A Midterm practice exam
library(rtweet)
library(tidyverse)
library(ggthemes)
library(rvest)
library(lubridate)
library(DBI)
library(odbc)
library(RODBC)A.1 Essay question
|Q1: If you were given a large (billions of records) dataset, what would you do to understand the quality and limitations of the data?
|A: This is a question that basically is covered in the slides of week 2. Some of the things we can do to profile (big) datasets:
- Understand what each column stores.
- Figure out the correct data types.
- Identify if there are missing observations by running aggregate functions (such as
summary). - Use
head()andtail()to view the first and last 6 rows of the dataset. - Get descriptive statistics of each column (min, max, mean, std, median, frequencies of categorical variables, etc.)
- Group by different groups of interest and estimate descriptive statistics.
- Select the variables that we care about, and the observations we care about (filter, subsample).
- Identify what questions the data can potentially answer.
In the exam, any combination that would include 4 or more of these points would have gotten full points.
A.2 Twitter API: rtweet
Q2: Use the rtweet function get_timeline to get the most recent 3000 tweets of the main ESPN twitter account (username: espn). Then, use the function as_date from the package lubridate to customize column created_at to date. Finally, store into a new tibble named e1 the ESPN tweets posted in September. How many tweets did ESPN post in September?
key = "key"
secret = "secret"
access = "access"
access_secret = "access_secret"
app_name = "appname"A: First create our toklen (keys excluded from knitted file with the option {r, include=FALSE}):
myToken = create_token(app = app_name,
consumer_key = key,
consumer_secret = secret,
access_token = access,
access_secret = access_secret)One way to find the number of tweets of e1 is to call the function nrow():
e = get_timeline("espn", n = 3000, token =myToken)
e$approxDate = as_date(e$created_at)
e1 = e %>% filter(approxDate >= "2021-09-01" & approxDate <= "2021-09-30")
nrow(e1)## [1] 516Q3: Now load a subset of the ESPN tweets stored in th tweetsPracticeExam.csv. Name this tibble p. Which one is the most frequently used source that ESPN uses to tweet from?
A:
p = read_csv("../data/tweetsPracticeExam.csv")
p %>% group_by(source) %>% count() %>% arrange(desc(n))## # A tibble: 8 × 2
## # Groups: source [8]
## source n
## <chr> <int>
## 1 Sprinklr 492
## 2 Twitter for iPhone 146
## 3 Twitter Web App 92
## 4 TweetDeck 88
## 5 Twitter Media Studio 60
## 6 WSC Sports 41
## 7 Twitter for Advertisers (legacy) 12
## 8 Twitter Media Studio - LiveCut 12Q4: How many tweets from the p tibble are retweets (i.e., they have a name in column retweet_name?)
A:
p %>% filter(!is.na(retweet_name)) %>% nrow## [1] 297Q5: In the p tibble, match the times that each of the following account is being retweeted by ESPN:
A: Below I am using the operator %in% to keep only rows where the retweet_name is one of the focal ones that the question asks. You did not have to do this to answer this question. You can answer the question without using the last filter.
p %>% filter(!is.na(retweet_name)) %>% group_by(retweet_name) %>% count() %>%
arrange(n) %>%
filter(retweet_name %in% c('DJ KHALED','Malika Andrews',
'ESPN College Football',
'NFL on ESPN',
'Adam Schefter',
'ESPN FC',
'ESPN Fantasy Sports'))## # A tibble: 7 × 2
## # Groups: retweet_name [7]
## retweet_name n
## <chr> <int>
## 1 DJ KHALED 1
## 2 ESPN Fantasy Sports 2
## 3 Malika Andrews 2
## 4 ESPN College Football 5
## 5 Adam Schefter 15
## 6 ESPN FC 19
## 7 NFL on ESPN 24A.3 Scraping
Q6: Scrape the URL: https://en.wikipedia.org/wiki/Data_analysisLinks to an external site. Use the html tag “p a” to extract all the links in this page. Then use the regular expression “[a-zA-Z ]+” to keep only links that are not references. Save the result to a single-column tibble. Name the column “link”. Remove any missing values. How many links did you end up with in the end?
