[ISLR] James, Witten, Hastie, and Tibshirani (2021). An Introduction to Statistical Learning: with Applications in R (2nd Edition). Springer. – 4장 “Classification”
김기영, 전명식, 강현철, 이성건 번역 (2015). Chatterjee and Hadi 지음. 예제를 통한 회귀분석 (5판). 자유아카데미.
보조 출처
Wooldridge (2016). Introductory Econometrics: A Modern Approach (6th Edition). Cengage Learning.
9.1 반응변수가 0/1인 경우
질적 변수
입시, 입사 등 선발과정: ‘잘함(good)’ vs ‘못함(poor)’
건강 연구: 반응변수는 암 발병 여부(yes vs. no), 설명변수는 나이, 성별, 흡연, 다이어트, 가족의 의료기록 등
금융: 반응변수는 회사의 지불능력(파산 vs. 지불능력 있음), 예측변수들은 회사와 관련된 다양한 금융 정보들
\(P(Y=1 \mid {\bf X}={\bf x}) =: p({\bf x})\)에 대한 확률 모형이 필요함.
9.2 로지스틱 회귀분석의 확률모형
9.2.1 로지스틱 선형모형
\(Y \in\{0,1\}\) 및 \({\bf X} \in \mathbb{R}^{p}\) 가정하고, \(p({\bf x})= P(Y=1 \mid {\bf X}={\bf x})\) 라 쓰면,
먼저 \(Y=0,1\)인 경우 \(E(Y) = P(Y=1)\)임을 기억하자. 마찬가지로 \(E(Y|{\bf X}={\bf x}) = P(Y=1|{\bf X}={\bf x}) = p({\bf x})\)이다.
따라서, 지난 7,8장에서 다룬 선형회귀분석 모형을 적용하자면 \(p({\bf x}) = \beta_0 + {\bf x}^{T} \boldsymbol{\beta}\) 식의 모형을 고려할 수 있고, 이 모형에서의 계수추정은 이미 7,8장에서 다룬 바 있다. 이 모형을 이진반응변수에 적합하면 안 되는 걸까?
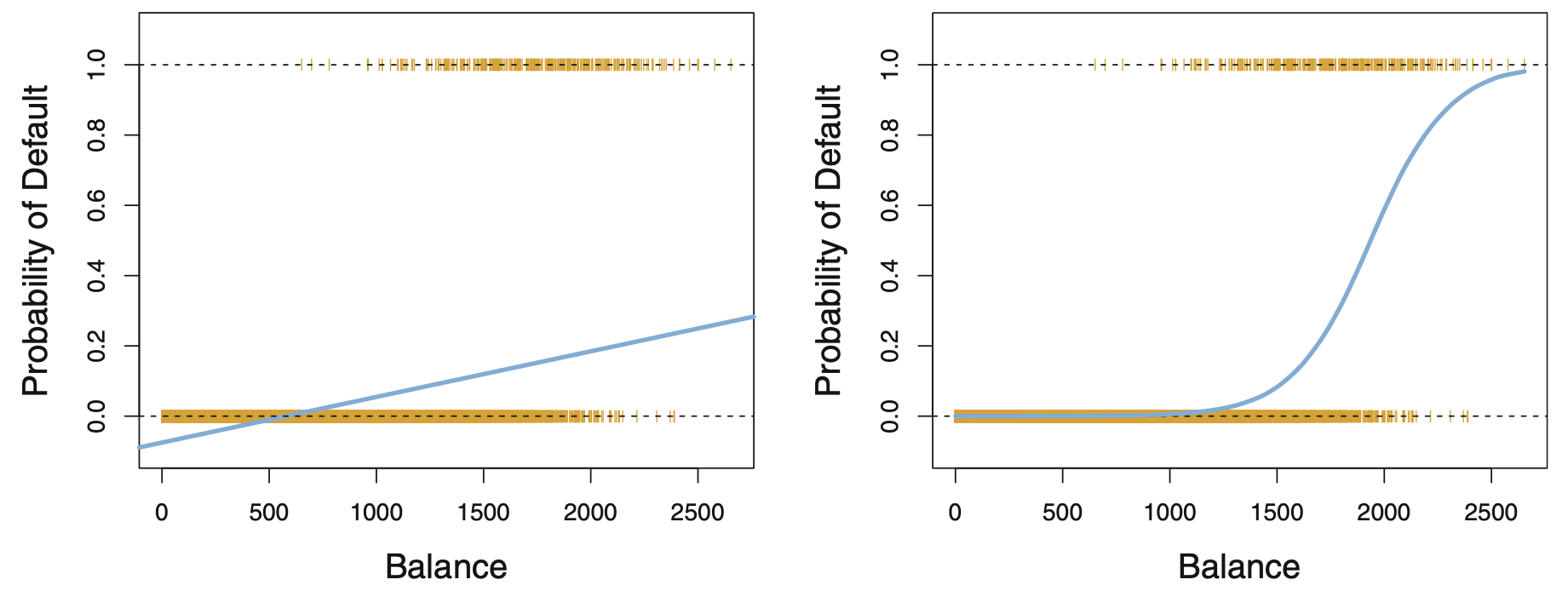
결론적으로 “완벽히 안 된다”라고 말할 수는 없지만, 여러 가지 문제가 발생한다. 가장 큰 문제는 조건부확률의 적합값에서 발생한다. \(P(Y=1|{\bf X}={\bf x}) = \beta_0 + {\bf x}^{T} \boldsymbol{\beta}\)의 좌변은 확률이니 \({\bf x}\)의 값에 상관없이 늘 0과 1사이에 있어야 한다. 그런데 \(\beta_0 + {\bf x}^{T} \boldsymbol{\beta}\) 항은 \({\bf x}\)의 값에 따라 0보다 작을 수도 있고 1보다 클 수도 있다. 즉, 선형회귀분석 모형에서는 \(p({\bf x})\)의 적합값이 0보다 작거나 1보다 클 수도 있다는 문제점이 있다. (아래 그림의 첫번째)
