En este capitulo se presenta una breve guía sobre el fundamento, selección y utilización de pruebas Post-Hoc.
13.1 Introducción
Tras obtener un resultado significativo en un análisis de varianza (ANOVA) o en una prueba de Kruskal-Wallis, el siguiente objetivo metodológico es determinar cuál de los grupos bajo estudio contribuye a esta significación estadística. Específicamente, se busca identificar qué grupos muestran diferencias significativas entre sí. En una situación donde se comparan cuatro grupos distintos, se necesitarían efectuar un total de seis comparaciones emparejadas:
Grupo 1 vs Grupo 2: Comparación 1
Grupo 1 vs Grupo 3: Comparación 2
Grupo 1 vs Grupo 4: Comparación 3
Grupo 2 vs Grupo 3: Comparación 4
Grupo 2 vs Grupo 4: Comparación 5
Grupo 3 vs Grupo 4: Comparación 6
Para abordar estas comparaciones múltiples, se pueden emplear dos estrategias principales:
Aplicar seis pruebas\(t\)de Student independientes.
Utilizar pruebas post hoc especializadas.
Sin embargo, es fundamental tener en cuenta que la primera estrategia, el uso repetido de pruebas\(t\)de Student, aumenta considerablemente la probabilidad de incurrir en un error de Tipo I (es decir, detectar diferencias significativas donde en realidad no las hay). Matemáticamente, la probabilidad acumulada de cometer un error de Tipo I se calcula mediante la fórmula:\(r = 1-(1-\alpha)^n\), donde: -\(\alpha\) es el nivel de significancia individual y -\(n\)es el número de pruebas.
Por ejemplo, con seis pruebas y un\(\alpha\)de 0.05, el error acumulado de Tipo I sería calculado como\(r = 1-(1-0.05)^6=0.26\). Si se incrementa el número de pruebas a 15, el riesgo de error de Tipo I superaría el 50%, haciendo que la estrategia sea comparable a lanzar una moneda al aire.
A continuación, se presentan ejemplos de cálculos para diferentes números de comparaciones:
1-(1-.05)^4# para 4 comparaciones
[1] 0.1854938
1-(1-.05)^6# para 6 comparaciones
[1] 0.2649081
1-(1-.05)^10# para 10 comparaciones
[1] 0.4012631
1-(1-.05)^15# para 15 comparaciones
[1] 0.5367088
1-(1-.05)^20# para 20 comparaciones
[1] 0.6415141
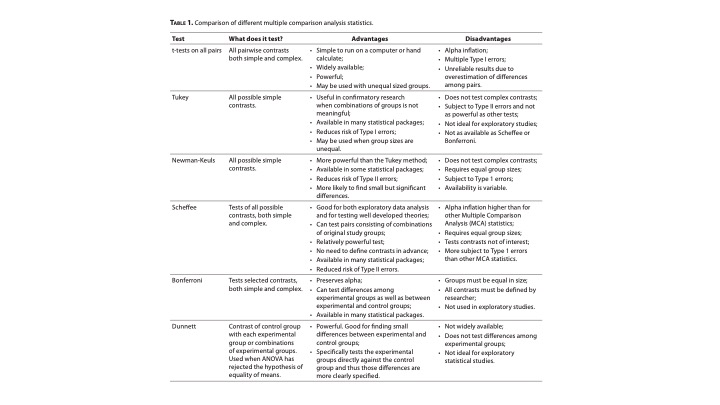
Cuando se permite un error de Tipo I para cada comparación individual, este nivel de error se denomina Tasa de Error de Comparación. En contraposición, el error total acumulado a lo largo de todas las comparaciones se conoce como tasa de error de familiar (Familywise Error Rate/Alpha Inflation). Para mantener el error Tipo I experimental dentro de un límite preestablecido (como un alfa de 0.05), existen diversas técnicas para comparaciones múltiples (comparaciones post-hoc). Estos procedimientos suelen llevar el nombre del científico que los desarrolló inicialmente y su elección depende de múltiples factores. Entre los métodos post-hoc más comunes se encuentran Bonferroni, Tukey, Scheffe, Fisher LSD, Newman-Keuls, Duncan y Dunnett.
Antes de proceder con la selección de un test post-hoc, recomiendo responder a las siguientes interrogantes:
¿Cuántos grupos se van a comparar?
¿Los grupos presentan varianzas homogéneas?
¿Existe un grupo que servirá como referencia?
¿Los datos se ajustan a una distribución normal?
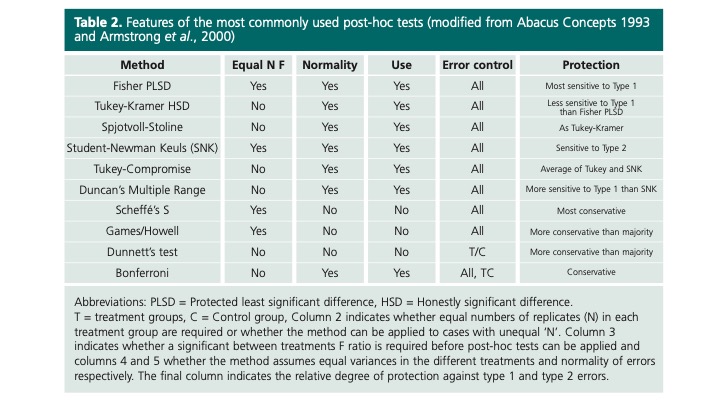
Las siguientes imágenes o tablas ofrecen guías que pueden facilitar la toma de decisiones sobre qué método post-hoc emplear. Es importante recordar que estas guías son orientativas y no deben considerarse como reglas estrictas.
{#fig16-1 fig-cap=“Fuente: McHugh M. L. (2011). Multiple comparison analysis testing in ANOVA. Biochemia medica, 21(3), 203–209. https://doi.org/10.11613/bm.2011.029)’ fig-aling=”center”}
Diagrama de selección pruebas post-hoc2
Con base a mi experiencia pueden seguir el siguiente árbol de decisión:
Árbol de decisión
Los siguientes apartados describen algunas de las pruebas post-hoc dónde se describe el fundamento, ventajas, desventajas y su implementación en R.
13.3 Método de Bonferroni
13.3.1 Introducción al Método de Bonferroni
El método de Bonferroni constituye una estrategia elemental pero eficaz para el control del error de Tipo I en múltiples comparaciones estadísticas. Específicamente, el nivel de significancia global \(\alpha\)s e divide entre el número total de hipótesis secundarias (\(H\)) que están siendo examinadas. En términos formales, el valor crítico ajustado de \(p\) se determina como \(\alpha/H\).
13.3.2 Consideraciones sobre la Potencia Estadística
El método de Bonferroni es inherentemente conservador, lo cual lleva a una alta tasa de errores de Tipo II, especialmente cuando el número de comparaciones (\(H\)) es grande. Entre más comparaciones se hagan más estricto será el método de Bonferroni.
En algunas ocasiones \(H\) se limita al número de comparaciones específicas de interés. Por ejemplo, si se tienen cuatro grupos y solo se desea comparar ciertos grupos entre sí, entonces \(H\) se ajustará acorde.
13.3.3 Ventajas y Desventajas del Método de Bonferroni
13.3.3.1 Ventajas
Simplicidad
\(H\) no excede el número total de comparaciones de interés
Especialmente útil en los casos que se requieren pocas comparaciones
Es el comodín de las pruebas post-hoc
13.3.3.2 Desventajas
Disminución en la potencia del test al aumentar el número de comparaciones
Entre más comparaciones se realicen, más estricta es la prueba
No es un prueba flexible
No es útil para comparaciones completjas
13.3.4 Implementación del método de Bonferroni en R
Para implementar el método de Bonferroni en R, se puede utilizar la función pairs.t.test. A continuación se describen los principales argumentos de esta función:
# Descripción de los argumentos de pairs.t.test- x: varaible cuantitativa, vector de respuesta- g: variable de agrupación- alternative: prueba de hipótesis bilateral o unilateral:"two.sided" (default), "greater" or "less"- paired: valor lógico para grupos pareados- p.adjusted.method; Métodos para la obtencióno de el valor ajusta de$p$"holm", "hochberg", "hommel", "bonferroni", "BH", "BY", "fdr","none"
La función pairs.t.test en R se usa para realizar pruebas t de Student por pares en datos con dos o más grupos. Esta función es especialmente útil cuando se quiere comparar las medias de varios grupos entre sí, después de haber encontrado diferencias significativas en un análisis de varianza (ANOVA).
13.3.4.1 Ejemplo del procedimiento de bonferroni en R
Ejemplo 13.1 Utilizando la librería MASS y la base de datos Cushings realice una prueba de ANOVA e indique entre grupos de Cushings se presentan la diferencias. Utilice el procedimiento de correción de Bonferroni
Para resolver este ejemplo utilizaremos la base de datos Cushings del paquete MASS
Cargar base de datos
library(MASS)data("Cushings")head(Cushings) # Visualizar los primeros 6 datos
Tetrahydrocortisone Pregnanetriol Type
a1 3.1 11.70 a
a2 3.0 1.30 a
a3 1.9 0.10 a
a4 3.8 0.04 a
a5 4.1 1.10 a
a6 1.9 0.40 a
Pairwise comparisons using t tests with non-pooled SD
data: Cushings$Tetrahydrocortisone and Cushings$Type
a b c
b 0.01 - -
c 0.74 1.00 -
u 0.26 1.00 1.00
P value adjustment method: bonferroni
#Es necesario cambiar el argumento pool.sd para que no tome un solo valor de desviación# estándar y se tome el valor para cada comparación. La desviación estándar agrupada es un# promedio ponderado de las desviaciones estándar de dos o más grupos. Las desviaciones# estándar individuales se promedian, con más "peso" dado a tamaños de muestra más grandes.
