8 เมนูเสริมที่น่าสนใจ
นอกจากเมนูการคำนวณและตัวแบบสถิติแบบมาตราฐานแล้ว โปรแกรม jamovi ยังเปิดโอกาสให้นักพัฒนาโปรแกรมสร้างชุดการทำงานเสริม เพื่อให้ผู้ใช้งานติดตั้งสำหรับการทำงานด้านสถิติอื่นๆ เพิ่มเติมได้ โดย สามารถเลือกการติดตั้งได้จากเมนูเครื่องหมาย + ที่มุมบนด้านขวา
Warningจะต้องการเชื่อมต่ออินเทอร์เน๊ตก่อนทำการติดตั้งเมนูเสริม
เมื่อกดเข้าไปแล้วจะพบชุดคำส่ังให้ติดตั้งเพิ่มเติมมากมาย
เมนูเสริมที่ผู้เขียนแนะนำ มีดังต่อไปนี้
8.1 surveymv
 เมนูนี้เหมาะสำหรับการสร้างกราฟแท่งแสดงจำนวน หรือสัดส่วนของตัวแปรแบบกลุ่ม (categorical) ที่มีการวัดแบบ nominal
เมนูนี้เหมาะสำหรับการสร้างกราฟแท่งแสดงจำนวน หรือสัดส่วนของตัวแปรแบบกลุ่ม (categorical) ที่มีการวัดแบบ nominal
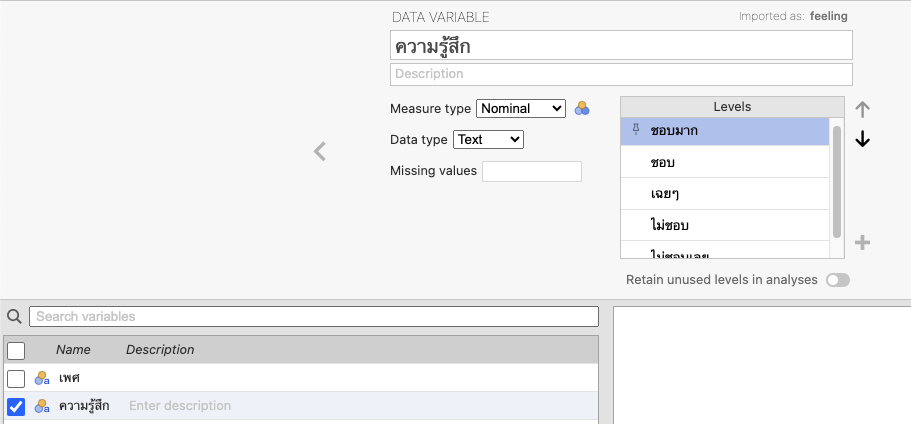
ลองใช้่ข้อมูล question.xlsx เปิดด้วย jamovi แล้วกำหนดระดับดังนี้
- เปลี่ยนชื่อตัวแปรจาก gender เป็นเพศ และเปลี่ยนชื่อตัวแปรจาก feeling เป็นความรู้สึก
- และเรียงลำดับความสำคัญดังนี้ ชอบมาก ชอบ เฉย ไม่ชอบ ไม่ชอบเลย
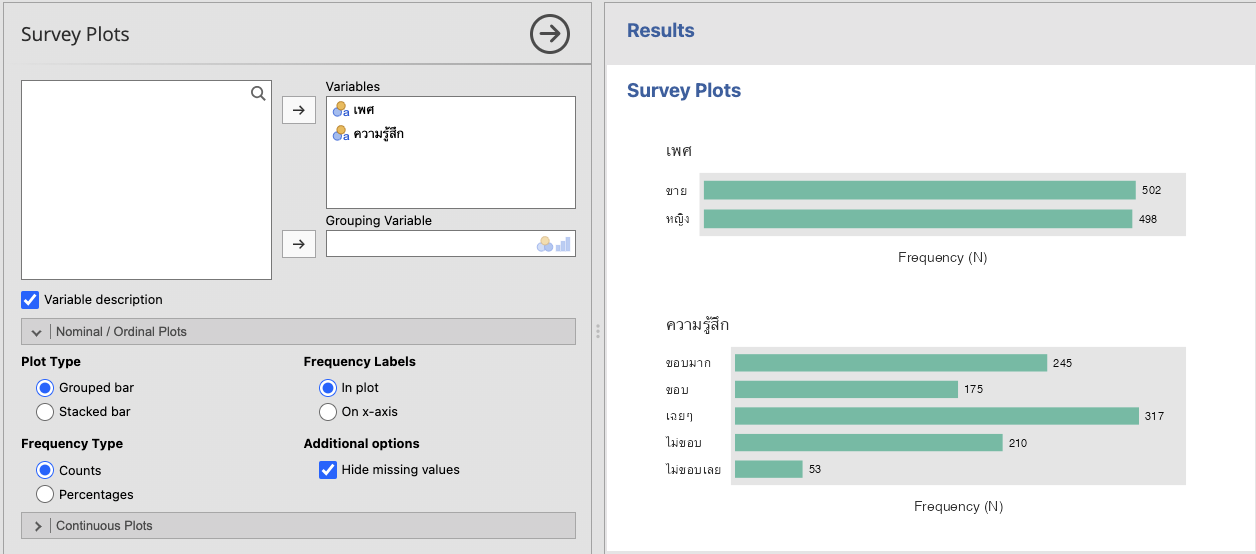
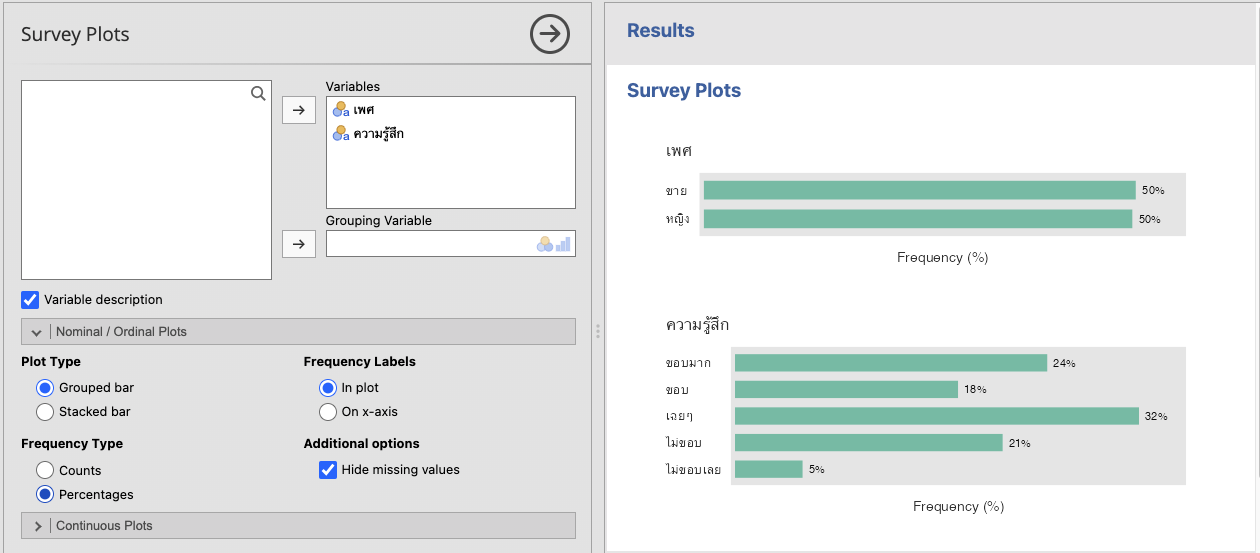
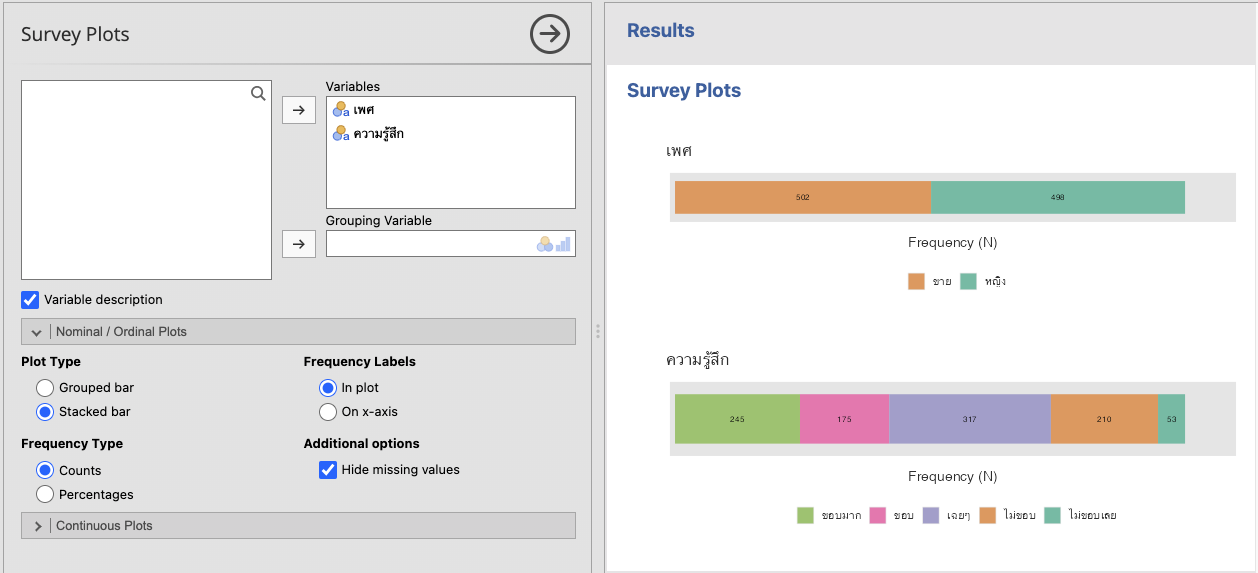
ผู้เขียนเลือกใช้ theme Hadley และจานสี Dark2
ถ้าพิจารณาความรู้สึกแยกตามเพศจะได้ กราฟต่างๆ ดังนี้
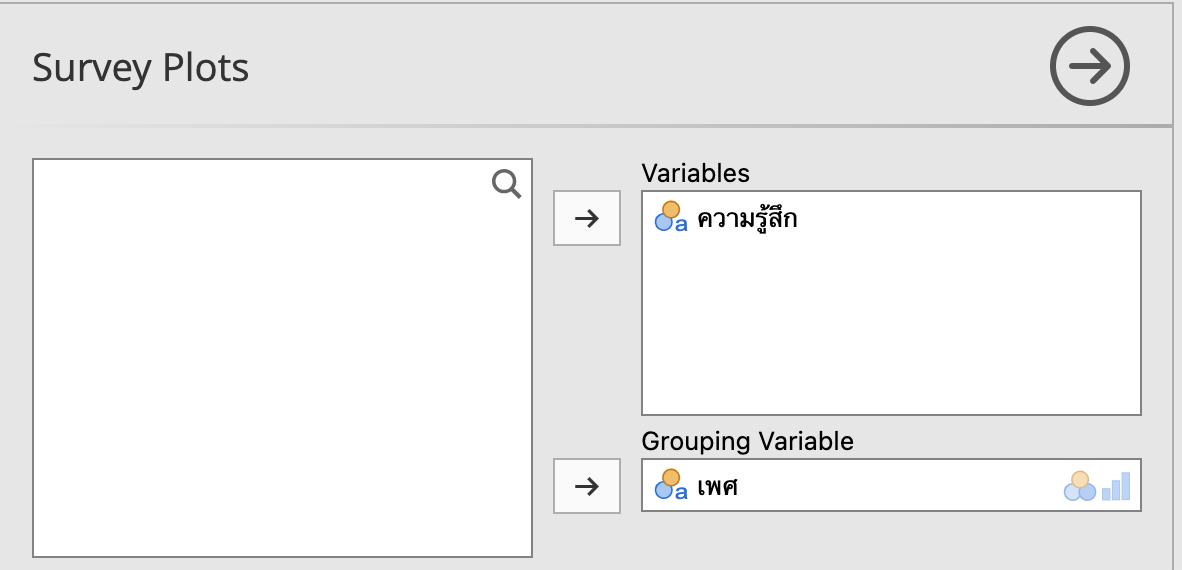
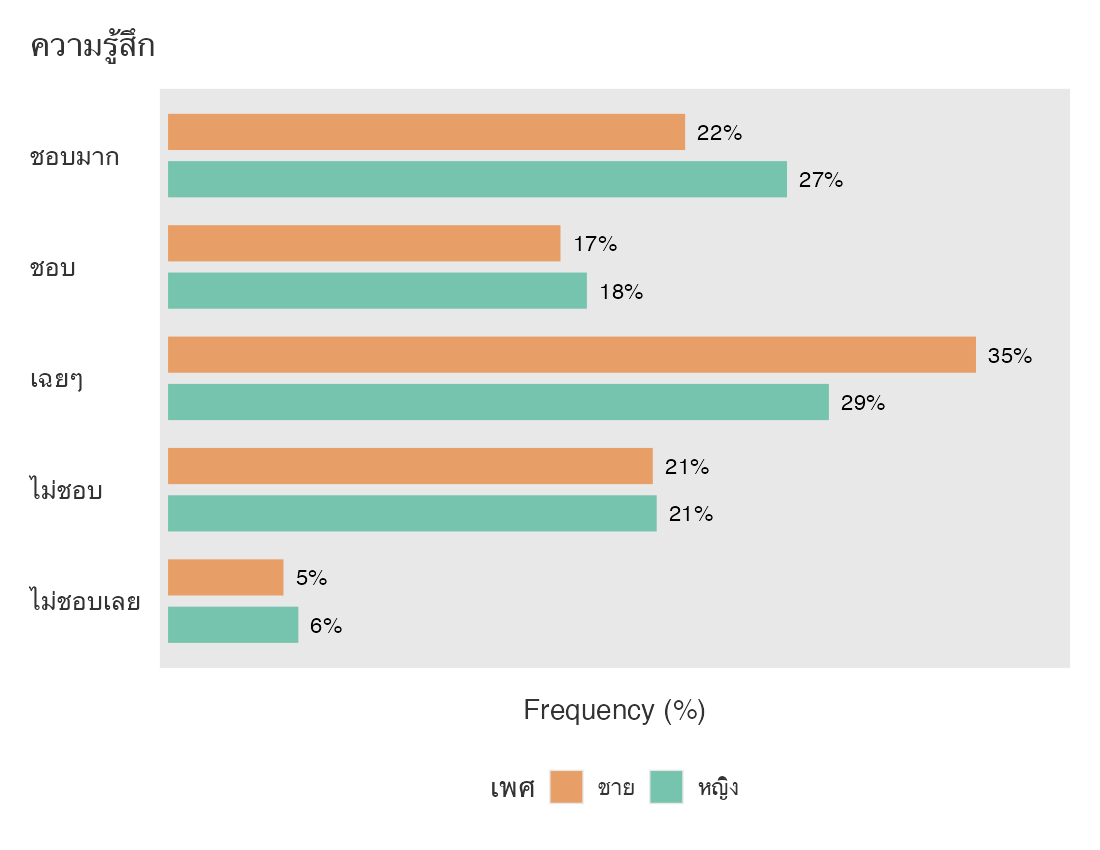
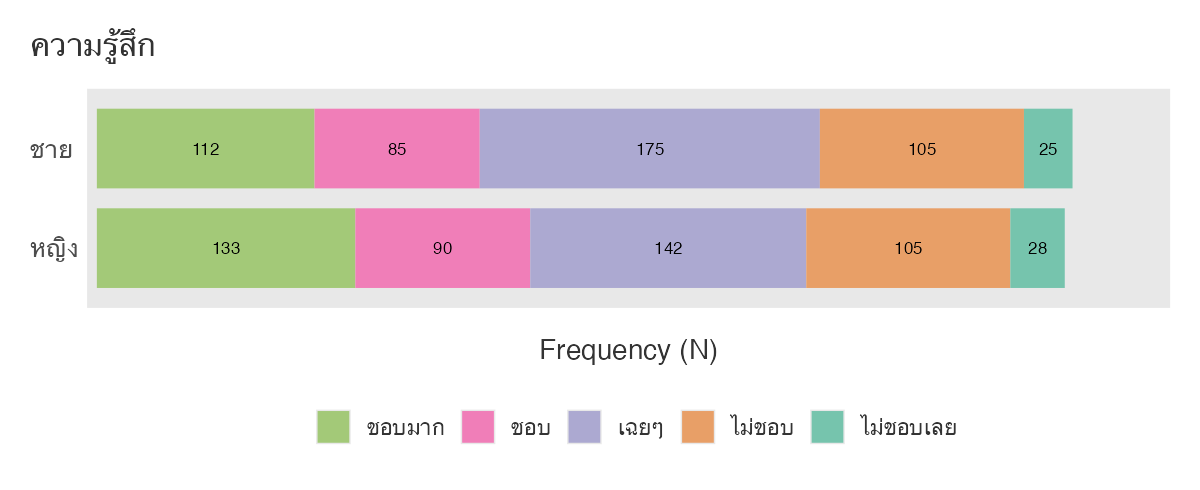
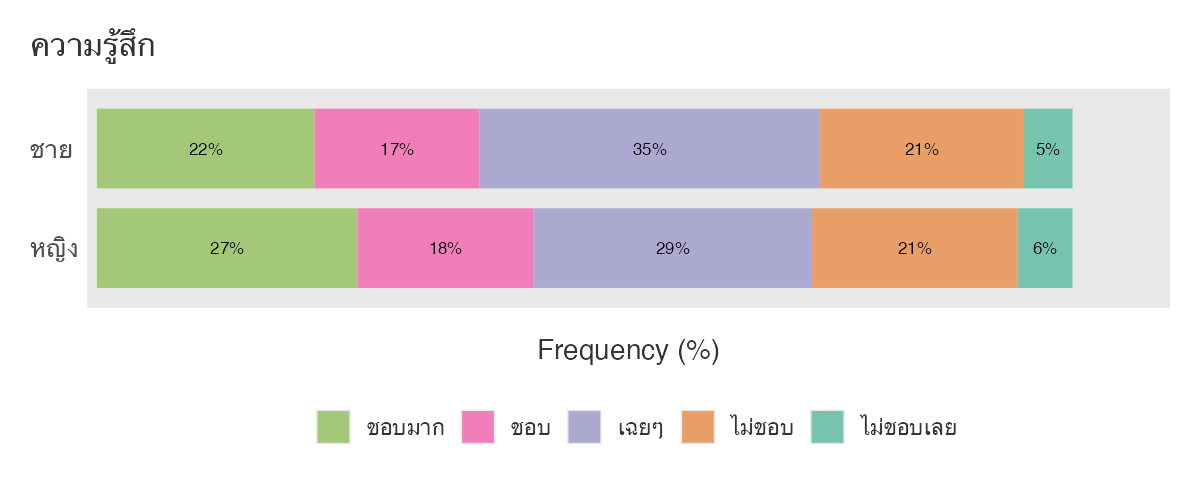
จะเห็นว่า jamovi ลองรับภาษาไทยได้ดีพอสมควรแล้ว
ต่อไปเป็นจะเป็นเมนูเสริมสำหรับการศึกษาตัวแบบความน่าจะเป็นที่สำคัญทางสถิติ
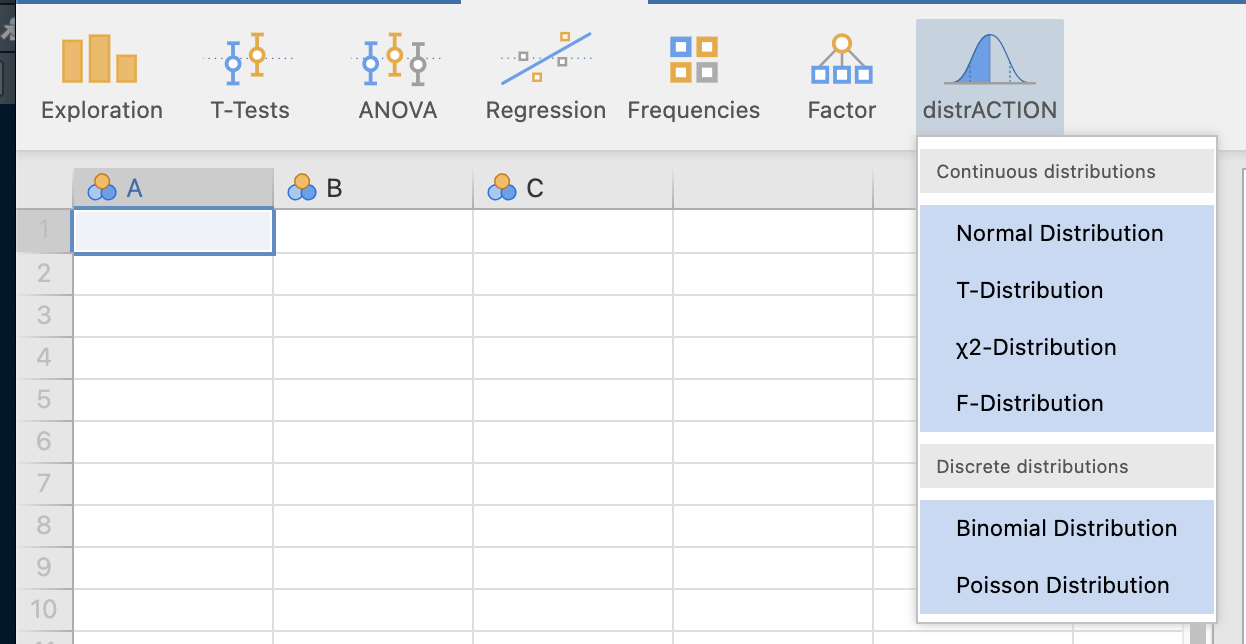
เมนเสริมที่น่าสนใจ สำหรับการศีกษาสถิิติหรือความน่าจะเป็นที่โปรแกรม jamovi มีอยู่ 2 เมนูและข้อมูลฟรี สำหรับฝึกใช้งาน ที่มาจากชุดคำสั่ง dataset ในโปรแกรมอาร์
8.2 เมนู distrACTION

เมื่อการติดตั้งแล้ว จะใช้การคำนวณความน่าจะเป็นที่ตัวแปรสุ่ม (random variable) เป็นตัวแปรแบบต่อเนื่อง (continuous) และเป็นจำนวนเต็ม (integer) เมนูจะใช้ในการคำนวณค่าความน่าจะเป็นและค่าควอไทร์ของการแจกแจงความน่าจะเป็น
8.2.1 การแจกแจงแบบปกติ (Normal Distribution)
การแจกแจงแบบปกติ (Normal Distribution) คือการแจกแจงความน่าจะเป็นที่ใช้กันอย่างแพร่หลายในทางสถิติและทฤษฎีความน่าจะเป็น มีลักษณะเป็นกราฟรูประฆังคว่ำ (bell curve) ซึ่งแสดงถึงการกระจายตัวของข้อมูลที่มีลักษณะสมมาตรรอบค่าเฉลี่ย (mean) และลดลงอย่างค่อยเป็นค่อยไปเมื่อห่างจากค่าเฉลี่ย
คุณสมบัติสำคัญของการแจกแจงแบบปกติ ได้แก่:
ค่าเฉลี่ย (Mean), ค่ามัธยฐาน (Median), และฐานนิยม (Mode): การแจกแจงแบบปกติจะมีค่าเฉลี่ย ค่ามัธยฐาน และฐานนิยมเท่ากัน และอยู่ตรงกลางของการแจกแจง
ความสมมาตร (Symmetry): กราฟของการแจกแจงแบบปกติเป็นสมมาตรซ้าย-ขวา ดังนั้นครึ่งซ้ายและครึ่งขวาของกราฟจะเป็นภาพสะท้อนของกันและกัน
