
4.3 Desarrollo de la Pipeline
Para empezar, cargaremos las librerías necesarias para acceder a las diferentes fuentes de datos.
Utilizaremos elasticsearch y elasticsearch_dsl para conectarnos con Elasticsearch. Como en homyspace utilizamos la versión de Amazon Web Services (AWS), también cargaremos requests_aws4auth. Esta librería nos permite autentificarnos con AWS utilizando las credenciales adecuadas.
A través de la librería de dropbox, seremos capaces de acceder a Dropbox, tanto para descargar documentos como para subirlos.
Con requests y zipfile extraeremos los archivos ZIP en los que tenemos comprimidos los documentos Shapefile de los distritos y de los inmuebles, cuyos distritos ya hemos identificado previamente.
Utilizaremos pandas y numpy para gestionar los datos. Con estas dos librerías realizaremos toda la limpieza de datos que sea necesaria.
Por último, geopandas y shapely nos permitirán tratar la información geoespacial, dándonos la posibilidad de crear y alterar documentos Shapefile.
Siguiendo los pasos necesarios para poder realizar la etapa de extracción, nos conectamos con Elasticsearch.
Habiendo instalado las librerías necesarias, así como habiendo desarrollado las funciones y la conexión a Dropbox y Elasticsearch respectivamente, nos disponemos a diferenciar las funciones creadas y utilizadas en función de la etapa de la ETL Pipeline a la que pertenecen.
Después, en la sección 4.3.4 Arquitectura final y gestión de la actualización indicaremos cómo unimos estas funciones para crear la ETL Pipeline que deseamos.
4.3.1 Extracción (extract)
Comenzaremos por la etapa de extracción. Como hemos mencionado en la sección 4.1.2 ETL Pipeline: Definición, el propósito de esta etapa es habilitar el acceso a la información para ser capaces de hacer uso de ella más adelante.
Dividiremos las funciones que hacemos en dos:
Por un lado tenemos getPropertiesData, getOpportunitiesData y getProposalsData. Estas tres funciones nos conectan con Elasticsearch, y nos permiten extraer los datos de los índices relacionados con inmuebles, oportunidades y propuestas, respectivamente. En la figura 4.3, representaría la parte relacionada con Elasticsearch de la etapa de extracción.
Por el otro, hemos creado las funciones getDistrictsFromDBX, getPropertiesFromDBX y getOpportunitiesFromDBX. Con estas funciones podemos acceder a los distritos censales y a los inmuebles y oportunidades cuyos distritos ya han sido asignados en previos lanzamientos de la ETL Pipeline.
Con este conjunto de funciones ya hemos satisfecho todos los requerimientos para acceder a la información que nos aporta valor. No obstante, todavía no ha sido tratada para que nos aporte ese valor. Para ello, necesitamos del proceso de transformación, en el cual ahondaremos a continuación.
4.3.2 Transformación (transform)
El proceso de transformación de los datos consiste en, dado un conjunto de información recibida como input, realizar una serie de alteraciones de ese input (ya sean adiciones, substracciones o modificaciones) para obtener un output que nos sea útil para un fin específico.
Al igual que en la etapa de extracción, podemos dividir las funciones para la transformación en dos:
Primero, tenemos las funciones que utilizaremos para, una vez recibidos los datos de los inmuebles y oportunidades, asignar a cada uno de ellos el distrito en el que se encuentran. En la figura 4.3, estas funciones equivalen a la 1 (assignDistrictsToProperties) y 2 (assignDistrictsToOpportunities) de la etapa de transformación.
El paso 3 (assignPropertiesToProposals) también pertenece a este subconjunto, aunque se diferencia en el hecho de que, como ya hemos asignado los inmuebles a sus distritos, todo lo que tendremos que hacer para localizar las propuestas será relacionarlas a sus inmuebles asociados, cuyos distritos ya han sido aclarados.
