第 8 章 R for difference-in-differences
library(dplyr)
library(magrittr)
library(ggplot2)8.1 Data Import
產生public資料
load(url("https://github.com/tpemartin/Econometric-Analysis/blob/master/data/public.rda?raw=true"))codebook: https://raw.githubusercontent.com/tpemartin/Econometric-Analysis/master/data/codebook.txt
8.2 資料屬性檢查
檢查平均就業量,變數定義
EMPFT:政策前全職員工數
EMPPT:政策前兼職員工數
EMPFT2:政策後全職員工數
EMPPT2:政策後兼職員工數
發現均為字串(chr),需改變資料屬性
public %>%
mutate_at(
vars(EMPFT,EMPPT,EMPFT2,EMPPT2),
funs(as.numeric)
) -> public 8.3 不同州,政策前後的改變
計算平均員工數
public %>%
group_by(STATE) %>% # 1 if NJ; 0 if Pa
summarise(mFT_before=mean(EMPFT,na.rm=T),
mPT_before=mean(EMPPT,na.rm=T),
mFT_after=mean(EMPFT2,na.rm=T),
mPT_after=mean(EMPPT2,na.rm=T)) %>%
ungroup ->
employment_change查看全職員工數
library(kableExtra)
employment_change %>%
select(STATE,mFT_before,mFT_after) %>%
kable("html")| STATE | mFT_before | mFT_after |
|---|---|---|
| 0 | 10.205 | 7.565 |
| 1 | 7.724 | 8.445 |
查看兼職員工數
employment_change %>%
select(STATE,mPT_before,mPT_after) %>%
kable("html")| STATE | mPT_before | mPT_after |
|---|---|---|
| 0 | 19.49 | 19.95 |
| 1 | 18.68 | 18.37 |
8.4 繪圖
整理資料格式:tidyr::gather()
library(tidyr)只看全職員工數
employment_FTchange <- employment_change %>%