ความเบ้ (Skewness): การแจกแจงแบบปกติมีค่า skewness เท่ากับ 0 หมายความว่าไม่มีความเบ้ไปทางซ้ายหรือขวา
ความกว้าง (Spread): การแจกแจงแบบปกติมีการกระจายตัวของข้อมูลที่สามารถวัดได้ด้วยส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation, σ) โดยประมาณ 68% ของข้อมูลจะอยู่ภายในระยะ ±1σ จากค่าเฉลี่ย ประมาณ 95% ของข้อมูลจะอยู่ภายในระยะ \(\pm 2\sigma\) และประมาณ 99.7% ของข้อมูลจะอยู่ภายในระยะ \(\pm 3\sigma\) จากค่าเฉลี่ย (กฎสาม σ หรือ Empirical Rule)
สูตรของฟังก์ชันความหนาแน่นความน่าจะเป็น (Probability Density Function, PDF) ของการแจกแจงแบบปกติ คือ:
\[f(x) =\displaystyle \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}, ~x,\mu\in \mathrm{R}~,\sigma^2>0\] ช่วงค่าความจะน่าจะเป็นที่ต้องการ
\[Pr(x_1\leq x\leq x_2)=F(x_1)-F(x_2) =\int_{x_1}^{x_2}f(s)ds=\int_{x_1}^{x_2} \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(s-\mu)^2}{2\sigma^2}}ds\]
การคำนวณค่าควอไทร์
\[F^{-1}_X(\alpha) =x,\alpha \in (0,1)\]
ที่ \(\mu\) คือค่าเฉลี่ย (Mean) และ \(\sigma\) คือส่วนเบี่ยงเบนมาตรฐาน (SD)
ถ้า \(\mu=0\) และ \(\sigma=1\) ก็คือการแจกแจงปกติมาตราฐานนั้นเอง
การใช้คำนวณนี้ใน jamovi จะต้องใส่ค่าพารามิเตอร์ Mean และ SD เข้าไปก่อน เพื่อจะสามารถหาค่าความน่าจะเป็นที่ต้องการได้
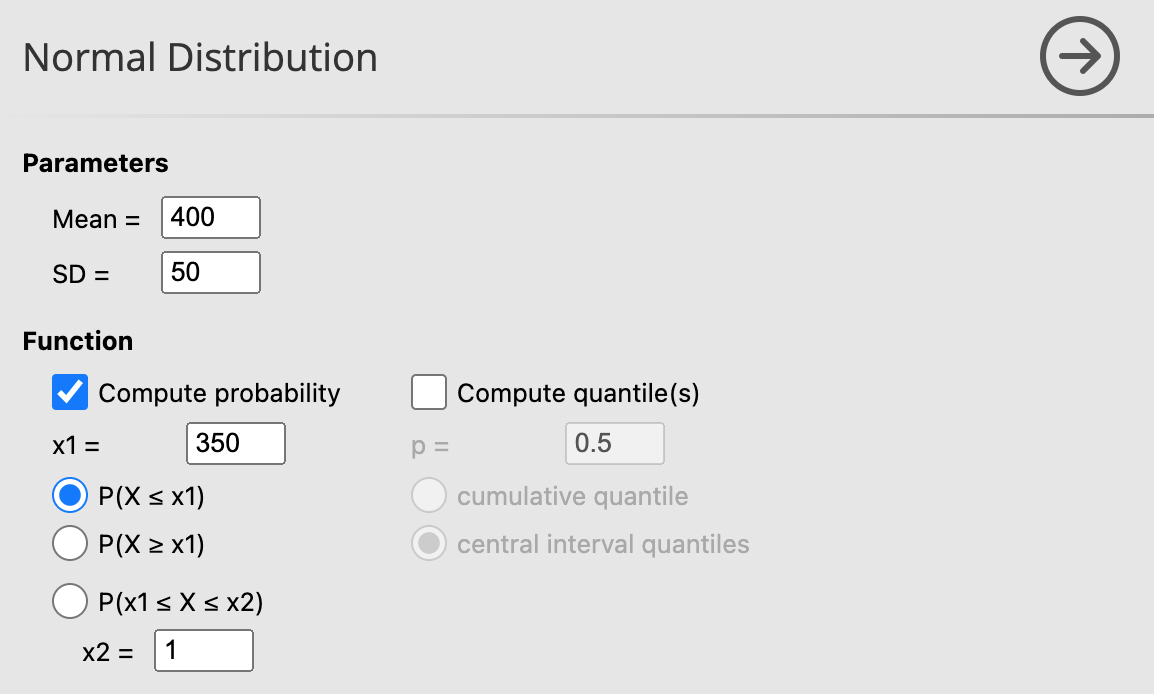
ตัวอย่าง ถ้าผลผลิตของข้าวเปลือกหอมมะลิไทยมีผลผลิตเฉลี่ยต่อไร่ คือ 400 กิโลกรัม และมีส่วนเบี่ยงเบนมาตราฐานคือ 60
- ความน่าจะเป็นที่ จะได้ข้าวหอมมะลิน้อยกว่า 350 กก./ไร่
| Input values | |
|---|---|
| Parameters | ‘Compute probability’ |
| Mean \(=400\) | \(\mathrm{x} 1=350\) |
| \(S D=50\) | Mode: \(\mathrm{P}(\mathrm{X} \leq \mathrm{x} 1)\) |
Result
Probability = 0.159
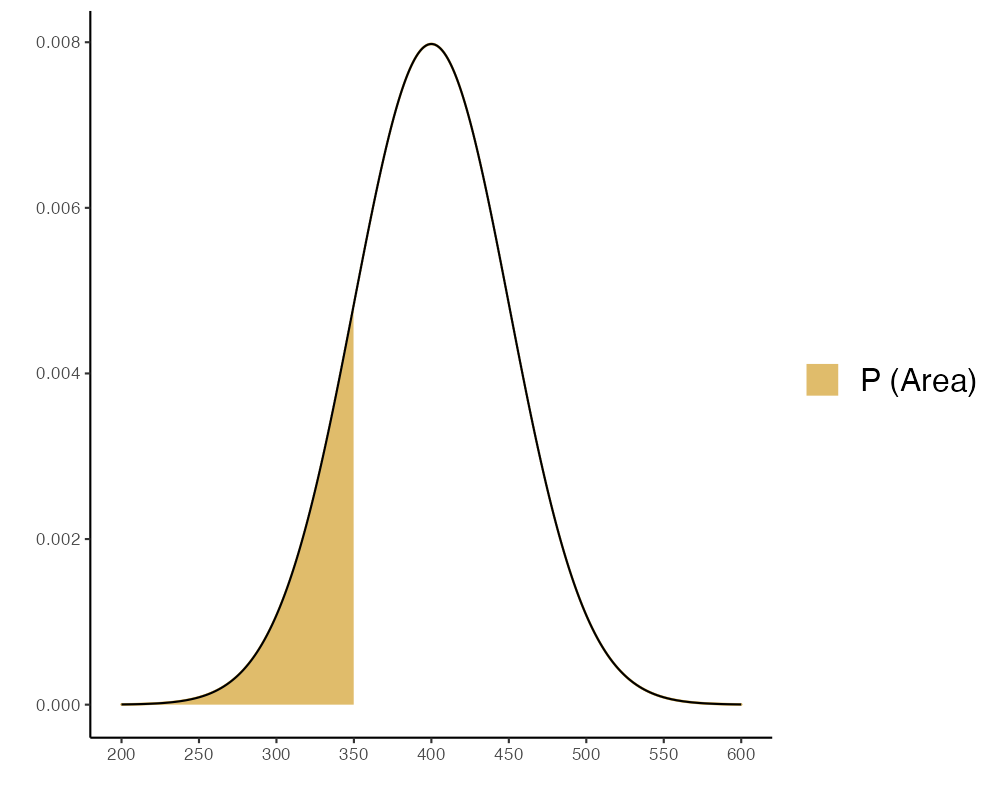
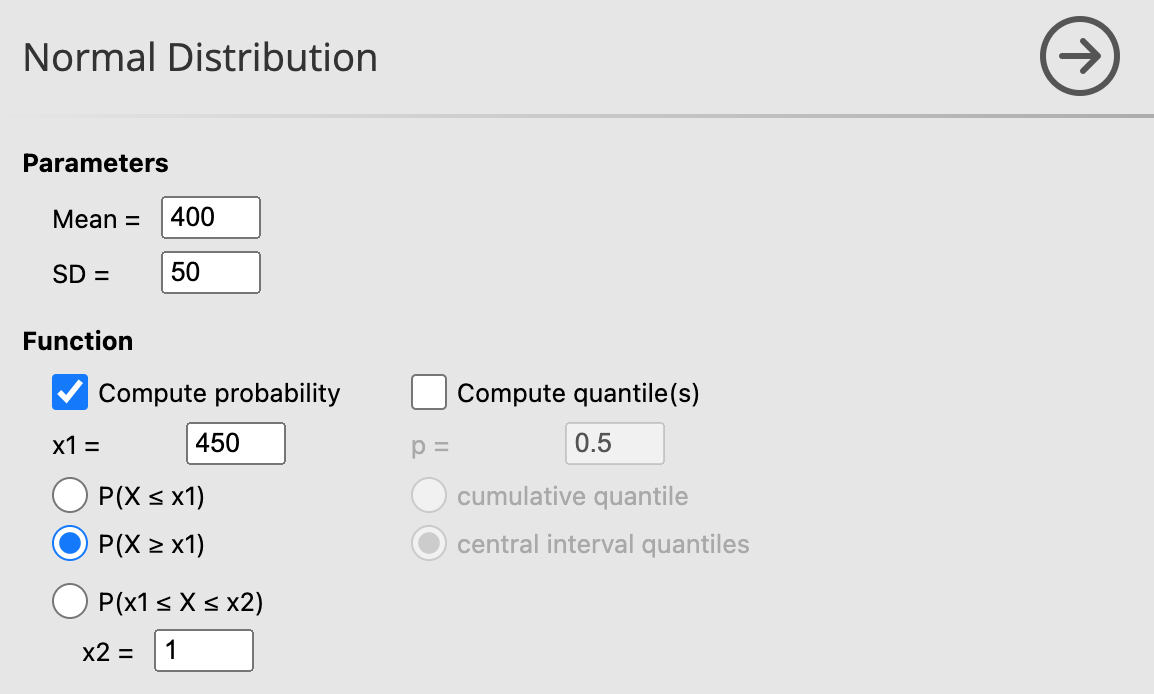
- ความน่าจะเป็นที่ จะได้ข้าวหอมมะลิมากกว่า 450 กก./ไร่
| Input values | |
|---|---|
| Parameters | ‘Compute probability’ |
| Mean \(=400\) | \(\mathrm{x} 1=450\) |
| \(S D=50\) | Mode: \(\mathrm{P}(\mathrm{X} \geq \mathrm{x} 1)\) |
Result
Probability = 0.159
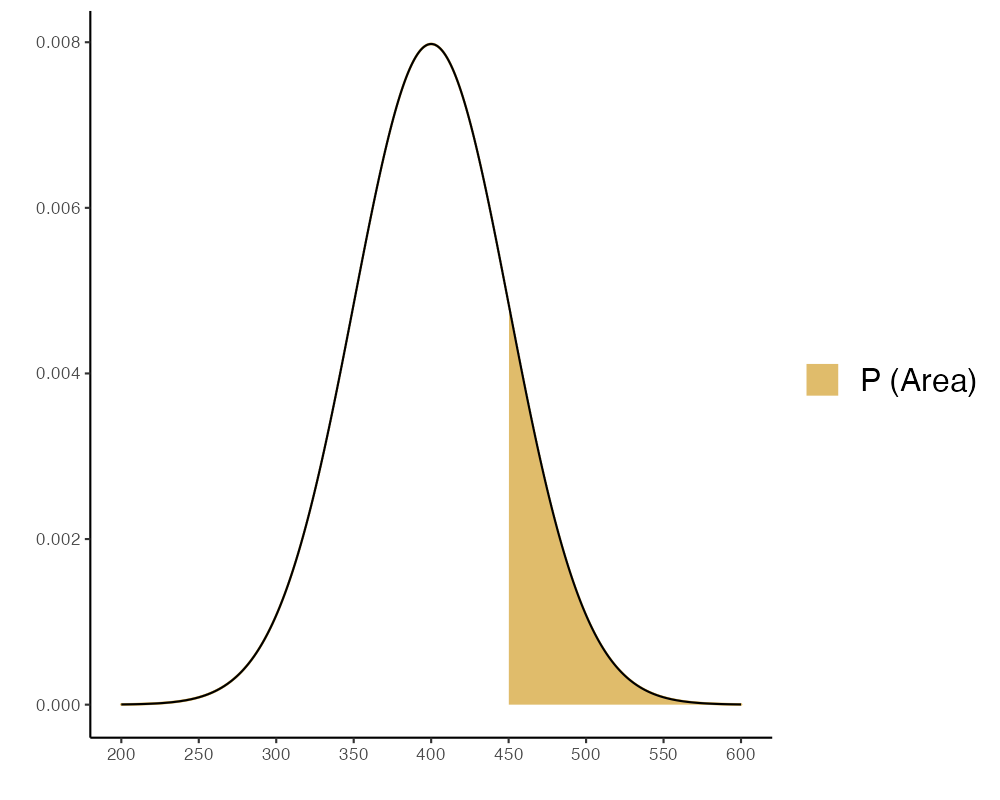
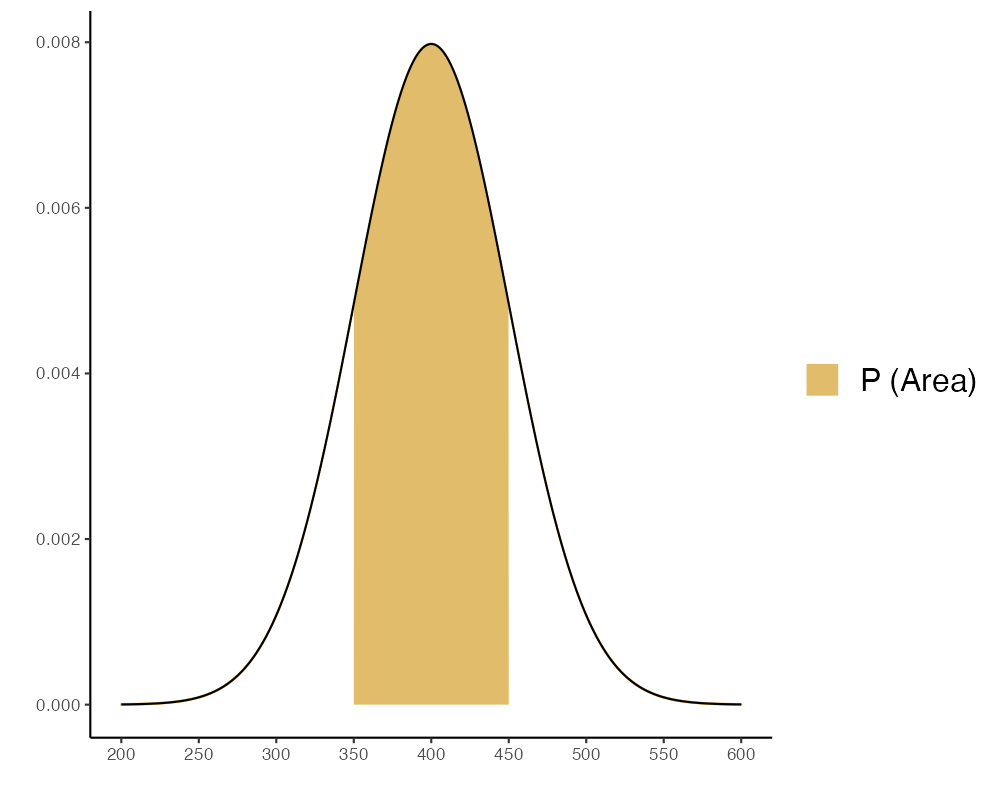
- ความน่าจะเป็นที่ จะได้ข้าวหอมมะลิมากกว่า 350 กก./ไร่ แต่ไม่เกิน 450 กก./ไร่
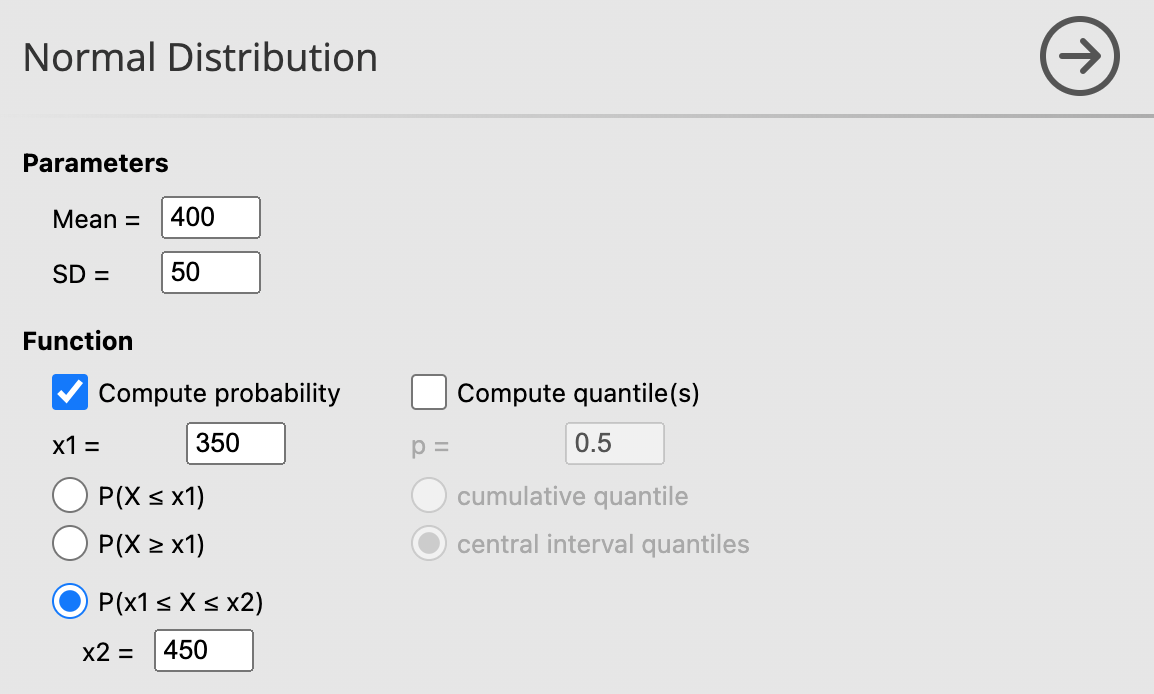
| Input values | |
|---|---|
| Parameters | ‘Compute probability’ |
| Mean \(=400\) | \(x 1=350\) |
| \(S D=50\) | Mode: \(x 2=450\) |
Result
Probability = 0.683
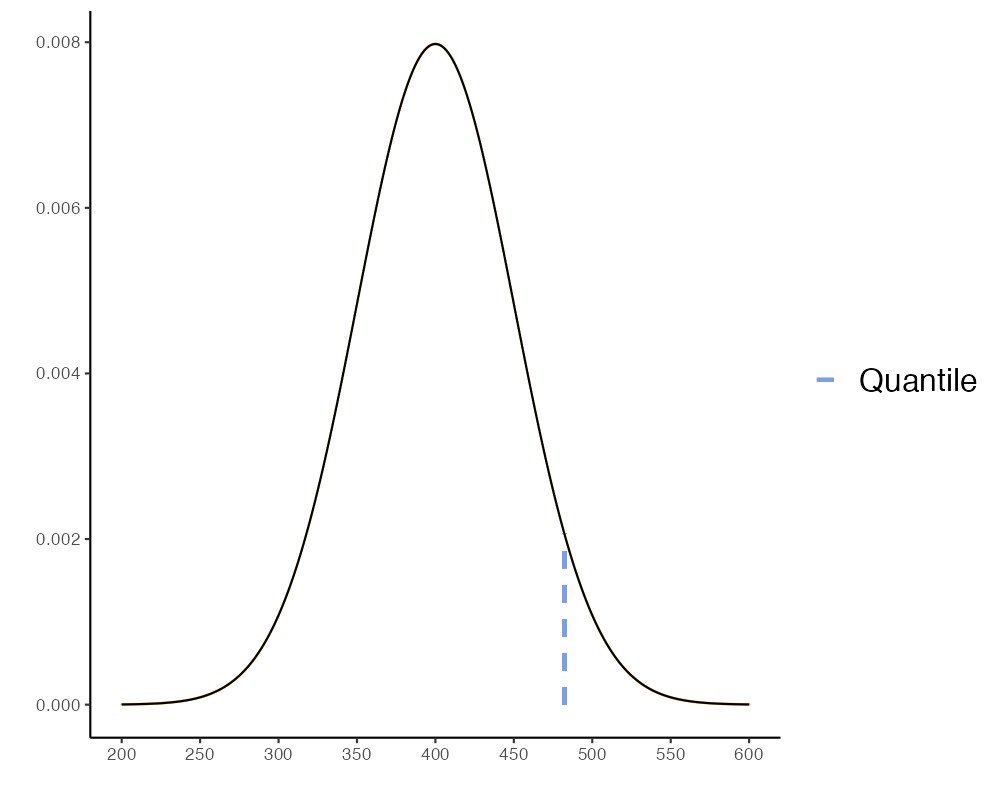
- ที่ค่าควอไทร์ .95 หรือ 95% จะผลิตข้าวได้สูงสุดเท่าไหร่