\(p({\bf x})\)의 적합값이 반드시 0과 1사이에 오게 하는 방법이 있다. 어떤 알려진 변환 \(g\)에 대하여 \(g( p({\bf x}) )=\beta_0 + {\bf x}^{T} \boldsymbol{\beta}\) 라고 가정하는 것이다. 이때 \(g\) 함수는 \(p_{\mathbf{x}}\) 를 선형함수인 \(\beta_0 + \mathbf{x}^T \boldsymbol{\beta}\) 와 연결시키는 함수로서 ‘연결함수’(link function)라 한다.
로지스틱 회귀분석모형의 link function은 logit function \(\log \{t /(1-t)\}\) 이다.
다른 대표적 link function은 probit function 으로, \(t \mapsto \int_{- \infty}^t \phi (u) du\)의 역함수로 정의된다 (단, \(\phi(u)\)는 표준정규분포의 확률밀도함수). 계량경제학에서 가격에 따른 선택을 연구할 때 많이 사용한다.
로짓 함수와 프로빗 함수 모두 정의역은 \((0,1)\)이고 치역은 모든 실수이다.
본 장에서는 logit link function을 중점적으로 다룬다.
FIGURE 4.2 in [ISLR]. Left: 파란색 선은 선형회귀분석(즉 최소제곱법)으로 추정한 확률값이다. 추정된 확률값이 음수도 된다! 오렌지색 점들은 자료에서의 \(y\)값 (\(0 / 1\)) 들이다. Right: 로지스틱 회귀분석으로 추정한 확률값이다. 모든 확률값들이 0과 1사이에 있다.
9.2.3 로지스틱 선형모형에서 계수의 의미
오즈(odds) (또는 \(y=1\) 의 오즈): 클래스 0 에 속할 확률에 대한 클래스 1 에 속할 확률의 비율로 정의된다. 어떤 질병이 걸릴 위험을 묘사할 때 절대위험차이(absolute risk difference), 상대위험비(relative risk ratio)와 함께 대표적으로 사용되는 지표이다.
로지스틱 다중회귀모형에서 \(\beta_j\)의 해석: (1)에서 \(X_{j}\) 가 한 단위 증가하면 \(y=1\) 의 오즈는 \(\exp \left(\beta_{j}\right)\) 배만큼 증가한다 (다른 독립변수들이 모두 일정하다는 가정 하에). 즉 \(\beta\)값을 \(Y\)의 평균적 증분으로 해석할 수 있는 선형회귀분석(7,8장)보다는 조금 우회적으로 해석이 된다.
요컨대,
로지스틱 단순선형회귀모형에서 \(\exp(\beta_1)\)은 unadjusted odds ratio
로지스틱 다중선형회귀모형에서 \(\exp(\beta_1)\)은 adjusted odds ratio (adjusted for \(X_2, \ldots, X_p\))가 된다.
TABLE 4.3 in [ISLR]. 로지스틱 회귀 모델의 추정 계수들의 예시. 이 모델의 설명변수는 계좌 잔액(balance), 소득(income), 그리고 학생여부(student yes)이다. 반응변수는 채무 불이행(default)이다. 소득은 천 달러 단위로 측정되었다.
카드 청구예정금액(balance)이 \(\$ 1,500\) 이고 연간수입(income) 이 \(\$ 40,000\) 인 학생 (student[Yes])에 대한 채무불이행(Default) 확률 추정값은?