Chapter 19 Cross-over designs
![]()
19.1 Learning objectives
By the end of this chapter, you will be able to:
- Understand how a cross-over RCT works
- Specify its advantages and disadvantages compared to a regular RCT
19.2 A within-subjects approach to the RCT
The standard two-arm RCT treats the intervention effect as a between-subjects factor: i.e., the intervention and control groups include different people. In the cross-over design, we treat intervention as a within-subjects factor, by comparing the same people in different phases of a study, during which they do or do not receive intervention. This is also known as a repeated measures design, because we test the same individuals in more than one condition. Because we have two groups who receive the period with and without intervention in counterbalanced order, we avoid the interpretive problems that arise with a simple pre-intervention vs post-intervention comparison (Chapter 5).
The benefit of the crossover design is that a potentially more accurate evaluation of intervention comparison is achieved, as we compare individuals to themselves as well as to controls who are different individuals. Another benefit is that power is higher than for a regular RCT: crossover designs typically require fewer individuals, as a separate control group is not necessary. In effect, with a cross-over design, we combine two sources of information about the efficacy of intervention: comparing individuals across the two phases (within subjects) and comparing the two groups in each phase (between subjects).
In drug trials, the typical cross-over design is split into three phases: an initial phase where two groups are randomized (exactly the same as a parallel group design) to intervention and control (Sibbald & Roberts, 1998). Once the first phase has elapsed, there is a washout phase (phase 2) where no intervention is given; this is important to allow any intervention effect to be removed before the groups are switched. Then phase 3 is started with the intervention and control conditions switched. By the end of the study, both groups have received intervention. The assessment of the intervention looks at the differences between phases 1 and 3 by group. If treatment is effective, we should see no group difference but a significant phase difference.
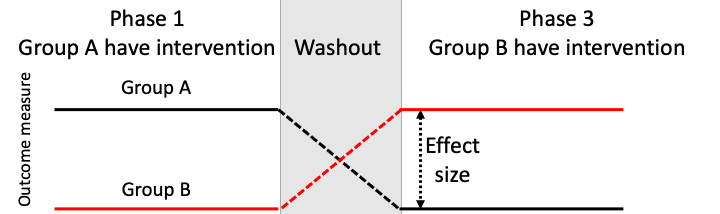
Figure 19.1: Schematic of a cross-over RCT
The suitability of a cross-over design, and the anticipated results, depend crucially on the nature of the intervention. A key question is whether or not the intervention is intended to have long-term effects that persist beyond the intervention phase. For most behavioural interventions, including those administered by speech-and-language therapists, educators and allied health professionals, the goal is to bring about long-term change. Exceptions would be communication aids such as auditory feedback masking, which decreases stuttering while the masker is switched on, but does not produce long-term change (Block et al., 1996). In this regard, most behavioural interventions are unlike pharmaceutical trials, which often focus on the ability of specific drugs to provide symptomatic relief. This makes results from the cross-over design difficult to interpret.
19.3 Delayed cross-over design (Wait list controls)
The delayed cross-over design or wait list control design is another type of within subject design that is more commonly used in situations where the effect of an intervention is likely to persist. We start by taking baseline measures from both groups. The impact of intervention is measured in Group A relative to their pre-intervention score. For Group B, intervention starts at the point when Group A stop the intervention.
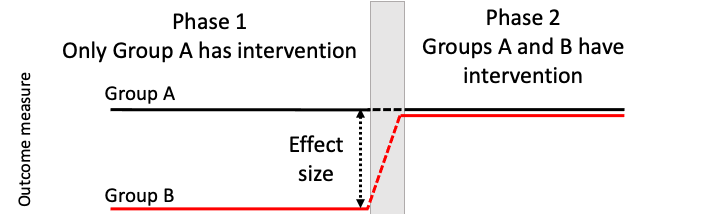
Figure 19.2: Schematic of a waitlist RCT
In many respects, this design resembles a regular RCT, and has some of the same benefits, in terms of controlling for effects of practice, maturation and regression to the mean. Relative to a standard RCT, it has some advantages:
- Group B serves as a replication sample. If benefits of intervention are seen in Group A, then we should see similar effects in Group B by the end of the study.
- As well as estimating immediate effects of intervention, Group A can provide an estimate of how far there is persistence of effects by comparing their score at the end of intervention with the final, post-intervention phase.
- An adaptive approach can be adopted, so that if no benefit of intervention is seen for Group A at the end of intervention, the study can be terminated.
