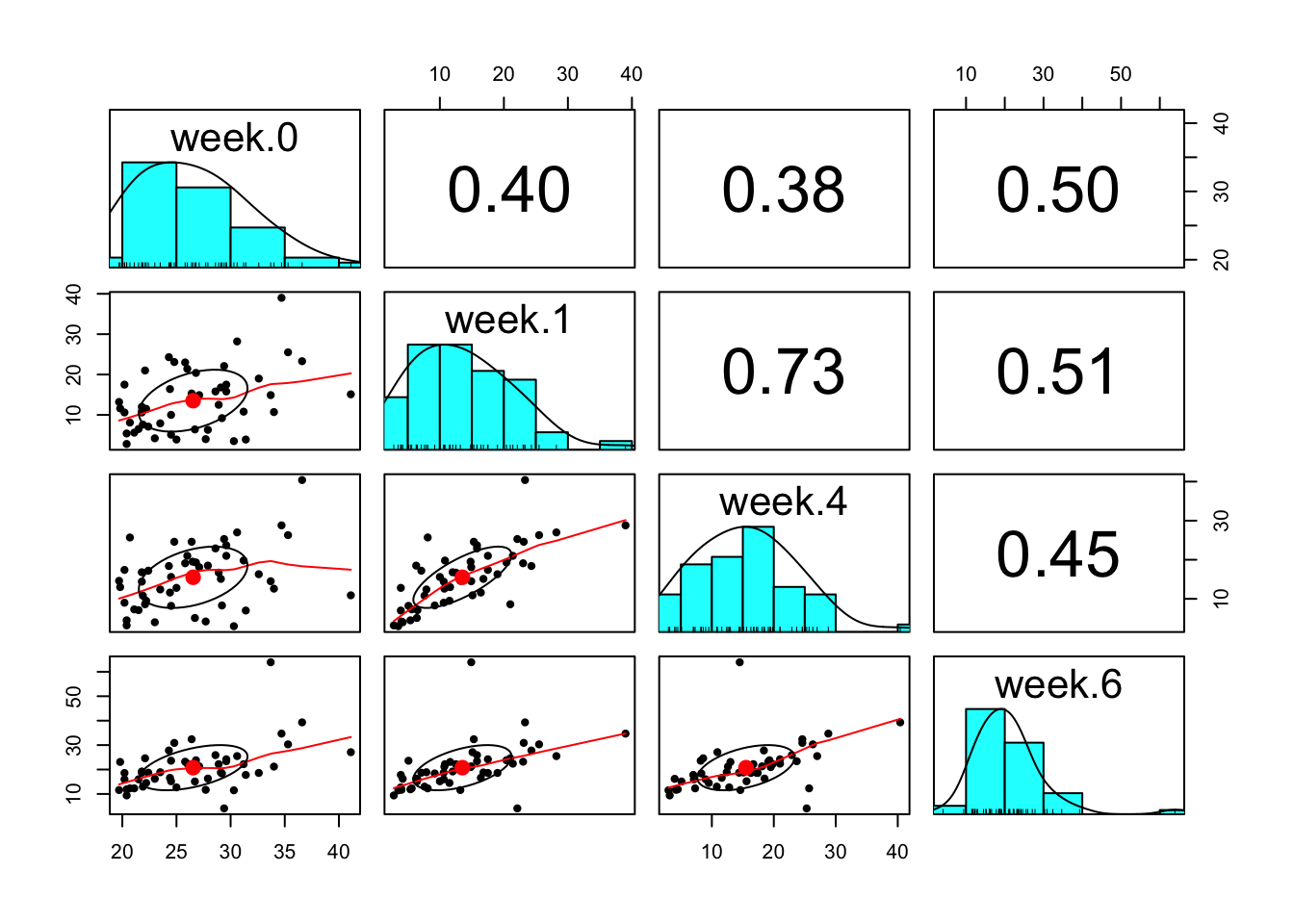
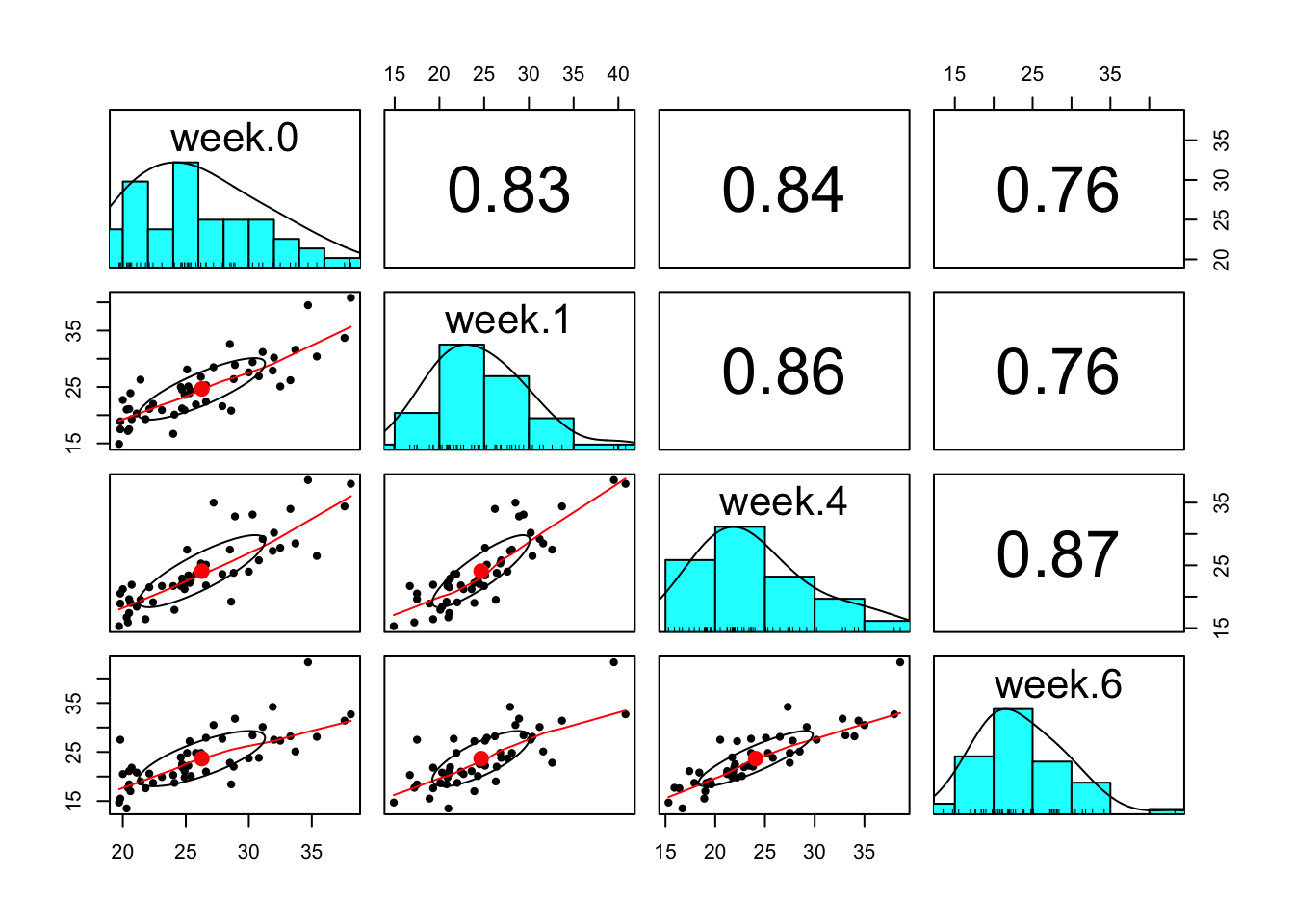
ID Group week lead
1.0 1 P 0 30.8
2.0 2 A 0 26.5
3.0 3 A 0 25.8
4.0 4 P 0 24.7
5.0 5 A 0 20.4
6.0 6 A 0 20.4
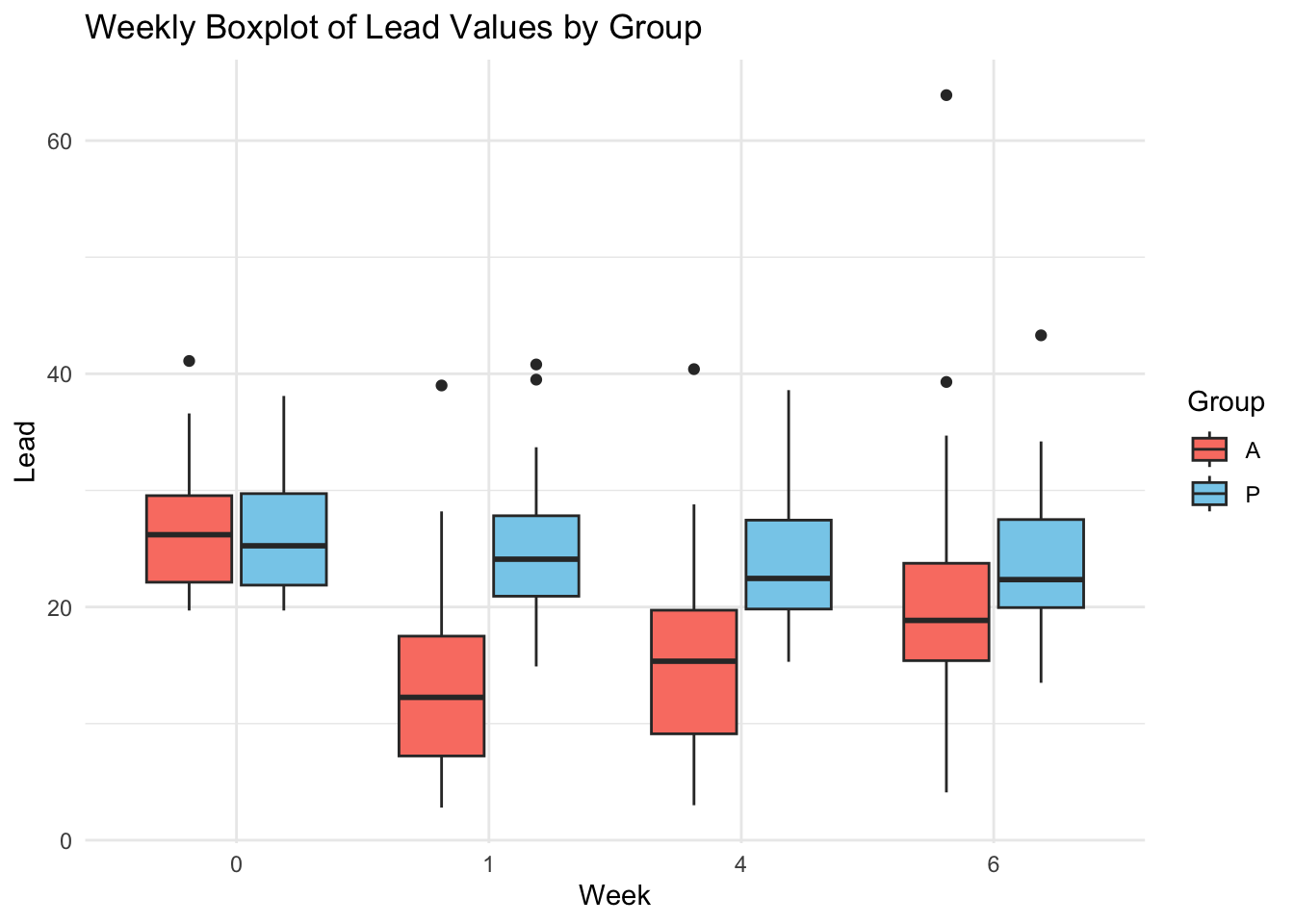
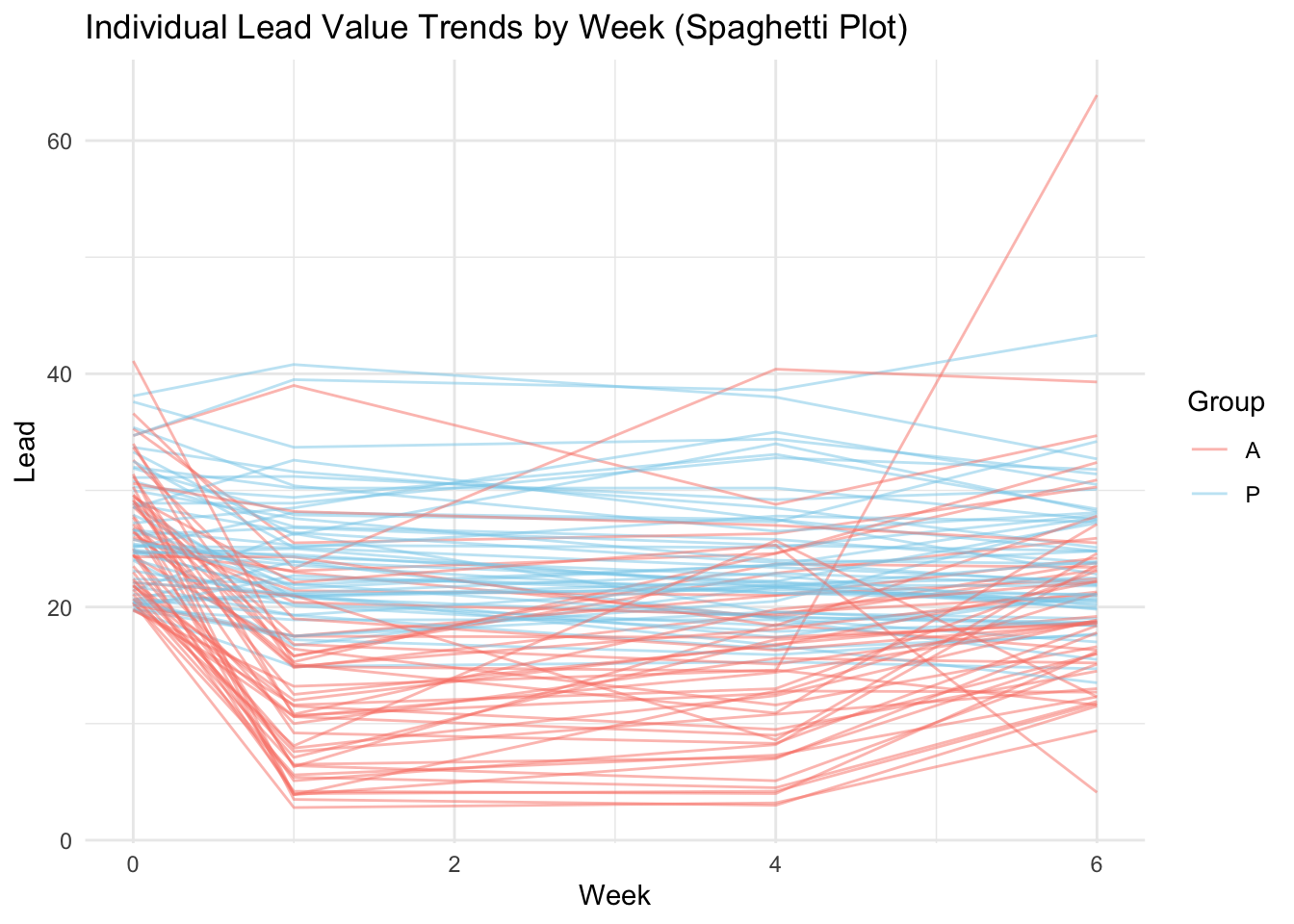
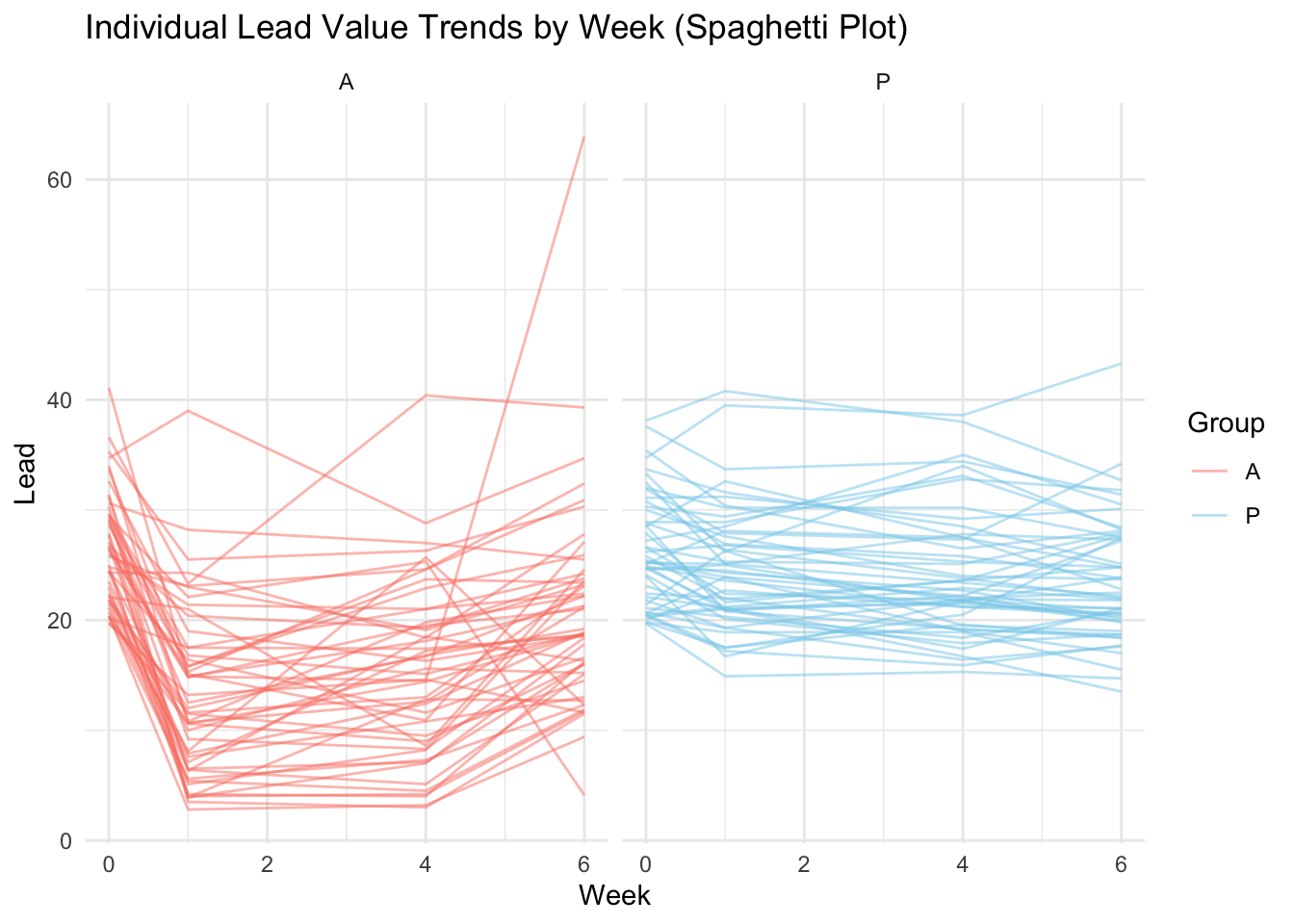
Boxplot, spaghetti plots
대조군(P): 점진적 감소
처치군(A): 1주 차에 급격 감소 후 다시 증가, 대조군에 비해 변동폭이 큼
library(ggplot2)
Attaching package: 'ggplot2'
The following objects are masked from 'package:psych':
%+%, alpha
