7 Quick introduction to R and the tidyverse
The motivation behind this book was to provide a way to access and analyse newspaper data using a programming language that I am familiar with. The reason is simple: you write what you know, and I know R best. With its interface, R-Studio, I think it has the easiest transition from someone used to spreadsheet programs, and you’ll realise that most of what you do is filter, sort, count and select columns in a data format called a dataframe.
7.1 What is R and why should you use it?
I think R and R-Studio have the easiest transition from someone used to Excel, and you’ll realise that most of what you do is filter, sort, count and select columns in a data format called a dataframe.
A dataframe is basically a spreadsheet - it contains rows with observations, and columns with variables. Each row is generally a thing, for want of a better word. A thing that wants to be counted, either by summarising it as a more general thing, or turning it into something else and then counting it, or removing some of the things first and then counting the leftovers. For me, thing might be a record of a newspaper title, or a newspaper article (and its text), or it might be a single word.
You can do a lot more interesting tasks with a thing in a dataframe. A thing might be a single polygon, in a huge dataframe of polygons or lines, all of which add up to a map, which we can then count, sort, filter and render as an image or even an interactive.
7.2 Using R
7.2.1 Base R commands
I don’t use them very much, but R does have a bunch of very well-developed commands for doing the sorting, filtering and counting mentioned above. If you want to learn base R, I recommend the following:
It is worth understanding the main types of data that you’ll come across, in your environment window. First, you’ll have dataframes. These are the spreadsheet-like objects which you’ll use in most analyses. They have rows and columns.
Next are variables. A variable is assigned to a name, and then used for various purposes.
You’ll often hear of an item called a vector. A vector is like a python list, if that means anything to you. A vector can be a single column in a dataframe (spreadsheet), which means they are used very often in R to manipulate data. A vector can have different types: for example, a character vector looks like this c("apples", "bananas", "oranges")
A dataframe is just a bunch of vectors side by side.
A vector is created with the command c(), with each item in the vector placed between the brackets, and followed by a comma. If your vector is a vector of words, the words need to be in inverted commas or quotation marks.
fruit = c("apples", "bananas", "oranges", "apples")
colour = c("green", "yellow", "orange", "red")
amount = c(2,5,10,8)You can create a dataframe using the data.frame() command. You just need to pass the function each of your vectors, which will become your columns.
fruit_data = data.frame(fruit,colour,amount, stringsAsFactors = FALSE)Notice above that the third column, the amount, has
All the items in a vector are coerced to the same type. So if you try to make a vector with a combination of numbers and strings, the numbers will be converted to strings. I wouldn’t worried too much about that for now.
So for example if you create this vector, the numbers will get converted into strings.
fruit = c("apples", 5, "oranges", 3)
fruit## [1] "apples" "5" "oranges" "3"Anyway, that’s a dataframe.
7.3 Tidyverse
Most of the work in these notebooks is done using a set of packages developed for R called the ‘tidyverse’. These enhance and improve a large range of R functions, with much nice syntax - and they’re faster too. It’s really a bunch of individual packages for sorting, filtering and plotting data frames. They can be divided into a number of diferent categories.
All these functions work in the same way. The first argument is the thing you want to operate on. This is nearly always a data frame. After come other arguments, which are often specific columns, or certain variables you want to do something with.
You installed the package in the last notebook. Make sure the library is loaded by running the following in an R chunk in a notebook:
library(tidyverse)Here are a couple of the most important ones
7.3.1 select(), pull()
select() allows you to select columns. You can use names or numbers to pick the columns, and you can use a - sign to select everything but a given column.
Using the fruit data frame we created above: We can select just the fruit and colour columns:
select(fruit_data, fruit, colour)## fruit colour
## 1 apples green
## 2 bananas yellow
## 3 oranges orange
## 4 apples redSelect everything but the colour column:
select(fruit_data, -colour)## fruit amount
## 1 apples 2
## 2 bananas 5
## 3 oranges 10
## 4 apples 8Select the first two columns:
select(fruit_data, 1:2)## fruit colour
## 1 apples green
## 2 bananas yellow
## 3 oranges orange
## 4 apples red7.3.2 group_by(), tally(), summarise()
The next group of functions group things together and count them. Sounds boring but you would be amazed by how much of data science just seems to be doing those two things in various combinations.
group_by() puts rows with the same value in a column of your dataframe into a group. Once they’re in a group, you can count them or summarise them by another variable.
