Chapter7 Multiple Imputation models for Multilevel data
7.1 Advanced Multiple Imputation models for Multilevel data
In this Chapter, we will apply more advanced multiple imputation models. With “advanced”, we mean multiple imputation models for Multilevel data, which are also called Mixed models. We start this Chapter with a brief introduction about multilevel data. Subsequently, we will shortly discuss the locations of missing values in Multilevel data. Finally, we will show examples of how to impute missing data in multilevel datasets using different multiple imputation models that can be used as part of the mice procedure.
7.2 Characteristics of Multilevel data
Multilevel data is also known as clustered data, where collected data is clustered into groups. Examples are observations of patients within the same hospitals or observations of students within the same schools. These data is clustered (or correlated) because assessments of patients or students within the same hospital or school (or cluster) are more equal to each other than assessments of patients or students between different hospitals or schools (Twisk (2006), Hox (2018)). It is called multilevel data because data is assessed at different levels. Data can be assessed at the level of the school when we would be interested in the school type, i.e. private or public. This data is assessed at two levels, i.e. the school level (highest level or level 2) and the students level (lowest level or level 1).
Data that is repeatedly assessed within the same person over time is another example of multilevel data. Examples are when variables as bodyweight are repeatedly assessed within the same individuals (clusters) over time. Here the clusters are the individuals. This type of data is also called longitudinal data. In this data assessments within the same individual may be more alike than assessments between individuals. This kind of data is also assessed at two levels, now the individuals are the highest level (level 2) and the time measurements are the lowest level (level 1). The different types of Multilevel data are graphically displayed in Figure 7.1. Multilevel data may also consist of data assessed at more than 2 levels, i.e. data that is assessed in different schools, classes and students or different regions, hospitals and patients.

Figure 7.1: Two-level data structure with measurements in different students within each school (left) and Two-level data structure with repeated assessments within individuals over time (right)
For the analysis of Multilevel data, multilevel regression models have to be used. Consequently, if multilevel data contain missing values, multilevel models have to be implemented during the multiple imputation process.
7.3 Multilevel data - Example datasets
In this Chapter we will use two example datasets to show multilevel imputation.
The first dataset is a classic multilevel dataset from the book of Hox et al (Hox (2018)) and is called the popular dataset. In this dataset the following information is available from 100 school classes: class (Class number), pupil (Pupil identity number within classes), extrav (Pupil extraversion), sex (Pupil gender), texp (Teacher experience (years)), popular (Pupil popularity), popteach (Teacher popularity).
The other example dataset is from The Amsterdam Growth and Health Longitudinal Study (AGGO). In this study persons were repeatedly assessed over time and growth, health and life-style factors were measured. Assessments are available of Gender, Fitness, Smoking, Hypercholestrolemia, Cholesterol level and Sum of Skinfolds. The dataset contains information of 147 patients which are assessed six times, once at baseline and at 5 repeated measurement occasions. This is an example of a longitudinal multilevel dataset. Usually, a dataset contains one row per subject and the separate variables are placed in the columns. When subjects are repeatedly assessed, additional variables are added for new assessments. This is also called a wide data format .
7.4 Multilevel data - Clusters and Levels
The two datasets that are used in this chapter can be organized by their level of assessment of information, resulting in different type of variables. These are graphically presented for the datasets that are used in this chapter, i.e. the Popularity and AGGO datasets in Figure 7.2 and Figure 7.3 respectively.

Figure 7.2: Popular dataset with level 1 and 2 variables.
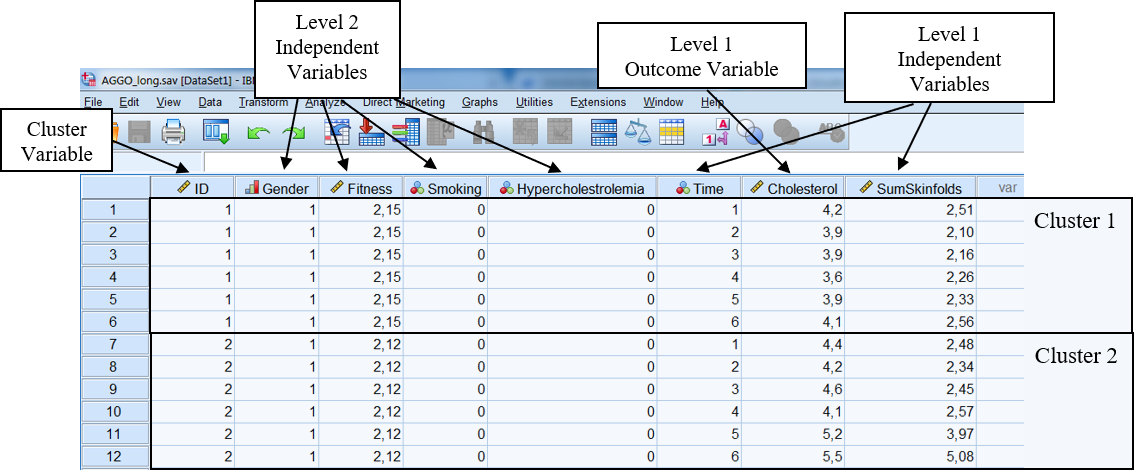
Figure 7.3: AGGO dataset with level 1 and 2 variables.
Level 1 outcome variable: The Student popular variable in the Popular dataset that is repeatedly assessed in the class or the Cholesterol variables that is repeatedly assessed over time within persons in the Aggo dataset. Other examples may be math test scores of individual students in a class or their Intelligent Quotient (IQ) scores. In other words, level one outcome information varies within a cluster or the value changes over time (i.e. does not have a fixed value).
Level 1 independent variable: These are variables that vary within a cluster, but now are used as independent variables. Examples are the extrav variable (Pupil extraversion) in the Popular dataset or the Time or Sum of Skinfold measurements that are repeatedly assessed within persons over time in the Aggo dataset. Other examples are hours that students in a class spent on their homework each week or the level of education of their parents.
Level 2 independent variables. These variables do not vary within a cluster but vary only between clusters. An example is the texp variable (teacher experience) in the Popular dataset or the Gender or Fitness variable in the Aggo dataset, which is only assessed at the start of the study, or in case of schools, if the school is a private or public school.
Level 4 is the cluster variable itself. This is a special variable which distinguishes the clusters. This could be the school identification number in the Popular dataset which form the blocks of measurement or the person identification number in the Aggo dataset that distinguishes individuals with repeated information over time.
In the next paragraph the type of statistical model is defined that is used to analyze multilevel data.
7.5 Longitudinal Multilevel data - from wide to long
In this Chapter we use an longitudinal example dataset from The Amsterdam Growth and Health Longitudinal Study (AGGO). In this study persons were repeatedly assessed over time. Usually, a dataset contains one row per subject and the separate variables are placed in the columns. When subjects are repeatedly assessed, additional variables are added for new assessments. This is also called a wide data format (Figure 7.4).
