Chapter 7 KMeans Cluster analysis
7.1 R Markdown
This is an R Markdown document. Markdown is a simple formatting syntax for authoring HTML, PDF, and MS Word documents. For more details on using R Markdown see http://rmarkdown.rstudio.com.
Notice The dplyr package is not stable recently.See my Tweet about this:https://twitter.com/MKTJimmyxu/status/1253752342333153281. That said, when you get stuck, just try to run it again at a future date.
Keep in mind that no programmer can avoid errors. I strongly agree with this quote from “CodeAcademy” that “Errors in your code mean you’re trying to do something cool.”
https://news.codecademy.com/errors-in-code-think-differently/
7.2 Segmentation
Objective - Dividing the target market or customers on the basis of some significant features which could help a company sell more products in less marketing expenses.
A potentially interesting question might be are some products (or customers) more alike than the others.
7.3 Market segmentation
Market segmentation is a strategy that divides a broad target market of customers into smaller, more similar groups, and then designs a marketing strategy specifically for each group. Clustering is a common technique for market segmentation since it automatically finds similar groups given a data set.
Imagine that you are the Director of Customer Relationships at Apple, and you might be interested in understanding consumers’ attitude towards iPhone 12 and Google’s Pixel 5. Once the product is created, the ball shifts to the marketing team’s court. As mentioned above, to understand which groups of customers will be interested in which kind of features, marketers will make use of market segmentation strategy. The cluster analysis algorithm is designed to address this problem. Doing this ensures the product is positioned to the right segment of customers with a high propensity to buy.
7.4 Examples of Objectives
1.Identify the type of customers who would respond to a particular offer
2.Identify high spenders among customers who will use the e-commerce channel for festive shopping
3.Identify customers who will default on their credit obligation for a loan or credit card
7.5 Dataset
The file segmetation.csv contains information on consumers’ perceptions toward a brand in the apparel industry. The purpose of the case analysis is to gain a better understanding of the consumer segments for the brand, in hopes that such understanding would allow the brand to develop effective segment- or product-specific advertising campaigns.
7.6 Questions
1.Can you perform a 5-cluster analysis? 2.How many observations do you have in each cluster? 3.List the cluster member IDs in each cluster.
#install.packages('dplyr')
library(dplyr) # sane data manipulation## Warning: package 'dplyr' was built under R version 4.1.3##
## Attaching package: 'dplyr'## The following object is masked from 'package:huxtable':
##
## add_rownames## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(tidyr) # sane data munging##
## Attaching package: 'tidyr'## The following object is masked from 'package:magrittr':
##
## extractlibrary(ggplot2) # needs no introduction
library(ggfortify) # super-helpful for plotting non-"standard" stats objects
#identifying your working directory
getwd() #confirm your working directory is accurate## [1] "C:/Users/zxu3/Documents/R/bookdownmktr/bookdown-demo-master"library(readr)
mydata <-read_csv('https://raw.githubusercontent.com/utjimmyx/regression/master/Segmentation.csv')## Rows: 221 Columns: 22## -- Column specification --------------------------------------------------------
## Delimiter: ","
## dbl (22): ID, Fashn, Price, Convnience, ShpTime, Fitness, Perceptn, ChNoise,...
##
## i Use `spec()` to retrieve the full column specification for this data.
## i Specify the column types or set `show_col_types = FALSE` to quiet this message.# read csv file #This allows you to read the data from my Github site.
#Open the data. Note that some students will see an Excel option in "Import Dataset";
#those that do not will need to save the original data as a csv and import that as a text file.
#rm(list = ls()) #used to clean your working environment
fit <- kmeans(mydata[,-1], 3, iter.max=1000)
#exclude the first column since it is "id" instead of a factor #or variable.
