0.87 |
| Nacimiento | 1 | 1.0 | 1.0 | 1.00 |
| Negrete | 0 | 0.5 | 0.2 | 0.23 |
| Quilaco | 1 | 0.5 | 0.2 | 0.57 |
| Quilleco | 1 | 1.0 | 0.2 | 0.73 |
| San Rosendo | 0 | 0.5 | 1.0 | 0.50 |
| Santa Barbara | 1 | 1.0 | 1.0 | 1.00 |
| Tucapel | 1 | 1.0 | 0.2 | 0.73 |
| Yumbel | 0 | 1.0 | 0.6 | 0.53 |
| Arauco | 1 | 0.5 | 0.6 | 0.70 |
| Cañete | 0 | 0.5 | 1.0 | 0.50 |
| Contulmo | 1 | 1.0 | 0.6 | 0.87 |
| Curanilahue | 1 | 1.0 | 0.4 | 0.80 |
| Lebu | 1 | 1.0 | 0.2 | 0.73 |
| Los Álamos | 1 | 0.5 | 0.2 | 0.57 |
| Tirúa | 0 | 1.0 | 1.0 | 0.67 |
# Dataframe GTM
kable(GTM, digits= 2, caption = "GTM Region del Biobío", align = 'r',
col.names = c("Municipalidades", "Intranet",
"Informatización procesos internos", "Estrategia a ciudadanos", "GTM"))| Municipalidades | Intranet | Informatización procesos internos | Estrategia a ciudadanos | GTM |
|---|---|---|---|---|
| Chiguayante | 1 | 1.00 | 1 | 1.00 |
| Concepción | 1 | 0.94 | 1 | 0.98 |
| Coronel | 0 | 0.83 | 0 | 0.28 |
| Florida | 0 | 0.89 | 1 | 0.63 |
| Hualpén | 1 | 0.94 | 1 | 0.98 |
| Hualqui | 1 | 0.94 | 0 | 0.65 |
| Lota | 0 | 0.33 | 0 | 0.11 |
| Penco | 0 | 0.33 | 1 | 0.44 |
| San Pedro de la Paz | 1 | 0.89 | 1 | 0.96 |
| Santa Juana | 1 | 0.56 | 0 | 0.52 |
| Talcahuano | 1 | 0.89 | 0 | 0.63 |
| Tomé | 1 | 0.94 | 1 | 0.98 |
| Alto Biobío | 0 | 0.50 | 0 | 0.17 |
| Antuco | 1 | 0.50 | 0 | 0.50 |
| Cabrero | 0 | 0.39 | 0 | 0.13 |
| Laja | 1 | 0.78 | 0 | 0.59 |
| Los Ángeles | 1 | 0.72 | 0 | 0.57 |
| Mulchén | 1 | 0.61 | 0 | 0.54 |
| Nacimiento | 0 | 0.94 | 0 | 0.31 |
| Negrete | 0 | 0.61 | 0 | 0.20 |
| Quilaco | 0 | 0.44 | 0 | 0.15 |
| Quilleco | 1 | 0.72 | 1 | 0.91 |
| San Rosendo | 1 | 0.00 | 0 | 0.33 |
| Santa Barbara | 1 | 0.67 | 0 | 0.56 |
| Tucapel | 1 | 0.67 | 0 | 0.56 |
| Yumbel | 0 | 0.50 | 0 | 0.17 |
| Arauco | 0 | 0.44 | 0 | 0.15 |
| Cañete | 0 | 0.39 | 0 | 0.13 |
| Contulmo | 0 | 0.50 | 0 | 0.17 |
| Curanilahue | 1 | 0.39 | 0 | 0.46 |
| Lebu | 0 | 0.50 | 0 | 0.17 |
| Los Álamos | 0 | 0.94 | 1 | 0.65 |
| Tirúa | 0 | 0.50 | 1 | 0.50 |
# Dimensión SML
kable(SML, digits= 2, caption = "SML Region del Biobío", align = 'r',
col.names = c("Municipalidades", "Digitalización trámites", "SML"))| Municipalidades | Digitalización trámites | SML |
|---|---|---|
| Chiguayante | 0.28 | 0.28 |
| Concepción | 1.00 | 1.00 |
| Coronel | 0.56 | 0.56 |
| Florida | 0.06 | 0.06 |
| Hualpén | 0.78 | 0.78 |
| Hualqui | 0.06 | 0.06 |
| Lota | 0.17 | 0.17 |
| Penco | 0.00 | 0.00 |
| San Pedro de la Paz | 1.00 | 1.00 |
| Santa Juana | 0.28 | 0.28 |
| Talcahuano | 0.61 | 0.61 |
| Tomé | 0.28 | 0.28 |
| Alto Biobío | 0.11 | 0.11 |
| Antuco | 0.06 | 0.06 |
| Cabrero | 0.06 | 0.06 |
| Laja | 0.11 | 0.11 |
| Los Ángeles | 1.00 | 1.00 |
| Mulchén | 0.33 | 0.33 |
| Nacimiento | 0.67 | 0.67 |
| Negrete | 0.33 | 0.33 |
| Quilaco | 0.06 | 0.06 |
| Quilleco | 0.17 | 0.17 |
| San Rosendo | 0.06 | 0.06 |
| Santa Barbara | 0.17 | 0.17 |
| Tucapel | 0.06 | 0.06 |
| Yumbel | 0.00 | 0.00 |
| Arauco | 0.11 | 0.11 |
| Cañete | 0.22 | 0.22 |
| Contulmo | 0.06 | 0.06 |
| Curanilahue | 0.06 | 0.06 |
| Lebu | 0.11 | 0.11 |
| Los Álamos | 0.50 | 0.50 |
| Tirúa | 0.17 | 0.17 |
Estadística descriptiva Dimensiones
# Aplicar la función stats_descr a todas las dimensiones
Descr_IT <- stats_descr(cuestionarios$IT)
Descr_RRHH <- stats_descr(cuestionarios$RRHH)
Descr_GTM <- stats_descr(cuestionarios$GTM)
Descr_SML <- stats_descr(cuestionarios$SML)# Creación Dataframe estadísticos descriptivos por dimensión
Caracterizar <- data.frame(Descr_IT, Descr_RRHH, Descr_GTM, Descr_SML)
kable(Caracterizar, digits = 2, align = 'r', caption =
"Estadística descriptiva Dimensiones IMTM 2022 Región del Biobío",
col.names = c("IT", "RRHH", "GTM","SML"))| IT | RRHH | GTM | SML | |
|---|---|---|---|---|
| Mínimo | 0.00 | 0.23 | 0.11 | 0.00 |
| Primer_Cuartil.25% | 0.28 | 0.63 | 0.17 | 0.06 |
| Media | 0.42 | 0.75 | 0.49 | 0.29 |
| Máximo | 0.83 | 1.00 | 1.00 | 1.00 |
| Mediana | 0.44 | 0.80 | 0.50 | 0.17 |
| Variación | 0.04 | 0.04 | 0.09 | 0.09 |
| Desviación_estandar | 0.21 | 0.19 | 0.29 | 0.30 |
| Tercer_Cuartil.75% | 0.56 | 0.87 | 0.63 | 0.33 |
| Rango | 0.83 | 0.77 | 0.89 | 1.00 |
| Rango_Intercuartil.75% | 0.28 | 0.23 | 0.46 | 0.28 |
| Asimetria | -0.41 | -0.48 | 0.36 | 1.22 |
| Curtosis | -0.53 | -0.31 | -1.08 | 0.24 |
Correlación entre dimensiones e indice
# Crear un data frame
corr <- select(cuestionarios, Provincia, Municipio, FIGEM, IT, RRHH,
GTM, SML, IMTM_2022)
# Aplicar funcion con en las variables
cor_IT <- cor(corr$IT, corr$IMTM_2022, use = "everything", method=c("pearson"))
cor_RRHH <- cor(corr$RRHH, corr$IMTM_2022, use = "everything", method=c("pearson"))
cor_GTM <- cor(corr$GTM, corr$IMTM_2022, use = "everything", method=c("pearson"))
cor_SML <- cor(corr$SML, corr$IMTM_2022, use = "everything", method=c("pearson"))
# Crear los nombres de las filas
nombres_correlacion <- c("Correlación con IT", "Correlación con RRHH",
"Correlación con GTM", "Correlación con SML")
# Crear lista de valores
valores_correlacion <- c(cor_IT, cor_RRHH, cor_GTM, cor_SML)
# Crear dataframe
correlacion_IMTM <- data.frame(nombres_correlacion, valores_correlacion) kable(correlacion_IMTM, digits = 3, align = 'r', caption =
"Correlación entre las dimensiones y el IMTM",
col.names = c("Dimensiones", "Correlación"))| Dimensiones | Correlación |
|---|---|
| Correlación con IT | 0.702 |
| Correlación con RRHH | 0.726 |
| Correlación con GTM | 0.770 |
| Correlación con SML | 0.808 |
Gráficos de caja
# Preparar dataframe
dif_dim <- cbind(cuestionarios[1:3], stack(cuestionarios[18:21]))
dif_dim <- rename(dif_dim, Valores = values, Dimensiones = ind)
qplot(data = dif_dim, y = Dimensiones, x = Valores, fill = Dimensiones,
geom = "boxplot", main = "Gráfico de caja Dimensiones IMTM 2022") +
scale_fill_brewer(palette = "Dark2")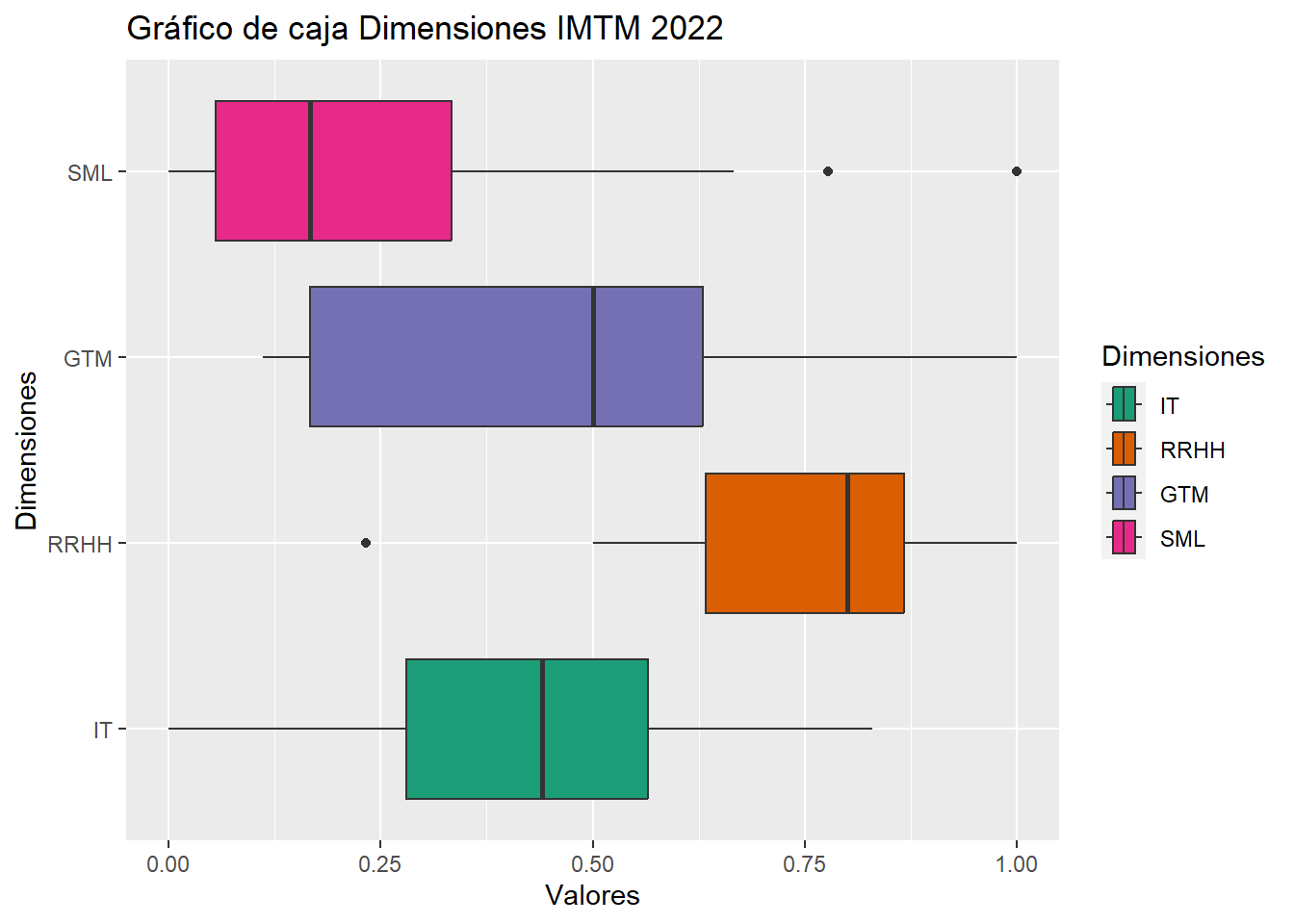
Objetivo 3: Comparar
Para Comparar la madurez digital entre los municipios de la región del Biobio al año 2022 se realizará un gráfico de puntos Cleveland, ademas de presentar los resultados de las variables.
