4 OCR and its problems
4.1 Introduction
OCR, or ‘Optical Character Recognition’, is a series of methods for turning the text in digitised images into machine-readable code.
4.2 What is it like in 19th century newspapers
This is a difficult question to answer, because it varies so much between projects, format and dates. The truth is, nobody really knows what it’s like, because that would involve having large sets of very accurate, manually transcribed newspapers, to compare to the OCR text. Subjectively, we can probably make a few generalisations.
It gets better as the software gets better, but not particularly quickly, because much of the quality is dependant on things to do with the physical form.
Digitising from print is much better than from microfilm. But print can still be bad.
Standard text is much better than non-standard. For example, different fonts, sizes, and so forth.
Advertisements seem to have particularly bad OCR - they are generally not in regular blocks of text, which the OCR software finds difficult, and they often used non-standard characters or fonts to stand out.
The time dimension is not clear: type probably got better, but it also got smaller, more columns.
Problems with the physical page have a huge effect: rips, tears, foxing, dark patches and so forth. Many errors are not because of the microfilm, digital image or software, and may not be fixable.
What does this all mean? Well, it introduces bias, and probably in non-random ways, but in ways that have implications for our work. If things are digitised from a mix of print and microfilm, for example, we might get very different results for the print portion, which might easily be mis-attributed to a historical finding. Perhaps there were twice as many mentions of cheese in the 1850s than in the 1890s? It’s probably best to rule out that this is not just because later newspapers had a difficult font, or they were digitised from microfilm instead of print.1
4.3 OCR report on the first some batches of historical newspapers
The files returned from newspaper digitisers contain a ‘predicted word accuracy score’ percentage for each page. These can be extracted and visualised, with some interesting conclusions. However it’s important to note these are not calculated by comparing actual results to the OCR, but rather use an internal algorithm. Some links worth reading to understand more about OCR and confidence scores:
OCR software calculates a confidence level for each character it detects. Word and page confidence levels can be calculated from the character confidences using algorithms either inside the OCR software or as an external customised process. The OCR software doesn’t know whether any character is correct or not – it can only be confident or not confident that it is correct. It will give it a confidence level from 0-9. True accuracy, i.e., whether a character is actually correct, can only be determined by an independent arbiter, a human. This can be done by proofreading articles or pages, or by manually re-keying the entire article or page and comparing the output to the OCR output. These methods are very time consuming. (http://www.dlib.org/dlib/march09/holley/03holley.html)
Because Abbyy Finereader is a commercial product, the software that predicts its accuracy is not freely available for inspection. As such, we should not make too much of the figure presented here, which certainly does not align with a human reader’s assessment of the page’s overall similarity to the words on the page images. (https://ryancordell.org/research/qijtb-the-raven-mla/)
4.4 Extract predicted word scores from the ALTO pages
Generate Library colour scheme palettes:
4.5 Visualisations:
4.5.1 What’s in this data?
The data includes 290,000 separate ALTO files, each representing one page. From the files, the ‘predicted word accuracy’ score has been extracted, and turned into a dataframe. The data contains about 117,000 files digitised from microfilm, and 173,000 digitised from print. This makes an interesting dataset to compare OCR quality scores across two different formats, by the same company at the same time.
Comparison between pages: This visualisation shows pages on the y axis and time on the x axis. Each page is a separate ‘band’. Lighter colours (yellow) represent a higher reported score.
Front pages have consistently lower scores than other pages. This is mostly because the front pages of 19th century newspapers contained mostly adverts, which OCR software finds difficult to process because of the variety in type and layout.
This visualisation also shows the existence of multiple editions: dark lines on pages 9, 17 etc. are front pages of subsequent editions which have also been scanned under the same date. Points have been randomly spaced out for readability.
