Chapter 2 R Warm-ups in Finance
2.1 Learning outcomes
By the end of this chapter you should be able to:
Use
Rto store and operate (arithmetic and logic) on arrays, vectors, and matricesApply
Rvectors to the calculation of net present value. ## Imagine This
You work for the division president of an aerospace company that makes testing equipment for high-tech manufacturers. Orders arrive “lumpy” at best as some quarters are big producers, others stretch the company’s credit revolver.
The president, call her Nancy, found a new way to make money: lease equipment. This would help finance operations and smooth cash flow. You had a follow-on idea: build a captive finance company to finance and insure the manufactured product for customers.
“Nice ideas,” Nancy quips. “Show me how we can make money.”
For starters we want to borrow low and sell (leases) high! How? We can define three salient factors:
- The “money factor”
- Sets the monthly payments
- Depends on the length and frequency of payment of the lease
- Also depends on the value of money at monthly forward borrowing rates
- Residual value of the equipment
- Uncertain based on competitors’ innovations, demand for manufacturers’ products, etc.
- Uncertain based on quality of equipment at end of lease (is there a secondary market?)
- Portfolio of leases
- By maturity
- By equipment class
- By customer segment
This simple vignette about leasing introduces us to the complexities and challenges of financial analytics. We see that cash flows evolve over time and may depend on various uncertain factors. The time series of cash flows and their underlying factors in turn have distributions of potential outcomes and also may be related to one another. Groups of cashflows may also be related to one another structurally through portfolios. These are simply combinations of sets of cashflows and, of course, their underlying and uncertain factors. Sets of cash flows and their factors may be delineated according to customer segments, classification of equipment, and introducing a timeing element, by their maturity.
2.1.1 Modeling process
Throughout financial analytics there is a modeling process we can deploy. Let’s begin the modeling process by identifying leasing cash flow components and financial considerations we might use to begin to build reasonable scenarios. In ourleasing scenario here is a concordance of cash flow elements with models that will be illustrated throughout this book:
- Lease payments
- Chapter 5: Term structure of interest rates
- Chapter 7: Credit risk of customers
- Chapter 4: Impact of economy on customers’ market value
- Residual cashflow
- Chapter 8: Operational risk
- Chapter 11: Aggregating risks
- Borrowing costs
- Chapter 5: Term structure of interest rates
- Chapter 7: Our own credit risk
- Collateral
- Chapter 10: Portfolio optimization
- Chapter 6: Market risk
- Regulatory issues
- Chapter 8: Operational risk
- Shareholder tolerance for risk
- Chapter 6: Market risk
- Chapter 9: Hedging
- Chapter 11: Capital requirements
In this first Chapter we will review some aspects of R programming to whet our appetite for further work in finance and risk. The first steps here will prepare the way for us to tackle the many issues encountered with financial time series, portfolios of risk and return factors, market, credit, and operational risk measurement, the aggregation of risk and return, and the fundamental measurement of volatility.
2.1.2 Chapter overview
In this first chapter we will
- Introduce
Rand calculations, arrays, text handling, graphics - Review basic finance and statistics content
- Use introductory
Rcalculations in financial and statistical examples - Extend introductory calculations with further examples
2.1.3 What is R?
R is software for interacting with data along a variety of user generated paths. With R you can create sophisticated (even interactive) graphs, you can carry out statistical and operational research analyses, and you can create and run simulations. R is also a programming language with an extensive set of built-in functions. With increasing experience, you can extend the language and write your own code to build your own financial analytical tools. Advanced users can even incorporate functions written in other languages, such as C, C++, and Fortran.
The current version of R derives from the S language. S has been around for more than twenty years and has been with extrensive use in statistics and finance, first as S and then as the commercially available S-PLUS. R is an open source implementation of the S language that is now a viable alternative to S-PLUS. A core team of statisticians and many other contributors work to update and improve R and to make versions that run well under all of the most popular operating systems. Importantly, R is a free, high-quality statistical software that will be useful as you learn financial analytics even though it is also a first-rate tool for professional statisticians, operational researchers, and financial analysts and engineers.(But see this post on a truly big data language APL: https://scottlocklin.wordpress.com/2013/07/28/ruins-of-forgotten-empires-apl-languages/)
2.1.4 R for analytics
There are several reasons that make R an excellent choice of software for an analytics course. Some benefits of using R include:
Ris free and available online.Ris open-source and runs onUNIX,Windows, andMacintoshoperating systems.Rhas a well-documented, context-based, help system enhanced by a wide, and deep, ranging user community globally and across several disciplines.Rhas excellent native static graphing capabilities. Interactive dynamic graphics are evolving along with the ability to embed analytics into online applications. WithRyou can build dashboards and websites to communicate results dynamically with consumers of the analytics you generate.Practitioners can easily migrate to the commercially supported
S-Plusprogram, if commercial software is required.SandS-Plusare the immediate ancestors of the R programming environment. Cloud computing is now available with large data implementations.R’s language has a powerful, easy-to-learn syntax with many built-in statistical and operational research functions. Just as important are the extensive web-scraping, text structuring, object class construction, and the extensible functional programming aspects of the language. A formal language definition is being developed. This will yield more standardization and better control of the language in future versions.Ris a computer programming language. For programmers it will feel more familiar than for others, for example Excel users.Rrequires array thinking and object relationships that are not necessarily native, but indeed are possible, in an Excel spreadsheet environment. In many ways, the Excel style andRstyle of environments complement one another.Even though it is not necessarily the simplest software to use, the basics are easy enough to master, so that learning to use
Rneed not interfere with learning the statistical, operational research, data, and domain-specific concepts encountered in an analytics-focused course.
There is at least one drawback.
- The primary hurdle to using
Ris that most existing documentation and plethora of packages are written for an audience that is knowledgable about statistics and operational research and has experience with other statistical computing programs. In contrast, this course intends to makeRaccessible to you, especially those who are new to both statistical concepts and statistical computing.
2.1.5 Hot and cold running resources
Much is available in books, e-books, and online for free. This is an extensive online commChaptery that links expert and novice modelers globally.
The standard start-up is at CRAN http://cran.r-project.org/manuals.html. A script in the appendix can be dropped into a workspace and played with easily. Other resources include
- Julian Faraway’s https://cran.r-project.org/doc/contrib/Faraway-PRA.pdf complete course on regression where you can imbibe deeply of the many ways to use
Rin statistics. - Along econometrics lines is Grant Farnsworth’s https://cran.r-project.org/doc/contrib/Farnsworth-EconometricsInR.pdf.
