7.1 基础介绍
本部分从data.table安装,内置的案例查看,到data.table的句式语法,实现基础行列筛选和聚合计算。
1.安装
安装详细信息请参考the Installation wiki,有关于不同系统安装首次以及相关说明。
install.packages("data.table")
# latest development version:
data.table::update.dev.pkg()2.使用说明
通过以下代码查看内置的使用案例。
library(data.table)
example(data.table)7.1.1 读取数据
在我实际工作中接触的数据大部分以数据库,csv,Excel等形式存在,并且CSV格式数据较少。但是data.table包读取数据的fread函数仅接受CSV格式。如果是Excel格式文件,需要通过如readxl,openxlsx等包读入后转换为data.table格式数据。
fread 函数可以直接读取CSV格式文件,无论是本地文件或者在线文件,如下所示:
案例中使用的数据集是R包
nycflights13带的flights数据集。
library(data.table)
input <- if (file.exists("./data/flights.csv")) {
"./data/flights.csv" #本地文件
} else {
"https://raw.githubusercontent.com/Rdatatable/data.table/master/vignettes/flights.csv" #在线文件需翻墙
}
flights <- fread(input) #具体参数请参照文档 实际工作中可能会用到的encoding参数,编码 encoding='UTF-8'
head(flights)
#> year month day dep_delay arr_delay carrier origin dest air_time distance
#> 1: 2014 1 1 14 13 AA JFK LAX 359 2475
#> 2: 2014 1 1 -3 13 AA JFK LAX 363 2475
#> 3: 2014 1 1 2 9 AA JFK LAX 351 2475
#> 4: 2014 1 1 -8 -26 AA LGA PBI 157 1035
#> 5: 2014 1 1 2 1 AA JFK LAX 350 2475
#> 6: 2014 1 1 4 0 AA EWR LAX 339 2454
#> hour
#> 1: 9
#> 2: 11
#> 3: 19
#> 4: 7
#> 5: 13
#> 6: 18本文读取本地文件,如果该数据集下载失败,可更改地址为(http://www.zhongyufei.com/datatable/data/flights.csv)
flights <- fread("http://www.zhongyufei.com/Rbook/data/flights.csv")数据集记录的是 2014 年,纽约市3大机场(分别为:JFK 肯尼迪国际机场、 LGA 拉瓜迪亚机场,和 EWR 纽瓦克自由国际机场)起飞的航班信息。
具体的记录信息(特征列),包括起飞时间、到达时间、延误时长、航空公司、始发机场、目的机场、飞行时长,和飞行距离等。
7.1.2 基本格式
DT[i, j, by]是data.table的基本样式,在不同位置上实现不同功能。

i-j-by
DT[i, j, by]
## R: i j by
## SQL: where | order by select | update group bydata.table个人理解主要有三大类参数,i参数做筛选,j参数做计算,by参数做分组.
拿Excel透视表类别,i位置参数当作『筛选』,by位置用来做汇总字段『行』,j位置当作『值』,如下所示:
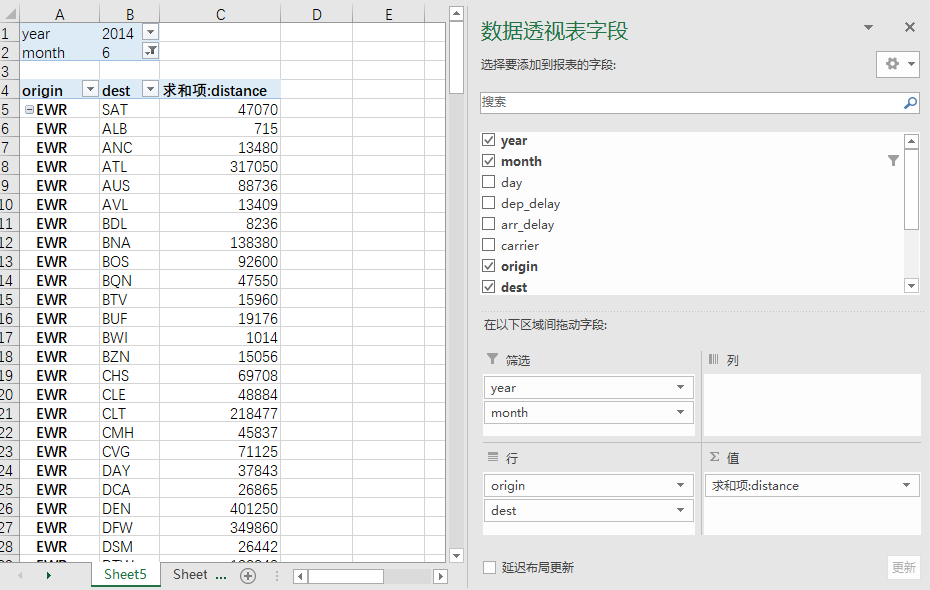
透视表截图
1.代码实例
代码求2014年6月,从各始发机场到各目的机场的飞行距离求和.