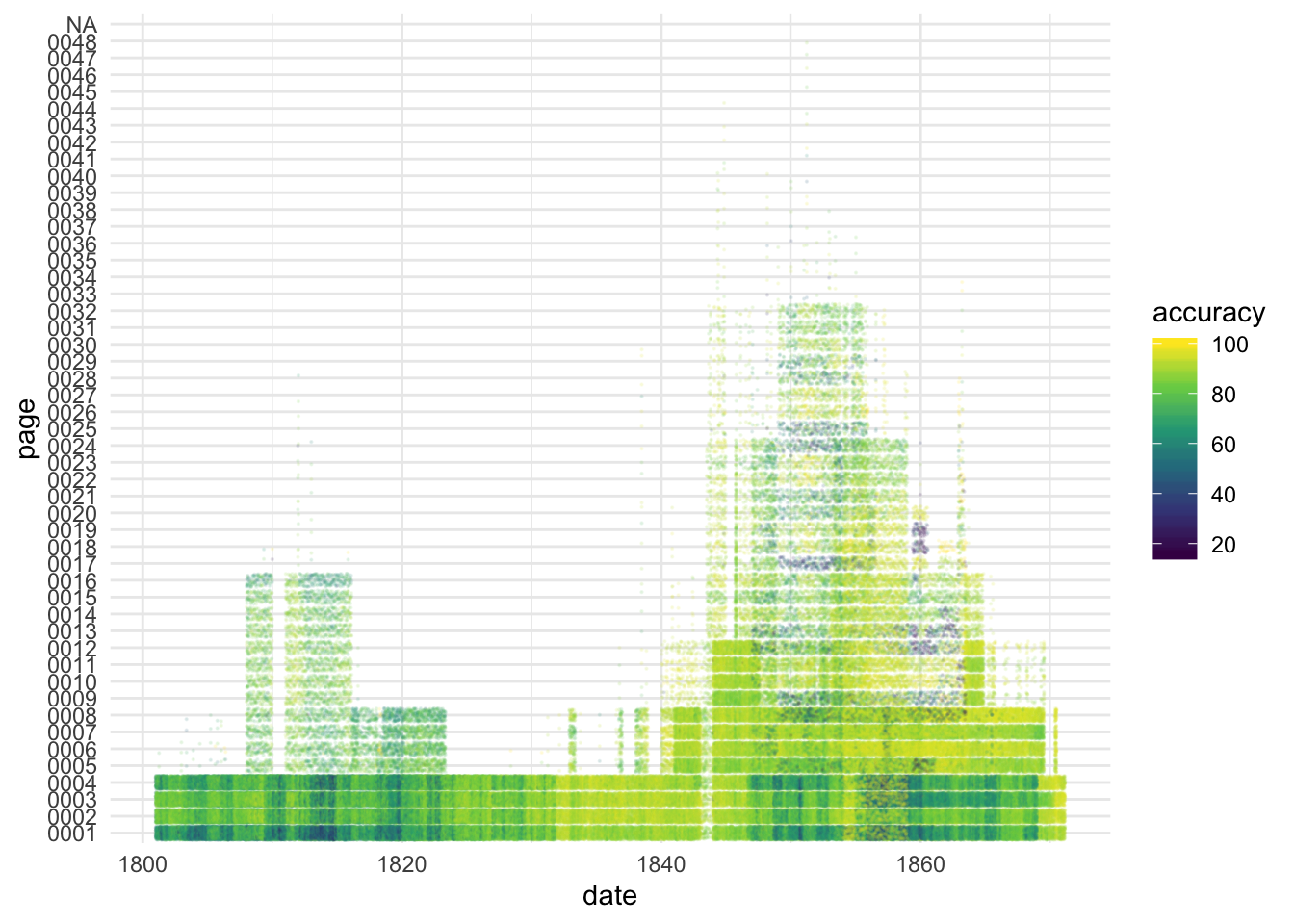
Figure 4.1: OCR accuracy visualised by page, across the dataset. Lighter colours represent higher accuracy. Clear difference between the front and subsequent pages can be seen.