Los resultados anteriores indican:
La comparación del grupo a vs grupo b es significativa ya que su valor de \(p\) ajustado por el método de bonferroni es 0.01
La comparación del grupo a vs grupo c no es significativa ya que su valor de \(p\) ajustado por el método de bonferroni es 0.74
La comparación del grupo a vs grupo u no es significativa ya que su valor de \(p\) ajustado por el método de bonferroni es 0.26
La comparación del grupo b vs grupo c no es significativa ya que su valor de \(p\) ajustado por el método de bonferroni es 1.00
La comparación del grupo b vs grupo u no es significativa ya que su valor de \(p\) ajustado por el método de bonferroni es 1.00
La comparación del grupo c vs grupo u no es significativa ya que su valor de \(p\) ajustado por el método de bonferroni es 1.00
Los valores sin ajustar de \(p\) para las comparaciones del grupo a vs b fueron
Welch Two Sample t-test
data: ab$Tetrahydrocortisone by ab$Type
t = -4.1499, df = 10.685, p-value = 0.001719
alternative hypothesis: true difference in means between group a and group b is not equal to 0
95 percent confidence interval:
-7.988307 -2.438360
sample estimates:
mean in group a mean in group b
2.966667 8.180000
Si multiplicamos el valor de p anterior por el número de comparaciones obtenemos el valor de\(p\)ajustado.\(0.001719*6=0.0103\)
Ejemplo 13.3rstatix es un paquete R que proporciona un conjunto de funciones para simplificar las operaciones de análisis de datos estadísticos. El paquete sigue el enfoque de “tidy data”, lo que facilita la manipulación de datos y análisis cuando se usa en combinación con otros paquetes del ecosistema tidyverse.
Algunas de las funciones más utilizadas en rstatix son:
anova_test(): Para realizar una prueba ANOVA.
t_test(): Para realizar pruebas t.
kruskal_test(): Para realizar la prueba de Kruskal-Wallis, que es una alternativa no paramétrica a la ANOVA.
compare_means(): Para realizar comparaciones post-hoc después de una ANOVA.
correlation_test(): Para realizar pruebas de correlación.
Se muestra el código para la realización de la corección de Bonferroni utlizando la librería rstatix
# A tibble: 6 × 10
.y. group1 group2 n1 n2 statistic df p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <chr>
1 Tetrahydro… a b 6 10 -4.15 10.7 0.002 0.01 *
2 Tetrahydro… a c 6 5 -1.95 4.02 0.123 0.738 ns
3 Tetrahydro… a u 6 6 -2.67 5.08 0.044 0.262 ns
4 Tetrahydro… b c 10 5 -1.33 4.16 0.252 1 ns
5 Tetrahydro… b u 10 6 -1.36 5.86 0.224 1 ns
6 Tetrahydro… c u 5 6 0.598 5.80 0.573 1 ns
Con el código anterior se realizan una serie de pruebas t de Student para comparar las medias de la variable Tetrahydrocortisone entre diferentes grupos especificados por la variable Type. Además, ajusta los valores p utilizando el método de Bonferroni para controlar la tasa de error de Tipo I.
Ejercicio 13.1 Realice una prueba post-hoc para Pregnanetriol por tipo (Type) de Cushings. Resuelva este ejercicio utilizando: a. pairs.t.test b. t_student de librería rstatix c. Realice los gráficos pertienetes d. Utilice la librería ggstatsplot
13.4 Tukey HSD Test
También conocido como Tukey HSD (“honestly significant difference” o “honest significant difference”). Este es el procedimiento más adecuado cuando el interés está en realizar todas las comparaciones por pares. Requiere igualdad de varianzas.
Para esta prueba se necesitan los valores de\(J\)y de\(Q\), además de un valor de tablas (\(Q\)). Se utiliza la siguiente formula:
\(n_i\) y\(n_j\)son el número de sujetos en el \(i\)-ésimo y \(j\)-ésimo grupo respectivamente.
\(J\) es el número de grupos a comparar.
\(v\) son los grados de libertad asociados a los cuadrados medios del error (MSE) en la tabla ANOVA.
\(Q\) proviene de una distribución del rango estudentizado para un \(\alpha\)especificado. Ver tabla Q.
En R puedes utilizar la función qtukey() para estimar \(Q\).
Ejemplo 13.4 Para resolver este ejemplo, partimos de los siguiente datos que muestran el peso medio de los recién nacidos en grupos de madres que fumaron a distintos tiempos durante el embarazo:
Tiempo de duración del tabaquismo en el embarazo
Peso en (kg)
<18 semanas
3.44 (n = 34)
18–31 semanas
3.39 (n = 24)
32+ semanas
3.27 (n = 77)
Después de realizar un ANOVA se sabe que el peso se asocia con la duración del tabaquismo y es estadísticamente significativo. Se procede a comparar los pesos medios al nacer para diferentes duraciones de tabaquismo. Los investigadores están interesados en las diferencias entre cualquiera de los grupos. Por lo tanto, se necesitan todas las comparaciones por pares para este la prueba de Tukey sería apropiada. Se conoce la siguiente información:
\(J = 3\)
\(n = 135\)
\(MSE = 0.022\) Obetenido del ANOVA
\(v = 126\)
\(Q = 3.36\) para \(\alpha = 0.05\)
Ahora se procede al cálculo de\(D_{ij}\)(la diferencia minina esperada)
-\(D_{ij}\) es la diferencia crítica que debe estar presente entre las medias de los grupos \(i\) y \(j\) para que sea estadísticamente significativa en \(\alpha = 0.05\). Por ejemplo:
El valor de \(p\) ajustada corresponde a la probabilidad de la distribución de Tukey. En R, esto se estima mediante la función ptukey.
13.4.1 Ventajas y Desventajas de la Prueba de Tukey
Aspecto
Ventajas
Desventajas
Error Tipo I
Controla eficazmente la tasa de error tipo I.
–
Tipo de Comparaciones
Útil para comparaciones de todos contra todos.
No es eficiente para comparaciones planeadas o específicas.
Simplicidad y Comodidad
Fácil de realizar y entender.
–
Poder Estadístico
Mayor poder estadístico en comparación con Bonferroni.
–
Supuestos Estadísticos
Requiere pocos supuestos y es robusta a pequeñas desviaciones.
Necesita que los datos cumplan con normalidad y homocedasticidad.
Sensibilidad a Atípicos
–
Sensible a valores atípicos.
Carga Computacional
–
Puede ser computacionalmente intensivo con muchos grupos.
