library(MASS)
data("birthwt")
table(birthwt$smoke, birthwt$low)
0 1
0 86 29
1 44 30Este capitulo se revisarán algunas de las pruebas de hipótesis para la comparación de variables cualitativas. En particular, se revisarán: la prueba de \(\chi^2\), la prueba exacta de Fisher y el test de Mcnemar. Sin embargo, antes revisaremos lo relacionado con la construcción de tablas de contingencia, ya que serán útiles indispensables para las pruebas de hipótesis que se revisarán en este capítulo. Además, aquí se revisará la realicación de gráficos de barras con proporciones utilizando la librería ggstatsplot. Hacía el final del capitulo se presentarán aspectos relacionados con el tamaño del efecto y finalmente realizaremos algunos ejercicios.
Antes de ver los detalles de las pruebas de hipótesis para variables cualitativas, es necesario revisar las tablas de contingencia.
Las tablas de contingencia permiten resumir datos de variables categóricas por lo tanto sson el primer paso para la realización de una prueba \(\chi^2\), para estimar riesgo relativos, odds ratio entre otros. Las tablas de contingencia son:
Por ejemplo
| Mortal | No mortal | No ataque | Totales | |
|---|---|---|---|---|
| Placebo | 18 | 171 | 10845 | 11304 |
| Aspirina | 5 | 99 | 10933 | 11037 |
table() en REn R se puede utilizar la función table() en combinación con la función prop.table() para crear tablas de contingencia. La función table es una función básica de R que permite contar los valores de un vector, mientras que la función prop.table() permite calcular las proporciones de los valores de una tabla.
Supongamos que es de nuestro interés conocer la relación entre el tabaquismo y el bajo peso al nacer. Para ello, se puede utilizar la base de datos birthwt que se encuentra en la librería MASS.
library(MASS)
data("birthwt")
table(birthwt$smoke, birthwt$low)
0 1
0 86 29
1 44 30Tome en cuenta que en las columnas se muestra el bajo peso al nacer y en las filas el tabaquismo. Generalmente se suele resevar las filas para la exposición y las columnas para el evento.
Ahora bien, si quisieramos obtener las proporciones de bajo peso al nacer entre las madres fumadoras y no fumadoras, se puede utilizar la función prop.table(). La cual necesita de una tabla para alimentarse.
table(birthwt$smoke, birthwt$low)|>
prop.table(2)
0 1
0 0.6615385 0.4915254
1 0.3384615 0.5084746# El número 2 indica que se desea obtener las proporciones por columna
# Si seleccionamos 1 se obtendrán las proporciones por filaLa prueba de ji cuadrado (\(\chi^2\)) de Pearson es una prueba estadística de contraste de hipótesis que se aplica para analizar datos recogidos en forma de número de observaciones en cada categoría (conteos) por ejemplo:
En resumen la prueba \(\chi^2\)
La prueba de \(\chi^2\) se basa en la independencia de dos criterios de clasificación
La prueba de \(\chi^2\) utiliza la diferencia de valores observados vs los datos esperados
La \(H_0\) en la prueba de \(\chi^2\) es: Que no hay dependencia de las variable estudiadas. Es decir que las proporción de individuos de un grupo es igual a la proporción de otro grupo. Si las proporciones entre las categorías, entonces podriamos decir que hay una depdencia entre las categorías.
La prueba de \(\chi^2\) se base en la distribución la cual presenta las siguientes características:
Dada una variable aleatoria \(y\) que sigue una distribución normal, con media \(\mu\) y varianza \(\sigma^2\) cada valor puede transformarse en la variable normal estándar \(z\) por medio de la siguiente formula:
\[z= \frac{y_i-\mu}{\sigma}\]
Cada valor de \(z\) puede elevarse al cuadrado para obtener \(z^2\). Cuando se estudia la distribución muestra de \(z^2\), se observa que sigue una distribución \(\chi^2\) con 1 grado de libertad. Es decir:
\[\chi^2_{(1)}= \lgroup\frac{y_i-\mu}{\sigma}\rgroup=z^2\]
Si todos los datos aleatorios de una muestra se eleva al cuadrado se obtiene:
\[\chi^2_{(n)}= z^2_1+z^2_2+ \cdot \ \cdot \ \cdot+ z^2_n\] Es la suma de los valores \(z^2\) resultantes tendrá una distribución \(\chi^2\), con \(n\) grados de libertad
Después de realizar una integral, la formula matemática de las distribución \(\chi^2\) es la siguiente:
\[f(u)=\frac{1}{\lgroup\frac{k}{2}-1\rgroup!}\ \frac{1}{2^{k/2}}u^{(k/2)-1}e^{-(u/2)}, u>0\]
Donde:
La media y la variancia de la distribución \(\chi^2\) son, respectivamente, \(k\) y \(2k\).
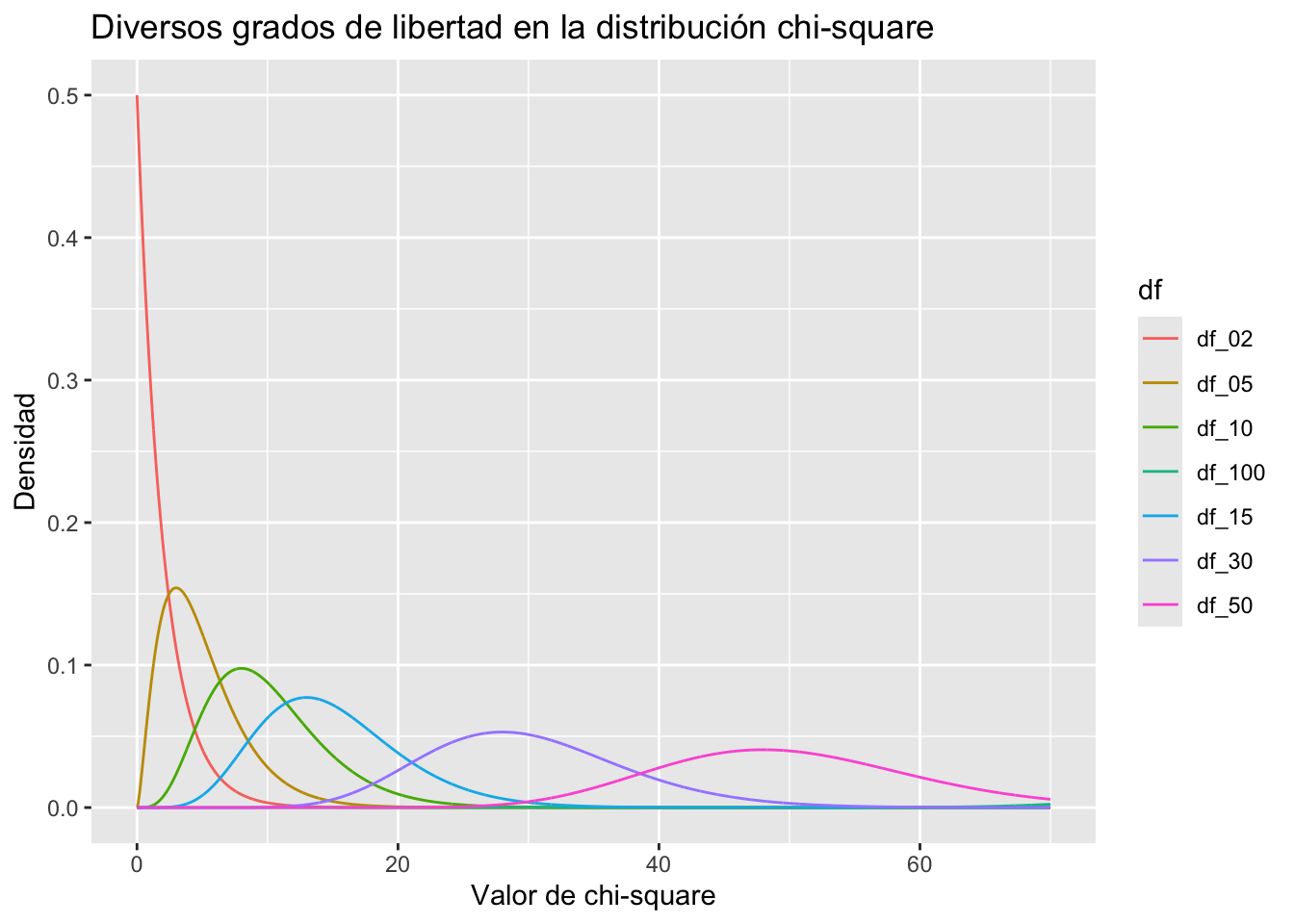
Rdchisq es la función densidad, permite graficar una distribuciónpchisq dado un valor de \(\chi^2\) con \(n\) grados de libertad devuelve la probabilidad de encontrar ese valorqchisq dada una probabilidad devuelve de encontrar ese valor en la distribución \(\chi^2\) con \(n\) grados de libertadrchisq genera datos a aleatorios de una distribución \(\chi^2\)La función chisq.tes() se compone de los siguiente argumentos:
Es decir, la podemos alimentar con una tabla o con dos vectores (x y y).
Vamos a realizar un ejemplo.
Ejemplo 11.1 Un grupo de investigadores desea conocer, si el fumar en el primer trimestre del embarazo se asocia al bajo peso de los recién nacidos. Estos datos fueron capturados en la base de datos “birthwt”. Utilice \(\alpha\) de 0.05, construya un gráfico de barras y reporte los valores esperados por casilla. Para este ejemplo se utilizó la base de datos birthwt utilizada en el capitulo 11.
Se puede crear una tabla con los datos para facilitar la resolución del ejercicio.
library(MASS)
data("birthwt")
## El siguiente código fue copiado del capitulo anterior
birthwt$low <-
factor(birthwt$low, labels = c("Normal", "Bajo"))
birthwt$race <-
factor(birthwt$race, labels = c("White", "Black", "Other"))
birthwt$smoke <-
factor(birthwt$smoke, labels = c("No fumadora", "Fumadora"))
birthwt$ht <-
factor(birthwt$ht, labels = c("No hipertensión", "Hipertensión"))
birthwt$ui <-
factor(birthwt$ui, labels = c("No irritabilidad", "Irritabilidad"))
birthwt$ht <-
factor(birthwt$ht, labels = c("No hipertensión", "Hipertensión"))
## Note como si sabe el orden de los niveles no es necesario declararlos
attach(birthwt)
tab1<-table(smoke, low)
tab1 low
smoke Normal Bajo
No fumadora 86 29
Fumadora 44 30Se puede crear un gráfico de barras para que nos oriente de las frecuencias de los recién nacidos con peso bajo entre las mujeres que fumaron en el primer trimestre del embarazo y las que no
barplot(tab1, legend=rownames(tab1), beside = T, col=c("#800000FF", "#D6D6CEFF"))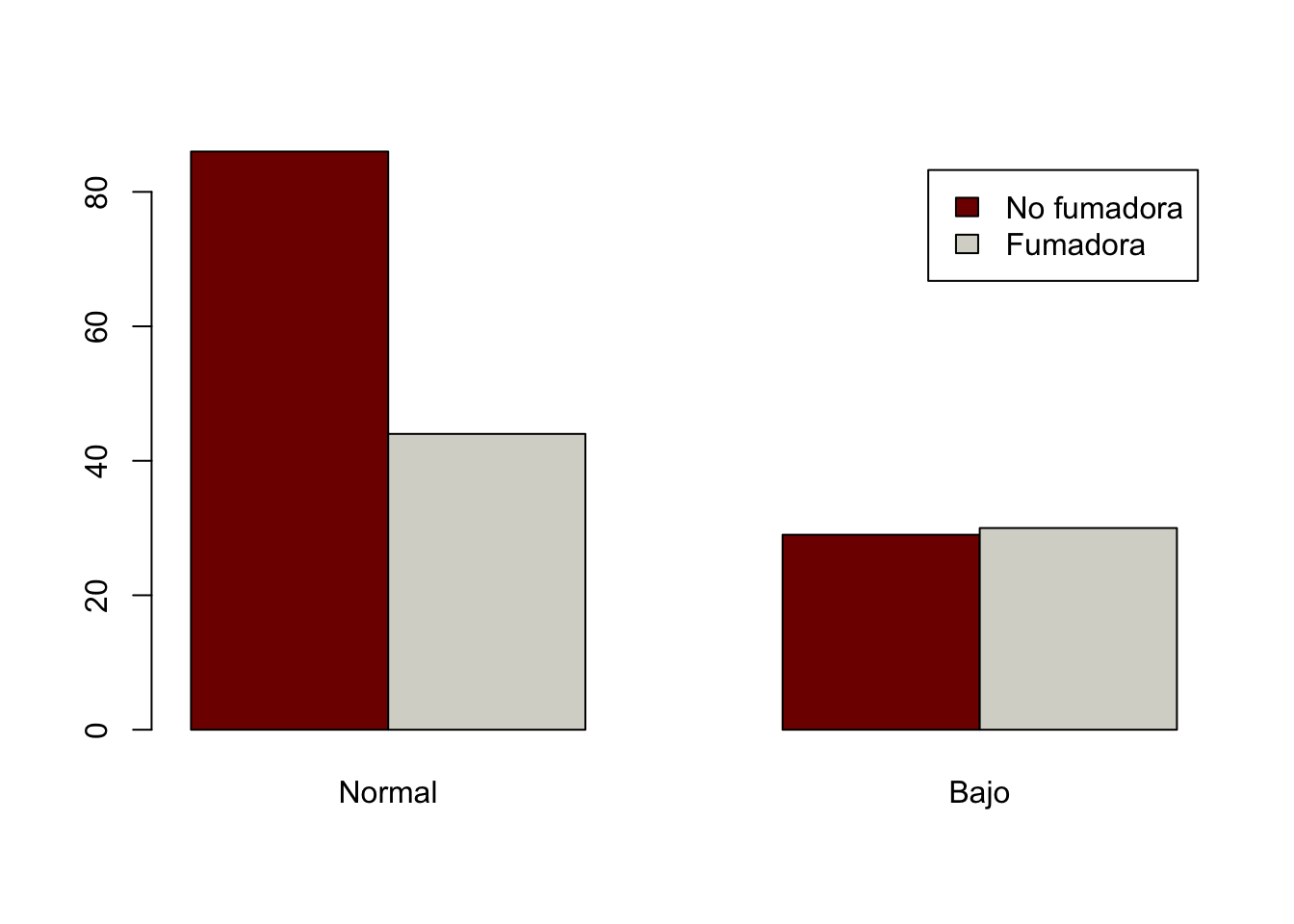
Una gráfica de conteos, no es lo más adecuado ya que puede mostrar información engañosa. Por lo tanto lo más adecuado es hacer una gráfica de proporciones utilizando la función prop.table. Específicamente, una comparación más adecuada sería comparar las proporciones por columna.