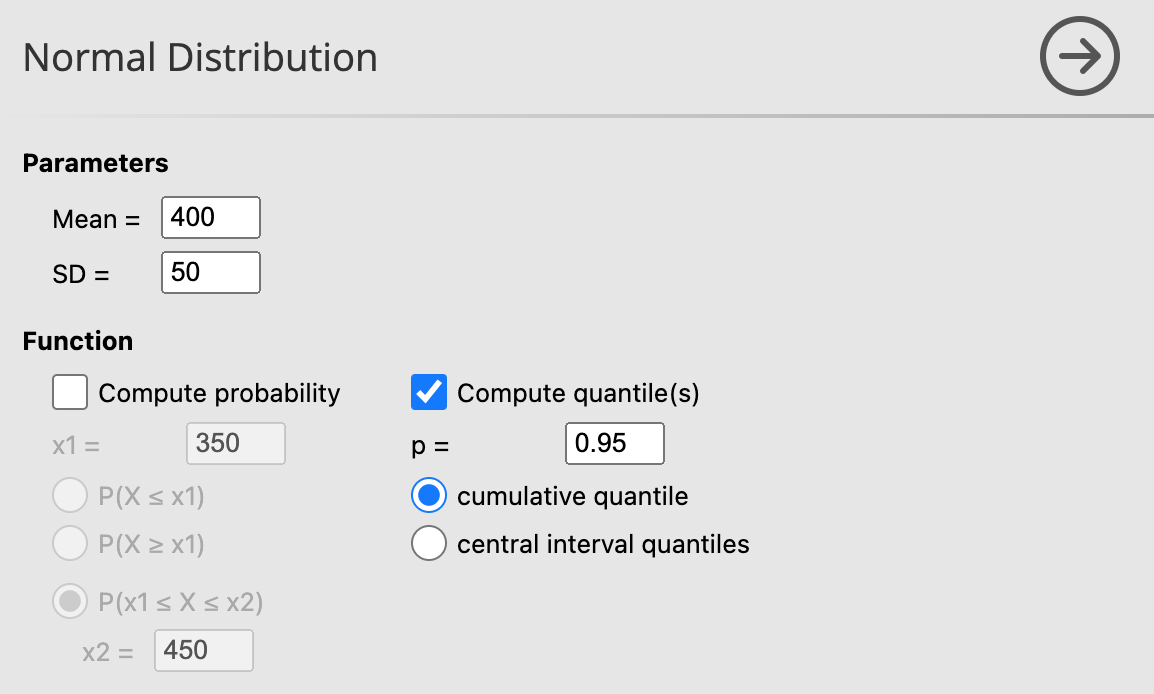
| Parameters | ‘Compute quantile(s)’ |
|---|---|
| Mean \(=400\) | \(p=0.95\) |
| \(S D=50\) | cumulative mode |
Result
Quantile 95 = 482
8.2.2 การแจกแจงแบบ t (t-Distribution)
การแจกแจงแบบ t (t-Distribution) หรือที่เรียกว่าการแจกแจงแบบสตูเดนต์ (Student’s t-Distribution) เป็นการแจกแจงทางสถิติที่ใช้ในการประมาณค่าของค่าเฉลี่ยของประชากรเมื่อขนาดของตัวอย่างมีขนาดเล็กหรือเมื่อส่วนเบี่ยงเบนมาตรฐานของประชากรไม่เป็นที่รู้จัก
คุณสมบัติสำคัญของการแจกแจงแบบ t มีดังนี้:
รูปแบบ: การแจกแจงแบบ t มีลักษณะคล้ายกับการแจกแจงแบบปกติ แต่จะมีหางที่ยาวกว่า (fatter tails) ซึ่งหมายความว่ามีความน่าจะเป็นที่จะได้ค่าที่อยู่ไกลจากค่าเฉลี่ยมากกว่า
อิสระ (Degrees of Freedom): การแจกแจงแบบ t ขึ้นอยู่กับค่าอิสระ (Degrees of Freedom, df) ซึ่งเท่ากับขนาดของตัวอย่างลบด้วยหนึ่ง ((df = n - 1)) การเพิ่มค่าอิสระจะทำให้การแจกแจงแบบ t เข้าใกล้การแจกแจงแบบปกติมากขึ้น
การใช้งาน: ใช้ในการทดสอบสมมติฐานสำหรับค่าเฉลี่ยของประชากรโดยเฉพาะในกรณีที่ขนาดตัวอย่างมีขนาดเล็กหรือส่วนเบี่ยงเบนมาตรฐานของประชากรไม่เป็นที่รู้จัก เช่น t-test สำหรับตัวอย่างเดียว (One-sample t-test), t-test สำหรับสองตัวอย่างอิสระ (Independent two-sample t-test), และ t-test สำหรับตัวอย่างคู่ (Paired sample t-test)
ฟังก์ชันความหนาแน่นความน่าจะเป็น (Probability Density Function, PDF) ของการแจกแจงแบบ t คือ:
\[f(t) =\displaystyle \frac{\Gamma\left(\frac{df + 1}{2}\right)}{\sqrt{df\pi} \Gamma\left(\frac{df}{2}\right)} \left(1 + \frac{t^2}{df}\right)^{-\frac{df + 1}{2}},df\geq1,t\in\mathrm{R}\]
ที่ \(\Gamma\) คือฟังก์ชันแกมมา และ \(df\) คือค่าอิสระ
ในโปรแกรม jamovi เป็นการแจกแจง t แบบทั่วไปคือ สามารถกำหนดการแจก t มีความไม่สมมาตรด้วย พารามิเตอร์ \(\lambda\) ดังนั้น โดยปกติแล้วค่า พารามิเตอร์ \(\lambda =0\) จะเป็นการแจกแจงแบบ t ที่ใช้กันอยู่ทั่วไป
8.2.3 การแจกแจงแบบไคสแควร์ (Chi-Square Distribution
การแจกแจงแบบไคสแควร์ (Chi-Square Distribution) เป็นการแจกแจงทางสถิติที่ใช้กันอย่างแพร่หลายในการทดสอบสมมติฐานเกี่ยวกับการกระจายความถี่และการวิเคราะห์ความแปรปรวน
คุณสมบัติของการแจกแจงแบบไคสแควร์
ความไม่สมมาตร: การแจกแจงแบบไคสแควร์มีลักษณะเป็นไม่สมมาตร โดยมีหางขวายาว ลักษณะการไม่สมมาตรจะลดลงเมื่อค่าของอิสระ (degrees of freedom, df) เพิ่มขึ้น และจะเข้าใกล้การแจกแจงแบบปกติมากขึ้นเมื่อ df มีค่าสูง
ค่าอิสระ (Degrees of Freedom, df): การแจกแจงแบบไคสแควร์ขึ้นอยู่กับค่า df ซึ่งมักจะเป็นจำนวนเต็มบวก ค่า df มากขึ้นจะทำให้การแจกแจงมีแนวโน้มเข้าใกล้การแจกแจงแบบปกติมากขึ้น
ฟังก์ชันความหนาแน่นความน่าจะเป็น (PDF): ฟังก์ชัน PDF ของการแจกแจงแบบไคสแควร์คือ
