
4.1 Fuente de datos
4.1.1 Introducción
Figura 4.1: Imagen que refleja la importancia de la preparación de los datos en un proyecto que gira en torno a los mismos.
Aunque no sea una tarea visible, la preparación de la información para que pueda ser explotada es la base de cualquier proyecto relacionado con la visualización de datos.
Es, por lo general, la parte del proyecto más laboriosa, extensa y, a menudo, técnica. Antes de explicar qué motivos nos llevan a decir esto, nos es necesario definir terminología básica que se utiliza en el campo de la adaptación de datos para su uso:
Limpieza de datos: data cleaning en inglés, consiste en detectar y tratar información incompleta, incorrecta, imprecisa o irrelevante procedente de un conjunto de datos, ya sea modificándola, reemplazándola o eliminándola del mismo conjunto. Forma parte del proceso de transformación de los datos, que explicaremos en la sección 4.1.2 ETL Pipeline: Definición.
Datos crudos: raw data en inglés, nos referimos al conjunto de datos antes de pasar por el proceso de limpieza.
Datos limpios: clean data en inglés, es el conjunto de datos tras haber pasado por el proceso de limpieza.
Aclarados estos términos, ya podemos adentrarnos en la explicación de por qué la preparación de la información puede ser tan compleja.
Para empezar, los datos crudos rara vez están adaptados para facilitar su explotación. Esto se puede deber a diferentes razones:
Los datos no han sido almacenados siguiendo una estructura que facilite su almacenamiento. El proceso a seguir para optimizar el almacenamiento de la información no tiene por qué ser el mismo que el empleado para optimizar su explotación.
Hay errores en el proceso de almacenamiento: Por ejemplo, los casos vacíos se gestionan de manera diferente en cada columna o en función del tipo de información almacenada. Un ejemplo claro de esto es rellenar los casos vacíos de una columna compuesta por elementos del tipo string con "" y los casos vacíos de una columna compuesta por elementos del tipo float con NA.
El conjunto de datos no va acompañado de un documento que explique el significado de cada columna.
Cada conjunto de datos está almacenado en una plataforma diferente.
Por otro lado, durante el proceso de limpieza de datos nos encontramos con problemas nuevos frecuentemente, por lo que la automatización de la limpieza de cada conjunto de datos que obtengamos es inviable. Para expresarnos de manera clara y concisa, reciclaremos la frase de Tolstói: “Todas las familias felices se parecen unas a otras, pero cada familia infeliz lo es a su manera”.
Para el proceso de adaptación de los datos crudos, diríamos algo así: “Los conjuntos de datos adaptados para su explotación se parecen unos a otros, pero cada conjunto de datos crudos es diferente a su manera”. Cada vez que tratemos un conjunto de datos por primera vez, tendremos que ser conscientes de esto. Todavía no existe ningún software capaz de recibir como input cualquier conjunto de datos y devolver como output los datos adaptados para su explotación.
4.1.2 ETL Pipeline: Definición
Las siglas representan Extract (extraer), Transform (transformar) y Load (cargar). Del mismo modo, una pipeline en ingeniería informática se refiere a un conjunto de elementos que se ejecutan secuencialmente, donde el output de cada elemento es el input del siguiente.
Por ende, Una ETL Pipeline es un conjunto de procesos que engloba extraer datos de diferentes fuentes de datos, transformarlos para permitir su uso y cargarlos en una base de datos o un sistema de alojamiento de archivos.
Para este proyecto, la ETL Pipeline que desarrollaremos tendrá como fin albergar en el sistema de almacenamiento a elegir, en este caso Dropbox debido a su facilidad de conexión a través de su API, un conjunto de datos adaptados para poder analizar el estado de cada distrito desde el punto de vista de la oferta (inmuebles), la demanda (oportunidades) y su intersección (propuestas).
4.1.3 Orígenes de datos
Utilizamos diferentes fuentes de datos para componer los distintos conjuntos de datos de los que hace uso la aplicación. Obtenemos los datos crudos de dos fuentes diferentes:
Del Instituto Nacional de Estadística obtenemos el archivo del tipo Shapefile que vamos a utilizar para definir los distritos censales 5. Para ello, tendremos que realizar una transformación de datos.
Este archivo crea multipolígonos (conjunto de puntos geográficos, cada uno con sus propias coordenadas, que al unirse crean un espacio cerrado) que delimitan cada sección censal en el mapa de España. No obstante, las secciones censales son demasiado pequeñas como para agrupar un conjunto de inmuebles lo suficientemente grande como para que las conclusiones extraídas sean significativas. Por ello, las disolvemos en los distritos censales que utilizaremos.
Cada distrito censal está compuesto por un conjunto de secciones censales, y disolverlas implica agrupar todos los multipolígonos de cada distrito censal y convertirlo en uno sólo.