First you need to create a new dataframe with the grouped fruit.
grouped_fruit = group_by(fruit_data, fruit)Next we use tally(). This counts all the instances of each fruit group.
tally(grouped_fruit)## # A tibble: 3 × 2
## fruit n
## <chr> <int>
## 1 apples 2
## 2 bananas 1
## 3 oranges 1See? Now the apples are grouped together rather than being two separate rows, and there’s a new column called n, which contains the result of the count.
If we specify that we want to count by something else, we can add that in as a ‘weight’, by adding wt = as an argument in the function.
tally(grouped_fruit, wt = amount)## # A tibble: 3 × 2
## fruit n
## <chr> <dbl>
## 1 apples 10
## 2 bananas 5
## 3 oranges 10That counts the amounts of each fruit, ignoring the colour.
7.3.3 filter()
Another quite obviously useful function. This filters the dataframe based on a condition which you set within the function. The first argument is the data to be filtered. The second is a condition (or multiple condition). The function will return every row where that condition is true.
Just red fruit:
filter(fruit_data, colour == 'red')## fruit colour amount
## 1 apples red 8Just fruit with at least 5 pieces:
filter(fruit_data, amount >=5)## fruit colour amount
## 1 bananas yellow 5
## 2 oranges orange 10
## 3 apples red 87.3.4 sort(), arrange(), top_n()
Another useful set of functions, often you want to sort things. The function arrange() does this very nicely. You specify the data frame, and the variable you would like to sort by.
arrange(fruit_data, amount)## fruit colour amount
## 1 apples green 2
## 2 bananas yellow 5
## 3 apples red 8
## 4 oranges orange 10Sorting is ascending by default, but you can specify descending using desc():
arrange(fruit_data, desc(amount))## fruit colour amount
## 1 oranges orange 10
## 2 apples red 8
## 3 bananas yellow 5
## 4 apples green 2If you `sortarrange() by a list of characters, you’ll get alphabetical order:
arrange(fruit_data, fruit)## fruit colour amount
## 1 apples green 2
## 2 apples red 8
## 3 bananas yellow 5
## 4 oranges orange 10You can sort by multiple things:
arrange(fruit_data, fruit, desc(amount))## fruit colour amount
## 1 apples red 8
## 2 apples green 2
## 3 bananas yellow 5
## 4 oranges orange 10Notice that now red apples are first.
7.3.5 left_join(), inner_join(), anti_join()
7.3.6 Piping
Another great feature of the tidyverse is that you can ‘pipe’ commands through a bunch of functions. This means that you can do one operate, and pass the result to another operation. The previous dataframe is passed as the first argument of the next function by using the pipe %>% command. It works like this:
fruit_data %>%
filter(colour != 'yellow') %>% # remove any yellow colour fruit
group_by(fruit) %>% # group the fruit by type
tally(amount) %>% # count each group
arrange(desc(n)) # arrange in descending order of the count## # A tibble: 2 × 2
## fruit n
## <chr> <dbl>
## 1 apples 10
## 2 oranges 10That code block, written in prose: “take fruit data, remove any yellow colour fruit, count the fruits by type and amount, and arrange in descending order of the total”
7.3.7 Plotting using ggplot()
The tidyverse includes a pretty great plotting library called ggplot2. This can be used by piping your dataframe to a function called ggplot(). The basic idea is that you add your data, then you can add plot elements which are called geoms. Some common ones are geom_line(), geom_bar() and geom_point().
To the geom function you add aesthetics, which is basically telling the function which bits of your data should be responsible for which parts of the visualisation. These are added using aes(). I’ll explain a bit more about some of these aesthetics as I go along.