\[f(x; k) = \frac{1}{2^{k/2} \Gamma(k/2)} x^{(k/2) - 1} e^{-x/2} \quad \text{for } x > 0\] ที่ \(k\) คือค่า df และ \(\Gamma\) คือฟังก์ชันแกมมา
##๒ การใช้งานของการแจกแจงแบบไคสแควร์
การทดสอบความเป็นอิสระ (Test of Independence): ใช้ในการทดสอบว่าตัวแปรสองตัวเป็นอิสระหรือไม่ โดยการทดสอบนี้จะใช้กับตารางความถี่ (contingency table)
การทดสอบความพอดี (Goodness-of-Fit Test): ใช้ในการทดสอบว่าสัดส่วนของตัวอย่างที่สังเกตได้ตรงกับสัดส่วนที่คาดหวังหรือไม่ เช่น การทดสอบว่าข้อมูลมาจากการแจกแจงแบบปกติหรือไม่
การวิเคราะห์ความแปรปรวน (ANOVA): ใช้ในการวิเคราะห์ความแปรปรวนระหว่างกลุ่มและภายในกลุ่ม
การประเมินความแปรปรวน (Variance Estimation): ใช้ในการประเมินความแปรปรวนของประชากร
8.2.4 การแจกแจงแบบ F (F-Distribution)
การแจกแจงแบบ F (F-Distribution) เป็นการแจกแจงความน่าจะเป็นที่สำคัญในสถิติ โดยเฉพาะในงานวิเคราะห์ความแปรปรวน (Analysis of Variance, ANOVA) และการทดสอบสมมติฐานที่เกี่ยวข้องกับความแปรปรวนของกลุ่มข้อมูลหลายกลุ่ม
คุณสมบัติของการแจกแจงแบบ F
ความไม่สมมาตร: การแจกแจงแบบ F มีลักษณะเป็นไม่สมมาตร และมีค่าตั้งแต่ 0 ถึง \(\infty\) โดยมีหางขวายาว
ค่าอิสระ (Degrees of Freedom): การแจกแจงแบบ F ขึ้นอยู่กับค่าอิสระสองค่า ซึ่งได้แก่ \(d_1\) และ \(d_2\) โดยที่ \(d_1\) เป็นค่าอิสระของตัวเศษ (numerator degrees of freedom) และ \(d_2\) เป็นค่าอิสระของตัวส่วน (denominator degrees of freedom)
ฟังก์ชันความหนาแน่นความน่าจะเป็น (PDF): ฟังก์ชัน PDF ของการแจกแจงแบบ F คือ: \[f(x; d_1, d_2) = \frac{\sqrt{\left(\frac{d_1 x}{d_1 x + d_2}\right)^{d_1} \left(1 - \frac{d_1 x}{d_1 x + d_2}\right)^{d_2}}}{x B\left(\frac{d_1}{2}, \frac{d_2}{2}\right)}\]
โดยที่ \(B\) คือฟังก์ชันเบตา, \(d_1\) คือค่าอิสระของตัวเศษ และ \(d_2\) คือค่าอิสระของตัวส่วน
การใช้งานของการแจกแจงแบบ F
การวิเคราะห์ความแปรปรวน (ANOVA): ใช้ในการเปรียบเทียบความแปรปรวนระหว่างกลุ่มต่าง ๆ กับความแปรปรวนภายในกลุ่มเดียวกัน เพื่อทดสอบสมมติฐานว่าค่าเฉลี่ยของกลุ่มต่าง ๆ เท่ากันหรือไม่
การทดสอบความแปรปรวนร่วม (Analysis of Covariance, ANCOVA): ใช้ในการตรวจสอบผลกระทบของตัวแปรร่วมควบคู่กับตัวแปรอิสระ
การทดสอบสมมติฐานเกี่ยวกับความแปรปรวนของสองประชากร: ใช้ในการเปรียบเทียบความแปรปรวนของสองประชากรเพื่อตรวจสอบว่าความแปรปรวนของทั้งสองกลุ่มมีค่าเท่ากันหรือไม่
ตัวอย่างการใช้การแจกแจงแบบ F
สมมติว่าคุณต้องการทดสอบว่าค่าเฉลี่ยของสามกลุ่มตัวอย่างมีค่าเท่ากันหรือไม่ คุณสามารถใช้ ANOVA ซึ่งการทดสอบนี้จะใช้การแจกแจงแบบ F ในการคำนวณค่า p-value
กำหนดสมมติฐาน:
- \(H_0\): ค่าเฉลี่ยของทุกกลุ่มเท่ากัน
- \(H_1\): ค่าเฉลี่ยของอย่างน้อยหนึ่งกลุ่มแตกต่างกัน
