2.1 前言
dplyr包是tidyverse系列的核心包之一。dplyr是A Grammar of Data Manipulation ,即dplyr是数据处理的语法。数据操作在数据库中往往被增、改、删、查四字描述,加上表连接查询基本涵盖了大部分的数据操作。
dplyr包通过提供一组动词来解决最常见的数据处理问题:
mutate()添加新变量,现有变量的函数select()筛选列,根据现有变量名称选择变量filter()筛选行,根据条件筛选summarise()按照一定条件汇总聚合arrange()行排序
以上动词都可以和group_by()结合,使我们可以按组执行以上任何操作。除了以上单个表操作的动词,dplyr中还有操作两表(表关联)的动词,可以通过vignette("two-table")查看学习。
2.1.1 安装
dplyr包可以直接安装。
## 最简单是的方式就是安装tidyverse
install.packages('tidyverse')
## 或者仅仅安装 tidyr:
install.packages('dplyr')
## 或者从github 安装开发版本
## install.packages("devtools")
devtools::install_github("tidyverse/dplyr")在开始使用前,请确保自己dplyr版本是较新版本,因为1.0.0版本有较大更新。
packageVersion('dplyr')
#> [1] '1.0.6'2.1.2 Excel and Sql 类比
与Excel相比,dplyr使用filter实现筛选,mutate实现列新增计算,summarise配合group_by实现数据透视表,arrange实现排序功能。
dplyr::left_join()等表连接功能,实现Excel中的vlookup,xlookup等函数效果。
请看案例:
案例中使用的数据集是R包
nycflights13带的flights数据集。
Excel实现
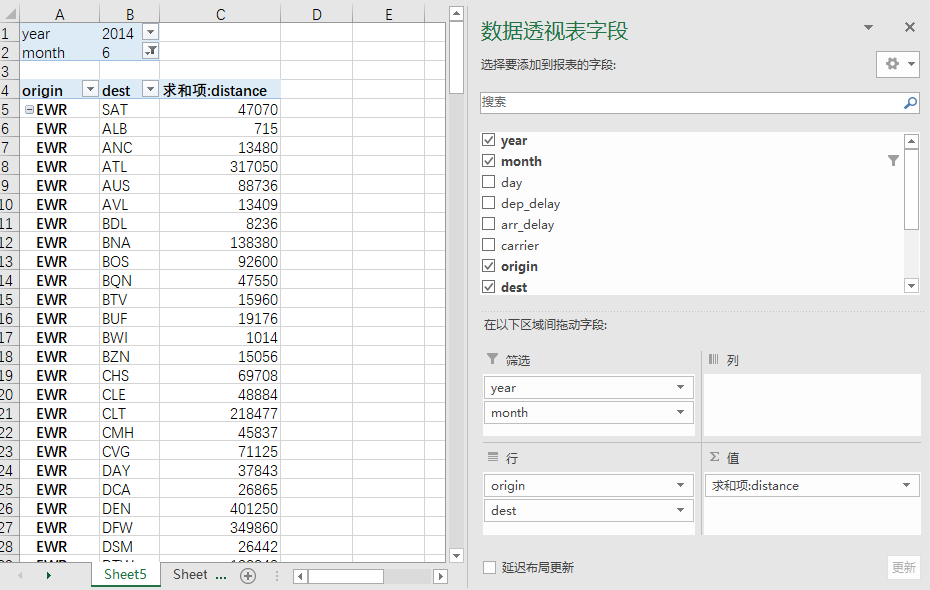
透视表截图
R实现:
library(tidyverse,warn.conflicts = FALSE)
data <- readr::read_csv("./data/flights.csv")
data %>%
filter(year==2014,month==6) %>%
group_by(origin,dest) %>%
summarise(distance求和项 = sum(distance))
#> # A tibble: 195 x 3
#> # Groups: origin [3]
#> origin dest distance求和项
#> <chr> <chr> <dbl>
#> 1 EWR ALB 715
#> 2 EWR ANC 13480
#> 3 EWR ATL 317050
#> 4 EWR AUS 88736
#> 5 EWR AVL 13409
#> 6 EWR BDL 8236
#> # ... with 189 more rowsSql实现:
select origin,dest,sum(distance) distance求和项 from flights where year = 2014 and month =6 group by origin,dest| origin | dest | distance求和项 |
|---|---|---|
| EWR | ALB | 715 |
| EWR | ANC | 13480 |
| EWR | ATL | 317050 |
| EWR | AUS | 88736 |
| EWR | AVL | 13409 |
| EWR | BDL | 8236 |
| EWR | BNA | 138380 |
| EWR | BOS | 92600 |
| EWR | BQN | 47550 |
| EWR | BTV | 15960 |
2.1.3 常见问题
- 筛选订单表中的1-5月订单数据,按照城市汇总,求每个城市的销售额和门店数(去重)?
data %>%
filter(between(月,1,5)) %>%
group_by(城市) %>%
summarise(金额 = sum(金额),门店数 = n_distinct(门店编码))- 近30天商品销量排名?
data %>%
filter(订单日期 >= Sys.Date()-30) %>%
group_by(分析大类,商品编码) %>%
summarise(商品销量 = sum(数量)) %>%
group_by(分析大类) %>%
mutate(商品排名 = dense_rank(desc(商品销量)))
# 注意用desc倒序,销量高排第一- 销售和库存形成笛卡尔积表,计算商品有货率、动销率?
Cheat Sheet
手册搬运于dplyr官方介绍,方便下载查阅。
dplyr-sheet
Rstudio提供的其它手册:https://www.rstudio.com/resources/cheatsheets/