As an example:
Bar chart of different types of fruit (one each of bananas and oranges, two types of apple)
fruit_data %>% ggplot() + geom_bar(aes(x = fruit))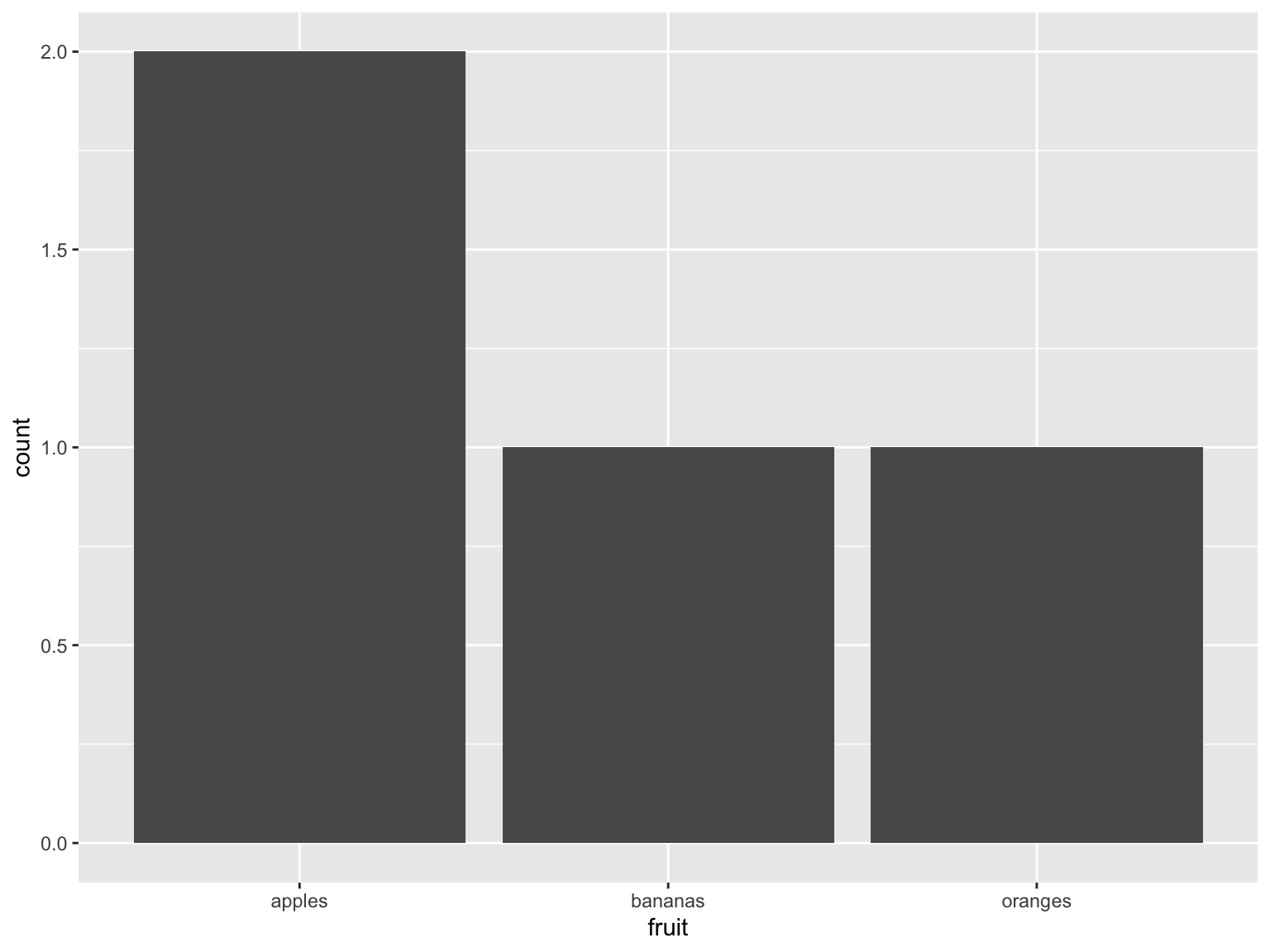
Figure 7.1: fruit
Counting the total amount of fruit:
fruit_data %>% ggplot() + geom_bar(aes(x = fruit, weight = amount))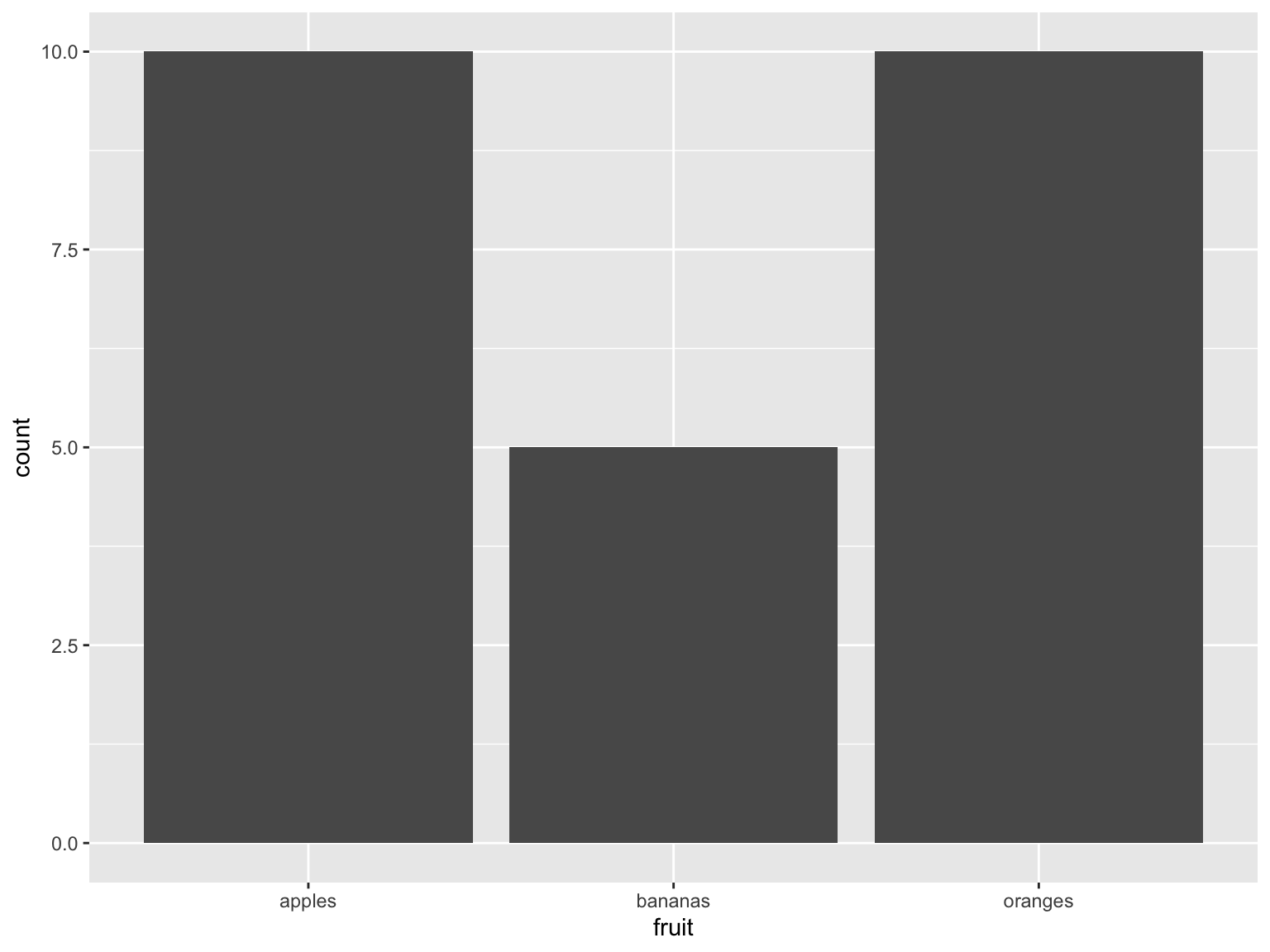
Figure 7.2: totals
Charting amounts and fruit colours:
fruit_data %>% ggplot() + geom_bar(aes(x = fruit, weight = amount, fill = colour)) 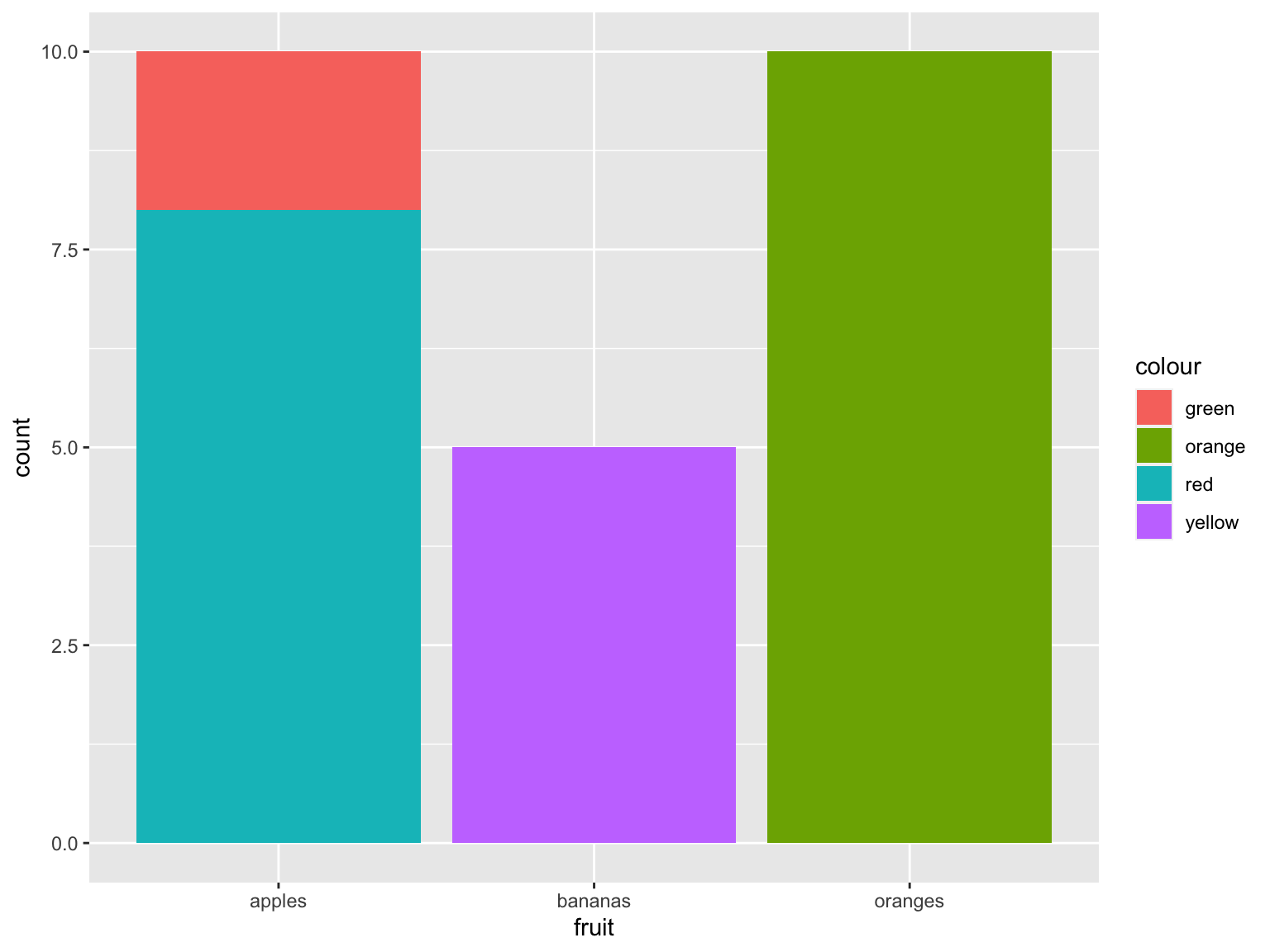
Figure 7.3: grouped fruit