La última de las funciones que necesitamos para completar el proceso de transformación es la que equivale al paso 4 en la figura 4.3. Con esta función agruparemos por distrito todo la información relativa a las oportunidades, los inmuebles y las propuestas.
De esta transformación obtendremos los datos que necesitamos para crear el mapa en la aplicación de gráficos interactivos. No obstante, para ello necesitamos almacenar esta información y la que hemos transformado en una plataforma de almacenamiento de datos. Nosotros hemos elegido Dropbox debido a la facilidad de conexión con su API y a que, además, podemos guardar hasta 2GB gratuitamente, lo cual es más que de sobra para nuestro caso de uso.
En la sección 7.1 Desarrollo de la aplicación mostramos las funciones que hemos utilizado para almacenar la información correspondiente en Dropbox.
4.3.3 Carga (load)
En la última etapa de la ETL Pipeline nos centramos en almacenar toda la información que hemos obtenido como output de la etapa de transformación.
Siguiendo la misma dinámica de las dos etapas anteriores, en la etapa de carga podemos diferenciar en dos las funciones creadas:
Por un lado, creamos las funciones backup, checkFileDetails y uploadDropbox. A través de las mismas subiremos los ficheros correspondientes a la platafroma de Dropbox.
Por el otro, tenemos las funciones savePropertiesToDBX, saveOpportunitiesToDBX, saveHeatmapToDBX y saveProposalsToDBX. Con estas funciones estamos transformando los datos en ficheros CSV o SHP y, para el último, comprimiéndolo en un ZIP antes de subirlos a Dropbox con ayuda de la función uploadDropbox.
Habiendo creado todas estas funciones, ya somos capaces de hacer uso de nuestra propia ETL Pipeline.
En la próxima sección describiremos cómo unimos todas estas funciones para que la ETL Pipeline funcione como debería, así como el proceso que seguimos para que la información se mantenga actualizada.