- Winston Chang’s http://www.cookbook-r.com/ and Hadley Wickham’s example at http://ggplot2.org/ are terrific online graphics resources.
2.2 Tickling the Ivories
Or if you paint and draw, the 2-minute pose will warm you up. In the RStudio console panel (in the SW pane of the IDE) play with these by typing these statements at the > symbol:
1 + (1:5)## [1] 2 3 4 5 6This will produce a vector from 2 to 6.
We can use alt- (hold alt and hyphen keys down simultaneously) to produce <-, and assign data to an new object. This is a from R’s predecessor James Chamber’s S (ATT Bell Labs) that was ported from the single keystroke \(\leftarrow\) in Ken Iverson’s APL (IBM), where it is reserved as a binary logical operator. We can now also use = to assign variables in R. But, also a holdover from APL, we will continue to use = only for assignments within functions. [Glad we got that over!]
Now let’s try these expressions.
x <- 1 + (1:5)
sum(x)## [1] 20prod(x)## [1] 720These actions assign the results of a calculation to a variable x and then sum and multiply the elements. x is stored in the active workspace. You can verify that by typing ls() in the console to list the objects in the workspace. Type in these statements as well.
ls()## [1] "x"length(x)## [1] 5x[1:length(x)]## [1] 2 3 4 5 6x[6:8]## [1] NA NA NAx[6:8] <- 7:9
x/0## [1] Inf Inf Inf Inf Inf Inf Inf Infx has length of 5 and we use that to index all of the current elements of x. Trying to access elements 6 to 8 produces na because they do not exist yet. Appending 7 to 9 will fill the spaces. Dividing by 0 produces inf.
(x1 <- x - 2)## [1] 0 1 2 3 4 5 6 7x1## [1] 0 1 2 3 4 5 6 7x/x1## [1] Inf 3.000000 2.000000 1.666667 1.500000 1.400000 1.333333 1.285714Putting parentheses around an expression is the same as printing out the result of the expression. Element-wise division (multiplication, addition, subtraction) produces inf as the first element.
2.2.1 Try this exercise
Suppose we have a gargleblaster machine that produces free cash flows of $10 million each year for 8 years. The machine will be scrapped and currently you believe you can get $5 million at the end of year 8 as salvage value. The forward curve of interest rates for the next 1 to 8 years is 0.06, 0.07, 0.05, 0.09, 0.09, 0.08, 0.08, 0.08.
- What is the value of $1 received at the end of each of the next 8 years? Use this script to begin the modeling process. Describe each calculation.
rates <- c(0.06, 0.07, 0.05, 0.09, 0.09,
0.08, 0.08, 0.08)
t <- seq(1, 8)
(pv.1 <- sum(1/(1 + rates)^t))What is the present value of salvage? Salvage would be at element 8 of an 8-element cash flow vector, and thus would use the eighth forward rate,
rate[8], andtwould be 8 as well. Eliminate the sum in the above script. Make a variable calledsalvageand assign salvage value to this variable. Use this variable in place of the1in the above script forpv.1. Call the new present valuepv.salvage.What is the present value of the gargleblaster machine? Type in these statements. The
repfunction makes an8element cash flow vector. We change the value of the 8th element of the cash flow vector to include salvage. Now use thepv.1statement above and substitutecashflowfor1. You will have your result.
cashflow <- rep(10, 8)
cashflow[8] <- cashflow[8] + salvageSome results follow. The present value of $1 is The present value of a $1 is this mathemetical formula. \[
PV = \sum_{t=1}^{8}\frac{1}{(1+r)^t}
\] This mathematical expression can be translated into R this way
rates <- c(0.06, 0.07, 0.05, 0.09, 0.09,
0.08, 0.08, 0.08)
t <- seq(1, 8)
(1/(1 + rates)^t)## [1] 0.9433962 0.8734387 0.8638376 0.7084252 0.6499314 0.6301696 0.5834904
## [8] 0.5402689(pv.1 <- sum(1/(1 + rates)^t))## [1] 5.792958We define rates as a vector using the c() concatenation function. We then define a sequence of 8 time indices t starting with 1. The present value of a $1 is sum of the vector element-by-element calculation of the date by date discounts \(1/(1+r)^t\).
The present value of salvage is the discounted salvage that is expected to occur at, and in this illustration only at, year 8. \[
PV_{salvage} = \frac{salvage}{(1+r)^8}
\] Translated into R we have
salvage <- 5
(pv.salvage <- salvage/(1 + rates[8])^8)## [1] 2.701344The present value of the gargleblaster machine is the present value of cashflows from operations from year 1 to year 8 plus the present value of salvage received in year 8. Salvage by definition is realized at the of the life of the operational cashflows upon disposition of the asset, here at year 8. \[
PV_{total} = \sum_{t=1}^{8}\frac{cashflow_t}{(1+r)^t} + \frac{salvage}{(1+r)^8}
\] This expression translates into R this way:
cashflow <- rep(10, 8)
cashflow[8] <- cashflow[8] + salvage
(pv.machine <- sum(cashflow/(1 + rates)^t))## [1] 60.63092The rep or “repeat” function creates cash flows of $10 for each of 8 years. We adjust the year 8 cash flow to reflect salvage so that \(cashflow_8 = 10 + salvage\). The [8] indexes the eighth element of the cashflow vector.
2.3 Building Some Character
Let’s type these expressions into the console at the > prompt:
x[length(x) + 1] <- "end"
x[length(x) + 1] <- "end"
x.char <- x[-length(x)]
x <- as.numeric(x.char[-length(x.char)])
str(x)## num [1:8] 2 3 4 5 6 7 8 9We have appended the string “end” to the end of x, twice.
- We use the
-negative operator to eliminate it. - By inserting a string of characters into a numeric vector we have forced
Rto transform all numerical values to characters. - To keep things straight we called the character version
x.char. - In the end we convert
x.charback to numbers that we check with thestr(ucture) function.
We will use this procedure to build data tables (we will call these “data frames”) when comparing distributions of variables such as stock returns.
Here’s a useful set of statements for coding and classifying variables. Type these statements into the console.
set.seed(1016)
n.sim <- 10
x <- rnorm(n.sim)
y <- x/(rchisq(x^2, df = 3))^0.5We did a lot of R here. First, we set a random seed to reproduce the same results every time we run this simulaton. Then, we store the number of simulations in n.sim and produced two new variables with normal and a weirder looking distribution (almost a Student’s t distribution). Invoking help will display help with distributions in the SE pane of the RStudio IDE.
z <- c(x, y)
indicator <- rep(c("normal", "abnormal"),
each = length(x))
xy.df <- data.frame(Variates = z, Distributions = indicator)Next we concatenate the two variables into a new variable z. We built into the variable indicator the classifier to indicate which is x and which is y. But let’s visualize what we want. (Paint in words here.) We want a column the first n.sim elements of which are x and the second are y. We then want a column the first n.sim elements of which are indicated by the character string “normal”, and the second n.sim elements by “abnormal”.
