Chapter 9 Two Level Longitudinal Data
9.1 Learning objectives
After finishing this chapter, you should be able to:
- Recognize longitudinal data as a special case of multilevel data, with time at Level One.
- Consider patterns of missingness and implications of that missing data on multilevel analyses.
- Apply exploratory data analysis techniques specific to longitudinal data.
- Build and understand a taxonomy of models for longitudinal data.
- Interpret model parameters in multilevel models with time at Level One.
- Compare models, both nested and not, with appropriate statistical tests and summary statistics.
- Consider different ways of modeling the variance-covariance structure in longitudinal data.
9.2 Case study: Charter schools
Charter schools were first introduced in the state of Minnesota in 1991 (U.S. Department of Education 2018). Since then, charter schools have begun appearing all over the United States. While publicly funded, a unique feature of charter schools is their independence from many of the regulations that are present in the public school systems of their respective city or state. Thus, charters will often extend the school days or year and tend to offer non-traditional techniques and styles of instruction and learning.
One example of this unique schedule structure is the KIPP (Knowledge is Power Program) Stand Academy in Minneapolis, MN. KIPP stresses longer days and better partnerships with parents, and they claim that 80% of their students go to college from a population where 87% qualify for free and reduced lunch and 95% are African-American or Latino (KIPP 2017). However, the larger question is whether or not charter schools are out-performing non-charter public schools in general. Because of the relative youthfulness of charter schools, data has just begun to be collected to evaluate the performance of charter versus non-charter schools and some of the factors that influence a school’s performance. Along these lines, we will examine data collected by the Minnesota Department of Education for all Minnesota schools during the years 2008-2010.
Comparisons of student performance in charter schools versus public schools have produced conflicting results, potentially as a result of the strong differences in the structure and population of the student bodies that represent the two types of schools. A study by the Policy and Program Studies Service of five states found that charter schools are less likely to meet state performance standards than conventional public schools (Finnigan et al. 2004). However, Witte et al. (2007) performed a statistical analysis comparing Wisconsin charter and non-charter schools and found that average achievement test scores were significantly higher in charter schools compared to non-charter schools, after controlling for demographic variables such as the percentage of white students. In addition, a study of California students who took the Stanford 9 exam from 1998 through 2002 found that charter schools, on average, were performing at the same level as conventional public schools (Buddin and Zimmer 2005). Although school performance is difficult to quantify with a single measure, for illustration purposes in this chapter we will focus on that aspect of school performance measured by the math portion of the Minnesota Comprehensive Assessment (MCA-II) data for 6th grade students enrolled in 618 different Minnesota schools during the years 2008, 2009, and 2010 (Minnesota Department of Education 2018). Similar comparisons could obviously be conducted for other grade levels or modes of assessment.
As described in GreenIII, Baker, and Oluwole (2003), it is very challenging to compare charter and public non-charter schools, as charter schools are often designed to target or attract specific populations of students. Without accounting for differences in student populations, comparisons lose meaning. With the assistance of multiple school-specific predictors, we will attempt to model sixth grade math MCA-II scores of Minnesota schools, focusing on the differences between charter and public non-charter school performances. In the process, we hope to answer the following research questions:
- Which factors most influence a school’s performance in MCA testing?
- How do the average math MCA-II scores for 6th graders enrolled in charter schools differ from scores for students who attend non-charter public schools? Do these differences persist after accounting for differences in student populations?
- Are there differences in yearly improvement between charter and non-charter public schools?
9.3 Initial Exploratory Analyses
9.3.1 Data organization
Key variables in chart_wide_condense.csv which we will examine to address the research questions above are:
schoolid= includes district type, district number, and school numberschoolName= name of schoolurban= is the school in an urban (1) or rural (0) location?charter= is the school a charter school (1) or a non-charter public school (0)?schPctnonw= proportion of non-white students in a school (based on 2010 figures)schPctsped= proportion of special education students in a school (based on 2010 figures)schPctfree= proportion of students who receive free or reduced lunches in a school (based on 2010 figures). This serves as a measure of poverty among school families.MathAvgScore.0= average MCA-II math score for all sixth grade students in a school in 2008MathAvgScore.1= average MCA-II math score for all sixth grade students in a school in 2009MathAvgScore.2= average MCA-II math score for all sixth grade students in a school in 2010
This data is stored in WIDE format, with one row per school, as illustrated in Table 9.1.
Table 9.1: The first six observations in the wide data set for the Charter Schools case study.
| schoolid | schoolName | urban | charter | schPctnonw | schPctsped | schPctfree | MathAvgScore.0 | MathAvgScore.1 | MathAvgScore.2 |
|---|---|---|---|---|---|---|---|---|---|
| Dtype 1 Dnum 1 Snum 2 | RIPPLESIDE ELEMENTARY | 0 | 0 | 0.0000000 | 0.1176471 | 0.3627451 | 652.8 | 656.6 | 652.6 |
| Dtype 1 Dnum 100 Snum 1 | WRENSHALL ELEMENTARY | 0 | 0 | 0.0303030 | 0.1515152 | 0.4242424 | 646.9 | 645.3 | 651.9 |
| Dtype 1 Dnum 108 Snum 30 | CENTRAL MIDDLE | 0 | 0 | 0.0769231 | 0.1230769 | 0.2615385 | 654.7 | 658.5 | 659.7 |
| Dtype 1 Dnum 11 Snum 121 | SANDBURG MIDDLE | 1 | 0 | 0.0977444 | 0.0827068 | 0.2481203 | 656.4 | 656.8 | 659.9 |
| Dtype 1 Dnum 11 Snum 193 | OAK VIEW MIDDLE | 1 | 0 | 0.0537897 | 0.0953545 | 0.1418093 | 657.7 | 658.2 | 659.8 |
| Dtype 1 Dnum 11 Snum 195 | ROOSEVELT MIDDLE | 1 | 0 | 0.1234177 | 0.0886076 | 0.2405063 | 655.9 | 659.1 | 660.3 |
For most statistical analyses, it will be advantageous to convert WIDE format to LONG format, with one row per year per school. To make this conversion, we will have to create a time variable, which under the LONG format is very flexible—each school can have a different number of and differently-spaced time points, and they can even have predictors which vary over time. Details for making this conversion in R can be found in Section 9.8, and the form of the LONG data in this study is exhibited in the next section.
9.3.2 Missing data
In this case, before we convert our data to LONG form, we should first address problems with missing data. Missing data is a common phenomenon in longitudinal studies. For instance, it could arise if a new school was started during the observation period, a school was shut down during the observation period, or no results were reported in a given year. Dealing with missing data in a statistical analysis is not trivial, but fortunately many multilevel packages (including the lme4 package in R) are adept at handling missing data.
First, we must understand the extent and nature of missing data in our study. Table 9.2, where 1 indicates presence of a variable and 0 indicates a missing value for a particular variable, is a helpful starting point. Among our 618 schools, 540 had complete data (all covariates and math scores for all three years), 25 were missing a math score for 2008, 35 were missing math scores in both 2008 and 2009, etc.
Table 9.2: A frequency table of missing data patterns. The number of schools with a particular missing data pattern are listed in the left column; the remaining columns of 0’s and 1’s describe the missing data pattern, with 0 indicating a missing value. Some covariates that are present for every school are not listed. The bottom row gives the number of schools with missing values for specific variables; the last entry indicates that 121 total observations were missing.
## charter MathAvgScore.2 MathAvgScore.1 MathAvgScore.0
## 540 1 1 1 1 0
## 25 1 1 1 0 1
## 4 1 1 0 1 1
## 35 1 1 0 0 2
## 6 1 0 1 1 1
## 1 1 0 1 0 2
## 7 1 0 0 1 2
## 0 14 46 61 121Statisticians have devised different strategies for handling missing data; a few common approaches are described briefly here:
- Include only schools with complete data. This is the cleanest approach analytically; however, ignoring data from 12.6% of the study’s schools (since 78 of the 618 schools had incomplete data) means that a large amount of potentially useful data is being thrown away. In addition, this approach creates potential issues with informative missingness. Informative missingness occurs when a school’s lack of scores is not a random phenomenon but provides information about the effectiveness of the school type (e.g., a school closes because of low test scores).
- Last observation carried forward. Each school’s last math score is analyzed as a univariate response, whether the last measurement was taken in 2008, 2009, or 2010. With this approach, data from all schools can be used, and analyses can be conducted with traditional methods assuming independent responses. This approach is sometimes used in clinical trials because it tends to be conservative, setting a higher bar for showing that a new therapy is significantly better than a traditional therapy. Of course, we must assume that a school’s 2008 score is representative of their 2010 score. In addition, information about trajectories over time is thrown away.
- Imputation of missing observations. Many methods have been developed for sensibly “filling in” missing observations, using imputation models which base imputed data on subjects with similar covariate profiles and on typical observed time trends. Once an imputed data set is created (or several imputed data sets), analyses can proceed with complete data methods that are easier to apply. Risks with the imputation approach include misrepresenting missing observations and overstating precision in final results.
- Apply multilevel methods, which use available data to estimate patterns over time by school and then combine those school estimates in a way that recognizes that time trends for schools with complete data are more precise than time trends for schools with fewer measurements. Laird (1988) demonstrates that multilevel models are valid under the fairly unrestrictive condition that the probability of missingness cannot depend on any unobserved predictors or the response. This is the approach we will follow in the remainder of the text.
Now, we are ready to create our LONG data set. Fortunately, many packages (including R) have built-in functions for easing this conversion, and the functions are improving constantly. (In fact, we plan to update our data wrangling code using the tidyverse in the near future.) The resulting LONG data set is shown in Table 9.3, where year08 measures the number of years since 2008:
| schoolName | charter | schPctsped | schPctfree | year08 | MathAvgScore | |
|---|---|---|---|---|---|---|
| 1 | RIPPLESIDE ELEMENTARY | 0 | 0.1176471 | 0.3627451 | 0 | 652.8 |
| 619 | RIPPLESIDE ELEMENTARY | 0 | 0.1176471 | 0.3627451 | 1 | 656.6 |
| 1237 | RIPPLESIDE ELEMENTARY | 0 | 0.1176471 | 0.3627451 | 2 | 652.6 |
| 2 | WRENSHALL ELEMENTARY | 0 | 0.1515152 | 0.4242424 | 0 | 646.9 |
| 620 | WRENSHALL ELEMENTARY | 0 | 0.1515152 | 0.4242424 | 1 | 645.3 |
| 1238 | WRENSHALL ELEMENTARY | 0 | 0.1515152 | 0.4242424 | 2 | 651.9 |
9.3.3 Exploratory analyses for general multilevel models
Notice the longitudinal structure of our data—we have up to three measurements of test scores at different time points for each of our 618 schools. With this structure, we can address questions at two levels:
- Within school—changes over time
- Between schools—effects of school-specific covariates (charter or non-charter, urban or rural, percent free and reduced lunch, percent special education, and percent non-white) on 2008 math scores and rate of change between 2008 and 2010.
As with any statistical analysis, it is vitally important to begin with graphical and numerical summaries of important variables and relationships between variables. We’ll begin with initial exploratory analyses that we introduced in the previous chapter, noting that we have no Level One covariates other than time at this point (potential covariates at this level may have included measures of the number of students tested or funds available per student). We will, however, consider the Level Two variables of charter or non-charter, urban or rural, percent free and reduced lunch, percent special education, and percent non-white. Although covariates such as percent free and reduced lunch may vary slightly from year to year within a school, the larger and more important differences tend to occur between schools, so we used percent free and reduced lunch for a school in 2010 as a Level Two variable.
As in Chapter 8, we can conduct initial investigations of relationships between Level Two covariates and test scores in two ways. First, we can use all 1733 observations to investigate relationships of Level Two covariates with test scores; although these plots will contain dependent points, since each school is represented by up to three years of test score data, general patterns exhibited in these plots tend to be real. Second, we can calculate mean scores across all years for each of the 618 schools; while we lose some information with this approach, we can more easily consider each plotted point to be independent. Typically, both types of exploratory plots illustrate similar relationships, and in this case, both approaches are so similar that we will only show plots using the second approach, with one observation per school.
Figure 9.1 shows the distribution of MCA math test scores as somewhat left skewed. MCA test scores for sixth graders are scaled to fall between 600 and 700, where scores above 650 for individual students indicate “meeting standards”. Thus, schools with averages below 650 will often have increased incentive to improve their scores the following year. When we refer to the “math score” for a particular school in a particular year, we will assume that score represents the average for all sixth graders at that school. In Figure 9.2, we see that test scores are generally higher for both schools in rural areas and for public non-charter schools. Note that in this data set there are 237 schools in rural areas and 381 schools in urban areas, as well as 545 public non-charter schools and 73 charter schools. In addition, we can see in Figure 9.3 that schools tend to have lower math scores if they have higher percentages of students with free and reduced lunch, with special education needs, or who are non-white.
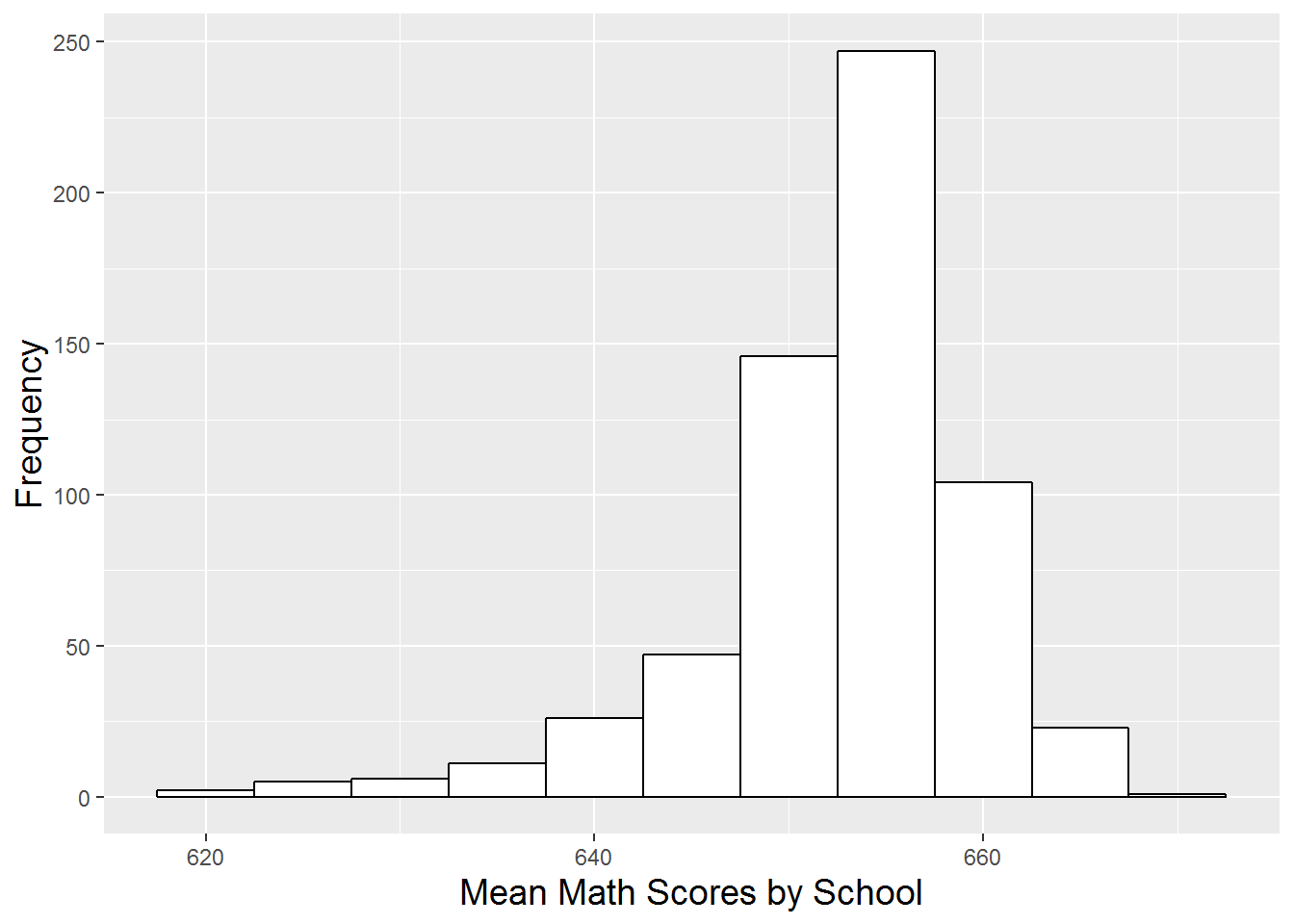
Figure 9.1: Histogram of mean sixth grade MCA math test scores over the years 2008-2010 for 618 Minnesota schools.
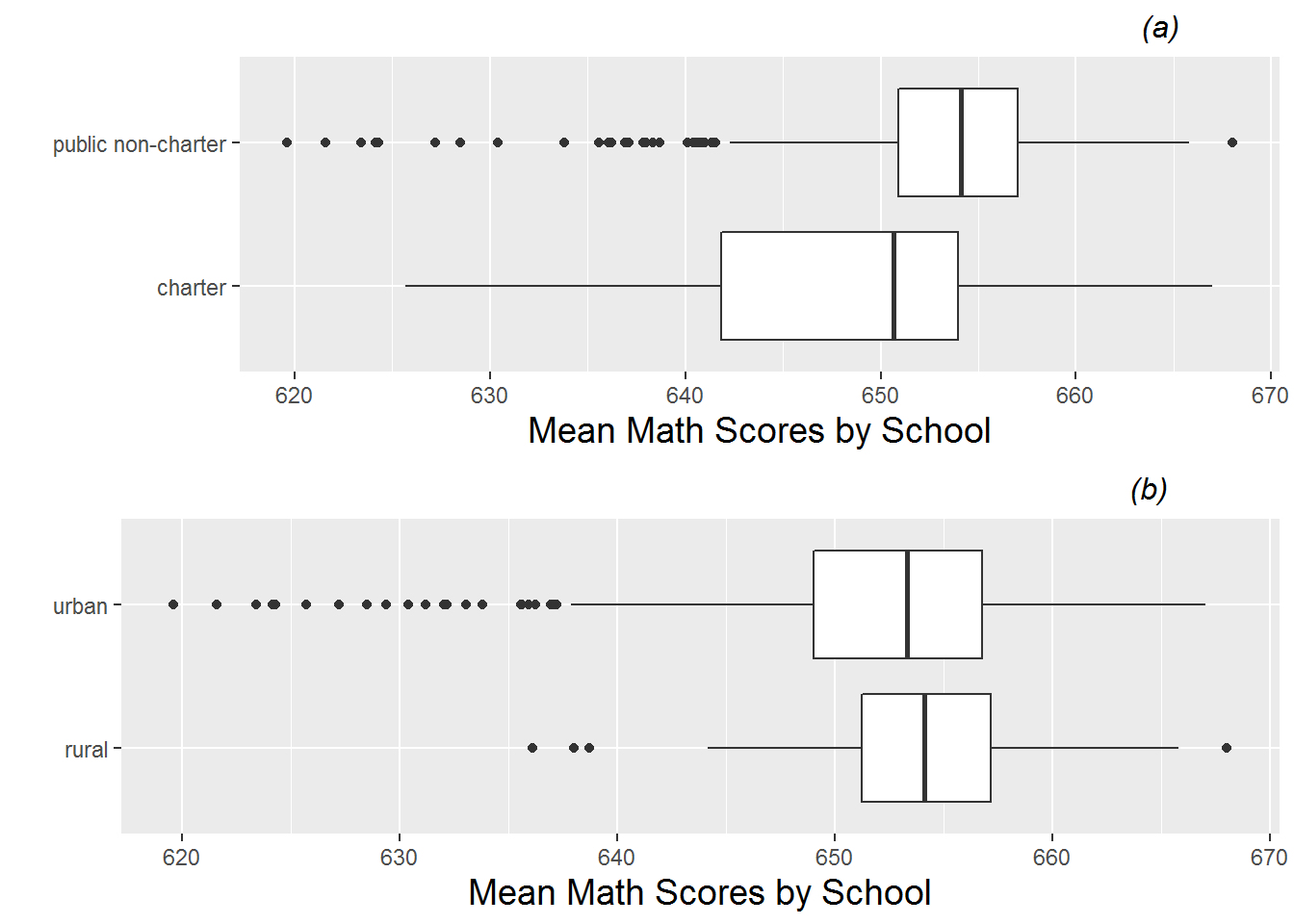
Figure 9.2: Boxplots of categorical Level Two covariates vs. average MCA math scores. Plot (a) shows charter vs. public non-charter schools, while plot (b) shows urban vs. rural schools.
