library(MASS)
data("Pima.tr")
data("birthwt")8 Laboratorio 6. Visualización de datos
Este laboratorio de R tiene como objetivo que el alumno comprenda los aspectos fundamentales para la visualización de datos. La visualización de datos es un aspecto fundamental en el análisis estadístico ya que permite la compresión rápida de la información, facilita el análisis y la comunicación de resultados. Además, es más fácil entender los datos gráficamente que entenderlos mediante tablas. En este capítulo se revisarán los aspectos básicos para la construcción de gráficas en R, para ello utilizaremos el paquete base que viene incluido en R pero también utilizaremos la librería ggplot que es el estándar actual para la construcción de gráficos en R.
Los gráficos son gratis en R.
Los objetivos de aprendizaje del capítulo son:
- Realizar gráficos mediante el paquete
BasedeR - Comprender y utilizar los argumentos básicos de las funciones que permiten crear gráficos en
R. - Comprender la sintaxis utilizada en
ggplot - Construir gráficos básicos mediante
ggplot
8.1 Gráficos utilizando el paquete base de R
Para la creación de gráficas necesitaremos importar algunas bases de datos que ya hemos utilizado anteriormente:
- Pima.tr
- birthwt
- Vacunacion
El siguiente código puede ser utilizado para importar los primeros dos DataFrame
Asegúrese de que puede ver las bases de datos en su ambiente de trabajo. Para la importación de la base de datos de vacunación utilice el menú de Rstudio conforme a lo revisado en Sección 6.4.1
8.1.1 Histogramas
Uno de los gráficos más utilizados para visualizar variables cuantitativas son los histogramas. Los histogramas permiten tener la siguiente información:
- Distribución de los datos
- Dispersión de la variable cuantitativa
- Ayudan a identificar donde están concentrados los datos
- Moda
- Valores atípicos
Los histogramas se crean con la función hist(). Vamos a comenzar a construir gráficos, del más sencillo a los más complejo. Es importante que identifique los argumentos que se van añadiendo ya que estos son comunes para los gráficos construidos desde el paquete base.
Vamos a construir un histograma básico. Para ello, vamos a utilizar la variable age del Dataframe Pima.tr de la librería MASS.
# Importar base de datos
library(MASS)
data("Pima.tr")# Construcción del histograma
hist(Pima.tr$age)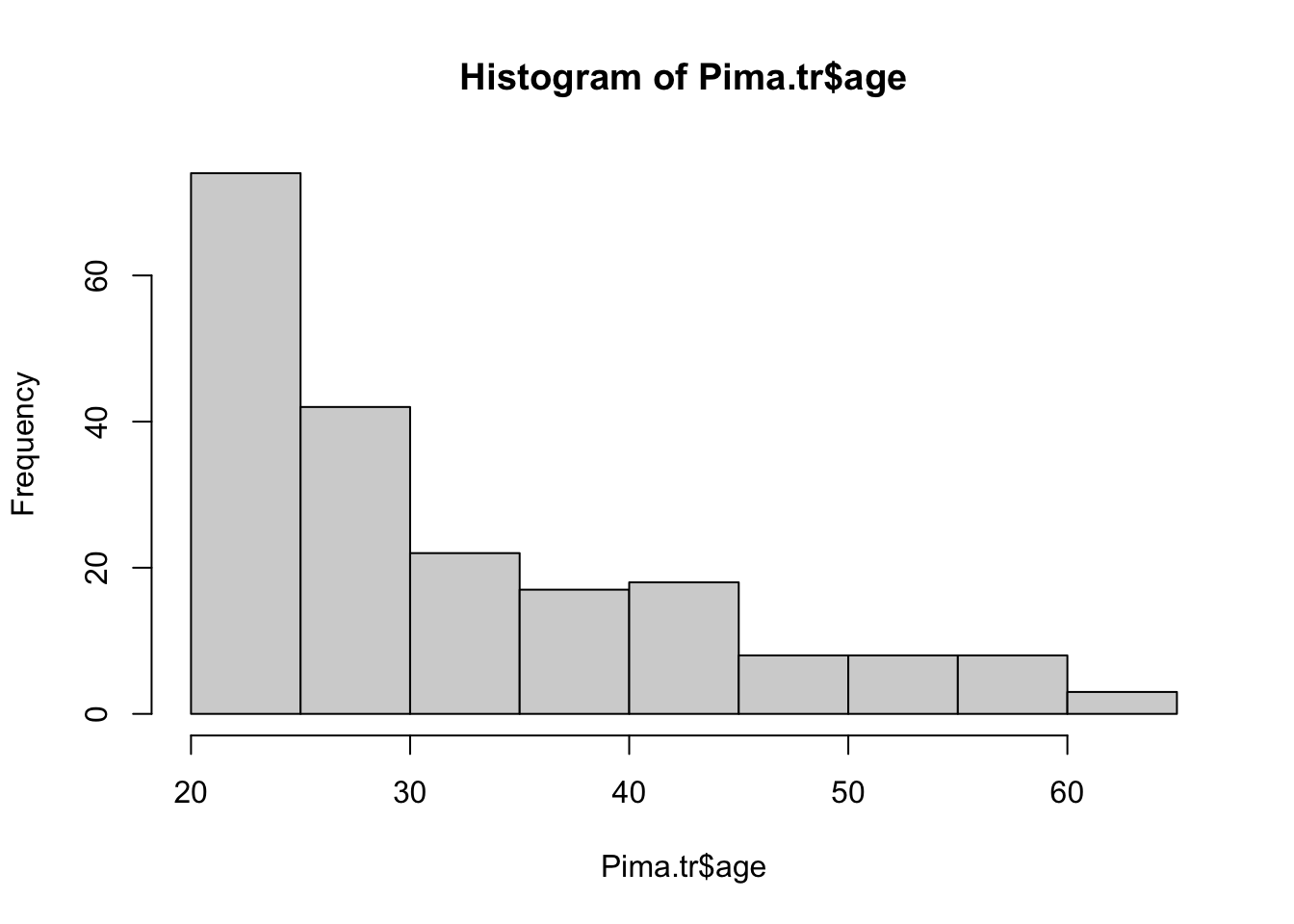
Una vez construido nuestro histograma, vamos a comenzar a modificarlo.
Con el freq = FALSE podemos obtener las densidades (valores integrados)
hist(Pima.tr$age, freq = F)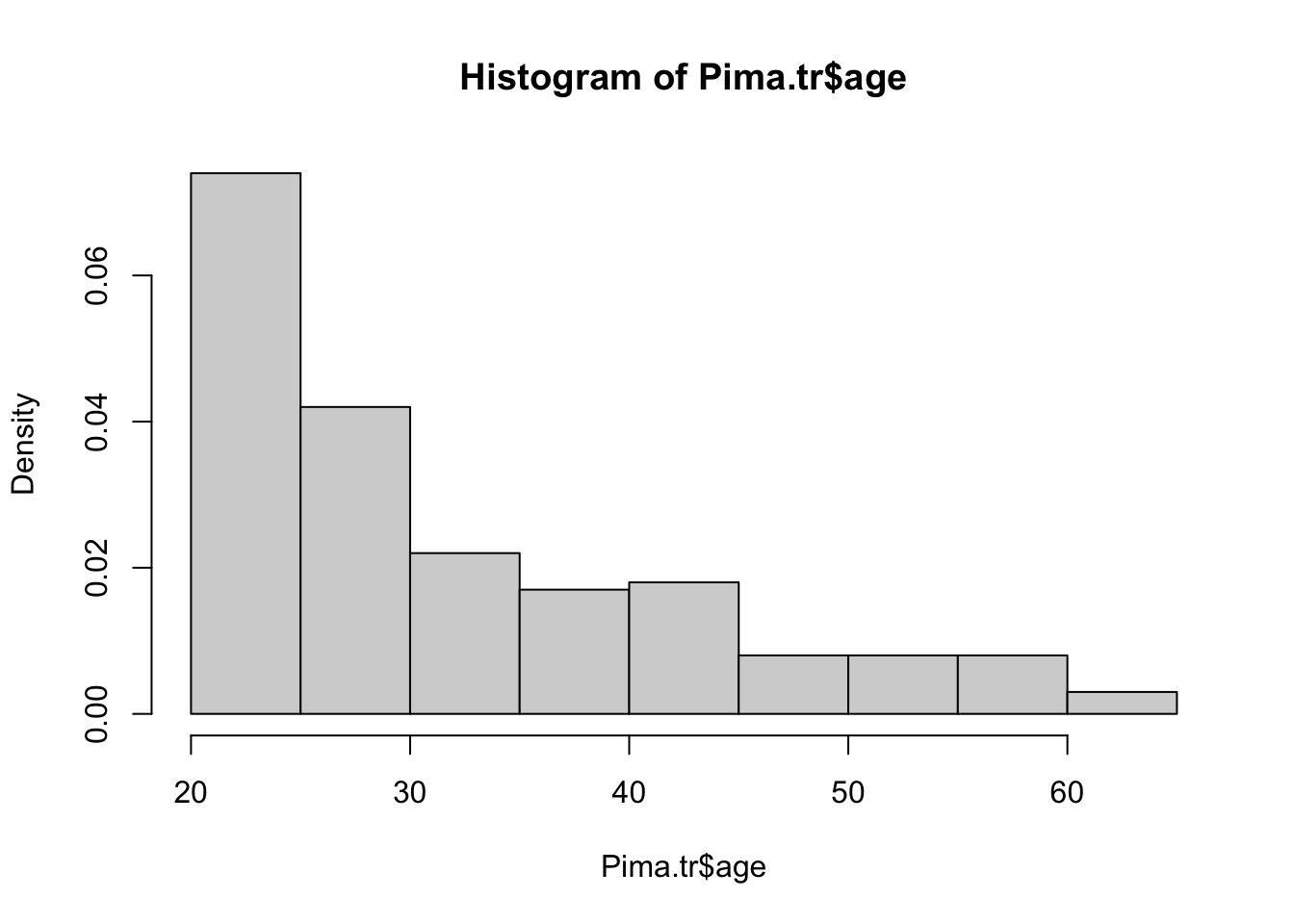
El argumento breaks nos permite cambiar los intervalos de clase por el número que establezcamos.
hist(Pima.tr$age, breaks = 20) #Histograma con 20 intervalos de clase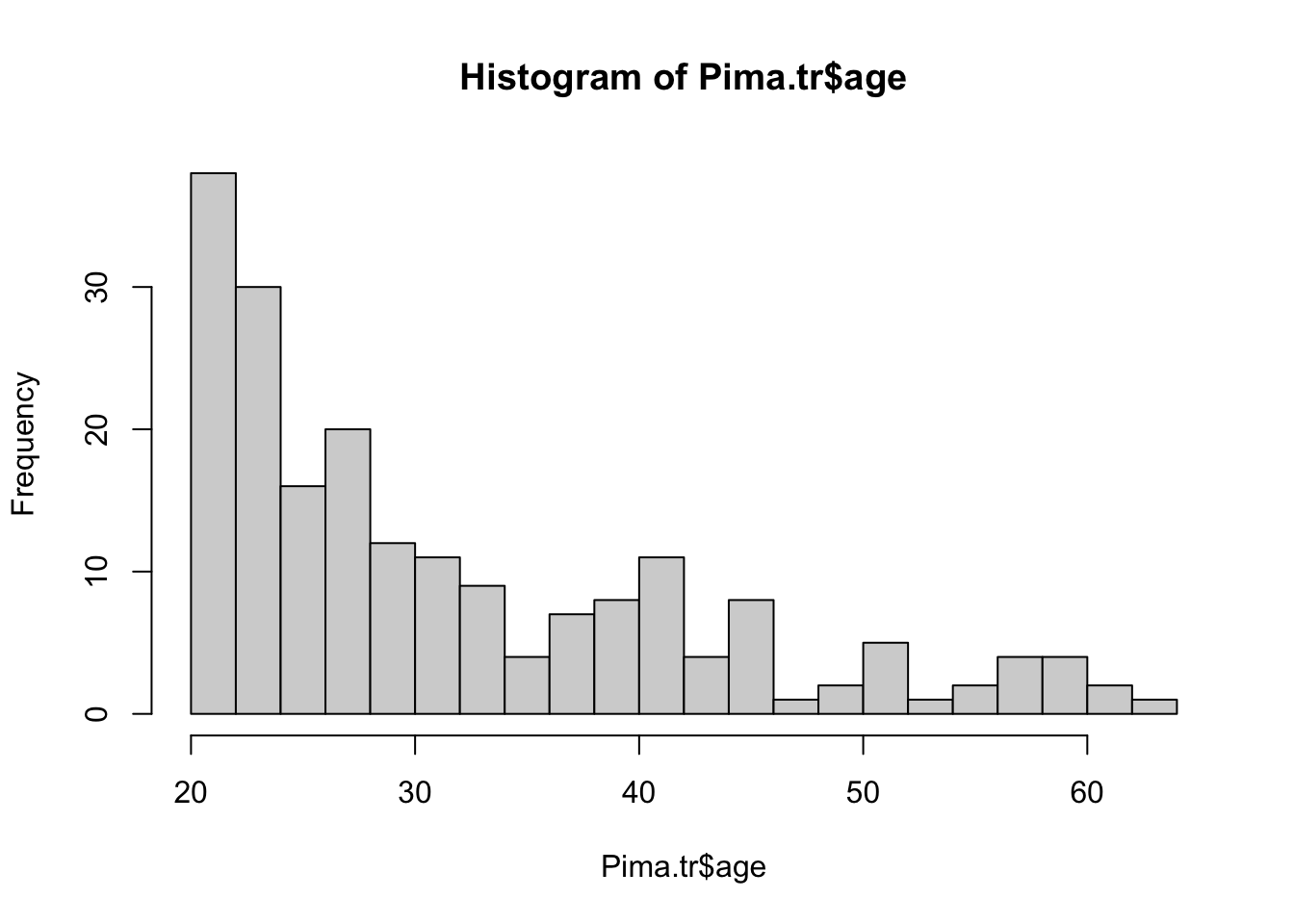
Podemos cambiar el título, para ellos utilizamos el argumento main y entre comillas podemos declarar el título que nos convenga.
hist(Pima.tr$age, breaks = 20, main = "Mi primer histograma :)")
También, con los argumentos ylab y xlab podemos cambiar los nombres de los ejes “y” y “x” respectivamente.
hist(Pima.tr$age, breaks = 20, main = "Mi primer histograma",
ylab = "Frecuencias", xlab= "Intervalos de clase para la edad")
Se puede cambiar el color de las barras, por ejemplo, podemos cambiarla por el color “cyan4” utilizando el argumento col
hist(Pima.tr$age, breaks = 20, main = "Mi primer histograma",
ylab = "Frecuencias", xlab= "Intervalos de clase para la edad",
col = "cyan4")
Note como cuando R reconoce el color y el texto cambia a ese color. Este es buen indicativo que de que R reconoció el color. En R los colores pueden ser leídos mediante nombres (como en el código anterior), mediante número o mediante el código de colores de RGB. Por ejemplo, con el siguiente código vamos a modificar el color “cyan4” y vamos a utilizar el color “#1C464D” que corresponde al color Midnight green. Los códigos de RBG son comunes para todos los programas, por lo que puede llevarlos y traerlos desde diferentes softwares.
hist(Pima.tr$age, breaks = 20, main = "Mi primer histograma",
ylab = "Frecuencias", xlab= "Intervalos de clase para la edad",
col = "#1C464D")
La universidad de Columbia desarrolló un manual que contiene algunos de los colores que pueden ser utilizados en R.
8.1.2 Barplot
Los barplots se utilizan para graficar datos categóricos y casi nunca para datos numéricos. No es buena idea representar datos numéricos con barras, a menos de que quiera ocultar información. Para construir un gráfico de barras, aplicamos la función barplot(). Tenga en cuenta que primero aplicamos la función table() para contar las entradas de cada categoría en particular en la columna de datos de interés. Por ejemplo, podemos utilizar la función barplot() para representar cuantas pacientes tienen diabetes y cuantas pacientes no lo tienen, para ello utilizamos el siguiente código:
# Necesitamos declarar y crear una tabla con los conteos
tab <- table(Pima.tr$type) ## Creamos un objeto llamado tab
# Ahora ya podemos graficar nuestro barplot
barplot(tab)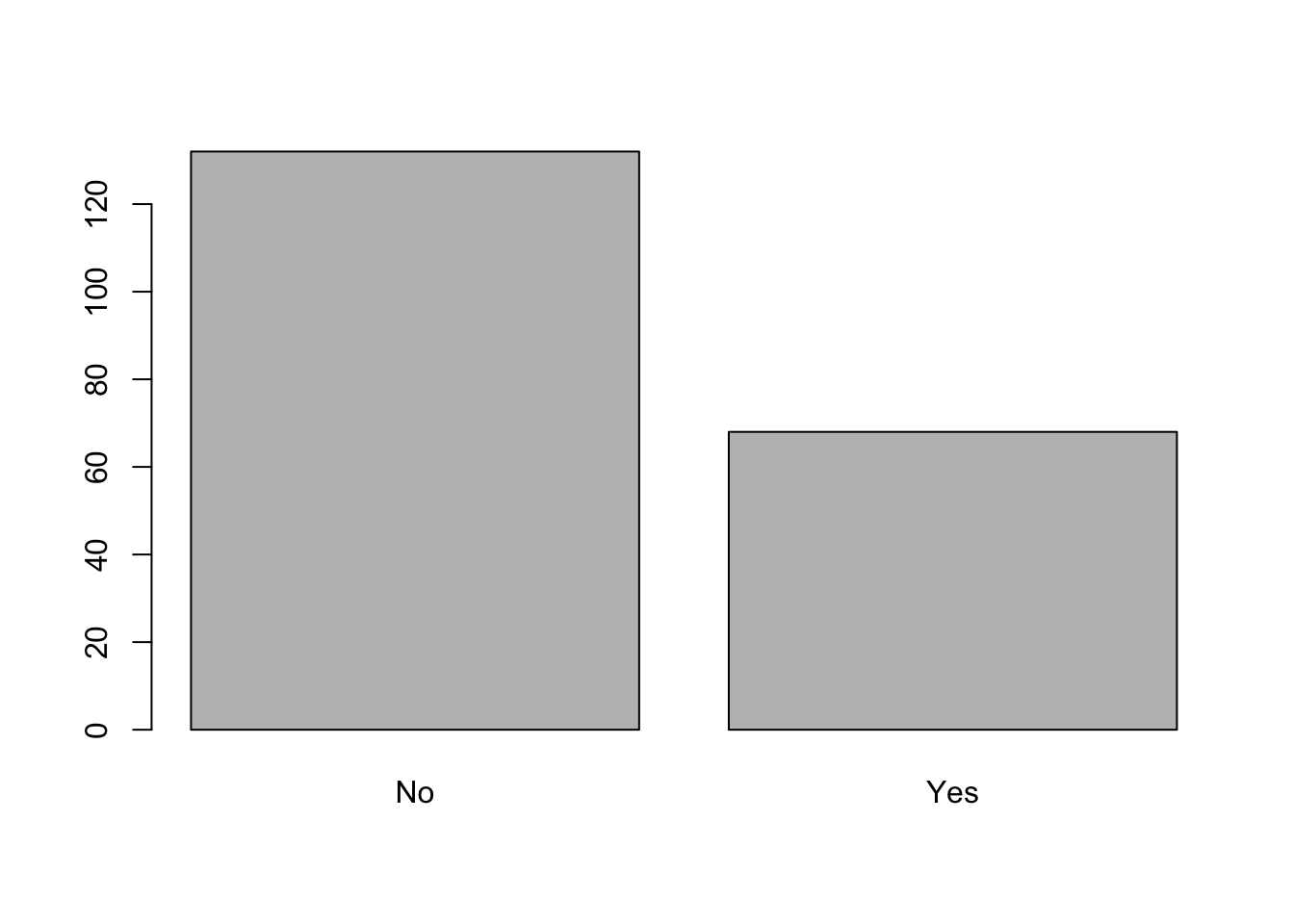
También podemos modificar el código para utilizar pipes
table(Pima.tr$type)|>
barplot(main="Gráfico de barras utilizando pipes")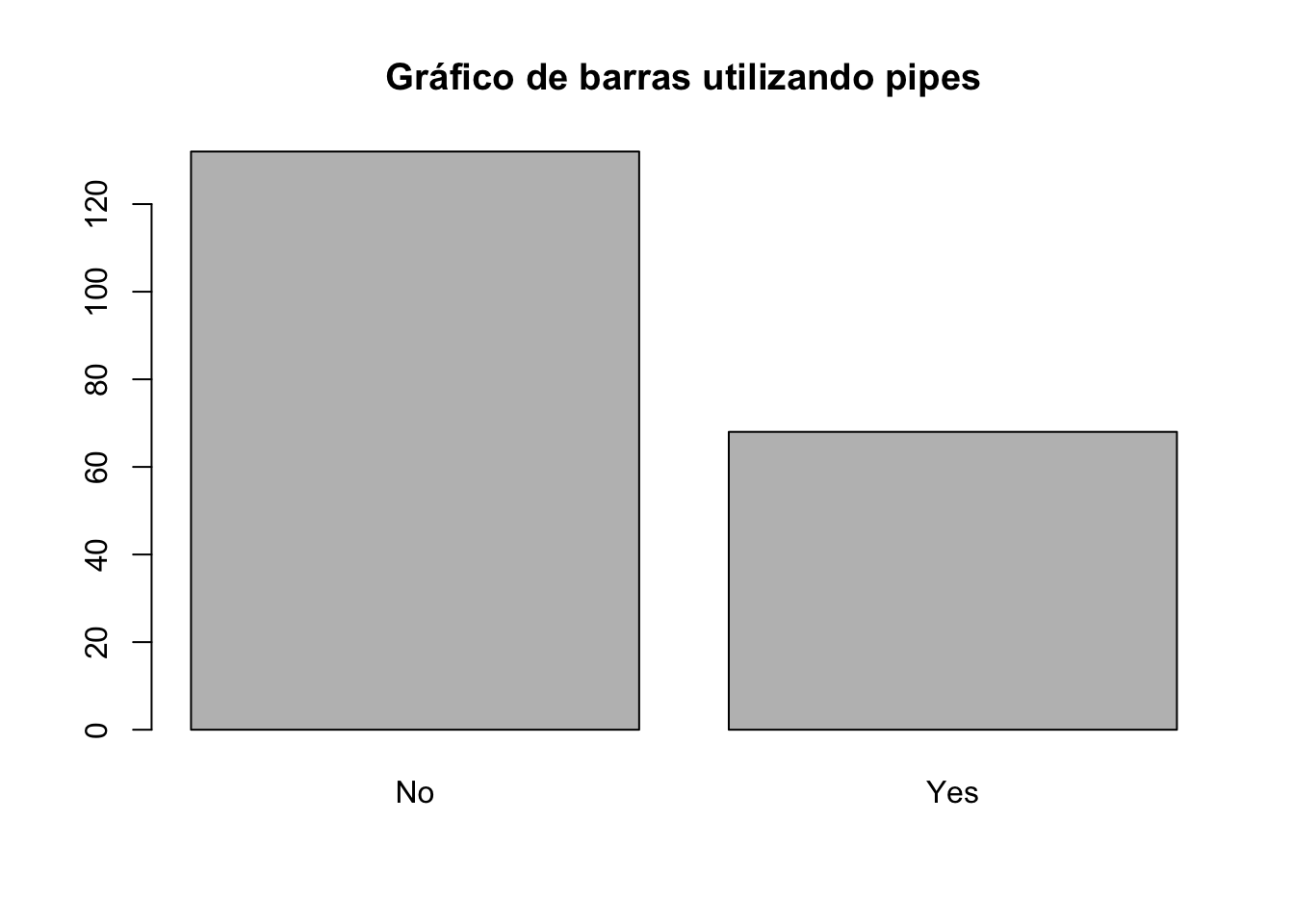
Al igual que con la función hist() podemos modificar estéticamente la gráfica.
barplot(tab, main = "Pacientes con y sin DM", xlab="Prescencia de DM", ylab="Conteos", col= c("darkslategray3", "goldenrod3"))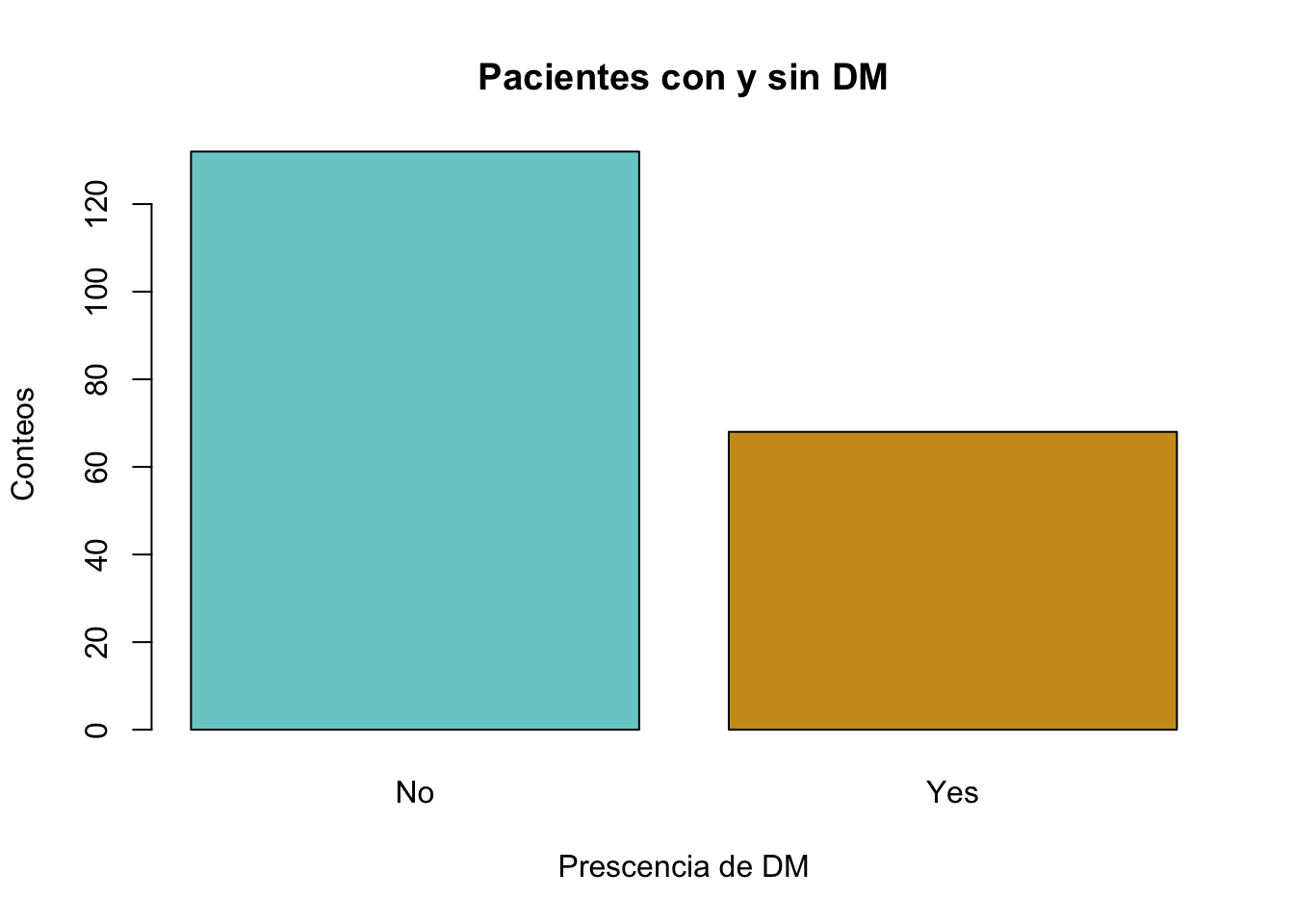
Note como los colores fueron indicados utilizando la función c.
Podemos aumentar el número de clasificaciones que pueden ser representadas en el barplot si aumentamos la complejidad de nuestra tabla. Por ejemplo, la siguiente tabla muestra el número de embarazos agrupado entre las pacientes con y sin DM.
tab1 <- table(Pima.tr$type, Pima.tr$npreg)
# Si no cambia el nombre el objeto se sobre escribirábarplot(tab1)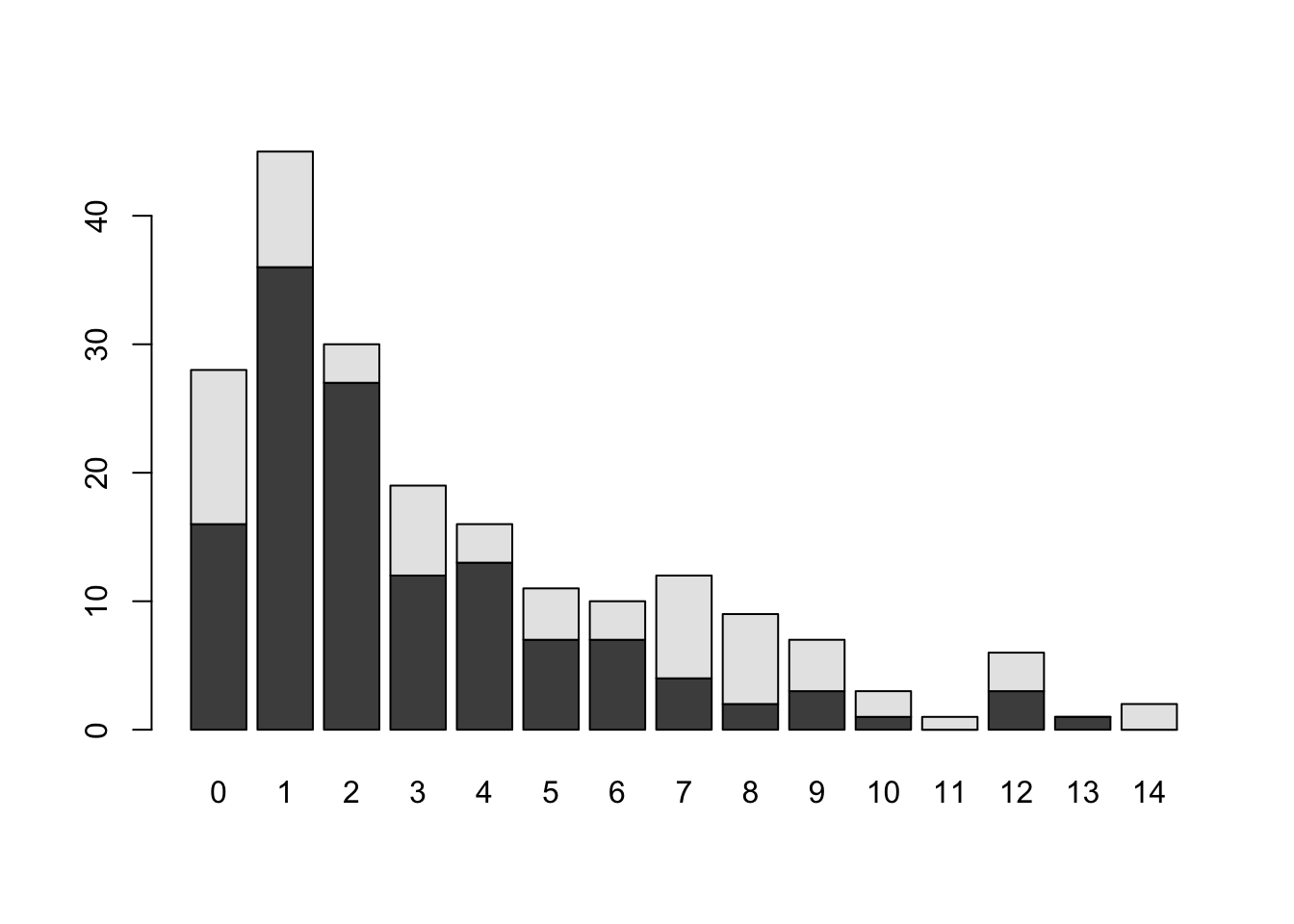
El resultado es poco entendible y necesita ser trabajado para producir una gráfica más amigable. Vamos a agregar legendas para los colores.