13.4.2 Supuestos para la pruba de Tukey
Normalidad de los datos
Homogenidad de varianzas
\(n\) igual para los grupos
13.4.3 Tukey implementación en R
Ejemplo 13.5 En R podemos utilizar la función TukeyHSD y aplicarla a un ANOVA, o bien la función tukey_hsd de la librería rstastix. Si retomamos el ejemplo del ejercio anterior:
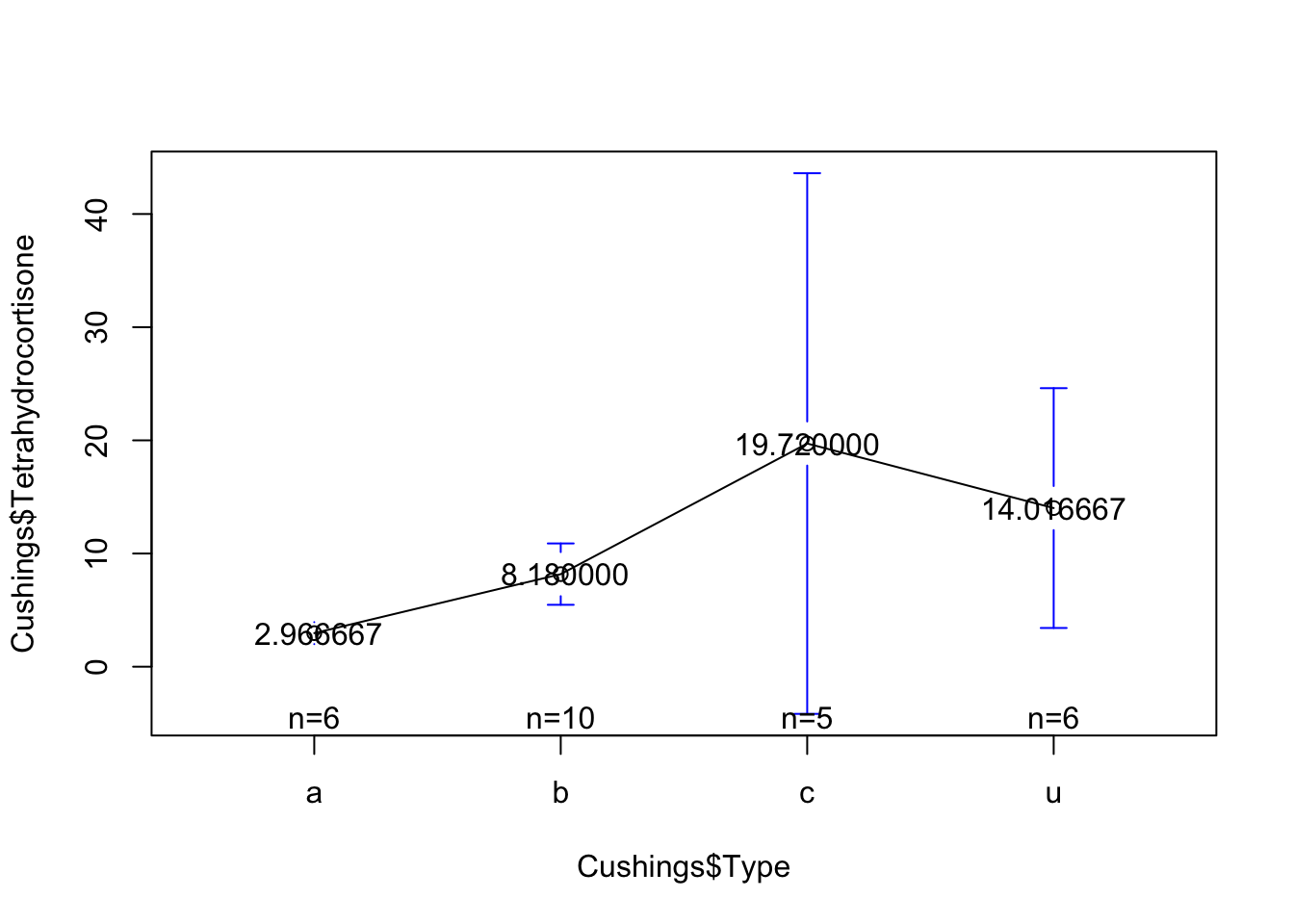
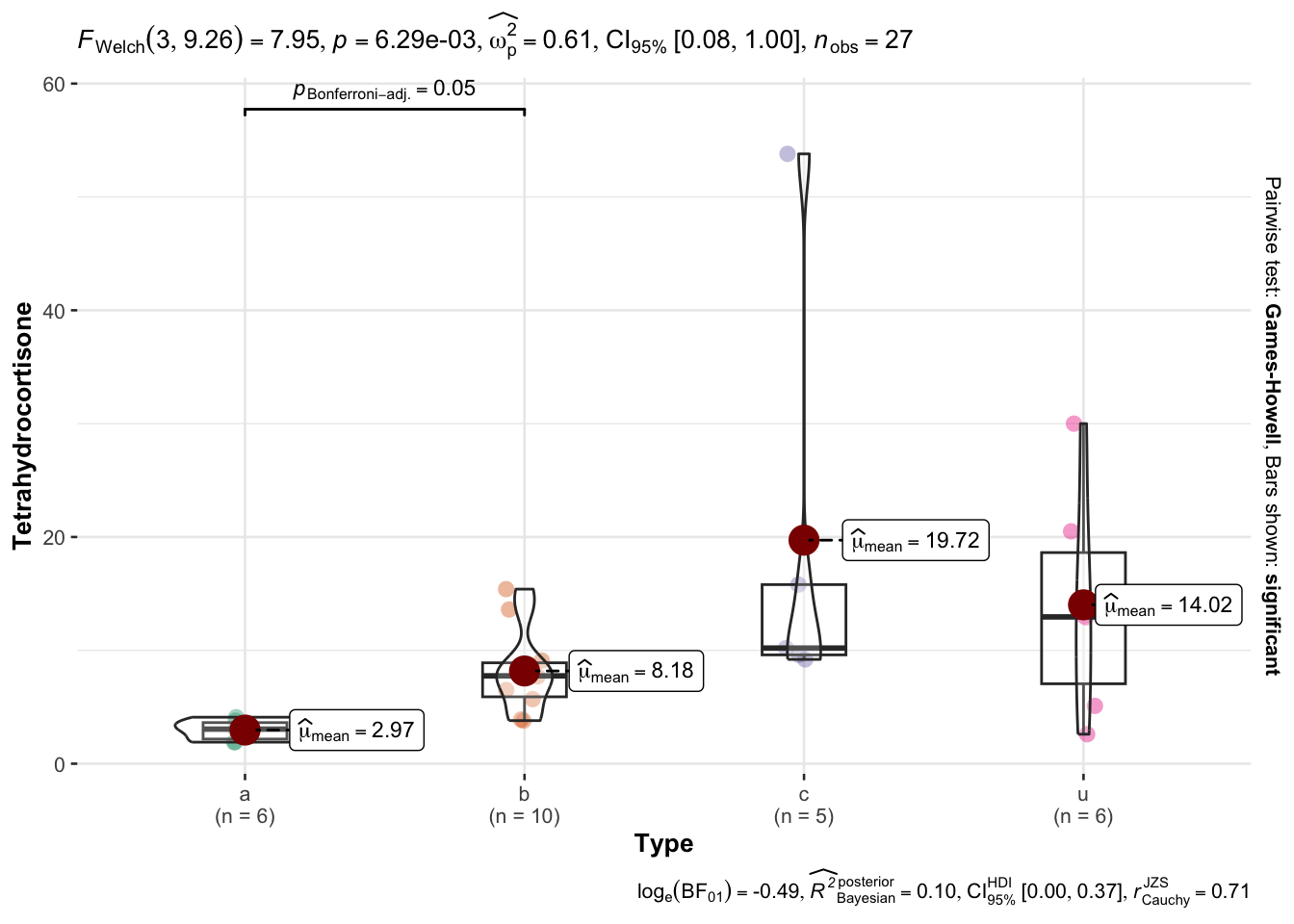
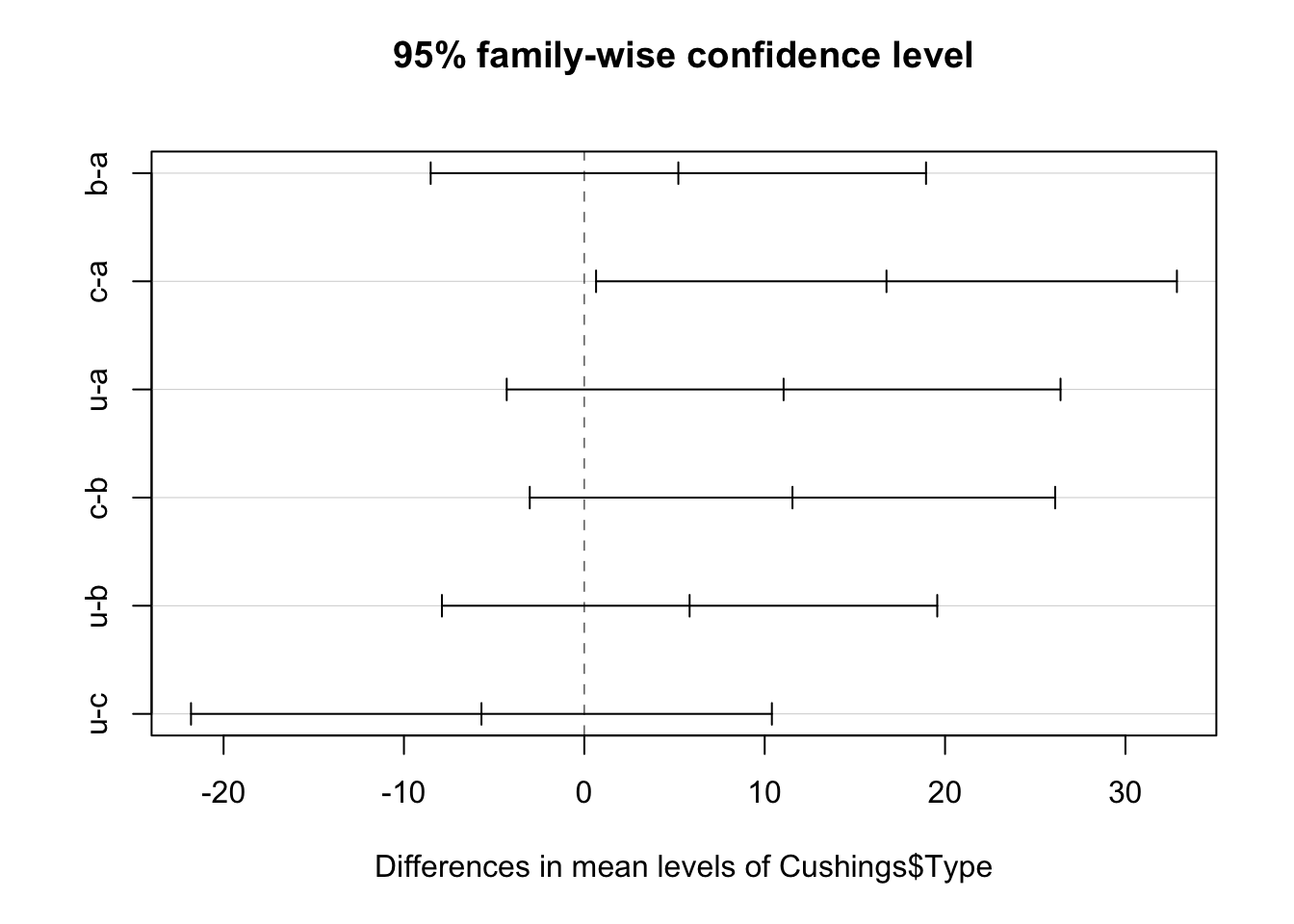
Los resultados anteriores indican la diferencia de las medias estimadas, los intervalos de confianza y el valor de p ajustado por el método de Tukey. Las medias y los intervalos de confianza corresponden a la resta de la media de un grupo vs la de otro. Por ejemplo si se comparan el grupo a vs el grupo b, las diferencias de medias sería: 2.9666667(media del grupo a)- 8.18(media del grupo b)=-5.2133333. La interpretación para la comparación del grupo b con el grupo a es como sigue: La diferencia de sus medias fue de 5.21, el IC bajo fue de -8.51, el IC alto fue de 18.94 y el valor de \(p\) ajustados por el método de Tukey fue de 0.721.
