Chapter 2 Rの基本操作
「R」はプログラミングの一種であり、コンピュータが理解できる言語を用いてコンピュータに指示を出して、必要なタスクを実行させることになる。ここでは、データ分析を目的としているので、コンピュータが理解できる言語を入力して、データの収集、加工、分析を指示・実行することになる。
2.1 Rのパッケージ
Rには、
- 三角関数(
sin、cos) - 平均値や分散を求める関数(
mean、var)
などの基本的な計算式は標準搭載されているが、より高度な機能をもった関数や統計手法などの場合はRに標準搭載されていない場合がある。したがって、これらの手法を利用する場合は、あらかじめRに追加しておく必要がある。 これらの手法は「パッケージ」としてまとめられ「CRAN(シーラン:Comprehensive R Archive Network)」と呼ばれるところに公開されている。この「パッケージ」をRにインストールして必要な作業を実行していくのである。
2.1.1 Rパッケージ「tidyverse」
Rの中で一番有名なパッケージが「tidyverse」

tidyverseは、単なるパッケージの寄せ集めではなく、さまざまな操作を統一的なインタフェースで直感的に行える「tidyなツール群」を指す。データの収集、加工、可視化などに便利なツールがまとめられており、R界隈では最も多く使用されているパッケージ。
tidyverseに含まれる以下のパッケージは、tidyverseという名前のパッケージをインストールすることでまとめてインストールすることができる。
- ggplot2: データを可視化するためのパッケージ
- dplyr: データにさまざまな操作を加えるためのパッケージ
- tidyr: データをtidy data(整理されたデータ)形式に変形するためのパッケージ
- readr: さまざまなフォーマットのデータを読み書きするためのパッケージ
- purrr: 関数型プログラミングのためのパッケージ
- tibble: tibbleというモダンなデータフレームを提供するパッケージ
- stringr: 文字列を操作するためのパッケージ
- forcats: 因子型ベクトルを操作するためのパッケージ
これ以外にもさまざまなパッケージが含まれている。
- jsonlite:JSONデータを扱うためのパッケージ