barplot(tab1, legend=rownames(tab1))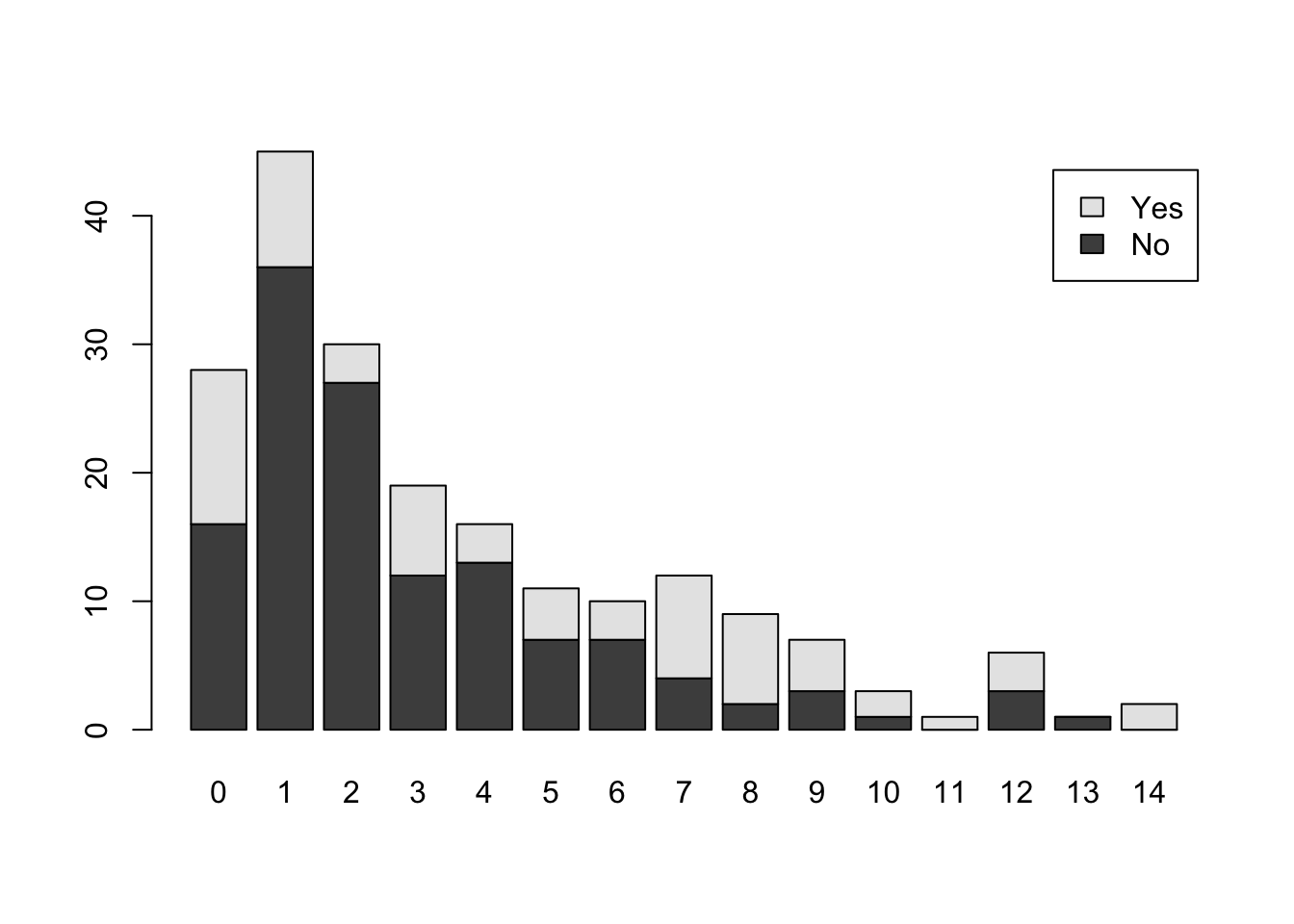
Podemos agregar rótulos en los ejes
barplot(tab1, legend=rownames(tab1), xlab="Número de embarazos", ylab="Conteos")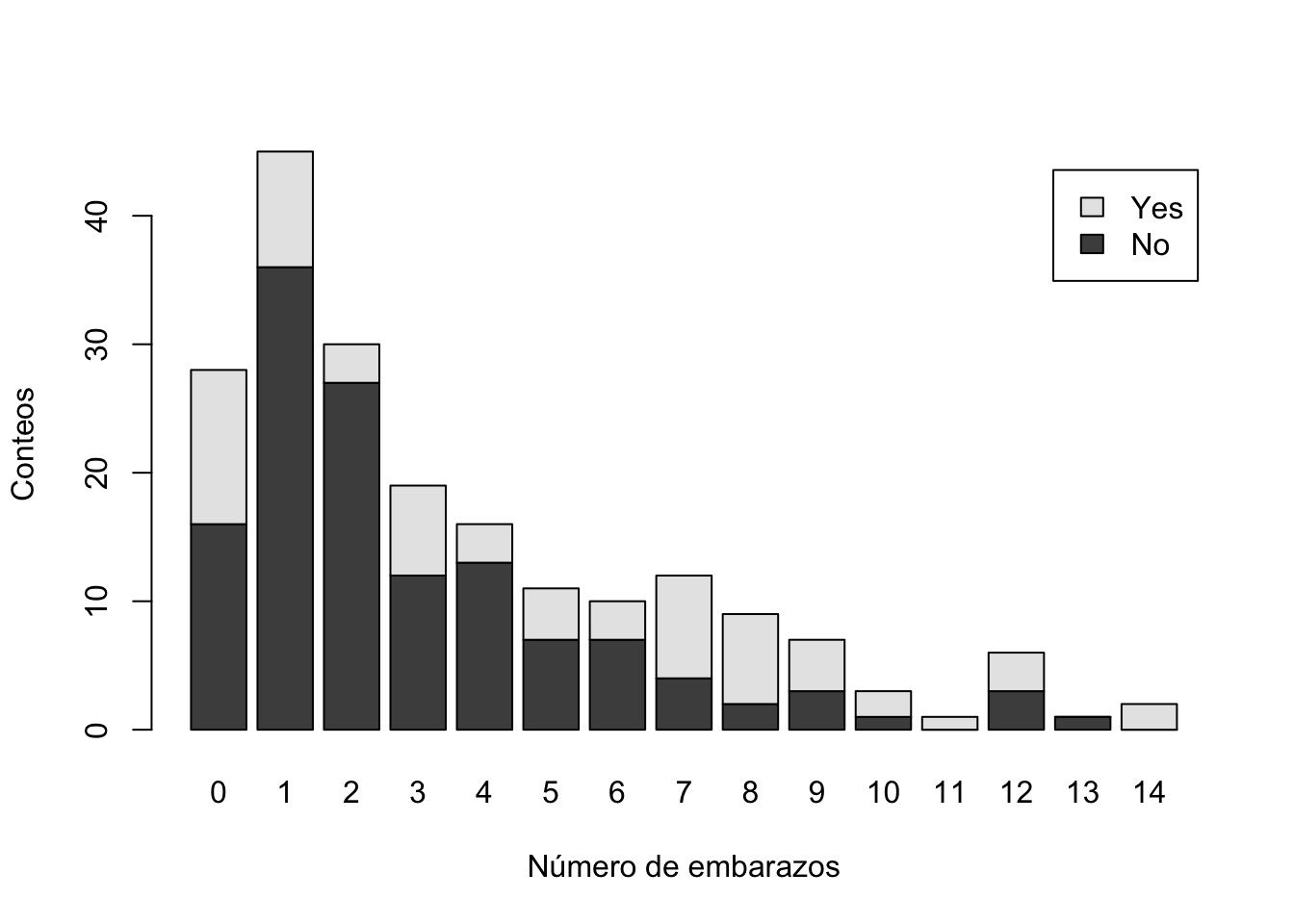
Podemos poner las barras a un lado de la otra
barplot(tab1, legend=rownames(tab1), xlab="Número de embarazos",
ylab="Conteos", beside = T)
barplot(tab1, legend=rownames(tab1), xlab="Número de embarazos",
ylab="Conteos", beside = T)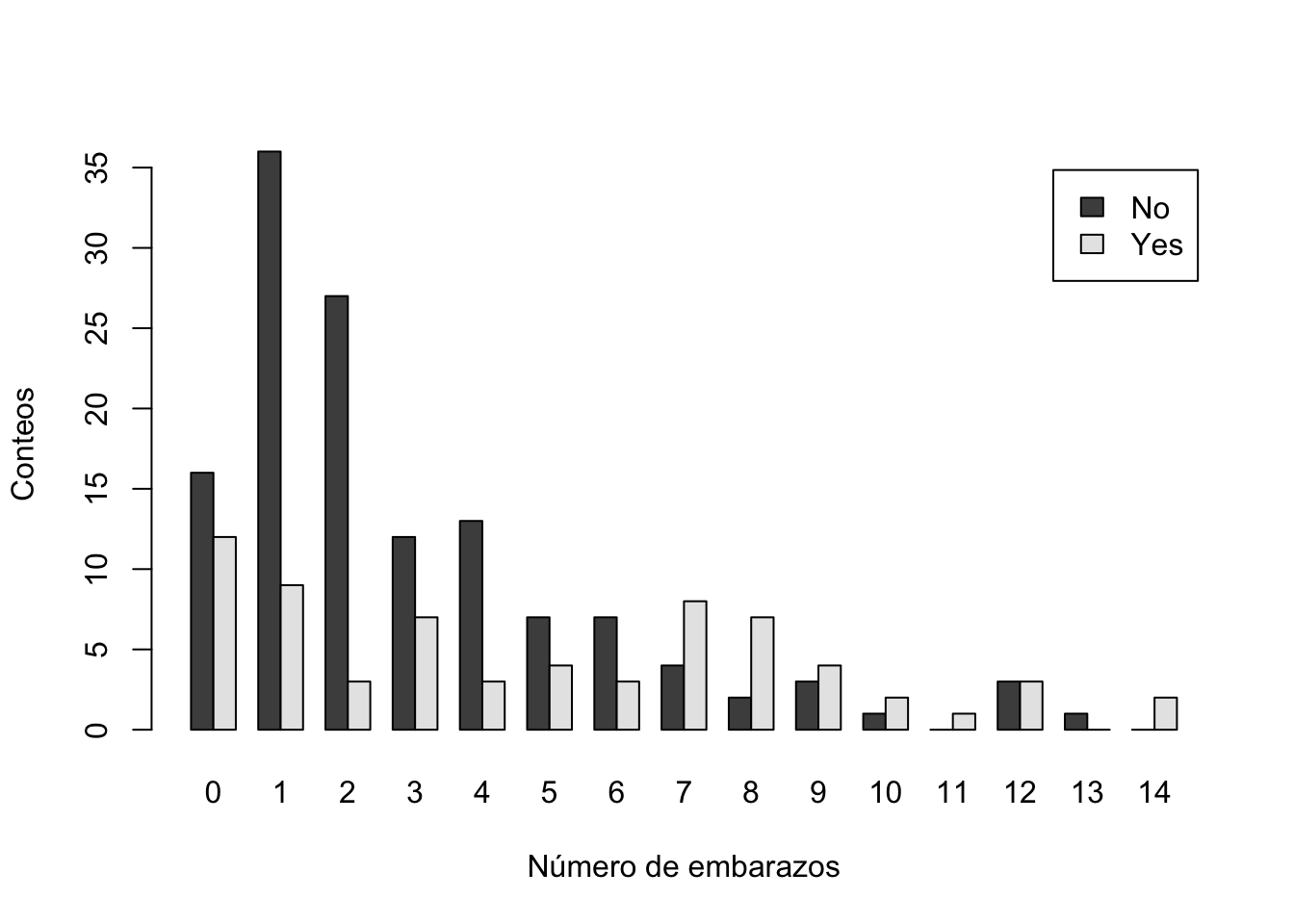
Si utiliza pipes su código puede ser:
table(Pima.tr$type, Pima.tr$npreg)|>
barplot(legend.text = T, beside = T,
col= c("darkslategray3", "goldenrod3"),
main = "Embarazos entre las mujeres \n con y sin diabetes", sub = "Este es un subtitulo",
ylab = "Número de pacientes",
xlab = "Número de embarazos")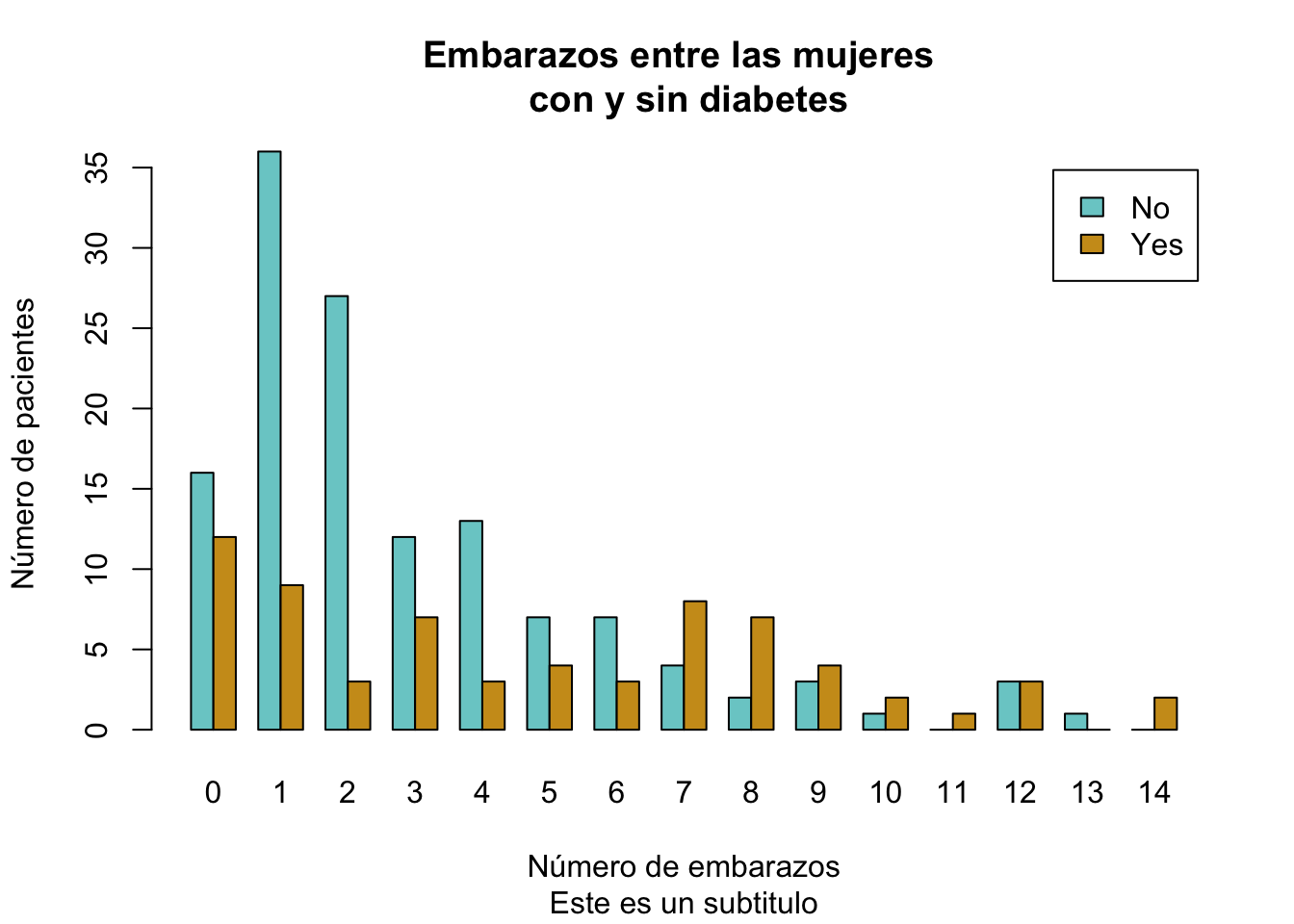
Note como agregamos nuevos argumentos.
Vamos a agregar algunos colores desde nuestras propias paletas. Primero debemos llamar a la librearía grDevices.
library(grDevices)Tener muchos colores no tendría sentido en la comparación del número de embarazos entre las pacientes con y sin diabetes. Por lo tanto creamos una nueva tabla únicamente con el número de embarazos.
tab2 <- table(Pima.tr$npreg)Posteriormente podemos crear nuestras propias paletas de 14 colores (los que necesitamos para cada número de embarazo)
n <- 15 # Cuantos colores necesito
p1 <- hcl.colors(n, palette = "Dynamic") #Tomamos 15 colores de la paleta dynamic
p2 <- hcl.colors(n, palette = "Earth")
p3 <- hcl.colors(n, palette = "Berlin")
p4 <- hcl.colors(n, palette = "Fall")
p5 <- hcl.colors(n, palette = "Sunset")Ahora podemos probar como queda nuestra gráfica
barplot(tab2, xlab="Número de embarazos",
ylab="Conteos", col=p1)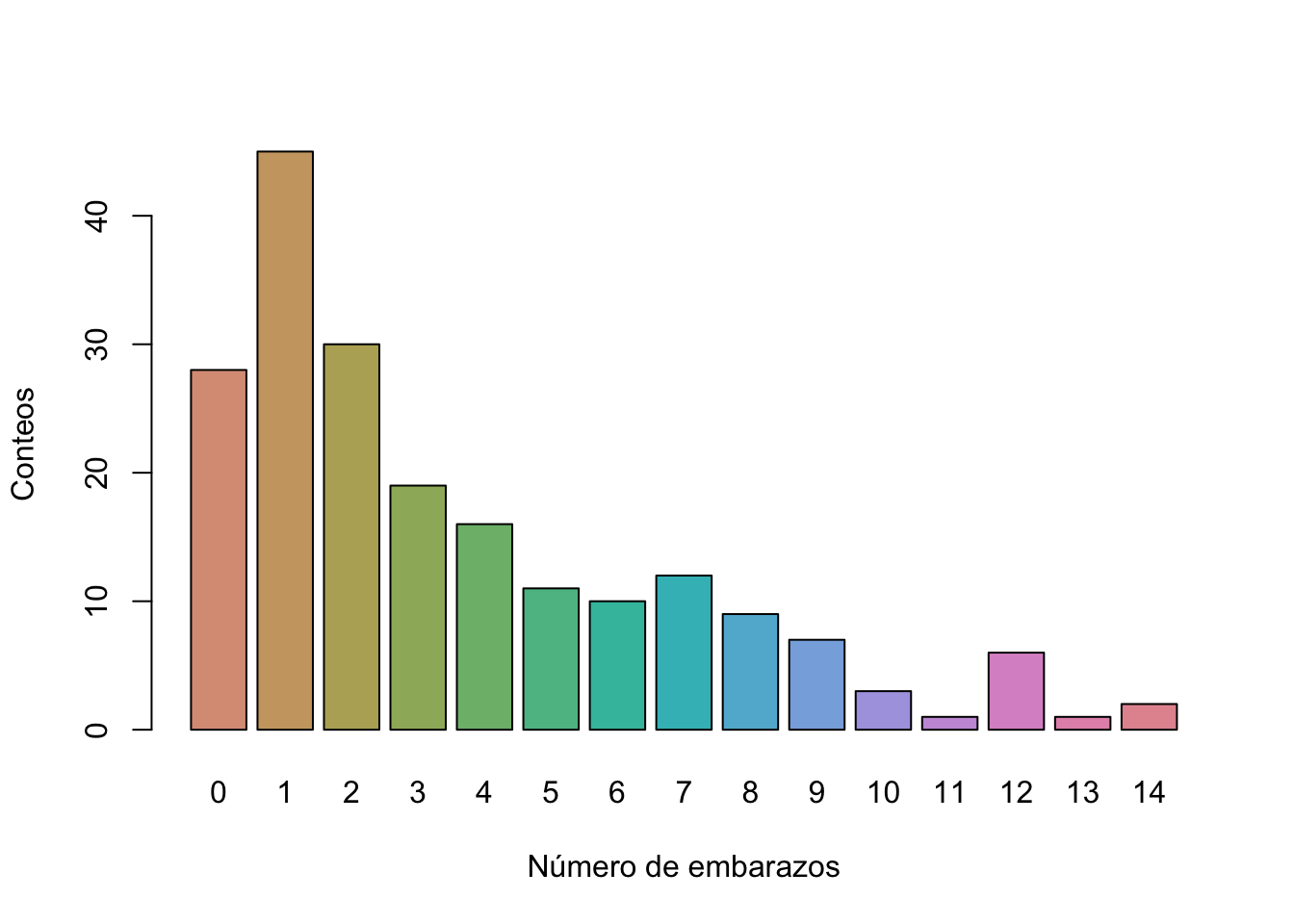
Podemos probar otras paletas
barplot(tab2, xlab="Número de embarazos",
ylab="Conteos", col=p2)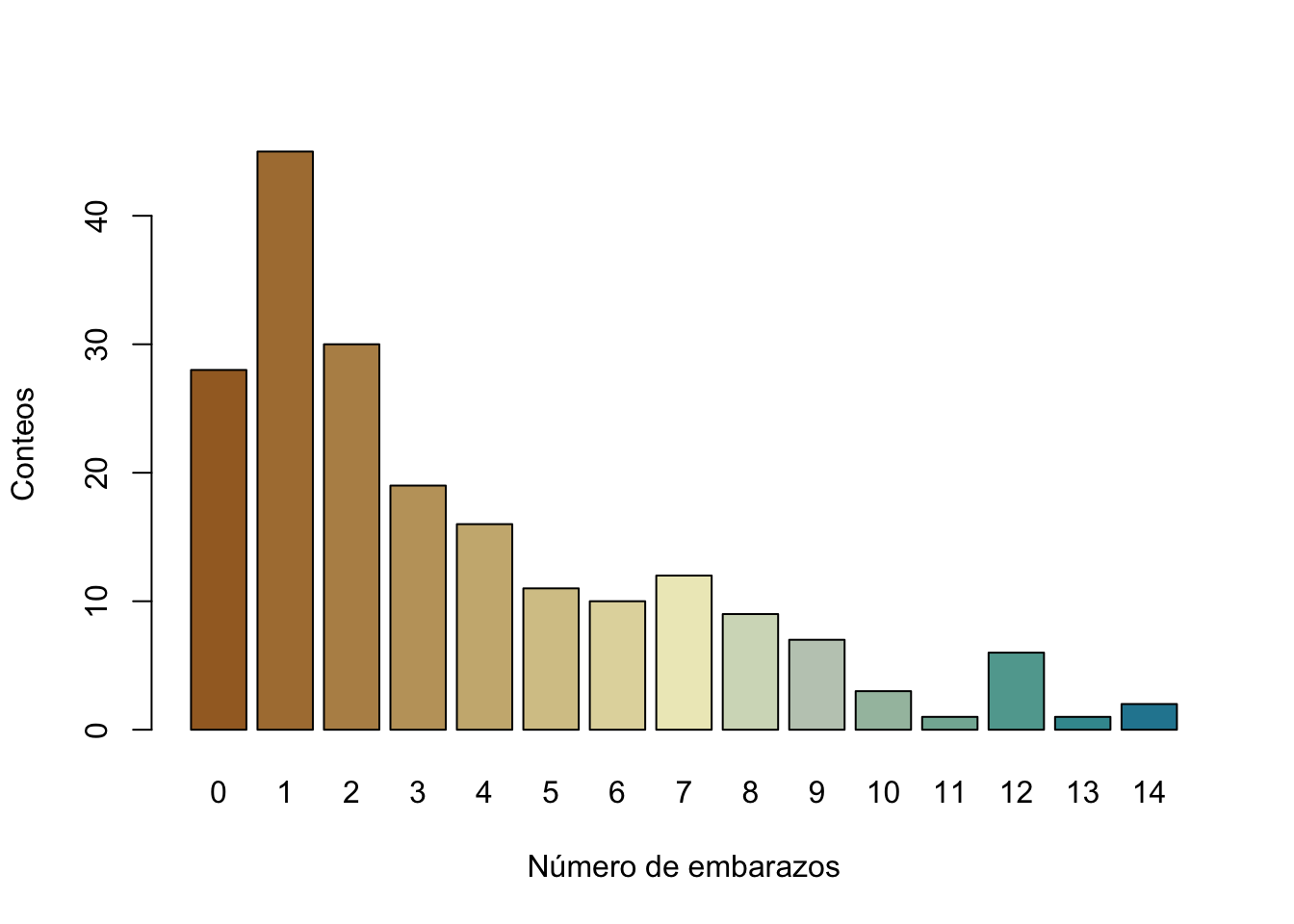
barplot(tab2, xlab="Número de embarazos",
ylab="Conteos", col=p3)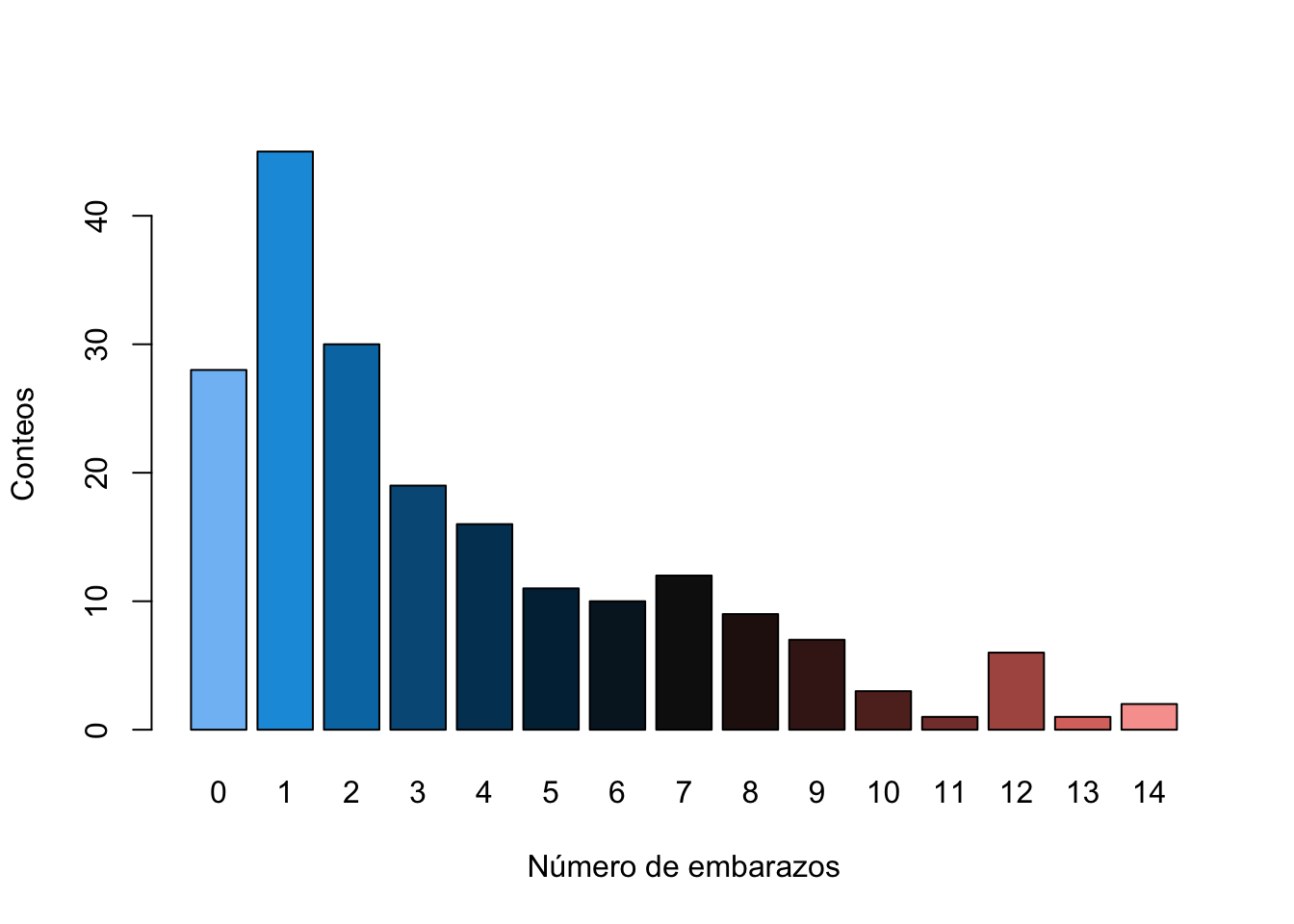
Podemos utilizar la función prop.table en el caso que nuestro interés sea graficar porcentajes en lugar de conteos.
tab3 <- prop.table(tab2)*100
# Para obtener porcentges es necesario muttiplicar por 100barplot(tab3, xlab="Número de embarazos",
ylab="Porcentaje", col=p3)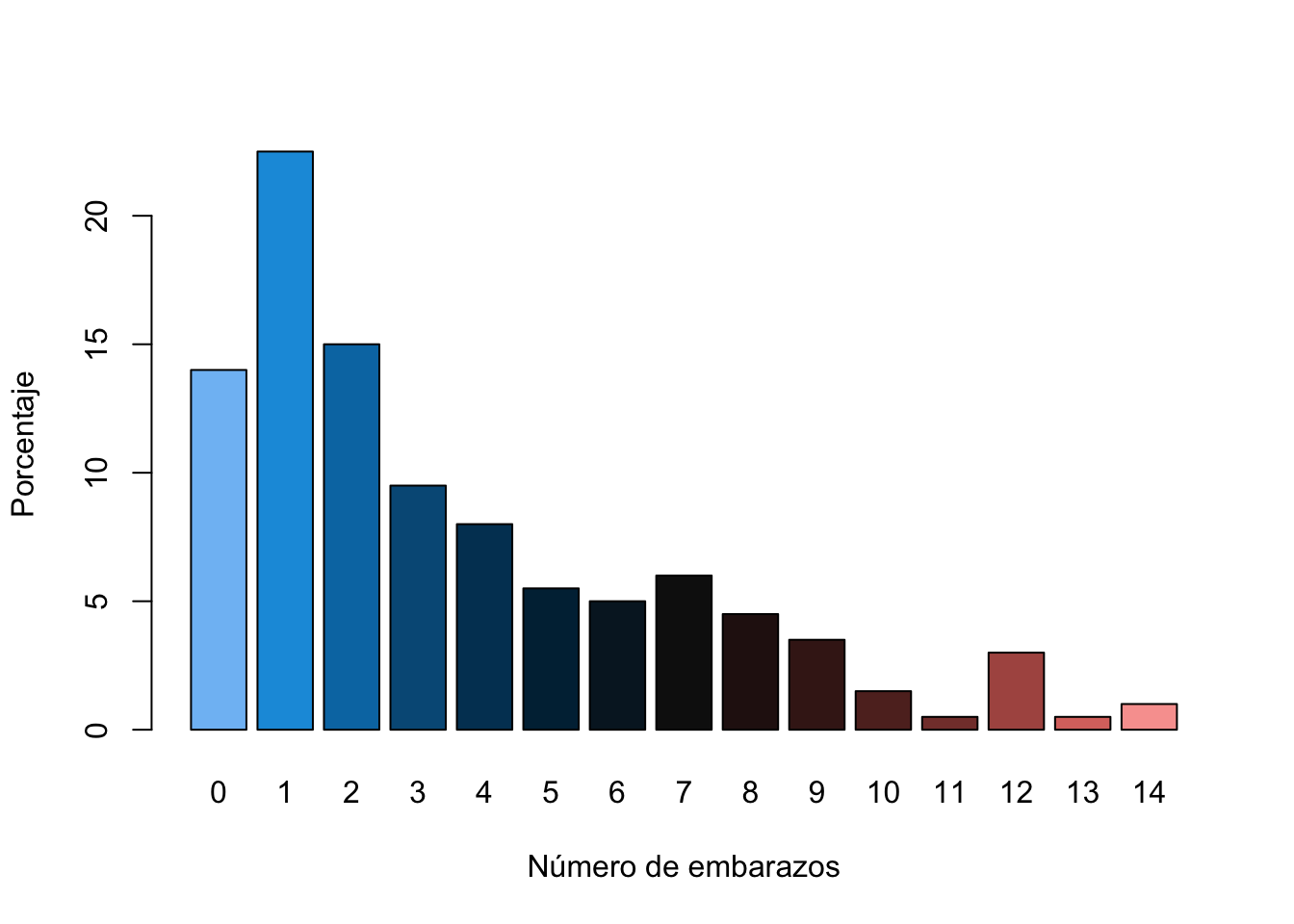
8.1.3 Ejercicios para barplot
Utilizando la base de datos base de datos `vacunación` realice un gráfico de barras donde en el eje de las x se encuentren cada una de las regiones o países y en el eje de la y se encuentre el total de vacunados. Apóyese de la función `tapply`. La figura @fig_7_1 muestra el resultado de este ejercicio mas no el código empleado. 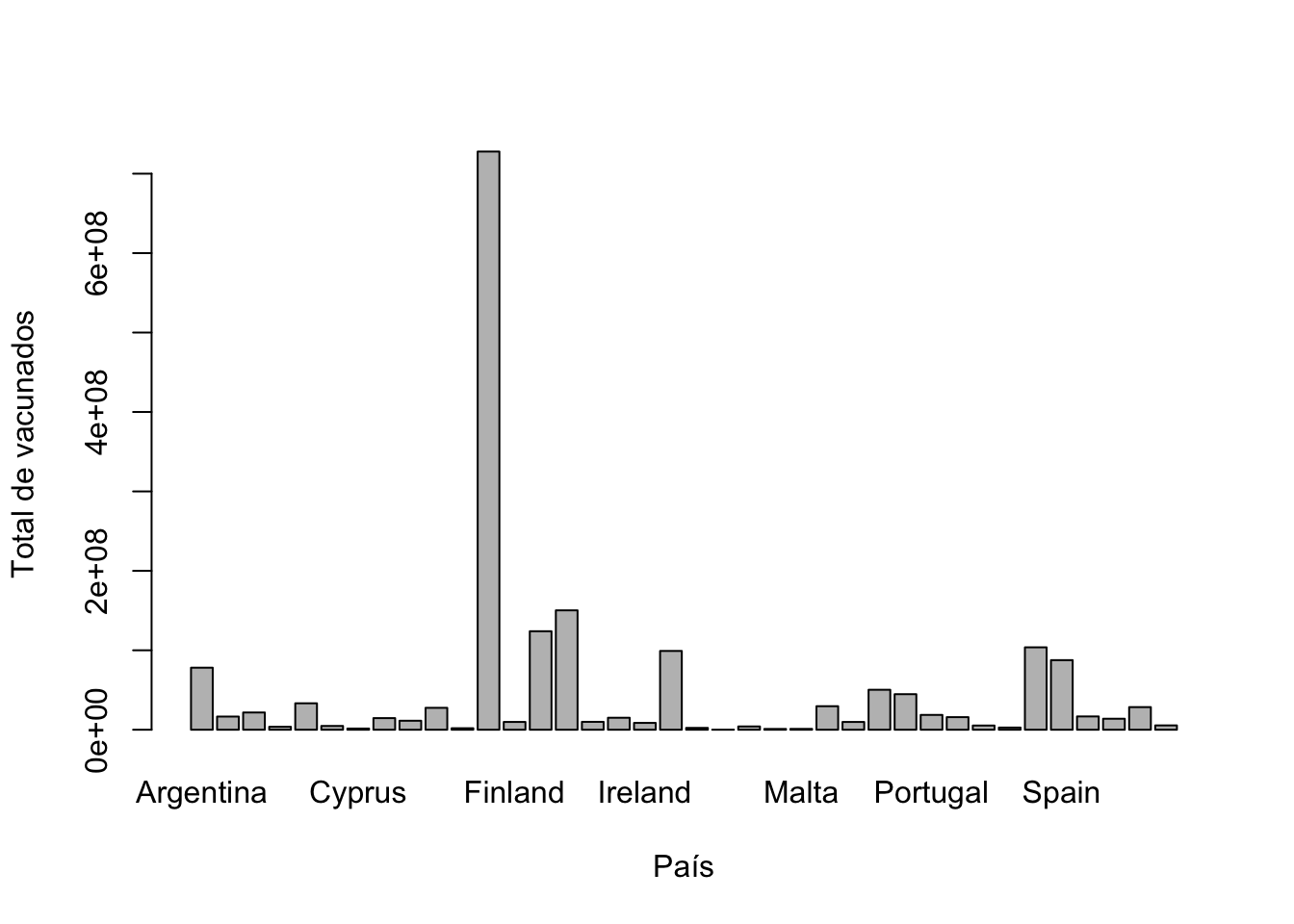
Dado el tamaño de la gráfica no es posible que se muestren todas la etiquetas de los países.
El código para resolver el ejercicio anterior fue:
barplot(tapply(Vacunacion$total_vaccinations, Vacunacion$location, sum), ylab = "Total de vacunados", xlab="País")8.1.4 Boxplot
La (fig_7_2?) muestra un ejemplo clásico de un boxplot. En un boxplot, la caja representa el rango intercuartil, la linea del centro del representa la mediana y los bordes de la caja representan el Q1 y Q3. Los bigotes representan el valor mínimo y máximo teórico, estos valores teóricos son los valores más pequeños y más grandes dentro de 1.5 veces el rango intercuartílico (1.5 * IQR) desde los cuartiles Q1 y Q3, respectivamente. Los puntos representan los outliers. Indican observaciones que son significativamente diferentes del resto de los datos y que se encuentran a 1.5 veces el IQR del Q1 o del Q3.

Para realizar un boxplot de las edades de las pacientes de la base de datos Pima.tr puede utilizar el siguiente código:
boxplot(Pima.tr$age, main="Grafico de caja y bigótes para las edades
de las pacientes de Pima", ylab="Edad (años)", col="#1C464D")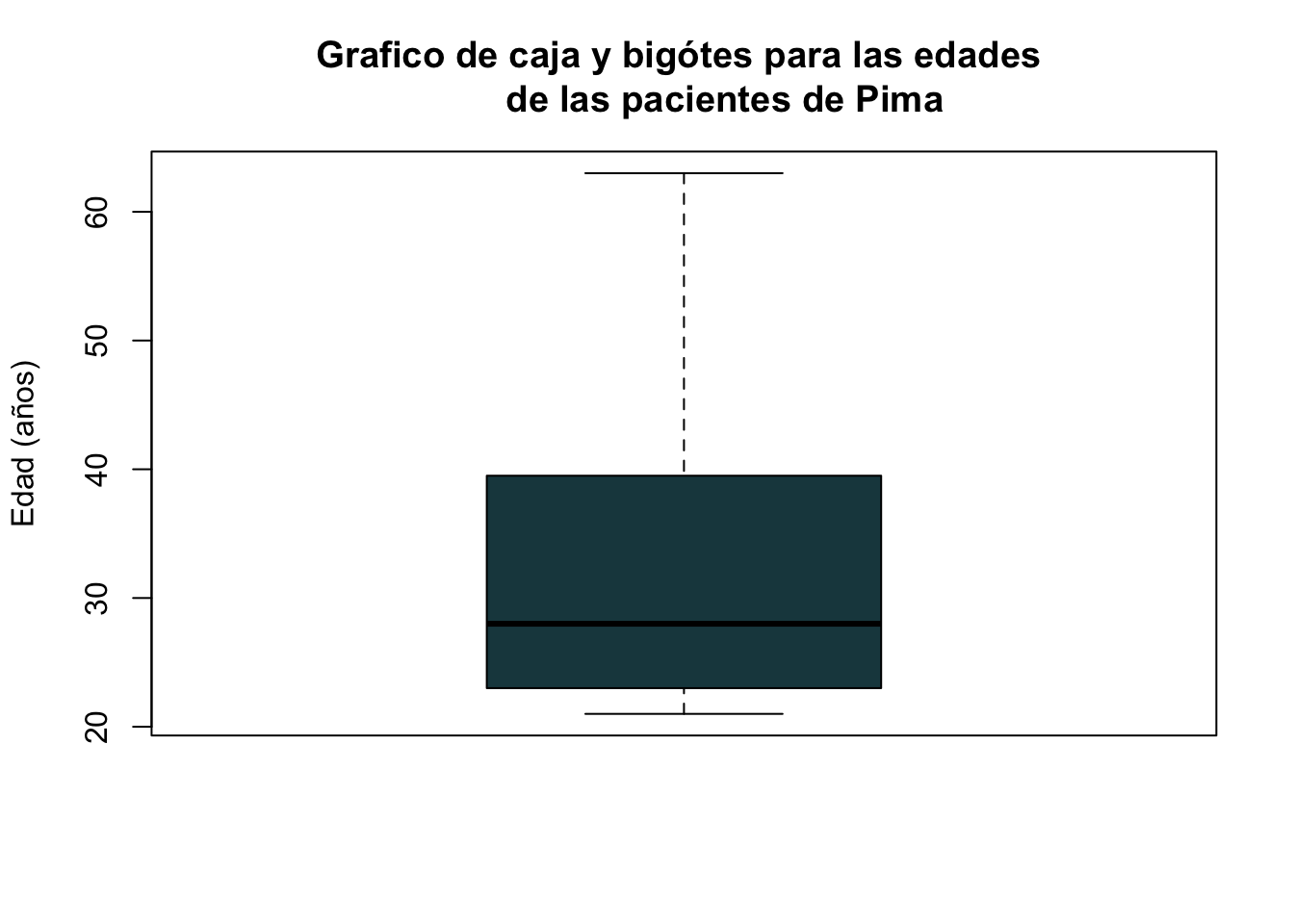
#Note como hay un enter el titulo que se ve reflejado en la gráficaTambién podemos cambiar el color del contorno de la caja con el argumento border.
boxplot(Pima.tr$age, main="Grafico de caja y bigótes para las edades
de las pacientes de Pima", ylab="Edad (años)", col="#EE964B",
border="#1C464D")
Note como ahora nos referimos a los colores con un código que comienza por un símbolo de # . Puede encontrar mayor información de los colores aquí
En algunas ocasiones es de nuestro interés tener una gráfica de forma horizontal. Para ello, utilizamos el argumento horizontal = T. Recuerde que la T en R es igual a TRUE. Puede utilizar ambas.
boxplot(Pima.tr$age, main="Grafico de caja y bigótes para las edades
de las pacientes de Pima", ylab="Edad (años)", col="#EE964B",
border="#1C464D", horizontal = T)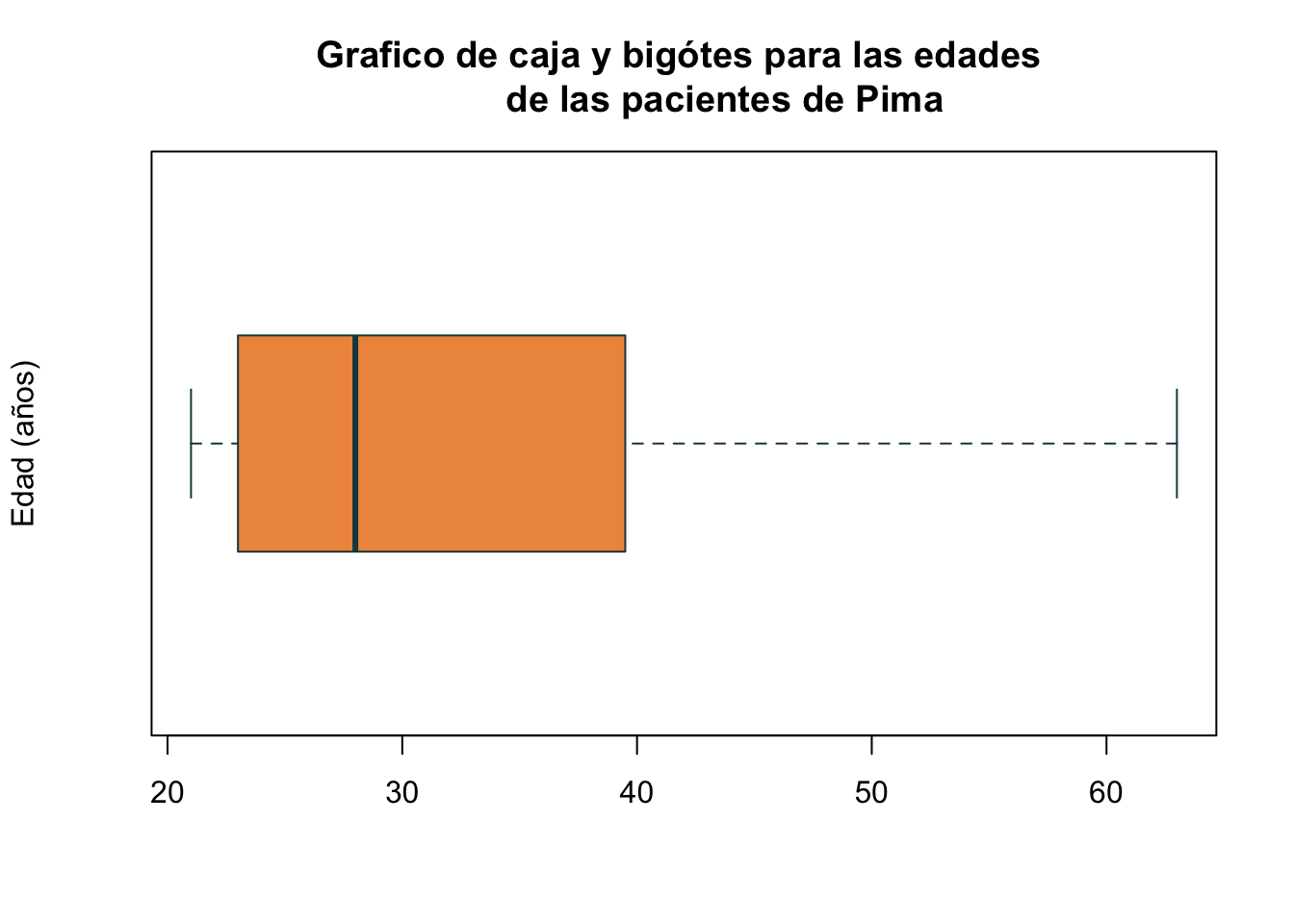
Note que las funciones por defecto tienen predefinidos algunos argumentos, en este caso el argumento horizontal se encuentra predefinido como FALSE.