Gráficos Cleveland de puntos agrupados por Provincia
# Preparar dataframe para Gráfico Cleveland de puntos IMTM agrupado por Provincia
plot <- select(cuestionarios, Provincia, Municipio, IMTM_2022, IT, RRHH, GTM, SML)
# Poner los nombres, ordenarlos primero por provincia y luego por IMTM
nameorder <- plot$Municipio[order(plot$Provincia, plot$IMTM_2022)]
# Convertir nombres en factor, con niveles en el orden de nameorder
plot$Municipio <- factor(plot$Municipio, levels = nameorder)# Realizar gráfico cleveland IMTM
ggplot(plot, aes(x = IMTM_2022, y = Municipio)) +
geom_segment(aes(yend = Municipio), xend = 0, colour = "grey50") +
geom_point(size = 2, aes(colour = Provincia)) + labs(title = "",
y = "Municipios", x = "Valores" ) + scale_colour_brewer(palette = "Set1", limits =
c("Concepción", "Biobío", "Arauco")) + theme_bw() + theme(panel.grid.major.y =
element_blank(), legend.position = c(0.99, 0.3), legend.justification = c(0.99, 0.3))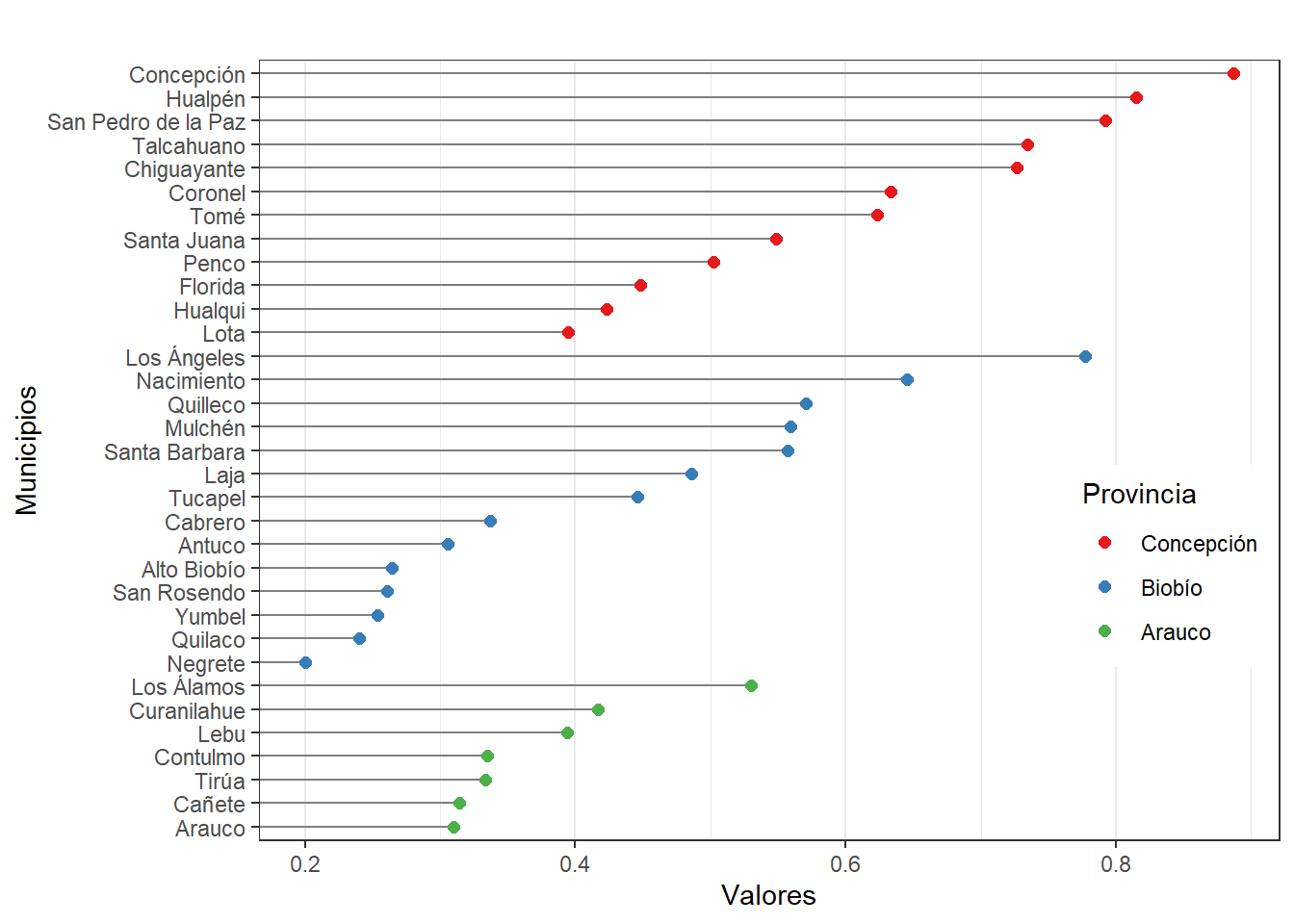
# Realizar gráfica cleveland IT
nameorder <- plot$Municipio[order(plot$Provincia, plot$IT)]
plot$Municipio <- factor(plot$Municipio, levels = nameorder)
ggplot(plot, aes(x = IT, y = Municipio)) +
geom_segment(aes(yend = Municipio), xend = 0, colour = "grey50") +
geom_point(size = 2, aes(colour = Provincia)) + labs(title = "",
y = "Municipios", x = "Valores" ) + scale_colour_brewer(palette = "Set1", limits =
c("Concepción", "Biobío", "Arauco")) + theme_bw() + theme(panel.grid.major.y =
element_blank(), legend.position = c(0.99, 0.3), legend.justification = c(0.99, 0.3))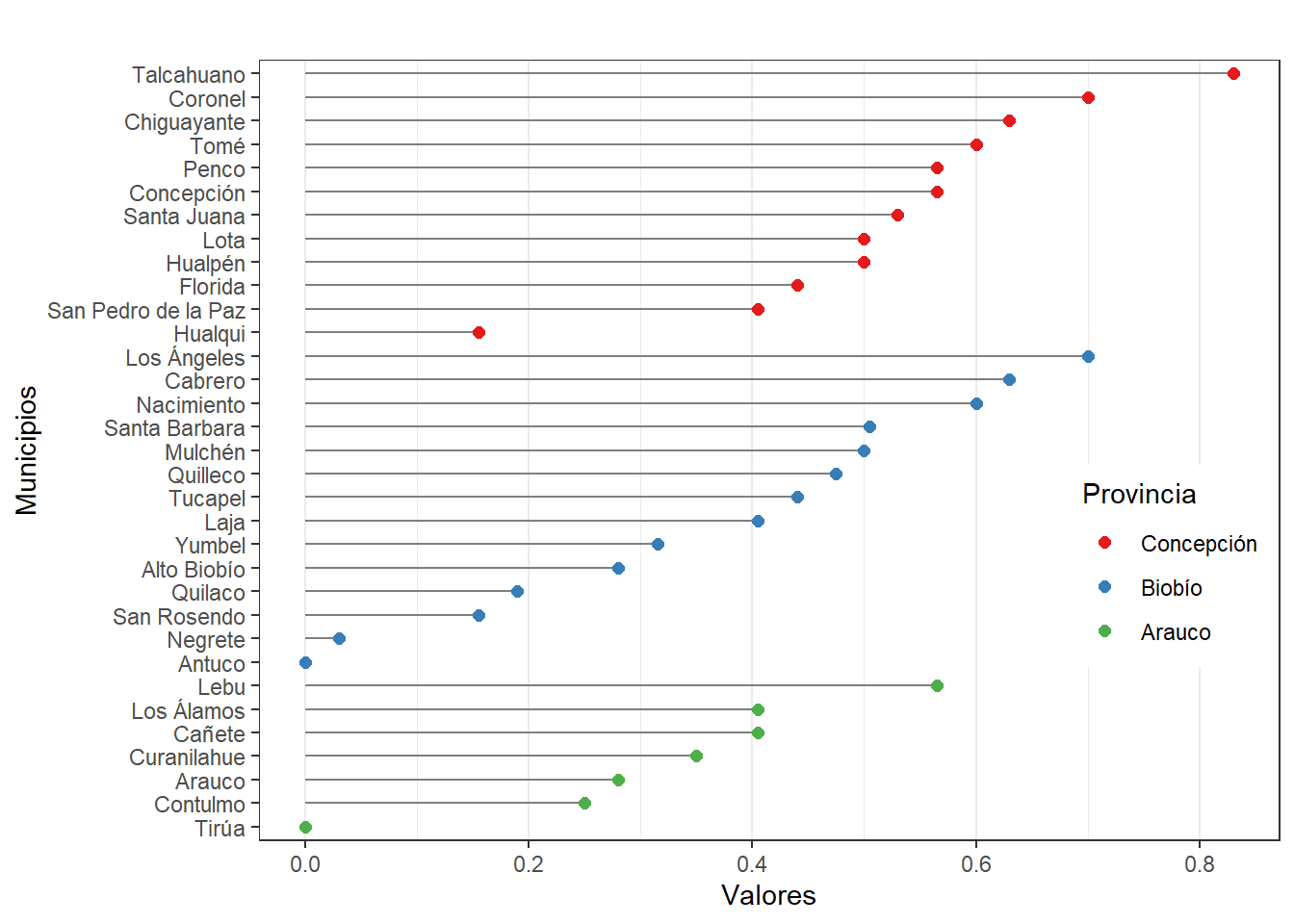
# Realizar gráfico cleveland RRHH
nameorder <- plot$Municipio[order(plot$Provincia, plot$RRHH)]
plot$Municipio <- factor(plot$Municipio, levels = nameorder)
ggplot(plot, aes(x = RRHH, y = Municipio)) +
geom_segment(aes(yend = Municipio), xend = 0, colour = "grey50") +
geom_point(size = 2, aes(colour = Provincia)) + labs(title = "",
y = "Municipios", x = "Valores" ) + scale_colour_brewer(palette = "Set1", limits =
c("Concepción", "Biobío", "Arauco")) + theme_bw() + theme(panel.grid.major.y =
element_blank(), legend.position = c(0.99, 0.3), legend.justification = c(0.99, 0.3))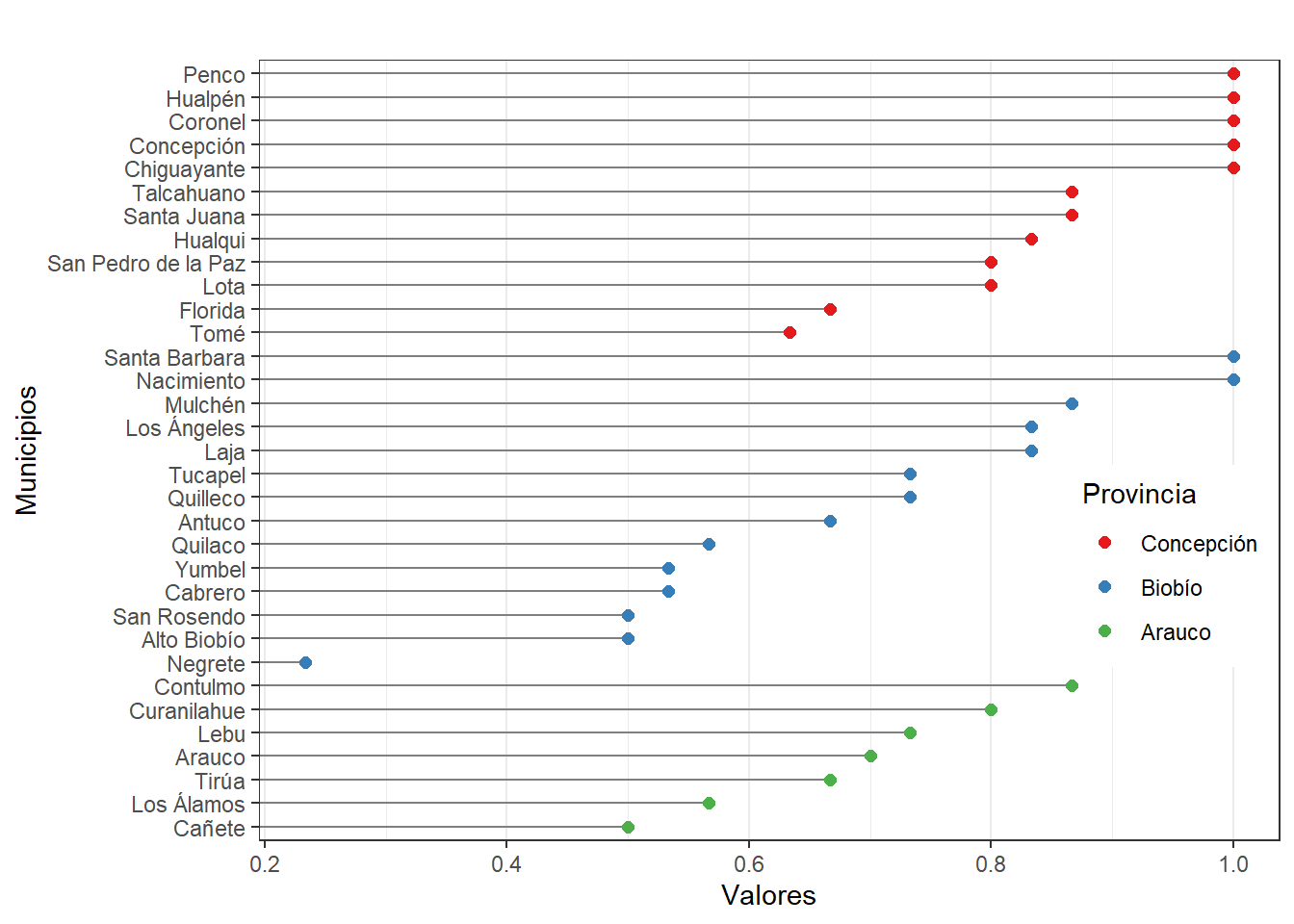
# Realizar gráfico cleveland GTM
nameorder <- plot$Municipio[order(plot$Provincia, plot$GTM)]
plot$Municipio <- factor(plot$Municipio, levels = nameorder)
ggplot(plot, aes(x = GTM, y = Municipio)) +
geom_segment(aes(yend = Municipio), xend = 0, colour = "grey50") +
geom_point(size = 2, aes(colour = Provincia)) + labs(title = "",
y = "Municipios", x = "Valores" ) + scale_colour_brewer(palette = "Set1", limits =
c("Concepción", "Biobío", "Arauco")) + theme_bw() + theme(panel.grid.major.y =
element_blank(), legend.position = c(0.99, 0.3), legend.justification = c(0.99, 0.3))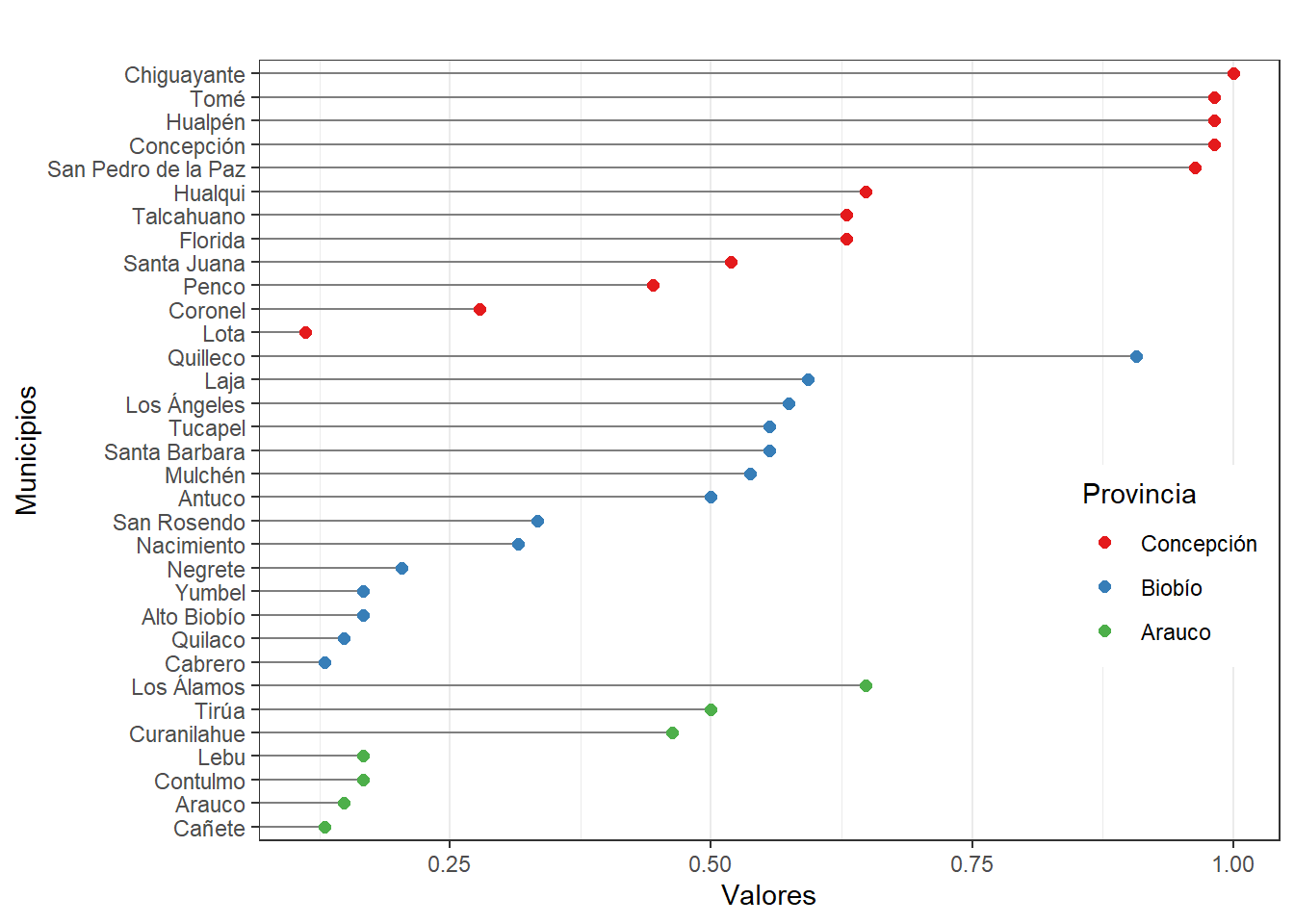