- xml2:XMLデータを扱うためのパッケージ
- httr:WebAPIを使うためのパッケージ
- rvest:Webスクレイピングのためのパッケージ
- lubridate:日付型/時間型のデータを操作するためのパッケージ
- hms:時刻を表すデータ型を提供するパッケージ
- blob:バイト列を表すデータ型を提供するパッケージ
Colabにはいくつかのパッケージがあらかじめ用意されているので、tidyverseもインストール無しで利用できる。そのため、tidyverseを利用する際は以下のコードを実行し、コンピュータに認識させておくだけで良い。
library(tidyverse)
ちなみにlibrary()でColabにインストール済のパッケージを確認できる。
library()2.2 Rに慣れる(宿題あり)
ここではRに慣れるために、基本的な操作を実行する。データマイニングや機械学習のいろいろな教科書に頻繁に登場するフィッシャーのiris(アヤメの花)のデータを使用する。

irisのデータセットは、イギリスの統計学者で生物学者のRonald Fisherが1936年に発表した論文The use of multiple measurements in taxonomic problemsの中で紹介したもので、機械学習レポジトリとして米国カリフォルニア大学アーバイン校におかれている世界的に有名なデータである。
3種の”iris”の各50個の花について、がくの長さと幅、花びらの長さと幅という変数の測定値を提供している。
具体的には、3種類のアヤメ(Versicolor, Virginica, Setosa)について、
がくの長さ(Sepal.length)
がくの幅(Sepal.Width)
花びらの長さ(Petal.Length)
花びらの幅(Petal.width)
をそれぞれ50個の標本を集め調べたデータになっている。これら4つの変数(特徴量)から3種類の”iris(アヤメ )“を分類しようというのが、このデータセットのねらいになっている。

2.2.1 データの特徴をつかむ
まずはこの”iris”のデータセットを読み込んで構造を確認する。
Rには100種類以上のデータセットが標準装備されており、その中に”iris”のデータセットも組み込まれている。(https://www.math.chuo-u.ac.jp/~sakaori/Rdata.html)