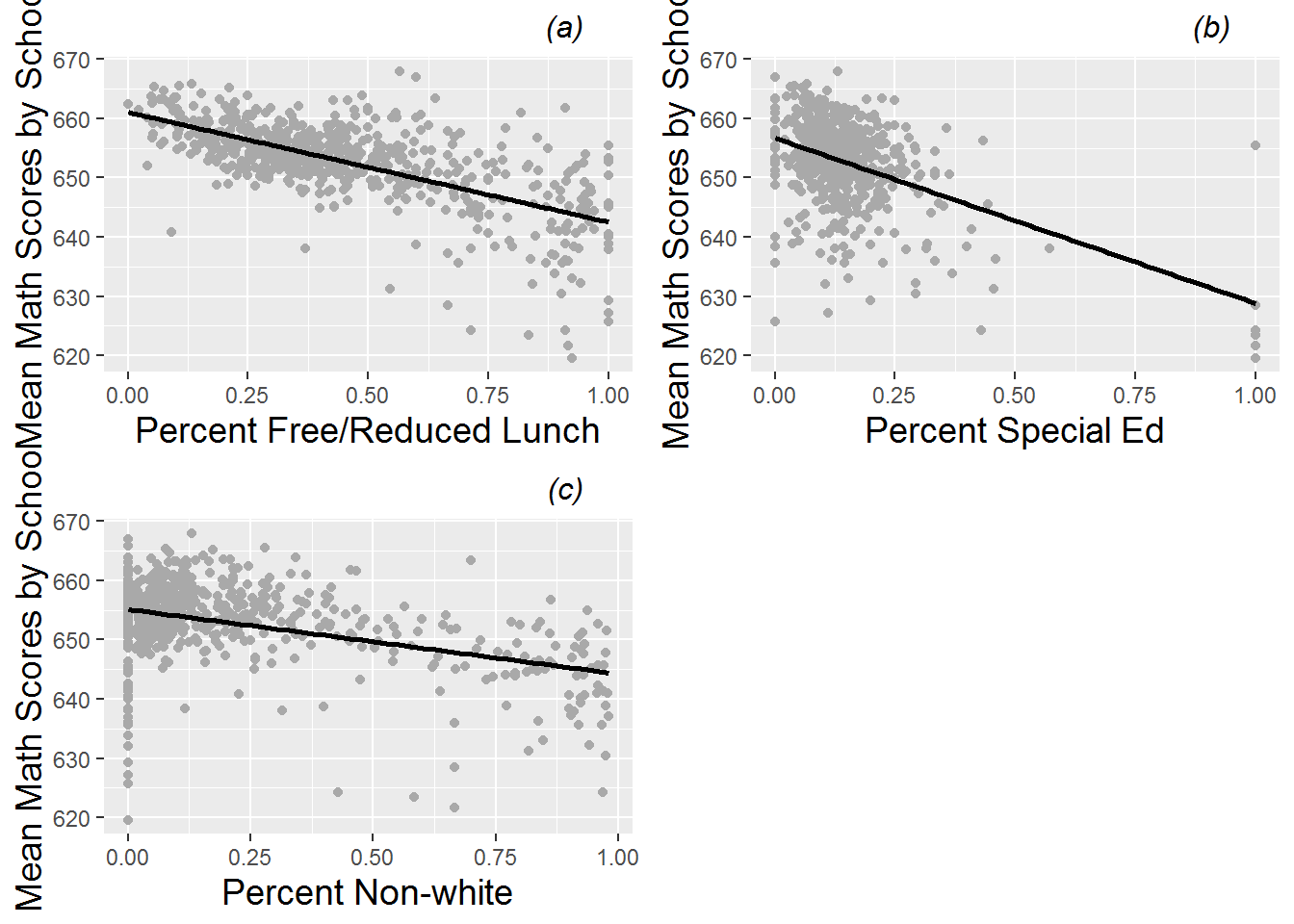
Figure 9.3: Scatterplots of average MCA math scores by (a) percent free and reduced lunch, (b) percent special education, and (c) percent non-white in a school.
9.3.4 Exploratory analyses for longitudinal data
In addition to the initial exploratory analyses above, longitudinal data—multilevel data with time at Level One—calls for further plots and summaries that describe time trends within and across individuals. For example, we can examine trends over time within individual schools. Figure 9.4 provides a lattice plot illustrating trends over time for the first 24 schools in the data set. We note differences among schools in starting point (test scores in 2008), slope (change in test scores over the three year period), and form of the relationship. These differences among schools are nicely illustrated in so-called spaghetti plots such as Figure 9.5, which overlays the individual schools’ time trends (for the math test scores) from Figure 9.4 on a single set of axes. In order to illustrate the overall time trend without making global assumptions about the form of the relationship, we overlaid in bold a nonparametric fitted curve through a loess smoother. LOESS comes from “locally weighted scatterplot smoother”, in which a low-degree polynomial is fit to each data point using weighted regression techniques, where nearby points receive greater weight. LOESS is a computationally intensive method which performs especially well with larger sets of data, although ideally there would be a greater diversity of x-values than the three time points we have. In this case, the loess smoother follows very closely to a linear trend, indicating that assuming a linear increase in test scores over the three year period is probably a reasonable simplifying assumption. To further examine the hypothesis that linearity would provide a reasonable approximation to the form of the individual time trends in most cases, Figure 9.6 shows a lattice plot containing linear fits through ordinary least squares rather than connected time points as in Figure 9.4.
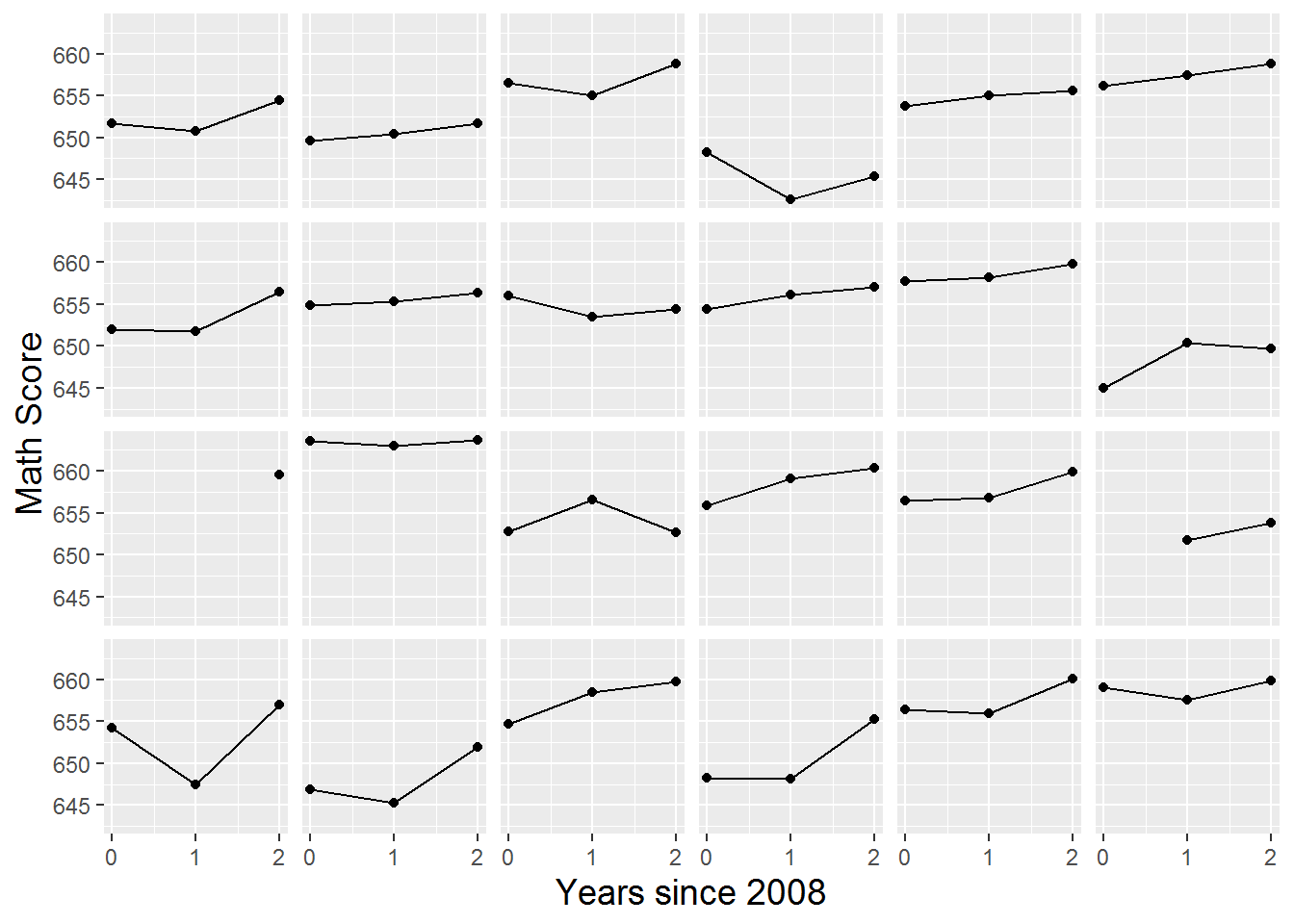
Figure 9.4: Lattice plot by school of math scores over time for the first 24 schools in the data set.
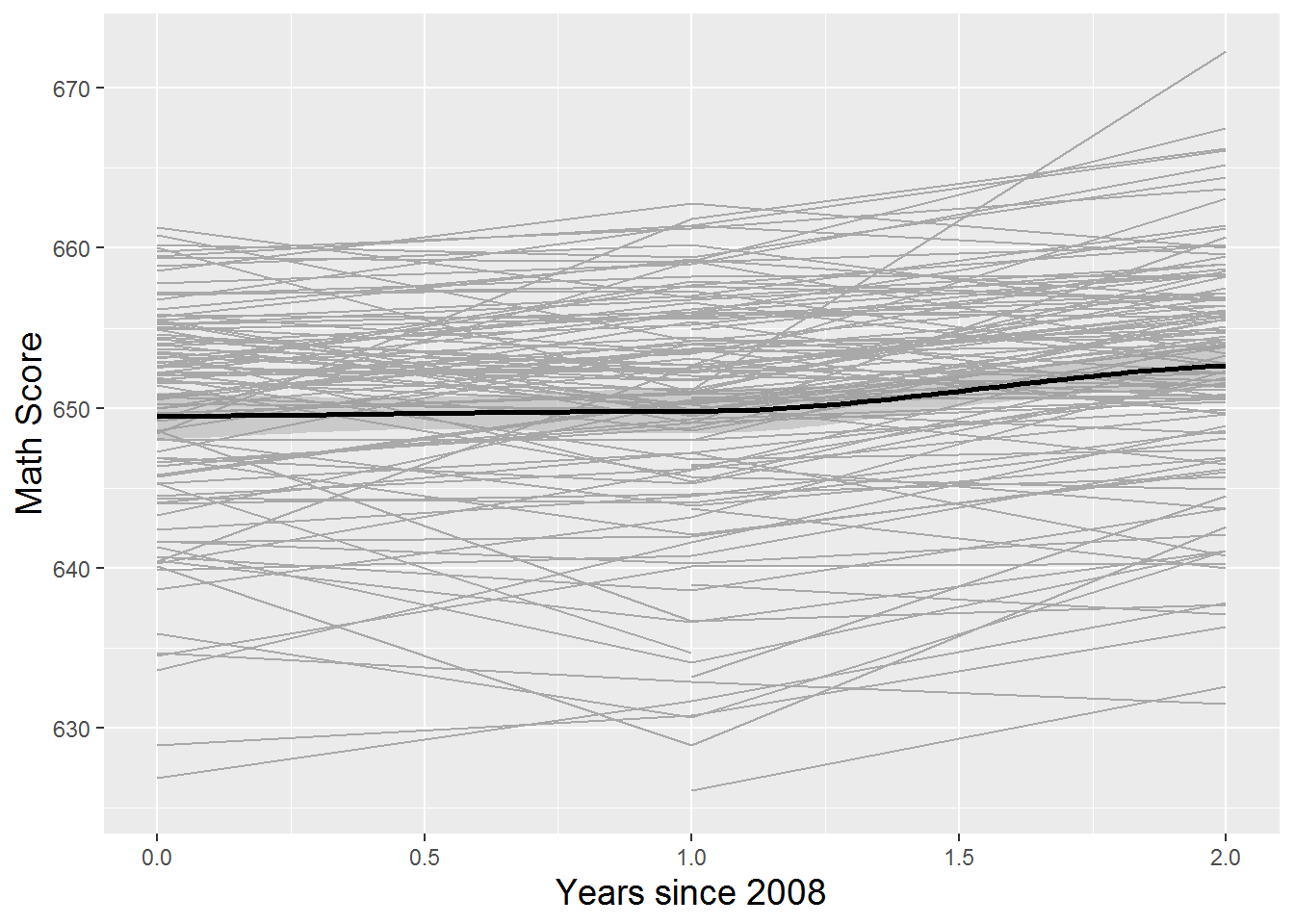
Figure 9.5: Spaghetti plot of math scores over time by school, for all the charter schools and a random sample of public non-charter schools, with overall fit using loess (bold).
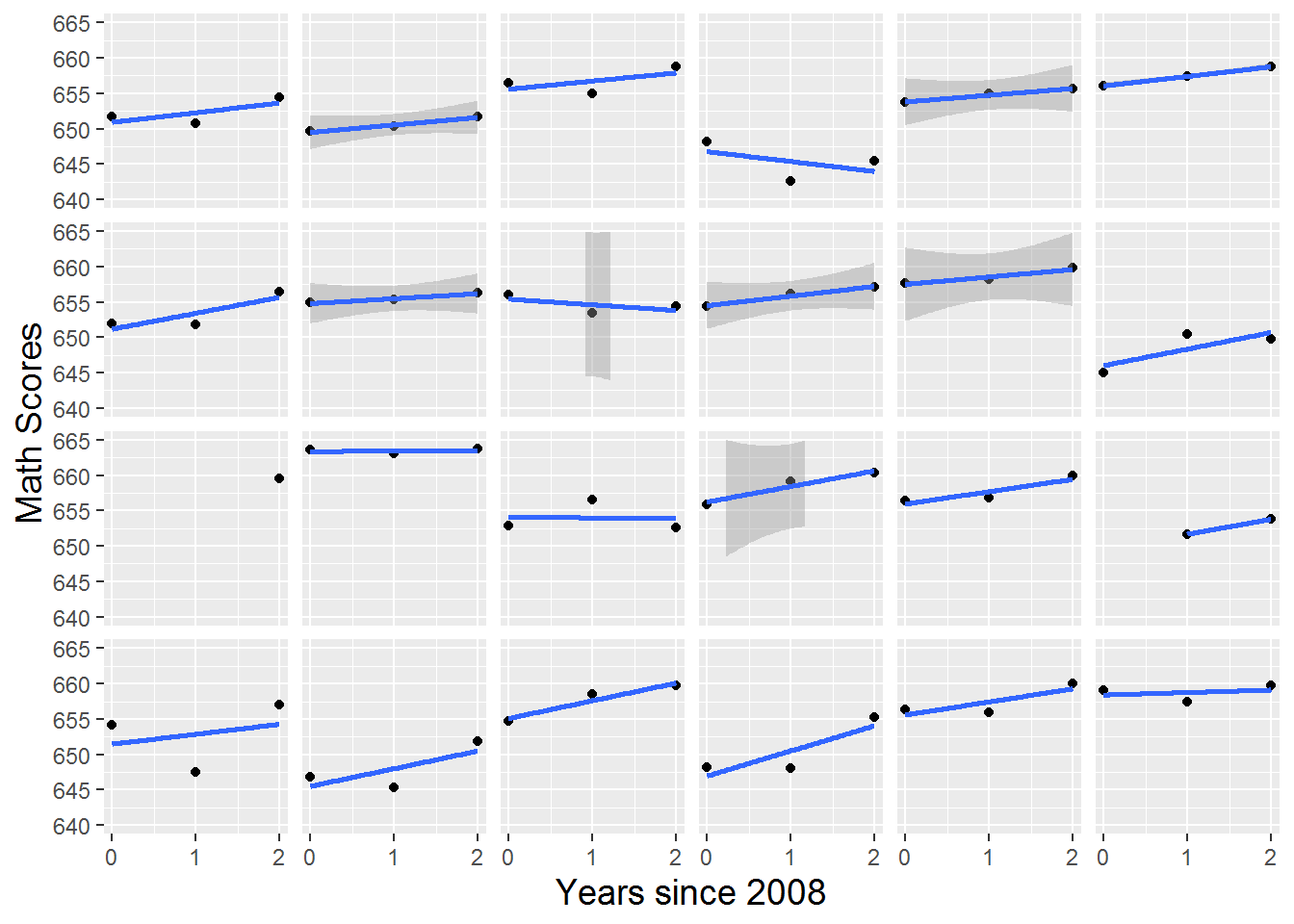
Figure 9.6: Lattice plot by school of math scores over time with linear fit for the first 24 schools in the data set.