# Realizar gráfico cleveland procesos
plot_prc <- select(cuestionarios, Provincia, Municipio, procesos)
nameorder <- plot_prc$Municipio[order(plot_prc$Provincia, plot_prc$procesos)]
plot_prc$Municipio <- factor(plot_prc$Municipio, levels = nameorder)
ggplot(plot_prc, aes(x = procesos, y = Municipio)) +
geom_segment(aes(yend = Municipio), xend = 0, colour = "grey50") +
geom_point(size = 2, aes(colour = Provincia)) + labs(title = "",
y = "Municipios", x = "Valores" ) + scale_colour_brewer(palette = "Set1", limits =
c("Concepción", "Biobío", "Arauco")) + theme_bw() + theme(panel.grid.major.y =
element_blank(), legend.position = c(0.99, 0.3), legend.justification = c(0.99, 0.3))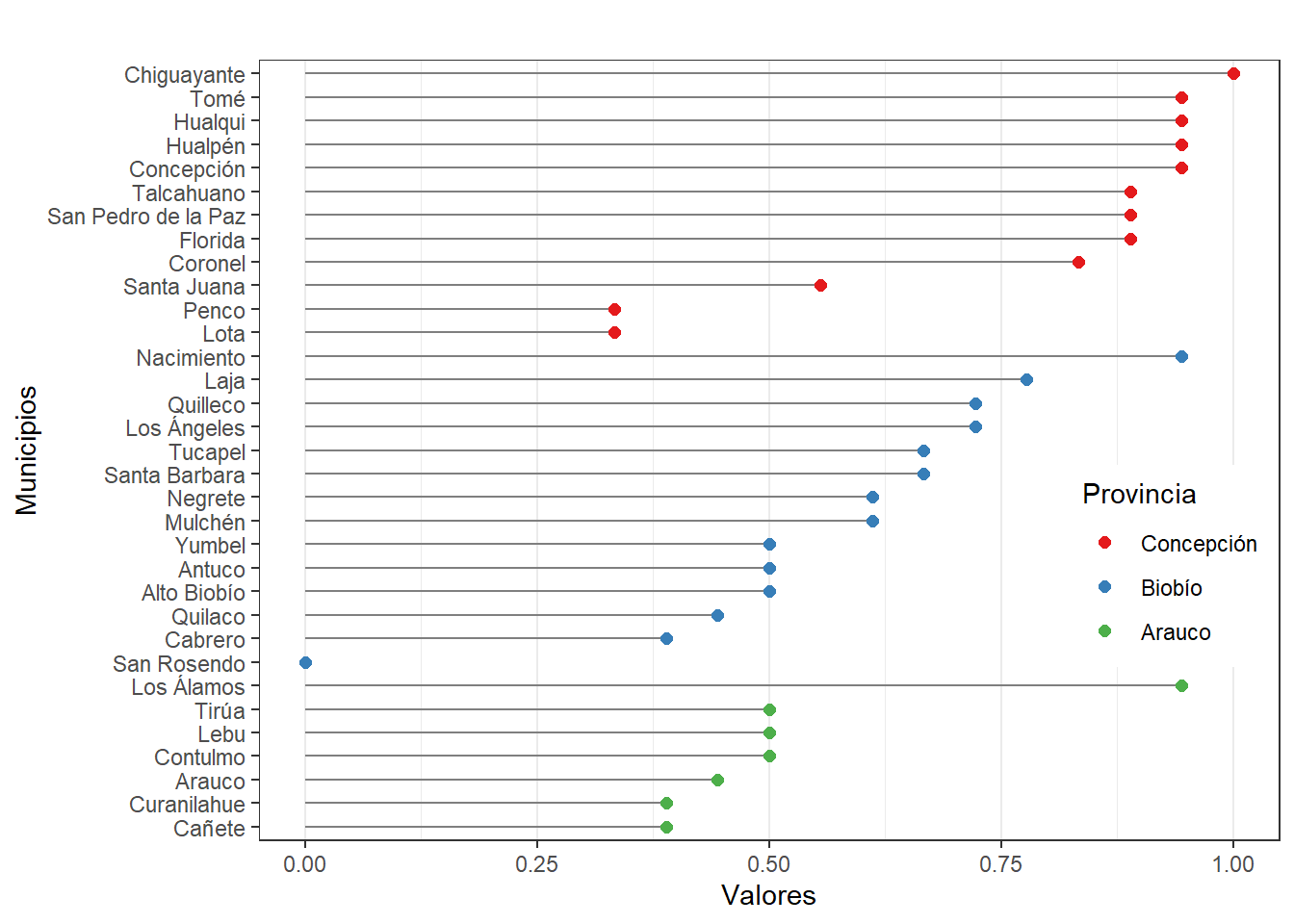
# Realizar gráfico cleveland SML
nameorder <- plot$Municipio[order(plot$Provincia, plot$SML)]
plot$Municipio <- factor(plot$Municipio, levels = nameorder)
ggplot(plot, aes(x = SML, y = Municipio)) +
geom_segment(aes(yend = Municipio), xend = 0, colour = "grey50") +
geom_point(size = 2, aes(colour = Provincia)) + labs(title = "",
y = "Municipios", x = "Valores" ) + scale_colour_brewer(palette = "Set1", limits =
c("Concepción", "Biobío", "Arauco")) + theme_bw() + theme(panel.grid.major.y =
element_blank(), legend.position = c(0.99, 0.3), legend.justification = c(0.99, 0.3))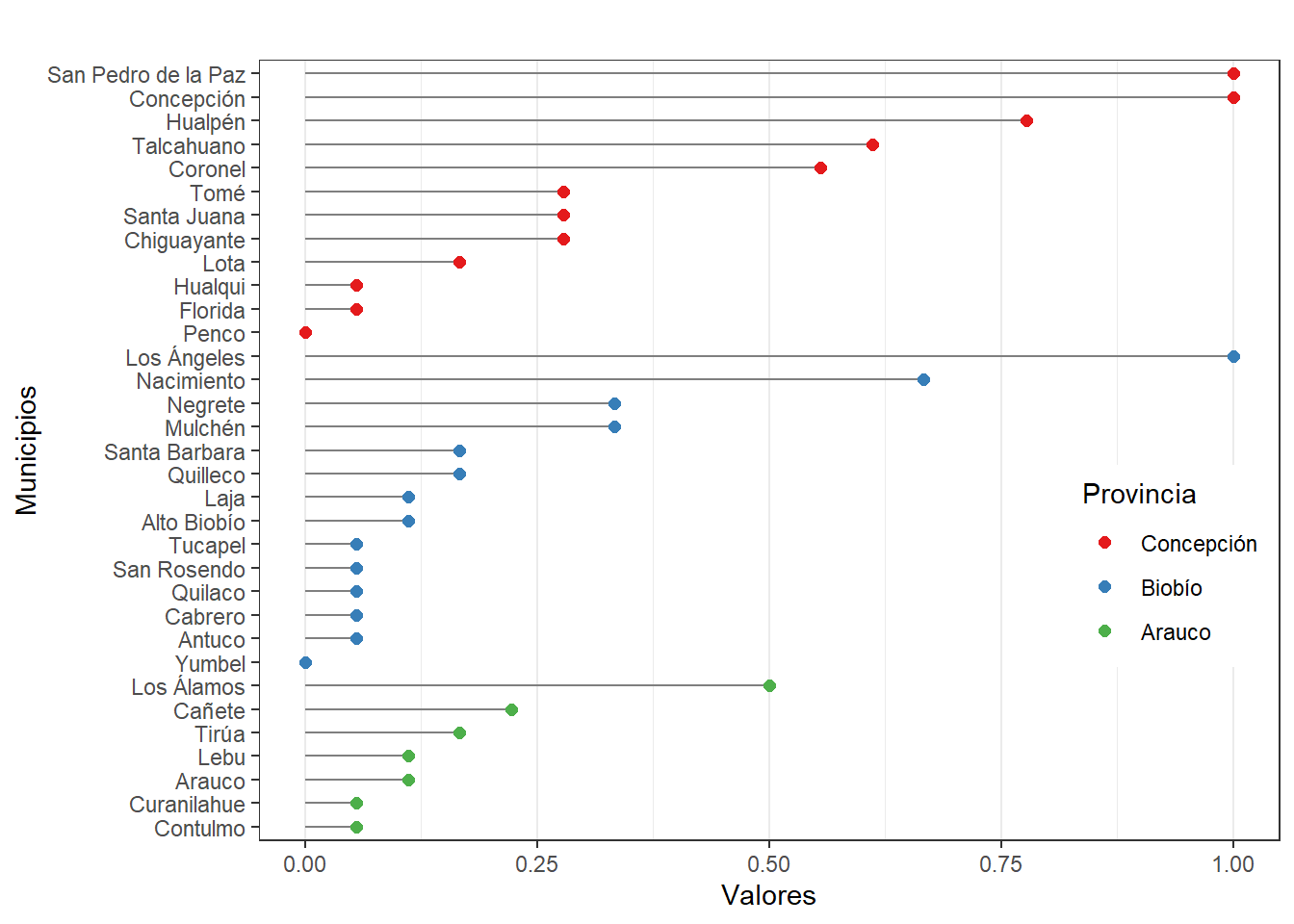
Resultados IT
# seg_info datos
Total_seg_info <- colSums(medidas_seguridad[ , 4:7], na.rm = TRUE)
txt_seg_info <- c("Antivirus", "Antispam", "Firewall", "Autentificación y Criptografia")
# Preparar dataframe
lista_seg_info <- c(1:4)
lista_seg_info <- factor(lista_seg_info)
Total_seg_info <- data.frame(lista_seg_info, txt_seg_info, Total_seg_info)
Total_seg_info <- mutate(Total_seg_info, no_seg_info = (33-Total_seg_info))
row.names(Total_seg_info) <- NULL# Crear tabla
kable(Total_seg_info, caption = "Total de medidas de seguridad", align= 'r',
col.names = c("Num", "Medidas de seguridad", "Total", "Faltantes"))| Num | Medidas de seguridad | Total | Faltantes |
|---|---|---|---|
| 1 | Antivirus | 28 | 5 |
| 2 | Antispam | 19 | 14 |
| 3 | Firewall | 27 | 6 |
| 4 | Autentificación y Criptografia | 19 | 14 |
# seg_info gráfico
ggplot(Total_seg_info, aes(x = lista_seg_info, y = Total_seg_info)) +
geom_col(aes(fill = txt_seg_info), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("") + scale_y_continuous("Cantidad") +
labs(title = "") + geom_text(aes(label = Total_seg_info), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill=guide_legend(title="Medidas de seguridad"))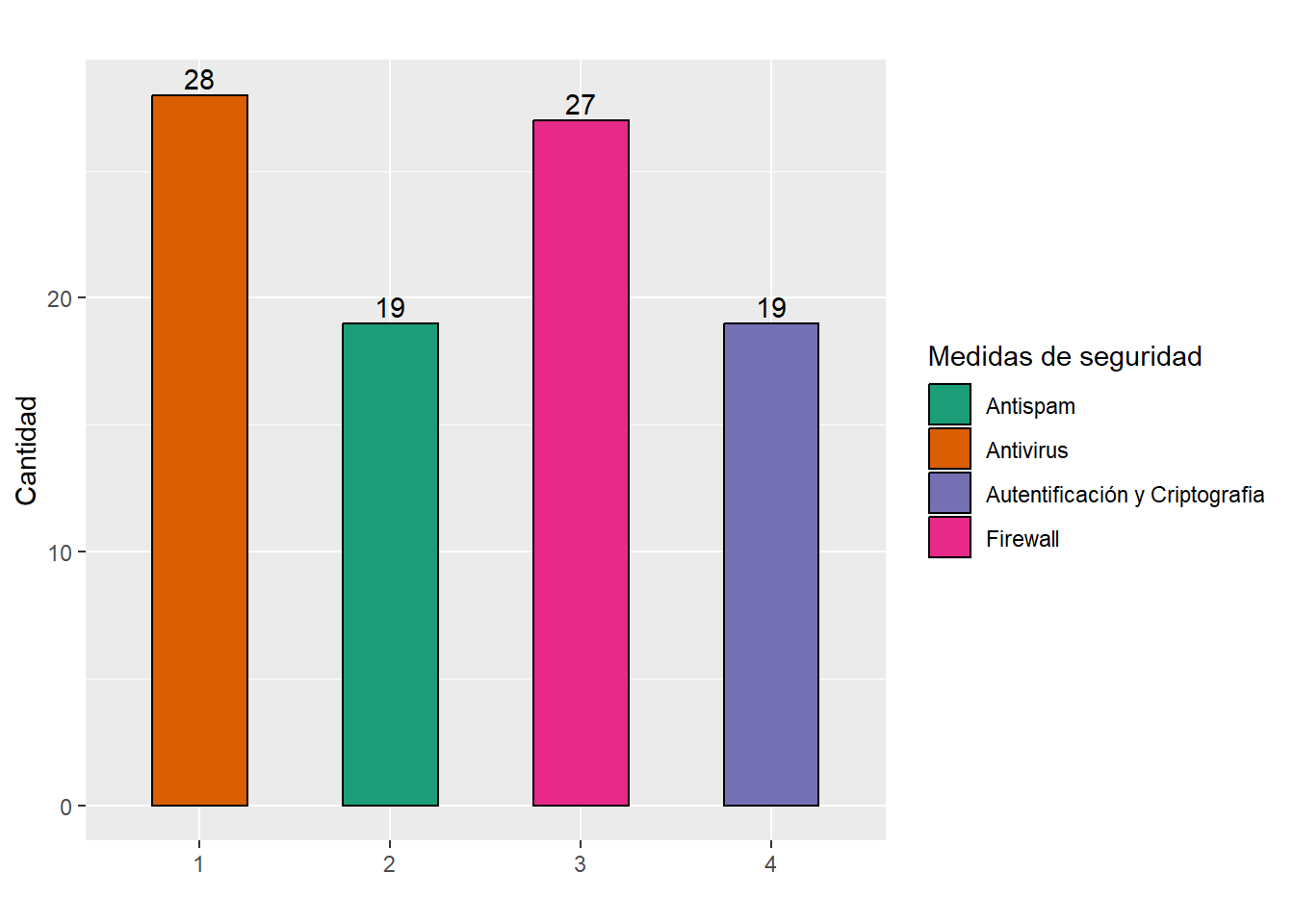
# num_serv datos
cant_serv <- c("Ninguno", "Uno", "Dos", "Tres", "Cuatro", "Seis", "Diez")
total_serv <- medidas_seguridad %>% count(cant_serv)
total_serv <- total_serv$n # Elim
Total_num_serv <- data.frame(cant_serv, total_serv)
