| Tipo de dato | Nombre | Ejemplo | Comprobar | Transformar |
|---|---|---|---|---|
| Entero | integer | 4 | is.integer() | as.integer() |
| Numérico | numeric | 4.4000000000000004 | is.numeric() | as.numeric() |
| Cadena | character | “4.4” | is.character() | as.character() |
| Factor | factor | cuatro | is.factor() | as.factor() |
| Lógico | logical | TRUE | is.logical() | as.logical() |
| Vacio | null | NULL | is.null() | NA |
| Perdido | NA | NA | is.na() | NA |
4 Laboratorio de R 2
- Autor: Edsaúl Emilio Pérez Guerrero
- Afiliación: Universidad de Guadalajara
- mail: edsaul.perezg@academicos.udg.mx
- Última actualización: 2024-09-11
Para R cada uno de los tipos de datos tiene propiedades muy distintas que lo distinguen de los otros, el tipo de dato entre otras cosas condicionará el tipo de operaciones que podemos hacer con ella. Por ejemplo, no podemos estimar la media de una variable dicotómica que represente la presencia o ausencia de una enfermedad. A pesar de estas restricciones, R intenta coercionar (transformar) los datos hacia uno más complejo. Sin embargo, no todos los tipos de datos pueden ser coercionados en otros.
Este laboratorio de R tiene como objetivo:
- Describir las características y propiedades de los tipos de variables y datos para
R - Utilizar funciones que permiten conocer el tipo de variable
- Transformar los tipo de variables en otros.
- Coerción de datos
4.1 Tipos de datos en R
La tabla Tabla 4.1 muestra una las principales tipos de datos en R.
4.1.1 Datos numéricos y enteros
Ambos tipos de datos se refieren a datos que contienen números. La principal diferencia radica en que los datos enteros no incluyen decimales ni punto decimal. En cambio, el dato numérico pueden tener una fracción decimal. Un dato numérico es el equivalente a una variable cuantitativa de tipo continua y un dato entero sería el equivalente que una variable cuantitativa discreta.
Para R ambos datos son similares y para fines prácticos para nosotros también lo serán. Podemos hacer el mismo tipo de operaciones con datos numéricos y datos enteros.
Podemos comprobar si cierto tipo de dato es numérico con la función:
is.numeric()Esta función nos dará como resultado TRUE si el dato u objeto es un dato de tipo numérico y FALSE si no lo es.
Algunos datos pueden ser convertidos en otro tipo de dato, siempre y cuando la coerción sea correcta (ver sección (ref?)(Coercion). Para convertir cierto tipo de dato en numérico utilice la función:
as.numeric()Para evaluar un dato entero (interger), utilice las siguientes funciones: is.numeric() y para convertir a un dato entero: as.numeric().
4.1.2 Cadenas de texto
La cadena de texto en R es un dato que podemos identificar por estar entre comillas. Este tipo de dato admite números, texto, espacios y símbolos, siempre y cuando estén entre comillas. El uso de cadena de texto debería limitarse a variables de identificación ya que la cantidad de operaciones que podemos hacer con ellos es limitada. Si por ejemplo, tenemos una variable que indica si el paciente padece o no hipertensión, cuyos valores son “si” y “no”; nos convendría más tener un factor (ver más adelante) que una cadena de texto. Ya que en el factor podemos tener niveles y establecer cual pudiera representar la ausencia o presencia de una enfermedad. En una cadena de texto son indistintos.
Utilice la función is.character() para comprobar si su variable es un carácter. Utilice la función as.character() para convertir una variable a cadena de texto. La ventaja más grande de las cadenas de texto es que podemos convertir prácticamente cualquier dato en una secuencia de caracteres (cadena de texto).
4.1.3 Factores
Los factores en R son un tipo de dato utilizado para representar una variable categórica en la que existen niveles. Es decir, en los factores, hay un nivel 1, un nivel 2 etc. Por ejemplo, para la variable hipertensión cuyas opciones son “No” y “Si”, el nivel más bajo será “No” y el nivel más alto “Si”. Ya que, a menos que se indique lo contrario, los niveles se ordenarán siguiendo una jerarquía alfanumérica. Para bioestadística este orden es especialmente importante, ya que muchas veces nos interesa comparar un grupo de pacientes con otro grupo de individuos con la ausencia de la enfermedad, como el caso de los riesgos.