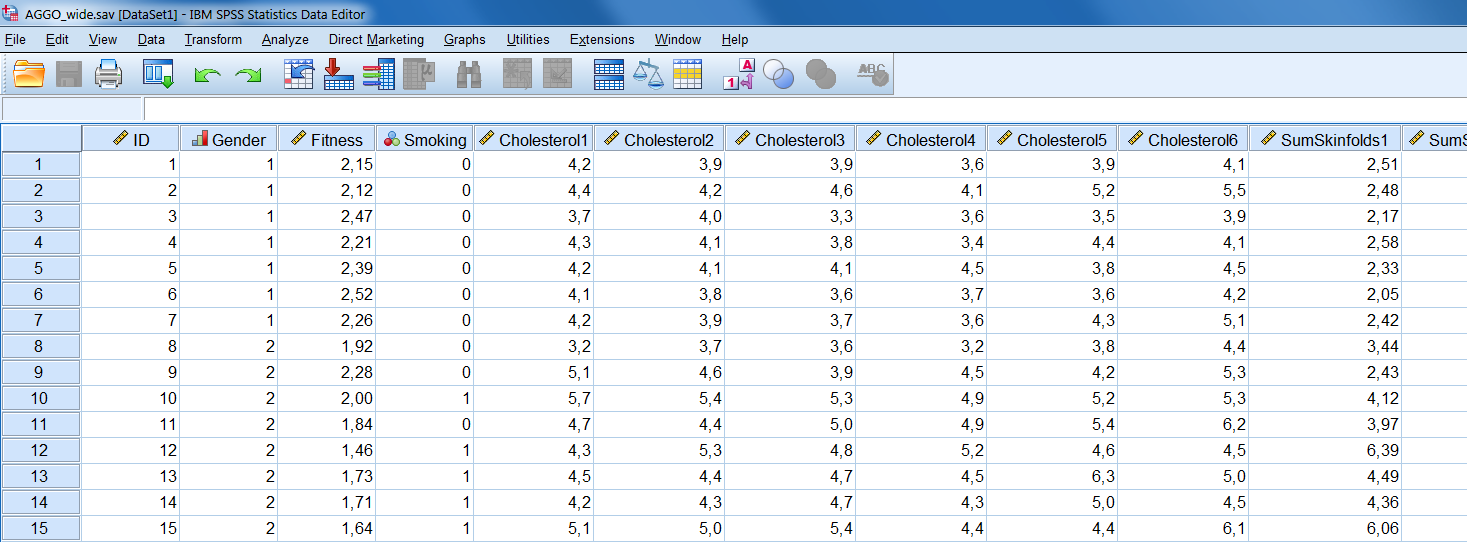
Figure 7.4: Example of the AGGO dataset in wide format.
In order to apply multilevel analyses, we need a long version of the data. For the analysis we have to convert the dataset into a long data format, which is explained in paragraph 7.6. An example of a long dataset is presented in Figure 7.5. The variable that separates the clusters is called the ID variable and the variable that distinguishes the measurements at different time points is the Time variable. This means that repeated assessment within a subject are stacked under each other. Each subject has multiple rows, one row for each repeated measurement.
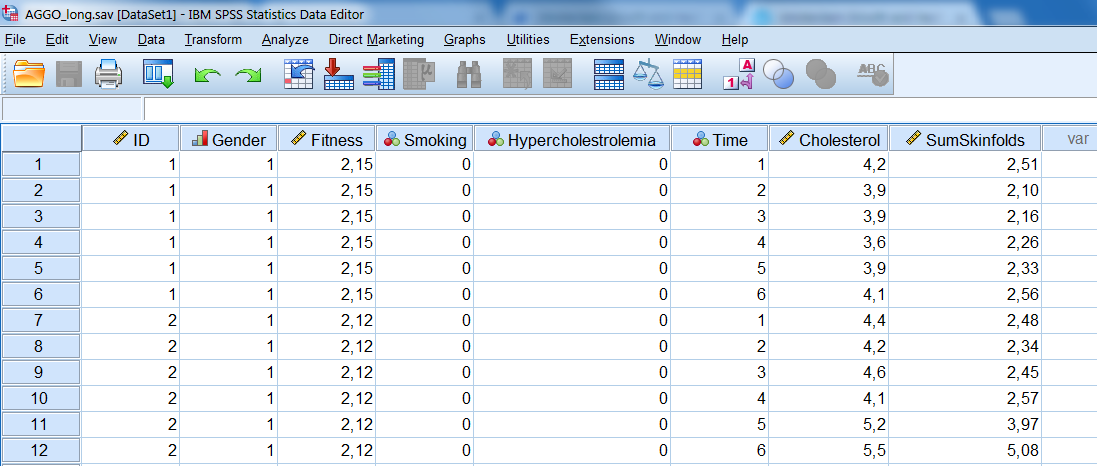
Figure 7.5: Example of the AGGO dataset in long format.
7.6 Restructuring from wide to long in SPSS
We start with the dataset in wide format, which is presented in (Figure 7.6). In this dataset, information is repeatedly assessed over time for the Cholesterol and Sum of Skinfold variables and this information is stored in the column variables. The repeated assessments are distinguished by the numbers at the end of the variable names. The number 1 indicates the first measurement, number 2, the second, etc. The Gender and Smoking variable is not repeatedly assessed over time. Each row represents a separate case.
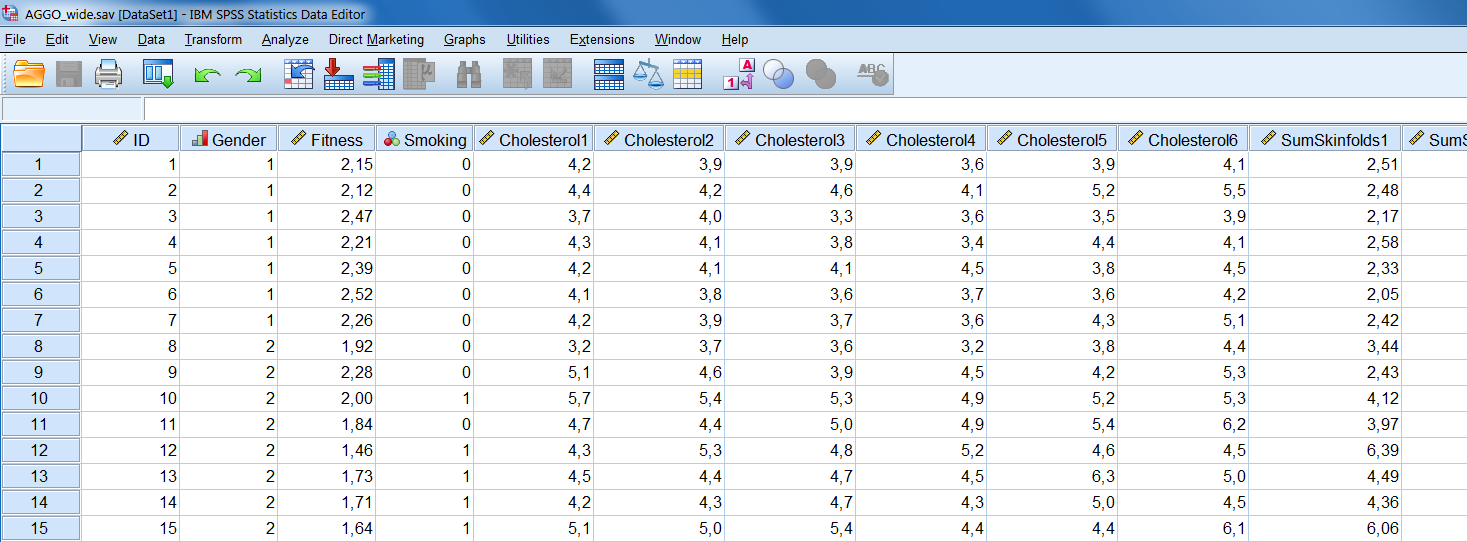
Figure 7.6: Example of a dataset in wide format.