パッケージの読み込み
最初に、データを加工するのに必要なパッケージを読み込む(→tidyverse)。
library(tidyverse)データの確認
次にデータ(
iris)を確認する ⇒ View()View(iris)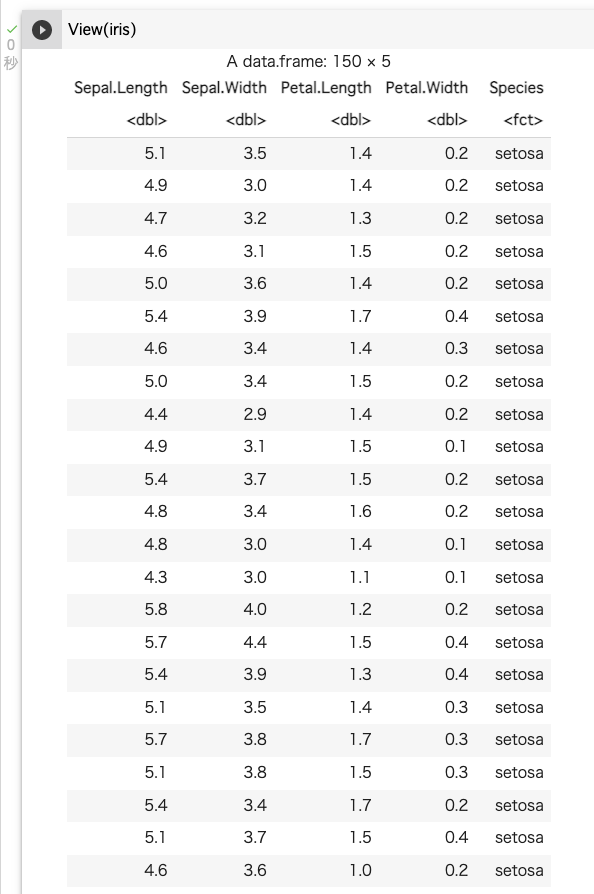
縦長のデータが出力される。1つの列が1つの変数、1つの行が1つの観測、1つのデーブルが1つのデータセットだけを表している。
irisデータの場合、列に5つの変数(がくの長さ、がくの幅、花びらの長さ、花びらの幅、種類)、行に150個の観測値(setosa:50個、versicolor:50個、virginica:50個)という構造になっている。この表の作りは人間にとって非常に見にくいデータ形式であるが、コンピュータにとっては処理しやすいデータ形式となっている。ベクトルの処理が得意なRで扱いやすいのはこの縦長なデータ形式に成形する必要がある。 このデータ形式をtidy dataと呼ぶ。 データ分析は、まずはこの形式にデータを成形することから始まる。tidyverseのパッケージの中にも、データをtidy dataの形式に変形するパッケージ(tidyrパッケージ、dplyrパッケージ)が用意されており、様々な関数を提供している。
また
head()を使えば、データの最初の数行だけを確認することができる。head(iris)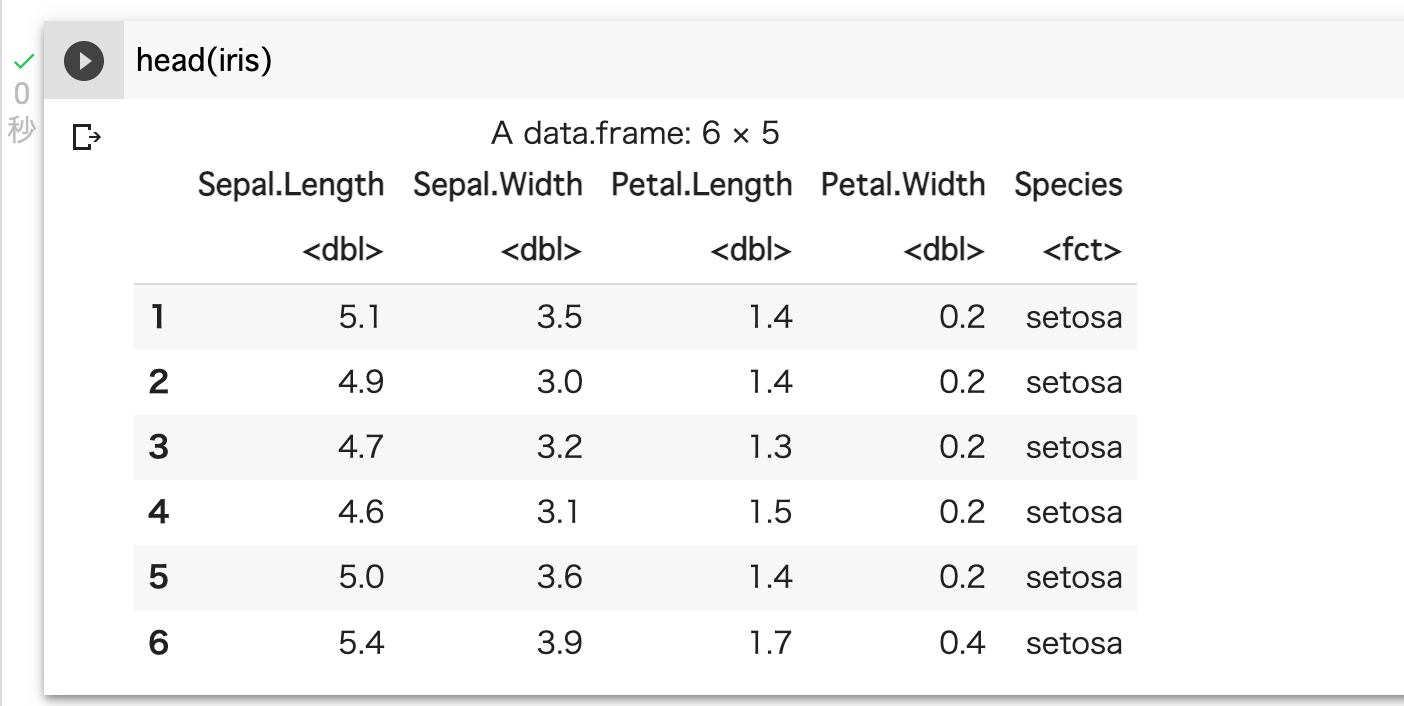
デフォルトでは6行を表示するようになっているが、
head()関数の中でn=**を指定することで、表示する行数を選択することができる。同様の
tail()関数を使用して、データセットの最後の数行を呼び出すことも可能。tail(iris, n = 3)基本統計量の確認(平均値、中央値、最大値、最小値)
データの特徴(最大値、最小値、平均値など)を数字で確認する。
summary()を使用する。summary(iris)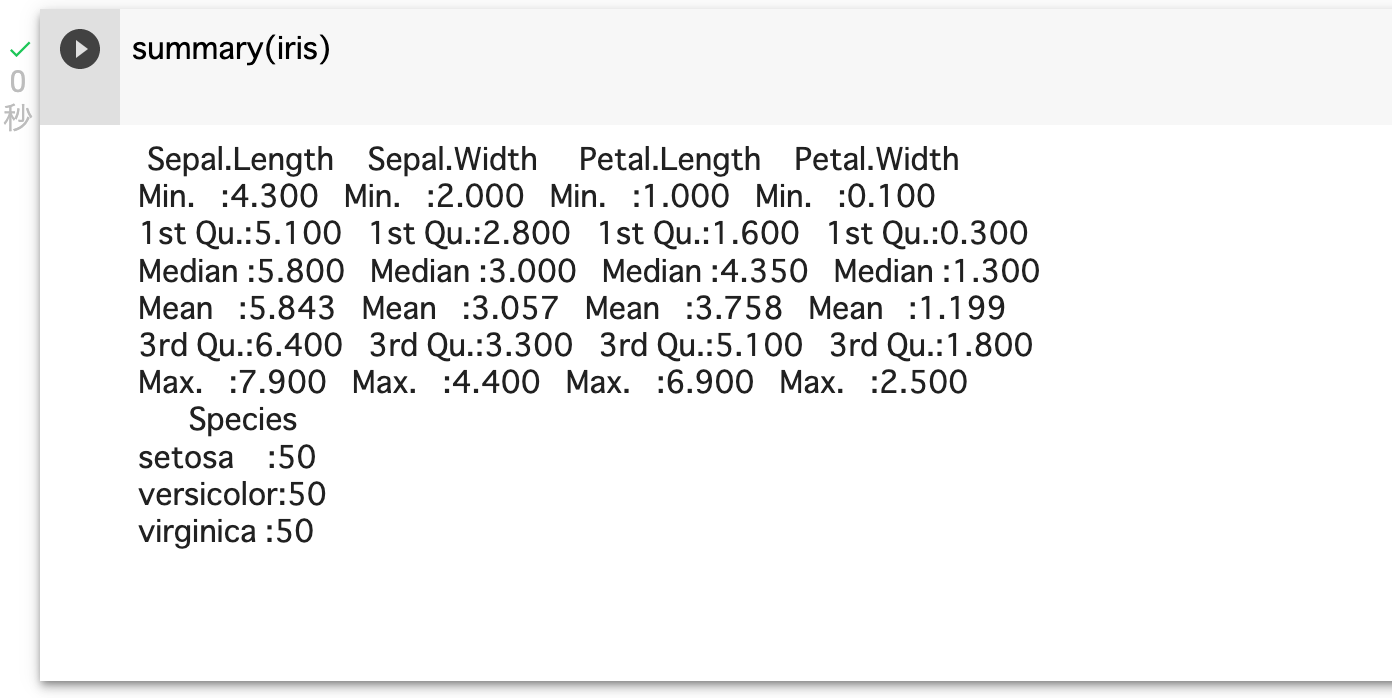
がくの長さ(Sepal.length)
がくの幅(Sepal.Width)
花びらの長さ(Petal.Length)
花びらの幅(Petal.width)