Los factores son especialmente útiles para manejar datos categóricos en análisis estadísticos y gráficos, porque aseguran que las operaciones estadísticas y las visualizaciones respeten la naturaleza categórica de los datos. Los factores son más complejos que los caracteres por que existe un orden. En la medida de lo posibles todas las variables categóricas deberían ser factores. Al menos así será en este libro.
Utilice las funciones is.factor() y as.factor() para este tipo de dato.
4.1.4 Datos lógicos
Otro tipo de dato muy útil en R es el dato lógico. Este solo puede tener dos valores TRUE y FALSE. Representan si una condición o estado se cumple (falso o verdadero).
Un dato lógico es la respuesta a diversas operaciones que representan condiciones. Por ejemplo, ¿Es mi dato una cadena de texto?¿La edad de los pacientes es mayor a 50 años?
Utilice las funciones is.logical() y as.logical() para este tipo de dato.
4.1.5 Datos vacíos y nulos
Supongamos que al ingreso de un paciente a nuestra investigación, no contaba con la medición de glucosa basal. Este dato no puede ser capturado en una base de datos. El dato no está disponible. Este dato sería un NA; un dato dejado en blanco intencionalmente. Recuerde que no le fue medida la concentración de glucosa la incio del estudio.
En cambio, un dato de tipo NULL es un dato vacío, que representa la ausencia de datos. Aunque son muy similares, existen diferencias sustanciales. Un dato NULL aparece sólo cuando R intenta recuperar un dato y no encuentra nada, mientras que NA es usado para representar explícitamente datos perdidos, omitidos o que por alguna razón son faltantes.
Si pedimos a R el valor de la concentración de glucosa en ayunas de una persona que no existe en la base de datos, obtendríamos un dato de tipo NULL. En cambio si pedimos la concentración de glucosa del paciente que tuvo la medición tendremos un NA. En el primer caso el paciente no existe y en el segundo si existe pero el dato no fue dejado explicitamente como vacío.