คำนวณสถิติการทดสอบ: คำนวณค่า F-statistic จากความแปรปรวนระหว่างกลุ่ม (MSB, Mean Square Between) และความแปรปรวนภายในกลุ่ม (MSW, Mean Square Within): \[F = \frac{MSB}{MSW}\]
เปรียบเทียบกับค่า F ที่วิกฤติ: ใช้ค่าอิสระ \(d_1 = k - 1\) และ \(d_2 = N - k\) (ที่ \(k\) คือจำนวนกลุ่มและ \(N\) คือขนาดตัวอย่างรวม) และเปรียบเทียบกับค่า F-critical ที่ระดับนัยสำคัญที่ต้องการ (เช่น 0.05)
Warningข้อควรระวัง
สำหรับการตัวแปรสุ่มที่เป็นตัวแปรแบบต่อเนื่อง ความน่าจะเป็นของ
\[ Pr(X = x)=0 \]
ถ้า \(x\) มีค่าเป็นจุด ที่ไม่ใช่ช่วง
8.2.5 การแจกแจงแบบทวินาม (Binomial Distribution
การแจกแจงแบบทวินาม (Binomial Distribution) เป็นการแจกแจงความน่าจะเป็นที่ใช้สำหรับการทดลองที่มีผลลัพธ์สองแบบ (เช่น สำเร็จ/ล้มเหลว, ชนะ/แพ้, ผ่าน/ไม่ผ่าน) และมีการทดลองซ้ำ ๆ กันหลายครั้งอย่างอิสระ การแจกแจงแบบทวินามจะบอกความน่าจะเป็นของการได้จำนวนครั้งของผลลัพธ์หนึ่งในจำนวนการทดลองทั้งหมด
คุณสมบัติของการแจกแจงแบบทวินาม
การทดลองซ้ำ: การทดลองต้องเป็นแบบซ้ำกันหลายครั้ง (n) และเป็นอิสระจากกัน
ผลลัพธ์สองแบบ: แต่ละการทดลองมีผลลัพธ์สองแบบ ซึ่งเรียกว่า “สำเร็จ” และ “ล้มเหลว” โดยความน่าจะเป็นของความสำเร็จคือ \(p\) และความน่าจะเป็นของความล้มเหลวคือ \(1 - p\)
ความน่าจะเป็นคงที่: ความน่าจะเป็นของการสำเร็จ (\(p\)) และความล้มเหลว (\(1 - p\)) คงที่ในแต่ละครั้งของการทดลอง
ฟังก์ชันความน่าจะเป็น (Probability Mass Function, PMF)
ฟังก์ชัน PMF ของการแจกแจงแบบทวินามคือ: \[ P(X = k) = \binom{n}{k} p^k (1 - p)^{n - k} \] โดยที่
\(\binom{n}{k}\) คือสัมประสิทธิ์ทวินาม (binomial coefficient) ซึ่งคำนวณได้จาก \(\frac{n!}{k!(n - k)!}\)
\(n\) คือจำนวนครั้งของการทดลอง
\(k\) คือจำนวนครั้งของการสำเร็จ
\(p\) คือความน่าจะเป็นของการสำเร็จในแต่ละครั้งของการทดลอง
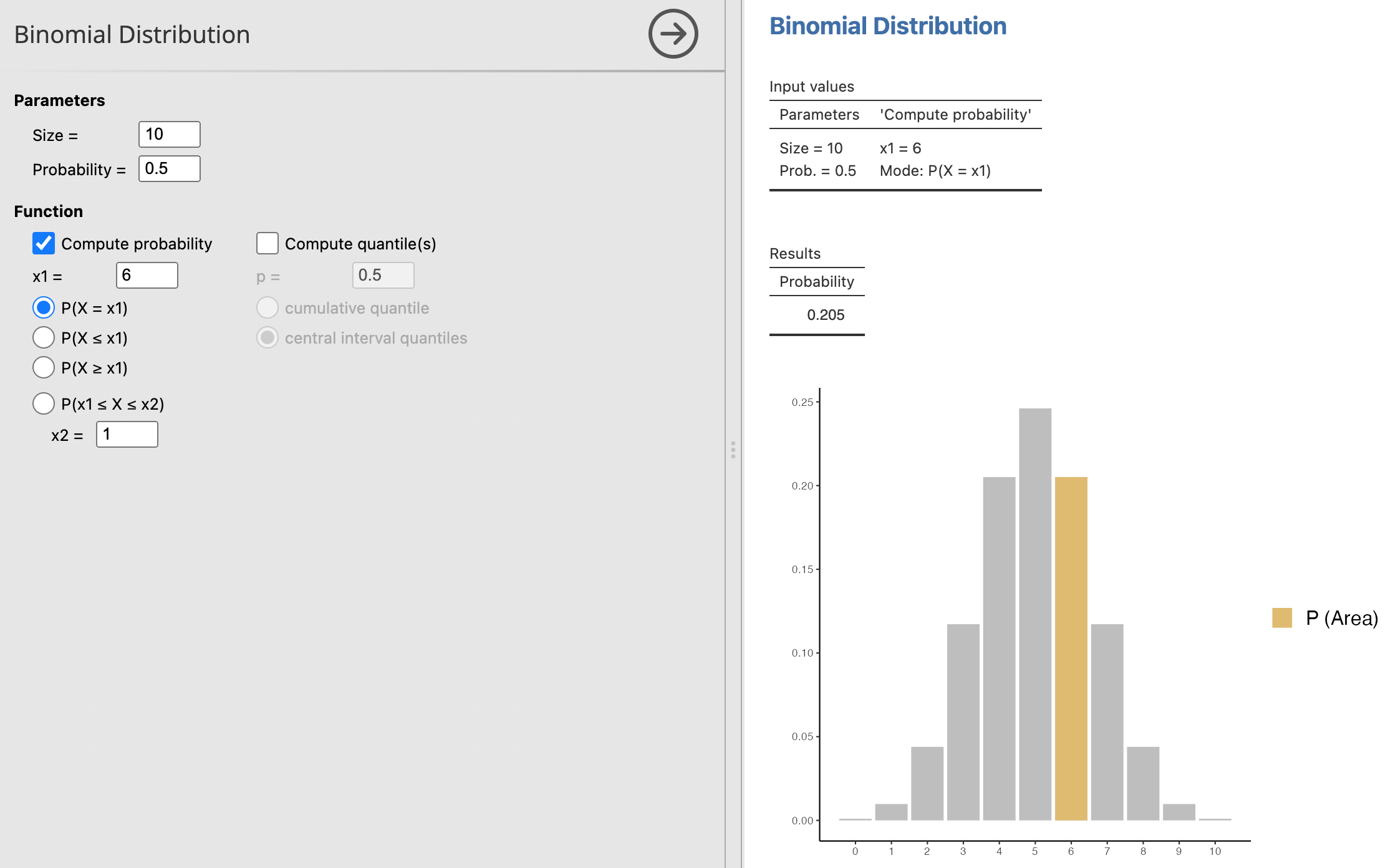
ตัวอย่าง
สมมติว่าคุณมีเหรียญที่คุณคาดว่าเป็นเหรียญยุติธรรม (คือมีความน่าจะเป็นของการออกหัวเท่ากับ 0.5) และคุณจะโยนเหรียญนี้ 10 ครั้ง คุณต้องการทราบความน่าจะเป็นของการออกหัว 6 ครั้งจากการโยน 10 ครั้ง
ในกรณีนี้:
\(n = 10\)
\(k = 6\)
\(p = 0.5\)
เราสามารถคำนวณความน่าจะเป็นได้ดังนี้: \[ P(X = 6) = \binom{10}{6} (0.5)^6 (1 - 0.5)^{10 - 6} \] \[ = \frac{10!}{6!4!} (0.5)^6 (0.5)^4 \] \[ = 210 \times (0.5)^{10} \] \[ = 210 \times 0.0009765625 \] \[ \approx 0.205 \]
ดังนั้น ความน่าจะเป็นของการออกหัว 6 ครั้งจากการโยนเหรียญ 10 ครั้งคือประมาณ 0.205 หรือ 20.5%
8.2.6 การแจกแจงแบบปัวซอง (Poisson Distribution)
การแจกแจงแบบปัวซอง (Poisson Distribution) เป็นการแจกแจงความน่าจะเป็นที่ใช้ในการสร้างแบบจำลองเหตุการณ์ที่เกิดขึ้นอย่างต่อเนื่องในช่วงเวลาหนึ่งหรือพื้นที่หนึ่งโดยไม่ขึ้นกับกัน และมีอัตราเฉลี่ยคงที่
คุณสมบัติของการแจกแจงแบบปัวซอง