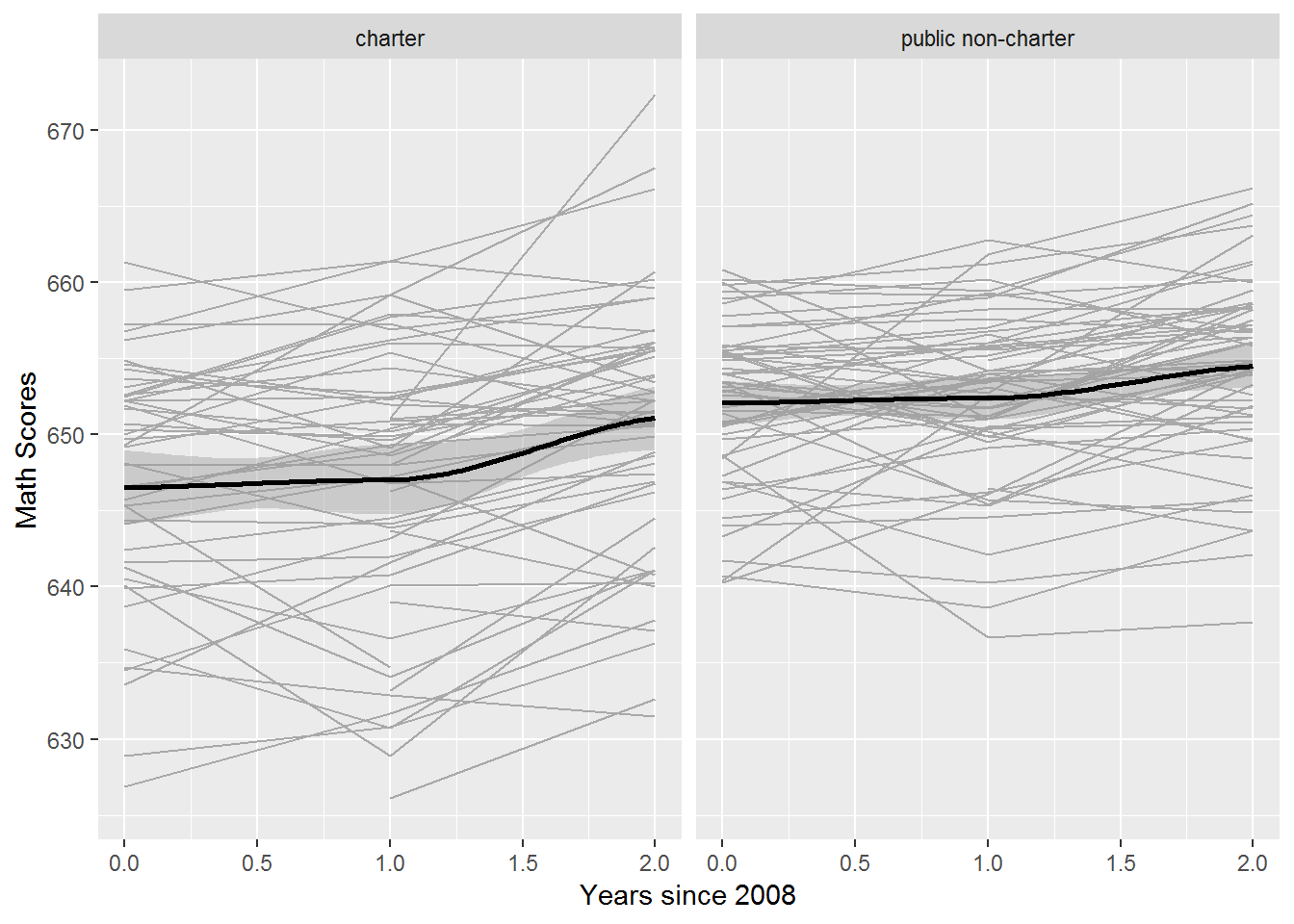
Figure 9.7: Spaghetti plot showing time trends for each school by school type, for a random sample of charter schools (left) and public non-charter schools (right), with overall fits using loess (bold).
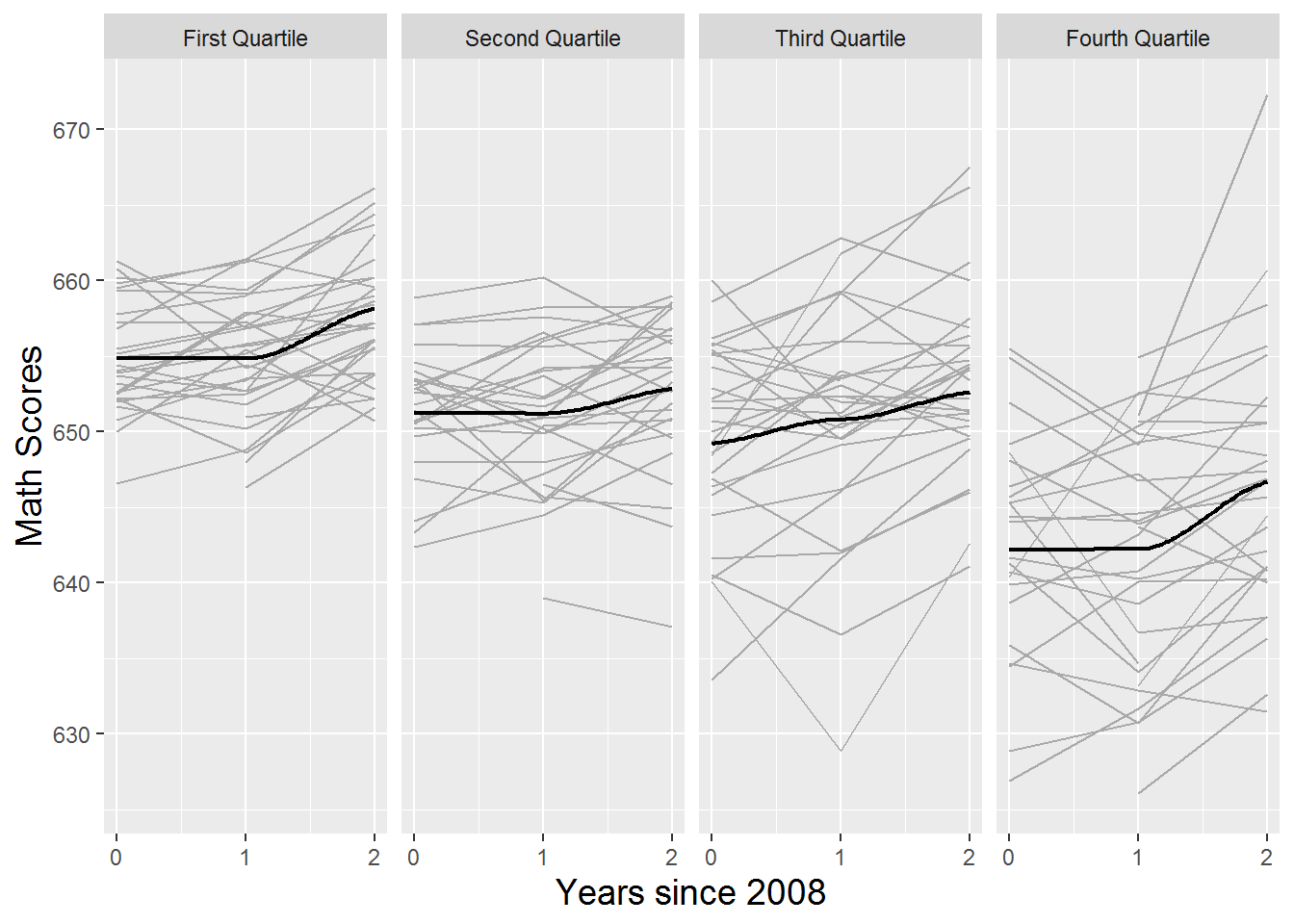
Figure 9.8: Spaghetti plot showing time trends for each school by quartiles of percent free and reduced lunch, with loess fits.
Just as we explored the relationship between our response (average math scores) and important covariates in Section 9.3.3, we can now examine the relationships between time trends by school and important covariates. For instance, Figure 9.7 shows that charter schools had math scores that were lower on average than public non-charter schools and more variable. This type of plot is sometimes called a trellis graph, since it displays a grid of smaller charts with consistent scales, where each smaller chart represents a condition–an item in a category. Trends over time by school type are denoted by bold loess curves. Public non-charter schools have higher scores across all years; both school types show little growth between 2008 and 2009, but greater growth between 2009 and 2010, especially charter schools. Exploratory analyses like this can be repeated for other covariates, such as percent free and reduced lunch in Figure 9.8. The trellis plot automatically divides schools into four groups based on quartiles of their percent free and reduced lunch, and we see that schools with lower percentages of free and reduced lunch students tend to have higher math scores and less variability. Across all levels of free and reduced lunch, we see greater gains between 2009 and 2010 than between 2008 and 2009.
9.4 Preliminary two-stage modeling
9.4.1 Linear trends within schools
Even though we know that every school’s math test scores were not strictly linearly increasing or decreasing over the observation period, a linear model for individual time trends is often a simple but reasonable way to model data. One advantage of using a linear model within school is that each school’s data points can be summarized with two summary statistics—an intercept and a slope (obviously, this is an even bigger advantage when there are more observations over time per school). For instance, we see in Figure 9.6 that sixth graders from the school depicted in the top right slot slowly increased math scores over the three year observation period, while students from the school depicted in the fourth column of the top row generally experienced decreasing math scores over the same period. As a whole, the linear model fits individual trends pretty well, and many schools appear to have slowly increasing math scores over time, as researchers in this study may have hypothesized.
Another advantage of assuming a linear trend at Level One (within schools) is that we can examine summary statistics across schools. Both the intercept and slope are meaningful for each school: the intercept conveys the school’s math score in 2008, while the slope conveys the school’s average yearly increase or decrease in math scores over the three year period. Figure 9.9 shows that point estimates and uncertainty surrounding individual estimates of intercepts and slopes vary considerably. In addition, we can generate summary statistics and histograms for the 618 intercepts and slopes produced by fitting linear regression models at Level One, in addition to R-square values which describe the strength of fit of the linear model for each school (Figure 9.10). For our 618 schools, the mean math score for 2008 was 651.4 (SD=7.28), and the mean yearly rate of change in math scores over the three year period was 1.30 (SD=2.51). We can further examine the relationship between schools’ intercepts and slopes. Figure 9.11 shows a general decreasing trend, suggesting that schools with lower 2008 test scores tend to have greater growth in scores between 2008 and 2010 (potentially because those schools have more room for improvement); this trend is supported with a correlation coefficient of -0.32 between fitted intercepts and slopes. Note that, with only 3 or fewer observations for each school, extreme or intractable values for the slope and R-square are possible. For example, slopes cannot be estimated for those schools with just a single test score, R-square values cannot be calculated for those schools with no variability in test scores between 2008 and 2010, and R-square values must be 1 for those schools with only two test scores.
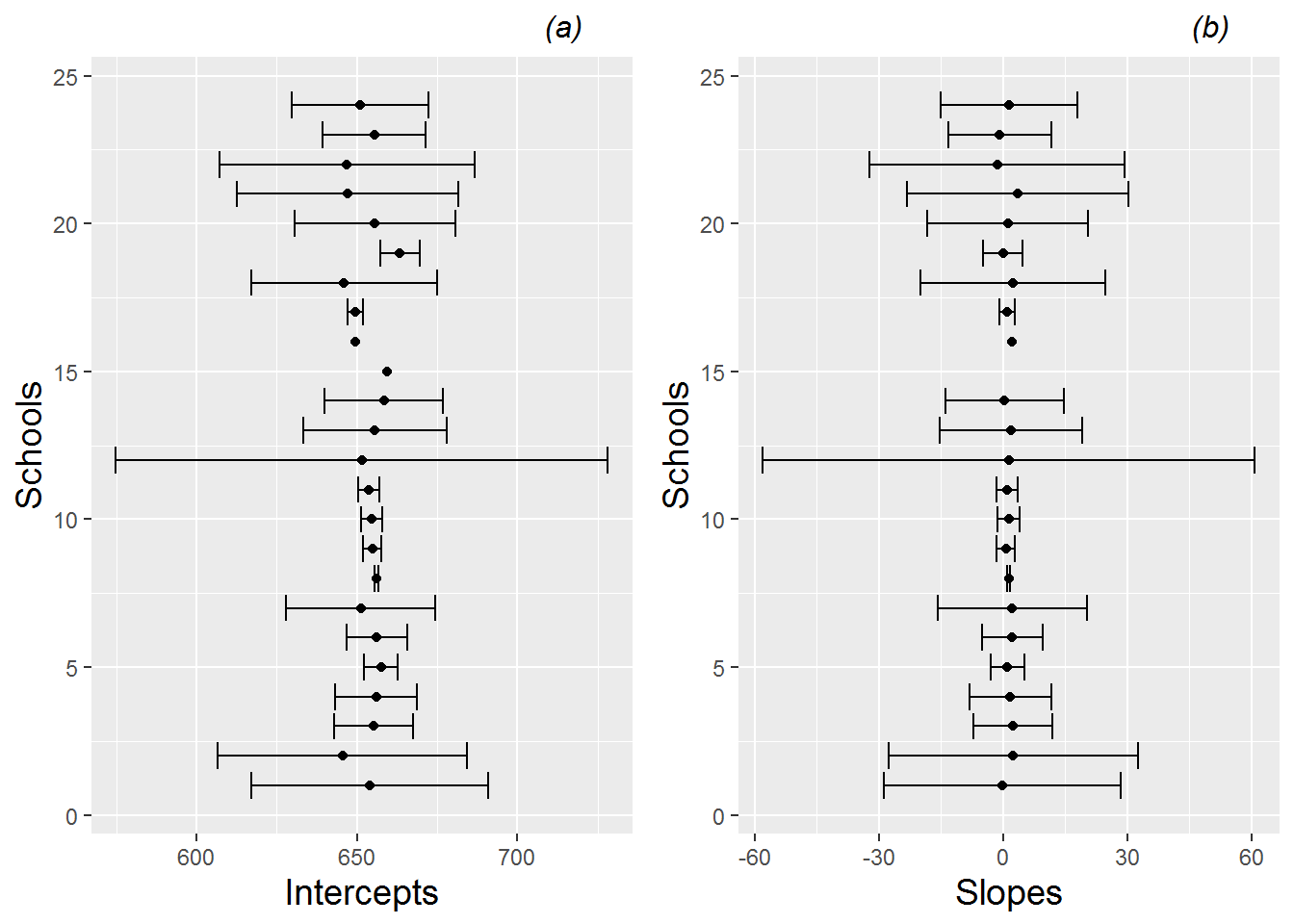
Figure 9.9: Point estimates and 95% confidence intervals for (a) intercepts and (b) slopes by school, for the first 24 schools in the data set.
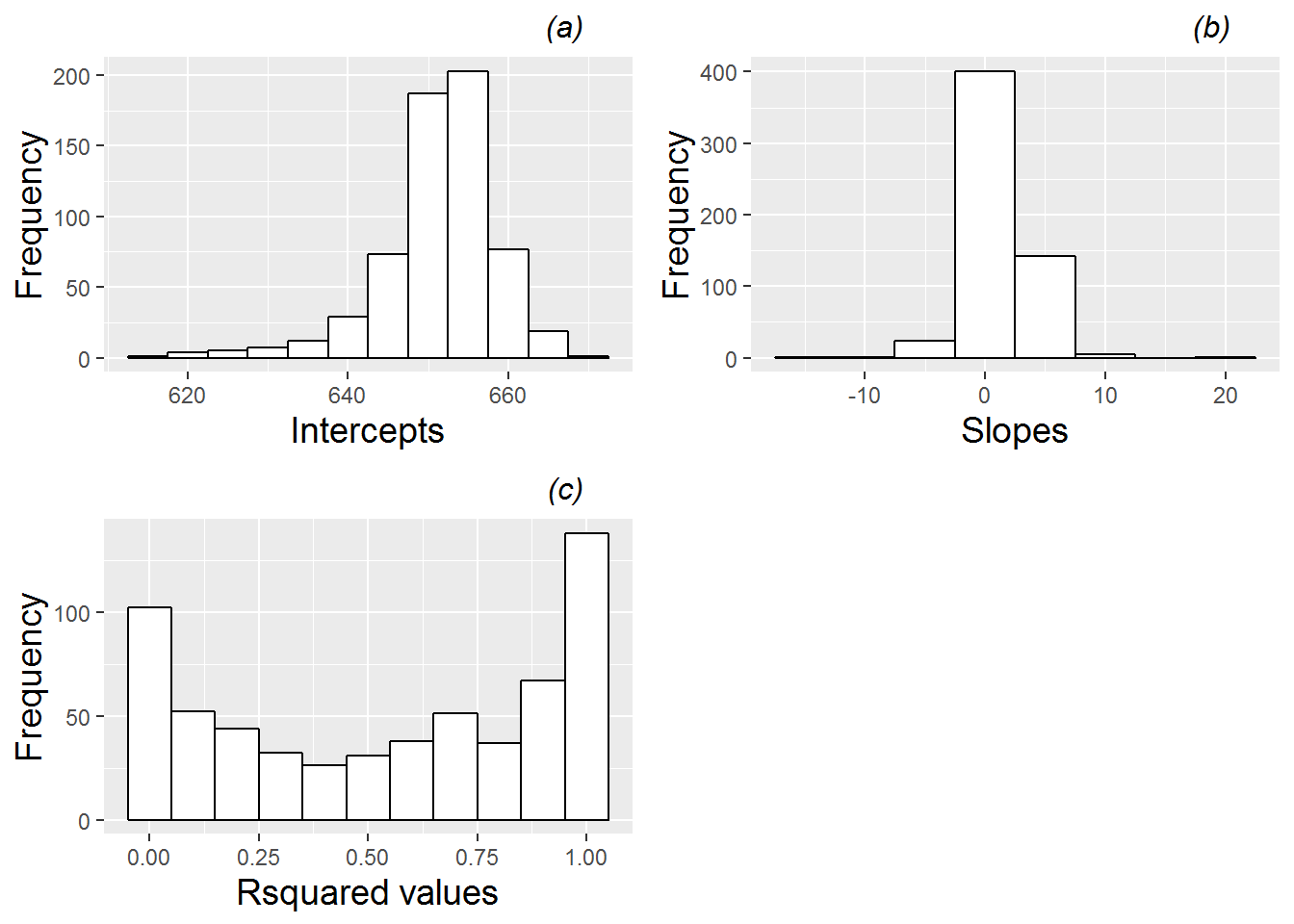
Figure 9.10: Histograms for (a) intercepts, (b) slopes, and (c) R-square values from fitted regression lines by school.