8.1.4.1 Boxplot por grupos
¿Qué pasaría si queremos graficar en un boxplot las edades de las pacientes de Pima.tr y agruparlas de acuerdo con la presencia de diabetes?. Para ello, podemos emplear el siguiente código (que después explicaré)
boxplot(Pima.tr$age~Pima.tr$type, main="Comparación de las edades entre las pacientes
con DM vs mujeres sin DM",
ylab="Edad (años)",
col = c("#1C464D", "#EE964B"))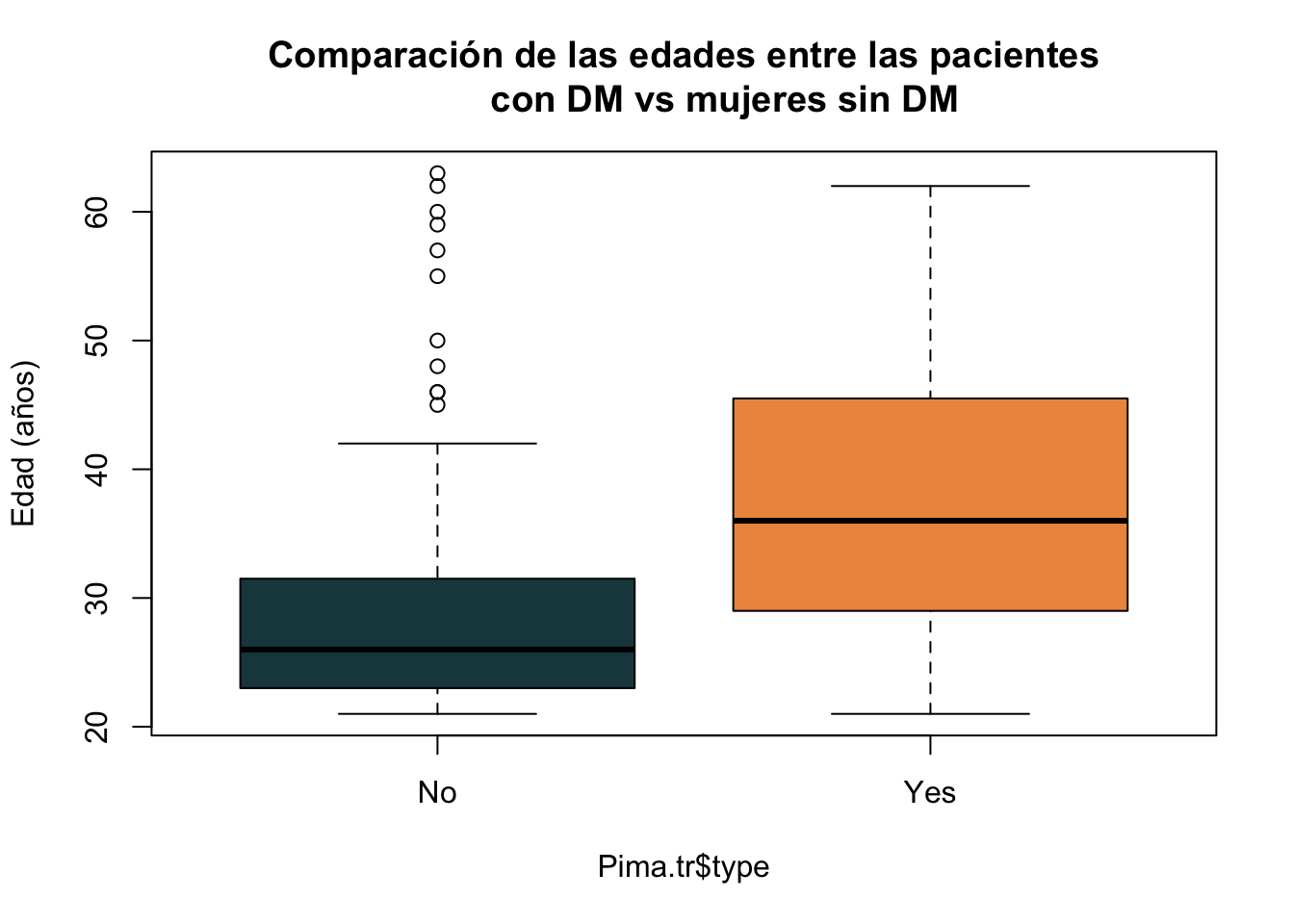
La principal peculiaridad del código es: Pima.tr$age~Pima.tr$type. Esta estrategia se conoce en R como “fórmula” y se lee como: la variable age agrupada por type. En este caso el símbolo ~ significa agrupación.
Ahora supongamos que queremos saber si hay una relación entre la edad y el número de embarazos.
boxplot(Pima.tr$age~Pima.tr$npreg,
main="Edad de acuerdo con el número de embarazos",
ylab = "Edad (años)", xlab="Número de embarazos")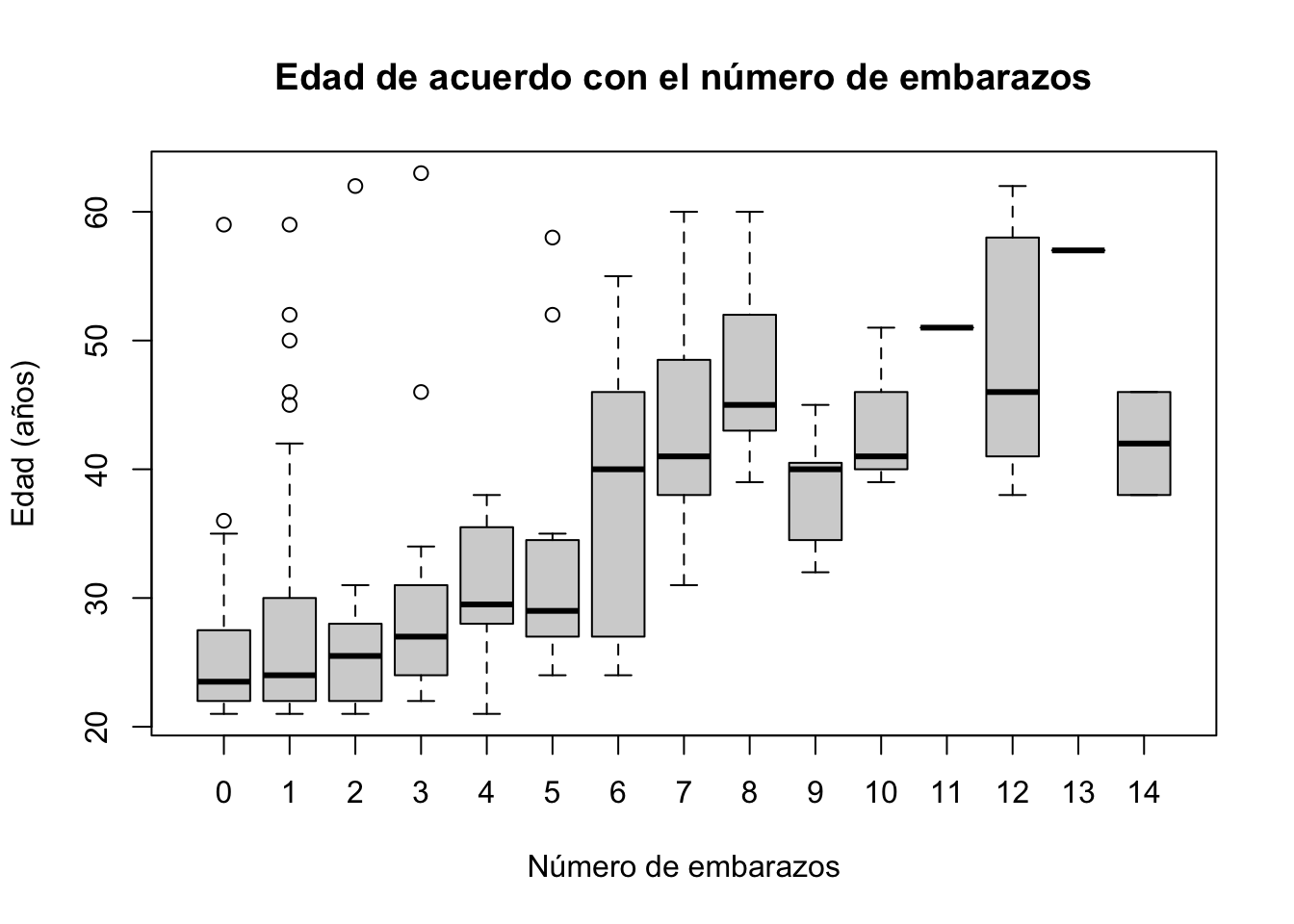
Ahora, vamos a crear una paleta de colores para cambiar los colores de las cajas. Vamos a crear un vector con los nombres de los colores y después vamos a utilizarlo.
Mi_Paleta <- c("#1C464D", "#19647E", "#28AFB0", "#1F271B",
"#8EC187", "#F4D35E", "#EE964B", "#1C2319",
"#F0A05B")Ahora al utilizar el argumento col lo asignaremos a nuestra paleta
boxplot(Pima.tr$age~Pima.tr$npreg,
main="Edad de acuerdo con el número de embarazos",
ylab = "Edad (años)", xlab="Número de embarazos",
col=Mi_Paleta)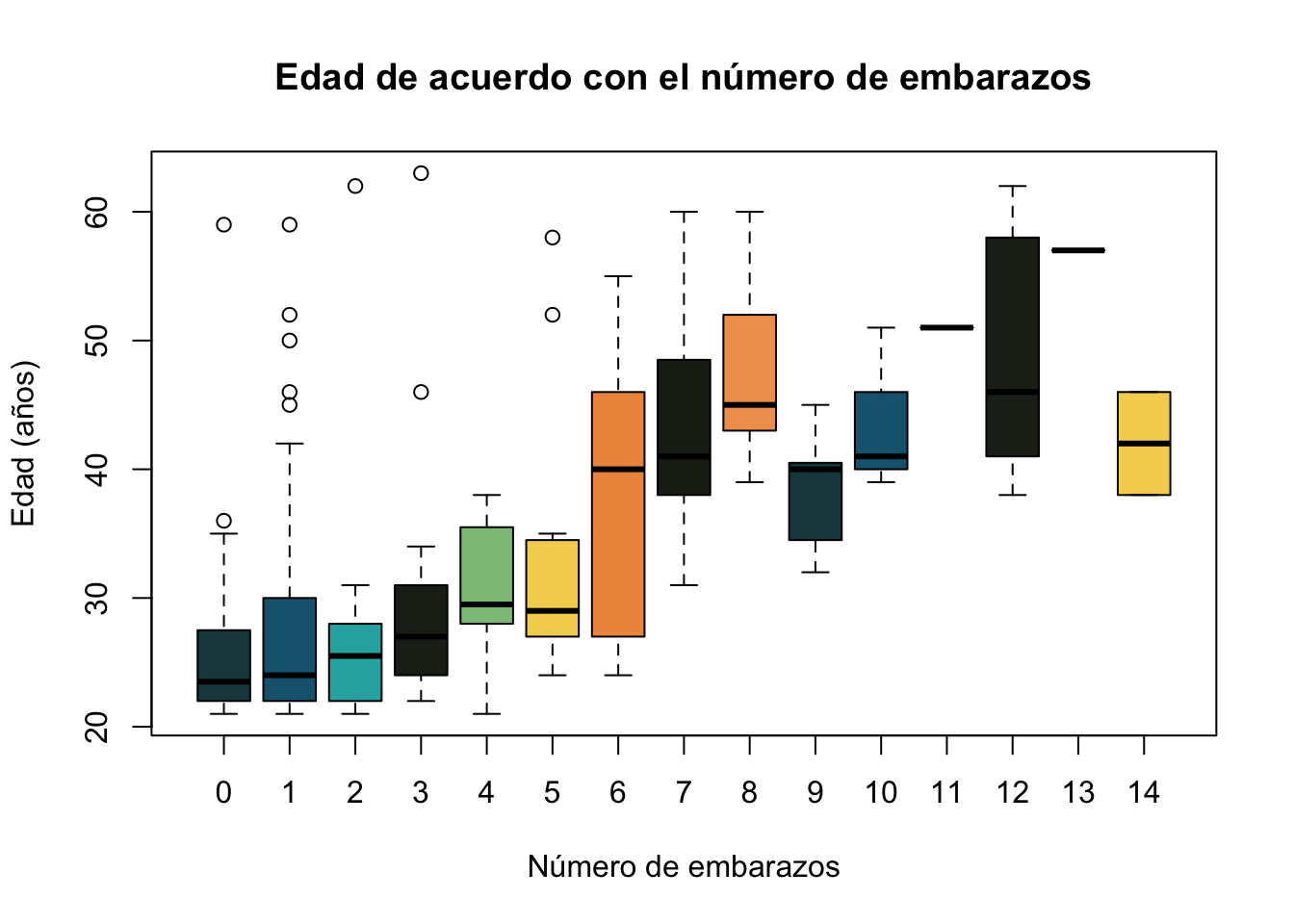
Note como los colores se repitieron, ya que hay 14 cajas y solo 9 colores
Las agrupaciones pueden ser mas complejas y tener dos variables de agrupación. Utilicemos el data frame birwth para explicarlo mejor.
Supongamos que queremos realizar una gráfica del peso del bebé al nacer (bwt) agrupado por el antecedente de tabaquismo en el embarazo (smoke) y la historia de hipertensión (ht). Podemos emplear el siguiente código:
boxplot(bwt~smoke*ht,
data = birthwt, main="Peso del recién nacido",
col = c("white", "steelblue"), frame = FALSE)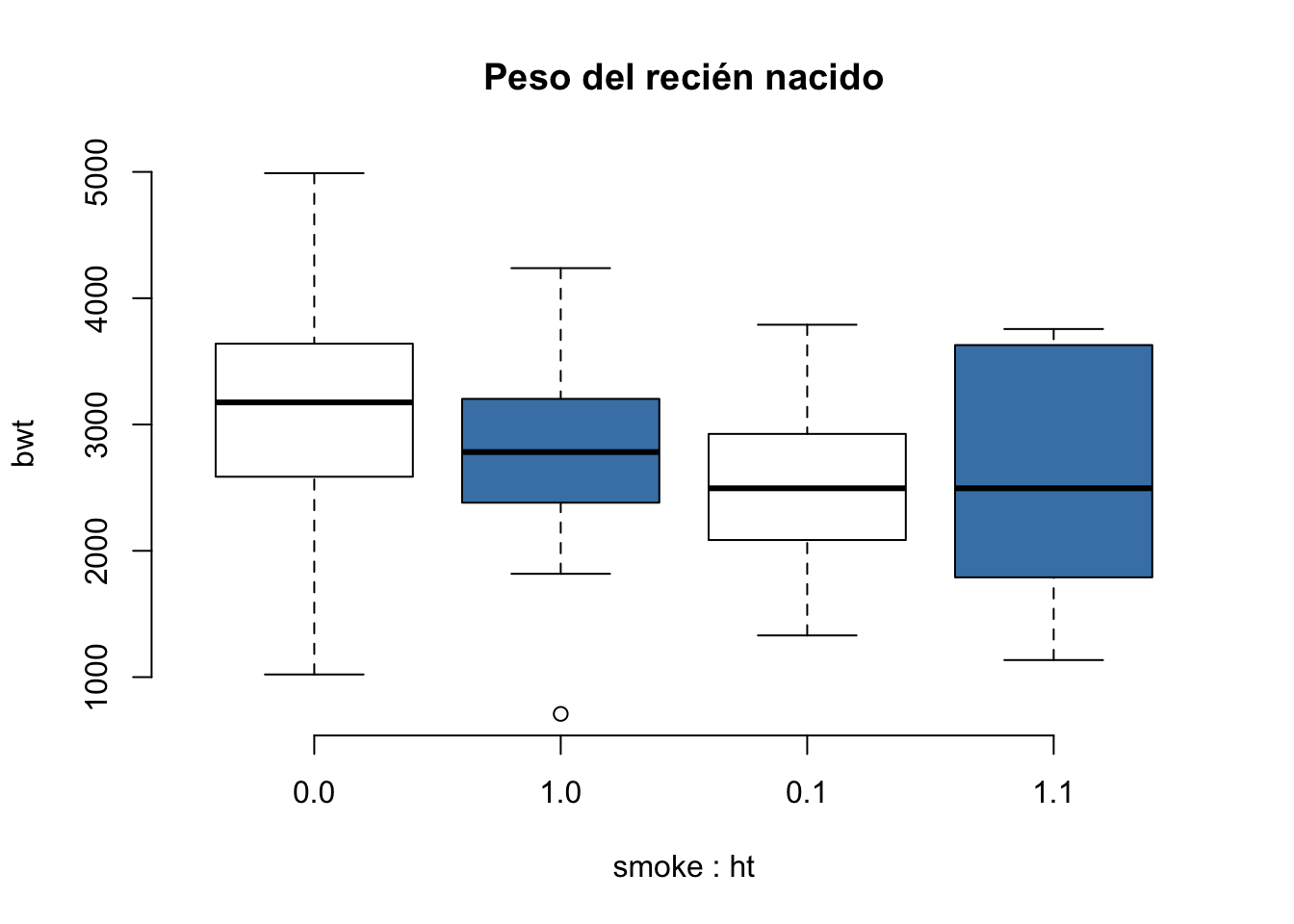
La sección de código bwt~smoke*ht indica el peso del recién nacido agrupado por el antecedente de tabaquismo y de hipertensión del madre. Con el argumento data podemos indicar de puede R obtener los datos y por tanto no es necesario utilizar el símbolo $.
8.2 Función plot()
En R, la función plot() es usada de manera general para crear gráficos. Esta una función de orden superior (gráfica casi cualquier cosa). Esta función tiene un comportamiento especial, pues dependiendo del tipo de dato con que se alimente, generará diferentes tipos de gráfica ver tabla (tbl_7_1?). Además, podemos cambiar su estética con los argumentos adecuados, tal cual lo hicimos en el gráfico de densidad.
plot() siempre pide un argumento x, que corresponde al eje X de una gráfica. x requiere un vector y si no especificamos este argumento, obtendremos un error y no se creará una gráfica. El argumento y no es necesario, pero sus características pueden cambiar el tipo de gráfico ver
Argumento x |
Argumento y |
Resultado |
|---|---|---|
| Ninguno | Error (x siempre es necesario) | |
| Entero/Numérico | Entero/Numérico | Scatterplot |
| Entero/Numérico | Ninguno | Gráficos de puntos por variable de indexación |
| Factor | Numérico | Boxplot |
| Factor | Factor | Gráfico de mosaico |
| Factor | Ninguno | Gráfico de Barras/Columnas |
8.3 Scatter plot
Los scatter plot son representaciones que permiten graficar dos variables cuantitivas. En el caso de R estos gráficos se construyen utilizando la función plot()
¿Existirá relación entre la edad edad y las concentraciones de glucosa en las mujeres de Pima.tr? Podemos comenzar con construir un Scatter plot
plot(Pima.tr$age, Pima.tr$glu)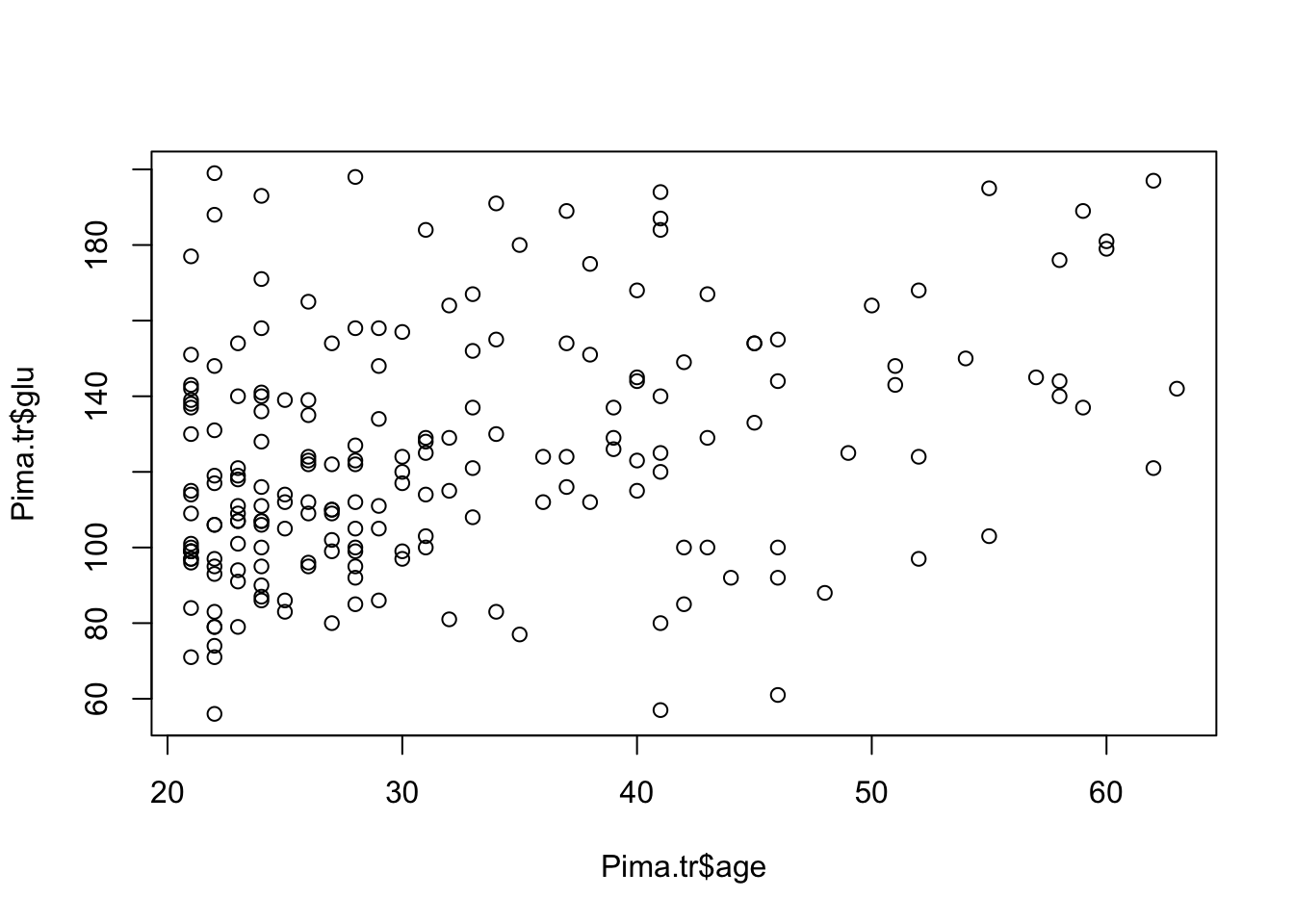
Al igual que las gráficas anteriores, podemos cambiar la estética de la gráfica anterior.
plot(Pima.tr$age, Pima.tr$glu, main = "Edad vs Glucosa en mujeres de Pima",
xlab="Edad", ylab="Glucosa", col="cyan4")
Podemos modifar la forma de los puntos con el argumento pch.
plot(Pima.tr$age, Pima.tr$glu, main = "Edad vs Glucosa en mujeres de Pima",
xlab="Edad", ylab="Glucosa", col="cyan4", pch=19)
En la figura Figura 8.1 se muestran las opciones de puntos disponibles en R, en su código solo basta con modificar el argumento pch y sustituirlo por el tipo de puntos que requiera.
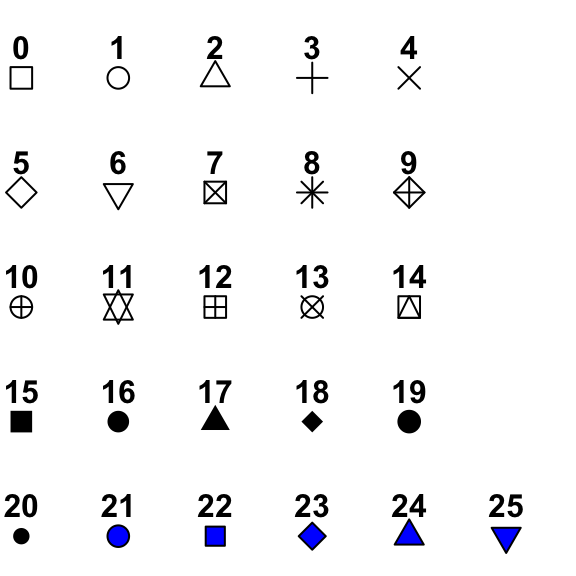
Podemos cambiar ahora los la forma de los puntos de nuestra gráfica. Pruebe la forma que usted prefiera
plot(Pima.tr$age, Pima.tr$glu, main = "Edad vs Glucosa en mujeres de Pima",
xlab="Edad", ylab="Glucosa", col="cyan4", pch=24)
Las gráficas en R se pueden construir en capas. Por ejemplo, a la gráfica anterior le podemos agregar texto, líneas etc.
Más adelante explicaremos a fondo las funciones para las pruebas de hipótesis, por ahora vamos a estimar el coeficientes de correlación para después agregar el resultado a la gráfica anterior.
Vamos a calcular el coeficiente:
cor.test(Pima.tr$age, Pima.tr$glu)
Pearson's product-moment correlation
data: Pima.tr$age and Pima.tr$glu
t = 5.1451, df = 198, p-value = 6.415e-07
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.2149050 0.4602209
sample estimates:
cor
0.343407 Ahora vamos a agregar el texto a nuestra gráfica, utilizando la función text. Recuerde que necesitamos capas, por lo que primero necesitamos una gráfica a la cual agregar el texto.
#Capa principal
plot(Pima.tr$age, Pima.tr$glu, main = "Edad vs Glucosa en mujeres de Pima",
xlab="Edad", ylab="Glucosa", col="cyan4", pch=24)
# Segunda capa
text(x=45, y=180, label="r=0.34; p<0.001")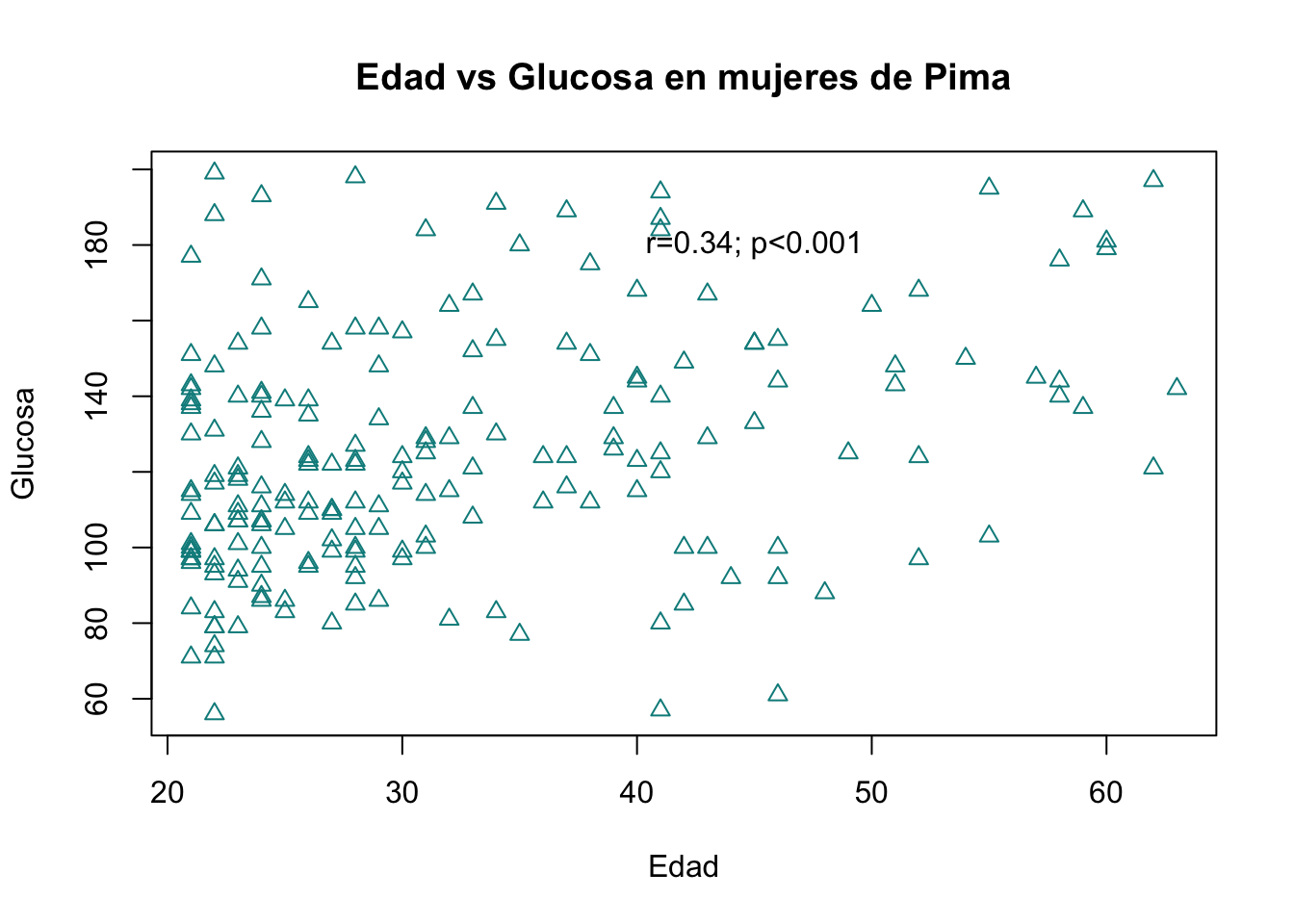
Podemos notar que la función text requiere que indiquemos las coordenadas en donde será colocado el texto (argumentos “x” y “y”) y el texto per se, en este caso con el argumento label. Note como el texto va entre comillas.
¿Qué pasaría si queremos que el texto no se encimen con los puntos? Una de las opciones es cambar los límites de los ejes y cambiar las coordenadas del texto, colocándole donde no se encimen.
#Capa principal
plot(Pima.tr$age, Pima.tr$glu, main = "Edad vs Glucosa en mujeres de Pima",xlab="Edad", ylab="Glucosa", col="cyan4", pch=24,
xlim = c(20,75), ylim=c(20,220))
# Segunda capa
text(x=60, y=50, label="r=0.34; p<0.001")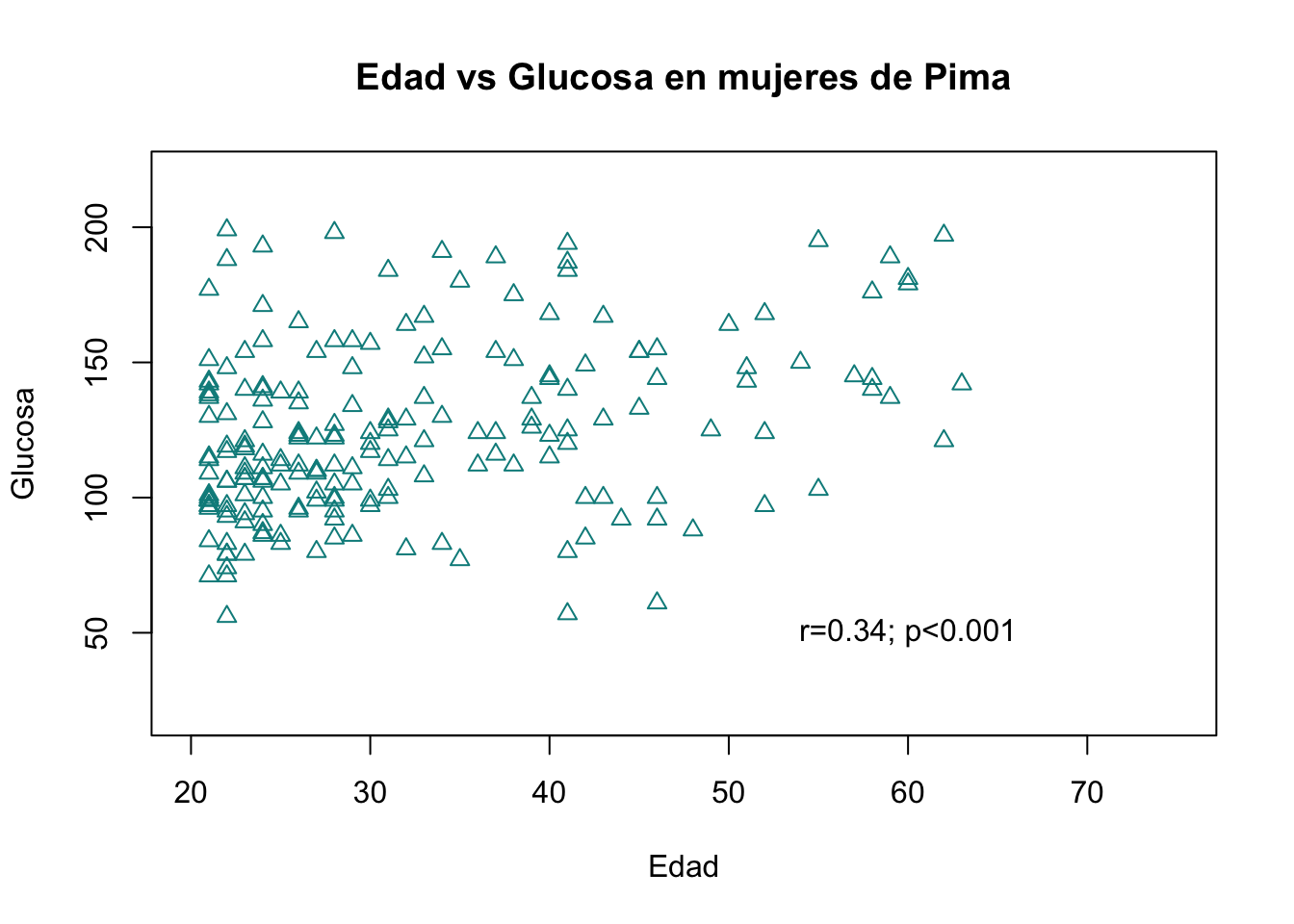
Observe como los argumentos xlim y ylim requieren de un valor mínimo y un valor máximo que deben de ir concatenados con la función c().
