8 SQL: Aggregating and summarizing results
In this chapter, we will discuss how we can aggregate and summarize results. We will again use the schema music_marketplace that describes a hypothetical marketplace for music. Recall that the schema includes the following tables:
songs: stores information about songs.label: stores information about music labels.artist: stores information about artists.artist_songs: stores which songs are produced by which artists.charts: stores the maximum rank that a songs achieves in the charts (the hypothetical marketplace has top-selling charts).
Recall that the Entity Relationship diagram of this schema is as follows:
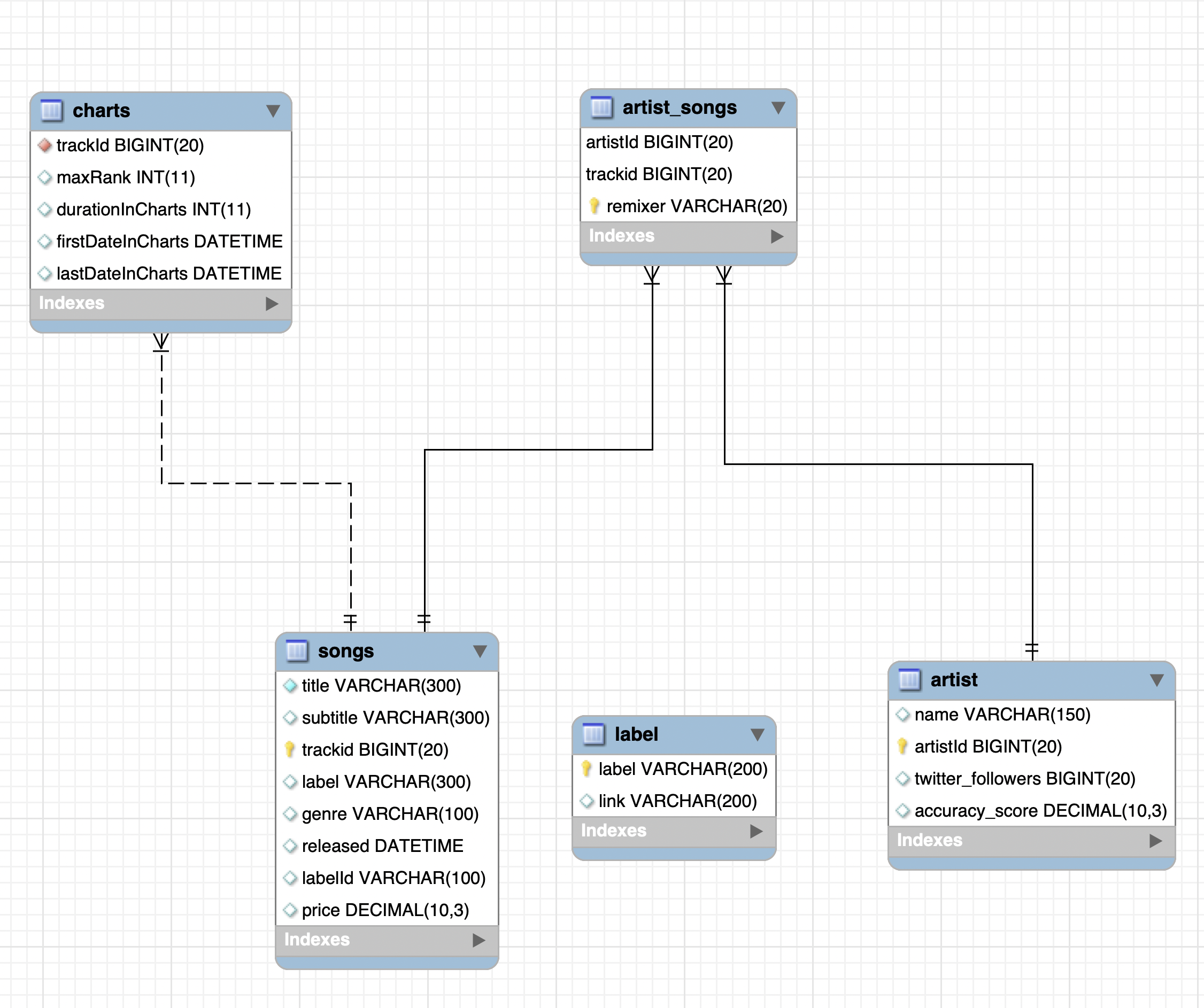
Figure 8.1: The Entity Relationship diagram of schema music_marketplace.
First, we will connect to the database (Section 4.1):
library(DBI)
library(odbc)
library(RODBC)
library(tidyverse)con = DBI::dbConnect(odbc::odbc(),
Driver= "MySQL",
Server='mysql-isys3350.bc.edu',
UID='your_username',
PWD= 'your_password',
Port= 3306)
Aggregation functions perform a calculation on the values of the selected column(s). In this chapter, we will discuss multiple such functions, including:
- count, min, max, avg, sum, std
- group by, having
We discuss these next.