Se pueden graficar las diferencias de las medias utilizando el siguiente código: plot
# A tibble: 6 × 9
term group1 group2 null.value estimate conf.low conf.high p.adj p.adj.signif
* <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 Type a b 0 5.21 -8.52 18.9 0.722 ns
2 Type a c 0 16.8 0.652 32.9 0.0394 *
3 Type a u 0 11.0 -4.30 26.4 0.22 ns
4 Type b c 0 11.5 -3.02 26.1 0.155 ns
5 Type b u 0 5.84 -7.89 19.6 0.647 ns
6 Type c u 0 -5.70 -21.8 10.4 0.762 ns
Ejercicio 13.2 Realice una prueba post-hoc de Tukey para Pregnanetriol por tipo (Type) de Cushings. Resuelva este ejercicio utilizando:
13.5 Test de Dunnet
En ciertas situaciones, el interés está en comparar varios grupos contra un grupo de referencia específico, en lugar de comparar cada grupo con todos los demás. Este es el caso, por ejemplo, cuando se desean comparar las concentraciones de una citocina en varios grupos de pacientes con un grupo control. Otro ejemplo de este tipo de comparaciones sería si en un estudio sobre la enfermedad de Cushing, el “Tipo a” de Cushing es nuestro grupo de referencia. Nos interesaría entonces comparar este grupo con los “Tipos b, c y u” de la enfermedad.
La estadística de prueba de Dunnett para comparar la media del \(i\)-ésimo grupo de tratamiento \(\bar{x}_i\) con la media del grupo de control \(\bar{x}_c\)s e calcula como:
\(\bar{x}_i\) y \(\bar{x}_c\) son las medias de la muestra del \(i\)-ésimo grupo de tratamiento y el grupo de control, respectivamente.
\(MSE\) es el Error Cuadrático Medio, generalmente obtenido de una tabla ANOVA.
\(n_i\) y \(n_c\)son los tamaños de muestra del \(i\)-ésimo grupo de tratamiento y el grupo de control, respectivamente.
El estadístico D se compara con un valor crítico obtenido de la distribución de Dunnett, que es una distribución específica que tiene en cuenta múltiples comparaciones
La hipótesis que se prueba en el test de Dunnet es:
Hipótesis Nula (\(H_0\)): La media del grupo de tratamiento \(i\) es igual a la media del grupo de control.
Hipótesis Alternativa (\(H_a\)): La media del grupo de tratamiento \(i\) es diferente de la media del grupo de control.
13.5.1 Implementación del test de Dunnet en R
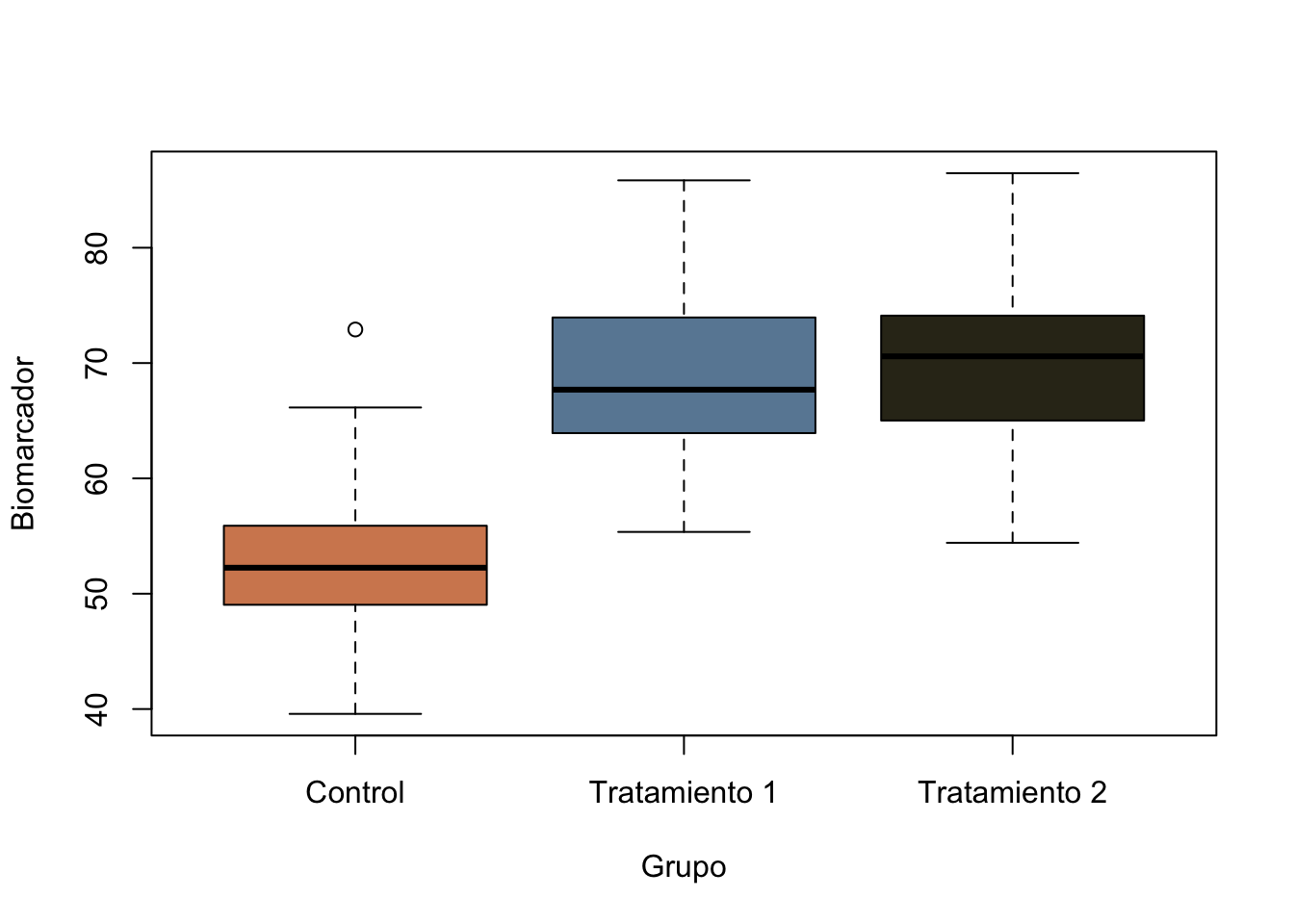
Ejemplo 13.7 Supongamos que es de nuestro interés comparar las concentraciones de un biomarcador en un grupo control y dos grupos con un tratamiento experimental. Para ello, vamos a crear un conjunto de datos ficticios:
set.seed(1234) # Sembrando la semilladatos <-data.frame(Grupo =rep(c("Control", "Tratamiento 1", "Tratamiento 2"), each =50),Biomarcador =c(rnorm(50, mean=56, sd =7), rnorm(50, mean=68, sd=7),rnorm(50, mean=70, sd =8)))datos$Grupo <-as.factor(datos$Grupo)head(datos) # visualizar los primeros 6 datos
Grupo Biomarcador
1 Control 47.55054
2 Control 57.94200
3 Control 63.59109
4 Control 39.58012
5 Control 59.00387
6 Control 59.54239
Podemos visualizar los datos:
boxplot(Biomarcador~Grupo, data=datos, col=c("#D3885E", "#6988A3", "#33301D",main="Concentraciones de un biomarcador"))
Procedemos a realizar la prueba de Levene para igualdad de varianzas y el ANOVA
car::leveneTest(datos$Biomarcador~datos$Grupo)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 1.3057 0.2741
147
aov(datos$Biomarcador~datos$Grupo)|>summary()
Df Sum Sq Mean Sq F value Pr(>F)
datos$Grupo 2 9376 4688 101.5 <2e-16 ***
Residuals 147 6792 46
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Ahora procedemos a realizar la prueba de Dunnet:
# Instale la librería si es necesarioDescTools::DunnettTest(x=datos$Biomarcador, g=datos$Grupo)
Registered S3 method overwritten by 'DescTools':
method from
reorder.factor gplots
Dunnett's test for comparing several treatments with a control :
95% family-wise confidence level
$Control
diff lwr.ci upr.ci pval
Tratamiento 1-Control 16.14808 13.11154 19.18462 2.2e-16 ***
Tratamiento 2-Control 17.33120 14.29466 20.36774 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Note como la comparación la hace con el primer nivel del factor
levels(datos$Grupo)
[1] "Control" "Tratamiento 1" "Tratamiento 2"
Del resultado anterior podemos ver que hay diferencias tanto en el tratamiento 1 como en el tratamiento 2
Ejercicio 13.3 Realice una prueba post-hoc de Dunnet para Pregnanetriol por tipo (Type) de Cushings. Considere al Cushing tipo “a” como grupo de referencia
13.5.2 Ventajas y Limitaciones del test de Dunnet
Ventajas: Es más poderosa estadísticamente que aplicar pruebas\(t\)individuales para cada comparación cuando se tiene un grupo de control.
