Chapter1 Working with SPSS and R
This book is about working with missing data methods in SPSS and R. This chapter shows some basic data management methods in SPSS and R that makes working with both software programs easier.
1.1 Data management in SPSS
When you open SPSS you are in the SPSS Data Editor window. Now you have the possibility to go to the Data View and Variable View windows. In the Data View window, you can enter data yourself or read in data by using the options in the file menu. In (Figure 1.1) you see an example of a dataset in the Data View window. Each row in the Data View window represents a case and in the columns you find the variable names. In the Data View window, you can start all kind of data manipulations by using the different menu’s above in the window.
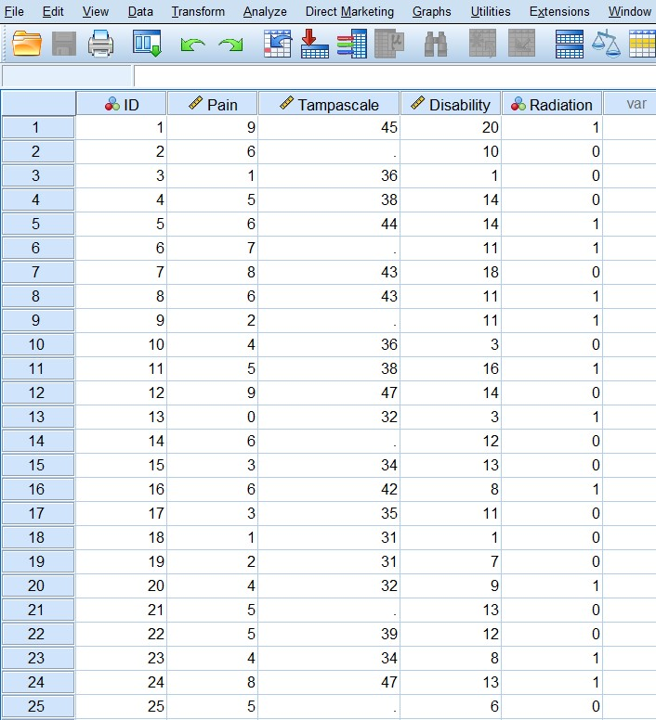
Figure 1.1: Data View window in SPSS
In the lower left corner of the window you can click on the tab Variable View and the Variable view window will appear (Figure 1.2).
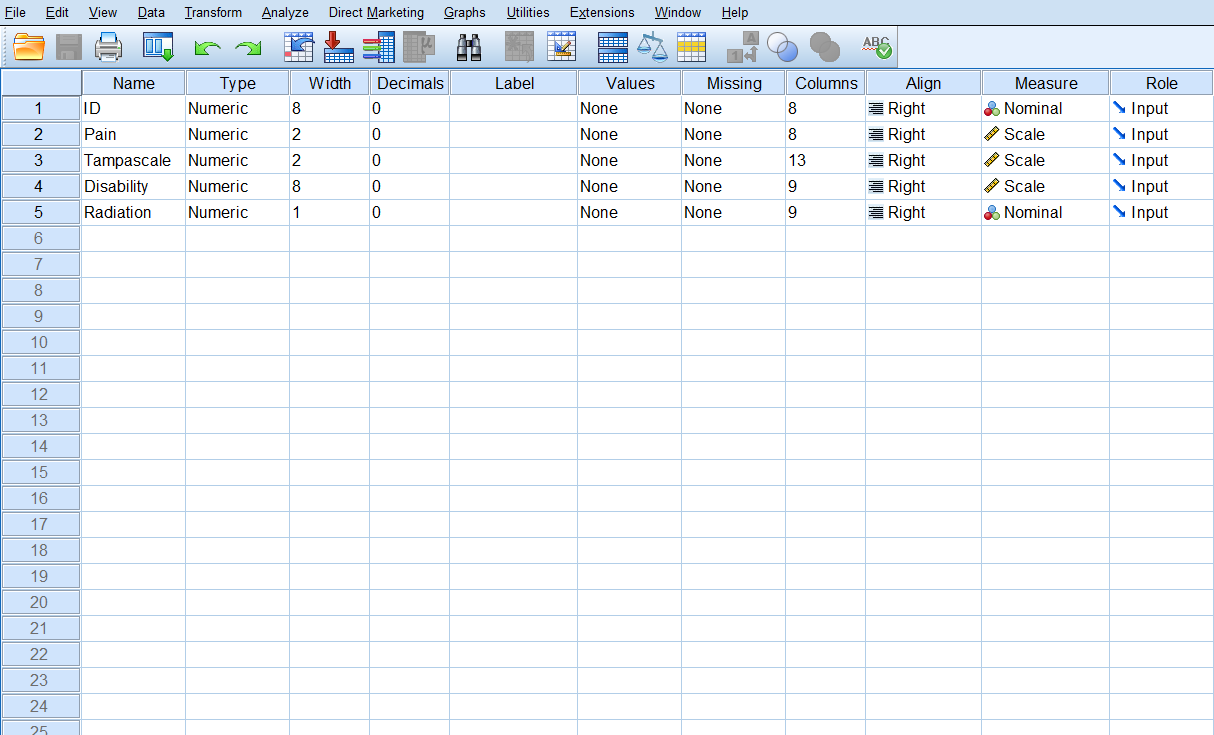
Figure 1.2: Variable View window in SPSS
In the Variable View window, you can add new variables, by entering the name in the name column. Further, you can change variable options as: Type: e.g. numeric or string variable; Width: number of digits; Decimals: the number of decimal places displayed; Label: add some extra information about the type of information in the variable; Values: To assign numbers to the categories of a variable; Missing: you can define specified data values as user-missing or system missing; Columns: To change the number of characters displayed in the Data View window; Align: to specify the alignment of the data; Measure: to specify the level of each variable, scale (continuous), ordinal or nominal; Role: Here you can define the role of the variable during your analysis. Examples are, Input for independent variable, Target for dependent or outcome variable, Both, independent and dependent variable. There are more possibilities, but most of the times you use the default Input setting.
1.2 Analyzing data in SPSS
All statistical procedures in SPSS can be found under the Analyze button (Figure 1.3). Here you also find the option “Multiple Imputation” which plays an important role in this manual.
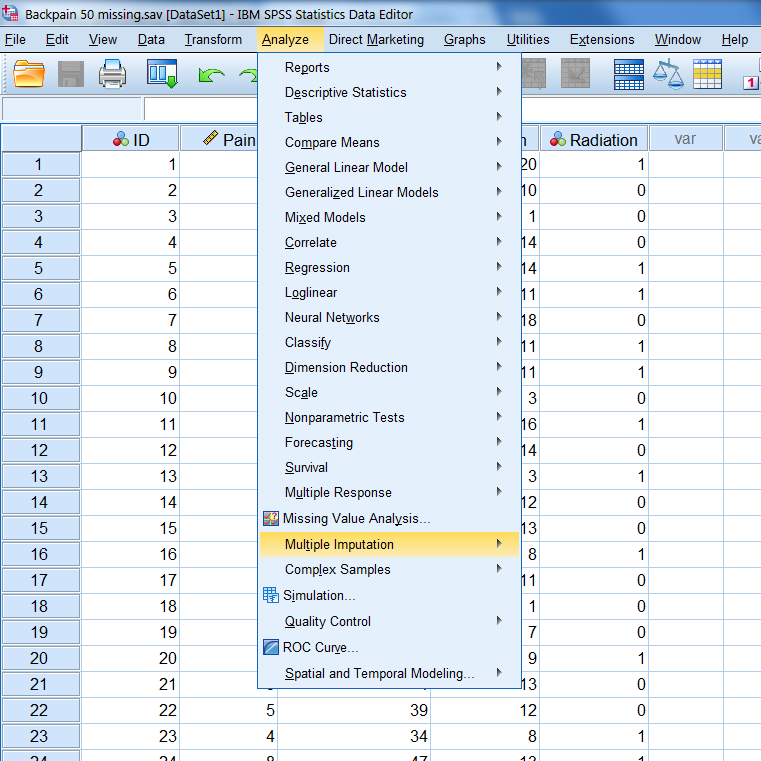
Figure 1.3: Statistical procedures that can be found under the Analyze menu in SPSS
1.3 The Output window in SPSS
If you have run your analyses in SPSS, an SPSS Output (or viewer) Window will pop-up. The main body of the Output Window consists of two panes (left and right panes). In the left pane you find an outline of the output. In the right pane you find the actual output of your statistical procedure (Figure 1.4).