Trabajar con NA puede ser un dolor un de cabeza, debemos evitarlos en la medida de lo posible. Nunca olvide está afirmación: Un NA siempre produce un NA.
4.2 Coerción de datos
Los datos en R se pueden transformar o coercionar de un tipo de dato a otro. Cuando hacemos operaciones en R se intentará convertir el dato a otro que sea correcto para poder realizar la operación. Por ejemplo, si intentamos calcular el promedio de un conjunto de datos, R intentará convertir los datos en numéricos, para poder realizar esta operación. Sin embargo, muchas veces obtenemos un error. Este error se presenta ya que la coerción tiene ciertas restricciones.
La coerción se da en el siguiente orden, pero no al revés:
lógico -> entero -> numérico -> cadena de texto (logical -> integer -> numeric -> character)
Los datos pueden ser coercionados del dato más restrictivo a los más flexibles. Puede encontrar un buen artículo sobre coerción en el siguiente blog
4.3 Importar un data frame
En este compendio trabajaremos con estructuras de datos ordenas. Estas estructuras reciben el nombre base de datos o data frame (del inglés). Los data frame tienen en las columnas las variables en las filas cada uno de los casos. Las figuras ?fig-fig41 y Figura 4.2, y la tabla Tabla 4.2 muestran algunos ejemplos de un data frame
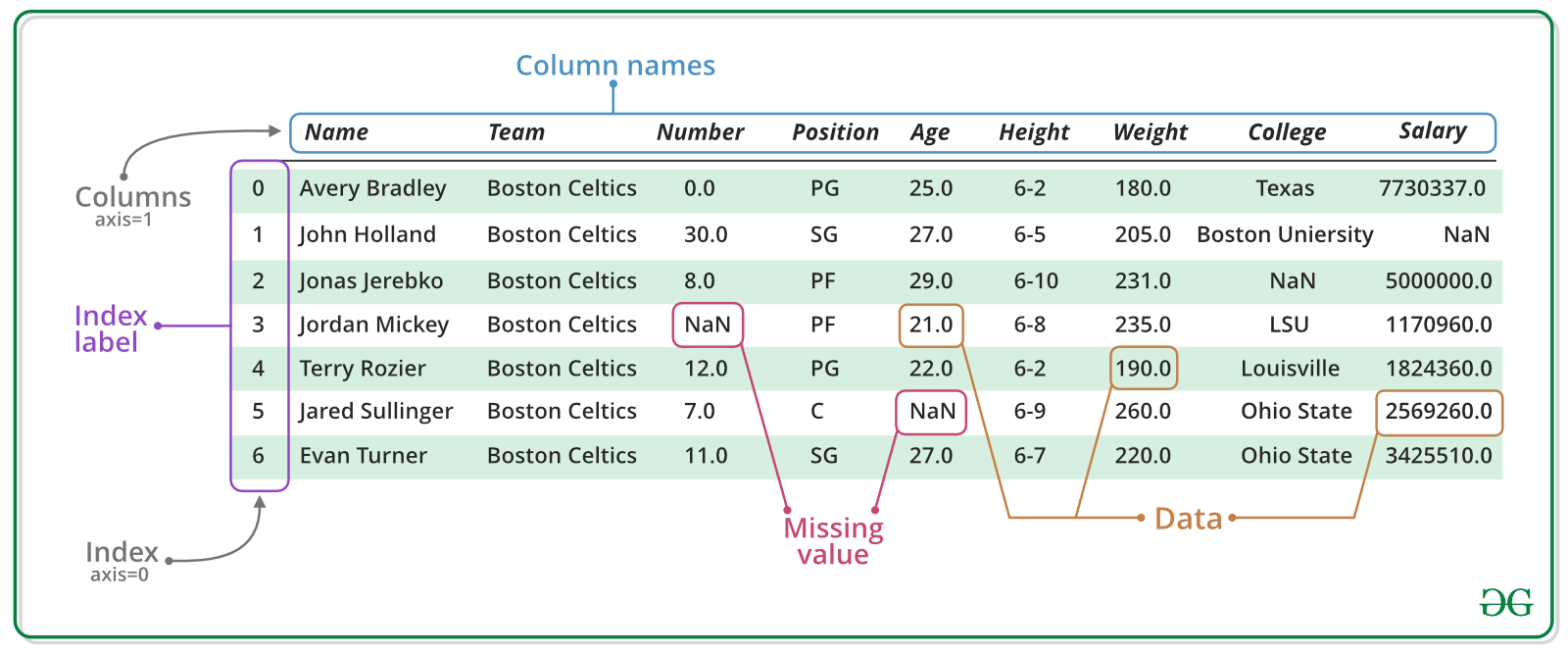
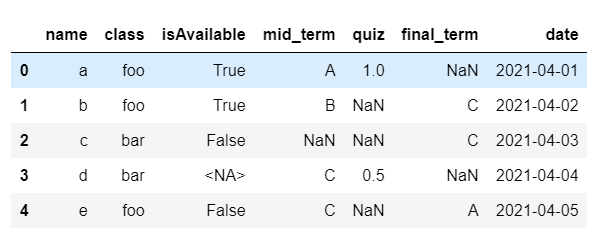
| npreg | glu | bp | skin | bmi | ped | age | type |
|---|---|---|---|---|---|---|---|
| 5 | 86 | 68 | 28 | 30.2 | 0.364 | 24 | No |
| 7 | 195 | 70 | 33 | 25.1 | 0.163 | 55 | Yes |
| 5 | 77 | 82 | 41 | 35.8 | 0.156 | 35 | No |
| 0 | 165 | 76 | 43 | 47.9 | 0.259 | 26 | No |
| 0 | 107 | 60 | 25 | 26.4 | 0.133 | 23 | No |
| 5 | 97 | 76 | 27 | 35.6 | 0.378 | 52 | Yes |
De momento exploraremos dos opciones para la exportación de data frames en R, la primera es cargar base de datos contenidas en paquetes y la segunda es utilizar el menú de RStudio para importar bases de datos que se encuentran guardados en extensiones como .txt, .xlsx, .cvs y.sav.