Now click on Data Restructure and following the next steps:
Step1 A new window opens with three options (Figure 7.7). The default is to Restructure selected variables into cases and that is exactly what we want to do if we want to restructure from wide to long data files.
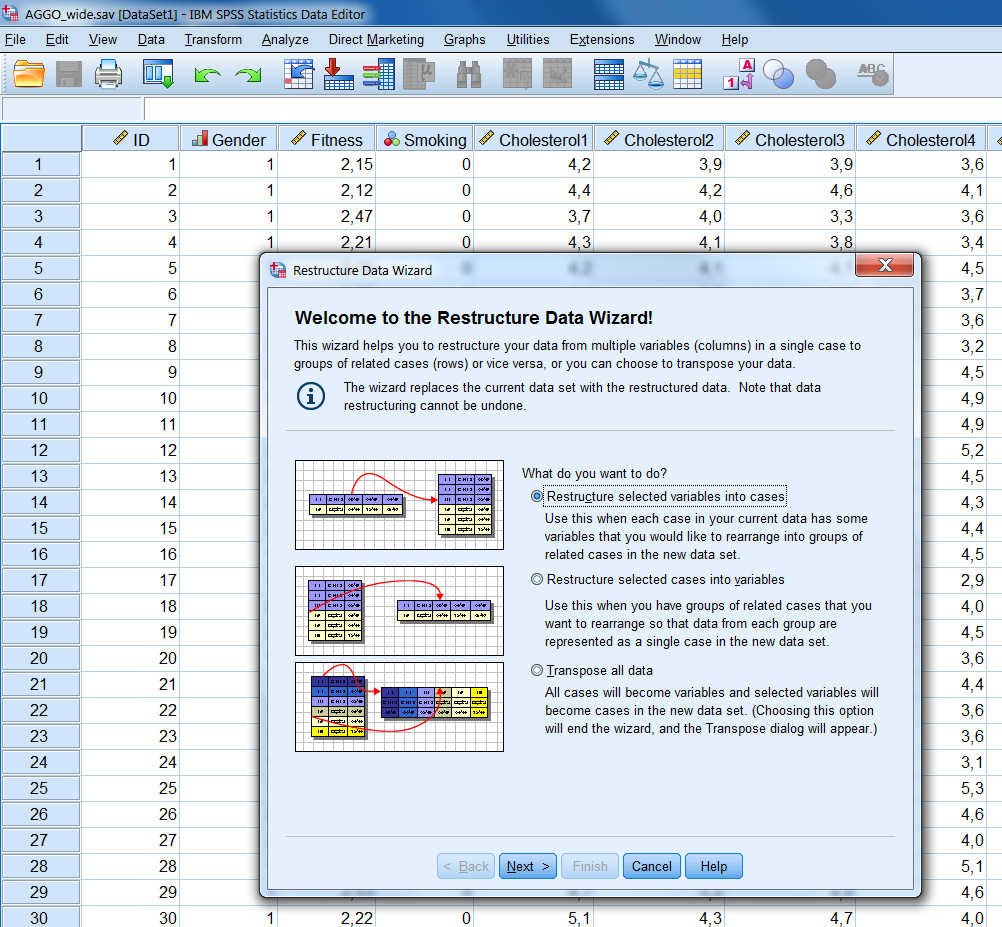
Figure 7.7: Step 1 of the Restructure Data Wizard.
Step 2 Click Next and a new window opens (Figure 7.8). In this window, you can choose how many variables you wish to restructure. Here we should think of the number of time varying variables (level 1) we have that we wish to examine. In our example dataset, we have two such variables: Cholesterol and Sum of Skinfolds. Therefore, we click the option More than one and type 2.
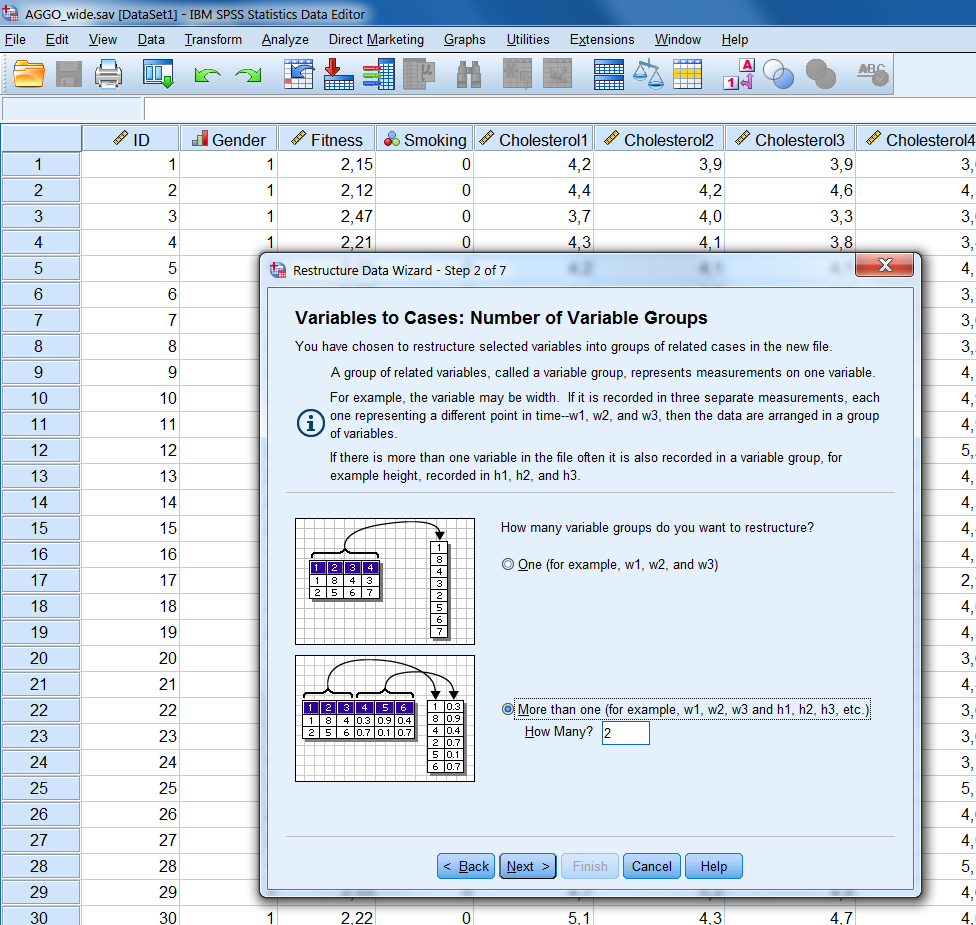
Figure 7.8: Step 2 of the Restructure Data Wizard.