row.names(Total_num_serv) <- NULL kable(Total_num_serv, caption = "Cantidad de servidores", align= 'r',
col.names = c("Cantidad", "Total"))| Cantidad | Total |
|---|---|
| Ninguno | 6 |
| Uno | 9 |
| Dos | 8 |
| Tres | 4 |
| Cuatro | 3 |
| Seis | 2 |
| Diez | 1 |
# num_serv gráfico
ggplot(Total_num_serv, aes(x = fct_reorder(cant_serv, total_serv), y = total_serv)) +
geom_col(aes(fill = cant_serv), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("Servidores") + scale_y_continuous("Frecuencia") +
labs(title = "") + geom_text(aes(label = total_serv), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill = "none") 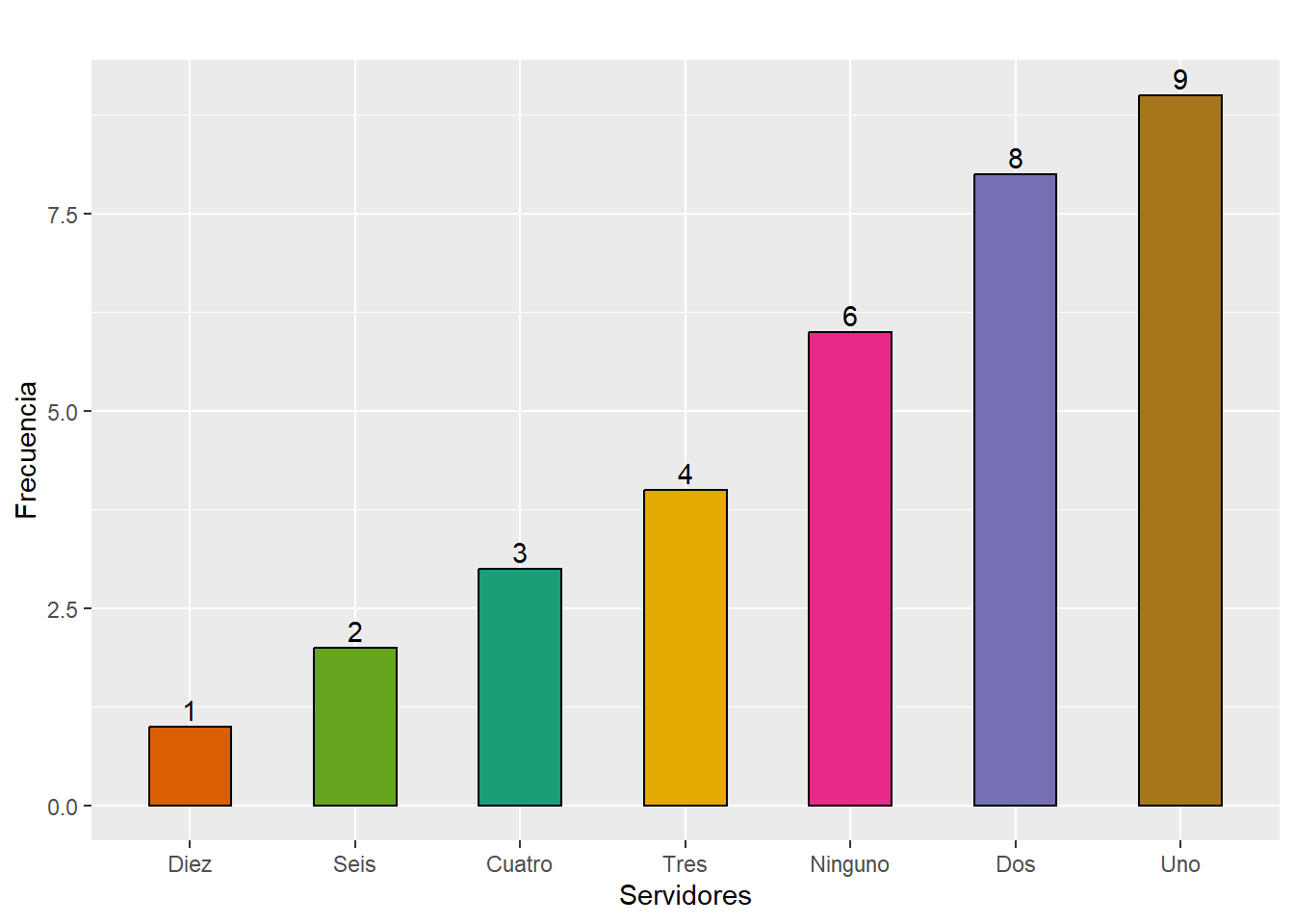
Resultados RRHH
# area_info datos
si_no <- c("No", "Si")
total_area_info <- RRHH %>% count(area_info)
total_area_info <- total_area_info$n
Total_area_info <- data.frame(si_no, total_area_info)
row.names(Total_area_info) <- NULL
kable(Total_area_info, caption = "Presencia de área informática municipal",
align= 'r', col.names = c("Presencia", "Total")) | Presencia | Total |
|---|---|
| No | 9 |
| Si | 24 |
# area_info gráfico
ggplot(Total_area_info, aes(x = si_no, y = total_area_info)) +
geom_col(aes(fill = si_no), colour = "black", position = "dodge", width = 0.5) +
scale_x_discrete("Presencia") + scale_y_continuous("Cantidad") +
labs(title = "") + geom_text(aes(label = total_area_info), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill = "none") 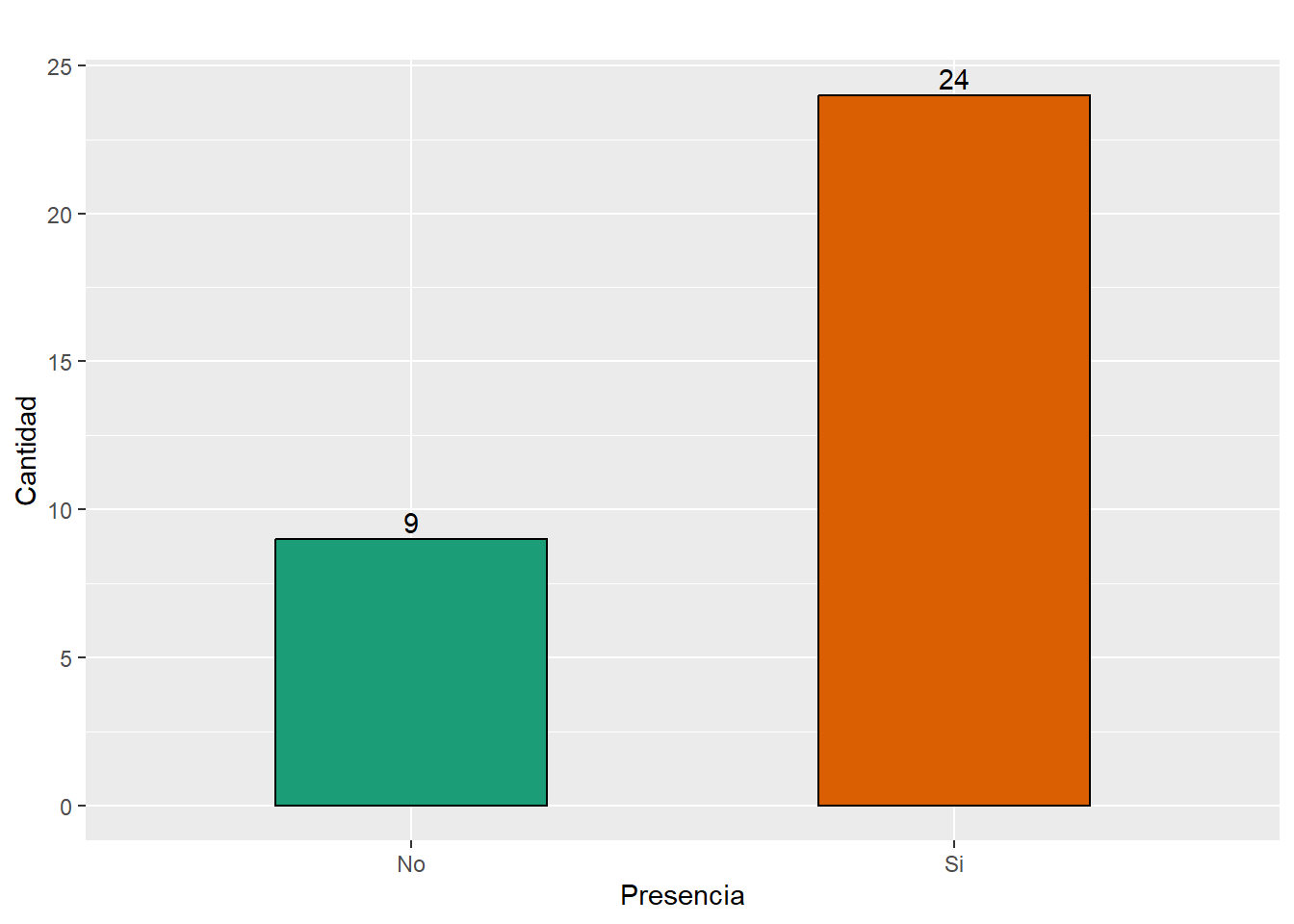
# educ_info datos
nivel_ed <- c("Tecnica nivel superior", "Superior pregrado", "Superior postgrado")
total_educ_info <- cuestionarios %>% count(educ_info_lvl)
total_educ_info <- total_educ_info$n
Total_educ_info <- data.frame(nivel_ed, total_educ_info)
row.names(Total_educ_info) <- NULL
kable(Total_educ_info, caption = "Nivel educacional encargado informática",
align= 'r', col.names = c("Nivel", "Total"))| Nivel | Total |
|---|---|
| Tecnica nivel superior | 11 |
| Superior pregrado | 19 |
| Superior postgrado | 3 |
# educ_info gráfico
ggplot(Total_educ_info, aes(x = nivel_ed, y = total_educ_info)) +
geom_col(aes(fill = nivel_ed), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("Nivel") + scale_y_continuous("Frecuencia") +
labs(title = "") + geom_text(aes(label = total_educ_info), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill = "none") 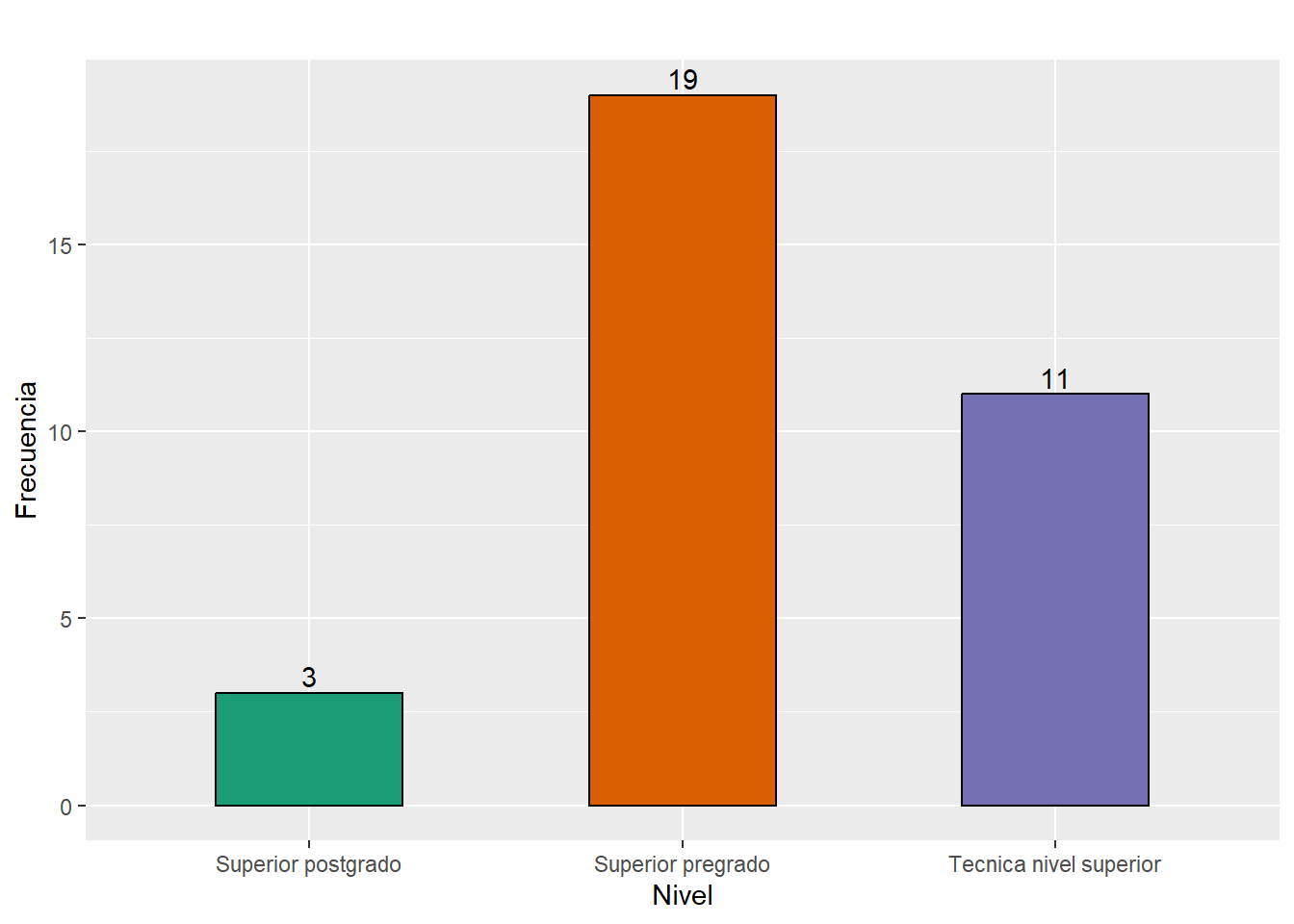
# org_info datos
org_info <- c("Alcalde", "Adm. Municipal", "DAF", "SECPLAN", "Secr. Municipal", "Otro")
total_org_info <- cuestionarios %>% count(org_info_dep)
total_org_info <- total_org_info$n
Total_org_info <- data.frame(org_info, total_org_info)
row.names(Total_org_info) <- NULL
kable(Total_org_info, caption = "Depencia de la unidad de informática",
align= 'r', col.names = c("Dependencia", "Total"))| Dependencia | Total |
|---|---|
| Alcalde | 1 |
| Adm. Municipal | 15 |
| DAF | 7 |
| SECPLAN | 4 |