4.3.1 Importar base de datos de paquetes
Muchas de las librerías de R tienen base de datos que podemos utilizar para resolver los ejemplos de ayuda de las funciones de esa librería. En este compendio estaremos utilizando algunas de estas bases de datos.
Vamos a cargar el data frame WeightLoss de la librería car. Para ello podemos utilizar el siguiente código:
# Primero cargamos la librería que contiene el data frame
library(car) Loading required package: carData# Después llamamos al data frame con la función data()
data("WeightLoss")# Tiene que ir entre comillasSi prestamos atención, ahora en nuestro ambiente de trabajo tendremos un objeto llamado WeightLoss.
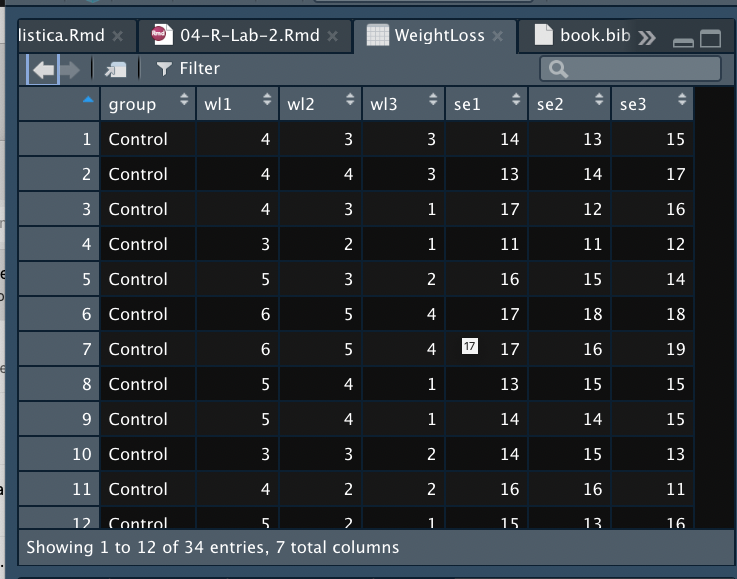
Si queremos visualizar esta base de datos, podemos utilizar la función View() y la base de datos se mostrará en el apartado superior izquierdo como lo muestra la figura Figura 4.3.
Un data frame es un objeto que a su vez tiene variables que pueden ser consideradas como objetos independientes. Si queremos acceder a los objetos (variables) de nuestra base de datos debemos utilizar la función attach() de esta forma podemos acceder a las variables de nuestra base de datos y hacer operaciones con ellas.
Por ejemplo:
attach(WeightLoss)Ahora utilizando la variable wl1 puedo estimar la media del peso al primer mes de un grupo de ratones.
mean(wl1)[1] 5.294118Si utilizamos la función mean(wl1) sin haber adjuntado nuestra base de datos, R nos dará el siguiente error:
Error in mean(wl1) : object 'wl1' not found4.3.2 Importar base de datos desde el menu de Rstudio
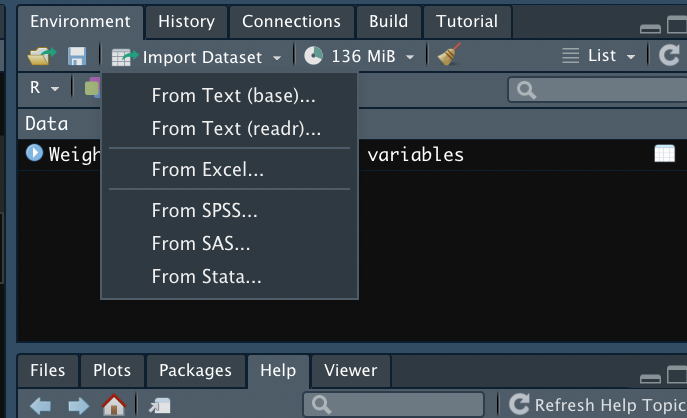
La figura Figura 4.4 muestra el menú de Rstudio con el que podemos exporta bases de datos de distintos formatos. En Rstudio podemos importar data frame con los siguientes formatos:
- Archivos de texto, formato .txt y .cvs.