について、それぞれ以下の基本統計量が出力される。
Min.:最小値
1st. Qu.:第一四分位
Median:中央値
Mean:平均値
3rd Qu.:第三四分位
Max.:最大値
データにおける特定の変数をピックアップして、基本統計量の数値を確認 ⇒
summary(data\$変数名)]summary(iris$Sepal.Length)
がくの長さ(Sepal.length)の記述統計量(最大値、最小値、平均値など)は以下のようになる。
最小値:4.300
第一四分位:5.100
中央値:5.800
平均値:5.843
第三四分位:6.400
最大値:7.900
データの可視化
plot()関数でデータの散布図を描くことができる。plot(iris)
ただ、これでは関心のある関係についての詳細が確認できない。
$演算子を使いデータから関心のある変数をピックアップし散布図を描いて、plot(X軸, Y軸)で出力する。ここではアヤメのがくの長さと幅の関係について図を描いてみる。plot(iris$Sepal.Length, iris$Sepal.Width)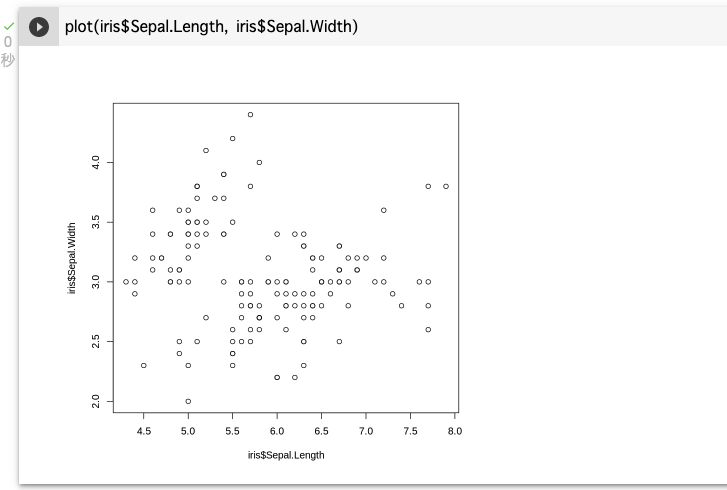
このplot関数は、Rにもともと組み込まれている基本的なプロット機能だが、このプロットからはその関係性をいまいち理解することはできない。
そこで登場するのが、tidyverseに組み込まれているggplot2というパッケージになる。
ggplot2は、Rの基本的なグラフィックス機能を拡張して、これまで以上に速く、簡単に出版品質のグラフィックスを作成できる。
審美的にデータを可視化する(
ggplotの利用)まずは以下のコードをコンソールに入力し実行する。
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width)) + geom_point()※Rは大文字と小文字が区別されることので注意。
※このとき
could not find function "ggplot"と表示される場合は、tidyverseがRに読み込めていない可能性があるので、library(tidyvese)を再度実行する。上記コードは、以下のステップで構成されている。