Limitaciones: Al igual que otros métodos de comparación múltiple, requiere que los datos cumplan ciertos supuestos como la homogeneidad de varianzas
13.5.3 Supuestos para el test de Dunnet
Normalidad
Igualdad de varianzas
Independiencia de los datos
13.6 Prueba de Scheffe
La prueba de Scheffe es un método post-hoc utilizado en el ANOVA. Este método es especialmente útil para comparaciones no planificadas. La ventaja de la prueba de Scheffe es que corrige el nivel de significancia (\(\alpha\)) tanto para comparaciones de medias simples como para comparaciones más complejas que involucran más de un par de medias simultáneamente.
13.6.1 Comparación con otros Métodos
A diferencia de las pruebas LSD de Fisher (prueba que no se revisa aquí) y Tukey, la prueba de Scheffe es más flexible pero tiene menor poder estadístico. Aquí hay una guía general para elegir entre Tukey y Scheffe:
Si solo necesita realizar comparaciones por pares, opte por el método de Tukey, ya que proporciona intervalos de confianza más estrechos.
Si tiene interés en comparar todas las combinaciones posibles de medias, tanto simples como complejas, utilice la prueba de Scheffe.
13.6.2 Cálculo de Diferencias Mínimas
Para aplicar la prueba de Scheffe, es necesario calcular las diferencias mínimas significativas entre los pares de grupos y compararlas con las diferencias absolutas observadas.
Por ejemplo:
Media del Grupo A: 36
Media del Grupo B: 34.5
Media del Grupo C: 35.6
Media del Grupo D: 36.21
Comparaciones
Valor absoluto
Diferencias mínimas
¿Significativa?
AB
1.5
0.32
Sí
AC
0.4
0.35
Sí
AD
0.21
0.33
No
BC
1.1
0.34
Sí
BD
1.71
0.32
Sí
CD
0.61
0.35
Sí
La fórmula para calcular las diferencias mínimas es la siguiente:
Es relevante mencionar que, aunque la prueba de Scheffe no requiere estrictamente que las varianzas sean homogéneas o que la distribución sea normal, es recomendable tener el mismo número de casos en cada grupo para que los resultados sean más robustos.
13.6.4 Ventajas y Desventajas de la Prueba de Scheffe
Aspecto
Descripción
Ventajas
- Bueno para análisis de datos exploratorios y para probar teorías bien desarrolladas.
- Puede probar pares que constan de combinaciones.
- Prueba relativamente poderosa.
- No es necesario definir contrastes de antemano.
- Disponible en muchos paquetes estadísticos.
- Riesgo reducido de errores de tipo II.
Desventajas
- Requiere grupos de igual tamaño.
- Prueba contrastes que no son de interés.
- Más sujeto a errores de tipo 1 que otras pruebas posthoc.
- Intervalosd de confianza amplios y poco poder estadístico
13.6.5 Implementación de la prueba de Scheffe en R
Ejemplo 13.8 En R podemos hacer la prueba de Scheffe utilizando la función scheffe.test del paquete agricolae. Realizaremos una prueba post-hoc de Scheffe de la base de datos Chusings del paquete MASS.
Warning in arrows(x, li, x, pmax(y - gap, li), col = barcol, lwd = lwd, :
zero-length arrow is of indeterminate angle and so skipped
Warning in arrows(x, ui, x, pmin(y + gap, ui), col = barcol, lwd = lwd, :
zero-length arrow is of indeterminate angle and so skipped
Realizar la prueba post-hoc La función scheffe.test tiene los siguientes argumentos:
y= modelo de ANOVA
trt= variable de clasificación para el ANOVA (tratamientos)
main= para especificar el título del modelo
group= permite la comparación por grupos (TRUE o FALSE)
console= para arrojar los resultados por consola
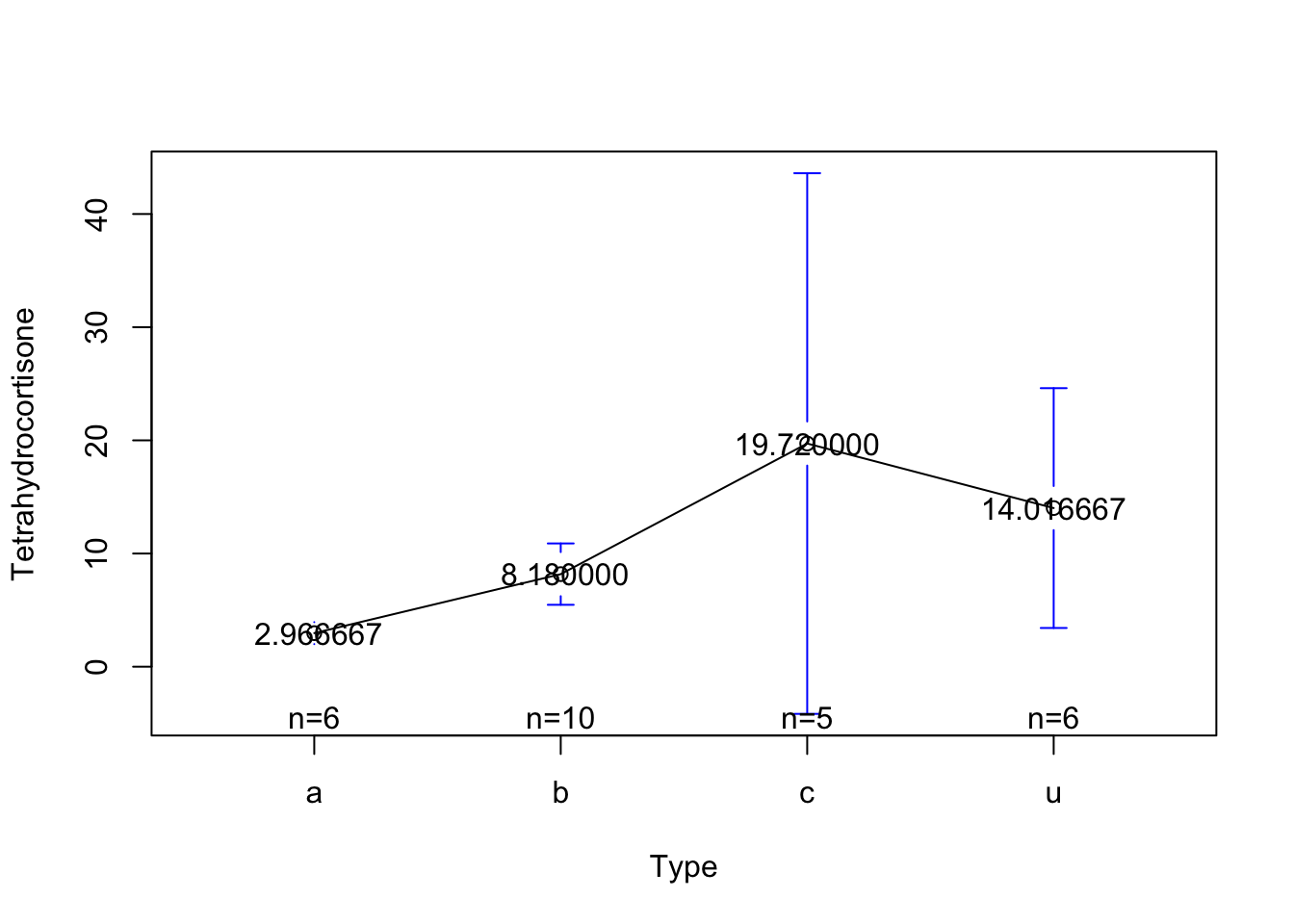
## Es necesarios crear un objetocomparaciones <-scheffe.test(y=Anova_Chusings, trt="Type", group = T, console = T)
Study: Anova_Chusings ~ "Type"
Scheffe Test for Tetrahydrocortisone
Mean Square Error : 92.33242
Type, means
Tetrahydrocortisone std r se Min Max Q25 Q50 Q75
a 2.966667 0.9244818 6 3.922848 1.9 4.1 2.175 3.05 3.625
b 8.180000 3.7891072 10 3.038625 3.8 15.4 5.900 7.75 8.900
c 19.720000 19.2388149 5 4.297265 9.2 53.8 9.600 10.20 15.800
u 14.016667 10.0958242 6 3.922848 2.6 30.0 7.050 12.95 18.625
Alpha: 0.05 ; DF Error: 23
Critical Value of F: 3.027998
Groups according to probability of means differences and alpha level( 0.05 )
Means with the same letter are not significantly different.