| Secr. Municipal | 4 |
| Otro | 2 |
# org_info_gráfico
ggplot(Total_org_info, aes(x = fct_reorder(org_info, total_org_info), y = total_org_info)) +
geom_col(aes(fill = org_info), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("") + scale_y_continuous("Frecuencia") +
labs(title = "") + geom_text(aes(label = total_org_info), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill=guide_legend(title="Dependencia"))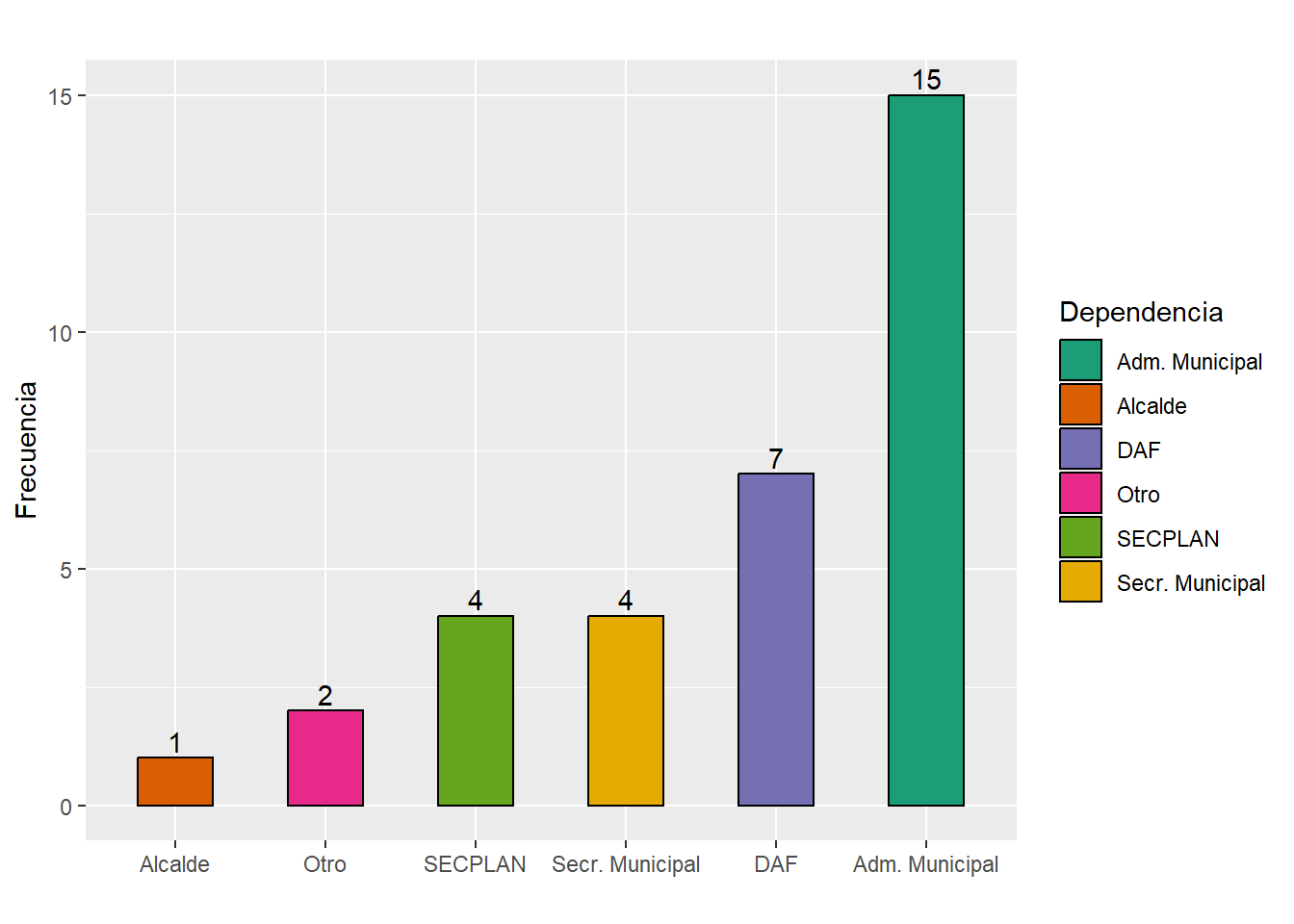
# intranet datos
total_intranet <- cuestionarios %>% count(intranet)
total_intranet <- total_intranet$n
Total_intranet <- data.frame(si_no, total_intranet)
row.names(Total_intranet) <- NULL
kable(Total_intranet, caption = "Presencia de intranet municipal",
align= 'r', col.names = c("Presencia", "Total"))| Presencia | Total |
|---|---|
| No | 16 |
| Si | 17 |
Resultados GTM
# intranet gráfico
ggplot(Total_intranet, aes(x = si_no, y = total_intranet)) +
geom_col(aes(fill = si_no), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("Presencia") + scale_y_continuous("Frecuencia") +
labs(title = "") + geom_text(aes(label = total_intranet), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill = "none") 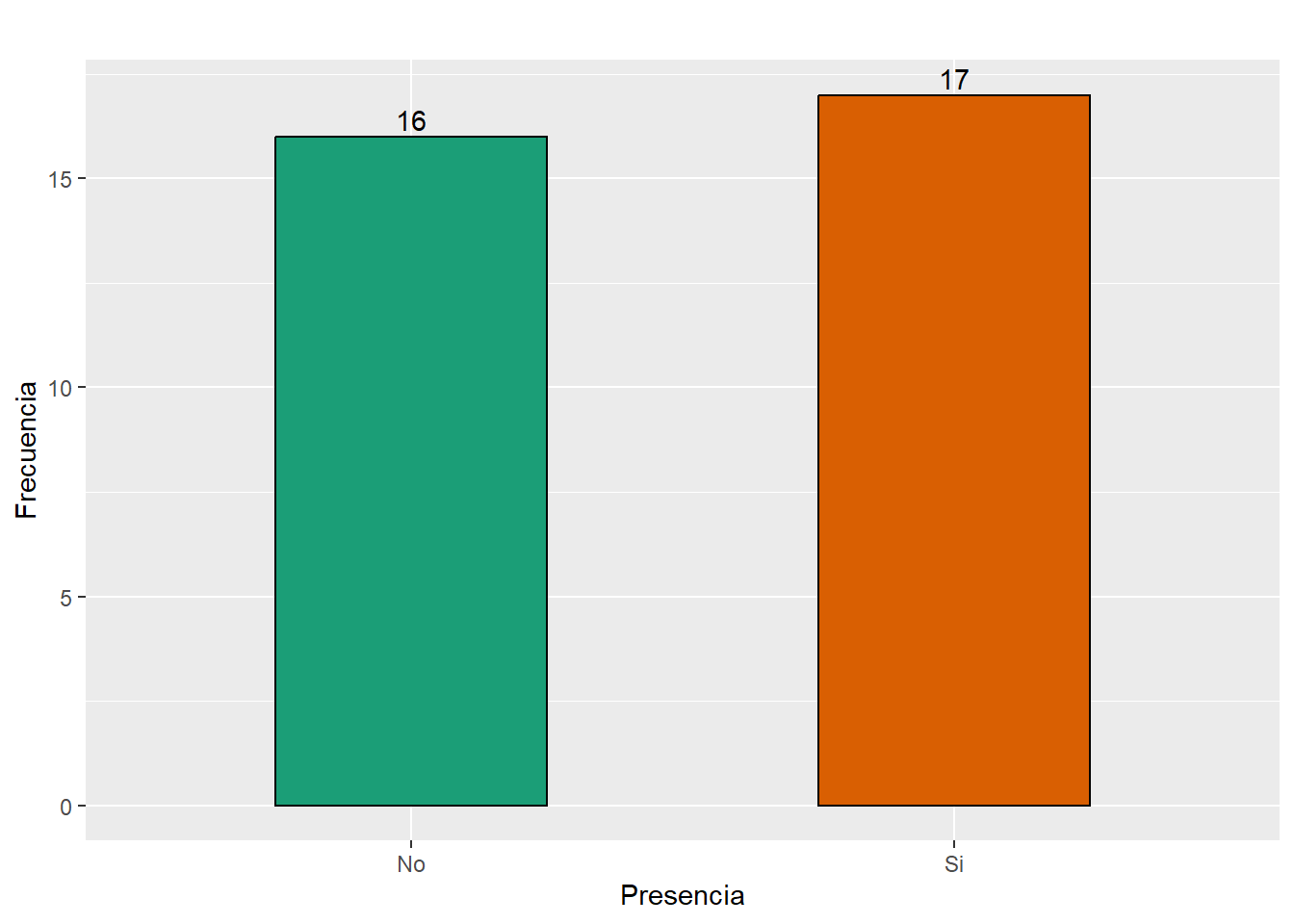
# estrategia_servicios datos
total_estrategia_s <- cuestionarios %>% count(estrategia_servicios)
total_estrategia_s <- total_estrategia_s$n
Total_estrategia_s <- data.frame(si_no, total_estrategia_s)
row.names(Total_estrategia_s) <- NULL
kable(Total_estrategia_s, caption = "Presencia de estrategia servicios municipales",
align= 'r', col.names = c("Presencia", "Total"))| Presencia | Total |
|---|---|
| No | 23 |
| Si | 10 |
# estrategia_servicios gráfico
ggplot(Total_estrategia_s, aes(x = si_no, y = total_estrategia_s)) +
geom_col(aes(fill = si_no), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("Presencia") + scale_y_continuous("Frecuencia") +
labs(title = "") + geom_text(aes(label = total_estrategia_s), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill = "none")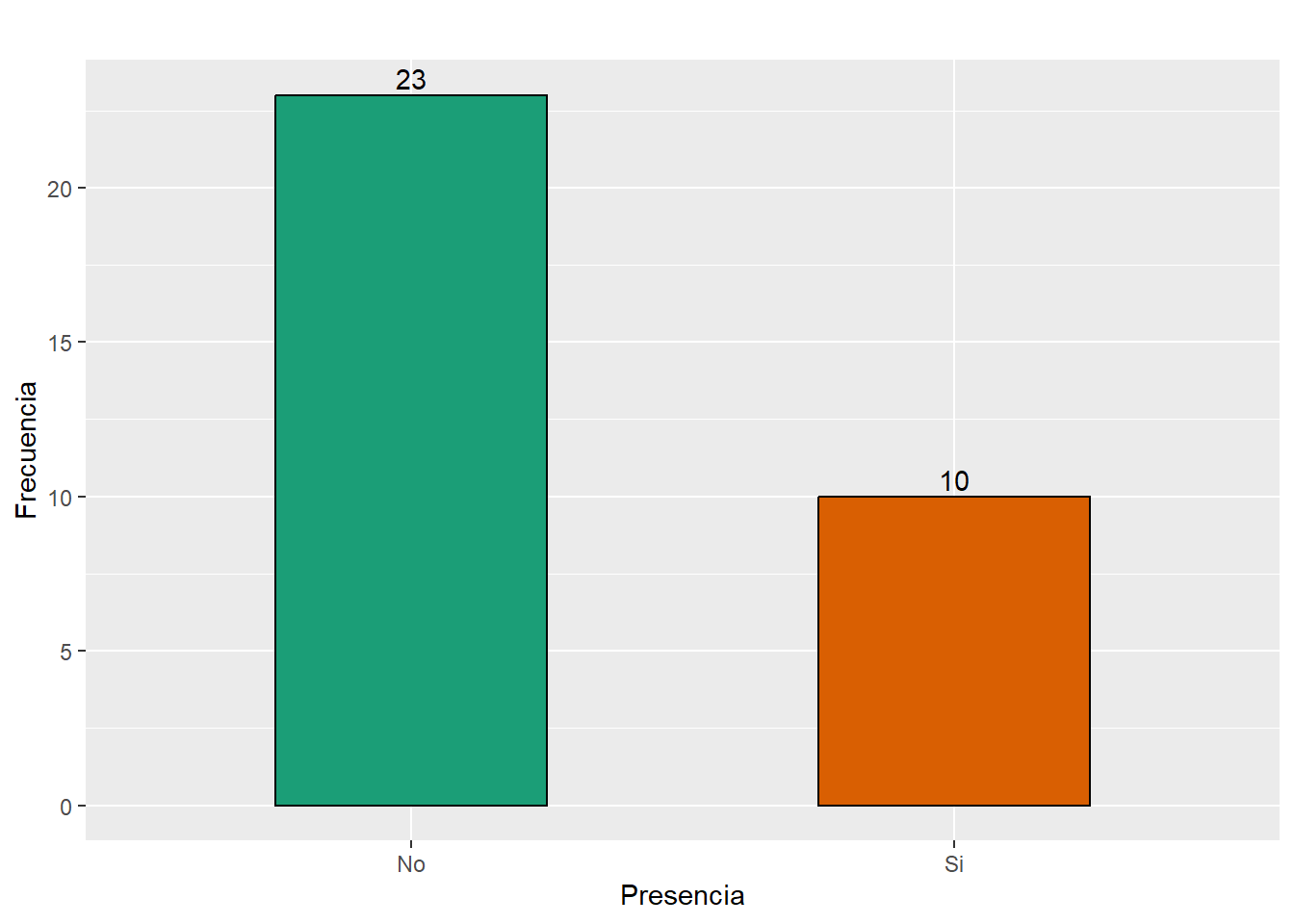
# estrategia_gestión datos
total_estrategia_g <- cuestionarios %>% count(estrategia_gestion)
total_estrategia_g <- total_estrategia_g$n
Total_estrategia_g <- data.frame(si_no, total_estrategia_g)
row.names(Total_estrategia_s) <- NULL
kable(Total_estrategia_g, caption = "Presencia de estrategia de gestión municipal",
align= 'r', col.names = c("Presencia", "Total"))| Presencia | Total |
|---|---|
| No | 22 |
| Si | 11 |
# estrategia_gestion gráfico
ggplot(Total_estrategia_g, aes(x = si_no, y = total_estrategia_g)) +
geom_col(aes(fill = si_no), colour = "black", position = "dodge",
width = 0.5) + scale_x_discrete("Presencia") + scale_y_continuous("Frecuencia") +
labs(title = "") + geom_text(aes(label = total_estrategia_g), vjust = -0.3) +
scale_fill_brewer(palette = "Dark2") + guides(fill = "none")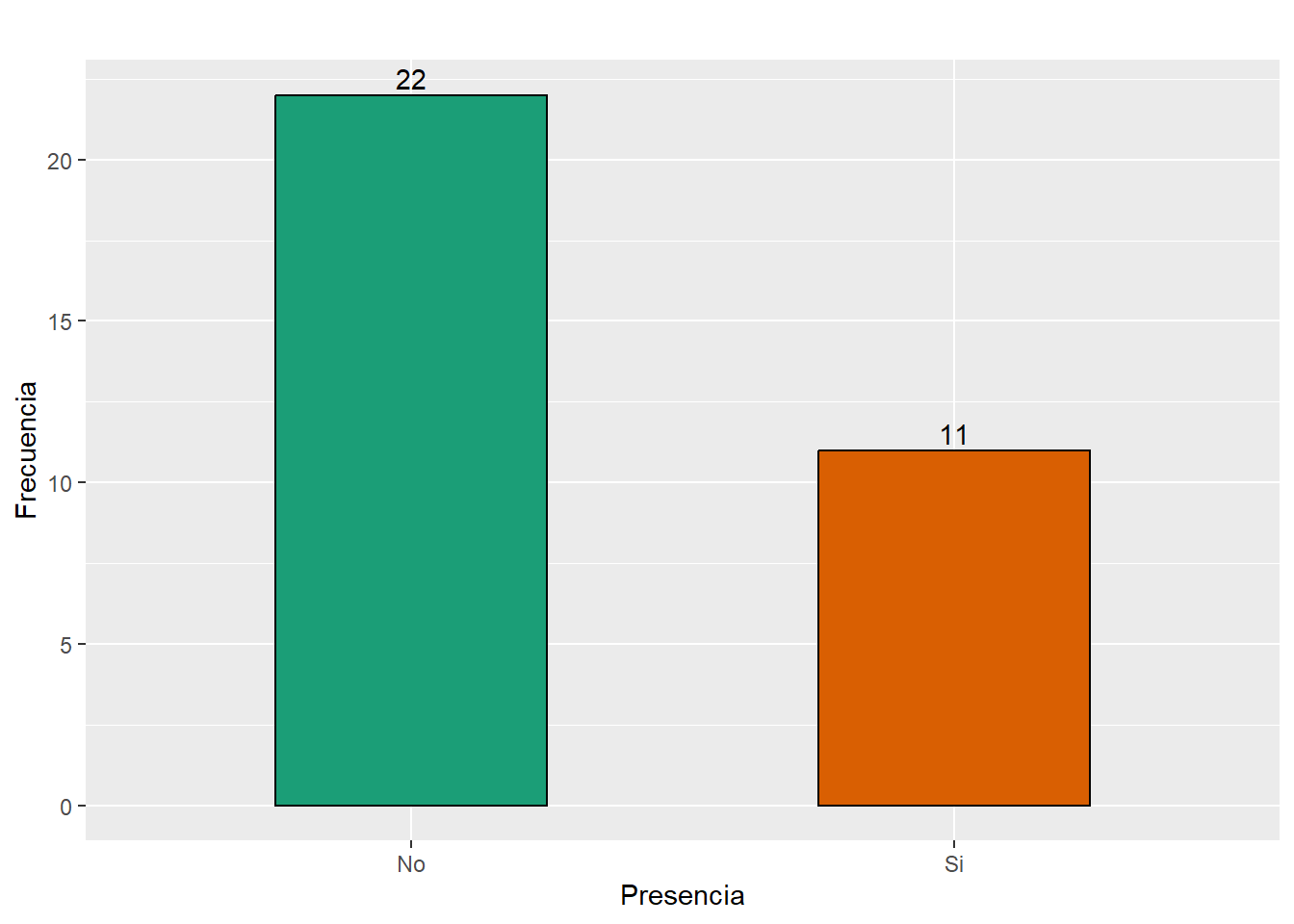
