한치록 (2024). 계량경제학 강의 (5판). 박영사. – 11장 “다중회귀 관련 추가 주제”
보조 출처
강근석, 유현조 (2016). R을 활용한 선형회귀분석. 교우사.
James, Witten, Hastie, and Tibshirani (2021). An Introduction to Statistical Learning: with Applications in R (2nd Edition). Springer.
Wooldridge (2016). Introductory Econometrics: A Modern Approach (6th Edition). Cengage Learning.
8.1 여러 선형 제약이 있는 경우의 가설검정
예를 들어 앞 예제에서 다음 가설을 검정하고 싶다고 하자. \[
H_0 : \beta_1 = \beta_2 = \beta_3.
\]
가설을 \({\bf A} \boldsymbol{\beta} = {\bf b}\)의 형태로 나타낼 수 있을 경우, 정규분포 이론을 이용하여 위 가설에 대한 F-검정을 유도할 수 있다. \(F\)검정의 원리를 이용해서 꼴로 나타내면 공식을 이용하여 더 복잡하고 현학적으로 실행할 수도 있다. 귀무가설은 \(H_{0}: \beta_{1}-\beta_{2}=0, \beta_{2}-\beta_{3}=0\) 이므로 \(\boldsymbol{\beta}=\left(\beta_{0}, \beta_{1}, \beta_{2}, \beta_{3}\right)^{T}\)에 대하여 다음과 같이 나타낼 수 있다.
즉, 남녀간에 school과 exper의 계수는 동일하고 절편만 다르다. 남성의 절편은 \(\beta_{0}\) 이고 여성의 절편은 \(\beta_{0}+\delta_{0}\)이다. 다른 말로 하면, female 더미변수는 남녀간에 절편을 상이하게 만들어 주는 역할을 한다.
다음 결과를 보고 연습문제를 풀어 보자.
data(Wages1, package="Ecdat")names(Wages1)
[1] "exper" "sex" "school" "wage"
Wages1$female01 <-as.numeric(Wages1$sex=='female')ols <-lm(log(wage) ~ school + exper + female01, data=Wages1)summary(ols)
Call:
lm(formula = log(wage) ~ school + exper + female01, data = Wages1)
Residuals:
Min 1Q Median 3Q Max
-3.9861 -0.2817 0.0477 0.3663 2.1668
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.016778 0.087504 -0.192 0.848
school 0.123361 0.006230 19.802 < 2e-16 ***
exper 0.035412 0.004514 7.845 5.79e-15 ***
female01 -0.242569 0.020453 -11.860 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5786 on 3290 degrees of freedom
Multiple R-squared: 0.1374, Adjusted R-squared: 0.1367
F-statistic: 174.7 on 3 and 3290 DF, p-value: < 2.2e-16
연습 1. 남성의 절편 추정치와 여성의 절편 추정치?
연습 2. 만약 위 5 번 행에서 여성 더미변수(female) 대신에 남성 더미변수(male \(=1-\) female)를 포함시키면 male 의 계수 추정값과 표준오차는 각각 무엇이겠는가?
연습 3. 이 결과에 따르면 같은 성별에서 경력이 동일할 때 학력에 1 년 차이가 나면 임금에는 약 몇 퍼센트의 차이가 나는 것으로 예측되는가?
연습 4. 이 결과에 따르면 여타 요소들이 동일한 여성과 남성 간에 어느 정도의 임금 격차가 있는 것으로 추정되는가? 여성의 임금이 높은가 남성의 임금이 높은가? 이 차이는 통계적으로 유의한가?
8.2.2 범주가 세 개 이상인 질적 변수의 더미변수화
예를 들어 연령대라는 범주형 변수에는 30대 이하(young), 40-50대(middle), 60대 이상(old) 3개의 값이 가능하다고 하자.
회귀분석에 연령대 변수를 반영하기 위하여는 아래와 같이 \(K-1\)개의 column을 만들어 주어야 한다.
아래 예제에서는 young 그룹을 기준군(reference)로 설정하였다. young 그룹은 수학적으로 \((0,0)^T\)에 대응하고, middle 그룹은 \((1,0)^T\)에, old 그룹은 \((0,1)^T\)에 대응한다.
# Create a dataframedf <-data.frame(gender =c("m", "f", "m", "m"),age_grp =c("young", "old", "middle", "middle"),city =c("Incheon", "Busan", "Jeju", "Daejeon"))# Print original datasetprint(df)
gender age_grp city
1 m young Incheon
2 f old Busan
3 m middle Jeju
4 m middle Daejeon
물론 reference group을 young이 아닌 다른 범주로 하여도 된다. 그 경우 회귀분석의 결과는 달라지지 않는다.
R에서 기초적인 회귀분석 함수들 (lm, glm)등은 질적 변수가 factor type이나 character type으로 설정되어 있을 경우, 자동적으로 더미코딩 후 결과를 반환해 준다. 그렇지만 모든 오픈소스 라이브러리들이 자동 더미코딩을 지원하는 것은 아니기 때문에, 더미코딩의 원리와 구현방식을 알고 있는 것이 좋다.