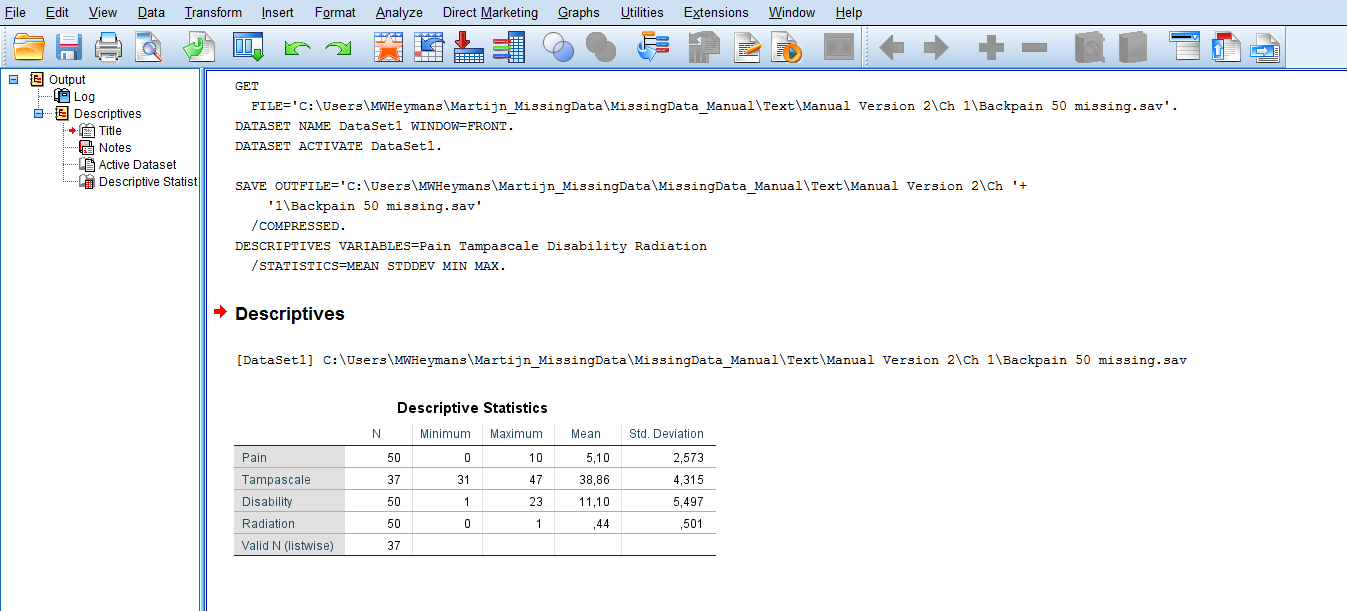
Figure 1.4: Part of the Output or Viewer window in SPSS after making use of Descriptive Statistics under the Analyze menu
1.4 The Syntax Editor in SPSS
In the syntax editor of SPSS, you use the SPSS syntax programming language. You can run all SPSS procedures by typing in commands in this syntax editor window, instead of using the graphical user interface, i.e. by using your mouse and clicking on the menu´s. You can get access to the syntax window in two ways. The first is just by opening a new syntax file by navigating to
File -> New -> Syntax.
This will open a new syntax window (Figure 1.5).
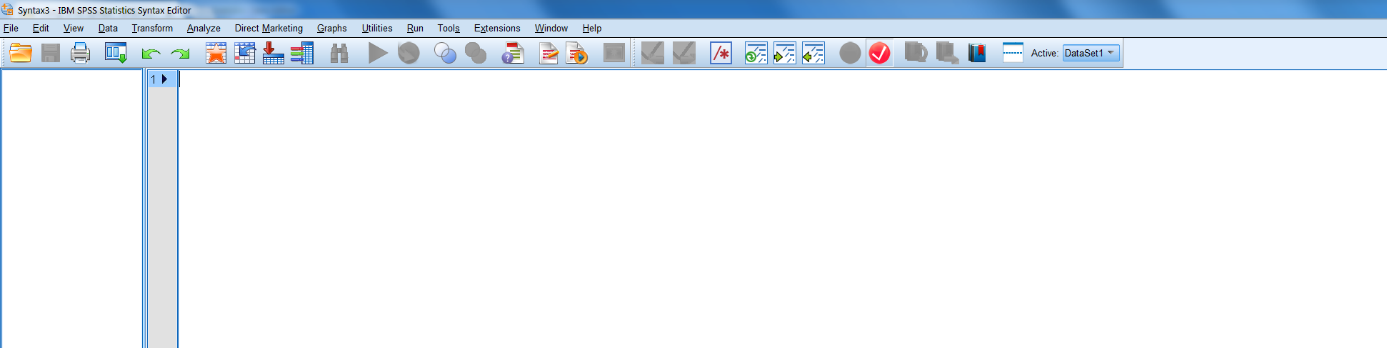
Figure 1.5: Screenshot of new syntax file
You can also generate syntax by accessing statistical procedures through the dropdown menus and clicking the Paste button instead of clicking the OK button after you have specified the options. Than a new Syntax Editor window will pop up or the new syntax will automatically be added to the open Syntax Editor window. In this manual we will not use SPSS syntax code to access statistical procedures. SPSS is most frequently used via the graphical user interface, and we will use that method also in this manual.
1.5 Reading and saving data in SPSS
You can Read data in via the SPSS menu File:
File -> Open -> Data.
All kind of file types can be selected. Of course the SPSS .sav files, but also .por, .xlsx, .cvs, SAS, Stata, etc. After you have selected a specific file type other than SPSS you may have to go through several steps before you see the data in the Data View window. Saving files in SPSS is possible via the Save Data As option under the menu File. You can choose the same kind of file types.