# procesos datos
T_proc <- colSums(procesos[ , 4:21], na.rm = TRUE) #1er paso
n_proc <- c("Inventario", "Oficina de Partes (Documentos)",
"Aseo y Ornato (Parques y Jardines)", "Planificación y control presupuestario",
"Ingreso/egreso Tesorería", "Rentas y Patentes", "Licencias de conducir",
"Permisos de circulación", "Juzgado de policía local y registro de multas", "Inspección",
"Administración del cementerio municipal", "Registro Social de hogares",
"Subsidios (incluye asistencia social y apoyo a la comunidad)", "OMIL (bolsa de empleo)", "Organizaciones comunitarias", "Dirección de obras municipales (DOM)",
"Administración de consultorios / farmacias", "Ventanilla única") #2do paso
l_proc <- c(1:18)
T_proc <- data.frame(l_proc, n_proc, T_proc) # 3er crear DF
row.names(T_proc) <- NULL # 4to paso quitar rownames
kable(T_proc, caption = "Total de procesos", align = 'c',
col.names = c("Num", "Nombre procesos", "Total")) # 5to paso crear tabla| Num | Nombre procesos | Total |
|---|---|---|
| 1 | Inventario | 28 |
| 2 | Oficina de Partes (Documentos) | 25 |
| 3 | Aseo y Ornato (Parques y Jardines) | 7 |
| 4 | Planificación y control presupuestario | 26 |
| 5 | Ingreso/egreso Tesorería | 32 |
| 6 | Rentas y Patentes | 32 |
| 7 | Licencias de conducir | 29 |
| 8 | Permisos de circulación | 31 |
| 9 | Juzgado de policía local y registro de multas | 27 |
| 10 | Inspección | 14 |
| 11 | Administración del cementerio municipal | 14 |
| 12 | Registro Social de hogares | 22 |
| 13 | Subsidios (incluye asistencia social y apoyo a la comunidad) | 19 |
| 14 | OMIL (bolsa de empleo) | 16 |
| 15 | Organizaciones comunitarias | 17 |
| 16 | Dirección de obras municipales (DOM) | 18 |
| 17 | Administración de consultorios / farmacias | 14 |
| 18 | Ventanilla única | 11 |
# cleveland procesos
ggplot(T_proc, aes(x = T_proc, y = reorder(n_proc, T_proc))) +
geom_point(size = 2) + labs(title = "", y = "Nombre procesos",
x = "Total procesos municipales" ) + theme_bw() +
theme(panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_line(colour = "gold", linetype = "dashed"))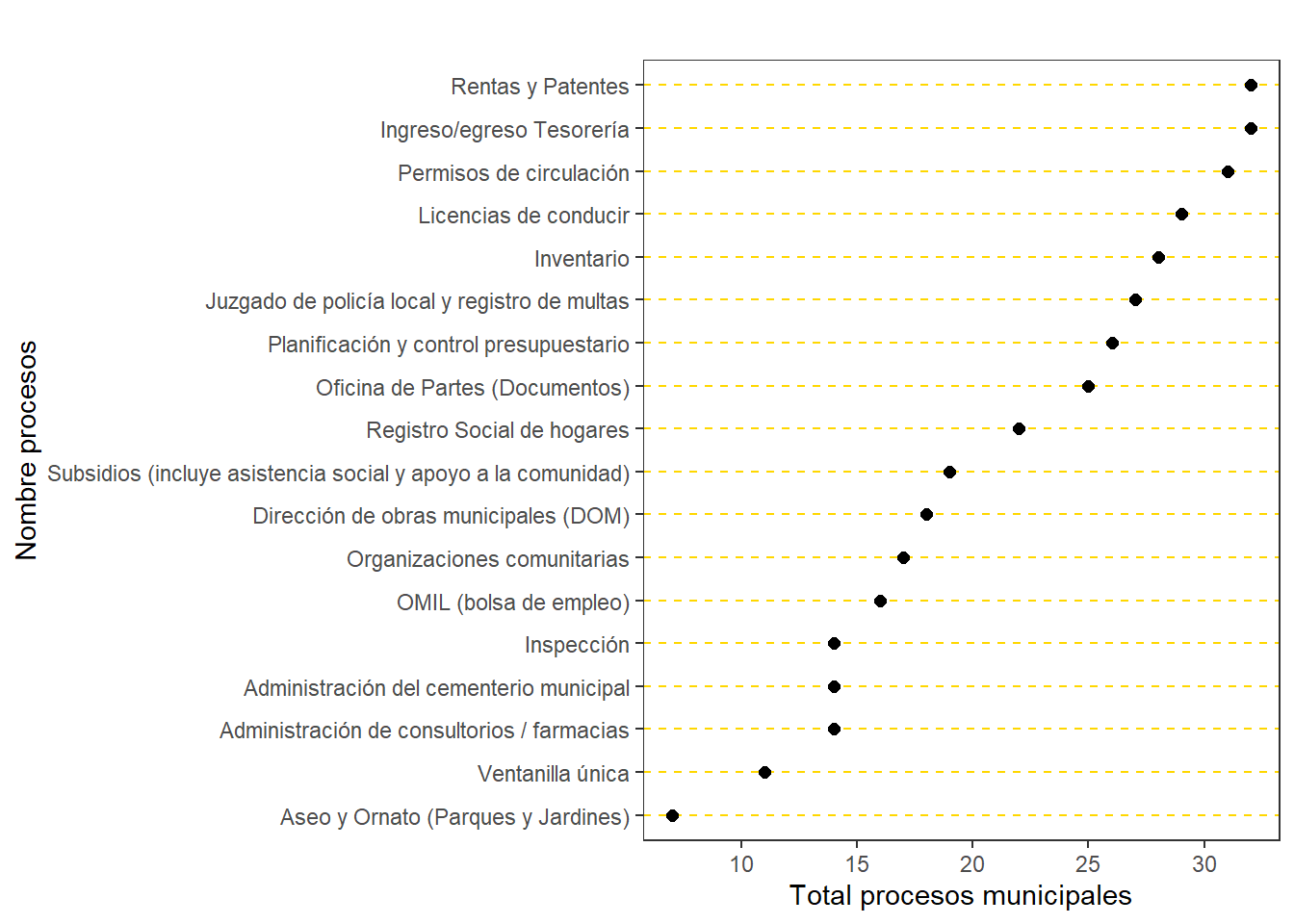
Correlación estrategias y subíndices
cor_es_t <- cor(cuestionarios$estrategia_servicios, cuestionarios$tramites,
use = "everything", method=c("pearson"))
cor_eg_p <- cor(cuestionarios$estrategia_gestion, cuestionarios$procesos,
use = "everything", method=c("pearson"))
n_estrategias <- c("Estrategia servicios", "Estrategia gestión")
n_subindice <- c("Subíndice tramites", "Subíndice procesos")
valores_correlacion <- c(cor_es_t, cor_eg_p)
cor_estrategias <- data.frame(n_estrategias, n_subindice, valores_correlacion)
kable(cor_estrategias, digits = 3, align = 'c', caption =
"Correlación entre estrategias y subíndices",