Podemos ahora agregar la línea de tendencia de la regresión utilizando la función lm(), la cual revisaremos más adelante.
#Capa principal
plot(Pima.tr$age, Pima.tr$glu, main = "Edad vs Glucosa en mujeres de Pima",xlab="Edad", ylab="Glucosa", col="cyan4", pch=24,
xlim = c(20,75), ylim=c(20,220))
# Segunda capa
text(x=60, y=50, label="r=0.34; p<0.001")
# Tercera capa
abline(lm(Pima.tr$glu~Pima.tr$age))
La función abline agrega una linea sobre una gráfica ya construida, en este caso agregamos la línea de regresión para marcar la tendencia.
Tanto la función abline como la función text no tienen sentido sin una gráfica previa. De hecho, sin una gráfica previa producirán un errorr
8.3.1 Ejercicios para Scatter plot
Utilizando la base de datos `birthwt` realice una gráfica tipo Scatter plot de la edad de las madres (`age`) y el peso de las madres (`bwt`). Cambíe el color y la forma de los puntos. Agruegue la línea de tendencia utilizando la función `lm()`.Utilizando la base de datos `birthwt` realice una gráfica tipo Scatter plot del peso de las madres (`bwt`) y el peso del recién nacido (`lwt`). Cambie el color y la forma de los puntos. Agruegue la línea de tendencia utilizando la función `lm()`Utilizando la base de datos `Pima.tr` realice una gráfica tipo Scatter plot de la edad (`age`) y de la glucosa (`glu`). Cambie el color y la forma de los puntos. Agregue la línea de tendencia utilizando la función `lm()`8.4 Plot means
Estos gráficos permiten la creación de gráficos de medias para diversos grupos. La función plotmeans se encuentra en la librería gplots, por lo que el primer paso es instalar y cargar esta librería.
install.packages("gplots")library(gplots)La función requiere que los datos sean alimentados por medio de una formula. Por ejemplo, con la base birthwt vamos a gráficar el peso de la madre (lwt) según la raza (race).
plotmeans(birthwt$lwt~birthwt$race)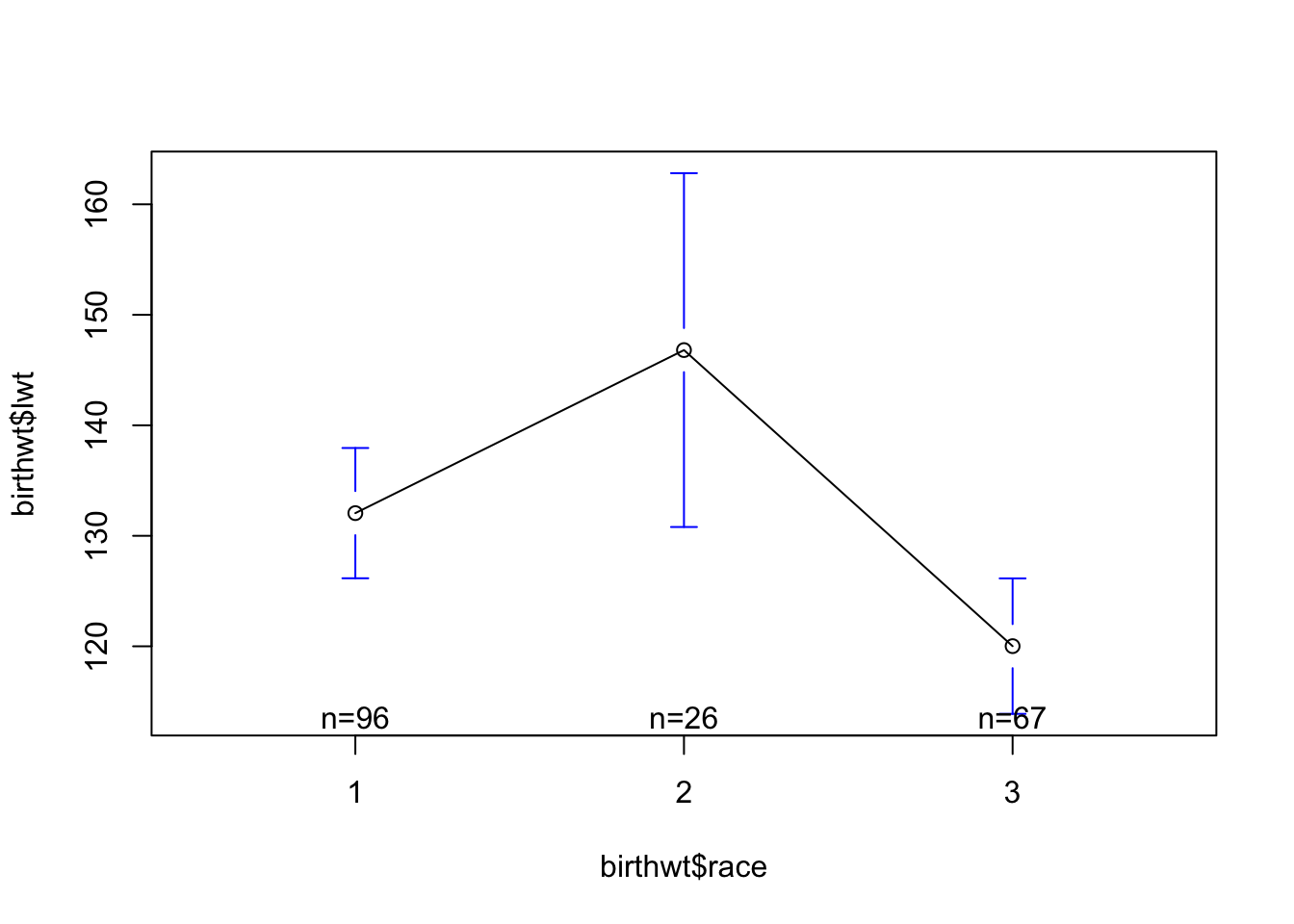
8.4.1 Gráficos de violín
Existe una alternativa a los boxplot que permite una apreciación de mayor calidad de la distribución de los datos. Estos gráficos se conocen como gráficos de violín, o violin plots. Los cuales conjuntan la distribución (forma) de los datos y un boxplot. La librería vioplot contiene la función vioplot() que requiere de un vector numérico o de una fórmula para alimentarse.
Procedemos a instalar y a cargar la librería.
install.packages("vioplot")library("vioplot")Cambiamos las etiquetas de las variable race y la convertimos a factor
birthwt$race <- factor(birthwt$race,
levels = c(1,2,3),
labels = c("White", "Black", "Other"))Las etiquetas de las variable race se obtuvieron después de utilizar help(birthwt).
vioplot(birthwt$lwt~birthwt$race,
ylab="Peso de la madre",
xlab = "Raza",
col=c("#28AFB0", "#8EC187", "#F4D35E"))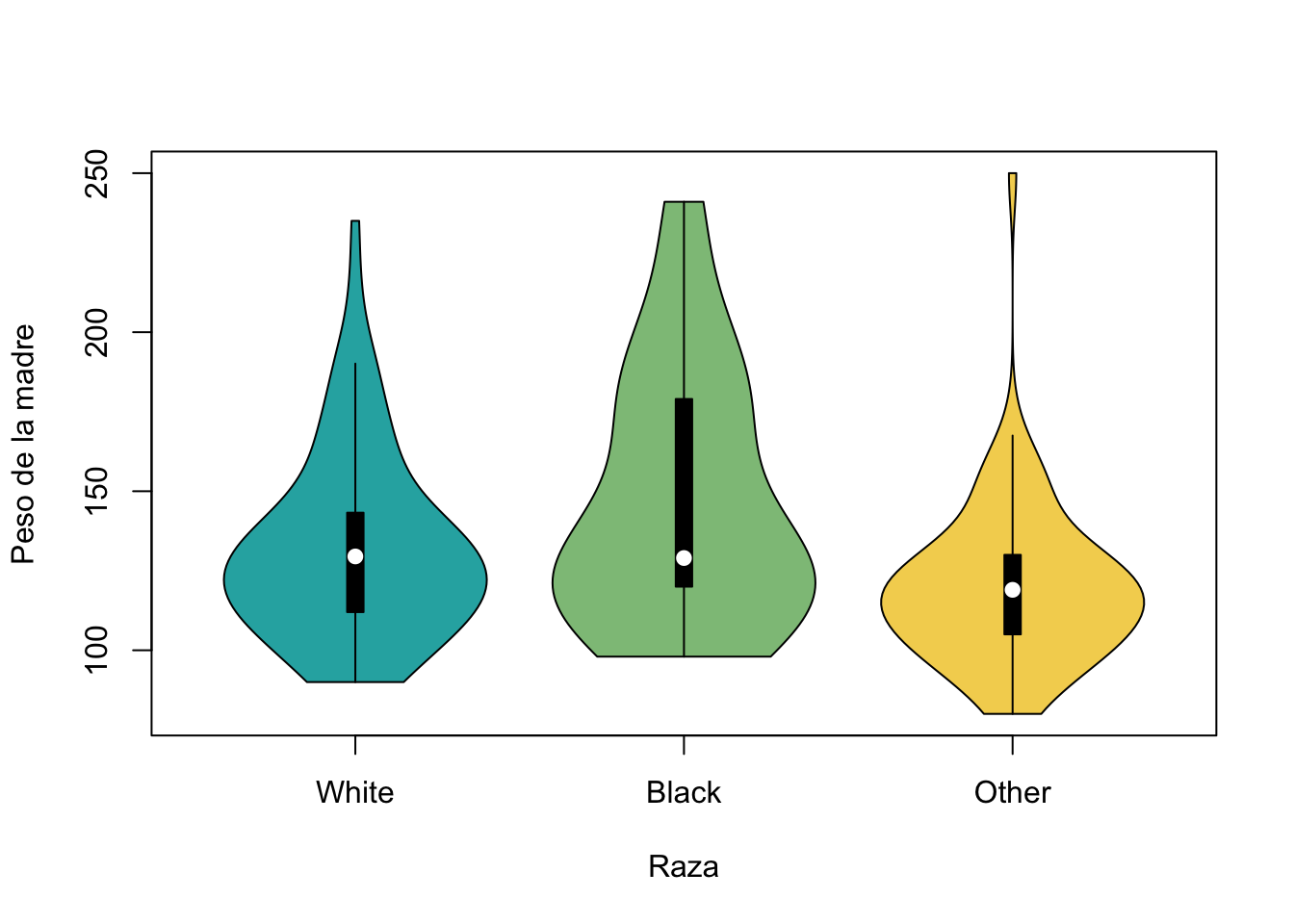
8.4.2 Matrices de correlación
Los diagramas de dispersión o matrices de correlación son extremadamente útiles para el análisis de datos explicativos y, por lo tanto, muchos paquetes R aportados brindan capacidades de diagramas de dispersión mejoradas o especializadas. En base R existe la función pairs(), que produce una matriz de diagramas de dispersión. No pierda de vista el símbolo ~. Utilizando la base Pima.tr podemos construir el siguiente gráfico
pairs(~glu+bp+skin+bmi+age, data = Pima.tr)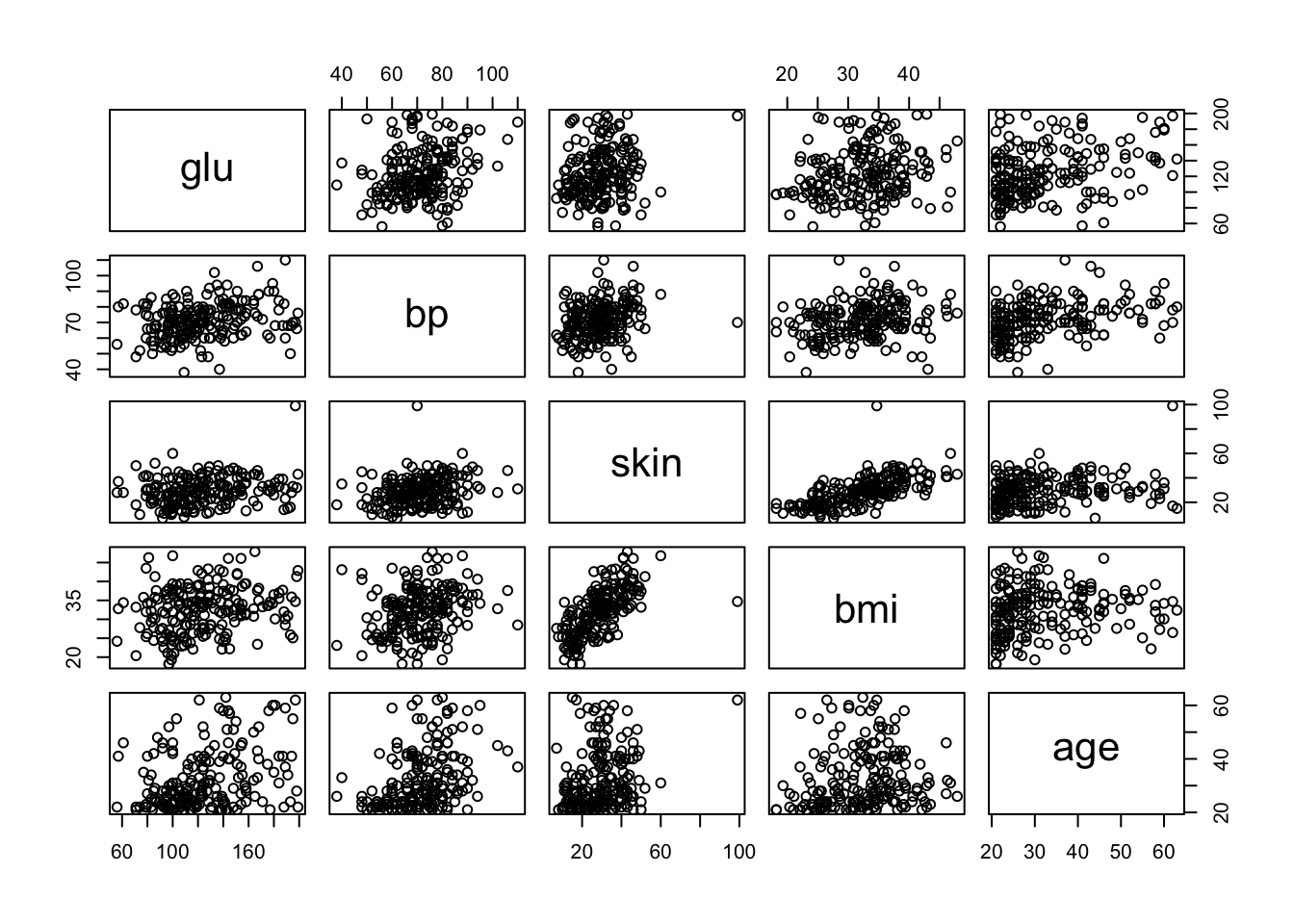
También se puede utilizar la función scatterplotMatrix de la librería car. Esta última no es necesario instalarla simplemente llamarla.
library(car)
scatterplotMatrix(~glu+bp+skin+bmi+age, data = Pima.tr)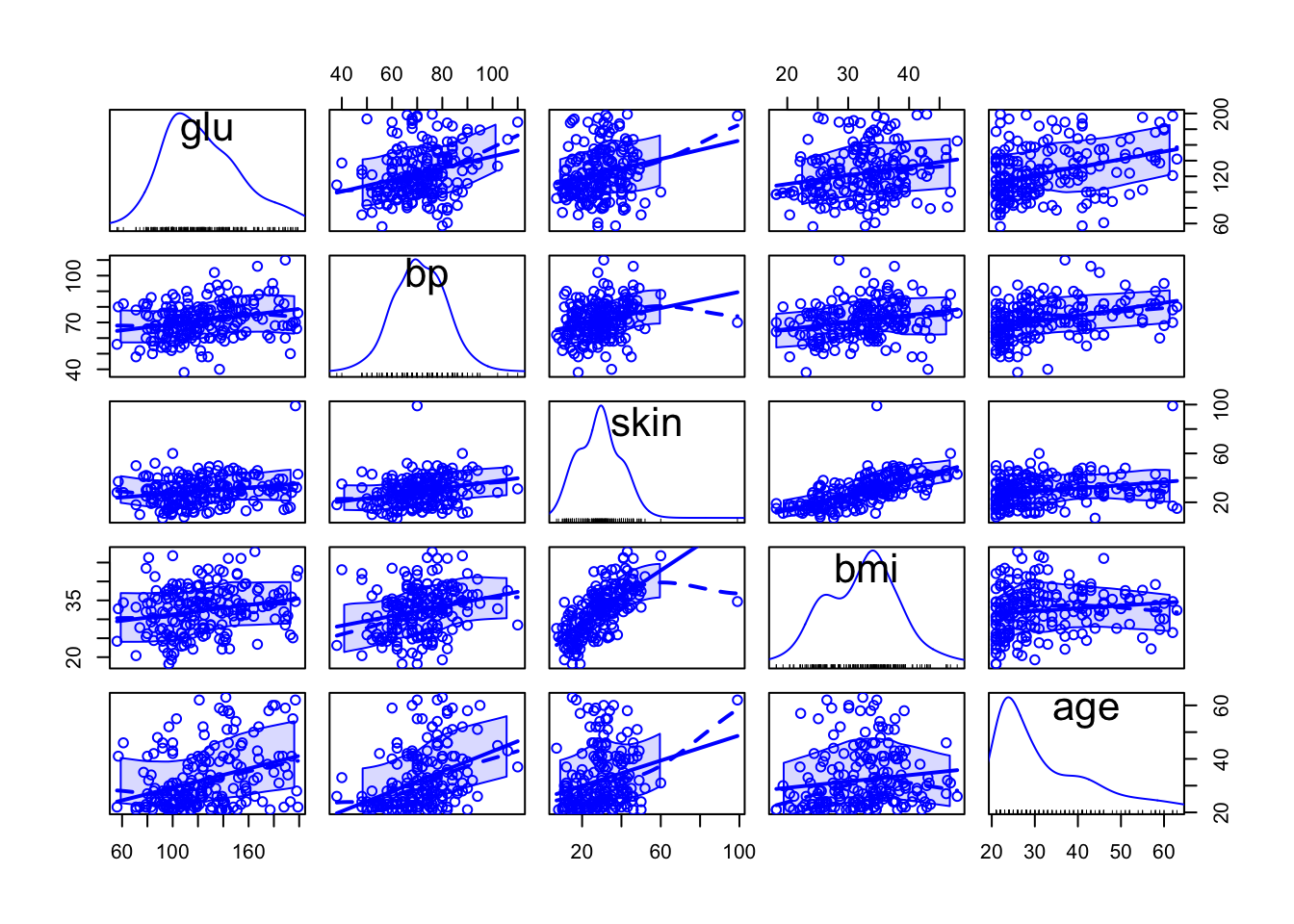
La librería psych tiene otras opciones muy interesantes para realizar matrices de correlación.
library(psych)
Attaching package: 'psych'The following object is masked from 'package:car':
logitpairs.panels(Pima.tr[,c("glu","bp","skin","bmi","age")])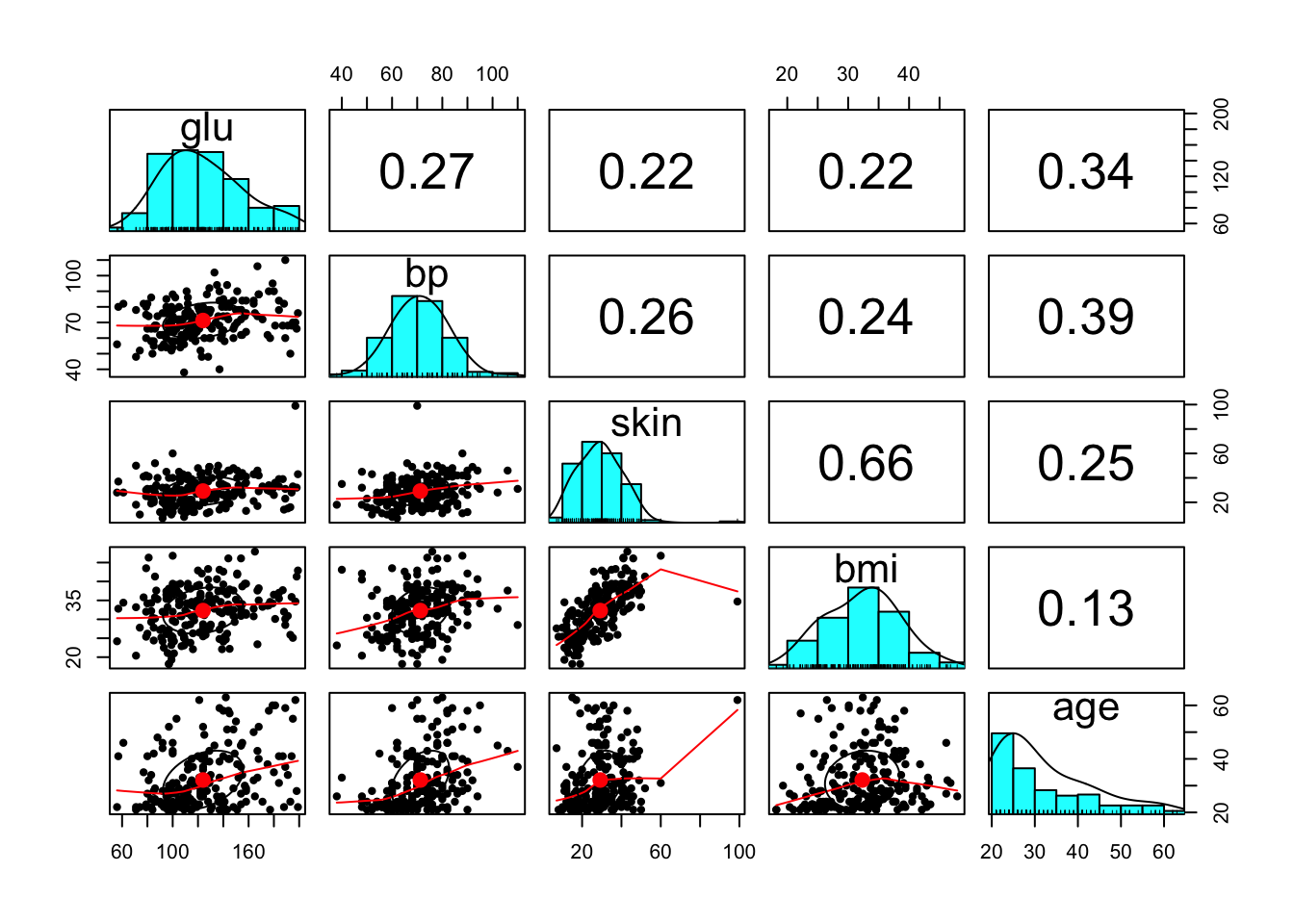
psych::cor.plot(Pima.tr[,c("glu","bp","skin","bmi","age")],
stars = T)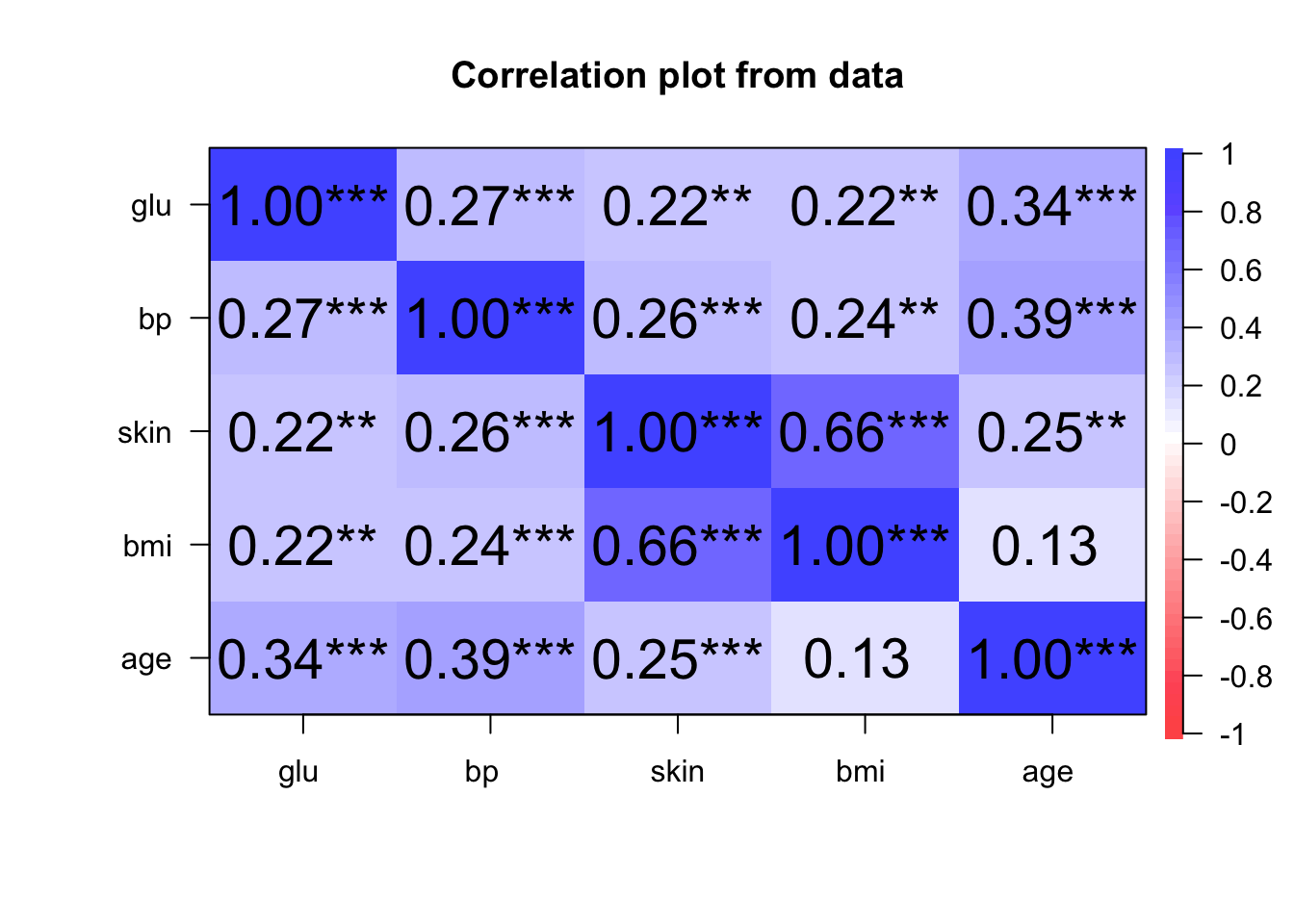
En el capítulo de correlación veremos más de este tipo de gráficas.
8.5 Resolución ejercicios
8.5.1 Resolución de ejercicios para Scatter plot
Resolución del Ejercicio 8.12
plot(birthwt$age, birthwt$bwt,
main ="Gráfico de dispersión",
ylab = "Peso del recién nacido",
xlab = "Edad de la madre",
pch=19,
col=10)
abline(lm(birthwt$bwt~birthwt$age))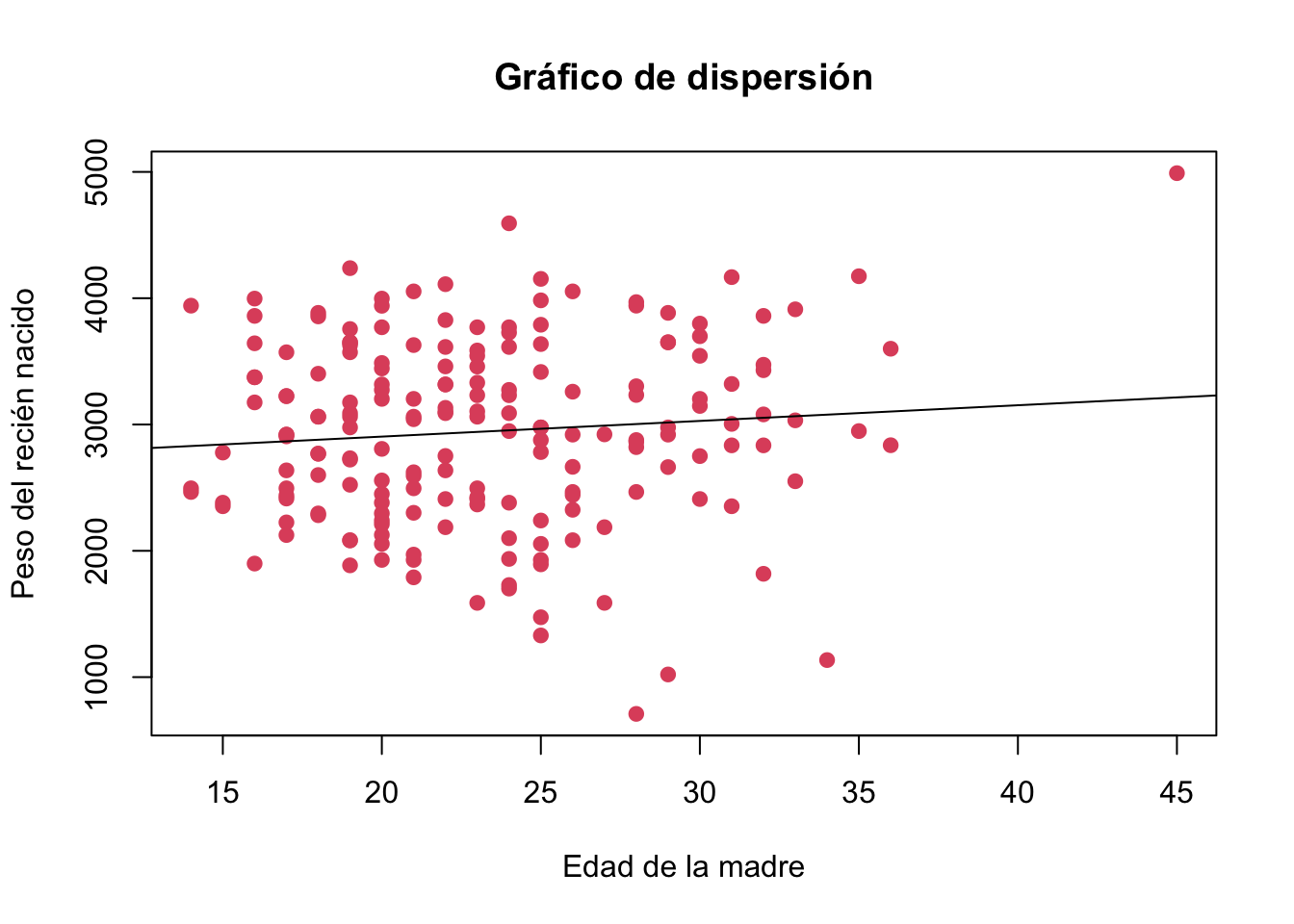
Resolución del ?exr-7_2
plot(birthwt$bwt, birthwt$lwt,
main ="Gráfico de dispersión",
ylab = "Peso de la madre",
xlab = "Peso del recién nacido",
pch=19,
col=10)
abline(lm(birthwt$lwt~birthwt$bwt))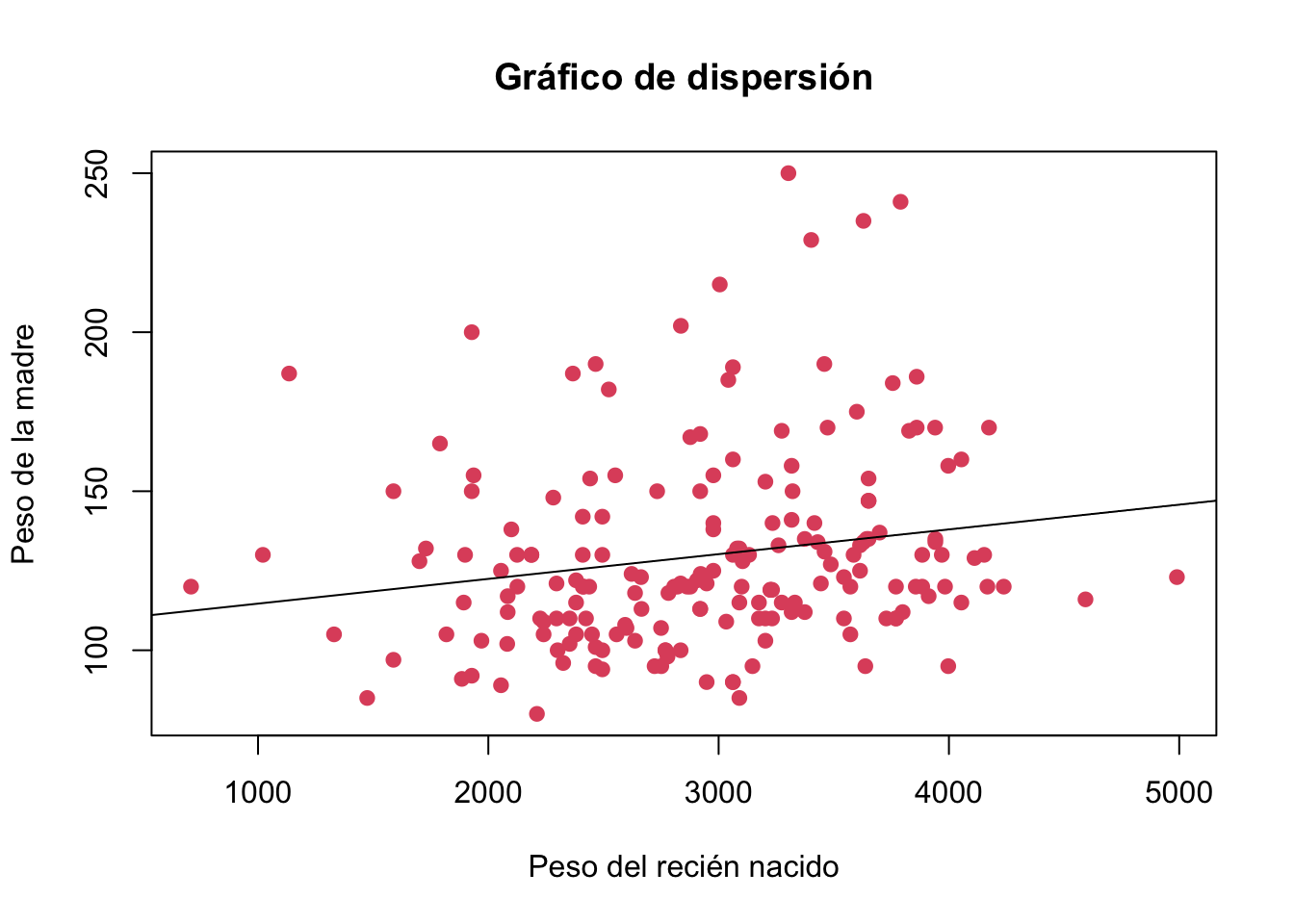
Resolución del Ejercicio 8.14
plot(Pima.tr$age, Pima.tr$glu,
main ="Gráfico de dispersión",
ylab = "Concentraciones de glucosa",
xlab = "Edad",
pch=19,
col=10)
abline(lm(Pima.tr$glu~Pima.tr$age))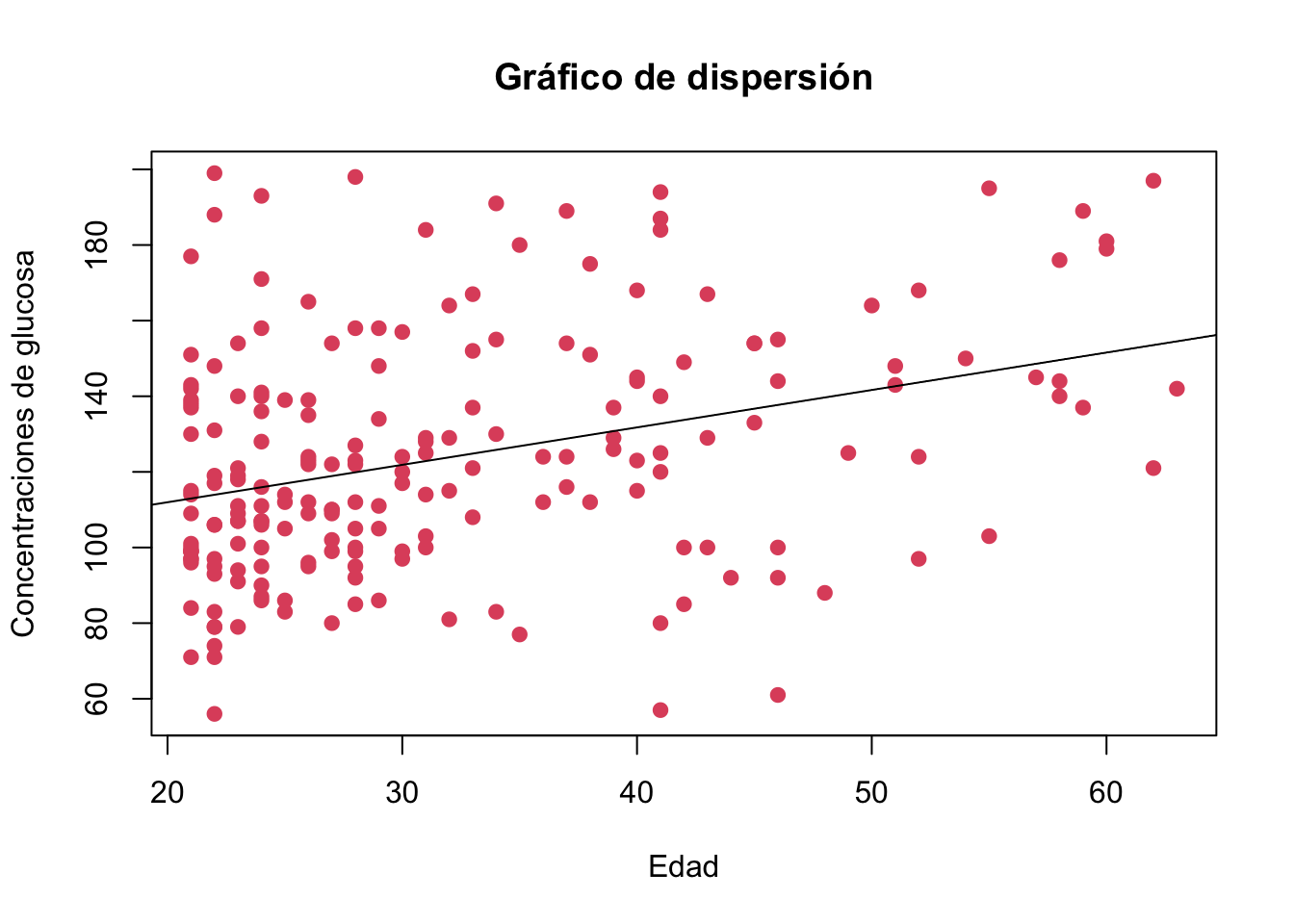
8.6 Gráficos utilizando ggplot2
Una de las librerías más utilizadas en R para la construcción de gráficas en ggplot2. De hecho, es el estándar para la construcción de gráficas. Esta librería está basada en The Grammar of Graphics de ahí el “gg”.
ggplot2 funciona por medio de capas, cada una de ellas aporta un componente en específico a su gráfico. Es importante que entienda el comportamiento de estas capas ya que le permitirá modificar y crear gráficas de una forma más eficiente. El error más común en ggplot2 es querer modificar la capa superior pero utilizando un código para modificar la capa más profunda. La figura Figura 8.2 muestra las principales capas y sus principales características.