- This design may encourage participation by clients and those referring them, as all participants have access to a potentially beneficial intervention and serve as their own controls.
There is, however, some debate around usefulness of wait-list designs in the psychological and behavioural interventions literature (Cunningham et al., 2013; Elliott & Brown, 2002; Furukawa et al., 2014). In particular, Cunningham et al. (2013) presented results that showed this design can potentially, artificially inflate intervention effect estimates. When a participant knows that they have to wait, this can induce a state of “resentful demoralization”, which can lead to poorer outcome - a kind of nocebo effect. Having said that, Cunningham et al noted that negative reactions to being on a wait list are likely to depend on the specific context. Studies showing nocebo effects have tended to focus on clinical psychology interventions, where distressed patients have been actively seeking help and may become disconsolate or irritated at having to wait.
Calder et al. (2021) used a delayed cross-over design to study the effect of an intervention designed to improve use of past tense -ed endings in children with Developmental Language Disorder. As well as comparing two groups who received intervention at different time points, they also compared different outcome measures. Here, for simplicity, we restrict consideration to the outcome measure of past tense endings - the grammatical element that the training had focused on. (In Chapter 20 we look at how the same study incorporated aspects of single case design to obtain additional evidence that intervention benefits are specific to the skills that are trained). Results are shown in Figure 19.3.
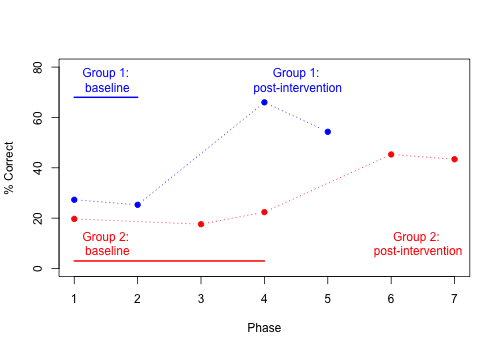
Figure 19.3: Mean per cent correct in delayed cross-over study by Calder et al, 2021 (data plotted from Calder et al’s Table 2).
First, we have the improvement in group 1 (blue) when phases 4-5 (post-intervention) are compared with phases 1-2 (baseline). Next, look at Group 2, in red. They provide two further pieces of evidence. First we can use them as a replication sample for Group 1, considering the change from phase 4-5 (baseline) to phase 6-7 (post-intervention): although the improvement on past-tense items is not as big as that seen in Group 1, it is evident by inspection, and again contrasts with a lack of improvement on untrained constructions. Finally, we can contrast the two groups at phases 4-5. This is more like the contrast performed in a standard RCT: a between-subjects contrast between treated vs untreated groups at the same time point. Here, the combined evidence from between- and within-subjects comparisons provides converging support for the effectiveness of the intervention. Nevertheless, we may wonder how specific the intervention effect is. Could it be a placebo effect, whereby children’s scores improve simply because they have the individual attention of an enthusiastic therapist? Maybe the children would have improved just as much if the therapist had simply spent the time reading to them, or playing with them. In Chapter 20 we move on to consider outcomes for the untrained constructions, which provide evidence against that interpretation.
19.4 Check your understanding
- Calder et al. (2021) provides a nice example of how to design a study to provide a stringent test of intervention by combining within- and between-subjects sources of evidence. It should be remembered, though, that results don’t always turn out as hoped. What could you conclude if:
- There was no difference between Groups 1 and 2 on past tense items at phase 4, with neither group showing any improvement over baseline?
- There was no difference between Groups 1 and 2 at phase 4, with both groups showing significant improvement over baseline?
- Group 1 improved at phase 4, but Group 2 did not improve between phase 4 and phase 6?
- Is it realistic to consider a possible ‘nocebo’ effect during the extended waitlist for Group 2? Is there any way to check for this?
When planning a study of this kind, the natural tendency is to assume that everything will work out and show the intervention to be effective. It helps to design a strong study if one anticipates the possibility of messy or inconclusive results such as those described here, and considers whether it is possible to design a study to avoid them.
- Take a look at a study by Varley et al. (2016), who used a self-administered computerized intervention with stroke patients who had apraxia of speech. The intervention group did training on speech production and perception for 6 weeks, whereas the active controls were given a sham intervention that involved visuospatial processing, and were told it was designed to improve their attention and memory. After the initial intervention period, there was a 4 week break, and then the two interventions were swapped over for another 6 weeks.
- Does this approach provide better control of internal validity than the waitlist control method used by Calder et al. (2021)?
- Are there downsides to the use of a ‘sham’ intervention?