ggplot()で、ggplotオブジェクトを作成することをRに指示。data = irisで、すべての操作はirisデータセットを使用することをggplot()に指示aes()は、審美的属性のことで、グラフをプロットする際のx軸やy軸を決めたり、因子型のデータにおいてプロット時の色や形を指定できる「
+」はグラフに要素を追加する際に使用する。このとき「+」は、常に行末に置く。行頭に置くとセッションが機能しないことがあるので注意。何かをプロットしようする際、コンソールに 「>」 の代わりに「+」 が表示された場合、それが原因である可能性が高い。この時はエスケープキーを押してコマンドを終了するとよい。geomで、どのようなグラフにしたいかをggplotに伝える。geomでは、プロットの種類を以下のように指定することができるgeom_bar() 棒グラフ geom_line() 折れ線グラフ geom_point() 散布図 geom_boxplot() 箱ひげ図 geom_errorbar() 誤差棒
折れ線グラフ「
geom_line」を追加してみる。ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width)) + geom_point() + geom_line()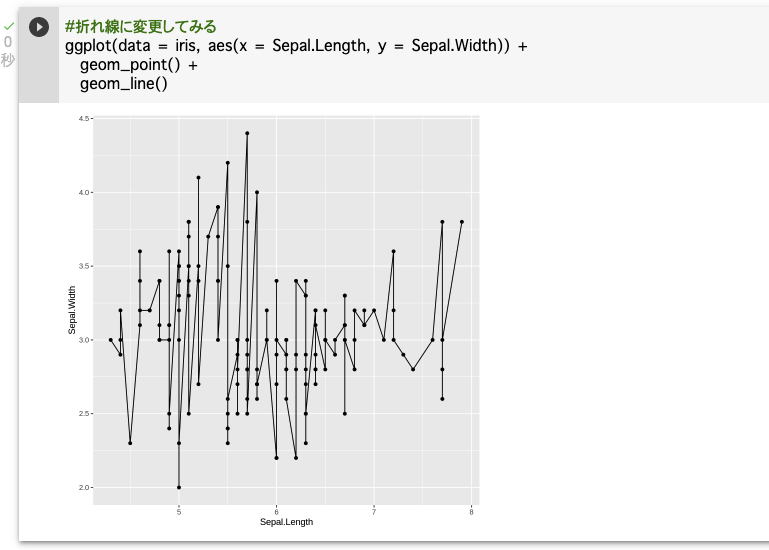
もっと分かりやすくグラフを変更したい場合、例えばアヤメの種類(Species)ごとに色をつけたり、トレンドラインを追加する場合は以下のコマンドのように入力する。
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point() + geom_line()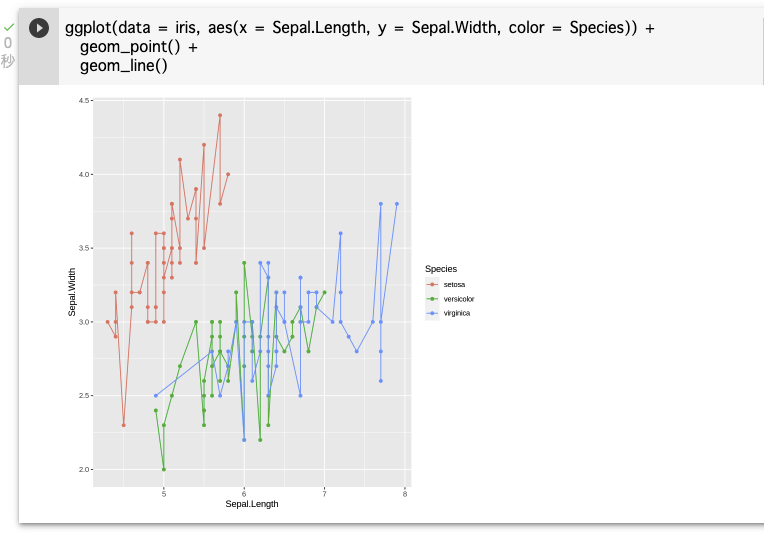
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point() + geom_smooth()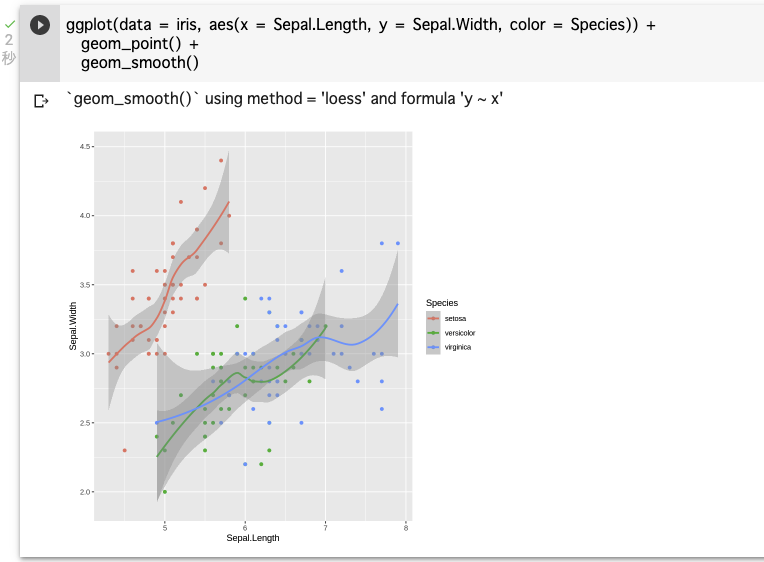
geom_smooth() は、グラフにトレンドラインを追加し、その周りに95%信頼区間を表す影をつけることができる。95%信頼区間とは、ものすごく簡単にいうと「対象の集団の平均値は大体これぐらいの間にあるはずだ」ということを区間で示したもの。折れ線グラフとは全く別物なので注意!