The rep function replicates the concatenation of “normal” and “abnormal” 10 times (the length(x)). The each feature concatenates 10 replications of “normal” to 10 replications of “abnormal”. We concatenate the variates into xy with the c() function.
We can see the first 5 components of the data frame components using the $ subsetting notation as below.
str(xy.df)## 'data.frame': 20 obs. of 2 variables:
## $ Variates : num 0.777 1.373 1.303 0.148 -1.825 ...
## $ Distributions: Factor w/ 2 levels "abnormal","normal": 2 2 2 2 2 2 2 2 2 2 ...head(xy.df$Variates, n = 5)## [1] 0.7773788 1.3733067 1.3025762 0.1482796 -1.8251426head(xy.df$Distributions, n = 5)## [1] normal normal normal normal normal
## Levels: abnormal normalThe str call returns the two vectors inside of xy. One is numeric and the other is a “factor” with two levels. R and many of the routines in R will interpret these as zeros and ones in developing indicator and dummy variables for regressions and filtering.
2.3.1 The plot thickens
We will want to see our handiwork, so load the ggplot2 library using install.packages("ggplot2"). (Visit Hadley Wickham’s examples at http://ggplot2.org/.)
This plotting package requires data frames. A “data frame” simply put is a list of vectors and arrays with names. An example of a data frame in Excel is just the worksheet. There are columns with names in the first row, followed by several rows of data in each column.
Here we have defined a data frame xy.df. All of the x and y variates are put into one part of the frame, and the distribution indicator into another. For all of this to work in a plot the two arrays must be of the same length. Thus we use the common n.sim and length(x) to insure this when we computed the series. We always examine the data, here using the head and tail functions.
Type help(ggplot) into the console for details. The ggplot2 graphics package embodies Hadley Wickham’s “grammar of graphics” we can review at http://ggplot2.org. Hadley Wickham has a very useful presentation with numerous examples at http://ggplot2.org/resources/2007-past-present-future.pdf.
As mentioned above, the package uses data frames to process graphics. A lot of packages other than ggplot2, including the base stats package, require data frames.
We load the library first. The next statement sets up the blank but all too ready canvas (it will be empty!) on which a density plot can be rendered.
library(ggplot2)
ggplot(xy.df, aes(x = Variates, fill = Distributions))
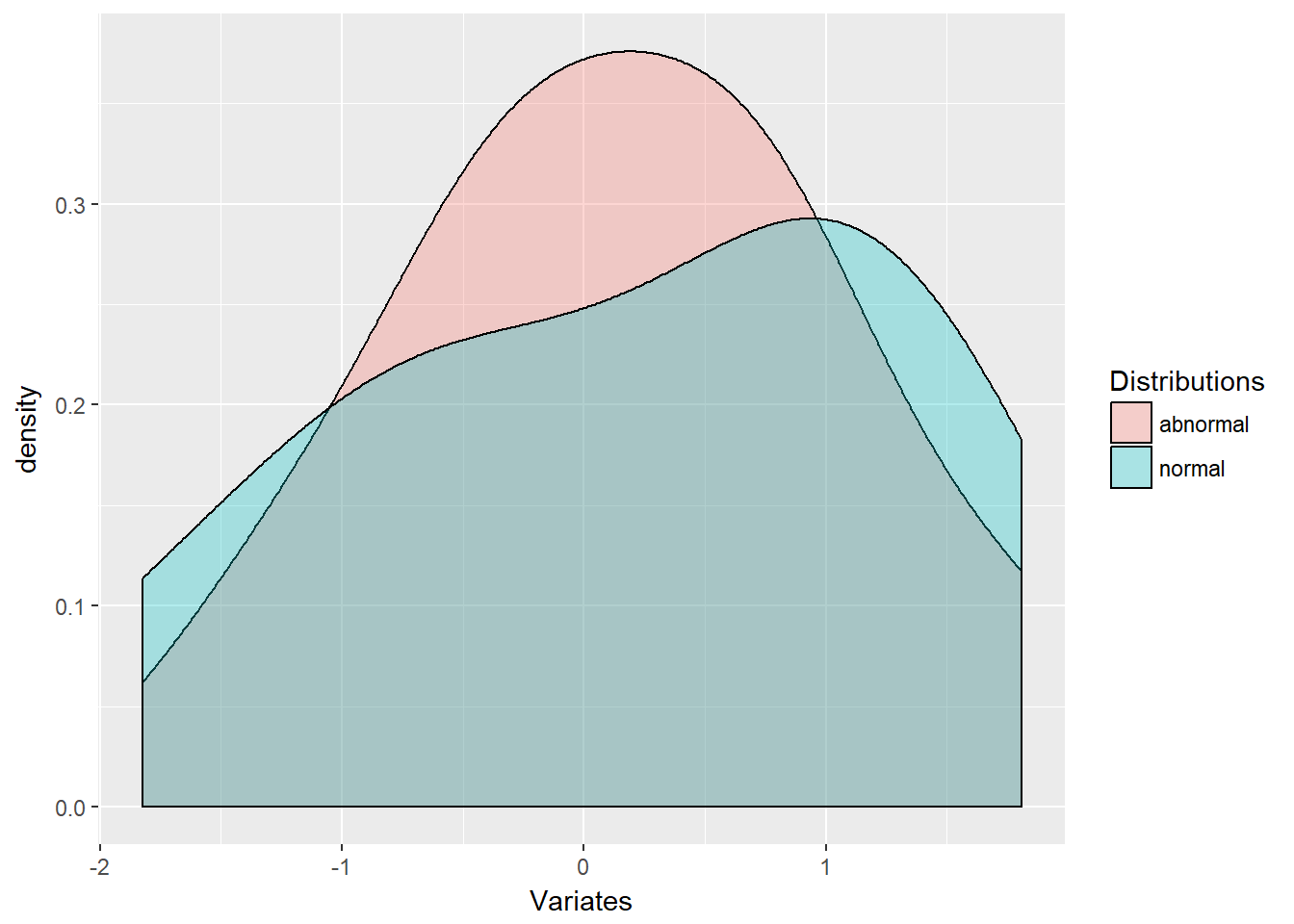
The data frame name xy.df is first followed by the aesthetics mapping of data. The next statement inserts a geometrical element, here a density curve, which has a transparency parameter aesthetic alpha.