1.5.1 Reading in R data into SPSS
When you have used the write.table function (see paragraph 1.11) to save R data you can easily read them in into SPSS by following the next steps:
File -> Open data -> “All files (.)”
than you will see the file you want to import in SPSS, here the “Backpain50 R file”.
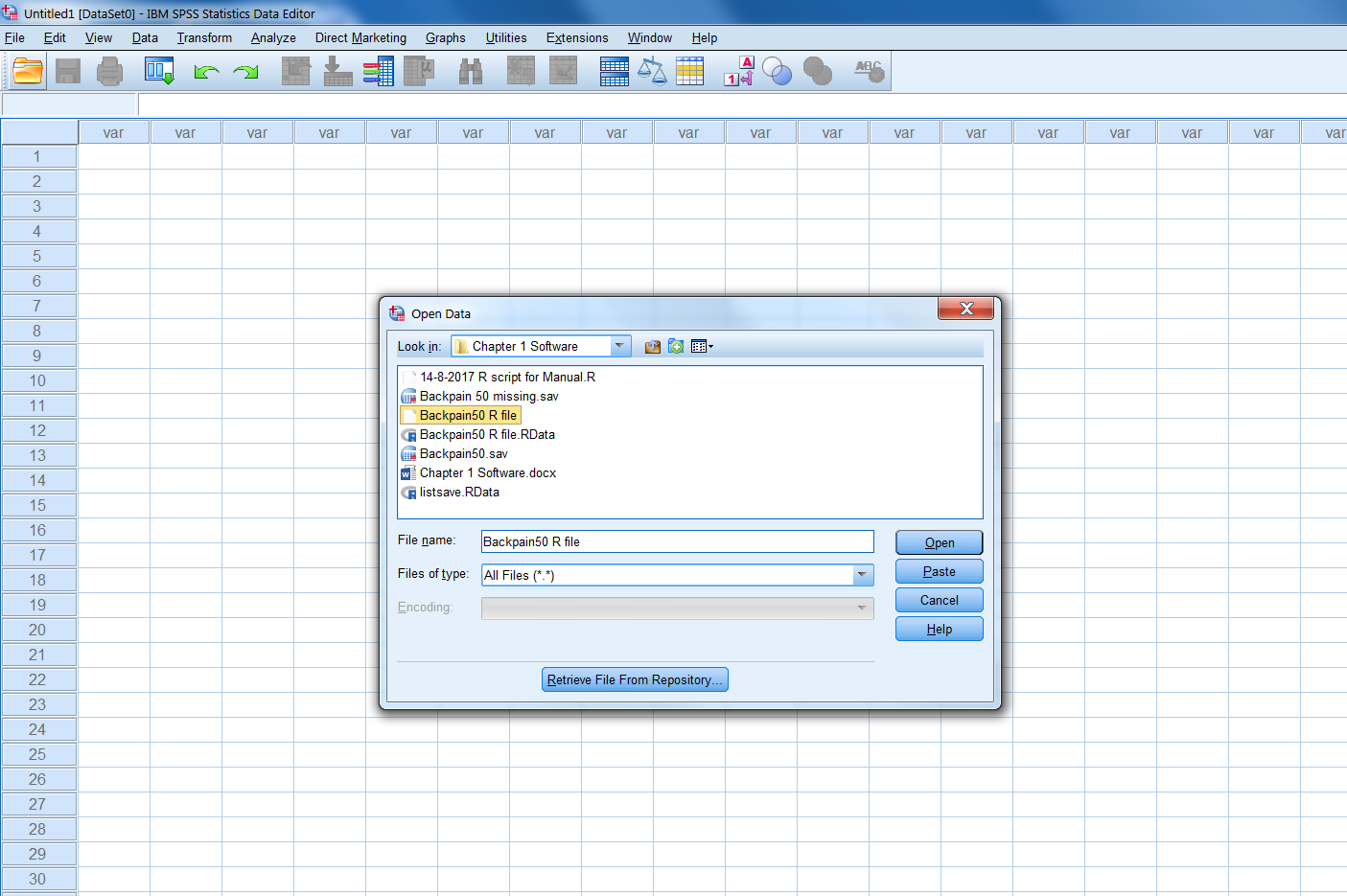
Figure 1.6: Choosing the dataset to import in SPSS
Then click Open (wait a couple of seconds) and click on next. You will see the following window that is part of the Text Import Wizard procedure in SPSS (Figure 1.7):
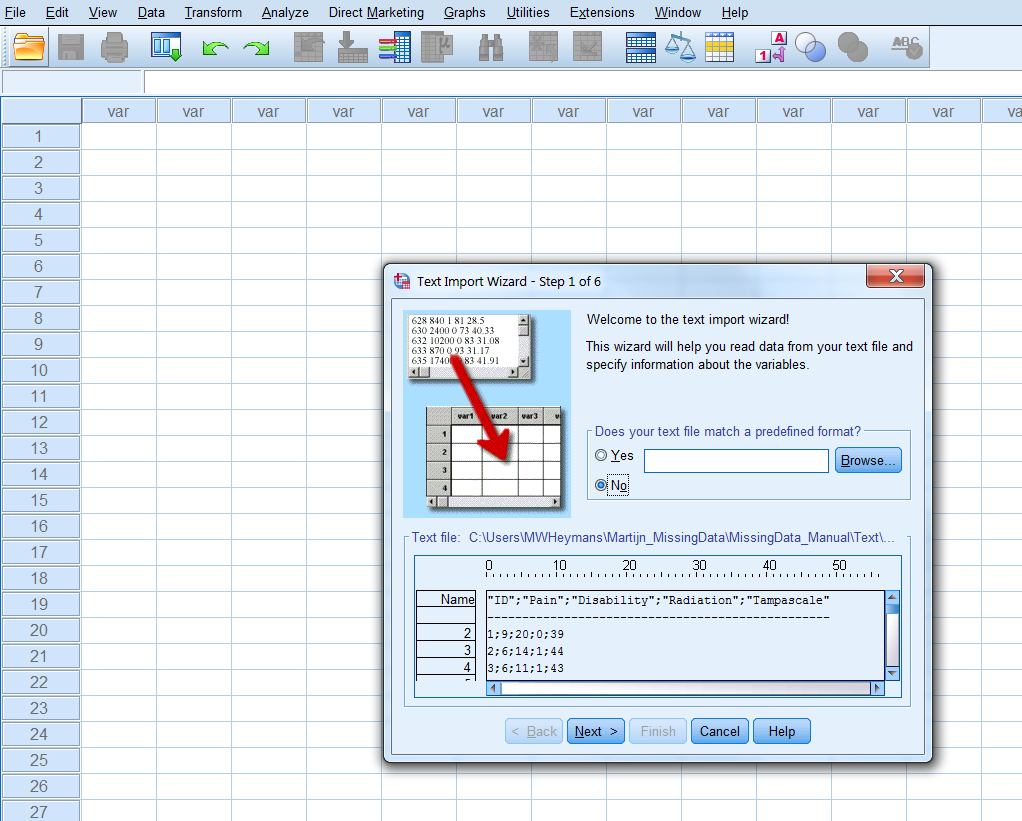
Figure 1.7: Step 1 of the Text Import Wizard
Then click the “Next >” button 5 times, passing by the following windows:
Step 2 of 6 (Figure 1.8): To change how variables are arranged: here delimited To include variable names included at the top of the file: here Yes. To set the decimal symbol: here a comma.
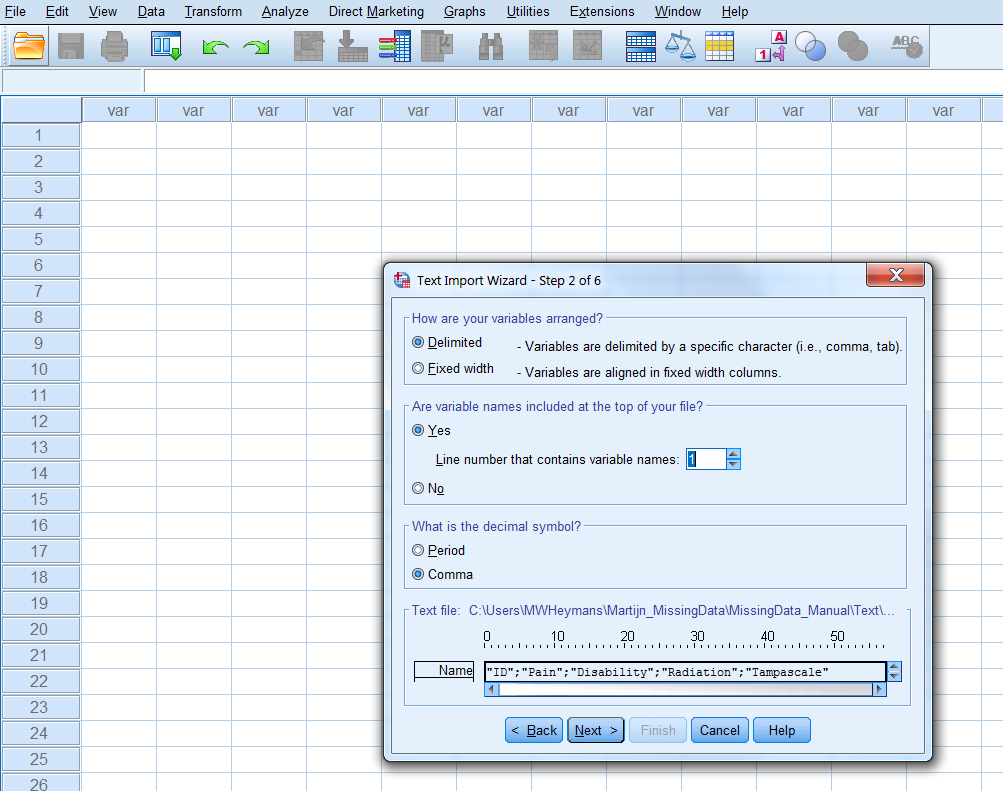
Figure 1.8: Step 2 of the Text Import Wizard
Step 3 of 6 (Figure 1.9):
On which line number begins the first case: here 2 How cases are represented: Each line is a case. How many cases you want to import: here all cases.
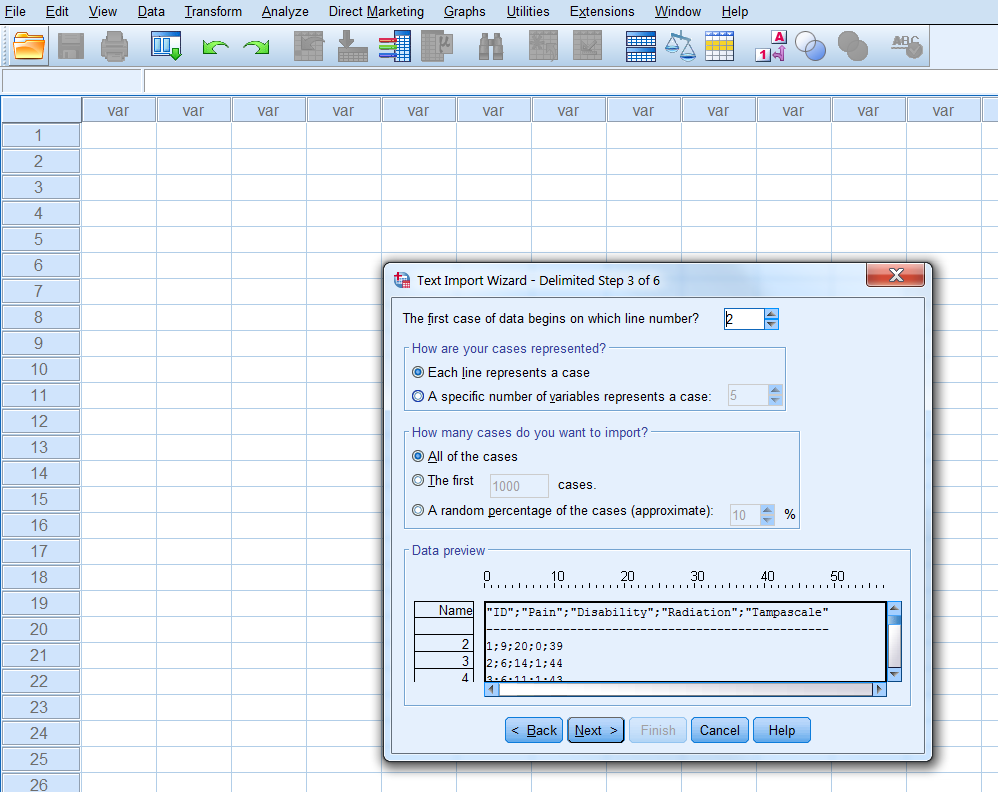
Figure 1.9: Step 3 of the Text Import Wizard
Step 4 of 6 (Figure 1.10): The delimiters that appear between variables; here the Semicolon. The text qualifier: here Double quote. Remove trailing spaces from string values: skip.