And just because it annoys me having random colours, we can map them to the actual colours:
fruit_data %>%
ggplot() +
geom_bar(aes(x = fruit, weight = amount, fill = colour)) +
scale_fill_manual(values = c("orange" = "orange",
"green" = "#8db600",
"red" = "#ff0800",
"yellow" = "#ffe135"))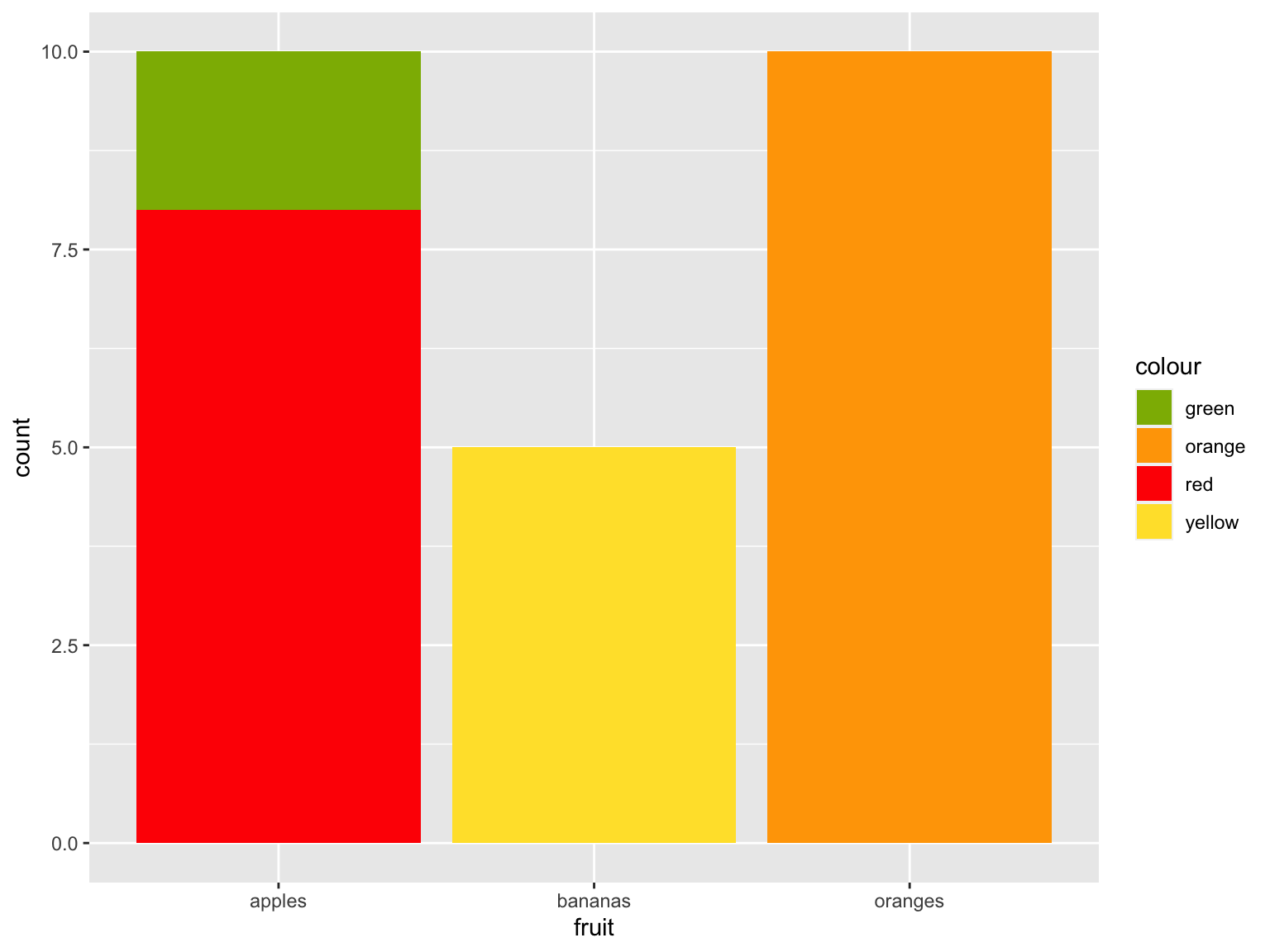
Figure 7.4: Fruit chart with nice colours
7.3.8 Doing this with newspaper data
Who cares about fruit? Nobody, that’s who. We want newspaper data! Let’s load a dataset of metadata for all the titles held by the library, and do some counting and sorting.