2.3.2 Try this example
Zoom in with xlim and lower x-axis and upper x-axis limits using the following statement:
ggplot(xy.df, aes(x = Variates, fill = Distributions)) +
geom_density(alpha = 0.3) + xlim(-1,
6)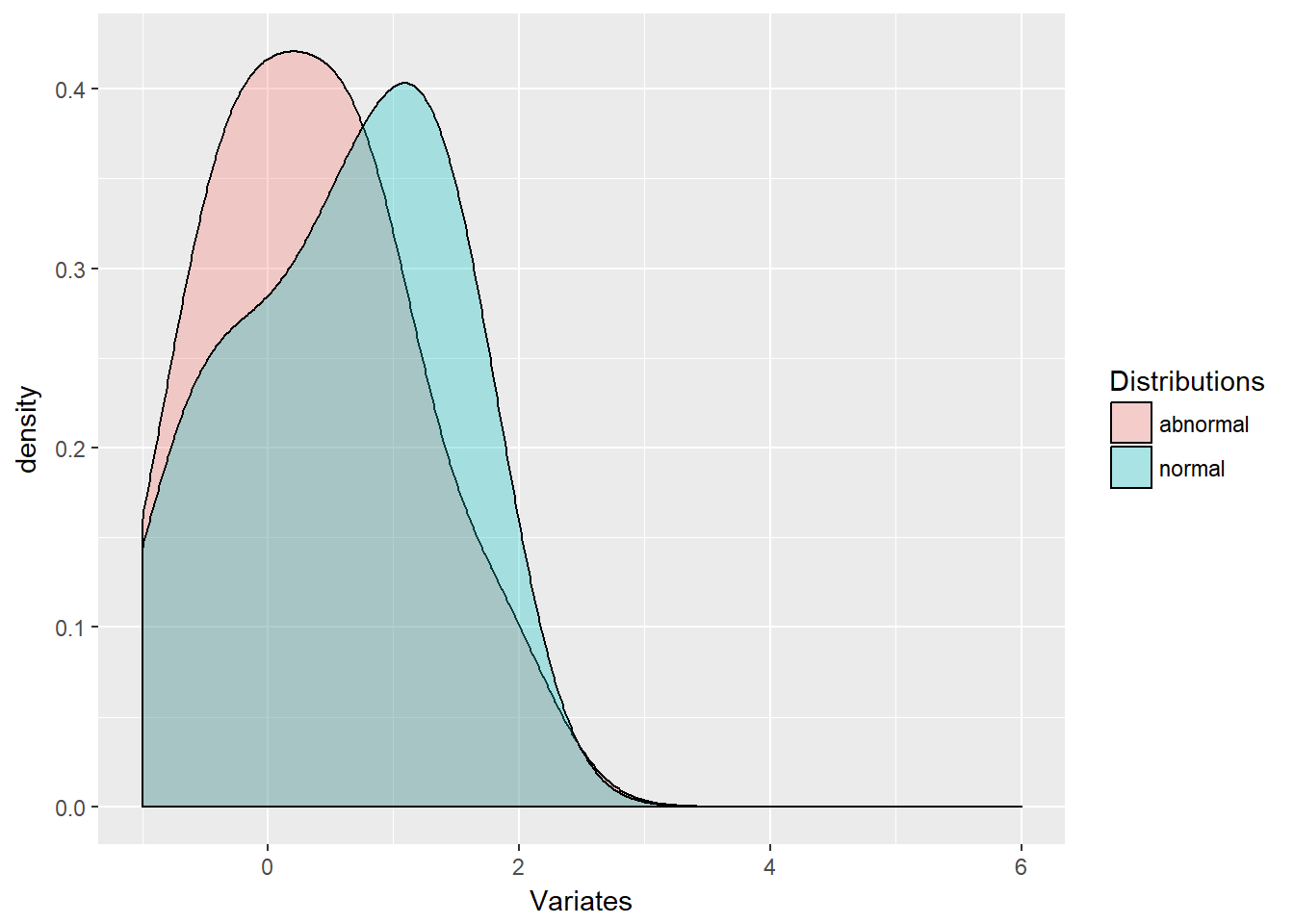
Now we are getting to extreme finance by visualizing the tail of this distribution.
2.4 Arrays and You
Arrays have rows and columns and are akin to tables. All of Excel’s worksheets are organized into cells that are tables with columns and rows. Data frames are more akin to tables in data bases. Here are some simple matrix arrays and functions. We start by making a mistake:
(A.error <- matrix(1:11, ncol = 4))## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 1The matrix() function takes as input here the sequence of numbers from 1 to 11. It then tries to put these 11 elements into a 4 column array with 3 rows. It is missing a number as the error points out. To make a 4 column array out of 11 numbers it needs a twelth number to complete the third row. We then type in these statements
(A.row <- matrix(1:12, ncol = 4))## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12(A.col <- matrix(1:12, ncol = 4, byrow = FALSE))## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12In A we take 12 integers in a row and specify they be organized into 4 columns, and in R this is by row. In the next statement we see that A.col and column binding cbind() are equivalent.
(R <- rbind(1:4, 5:8, 9:12)) # Concatenate rows## [,1] [,2] [,3] [,4]
## [1,] 1 2 3 4
## [2,] 5 6 7 8
## [3,] 9 10 11 12(C <- cbind(1:3, 4:6, 7:9, 10:12)) # concatenate columns## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12A.col == C## [,1] [,2] [,3] [,4]
## [1,] TRUE TRUE TRUE TRUE
## [2,] TRUE TRUE TRUE TRUE
## [3,] TRUE TRUE TRUE TRUEUsing the outer product allows us to operate on matrix elements, first picking the minimum, then the maximum of each row. The pmin and pmax compare rows element by element. If you used min and max you would get the minimum and maximum of the whole matrix.
(A.min <- outer(3:6/4, 3:6/4, FUN = pmin)) ### [,1] [,2] [,3] [,4]
## [1,] 0.75 0.75 0.75 0.75
## [2,] 0.75 1.00 1.00 1.00
## [3,] 0.75 1.00 1.25 1.25
## [4,] 0.75 1.00 1.25 1.50(A.max <- outer(3:6/4, 3:6/4, FUN = pmax)) ### [,1] [,2] [,3] [,4]
## [1,] 0.75 1.00 1.25 1.5
## [2,] 1.00 1.00 1.25 1.5
## [3,] 1.25 1.25 1.25 1.5
## [4,] 1.50 1.50 1.50 1.5We build a symmetrical matrix and replace the diagonal with 1. A.sym looks like a correlation matrix. Here all we were doing is playing with shaping data.