Step 3 We click Next and a new window opens (Figure 7.9). In this window, we should first define which variable should be used as our case group identifier. SPSS by default makes a new variable for this named Id. You can also use the ID variable in your dataset (you usually have such a variable): by clicking the arrow next to the Use case number option, you can select Use selected variable and after that drag the ID variable in your dataset (here ID) to this pane. Subsequently, we should define the variables in our broad dataset that should be restructured to one new long variable under Variables to be transposed. In our case this refers to two new variables. We rename trans1 into Cholesterol and select the 6 Cholesterol variables by holding down the Ctrl or Shift key. Next, we move these variables to the pane on the right and continue with the second variable (Figure 7.9). Now we change trans2 into SumSkinfolds and repeat the procedures for the Sum of Skinfolds variables.
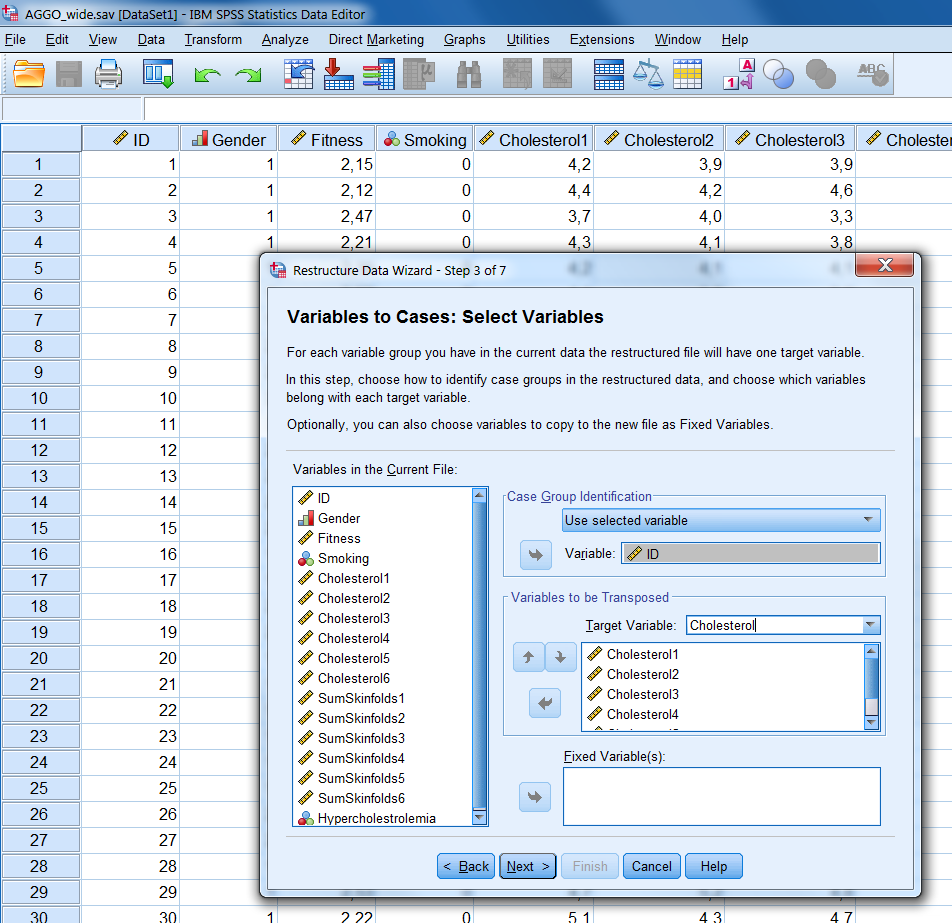
Figure 7.9: Step 3 of the Restructure Data Wizard.
Step 4 We click Next and a new window opens (Figure 7.10). In this window, we can create so called Index variables. In longitudinal data analyses the index variable refers to the time points. We therefore only want one index variable. This is the default, so we can click Next again.
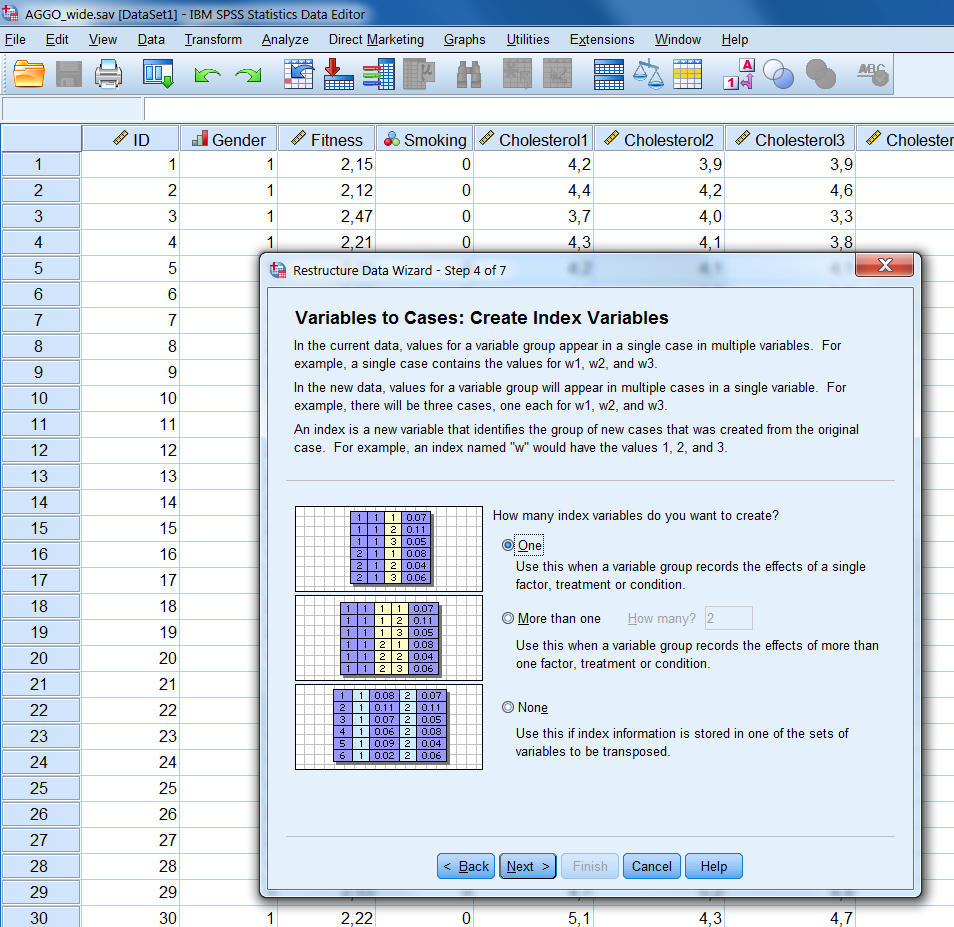
Figure 7.10: Step 4 of the Restructure Data Wizard.