Vamos a explicar de forma muy general el funcionamiento de las capas en ggplot2. Para ello vamos a utilizar el Dataframe Pimar.tr de la librería MASS.
Supongamos que es nuestro interés observar la relación entre el IMC y la glucosa en ayunas de las mujeres de Pima. Para ello, vamos a construir una gráfica utilizando ggplot2.
Si lo requiere instale la librería ggplot2
# Si lo requiere
install.packages("ggplot2")Llamamos la librería
library(ggplot2)
Attaching package: 'ggplot2'The following objects are masked from 'package:psych':
%+%, alphaImportamos la base de datos
library(MASS)
data("Pima.tr")La primer capa de ggplot2 son los datos. ggplot2 necesita un Dataframe para poder construir un gráfico, en ciertas circunstancias no es necesario un Dataframe pero si la mayoría de los casos. Esta es una de las principales diferencias entre construir gráficas en el paquete base y en ggplot2.
# Primera capa de ggplot2
ggplot(data = Pima.tr)
Si utiliza pipes el código es el siguiente
Pima.tr|>
ggplot()Como lo habrá notado tenemos un lienzo en blanco (en gris en este caso), hemos construido nuestra primera capa. Ahora tenemos que indicarle que variables deben de ir en el eje de las “x” y cual en el de las “y” utilizando la siguiente capa. La capa aesthetic
ggplot(data = Pima.tr, mapping = aes(x=bmi, y=glu))
O bien:
Pima.tr|>
ggplot(mapping = aes(x=bmi, y=glu))Para indicarle a ggplot2 que variables deben de conformar el eje de las “x” y el eje de las “y” utilizamos el código: mapping = aes(x=bmi, y=glu). Donde indicamos la estética con aes mediante el “mapeo” mapping. Una explicación más técnica de esto sería: El argumento mapping en ggplot2 se utiliza para definir el “mapeo” estético de las variables de su conjunto de datos a las propiedades visuales de los elementos del gráfico, como los ejes, colores, tamaños, formas, etc. Se especifica mediante la función aes(), que crea una lista de mapeos estéticos.
Hasta ahora no le hemos pedido de ggplot2 que muestre una forma o geometría. La siguiente capa nos ayuda precisamente a esto, a indicarle a ggplot2 mediante que forma quiero que se muestren mis datos.
Pima.tr|>
ggplot(mapping = aes(x=bmi, y=glu))+
geom_point()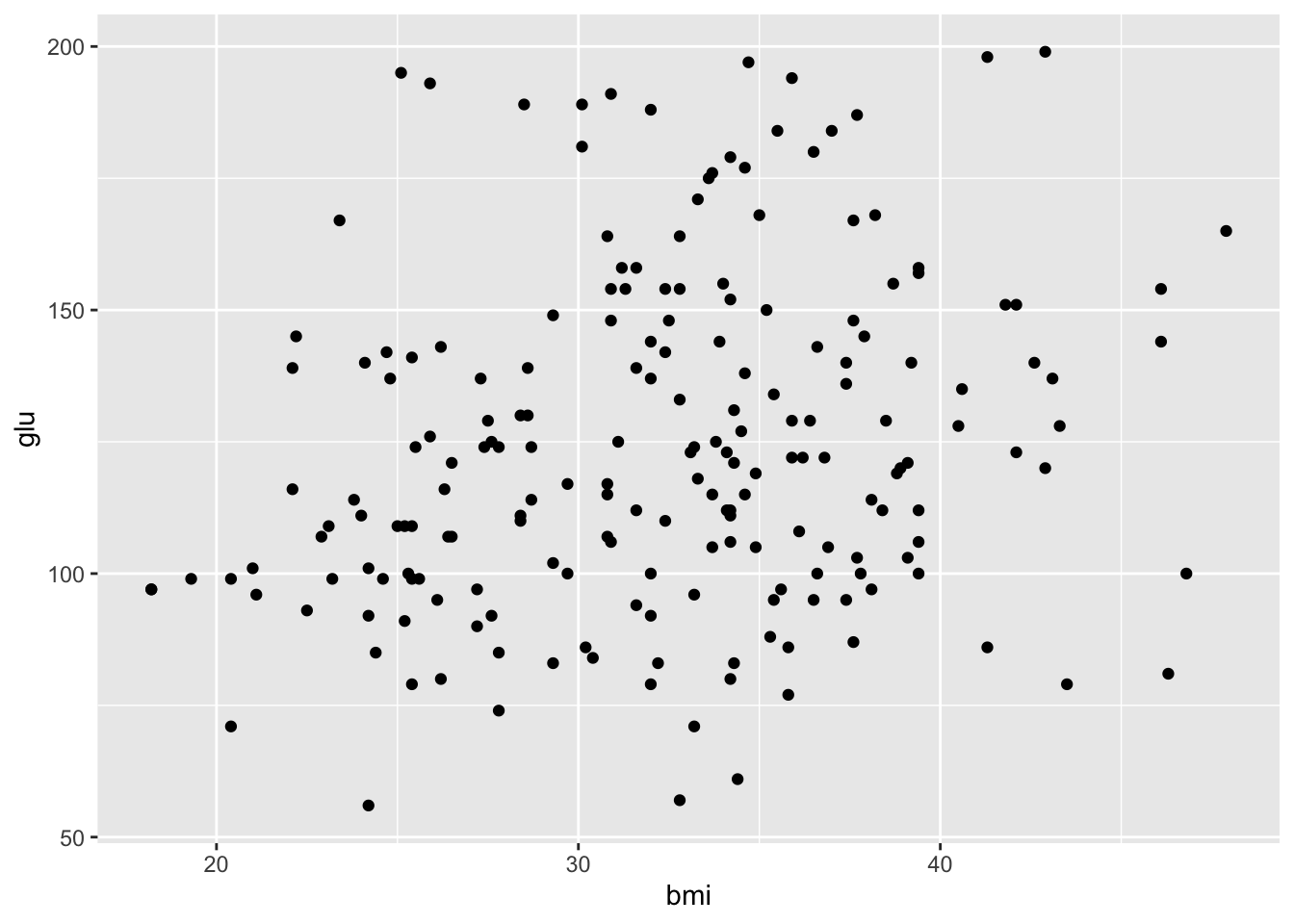
En ggplot2, los “geoms” (abreviatura de “geometries” o geometrías) son los componentes que determinan cómo se visualizan los datos en el gráfico, es decir mediante que geometría serán representados. Cada geom corresponde a un tipo específico de gráfico o elemento gráfico, como puntos, líneas, barras, cajas, etc. Los geoms se añaden a un objeto ggplot mediante funciones específicas que comienzan con geom_.
Note como la geometrías fueron añadidas utilizando +. En ggplot2, el signo+ se utiliza para agregar capas y componentes adicionales a un objeto ggplot. Podríamos decir que el signo de + nos permite concatenar estos componentes del gráfico.
Hasta aquí tenemos nuestro primer gráfico utilizando ggplot2. Las tres capas que son necesarias para la construcción de un gráfico son: data, aestethic y geometrics.
Ahora, supongamos que necesitamos crear dos gráficos de dispersión (uno al lado del otro) como el construido en el ejemplo anterior. Debe de mostrarse un gráfico para las mujeres con diabetes y otro para las mujeres sin diabetes. El siguiente código nos dará este gráfico:
Pima.tr |>
ggplot(mapping = aes(x = bmi, y = glu)) +
geom_point() +
facet_wrap(~ type) + # Agregar la capa de facetas
labs(title = "Relación entre BMI y Glucosa por Tipo", # Cambiar títulos
x = "Índice de Masa Corporal (BMI)", y = "Nivel de Glucosa")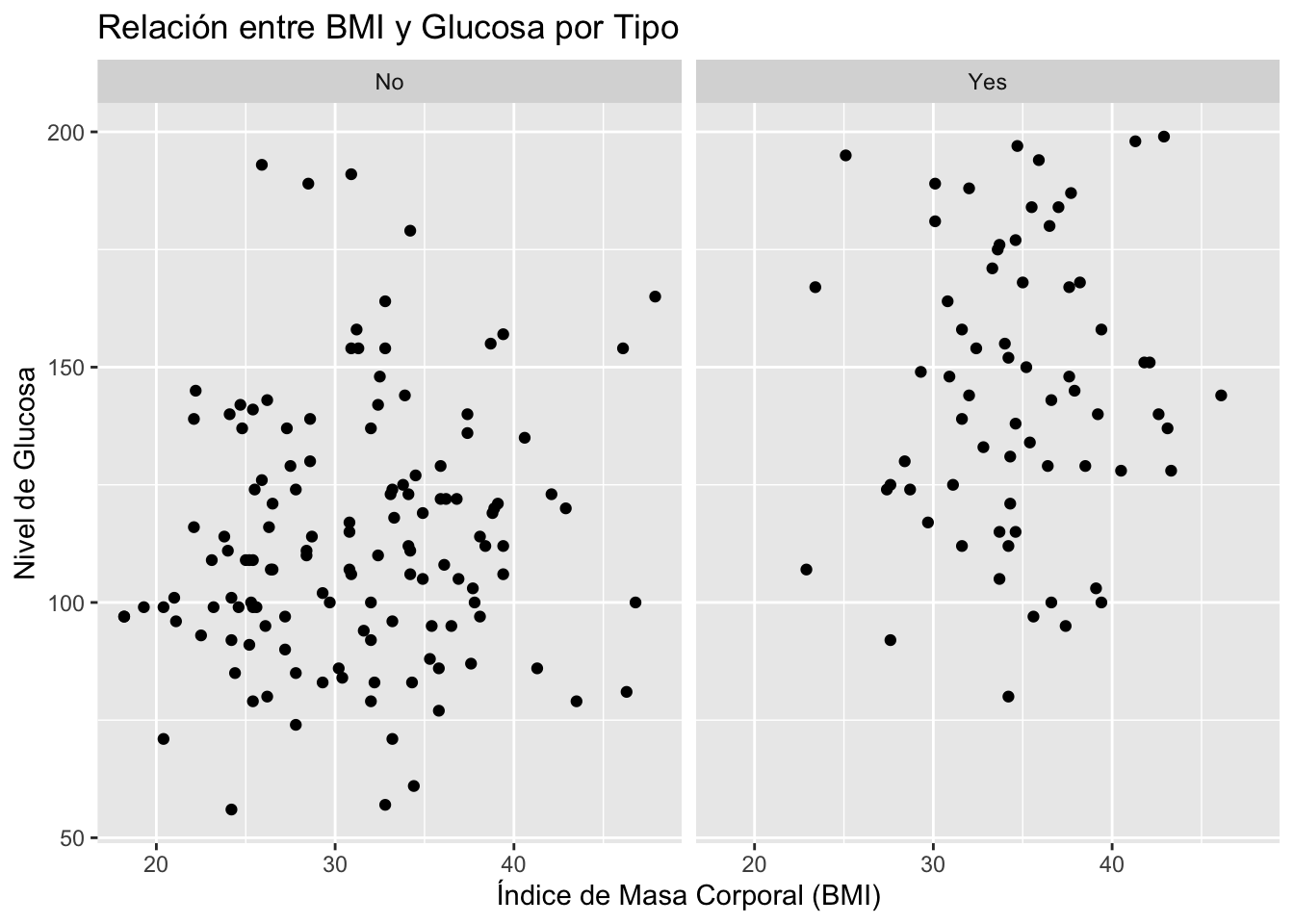
La función facet_wrap(~ type) divide el gráfico en múltiples paneles basados en la variable type. Recuerde el símbolo ~ se utiliza para agrupar. Cada panel muestra una subpoblación de los datos, permitiendo la comparación de la relación entre BMI y glucosa entre diferentes tipos.
Además, en este código añadimos títulos a los ejes y al gráfico.
Imagine ahora que es de su interés agregar estimaciones estadísticas a su gráfico, por ejemplo una línea con la ecuación de la recta que indique la tendencia de los datos, además queremos modificar el estilo del gráfico haciéndolo más minimalista.
# Crear el gráfico con facetas y capas estadísticas
Pima.tr |>
ggplot(mapping = aes(x = bmi, y = glu)) +
geom_point() +
geom_smooth(method = "lm", se = TRUE, color = "blue") + # Línea de tendencia
facet_wrap(~ type) + # Facetas
labs(title = "Relación entre BMI y Glucosa por Tipo con Estadísticas", x = "Índice de Masa Corporal (BMI)", y = "Nivel de Glucosa") +
theme_minimal()`geom_smooth()` using formula = 'y ~ x'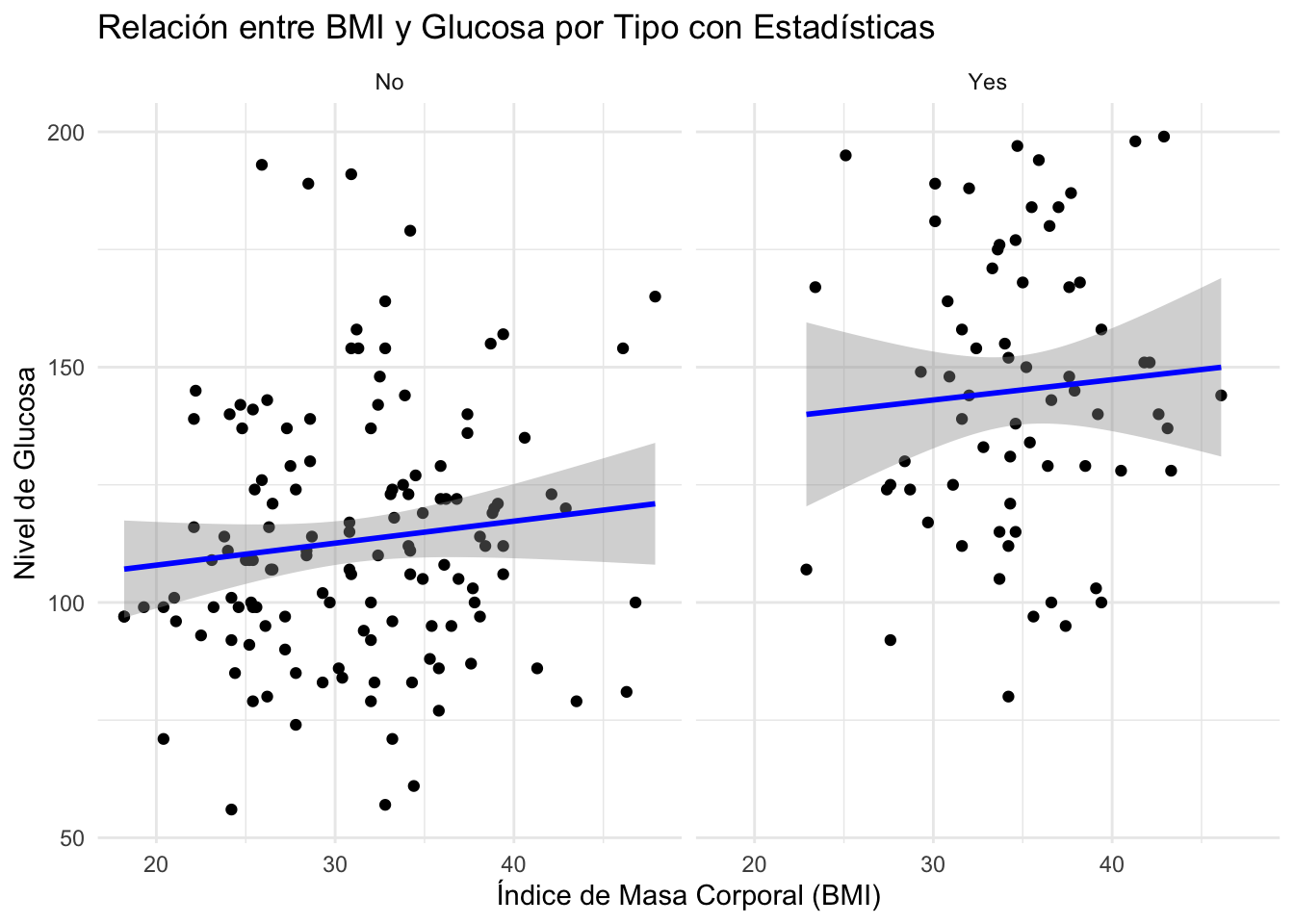
Parte de las nuevas líneas de código corresponden a la capa statistics, con lo cual agregamos la línea de tendencia. geom_smooth() añade una capa de línea de tendencia utilizando el método method = "lm" para regresión lineal. Note como a pesar de que geom_smooth está antes de la capa de faceta, ggplot2 supo exactamente el orden jerárquico de las capas y primero separó por la variable type y luego estimo la línea de tendencia.
Finalmente, la última línea del código (theme_minimal()), nos permitió modificar la apariencia del gráfico final.
Vamos a ahora a crear un gráfico de boxplot para las concentraciones de glucosa (glu) separado por las mujeres con y sin diabetes, del Dataframe Pima.tr
Pima.tr|>
ggplot(mapping = aes(x= type, y= glu, fill = type))+
geom_boxplot()+
labs(title = "Comparación de las concentraciones de glucosa", x = "Diabetes", y = "Nivel de Glucosa") +
theme_dark()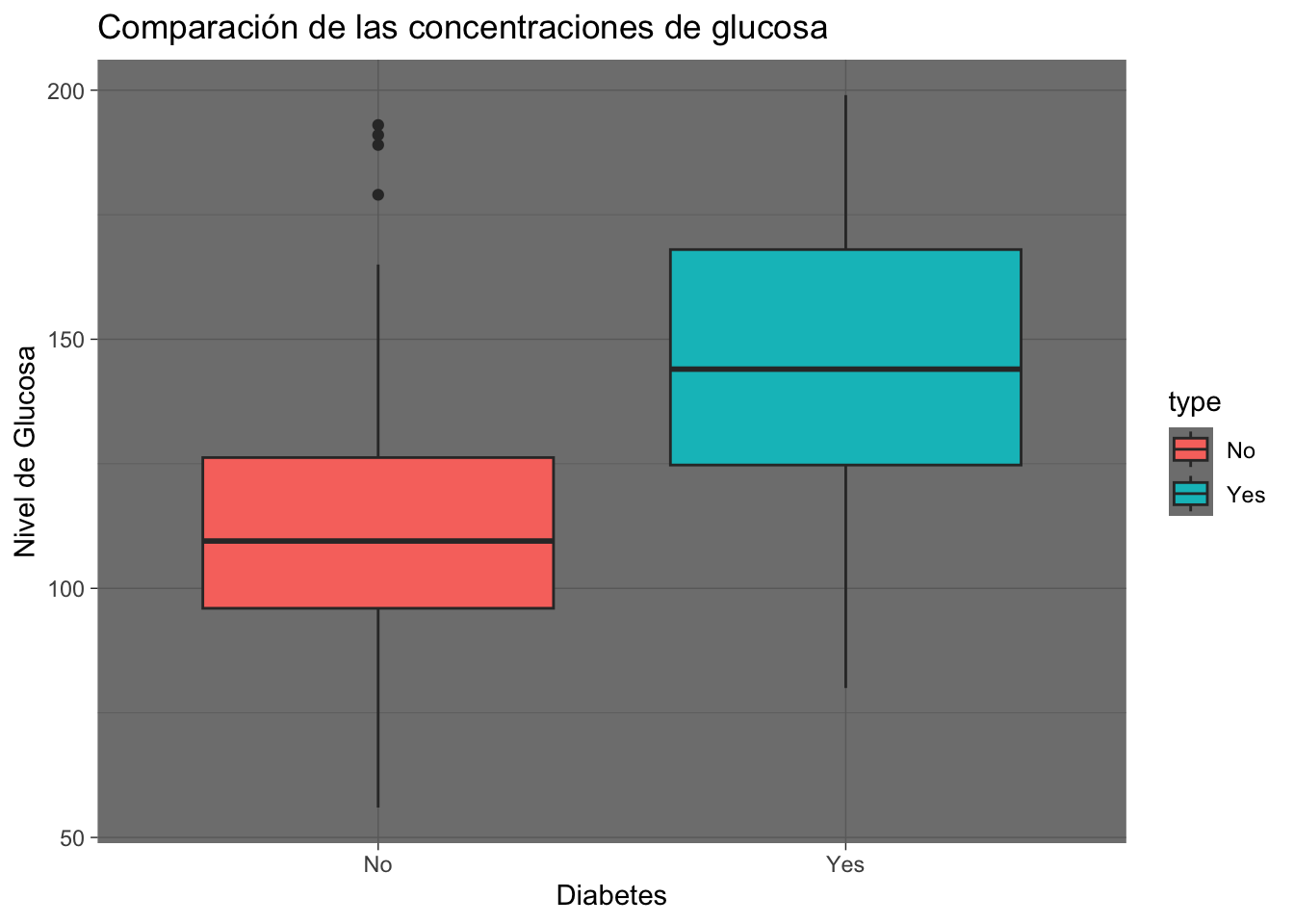
El código anterior, añadimos el argumento fill = type para aes los que nos permitió separar a las pacientes con y sin diabetes. El argumento fill en este caso colorea el interior de los boxplot, uno para las mujeres con diabetes y otro para las mujeres sin diabetes. Además, añadimos la geometría geom_boxplot y el tema dark mediante theme_dark
Si en el código anterior sustituimos el fill = type por col = type en lugar del interior se colorea el contorno de las figuras.
Pima.tr|>
ggplot(mapping = aes(x= type, y= glu, col = type))+
geom_boxplot()+
labs(title = "Comparación de las concentraciones de glucosa", x = "Diabetes", y = "Nivel de Glucosa") +
theme_dark()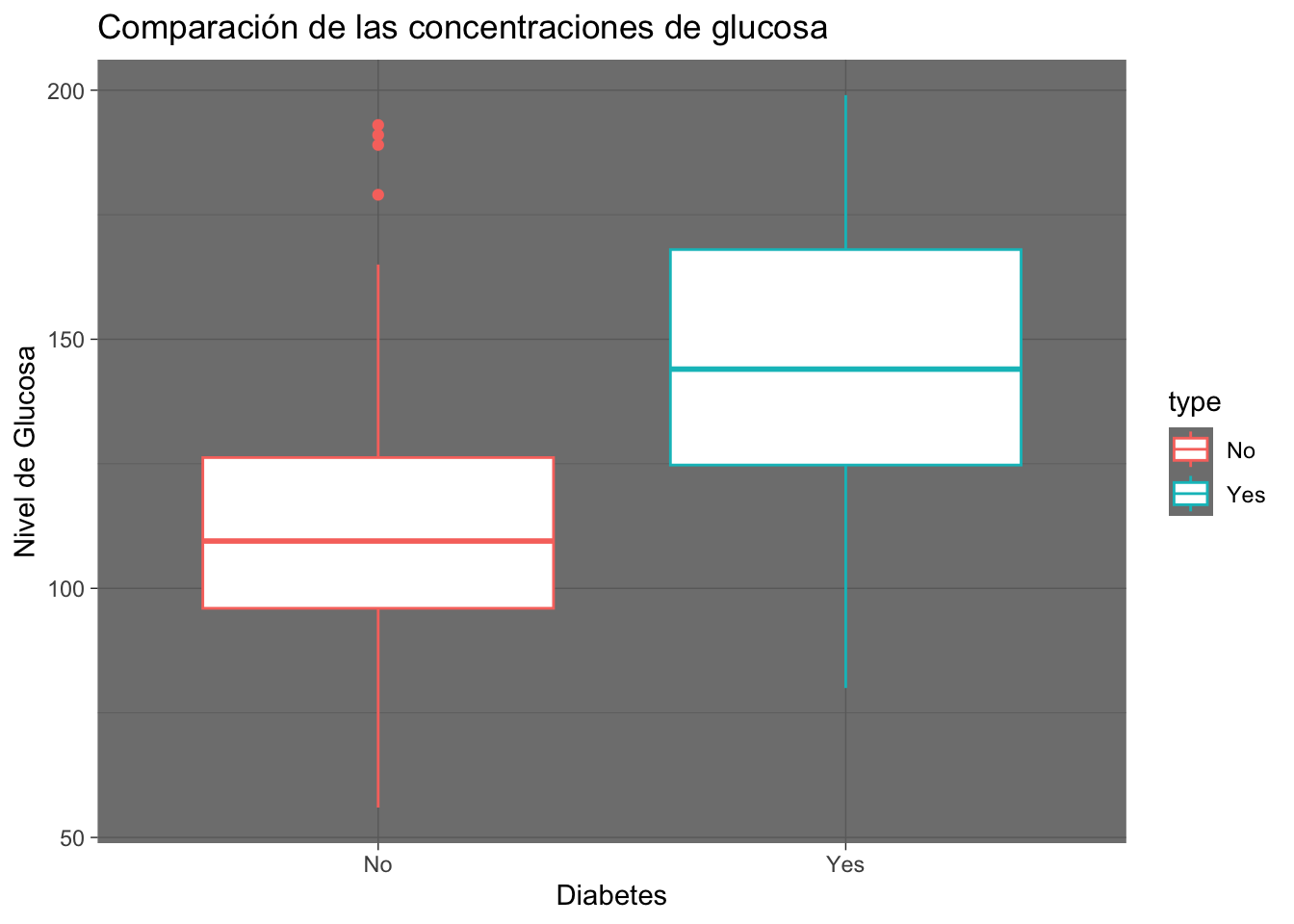
Vamos a combinar dos argumentos en aes lo cual nos permitirá tener dos agrupaciones una para fill y otra para col.
Pima.tr|>
ggplot(mapping = aes(x= type, y= glu, col = type, fill = as.factor(npreg)))+
geom_boxplot()+
labs(title = "Comparación de las concentraciones de glucosa", x = "Diabetes", y = "Nivel de Glucosa") +
theme_linedraw()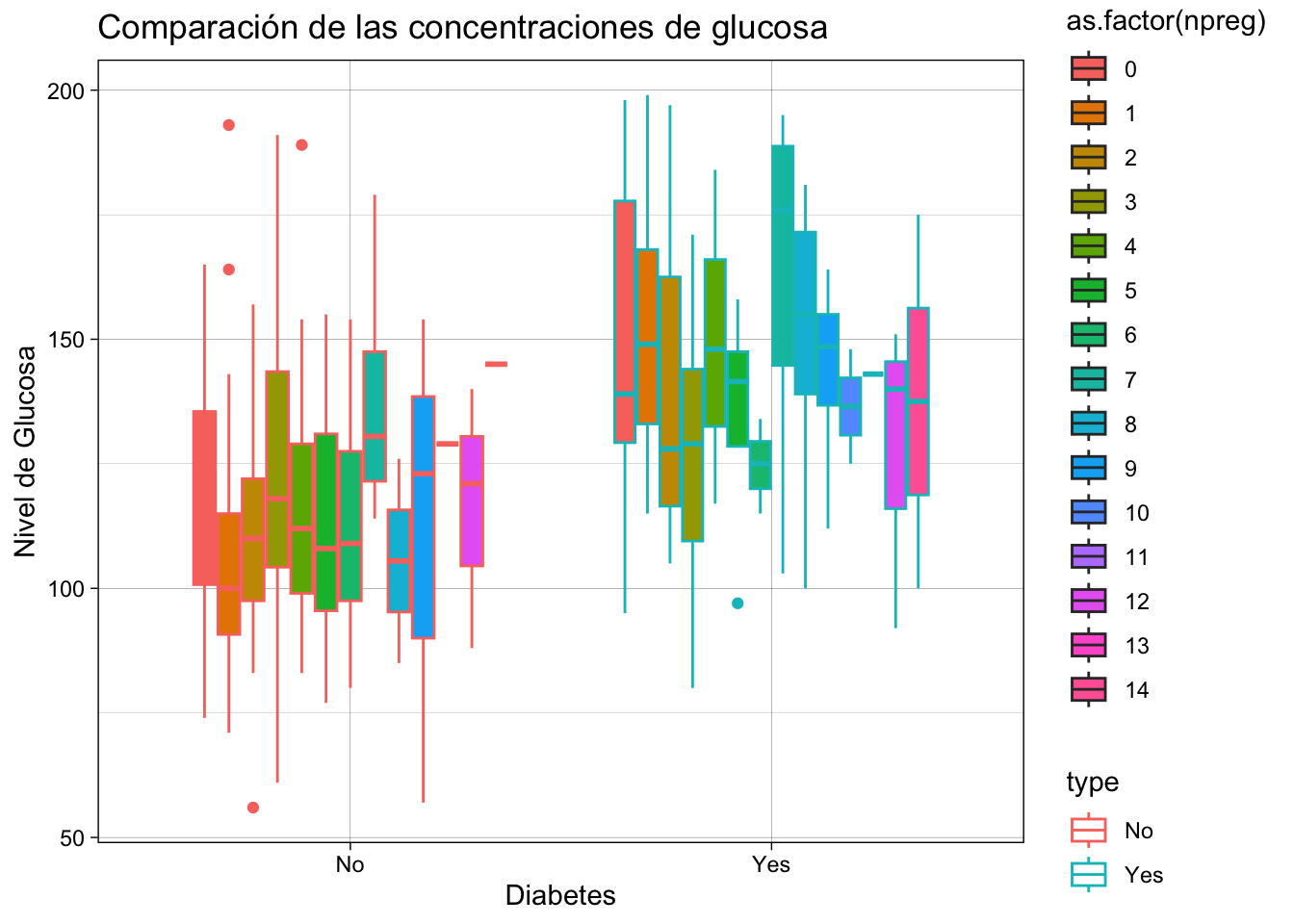
Este código nos permitió separar tanto por la variable type como para el número de embarazos
La última capa que nos falta por ejemplificar es la de coordinate la cual permite modificaciones en los ejes, por ejemplo, que se muestre el logaritmo de las concentraciones de glucosa en lugar de las concentraciones originales. La capa de coordenadas en ggplot2, manejada por funciones como coord_cartesian(), coord_fixed(), coord_flip(), coord_polar(), entre otras, se utiliza para ajustar la escala y los límites del área de dibujo, y para cambiar la forma en que los datos se proyectan en el gráfico. En este libro no se revisará esta capa ya que no se abordarán modificaciones sobre los ejes (salvo para la creación de gráficos de sectores).
8.6.1 Ejemplos de sintaxis en ggplot2
Scatter plots): Utilizados para mostrar la relación entre dos variables cuantitativas.
ggplot(data, aes(x = variable1, y = variable2)) +
geom_point()Gráficos de líneas (Line plots): Útiles para mostrar tendencias a lo largo del tiempo o de otra variable continua.
ggplot(data, aes(x = variable1, y = variable2)) +
geom_line()Gráficos de barras (Bar plots): Pueden ser utilizados tanto para datos categóricos como para datos continuos.
ggplot(data, aes(x = varible_factor, y = variable_numerica)) +
geom_bar(stat = "identity")Histogramas: Para visualizar la distribución de una variable continua.
ggplot(data, aes(x = variable_numerica)) +
geom_histogram()Box plots: Para mostrar la distribución de una variable continua a través de sus cuartiles y posibles valores atípicos.
ggplot(data, aes(x = varible_factor, y = variable_numerica)) +
geom_boxplot()Diagramas de violín: Combinan características de los diagramas de caja y los histogramas.
ggplot(data, aes(x = varible_factor, y = variable_numerica)) +
geom_violin()Diagramas de densidad: Para estimar la densidad de probabilidad de una variable continua.
ggplot(data, aes(x = variable_numerica)) +
geom_density()Diagramas de área: Similares a los gráficos de líneas pero con el área debajo de la línea rellenada.
ggplot(data, aes(x = variable1, y = variable2)) +
geom_area()Heatmaps: Para mostrar la intensidad de valores en una matriz.
ggplot(data, aes(x = variable1, y = variable2, fill = intensity_variable)) +
geom_tile()Gráficos de facetas (Faceted plots): Permiten dividir un gráfico en múltiples paneles según los niveles de una variable.
ggplot(data, aes(x = variable1, y = variable2)) +
geom_point() +
facet_wrap(~ varible_factor)Gráficos de burbujas (Bubble plots): Una extensión de los diagramas de dispersión donde el tamaño de los puntos refleja una tercera variable.
ggplot(data, aes(x = variable1, y = variable2, size = variable3)) +
geom_point()Gráficos de barras apiladas (Stacked bar plots): Para mostrar la composición de cada categoría.
ggplot(data, aes(x = varible_factor, y = variable_numerica, fill = variable_agrupacion)) +
geom_bar(stat = "identity", position = "stack")8.7 Ejercicios ?sec-Visualización
Ejercicio 8.1 Utilizando la base de datos base de datos birtwht de la librería MASSS realice un histograma con 10 intervalos de clase para la variable age. Cambie el color de las barras, agregue un título y rótulos en los ejes.