- Archivos desde excel, formato .xlsx
- Archivos de SPSS, formato .sav
- Archivos de SAS, formato .sas
- Archivos de STATA
Al hacer clic en cualquiera de las opciones, lo primero que debemos de hacer es seleccionar el archivo que queremos importar. Ver Figura 4.5
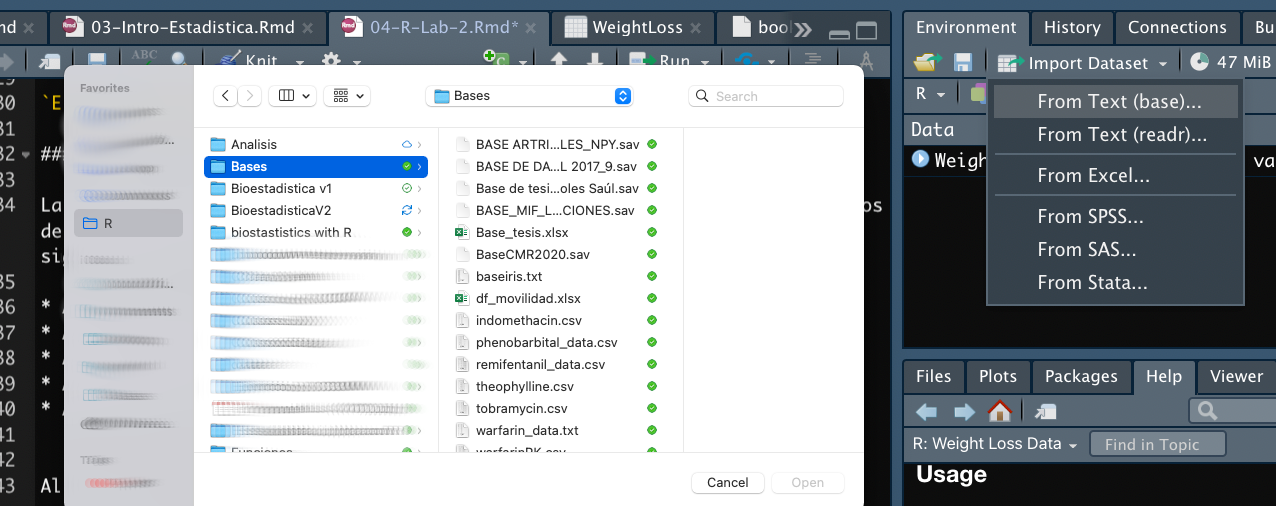
4.3.2.1 Archivos .txt y .cvs
Las siguientes líneas explican a grandes rasgos como importar archivos de texto y separados por comas. Ambos se pueden exportar desde el menú: Import Dataset->From Text (base) en la últimas versiones de Rstudio importar cualquiera de los tipos de archivos no debería llevar mayor complicación y Rstudio debería reconocer el tipo de separador correcto de los archivos. Sin embargo, el separador común para los archivos .txt es white space (ver figura Figura 4.6) y para los archivos es .cvs es comma (ver figura ?fig-fig18)). Si tenemos el separdor correcto, nuestra base de datos se previsualizará en un rectángulo o cuadrado en donde las variables están perfectamente alineadas como lo muestran las figuras . Si tiene el separador incorrecto su base se previsualizará como lo muestra la figura ?fig-fig21.