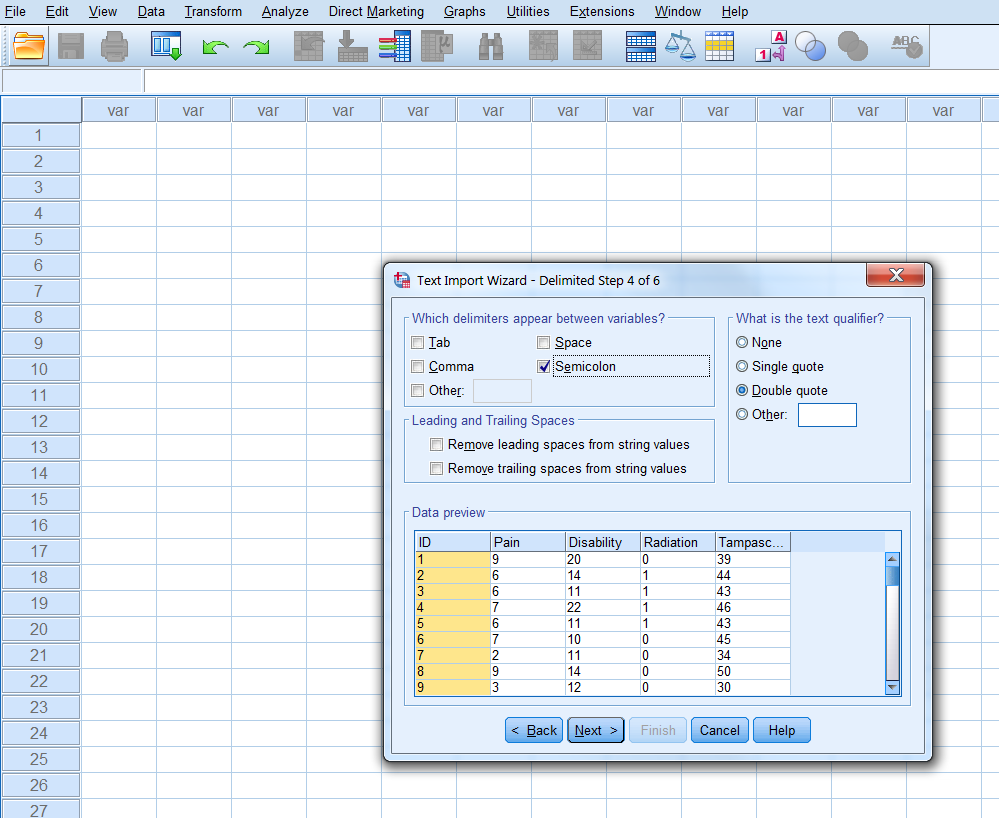
Figure 1.10: Step 4 of the Text Import Wizard
Step 5 of 6 (Figure 1.11): Here you overwrite the Data format of the variable (you can also change that in the Variable View window, when the data has been read in).
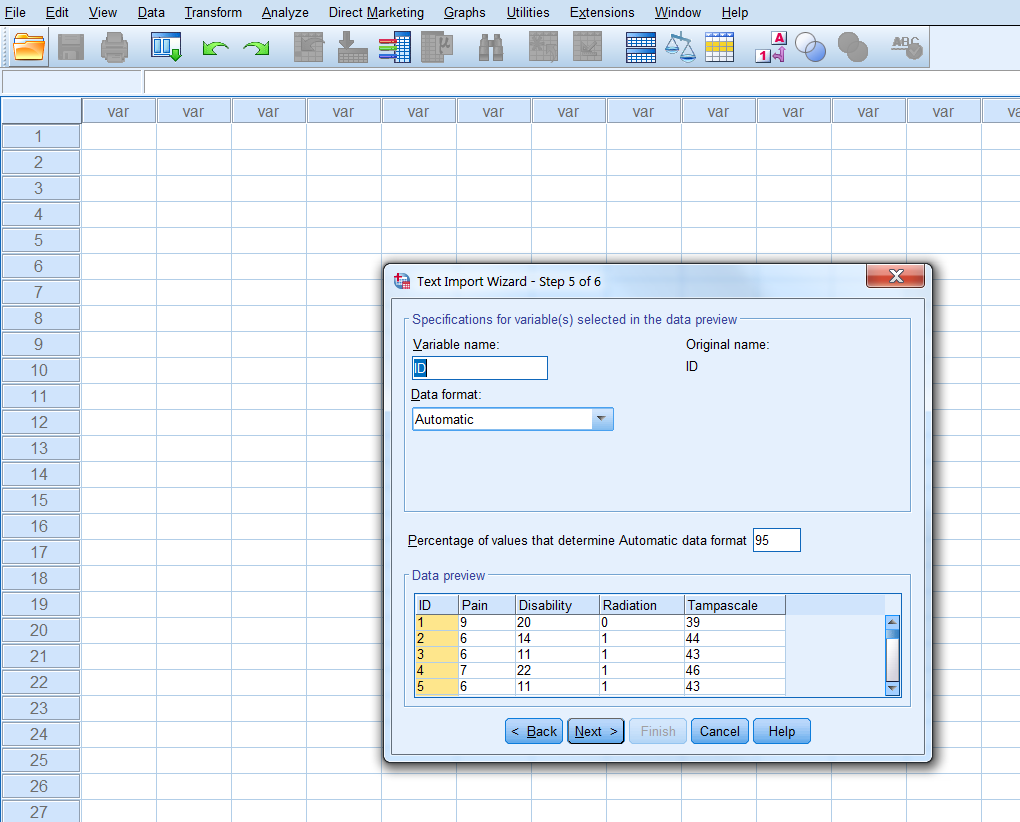
Figure 1.11: Step 5 of the Text Import Wizard
Step 6 of 6: To save your specifications of the previous steps into a separate file (Figure 1.12).
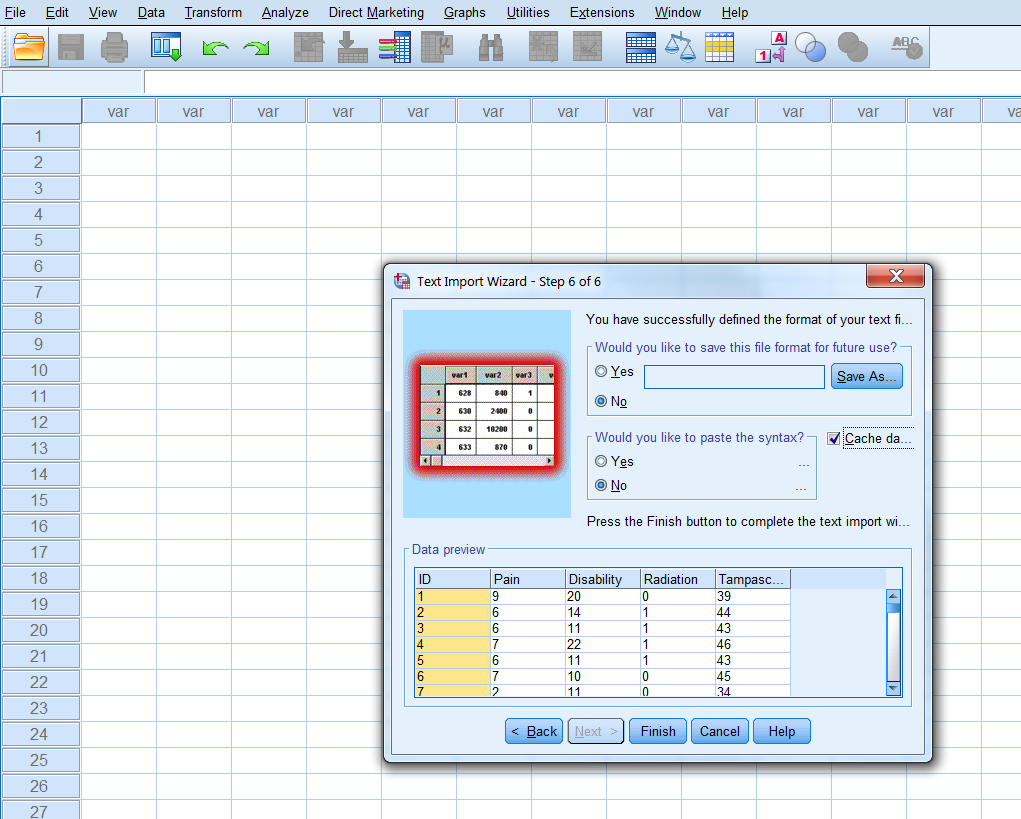
Figure 1.12: Step 6 of the Text Import Wizard
Then click finish and the data is imported in a new SPSS file. In that file you can of course change all kind of variable and data settings in the Variable View Window.