Step 5 A new window opens again (Figure 7.11). This window allows us to create the index/time variable. The default is to use sequential numbers, which we also choose. In case of unequal time points you can redefine these numbers later in the long file with the Compute command in SPSS. We can change the name index1, by double clicking on it. Rename it in “Time”. In addition we can define a label for this variable in the same way.
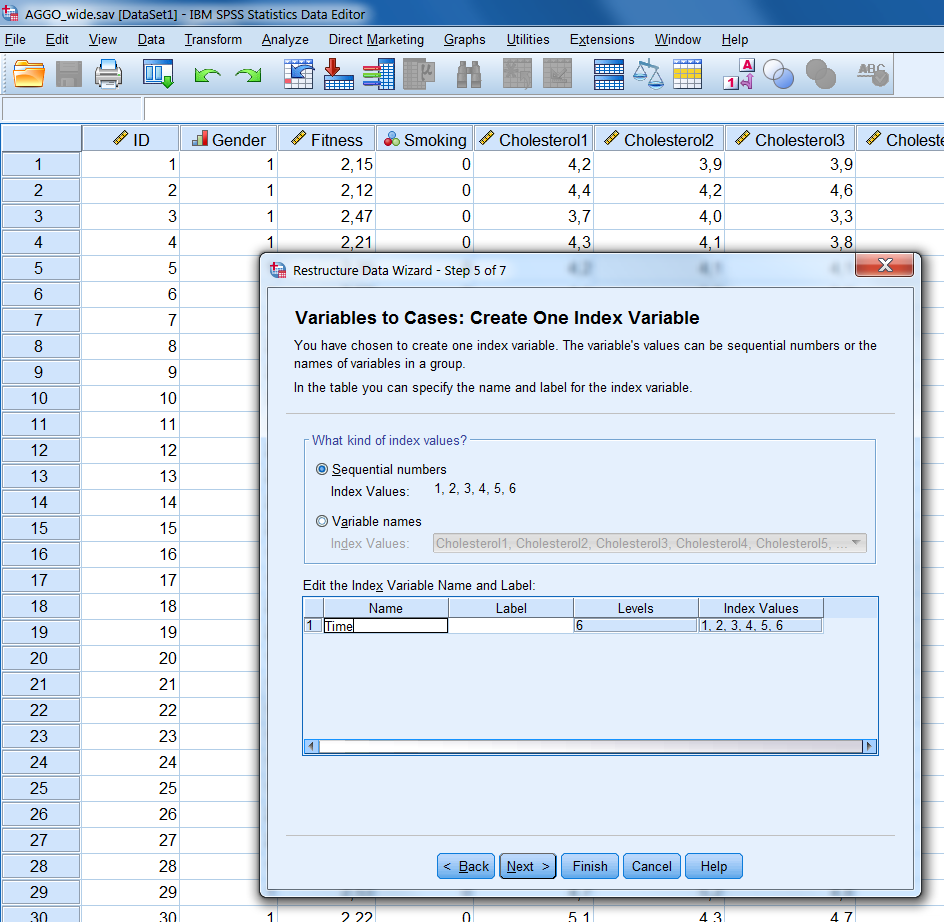
Figure 7.11: Step 5 of the Restructure Data Wizard.
Step 6 Click Next and a new window opens again (Figure 7.12). Here the only important thing is that we should choose what to do with the other variables in our dataset. We can either Drop them, meaning that we will not be able to use them in the subsequent analyses, or Keep them and treat them as fixed (time independent). In this case we choose this latter option.
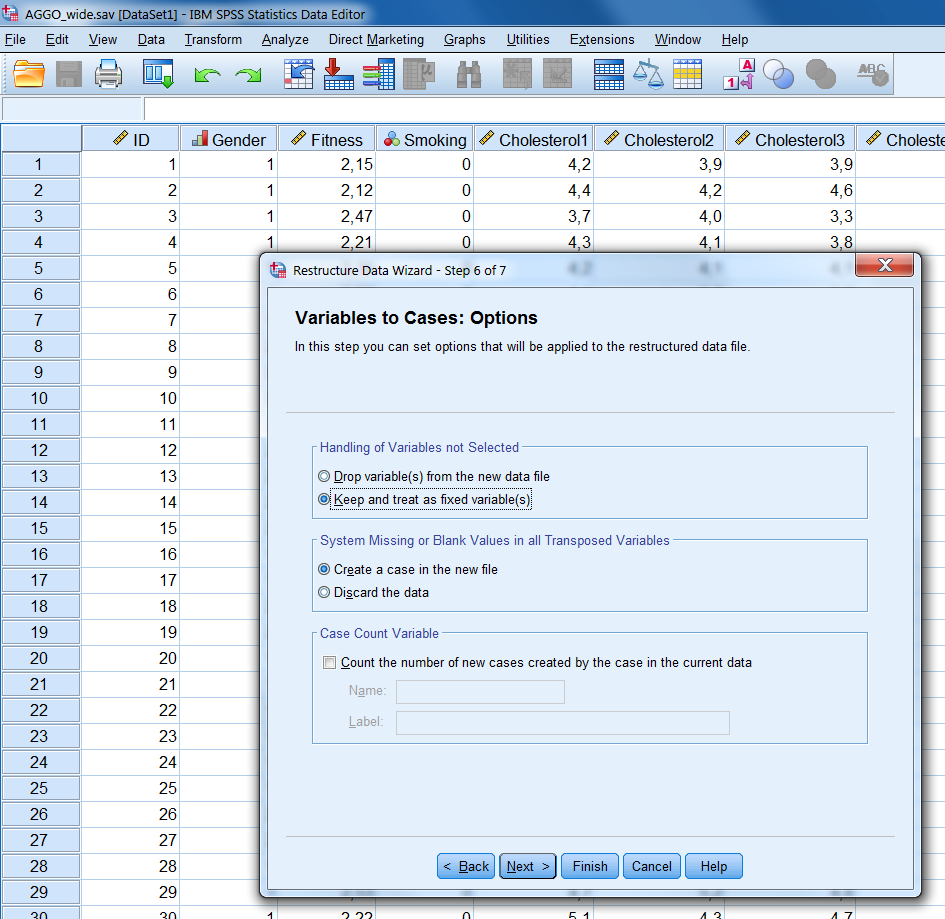
Figure 7.12: Step 6 of the Restructure Data Wizard.
Click on Next and the last window will open (Figure 7.13).
Figure 7.13: Last step of the Restructure Data Wizard.
This is the final step. Click on Finish (if we wish to paste the syntax we can choose for that here). Be aware that your converted dataset replaces now your original dataset (Figure 7.14). To keep both datasets, use for Save as in the menu file and choose another file name for the converted file.