tab1|>
prop.table(2)|>
barplot(tab1, beside = T,
ylab = "Proporción", names=c("Madre fumadora", "Madre no fumadora"),
col=c("#800000FF", "#D6D6CEFF"))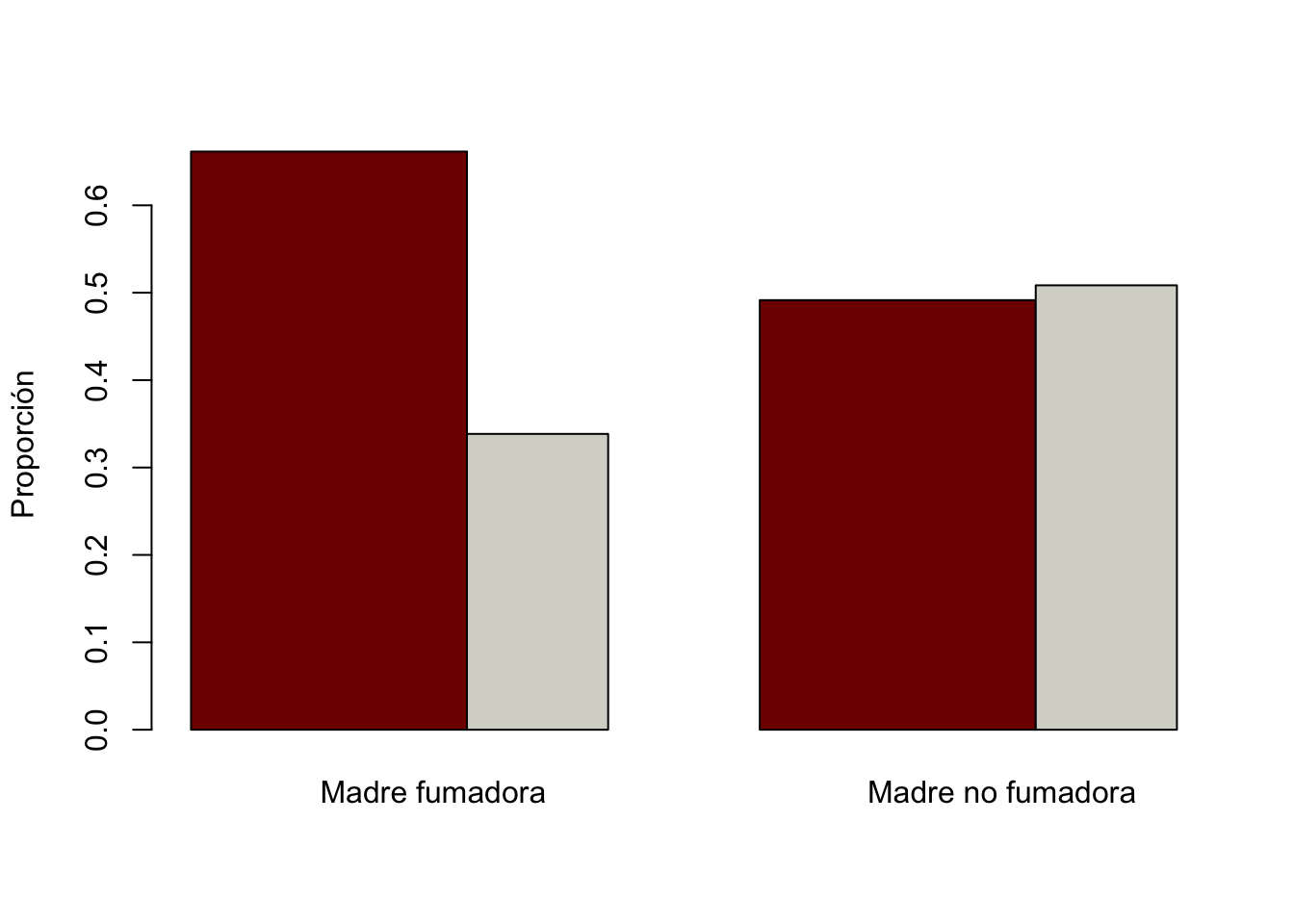
En ggplot2() se puede realizar un gráfico de barras con proporciones utilizando el siguiente código:
# Cargar las librerías necesarias
library(ggplot2) # Para crear gráficos utilizando ggplot2
# Crear la gráfica directamente desde el conjunto de datos birthwt
birthwt|>
ggplot(aes(x=smoke, fill=low))+ # Fill nos permite separar por colores utilizando la variable low
geom_bar(stat="count", position="fill")+ # Position fill nos permite obtener las proporciones
scale_fill_manual(values = c("#800000FF", "#D6D6CEFF")) + # Especificar los colores de las barras
ylab("Proporción") + # Etiquetar el eje Y
xlab("") + # Quitar la etiqueta del eje X (opcional)
labs(fill = "") + # Quitar la etiqueta de la leyenda (opcional)
theme_minimal() + # Usar un tema minimalista para el gráfico
scale_x_discrete(labels = c("Madre no fumadora", "Madre fumadora")) # Etiquetar los valores del eje X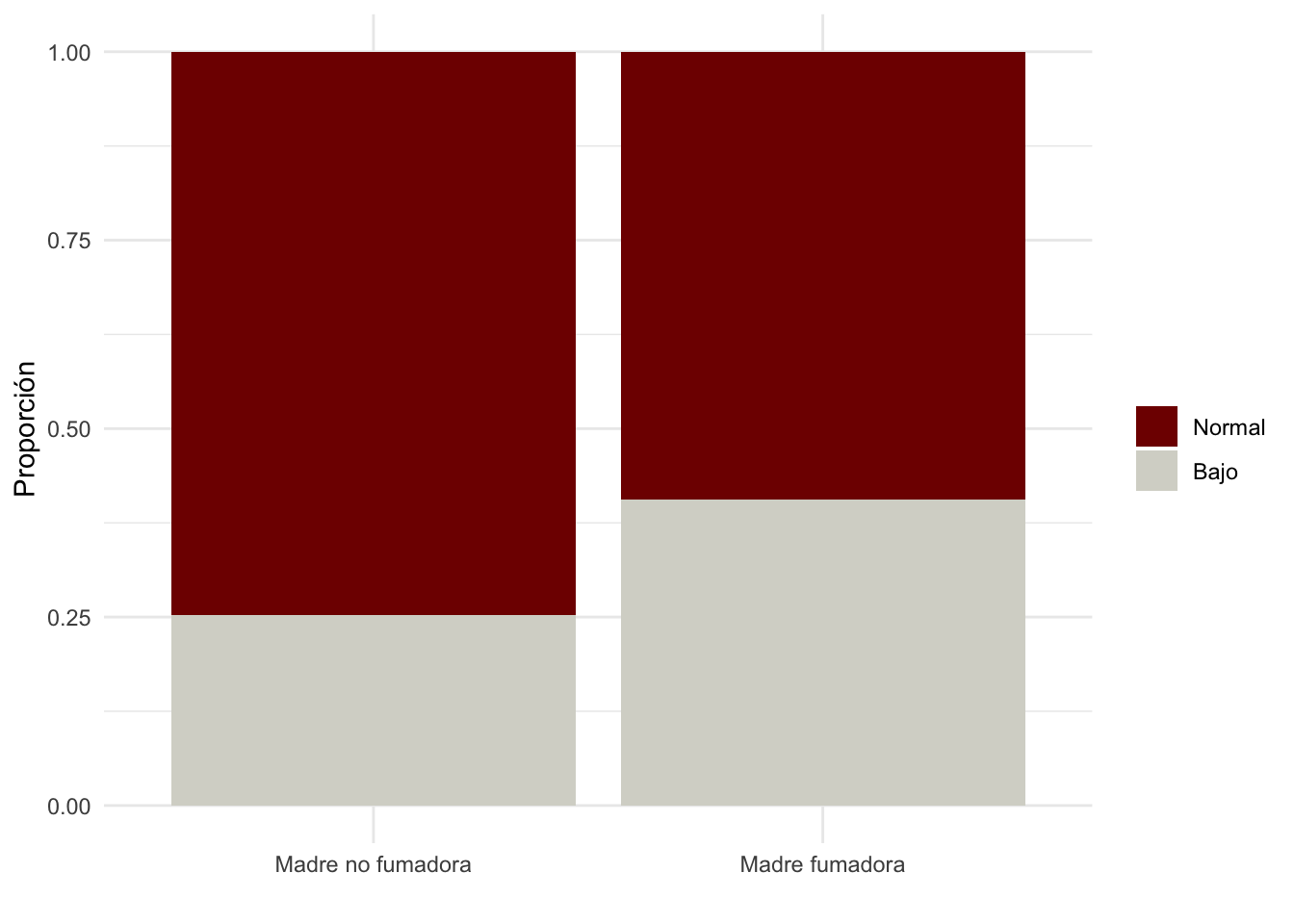
También podemos realizar un gráfico de mosaicos, el cual nos permite visualizar la relación entre las variables cualitativas de una forma más efectiva.
mosaicplot(tab1, color = c("#800000FF", "#D6D6CEFF"),
main="Gráfico de mosaico para la relación \n entre el tabaquismo y el bajo peso al nacer.\n Con conteos")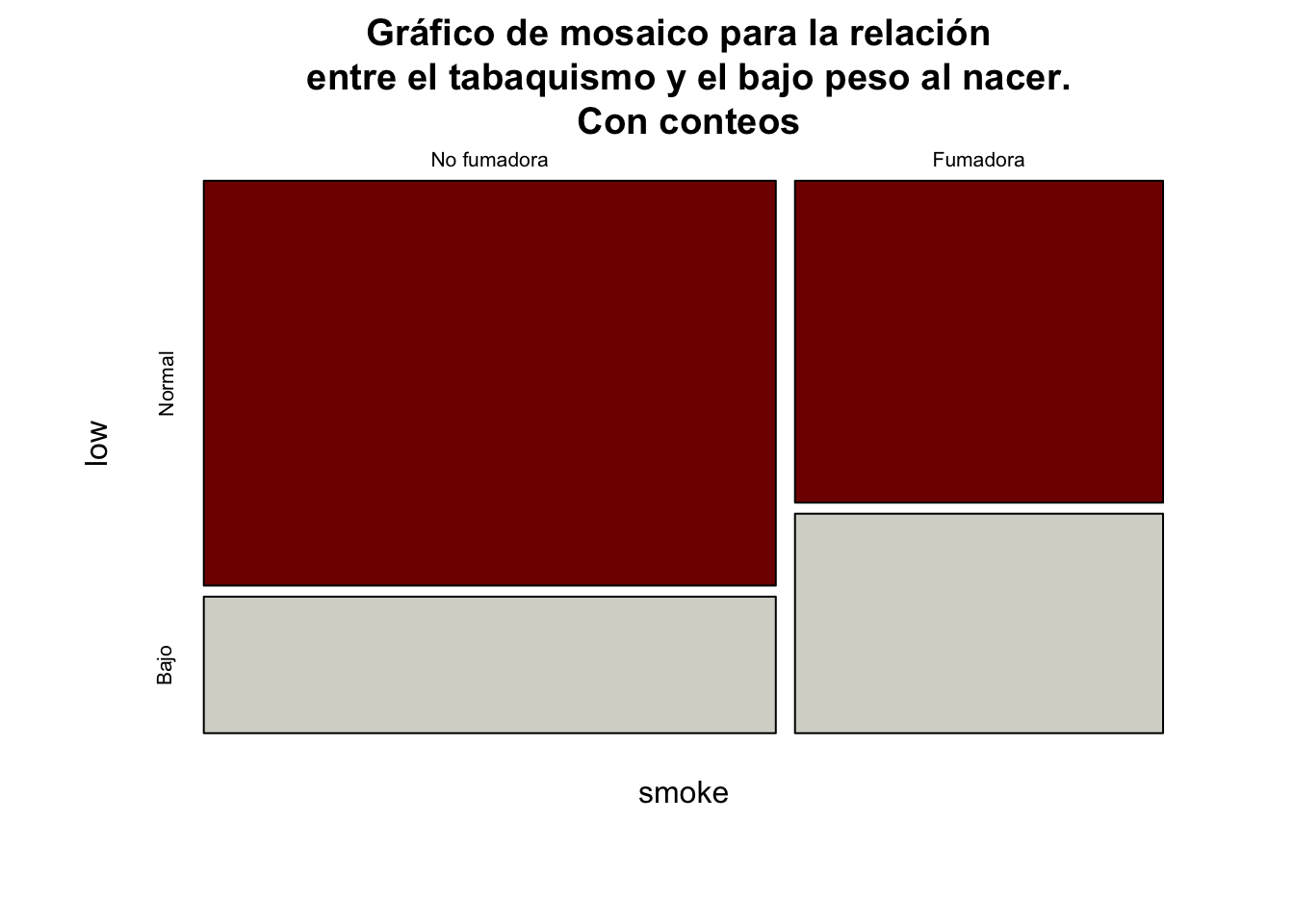
prop.table(tab1,2)|>
mosaicplot(color = c("#800000FF", "#D6D6CEFF"),
main="Gráfico de mosaico para la relación \n entre el tabaquismo y el bajo peso al nacer.\n Con proporciones")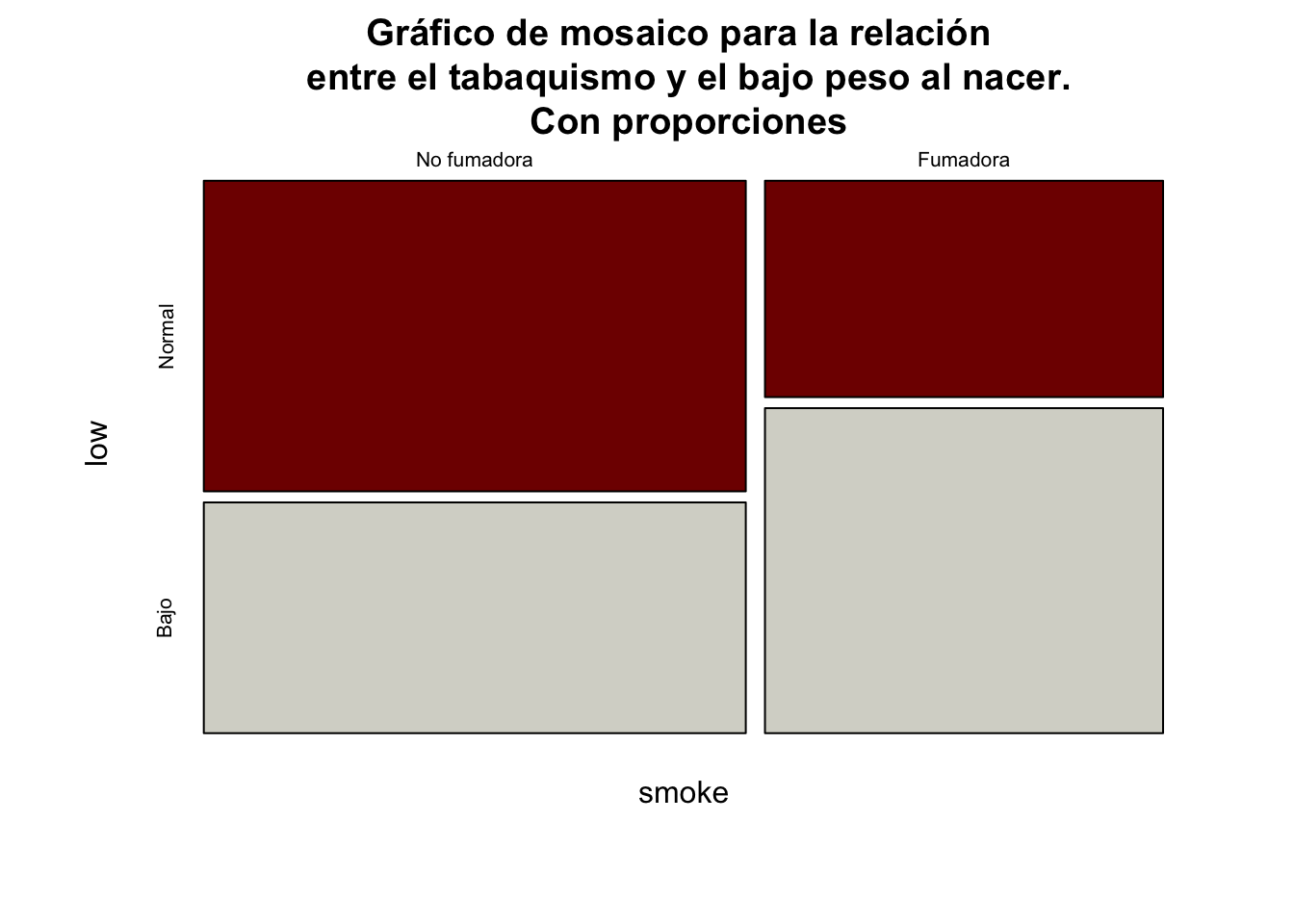
Para realizar la prueba de \(\chi^2\) utilice el siguiente código
chisq.test(tab1)
Pearson's Chi-squared test with Yates' continuity correction
data: tab1
X-squared = 4.2359, df = 1, p-value = 0.03958chisq.test(smoke,low)
Pearson's Chi-squared test with Yates' continuity correction
data: smoke and low
X-squared = 4.2359, df = 1, p-value = 0.03958# Recuerde que hicimos un attachEs posible extraer parámetros de la función chis.test si se guarda en un objeto
x2tab1<-chisq.test(tab1)
x2tab1$observed #Valores observados low
smoke Normal Bajo
No fumadora 86 29
Fumadora 44 30x2tab1$p.value # Valor p[1] 0.03957697x2tab1$expected # Valores esperados low
smoke Normal Bajo
No fumadora 79.10053 35.89947
Fumadora 50.89947 23.10053La pérdida de continuidad, o corrección de continuidad, es un ajuste que se realiza al aplicar la prueba \(\chi^2\) cuando se trata de datos discretos en tablas de contingencia de 2x2, especialmente cuando los tamaños de muestra son pequeños. Este ajuste tiene como objetivo corregir la sobreestimación de la estadística chi-cuadrado que puede ocurrir debido a la discreción de los datos.