(A.sym <- A.max - A.min - 0.5)## [,1] [,2] [,3] [,4]
## [1,] -0.50 -0.25 0.00 0.25
## [2,] -0.25 -0.50 -0.25 0.00
## [3,] 0.00 -0.25 -0.50 -0.25
## [4,] 0.25 0.00 -0.25 -0.50diag(A.sym) <- 1
A.sym## [,1] [,2] [,3] [,4]
## [1,] 1.00 -0.25 0.00 0.25
## [2,] -0.25 1.00 -0.25 0.00
## [3,] 0.00 -0.25 1.00 -0.25
## [4,] 0.25 0.00 -0.25 1.002.4.1 Try this exercise
The inner product %*% cross-multiplies successive elements of a row with the successive elements of a column. If there are two rows with 5 columns, there must be a matrix at least with 1 column that has 5 rows in it.
Let’s run these statements.
n.sim <- 100
x.1 <- rgamma(n.sim, 0.5, 0.2)
x.2 <- rlnorm(n.sim, 0.15, 0.25)
hist(x.1)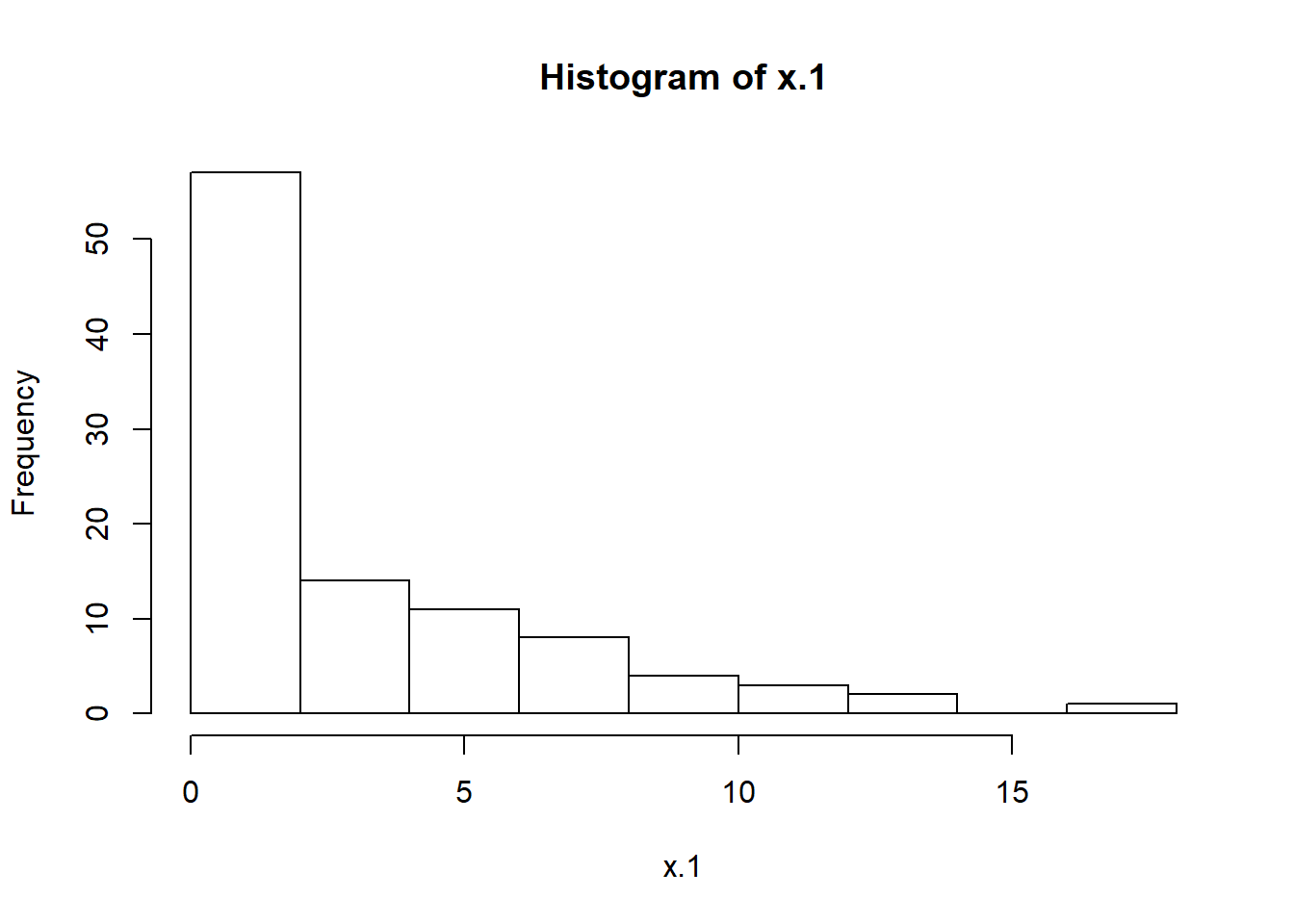
hist(x.2)
X <- cbind(x.1, x.2)rgamma allows us to generate n.sim versions of the gamma distribution with scale parameter 0.5 and shape parameter 0.2. rlnorm is a popular financial return distribution with mean 0.15 and standard deviation 0.25. We can call up ??distributions to get detailed information. Let’s plot the histograms of each simulated random variate using hist().
The cbind function binds into matrix columns the row arrays x.1 and x.2. These might be simulations of operational and financial losses. The X matrix could look like the “design” matrix for a regression.
Let’s simulate a response vector, say equity, and call it y and look at its histogram.
y <- 1.5 * x.1 + 0.8 * x.2 + rnorm(n.sim,
4.2, 5.03)Now we have a model for \(y\):
\[ y = X \beta + \varepsilon \]
where \(y\) is a 100 \(\times\) 1 (rows \(\times\) columns) vector, \(X\) is a 100 \(\times\) 2 matrix, \(\beta\) is a 2 \(\times\) 1 vector, and \(\epsilon\) is a 100 \(\times\) 1 vector of disturbances (a.k.a., “errors”).
Multiplying out the matrix term \(X \beta\) we have
\[ y = \beta_1 x_1 + \beta_2 x_2 + \varepsilon \]
where \(y\), \(x_1\), \(x_2\), and \(\varepsilon\) are all vectors with 100 rows for simulated observations.
If we look for \(\beta\) to minimize the sum of squared \(\varepsilon\) we would find that the solution is
\[ \hat{\beta} = (X^T X)^{-1} X^{T} y. \]
Where \(\hat{\beta}\) is read as “beta hat”.