Tetrahydrocortisone groups
c 19.720000 a
u 14.016667 a
b 8.180000 a
a 2.966667 a
comparaciones
$statistics
MSerror Df F Mean CV
92.33242 23 3.027998 10.45556 91.90307
$parameters
test name.t ntr alpha
Scheffe Type 4 0.05
$means
Tetrahydrocortisone std r se Min Max Q25 Q50 Q75
a 2.966667 0.9244818 6 3.922848 1.9 4.1 2.175 3.05 3.625
b 8.180000 3.7891072 10 3.038625 3.8 15.4 5.900 7.75 8.900
c 19.720000 19.2388149 5 4.297265 9.2 53.8 9.600 10.20 15.800
u 14.016667 10.0958242 6 3.922848 2.6 30.0 7.050 12.95 18.625
$comparison
NULL
$groups
Tetrahydrocortisone groups
c 19.720000 a
u 14.016667 a
b 8.180000 a
a 2.966667 a
attr(,"class")
[1] "group"
Interpretación
El test de Scheffe arroja entre otras cosas estadística descriptiva por grupos, grados de libertad e indica si las comparaciones son significativas o no sin dar un valor de \(p\) en especifico. La siguiente tabla ejemplifica de una manera didáctiva los resultados obtenidos para el ejemplo anterior
Grupo (tratamiento)
Media
Grupo comparación
Significancia
c
19.72
a
Misma letra (no significancia)
u
14.01
a
Misma letra (no significancia)
b
8.18
a
Misma letra (no significancia)
a
2.97
a
Misma letra (no significancia)
Al tener la misma letra en el grupo de comparación todas las medias son iguales, la función asigna conforme al abecedario la letra en este grupo de comparación. En el ejemplo anterior, todas las comparaciones fueron iguales las letras, en este caso, la letra “a” son iguales.
Ejemplo 13.9 Otro ejemplo. En este caso se utilizará la base de dato sweetpopato contenida en el paquete agricolae. En esta base hay cuatro grupos (cc, fc, ff, oo) que se encuentran en la variable virus.
virus yield
1 cc 28.5
2 cc 21.7
3 cc 23.0
4 fc 14.9
5 fc 10.6
6 fc 13.1
7 ff 41.8
8 ff 39.2
9 ff 28.0
10 oo 38.2
11 oo 40.4
12 oo 32.1
El siguiente código se utilizó para realizar un ANOVA de la variable yield agrupado por la variable virus
El siguiente código se utilizó para realizar la prueba post-hoc de Scheffe del modelo de ANOVA anterior.
comparison <-scheffe.test(model,"virus", group=TRUE,console=TRUE,main="Yield of sweetpotato\nDealt with different virus")
Study: Yield of sweetpotato
Dealt with different virus
Scheffe Test for yield
Mean Square Error : 22.48917
virus, means
yield std r se Min Max Q25 Q50 Q75
cc 24.40000 3.609709 3 2.737953 21.7 28.5 22.35 23.0 25.75
fc 12.86667 2.159475 3 2.737953 10.6 14.9 11.85 13.1 14.00
ff 36.33333 7.333030 3 2.737953 28.0 41.8 33.60 39.2 40.50
oo 36.90000 4.300000 3 2.737953 32.1 40.4 35.15 38.2 39.30
Alpha: 0.05 ; DF Error: 8
Critical Value of F: 4.066181
Minimum Significant Difference: 13.52368
Means with the same letter are not significantly different.
yield groups
oo 36.90000 a
ff 36.33333 a
cc 24.40000 ab
fc 12.86667 b
La siguiente tabla ayuda con la interpretación
G r u p o
Meida del grupo
Co mpa rac ión
Interpretación
Interpretación
o o
36.9
a
El grupo oo es igual al ff y al cc. Todos tienen a
El grupo oo es distinto del fc (uno tiene a y el otro b)
f f
36.3
a
el grupo ff es igual al oo y al cc. Todos tienen a
El grupo ff es distinto del fc (uno tiene a y el otro b)
c c
24.4
ab
el grupo cc es igual a todos los grupos tiene a y b
f c
12.87
b
el grupo fc es disinto al oo y ff (no tienen b)
Ejercicio 13.4 Asuma que se cumplen todos los supuestos para realizar la pureba de Scheffe y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Interprete sus resultados
13.7 Test de Dunn
La prueba de Dunn es una prueba post-hoc no paramétrica utilizada para identificar diferencias significativas entre las medianas de distintos grupos. Aunque sigue un principio similar al de la corrección de Bonferroni, es específica para análisis no paramétricos.
En esta prueba post-hoc las hipótesis se establecen de la siguient form:
Hipótesis Nula: No hay diferencias significativas entre las medianas de los grupos.
Hipótesis Alternativa: Existen diferencias significativas entre las medianas de al menos dos grupos.
13.7.1 Consideraciones para emplear el test de Dunn
La prueba de Dunn es especialmente útil cuando:
Se desea comparar un subconjunto específico de todos los pares posibles de grupos.
No se está haciendo una comparación con un grupo control.
Se han utilizado pruebas no paramétricas como Kruskal-Wallis para el análisis inicial.
Si se está comparando con un grupo control, la prueba de Dunnett o T3 de Dunnet serían más apropiada.
13.7.2 Implementación en R
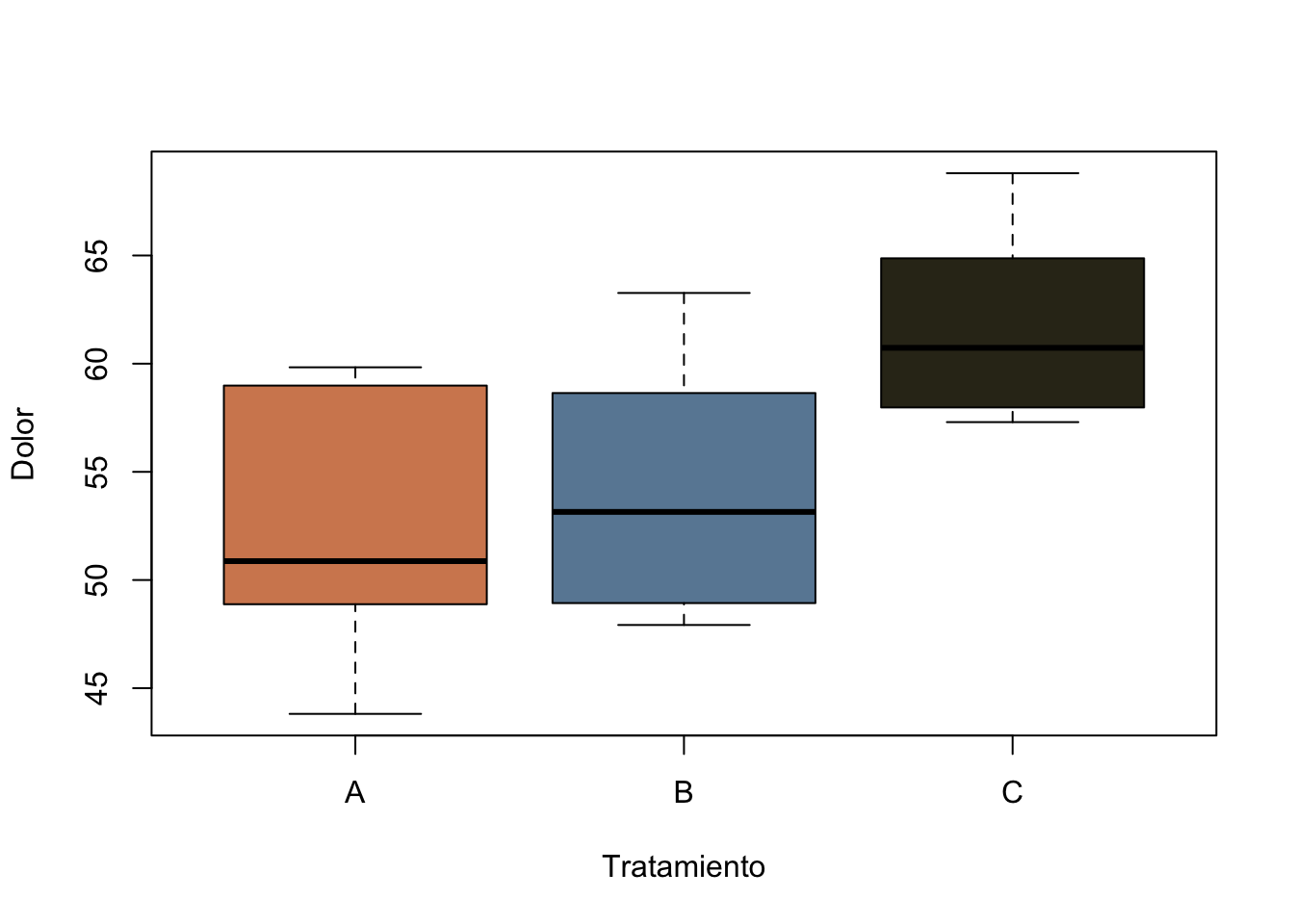
Ejemplo 13.10 Supongamos que es de nuestro interés la efectividad de 3 tratamiento para reducir el dolor medido en una escala de dolor de 0 a 100. Sabemos por estudios previos que los datos nos ajustan a una distribución normal y que debemos realizar una prueba post-hoc para conocer en que grupos están la diferencias.