8.1 Summarization
In SQL, we can estimate simple summary statistics of a column as follows:
SELECT min(maxRank), max(maxRank), avg(maxRank), std(maxRank), sum(maxRank)
FROM music_marketplace.charts;| min(maxRank) | max(maxRank) | avg(maxRank) | std(maxRank) | sum(maxRank) |
|---|---|---|---|---|
| 1 | 100 | 45.2291 | 28.63897 | 289059 |
Note that there is not a predefined function to estimate the
medianof a column!
The function count calculates the number of rows of the result. It is identical to nrow in R:
SELECT count(*)
FROM music_marketplace.charts t1;| count(*) |
|---|
| 6391 |
8.2 Group by
Similar to the group_by function in R, we can group results based on one or more columns. For instance, we can count how many songs per genre exist in the table songs:
SELECT genre, count(*)
FROM music_marketplace.songs
GROUP BY genre
LIMIT 10;| genre | count(*) |
|---|---|
| -1 | 2158 |
| Big Room | 40 |
| Breaks | 948 |
| Dance | 1032 |
| Deep House | 8289 |
| DJ Tools | 503 |
| Drum & Bass | 1680 |
| Dubstep | 736 |
| Electro House | 2939 |
| Electronica / Downtempo | 4977 |
Of course, we can group by multiple columns:
SELECT genre, label, count(*)
FROM music_marketplace.songs
WHERE genre != -1
GROUP BY genre, label
LIMIT 10;| genre | label | count(*) |
|---|---|---|
| Big Room | +Mas Label | 3 |
| Big Room | AFTERCLUV DANCE LAB | 1 |
| Big Room | Anghellic Records | 1 |
| Big Room | Armind (Armada) | 1 |
| Big Room | ARVA | 1 |
| Big Room | Better Than Records | 1 |
| Big Room | Columbia (Sony) | 2 |
| Big Room | Disruptor Records/Columbia | 1 |
| Big Room | Dmn Records | 9 |
| Big Room | Doner Music | 1 |
On top of the GROUP BY clause, we can use the HAVING close, which specifies a condition to filter the result. SQL applies the HAVING condition on the result of the GROUP BY (i.e., after filtering in the WHERE clause). For instance, we can extend the previous query as follows:
SELECT genre, label, count(*)
FROM music_marketplace.songs
WHERE genre != -1
GROUP BY genre, label
HAVING count(*) > 50
LIMIT 10;| genre | label | count(*) |
|---|---|---|
| Dance | Jalapeno Records | 87 |
| Dance | LNG Music | 94 |
| Deep House | Anjunadeep | 68 |
| Deep House | City Life | 94 |
| Deep House | Club Session | 69 |
| Deep House | Doppelgaenger | 88 |
| Deep House | Flagman | 112 |
| Deep House | Get Physical Music | 69 |
| Deep House | HiFi Stories | 54 |
| Deep House | High Pro-File Recordings | 98 |
GROUP BY clause, the select clause can only inlcude the columns used to group by and aggregations (e.g., avg, count, sum, etc.).
HAVING clause compare with the WHERE clause? The WHERE clause filters the results before the grouping; the HAVING clause filters the results after the grouping. In addition, a WHERE clause can refer to any columns in the selected tables but cannot filter on aggregate functions. On the other hand, a HAVING clause can only filter on columns that are included in the SELECT clause and can apply aggregate functions.
Here is a different example:
SELECT genre, label, count(*), max(price), avg(price)
FROM music_marketplace.songs
WHERE genre != -1
GROUP BY genre, label
HAVING avg(price) > 0 and count(*) > 100
LIMIT 10;| genre | label | count(*) | max(price) | avg(price) |
|---|---|---|---|---|
| Deep House | Flagman | 112 | 1.49 | 1.490000 |
| Deep House | Variety Music | 180 | 1.49 | 1.490000 |
| Deep House | Voltaire Music | 103 | 1.49 | 1.490000 |
| DJ Tools | SuperNova Records | 103 | 1.49 | 1.490000 |
| Electro House | Club Session | 151 | 1.49 | 1.490000 |
| Electro House | RH2 | 136 | 1.49 | 1.490000 |
| Electronica / Downtempo | Manifold Records | 108 | 1.49 | 1.236389 |
| Funk / Soul / Disco | RCA Records Label | 129 | 1.49 | 1.490000 |
| Hard Dance | Fireball Recordings | 101 | 1.49 | 1.490000 |
| Hard Dance | Hard Dance Coalition | 112 | 1.49 | 1.467768 |
For comments, suggestions, errors, and typos, please email me at: kokkodis@bc.edu