La sobreestimación en la estadística chi-cuadrado (^2) ocurre debido a la naturaleza discreta de los datos cuando se aplican a tablas de contingencia, especialmente en tablas pequeñas (como las de 2x2). Esta discreción puede causar que las diferencias entre las frecuencias observadas y esperadas se magnifiquen de manera que la estadística chi-cuadrado sea mayor de lo que debería ser si los datos fueran continuos.
El ajuste más comúnmente utilizado es la corrección de continuidad de Yates, que consiste en restar 0.5 de las diferencias absolutas entre las frecuencias observadas y esperadas en cada celda de la tabla antes de calcular la estadística \(\chi^2\). Esto suaviza las discrepancias y reduce el valor de \(\chi^2\), lo que hace la prueba más conservadora.
La fórmula ajustada con la corrección de continuidad de Yates para una tabla 2x2 es:
\[ \chi^2 = \sum \frac{(|O - E| - 0.5)^2}{E} \]
Mi recomendación es que siempre se aplique la corrección de continuidad, ya que es un ajuste conservador que puede ayudar a evitar falsos positivos en la prueba \(\chi^2\). Además, cuando los conteos son grandes, la corrección de continuidad no afecta significativamente los resultados de la prueba.
Los valores observados pueden ayudarnos a decidir sobre si utilizar la prueba de \(\chi^2\) o la prueba exacta de Fisher (conteos esperados menores 5). Cuanto se tienen conteos esperado menores a 5, no se recomienda utilizar la prueba de \(\chi^2\) debido a que se pierde la continuidad y una corrección de continuidad no es suficiente.
Algunas de las características de la prueba exacta de Fisher son:
\[\frac{(a+c)!(a+b)!(b+d)!(c+d)!}{n!a!b!c!d!}\]
Ejemplo 11.2 Suponga que en el ejemplo Ejemplo 11.1 se presentaron valores esperados menores a 5. Por lo tanto no podemos emplear la prueba de \(\chi^2\), debido a que hay una pérdida en la continuidad.
Resuelva el mismo problema utilizando la prueba exacta de Fisher
fisher.test(tab1, conf.int = T, conf.level = 0.95)
Fisher's Exact Test for Count Data
data: tab1
p-value = 0.03618
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
1.028780 3.964904
sample estimates:
odds ratio
2.014137 ggstatsplotggstatsplot es una extensión del paquete ggplot2 para crear gráficos con detalles de pruebas estadísticas incluidas en los propios gráficos ricos en información. En un flujo de trabajo de análisis de datos exploratorio típico, la visualización de datos y el modelado estadístico son dos fases diferentes: la visualización informa al modelado y el modelado, a su vez, puede sugerir un método de visualización diferente, y así sucesivamente. La idea central de ggstatsplot es simple: combinar estas dos fases en una en forma de gráficos con detalles estadísticos, lo que hace que la exploración de datos sea más simple y rápida.
Vamos a utilizar la librería ggstatsplot para evaluar si hay una asociación entre el fumar durante el embarazo y el bajo peso al nacer.
# install.packages("ggstatsplot")
library(ggstatsplot)
ggstatsplot::ggbarstats(
data = birthwt, # Base de datos
x= low, # Variable en el eje de las x
y=smoke, # Variable en el eje de las y,
type = "parametric", # Tipo de prueba
title = "Comparación de la propoción de bajo peso al nacer entre las madres fumadoras y no fumadoras",
subtitle = "Comparación utilizando chi2") # Puede agregar sub titulo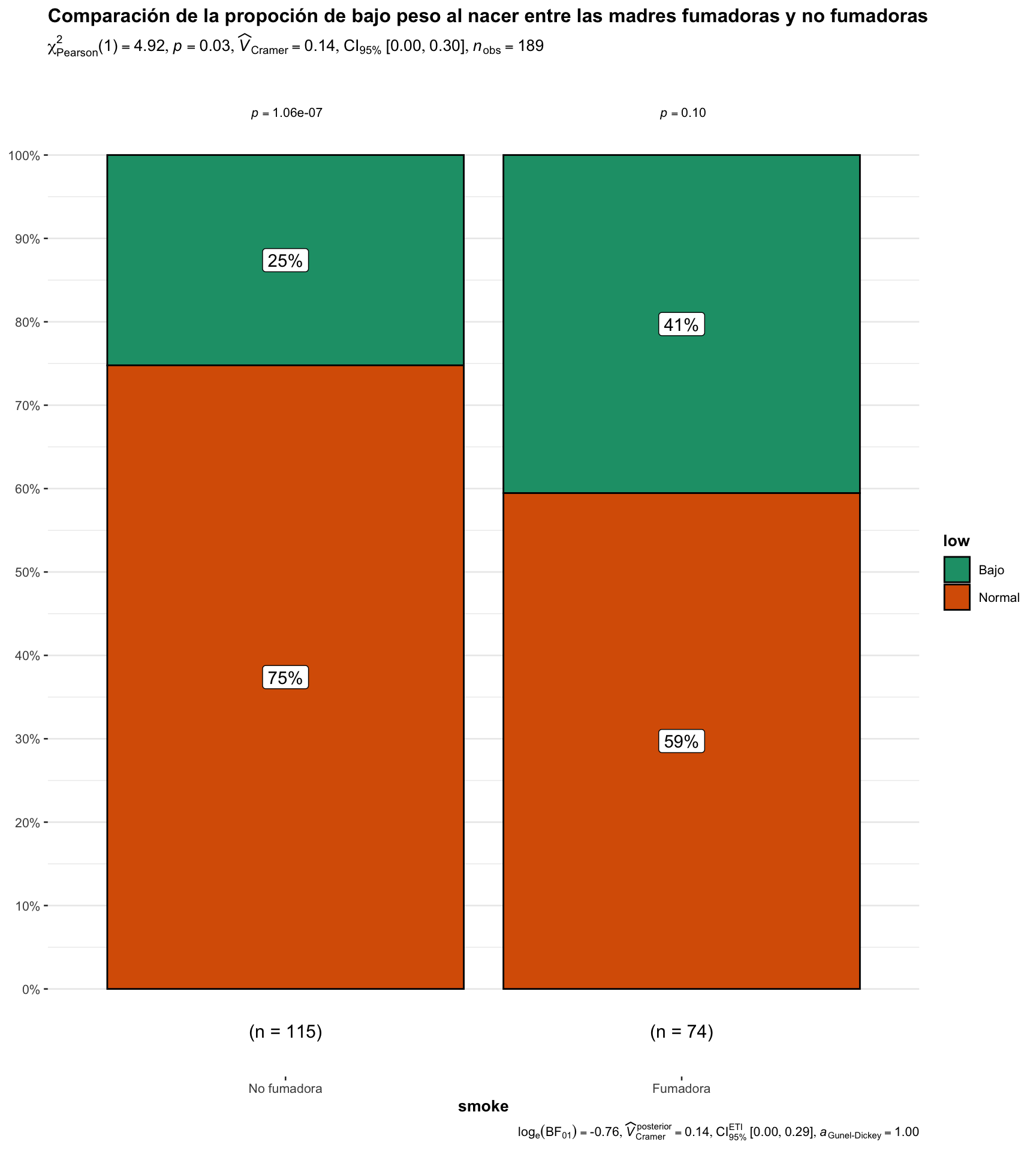
Entre toda la información que proporciona la gráfica anterior se encuentra la ( V ) de Cramér. Esta es una medida del tamaño del efecto para la prueba \(\chi^2\). En él se mide la forma en que están asociados dos campos categóricos. La formula para calcular la ( V ) de Cramér es la siguiente:
[ V = ]
Donde:
Donde:
Una ( V ) de Cramér cercana a 0 sugiere que hay una relación muy débil o inexistente entre las variables, mientras que un valor cercano a 1 sugiere una fuerte relación entre las variables. Es importante notar que aunque la ( V ) de Cramér puede indicar la fuerza de una relación, no indica la dirección de dicha relación.
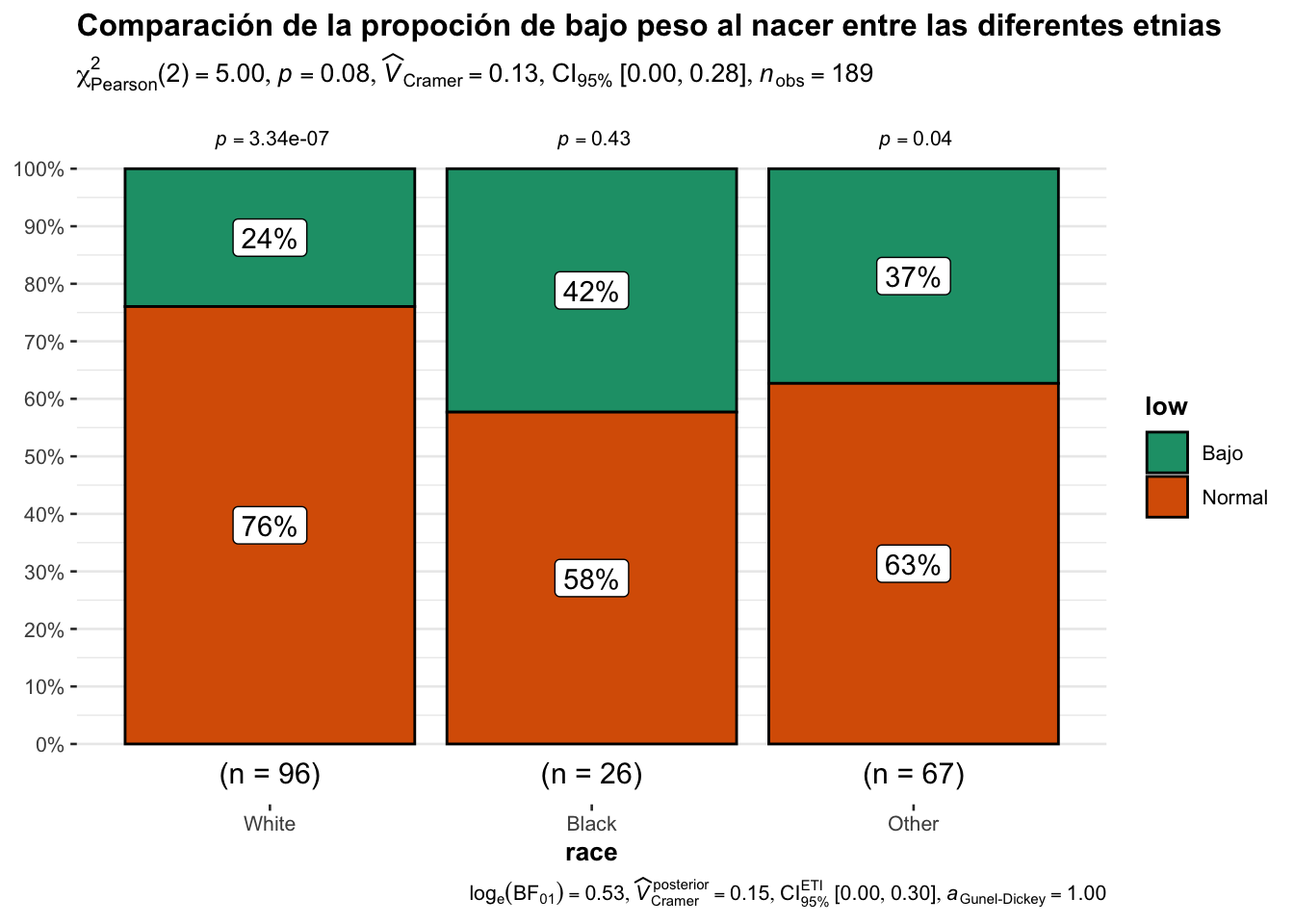
Ejercicio 11.1 Un grupo de investigadores, desea conocer si la raza es independiente al bajo peso al nacer. Utilice la base birthwt, cree una tabla de contingencia y un gráfico de barras con proporciones. Además, compruebe su resultado utilizando la librería ggstatsplot.