Download from here: British Library Research Repository
You would need to extract into your project folder first, if you’re following along:
read_csv reads the csv from file.
title_list = read_csv('data/BritishAndIrishNewspapersTitleList_20191118.csv')##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## .default = col_character(),
## title_id = col_double(),
## nid = col_double(),
## nlp = col_double(),
## first_date_held = col_double(),
## publication_date_one = col_double(),
## publication_date_two = col_double()
## )
## ℹ Use `spec()` for the full column specifications.Select some particularly relevant columns:
title_list %>%
select(publication_title,
first_date_held,
last_date_held,
country_of_publication)## # A tibble: 24,927 × 4
## publication_title first_date_held last_date_held country_of_publi…
## <chr> <dbl> <chr> <chr>
## 1 "Corante, or, Newes from It… 1621 1621 The Netherlands
## 2 "Corante, or, Newes from It… 1621 1621 The Netherlands
## 3 "Corante, or, Newes from It… 1621 1621 The Netherlands
## 4 "Corante, or, Newes from It… 1621 1621 England
## 5 "Courant Newes out of Italy… 1621 1621 The Netherlands
## 6 "A Relation of the late Occ… 1622 1622 England
## 7 "A Relation of the late Occ… 1622 1622 England
## 8 "A Relation of the late Occ… 1622 1622 England
## 9 "A Relation of the late Occ… 1622 1622 England
## 10 "A Relation of the late Occ… 1622 1622 England
## # … with 24,917 more rowsArrange in order of the latest date of publication, and then by the first date of publication:
title_list %>%
select(publication_title,
first_date_held,
last_date_held,
country_of_publication) %>%
arrange(desc(last_date_held), first_date_held)## # A tibble: 24,927 × 4
## publication_title first_date_held last_date_held country_of_publi…
## <chr> <dbl> <chr> <chr>
## 1 Shrewsbury chronicle 1773 Continuing England
## 2 London times|The Times|Time… 1788 Continuing England
## 3 Observer (London)|Observer … 1791 Continuing England
## 4 Limerick chronicle 1800 Continuing Ireland
## 5 Hampshire chronicle|The Ham… 1816 Continuing England
## 6 The Inverness Courier, and … 1817 Continuing Scotland
## 7 Sunday times (London)|Sunda… 1822 Continuing England
## 8 The Impartial Reporter, etc 1825 Continuing Northern Ireland
## 9 Impartial reporter and farm… 1825 Continuing Northern Ireland
## 10 Aberdeen observer 1829 Continuing Scotland
## # … with 24,917 more rowsGroup and count by country of publication:
title_list %>%