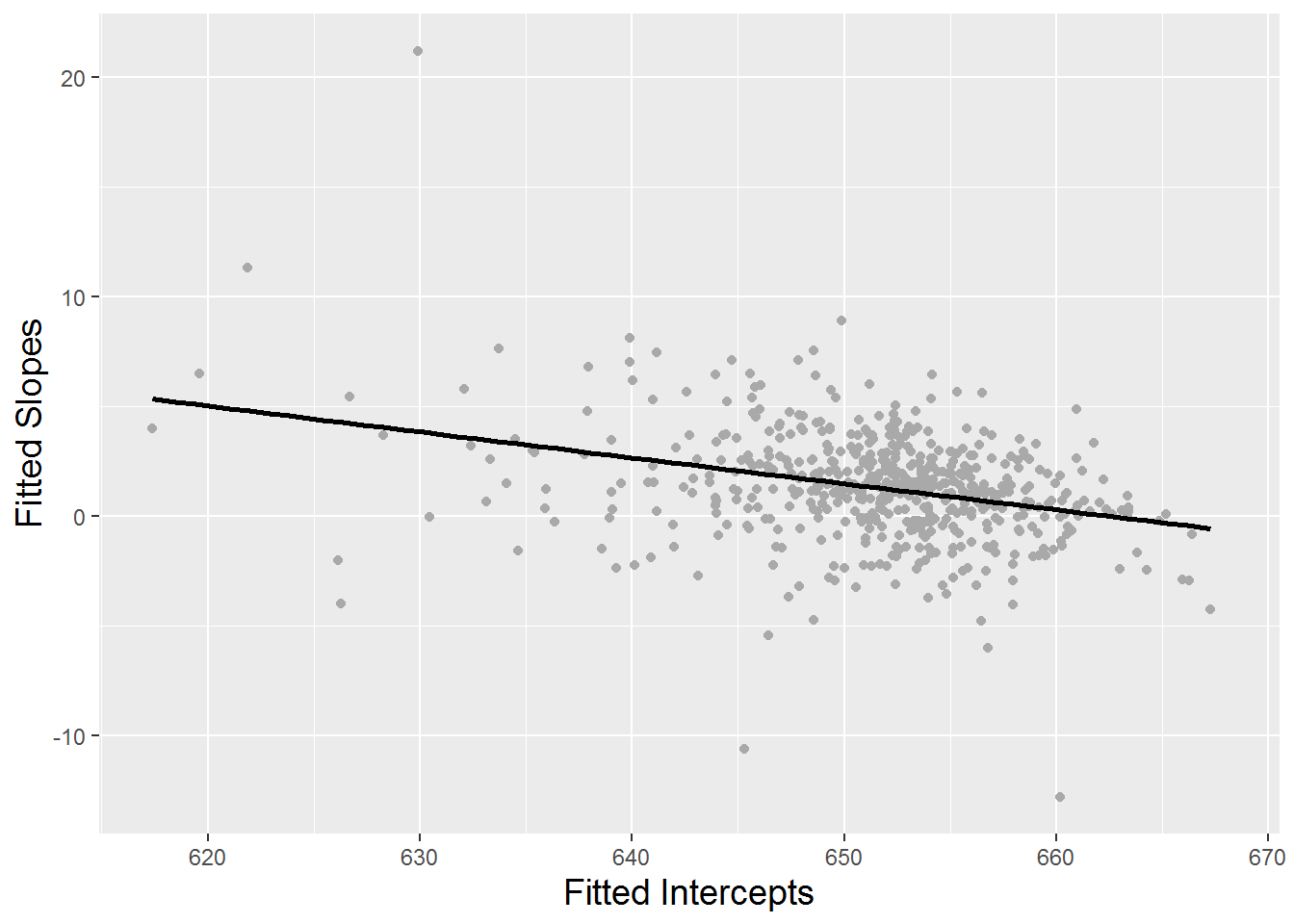
Figure 9.11: Scatterplot showing the relationship between intercepts and slopes from fitted regression lines by school.
9.4.2 Effects of level two covariates on linear time trends
Summarizing trends over time within schools is typically only a start, however. Most of the primary research questions from this study involve comparisons among schools, such as: (a) are there significant differences between charter schools and public non-charter schools, and (b) do any differences between charter schools and public schools change with percent free and reduced lunch, percent special education, or location? These are Level Two questions, and we can begin to explore these questions by graphically examining the effects of school-level variables on schools’ linear time trends. By school-level variables, we are referring to those covariates that differ by school but are not dependent on time. For example school type (charter or public non-charter), urban or rural location, percent non-white, percent special education, and percent free and reduced lunch are all variables which differ by school but which don’t change over time, at least as they were assessed in this study. Variables which would be time-dependent include quantities such as per pupil funding and reading scores.
Figure 9.12 shows differences in the average time trends by school type, using estimated intercepts and slopes to support observations from the spaghetti plots in Figure 9.7. Based on intercepts, charter schools have lower math scores, on average, in 2008 than public non-charter schools. Based on slopes, however, charter schools tend to improve their math scores at a slightly faster rate than public schools, especially at the seventy-fifth percentile and above. By the end of the three year observation period we would nevertheless expect charter schools to have lower average math scores than public schools. For another exploratory perspective on school type comparisons, we can examine differences between school types with respect to math scores in 2008 and math scores in 2010. As expected, boxplots by school type (Figure 9.13) show clearly lower math scores for charter schools in 2008, but differences are slightly less dramatic in 2010.
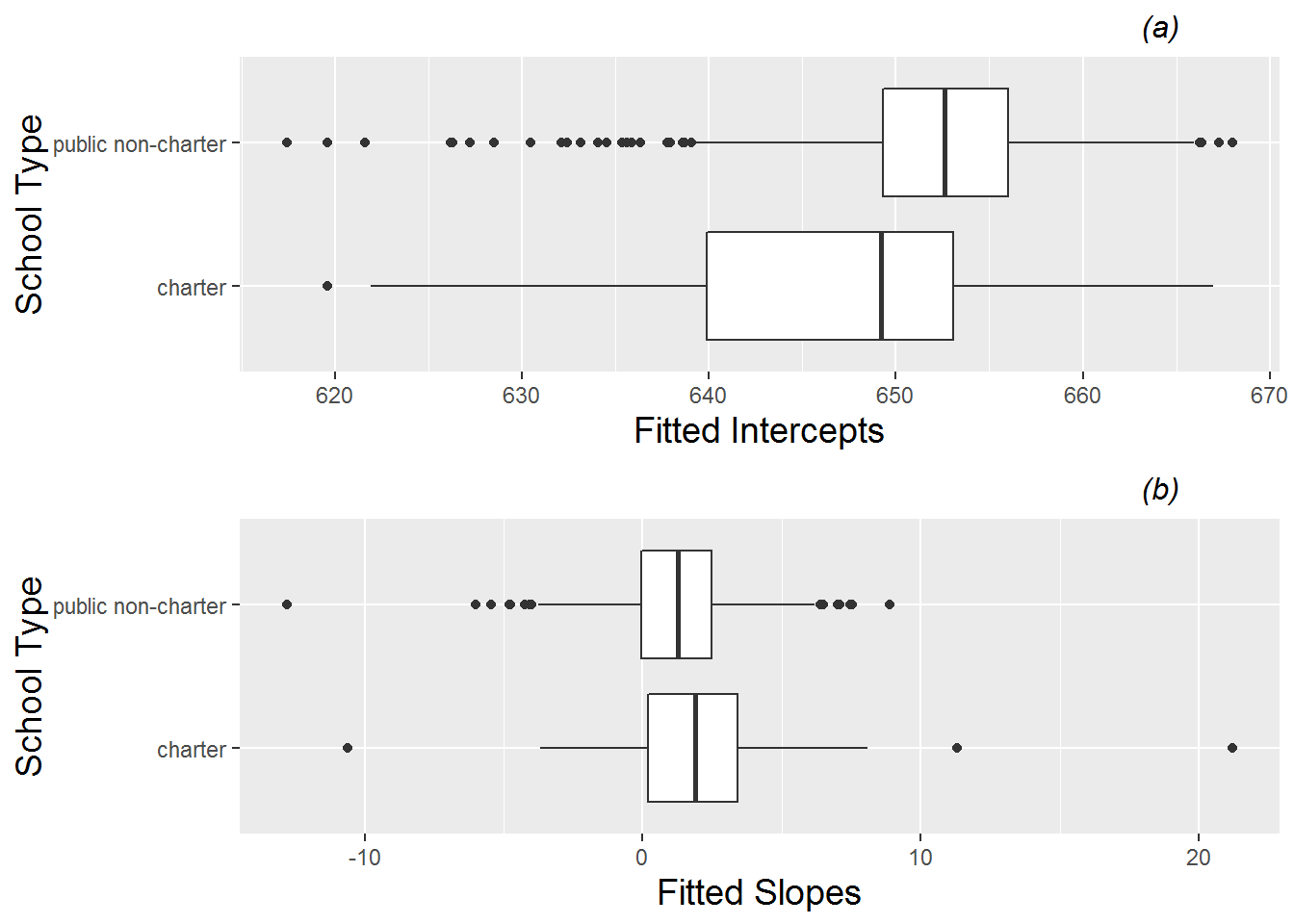
Figure 9.12: Boxplots of (a) intercepts and (b) slopes by school type (charter vs. public non-charter).
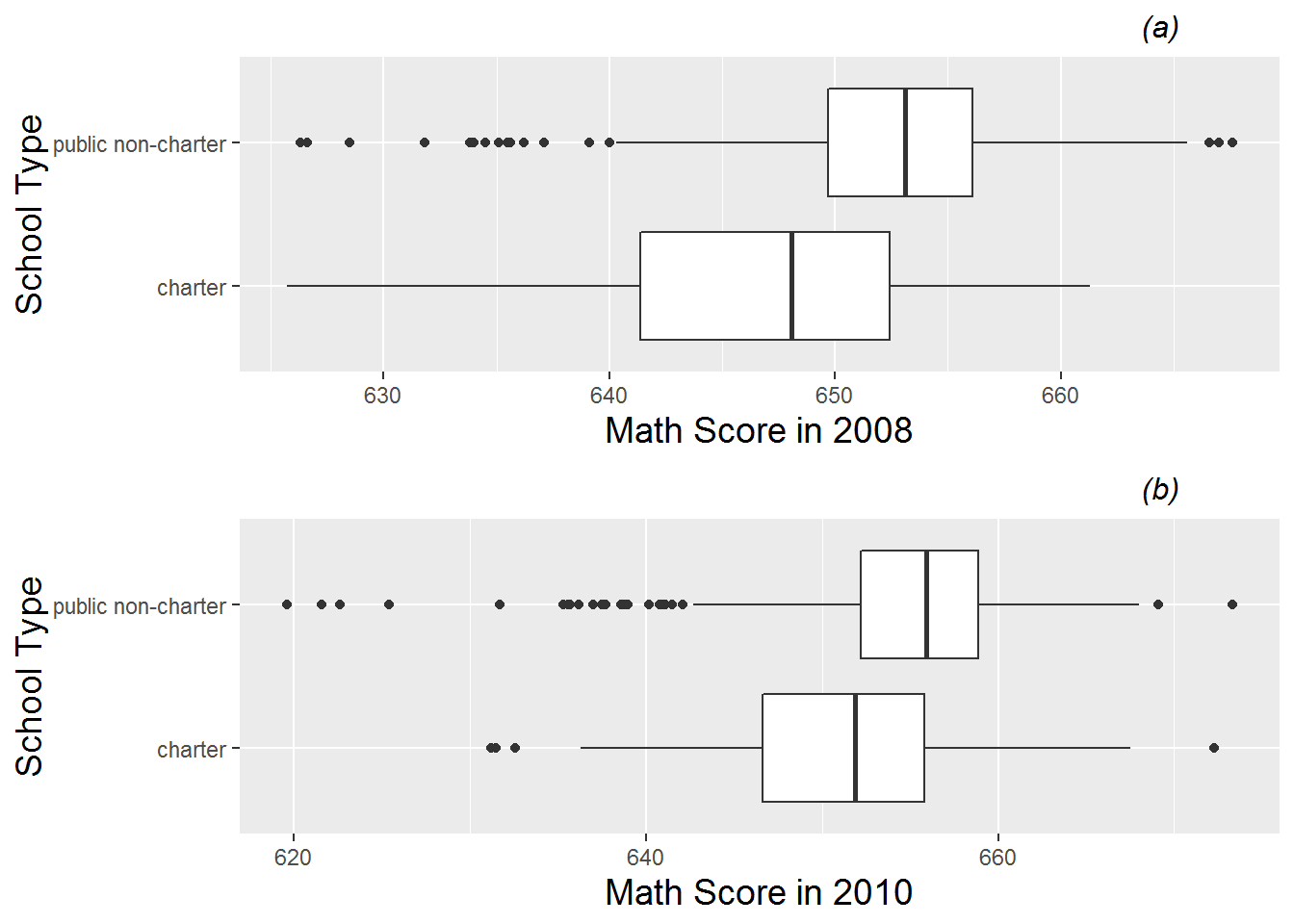
Figure 9.13: Boxplots of (a) 2008 and (b) 2010 math scores by school type (charter vs. public non-charter).
Any initial exploratory analyses should also investigate effects of potential confounding variables such as school demographics and location. If we discover, for instance, that those schools with higher levels of poverty (measured by the percentage of students receiving free and reduced lunch) display lower test scores in 2008 but greater improvements between 2008 and 2010, then we might be able to use percentage of free and reduced lunch in statistical modeling of intercepts and slopes, leading to more precise estimates of the charter school effects on these two outcomes. In addition, we should also look for any interaction with school type—any evidence that the difference between charter and non-charter schools changes based on the level of a confounding variable. For example, do charter schools perform better relative to non-charter schools when there is a large percentage of non-white students at a school?
With a confounding variable such as percentage of free and reduced lunch, we will treat this variable as continuous to produce the most powerful exploratory analyses. We can begin by examining boxplots of free and reduced lunch percentage against school type (Figure 9.14). We observe that charter schools tend to have greater percentages of free and reduced lunch students as well as greater school-to-school variability. Next, we can use scatterplots to graphically illustrate the relationships between free and reduced lunch percentages and significant outcomes such as intercept and slope (also Figure 9.14). In this study, it appears that schools with higher levels of free and reduced lunch (i.e., greater poverty) tend to have lower math scores in 2008, but there is little evidence of a relationship between levels of free and reduced lunch and improvements in test scores between 2008 and 2010. These observations are supported with correlation coefficients between percent free and reduced lunch and intercepts (r=-0.61) and slopes (r=-0.06).
A less powerful but occasionally informative way to look at the effect of a continuous confounder on an outcome variables is by creating a categorical variable out of the confounder. For instance, we could classify any school with a percentage of free and reduced lunch students above the median as having a high percentage of free and reduced lunch students and all other schools as having a low percentage of free and reduced lunch students. Then we could examine a possible interaction between percent free and reduced lunch and school type through a series of four boxplots (Figure 9.15). In fact, these boxplots suggest that the gap between charter and public non-charter schools in 2008 was greater in schools with a high percentage of free and reduced lunch students, while the difference in rate of change in test scores between charter and public non-charter schools appeared similar for high and low levels of free and reduced lunch. We will investigate these trends more thoroughly with statistical modeling.
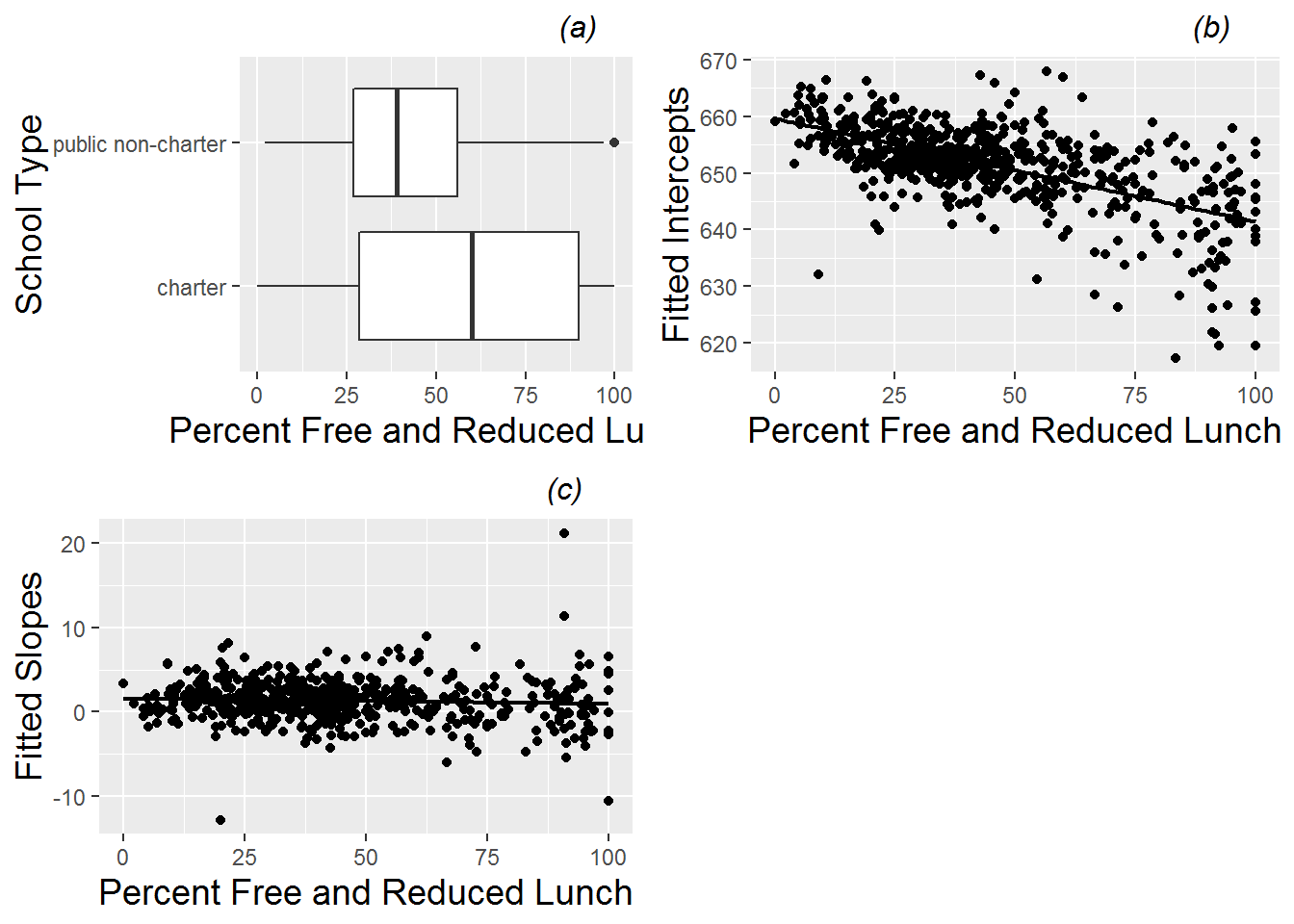
Figure 9.14: (a) Boxplot of percent free and reduced lunch by school type (charter vs. public non-charter), along with scatterplots of (b) intercepts and (c) slopes from fitted regression lines by school vs. percent free and reduced lunch.