4.6 Highest and lowest results:
The lowest results are all from the Lady’s Newspaper - this was an illustrated title and so the score is probably meaningless.
| accuracy | nlp | date | page |
|---|---|---|---|
| 15.8 | 0002254 | 1859-09-03 | 0005 |
| 16.5 | 0002254 | 1859-12-31 | 0019 |
| 16.5 | 0002254 | 1860-01-07 | 0019 |
| 16.5 | 0002254 | 1860-07-21 | 0013 |
| 16.5 | 0002254 | 1862-01-25 | 0013 |
| 16.5 | 0002254 | 1862-04-19 | 0013 |
| 16.6 | 0002254 | 1859-10-22 | 0019 |
| 16.7 | 0002254 | 1859-11-12 | 0012 |
| 16.7 | 0002254 | 1860-01-21 | 0019 |
| 16.7 | 0002254 | 1860-09-08 | 0012 |
The highest scores are blank pages:
| accuracy | nlp | date | page |
|---|---|---|---|
| 100 | 0002083 | 1853-10-15 | 0006 |
| 100 | 0002083 | 1853-10-26 | 0010 |
| 100 | 0002083 | 1853-11-09 | 0010 |
| 100 | 0002083 | 1853-11-14 | 0010 |
| 100 | 0002083 | 1853-11-15 | 0010 |
| 100 | 0002083 | 1853-11-16 | 0010 |
| 100 | 0002083 | 1853-11-17 | 0010 |
| 100 | 0002083 | 1853-11-19 | 0010 |
| 100 | 0002083 | 1853-11-21 | 0010 |