select(mFT_before,mFT_after,STATE)
employment_FTchange %>% kable("html")| mFT_before | mFT_after | STATE |
|---|---|---|
| 10.205 | 7.565 | 0 |
| 7.724 | 8.445 | 1 |
employment_FTchange %>%
filter(STATE==0) %>%
gather(type,employment,-STATE) -> EMFT0
EMFT0
employment_FTchange %>%
filter(STATE==1) %>%
gather(type,employment,-STATE) -> EMFT1
EMFT1
EMFT<-rbind(EMFT0,EMFT1)
EMFT當filter條件會套用在某個變數(這裡的STATE)的所有狀況時,可以用group_by()一次做完。你會怎麼改寫上述程式?
繪圖
group會定義那些點可以連在一起。
EMFT %>%
ggplot() +
geom_point(aes(x=type,y=employment,color=STATE))+
geom_line(aes(x=type,y=employment,group=STATE,color=STATE))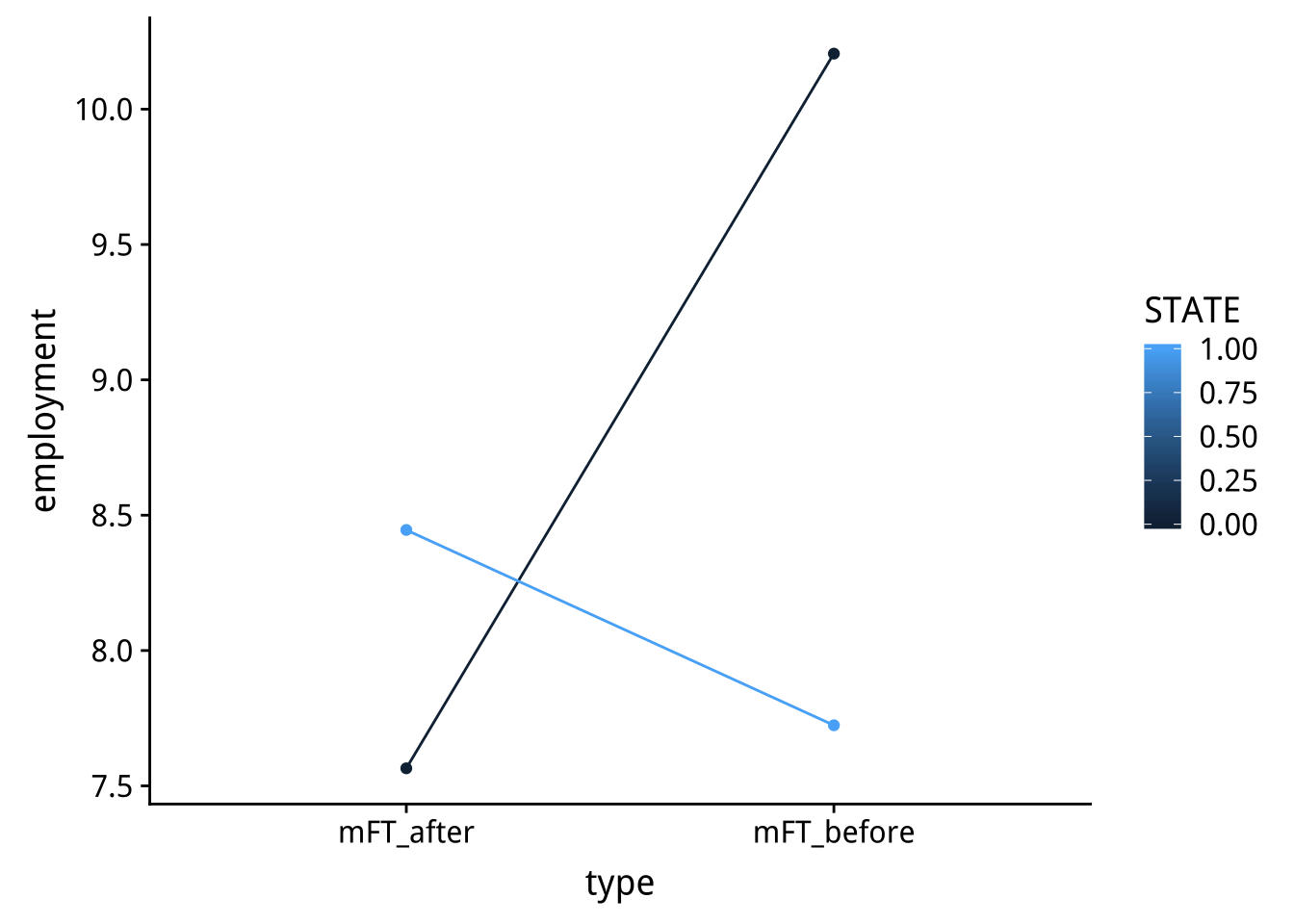
上面圖形有什麼問題?
更改變數屬性
EMFT %>% mutate(
type=ordered(type,levels=c("mFT_before","mFT_after")),
STATE=factor(STATE,labels=c("PA","NJ"))
) -> EMFTfinal修改屬性後的圖形
EMFTfinal %>%
ggplot() +
geom_point(aes(x=type,y=employment,color=STATE))+
geom_line(aes(x=type,y=employment,group=STATE,color=STATE))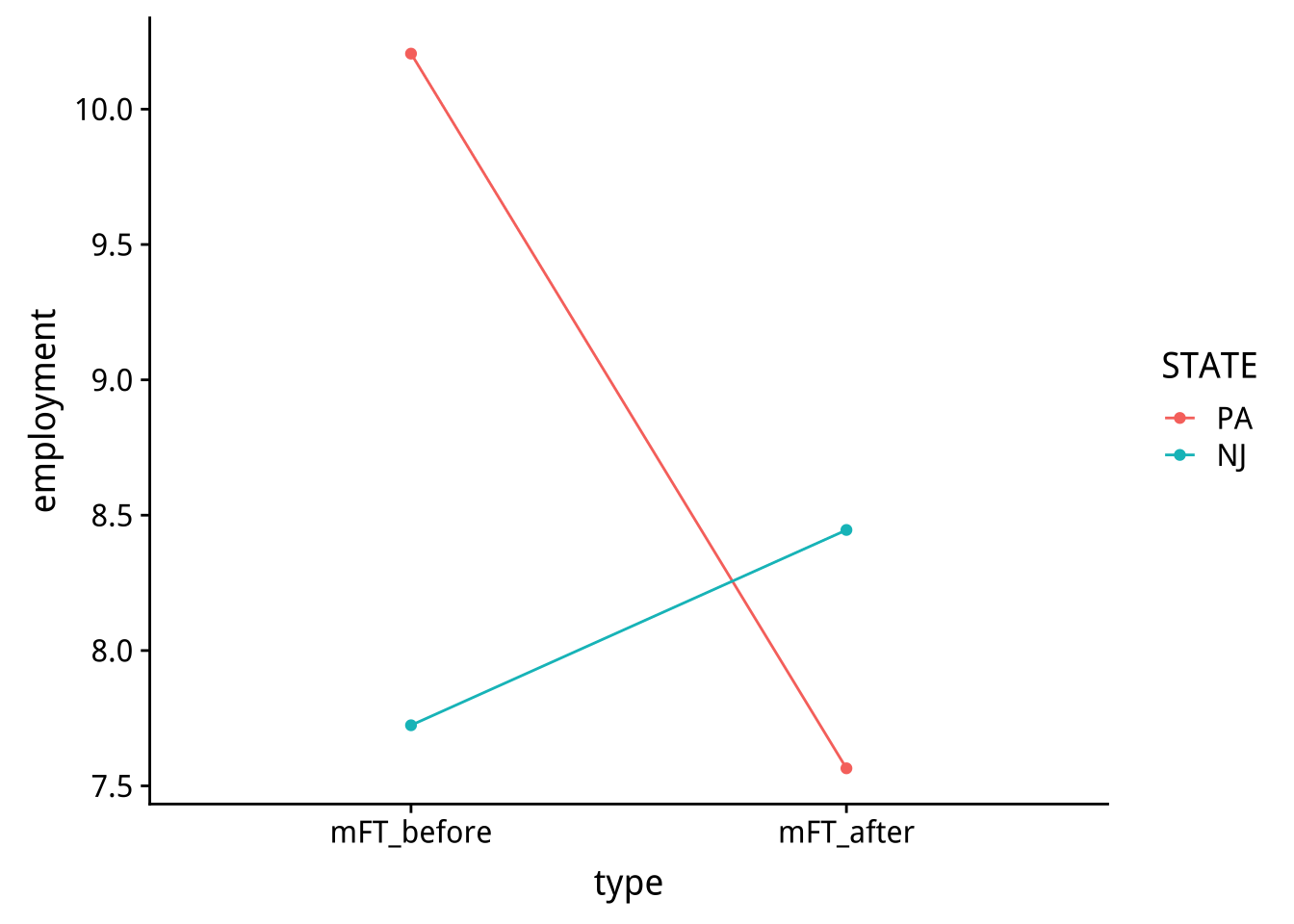
8.5 Difference-in-differences
資料整理
public %>%
select(STATE,EMPFT,EMPFT2) %>%
group_by(STATE) %>%
gather(type,emp,-STATE) -> public2產生虛擬變數
public2 %>%
mutate(
STATE1=(STATE==1),
AFTER=(type=="EMPFT2"),
PolicyImpact=STATE1*AFTER
) -> public2DD估計