เหตุการณ์เกิดขึ้นอย่างอิสระ: การเกิดเหตุการณ์หนึ่งไม่ได้ส่งผลต่อการเกิดเหตุการณ์อื่น ๆ
เหตุการณ์เกิดขึ้นอย่างสม่ำเสมอ: ความน่าจะเป็นของการเกิดเหตุการณ์ในช่วงเวลาหรือพื้นที่หนึ่ง ๆ เป็นสัดส่วนกับขนาดของช่วงเวลาหรือพื้นที่นั้น ๆ
ไม่สามารถเกิดเหตุการณ์พร้อมกันได้: ความน่าจะเป็นของการเกิดเหตุการณ์มากกว่าหนึ่งเหตุการณ์ในช่วงเวลาหรือพื้นที่เล็ก ๆ มากนั้นมีค่าเป็นศูนย์
ฟังก์ชันความน่าจะเป็น (Probability Mass Function, PMF)
ฟังก์ชัน PMF ของการแจกแจงแบบปัวซองคือ: \[ P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!},~k =0,1,2,3,\cdots \] ที่:
\(X\) คือจำนวนครั้งของเหตุการณ์ที่เกิดขึ้น
\(k\) คือจำนวนครั้งของเหตุการณ์ที่เราสนใจ (เช่น จำนวนการโทรเข้ามาที่ศูนย์บริการในหนึ่งชั่วโมง)
\(\lambda\) คือค่าเฉลี่ยของเหตุการณ์ที่เกิดขึ้นต่อช่วงเวลาหรือพื้นที่หน่วย (เช่น ค่าเฉลี่ยของการโทรเข้ามาที่ศูนย์บริการในหนึ่งชั่วโมง)
\(e\) คือค่าคงที่ทางคณิตศาสตร์ (ประมาณ 2.71828)
ตัวอย่าง
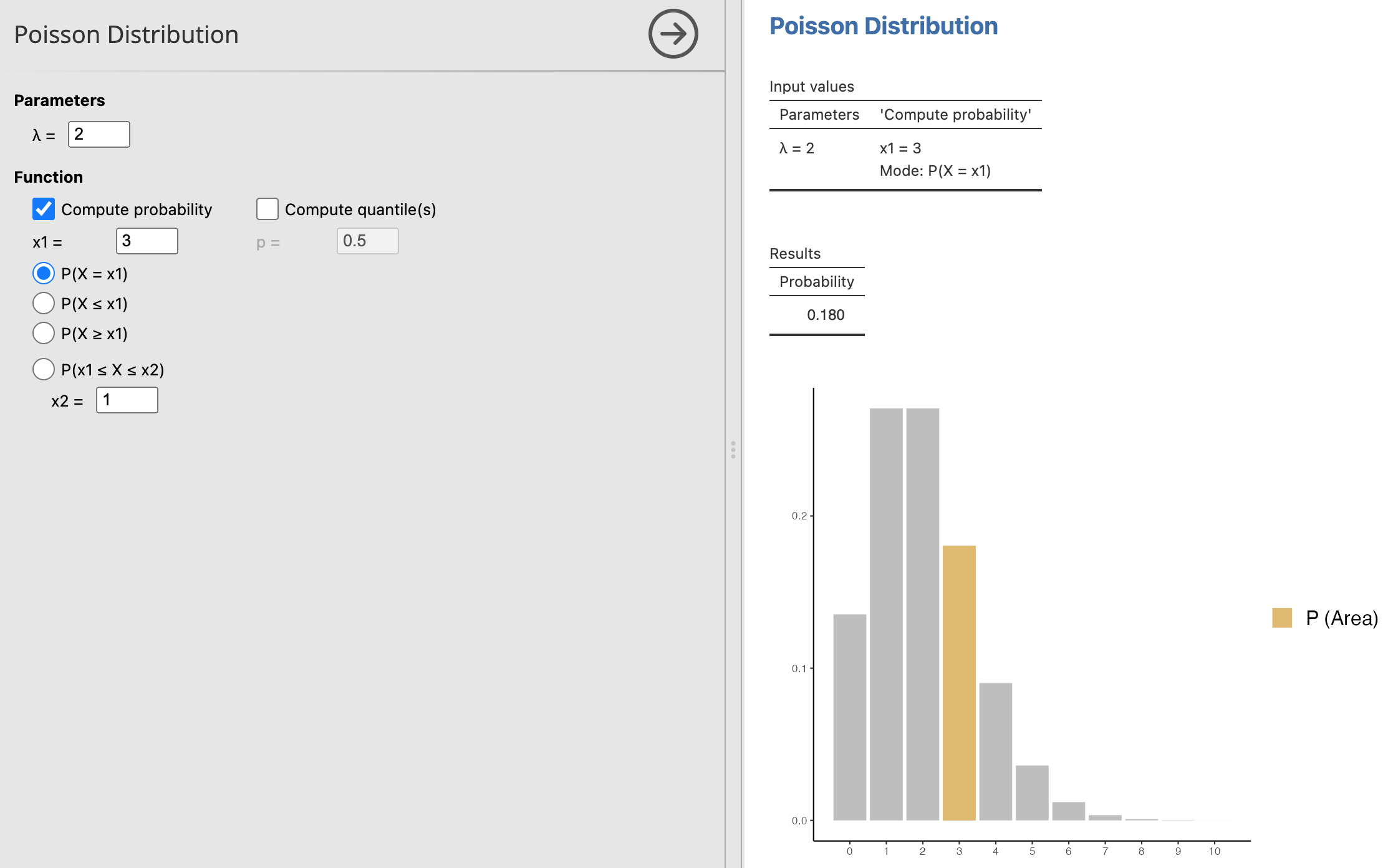
สมมติว่าคุณต้องการทราบความน่าจะเป็นที่ในหนึ่งชั่วโมงจะมีการโทรเข้ามาที่ศูนย์บริการลูกค้า 3 ครั้ง โดยที่ค่าเฉลี่ยของการโทรเข้ามาคือ 2 ครั้งต่อชั่วโมง
ในกรณีนี้:
\(\lambda = 2\)
\(k = 3\)
เราสามารถคำนวณความน่าจะเป็นได้ดังนี้:
\[ P(X = 3) = \frac{2^3 e^{-2}}{3!} \]
\[ = \frac{8 \cdot e^{-2}}{6} \]
\[ = \frac{8}{6} \cdot e^{-2} \]
\[ = \frac{4}{3} \cdot 0.1353 \]
\[ \approx 0.1804 \]
ดังนั้น ความน่าจะเป็นที่ในหนึ่งชั่วโมงจะมีการโทรเข้ามาที่ศูนย์บริการลูกค้า 3 ครั้งคือประมาณ 0.1804 หรือ 18.04%
การใช้งานของการแจกแจงแบบปัวซอง
การแจกแจงแบบปัวซองถูกใช้ในหลากหลายสาขา เช่น:
การบริหารจัดการทรัพยากร: เช่น การประเมินจำนวนการโทรเข้ามาที่ศูนย์บริการลูกค้าในช่วงเวลาหนึ่ง
การวิเคราะห์ทางการแพทย์: เช่น การวิเคราะห์จำนวนผู้ป่วยที่มาถึงห้องฉุกเฉินในช่วงเวลาหนึ่ง
การวิเคราะห์อัตราการเกิดเหตุการณ์: เช่น การวิเคราะห์จำนวนการเกิดอุบัติเหตุในช่วงเวลาหนึ่งหรือพื้นที่หนึ่ง
การจัดการขนส่งและโลจิสติกส์: เช่น การวิเคราะห์จำนวนยานพาหนะที่ผ่านทางแยกในช่วงเวลาหนึ่ง
การแจกแจงแบบปัวซองเป็นเครื่องมือที่มีประโยชน์ในการวิเคราะห์และประเมินเหตุการณ์ที่เกิดขึ้นต่อเนื่องในช่วงเวลาหรือพื้นที่ โดยเฉพาะเมื่อเหตุการณ์นั้น ๆ มีอัตราเฉลี่ยคงที่

เมื่อทำการติดตั้งเมนูนี้ จะสามารถเลือกนำเข้าข้อมูลมาวิเคราะห์ได้
8.2.7 jReshape สำหรับการเปลี่ยนโครงสร้าง (reshape)
การ Reshape ข้อมูล คืออะไร?
Reshape ข้อมูล คือกระบวนการเปลี่ยนโครงสร้างของข้อมูลจากรูปแบบหนึ่งไปเป็นอีกรูปแบบหนึ่ง เพื่อให้เหมาะสมกับการวิเคราะห์หรือการแสดงผล เช่น เปลี่ยนจาก Wide Format เป็น LongFormat หรือในทางกลับกันก็ได้
รูปแบบของข้อมูลในการ Reshape
Wide Format (รูปแบบกว้าง)