#3 means you want to have 3 clusters
table(fit$cluster)##
## 1 2 3
## 87 72 62barplot(table(fit$cluster), col="#336699") #plot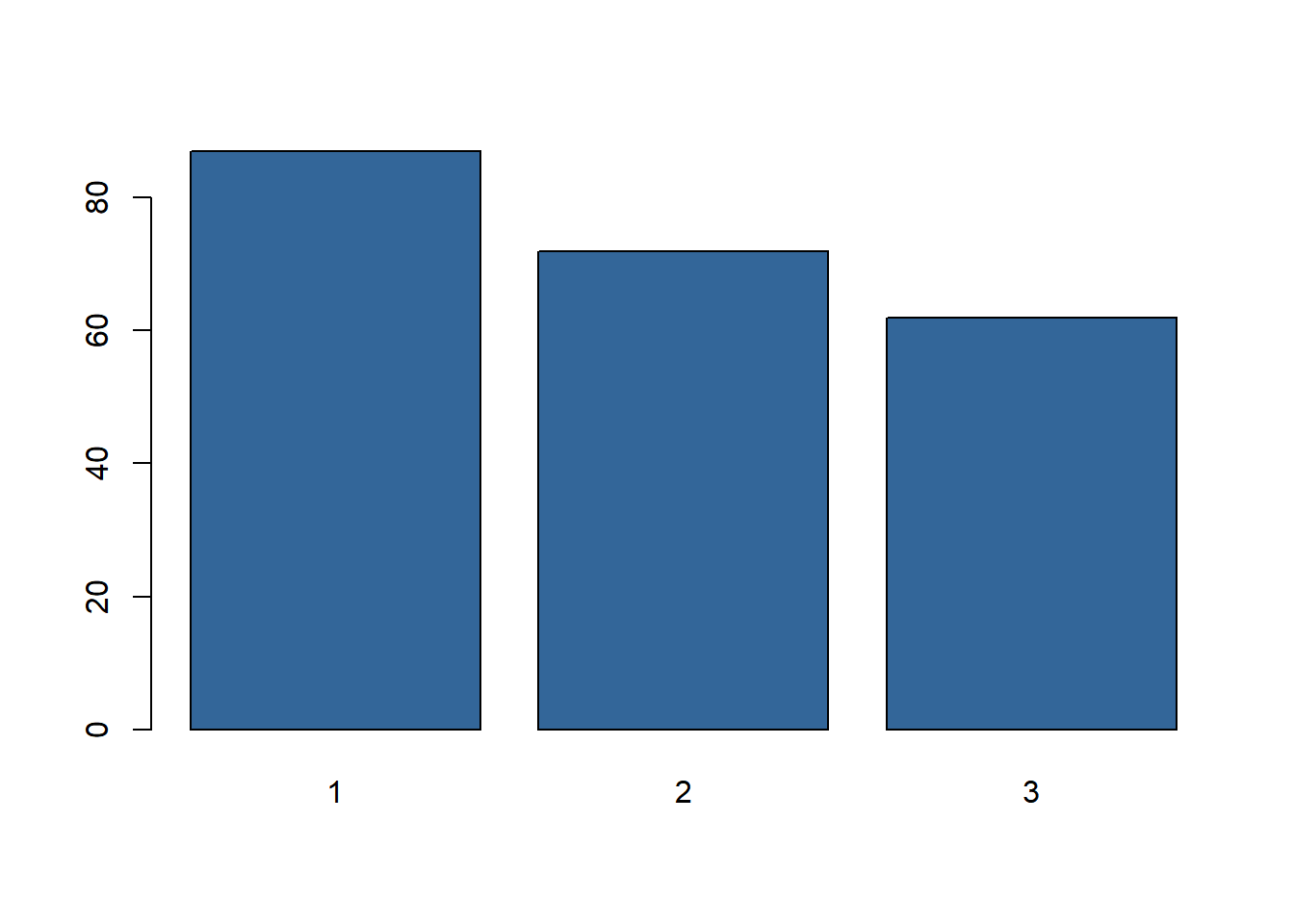
pca <- prcomp(mydata[,-1]) #principle component analysis
pca_data <- mutate(fortify(pca), col=fit$cluster)
#We want to examine the cluster memberships for each #observation - see last column
ggplot(pca_data) + geom_point(aes(x=PC1, y=PC2, fill=factor(col)),
size=3, col="#7f7f7f", shape=21) + theme_bw(base_family="Helvetica")## Warning in grid.Call(C_stringMetric, as.graphicsAnnot(x$label)): font family not