## LLM prompt example# 나: 내가 R에서 그림을 하나 그릴 건데 나좀 도와줘. 데이터는 이렇게 생겼어.# > head(tlcl, 20)# ID Group week lead# 1.0 1 P 0 30.8# 2.0 2 A 0 26.5# 3.0 3 A 0 25.8# 4.0 4 P 0 24.7# 5.0 5 A 0 20.4# 6.0 6 A 0 20.4# 7.0 7 P 0 28.6# 8.0 8 P 0 33.7# 9.0 9 P 0 19.7# 10.0 10 P 0 31.1# 11.0 11 P 0 19.8# 12.0 12 A 0 24.8# 13.0 13 P 0 21.4# 14.0 14 A 0 27.9# 15.0 15 P 0 21.1# 16.0 16 P 0 20.6# 17.0 17 P 0 24.0# 18.0 18 P 0 37.6# 19.0 19 A 0 35.3### 나: 그룹, 시점별로 boxplot을 그려줘# 그룹과 주별 boxplotggplot(tlcl, aes(x =factor(week), y = lead, fill = Group)) +geom_boxplot() +labs(title ="Weekly Boxplot of Lead Values by Group",x ="Week",y ="Lead") +theme_minimal() +scale_fill_manual(values =c("P"="skyblue", "A"="salmon"))
# LLM prompt example: 좋아. 