Compar.Cuali(birthwt$race, birthwt$low)[1] "Tabla de contingencia"
y
x Normal Bajo
White 73 23
Black 15 11
Other 42 25
[1] "Tabla de contingencia con proporciones"
y
x Normal Bajo
White 0.5615385 0.3898305
Black 0.1153846 0.1864407
Other 0.3230769 0.4237288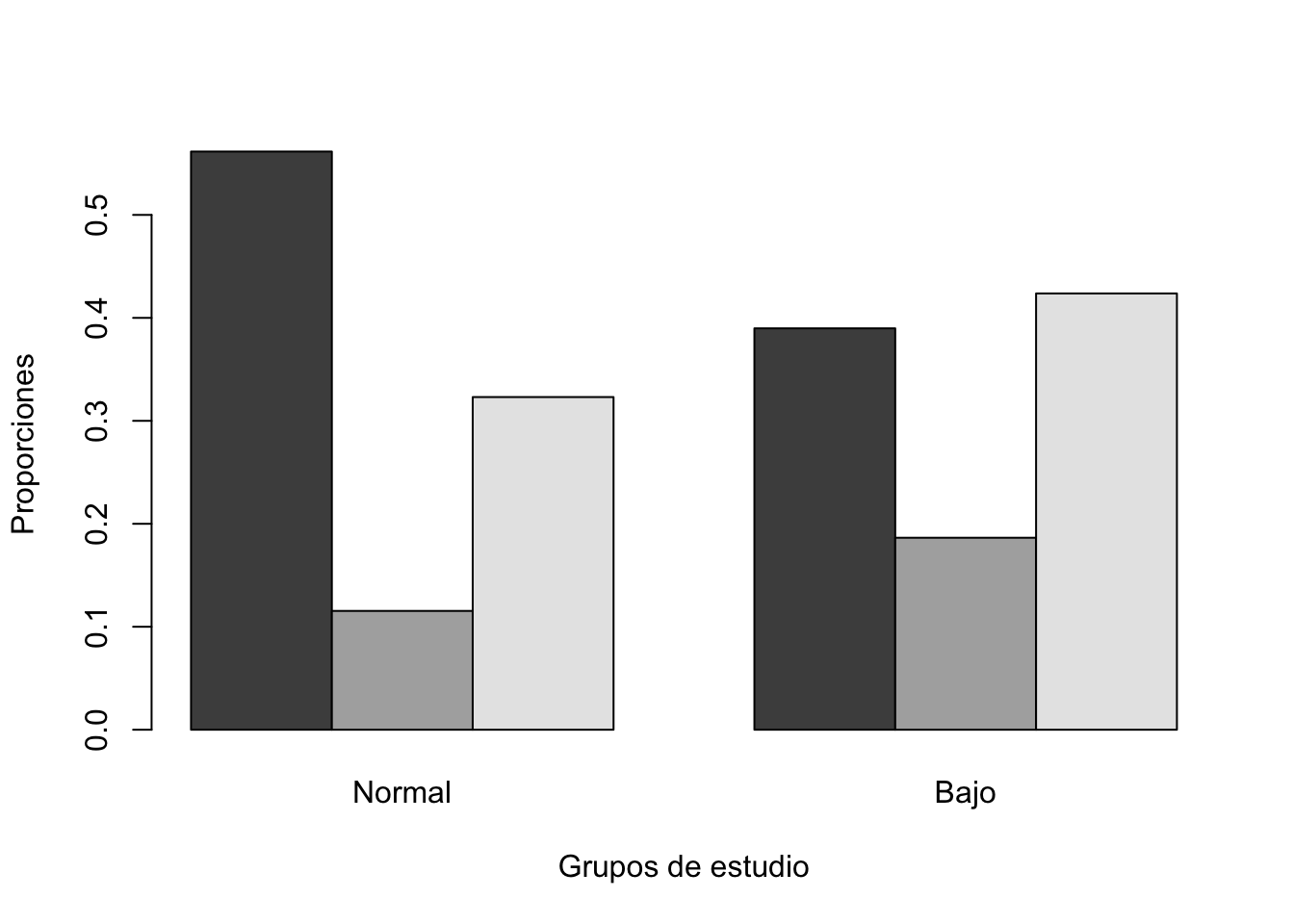
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x Normal Bajo
White 66.03175 29.968254
Black 17.88360 8.116402
Other 46.08466 20.915344
Pearson's Chi-squared test
data: tab
X-squared = 5.0048, df = 2, p-value = 0.08189
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 0.07889
alternative hypothesis: two.sidedLos resultados anteriores muestran que el bajo peso al nacer es independiente a la raza. Utilizando ggstastplot los resultados se muestran a continuación:
ggstatsplot::ggbarstats(
data = birthwt,
x= low,
y=race,
title = "Comparación de la propoción de bajo peso al nacer entre las diferentes etnias"
)
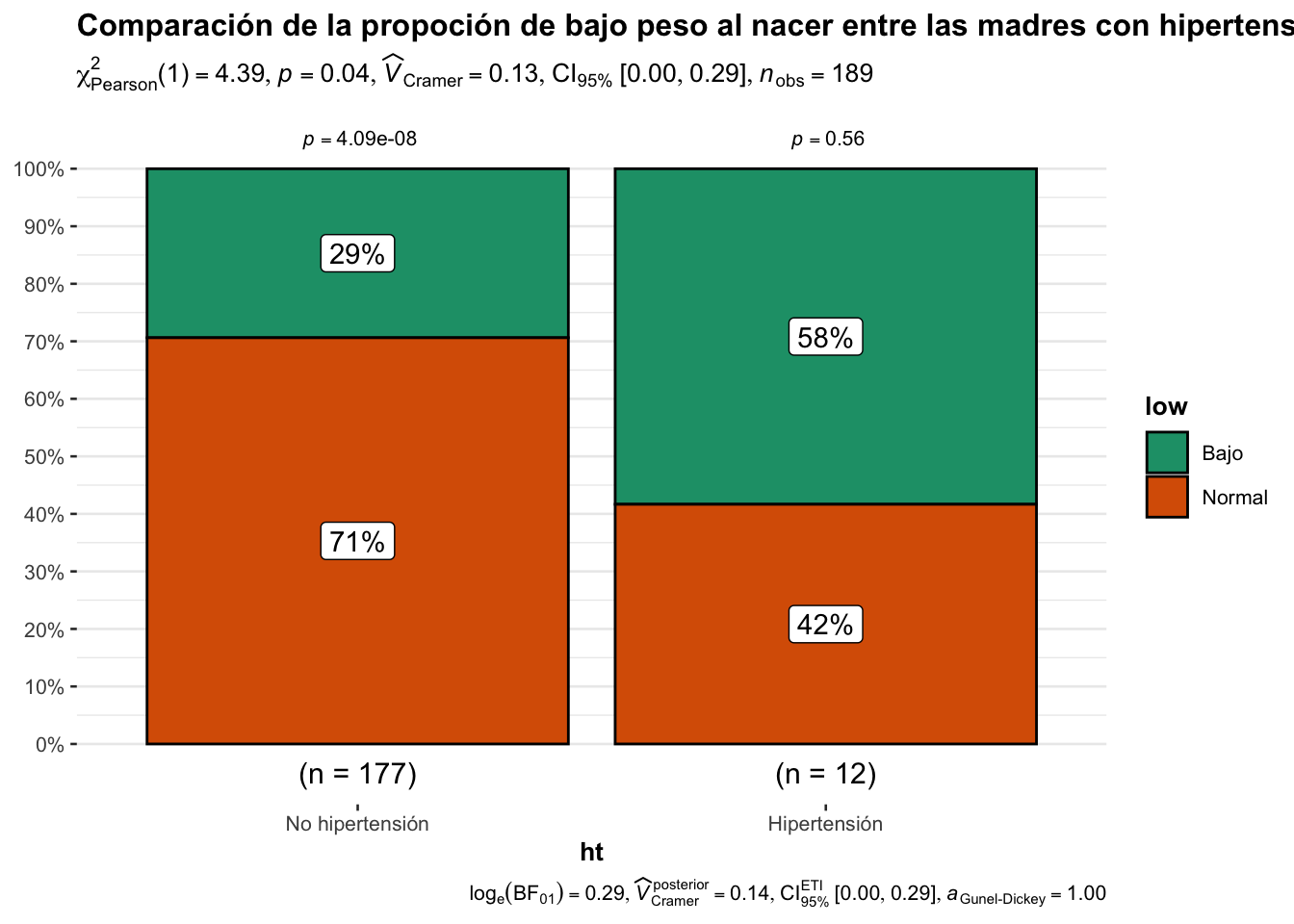
Ejercicio 11.2 ¿el bajo peso al nacer se asocia a la hipertensión previa al embarazo?. Utilice la base birthwt, cree una tabla de contingencia y un gráfico de barras con proporciones. Además, compruebe su resultado utilizando la librería ggstatsplot.
Compar.Cuali(birthwt$ht, birthwt$low)[1] "Tabla de contingencia"
y
x Normal Bajo
No hipertensión 125 52
Hipertensión 5 7
[1] "Tabla de contingencia con proporciones"
y
x Normal Bajo
No hipertensión 0.96153846 0.88135593
Hipertensión 0.03846154 0.11864407Warning in chisq.test(tab): Chi-squared approximation may be incorrect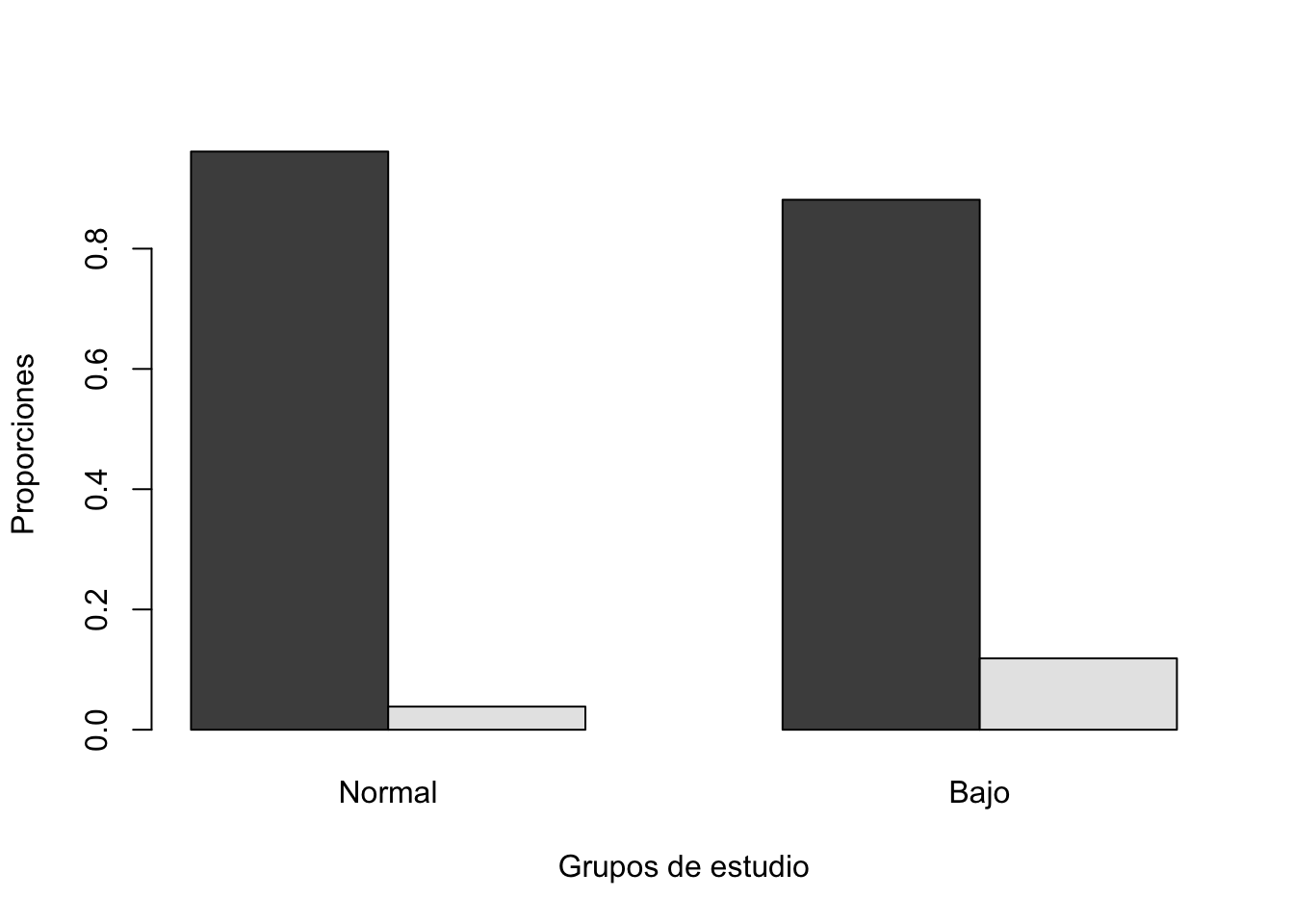
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x Normal Bajo
No hipertensión 121.746032 55.253968
Hipertensión 8.253968 3.746032
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 3.1431, df = 1, p-value = 0.07625
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 0.05161
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.8679484 13.9894703
sample estimates:
odds ratio
3.340866 ggstatsplot::ggbarstats(
data = birthwt,
x= low,
y=ht,
title = "Comparación de la propoción de bajo peso al nacer entre las madres con hipertensión"
)
Ejercicio 11.3 ¿El antecedente de tabaquismo es independiente de la raza?. Utilice la base birthwt, cree una tabla de contingencia y un gráfico de barras con proporciones. Además, compruebe su resultado utilizando la librería ggstatsplot.