You can also skip step 2 to 5 by clicking the Finish button twice when you are at step 1. Than you use all default settings, which is most of the times an efficient option.
1.6 R and RStudio
RStudio is an integrated environment to work with the software program R. Consequently, to work with RStudio, R has to be installed. RStudio uses the R language and is also freely available. In this manual we will show possibilities and options in RStudio that are needed to run the R code that are discussed in this manual. For more information about RStudio and its possibilities visit the RStudio website.
When you open RStudio the following screen will appear.
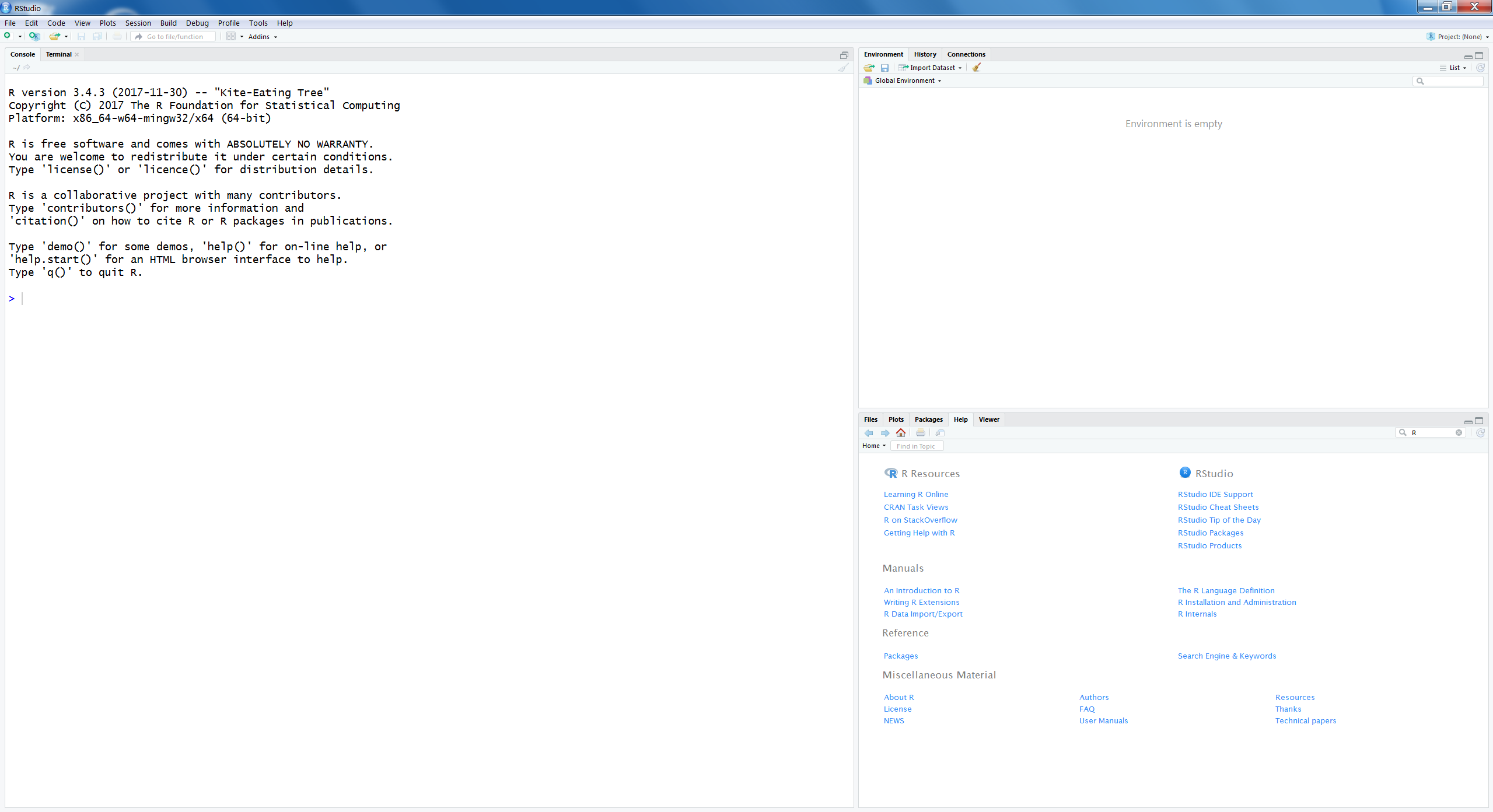
Figure 1.13: First screen that appears after you have started RStudio
There are three windows opened:
- On the left is the Console window
This is the main window to run R code (see below for more information about the Console window).
Right above is the window where you can choose between the Environment and History tabs (e.g. history tracks the code you typed in the Console window).
At the right site below is the window where you can choose between Files, Plots, Packages, Help and Viewer tabs.
1.6.1 The role of the Console Window
When you enter code in the Console window you will directly receive a result. For example, when you type 3 + 3 the result will appear directly.
3 + 3## [1] 6Other multiplication procedures as divide, square, etc. can also be executed. The main use for R is its functions. For example, to generate 20 random numbers you use the following function code (we will discuss more about functions in R later):
rnorm(20)## [1] -0.15265720 -0.02100179 -1.82590428 -0.20612067 1.85884034 1.61404391
## [7] -0.25600437 0.92782453 -0.85635842 -0.71811532 2.13174578 0.32112360
## [13] -0.88732911 -0.52719273 -0.31290943 -2.36800655 -0.49681994 0.69888017
## [19] -1.61057051 -0.12430563The number [1] between brackets is the index of the first number or item in the vector.
1.6.2 R assignments and objects
In R it is possible to create objects and to assign values to these objects. In this way it is possible to store some intermediate results and recall or use them later on. Assigning values to objects is done by using the assignment operator <- . You can also use the = sign as an assignment operator. This is not recommended because this is also a symbol used for mathematical operations. For example, when we want to assign the value 3 to the object x, we use:
x <- 3 When we subsequently type in the letter x we get the following result:
x ## [1] 3Now the value 3 is assigned to the object x. In R all kind of information can be assigned to an object, i.e. one number, a vector of numbers, results from analysis or other R objects such as data frames, matrices or lists. Objects can have all kinds of different names, composed of different letters and numbers. Note that some letters and words are used by R itself. It is not recommended to use these leters as names for objects in R that you create yourself. For example, the letter T and F are used as TRUE and FALSE by R. Other letters that are already in use are c, q, t, C, D, I and diff, df, and pt.
1.6.3 Vectors, matrices, lists and data frames
Vectors
A vector can be created by the following code:
y <- c(1, 2, 3, 4, 5)
y## [1] 1 2 3 4 5The numbers 1, 2, 3, 4 and 5 are assigned to the data vector y. The “c” in the above code stand for concatenate which makes that all separate (one-vector) numbers are merged into one vector. It is also possible to create character vectors, which are vectors that contain strings (text). An example:
y <- c("a", "b", "test")
y## [1] "a" "b" "test"Vectors can also be made by using the “:” symbol. With that symbol it is easy to generate a sequence of numbers. An example:
y <- 1:10
y## [1] 1 2 3 4 5 6 7 8 9 10Matrix
You can create a matrix by using the matrix function.
matrix(c(1, 2, 3, 4, 5, 6), nrow=2, ncol=3)## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6Now we have created a matrix with 2 rows and 3 columns. In essence we converted the vector c(1, 2, 3, 4, 5, 6) into a matrix.