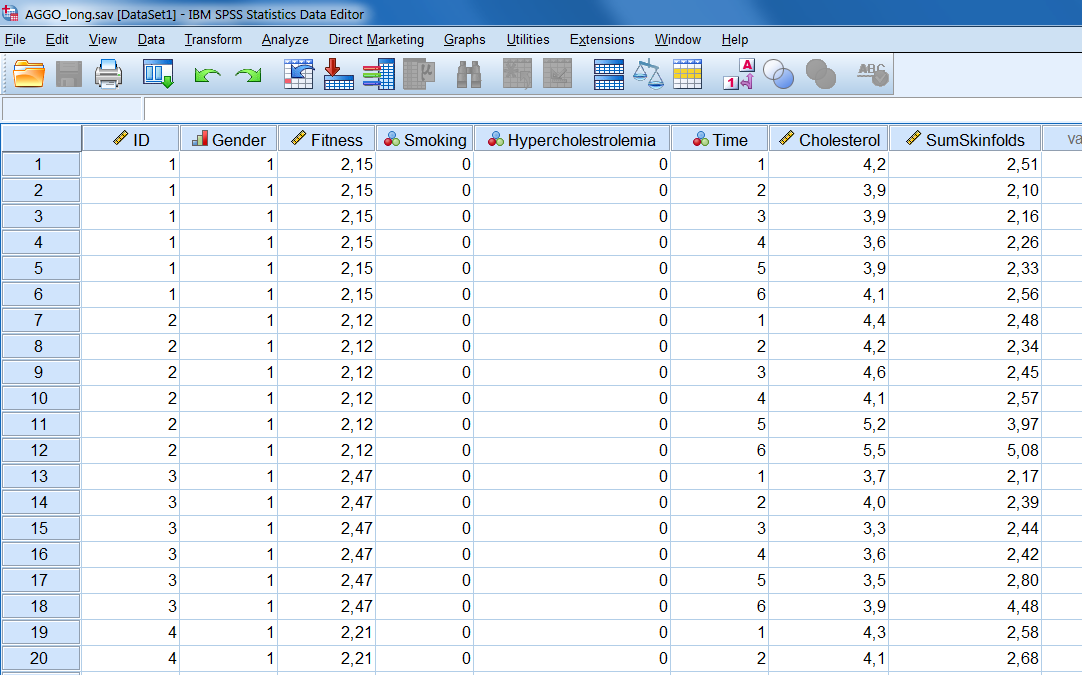
Figure 7.14: Example of the AGGO dataset in wide format.
Figure 7.14. Converted wide to long dataset.
7.7 Restructuring from wide to long in R
To convert a dataset in R from wide to long, you can use the reshape function. Before you convert a wide dataset, it is a good idea to redesign the dataset a little bit and to place all variables in the order of their names. It is than easier to apply the reshape function. You see an example in the R code below, where all Cholesterol variables are nicely ordered.
library(foreign)
dataset <- read.spss(file="AGGO_wide.sav", to.data.frame = T)
head(dataset, 10)## ID Gender Fitness Smoking Cholesterol1 Cholesterol2 Cholesterol3
## 1 1 1 2.151339 0 4.2 3.9 3.9
## 2 2 1 2.119814 0 4.4 4.2 4.6
## 3 3 1 2.472159 0 3.7 4.0 3.3
## 4 4 1 2.205836 0 4.3 4.1 3.8
## 5 5 1 2.393320 0 4.2 4.1 4.1
## 6 6 1 2.523713 0 4.1 3.8 3.6
## 7 7 1 2.260524 0 4.2 3.9 3.7
## 8 8 2 1.915354 0 3.2 3.7 3.6
## 9 9 2 2.278520 0 5.1 4.6 3.9
## 10 10 2 2.002636 1 5.7 5.4 5.3
## Cholesterol4 Cholesterol5 Cholesterol6 SumSkinfolds1 SumSkinfolds2
## 1 3.6 3.92 4.13 2.51 2.10
## 2 4.1 5.18 5.50 2.48 2.34
## 3 3.6 3.48 3.85 2.17 2.39
## 4 3.4 4.35 4.06 2.58 2.68
## 5 4.5 3.81 4.52 2.33 2.02
## 6 3.7 3.57 4.24 2.05 2.09
## 7 3.6 4.32 5.08 2.42 2.93
## 8 3.2 3.82 4.42 3.44 3.78
## 9 4.5 4.22 5.27 2.43 2.72
## 10 4.9 5.24 5.34 4.12 4.83
## SumSkinfolds3 SumSkinfolds4 SumSkinfolds5 SumSkinfolds6 Hypercholestrolemia
## 1 2.16 2.26 2.33 2.56 0
## 2 2.45 2.57 3.97 5.08 0
## 3 2.44 2.42 2.80 4.48 0
## 4 2.84 3.00 2.85 2.77 0
## 5 2.00 2.27 1.94 2.16 0
## 6 2.25 2.24 2.66 2.73 0
## 7 3.14 3.35 3.90 4.01 0
## 8 4.78 4.86 5.49 6.25 0
## 9 3.06 3.72 5.28 5.11 1
## 10 6.21 6.35 5.99 3.70 1Now it is easy to convert the dataset by using the following code. The object dataset_long shows the results (first 10 patients shown):
# Reshape wide to long
dataset_long <- reshape(dataset, idvar = "ID", varying = list(5:10, 11:16), timevar="Time",
v.names = c("Cholesterol", "SumSkinfolds"), direction = "long")
#dataset_longThe long dataset is not ordered yet by ID and Time. This can be done by using the order function.
dataset_long <- dataset_long[order(dataset_long$ID, dataset_long$Time), ]
#dataset_longNow that we have restructured the dataset we are going to discover how missing data in multilevel data can be imputed.
7.8 Missing data at different levels
Missing data in multilevel studies can occur at the same levels as measurements as was discussed in paragraph 7.4. In other words, missing data can occur at the level of:
The Level 1 outcome variable: Missing data is present in the popularity or cholesterol variable. Note that when Mixed models are used and there is only missing data in the outcome variable, imputation of missing values is not necessary. Full information maximum likelihood procedures, that are used to estimate the parameters of a mixed model, can be used to get estimates of regression coeficients and standard errors.
The Level 1 independent variable: Missing data occur at the level of the independent variables that vary within a cluster. Examples are missing data in the extrav variable (Pupil extraversion) or the Sum of Skinfold variable or the age or IQ scores of students within a class.
The Level 2 independent variables: Missing values are located in the variables that have a constant value within a cluster. For example, in the texp variable (teacher experience) or in the Fitness variable assessed at baseline or if data is missing for the variable if a school is a private or public school. Other examples are when data is missing for variables as gender or educational level of persons that were repeatedly assessed over time.
The Cluster level variable: Missing data may be present in the cluster variable itself, for example if students did not fill in the name of the school or patients did not fill in the name of the hospital they were treated.