이번엔 spagetti plot을 그려보자. 전체적인 트렌드 변화가 아니라 개개인별 트렌드의 변화를 보기 위함이야.# 그룹과 주별 spaghetti plotggplot(tlcl, aes(x = week, y = lead, group = ID, color = Group)) +geom_line(alpha =0.5) +labs(title ="Individual Lead Value Trends by Week (Spaghetti Plot)",x ="Week",y ="Lead") +theme_minimal() +scale_color_manual(values =c("P"="skyblue", "A"="salmon"))
# LLM prompt example: 두 그룹에 대해서 panel을 분리해줘# 그룹별 패널을 분리한 스파게티 플롯ggplot(tlcl, aes(x = week, y = lead, group = ID)) +geom_line(aes(color = Group), alpha =0.5) +labs(title ="Individual Lead Value Trends by Week (Spaghetti Plot)",x ="Week",y ="Lead") +theme_minimal() +scale_color_manual(values =c("P"="skyblue", "A"="salmon")) +facet_wrap(~ Group)
# just linear regression!# make referecne category for "P"tlcl$Group.f =relevel(factor(tlcl$Group), ref="P")tlc.lm =lm(lead ~factor(week)*Group.f, data=tlcl)summary(tlc.lm)
Call:
lm(formula = lead ~ factor(week) * Group.f, data = tlcl)
Residuals:
Min 1Q Median 3Q Max
-16.662 -4.621 -0.993 3.673 43.138
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 26.272 0.937 28.038 < 2e-16 ***
factor(week)1 -1.612 1.325 -1.216 0.2245
factor(week)4 -2.202 1.325 -1.662 0.0974 .