8.3 상호작용항 (interaction term)
예를 이용하여 상호작용 항의 의미를 파악해 보자.
식 (1)의 우변에 female \(\times\) school 라는 상호작용항(interaction term, 서로 곱한 항, 교차항) 을 추가해 보자. 그러면 모형은 다음이 된다.
따라서, (1A)에서 female 의 계수인 \(\delta_{0}\) 은 여성과 남성 간 절편의 차이이며, 상호작용항 female \(\times\) school 의 계수인 \(\delta_{1}\) 은 여성과 남성 간 school의 계수의 차이에 대응한다. exper의 계수 는 남녀간에 차이가 없다. 다시 말하면, 모형 (1A)에서는 남녀간에 절편과 school 의 기울기가 모두 상이하지만 exper의 계수는 동일하도록 설정되었다.
8.3.1 Example
다음을 실행하여 보자. 2번 행에서 female이라는 변수를 만든다. 3번 행에서 female*school이라는 표현은 female+school+female:school과 동일하다. 즉, female, school, 그리고 그 상호작용 항인 female:school을 모두 우변에 포함시킨다는 뜻이다(R에서 상호작용항을 만들 때 콜론 부호 ’:’을 사용한다).
Call:
lm(formula = log(wage) ~ female * school + exper, data = Wages1)
Residuals:
Min 1Q Median 3Q Max
-3.9856 -0.2813 0.0484 0.3663 2.1666
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.0121960 0.1089885 -0.112 0.9109
female -0.2528782 0.1475700 -1.714 0.0867 .
school 0.1229849 0.0081974 15.003 < 2e-16 ***
exper 0.0353783 0.0045399 7.793 8.73e-15 ***
female:school 0.0008818 0.0124997 0.071 0.9438
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5787 on 3289 degrees of freedom
Multiple R-squared: 0.1374, Adjusted R-squared: 0.1364
F-statistic: 131 on 4 and 3289 DF, p-value: < 2.2e-16
다음 연습문제들을 풀어 보자. 9번은 특히 중요하다.
연습 5. 이 결과에 따르면 남성의 경우 절편과 기울기(school 과 exper의 계수) 추정값 들은 각각 얼마인가? 힌트: 계산이 필요 없음
연습 6. 이 결과에 따르면 여성의 경우 절편과 기울기(school과 exper의 계수) 추정값 들은 각각 얼마인가? 힌트: 계산이 필요함
연습 7. 이 추정 결과에 따르면 학력의 효과(즉, school 의 기울기)는 남성과 여성 중 어느 쪽이 더 큰가? 남성과 여성간에 학력의 효과에 통계적으로 유의한 차이가 있는가?
연습 8. 위의 모형에서 절편과 school 의 계수는 남녀간에 차이가 있지만 exper의 계수는 동일하다. 절편과 모든 기울기에서 남녀간에 차이가 있을 수 있는 선형모형은?
연습 9. 다음은 많은 사람들이 실수를 범하는 내용이다. 다음 모형 $ ()={0}+{1} +_{1}( )+ $ 에서 남성과 여성의 절편과 기울기는 각각 무엇이며 남성과 여성의 절편과 기울기에 어떤 제약이 존재하는지 설명하라. 이 모형에서는 우변에 female 변수가 없이 \(\log (\) wage \()\) 를 school 항과 female \(\times\) school 만으로 회귀시키고 있는데, 이 모형의 문제점은 무엇이며, 이 문제를 해결하기 위해서는 모형을 어떻게 바꾸어야 하는가?
8.3.2 상호작용항의 기능
상호작용항, 즉 서로 곱한 항은, 교차되는(곱해지는) 한 변수의 계수(“영향”)이 교차되는 다른 변수의 값에 따라 달라지도록 해 준다. 참고로, \(D\) 변수를 \(D \times 1\), 즉 \(D\) 변수와 상수항(1)의 상호작용항이라 이해하면, ’상호작용항은 계수를 상이하게 해 준다’고 일반화하여도 틀리지 않다.