col.names = c("Estrategias", "Subíndices", "Correlación"))| Estrategias | Subíndices | Correlación |
|---|---|---|
| Estrategia servicios | Subíndice tramites | 0.299 |
| Estrategia gestión | Subíndice procesos | 0.556 |
Resultados SML
T_tramite <- colSums(tramites[ , 4:26], na.rm = TRUE)
n_tramite <- c("Obtención de Patente comercial",
"Renovación de la Patente comercial", "Pago de la Patente comercial",
"Obtención de la Patente industrial", "Renovación de la Patente industrial",
"Obtención de Patente de alcoholes", "Renovación de la Patente de alcoholes",
"Pago de la Patente de alcoholes", "Certificado de no expropiación",
"Permiso de demolición", "Obtención de Permiso de edificación",
"Renovación de Permiso de edificación", "Pago de Permiso de edificación",
"Permiso de uso de bienes nacionales de uso público", "Informe de zonificación",
"Recepción de obra", "Certificado de informaciones previas", "Permiso de circulación",
"Pago de multas en Juzgado de policía local", "Solicitud de corte y poda de árboles",
"Solicitud de cambio de domicilio", "Obtención de Patente comercial", "Otro")
l_tramite <- c(1:23)
T_tramites <- data.frame(l_tramite, n_tramite, T_tramite)
row.names(T_tramites) <- NULL
kable(T_tramites, caption = "Total de trámites", align= 'r', col.names =
c("Num", "Nombre trámites", "Total"))| Num | Nombre trámites | Total |
|---|---|---|
| 1 | Obtención de Patente comercial | 6 |
| 2 | Renovación de la Patente comercial | 8 |
| 3 | Pago de la Patente comercial | 16 |
| 4 | Obtención de la Patente industrial | 4 |
| 5 | Renovación de la Patente industrial | 5 |
| 6 | Obtención de Patente de alcoholes | 3 |
| 7 | Renovación de la Patente de alcoholes | 5 |
| 8 | Pago de la Patente de alcoholes | 10 |
| 9 | Certificado de no expropiación | 8 |
| 10 | Permiso de demolición | 8 |
| 11 | Obtención de Permiso de edificación | 8 |
| 12 | Renovación de Permiso de edificación | 6 |
| 13 | Pago de Permiso de edificación | 8 |
| 14 | Permiso de uso de bienes nacionales de uso público | 5 |
| 15 | Informe de zonificación | 7 |
| 16 | Recepción de obra | 7 |
| 17 | Certificado de informaciones previas | 7 |
| 18 | Permiso de circulación | 29 |
| 19 | Pago de multas en Juzgado de policía local | 9 |
| 20 | Solicitud de corte y poda de árboles | 3 |
| 21 | Solicitud de cambio de domicilio | 3 |
| 22 | Obtención de Patente comercial | 4 |
| 23 | Otro | 7 |
ggplot(T_tramites, aes(x = T_tramite, y = reorder(n_tramite, T_tramite))) +
geom_point(size = 1) + labs(title = "", y = "Nombre trámite",
x = "Total de trámites municipales" ) + theme_bw() +
theme(panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_line(colour = "coral", linetype = "dashed"))
Objetivo 2: Categorizar
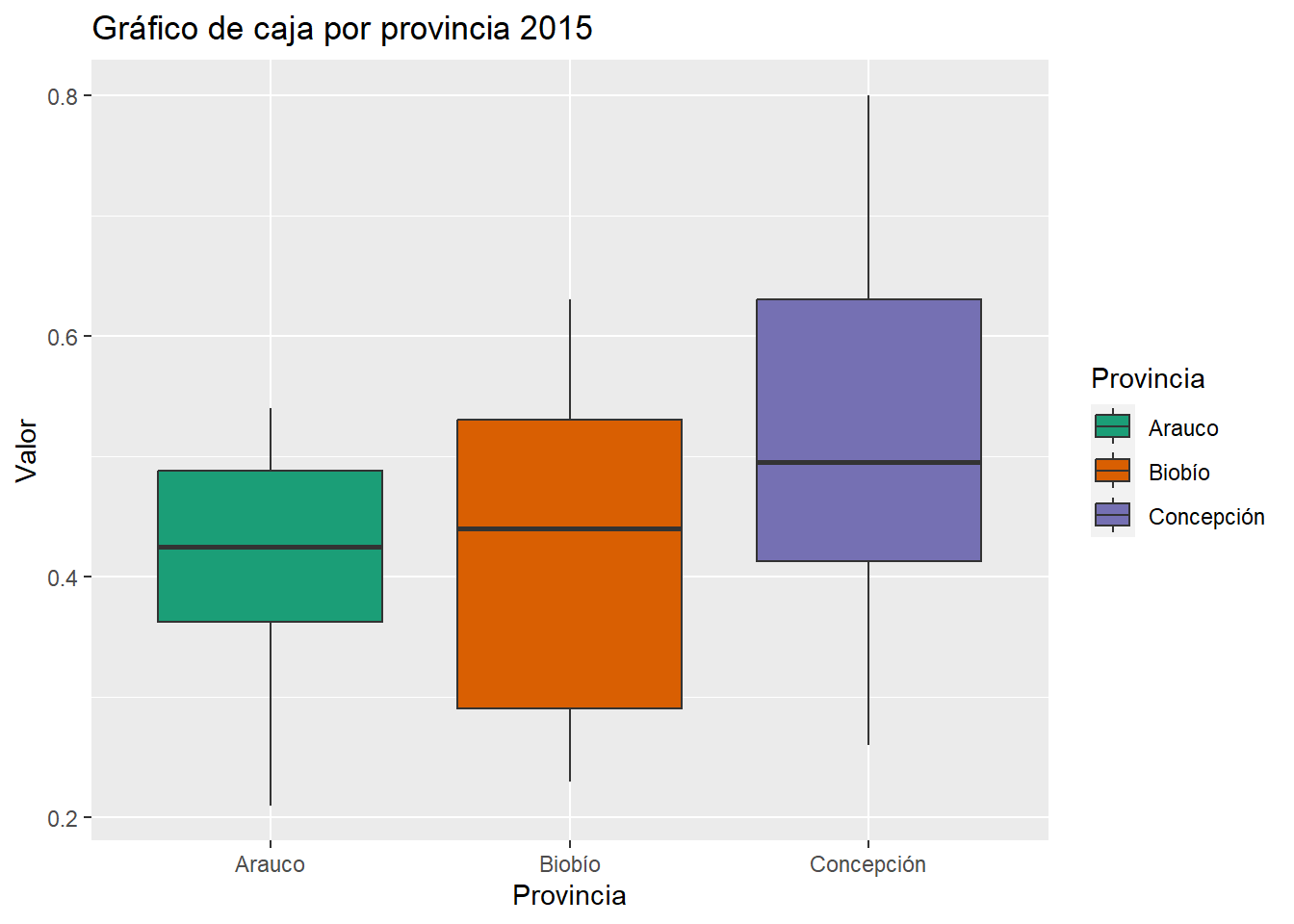
Para Categorizar según FIGEM y Provincia se filtrará el Dataframe y se realizará estadística descriptiva, también gráficos de caja.