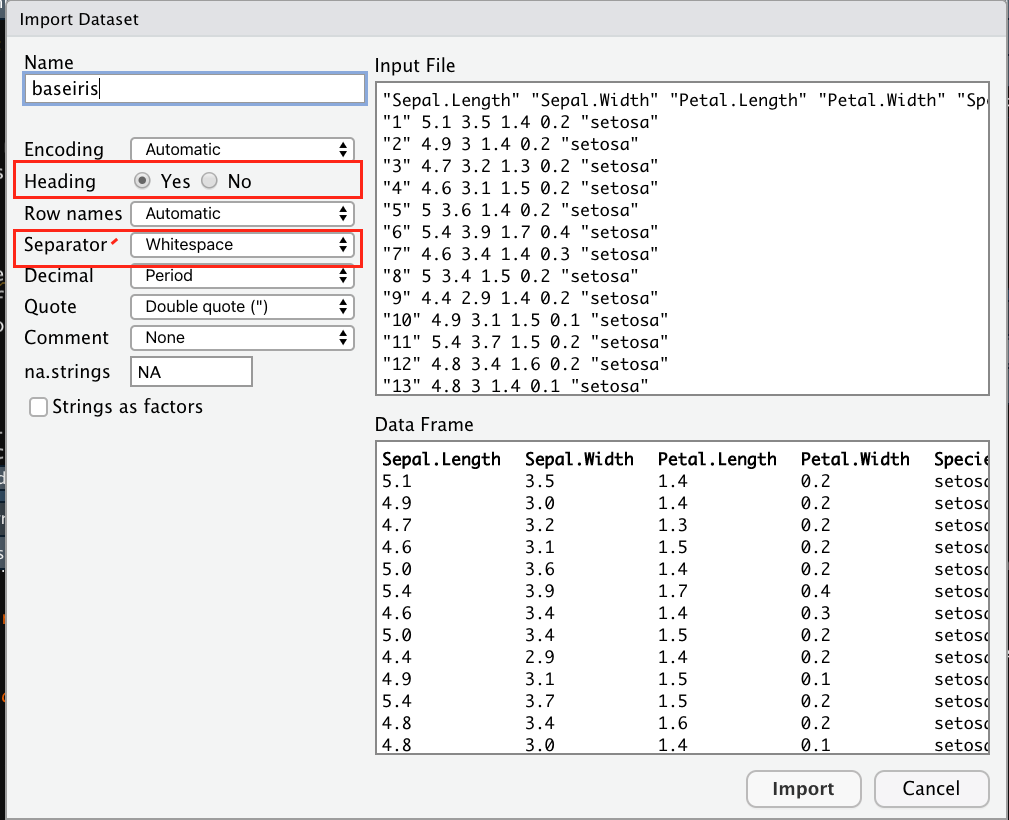
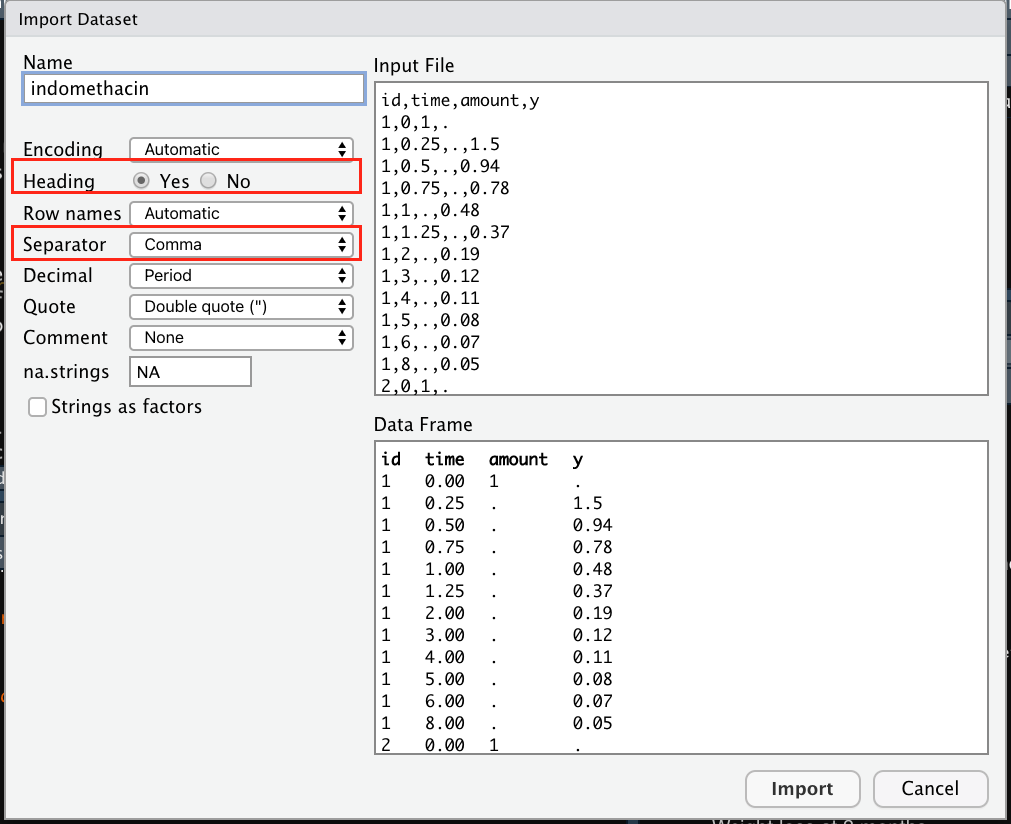
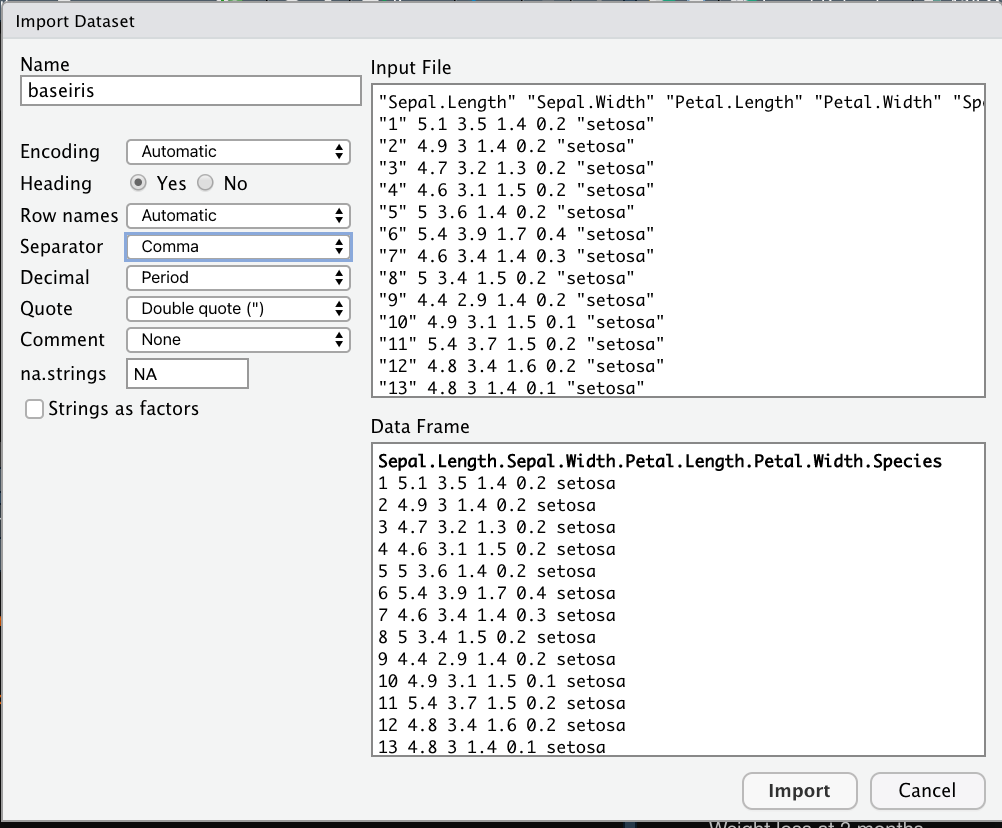
Puede visualizar algunos ejemplos en:
4.3.2.2 Importar archivos con extensión .xlsx, .sav. y sas
Importar archivos desde excel, desde SPSS o de desde Sas, no requiere mayores complicaciones por lo que no se explicarán a fondo en este compendio. Solo es necesario seguir el menú de Rstudio, es muy intuitivo. Sin embargo puede consultar algunos ejemplos en:
4.4 Ejercicios Laboratorio de R 02
El objetivo de estos ejercicios es que, una vez que exportemos una base de datos, podamos identificar el tipo de variable para R
Importe la base de datos birthwt de la librería MASS a su ambiente de trabajo. Esta base contiene información de variables asociadas al bajo peso en el nacimiento de algunos infantes. Para importar la base de datos a su ambiente de trabajo utilice el siguiente código (puede copiar y pegar)
library(MASS)
data("birthwt")
attach(birthwt)## Paso importanteUtilice la función de ayuda para obtener la información de las variables de la base birthwt.