Compar.Cuali(birthwt$race, birthwt$smoke)[1] "Tabla de contingencia"
y
x No fumadora Fumadora
White 44 52
Black 16 10
Other 55 12
[1] "Tabla de contingencia con proporciones"
y
x No fumadora Fumadora
White 0.3826087 0.7027027
Black 0.1391304 0.1351351
Other 0.4782609 0.1621622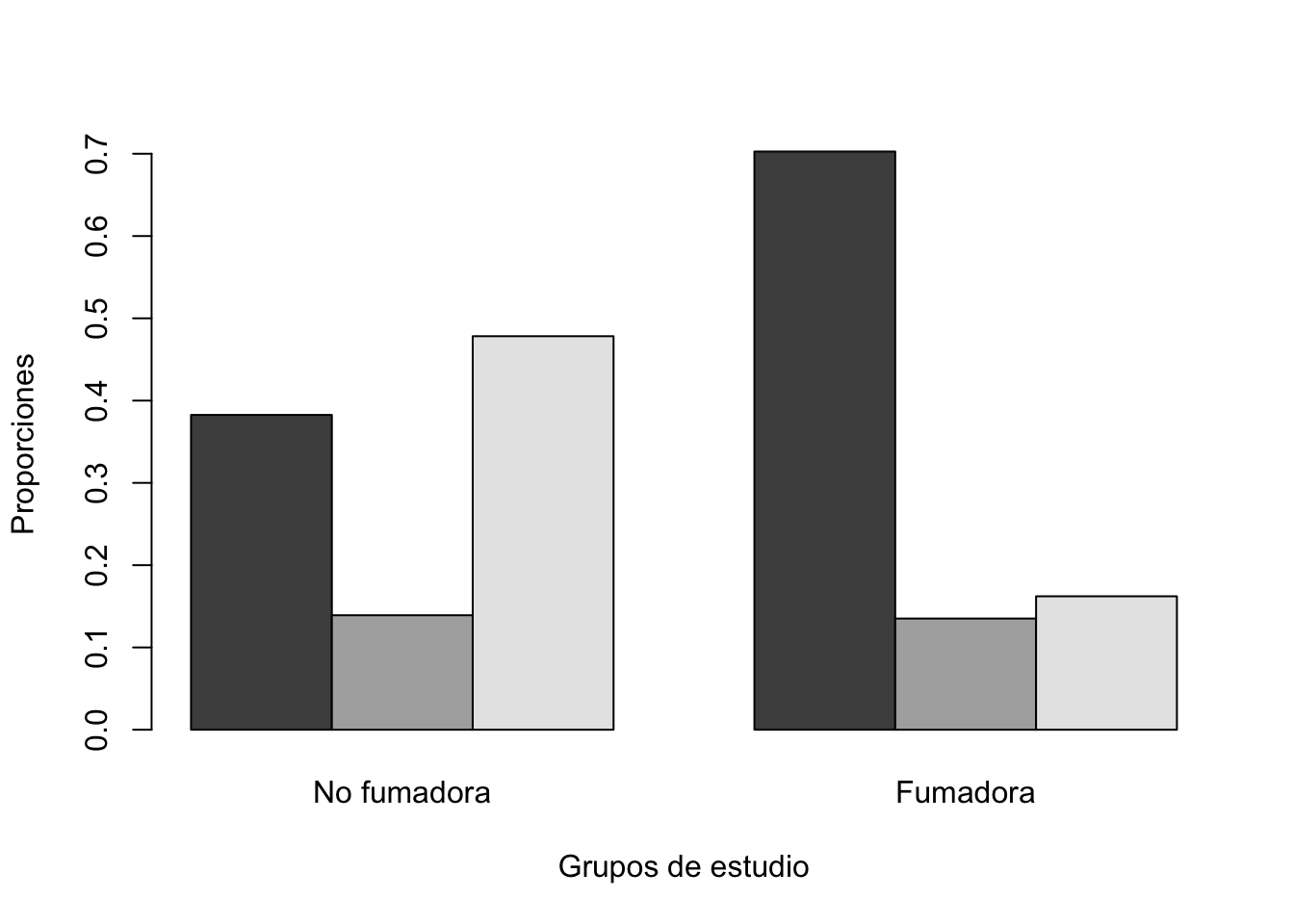
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x No fumadora Fumadora
White 58.41270 37.58730
Black 15.82011 10.17989
Other 40.76720 26.23280
Pearson's Chi-squared test
data: tab
X-squared = 21.779, df = 2, p-value = 1.865e-05
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 9.799e-06
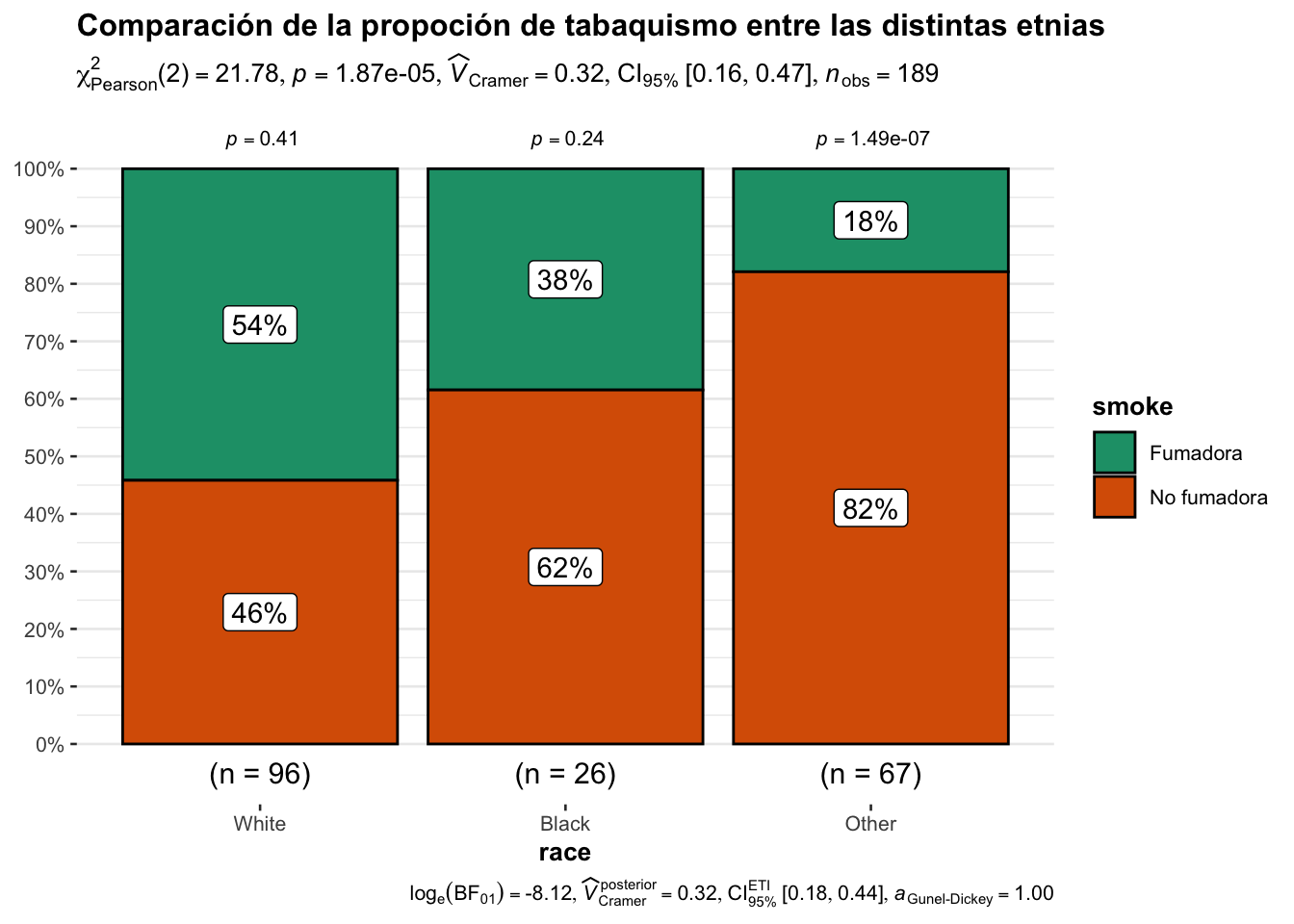
alternative hypothesis: two.sidedggstatsplot::ggbarstats(
data = birthwt,
x= smoke,
y=race,
title = "Comparación de la propoción de tabaquismo entre las distintas etnias"
)
Ejercicio 11.4 Resuelva las preguntas anteriores, esta vez utilizando la prueba exacta de Fisher
Ejercicio 11.5 Compruebe si las suposiciones obetenidas del EDA de birthwt son ciertas. Elija la prueba de hipótesis adecuada. Este ejercicio solo es para variables cualitativas. Además, compruebe su resultado utilizando la librería ggstatsplot.
Ejercicio 11.6 Utilizando la base Melanoma de la librería MASS contiene los datos 205 pacientes originarios de Dinamarca que fueron diagnosticados con Melanoma entre los años 1962 a 1977. Si quiere conocer el significado de cada una de las variables, después de cargar la librería MASS utilice el siguiente comando help(“Melanoma”). Esta base de datos se utilizó anteriormente en el capitulo 11.
Repita la resolución de estos ejercicios utilizando la librería ggstatsplot y JASP.
# Cargar la librería y base de datos
library(MASS)
data("Melanoma")head(Melanoma) time status sex age year thickness ulcer
1 10 3 1 76 1972 6.76 1
2 30 3 1 56 1968 0.65 0
3 35 2 1 41 1977 1.34 0
4 99 3 0 71 1968 2.90 0
5 185 1 1 52 1965 12.08 1
6 204 1 1 28 1971 4.84 1# Para identificar que variables cambiar
summary(Melanoma) time status sex age year
Min. : 10 Min. :1.00 Min. :0.0000 Min. : 4.00 Min. :1962
1st Qu.:1525 1st Qu.:1.00 1st Qu.:0.0000 1st Qu.:42.00 1st Qu.:1968
Median :2005 Median :2.00 Median :0.0000 Median :54.00 Median :1970
Mean :2153 Mean :1.79 Mean :0.3854 Mean :52.46 Mean :1970
3rd Qu.:3042 3rd Qu.:2.00 3rd Qu.:1.0000 3rd Qu.:65.00 3rd Qu.:1972
Max. :5565 Max. :3.00 Max. :1.0000 Max. :95.00 Max. :1977
thickness ulcer
Min. : 0.10 Min. :0.000
1st Qu.: 0.97 1st Qu.:0.000
Median : 1.94 Median :0.000
Mean : 2.92 Mean :0.439
3rd Qu.: 3.56 3rd Qu.:1.000
Max. :17.42 Max. :1.000 Las variables a recodificar son: - sex - status - ulcer
# Cambiar variables numéricas a factores
# Si ya lo realizó con anterioridad omita este paso
Melanoma$status2 <- cut(Melanoma$status, breaks = c(-1,1,Inf),
labels = c("died from melanoma", "Others") )
Melanoma$status <- factor(Melanoma$status,
labels = c("died from melanoma", "alive", "Dead from other causes"))
Melanoma$sex <- factor (Melanoma$sex,
labels = c("Female", "Male"))
Melanoma$ulcer <- factor(Melanoma$ulcer,
labels = c("absence", "presence"))Se “corta” la variable edad para identificar los individuos con una edad mayor a 50 y menor o igual a 50:
Melanoma$age_factor <- cut(Melanoma$age, breaks = c(0,50,Inf),
