2.7 行操作
行操作指不同字段间的计算,如Excle的列与列之间计算,Excle中的函数对行列不敏感,没有明显区别,但是R中tidyverse里列计算简单,行间计算依赖rowwise()函数实现。
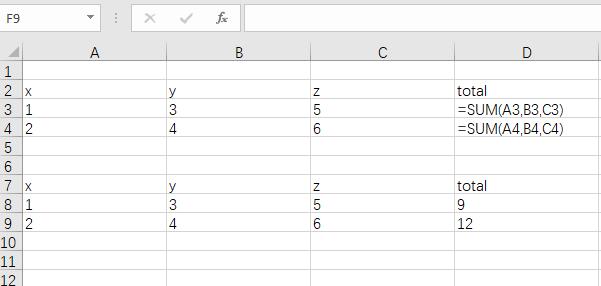
Excel-sum
df <- tibble(x = 1:2, y = 3:4, z = 5:6)
df %>% rowwise()
#> # A tibble: 2 x 3
#> # Rowwise:
#> x y z
#> <int> <int> <int>
#> 1 1 3 5
#> 2 2 4 6
df %>% rowwise() %>% mutate(total = sum(c(x, y, z))) #返回结果与Excel一致
#> # A tibble: 2 x 4
#> # Rowwise:
#> x y z total
#> <int> <int> <int> <int>
#> 1 1 3 5 9
#> 2 2 4 6 12
df %>% mutate(total = sum(c(x, y, z))) # 返回结果不符合预期
#> # A tibble: 2 x 4
#> x y z total
#> <int> <int> <int> <int>
#> 1 1 3 5 21
#> 2 2 4 6 21通过自己定义函数实现:
fun1 <- function(x,y,z){
x+y+z
}
df %>% mutate(total = fun1(x,y,z))
#> # A tibble: 2 x 4
#> x y z total
#> <int> <int> <int> <int>
#> 1 1 3 5 9
#> 2 2 4 6 122.7.1 比较差异
像group_by(),rowwise()并没有做任何事情,它的作用是改变其他动词的工作方式。
注意以下代码返回结果不同:
df %>% mutate(m = mean(c(x, y, z)))
#> # A tibble: 2 x 4
#> x y z m
#> <int> <int> <int> <dbl>
#> 1 1 3 5 3.5
#> 2 2 4 6 3.5
df %>% rowwise() %>% mutate(m = mean(c(x, y, z)))
#> # A tibble: 2 x 4
#> # Rowwise:
#> x y z m
#> <int> <int> <int> <dbl>
#> 1 1 3 5 3
#> 2 2 4 6 4df %>% mutate(m = mean(c(x, y, z)))返回的结果是x,y,z散列全部数据的均值;df %>% rowwise() %>% mutate(m = mean(c(x, y, z)))通过rowwise改变了mean的作为范围,返回的某行x,y,z列3个数字的均值。两种动词的作用的范围因为rowwise完全改变。
可以选择在调用中提供“标识符”变量rowwise()。这些变量在您调用时被保留summarise(),因此它们的行为与传递给的分组变量有些相似group_by():
df <- tibble(name = c("Mara", "Hadley"), x = 1:2, y = 3:4, z = 5:6)
df %>%
rowwise() %>%
summarise(m = mean(c(x, y, z)))
#> `summarise()` has ungrouped output. You can override using the `.groups` argument.
#> # A tibble: 2 x 1
#> m
#> <dbl>
#> 1 3
#> 2 4
df %>%
rowwise(name) %>%
summarise(m = mean(c(x, y, z)))
#> `summarise()` has grouped output by 'name'. You can override using the `.groups` argument.
#> # A tibble: 2 x 2
#> # Groups: name [2]
#> name m
#> <chr> <dbl>
#> 1 Mara 3
#> 2 Hadley 42.7.2 常用案例
df <- tibble(x = runif(6), y = runif(6), z = runif(6))
# Compute the mean of x, y, z in each row
df %>% rowwise() %>% mutate(m = mean(c(x, y, z)))
#> # A tibble: 6 x 4
#> # Rowwise:
#> x y z m
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.735 0.500 0.234 0.489
#> 2 0.104 0.423 0.706 0.411
#> 3 0.347 0.355 0.559 0.420
#> 4 0.600 0.461 0.0523 0.371
#> 5 0.826 0.114 0.481 0.474
#> 6 0.982 0.823 0.831 0.879
# Compute the minimum of x and y in each row
df %>% rowwise() %>% mutate(m = min(c(x, y, z)))
#> # A tibble: 6 x 4
#> # Rowwise:
#> x y z m
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.735 0.500 0.234 0.234
#> 2 0.104 0.423 0.706 0.104
#> 3 0.347 0.355 0.559 0.347
#> 4 0.600 0.461 0.0523 0.0523
#> 5 0.826 0.114 0.481 0.114
#> 6 0.982 0.823 0.831 0.823
# In this case you can use an existing vectorised function:
df %>% mutate(m = pmin(x, y, z))
#> # A tibble: 6 x 4
#> x y z m
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.735 0.500 0.234 0.234
#> 2 0.104 0.423 0.706 0.104
#> 3 0.347 0.355 0.559 0.347
#> 4 0.600 0.461 0.0523 0.0523
#> 5 0.826 0.114 0.481 0.114
#> 6 0.982 0.823 0.831 0.823键入每个变量名称很繁琐,通过c_across()使更简单。
df <- tibble(id = 1:6, w = 10:15, x = 20:25, y = 30:35, z = 40:45)
rf <- df %>% rowwise(id)
rf %>% mutate(total = sum(c_across(w:z)))
rf %>% mutate(total = sum(c_across(where(is.numeric))))
rf %>%
mutate(total = sum(c_across(w:z))) %>%
ungroup() %>%
mutate(across(w:z, ~ . / total))有关更多信息请查看 vignette(“rowwise”)。