ข้อมูลถูกจัดให้อยู่ในรูปแบบที่แต่ละตัวแปรมีคอลัมน์ของตัวเอง
นิยมใช้สำหรับรายงานหรือการแสดงผลแบบตารางหรือใช้สำหรับการวิเคราะห์ด้วยโปรแกรม Excel
ตัวอย่าง
Long Format (รูปแบบยาว)
ข้อมูลถูกแปลงให้แต่ละค่าของตัวแปรแยกเป็นแถว
นิยมใช้สำหรับการวิเคราะห์ข้อมูลด้วยโปรแกรม jamovi JASP หรือ R
ตัวอย่าง
เนื้อหาส่วนนี้ได้รับทำการเขียนขึ้น หลังจากที่ jamovi ออกโปรแกรมรุ่น 2.6.44 ในหลายๆ กรณีผู้เขียนพบโจทย์เสริมความเข้าใจในวิชาสถิติพื้นฐาน จะแสดงข้อมูลอยู่รูปของ wide format เพื่อให้ง่ายสำหรับการคำนวณด้วยเครื่องคิดเลข หรือโปรแกรม Excel ทำให้นักศึกษาหรือผู้อ่าน จำเป็นต้องจัดข้อมูลให้อยู่ในรูป Long format เพื่อให้สามารถ นำไปวิเคราะห์ต่อด้วย jamovi ได้ ดังนั้นถ้าต้องการใช้ Excel ในการเปลี่ยนจาก wide ไปเป็น Long จำเป็นต้องใช้ Excel ในรุ่นที่สามารถใช้งาน Power Query ได้ จะได้ไม่เสียเวลามากจนเกินไป แล้วก็นำผลที่ได้มาใส่ในโปรแกรม jamovi อีก จึงเป็นการทำงาน 2 ขั้นตอน
โมดูล jReshape จะทำให้สามารถดำเนินการแปลงข้อมูลแล้วทำวิเคราะห์ต่อไปได้ทันที
และเมื่อได้ทำการติดตั้งโมดูลนี้แล้วจะพบไอคอนใหม่ ชื่อว่า Data ปรากฏขึ้น
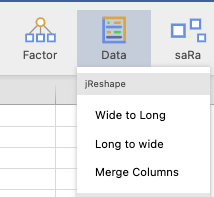
โดยฟังก์ชันการทำงาน 3 แบบ คือ
Wide to Long ทำการแปลงข้อมูลจาก Wide ไปเป็น Long
Long to Wide ทำการแปลงข้อมูลจาก Long ไปเป็น Wide
Merge Columns ทำการรวม 2 ตาราง โดยที่แต่ละตาราง มีตัวแปร 1 ตัวเหมือนกัน เพื่อทำหน้าที่เป็นตัวเชื่อม
ตัวอย่างการแปลงจาก wide เป็น long ด้วย jamovi
Download ข้อมูลจาก googledrive ชื่อ
df_wide.xlsxเปิดไฟล์ด้วย jamovi เลือก icon
Data\(\rightarrow\)Wide to Longแล้วทำตามภาพด้านล่าง
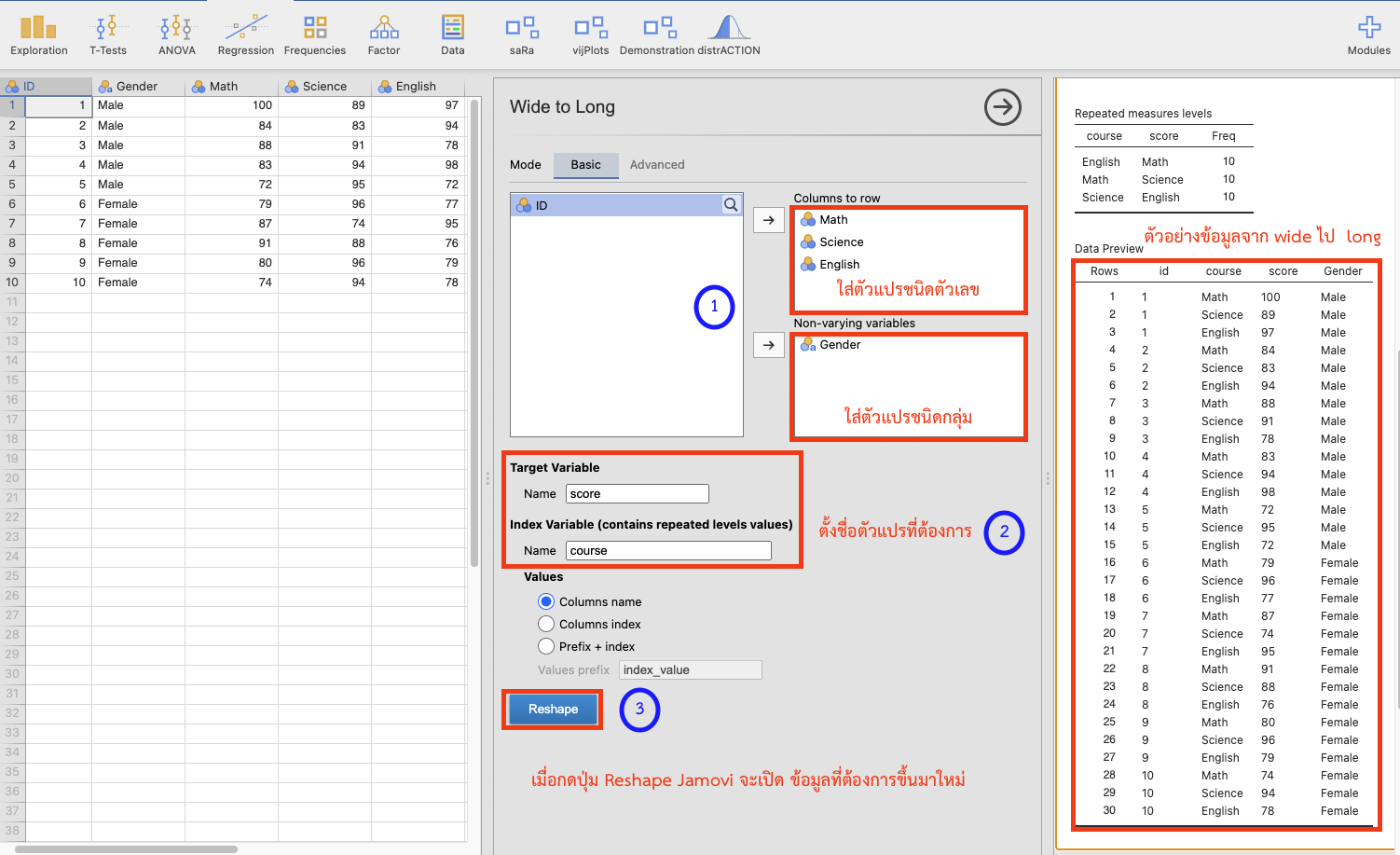
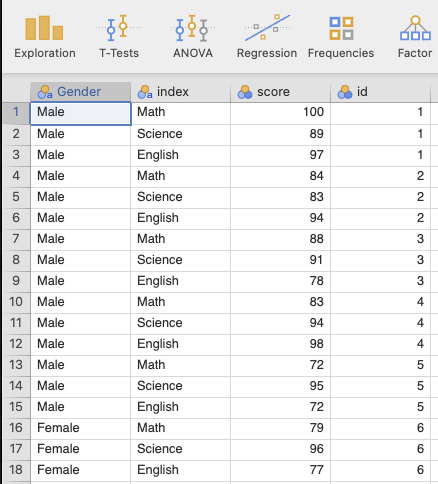
- หลังจากกดปุ้ม Reshape jamovi จะเปิดข้อมูลที่ทำการแปลงแล้วขึ้นมา
ตัวอย่างการแปลงจาก long เป็น wide ด้วย jamovi
จะผลลัพธ์ที่ได้จาก wide to long ย้อนกลับไป
- เลือก icon
Data\(\rightarrow\)Long to Wideแล้วทำตามภาพด้านล่าง
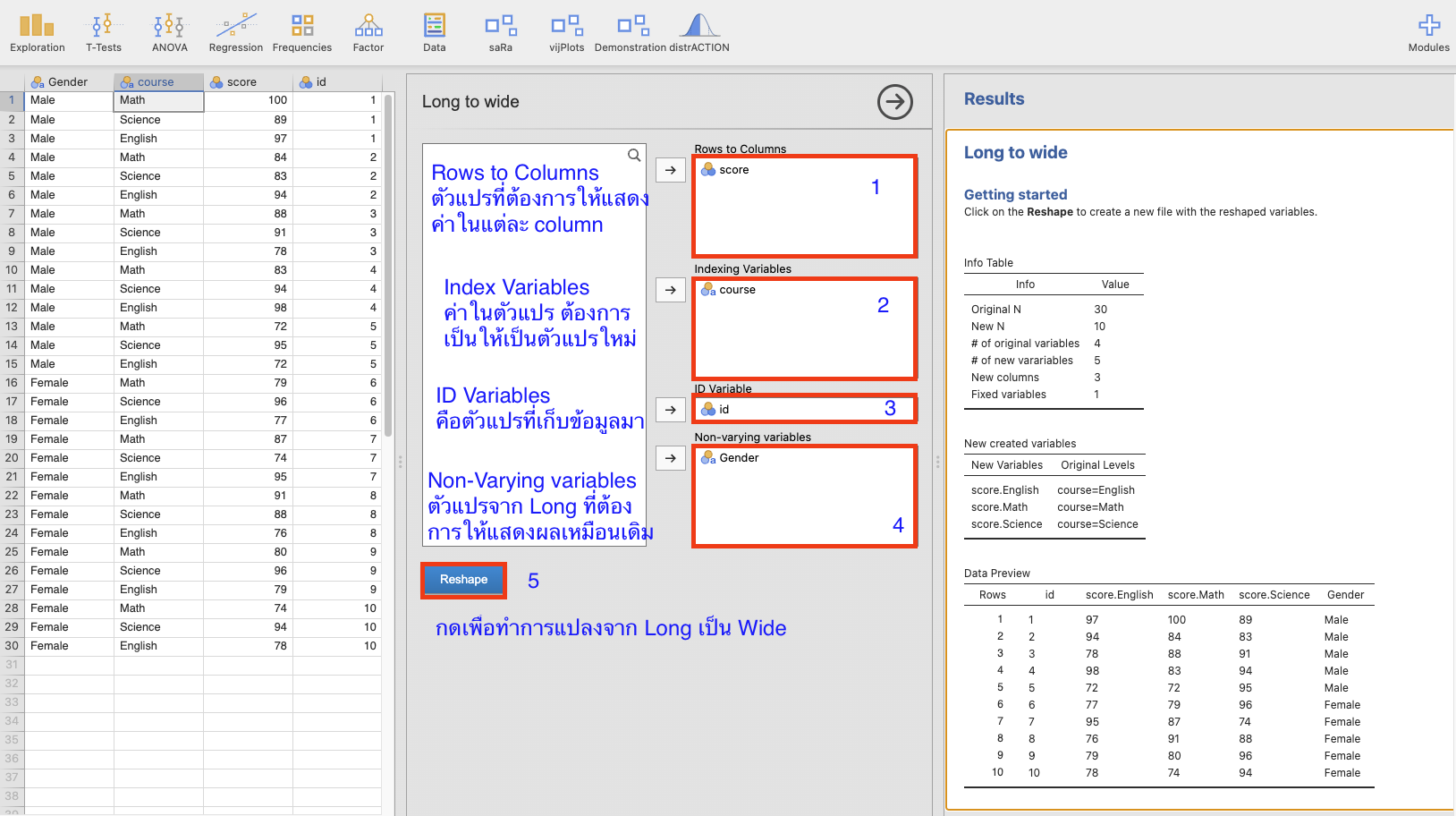
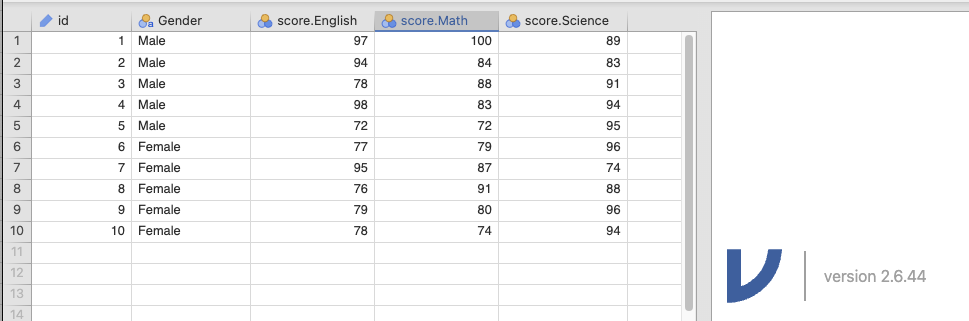
- กด
Reshapeเพื่อทำการแปลง jamovi จะเปิด ข้อมูลที่ทำการแปลงแล้วขึ้นมา
ตัวอย่างการ Merge Columns
ตัวอย่างการ Merge Columns ด้วย jReshape โดยใช้ไฟล์ table1.csv และ table2.csv
- เปิดไฟล์ table1.csv ด้วย jamovi \(\rightarrow\) เลือก icon
Data\(\rightarrow\) `เลือก Merge columns แล้วทำตามดังภาพ
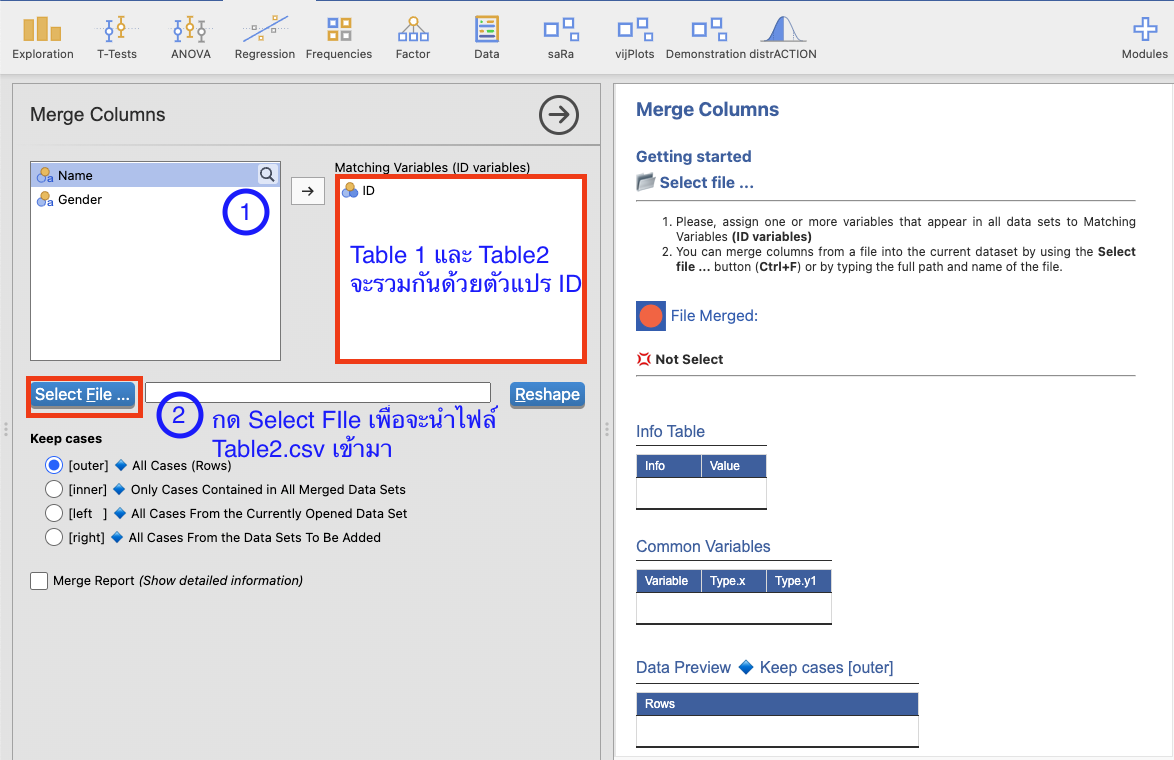
- กด
Add Filesนำไฟล์ Table2.csv เข้ามา แล้วกดConfirm
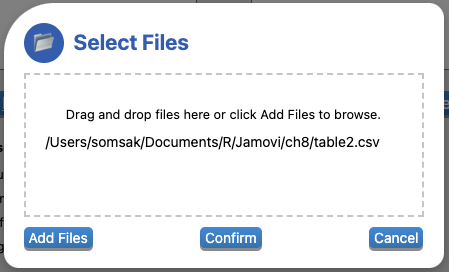
Warningไฟล์ที่สามารถ นำเข้ามาเข้ารวมด้วย Merge columns ได้
จะต้องเป็นนามสกุลดังต่อไปนี้เท่านั้น (.omv, .omt, .csv, .tsv, .rdata, .rda, .rds, .sav, .zsav, .dta, .sas7bdat, .sd2, .sd7, .xpt, .stx, .stc).