FIGEM_1 <- filter(cuestionarios, FIGEM== 1)
FIGEM_2 <- filter(cuestionarios, FIGEM== 2)
FIGEM_3 <- filter(cuestionarios, FIGEM== 3)
FIGEM_4 <- filter(cuestionarios, FIGEM== 4)
FIGEM_5 <- filter(cuestionarios, FIGEM== 5)
Provincia_conce <- filter(cuestionarios, Provincia== "Concepción")
Provincia_biobio <- filter(cuestionarios, Provincia== "Biobío")
Provincia_arauco <- filter(cuestionarios, Provincia== "Arauco")Estadística descriptiva FIGEM
Descr_F1 <- stats_descr(FIGEM_1$IMTM_2022)
Descr_F2 <- stats_descr(FIGEM_2$IMTM_2022)
Descr_F3 <- stats_descr(FIGEM_3$IMTM_2022)
Descr_F4 <- stats_descr(FIGEM_4$IMTM_2022)
Descr_F5 <- stats_descr(FIGEM_5$IMTM_2022)
Categorizar_F <- data.frame(Descr_F1, Descr_F2, Descr_F3, Descr_F4, Descr_F5)
kable(Categorizar_F, digits = 2, align = 'r', caption =
"Estadística descriptiva IMTM 2022 por FIGEM",
col.names = c("1", "2", "3","4", "5"))| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| Mínimo | 0.73 | 0.39 | 0.26 | 0.31 | 0.20 |
| Primer_Cuartil.25% | 0.73 | 0.50 | 0.34 | 0.35 | 0.26 |
| Media | 0.79 | 0.59 | 0.45 | 0.40 | 0.36 |
| Máximo | 0.89 | 0.78 | 0.65 | 0.49 | 0.57 |
| Mediana | 0.79 | 0.62 | 0.42 | 0.40 | 0.33 |
| Variación | 0.00 | 0.02 | 0.02 | 0.02 | 0.01 |
| Desviación_estandar | 0.07 | 0.14 | 0.13 | 0.12 | 0.12 |
| Tercer_Cuartil.75% | 0.81 | 0.63 | 0.56 | 0.44 | 0.45 |
| Rango | 0.16 | 0.38 | 0.38 | 0.18 | 0.37 |
| Rango_Intercuartil.75% | 0.08 | 0.13 | 0.22 | 0.09 | 0.18 |
| Asimetria | 0.32 | -0.03 | 0.06 | 0.00 | 0.35 |
| Curtosis | -1.77 | -1.75 | -1.69 | -2.75 | -1.38 |
Boxplot IMTM 2022 según FIGEM
cuestionarios$FIGEM <- factor(cuestionarios$FIGEM)
qplot(data = cuestionarios, x = FIGEM, y = IMTM_2022, fill = FIGEM,
geom = "boxplot", ylab = "Valor", main = "Gráfico de caja por FIGEM 2022") +
scale_fill_brewer(palette = "Dark2")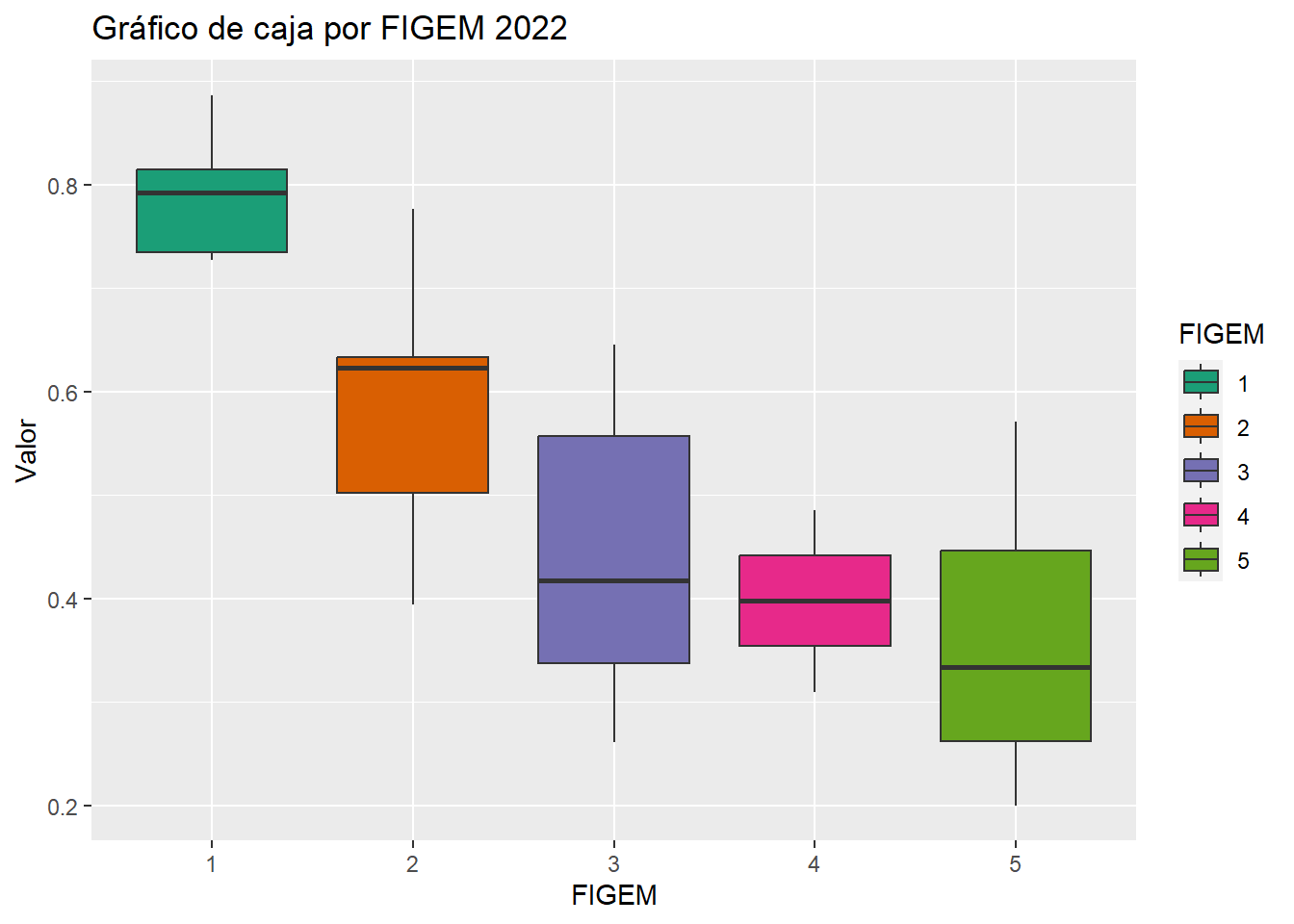
Boxplot IMTM 2015 según FIGEM
IMTM_2015$FIGEM <- factor(IMTM_2015$FIGEM)
qplot(data = IMTM_2015, x = FIGEM, y = IMTM_2015, fill = FIGEM,
geom = "boxplot", ylab = "Valor", main = "Gráfico de caja por FIGEM 2015") +
scale_fill_brewer(palette = "Dark2")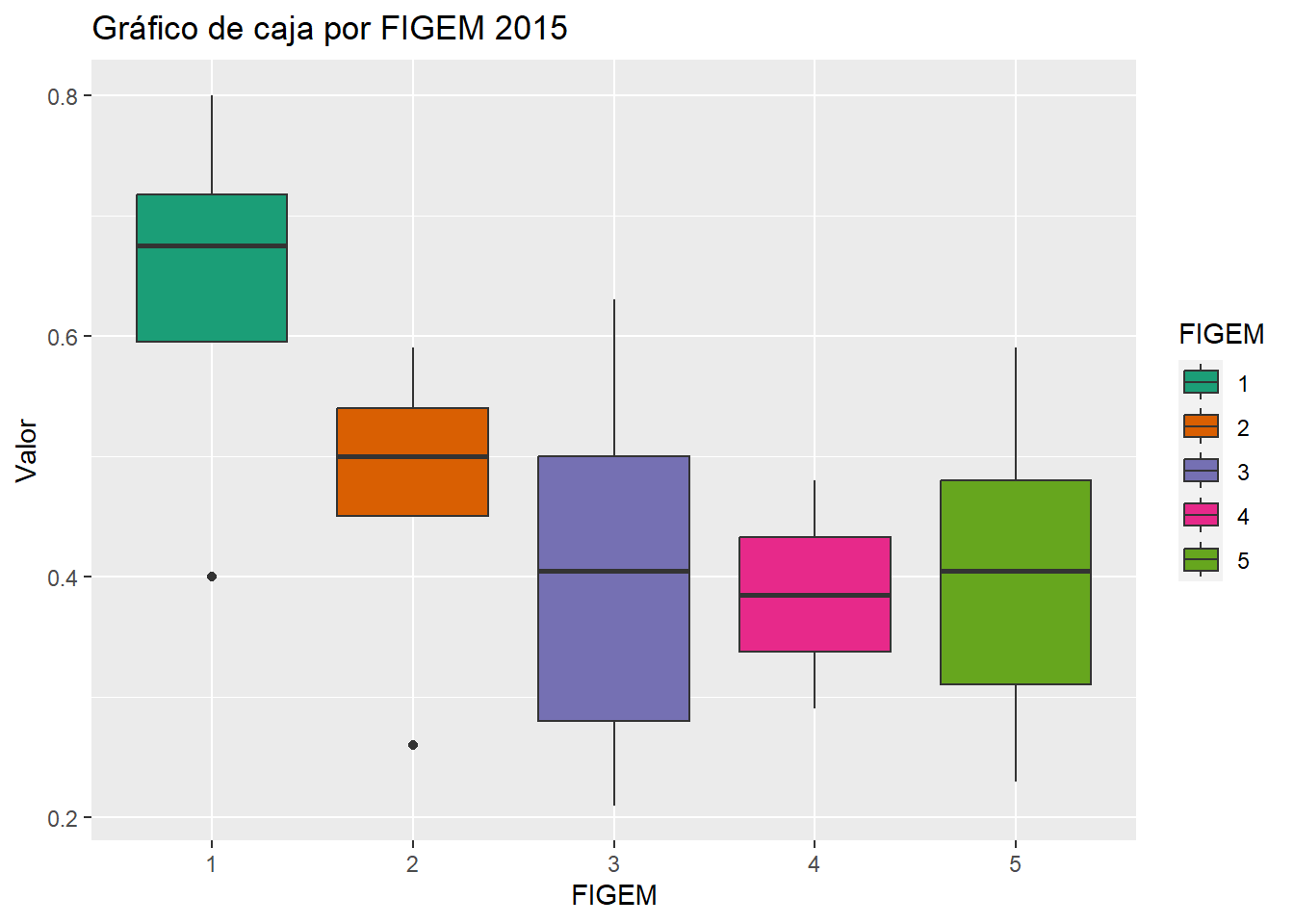
Estadística descriptiva Provincia
Descr_Concepcion <- stats_descr(Provincia_conce$IMTM_2022)
Descr_Biobio <- stats_descr(Provincia_biobio$IMTM_2022)
Descr_Arauco <- stats_descr(Provincia_arauco$IMTM_2022)
Categorizar_P <- data.frame(Descr_Concepcion, Descr_Biobio, Descr_Arauco)
kable(Categorizar_P, digits = 2, align = 'r', caption =
"Estadística descriptiva IMTM 2022 por provincia",
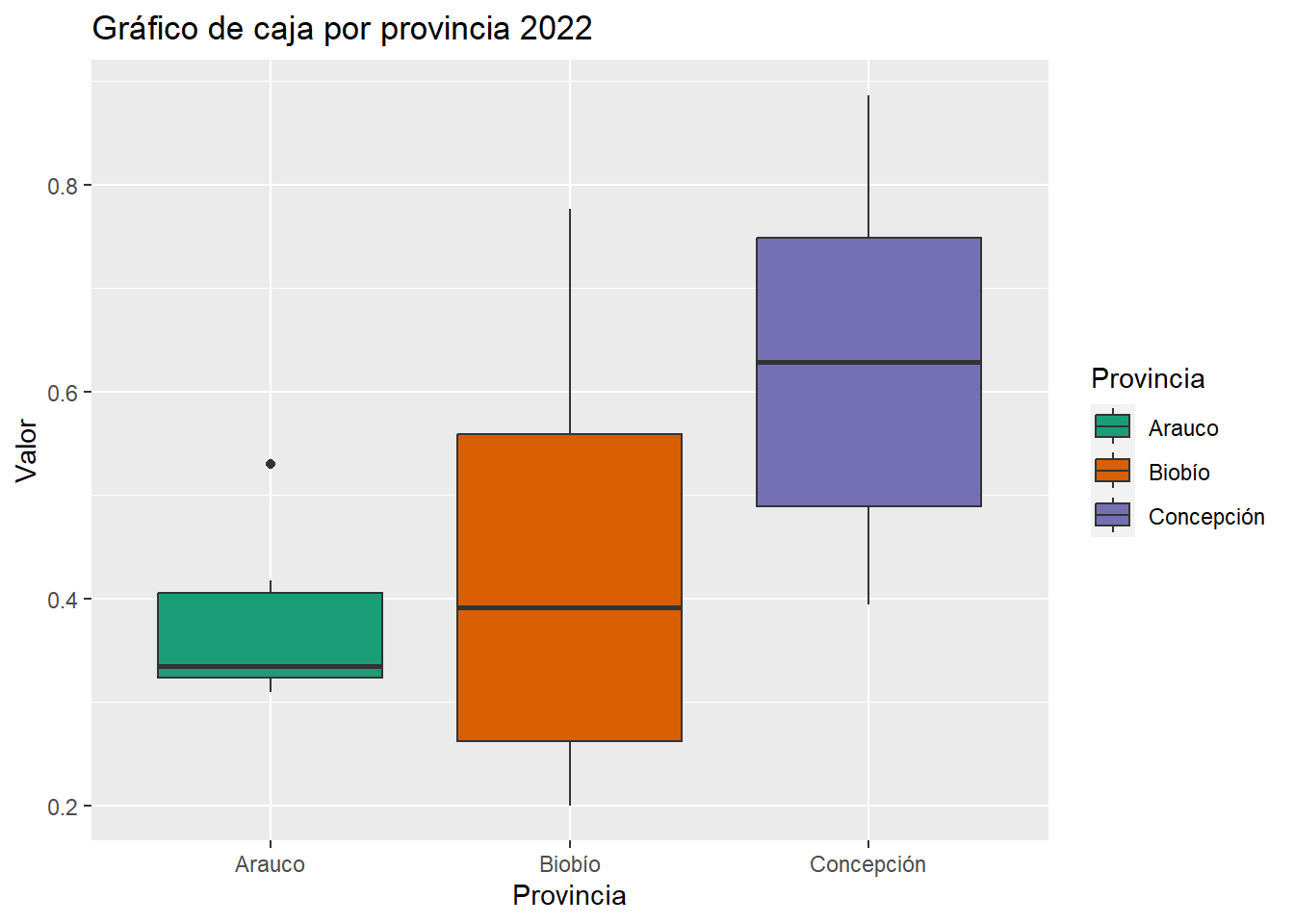
col.names = c("Concepción", "Biobío", "Arauco"))| Concepción | Biobío | Arauco | |
|---|---|---|---|
| Mínimo | 0.39 | 0.20 | 0.31 |
| Primer_Cuartil.25% | 0.49 | 0.26 | 0.32 |
| Media | 0.63 | 0.42 | 0.38 |
| Máximo | 0.89 | 0.78 | 0.53 |
| Mediana | 0.63 | 0.39 | 0.33 |
| Variación | 0.03 | 0.03 | 0.01 |
| Desviación_estandar | 0.17 | 0.18 | 0.08 |
| Tercer_Cuartil.75% | 0.75 | 0.56 | 0.41 |
| Rango | 0.49 | 0.58 | 0.22 |
| Rango_Intercuartil.75% | 0.26 | 0.30 | 0.08 |
| Asimetria | 0.03 | 0.40 | 0.88 |
| Curtosis | -1.58 | -1.27 | -0.79 |