factor(week)6 -2.626 1.325 -1.982 0.0482 *
Group.fA 0.268 1.325 0.202 0.8398
factor(week)1:Group.fA -11.406 1.874 -6.086 2.75e-09 ***
factor(week)4:Group.fA -8.824 1.874 -4.709 3.47e-06 ***
factor(week)6:Group.fA -3.152 1.874 -1.682 0.0934 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.626 on 392 degrees of freedom
Multiple R-squared: 0.3284, Adjusted R-squared: 0.3164
F-statistic: 27.38 on 7 and 392 DF, p-value: < 2.2e-16
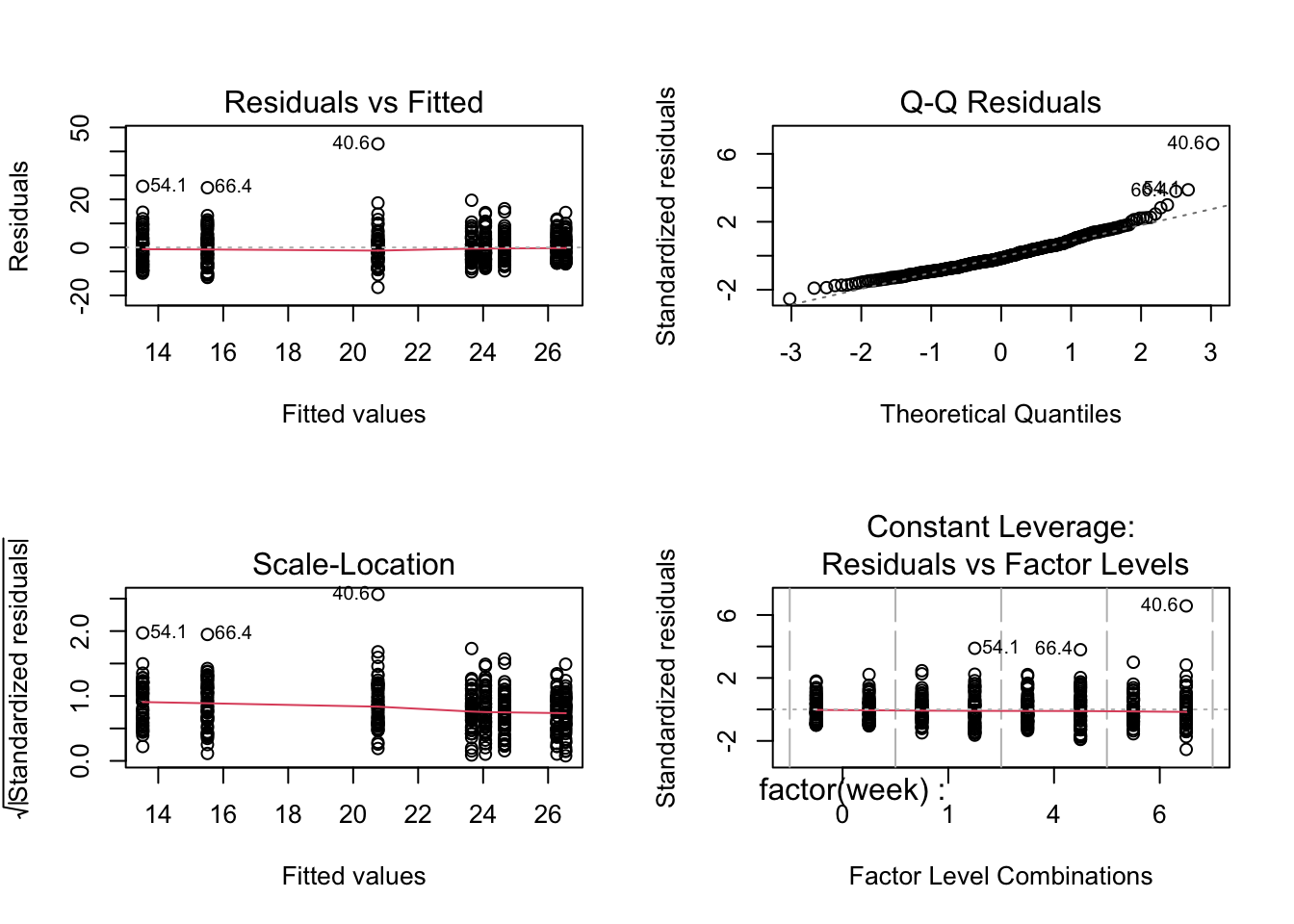
# anova(tlc.lm)par(mfrow=c(2,2))plot(tlc.lm)
11.3 반복측정의 상관관계를 고려한 회귀분석 1: 일반 선형 모형 (general linear model) 기반 방법
11.3.1 개요
일반화선형모형 (Generalized linear model)과는 지칭하는 모형 명이 다름에 주의!
식 1과 모형은 동일하나, error term에 대한 가정이 완화된다. 각 개채 \(i\)에 대하여, \(\boldsymbol{\epsilon}_i = (\epsilon_{i1}, \epsilon_{i2}, \ldots, \epsilon_{iK})^T\)라 하면, (\(K\): 최대 관찰 횟수), 일반선형모형은 다음처럼 특수한 구조를 가진 공분산 모형들을 허용한다.