| 100 | 0002083 | 1853-11-23 | 0010 |
4.7 Page-by-page OCR visualisation
We can look at the difference in OCR accuracy by page position. The front page consistently has the lowest predicted accuracy. The exception is a group of first-page files in late 1860s: these were copies of the Sun and Central Press which were printed with two columns and large type, and without adverts on the first page.
In general the predicted accuracy scores move upwards over time, and variation decreases. This is particularly clear in titles processed from print as the ntext
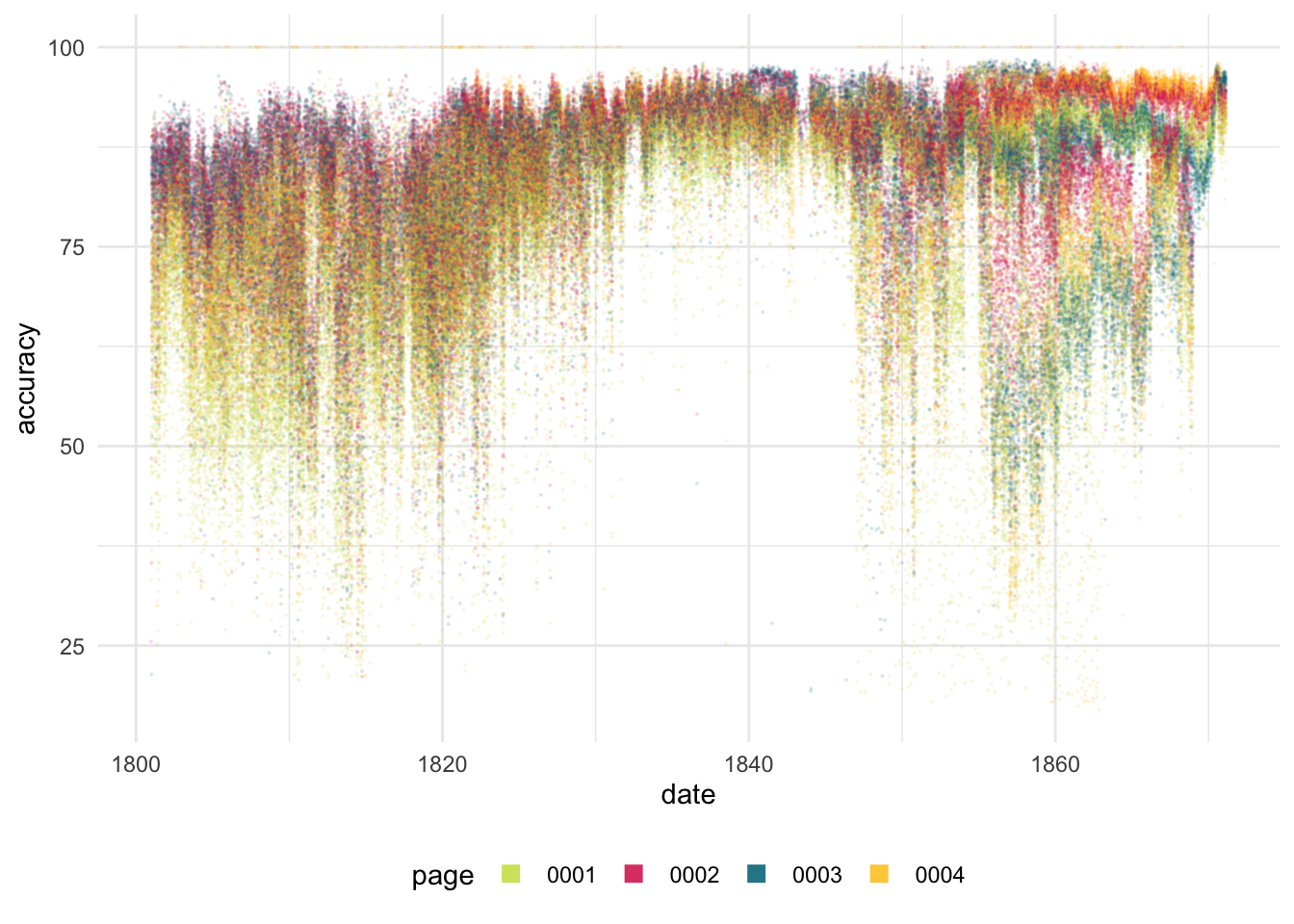
Figure 4.2: Visualising OCR accuracy scores. Each dot represents a single page, positioned by date and reported accuracy. Pages are coloured by page position. Only the first four page positions are shown, for readability
4.8 Microfilm vs print:
Approximately half of the data is from titles which were processed from microfilm, allowing a useful comparison between the scores of microfilm and print titles. The microfilm titles have, as expected, consistently lower accuracy, particularly the distribution.