7.9 Sporadically and systematically missing data
Missing values can be found within a cluster in variables assessed at different levels. If some of these values are missing, these are called sporadically missing values. If all values for a variable within a cluster are missing these are called systematically missing data (Figure 7.15). The multilevel imputation models that are discussed in this chapter can handle both types of missing data.
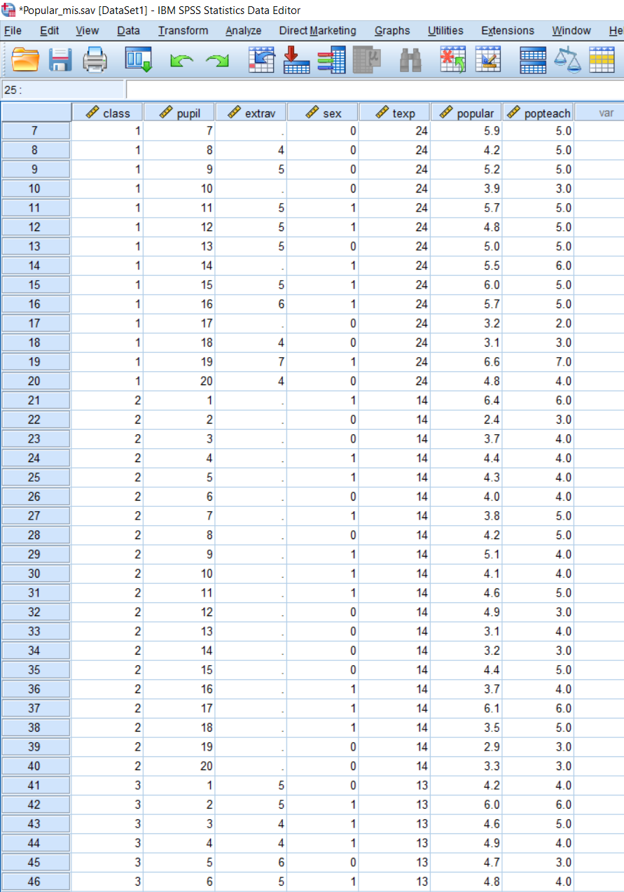
Figure 7.15: Popular Dataset with sporadically missing data in class (cluster) 1 and systematically missing data in class (cluster) 2 of the extrav variable (Pupil extraversion)
7.10 Multilevel Multiple Imputation models
There are two factors important when multilevel imputation models are used. At which level are the missing values located, which determines the imputation method, and how to design the predictormatrix to apply multilevel multiple imputation. We start with explaining how to design the predictormatrix.
7.11 The Predictormatrix
In Paragraph 4.9 the meaning and use of the predictormatrix in the mice function was explained. It was explained that you can include and exclude variables in the imputation model by asigning them the value 1 or 0 respectively. The predictormatrix for multilevel imputations models allows for more possibilities, depending on if you want to include multilevel models with fixed effects only or fixed and random effects and cluster means. The following values in the predictor matrix are allowed:
| Setting | Description |
|---|---|
| -2 | to indicate the cluster variable |
| 1 | imputation model with a fixed effect and a random intercept. |
| 2 | imputation model with a fixed effect, random intercept and random slope. |
| 3 | imputation model with a fixed effect, random intercept and cluster means. |
| 4 | imputation model with a fixed effect, random intercept and random slope and cluster means. |
For example, if we want to impute missing data in the Pupil extraversion variable extrav in the popular dataset and we use the variables sex, texp, popular and popteach in our imputation model, by defining fixed effects for all variables and also a random effect for the popular variable, without using the pupil variable, the predictormatrix is:
## class pupil extrav sex texp popular popteach
## class 0 0 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav -2 0 0 1 1 2 1
## sex 1 0 1 0 1 1 1
## texp 1 0 1 1 0 1 1
## popular 1 0 1 1 1 0 1
## popteach 1 0 1 1 1 1 07.12 Missing data in continuous variables
7.12.1 Imputation methods
As default imputation method for continuous variables, mice uses pmm. However, to impute multilevel missing values in continuous variables several other methods have been developed that can be defined as imputation method within the mice function. Table 7.2 shows which methods are developed for multilevel models and which package has to be installed to use the method.
| Package | Method | Description | SP* | SY* | HO† | HE† | Notes |
|---|---|---|---|---|---|---|---|
mice
|
2l.norm | Linear Mixed model | X | Does not handle predictors that are specified as fixed effects (1 in the predictormatrix). The current advice is to specify all predictors as random effects (2 in the predictormatrix). | |||
| 2l.lmer | Linear Mixed model | X | X | ||||
| 2l.pan | Linear Mixed model (PAN method) | X | |||||
micemd
|
2l.glm.norm | Linear Mixed model | X | X | X | ||
| 2l.jomo | Generalized Linear Mixed model | X | For continuous or binary variables. | ||||
| 2l.2stage.norm | Two-level normal model | X | X | X | Two-stage imputation: at step 1, a linear regression model is fitted to each observed cluster; at step 2, estimates obtained from each cluster are combined according to a linear random effects model. | ||
| 2l.2stage.pmm | Two-level normal model with PMM | X | X | X | Same as 2l.2stage.norm but with PMM. | ||
miceadds
|
2l.continuous | Linear Mixed model | X | X | |||
| 2l.pmm | Linear Mixed model with PMM | X | X | Same as 2l.continuous but with PMM. | |||
| * SP; sporadically missing, SY: systematically missing † HO; homogeneous error variance, HE: heterogeneous error variance |
7.12.2 Example: Level-1 missing values
To multiple impute (5 times, 10 iterations) missing data in the Popular dataset in the extrav (Pupil extraversion) variable with as imputation method 2l.lmer, using an imputation model including all other variables, except the Pupil identity number variable and using all variables as fixed effects, and only the popular variable as random effect the predictor matrix and imputation procedure is:
library(mice)
load("Popular_mis.Rdata")
popular_mis %>% print(n = 25)## # A tibble: 2,000 × 7
## class pupil extrav sex texp popular popteach
## <dbl> <dbl> <dbl> <dbl+lbl> <dbl> <dbl> <dbl>
## 1 1 1 5 1 [girl] 24 6.3 6
## 2 1 2 7 0 [boy] 24 4.9 5
## 3 1 3 NA 1 [girl] 24 5.3 6
## 4 1 4 3 1 [girl] 24 4.7 5
## 5 1 5 5 1 [girl] 24 6 6
## 6 1 6 4 0 [boy] 24 4.7 5
## 7 1 7 NA 0 [boy] 24 5.9 5
## 8 1 8 4 0 [boy] 24 4.2 5
## 9 1 9 5 0 [boy] 24 5.2 5
## 10 1 10 5 0 [boy] 24 3.9 3
## 11 1 11 5 1 [girl] 24 5.7 5
## 12 1 12 5 1 [girl] 24 4.8 5
## 13 1 13 5 0 [boy] 24 5 5
## 14 1 14 NA 1 [girl] 24 5.5 6
## 15 1 15 5 1 [girl] 24 6 5
## 16 1 16 6 1 [girl] 24 5.7 5
## 17 1 17 4 0 [boy] 24 3.2 2
## 18 1 18 4 0 [boy] 24 3.1 3
## 19 1 19 7 1 [girl] 24 6.6 7
## 20 1 20 4 0 [boy] 24 4.8 4
## 21 2 1 NA 1 [girl] 14 6.4 6
## 22 2 2 4 0 [boy] 14 2.4 3
## 23 2 3 6 0 [boy] 14 3.7 4
## 24 2 4 5 1 [girl] 14 4.4 4
## 25 2 5 5 1 [girl] 14 4.3 4
## # … with 1,975 more rows# Set imputation method
impmethod <- character(ncol(popular_mis))