select(publication_title,
first_date_held,
last_date_held,
country_of_publication) %>%
arrange(desc(last_date_held)) %>%
group_by(country_of_publication) %>%
tally()## # A tibble: 40 × 2
## country_of_publication n
## <chr> <int>
## 1 Bermuda Islands 24
## 2 Cayman Islands 1
## 3 England 20465
## 4 England|Hong Kong 1
## 5 England|India 2
## 6 England|Iran 2
## 7 England|Ireland 10
## 8 England|Ireland|Northern Ireland 10
## 9 England|Jamaica 7
## 10 England|Malta 2
## # … with 30 more rowsArrange again, this time in descending order of number of titles for each country:
title_list %>%
select(publication_title,
first_date_held,
last_date_held,
country_of_publication) %>%
arrange(desc(last_date_held)) %>%
group_by(country_of_publication) %>%
tally() %>%
arrange(desc(n))## # A tibble: 40 × 2
## country_of_publication n
## <chr> <int>
## 1 England 20465
## 2 Scotland 1778
## 3 Ireland 1050
## 4 Wales 1019
## 5 Northern Ireland 415
## 6 England|Wales 58
## 7 Bermuda Islands 24
## 8 England|Scotland 13
## 9 England|Ireland 10
## 10 England|Ireland|Northern Ireland 10
## # … with 30 more rowsFilter only those with more than 100 titles:
title_list %>%
select(publication_title,
first_date_held,
last_date_held,
country_of_publication) %>%
arrange(desc(last_date_held)) %>%
group_by(country_of_publication) %>%
tally() %>%
arrange(desc(n)) %>%
filter(n>=100)## # A tibble: 5 × 2
## country_of_publication n
## <chr> <int>
## 1 England 20465
## 2 Scotland 1778
## 3 Ireland 1050
## 4 Wales 1019
## 5 Northern Ireland 415Make a simple bar chart:
title_list %>%
select(publication_title,
first_date_held,
last_date_held,
country_of_publication) %>%
arrange(desc(last_date_held)) %>%
group_by(country_of_publication) %>%
tally() %>%
arrange(desc(n)) %>%
filter(n>=100) %>%
ggplot() +
geom_bar(aes(x = country_of_publication, weight = n))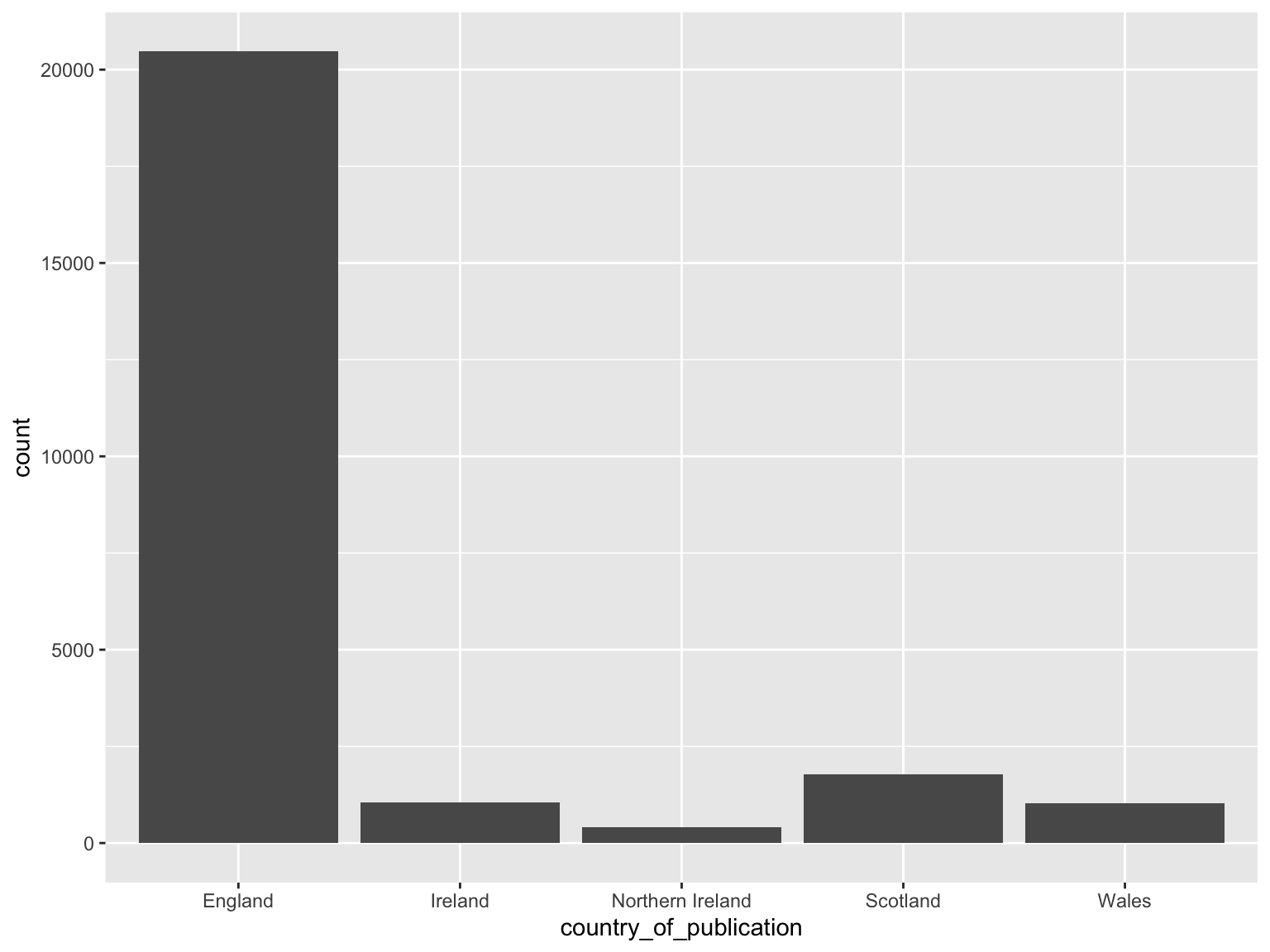
Figure 7.5: barchart
So that’s a very quick introduction to R. There’s loads of places to learn more.
The Pirate’s Guide to R, a good beginners guide to base R