## found in Windows font database## Warning in grid.Call(C_stringMetric, as.graphicsAnnot(x$label)): font family not
## found in Windows font database## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database## Warning in grid.Call.graphics(C_text, as.graphicsAnnot(x$label), x$x, x$y, :
## font family not found in Windows font database## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database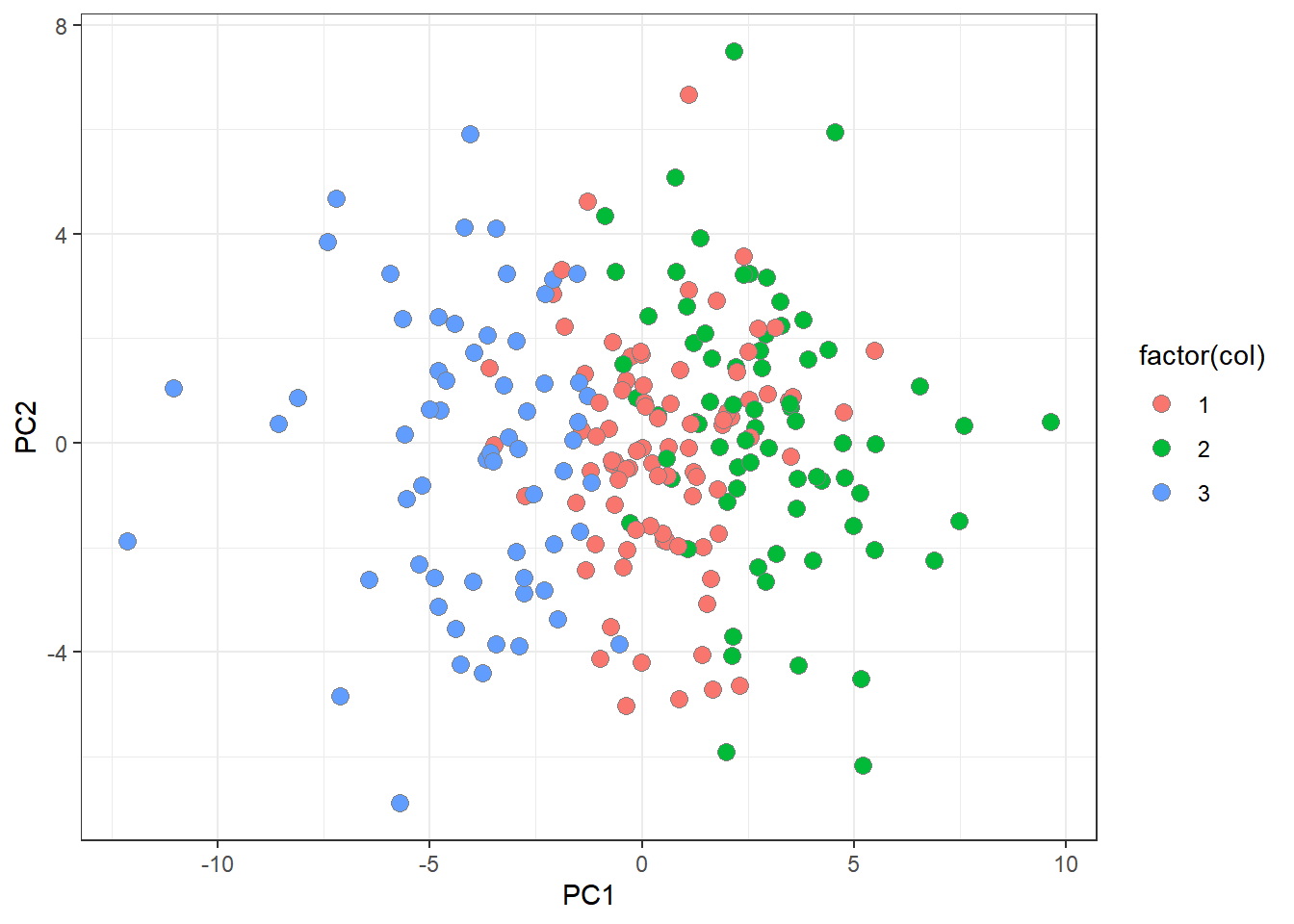
autoplot(fit, data=mydata[,-1], frame=TRUE, frame.type='norm')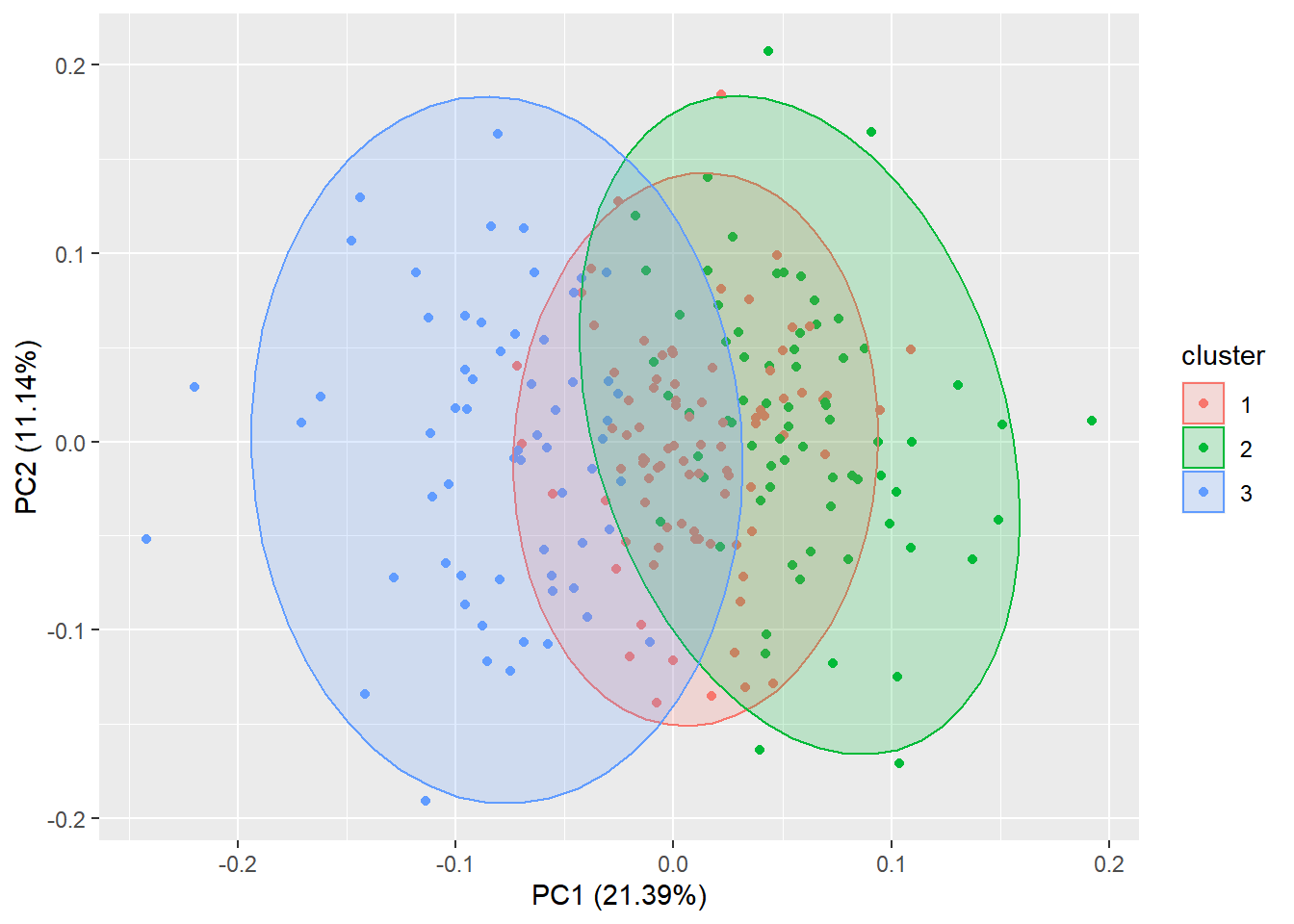
write.csv(pca_data, "pca_data.csv")
#save your cluster solutions in the working directory
#We want to examine the cluster memberships for each observation - see last column of pca_data7.7 References
Cluster analysis - reading (p.385-p.399) https://faculty.marshall.usc.edu/gareth-james/ISL/ISLR%20Seventh%20Printing.pdf
Introduction to k-Means clustering in R https://www.r-bloggers.com/introduction-to-k-means-clustering-in-r/
Comparison of similarity coefficients used for cluster analysis with dominant markers in maize (Zea mays L) https://www.scielo.br/scielo.php?script=sci_arttext&pid=S1415-47572004000100014&lng=en&nrm=iso
Principal Component Methods in R: Practical Guide http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/118-principal-component-analysis-in-r-prcomp-vs-princomp/