#General linear model using ML & REMLlibrary(nlme)# sorting data by ID and weeko <-order(tlcl$Group, tlcl$ID, tlcl$week)tlcl <- tlcl[o,]# ML estimationtlc.ml =gls(lead ~factor(week)*Group.f, data=tlcl, method="ML",correlation =corCompSymm(form =~1| ID))# "~ 1": 관측치들 사이의 등분산을 가정함# "|ID": 반복 측정된 데이터의 그룹화 변수가 ID임을 알려줌summary(tlc.ml)
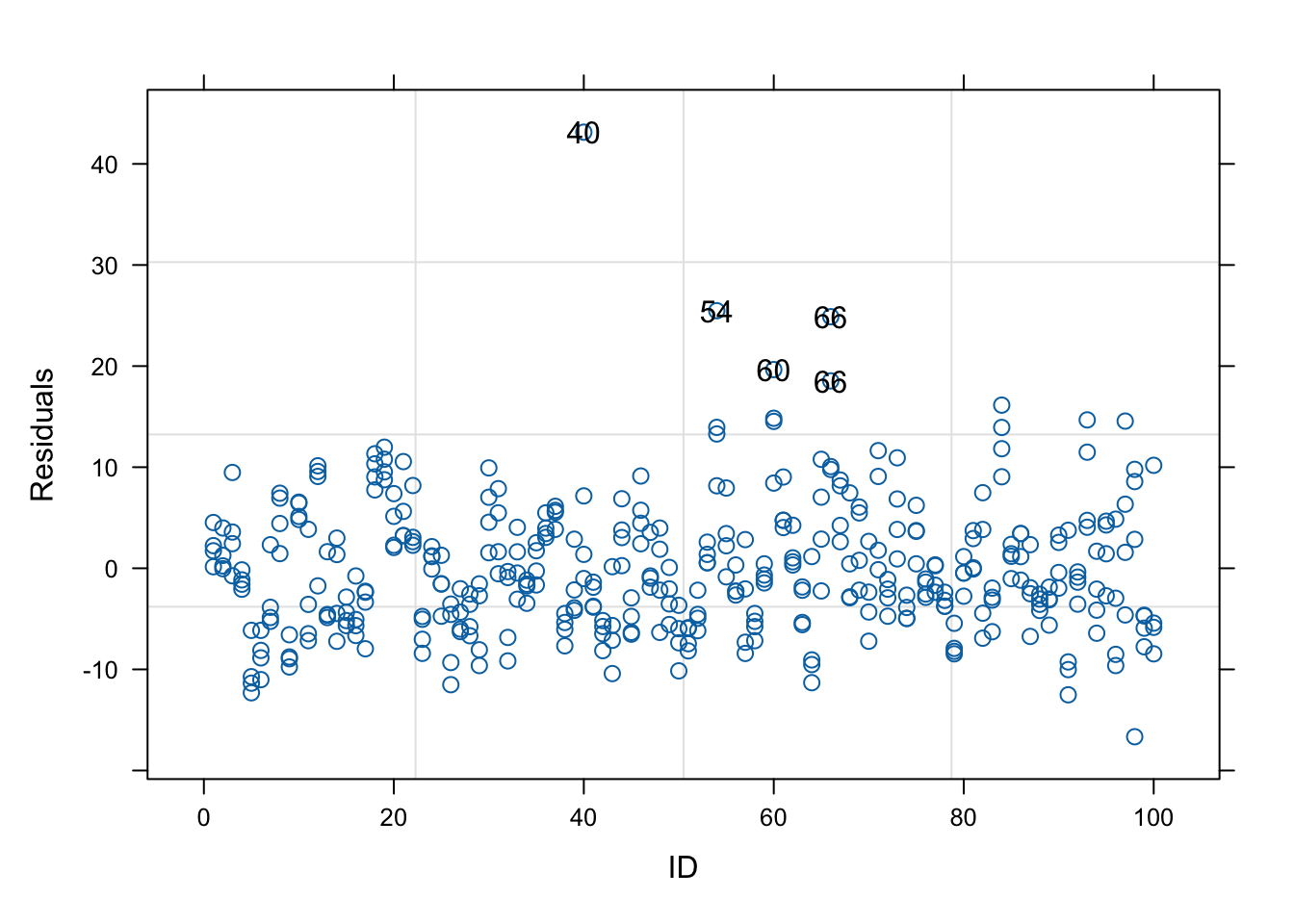
# model diagnosis# 목적: 각 ID별로 잔차를 시각화하여 특정 ID에서 비정상적으로 큰 잔차가 있는지 확인# resid(.)~ID: 잔차를 ID별로 플로팅, 특정 관측치가 모델과 큰 차이를 보이는지 확인 가능# id=0.01: 잔차가 상위 1%에 속하는 이상치에 ID를 표시# 어떤 ID가 큰 잔차를 가지면, 그 데이터가 모델에 잘 맞지 않거나 비정상적인 패턴을 가질 가능성이 있음.plot(tlc.ml, resid(.)~ID, id=0.01)
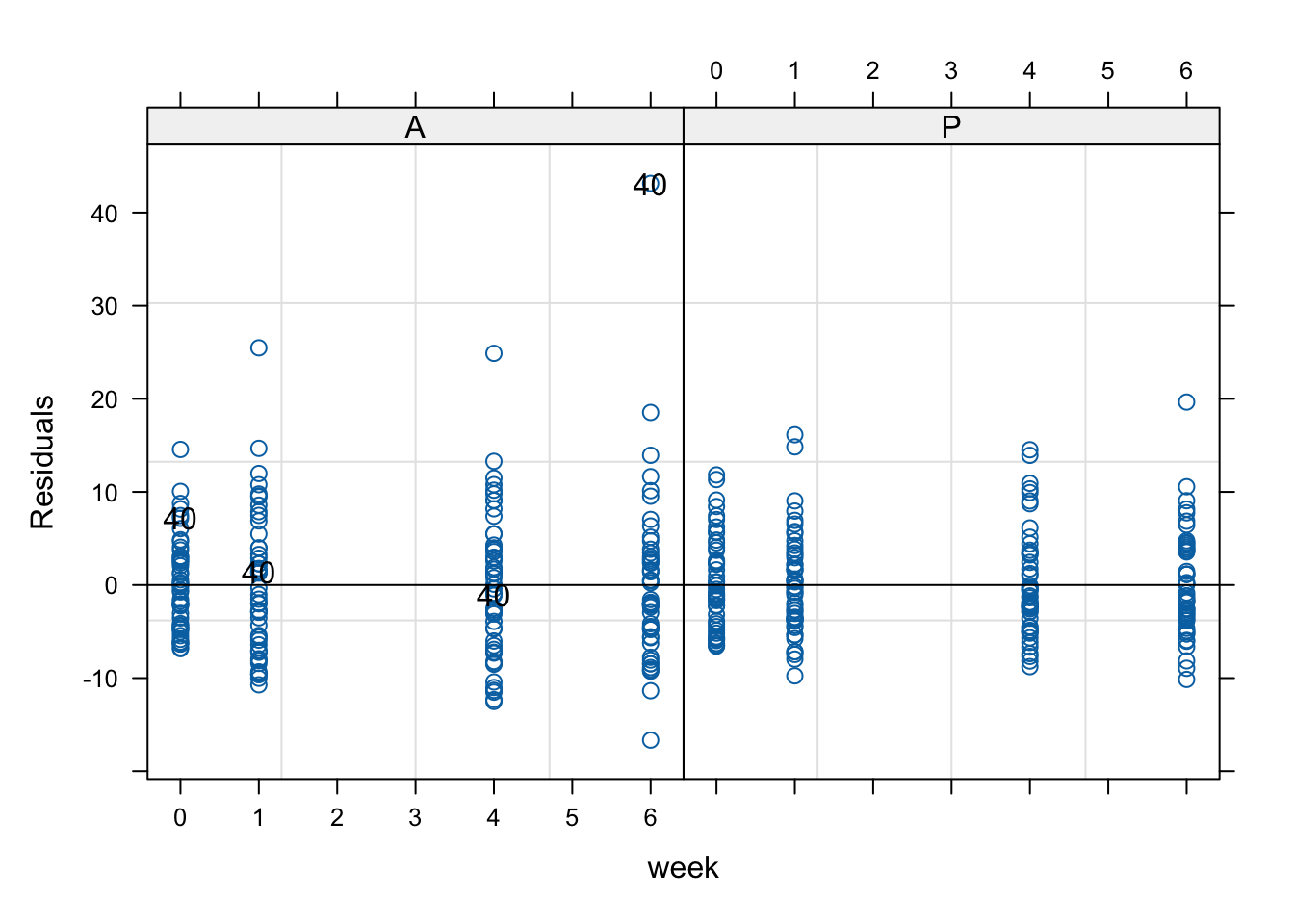
# 목적: week별로 잔차를 시각화하여 시간에 따른 잔차의 변화를 Group별로 확인합니다. 이는 시간에 따라 잔차가 특정 방향으로 편향되는지 확인하는 데 유용합니다.# 설명:# resid(.)~week | Group: Group별로 week에 따른 잔차를 플로팅합니다.# abline=0: 기준선(y = 0)을 추가하여 잔차의 편향을 시각화합니다.# id=~ID==40: ID가 40인 관측치의 잔차를 강조 표시합니다. 