Resolución ejercicio ?exr-7_8
# Si lo requiere
library(MASS)
data("birthwt")hist(birthwt$age, breaks = 10,
main = "Histograma para la varible edad",
col = 1:10, xlab = "Intervalos de clase",
ylab = "Frecuencia")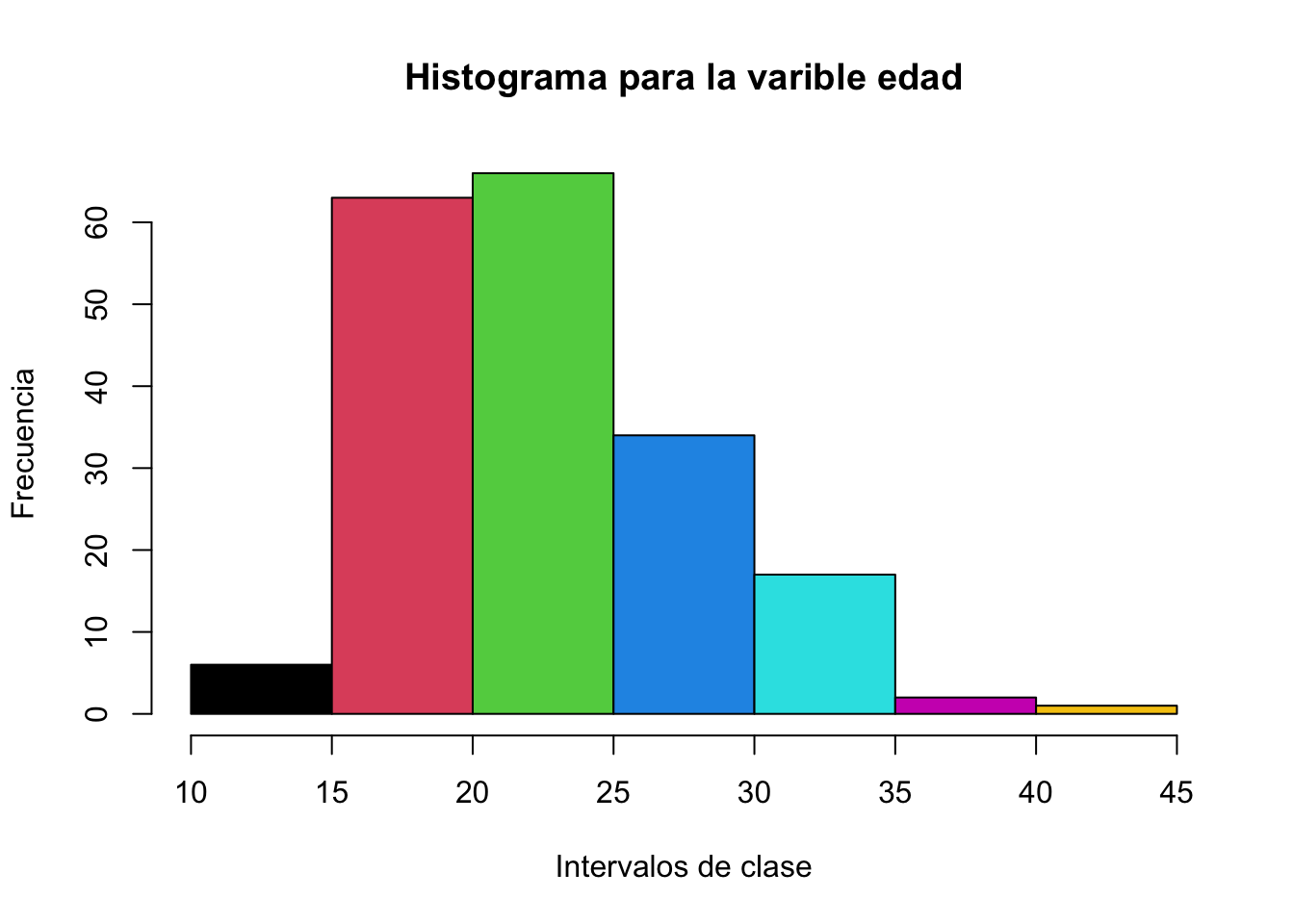
Ejercicio 8.2 Realice una gráfico de densidad para la variable bwt. Agregue un título y rótulos en los ejes.
Resolución ejercicio Ejercicio 8.2
density(birthwt$bwt)|>
plot(main = "Grafico de densidad para la variable bwt", col="cyan4",
ylab = "Densidad", xlab = "bwt")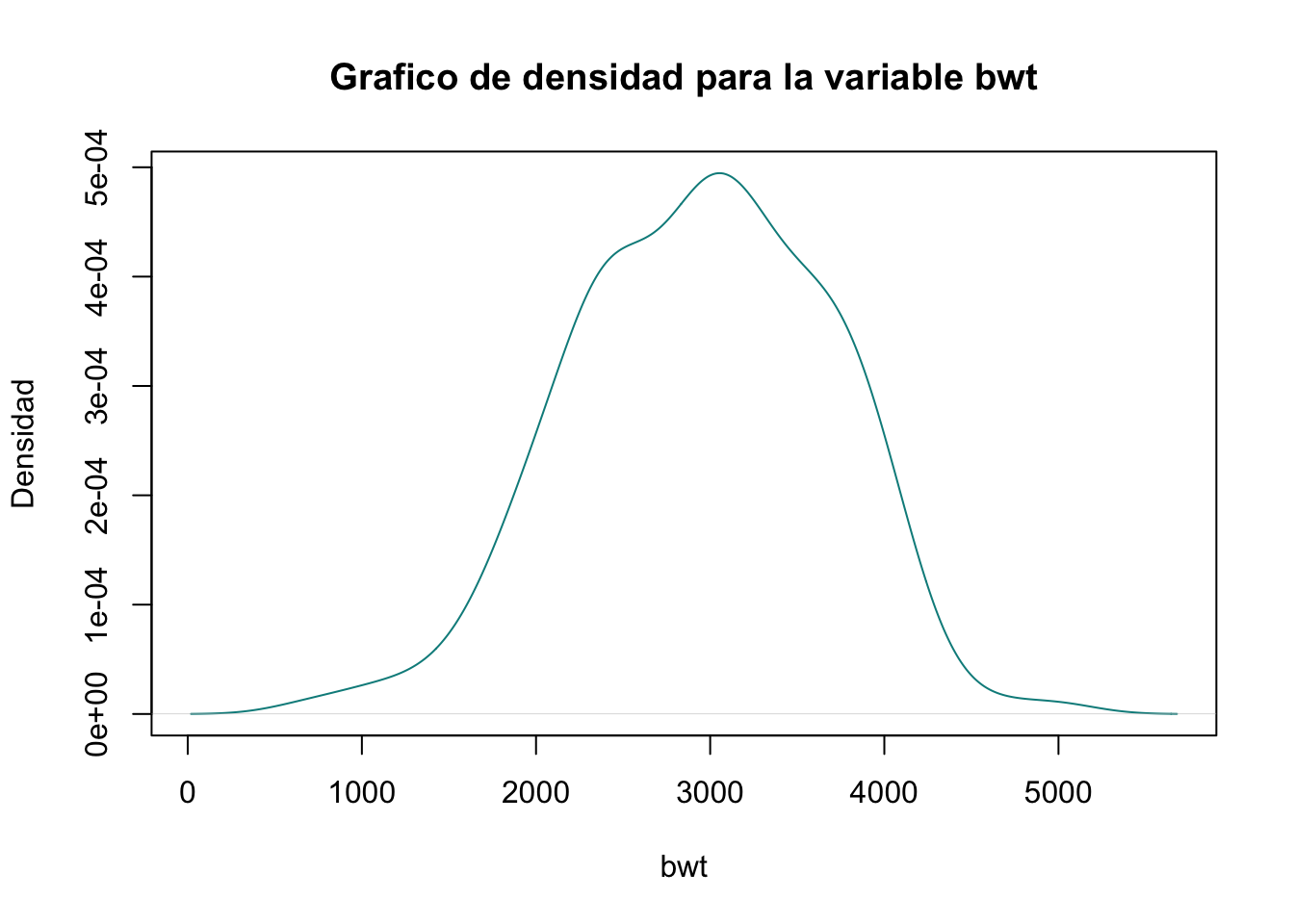
Ejercicio 8.3 Repita los ejercicios anteriores pero esta vez utilizando ggplot2
Resolución ejercicio Ejercicio 8.3
# Si es necesario
library(ggplot2)birthwt|>
ggplot(mapping = aes(x=age))+
geom_histogram(bins = 10, fill = 1:10)+
labs(title = "Histograma para la varaible age",
x = "Conteos",
y = "Intervalos de clase")+
theme_dark()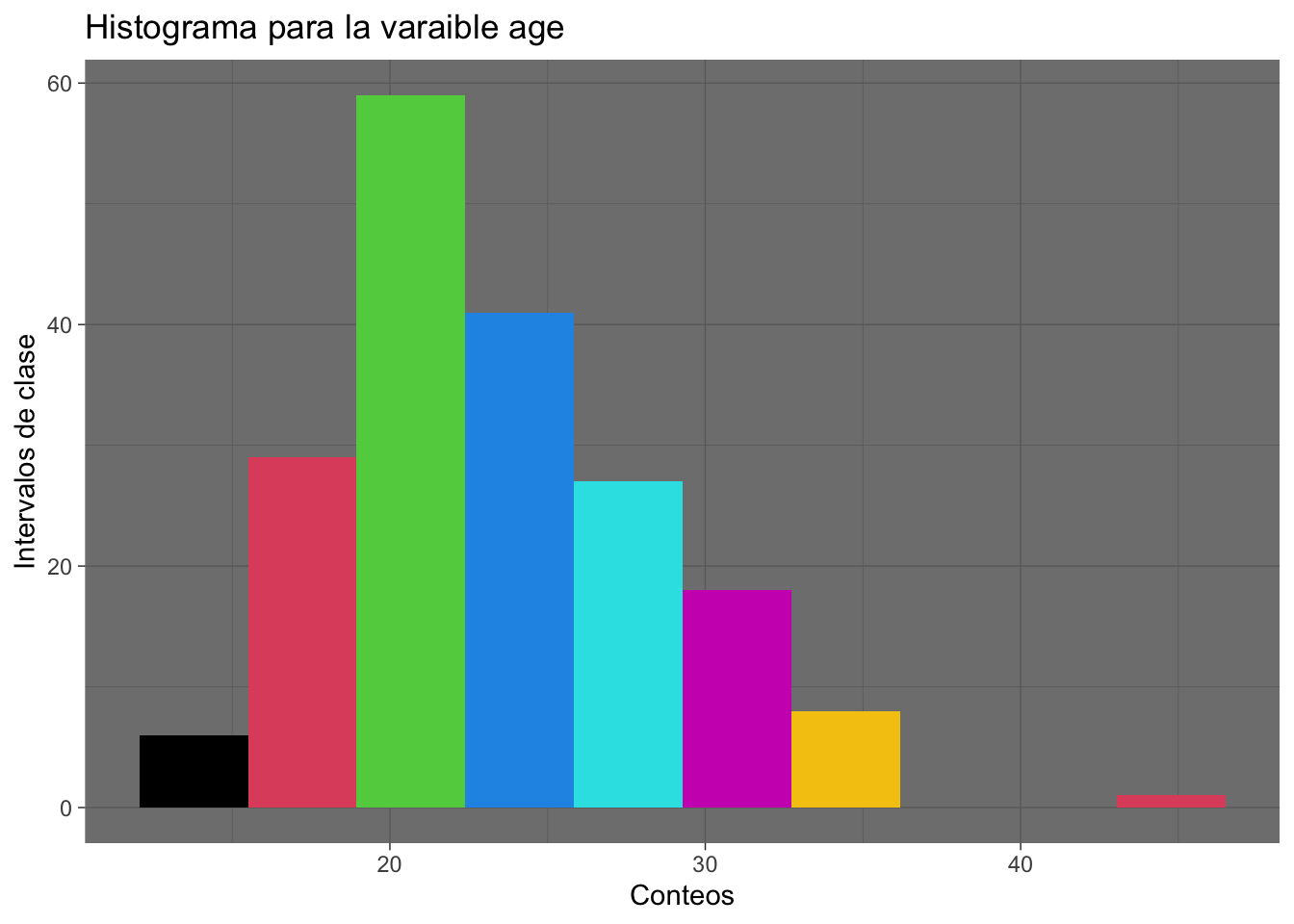
birthwt|>
ggplot(mapping = aes(x=age))+
geom_density()+
labs(title = "Grafico de densidad para la varaible age")+
theme_dark()
Ejercicio 8.4 Utilizando ggplot2 genere dos gráficos de densidad para la variable bwt (peso de los recién nacidos en g) de la base de datos birthwt separando a la madres que fumaron y las que no fumaron en el embarazo (variable somke). Uno de los gráficos deberá de hacer la división utilizando aes y otro mediante la capa faceta.
Resolución ejercicio Ejercicio 8.4
birthwt$smoke <- factor(birthwt$smoke,
labels = c("No fumó", "Si fumó"))
birthwt|>
ggplot(mapping = aes(x=bwt, col=smoke, fill = smoke))+
geom_density(alpha=0.5)+ # 1= sin transparencia
labs(title = "Grafico de densidad de las madres
que fumaron vs las madres que no fumaron",
x = "Peso de los recién nacidos en g")+
theme_minimal()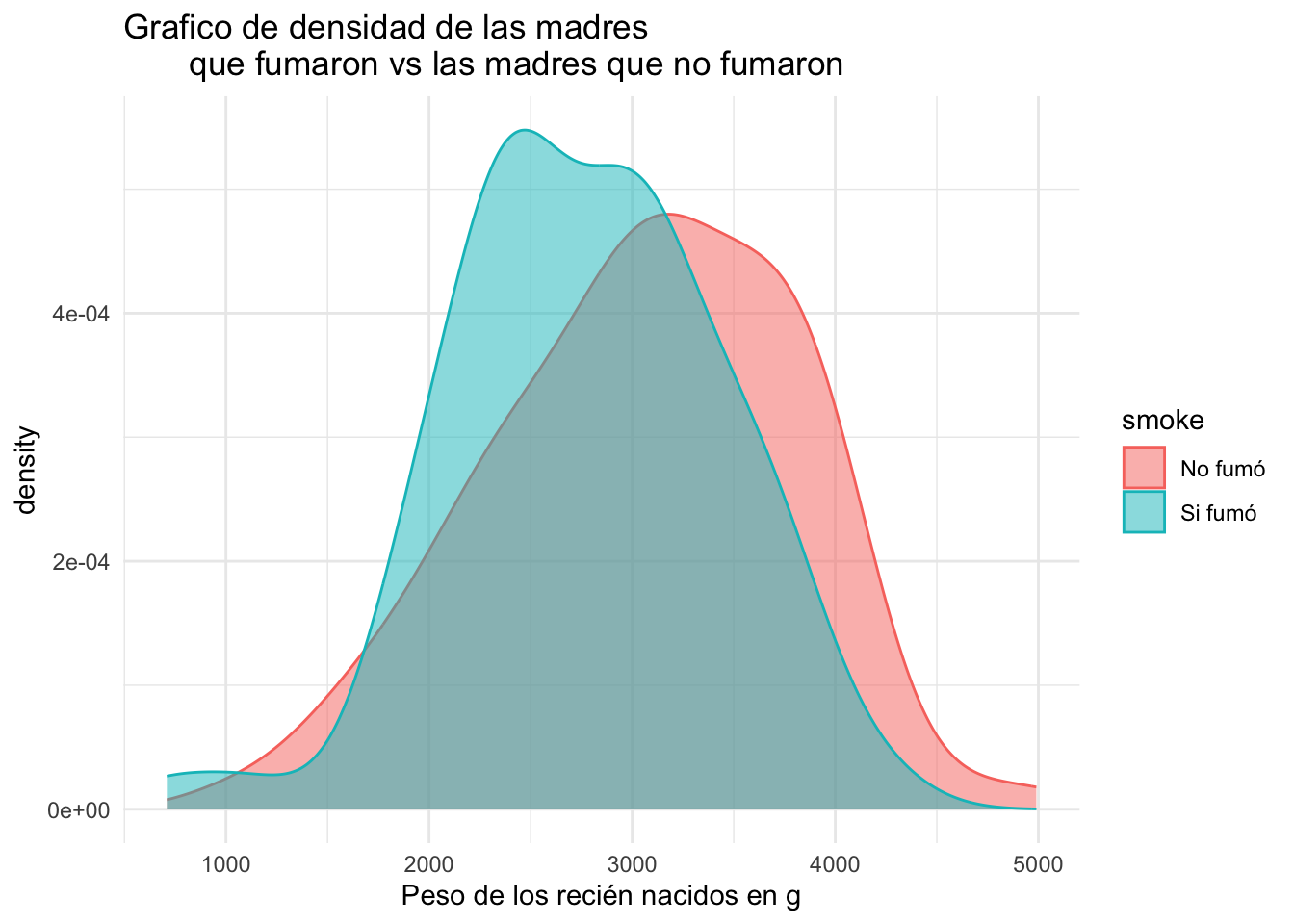
birthwt|>
ggplot(mapping = aes(x=bwt, fill=smoke))+
geom_density(alpha=0.5)+ # 1= sin transparencia
labs(title = "Grafico de densidad de las madres
que fumaron vs las madres que no fumaron",
x = "Peso de los recién nacidos en g")+
facet_grid(~smoke)+
theme_minimal()
Ejercicio 8.5 Realice un boxplot para la variable glu agrupada por la variable type. Utilice la base Pima.tr. Cambie colores y agregue títulos
Resolución ejercicio Ejercicio 8.5
library(MASS)
data("Pima.tr")
boxplot(Pima.tr$glu~Pima.tr$type,
main="Comparación de glucosa agrupo por la variable type",
col = c("#999999", "#E69F00"), xlab = "Grupos de estudio",
ylab = "Glucosa mg/dL")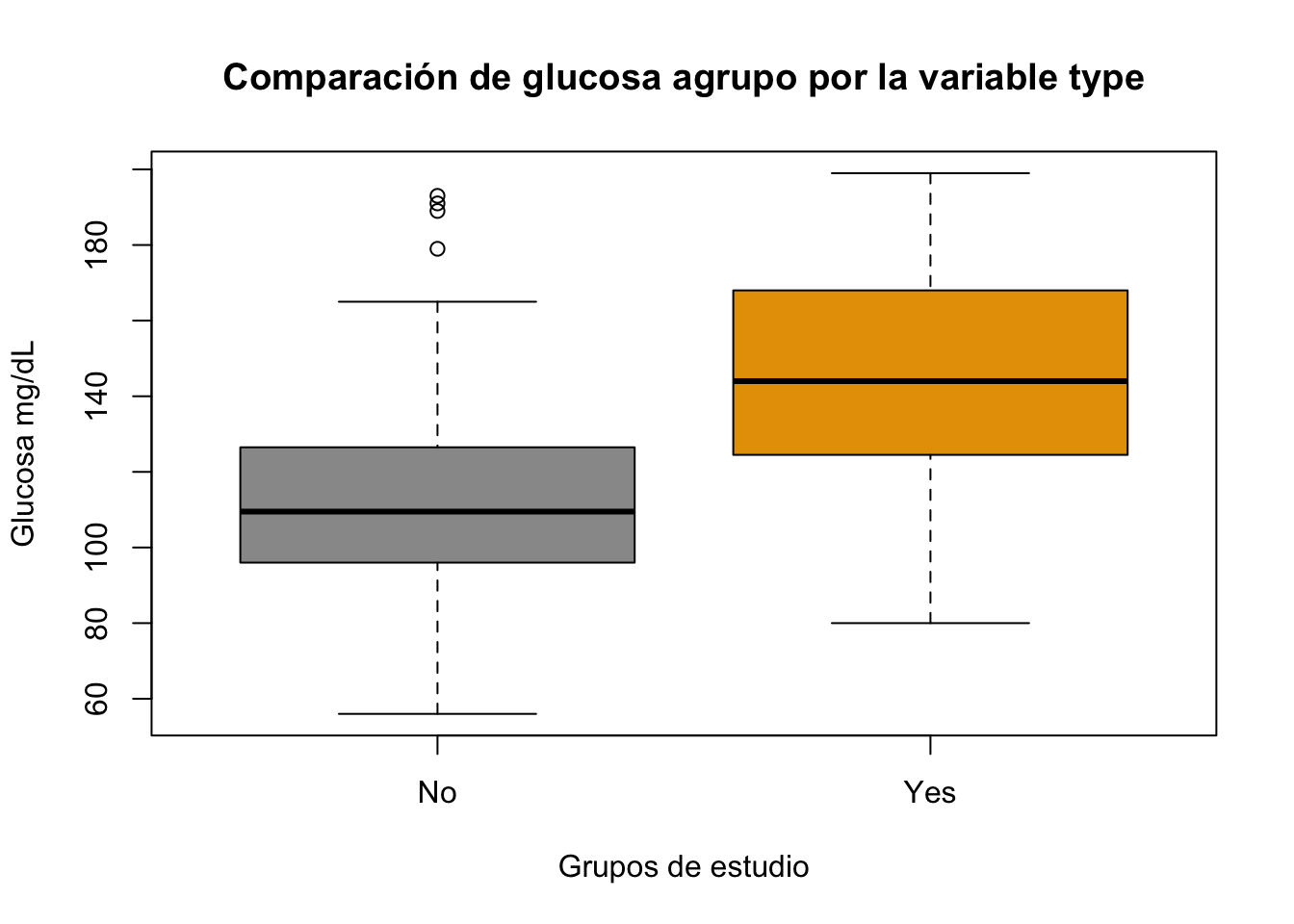
Ejercicio 8.6 Realice un boxplot para la variable skin agrupada por la variable type. Utilice la base Pima.tr. Cambie colores y agregue títulos
Resolución ejercicio Ejercicio 8.6
boxplot(Pima.tr$skin~Pima.tr$type,
main="Comparación de skin agrupo por la variable type",
col = c("#999999", "#E69F00"),
xlab = "Grupos de estudio", ylab = "skin")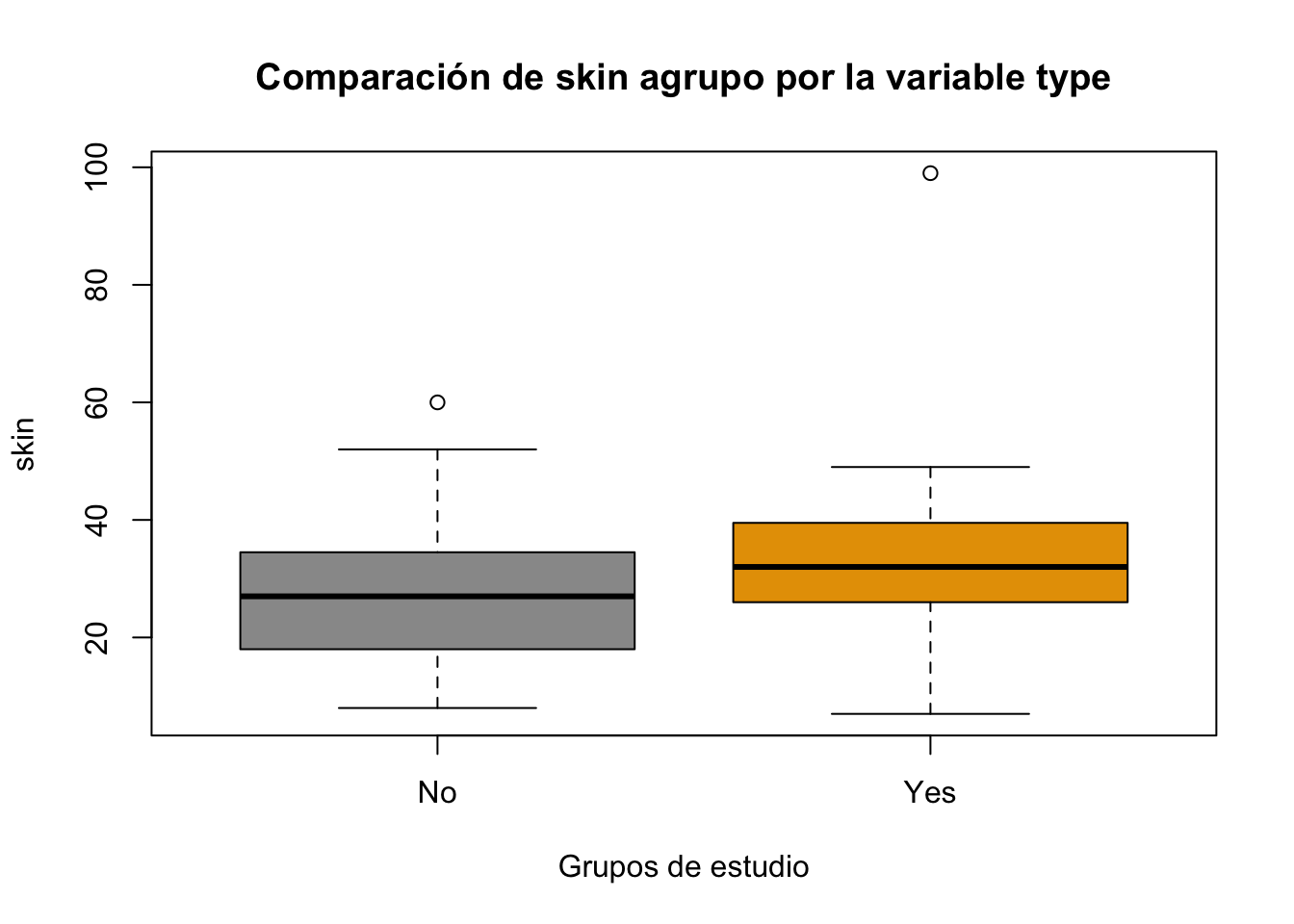
::: {.Exercise #exr-7_14}} Utilizando la base birthwt realice un boxplot en el que agrupe la edad de la madre (age) de acuerdo al antecedente de hipertensión (ht) y el antecedente de tabaquismo de la madre (smoke). :::
Resolución ejercicio ?exr-7_14
boxplot(birthwt$age~birthwt$ht*birthwt$smoke,
main="Comparación de la edad agrupad por ht y smoke",
col = c("#999999", "#E69F00"),
xlab = "Grupos de estudio", ylab = "Edad",
names=c("Hipertensión \n no smoke",
"Hipertensión \n smoke",
"No hipertensión \n no smoke",
"No hipertensión \n smoke"))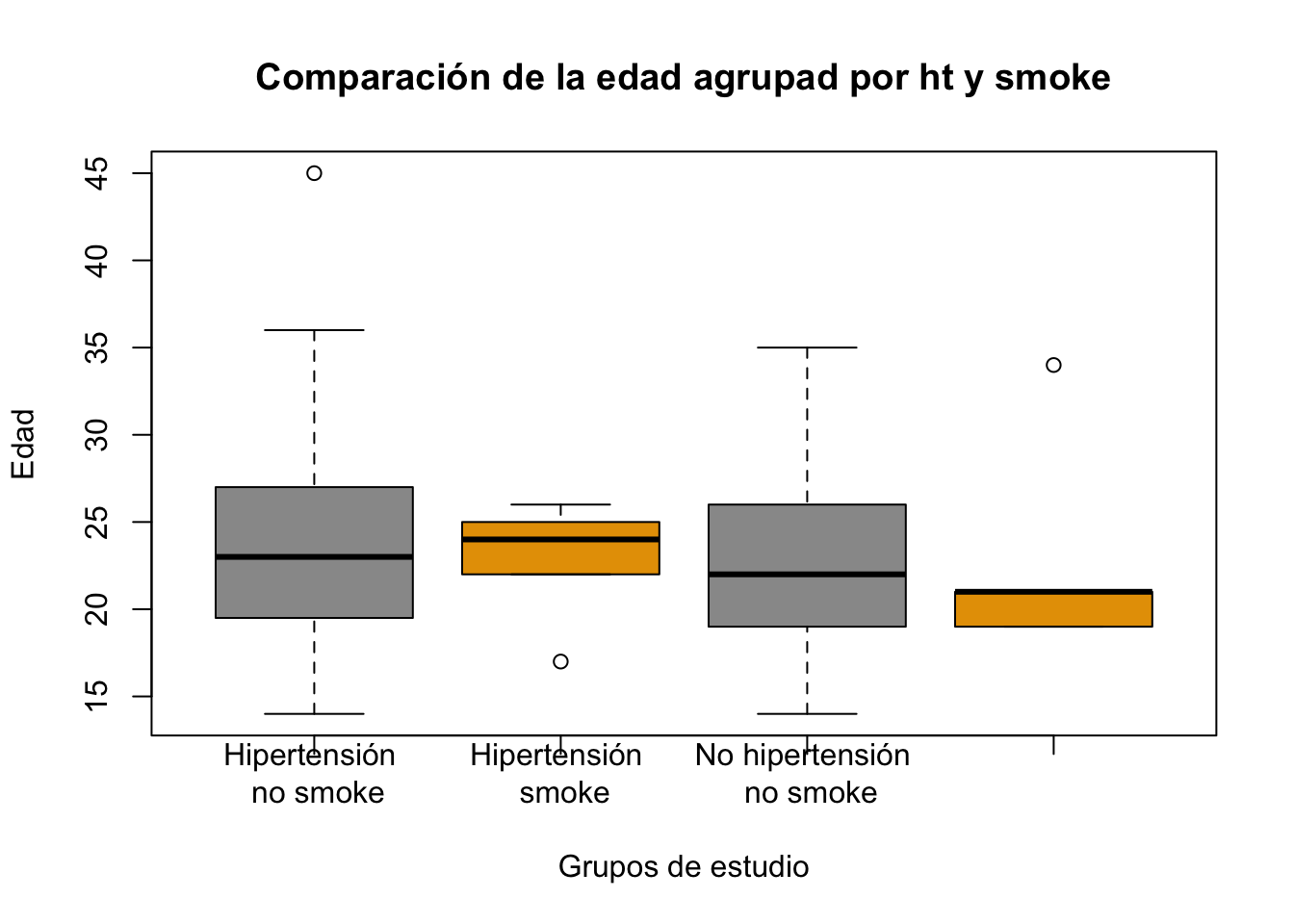
Ejercicio 8.7 Utilizando la base de datos vacunacion seleccione las primeras 50 filas para realizar un boxplot del total de pacientes total_vaccinations vacunados agrupado por el tipo de vacuna vaccine. ¿Tiene sentido hacer esta gráfica?
Resolución ejercicio Ejercicio 8.7
Vacunacion <- readxl::read_excel("Bases/Vacunacion.xlsx")
boxplot(total_vaccinations~vaccine, data = Vacunacion[1:50,])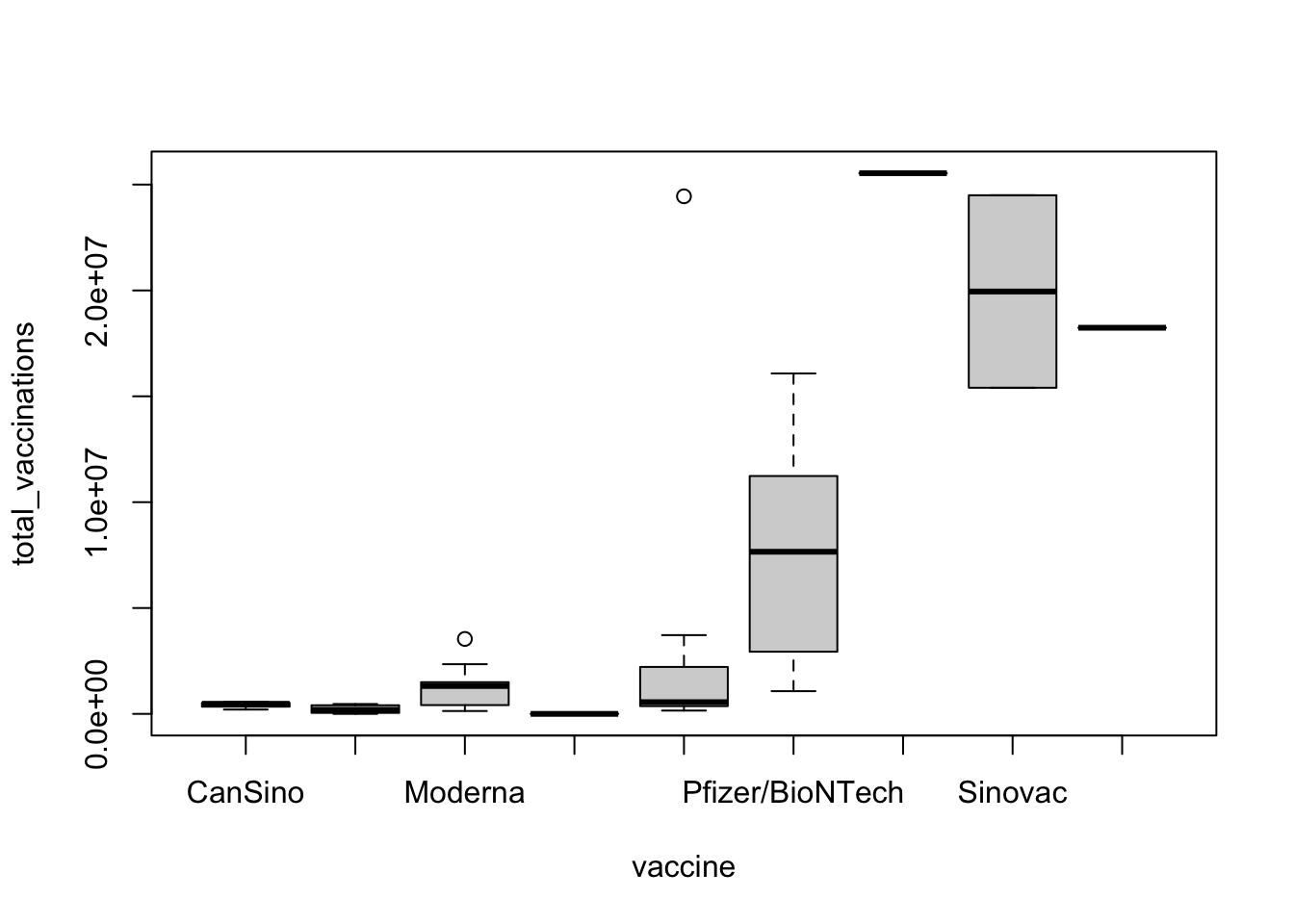
Ejercicio 8.8 Utilizando la base birthwt realice un boxplot en el que agrupe el peso de los recién nacidos(bwt) de acuerdo al antecedente de hipertensión (ht) y el antecedente de tabaquismo de la madre (smoke). Esta vez realice el ejercicio utilizando ggplot2, cambien títulos y rótulos de los ejes
Resolución ejercicio Ejercicio 8.8
birthwt$smoke <- factor(birthwt$smoke,
labels = c("No fumó", "Si fumó"))
birthwt$ht <- factor(birthwt$ht,
labels = c("Sin HTA", "HTA"))
birthwt|>
ggplot(mapping = aes(x=smoke, y=bwt, fill=ht))+
geom_boxplot()+
labs(title = "Comparación de la edad agrupado por ht y smoke",
x = "Antecdente de tabaquismo",
y = "Peso del recién nacido en g")+
theme_minimal()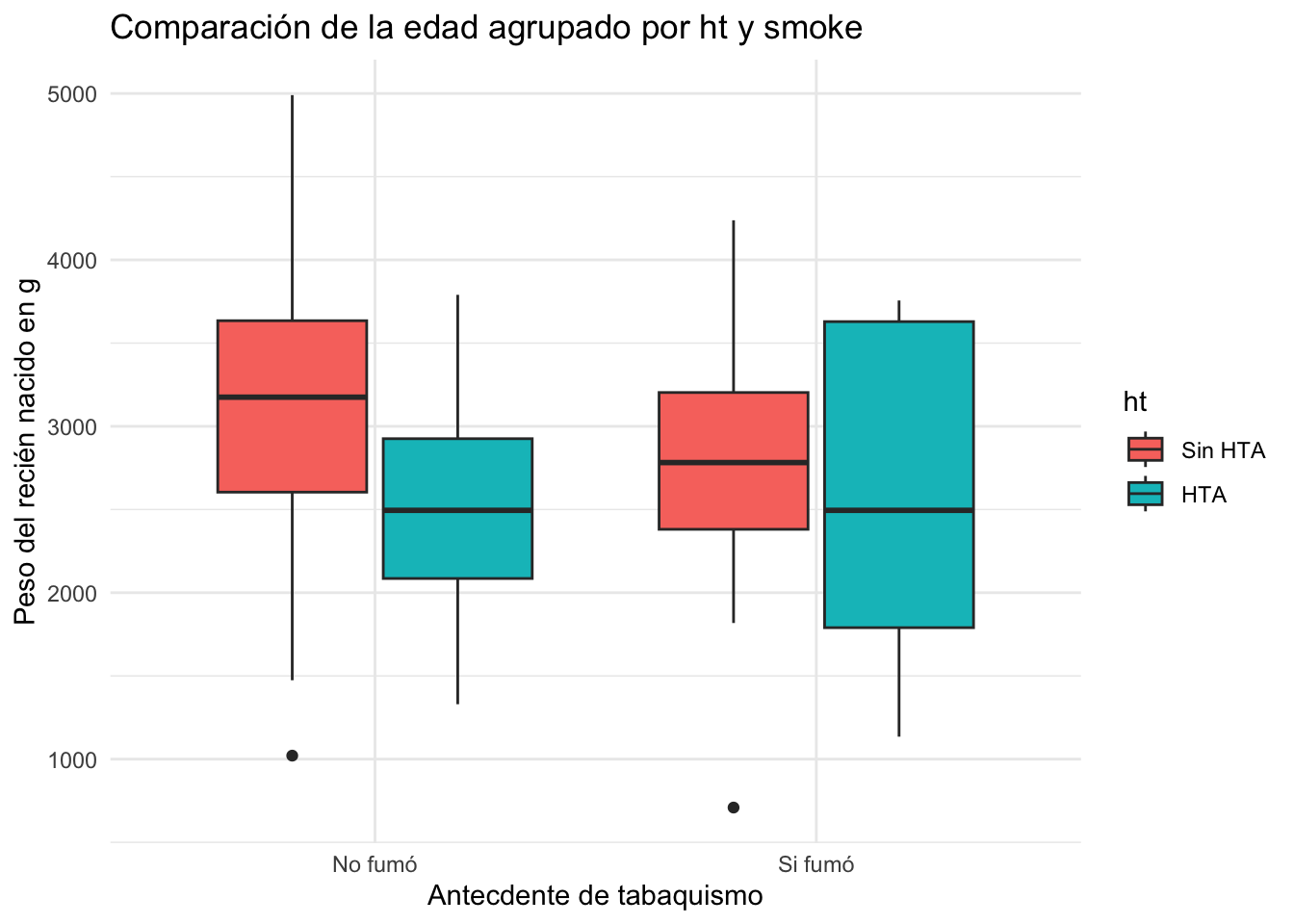
Ejercicio 8.9 Realice un gráfico de violín para la variable glu agrupada por la variable type. Utilice la base Pima.tr. Cambie colores y agregue títulos, utilice R basey luego ggplot2.