List
Another object is called a list. A list can contain components of different formats. Let’s look at an example using the following code:
x <- 1:5
x## [1] 1 2 3 4 5y <- c("a", "b", "test")
z <- list(x=x, y=y)
z## $x
## [1] 1 2 3 4 5
##
## $y
## [1] "a" "b" "test"With this code you created the list object z consisting of the two components x and y which are the vectors that were created above. You see that in a list two components of different data type can be combined, a numeric and a character factor. The names of the list components are indicated by the dollar sign, $. The list component can be obtained separately by typing z$x for component x or x$y for component y.
Dataframe
Mostly we work with datasets that contain information of different variables and persons. In R such a dataset is called a dataframe. Typically, a dataframe is created by reading in an existing dataset. How to create a dataframe by reading in a dataset will be further discussed in the paragraph “Reading in and saving data”.
1.6.4 Indexing Vectors, Matrices, Lists and Data frames
Vectors
An important operation in R is to select a subset of elements of a given vector. This is called indexing vectors. This subset can be assigned to another vector. For example:
y <- c(3, 5, 2, 8, 5, 4, 8, 1, 3, 6)
y[c(1, 4)]## [1] 3 8The R code y[c(1, 4)], extracts the first and fourth element of the vector. Another example is by using the “:” symbol, to extract several subsequent elements:
y[2:5]## [1] 5 2 8 5The R code y[2:5], extracts the second to the fifth element of the vector.
A minus sign excludes the specific element from the vector, like:
y[-3]## [1] 3 5 8 5 4 8 1 3 6The R code y[-3], excludes the third element of the vector (i.e. 2). A new vector z can be created where the third and fourth element of the y vector are excluded:
z <- y[-c(3, 4)]
z## [1] 3 5 5 4 8 1 3 6Matrices
When we index matrices we can choose to index rows, columns or both. Here are some examples:
First construct the matrix z:
z <- matrix(1:9, nrow=3)
z## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9Extract from the first row the number in the second column
z[1, 2]## [1] 4Extract all numbers in each column in the first row
z[1, ]## [1] 1 4 7Extract all numbers in each row of the first column
z[, 1]## [1] 1 2 3A minus sign can also be used to delete specific elements or complete rows or columns.
You can omit the first row from the matrix z
z[-1, ]## [,1] [,2] [,3]
## [1,] 2 5 8
## [2,] 3 6 9Lists
First create a list with 3 components, each component consists of a vector of the same length and with 10 elements each.
k <- list(a=1:10, b=11:20, c=21:30)
k## $a
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $b
## [1] 11 12 13 14 15 16 17 18 19 20
##
## $c
## [1] 21 22 23 24 25 26 27 28 29 30Index the individual component b by using the following code:
k$b## [1] 11 12 13 14 15 16 17 18 19 20k[["b"]]## [1] 11 12 13 14 15 16 17 18 19 20k[[2]]## [1] 11 12 13 14 15 16 17 18 19 20To extract individual list components double square brackets are used, compared to single brackets for indexing vectors and matrices.
When you use single brackets, you get the following results:
k["b"]## $b
## [1] 11 12 13 14 15 16 17 18 19 20The difference between using single and double brackets is that single brackets return the component data type, which is in this case a vector (but could be any kind of data type) and single brackets always return a list.
Data frames
Indexing data frames follows the same method as indexing matrices, but we can also use the method that is used to index lists, since data frames are essentially lists of vectors of the same length. Data frames consist of rows and columns which can be accessed separately or both to extract specific elements. We use the data frame that was constructed in R code 1.11.
z## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9To index the first column you use:
z[, 1]## [1] 1 2 3k$a## [1] 1 2 3 4 5 6 7 8 9 10The second row can be accessed by using:
z[2, ]## [1] 2 5 81.6.5 Vectorized Calculation
With R it is possible to perform vectorized calculations. This means that you can do calculations elementwise, i.e. the same calculation is done on each element of an object. Let’s look at an example.
First create a vector z with numerical variables.
z <- c(1, 2, 3, 4, 5, 6, 7, 8)
z## [1] 1 2 3 4 5 6 7 8Now you can fairly easy square each element of the vector by typing:
z^2## [1] 1 4 9 16 25 36 49 64We see that each element is squared. You can do these vectorized calculations by using all kinds of mathematical functions, e.g. taking the square root, logarithms, adding constant values to each element, etc.
1.6.6 R Functions
Functions play an important role in R. A function name is followed by a set of parentheses which contain some arguments. We take as an example the sum function. We can use it as follows:
sum(3,4)## [1] 7The arguments in this function are the numbers 3 and 4 and the result is their sum. This function uses as arguments numbers or complete vectors.
If you want to see the formal arguments of each function you can use the args function. For example, you can use it for the matrix function:
args(matrix)## function (data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
## NULLAs a result the arguments of the functions are listed with their default settings. In this case the arguments are:
data: an optional data vector (including a list or expression vector).
nrow: the desired number of rows.
ncol: the desired number of columns.
byrow: logical. If FALSE (the default) the matrix is filled by columns, otherwise the matrix is filled by rows.
dimnames: A dimnames attribute for the matrix: NULL or a list of length 2 giving the row and column names respectively. An empty list is treated as NULL, and a list of length one as row names. The list can be named, and the list names will be used as names for the dimensions. You can write functions yourself but in R many functions are available which means that many calculations are done by using function calls.
1.7 The Help function
There are several possibilities to start the help facilities in R and to get more information about functions and their arguments in R.
You can just type help or use the question mark as follows:
help(matrix)
?matrixIn both ways the help tutorial for the matrix function will be activated and appear in your web browser or in help tab in the right corner below when you use R studio.
1.8 Working with script files
If you want to use R code and functions more than once it is useful to work with scripts files. In this way you can type and save R code and reuse it. To create a script file in R is easy.
After you have started RStudio you go to
File -> New File -> R Scripts
A new window will open on the left side above. In that file you can type for example the self-written function print.sum.test. (Figure 1.14). You can save the script file by using the Save option under the File menu, open it again and use it whenever you want.
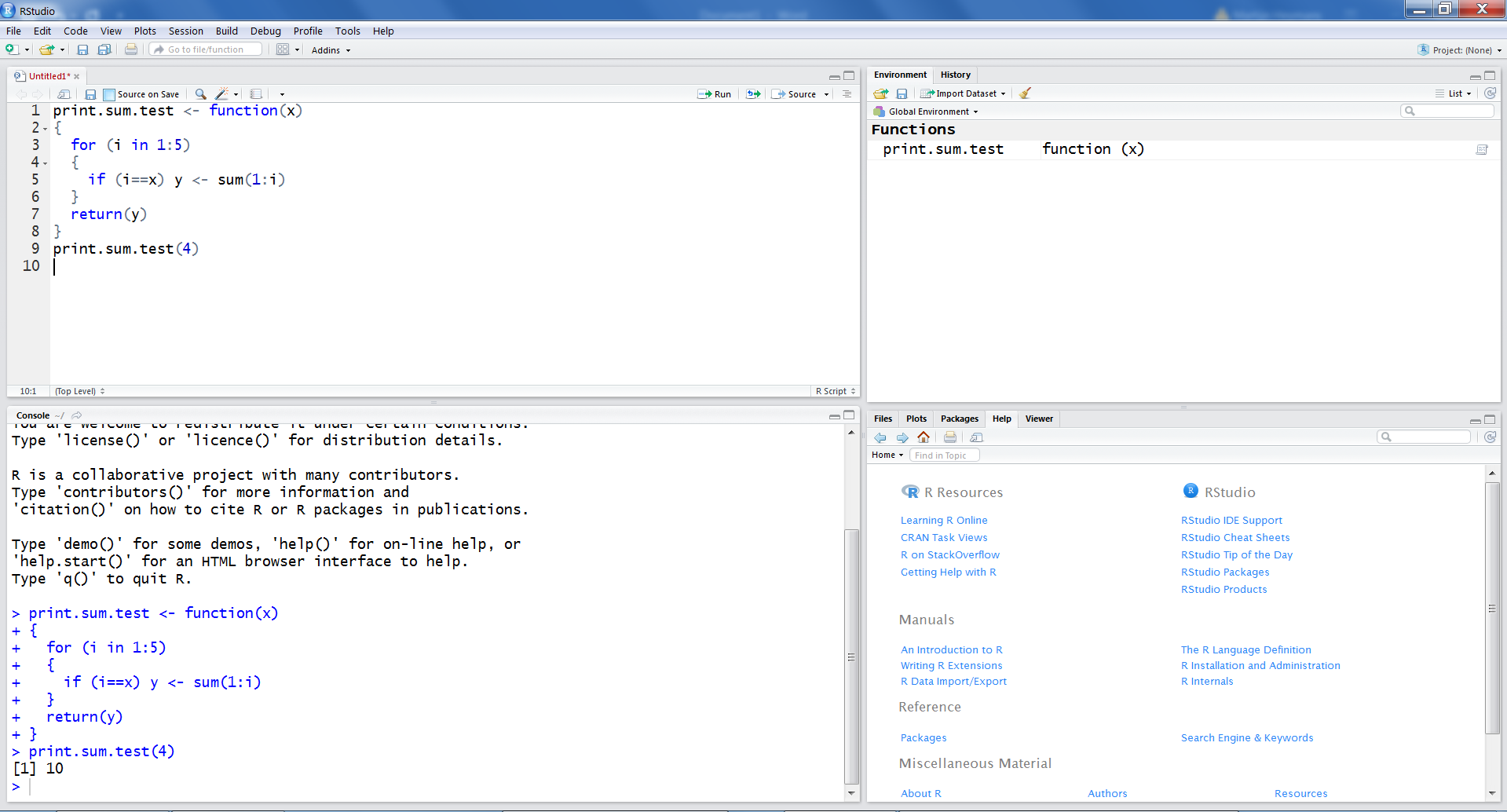
Figure 1.14: Script file example in RStudio
1.9 Creating a working directory
It is a good idea to keep your R files at the same place when you are doing data analysis for some kind of project. If you do not use a separate directory, R will use a default directory, that will mostly be in Windows in the documents folder. All files that you have to use or save during your R session are in that directory. To locate your working directory, you can type in the Console window:
getwd()You can change the working directory in another way. Go in RStudio to the window on the right site below and go to the Files tab and click on the right site of the screen on the three dots. Than a window will open and you can browse to your preferred folder. Then choose for More in the Files tab and then select “Set As Working Directory” (Figure 1.15). Now you have set your preferred working directory. You can check if your directory is set correctly by choosing “Go To Working Directory”.