これらグラフからがくの長さ(Sepal.length)とがくの幅(Sepal.Width)には相関があるように見える
さらに種類(Species)ごとにもっと違いの差をつけて区別する。
⇒
aes()(審美的属性)の中で、Speciesごとに差をつける。ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(size = Species, shape = Species)) + geom_smooth(aes(linetype = Species))
ただここまでやりすぎると、反対に見にくい(醜い)グラフになってしまう。一般的には、グラフには、自身の主張を伝えるのに必要な情報量だけで十分で、それ以上の情報は含まれていない方が良い。グラフィックを読み手に分かりやすくすることを心がけ作成することが望ましい。ポイントの形を変更するのも工夫の一つ。
ggplotで使用できるshapeは25種類あり、それぞれのshapeには数字、つまり下の図のshapeの左にある数字で指定することができる。
また、R にはたくさんの色が用意されているので、グラフに最適な色を選ぶこともできる。
“red” のようなカラーが数百色あり,Rのコンソールに
colors()と打ち込めば列挙される。以下では、これらを盛り込んだグラフを描画する。
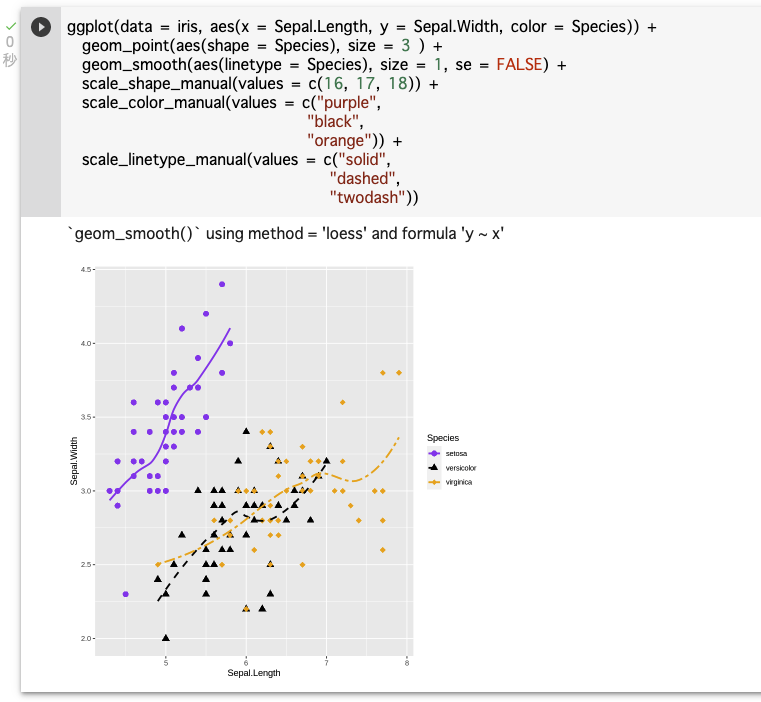
scale_shape関数を使って図形の形を指定することができる(形→scale_shape_manual()、色→scale_color_manual())。※size = 3 を指定して点(プロット)を少し大きくしている
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange"))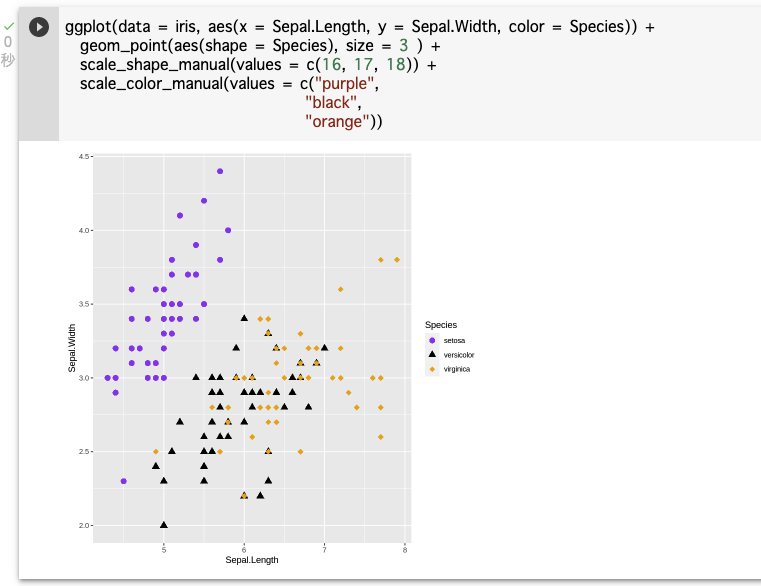
さらに描画される線の種類を変えることも可能。これには6つのオプションがあり、それぞれに番号と名前がついている。

線の種類は、
scale_linetype関数を使って線種を指定することができる。名前、数字どちらでも指定可能。名前で指定する場合は引用符で囲み、数字で指定する場合は囲わないようにする。
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(size = Species, shape = Species)) + geom_smooth(aes(linetype = Species))上記のグラフを元に、線の種類を変えてみる。
※95%信頼区間の影は、
geom_smooth()関数の呼び出しの中で、se = FALSEと入力することで消すことができる。ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash"))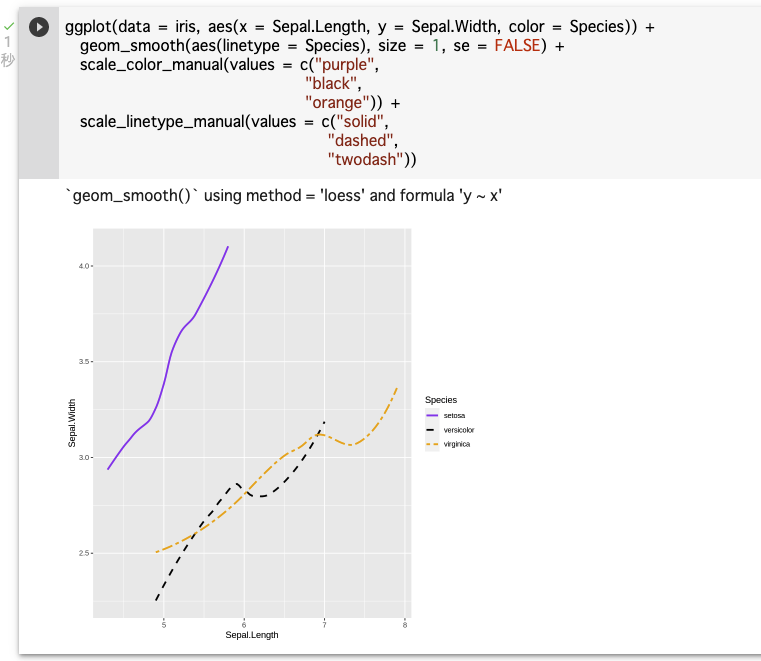
ここまでの内容を1つにまとめて、より直感的に理解しやすいグラフィックにすることができる。
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash"))
参考
ggplotはfacetとという関数も使用できる。