Resolución ejercicio Ejercicio 8.10
library(MASS)
data("Pima.tr")vioplot::vioplot(Pima.tr$glu~Pima.tr$type,
main="Comparación de glucosa agrupo por la variable type",
col = c("#999999", "#E69F00"),
xlab = "Grupos de estudio", ylab = "Glucosa mg/dL")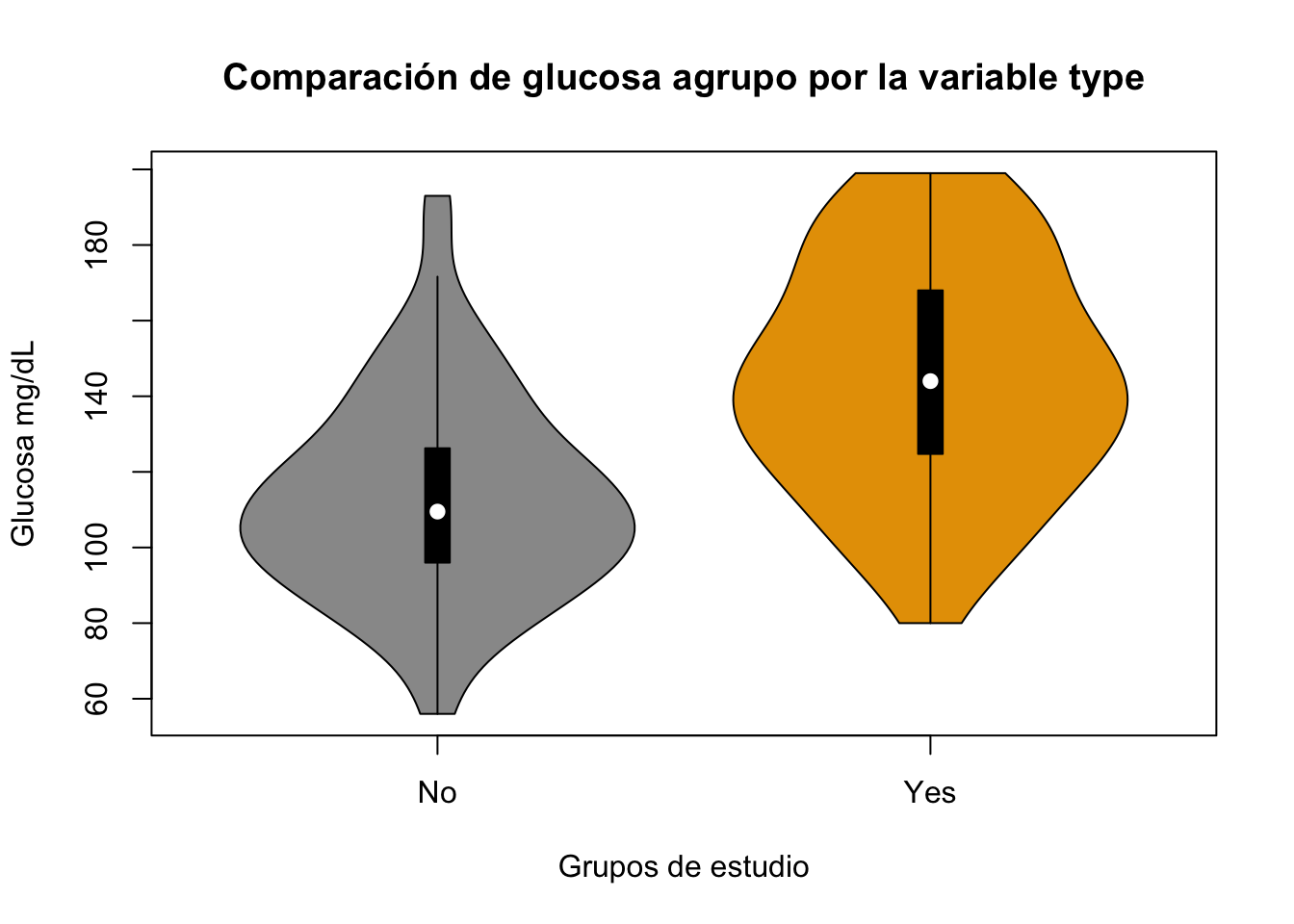
El símbolo :: permite acceder a las funciones de una librería sin necesidad de cargarla en el ambiente de trabajo. Para Este ejemplo, accedimos a la función vioplot() de la librería vioplot.
Pima.tr|>
ggplot(mapping = aes(x=type, y=glu))+
geom_violin(aes(col=type, fill=type, alpha = 0.5))+
geom_boxplot(aes(fill=type))+
theme_minimal()+
labs(title ="Comparación de glucosa agrupo por la variable type",
x = "Grupos",
y = "Glucosa (mg/dL)")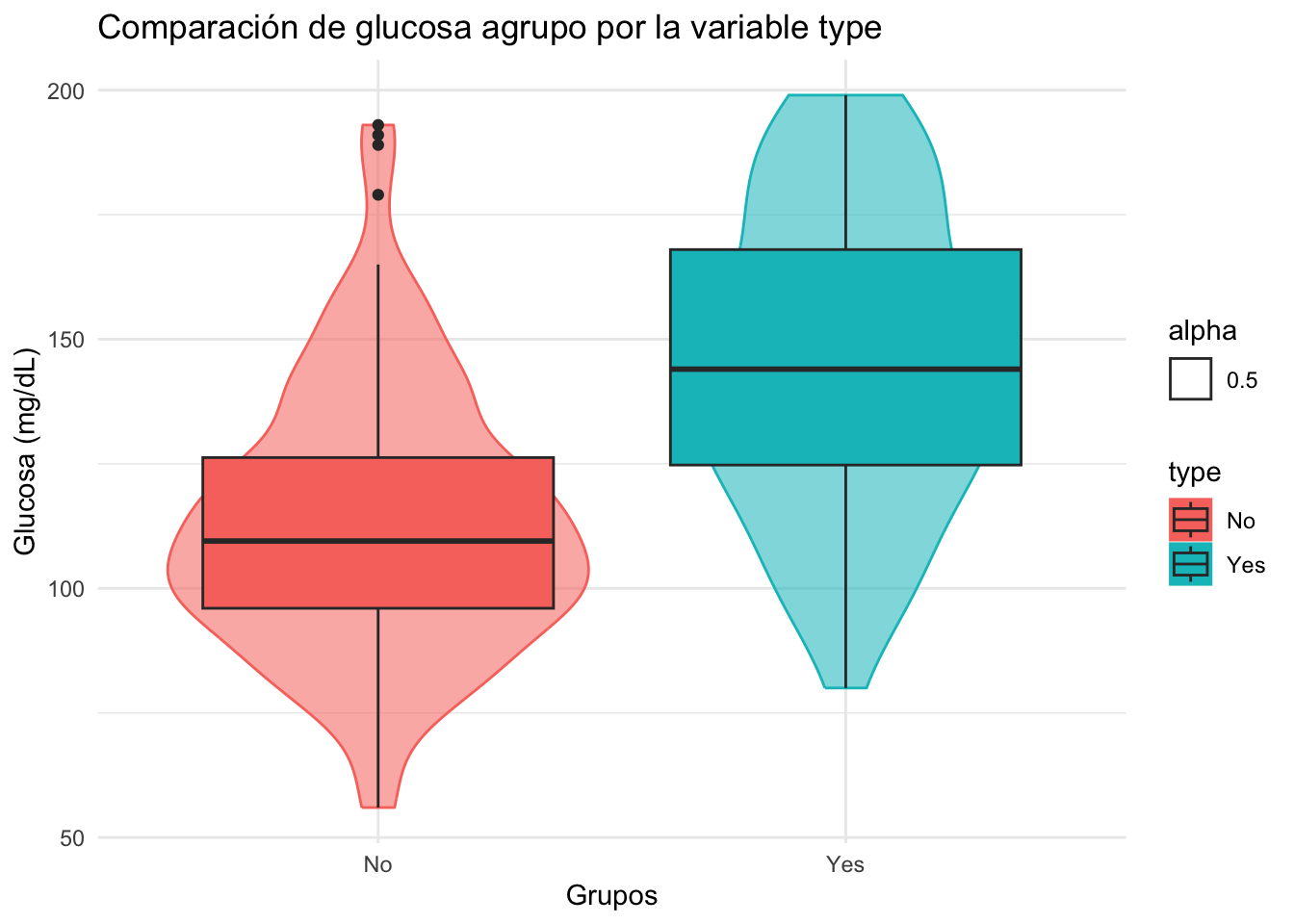
Ejercicio 8.10 Realice un gráfico de violín para la variable skin agrupada por la variable type. Utilice la base Pima.tr. Cambie colores y agregue títulos, utilice R base
Resolución ejercicio Ejercicio 8.10
vioplot::vioplot(Pima.tr$skin~Pima.tr$type,
main="Comparación de skin agrupo por la variable type",
col = c("#999999", "#E69F00"),
xlab = "Grupos de estudio", ylab = "skin")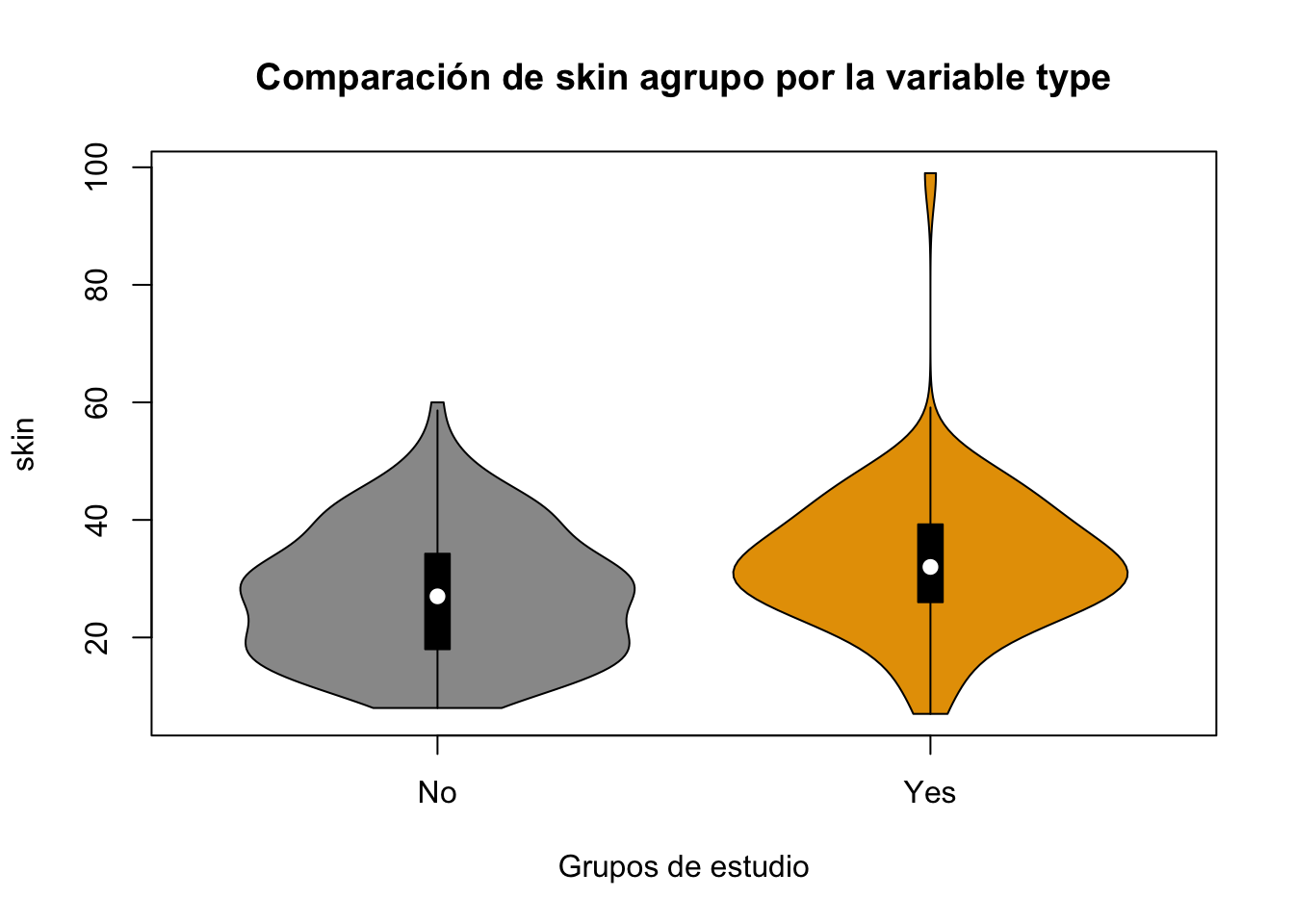
Ejercicio 8.11 Utilizando la base birthwt realice un gráfico de violín en el que agrupe la edad de la madre (age) de acuerdo al antecedente de hipertensión (ht) y el antecedente de tabaquismo de la madre (smoke)
vioplot::vioplot(birthwt$age~birthwt$ht*birthwt$smoke,
main="Comparación de la edad agrupad por ht y smoke",
col = c("#999999", "#E69F00"), xlab = "Grupos de estudio", ylab = "Edad",
names=c("Hipertensión \n no smoke", "Hipertensión \n smoke",
"No hipertensión \n no smoke", "No hipertensión \n smoke"))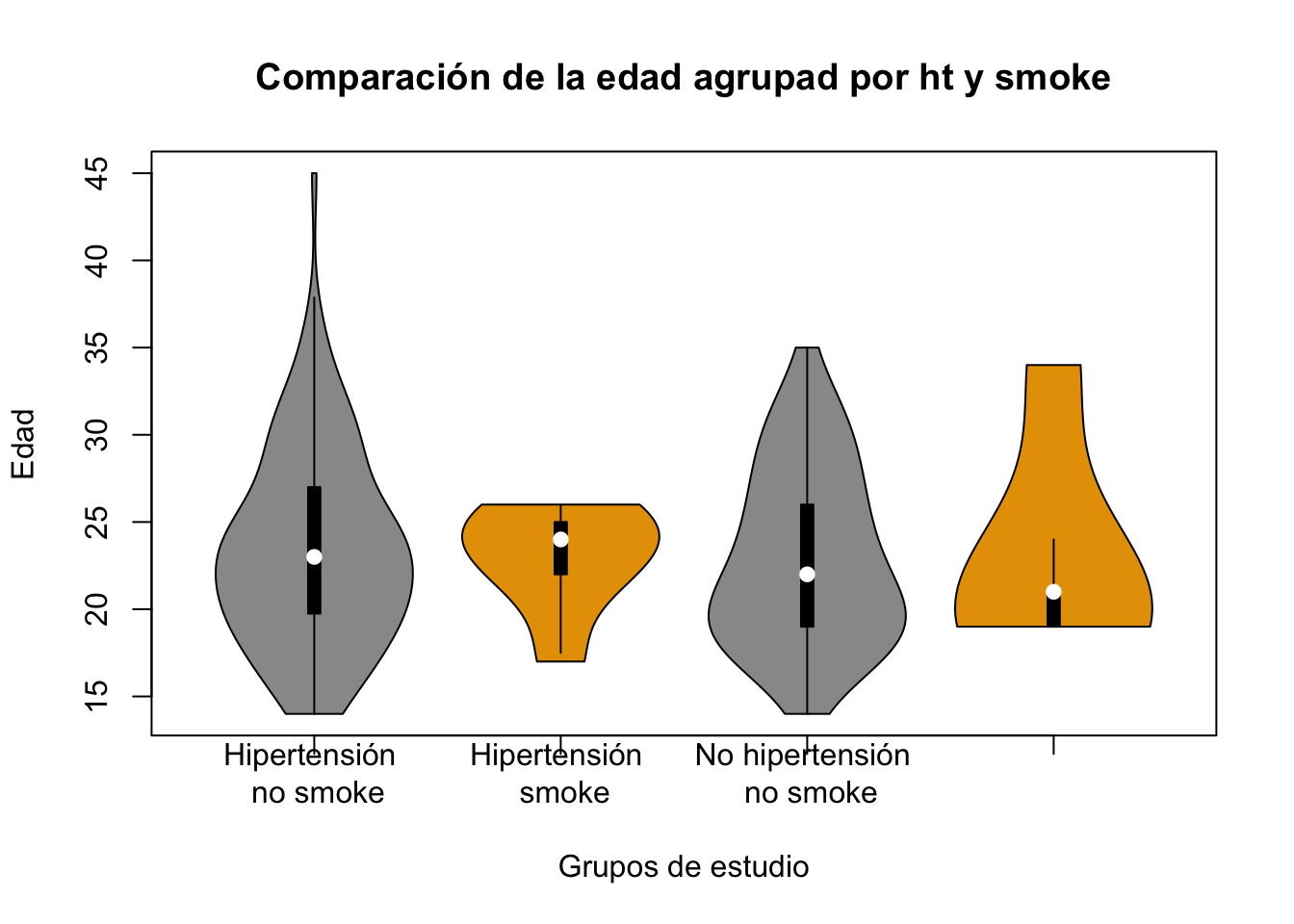
Ejercicio 8.12 Utilizando la base de datos Cushings de la librería MASS genere un gráfico de barras y otro de sectores para la variable Type. Cambie los colores, títulos de los ejes y el gráfico.
Resolución ejercicio Ejercicio 8.12
library(MASS)
data(Cushings)
# Crear paleta de colores
colores <- c("#fd7f6f", "#7eb0d5", "#b2e061", "#bd7ebe", "#ffb55a", "#ffee65", "#beb9db", "#fdcce5", "#8bd3c7")
table(Cushings$Type)->tab # Objeto con los conteos
barplot(tab, col = colores,
ylab = "Frecuencia",
xlab = "Tipo de Cushing",
main ="Frecuencia de los tipos de Cushings")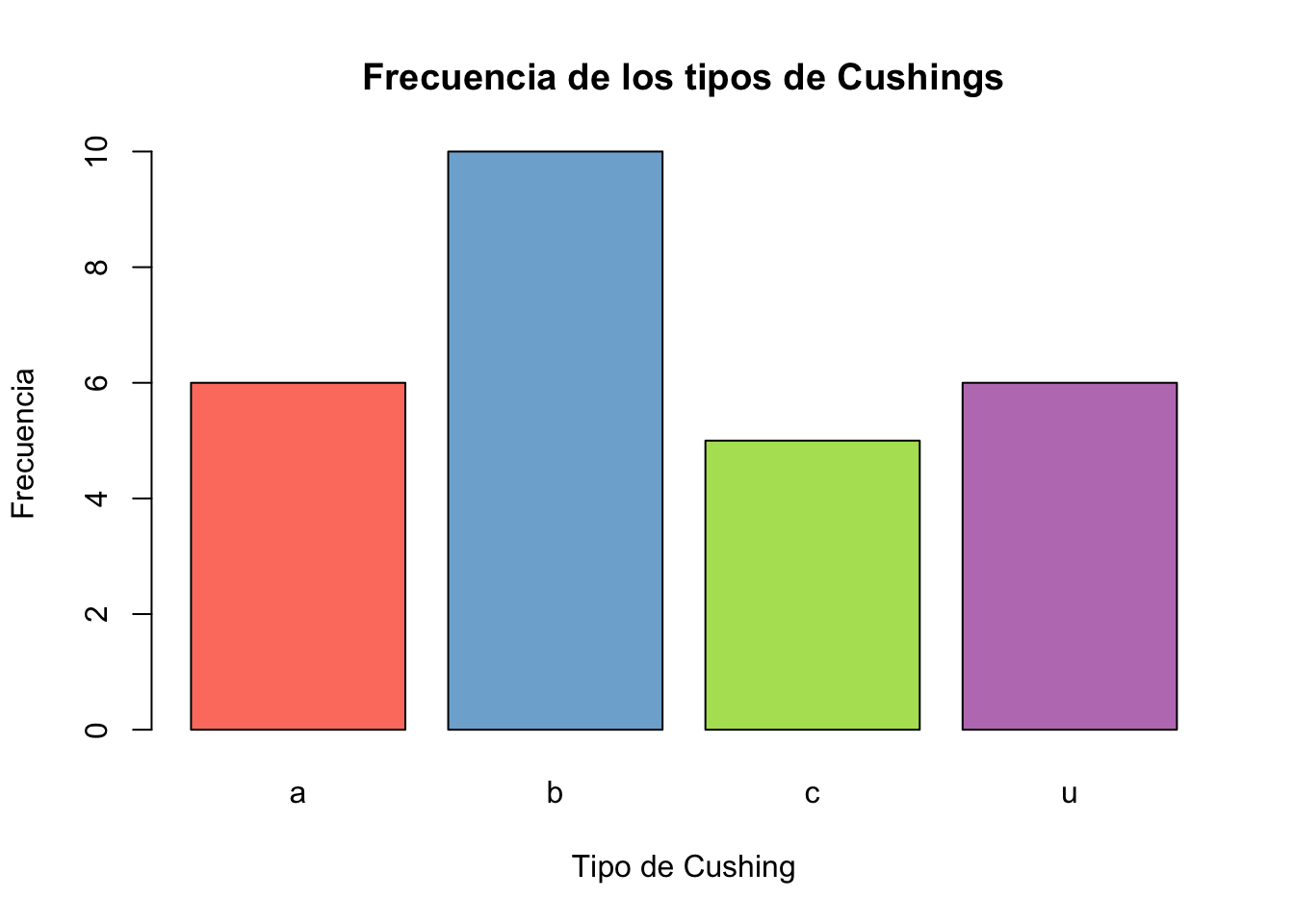
pie(tab,
col = colores,
main="Frecuencia de los tipos de Cushings")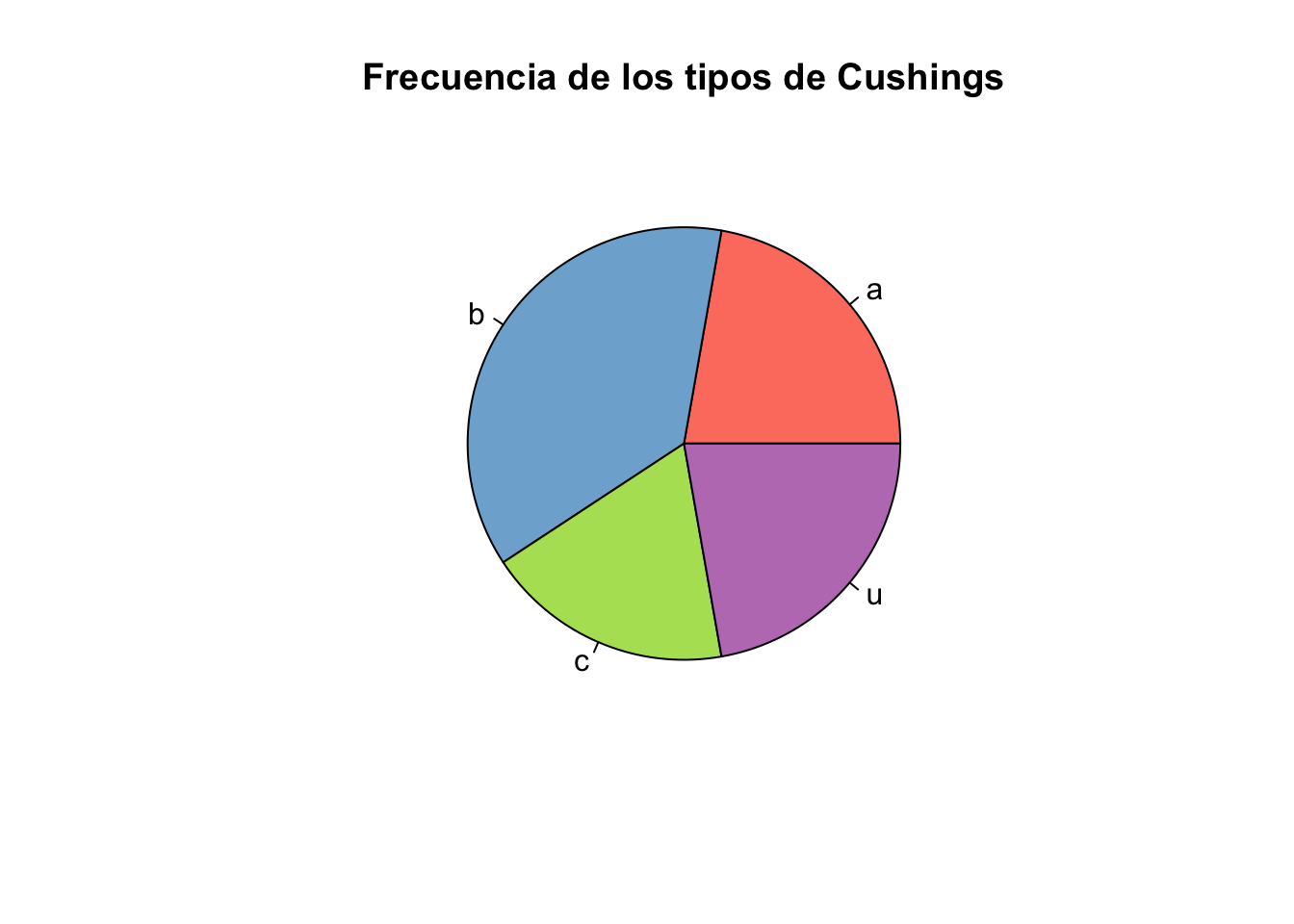
Ejercicio 8.13 Repita el ejercicio anterior pero esta vez utilizando ggplot2
Resolución ejercicio ?exr-7_2
# Si es necesario
library(MASS)
data("Cushings")
library(ggplot2)Cushings|>
ggplot(mapping = aes(x=Type, fill = Type))+
geom_bar()+
labs(title = "Gráfico de barras para el tipo de Cushing",
x = "Conteos",
y = "Tipo de Cushing")+
theme_bw()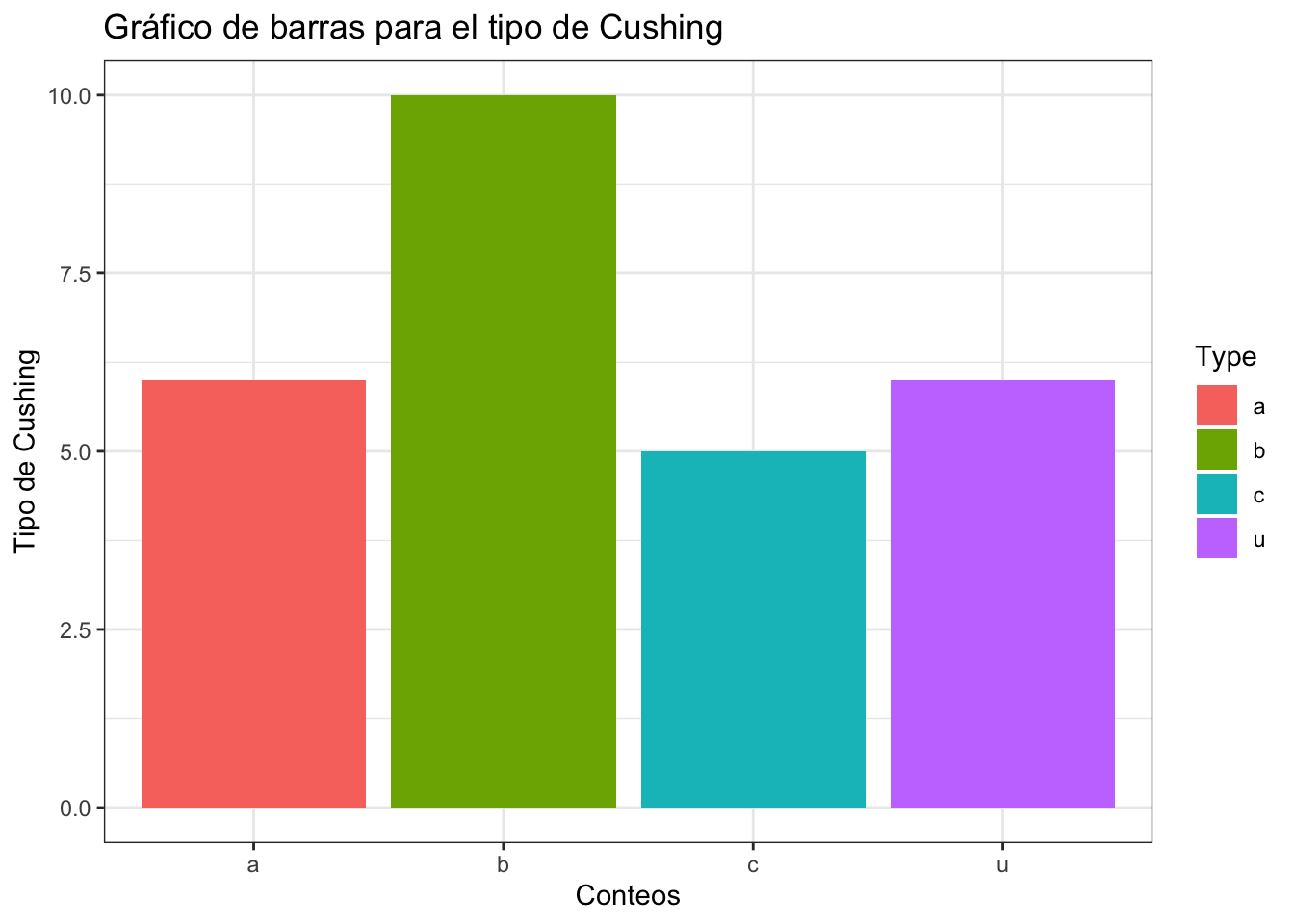
La creación de un gráfico de sectores utilizando ggplot2 es un tanto laboriosa, lo primero que se tiene que relizar es tener un Dataframe con los conteos de tipo de cushing en un variable y otra con el tipo de cushing
Tabla_conteos <- data.frame(
Tipo= c("a", "b", "c", "u"),
Conteo= c(6,10,5,6)
)
Tabla_conteos|>
ggplot(mapping = aes(x="", y=Conteo, fill = Tipo))+
geom_bar(stat="identity", width=1) +
coord_polar("y", start=0)+
labs(title = "Gráfico de sectores para el tipo de Cushing",
x = "Conteos",
y = "Tipo de Cushing")+
theme_bw()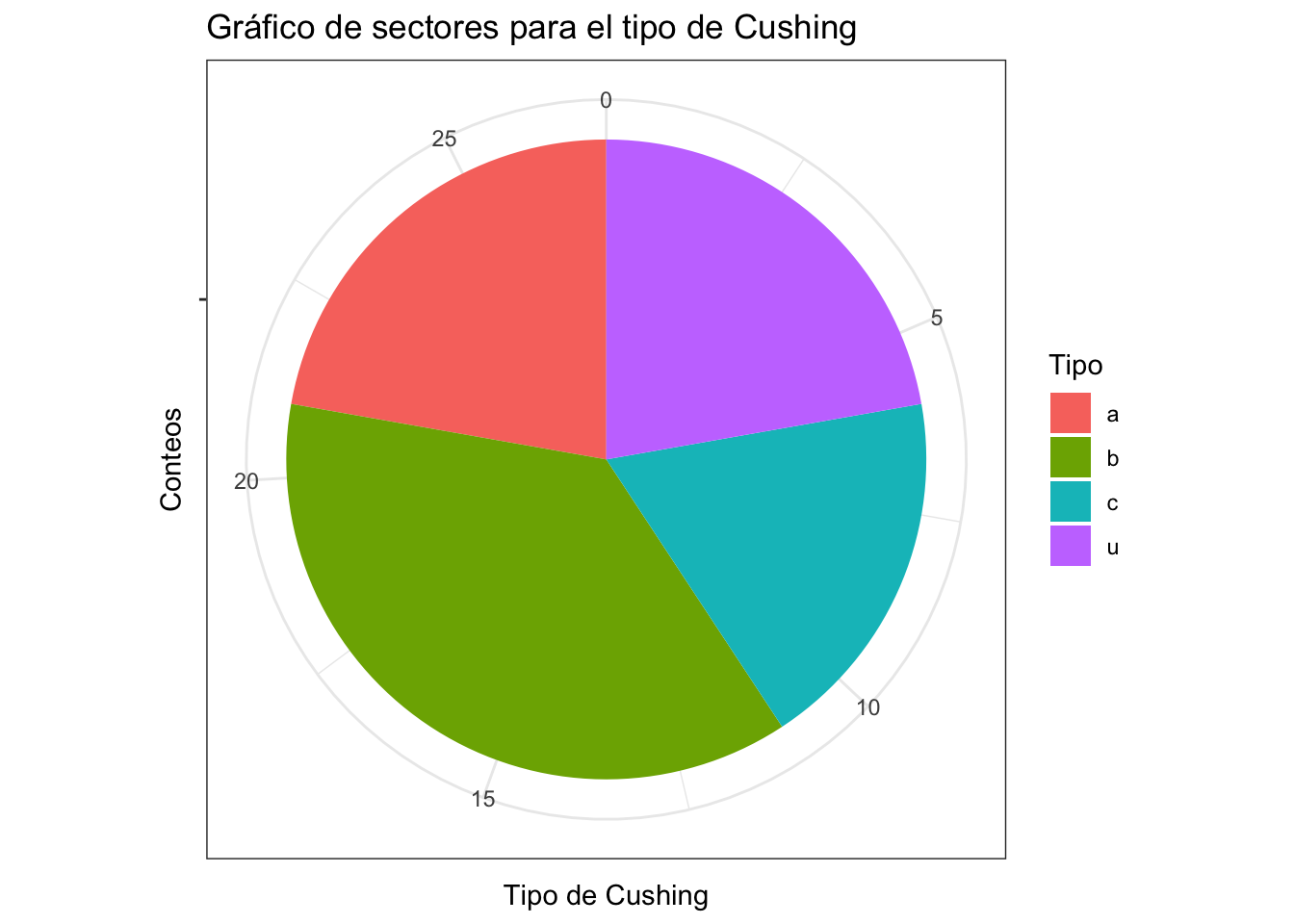
Ejercicio 8.14 Utilizando la base de datos birthwt de la librería MASS genere un gráfico de barras y otro de sectores para la variable race.