Particularly apparent is the difference in improvement over time: There’s no obvious increase in the scores of microfilm titles over time, but there is a significant change in print titles: from 1825 the predicted accuracy scores for print increase significantly, and the variation reduces noticeably.
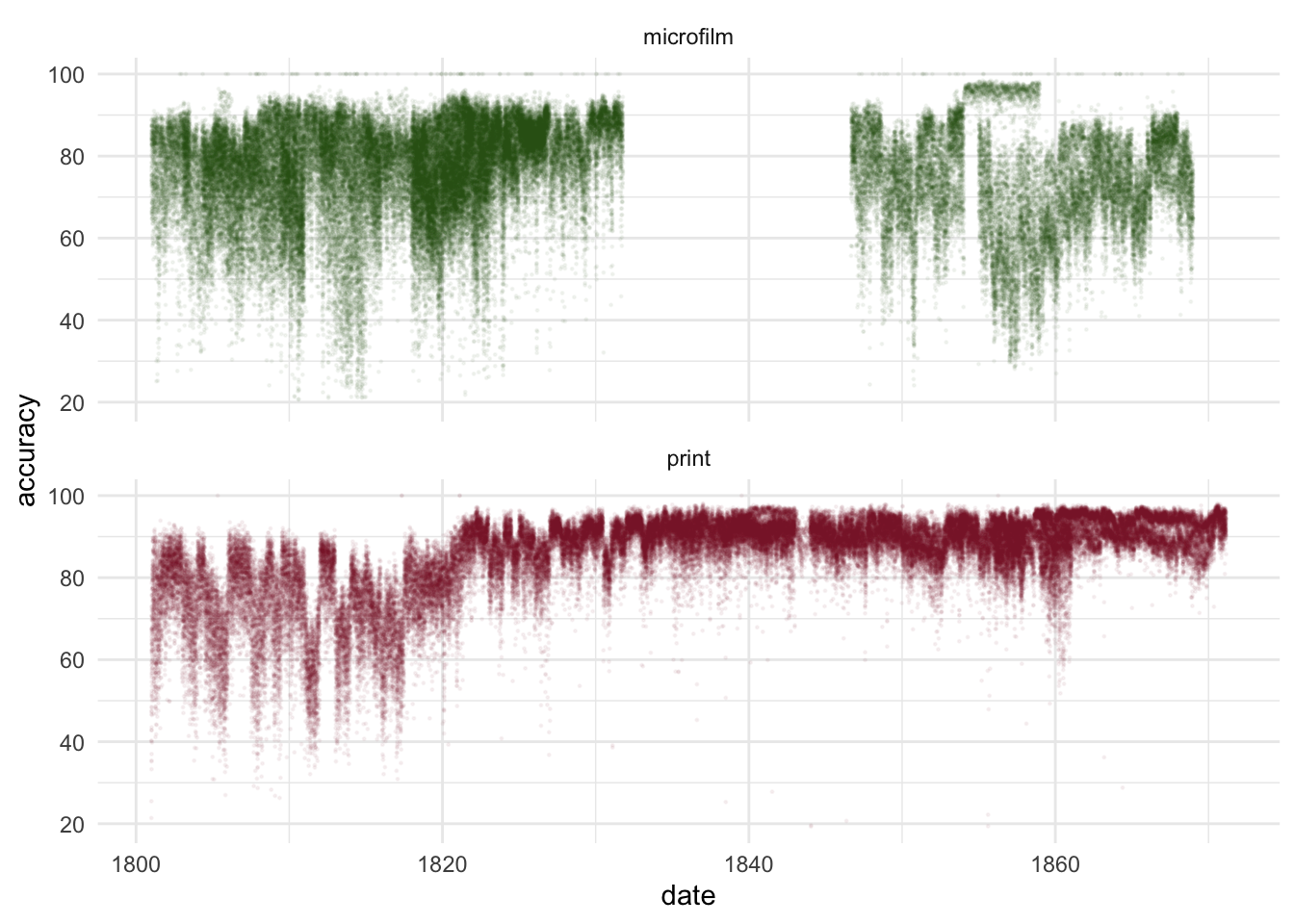
Figure 4.3: Microfilm vs Print: difference in the distribution and evolution of accuracy scores for titles digitised from both formats.
Charting the average score (averaged over an entire year, so take with a pinch of salt) shows the different between microfilm and print more starkly:
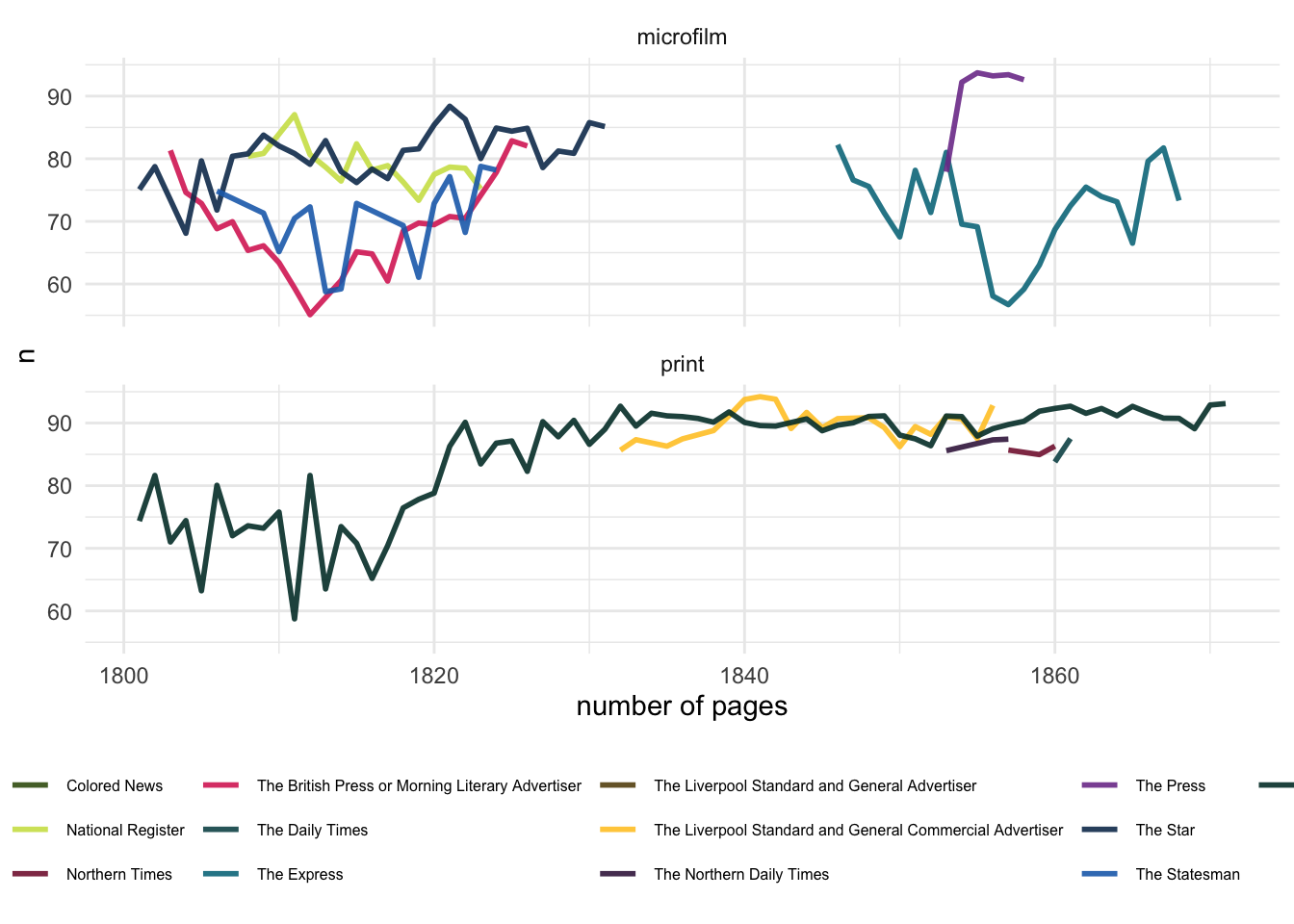
Figure 4.4: A broad view of improvement. Print titles show much more improvement in the assessed accuracy of the OCR over time
4.9 Conclusions
This short report shows that the OCR accuracy -if the predicted word accuracy score included in the ALTO metadata is in any way a useful proxy - improves over time, and from 1825 onwards, the predicted scores for titles scanned from print are particularly high and consistent. Pages of advertising, as expected, show the lowest accuracy scores, and the scores are meaningless for illustrated titles.
These reports could be generated for each batch going forward, and made available to researchers using the OCR for research.
4.10 Impact on analysis
It depends. Broad analysis still seems to work - keyword searches, for example, come up with broadly expected results. It might be more important in finer work, for example Natural Language Processing (NLP). NLP relies on
Why You (A Humanist) Should Care About Optical Character Recognition
Mark John Hill and Simon Hengchen, ‘Quantifying the Impact of Dirty Ocr on Historical Text Analysis: Eighteenth Century Collections Online as a Case Study’, Digital Scholarship in the Humanities : DSH, 2019 <https://doi.org/10.1093/llc/fqz024>, @Cordell_2017, @Piotrowski_2012, @cordell-ocr, @evershed-ocr.↩