- เลือกการรวมที่ต้องการ (
outter,inner,left,right) แล้วกดปุ่ม `Reshape เพื่อเปิด jamovi ขึ้นมาใหม่พร้อมตารางผ่านการรวมแล้ว
เลือก
outer→ เอาทุกข้อมูลจากทั้งสองตาราง (รวมทุกID)รวมข้อมูลทั้งหมดจาก ทั้งสองตาราง
ถ้าไม่มีข้อมูลในตารางใด → เติม
NA
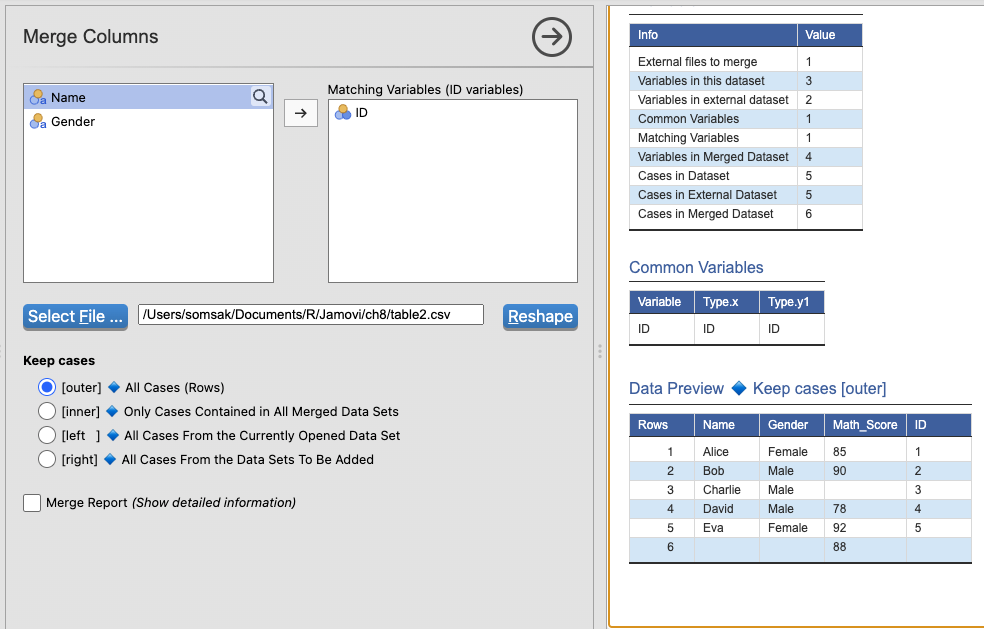
| ID | Name | Gender | Math_Score |
|---|---|---|---|
| 1 | Alice | Female | 85 |
| 2 | Bob | Male | 90 |
| 3 | Charlie | Male | NA |
| 4 | David | Male | 78 |
| 5 | Eva | Female | 92 |
| 6 | NA | NA | 88 |
- สังเกต: ทั้ง
ID = 3และID = 6อยู่ในผลลัพธ์ แต่ค่าที่ไม่มีในอีกตารางจะเป็นNA
- เหมาะสำหรับ: เมื่อต้องการเก็บข้อมูลทั้งหมด ไม่ว่าจะอยู่ในตารางใดก็ตาม
เลือก
inner→ เอาเฉพาะข้อมูลที่ตรงกันในทั้งสองตารางเก็บเฉพาะแถวที่มีค่าตรงกันในทั้งสองตาราง
ถ้าค่าใน
IDของTable2 ไม่มีในTable1 → หายไปถ้าค่าใน
IDของTable1 ไม่มีในTable2 → หายไป
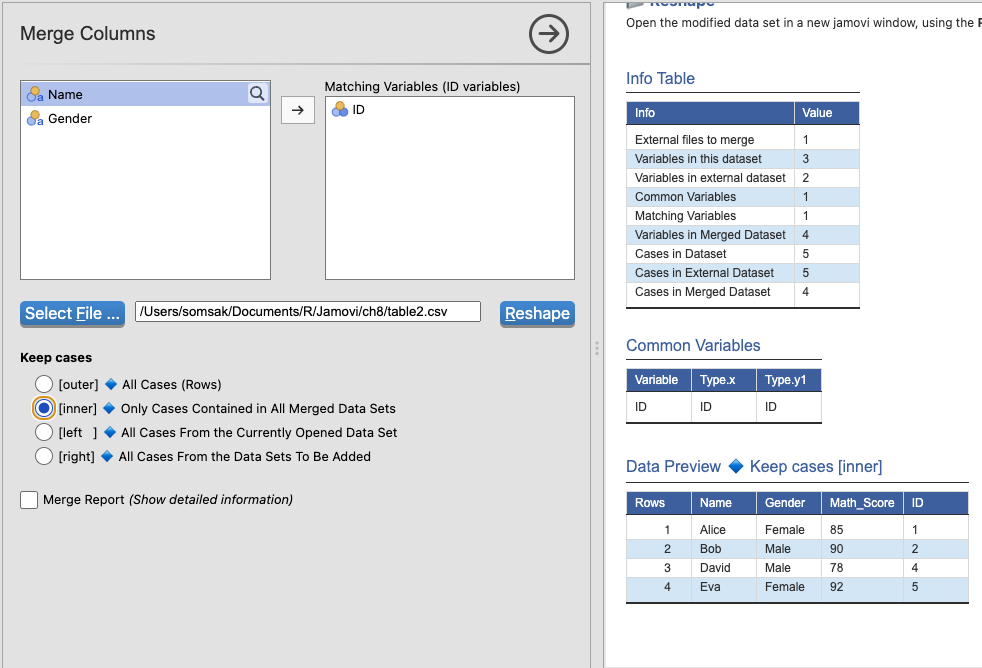
| ID | Name | Gender | Math_Score |
|---|---|---|---|
| 1 | Alice | Female | 85 |
| 2 | Bob | Male | 90 |
| 4 | David | Male | 78 |
| 5 | Eva | Female | 92 |
สังเกต: Charlie (ID = 3) และ ID = 6 ไม่อยู่ในผลลัพธ์ เพราะไม่มีข้อมูลตรงกัน
เหมาะสำหรับ: เมื่อต้องการเฉพาะข้อมูลที่มีอยู่ทั้งสองตาราง เช่น ต้องการเฉพาะนักเรียนที่มีคะแนนเท่านั้น
เลือก
left→ เอาข้อมูลทั้งหมดจากTable2 + เติมข้อมูลจากTable1เอาข้อมูลทั้งหมดจาก ตารางหลัก (Table2)
ถ้าข้อมูล ในTable1ตรงกับTable2 → เติมข้อมูลเข้าไป
ถ้า ไม่มีข้อมูลในTable1 → ได้ค่า
NA
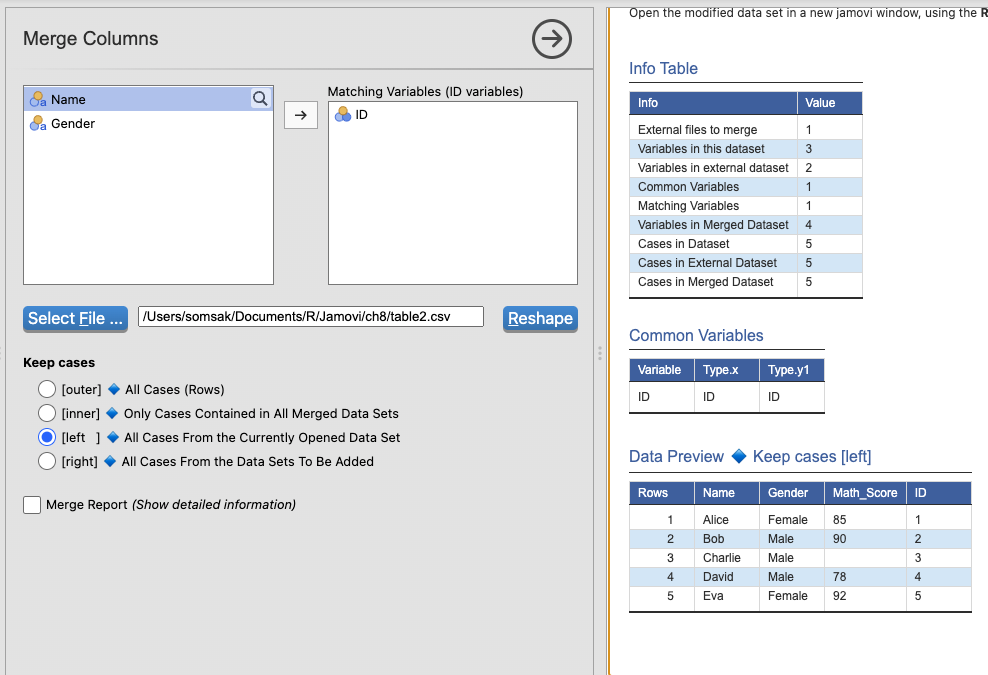
| ID | Name | Gender | Math_Score |
|---|---|---|---|
| 1 | Alice | Female | 85 |
| 2 | Bob | Male | 90 |
| 3 | Charlie | Male | NA |
| 4 | David | Male | 78 |
| 5 | Eva | Female | 92 |
สังเกต:
Charlie (ID = 3)ไม่มีคะแนน Math เลยได้NAเหมาะสำหรับ: เมื่อเราต้องการเก็บข้อมูลทั้งหมดจากตารางหลัก (เช่น รายชื่อนักเรียนทั้งหมด) แม้ว่าบางคนจะไม่มีคะแนนก็ตาม
เลือก
right→ เอาข้อมูลทั้งหมดจากTable1 + เติมข้อมูลจากTable2เอาข้อมูลทั้งหมดจาก Table1 (ตารางที่เราจะเข้าร่วม)
ถ้าข้อมูล ในTable2ตรงกับTable1 → เติมข้อมูลเข้าไป
ถ้า ไม่มีข้อมูลในTable2 → ได้ค่า
NA
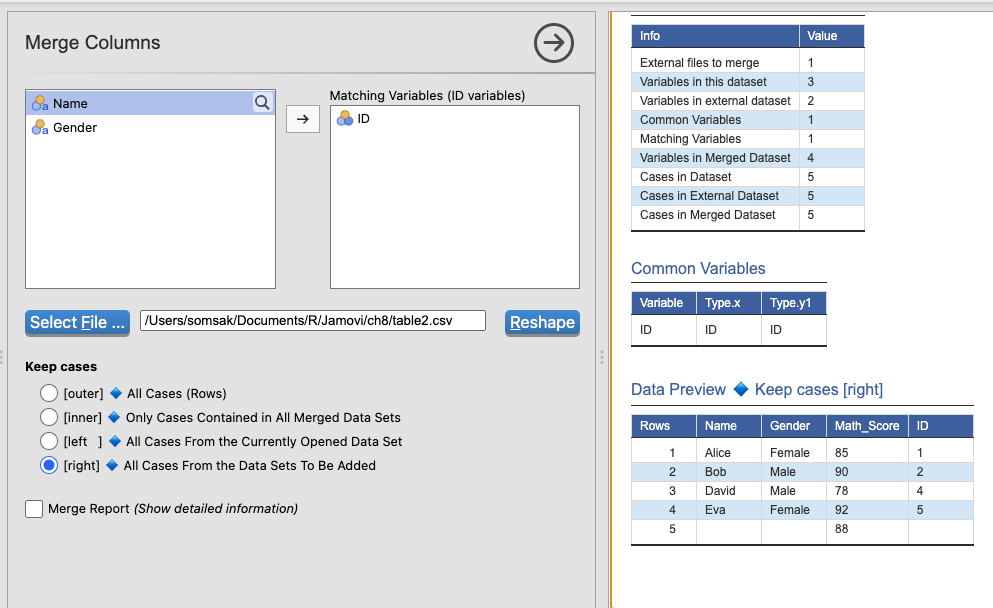
| ID | Name | Gender | Math_Score |
|---|---|---|---|
| 1 | Alice | Female | 85 |
| 2 | Bob | Male | 90 |
| 4 | David | Male | 78 |
| 5 | Eva | Female | 92 |
| 6 | NA | NA | 88 |
สังเกต:
ID = 6ไม่มีในstudentsเลยได้NAในNameและGenderเหมาะสำหรับ: เมื่อต้องการเก็บข้อมูลจากตารางคะแนนทั้งหมด แม้ว่าบางคนจะไม่มีข้อมูลนักเรียน
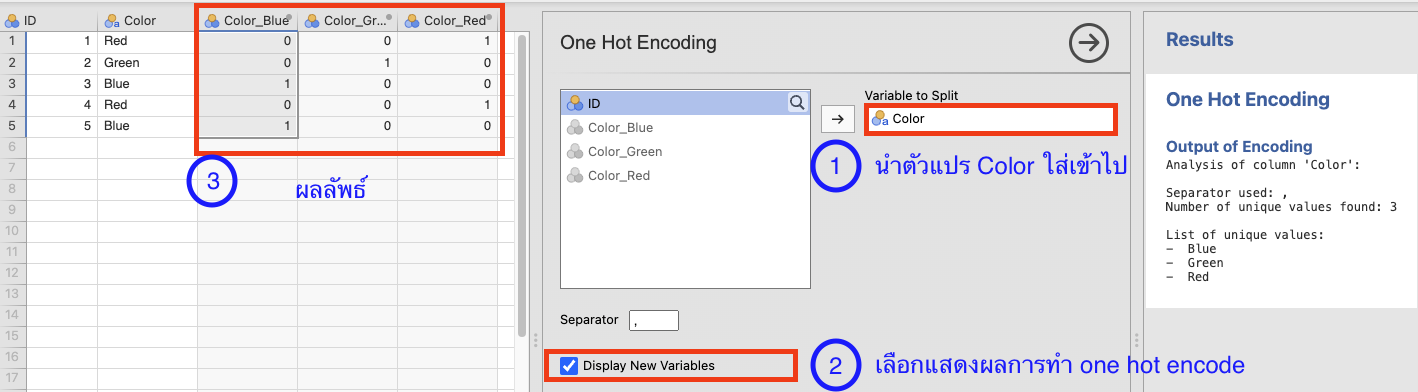
8.3 OneHotEncoding
NoteOne-Hot Encoding คืออะไร?
One-Hot Encoding (OHE) เป็นเทคนิคในการแปลงข้อมูลประเภทที่เป็น หมวดหมู่ (Categorical Data) ให้กลายเป็น ข้อมูลตัวเลข เพื่อให้สามารถนำไปใช้กับโมเดลทางสถิติหรือ Machine Learning ได้
ทำไมต้องใช้ One-Hot Encoding? บางอัลกอริธึม เช่น Linear Regression, Logistic Regression, Neural Networks ไม่สามารถทำงานกับ ตัวแปรหมวดหมู่ (Categorical Variables) โดยตรงได้ จำเป็นต้องแปลงข้อมูลเป็นตัวเลขก่อน
วิธีการทำ One-Hot Encoding
สร้างคอลัมน์ใหม่ สำหรับแต่ละค่าที่เป็นไปได้ของตัวแปรหมวดหมู่
แทนค่าด้วย 1 หรือ 0
1หมายถึง แถวนี้อยู่ในหมวดหมู่นั้น0หมายถึง แถวนี้ ไม่ได้ อยู่ในหมวดหมู่นั้น
เมื่อทำการติดตั้งแล้ว มี icon Data ขึ้นมา เหมือนกับ rReshape
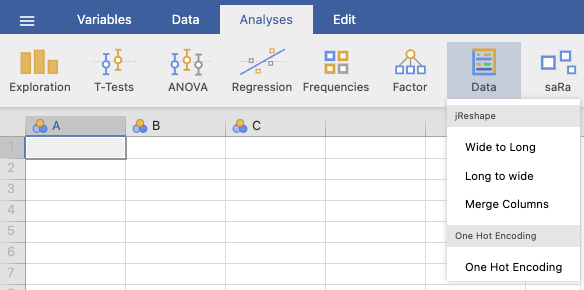
ตัวอย่างการใช้งาน เมนู One hot Encoding
Download ข้อมูลจาก googledrive ชื่อ color.xlsx
- เปิดไฟล์
color.xlsxด้วย jamovi \(\rightarrow\) iconData\(\rightarrow\) เลือกเมนู One Hot Encoding แล้วทำตามภาพ