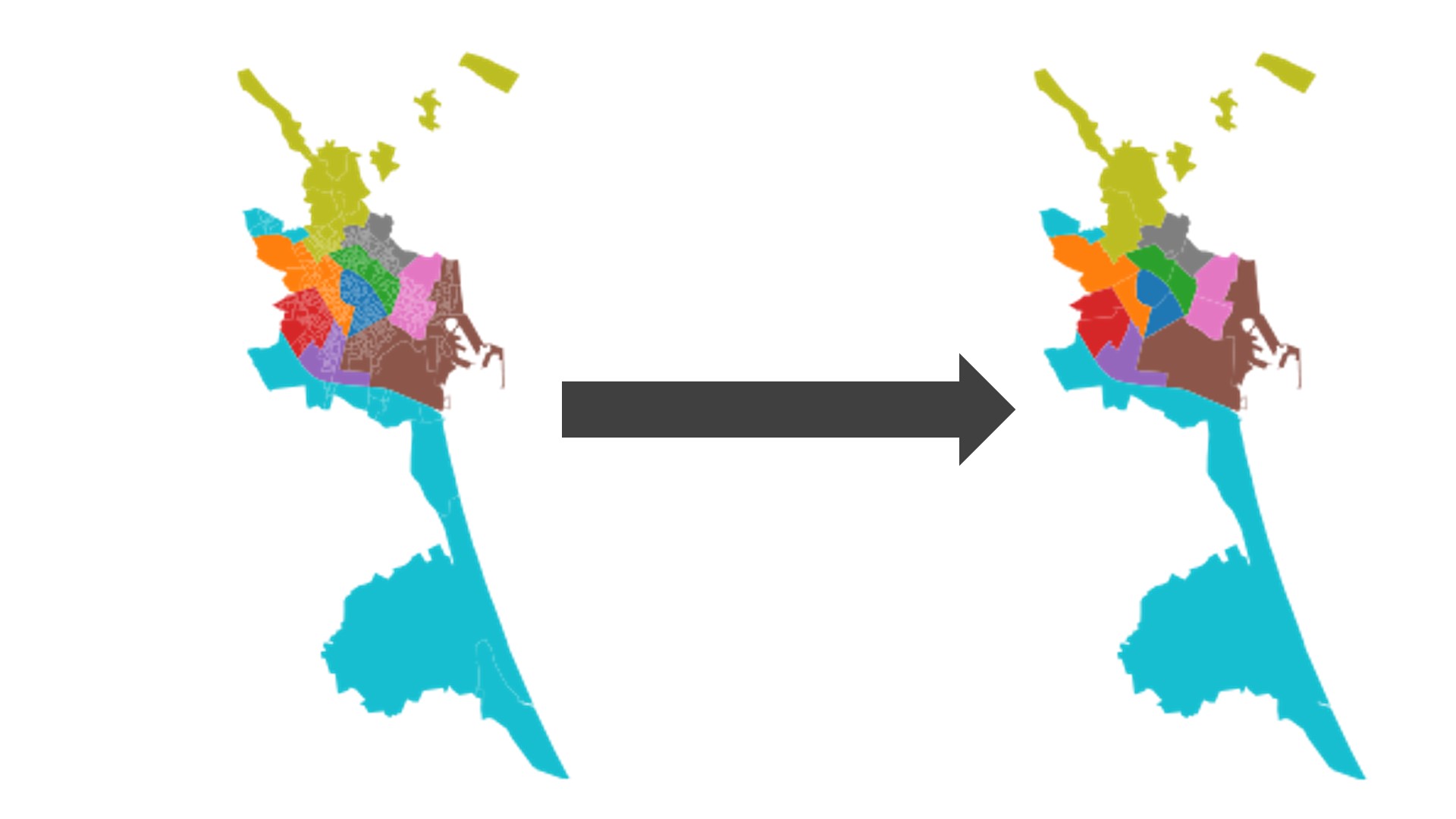
Figura 4.2: Imagen que refleja la disolución de las secciones censales del municipio de Valencia a distritos censales.
Fuente: INE.
De hecho, esta es la primera ETL Pipeline de la que hacemos uso. ¿Por qué? Porque estamos extrayendo los datos del INE (extract), transformándolos de su unidad original como secciones censales a distritos censales (transform) y, por último, subiendo la información ya transformada a Dropbox para poder cargarla y utilizarla cuando nos sea conveniente (load). Por ende, podemos decir que para construir nuestra ETL Pipeline principal es necesario crear una previa, menos compleja.
Por otro lado, los datos de homyspace los obtenemos de Elasticsearch: recurrimos a diferentes índices para obtener la información. Como hemos indicado en la sección 3.4.2 Captación, un índice es una base de datos que, por lo general, almacena todo el contenido relacionado con un concepto. Ya que estamos interesados en las oportunidades, propuestas e inmuebles de homyspace, necesitamos conectarnos a Elasticsearch para acceder a sus índices correspondientes.
Para extraer estos datos, volvemos a recurrir a python ¿No es la primera vez que nombras este programa?. Creamos una función a la que llamamos getData, a la cual pasaremos como input el índice en cuestión, las columnas que deseamos extraer de ese índice, y filtros opcionales.
Habiendo utilizado la primera pieza de código para preparar la información geoespacial del INE para su uso, y teniendo la capacidad de extraer datos de los diferentes índices de Elasticsearch a través de la segunda pieza de código, ya estamos preparados para poder diseñar y desarrollar la pipeline que vamos a utilizar para adaptar los datos para el uso por parte de la aplicación.