A:
r = read_html("https://en.wikipedia.org/wiki/Data_analysis")
r1 = r %>% html_nodes("p a") %>%
html_text()
r2 = r1 %>% str_extract("[a-zA-Z ]+") %>% as_tibble_col("link") %>%
filter(!is.na(link))
nrow(r2 )## [1] 84Q7: Create a new custom function that:
- Takes as input a wiki concept.
- Visits its wikipedia page.
- Extracts all the links.
- Removes any missing values.
- Returns a tibble with two columns: the first column stores the link, and the second column stores the scraped wiki concept.
By using a function from the map() family, call your new custom function with the following wiki concepts as input:** c('Data_mining','Data_analysis','Data_science') Store the result into a single tibble.How many rows does this final tibble have?
A:
getWikis = function(wikiConcept){
r = read_html(paste("https://en.wikipedia.org/wiki/",wikiConcept,sep=""))
r1 = r %>% html_nodes("p a") %>%
html_text()
r2 = r1 %>% str_extract("[a-zA-Z ]+") %>% as_tibble_col("link") %>%
filter(!is.na(link)) %>% mutate(concept = wikiConcept)
return(r2)
}
d = c('Data_mining','Data_analysis','Data_science') %>% map_dfr(getWikis)
nrow(d)## [1] 248A.4 Databases
Q8: Load the following dataset into R: wiki.csv
Based on this dataset, create an ERD that identifies the following two entities and their relationship:
- concept
- link
The entity concept can have additional fields such as:
- description
- wikipedia_link
The entity link can have additional fields such as:
- description
- date_scraped
Take a screenshot of your ERD and upload it here.
A:
Below is an ERD that works for this example:
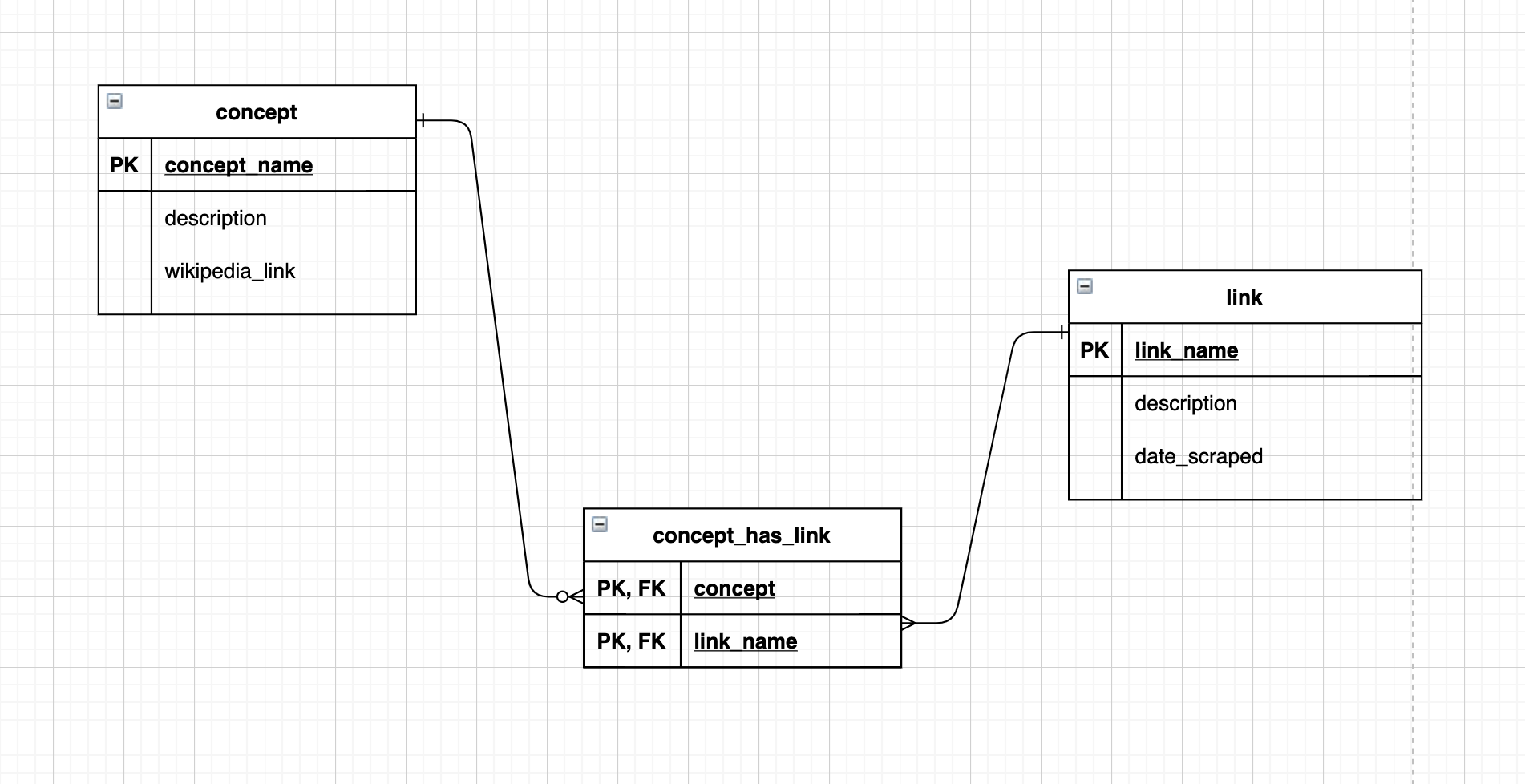
How could you have come up with the relationship cardinalities? Run the following which shows that links might appear in multiple concepts:
d %>% count(concept,link) %>% filter(n > 1)## # A tibble: 20 × 3
## concept link n
## <chr> <chr> <int>
## 1 Data_analysis "business intelligence" 2
## 2 Data_analysis "descriptive statistics" 2
## 3 Data_analysis "exploratory data analysis" 2
## 4 Data_analysis "hypotheses" 2
## 5 Data_analysis "type " 2
## 6 Data_mining "cluster analysis" 2
## 7 Data_mining "data analysis" 2
## 8 Data_mining "data management" 2
## 9 Data_mining "data sets" 2
## 10 Data_mining "KDD" 2
## 11 Data_mining "machine learning" 3
## 12 Data_mining "overfitting" 2
## 13 Data_mining "predictive analytics" 2
## 14 Data_mining "SIGKDD" 2
## 15 Data_mining "statistics" 2
## 16 Data_science "American Statistical Association" 2
## 17 Data_science "big data" 2
## 18 Data_science "C" 2
## 19 Data_science "machine learning" 2
## 20 Data_science "statistics" 2Q9: For each one of the tables in your ERD, explain whether they are in 1NF, 2NF, or 3NF.
A:
All tables are in 3NF. There are no derived columns (i.e., columns that we can generate by combining other columns in the table), and there are no multiple entities within each table.
Q10: Create all tables in your ERD by connecting to your your_username_db schema.
Then load all tables with the appropriate content. Assume missing values when necessary.
How many rows did your larger table end up with?