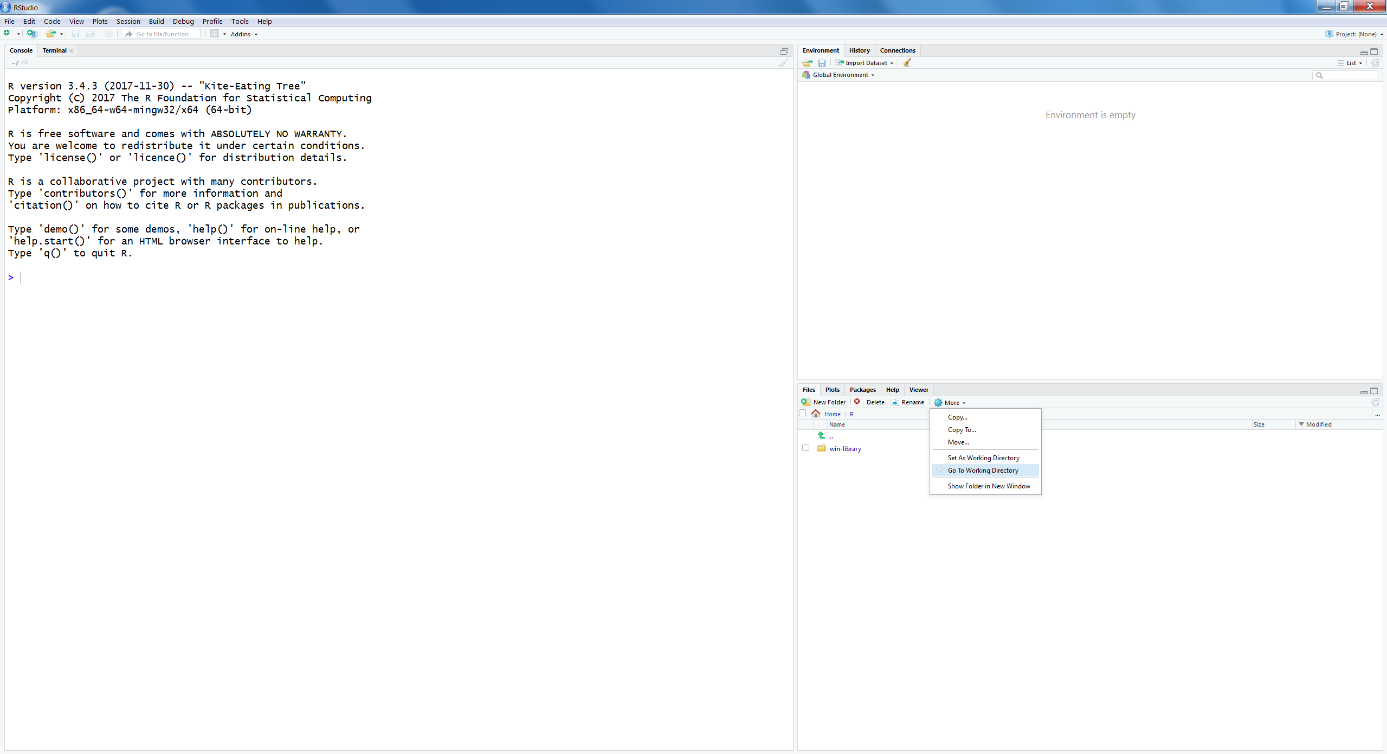
Figure 1.15: Working directory selection in RStudio
1.10 Reading in data in RStudio
There are several procedures in RStudio to read in datasets.
Import datasets via “Import Dataset”
An easy way is via the window at the right site above. There you will find in the Environment tab the button “Import Dataset”. When you click on it you can choose between different kind of file types, i.e. From Text, Excel, SPSS, SAS and Stata. When you apply this procedure for the first time RStudio asks for your permission to download a package called “haven”. This package is built to import and export data from several types.
Once the haven package is installed, you can also read in data directly from the Console window by using:
library(haven)
dataset <- read_sav(file= "data/Backpain50.sav")Using the foreign package
Another way to import an dataset is by making use of the foreign package. You find this package under the Packages Tab in the window at the right site below under the heading “System Library”. Install that package first. The foreign package includes the function read.spss to read in SPSS files, or read.cvs to read in tabular data.
You use the following code to import an SPSS dataset:
library(foreign)
dataset <- read.spss(file= "data/Backpain50.sav", to.data.frame = T)Read.table
You can use the read.table function to read in matrices and data frames by using:
dataset <- read.table(file="data/Backpain50 R file")Load
You can Load a dataset or other objects as lists by using:
load(file="data/listsave.RData")1.11 Saving data in RStudio
Datasets can be saved by using different commands.
write.table
You can use the write.table function to save data frames (datasets):
library(foreign)
dataset <- read.spss(file= "data/Backpain50.sav", to.data.frame = T)
write.table(dataset, file="data/Backpain50 R file")Before you can read a dataset in SPSS you have to use write.table in the following way:
write.table(dataset, file="data/Backpain50 R file", sep=";", dec=",", row.names=F)The extra parameter settings, mean: sep=“;”, separate each variable by an “;” indicator. dec=“,”, use for decimals a “,” instead of an “.”. row.names=F , Do not add an extra column with row.names.
These files can then be easily imported in SPSS by using the steps that were explained in paragraph 1.5.1.
Save
You can also use the command save to save datasets, according to (notice the .RData extension):
library(foreign)
dataset <- read.spss(file= "data/Backpain50.sav", to.data.frame = T)
save(dataset, file="data/Backpain50 R file.RData")You can also use save without the .Rdata extension:
library(foreign)
dataset <- read.spss(file= "data/Backpain50.sav", to.data.frame = T)
save(dataset, file="data/Backpain50 R file")To get direct access to the data that you have saved, you can use the get function in combination with the load function like this:
library(foreign)
dataset <- read.spss(file= "data/Backpain50.sav", to.data.frame = T)
save(dataset, file="data/Backpain50 R file")
get(load(file="data/Backpain50 R file"))With save, you can save any R object, also lists such as:
x <- list(a=1, b="example", c=3)
save(x, file="data/listsave.RData")1.12 Installing R Packages
When R is installed on your computer also a folder called library is created. This folder contains packages that are part of the basic installation. A package is a collection of different functions written in the R language. Besides packages that are part of the basic installation of R there are also packages that are not part of the basic installation but are written by others, i.e. the add-on packages. Packages can be downloaded from the CRAN website (https://cran.r-project.org/). Currently, there are thousands of user-written packages available on the CRAN website.
Before you can use a specific package that is not part of the basic installation, you have to install it in your R library. In this manual we will use the mice package to do all kind of imputation procedures, such as multiple imputation. mice is not part of the R basic installation and you have to install it first. There are several procedures in RStudio to install a package. One way is to use the install.packages function in the Console window:
install.packages("mice")The mice package will be automatically downloaded from the CRAN website.