library(data.table)
flights <- fread("./data/flights.csv")
flights[year==2014 & month==6,.(求和项distance=sum(distance)),by=.(origin,dest)]
#> origin dest 求和项distance
#> 1: JFK LAX 2663100
#> 2: JFK DFW 82069
#> 3: JFK LAS 795792
#> 4: JFK SFO 1967946
#> 5: JFK SAN 349778
#> ---
#> 191: EWR ANC 13480
#> 192: EWR BZN 15056
#> 193: LGA TVC 7205
#> 194: LGA BZN 3788
#> 195: JFK HYA 9802.代码解释
i 的部分:条件year==2014 和 month==6 ;
j 的部分:求和项distance=sum(distance),写在.()中或者list()中;
by 的部分.(origin,dest),重点是写在.()中,和Excel透视表一一对应。
至于为什么要用.()包裹起来,最开始默认为格式强制要求。就这个问题我想说:大部分人可能觉得是比较“怪异”的用法,并且不理解,从而可能留下data.table不好用,很古怪的印象,但是我觉得任何东西存在即合理,你学一个东西总得接受一些你可能不认可的东西,这样可能才是真正的学习,就像拿Python来做数据分析,我刚开始觉得pandas很难用,很反人类,但是后来知道python代码可以直接打包封装成exe后,觉得真香,说这么多主要是想表达我们学会挑选合适的工具用,适应它,用好它就可以了。
7.1.3 i j by 使用
使用data.table处理数据,接下来我们就用该函数读取数据演示i,j,by的简单使用。
7.1.3.1 i行筛选
行筛选是一种很常见的数据操作行为,类似我们Excel中的筛选,即按照一定条件筛选符合要求的数据。条件筛选一般分为单条件筛选、多条件筛选;
在筛选时涉及到条件判断,R语言中常用的条件判断分为逻辑运算、关系运算。常用的关系运算符 >、 <、==、!=、>=、<=分别代表大于、小于、等于、不等于、大于等于、小于等于。常用的逻辑运算符 &、|、!等。
#单条件筛选
filghts[year == 2014] #筛选year==2014
#多条件筛选 用 & 链接
flights[ year == 2014 & month == 6]
# | 相当于中文条件或
flights[ month == 5 | month == 6]
# %in% 类似sql中in用法
flights[month %in% c(1,3,5,7,9)]
# %between% 类似sql中between and 用法
flights[month %between% c(1,7)]7.1.3.2 j列操作
数据集较大、字段较多时,由于无效信息较多可以做适当精选,这时需要我们筛选列。与sql中的select用法一致,即保留想要的字段。
.()或list()是data.table中的比较特殊的实现列筛选的用法。常规数字索引,字符向量索引同样有效。
#注意前面的. .()
flights[,.(year,month,day,dep_delay,carrier,origin)]
#> year month day dep_delay carrier origin
#> 1: 2014 1 1 14 AA JFK
#> 2: 2014 1 1 -3 AA JFK
#> 3: 2014 1 1 2 AA JFK
#> 4: 2014 1 1 -8 AA LGA
#> 5: 2014 1 1 2 AA JFK
#> ---
#> 253312: 2014 10 31 1 UA LGA
#> 253313: 2014 10 31 -5 UA EWR
#> 253314: 2014 10 31 -8 MQ LGA
#> 253315: 2014 10 31 -4 MQ LGA
#> 253316: 2014 10 31 -5 MQ LGA
# flights[,list(year,month,day,dep_delay,carrier,origin)] same above
# not run
# flights[,1:3]
# not run
# flights[,c('year','month','day')]setcolorder函数可以调整列的顺序,将常用的字段信息排在前面可以用过该函数实现。
# not run
# setcolorder(x = flights,neworder = c( "month","day","dep_delay" ,"arr_delay","carrier" ))
# 按照指定列顺序排序 其余字段保持不变,不是建立副本,是直接修改了flights 数据的列顺序- 常规计算
根据最开始的Excel透视表截图,我们想要获得如截图一样的结果该怎么实现呢?代码如下:
flights[year==2014 & month==6,.(求和项distance=sum(distance),平均距离=mean(distance)),by=.(origin,dest)]在i的位置做筛选,j的位置做计算,by指定分组字段。在j的位置可以做各种各样的计算,R中自带的函数,或者是自己定义的函数。
myfun <- function(x){
x^2/2
}
flights[year==2014 & month==6,.(myfun(distance)),by=.(origin,dest)]
#> origin dest V1
#> 1: JFK LAX 3062813
#> 2: JFK LAX 3062813
#> 3: JFK LAX 3062813
#> 4: JFK LAX 3062813
#> 5: JFK LAX 3062813
#> ---
#> 26484: JFK HYA 19208
#> 26485: JFK HYA 19208
#> 26486: JFK HYA 19208
#> 26487: JFK HYA 19208
#> 26488: JFK HYA 192087.1.3.3 by 分组
分组是按照某种分组实现一定条件下某种聚合方式的计算。分组可以是单字段,多字段以及条件字段等。
1.按月分组
flights[,.(sum(distance)),by=.(month)]
#> month V1
#> 1: 1 25112563
#> 2: 2 22840391
#> 3: 3 28716598
#> 4: 4 27816797
#> 5: 5 28030020
#> 6: 6 29093557
#> 7: 7 30059175
#> 8: 8 30322047
#> 9: 9 27615097
#> 10: 10 289008342.多条件分组
dt <- flights[,.(sum(distance)),by=.(carrier,origin)]
head(dt)
#> carrier origin V1
#> 1: AA JFK 20492213
#> 2: AA LGA 12365282
#> 3: AA EWR 3550217
#> 4: AS EWR 1378748
#> 5: B6 JFK 38117662
#> 6: B6 EWR 4508574
#可直接重新命名
dt <- flights[,.(sum(distance)),by=.(newcol1 = carrier,newcol2 = origin)]
head(dt)
#> newcol1 newcol2 V1
#> 1: AA JFK 20492213
#> 2: AA LGA 12365282
#> 3: AA EWR 3550217
#> 4: AS EWR 1378748
#> 5: B6 JFK 38117662
#> 6: B6 EWR 45085743.按月份是否大于6分组
即得到是否大于6的两类分组
dt <- flights[,.(sum(distance)),by=.(month>6)] #by里面可以做计算
head(dt)
#> month V1
#> 1: FALSE 161609926
#> 2: TRUE 1168971537.1.4 行列筛选总结
行筛选在 i 的位置上进行, 列筛选在 j 的位置上进行;data.table中j的位置比较灵活多变,但是i的位置大部分时候都是进行条件筛选。我们通过上述的行列筛选已经大概知道data.table中i,j的用法。也就是我们常规数据清洗过程中的数据筛选过程,筛选符合要求的数据记录。
dt <- flights[ year == 2014 & month == 6 & day >=15,.(year,month,day,dep_delay,carrier,origin)]
head(dt)
#> year month day dep_delay carrier origin
#> 1: 2014 6 15 -4 AA JFK
#> 2: 2014 6 15 -8 AA JFK
#> 3: 2014 6 15 -12 AA JFK
#> 4: 2014 6 15 -4 AA LGA
#> 5: 2014 6 15 -3 AA JFK
#> 6: 2014 6 15 5 AA JFK