(I will grade your code)
A:
con = DBI::dbConnect(odbc::odbc(),
Driver= "MySQL",
Server='mysql-isys3350.bc.edu',
UID='username',
PWD= 'password',
Port= 3306,
Database = "username_db")CREATE TABLE kokkodis_student_db.link (
link_name VARCHAR(100),
description VARCHAR(150),
date_scraped DATE,
PRIMARY KEY (link_name)
);CREATE TABLE kokkodis_student_db.concept (
concept_name VARCHAR(100),
description VARCHAR(150),
wikipedia_link VARCHAR(150),
PRIMARY KEY (concept_name)
);CREATE TABLE kokkodis_student_db.concept_has_link (
link_name VARCHAR(100),
concept_name VARCHAR(100),
PRIMARY KEY (concept_name,link_name),
CONSTRAINT fk_concept
FOREIGN KEY (concept_name)
REFERENCES kokkodis_student_db.concept (concept_name),
CONSTRAINT fk_link
FOREIGN KEY (link_name)
REFERENCES kokkodis_student_db.link (link_name)
);Next, we load the data:
d %>% select(concept) %>% distinct %>%
mutate(wikipedia_link = paste("https://en.wikipedia.org/wiki/",concept,sep=""), description = NA) %>%
rename(concept_name = concept)-> conceptdbWriteTable(con,"concept", concept, append = T)For verification it is always a good idea to run a select query:
select * from concept;| concept_name | description | wikipedia_link |
|---|---|---|
| Data_analysis | NA | https://en.wikipedia.org/wiki/Data_analysis |
| Data_mining | NA | https://en.wikipedia.org/wiki/Data_mining |
| Data_science | NA | https://en.wikipedia.org/wiki/Data_science |
d %>% select(link) %>% distinct %>% mutate(date_scraped = today(), description = NA) %>%
rename(link_name = link) -> linkdbWriteTable(con,"link", link, append = T)d %>% select(link,concept) %>% distinct %>%
rename(link_name = link, concept_name = concept) -> concept_has_linkselect * from link;| link_name | description | date_scraped |
|---|---|---|
| AAAI | NA | 2021-11-06 |
| ADVISE | NA | 2021-11-06 |
| AI | NA | 2021-11-06 |
| American Statistical Association | NA | 2021-11-06 |
| Andrew Gelman | NA | 2021-11-06 |
| Association for Computing Machinery | NA | 2021-11-06 |
| Bayes | NA | 2021-11-06 |
| Ben Fry | NA | 2021-11-06 |
| Bonferroni correction | NA | 2021-11-06 |
| Boundary element | NA | 2021-11-06 |
dbWriteTable(con,"concept_has_link", concept_has_link, append = T)select * from concept_has_link;| link_name | concept_name |
|---|---|
| AAAI | Data_mining |
| ADVISE | Data_mining |
| AI | Data_mining |
| American Statistical Association | Data_science |
| Andrew Gelman | Data_science |
| Association for Computing Machinery | Data_mining |
| Bayes | Data_mining |
| Ben Fry | Data_science |
| Bonferroni correction | Data_analysis |
| Boundary element | Data_analysis |
Q11:
Using the table team_in_game, retrieve all rows that do not store information about “Miami Heat” and “Boston Celtics” and store them in a dataframe (tibble). How many rows does the tibble have?
A:
query = 'SELECT points_scored, team_name FROM kokkodis_student_db.team_in_game
WHERE team_name not in ("Miami Heat", "Boston Celtics");'
t = dbGetQuery(con,query) %>% as_tibble
t ## # A tibble: 448 × 2
## points_scored team_name
## <int> <chr>
## 1 116 Los Angeles Clippers
## 2 109 Los Angeles Lakers
## 3 121 Milwaukee Bucks
## 4 122 Denver Nuggets
## 5 124 Sacramento Kings
## 6 113 Orlando Magic
## 7 123 Brooklyn Nets
## 8 108 Denver Nuggets
## 9 121 Los Angeles Clippers
## 10 115 Dallas Mavericks
## # … with 438 more rowsQ12:
Using the tibble from the previous question, what is the average points_scored of “Los Angeles Lakers”?
A:
t %>% filter(team_name=='Los Angeles Lakers') %>% summarize(mean(points_scored))## # A tibble: 1 × 1
## `mean(points_scored)`
## <dbl>
## 1 109.