labels = c("50 o menos", "Más de 50"))Para facilitar el análisis cree una función:
Compar.Cuali <- function(x, y){
tab <- table(x,y)# Conteos
print("Tabla de contingencia")
print(tab)
prop <- prop.table(tab,2)
print("Tabla de contingencia con proporciones")
print(prop)
barplot(prop, beside=T, ylab="Proporciones", xlab="Grupos de estudio")
x2 <- chisq.test(tab)
print("Pureba de chi2")
print("Valores esperados")
print(x2$expected)# Conocer los valores esperados
print(x2)
fisher <- fisher.test(tab)
print("Prueba exacta de Fisher")
print(fisher)
}Ahora ya podemos responder las cuestiones del problema
Compar.Cuali(Melanoma$age_factor, Melanoma$status)[1] "Tabla de contingencia"
y
x died from melanoma alive Dead from other causes
50 o menos 20 65 2
Más de 50 37 69 12
[1] "Tabla de contingencia con proporciones"
y
x died from melanoma alive Dead from other causes
50 o menos 0.3508772 0.4850746 0.1428571
Más de 50 0.6491228 0.5149254 0.8571429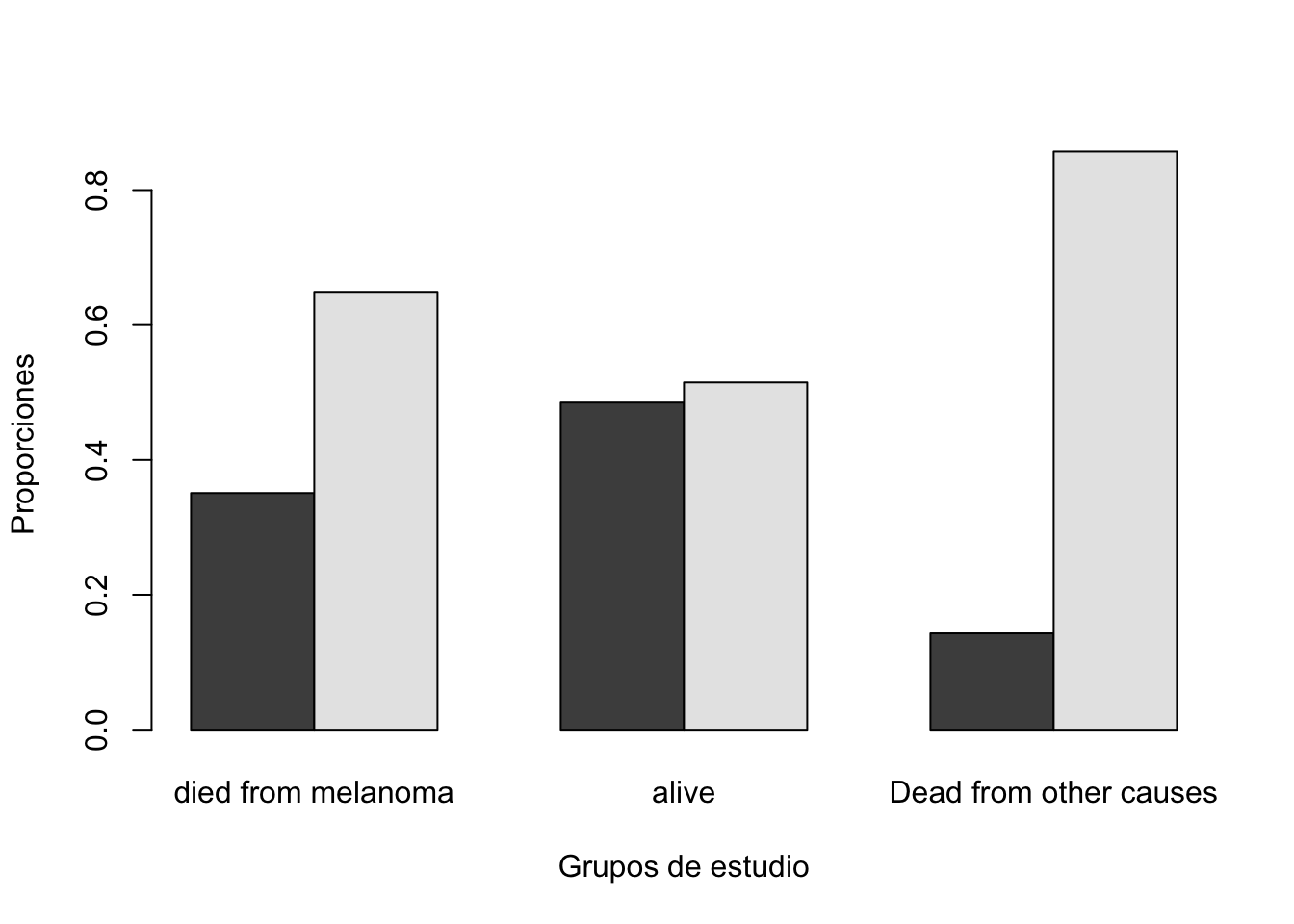
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x died from melanoma alive Dead from other causes
50 o menos 24.19024 56.86829 5.941463
Más de 50 32.80976 77.13171 8.058537
Pearson's Chi-squared test
data: tab
X-squared = 7.8235, df = 2, p-value = 0.02001
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 0.02067
alternative hypothesis: two.sidedCompar.Cuali(Melanoma$sex, Melanoma$status)[1] "Tabla de contingencia"
y
x died from melanoma alive Dead from other causes
Female 28 91 7
Male 29 43 7
[1] "Tabla de contingencia con proporciones"
y
x died from melanoma alive Dead from other causes
Female 0.4912281 0.6791045 0.5000000
Male 0.5087719 0.3208955 0.5000000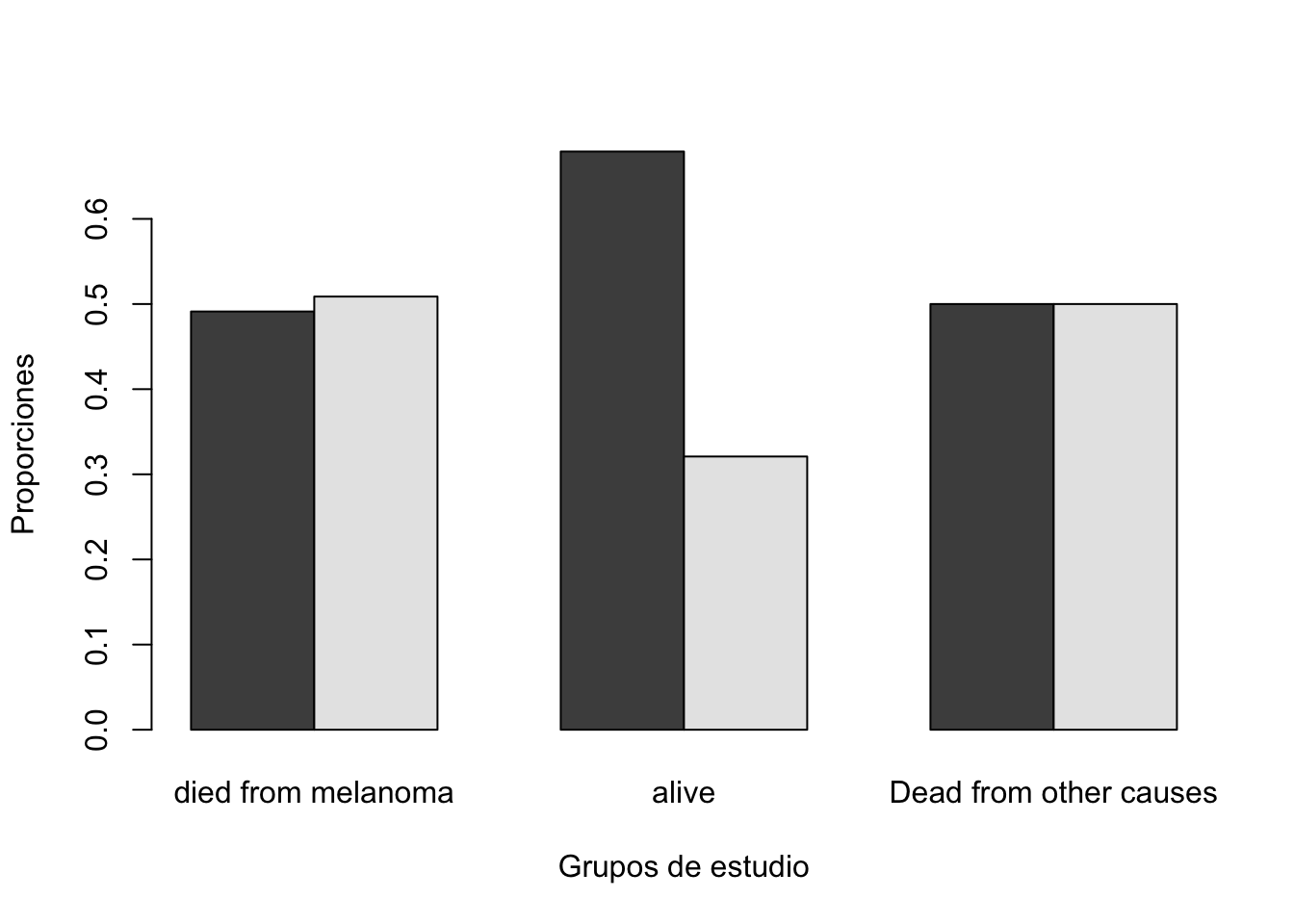
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x died from melanoma alive Dead from other causes
Female 35.03415 82.36098 8.604878
Male 21.96585 51.63902 5.395122
Pearson's Chi-squared test
data: tab
X-squared = 6.793, df = 2, p-value = 0.03349
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 0.03249
alternative hypothesis: two.sidedCompar.Cuali(Melanoma$ulcer, Melanoma$status)[1] "Tabla de contingencia"
y
x died from melanoma alive Dead from other causes
absence 16 92 7
presence 41 42 7
[1] "Tabla de contingencia con proporciones"
y
x died from melanoma alive Dead from other causes
absence 0.2807018 0.6865672 0.5000000
presence 0.7192982 0.3134328 0.5000000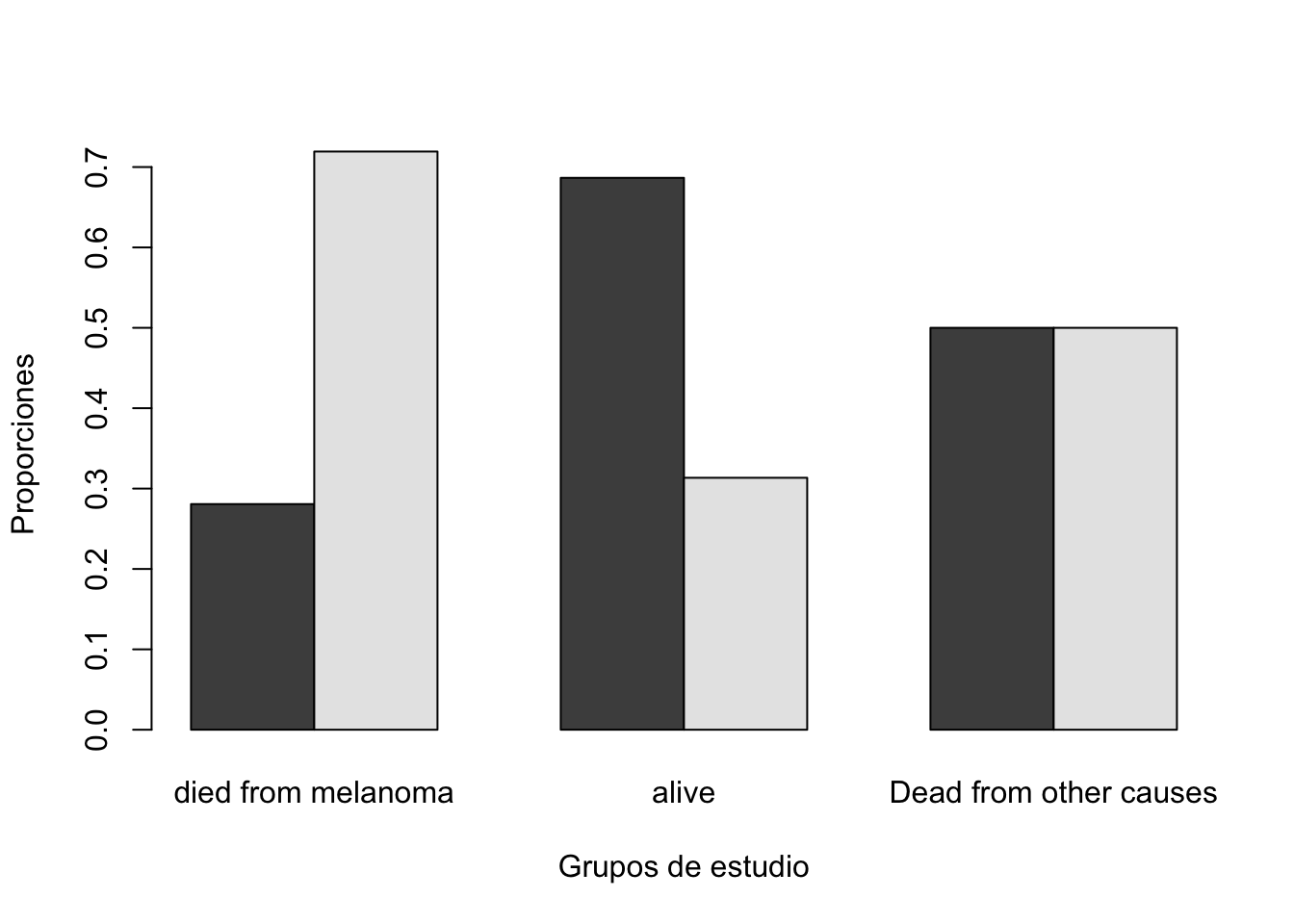
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x died from melanoma alive Dead from other causes
absence 31.97561 75.17073 7.853659
presence 25.02439 58.82927 6.146341
Pearson's Chi-squared test
data: tab
X-squared = 26.974, df = 2, p-value = 1.389e-06
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 8.071e-07
alternative hypothesis: two.sidedCompar.Cuali(Melanoma$age_factor, Melanoma$status2)[1] "Tabla de contingencia"
y
x died from melanoma Others
50 o menos 20 67
Más de 50 37 81
[1] "Tabla de contingencia con proporciones"
y
x died from melanoma Others
50 o menos 0.3508772 0.4527027
Más de 50 0.6491228 0.5472973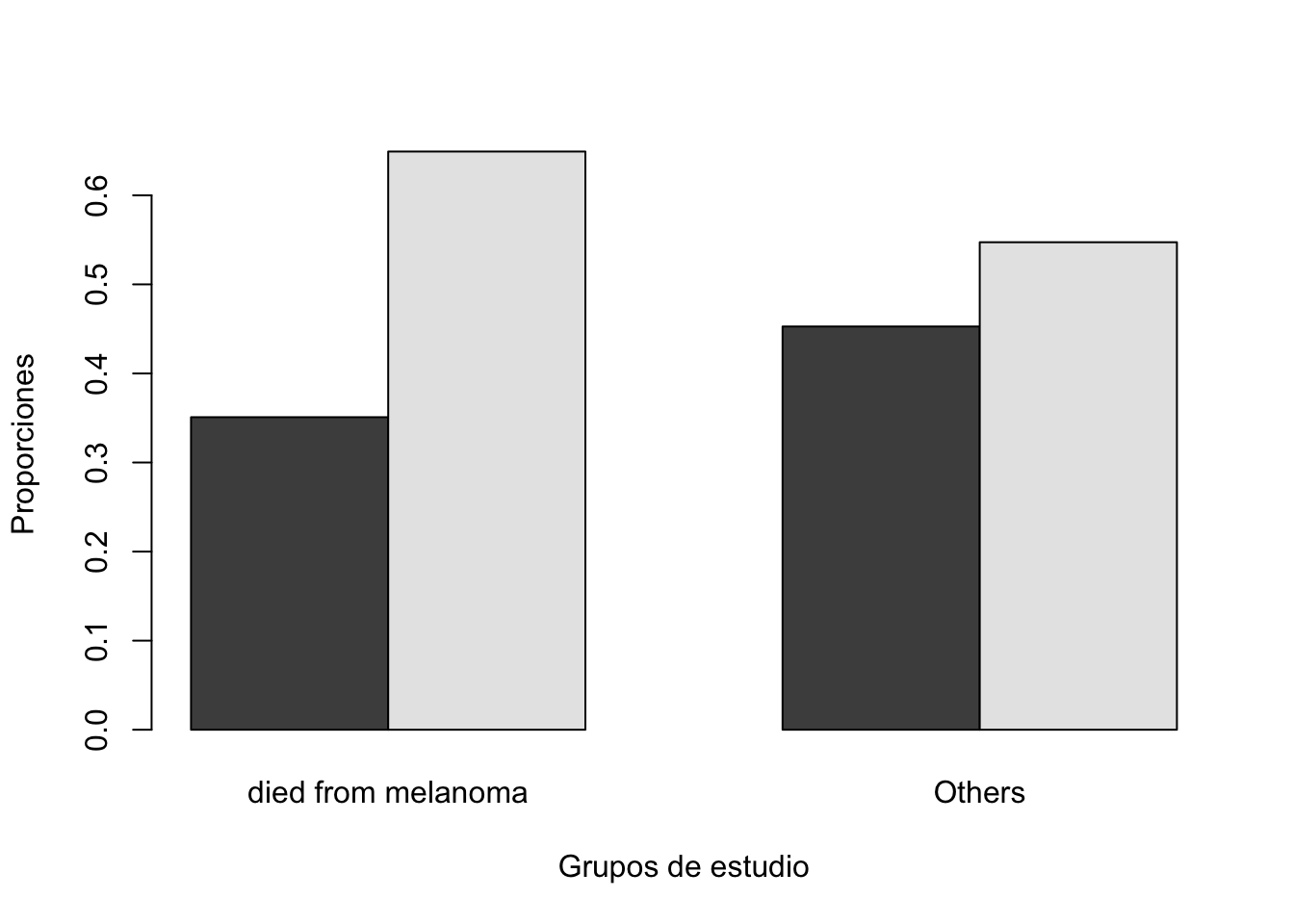
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x died from melanoma Others