facet_wrap()をプロットに追加することで、軸を標準化しながら、3種類(Species)をそれぞれのグラフに分割することができる。
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(size = 3) +
geom_smooth(size = 1, se = FALSE) +
facet_wrap(~ Species)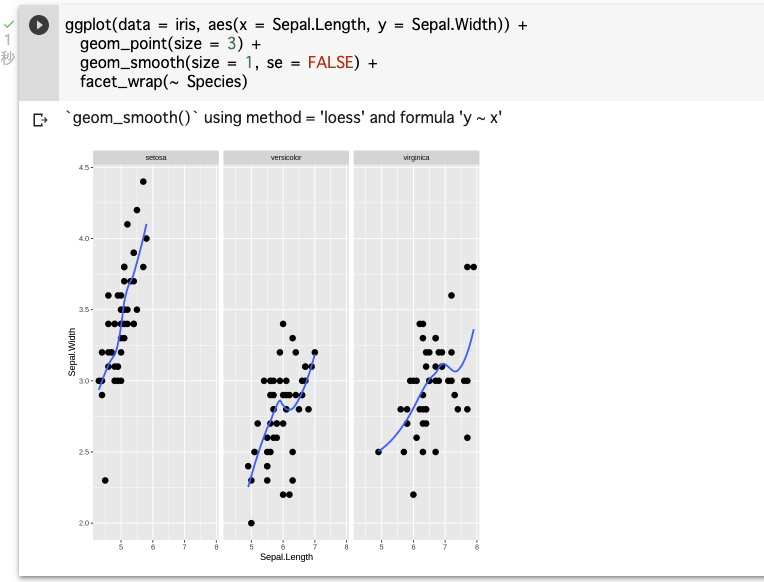
より洗練されたデザインに
これらのグラフを、プレゼンや論文で使用するためには、より洗練されたデザインで作成する必要がある。人に伝えるためのグラフィックは、視覚的にきれいでわかりやすく、かつ、ポイントを伝えるのに十分な情報が含まれていなければならない。
自身がどれだけ完璧な分析ができたとしても、それを誰にも伝えることができなければ意味がない。
ggplotには、このグラフィックのデザインに役立ついくつかのテーマがプリインストールされていて、それらを任意のプロットに追加することができる。


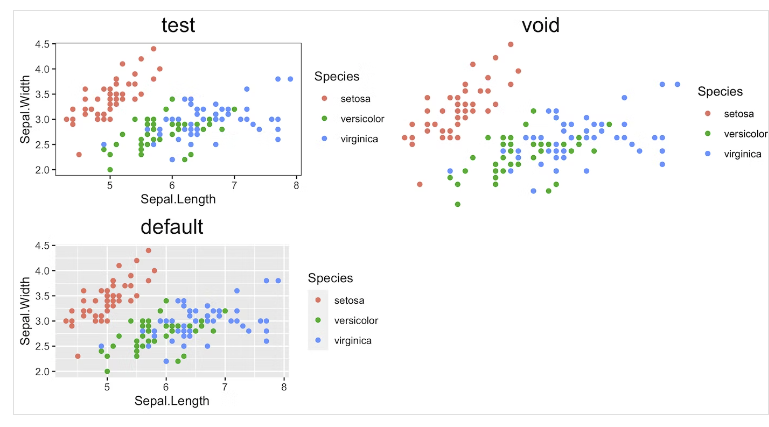
その代表的なものを次のグラフに適用してみる。
①
theme_bw()ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash")) + theme_bw()②
theme_minimal()ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash")) + theme_minimal()③
theme_classic()ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash")) + theme_classic()グラフタイトルと軸ラベルの設定
labsでは、グラフの軸ラベル・タイトル・キャプションを付けることもできる。ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash")) + theme_classic() + labs(x = "Sepal Length", y = "Sepal Width", title = "Sepal Width as a Function of Sepal Length", subtitle = "Data from R. A. Fischer's iris dataset, 1936", caption = "Made in R with ggplot2")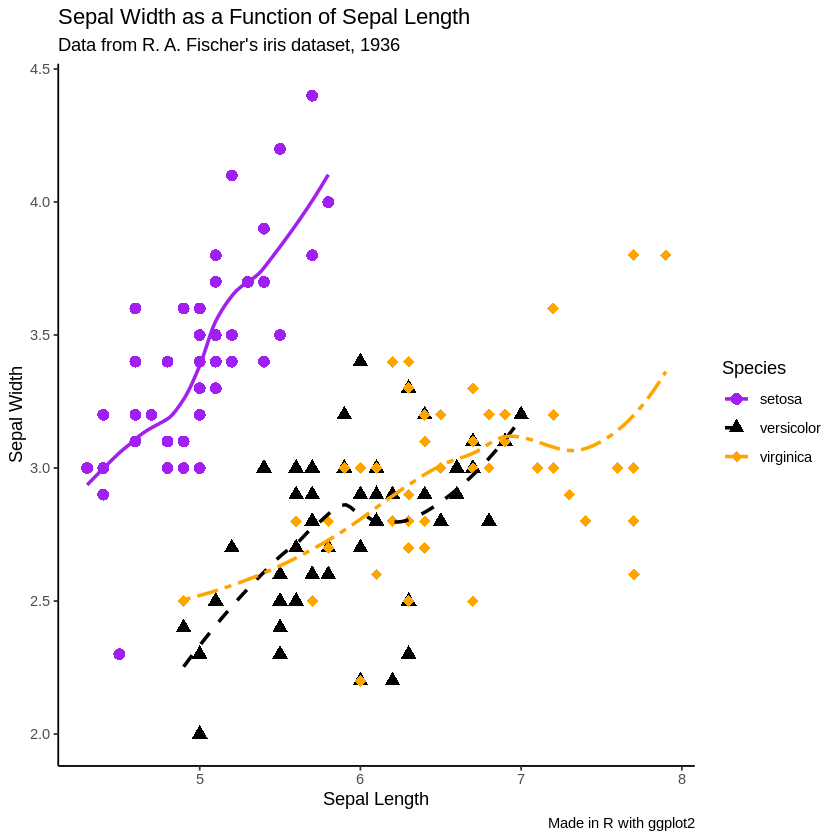
ただし、Colabにおいてグラフタイトルや軸ラベルを日本語入力する場合、文字化けが発生してしまう。
ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash")) + theme_classic() + labs(x = "がくの長さ", y = "がくの幅", title = "がくの長さと幅の相関関係(アヤメ)", subtitle = "Data from R. A. Fischer's iris dataset, 1936", caption = "Made in R with ggplot2").png)