The result \(y\) with its hist() is
hist(y)
The rubber meets the road here as we compute \(\hat{\beta}\).
X <- cbind(x.1, x.2)
XTX.inverse <- solve(t(X) %*% X)
(beta.hat <- XTX.inverse %*% t(X) %*%
y)## [,1]
## x.1 1.660246
## x.2 3.900737The beta.hat coefficients are much different than our model for y. Why? Because of the innovation, error, disturbance term rnorm(n.sim, 1, 2) we added to the 1.5*x.1 + 0.8 * x.2 terms.
Now for the estimated \(\varepsilon\) where we use the matrix inner product %*%. We need to be sure to pre-multiply beta.hat with X!
e <- y - X %*% beta.hathist(e)
We see that the “residuals” are almost centered at 0.
2.4.2 More about residuals
For no charge at all let’s calculate the sum of squared errors in matrix talk, along with the number of obervations n and degrees of freedom n - k, all to get the standard error of the regression e.se. Mathematically we are computing
\[ \sigma_{\varepsilon} = \sqrt{\sum_{i=1}^N \frac{\varepsilon_i^2}{n-k}} \]
(e.sse <- t(e) %*% e)## [,1]
## [1,] 3003.548(n <- dim(X)[1])## [1] 100(k <- nrow(beta.hat))## [1] 2(e.se <- (e.sse/(n - k))^0.5)## [,1]
## [1,] 5.536104The statement dim(X)[1] returns the first of two dimensions of the matrix X.
Finally, again for no charge at all, lets load library psych (use install.packages("psych") as needed). We will use pairs.panels() for a pretty picture of our work in this try out. First column bind cbind() the y, X, and e arrays to create a data frame for pairs.panel().
library(psych)
all <- cbind(y, X, e)We then invoke the pairs.panels() function using the all array we just created. The result is a scatterplot matrix with histograms of each variate down the diagonal. The lower triangle of the matrix is populated with scatterplots. The upper triangle of the matrix has correlations depicted with increasing font sizes for higher correlations.
pairs.panels(all)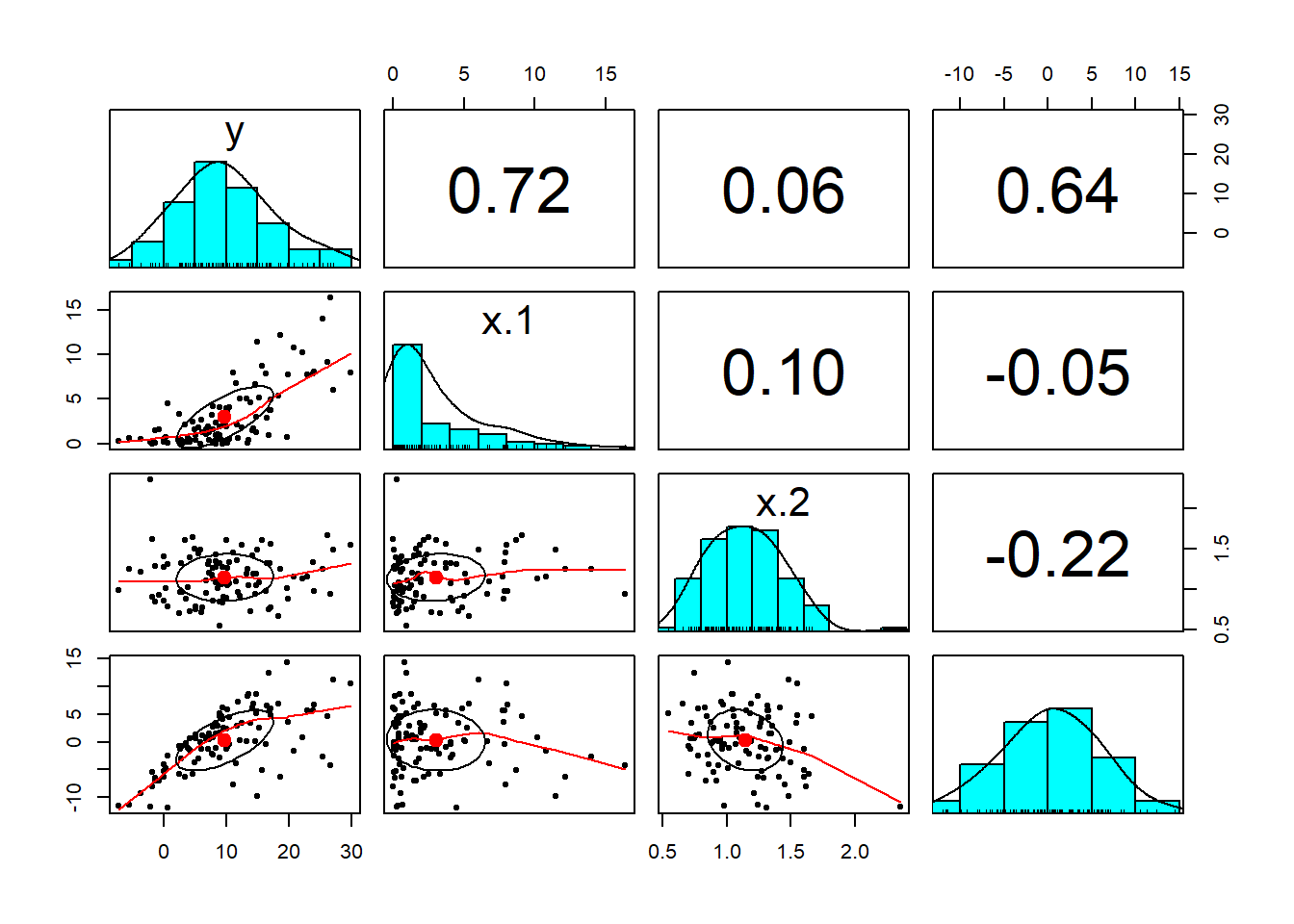 We will use this tool again and again to explore the multivariate relationships among our data.
We will use this tool again and again to explore the multivariate relationships among our data.
2.5 More Array Work
We show off some more array operations in the following statements.
nrow(A.min)## [1] 4ncol(A.min)## [1] 4dim(A.min)## [1] 4 4We calculate the number of rows and columns first. We then see that these exactly correspond to the two element vector produced by dim. Next we enter these statements into the console.
rowSums(A.min)## [1] 3.00 3.75 4.25 4.50colSums(A.min)## [1] 3.00 3.75 4.25 4.50apply(A.min, 1, sum)## [1] 3.00 3.75 4.25 4.50apply(A.min, 2, sum)## [1] 3.00 3.75 4.25 4.50We also calculate the sums of each row and each column. Alternatively we can use the apply function on the first dimension (rows) and then on the second dimension (columns) of the matrix. Some matrix multiplications follow below.