Creación de data frame ficticio
#Creación de un data framedatos <-data.frame(Tratamiento =rep(c("A", "B", "C"), each =10),Dolor =c(runif(10, 40, 60),runif(10, 45, 65),runif(10, 55, 70)))
Visualizar el data frame
#Visualizar los primeros 6 datoshead(datos)
Tratamiento Dolor
1 A 47.05997
2 A 59.61917
3 A 50.77766
4 A 48.88068
5 A 58.98734
6 A 49.04967
boxplot(Dolor~Tratamiento, data=datos, col=c("#D3885E", "#6988A3", "#33301D",main="Escala del dolor en tres distintos tratamientos"))
Realizar Kruskal-Wallis
kruskal.test(Dolor ~ Tratamiento, data = datos)
Kruskal-Wallis rank sum test
data: Dolor by Tratamiento
Kruskal-Wallis chi-squared = 10.97, df = 2, p-value = 0.004148
Prueba post-hoc
library(dunn.test)dunn.test(datos$Dolor, datos$Tratamiento, kw=T)# Es necesario cambiar el paramétro kw para indicar que la comparación viene de un ANOVA
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 10.9703, df = 2, p-value = 0
Comparison of x by group
(No adjustment)
Col Mean-|
Row Mean | A B
---------+----------------------
B | -0.609600
| 0.2711
|
C | -3.124203 -2.514602
| 0.0009* 0.0060*
alpha = 0.05
Reject Ho if p <= alpha/2
También se puede realizar utilizando la librería rstastix aunque el método de ajuste del valor de p es distinto al de la función dunn.test
rstatix::dunn_test(data = datos, formula = Dolor~Tratamiento)
# A tibble: 3 × 9
.y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
1 Dolor A B 10 10 0.610 0.542 0.542 ns
2 Dolor A C 10 10 3.12 0.00178 0.00535 **
3 Dolor B C 10 10 2.51 0.0119 0.0238 *
13.7.3 Ventajas
No Paramétrica: Útil cuando los datos no se distribuyen normalmente o cuando las varianzas son diferentes.
Comparaciones por pares: Permite comparar cada par de grupos para determinar cuáles son significativamente diferentes entre sí.
Menos restrictiva: Menos supuestos en comparación con pruebas paramétricas como el ANOVA.
Adecuada para muestras pequeñas: Puede ser más fiable que otras pruebas post-hoc cuando el tamaño de la muestra es pequeño.
13.7.4 Desventajas
Menor Poder Estadístico: Al ser una prueba no paramétrica, puede tener menos poder para detectar diferencias reales en comparación con pruebas paramétricas.
Solamente para dos grupos: La prueba de Dunn originalmente fue diseñada para comparar solo dos grupos a la vez, aunque existen extensiones para más grupos (prueba complejas).
Riesgo de Error Tipo I: Al igual que otras pruebas post-hoc, incrementa el riesgo de encontrar diferencias significativas por azar (error de Tipo I) debido a las comparaciones múltiples.
Ejercicio 13.5 Asuma que se cumplen todos los supuestos para realizar la prueba de Dunn y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Interprete sus resultados
13.8 Dunnett T3
La prueba T3 de Dunnett es una extensión del test de Dunnett estándar y se utiliza para realizar comparaciones múltiples entre grupos cuando las varianzas no son homogéneas. Esta prueba de comparación a priori o múltiple utilizada para determinar si la media de una condición de control difiere de la de dos o más condiciones experimentales en un análisis de varianza. Se puede utilizar para tamaños de iguales y desiguales donde las variaciones son desiguales. Se podría decir que es el equivalente no paramétrico de la prueba de Dunnet. Esta prueba tiene en cuenta la mayor probabilidad de cometer un error de tipo I cuantas más comparaciones se realicen. Algunos autores recomiendan su uso para n<50.
13.8.1 Implementación de la prueba Dunnett T3 en R
Ejemplo 13.11
Instalación del paquete
install.packages("PMCMRplus") # Si es necesario instale la librería
Cargar la librería
library(PMCMRplus)
# Crear datos de ejemplo con varianzas heterogéneasgroupA <-rnorm(10, mean =50, sd =10)groupB <-rnorm(10, mean =55, sd =15)groupC <-rnorm(10, mean =53, sd =20)groupControl <-rnorm(10, mean =52, sd =12)# Combinar los datos en un data framedata <-data.frame(value =c(groupA, groupB, groupC, groupControl),group =factor(rep(c("A", "B", "C", "Control"), each =10)))# Realizar ANOVAmodel <-aov(value ~ group, data = data)# Realizar prueba T3 de DunnettdunnettT3Test(model, var.equal=F)
Pairwise comparisons using Dunnett's T3 test for multiple comparisons
with unequal variances
data: value by group
A B C
B 1 - -
C 1 1 -
Control 1 1 1
P value adjustment method: single-step
alternative hypothesis: two.sided
Puede consultar más información de la función dunnettT3Test en: https://rdrr.io/cran/PMCMRplus/man/dunnettT3Test.html
13.8.2 Ventajas Dunnett T3
Control de Error Tipo I: Al igual que con la prueba de Dunnett estándar, el riesgo de errores de Tipo I se controla de manera efectiva.
Varianzas Heterogéneas: Puede ser aplicada cuando las varianzas entre los grupos no son iguales.
Comparación con un Grupo Control: Es útil cuando se tiene un grupo de control específico al que se desean comparar otros grupos.
13.8.2.1 Desventajas Dunnett T3
Complejidad Computacional: Puede ser más compleja de calcular que la prueba de Dunnett estándar.
Poder Estadístico: Podría tener menos poder estadístico que otros métodos cuando las varianzas son en realidad homogéneas.
Disponibilidad en Software: No todos los paquetes estadísticos incluyen esta prueba específica.
Ejercicio 13.6 Asuma que se cumplen todos los supuestos para realizar la prueba de T3 de Dunnet y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Tome como grupo control al grupo de Cushing “a”. Interprete sus resultados
13.9 Games-Howell
Prueba que se utiliza para determinar cuál de tres o más medias difieren entre sí cuando la relación F en un análisis de varianza es significativa. Fue desarrollado para tratar con grupos con varianzas desiguales. Se puede utilizar con grupos de igual o diferente tamaño. Se basa en la estadística de rango estudentizado
La prueba de Games-Howell es una prueba post hoc no paramétrica que se utiliza para comparaciones múltiples después de un análisis de varianza (ANOVA) cuando los supuestos de homogeneidad de varianzas no se cumplen. Esta prueba calcula intervalos de confianza para cada par de medias y compara si se solapan o no para determinar la significancia estadística.
13.9.1 Games-Howell implementación en R
Ejemplo 13.12 Una forma de estimar la prueba post-hoc de Games-Howell en R es utilizando la función posthocTGH del paquete rosetta. Para realizar la comparación post-hoc entre los distintos tipos de Cushings y las concentraciones de tetrahidrocortisona utilice el siguiente código:
La función posthocTGH requiere que las variables se encuentren separadas por una coma, primero se pone la variable de prueba cuantitativa y luego la variable de agrupación.
Puede encontrar mayor información y otras funciones para realizar la pruab de Games-Howell en: https://rpubs.com/aaronsc32/games-howell-test
Ejercicio 13.7 Asuma que se cumplen todos los supuestos para realizar la prueba de Games-Howell y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Interprete sus resultados
13.10 Holms
La corrección de Holm es un método de ajuste de la tasa de error de Tipo I en pruebas estadísticas múltiples. Se utiliza para controlar el error de Tipo I global en conjuntos de pruebas, ajustando el nivel de significancia de cada prueba individual. Holm es una extensión del procedimiento de Bonferroni y es menos conservador que este último
El procedimiento de Holm es un método secuencial diseñado para incrementar el poder estadístico de un conjunto de pruebas mientras controla el error de Tipo I a nivel familiar (familywise Type I error). El primer paso en el procedimiento de Holm consiste en realizar todas las pruebas individuales para obtener sus respectivos valores p. Estos se ordenan en orden ascendente, desde el valor p más bajo hasta el más alto. La prueba con el valor p más bajo se somete primero a una corrección de Bonferroni. Si esta prueba no resulta ser estadísticamente significativa, el procedimiento se detiene y se concluye que ninguna de las pruebas es significativa. De lo contrario, el proceso continúa, ajustando los niveles de significancia para las pruebas restantes. Este proceso se repite tantas veces como sea necesario.
La principal diferencia entre Bonferroni y Holms, es que en Bonferroni se cuantas comparaciones cmo grupo hay; Holms solo lo hacen para las que son significativas.
13.10.1 Holms implementación en R
Ejemplo 13.13 Existen múltiples formas de utilizar este procedimiento en R, de hecho, es la prueba post-hoc que se realiza por default en la mayoría las funciones. Para utilizar esta prueba post-hoc podemos:
Utilizar la función pairwise.t.test() o pairwise.table() cambiando el argumento p.adjust.method por “holm”
Utilizar la función t_test de la librería rstastix
Utilizando la función ggbetweenstats de la librería ggstatplot
Ejercicio 13.8 Asuma que se cumplen todos los supuestos para realizar la prueba de Holms y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Realice la prueba por los tres métodos descritos en el compendio.
13.10.2 Ventajas y desventajas
Aspecto
Ventajas y Desventajas
Ventajas
Menos conservador
Mientras que la corrección de Bonferroni puede ser muy conservadora, la corrección de Holm ofrece un equilibrio.
Control del error
Ayuda a controlar el error de Tipo I en pruebas múltiples.
Facilidad de uso
Es fácil de calcular y entender, y está ampliamente disponible en software estadístico.
Desventajas
Errores Tipo II
Aumenta la probabilidad de errores de Tipo II (no rechazar una hipótesis nula falsa).
Poder estadístico
Hay métodos más modernos y menos conservadores disponibles, aunque Holm es más poderoso que Bonferroni.
13.11 Hommel
El procedimiento de Hommel es un método adaptativo y flexible que ofrece un equilibrio entre el control del error de Tipo I y el mantenimiento de la potencia estadística. Es más potente que los métodos de Bonferroni y Holm. El procedimiento de Hommel ajusta cada valor p según todas las demás comparaciones y utiliza una estrategia de búsqueda para encontrar el mayor valor p ajustado que todavía es menor que el nivel de significancia.