4.3.4 Arquitectura final y gestión de su actualización
A continuación definiremos la estructura que sigue la ETL Pipeline para aportarnos los datos de los que la aplicación de gráficos interactivos se alimenta.
# Extraemos los inmuebles, los asociamos a sus distritos y los almacenamos en Dropbox
propertiesData = getPropertiesData()
properties = assignDistrictsToProperties(propertiesData)
savePropertiesToDBX(properties)
# Extraemos las oportunidades, las asociamos a sus distritos y las almacenamos en Dropbox
opportunitiesData = getOpportunitiesData()
opportunities = assignDistrictsToOpportunities(opportunitiesData)
saveOpportunitiesToDBX(opportunities)
# Extraemos las propuestas, las asociamos a sus inmuebles y las almacenamos en Dropbox
proposalsData = getProposalsData()
proposalsData = assignDistrictsToProposals(proposalsData)
saveProposalsToDBX(proposalsData)
# Agrupamos los datos de las propuestas por distritos y los almacenamos en Dropbox
heatmap_data = groupByDistricts(proposalsData)
saveHeatmapToDBX(heatmap_data)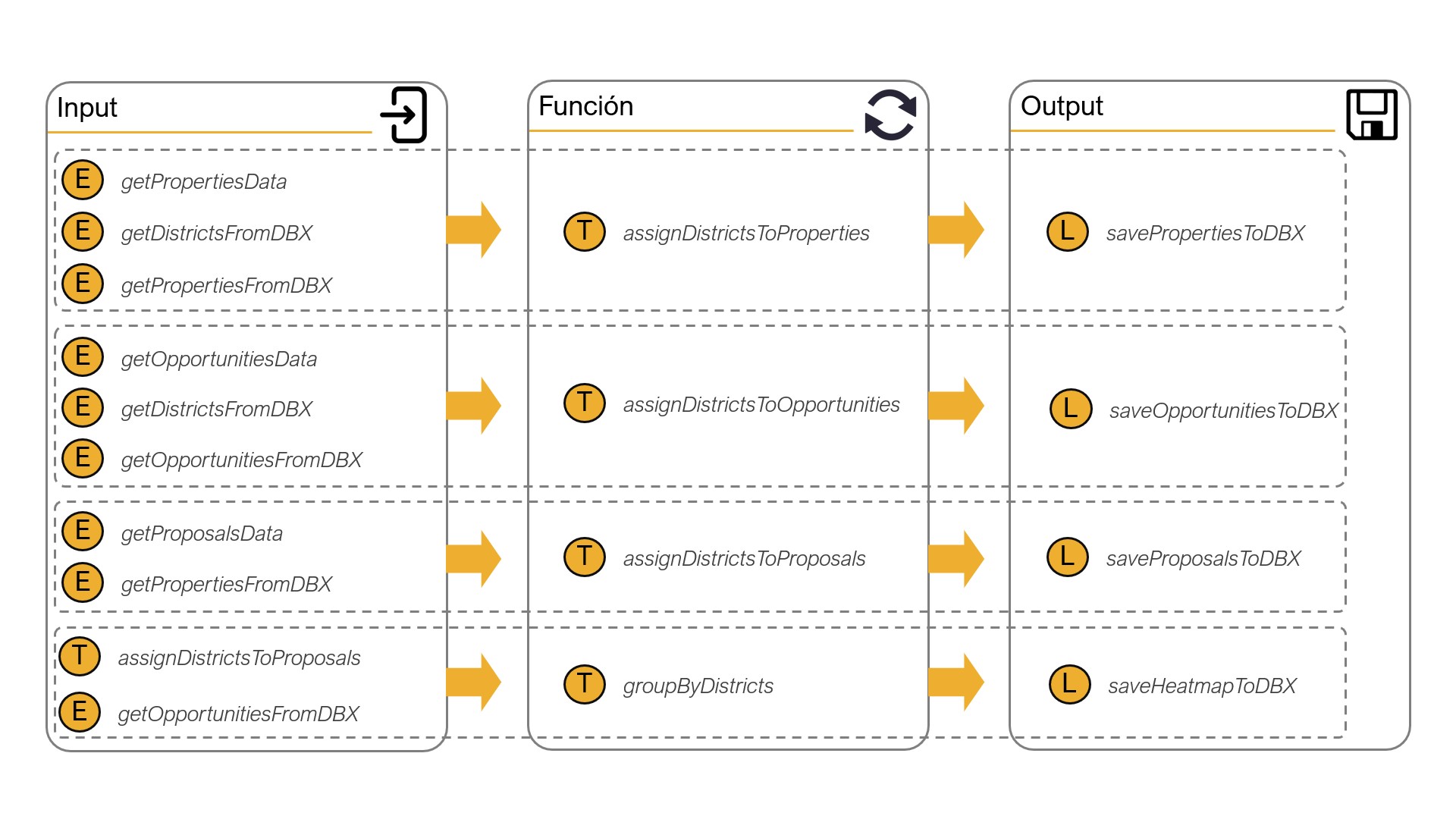
Figura 4.4: Funciones utilizadas como inputs, transformadores y outputs respectivamente.
En lo relativo a la actualización, la realizamos ejecutando la ETL Pipeline los viernes por la tarde, una vez la jornada laboral ha finalizado con el Planificador de tareas de Windows. Esto nos permite ejecutar de manera automática el código semanalmente.
¿Por qué semanalmente? Lo ejecutamos únicamente una vez por semana ya que la información no aumenta de forma notable de un día para otro, y el coste de oportunidad de correr el código es que no se debería utilizar la aplicación de gráficos interactivos mientras la ETL Pipeline está en proceso, y el tiempo de ejecución es de unos cuantos minutos. En el futuro automatizaremos este proceso para poder ejecutarlo desde la nube, permitiéndonos realizar la actualización durante horas no lectivas.