특정 ID의 잔차가 어떻게 분포되는지 확인할 수 있습니다.# 해석: 잔차가 특정 week에서 일정한 패턴이나 추세를 보인다면, 이는 모델이 시간에 따라 데이터의 패턴을 제대로 반영하지 못하고 있음을 나타낼 수 있습니다.plot(tlc.ml,resid(.)~week | Group, abline=0, id=~ID==40)
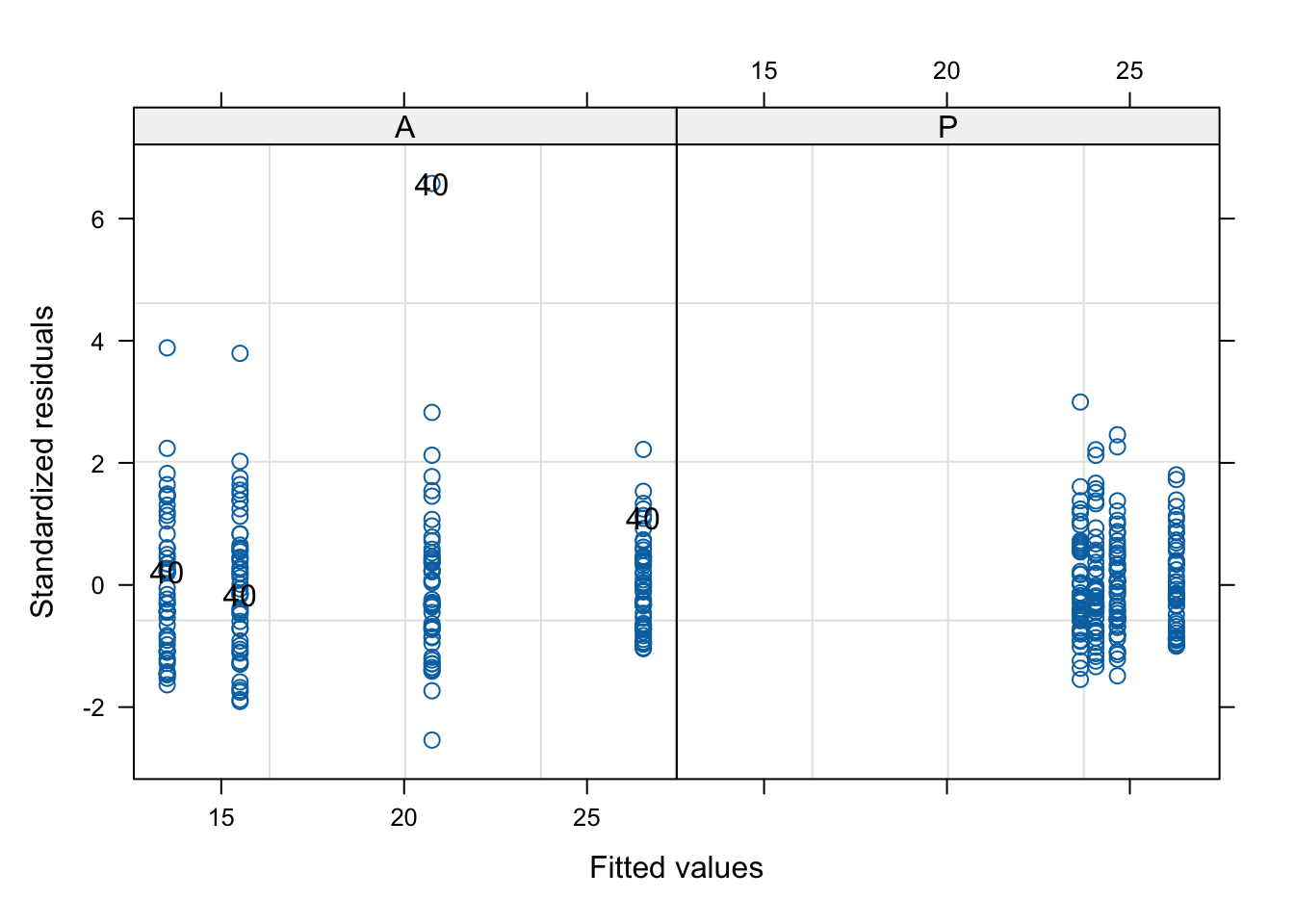
# 목적: 예측된 값(fitted(.))에 대한 잔차를 플로팅하여 Group별로 적합도 검토 및 패턴을 확인합니다.# 설명:# resid(.,type="p")~fitted(.) | Group: 예측된 값에 대한 피어슨 잔차(Pearson residuals)를 Group별로 플로팅합니다.# id=~ID==40: ID가 40인 관측치의 잔차를 강조 표시합니다.# 해석: 이상적인 경우 잔차는 예측된 값과 무관하게 무작위로 분포해야 합니다. 잔차가 특정 패턴을 보이면, 모델에 비선형성이나 오차의 이분산성(heteroscedasticity) 등의 문제가 있을 수 있습니다.plot(tlc.ml,resid(.,type="p")~fitted(.) | Group, id=~ID==40)
11.4 반복측정의 상관관계를 고려한 회귀분석 2: 일반화 추정 방정식 (generalized estimating equation, GEE) 기반 방법
11.4.1 개요
위의 방법 일반 선형 모형 + (RE)ML 방법은 공분산 행렬에 대한 가정이 올바르다는 전제 하에서 모수를 추정한다. 만약 가정이 성립하지 않으면, \(\widehat{\beta}\)의 표준오차 계산이 정확하지 않을 수 있다. (즉 유의한/비유의한 변수를 잘못 검출할 수 있다.)