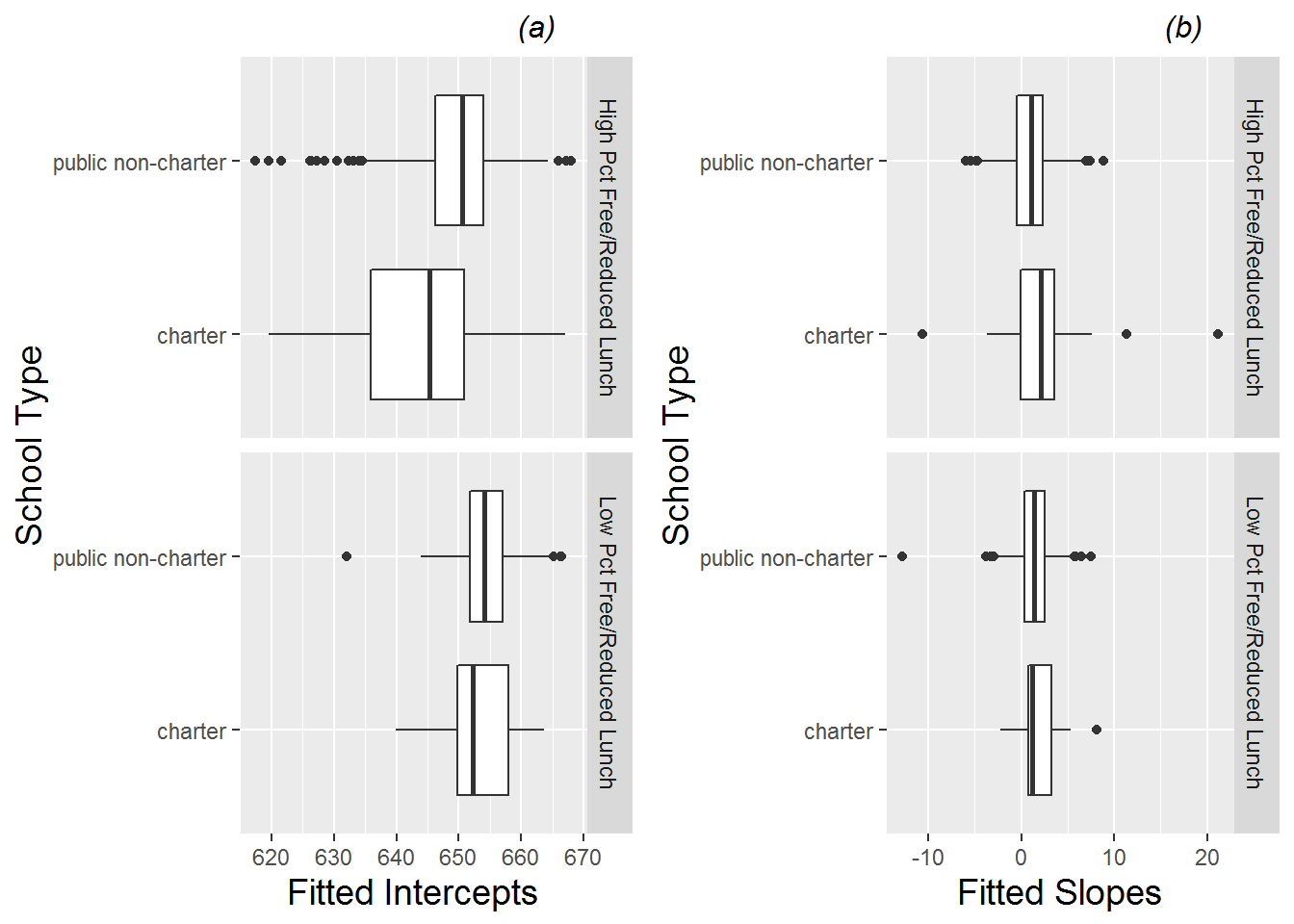
Figure 9.15: Boxplots of (a) intercepts and (b) slopes from fitted regression lines by school vs. school type (charter vs. public non-charter), separated by high and low levels of percent free and reduced lunch.
The effect of other confounding variables (e.g., percent non-white, percent special education, urban or rural location) can be investigated in a similar fashion to free and reduced lunch percentage, both in terms of main effect (variability in outcomes such as slope and intercept which can be explained by the confounding variable) and interaction with school type (ability of the confounding variable to explain differences between charter and public non-charter schools). We leave these explorations as an exercise.
9.4.3 Error structure within schools
Finally, with longitudinal data it is important to investigate the error variance-covariance structure of data collected within a school (the Level Two observational unit). In multilevel data, as in the examples we introduced in Chapter 7, we suspect observations within group (like a school) to be correlated, and we strive to model that correlation. When the data within group is collected over time, we often see distinct patterns in the residuals that can be modeled—correlations which decrease systematically as the time interval increases, variances that change over time, correlation structure that depends on a covariate, etc. A first step in modeling the error variance-covariance structure is the production of an exploratory plot such as Figure 9.16. To generate this plot, we begin by modeling MCA math score as a linear function of time using all 1733 observations and ignoring the school variable. This population (marginal) trend is illustrated in Figure 9.5 and is given by: \[\begin{equation} \hat{Y}_{ij}=651.69+1.20\textstyle{Time}_{ij}, \tag{9.1} \end{equation}\]where \(\hat{Y}_{ij}\) is the predicted math score of the \(i^{th}\) school at time \(j\), where time \(j\) is the number of years since 2008. In this model, the predicted math score will be identical for all schools at a given time point \(j\). Residuals \(Y_{ij}-\hat{Y}_{ij}\) are then calculated for each observation, measuring the difference between actual math score and the average overall time trend. Figure 9.16 then combines three pieces of information: the upper right triangle contains correlation coefficients for residuals between pairs of years, the diagonal contains histograms of residuals at each time point, and the lower left triangle contains scatterplots of residuals from two different years. In our case, we see that correlation between residuals from adjacent years is strongly positive (0.81-0.83) and does not drop off greatly as the time interval between years increases.
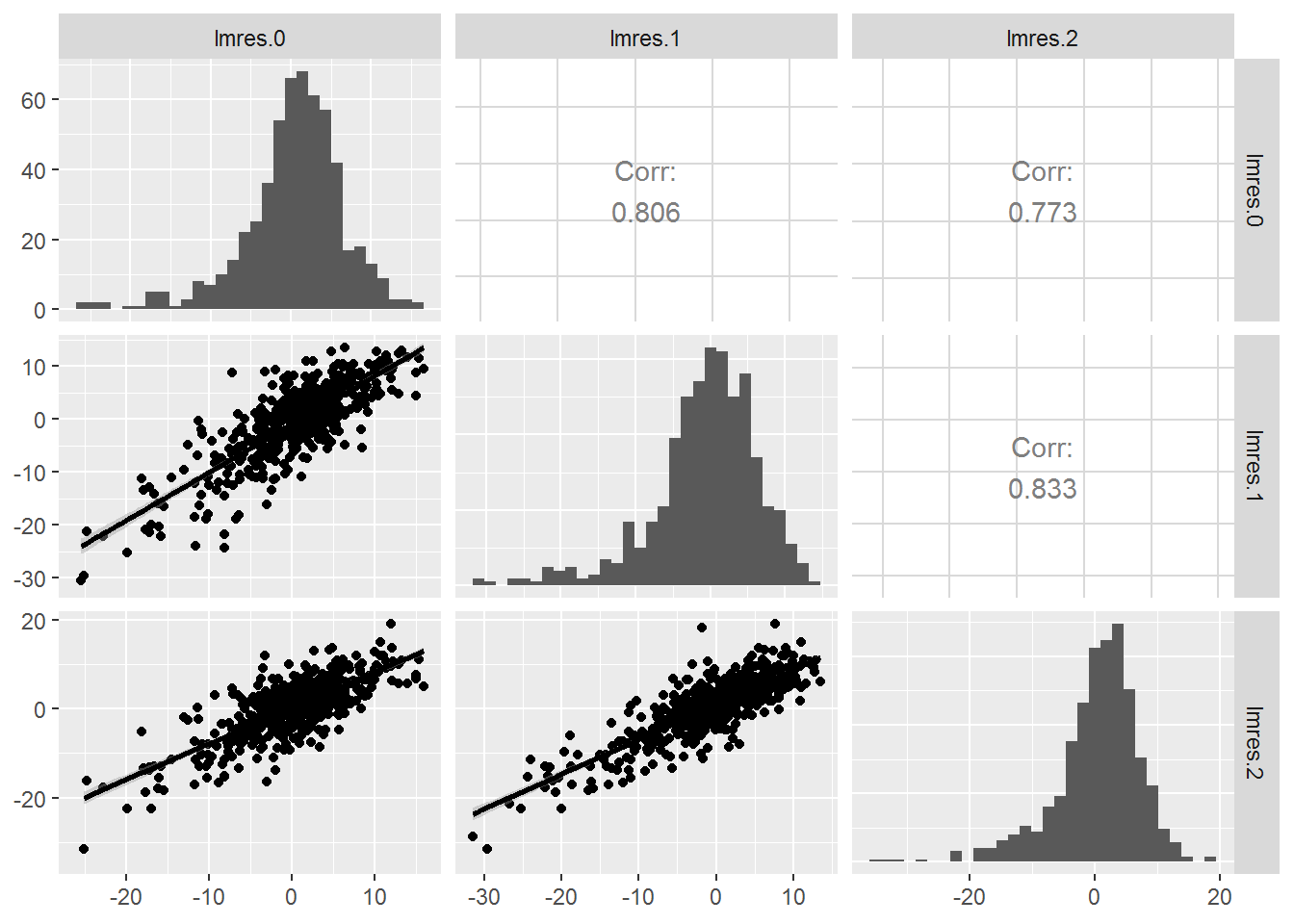
Figure 9.16: Correlation structure within school. The upper right contains correlation coefficients between residuals at pairs of time points, the lower left contains scatterplots of the residuals at time point pairs, and the diagonal contains histograms of residuals at each of the three time points.
9.5 Initial models
Throughout the exploratory analysis phase, our original research questions have guided our work, and now with modeling we return to familiar questions such as:
- are differences between charter and public non-charter schools (in intercept, in slope, in 2010 math score) statistically significant?
- are differences between school types statistically significant, even after accounting for school demographics and location?
- do charter schools offer any measurable benefit over non-charter public schools, either overall or within certain subgroups of schools based on demographics or location?
As you might expect, answers to these questions will arise from proper consideration of variability and properly identified statistical models. As in Chapter 8, we will begin model fitting with some simple, preliminary models, in part to establish a baseline for evaluating larger models. Then, we can build toward a final model for inference by attempting to add important covariates, centering certain variables, and checking assumptions.
9.5.1 Unconditional means model
In the multilevel context, we almost always begin with the unconditional means model, in which there are no predictors at any level. The purpose of the unconditional means model is to assess the amount of variation at each level, and to compare variability within school to variability between schools. Define \(Y_{ij}\) as the MCA-II math score from school \(i\) and year \(j\). Using the composite model specification from Chapter 8:
\[\begin{equation} Y _{ij} = \alpha_{0} + u_{i} + \epsilon_{ij} \textrm{ with } u_{i} \sim N(0, \sigma^2_u) \textrm{ and } \epsilon_{ij} \sim N(0, \sigma^2) \end{equation}\]the unconditional means model can be fit to the MCA-II data:
Formula: MathAvgScore ~ 1 + (1 | schoolid)
Random effects:
Groups Name Variance Std.Dev.
schoolid (Intercept) 41.87 6.471
Residual 10.57 3.251
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 652.7460 0.2726 2395From this output, we obtain estimates of our three model parameters:
\(\hat{\alpha}_{0}\) = 652.7 = the mean math score across all schools and all years
\(\hat{\sigma}^2\)= 10.6 = the variance in within-school deviations between individual scores and the school mean across all years
\(\hat{\sigma}^2_u\)= 41.9 = the variance in between-school deviations between school means and the overall mean across all schools and all years
Based on the intraclass correlation coefficient:
\[\begin{equation} \hat{\rho}=\frac{\hat{\sigma}^2_u}{\hat{\sigma}^2_u + \hat{\sigma}^2} = \frac{41.869}{41.869+10.571}= 0.798 \end{equation}\]79.8 percent of the total variation in math scores is attributable to difference among schools rather than changes over time within schools. We can also say that the average correlation for any pair of responses from the same school is 0.798.
9.5.2 Unconditional growth model
The second model in most multilevel contexts introduces a covariate at Level One (see Model B in Chapter 8). With longitudinal data, this second model introduces time as a predictor at Level One, but there are still no predictors at Level Two. This model is then called the unconditional growth model. The unconditional growth model allows us to assess how much of the within-school variability can be attributed to systematic changes over time.
At the lowest level, we can consider building individual growth models over time for each of the 618 schools in our study. First, we must decide upon a form for each of our 618 growth curves. Based on our initial exploratory analyses, assuming that an individual school’s MCA-II math scores follow a linear trend seems like a reasonable starting point. Under the assumption of linearity, we must estimate an intercept and a slope for each school, based on their 1-3 test scores over a period of three years. Compared to time series analyses of economic data, most longitudinal data analyses have relatively few time periods for each subject (or school), and the basic patterns within subject are often reasonably described by simpler functional forms.
Let \(Y_{ij}\) be the math score of the \(i^{th}\) school in year \(j\). Then we can model the linear change in math test scores over time for School \(i\) according to Model B:
\[\begin{equation} Y_{ij} = a_{i} + b_{i}Year08_{ij} + \epsilon_{ij} \textrm{ where } \epsilon_{ij} \sim N(0, \sigma^2) \end{equation}\]The parameters in this model \((a_{i}, b_{i},\) and \(\sigma^2)\) can be estimated through OLS methods. \(a_{i}\) represents the true intercept for School \(i\)—i.e., the expected test score level for School \(i\) when time is zero (2008)—while \(b_{i}\) represents the true slope for School \(i\)—i.e., the expected yearly rate of change in math score for School \(i\) over the three year observation period. Here we use Roman letters rather than Greek for model parameters since models by school will eventually be a conceptual first step in a multilevel model. The \(\epsilon_{ij}\) terms represent the deviation of School \(i\)’s actual test scores from the expected results under linear growth—the part of school \(i\)’s test score at time \(j\) that is not explained by linear changes over time. The variability in these deviations from the linear model is given by \(\sigma^2\). In Figure 9.17, which illustrates a linear growth model for Norwood Central Middle School, \(a_{i}\) is estimated by the \(y\)-intercept of the fitted regression line, \(b_{i}\) is estimated by the slope of the fitted regression line, and \(\sigma^2\) is estimated by the variability in the vertical distances between each point (the actual math score in year \(j\)) and the line (the predicted math score in year \(j\)).
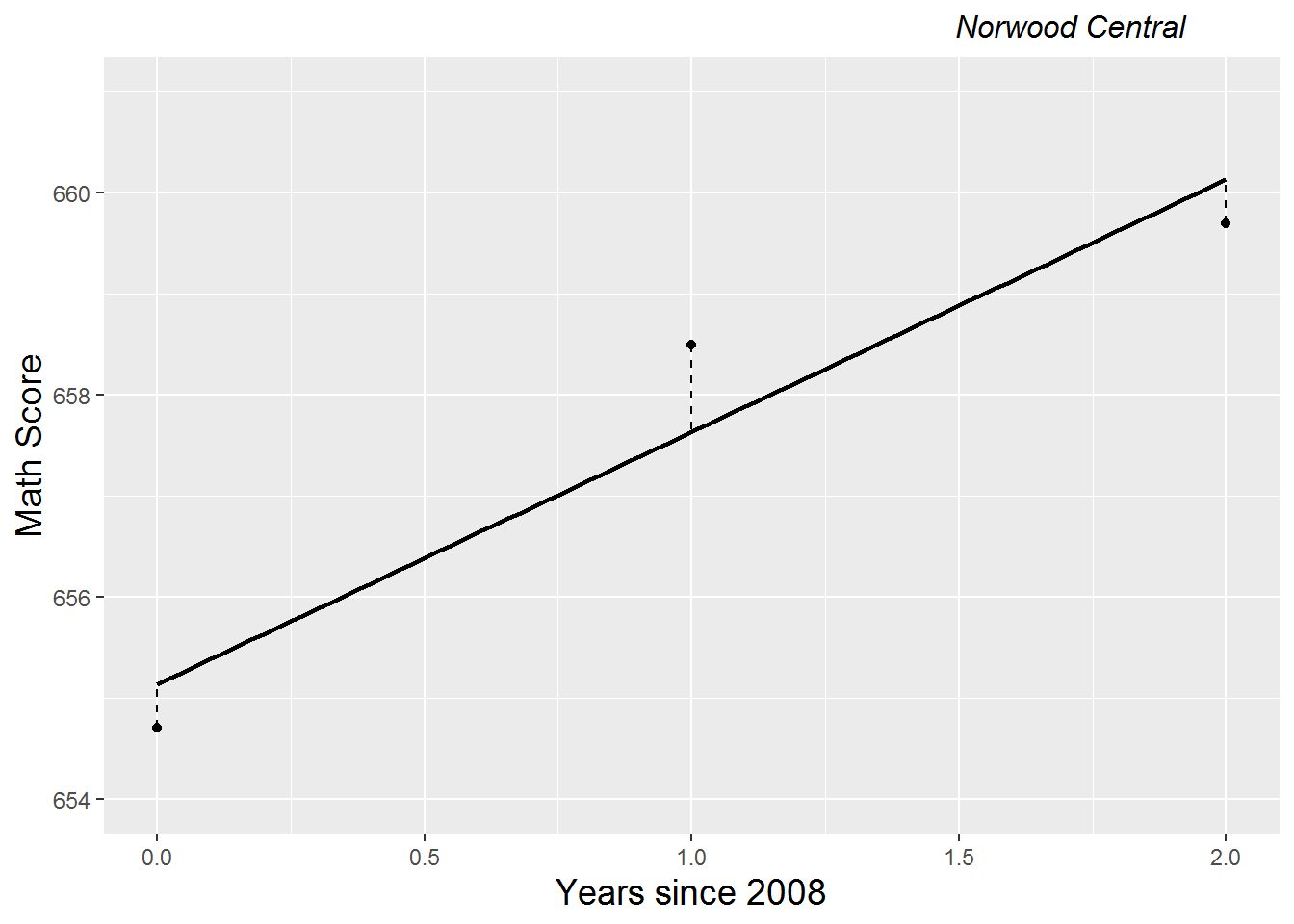
Figure 9.17: Linear growth model for Norwood Central Middle School
In a multilevel model, we let intercepts (\(a_{i}\)) and slopes (\(b_{i}\)) vary by school and build models for these intercepts and slopes using school-level variables at Level Two. An unconditional growth model features no predictors at Level Two and can be specified either using formulations at both levels:
- Level One: \[\begin{equation} Y_{ij}=a_{i}+b_{i}Year08_{ij} + \epsilon_{ij} \end{equation}\]
- Level Two: \[\begin{eqnarray*} a_{i}=\alpha_{0} + u_{i}\\ b_{i}=\beta_{0} + v_{i} \end{eqnarray*}\]
where \(\epsilon_{ij}\sim N(0,\sigma^2)\) and \[ \left[ \begin{array}{c} u_{i} \\ v_{i} \end{array} \right] \sim N \left( \left[ \begin{array}{c} 0 \\ 0 \end{array} \right], \left[ \begin{array}{cc} \sigma_{u}^{2} & \\ \sigma_{uv} & \sigma_{v}^{2} \end{array} \right] \right) . \]
As before, \(\sigma^2\) quantifies the within-school variability (the scatter of points around schools’ linear growth trajectories), while now the between-school variability is partitioned into variability in initial status \((\sigma^2_u)\) and variability in rates of change \((\sigma^2_v)\).
Using the composite model specification, the unconditional growth model can be fit to the MCA-II test data:
Formula: MathAvgScore ~ year08 + (year08 | schoolid)
Random effects:
Groups Name Variance Std.Dev. Corr
schoolid (Intercept) 39.4416 6.2803
year08 0.1105 0.3324 0.72
Residual 8.8200 2.9699
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 651.40766 0.27934 2331.95
year08 1.26496 0.08997 14.06 AIC = 10351.51
BIC = 10384.26From this output, we obtain estimates of our six model parameters:
- \(\hat{\alpha}_{0}\) = 651.4 = the mean math score for the population of schools in 2008.
- \(\hat{\beta}_{0}\) = 1.26 = the mean yearly change in math test scores for the population during the three year observation period.
- \(\hat{\sigma}^2\) = 8.82 = the variance in within-school deviations.
- \(\hat{\sigma}^2_u\) = 39.4 = the variance between schools in 2008 scores.
- \(\hat{\sigma}^2_v\) = 0.11 = the variance between schools in rates of change in math test scores during the three year observation period.