lm(emp~STATE1+AFTER+PolicyImpact,data=public2)->DD_result
DD_result另一種方式是使用factor(x1)*factor(x2)產生所有變數
lm(emp~factor(STATE)*factor(type),data=public2)factor(x1)*factor(x2)與factor(x1):factor(x2)的不同
lm(emp~factor(STATE):factor(type),data=public2)8.6 聚類標準誤:library(clubSandwich)
library(clubSandwich)public2 %>%
mutate(cluster=factor(STATE):factor(type)) -> public2coef_test(DD_result, vcov = "CR2", cluster = public2$cluster)## Coef Estimate SE d.f. p-val (Satt)
## 1 (Intercept) 10.21 2.41e-15 1.00 <0.001
## 2 STATE1TRUE -2.48 3.24e-15 1.82 <0.001
## 3 AFTERTRUE -2.64 4.93e-15 1.92 <0.001
## 4 PolicyImpact 3.36 5.40e-15 3.55 <0.001
## Sig.
## 1 ***
## 2 ***
## 3 ***
## 4 ***8.7 Panel: Fixed effect
library(plm)library(readr)
fatality <- read_csv("https://raw.githubusercontent.com/tpemartin/Econometric-Analysis/master/Part%20II/fatality.csv")宣告資料為Panel data frame
fatality<-pdata.frame(fatality,c("state","year"))迴歸模型: \[mrall_{it}=\alpha_i+\beta_1 BeerTax_{it}+\epsilon_{it}\]
fe1<-plm(mrall~beertax, data=fatality, model='within', effect='individual')
summary(fe1)聚類標準誤
coef_test(fe1, vcov = "CR2", cluster = fatality$state)## Coef Estimate SE d.f. p-val (Satt) Sig.
## 1 beertax -6.56e-05 3.03e-05 8.31 0.0611 .