예를 들어 아래 선형모형을 고려하여 보자. 여기서 \(D\)는 이진변수이다. \[Y=\beta_{0}+\beta_{1} X+\delta_{0} D+ \varepsilon \tag{4}\]\[Y=\beta_{0}+\beta_{1} X+\delta_{0} D+\delta_{1}(D \cdot X)+\varepsilon \tag{5}\]
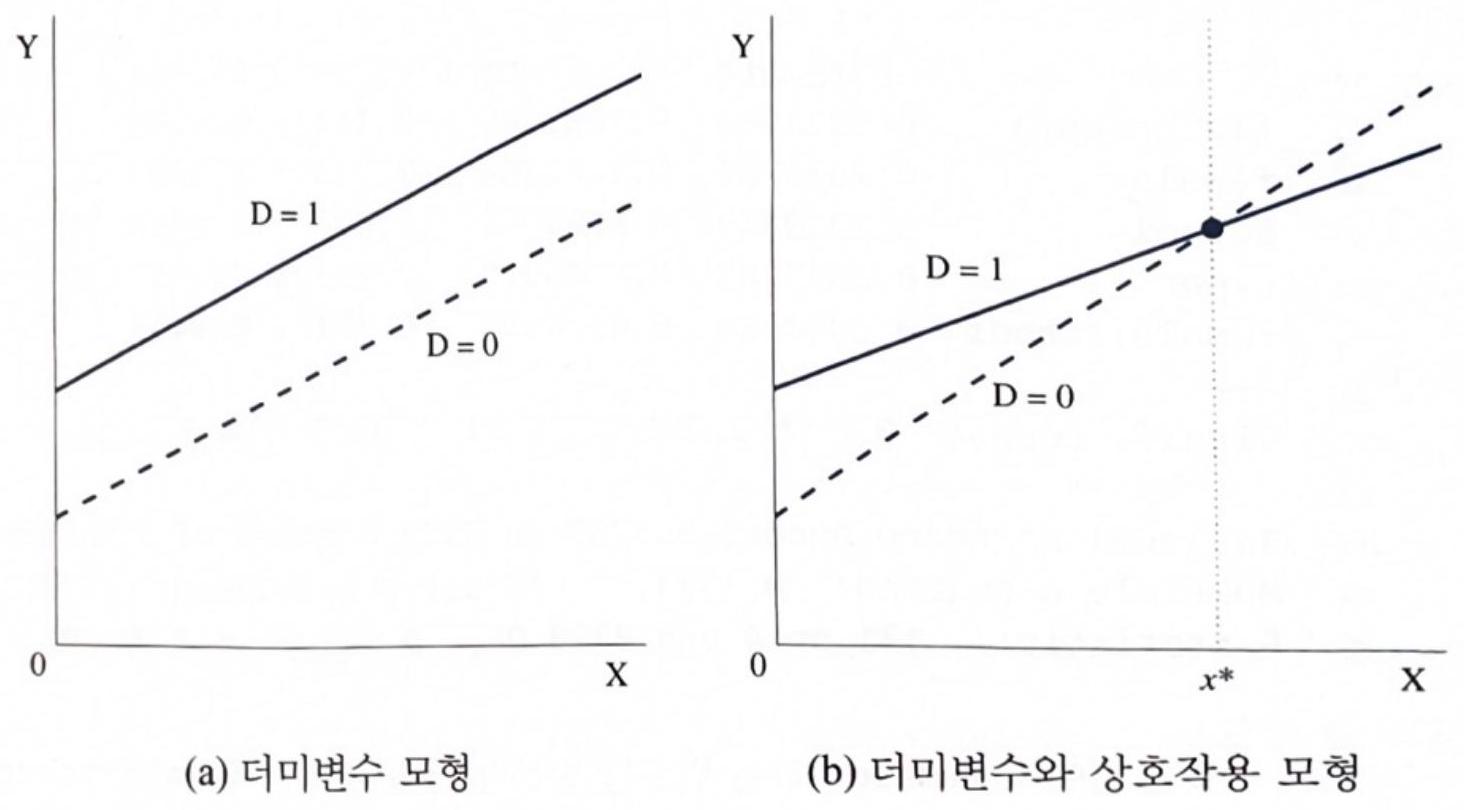
그림과 함께 생각하여 보자.
[그림. 더미변수 모형과 상호작용 모형의 비교]
그림 (a)에는 더미변수만 존재하므로 \(D=1\) 과 \(D=0\) 간에 \(X\) 의 기울기는 동일하고 절편만 상이하다. 절편의 차이는 \(D\) 의 계수로서, 그림의 경우 양수이다.
그림 (b)에는 더미변수와 상호작용항이 모두 포함 되므로 절편도 상이하고 기울기도 상이하다. 여기서 절편의 차이는 \(D\) 의 계수(그림의 경우 양수)이며, 상호작용항의 계수는 기울기의 차이(그림의 경우 음수)이다.
8.3.3 Example
위의 코드 예제에서, female 변수의 계수 추정값은 -0.2528782 이며 상호작용항의 계수는 0.0008818 이다. 이에 의하면 exper가 동일할 때 일정 수준의 학교교육 이하에서는 남성의 평균 임금이 더 높고, 그 이상의 학교교육에서는 여성의 평균 임금이 더 높은 것으로 추정된다. - 여성과 남성 간 임금의 기댓값이 동일해지 는 학교교육 수준은, 상호작용항의 계수가 0 과 가깝고 통계적으로 전혀 유의하지 않지만 그래도 계산해 보면, \(0.2528782 / 0.0008818=286.775\), 약 290 년으로 추정된다. 대략 \(6-16\) 년의 학교교육 연수를 고려하면, 위 예제의 결과는, exper를 통제할 때 모든 교육수준에서 여성의 평균 임금이 남성의 평균 임금보다 더 낮은 것으로 추정되었음을 보여준다.