これはColabに日本語フォントがインストールされていないために起こる。そのため日本語でグラフを出力する際は、以下の
apt-getコマンドを使ってフォントを追加する必要がある。system("apt-get install -y fonts-noto-cjk")
インストールしたフォント一覧を表示する(インストールには30秒ほどかかります)。
systemfonts::system_fonts()
表示されたフォント一覧からfamilyに “CJK” が付いているフォントを指定することになる。 “CJK”は、Chinese Japanese Korean の略で、日本語対応しているフォントになる。
ここでは、“Noto Sans CJK JP” をフォントに指定する。グラフの包括的なデザインを決める
theme関数の中でbase_family = "Noto Sans CJK JP"と指定すれば日本語表示に対応する。ggplot(data = iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point(aes(shape = Species), size = 3 ) + geom_smooth(aes(linetype = Species), size = 1, se = FALSE) + scale_shape_manual(values = c(16, 17, 18)) + scale_color_manual(values = c("purple", "black", "orange")) + scale_linetype_manual(values = c("solid", "dashed", "twodash")) + theme_classic(base_family = "Noto Sans CJK JP") + labs(x = "がくの長さ", y = "がくの幅", title = "がくの長さと幅の相関関係(アヤメ)", subtitle = "Data from R. A. Fischer's iris dataset, 1936", caption = "Made in R with ggplot2").png)
2.2.2 Homework(宿題)①
内容
Rの使い方に慣れるために、“iris(アヤメ )”のデータセットを使った簡単な分析・グラフの作成を行う。
【問題1(配点:5点)】、【問題2(配点:5点)】、【問題3(配点:10点)】の3つの設問(計30点)について、出力結果をWord等に貼り付けCanvasから提出してください
提出期限:2022年9月16日(金)2359まで
提出方法:Canvasから提出
※100点満点で成績をつけるうちの20点になります。
| 問題1(配点:5点) |
|---|
残りの
についての記述統計量を求めよ。 |
| 問題2(配点:5点) |
|---|
として、
|
| 問題3(配点:10点) |
|---|
以下のグラフについて、
X軸 ⇒ 花びらの長さ(Petal.Length) Y軸 ⇒ 花びらの幅(Petal.width) としたグラフを描画せよ。 ※軸ラベルとタイトルもそれに合わせて変更してください。 ※図をExportしてWord等に貼り付けてください。 |