(A.inner <- A.sym %*% t(A.min[, 1:dim(A.min)[2]]))## [,1] [,2] [,3] [,4]
## [1,] 0.750 0.7500 0.8125 0.875
## [2,] 0.375 0.5625 0.5000 0.500
## [3,] 0.375 0.5000 0.6875 0.625
## [4,] 0.750 0.9375 1.1250 1.375Starting from the inner circle of embedded parentheses we pull every row (the [,col] piece) for columns from the first to the second dimension of the dim() of A.min. We then transpose (row for column) the elements of A.min and cross left multiply in an inner product this transposed matrix with A.sym.
We have already deployed very useful matrix operation, the inverse. The R function solve() provides the answer to the question: what two matrices, when multiplied by one another, produces the identity matrix? The identity matrix is a matrix of all ones down the diagonal and zeros elsewhere.
(A.inner.invert <- solve(A.inner))## [,1] [,2] [,3] [,4]
## [1,] 4.952381e+00 -3.047619 -1.142857 -1.523810
## [2,] -2.285714e+00 6.857143 -2.285714 0.000000
## [3,] 1.268826e-16 -2.285714 6.857143 -2.285714
## [4,] -1.142857e+00 -1.142857 -3.428571 3.428571Now we use our inverse with the original matrix we inverted.
(A.result <- A.inner %*% A.inner.invert)## [,1] [,2] [,3] [,4]
## [1,] 1.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
## [2,] 2.220446e-16 1.000000e+00 0.000000e+00 0.000000e+00
## [3,] 1.110223e-16 1.110223e-16 1.000000e+00 4.440892e-16
## [4,] 2.220446e-16 -4.440892e-16 -8.881784e-16 1.000000e+00When we cross multiply A.inner with its inverse, we should, and do, get the identity matrix that is a matrix of ones in the diagonal and zeros in the off-diagonal elements.
2.6 Summary
We covered very general data manipulation in R including arithmetical operations, vectors and matrices, their formation and operations, and data frames. We used data frames as inputs to plotting functions. We also built a matrix-based linear regression model and a present value calculator.
2.7 Further Reading
This introductory chapter covers material from Teetor, chapters 1, 2, 5, 6. Present value, salvage, and other valuation topics can be found in Brealey et al. under present value in the index of any of several editions.
2.8 Practice Set
2.8.1 Purpose, Process, Product
These practice sets will repeat various R features in this chapter. Specifically we will practice defining vectors, matrices (arrays), and data frames and their use in present value, growth, future value calculations, We will build on this basic practice with the computation of ordinary lease squares coefficients and plots using ggplot2. We will summarize our findings in debrief documented with an R markdown file and output.
2.8.2 R Markdown set up
Open a new
R Markdownpdf document file and save it with file nameMYName-FIN654-PS01to your working directory. TheRmdfile extension will automatically be appended to the file name. Create a new folder calleddatain this working directory and deposit the.csvfile for practice set #2 to this directory.Modify the
YAMLheader in theRmdfile to reflect the name of this practice set, your name, and date.Replace the
R Markdownexample in the new file with the following script.
## Practice set 1: present value
(INSERT results here)
## Practice set 2: regression
(Insert results here)- Click
knitin theRstudiocommand bar to produce thepdfdocument.
2.8.3 Set A
2.8.3.1 Problem
We work for a mutual fund that is legally required to fair value the stock of unlisted companies it owns. Your fund is about to purchase shares of InUrCorner, a U.S. based company, that provides internet-of-things legal services.
We sampled several companies with business plans similar to InUrCorner and find that the average weighted average cost of capital is 18%.
InUrCorner sales is $80 million and projected to growth at 50% per year for the next 3 years and 15% per year thereafter.
Cost of services provided as a percent of sales is currently 75% and projected to be flat for the foreseeable future.
Depreciation is also constant at 5% of net fixed assets (gross fixed asset minus accumulated depreciation), as are taxes (all-in) at 35% of taxable profits.
Discussions with InUrCorner management indicate that the company will need an increase in working capital at the rate of 15% each year and an increase in fixed assets at the rate of 10% of sales each year. Currently working capital is $10, net fixed assets is $90, and accumulated depreciation is $15.
2.8.3.2 Questions
- Let’s project
sales,cost, increments to net fixed assetsNFA, increments to working capitalWC,depreciation,tax, and free cash flowFCFfor the next 4 years. We will use a table to report the projection.
Let’s use this code to build and display a table.
# Form table of results
table.names <- c("Sales", "Cost", "Working Capital (incr.)",
"Net Fixed Assets (incr.)", "Free Cash Flow")
# Assign projection labels
table.year <- year # Assign projection years
table.data <- rbind(sales, cost, WC.incr,
NFA.incr, FCF) # Layer projections
rownames(table.data) <- table.names # Replace rows with projection labels
colnames(table.data) <- table.year # Replace columns with projection years
knitr::kable(table.data) # Display a readable table- Modify the assumptions by +/- 10% and report the results.
2.8.4 Set B
2.8.4.1 Problem
We work for a healthcare insurer and our management is interested in understanding the relationship between input admission and outpatient rates as drivers of expenses, payroll, and employment. We gathered a sample of 200 hospitals in a test market in this data set.
x.data <- read.csv("data/hospitals.csv")2.8.4.2 Questions
Build a table that explores this data set variable by variable and relationships among variables.
Investigate the influence of admission and outpatient rates on expenses and payroll. First, form these arrays.
Next, compute the regression coefficients.
Finally, compute the regression statistics.
- Use this code to investigate further the relationship among predicted expenses and the drivers, admissions and outpatients.
require(reshape2)
require(ggplot2)
actual <- y
predicted <- X %*% beta.hat
residual <- actual - predicted
results <- data.frame(actual = actual,
predicted = predicted, residual = residual)
# Insert comment here
min_xy <- min(min(results$actual), min(results$predicted))
max_xy <- max(max(results$actual), max(results$predicted))
# Insert comment here
plot.melt <- melt(results, id.vars = "predicted")
# Insert comment here
plot.data <- rbind(plot.melt, data.frame(predicted = c(min_xy,
max_xy), variable = c("actual", "actual"),
value = c(max_xy, min_xy)))
# Insert comment here
p <- ggplot(plot, aes(x = predicted,
y = value)) + geom_point(size = 2.5) +
theme_bw()
p <- p + facet_wrap(~variable, scales = "free")
p2.8.5 Practice Set Debrief
List the R skills needed to complete these practice labs.