대신 일반화 추정 방정식 (generalized estimating equation, GEE) 방법에서 공분산 행렬에 대한 “샌드위치 강건 공분산”(sandwich robust variance) 추정량을 이용하면, 공분산 모형 가정에 강건한(robust) 표준오차 계산이 가능하다.
주의점은, \(\widehat{\beta}\)의 계산 과정에서 가상관행렬(working correlation matrix)의 지정을 필요로 한다. 어떠한 가상관행렬 구조도 상관없으나, 가상관행렬이 error의 true 상관행렬 \({\rm Var}(\boldsymbol{\epsilon}_i)\)와 가까울수록 결과적인 \(\widehat{\beta}\)의 분산이 줄어든다. (좋아진다는 뜻이다) 대표적인 옵션은 아래 세 개이다.
GEE 가상관행렬 옵션에서 ’independece’을 선택 하여 나온 결과의 Naive S.E.는 맨 위의 개체내 상관관계를 무시한 회귀분석에서 나온 S.E.와 동일함 (정확히 같다. 왜냐면 가정과 추정방법이 동일해지기 때문)
‘exchangeable’을 선택하여 나온 결과의 Naive S.E.는 위의 일반선형 모형에서 ’corCompSymm’ 옵션을 지정한 최대가능도 방법 결과와 동일함 (역시 가정과 추정방법이 동일해지기 때문에 정확히 같은 결과이다)
Robust S.E.는 샌드위치 추정량을 이용한 강전한 표준오차를 의미. 가상관행렬 옵션지정에 상관없이 결과는 동일함.
Naive S.E.의 값보다는 Robust S.E.의 값이 대체로 작음. 즉 더 좁은 신뢰구간을 얻을 수 있음 (통계적으로 효율적efficient임)
# General linear model using GEElibrary(gee)# independence working correlationtlcl.gee.indep =gee(lead ~factor(week)*Group.f, id=ID,corstr="independence", data=tlcl)