13.11.1 Ventajas
Mayor Potencia: Comparado con Bonferroni y Holm, Hommel ofrece una mayor potencia estadística, lo que significa una menor probabilidad de errores de Tipo II.
Control del Error de Tipo I: Similar a Bonferroni y Holm, ayuda a controlar el error de Tipo I en pruebas múltiples.
13.11.2 Desventajas
Complejidad Computacional: El método de Hommel puede ser más complejo de calcular que otros métodos como Bonferroni o Holm, especialmente para un gran número de pruebas.
No es Óptimo para Todas las Situaciones: Hay métodos más modernos y menos conservadores disponibles.
13.11.3 Implementación de la prueba Hommel en R
Ejemplo 13.14
Utilizar la función pairwise.t.test() o pairwise.table() cambiando el argumento p.adjust.method por “hommel”
Utilizar la función t_test de la librería rstastix
Utilizando la función ggbetweenstats de la librería ggstatplot
Ejercicio 13.9 Asuma que se cumplen todos los supuestos para realizar la prueba de Hommel y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Realice la prueba por los tres métodos descritos en el compendio.
13.12 Benjamini-Hochberg
El procedimiento de Benjamini-Hochberg, también conocido como corrección FDR (False Discovery Rate), es un enfoque diseñado para controlar la tasa de descubrimientos falsos en múltiples pruebas de hipótesis. A diferencia de otros métodos como Bonferroni o Holm, que buscan controlar la tasa de error de Tipo I en toda la familia de pruebas, Benjamini-Hochberg se centra en controlar la proporción de errores Tipo I entre las hipótesis rechazadas.
13.12.1 ¿Cómo ejecutar el procedimiento de Benjamini-Hochberg
Ordene los valores p individuales en orden ascendente.
Asigne rangos a los valores p. Por ejemplo, el más pequeño tiene un rango de 1, el segundo más pequeño un rango de 2. Calcule el valor crítico de Benjamini-Hochberg para cada valor p individual utilizando la fórmula \((i/m)Q\) donde:
\(i\) = rango del valor \(p\) individual,
\(m\) = número total de pruebas,
\(Q\) = tasa de falsos descubrimientos (un porcentaje, elegido por el investigador).
Compare sus valores \(p\) originales con el valor crítico B-H calculado en el paso anterior. Identifique el valor p más grande que sea menor que el valor crítico.
Por ejemplo, si se realizan 8 pruebas y se elije un calor de \(Q\) de 25% solamente la comparación en el grupo A sería significativa
Variable
Valor de P
Rango
\((i/m)Q\)
Grupo A
0.001
1
0.03125
Grupo B
0.008
2
0.0625
Grupo C
0.039
3
0.09375
Grupo D
0.041
4
0.125
Grupo E
0.042
5
0.15625
Grupo F
0.06
6
0.1875
Grupo G
0.074
7
0.21875
Grupo H
0.205
8
0.25
El valor que se elige para \(Q\), que es la tasa de falsos descubrimientos permitidos, depende del contexto de la investigación y del nivel de rigor que se desee. No hay un valor “habitual” para Q que sea universalmente aceptado en todas las disciplinas, pero un valor comúnmente utilizado es 0.05, similar al nivel de significancia \(\alpha\) que se usa en pruebas estadísticas clásicas
13.12.2 Ventajas
Control de FDR: Este método controla la Tasa de Descubrimiento Falso, lo que es a menudo más deseable en contextos donde se realizan muchas pruebas simultáneas.
Mayor potencia estadística: Comparado con métodos más conservadores como Bonferroni, ofrece más poder estadístico, reduciendo la tasa de errores de Tipo II.
Aplicabilidad: Es aplicable en una amplia gama de disciplinas y tipos de datos.
13.12.3 Desventajas
No es siempre riguroso: En ciertos escenarios puede ser menos conservador en términos de control del error Tipo I comparado con otros métodos.
Dependencia estructural: Su rendimiento puede verse afectado si hay una estructura de dependencia compleja entre las pruebas.
13.12.4 Implementación de la prueba Benjamini-Hochberg en R
Ejemplo 13.15
Utilizar la función pairwise.t.test() o pairwise.table() cambiando el argumento p.adjust.method por “BH”
Utilizar la función t_test de la librería rstastix
Utilizando la función ggbetweenstats de la librería ggstatplot
Ejercicio 13.10 Asuma que se cumplen todos los supuestos para realizar la prueba de BH y realice esta comparación post-hoc para Pregnanetriol por tipo (Type). Realice la prueba por los tres métodos descritos en el compendio.
13.13 Nemenyi Test
La prueba de Nemenyi es la misma que la prueba de Tukey HSD , excepto que probamos la diferencia entre rangos de los grupos. La corrección Nemenyi estima un valor q para la distribución de Tukey;
\[q= \frac{|\bar{R}_i-\bar{R}_j|}{s.e.}\] Donde:
\[s.e=\sqrt{\frac{k(n+1)}{12}}\]
donde k = el número de grupos y n = el tamaño total de la muestra donde el grupo los tamaños son todos iguales. El estadístico q tiene una distribución q de rango studentizado y se compara con el valor de tablas para obtener los valores de \(p\) (igual que Tukey)
13.13.1 Nemenyi implementación en R
Ejemplo 13.16 Se puede utilizar la función NemenyiTest del paquete DescTool. Siguiendo con el ejemplo de la base de datos Chushings tendriamos lo siguiente:
Las comparaciones múltiples generalmente se realizan solo después de que una prueba F revela significación. En cualquier caso, se necesita ANOVA para calcular MSE.
Muchos paquetes estadísticos realizan la prueba de Tukey u otros procedimientos de comparaciones múltiples, y calculan el valor \(p\) para cada comparación, que se puede utilizar para decidir qué grupos son significativamente diferentes de los demás.
Es posible que la prueba F sea significativa, pero ninguna de las comparaciones por pares es significativa. Por el contrario, la prueba F puede no mostrar significación, pero la comparación para un par específico aún puede ser significativa. Esto sucede porque ambos requieren un patrón gaussiano, pero los datos prácticos rara vez siguen un patrón gaussiano exacto. Las pruebas F y Tukey se comportan de manera diferente para la desviación del patrón gaussiano. El problema puede surgir con mayor frecuencia para n pequeña.
Si se presenta el fenómeno descrito en el punto anterior, se recomienda utilizar otra pureba post-hoc
Los procedimientos anteriores son válidos solo para comparaciones planificadas previamente. A veces, la idea de probar la significación estadística entre dos o más grupos surge después de ver los datos observados (esto a veces se denomina espionaje de datos)
13.15 Ejercicios
Ejercicio 13.11 En el ejercicio @ref(exr:exr-13-11) comparó 5 variables entre pacientes con lupus eritematoso sistémico con nefropatía, pacientes con lupus eritematoso sistémico sin nefropatía y un grupo control. Para ello, utilizó la base de datos original del artículo: “Serum levels of adiponectin and leptin as biomarkers of proteinuria in lupus nephritis”, que se encuentra publicada como material adicional en (https://ndownloader.figstatic.com/files/9307021). Utilizó de esta base la variable Groups_NLSLEvsSLE.
Para la comparación de estas 5 variables (Age, Leptin, Leptin_BMI, Adiponectin, Adiponectin_BMI), realice la prueba post-hoc más adecuada.
Justifique la prueba a realizar
Entregue su código en R
Entregue una interpretación de sus hallazgos
Si su objetivo es compararse con el grupo control, ¿qué prueba estadística post-hoc utilizaría?
Ejercicio 13.12 La función t_test de la librería rstastix contiene las siguientes pruebas post-hoc: “holm”, “hochberg”, “hommel”, “bonferroni”, “BH”, “BY” y “fdr”. Realice una pequeña investigación de cada una de las pruebas que incluye:
Fundamento
Ventajas
Desventajas
Si necesita varianzas iguales
Si necesita una distrubución normal
Si necesita grupos con \(n\) igual
Ejercicio 13.13 Realice su propio árbol de decisión para la selección de una prueba post-hoc
González MÁM, Villegas AS, Atucha ET, Fajardo JF. Bioestadística amigable [Internet]. Elsevier Health Sciences; 2020.
Harrison, Ewen., Pius, Riinu. R for Health Data Science. Estados Unidos: CRC Press, 2020.
Wilson, J., Chen, D., Peace, K. E. (2023). Statistical Analytics for Health Data Science with SAS and R. Estados Unidos: CRC Press.
Upton, Graham., Cook, Ian. A Dictionary of Statistics 3e. Reino Unido: OUP Oxford, 2014.
Vogt, W. Paul., Johnson, R. Burke. Dictionary of Statistics & Methodology: A Nontechnical Guide for the Social Sciences. Reino Unido: SAGE Publications, 2011.
 {#fig16-1 fig-cap=“Fuente: McHugh M. L. (2011). Multiple comparison analysis testing in ANOVA. Biochemia medica, 21(3), 203–209. https://doi.org/10.11613/bm.2011.029)’ fig-aling=”center”}
{#fig16-1 fig-cap=“Fuente: McHugh M. L. (2011). Multiple comparison analysis testing in ANOVA. Biochemia medica, 21(3), 203–209. https://doi.org/10.11613/bm.2011.029)’ fig-aling=”center”}