What are the packages used to compute and graph results. Explain each of them.
How well did the results begin to answer the business questions posed at the beginning of each practice lab?
2.9 Project
2.9.1 Purpose
This project will allow us to practice various R features using live data to support a decision regarding the provision of captive financing to customers at the beginning of this chapter. We will focus on translating regression statistics into R, plotting results, and interpreting ordinary least squares regression outcomes.
2.9.2 Problem
As we researched how to provide captive financing and insurance for our customers we found that we needed to understand the relationships among lending rates and various terms and conditions of typical equipment financing contracts.
We will focus on one question:
What is the influence of terms and conditions on the lending rate of fully committed commercial loans with maturities greater than one year?
2.9.3 Data
The data set commloan.csv contains data from the St. Louis Federal Reserve Bank’s FRED website we will use to get some high level insights. The quarterly data extends from the first quarter of 2003 to the second quarter of 2016 and aggregates a survey administered by the St. Louis Fed. There are several time series included. Each is by the time that pricing terms Were set and by commitment, with maturities more than 365 Days from a survey of all commercial banks. Here are the definitions.
2.9.4 Work Flow
- Prepare the data.
- Visit the FRED website. Include any information on the site to enhance the interpretation of results.
- Use
read.csvto read the data intoR. Be sure to set the project’s working directory where the data directory resides. Usena.omit()to clean the data.
# setwd('C:/Users/Bill
# Foote/bookdown/bookdown-demo-master')
# the project directory
x.data <- read.csv("data/commloans.csv")
x.data <- na.omit(x.data)Assign the data to a variable called
x.data. Examine the first and last 5 entries. Run asummaryof the data set.What anomalies appear based on these procedures?
- Explore the data.
- Let’s plot the time series data using this code:
require(ggplot2)
require(reshape2)
# Use melt() from reshape2 to build
# data frame with data as id and
# values of variables
x.melted <- melt(x.data[, c(1:4)], id = "date")
ggplot(data = x.melted, aes(x = date,
y = value)) + geom_point() + facet_wrap(~variable,
scales = "free_x")Describe the data frame that
melt()produces.Let’s load the
psychlibrary and produce a scatterplot matrix. Interpret this exploration.
- Analyze the data.
- Let’s regress
rateon the rest of the variables inx.data. To do this we form a matrix of independent variables (predictor or explanatory variables) in the matrixXand a separate vectoryfor the dependent (response) variablerate. We recall that the1vector will produce a constant intercept in the regression model.
y <- as.vector(x.data[, "rate"])
X <- as.matrix(cbind(1, x.data[, c("prepaypenalty",
"maturity", "size", "volume")]))
head(y)
head(X)Explain the code used to form
yandX.Calculate the \(\hat{\beta}\) coefficients and interpret their meaning.
Calculate actual and predicted
ratesand plot using this code.
# Insert comment here
require(reshape2)
require(ggplot2)
actual <- y
predicted <- X %*% beta.hat
residual <- actual - predicted
results <- data.frame(actual = actual,
predicted = predicted, residual = residual)
# Insert comment here
min_xy <- min(min(results$actual), min(results$predicted))
max_xy <- max(max(results$actual), max(results$predicted))
# Insert comment here
plot.melt <- melt(results, id.vars = "predicted")
# Insert comment here
plot.data <- rbind(plot.melt, data.frame(predicted = c(min_xy,
max_xy), variable = c("actual", "actual"),
value = c(max_xy, min_xy)))
# Insert comment here
p <- ggplot(plot, aes(x = predicted,
y = value)) + geom_point(size = 2.5) +
theme_bw()
p <- p + facet_wrap(~variable, scales = "free")
pInsert explanatory comments into the code chunk to document the work flow for this plot.
Interpret the graphs of actual and residual versus predicted values of
rate.Calculate the standard error of the residuals, Interpret its meaning.
- Interpret and present results.
We will produce an
R Markdowndocument with code chunks to document and interpret our results.The format will introduce the problem to be analyzed, with sections that discuss the data to be used, and which follow the work flow we have defined.
2.9.5 Assessment
We will use the following rubric to assess our performance in producing analytic work product for the decision maker.
The text is laid out cleanly, with clear divisions and transitions between sections and sub-sections. The writing itself is well-organized, free of grammatical and other mechanical errors, divided into complete sentences, logically grouped into paragraphs and sections, and easy to follow from the presumed level of knowledge.
All numerical results or summaries are reported to suitable precision, and with appropriate measures of uncertainty attached when applicable.
All figures and tables shown are relevant to the argument for ultimate conclusions. Figures and tables are easy to read, with informative captions, titles, axis labels and legends, and are placed near the relevant pieces of text.
The code is formatted and organized so that it is easy for others to read and understand. It is indented, commented, and uses meaningful names. It only includes computations which are actually needed to answer the analytical questions, and avoids redundancy. Code borrowed from the notes, from books, or from resources found online is explicitly acknowledged and sourced in the comments. Functions or procedures not directly taken from the notes have accompanying tests which check whether the code does what it is supposed to. All code runs, and the
R Markdownfileknitstopdf_documentoutput, or other output agreed with the instructor.Model specifications are described clearly and in appropriate detail. There are clear explanations of how estimating the model helps to answer the analytical questions, and rationales for all modeling choices. If multiple models are compared, they are all clearly described, along with the rationale for considering multiple models, and the reasons for selecting one model over another, or for using multiple models simultaneously.
The actual estimation and simulation of model parameters or estimated functions is technically correct. All calculations based on estimates are clearly explained, and also technically correct. All estimates or derived quantities are accompanied with appropriate measures of uncertainty.
The substantive, analytical questions are all answered as precisely as the data and the model allow. The chain of reasoning from estimation results about the model, or derived quantities, to substantive conclusions is both clear and convincing. Contingent answers (for example, “if X, then Y , but if A, then B, else C”) are likewise described as warranted by the model and data. If uncertainties in the data and model mean the answers to some questions must be imprecise, this too is reflected in the conclusions.
All sources used, whether in conversation, print, online, or otherwise are listed and acknowledged where they used in code, words, pictures, and any other components of the analysis.
2.10 References
Brealey, Richard, stewart Myers, and Franklyn Allen. 2016. Principles of Corporate Finance, revised edition. New York: McGraw-Hill.
Teetor, Paul. 2011. R Cookbook. Sebastopol, CA: O’Reilly.