names(impmethod) <- colnames(popular_mis)
impmethod["extrav"] <- "2l.lmer"
impmethod## class pupil extrav sex texp popular popteach
## "" "" "2l.lmer" "" "" "" ""# set default predictor matrix
pm <- make.predictorMatrix(popular_mis)
pm## class pupil extrav sex texp popular popteach
## class 0 1 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav 1 1 0 1 1 1 1
## sex 1 1 1 0 1 1 1
## texp 1 1 1 1 0 1 1
## popular 1 1 1 1 1 0 1
## popteach 1 1 1 1 1 1 0# create imputation model for extrav variable
pm[, "pupil"] <- 0
pm["extrav", c("class", "pupil", "extrav", "sex", "texp", "popular", "popteach")] <- c(-2, 0, 0, 1, 1, 2, 1)
pm## class pupil extrav sex texp popular popteach
## class 0 0 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav -2 0 0 1 1 2 1
## sex 1 0 1 0 1 1 1
## texp 1 0 1 1 0 1 1
## popular 1 0 1 1 1 0 1
## popteach 1 0 1 1 1 1 0# run multiple imputations
res.mice.md <- mice(popular_mis, m=5, predictorMatrix = pm,
method=impmethod, maxit=10, printFlag = FALSE, seed=1874)
res.mice.md## Class: mids
## Number of multiple imputations: 5
## Imputation methods:
## class pupil extrav sex texp popular popteach
## "" "" "2l.lmer" "" "" "" ""
## PredictorMatrix:
## class pupil extrav sex texp popular popteach
## class 0 0 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav -2 0 0 1 1 2 1
## sex 1 0 1 0 1 1 1
## texp 1 0 1 1 0 1 1
## popular 1 0 1 1 1 0 17.13 Missing data in Dichotomous variables
7.13.1 Imputation methods
To impute multilevel missing values in dichotomous variables several methods have been developed that can be defined as imputation method within the mice function. Table 7.3 shows which methods are developed for multilevel models and which package has to be installed to use the method.
| Package | Method | Description | SP* | SY* | Notes |
|---|---|---|---|---|---|
mice
|
2l.bin | Generalized Linear Mixed model | X | X | 20-50 iterations are recommended and may be hard to run in small datasets |
micemd
|
2l.2stage.bin | Generalized Linear Mixed model | X | X | |
| 2l.glm.bin | Two-level model | X | X | ||
miceadds
|
2l.binary | Generalized Linear Mixed model | X | X | |
| * SP; sporadically missing, SY: systematically missing |
7.13.2 Example: Level-1 missing values
To multiple impute (5 times, 10 iterations) missing data in the Popular dataset in the sex variable with as imputation method 2l.bin, using an imputation model including all other variables, except the Pupil identity number variable and using all variables as fixed effects, and only the popular variable as random effect the predictor matrix and imputation procedure is:
library(mice)
load("Popular_mis_di.Rdata")
# define dichotomous variable
popular_mis_di$sex <- factor(popular_mis_di$sex)
popular_mis_di %>% print(n = 25)## # A tibble: 2,000 × 7
## class pupil extrav sex texp popular popteach
## <dbl> <dbl> <dbl> <fct> <dbl> <dbl> <dbl>
## 1 1 1 5 1 24 6.3 6
## 2 1 2 7 0 24 4.9 5
## 3 1 3 4 <NA> 24 5.3 6
## 4 1 4 3 1 24 4.7 5
## 5 1 5 5 1 24 6 6
## 6 1 6 4 0 24 4.7 5
## 7 1 7 5 <NA> 24 5.9 5
## 8 1 8 4 0 24 4.2 5
## 9 1 9 5 0 24 5.2 5
## 10 1 10 5 0 24 3.9 3
## 11 1 11 5 1 24 5.7 5
## 12 1 12 5 1 24 4.8 5
## 13 1 13 5 0 24 5 5
## 14 1 14 5 <NA> 24 5.5 6
## 15 1 15 5 1 24 6 5
## 16 1 16 6 1 24 5.7 5
## 17 1 17 4 0 24 3.2 2
## 18 1 18 4 0 24 3.1 3
## 19 1 19 7 1 24 6.6 7
## 20 1 20 4 0 24 4.8 4
## 21 2 1 8 <NA> 14 6.4 6
## 22 2 2 4 0 14 2.4 3
## 23 2 3 6 0 14 3.7 4
## 24 2 4 5 1 14 4.4 4
## 25 2 5 5 1 14 4.3 4
## # … with 1,975 more rows# Set imputation method
impmethod <- character(ncol(popular_mis_di))
names(impmethod) <- colnames(popular_mis_di)
impmethod["sex"] <- "2l.bin"
impmethod## class pupil extrav sex texp popular popteach
## "" "" "" "2l.bin" "" "" ""# set default predictor matrix
pm <- make.predictorMatrix(popular_mis_di)
pm## class pupil extrav sex texp popular popteach
## class 0 1 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav 1 1 0 1 1 1 1
## sex 1 1 1 0 1 1 1
## texp 1 1 1 1 0 1 1
## popular 1 1 1 1 1 0 1
## popteach 1 1 1 1 1 1 0# create imputation model for sex variable
pm[, "pupil"] <- 0
pm["sex", c("class", "pupil", "extrav", "sex", "texp", "popular", "popteach")] <- c(-2, 0, 1, 0, 1, 2, 1)
pm## class pupil extrav sex texp popular popteach
## class 0 0 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav 1 0 0 1 1 1 1
## sex -2 0 1 0 1 2 1
## texp 1 0 1 1 0 1 1
## popular 1 0 1 1 1 0 1
## popteach 1 0 1 1 1 1 0# run multiple imputations
res.mice.md <- mice(popular_mis_di, m=5, predictorMatrix = pm,
method=impmethod, maxit=10, printFlag = FALSE, seed=1983)
res.mice.md## Class: mids
## Number of multiple imputations: 5
## Imputation methods:
## class pupil extrav sex texp popular popteach
## "" "" "" "2l.bin" "" "" ""
## PredictorMatrix:
## class pupil extrav sex texp popular popteach
## class 0 0 1 1 1 1 1
## pupil 1 0 1 1 1 1 1
## extrav 1 0 0 1 1 1 1
## sex -2 0 1 0 1 2 1
## texp 1 0 1 1 0 1 1
## popular 1 0 1 1 1 0 1