Resolución ejercicio Ejercicio 8.14
data("birthwt")
table(birthwt$race)->tab1
barplot(tab1, col=colores,
xlab="Étnia",
ylab="Frecuencias",
main="Étnia de las pacientes")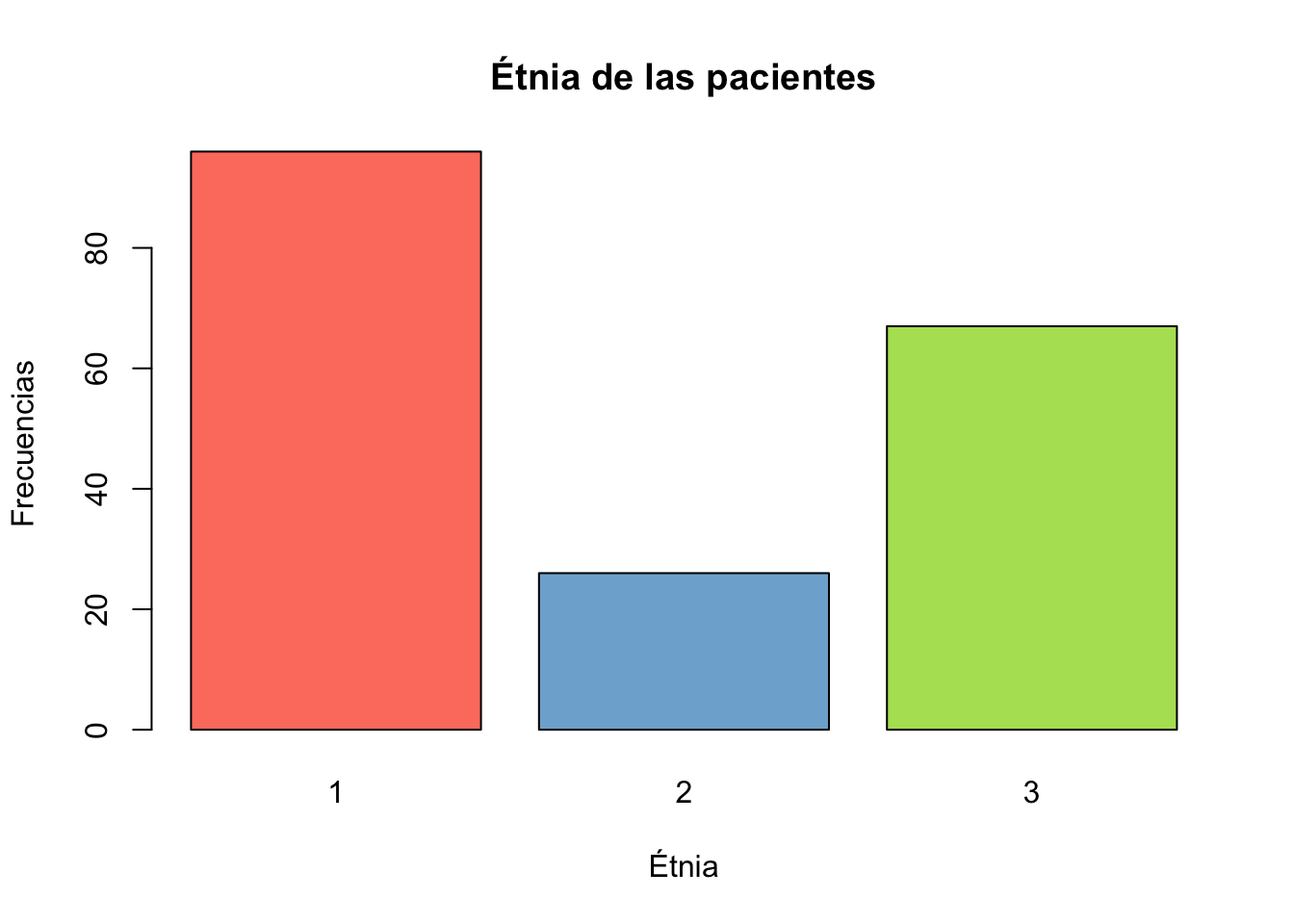
pie(tab1, col = colores)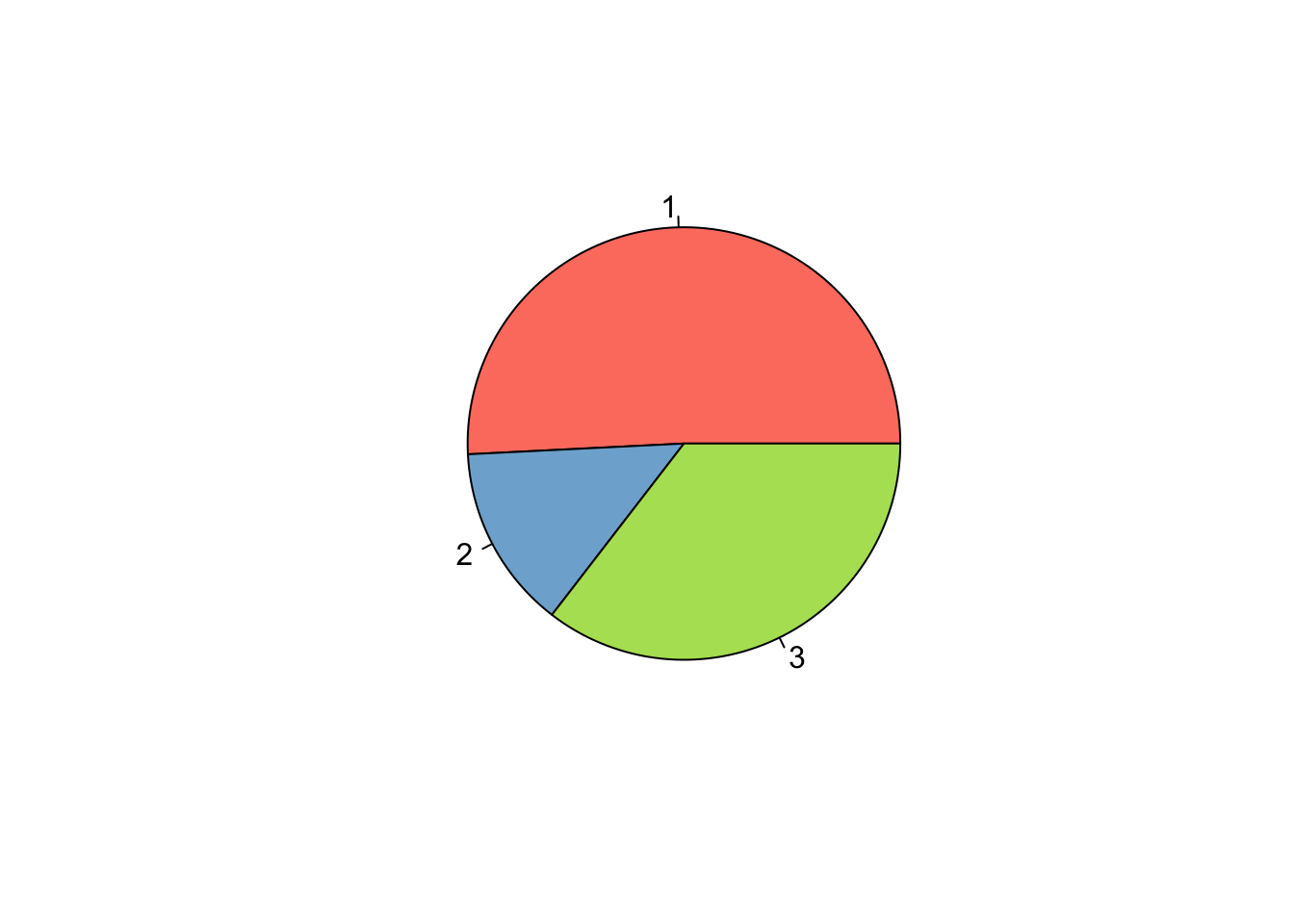
Ejercicio 8.15 Repita la gráfica de barras del ejercicio anterior utilizando la función plot() y luego mediante ggplot2.
Resolución ejercicio Ejercicio 8.15
# Si es necesario
library(MASS)
data("birthwt")
library(ggplot2)birthwt$race <- factor(birthwt$race,
labels = c("Grupo étnico White",
"Grupo étnico Black",
"Grupo étnico Otro"))
colores <- c("#fd7f6f", "#7eb0d5", "#b2e061", "#bd7ebe",
"#ffb55a", "#ffee65", "#beb9db", "#fdcce5",
"#8bd3c7")
plot(birthwt$race,
col=colores,
xlab="Grupo étnico",
ylab= "Conteos")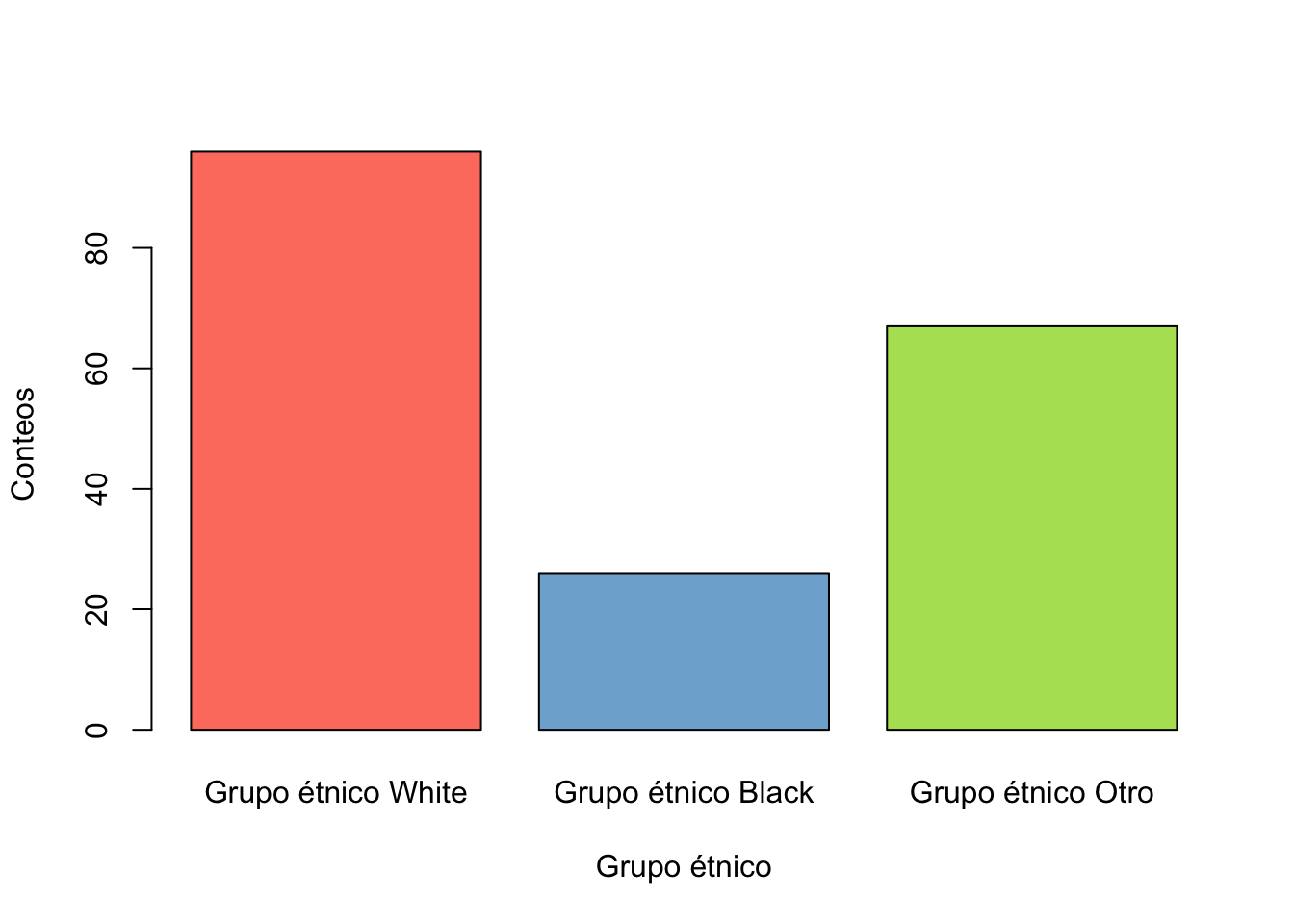
birthwt|>
ggplot(mapping = aes(x = race, fill = race))+
geom_bar()+
theme_classic()+
labs(title = "",
x = "Grupo étnico",
y = "Conteo")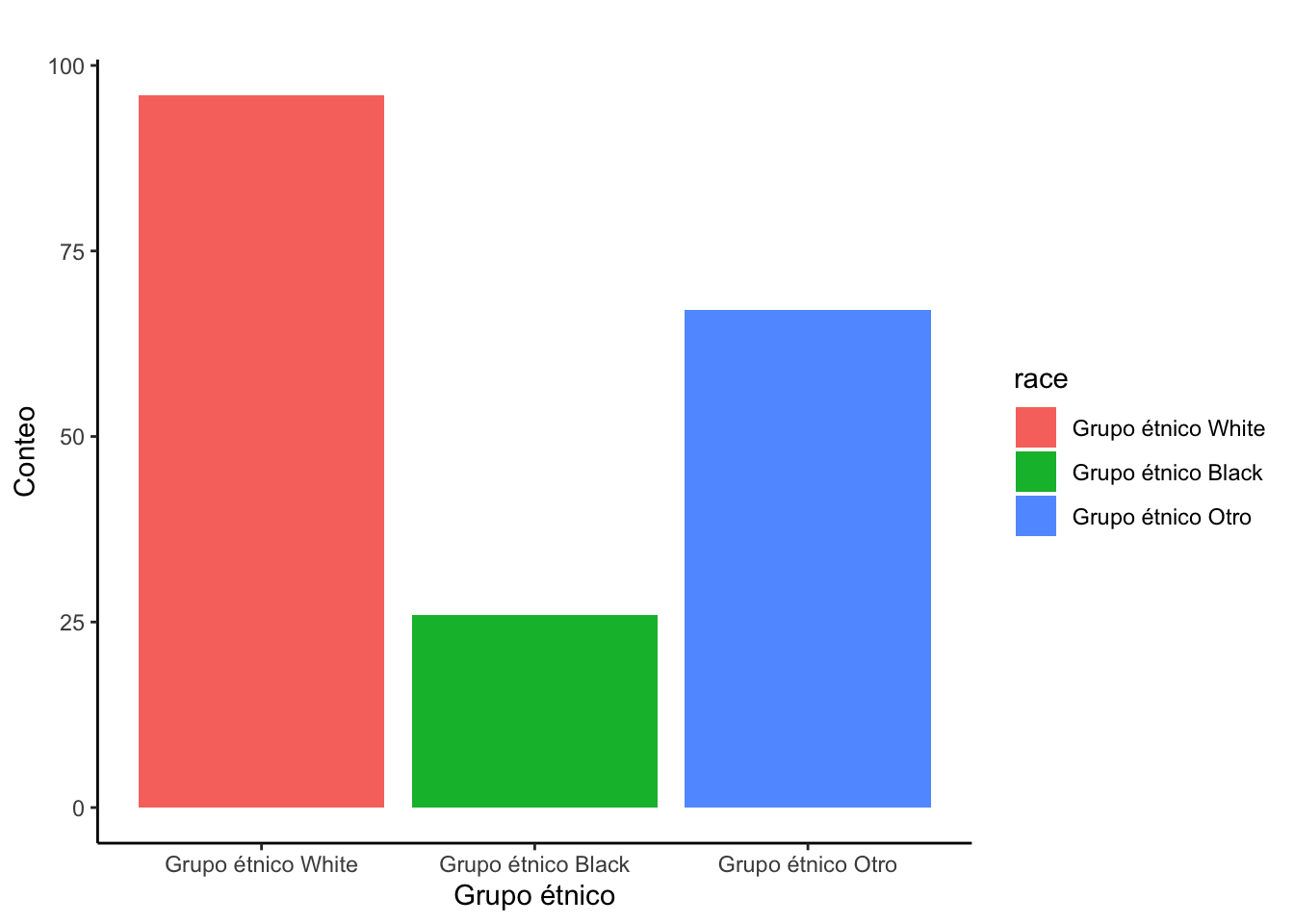
Ejercicio 8.16 Utilizando la base de datos birthwt de la librería birthwt genere un gráfico de mosaico con las proporciones de las variables low y ht. Realice una interpretación de su gráfico
Resolución ejercicio Ejercicio 8.16
birthwt$low <- factor(birthwt$low,
labels = c("Peso normal", "Bajo peso"))
birthwt$ht <- factor(birthwt$ht,
labels = c("No HTA", "Si HTA"))
table(birthwt$low, birthwt$ht)|>
mosaicplot(col=colores,
main="Gráfico de mosaicos para bajo peso e HTA")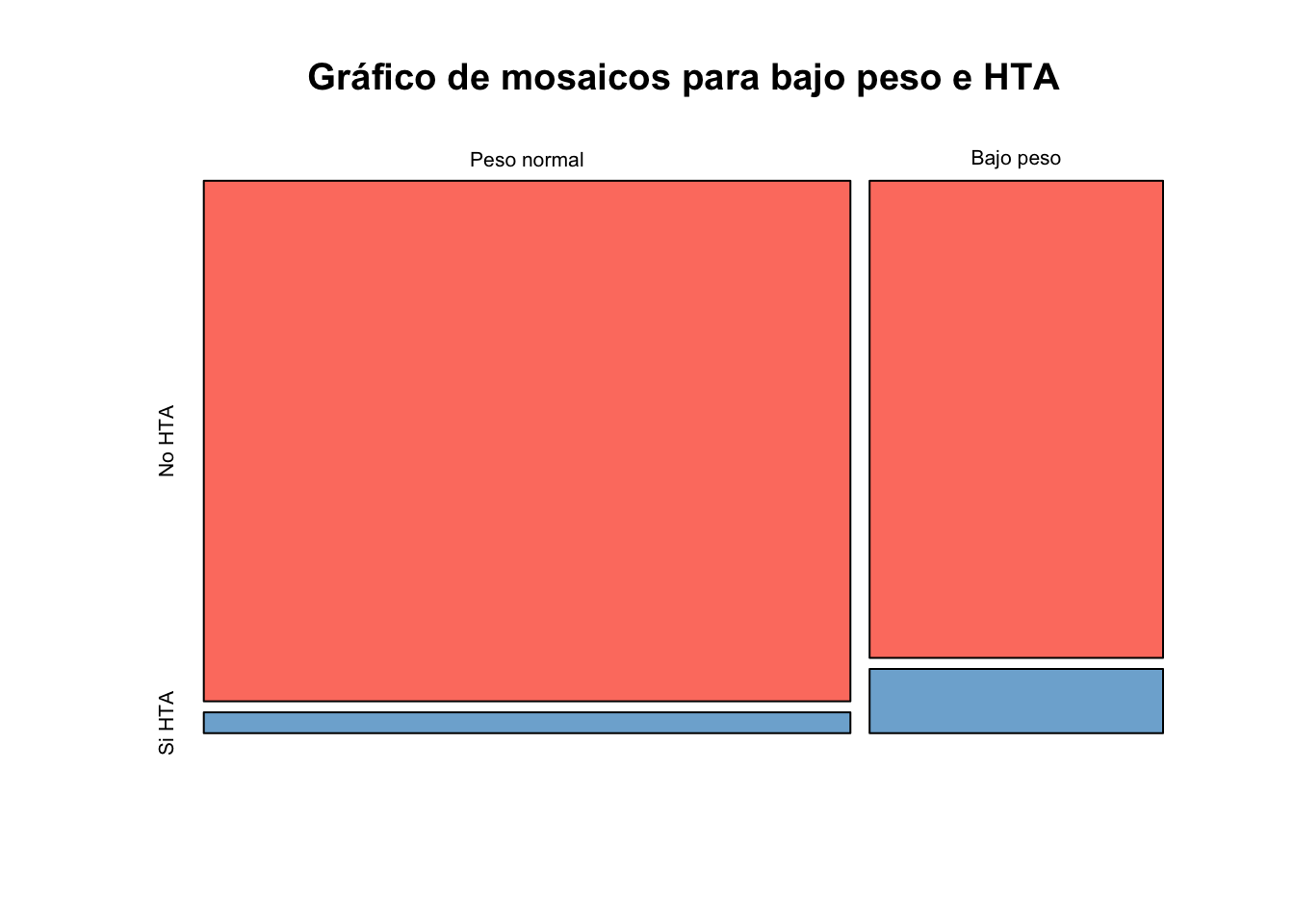
Ejercicio 8.17 Se tiene un conjunto de datos que incluye el tipo de tratamiento recibido por pacientes con una enfermedad específica: Tratamiento A, Tratamiento B, o Tratamiento C.
- Cree un vector que represente el tipo de tratamiento recibido por 150 pacientes, asegurándose de que los tratamientos estén distribuidos de manera no uniforme. Siembre la semilla: 123
- Utilice la función
tablepara obtener la frecuencia de cada tipo de tratamiento. - Emplee
barplotpara crear un gráfico de barras que muestre visualmente estas frecuencias. Cambie los títulos de los ejes y el título del gráfico
Resolución ejercicio Ejercicio 8.17
set.seed(123)
tratamientos <- sample(x=c("Tratamiento A",
"Tratamiento B",
"Tratamiento C"),
size = 150,
replace = T)
table(tratamientos)tratamientos
Tratamiento A Tratamiento B Tratamiento C
42 54 54 barplot(table(tratamientos), col=colores,
xlab="Tratamientos",
ylab="Frecuencias",
main="Tratamientos de una enfermedad")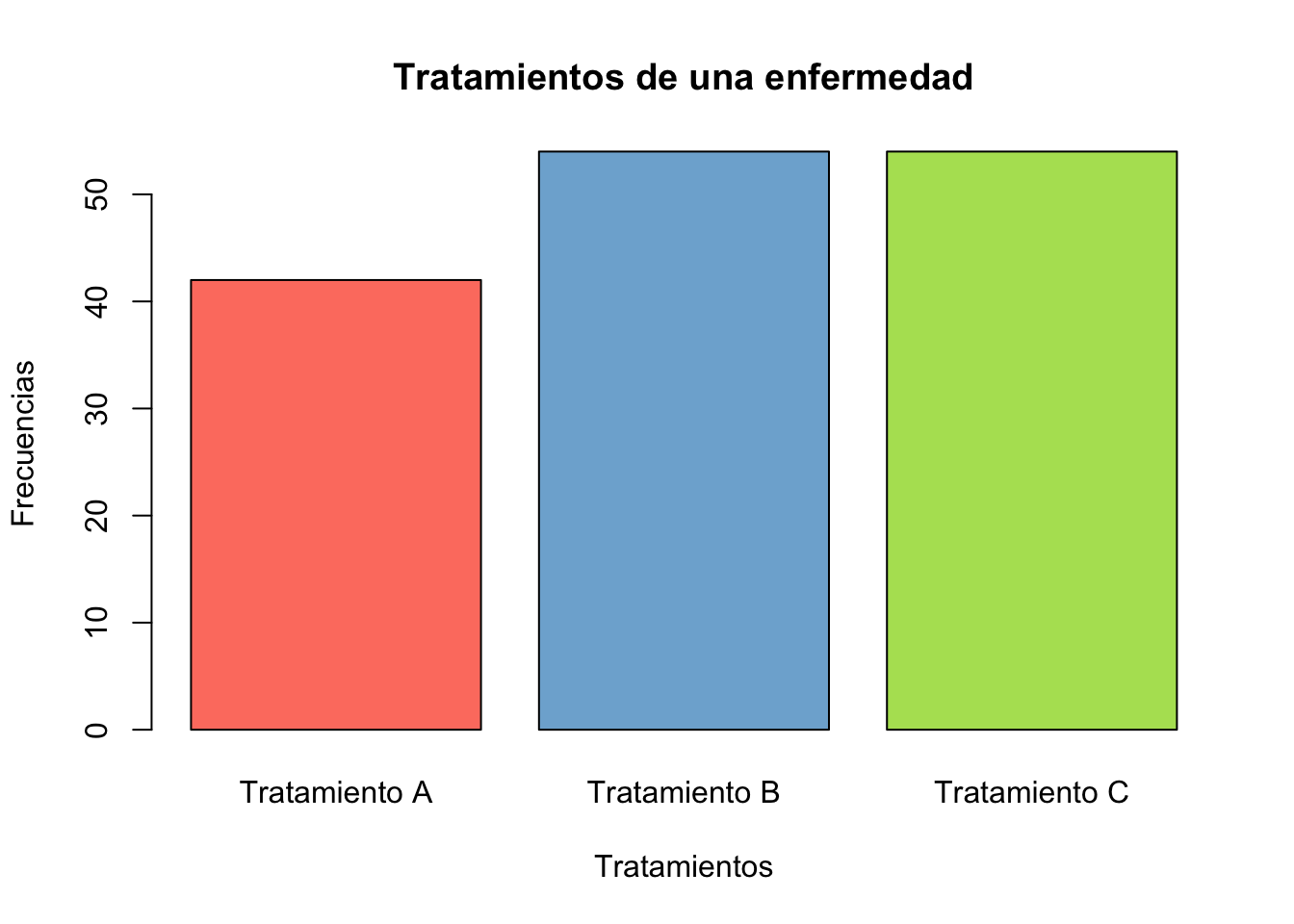
Ejercicio 8.18 ¿Qué necesita para poder recrear esta gráfica en ggplot2? Cree la gráfica del ejercicio anterior en ggplot2
Resolución ejercicio Ejercicio 8.18
Puede crear el gráfico directamente
ggplot(mapping = aes(x=tratamientos, fill = tratamientos))+
geom_bar()+
labs(title = "Tratamientos de una enfermedad",
x ="Tratamientos",
y="Frecuencias")+
theme_light()
Ejercicio 8.19 Cree un gráfico de dispersión que muestre la relación entre el índice de masa corporal (bmi) y los niveles de glucosa (glu) en la base de datos Pima.tr. Añadir una línea de tendencia con su intervalo de confianza.
- Cargue las librerías necesarias (
ggplot2yMASS). - Utilice el conjunto de datos
Pima.tr. - Cree un gráfico de dispersión de
bmivs.glu. - Añada una línea de tendencia con método de regresión lineal (lm).
- Incluya etiquetas en los ejes y un título.
Resolución ejercicio Ejercicio 8.19
# Si es necesario
library(ggplot2)
library(MASS)# Crear el gráfico de dispersión con línea de tendencia
ggplot(Pima.tr, aes(x = bmi, y = glu)) +
geom_point() + # Agregar puntos
geom_smooth(method = "lm", se = TRUE,
color = "blue") + # Línea de tendencia con intervalo de confianza
labs(title = "Relación entre BMI y Glucosa",
x = "Índice de Masa Corporal (BMI)",
y = "Nivel de Glucosa") + # Añadir etiquetas
theme_minimal() # Aplicar tema minimalista`geom_smooth()` using formula = 'y ~ x'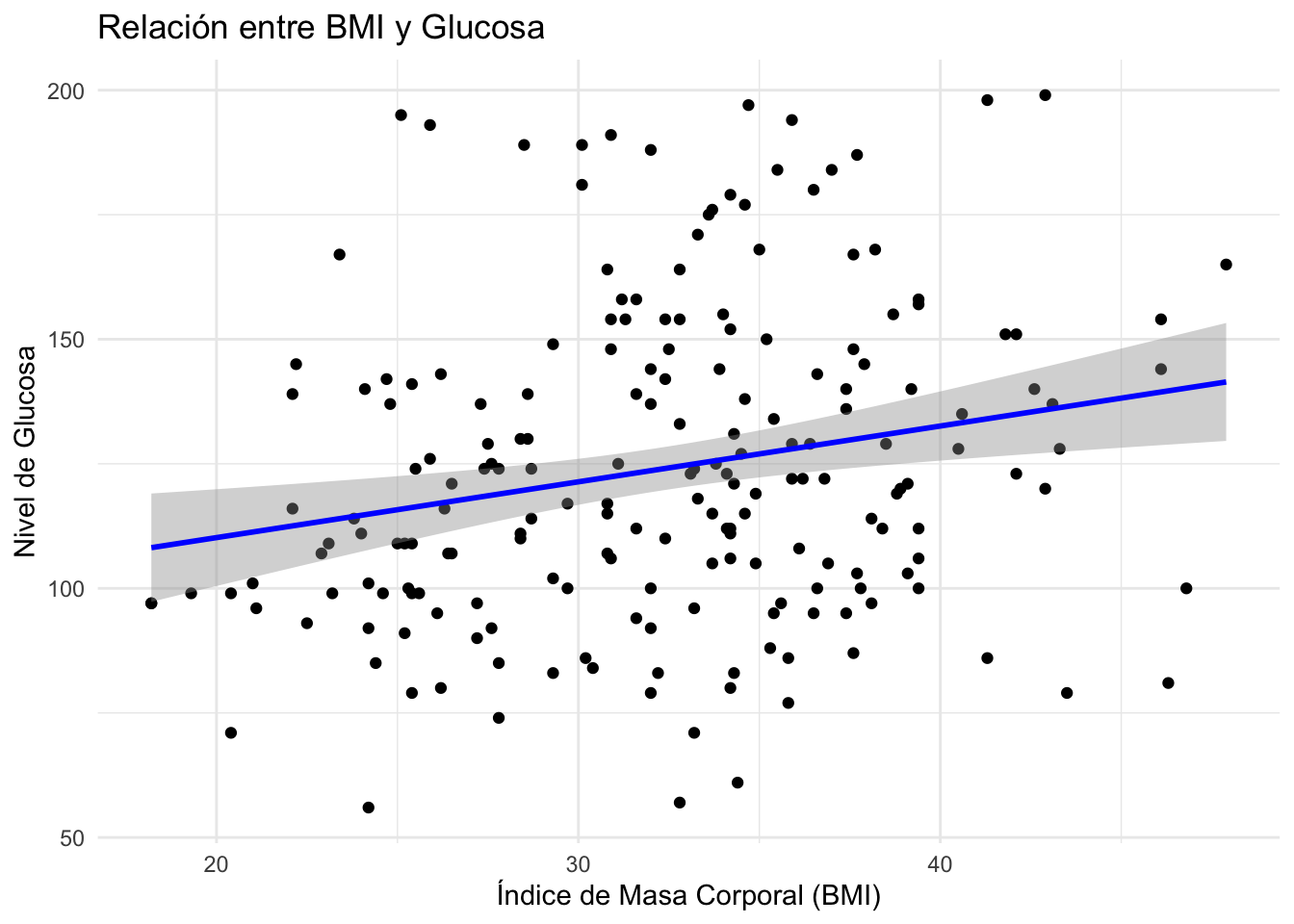
Ejercicio 8.20 Cree un gráfico de barras que muestre la distribución del número de personas con diabetes (type) en función de la clase de peso (bmi). Utilice la capa faceta para agrupar por la variable type.
Resolución ejercicio Ejercicio 8.20
# Si es necesario
library(ggplot2)
library(MASS)# Crear el gráfico de barras facetado por 'type'
ggplot(Pima.tr, aes(x = bmi)) +
geom_bar(fill = "skyblue") + # Gráfico de barras con color de relleno
facet_wrap(~ type) + # Facetar por la variable 'type'
labs(title = "Distribución de BMI por Tipo de Diabetes",
x = "Índice de Masa Corporal (BMI)", y = "Frecuencia") +
# Añadir etiquetas
theme_minimal() # Aplicar tema minimalista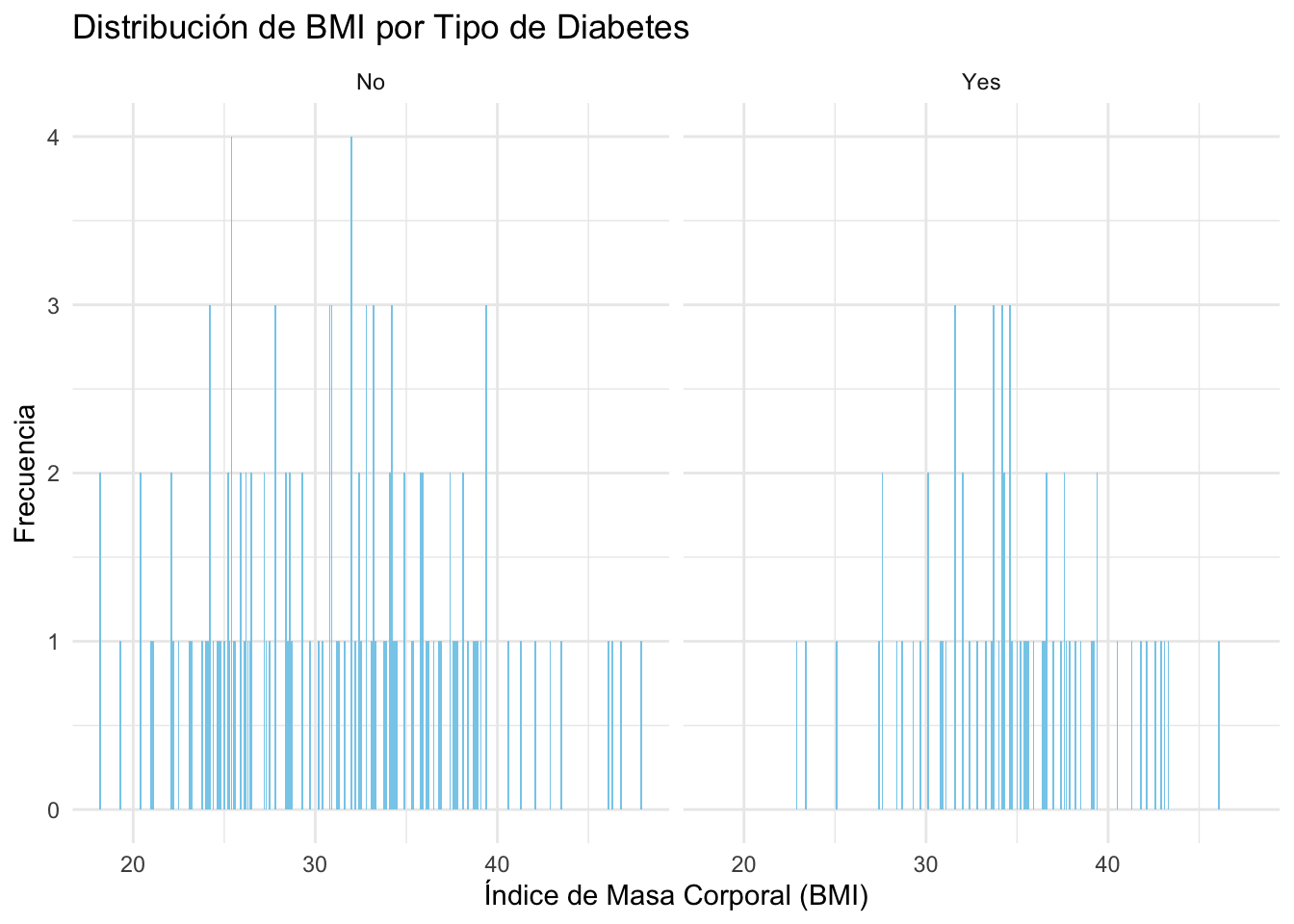
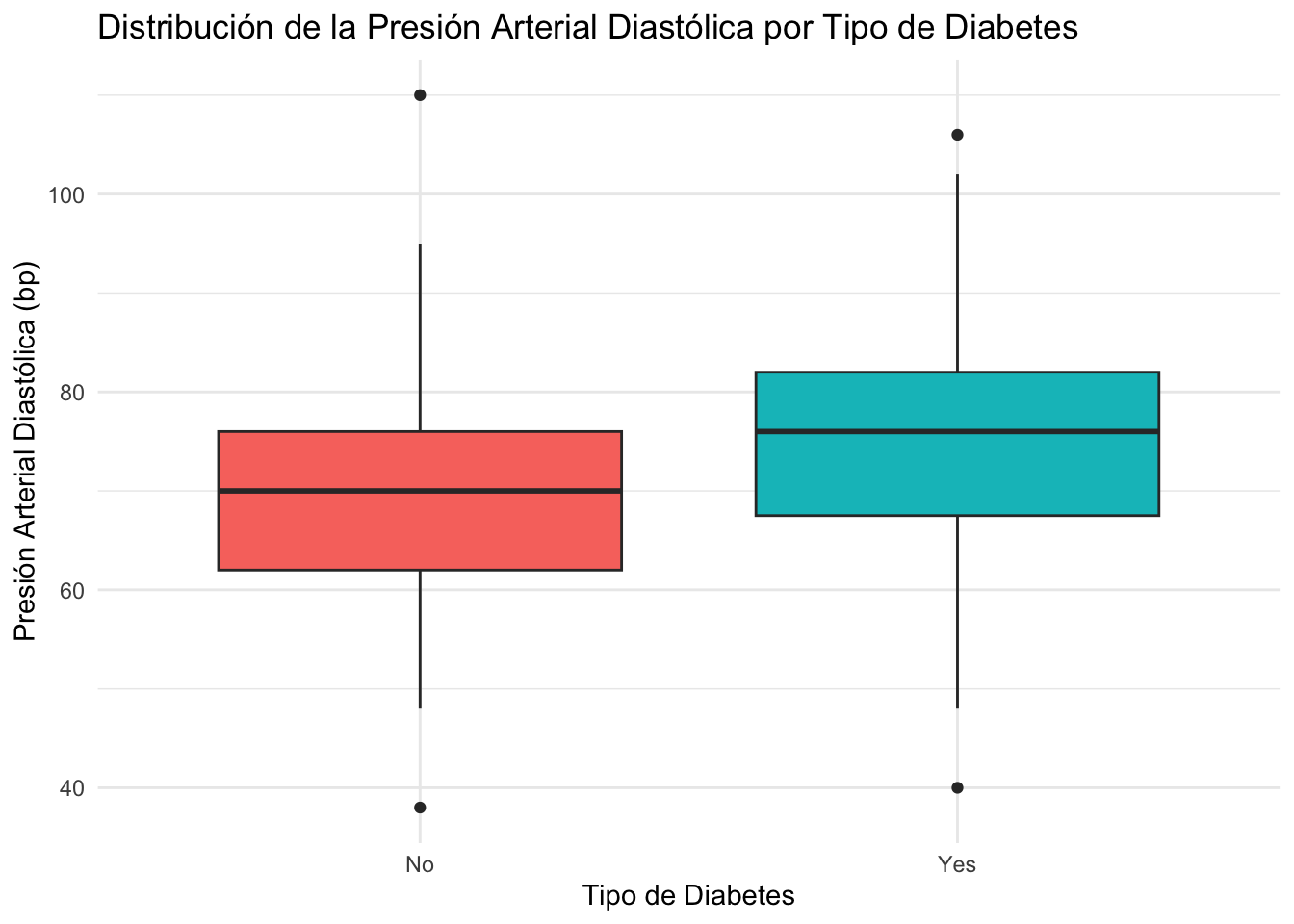
Ejercicio 8.21 Cree un boxplot que muestre la distribución de la presión arterial diastólica (bp) en función del tipo de diabetes (type). Aplicar un tema y personalizar el gráfico.
- Cargue las librerías necesarias (
ggplot2yMASS). - Utilice el conjunto de datos
Pima.tr. - Cree un boxplot de bp en función de
type. - Personalice el gráfico aplicando un tema y añadiendo etiquetas en los ejes y un título.
Resolución ejercicio Ejercicio 8.21
# Si es necesario
library(ggplot2)
library(MASS)# Crear el boxplot de 'bp.diast' en función de 'type'
ggplot(Pima.tr, aes(x = type, y = bp, fill = type)) +
geom_boxplot() + # Crear boxplot
labs(title = "Distribución de la Presión Arterial Diastólica por Tipo de Diabetes",
x = "Tipo de Diabetes", y = "Presión Arterial Diastólica (bp)") +
# Añadir etiquetas
theme_minimal() + # Aplicar tema minimalista
theme(legend.position = "none") # Eliminar la leyenda