50 o menos 24.19024 62.80976
Más de 50 32.80976 85.19024
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 1.3547, df = 1, p-value = 0.2445
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 0.2093
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.3273099 1.2830743
sample estimates:
odds ratio
0.654837 Compar.Cuali(Melanoma$sex, Melanoma$status2)[1] "Tabla de contingencia"
y
x died from melanoma Others
Female 28 98
Male 29 50
[1] "Tabla de contingencia con proporciones"
y
x died from melanoma Others
Female 0.4912281 0.6621622
Male 0.5087719 0.3378378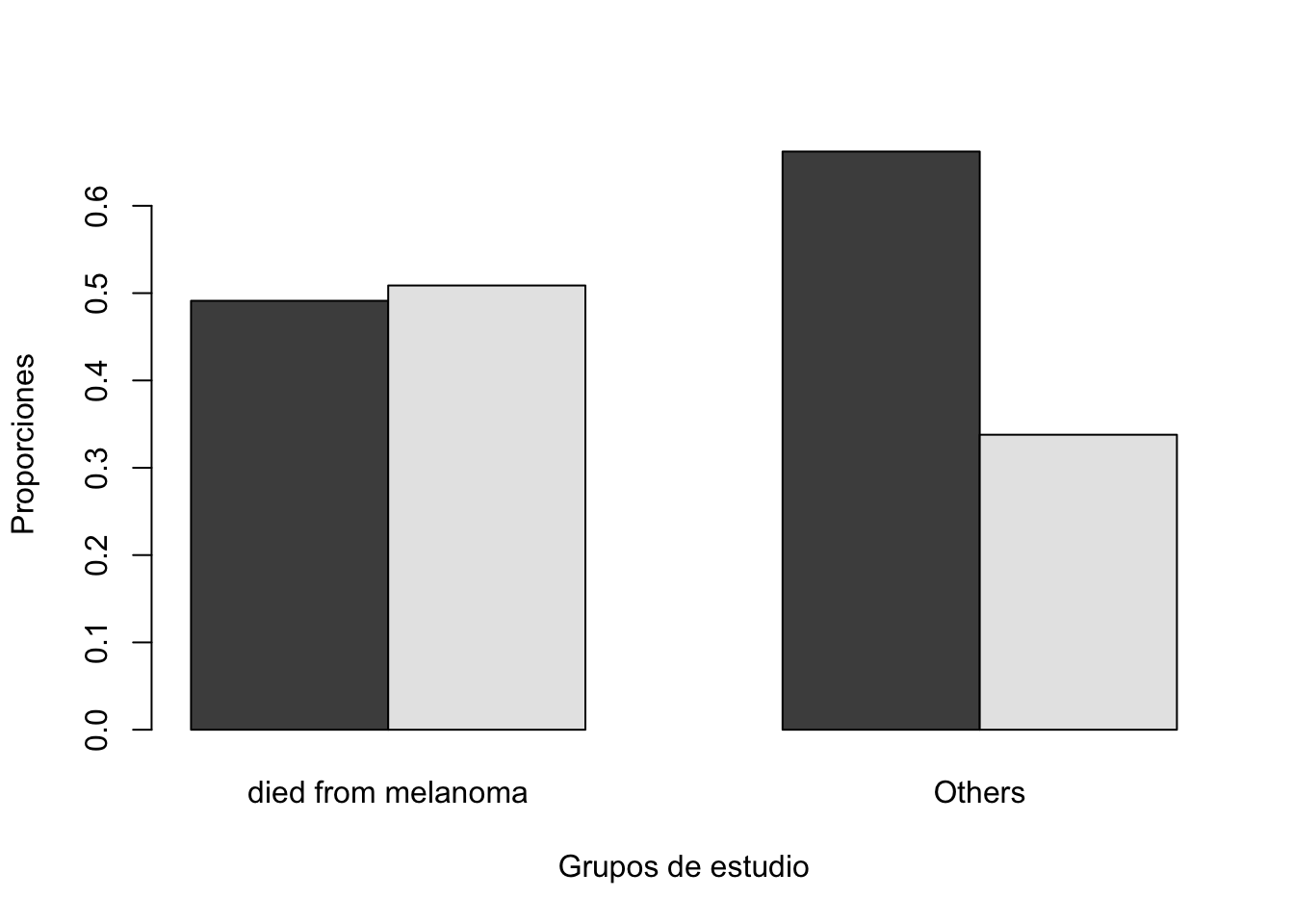
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x died from melanoma Others
Female 35.03415 90.96585
Male 21.96585 57.03415
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 4.3803, df = 1, p-value = 0.03636
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 0.02628
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.2527608 0.9625712
sample estimates:
odds ratio
0.4943874 Compar.Cuali(Melanoma$ulcer, Melanoma$status2)[1] "Tabla de contingencia"
y
x died from melanoma Others
absence 16 99
presence 41 49
[1] "Tabla de contingencia con proporciones"
y
x died from melanoma Others
absence 0.2807018 0.6689189
presence 0.7192982 0.3310811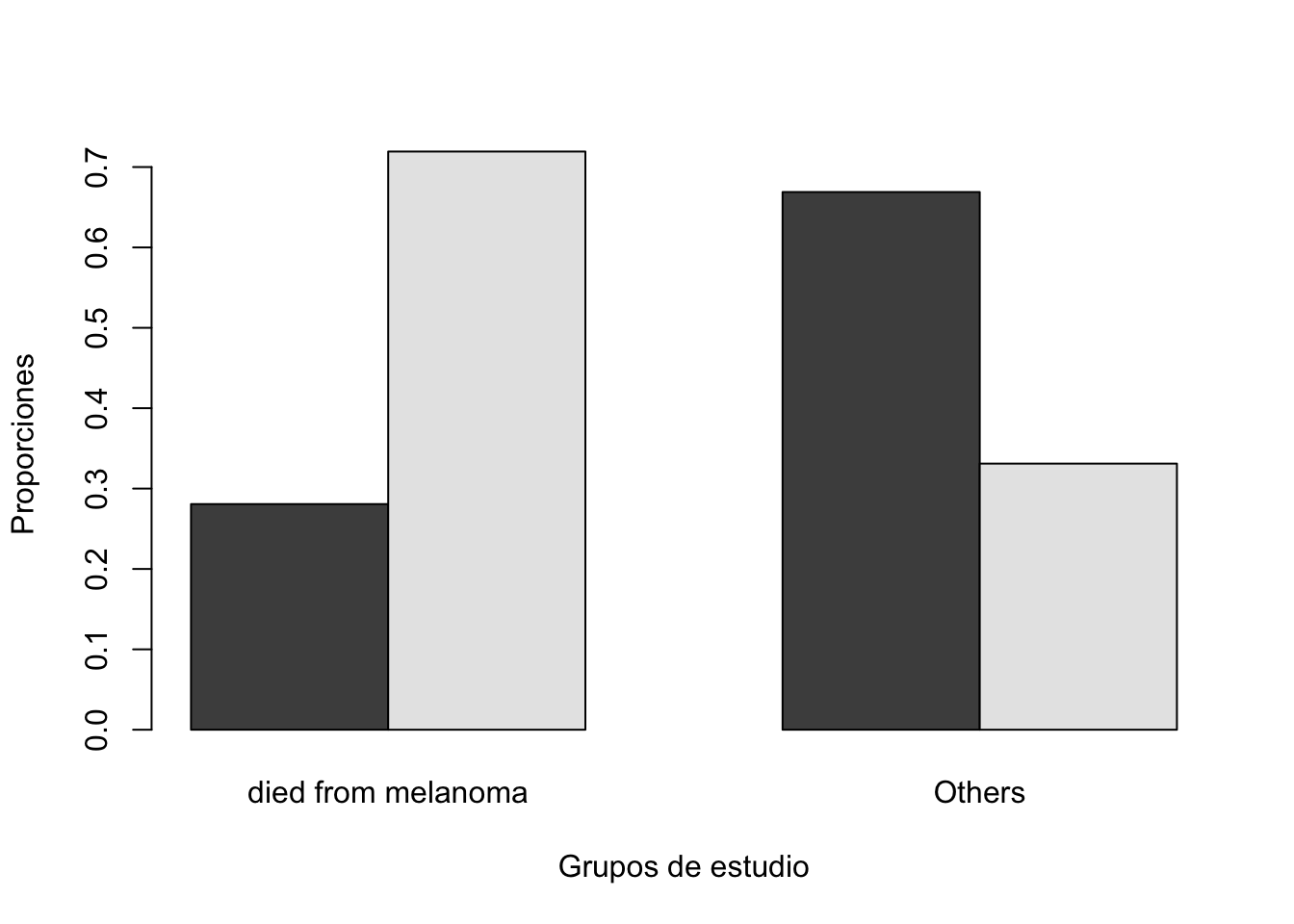
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x died from melanoma Others
absence 31.97561 83.02439
presence 25.02439 64.97561
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 23.631, df = 1, p-value = 1.167e-06
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 7.134e-07
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.09226445 0.39543158
sample estimates:
odds ratio
0.1948651 Ejercicio 11.7 Descargue la base Fertility de: https://vincentarelbundock.github.io/Rdatasets/csv/AER/Fertility.csv
Identifique que factores (variables cualitativas) se asocian con la fertilidad, medida como más de dos hijos. Puede encontrar información de la base aquí: https://vincentarelbundock.github.io/Rdatasets/doc/AER/Fertility.html
Importar base de datos
df <- read.csv("Bases/Fertility.csv", stringsAsFactors = T)Se explora la base mediante la función summary y `head``
head(df) X morekids gender1 gender2 age afam hispanic other work
1 1 no male female 27 no no no 0
2 2 no female male 30 no no no 30
3 3 no male female 27 no no no 0
4 4 no male female 35 yes no no 0
5 5 no female female 30 no no no 22
6 6 no male female 26 no no no 40summary(df) X morekids gender1 gender2 age
Min. : 1 no :157742 female:123670 female:124131 Min. :21.00
1st Qu.: 63664 yes: 96912 male :130984 male :130523 1st Qu.:28.00
Median :127328 Median :31.00
Mean :127328 Mean :30.39
3rd Qu.:190991 3rd Qu.:33.00
Max. :254654 Max. :35.00
afam hispanic other work
no :241498 no :235757 no :240306 Min. : 0.00
yes: 13156 yes: 18897 yes: 14348 1st Qu.: 0.00
Median : 5.00
Mean :19.02
3rd Qu.:44.00
Max. :52.00 visdat::vis_dat(df)Se identifican los factores (variables cualitativas) asociados a la fertilidad (morekids).
Aunque carece de un sentido biológico, para fines de poner el práctica las pruebas de hipótesis revisadas, se probará si el genero del primero y del segundo hijo se asocian a la fertilidad