- \(\hat{\rho}_{uv}\) = 0.72 = the correlation in schools’ 2008 math score and their rate of change in scores between 2008 and 2010.
We see that schools had a mean math test score of 651.4 in 2008 and their mean test scores tended to increase by 1.26 points per year over the three year observation period, producing a mean test score at the end of three years of 653.9. According to the t-value (14.1), the increase in mean test scores noted during the three year observation period is statistically significant.
The estimated within-school variance \(\hat{\sigma}^2\) decreased by about 17% from the unconditional means model, implying that 17% of within-school variability in test scores can be explained by a linear increase over time:
\[\begin{equation} \textrm{Pseudo }R^2_{L1} = \frac{\hat{\sigma}^2(\textrm{uncond means}) - \hat{\sigma}^2(\textrm{uncond growth})}{\hat{\sigma^2}(\textrm{uncond means})} = \frac{10.571-8.820}{10.571}= 0.17 \end{equation}\]9.5.3 Modeling other trends over time
While modeling linear trends over time is often a good approximation of reality, it is by no means the only way to model the effect of time. One alternative is to model the quadratic effect of time, which implies adding terms for both time and the square of time. Typically, to reduce the correlation between the linear and quadratic components of the time effect, the time variable is often centered first; we have already “centered” on 2008. Modifying Model B to produce an unconditional quadratic growth model would take the following form:
- Level One: \[\begin{equation} Y_{ij}=a_{i}+b_{i}Year08_{ij}+c_{i}Year08^{2}_{ij} + \epsilon_{ij} \end{equation}\]
- Level Two: \[\begin{eqnarray*} a_{i} & = & \alpha_{0} + u_{i}\\ b_{i} & = & \beta_{0} + v_{i}\\ c_{i} & = & \gamma_{0} + w_{i} \end{eqnarray*}\] where \(\epsilon_{ij}\sim N(0,\sigma^2)\) and \[ \left[ \begin{array}{c} u_{i} \\ v_{i} \\ w_{i} \end{array} \right] \sim N \left( \left[ \begin{array}{c} 0 \\ 0 \\ 0 \end{array} \right], \left[ \begin{array}{ccc} \sigma_{u}^{2} & & \\ \sigma_{uv} & \sigma_{v}^{2} & \\ \sigma_{uw} & \sigma_{vw} & \sigma_{w}^{2} \end{array} \right] \right) . \]
\[\begin{eqnarray*} a_{i} & = & \alpha_{0} + u_{i}\\ b_{i} & = & \beta_{0}\\ c_{i} & = & \gamma_{0} \end{eqnarray*}\]
where \(u_{i}\sim N(0,\sigma^2_u)\). Models like this are frequently used in practice—they allow for a separate overall effect on test scores for each school while minimizing parameters that must be estimated. The tradeoff is that this model does not allow linear and quadratic effects to differ by school, but we have little choice here without more observations per school. Thus, using the composite model specification, the unconditional quadratic growth model with random intercept for each school can be fit to the MCA-II test data:
Formula: MathAvgScore ~ yearc + yearc2 + (1 | schoolid)
Random effects:
Groups Name Variance Std.Dev.
schoolid (Intercept) 43.050 6.561
Residual 8.523 2.919
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 651.94235 0.29229 2230.448
yearc 1.26993 0.08758 14.501
yearc2 1.06841 0.15046 7.101 AIC = 10308.16
BIC = 10335.45From this output, we see that the quadratic effect is positive and significant (t=7.1), in this case indicating that increases in test scores are greater between 2009 and 2010 than between 2008 and 2009. Based on AIC and BIC values, the quadratic growth model outperforms the linear growth model (AIC: 10308 vs. 10352; BIC: 10335 vs. 10384) with 1 fewer parameter to estimate in the quadratic growth model (1 extra fixed effect and 2 fewer variance components).
Another frequently used approach to modeling time effects is the piecewise linear model. In this model, the complete time span of the study is divided into two or more segments, with a separate slope relating time to the response in each segment. In our case study there is only one piecewise option—fitting separate slopes in 2008-09 and 2009-10. With only 3 time points, creating a piecewise linear model is a bit simplified, but this idea can be generalized to segments with more than two years each. Like the model for quadratic growth, we now have an extra equation at Level Two and must restrict our error terms to only the equation for the intercept:
- Level One: \[\begin{equation} Y_{ij}=a_{i}+b_{i}Year0809_{ij}+c_{i}Year0810_{ij} + \epsilon_{ij} \end{equation}\]
- Level Two: \[\begin{eqnarray*} a_{i} & = & \alpha_{0} + u_{i}\\ b_{i} & = & \beta_{0} \\ c_{i} & = & \gamma_{0} \end{eqnarray*}\] where error distributions are the same as in the unconditional quadratic growth model. Using the composite model specification, the piecewise linear growth model can be fit using statistical software:
Formula: MathAvgScore ~ year0809 + year0810 + (1 | schoolid)
Random effects:
Groups Name Variance Std.Dev.
schoolid (Intercept) 43.050 6.561
Residual 8.523 2.919
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 651.7408 0.2932 2222.750
year0809 0.2015 0.1753 1.149
year0810 2.5399 0.1752 14.501 AIC = 10306.77
BIC = 10334.06 The performance of this model is very similar to the quadratic growth model by AIC and BIC measures, and the story told by fixed effects estimates is also very similar. While the mean yearly increase in math scores was 0.2 points between 2008 and 2009, it was 2.3 points between 2009 and 2010.
Despite the good performances of the quadratic growth and piecewise linear models on our three-year window of data, we will continue to use linear growth assumptions in the remainder of this chapter. Not only is a linear model easier to interpret and explain, but it’s probably a more reasonable assumption in years beyond 2010. Predicting future performance is more risky by assuming a steep one year rise or a non-linear rise will continue, rather than by using the average increase over two years.
9.6 Building to a final model
9.6.1 Uncontrolled effects of school type
Initially, we can consider whether or not there are significant differences in individual school growth parameters (intercepts and slopes) based on school type. From a modeling perspective, we would build a system of two Level Two models:
\[\begin{eqnarray*} a_{i} & = & \alpha_{0} + \alpha_{1}Charter_i + u_{i} \\ b_{i} & = & \beta_{0} + \beta_{1}Charter_i + v_{i} \end{eqnarray*}\]where \(Charter_i=1\) if School \(i\) is a charter school and \(Charter_i=0\) if School \(i\) is a non-charter public school. In addition, the error terms at Level Two are assumed to follow a multivariate normal distribution:
\[ \left[ \begin{array}{c} u_{i} \\ v_{i} \end{array} \right] \sim N \left( \left[ \begin{array}{c} 0 \\ 0 \end{array} \right], \left[ \begin{array}{cc} \sigma_{u}^{2} & \\ \sigma_{uv} & \sigma_{v}^{2} \end{array} \right] \right) . \]
With a binary predictor at Level Two such as school type, we can write out what our Level Two model looks like for public non-charter schools and charter schools.
- Public schools
- Charter schools
Formula: MathAvgScore ~ charter + year08 + charter:year08 + (year08 |
-3.1935 -0.4710 0.0129 0.4660 3.4592
Random effects:
Groups Name Variance Std.Dev. Corr
schoolid (Intercept) 35.8318 5.9860
year08 0.1311 0.3621 0.88
Residual 8.7845 2.9639
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 652.05844 0.28449 2291.998
charter -6.01843 0.86562 -6.953
year08 1.19709 0.09427 12.698
charter:year08 0.85571 0.31430 2.723 AIC = 10307.6
BIC = 10351.26 Armed with our parameter estimates, we can offer concrete interpretations:
Fixed effects:
- \(\hat{\alpha}_{0} = 652.1.\) The estimated mean test score for 2008 for non-charter public schools is 652.1.
- \(\hat{\alpha}_{1}= -6.02.\) Charter schools have an estimated test score in 2008 which is 6.02 points lower than public non-charter schools.
- \(\hat{\beta}_{0}= 1.20.\) Public non-charter schools have an estimated mean increase in test scores of 1.20 points per year.
- \(\hat{\beta}_{1}= 0.86.\) Charter schools have an estimated mean increase in test scores of 2.06 points per year over the three year observation period, 0.86 points higher than the mean yearly increase among public non-charter schools.
Variance components:
- \(\hat{\sigma}_u= 5.99.\) The estimated standard deviation of 2008 test scores is 5.99 points, after controlling for school type.
- \(\hat{\sigma}_v= 0.36.\) The estimated standard deviation of yearly changes in test scores during the three year observation period is 0.36 points, after controlling for school type.
- \(\hat{\rho}_{uv}= 0.88.\) The estimated correlation between 2008 test scores and yearly changes in test scores is 0.88, after controlling for school type.
- \(\hat{\sigma}= 2.96.\) The estimated standard deviation in residuals for the individual growth curves is 2.96 points.
Based on t-values reported by R, the effects of year08 and charter both appear to be statistically significant, and there is also significant evidence of an interaction between year08 and charter. Public schools had a significantly higher mean math score in 2008, while charter schools had significantly greater improvement in scores between 2008 and 2010 (although the mean score of charter schools still lagged behind that of public schools in 2010, as indicated in the graphical comparison of models B and C in Figure 9.18). Based on pseudo R-square values, the addition of a charter school indicator to the unconditional growth model has decreased unexplained school-to-school variability in 2008 math scores by 4.7%, while unexplained variability in yearly improvement actually increased slightly. Obviously, it makes little sense that introducing an additional predictor would reduce the amount of variability in test scores explained, but this is an example of the limitations in the pseudo \(R^2\) values discussed in Section 8.7.2.
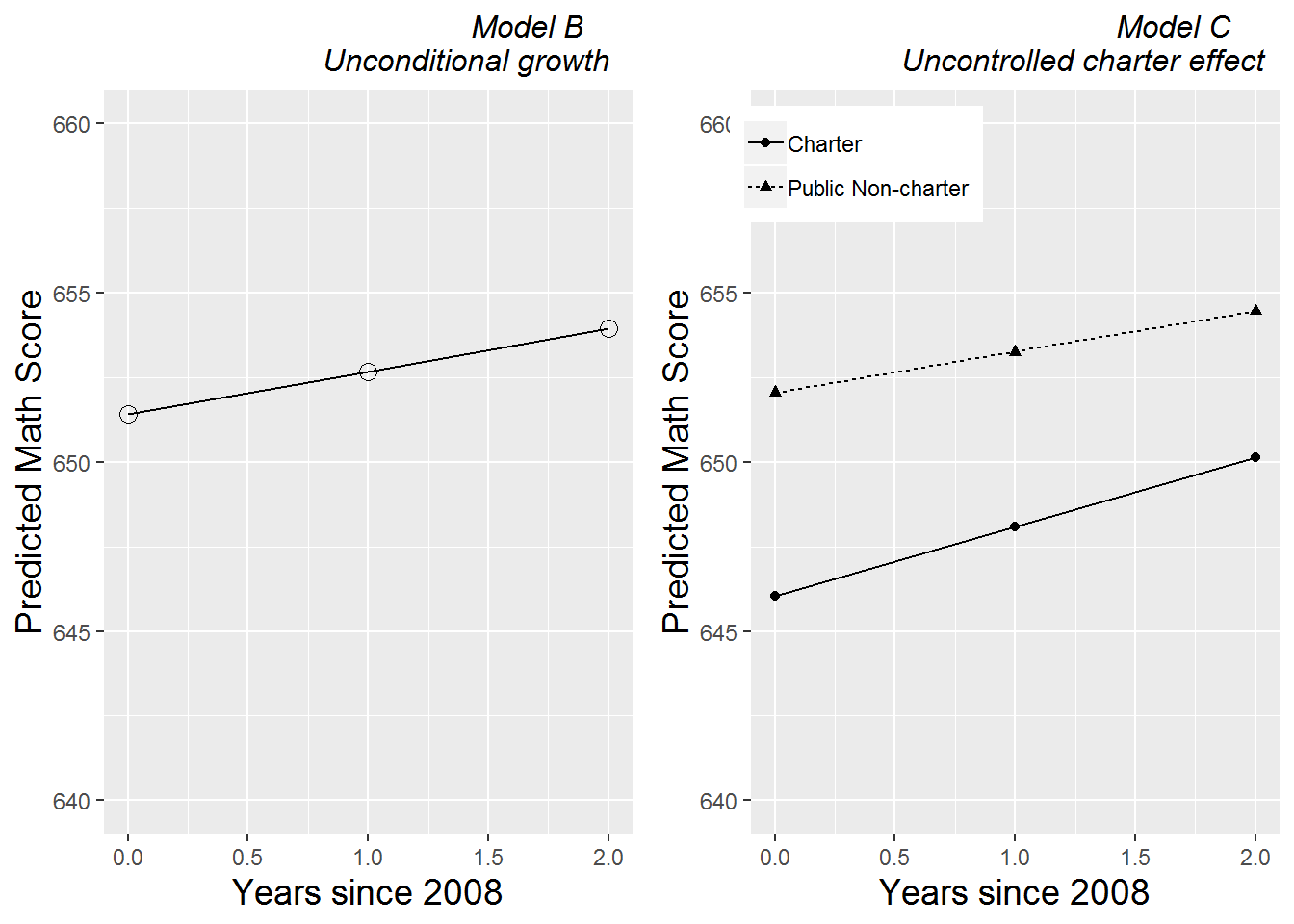
Figure 9.18: Fitted growth curves for Models B and C.
9.6.2 Add percent free and reduced lunch as a covariate
Although we will still be primarily interested in the effect of school type on both 2008 test scores and rate of change in test scores (as we observed in Model C), we can try to improve our estimates of school type effects through the introduction of meaningful covariates. In this study, we are particularly interested in Level Two covariates—those variables which differ by school but which remain basically constant for a given school over time—such as urban or rural location, percentage of special education students, and percentage of students with free and reduced lunch. In Section 9.4, we investigated the relationship between percent free and reduced lunch and a school’s test score in 2008 and their rate of change from 2008 to 2010.
Based on these analyses, we will begin by adding percent free and reduced lunch as a Level Two predictor for both intercept and slope (Model D):
- Level One: \[\begin{equation} Y_{ij}=a_{i} + b_{i}Year08_{ij} + \epsilon_{ij} \end{equation}\]
- Level Two: \[\begin{eqnarray*} a_{i} & = & \alpha_{0} + \alpha_{1}Charter_i + \alpha_{2}schpctfree_i + u_{i}\\ b_{i} & = & \beta_{0} + \beta_{1}Charter_i + \beta_{2}schpctfree_i + v_{i} \end{eqnarray*}\]
The composite model is then:
\[\begin{equation} Y_{ij}= [\alpha_{0}+\alpha_{1}Charter_i +\alpha_{2}schpctfree_i + \beta_{0}Year08_{ij} + \beta_{1}Charter_iYear08_{ij} + \\ \beta_{2}schpctfree_iYear08_{ij}] + [u_{i} + v_{i}Year08_{ij} + \epsilon_{ij}] \end{equation}\]where error terms are defined as in Model C.
Formula: MathAvgScore ~ charter + SchPctFree + year08 + charter:year08 +
SchPctFree:year08 + (year08 | schoolid)
Random effects:
Groups Name Variance Std.Dev. Corr
schoolid (Intercept) 19.1318 4.3740
year08 0.1603 0.4004 0.51
Residual 8.7981 2.9662
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 659.278483 0.444688 1482.565
charter -3.439938 0.712832 -4.826
SchPctFree -0.166539 0.008907 -18.697
year08 1.641369 0.189499 8.662
charter:year08 0.980755 0.318583 3.078
SchPctFree:year08 -0.010409 0.003839 -2.711 AIC = 9988.308
BIC = 10042.88 Compared to Model C, the introduction of school-level poverty based on percentage of students receiving free and reduced lunch in Model D leads to similar conclusions about the significance of the charter school effect on both the intercept and the slope, although the magnitude of these estimates change after controlling for poverty levels. The estimated gap in test scores between charter and non-charter schools in 2008 is smaller in Model D, while estimates of improvement between 2008 and 2010 increase for both types of schools. Inclusion of free and reduced lunch reduces the unexplained variability between schools in 2008 math scores by 27%, while unexplained variability in rates of change between schools again increases slightly based on pseudo \(R^2\) values. A likelihood ratio test using maximum likelihood estimates illustrates that adding free and reduced lunch as a Level Two covariate significantly improves our model (\(\chi^2 = 341.5, df=2, p<.001\)). Specific fixed effect parameter estimates are given below:
\(\hat{\alpha}_{0}= 659.3.\) The estimated mean math test score for 2008 is 659.3 for non-charter public schools with no students receiving free and reduced lunch.
\(\hat{\alpha}_{1}= -3.44.\) Charter schools have an estimated mean math test score in 2008 which is 3.44 points lower than non-charter public schools, controlling for effects of school-level poverty.
\(\hat{\alpha}_{2}= -0.17.\) Each 10% increase in the percentage of students at a school receiving free and reduced lunch is associated with a 1.7 point decrease in mean math test scores for 2008, after controlling for school type.
\(\hat{\beta}_{0}= 1.64.\) Public non-charter schools with no students receiving free and reduced lunch have an estimated mean increase in math test score of 1.64 points per year during the three years of observation.
\(\hat{\beta}_{1}= 0.98.\) Charter schools have an estimated mean yearly increase in math test scores over the three year observation period of 2.62, which is 0.98 points higher than the annual increase for public non-charter schools, after controlling for school-level poverty.
\(\hat{\beta}_{2}= -0.010.\) Each 10% increase in the percentage of students at a school receiving free and reduced lunch is associated with a 0.10 point decrease in rate of change over the three years of observation, after controlling for school type.
9.6.3 A potential final model with three Level Two covariates
We now begin iterating toward a “final model” for these data, on which we will base conclusions. Being cognizant of typical features of a “final model” as outlined in Chapter 8, we offer one possible final model for this data—Model F:
- Level One: \[\begin{equation} Y_{ij}= a_{i} + b_{i}Year08_{ij} + \epsilon_{ij} \end{equation}\]
- Level Two: \[\begin{eqnarray*} a_{i} & = & \alpha_{0} + \alpha_{1}Charter_i + \alpha_{2}urban_i + \alpha_{3}schpctsped_i + \alpha_{4}schpctfree_i + u_{i} \\ b_{i} & = & \beta_{0} + \beta_{1}Charter_i + \beta_{2}urban_i + \beta_{3}schpctsped_i + v_{i} \end{eqnarray*}\]
where we find the effect of charter schools on 2008 test scores after adjusting for urban or rural location, percentage of special education students, and percentage of students that receive free or reduced lunch, and the effect of charter schools on yearly change between 2008 and 2010 after adjusting for urban or rural location and percentage of special education students. We can use AIC and BIC criteria to compare Model F with Model D, since the two models are not nested. By both criteria, Model F is significantly better than Model D: AIC of 9855 vs. 9988, and BIC of 9956 vs. 10043. Based on the R output below, we offer interpretations for estimates of model fixed effects:
Formula:
MathAvgScore ~ charter + urban + SchPctFree + SchPctSped + charter:year08 +
-3.2959 -0.4966 0.0121 0.4727 4.0825
Random effects:
Groups Name Variance Std.Dev. Corr
schoolid (Intercept) 16.946784 4.11665
year08 0.003426 0.05853 1.00
Residual 8.823187 2.97038
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 661.010451 0.512890 1288.796
charter -3.222815 0.698546 -4.614
urban -1.113831 0.427568 -2.605
SchPctFree -0.152814 0.008096 -18.874
SchPctSped -0.117703 0.020612 -5.710
year08 2.144274 0.200852 10.676
charter:year08 1.030848 0.315137 3.271
urban:year08 -0.527497 0.186466 -2.829
SchPctSped:year08 -0.046740 0.010165 -4.598 AIC = 9884.646
BIC = 9955.595 - \(\hat{\alpha}_{0}= 661.0.\) The estimated mean math test score for 2008 is 661.0 for public schools in rural areas with no students qualifying for special education or free and reduced lunch.