Another way is to use the window on the right site below and go to the Packages tab. When you click “Install” a new window is opened. Than you can type “mice” on the blank line under “Packages (separate multiple with space or comma):” (Figure 1.16 and Figure 1.17).
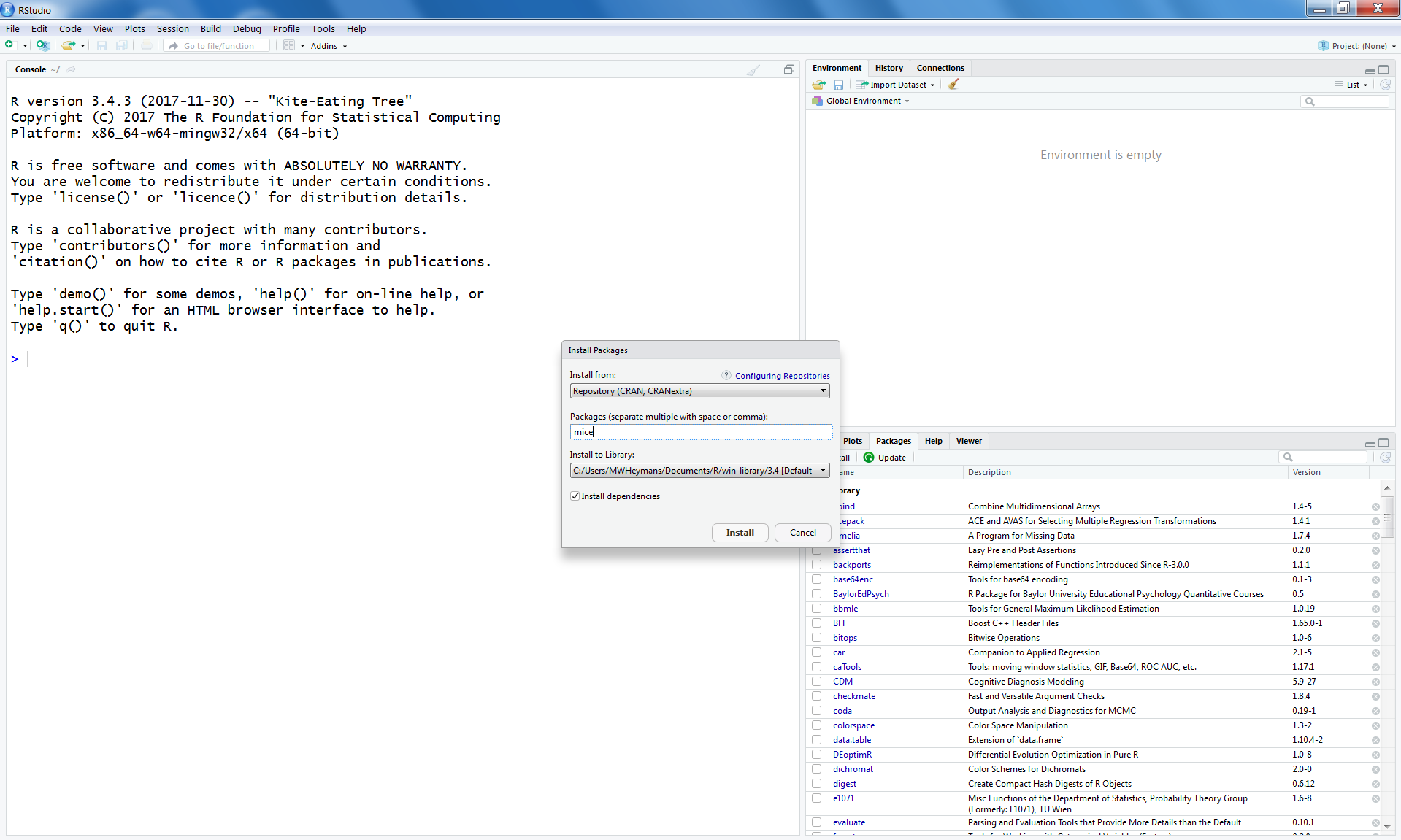
Figure 1.16: Install packages Window in RStudio to install packages from the CRAN website
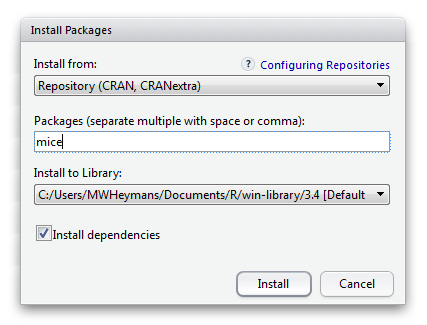
Figure 1.17: Enlarged Install packages Window in RStudio to install packages from the CRAN website
After you have clicked on “Install” the package will be downloaded from the CRAN website automatically and will be listed in the Package list named “User Library”.
Another way is to go to the CRAN website and download the package as a zip file in a directory on your computer, for example your working directory or in your library. Again use the window on the right site below and go to the Packages tab. When you choose Install a new window is opened. Now under “Install from:” choose for “Package Archive File (.zip; .tar.gz)” (Figure 1.18 and Figure 1.19). Than you can browse to the zip file and install the package.
Figure 1.18: Install packages Window in RStudio to install packages from zip files
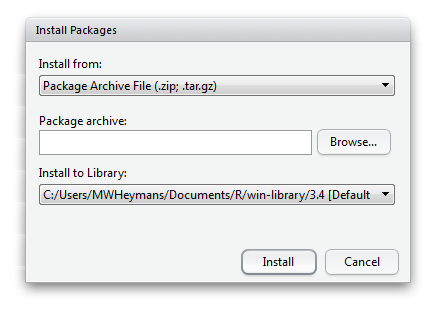
Figure 1.19: Enlarged Install packages Window in RStudio to install packages from zip files
1.13 Loading R Packages
Once an add-on (user written) R package has been installed you have to load it to get access to all functions that are part of that package. To load a library, you can use the function library() or require().
You have to load add-on packages each time you start a new R session.
1.14 Updating R Packages
To keep the add-on packages up to date you can use the update.packages() function.
update.packages()R will ask you if you want to update each package. If you type “y” in the Console window, R will update the package.
In RStudio updating packages can be done in the Package tab as well. You can click on the Update button. A new window will open that contains a list of all packages that need to be updated. Subsequently you can select the packages you want to update.
1.15 Useful Missing data Packages and links
The main package that we will use in this manual is mice which stand for Multivariate Imputation by Chained Equations (MICE) (Van Buuren, 2009). Other packages that can be used to impute data or that can be used to do analyses after imputation are listed below.
psfmi Prediction Model Selection and Performance Evaluation in Multiple Imputed data sets. Package to pool and select variables for logistic and Cox regression models. Validation with cross-validation and bootstrapping in Multiply Imputed data sets is also possible. See for more information.
miceadds Package contains some additional multiple imputation functions (Robitzsch et al., 2017). See for more information.
micemd Package contains additional functions for the mice package to perform multiple imputation in two-level (Multilevel) data (Audigier & Resche-Rigon, 2017). See for more information.
mi Provides functions for data manipulation, imputing missing values in an approximate Bayesian framework, diagnostics of the models used to generate the imputations, confidence-building mechanisms to validate some of the assumptions of the imputation algorithm, and functions to analyze multiply imputed data sets (Gelman et al., 2015). See for more information.
MItools Small package to perform analyses and combine results from multiple-imputation datasets (Lumley, 2015). See for more information.
norm Package is for the Analysis of multivariate normal datasets with missing values. It contains the mi.inference function. This function combines estimates and standard errors to produce a single inference. Uses the technique described by Rubin (1987), which are called the Rubin’s Rules (RR) (Novo, 2015). See for more information.
vim (visualization and imputation of missing values) Package includes tools for the visualization of missing and/or imputed values. In addition, the quality of imputation can be visually explored using various univariate, bivariate, multiple and multivariate plot methods (Templ et al., 2017). See for more information.
MKmisc Contains several functions for statistical data analysis; e.g. for sample size and power calculations, computation of confidence intervals, and generation of similarity matrices. This package contains the mi.t.test function for pooling t-tests after multiple imputation (Kohl, 2016). See for more information.
mvnmle Package estimates the maximum likelihood estimate of the mean vector and variance-covariance matrix for multivariate normal data with missing values. This package is needed for the mlest function this is used for Little’s MCAR test in Cahpter 2. See for more information.
finalfit
Package provides functions that help you quickly create elegant final results tables and plots after regression modelling and also provides functions to evaluate missing data. The package will be used in Chapter 2 to compare group means and proportions between observed and missing data. The package is also compatible with the mice function.
See for more information.