Compar.Cuali(df$gender1, df$morekids)[1] "Tabla de contingencia"
y
x no yes
female 76044 47626
male 81698 49286
[1] "Tabla de contingencia con proporciones"
y
x no yes
female 0.4820783 0.4914355
male 0.5179217 0.5085645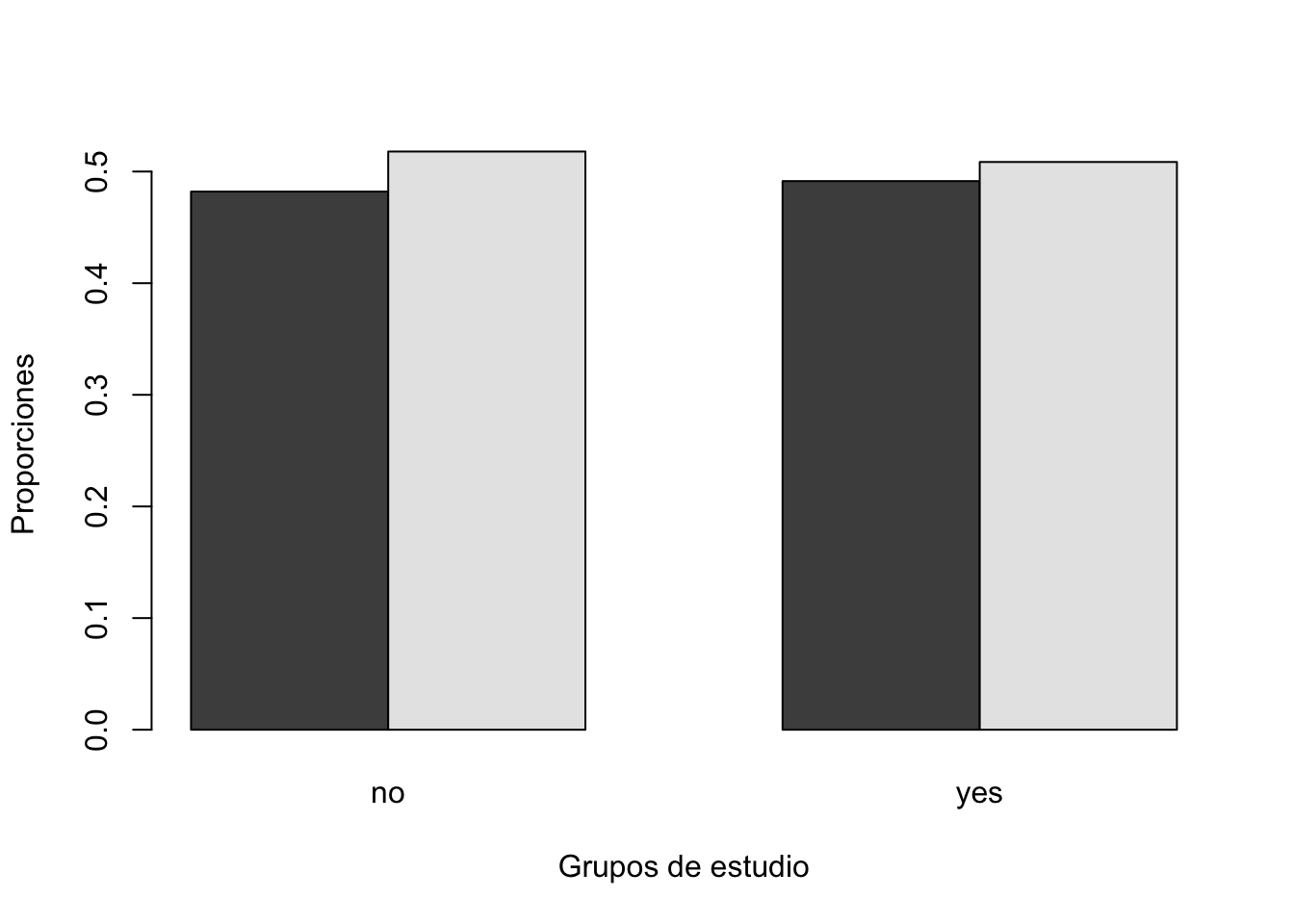
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x no yes
female 76605.72 47064.28
male 81136.28 49847.72
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 21.004, df = 1, p-value = 4.582e-06
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 4.532e-06
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.9479167 0.9788108
sample estimates:
odds ratio
0.9632187 Compar.Cuali(df$gender2, df$morekids)[1] "Tabla de contingencia"
y
x no yes
female 76361 47770
male 81381 49142
[1] "Tabla de contingencia con proporciones"
y
x no yes
female 0.4840879 0.4929214
male 0.5159121 0.5070786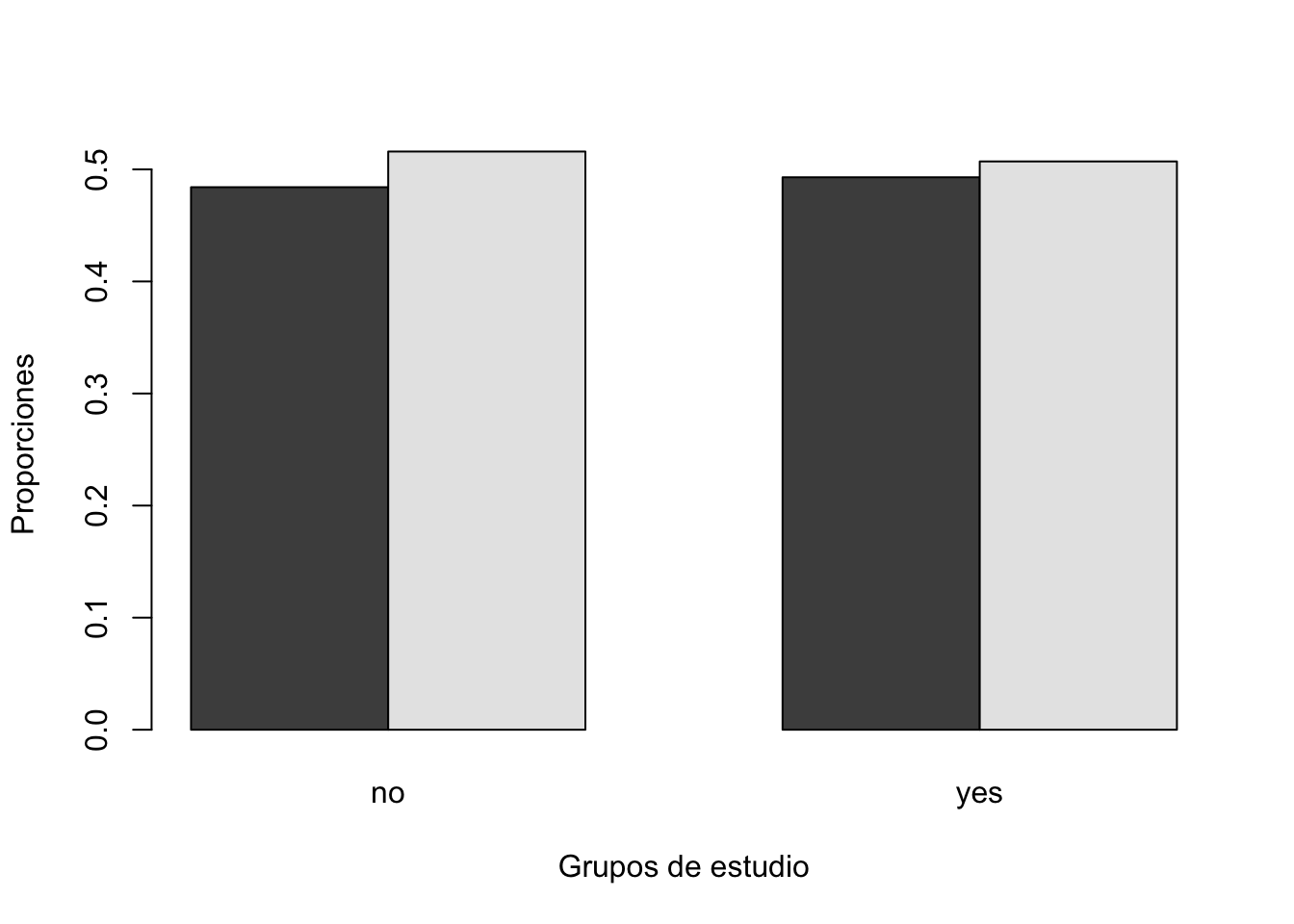
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x no yes
female 76891.28 47239.72
male 80850.72 49672.28
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 18.713, df = 1, p-value = 1.519e-05
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value = 1.507e-05
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.9498882 0.9808675
sample estimates:
odds ratio
0.9652482 Se procede con el resto de las variables
Compar.Cuali(df$afam, df$morekids)[1] "Tabla de contingencia"
y
x no yes
no 150611 90887
yes 7131 6025
[1] "Tabla de contingencia con proporciones"
y
x no yes
no 0.95479327 0.93783020
yes 0.04520673 0.06216980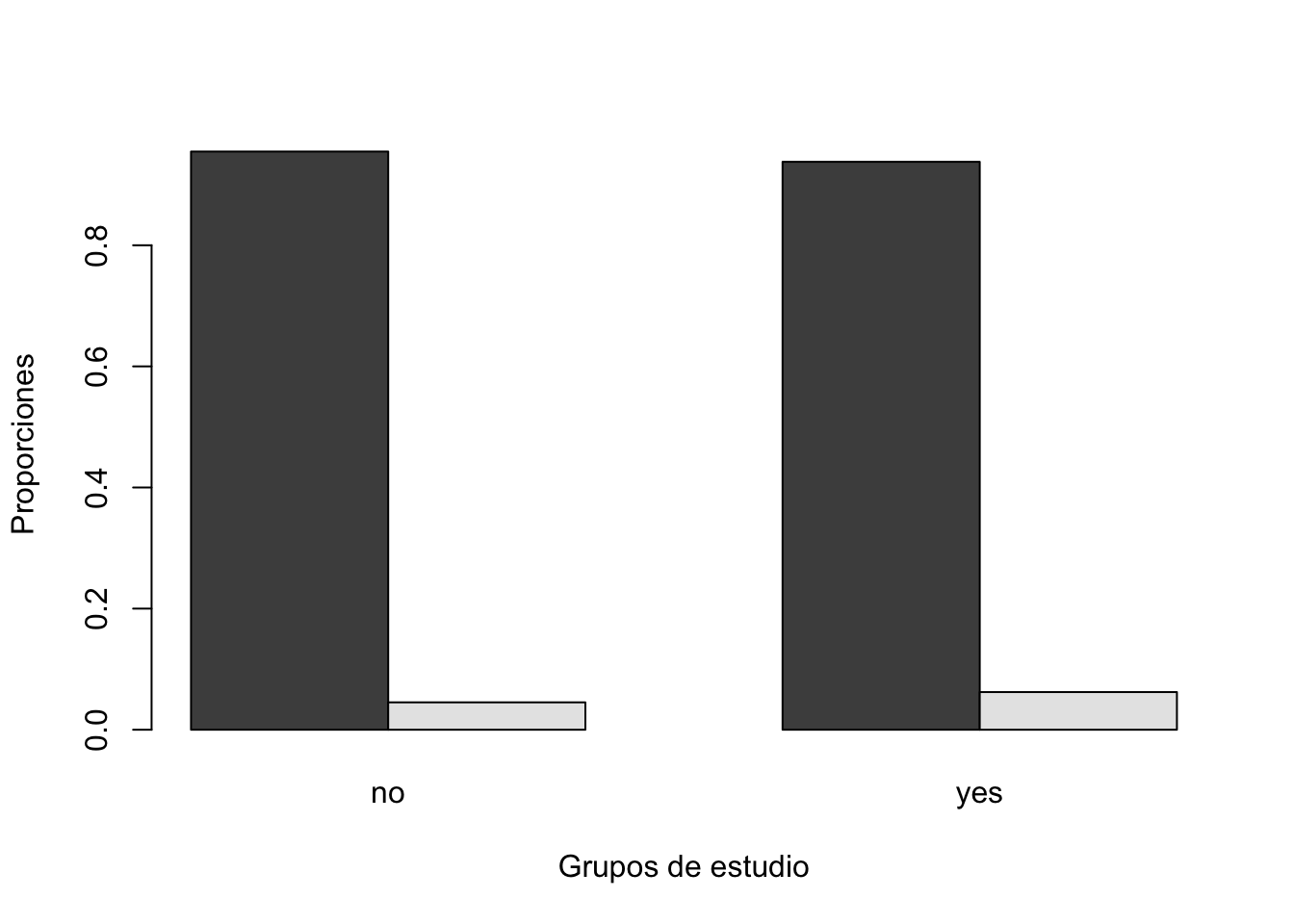
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x no yes
no 149592.693 91905.307
yes 8149.307 5006.693
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 352.23, df = 1, p-value < 2.2e-16
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value < 2.2e-16
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
1.351363 1.450640
sample estimates:
odds ratio
1.400066 Compar.Cuali(df$hispanic, df$morekids)[1] "Tabla de contingencia"
y
x no yes
no 148554 87203
yes 9188 9709
[1] "Tabla de contingencia con proporciones"
y
x no yes
no 0.94175299 0.89981633
yes 0.05824701 0.10018367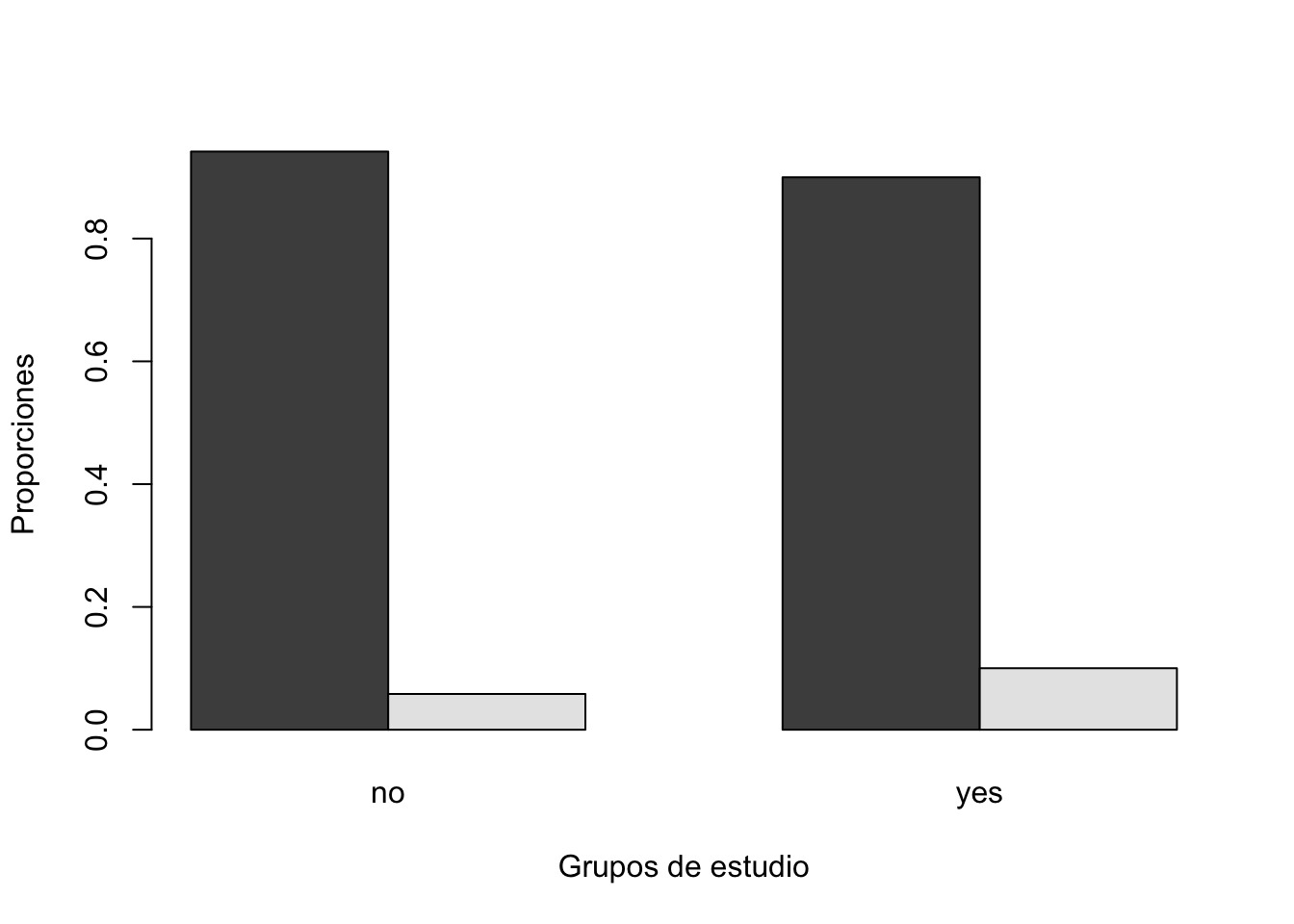
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x no yes
no 146036.51 89720.493
yes 11705.49 7191.507
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 1536.1, df = 1, p-value < 2.2e-16
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value < 2.2e-16
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
1.747233 1.854629
sample estimates:
odds ratio
1.800196 Compar.Cuali(df$other, df$morekids)[1] "Tabla de contingencia"
y
x no yes
no 150037 90269
yes 7705 6643
[1] "Tabla de contingencia con proporciones"
y
x no yes
no 0.95115442 0.93145328
yes 0.04884558 0.06854672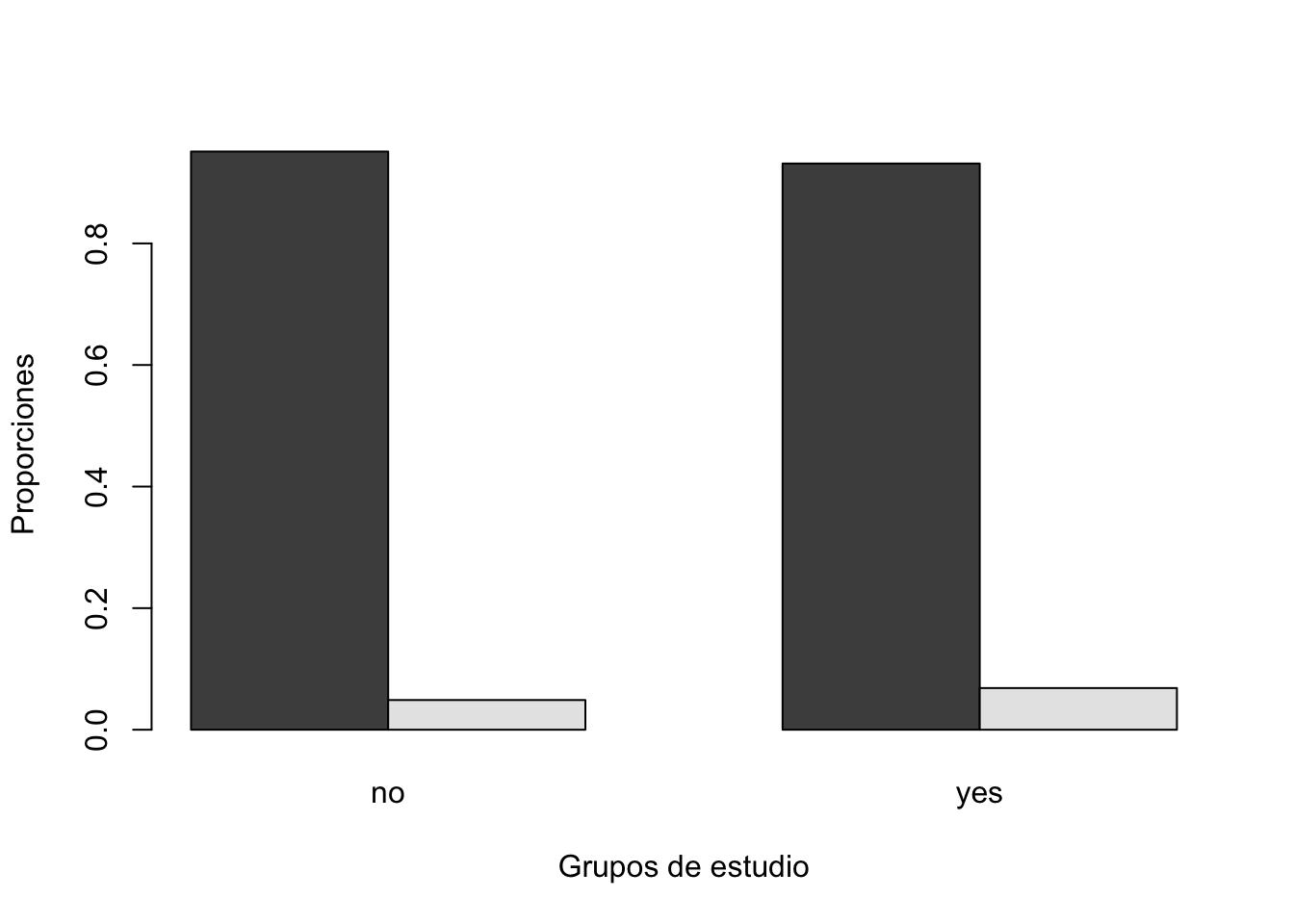
[1] "Pureba de chi2"
[1] "Valores esperados"
y
x no yes
no 148854.324 91451.676
yes 8887.676 5460.324
Pearson's Chi-squared test with Yates' continuity correction
data: tab
X-squared = 437.86, df = 1, p-value < 2.2e-16
[1] "Prueba exacta de Fisher"
Fisher's Exact Test for Count Data
data: tab
p-value < 2.2e-16
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
1.385122 1.482550
sample estimates:
odds ratio
1.432969