- \(\hat{\alpha}_{1}= -3.22.\) Charter schools have an estimated mean math test score in 2008 which is 3.22 points lower than non-charter public schools, after controlling for urban or rural location, percent special education, and percent free and reduced lunch.
- \(\hat{\alpha}_{2}= -1.11.\) Schools in urban areas have an estimated mean math score in 2008 which is 1.11 points lower than schools in rural areas, after controlling for school type, percent special education, and percent free and reduced lunch.
- \(\hat{\alpha}_{3}= -0.118.\) A 10% increase in special education students at a school is associated with a 1.18 point decrease in estimated mean math score for 2008, after controlling for school type, urban or rural location, and percent free and reduced lunch.
- \(\hat{\alpha}_{4}= -0.153.\) A 10% increase in free and reduced lunch students at a school is associated with a 1.53 point decrease in estimated mean math score for 2008, after controlling for school type, urban or rural location, and percent special education.
- \(\hat{\beta}_{0}= 2.14.\) Public non-charter schools in rural areas with no students qualifying for special education have an estimated increase in mean math test score of 2.14 points per year over the three year observation period, after controlling for percent of students receiving free and reduced lunch.
- \(\hat{\beta}_{1}= 1.03.\) Charter schools have an estimated mean annual increase in math score that is 1.03 points higher than public non-charter schools over the three year observation period, after controlling for urban or rural location, percent special education, and percent free and reduced lunch.
- \(\hat{\beta}_{2}= -0.53.\) Schools in urban areas have an estimated mean annual increase in math score that is 0.53 points lower than schools from rural areas over the three year observation period, after controlling for school type, percent special education, and percent free and reduced lunch.
- \(\hat{\beta}_{3}= -0.047.\) A 10% increase in special education students at a school is associated with an estimated mean annual increase in math score that is 0.47 points lower over the three year observation period, after controlling for school type, urban or rural location, and percent free and reduced lunch.
From this model, we again see that 2008 sixth grade math test scores from charter schools were significantly lower than similar scores from public non-charter schools, after controlling for school location and demographics. However, charter schools showed significantly greater improvement between 2008 and 2010 compared to public non-charter schools, although charter school test scores were still lower than public school scores in 2010, on average. We also tested several interactions between Level Two covariates and charter schools and found none to be significant, indicating that the 2008 gap between charter schools and public non-charter schools was consistent across demographic subgroups. The faster improvement between 2008 and 2010 for charter schools was also consistent across demographic subgroups (found by testing three-way interactions). Controlling for school location and demographic variables provided more reliable and nuanced estimates of the effects of charter schools, while also providing interesting insights. For example, schools in rural areas not only had higher test scores than schools in urban areas in 2008, but the gap grew larger over the study period given fixed levels of percent special education, percent free and reduced lunch, and school type. In addition, schools with higher levels of poverty lagged behind other schools and showed no signs of closing the gap, and schools with higher levels of special education students had both lower test scores in 2008 and slower rates of improvement during the study period, again given fixed levels of other covariates.
As we demonstrated in this case study, applying multilevel methods to two-level longitudinal data yields valuable insights about our original research questions while properly accounting for the structure of the data.
9.7 Covariance structure among observations
Part of our motivation for framing our model for multilevel data was to account for the correlation among observations made on the same school (the Level Two observational unit). Our two-level model, through error terms on both Level One and Level Two variables, actually implies a specific within-school covariance structure among observations, yet we have not (until now) focused on this imposed structure; for example:
- What does our two-level model say about the relative variability of 2008 and 2010 scores from the same school?
- What does it say about the correlation between 2008 and 2009 scores from the same school?
In this section, we will describe the within-school covariance structure imposed by our two-level model and offer alternative covariance structures that we might consider, especially in the context of longitudinal data. In short, we will discuss how we might decide if our implicit covariance structure in our two-level model is satisfactory for the data at hand. Then, in the succeeding optional section, we provide derivations of the imposed within-school covariance structure for our standard two-level model using results from probability theory.
9.7.1 Standard covariance structure
We will use Model C (uncontrolled effects of school type) to illustrate covariance structure within subjects. Recall that, in composite form, Model C is: \[\begin{eqnarray*} Y_{ij} & = & a_{i}+b_{i}Year08_{ij}+ \epsilon_{ij} \\ & = & (\alpha_{0}+ \alpha_{1}Charter_i + u_{i}) + (\beta_{0}+\beta_{1}Charter_i +v_{i}) Year08_{ij} + \epsilon_{ij} \\ & = & [\alpha_{0}+\alpha_{1}Charter_i + \beta_{0}Year08_i + \beta_{1}Charter_iYear08_{ij}] + [u_{i} + v_{i}Year08_{ij} + \epsilon_{ij}] \end{eqnarray*}\]where \(\epsilon_{ij}\sim N(0,\sigma^2)\) and \[ \left[ \begin{array}{c} u_{i} \\ v_{i} \end{array} \right] \sim N \left( \left[ \begin{array}{c} 0 \\ 0 \end{array} \right], \left[ \begin{array}{cc} \sigma_{u}^{2} & \\ \sigma_{uv} & \sigma_{v}^{2} \end{array} \right] \right) . \]
For School \(i\), the covariance structure for the three time points has general form: \[ Cov(\mathbf{Y}_i) = \left[ \begin{array}{cccc} Var(Y_{i1}) & Cov(Y_{i1},Y_{i2}) & Cov(Y_{i1},Y_{i3}) \\ Cov(Y_{i1},Y_{i2}) & Var(Y_{i2}) & Cov(Y_{i2},Y_{i3}) \\ Cov(Y_{i1},Y_{i3}) & Cov(Y_{i2},Y_{i3}) & Var(Y_{i3}) \end{array} \right] \] where, for instance, \(Var(Y_{i1})\) is the variability in 2008 test scores (time \(j=1\)), \(Cov(Y_{i1},Y_{i2})\) is the covariance between 2008 and 2009 test scores (times \(j=1\) and \(j=2\)), etc. Since covariance measures the tendency of two variables to move together, we expect positive values for all three covariance terms in \(Cov(\mathbf{Y}_i)\), since schools with relatively high test scores in 2008 are likely to also have relatively high test scores in 2009 or 2010. The correlation between two variables then scales covariance terms to values between -1 and 1, so by the same rationale, we expect correlation coefficients between two years to be near 1. If observations within school were independent—that is, knowing a school had relatively high scores in 2008 tells nothing about whether that school will have relatively high scores in 2009 or 2010—then we would expect covariance and correlation values near 0.
It is important to notice that the error structure at Level Two is not the same as the within-school covariance structure among observations. That is, the relationship between \(u_{i}\) and \(v_{i}\) from the Level Two equations is not the same as the relationship between test scores from different years at the same school (e.g., the relationship between \(Y_{i1}\) and \(Y_{i2}\)). In other words, \[ Cov(\mathbf{Y}_i) \neq \left[ \begin{array}{c} u_{i} \\ v_{i} \end{array} \right] \sim N \left( \left[ \begin{array}{c} 0 \\ 0 \end{array} \right], \left[ \begin{array}{cc} \sigma_{u}^{2} & \\ \sigma_{uv} & \sigma_{v}^{2} \end{array} \right] \right) . \] Yet, the error structure and the covariance structure are connected to each other, as we will now explore.
Using results from probability theory (see Section 9.7.5), we can show that: \[\begin{eqnarray*} Var(Y_{ij}) & = & \sigma_{u}^{2} + t^{2}_{ij} \sigma_{v}^{2} + \sigma^{2} + 2t_{ij}\sigma_{uv}, \\ Cov(Y_{ij},Y_{ik}) & = & \sigma_{u}^{2} + t_{ij}t_{ik} \sigma_{v}^{2} + (t_{ij}+t_{ik})\sigma_{uv} \end{eqnarray*}\]for all \(i\), where our time variable (year08) has values \(t_{i1}=0\), \(t_{i2}=1\), and \(t_{i3}=2\) for every School \(i\). Intuitively, these formulas are sensible. For instance, \(Var(Y_{i1})\), the uncertainty (variability) around a school’s score in 2008, increases as the uncertainty in intercepts and slopes increases, as the uncertainty around that school’s linear time trend increases, and as the covariance between intercept and slope residuals increases (since if one is off, the other one is likely off as well). Also, \(Cov(Y_{i1},Y_{i2})\), the covariance between 2008 and 2009 scores, does not depend on Level One error. Thus, in the 3-by-3 within-school covariance structure of the charter schools case study, our standard two-level model determines all 6 covariance matrix elements through the estimation of four parameters (\(\sigma_{u}^{2}, \sigma_{uv}, \sigma_{v}^{2}, \sigma^2\)) and the imposition of a specific structure related to time.
In fact, these values will be identical for every School \(i\), since scores were assessed at the same three time points. Thus, we will drop the \(i\) subscript moving forward.
Written in matrix form, our two-level model implicitly imposes this estimated covariance structure on within-school observations for any specific School \(i\): \[ \hat{Cov}(\mathbf{Y}) = \left[ \begin{array}{cccc} 44.66 & & \\ 37.77 & 48.50 & \\ 39.58 & 41.84 & 52.80 \end{array} \right] \] and this estimated covariance matrix can be converted into an estimated within-school correlation matrix using the identity \(Corr(Y_{1},Y_{2})=\frac{Cov(Y_{1},Y_{2})}{Var(Y_{1}) Var(Y_{2})}\): \[ \hat{Corr}(\mathbf{Y}) = \left[ \begin{array}{cccc} 1 & & \\ .812 & 1 & \\ .815 & .827 & 1 \end{array} \right] \]
A couple of features of these two matrices can be highlighted that offer insights into implications of our standard two-level model on the covariance structure among observations at Level One from the same school:
- Many longitudinal data sets show higher correlation for observations that are closer in time. In this case, we see that correlation is very consistent between all pairs of observations from the same school; the correlation between test scores separated by two years (.815) is approximately the same as the correlation between test scores separated by a single year (.812 for 2008 and 2009 scores; .827 for 2009 and 2010 scores).
- Many longitudinal data sets show similar variability at all time points. In this case, the variability in 2010 (52.80) is about 18% greater than the variability in 2008 (44.66), while the variability in 2009 is in between (48.50).
- Our two-level model actually imposes a quadratic structure on the relationship between variance and time; note that the equation for \(Var(Y_{j})\) contains both \(t^{2}_{j}\) and \(t_{j}\). The variance is therefore minimized at \(t=\frac{-\sigma_{uv}}{\sigma^{2}_{v}}\). With the charter school data, the variance in test scores is minimized when \(t=\frac{-\sigma_{uv}}{\sigma^{2}_{v}}=\frac{-1.81}{0.23}=-8.0\); that is, the smallest within-school variance in test scores is expected 8.0 years prior to 2008 (i.e., in 2000), and the variance increases parabolically from there. In general, cases in which \(\sigma^{2}_{v}\) and \(\sigma_{uv}\) are relatively small have little curvature and fairly consistent variability over time.
- There is no requirement that time points within school need to be evenly spaced or even that each school has an equal number of measurements over time, which makes the two-level model structure nicely flexible.
9.7.2 Alternative covariance structures
The standard covariance structure that’s implied by our multilevel modeling structure provides a useful model in a wide variety of situations—it provides a reasonable model for Level One variability with a relatively small number of parameters, and it has sufficient flexibility to accommodate irregular time intervals as well as subjects with different number of observations over time. However, there may be cases in which a better fitting model requires additional parameters, or when a simpler model with fewer parameters still provides a good fit to the data. Here is an outline of a few alternative error structures:
- Unstructured - Every variance and covariance term for observations within a school is a separate parameter and is therefore estimated uniquely; no patterns among variances or correlations are assumed. This structure offers maximum flexibility but is most costly in terms of parameters estimated.
- Compound symmetry - Assume variance is constant across all time points and correlation is constant across all pairs of time points. This structure is highly restrictive but least costly in terms of parameters estimated.
- Autoregressive - Assume variance is constant across all time points, but correlation drops off in a systematic fashion as the gap in time increases. Autoregressive models expand compound symmetry by allowing for a common structure where points closest in time are most highly correlated.
- Toeplitz - Toeplitz is similar to the autoregressive model, except that it does not impose any structure on the decline in correlation as time gaps increase. Thus, it requires more parameters to be estimated than the autoregressive model while providing additional flexibility.
- Heterogeneous variances - The assumption that variances are equal across time points found in the compound symmetry, autoregressive, and Toeplitz models can be relaxed by introducing additional parameters to allow unequal (heterogeneous) variances.
When the focus of an analysis is on stochastic parameters (variance components) rather than fixed effects, parameter estimates are typically based on restricted maximum likelihood (REML) methods; model performance statistics then reflect only the stochastic portion of the model. Models with the same fixed effects but different covariance structures can be compared as usual—with AIC and BIC measures when models are not nested and with likelihood ratio tests when models are nested. However, using a chi-square distribution to conduct a likelihood ratio test in these cases can often produce a conservative test, with p-values that are too large and not rejected enough (Raudenbush and Bryk (2002); Singer and Willett (2003); J. Faraway (2005)). In Section 10.6, we introduce the parametric bootstrap as a potentially better way of testing models nested in their random effects.
9.7.3 Covariance structure in non-longitudinal multilevel models
Careful modeling and estimation of the Level One covariance matrix is especially important and valuable for longitudinal data (with time at Level One) and as we’ve seen, our standard two-level model has several nice properties for this purpose. The standard model is also often appropriate for non-longitudinal multilevel models as discussed in Chapter 8, although we must remain aware of the covariance structure implicitly imposed. In other words, the ideas in this section generalize even if time isn’t a Level One covariate.
As an example, in Case Study 8.2 where Level One observational units are musical performances rather than time points, the standard model implies the following covariance structure for Musician \(i\) in Model C, which uses an indicator for large ensembles as a Level One predictor: \[\begin{eqnarray*} Var(Y_{ij}) & = & \sigma_{u}^{2} + \textstyle{Large}^{2}_{ij} \sigma_{v}^{2} + \sigma^{2} + 2\textstyle{Large}_{ij}\sigma_{uv} \\ & = & \left\{ \begin{array}{ll} \sigma^{2} + \sigma_{u}^{2} & \mbox{if $\textstyle{Large}_{ij}=0$} \\ \sigma^{2} + \sigma_{u}^{2} + \sigma_{v}^{2} + 2\sigma_{uv} & \mbox{if $\textstyle{Large}_{ij}=1$} \end{array} \right. \end{eqnarray*}\] and \[\begin{eqnarray*} Cov(Y_{ij},Y_{ik}) & = & \sigma_{u}^{2} + \textstyle{Large}_{ij}\textstyle{Large}_{ik} \sigma_{v}^{2} + (\textstyle{Large}_{ij} + \textstyle{Large}_{ik}) \sigma_{uv} \\ & = & \left\{ \begin{array}{ll} \sigma_{u}^{2} & \mbox{if $\textstyle{Large}_{ij}=\textstyle{Large}_{ik}=0$} \\ \sigma_{u}^{2} + \sigma_{uv} & \mbox{if $\textstyle{Large}_{ij}=0$ and $\textstyle{Large}_{ik}=1$ or vice versa} \\ \sigma_{u}^{2} + \sigma_{v}^{2} + 2\sigma_{uv} & \mbox{if $\textstyle{Large}_{ij}=\textstyle{Large}_{ik}=1$} \end{array} \right. \end{eqnarray*}\]Note that, in the Music Performance Anxiety case study, each subject will have a unique Level One variance-covariance structure, since each subject has a different number of performances and a different mix of large ensemble and small ensemble or solo performances.
9.7.4 Final thoughts regarding covariance structures
In the charter school example, as is often true in multilevel models, the choice of covariance matrix does not greatly affect estimates of fixed effects. The choice of covariance structure could potentially impact the standard errors of fixed effects, and thus the associated test statistics, but the impact appears minimal in this particular case study. In fact, the standard model typically works very well. So is it worth the time and effort to accurately model the covariance structure? If primary interest is in inference regarding fixed effects, and if the standard errors for the fixed effects appear robust to choice of covariance structure, then extensive time spent modeling the covariance structure is not advised. However, if researchers are interested in predicted random effects and estimated variance components in addition to estimated fixed effects, then choice of covariance structure can make a big difference. For instance, if researchers are interested in drawing conclusions about particular schools rather than charter schools in general, they may more carefully model the covariance structure in this study.