help("birthwt")La información que muestra la ayuda es aproximadamente la siguiente:
low: indicator of birth weight less than 2.5 kg.
age: mother’s age in years.
lwt: mother’s weight in pounds at last menstrual period.
race: mother’s race (1 = white, 2 = black, 3 = other).
smoke: smoking status during pregnancy.
ptl:number of previous premature labours.
ht: history of hypertension.
ui: presence of uterine irritability.
ftv: number of physician visits during the first trimester.
bwt: birth weight in grams
Para comprobar la estructura de una base de datos en general puede utilizar la función str como sigue:
str(birthwt)'data.frame': 189 obs. of 10 variables:
$ low : int 0 0 0 0 0 0 0 0 0 0 ...
$ age : int 19 33 20 21 18 21 22 17 29 26 ...
$ lwt : int 182 155 105 108 107 124 118 103 123 113 ...
$ race : int 2 3 1 1 1 3 1 3 1 1 ...
$ smoke: int 0 0 1 1 1 0 0 0 1 1 ...
$ ptl : int 0 0 0 0 0 0 0 0 0 0 ...
$ ht : int 0 0 0 0 0 0 0 0 0 0 ...
$ ui : int 1 0 0 1 1 0 0 0 0 0 ...
$ ftv : int 0 3 1 2 0 0 1 1 1 0 ...
$ bwt : int 2523 2551 2557 2594 2600 2622 2637 2637 2663 2665 ...Podrá notar que existen algunas variables que no se encuentran correctamente clasificadas, por ejemplo: la variable low es reconocida por R como una variable numérica cuando de acuerdo con la descripción de la base debería ser un factor. Recuerde que podemos coercionar o transformar los datos para poder trabajar adecuadamente con ellos. Las siguientes lineas de código muestran como hacer esta transformación.
Primero verificamos de nueva cuenta con la función class el tipo de variable
class(low)[1] "integer"Efectivamente es un variable numérica y debería de ser un factor. Podemos transformarla a factor con el siguiente código:
low <- as.factor(low)Del código anterior podemos destacar algunos puntos. El primero es que sobre escribimos al objeto low. El segundo es que no sobre escribimos en la base birthwt sino en el objeto low que se creo después de adjuntar la base de datos utilizando la función attach.Para entender este concepto podemos imaginar al objeto birthwtcomo un gran objeto que contiene a su vez muchos objetos dentro de él (cada una de las variables). Ver Figura 4.7 Para acceder a estas variables una de las estrategias es utilizar la función attach
Ahora podemos comprobar el tipo de objeto que tenemos:
class(low)[1] "factor"Ejercicio 4.1 Repita estos pasos para cada uno de las variables que no se encuentran bien clasificadas.
Ejercicio 4.2 Importe la base Pima.tr de la librería MASS y utilizando los pasos descritos en el ejercicio anterior identifique el tipo de variables para cada una de las variables contenidas en esta base de datos. De ser necesario cambie el tipo de dato para que R las lea de adecuadamente.
Ejercicio 4.3 Importe la base birthwt de la librería MASS y utilizando los pasos descritos en el ejercicio anterior identifique el tipo de variables para cada una de las variables contenidas en esta base de datos. De ser necesario cambie el tipo de dato para que R las lea de adecuadamente.
Ejercicio 4.4 Importe la base Melanoma de la librería MASS y utilizando los pasos descritos en el ejercicio anterior identifique el tipo de variables para cada una de las variables contenidas en esta base de datos. De ser necesario cambie el tipo de dato para que R las lea de adecuadamente.
Ejercicio 4.5 Importe la base Tipos de varibles.rds que se encuentra en su carpeta de bases. Esta base de datos se encuentra en formato .rds, para importar su base utilice la función readRDS() y después clasifique cada una de las variables que se encuentran ahí. De ser necesario cambie el tipo de dato para que R las lea de adecuadamente.