9.7.5 Details of covariance structures (Optional)
Using Model C as specified in Section 9.7.1, we specified the general covariance structure for School \(i\) as: \[ Cov(\mathbf{Y}_i) = \left[ \begin{array}{cccc} Var(Y_{i1}) & Cov(Y_{i1},Y_{i2}) & Cov(Y_{i1},Y_{i3}) \\ Cov(Y_{i1},Y_{i2}) & Var(Y_{i2}) & Cov(Y_{i2},Y_{i3}) \\ Cov(Y_{i1},Y_{i3}) & Cov(Y_{i2},Y_{i3}) & Var(Y_{i3}) \end{array} \right] \] If \(Y_1 = a_1 X_1 + a_2 X_2 + a_3\) and \(Y_2 = b_1 X_1 + b_2 X_2 + b_3\) where \(X_1\) and \(X_2\) are random variables and \(a_i\) and \(b_i\) are constants for \(i=1,2,3\), then we know from probability theory that: \[\begin{eqnarray*} Var(Y_1) & = & a^{2}_{1} Var(X_1) + a^{2}_{2} Var(X_2) + 2 a_1 a_2 Cov(X_1,X_2) \\ Cov(Y_1,Y_2) & = & a_1 b_1 Var(X_1) + a_2 b_2 Var(X_2) + (a_1 b_2 + a_2 b_1) Cov(X_1,X_2) \end{eqnarray*}\] Applying these identities to Model C, we first see that we can ignore all fixed effects, since they do not contribute to the variability. Thus, \[\begin{eqnarray*} Var(Y_{ij}) & = & Var(u_{i}+v_{i}\textstyle{Year08}_{ij}+\epsilon_{ij}) \\ & = & Var(u_{i}) + \textstyle{Year08}^{2}_{ij} Var(v_{i}) + Var(\epsilon_{ij}) + 2\textstyle{Year08}_{ij} Cov(u_{i},v_{i}) \\ & = & \sigma_{u}^{2} + \textstyle{Year08}^{2}_{ij} \sigma_{v}^{2} + \sigma^{2} + 2\textstyle{Year08}_{ij}\sigma_{uv} \\ & = & \sigma_{u}^{2} + t^{2}_{j} \sigma_{v}^{2} + \sigma^{2} + 2t_{j}\sigma_{uv} \end{eqnarray*}\] where the last line reflects the fact that observations were taken at the same time points for all schools. We can derive the covariance terms in a similar fashion: \[\begin{eqnarray*} Cov(Y_{ij},Y_{ik}) & = & Cov(u_{i}+ v_{i}\textstyle{Year08}_{ij}+\epsilon_{ij}, u_{i}+v_{i}\textstyle{Year08}_{ik}+\epsilon_{ik}) \\ & = & Var(u_{i}) + \textstyle{Year08}_{ij}\textstyle{Year08}_{ik} Var(v_{i}) + (\textstyle{Year08}_{ij} + \textstyle{Year08}_{ik}) Cov(u_{i},v_{i}) \\ & = & \sigma_{u}^{2} + t_{j}t_{k} \sigma_{v}^{2} + (t_{j}+t_{k})\sigma_{uv} \end{eqnarray*}\]In Model C, we obtained the following estimates of variance components: \(\hat{\sigma}^{2}=8.69\), \(\hat{\sigma}^{2}_{u}=35.97\), \(\hat{\sigma}^{2}_{v}=0.23\), and \(\hat{\sigma}_{uv}=\hat{\rho}\hat{\sigma_{u}}\hat{\sigma_{v}}=1.81\). Therefore, our two level model implicitly imposes this covariance structure on within subject observations: \[ Cov(\mathbf{Y}_i) = \left[ \begin{array}{cccc} 44.66 & & \\ 37.77 & 48.50 & \\ 39.58 & 41.84 & 52.80 \end{array} \right] \] and this covariance matrix can be converted into a within-subject correlation matrix: \[ Corr(\mathbf{Y}_i) = \left[ \begin{array}{cccc} 1 & & \\ .812 & 1 & \\ .815 & .827 & 1 \end{array} \right] \]
9.8 Notes on Using R (Optional)
The model below is our final model with \(\sigma_{uv}\) set to 0—i.e., we have added the restriction that Level Two error terms are uncorrelated. Motivation for this restriction came from repeated estimates of correlation in different versions of the final model near 1, when empirically a slightly negative correlation might be expected. As we will describe in Chapter 10, inclusion of the Level Two correlation as a model parameter appears to lead to boundary constraints—maximum likelihood parameter estimates near the maximum or minimum allowable value for a parameter. A likelihood ratio test using full maximum likelihood estimates confirms that the inclusion of a correlation term does not lead to an improved model (LRT test statistic = .223 on 1 df, \(p=.637\)). Estimates of fixed effects and their standard errors are extremely consistent with the full model in Section 9.6.3; only the estimates of the variability in \(\sigma_{1}\) is noticeably higher.
# Modified final model
model.f2a <- lmer(MathAvgScore ~ charter + urban + SchPctFree +
SchPctSped + charter:year08 + urban:year08 +
SchPctSped:year08 + year08 +
(1|schoolid) + (0+year08|schoolid), REML=T, data=chart.long)
# print(summary(model.f2a), correlation=FALSE, show.resids=FALSE)
tmp <- capture.output(summary(model.f2a))
cat(tmp[c(2:4, 12:31)], sep='\n')Formula:
MathAvgScore ~ charter + urban + SchPctFree + SchPctSped + charter:year08 +
urban:year08 + SchPctSped:year08 + year08 + (1 | schoolid) +
-3.3109 -0.4960 0.0150 0.4728 4.0940
Random effects:
Groups Name Variance Std.Dev.
schoolid (Intercept) 17.3551 4.1659
schoolid.1 year08 0.1139 0.3375
Residual 8.7163 2.9523
Number of obs: 1733, groups: schoolid, 618
Fixed effects:
Estimate Std. Error t value
(Intercept) 661.017692 0.515461 1282.382
charter -3.224687 0.703173 -4.586
urban -1.116628 0.430421 -2.594
SchPctFree -0.152945 0.008096 -18.890
SchPctSped -0.117770 0.020739 -5.679
year08 2.142708 0.202090 10.603
charter:year08 1.033413 0.317175 3.258
urban:year08 -0.524420 0.187679 -2.794
SchPctSped:year08 -0.046722 0.010219 -4.572cat(" AIC = ", AIC(model.f2a), '\n', "BIC = ", BIC(model.f2a)) AIC = 9882.823
BIC = 9948.314# LRT comparing final model in chapter (model.f2ml) with maximum
# likelihood estimates to modified final model (model.f2aml)
# with uncorrelated Level Two errors.
anova(model.f2ml,model.f2aml)...
Df AIC BIC logLik deviance Chisq Chi Df Pr(>Chisq)
model.f2aml 12 9855.5 9920.9 -4915.7 9831.5
model.f2ml 13 9857.2 9928.2 -4915.6 9831.2 0.2231 1 0.6367
...9.9 Exercises
9.9.1 Conceptual Exercises
Parenting and Gang Activity. Walker-Barnes and Mason (2001) describe “Ethnic differences in the effect of parenting on gang involvement and gang delinquency: a longitudinal, hierarchical linear modeling perspective”. In this study, 300 ninth graders from one high school in an urban southeastern city were assessed at the beginning of the school year about their gang activity, the gang activity of their peers, behavior of their parents, and their ethnic and cultural heritage. Then, information about their gang activity was collected at 7 additional occasions during the school year. For this study: (a) give the observational units at Level One and Level Two, and (b) list potential explanatory variables at both Level One and Level Two.
Describe the difference between the wide and long formats for longitudinal data in this study.
Describe scenarios or research questions in which a lattice plot would be more informative than a spaghetti plot, and other scenarios or research questions in which a spaghetti plot would be preferable to a lattice plot.
Walker-Barnes and Mason summarize their analytic approach in the following way:
The first series [of analyses] tested whether there was overall change and/or significant individual variability in gang [activity] over time, regardless of parenting behavior, peer behavior, or ethnic and cultural heritage. Second, given the well documented relation between peer and adolescent behavior . . . HLM analyses were conducted examining the effect of peer gang [activity] on [initial gang activity and] changes in gang [activity] over time. Finally, four pairs of analyses were conducted examining the role of each of the four parenting variables on [initial gang activity and] changes in gang [activity].
The last series of analyses controlled for peer gang activity and ethnic and cultural heritage, in addition to examining interactions between parenting and ethnic and cultural heritage.
Although the authors examined four parenting behaviors—behavioral control, lax control, psychological control, and parental warmth—they did so one at a time, using four separate multilevel models. Based on their description, write out a sample model from each of the three steps in the series. For each model, (a) write out the two-level model for predicting gang activity, (b) write out the corresponding composite model, and (c) determine how many model parameters (fixed effects and variance components) must be estimated.
- The table below shows a portion of Table 2: Results of Hierarchical Linear Modeling Analyses Modeling Gang Involvement from Walker-Barnes and Mason (2001). Provide interpretations of significant coefficients in context.
| Predictor | γ | SE |
|---|---|---|
| Intercept (initial Status) | ||
| Base (intercept for predicting int term) | -.219 | .160 |
| Peer behavior | .252** | .026 |
| Black Ethnicity | .671* | .289 |
| White/Other ethnicity | .149 | .252 |
| Parenting | .076 | .050 |
| Black Ethnicity X Parenting | -.161+ | .088 |
| White/Other ethnicity X Parenting | -.026 | .082 |
| . Slope(change) | ||
| . Base(intercept for predicting slope term) | .028 | .030 |
| . Peer behavior | -.011* | .005 |
| . Black ethnicity | -.132* | .054 |
| . White/Other ethnicity | -.059 | .046 |
| . Parenting | -.015+ | .009 |
| . Black Ethnicity X Parenting | -.048** | .017 |
| . White/Other ethnicity X Parenting | .016 | .015 |
Note: Table reports values for \(\gamma\)s in the final model with all variables entered. * \(p<.05\); ** \(p<.01\); + \(p<.10\)
Charter Schools. Differences exist in both sets of boxplots in Figure 9.12. What do these differences imply for multilevel modeling?
What implications do the scatterplots in Figure 9.14 (b) and (c) have for multilevel modeling? What implications does the boxplot in Figure 9.14 (a) have?
What are the implications of Figure 9.15 for multilevel modeling?
Sketch a set of boxplots to indicate an obvious interaction between percent special education and percent non-white in modeling 2008 math scores. Where would this interaction appear in the multilevel model?
In Model A, \(\sigma^2\) is defined as the variance in within-school deviations and \(\sigma^2_u\) is defined as the variance in between-school deviations. Give potential sources of within-school and between-school deviations.
In Chapter 8 Model B is called the “random slopes and intercepts model”, while in this chapter Model B is called the “unconditional growth model”. Are these models essentially the same or systematically different? Explain.
In Section 8.7, why don’t we examine the pseudo \(R^2\) value for Level Two?
If we have test score data from 2001-2010, explain how we’d create new variables to fit a piecewise model.
In Section 9.6.2, could we have used percent free and reduced lunch as a Level One covariate rather than 2010 percent free and reduced lunch as a Level Two covariate? If so, explain how interpretations would have changed. What if we had used average percent free and reduced lunch over all three years or 2008 percent free and reduced lunch instead of 2010 percent free and reduced lunch - how would this have changed the interpretation of this term?
In Section 9.6.2, why do we look at a 10 percent increase in the percentage of students receiving free and reduced lunch when interpreting \(\hat{\alpha}_{2}\)?
In Section 9.6.3, if the gap in 2008 math scores between charter and non-charter schools differed for schools of different poverty levels (as measured by percent free and reduced lunch), how would the final model have differed?
Explain in your own words why “the error structure at Level Two is not the same as the within-school covariance structure among observations”.
Here is the estimated unstructured covariance matrix for Model C: \[ Cov(\mathbf{Y}_i) = \left[ \begin{array}{cccc} 41.87 & & \\ 36.46 & 48.18 & \\ 35.20 & 39.84 & 45.77 \end{array} \right] \] Explain why this matrix cannot represent an estimated covariance matrix with a compound symmetry, autoregressive, or Toeplitz structure. Also explain why it cannot represent our standard two-level model.
9.9.2 Guided Exercise
- Teen Alcohol Use. Curran, Stice, and Chassin (1997) collected data on 82 adolescents at three time points starting at age 14 to assess factors that affect teen drinking behavior. Key variables in the data set
alcohol.csv(accessed via Singer and Willett (2003)) are as follows:id= numerical identifier for subjectage= 14, 15, or 16coa= 1 if the teen is a child of an alcoholic parent; 0 otherwisemale= 1 if male; 0 if femalepeer= a measure of peer alcohol use, taken when each subject was 14. This is the square root of the sum of two 6-point items about the proportion of friends who drink occasionally or regularly.alcuse= the primary response. Four items—(a) drank beer or wine, (b) drank hard liquor, (c) 5 or more drinks in a row, and (d) got drunk—were each scored on an 8-point scale, from 0=“not at all” to 7=“every day”. Thenalcuseis the square root of the sum of these four items.
Primary research questions included:
- do trajectories of alcohol use differ by parental alcoholism?
- do trajectories of alcohol use differ by peer alcohol use?
- Identify Level One and Level Two predictors.
- Perform a quick EDA. What can you say about the shape of
alcuse, and the relationship betweenalcuseandcoa,male, andpeer? Appeal to plots and summary statistics in making your statements. - Generate a plot as in Figure 9.4 with alcohol use over time for all 82 subjects. Comment.
- Generate three spaghetti plots with loess fits similar to Figure 9.7 (one for
coa, one formale, and one after creating a binary variable frompeer). Comment on what you can conclude from each plot. - Fit a linear trend to the data from each of the 82 subjects using
ageas the time variable. Generate histograms as in Figure 9.10 showing the results of these 82 linear regression lines, and generate pairs of boxplots as in Figure 9.10 forcoaandmale. No commentary necessary. [Hint: to produce Figure 9.10, you will need a data frame with one observation per subject.] - Repeat 5 using centered age (age14=age-14) as the time variable. Also generate a pair of scatterplots as in Figure 9.14 for peer alcohol use. Comment on trends you observe in these plots. [Hint: after forming age14, append it to your current data frame.]
- Discuss similarities and differences between (5) and (6). Why does using
age14as the time variable make more sense in this example? - (Model A) Run an unconditional means model. Report and interpret the intraclass correlation coefficient.
- (Model B) Run an unconditional growth model with
age14as the time variable at Level One. Report and interpret estimated fixed effects, using proper notation. Also report and interpret a pseudo-Rsquare value. - (Model C) Build upon the unconditional growth model by adding the effects of having an alcoholic parent and peer alcohol use in both Level Two equations. Report and interpret all estimated fixed effects, using proper notation.
- (Model D) Remove the child of an alcoholic indicator variable as a predictor of slope in Model C (it will still be a predictor of intercept). Write out Model D as both a two-level and a composite model using proper notation (including error distributions); how many parameters (fixed effects and variance components) must be estimated? Compare Model D to Model C using an appropriate method and state a conclusion.
9.9.3 Open-ended Exercises
UCLA Nurse Blood Pressure Study. A study by Goldstein and Shapiro (2000) collected information from 203 registered nurses in the Los Angeles area between 24 and 50 years of age on blood pressure and potential factors that contribute to hypertension. This information includes family history, including whether the subject had one or two hypertensive parents, as well as a wide range of measures of the physical and emotional condition of each nurse throughout the day. Researchers sought to study the links between blood pressure and family history, personality, mood changes, working status, and menstrual phase.
Data from this study provided by Weiss (2005) includes observations (40-60 per nurse) repeatedly taken on the 203 nurses over the course of a single day. The first blood pressure measurement was taken half an hour before the subject’s normal start of work, and was measured approximately every 20 minutes for the rest of the day. At each blood pressure reading, the nurses also rate their mood on several dimensions, including how stressed they feel at the moment the blood pressure is taken. In addition, the activity of each subject during the 10 minutes before each reading was measured using an actigraph worn on the waist. Each of the variables innursebp.csvis described below:SNUM: subject identification numberSYS: systolic blood pressure (mmHg)DIA: diastolic blood pressure (mmHg)HRT: heart rate (beats per minute)MNACT5: activity level (frequency of movements in 1-minute intervals, over a 10-minute period )PHASE: menstrual phase (follicular—beginning with the end of menstruation and ending with ovulation, or luteal—beginning with ovulation and ending with pregnancy or menstruation)DAY: workday or non-workdayPOSTURE: position during blood pressure measurement—either sitting, standing, or recliningSTR,HAP,TIR: self-ratings by each nurse of their level of stress, happiness and tiredness at the time of each blood pressure measurement on a 5-point scale, with 5 being the strongest sensation of that feeling and 1 the weakestAGE: age in yearsFH123: coded as either NO (no family history of hypertension), YES (1 hypertensive parent), or YESYES (both parents hypertensive)time: in minutes from midnighttimept: number of the measurement that day (approximately 50 for each subject)timepass: time in minutes beginning with 0 at time point 1
- Completion Rates at US Colleges. Education researchers wonder which factors most affect the completion rates at US colleges. Using the IPEDS database containing data from 1310 institutions over the years 2002-2009 (National Center for Education Statistics 2018), the following variables were assembled in
colleges.csv:id= unique identification number for each college or university
Response:
rate= completion rate (number of degrees awarded per 100 students enrolled)yearinstpct= percentage of students who receive an institutional grantinstamt= typical amount of an institutional grant among recipients (in $1000s)faculty= mean number of full-time faculty per 100 students in between 2002-2009tuition= mean yearly tuition in between 2002 and 2009 (in $1000s)
Using systolic blood pressure as the primary response, write a short report detailing factors that are significantly associated with higher systolic blood pressure. Be sure to support your conclusions with appropriate exploratory plots and multilevel models. In particular, how are work conditions—activity level, mood, and work status—related to trends in blood pressure levels? As an appendix to your report, describe your modeling process—how did you arrive at your final model, which covariates are Level One or Level Two covariates, what did you learn from exploratory plots, etc.
Potential alternative directions: consider diastolic blood pressure or heart rate as the primary response variable, or even try modeling emotion rating using a multilevel model.
Perform exploratory analyses and run multilevel models to determine significant predictors of baseline (2002) completion rates and changes in completion rates between 2002 and 2009. In particular, is the percentage of grant recipients or the average institutional grant awarded related to completion rate?
References
U.S. Department of Education. 2018. “National Charter School Resource Center: Frequently Asked Questions.” Accessed June 25. https://charterschoolcenter.ed.gov/faqs.
KIPP. 2017. “KIPP North Star Academy.” http://www.kipp.org/school/kipp-north-star-academy/.
Finnigan, Kara, Nancy Adelman, Lee Anderson, Lynyonne Cotton, Mary Beth Donnelly, and Tiffany Price. 2004. “Evaluation of Public Charter Schools Program: Final Evaluation Report.” Washington, D.C.: U.S. Department of Education.
Witte, John, David Weimer, Arnold Shober, and Paul Schlomer. 2007. “The Performance of Charter Schools in Wisconsin.” Journal of Policy Analysis and Management 26 (3): 557–73. doi:10.1002/pam.20265.
Buddin, Richard, and Ron Zimmer. 2005. “Student Achievement in Charter Schools: A Complex Picture.” Journal of Policy Analysis and Management 24 (2): 351–71. doi:10.1002/pam.20093.
Minnesota Department of Education. 2018. “Minnesota Department of Education Data Center.” Accessed June 25. https://education.mn.gov/MDE/Data/.
GreenIII, Preston C., Bruce D. Baker, and Joseph O. Oluwole. 2003. “Having It Both Ways: How Charter Schools Try to Obtain Funding of Public Schools and the Autonomy of Private Schools.” Emory Law Journal 63 (2): 303–37.
Laird, Nan M. 1988. “Missing Data in Longitudinal Studies.” Statistics in Medicine 7 (1-2): 305–15. doi:10.1002/sim.4780070131.
Raudenbush, Stephen W., and Anthony S. Bryk. 2002. Hierarchical Linear Models: Applications and Data Analysis Methods. 2nd ed. SAGE Publications, Inc.
Singer, Judith D., and John B. Willett. 2003. Applied Longitudinal Data Analysis: Modeling Change and Event Occurrence. 1st ed. New York, New York: Oxford University Press, Inc.
J. Faraway, Julian. 2005. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models. Boca Raton, FL: Chapmen & Hall/ CRC.
Walker-Barnes, Chanequa J., and Craig A. Mason. 2001. “Ethnic Differences in the Effect of Parenting on Gang Involvement and Gang Delinquency: A Longitudinal, Hierarchical Linear Modeling Perspective.” Child Development 72 (6): 1814–31. doi:10.1111/1467-8624.00380.
Curran, Patrick J., Eric Stice, and Laurie Chassin. 1997. “The Relation Between Adolescent Alcohol Use and Peer Alcohol Use: A Longitudinal Random Coefficients Model.” Journal of Consulting and Clinical Psychology 65 (1): 130–40. doi:10.1037/0022-006X.65.1.130.
Goldstein, I. B., and D. Shapiro. 2000. “Ambulatory Blood Pressure in Women: Family History of Hypertension and Personality.” Psychology, Health & Medicine 5 (3). Taylor & Francis: 227–40. doi:10.1080/713690197.
Weiss, Robert E. 2005. Modeling Longitudinal Data. New York, NY: Springer-Verlag.
National Center for Education Statistics. 2018. “The Integrated Postsecondary Education Data System.” Accessed June 25. https://nces.ed.gov/ipeds/.