Chapter 6 Time Weighted Control Charts in Phase II
Shewhart control charts like the \(\overline{X}\)-\(R\) charts discussed in Chapter 4 are very useful in Phase I. They can quickly detect a large shift in the mean or variance, and the patterns on the chart defined by the Western Electric rules mentioned in Section 4.2.3, are helpful in hypothesizing the cause of out-of-control conditions. If it can be demonstrated that a process is in “in-control” with a capability index of 1.5 or higher in Phase I, then there will be no more than 1,350 ppm (or 0.135%) nonconforming output in future production (as long as the process mean does not shift by more that 1.5 standard deviations). Therefore, to maintain a high quality level it is important that small shifts in the mean on the order of one standard deviation are quickly detected and corrected in during Phase II monitoring.
However, Shewhart charts are not sensitive to small shifts in the mean when used for Phase II process monitoring. When the only out-of-control signal used on a Shewhart chart is a point beyond the control limits, the OC may be too high and the ARL too long to quickly detect a small shift in the process mean. If additional sensitizing rules (like the Western Electric rules) are used in Phase II to decrease the out-of-control ARL, they also dramatically decrease the in-control ARL. This could cause unnecessary process adjustments or searches for causes. The solution is to use time weighted control charts. These charts plot the cumulative or weighted sums of all past observations, and are more likely to detect a small shift in the process mean.
6.1 Time Weighted Control Charts when the In-control \(\mu\) and \(\sigma\) are known
To introduce the time weighted control charts, consider the random data produced by the R code below. The first 7 observations in the vector \(\verb!x1!\) are random observations from a normal distribution with mean \(\mu=50\) and standard deviation \(\sigma=5\). The next 8 observations in the vector \(\verb!x2!\) are random observations from the normal distribution with mean \(\mu=56.5\) and standard deviation \(\sigma=5\). Next, the code creates a Shewhart individuals chart of the data in both vectors assuming the known in-control mean and standard deviarion are \(\mu=50\) and \(\sigma=5\). This chart is shown in Figure 6.1.
The vertical dashed line in the figure shows the point where the mean increased from 50 to 56.5. However, there are no points outside the control limits. It can be observed that all the points lie above the centerline on the right side of the chart.
library(qcc)
# random data from normal N(50,5) followed by N(56.6, 5)
set.seed(109)
x1<-rnorm(7,50,5)
set.seed(115)
x2<-rnorm(8,56.6,5)
# individuals chart assuming mu=50, sigma=5
library(qcc)
qcc(x1, type="xbar.one",center=50,std.dev=5,newdata=x2)This might suggest that the mean has increased, but, even using the Western Electric sensitizing rules, no out-of-control signal should be assumed until the 7th consecutive point above the center line occurs at the 14th point on the chart.
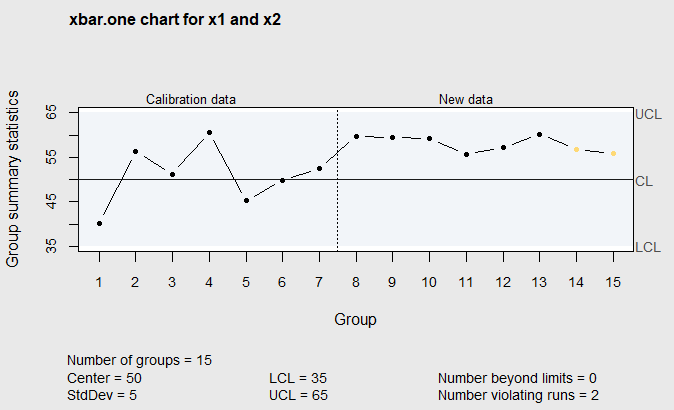
Figure 6.1 Individuals Chart of Random Data
To enhance the sensitivity of the control chart, without using the Western Electric rules that decrease the ARL\(_0\) and increase the chance of a false positive, consider the cumulative sums of deviations from the centerline defined in Equation (6.1) \[\begin{equation} C_i=\sum_{k=1}^{i}(X_k-\mu), \tag{6.1} \end{equation}\]
and shown in Table 6.1.
Table 6.1 Cumulative Sums of Deviations from the Mean
| Observation | Value | Deviation from \(\mu =50\) | \(C_i\) |
|---|---|---|---|
| 1 | 40.208 | -9.792 | -9.792 |
| 2 | 56.211 | 6.211 | -3.581 |
| 3 | 51.236 | 1.236 | -2.345 |
| 4 | 60.686 | 10.686 | 8.341 |
| 5 | 45.230 | -4.770 | 3.571 |
| 6 | 49.849 | -0.151 | 3.420 |
| 7 | 52.491 | 2.491 | 5.912 |
| 8 | 59.762 | 9.762 | 15.674 |
| 9 | 59.462 | 9.462 | 25.135 |
| 10 | 59.302 | 9.302 | 34.437 |
| 11 | 55.679 | 5.679 | 40.117 |
| 12 | 57.155 | 7.155 | 47.272 |
| 13 | 60.219 | 10.219 | 57.491 |
| 14 | 56.770 | 6.771 | 64.261 |
| 15 | 55.949 | 5.948 | 70.210 |
Figure 6.2 is a plot of the cumulative sums \(C_i\) by observation number \(i\) . In this figure, it can be seen that the cumulative sums of deviations from \(\mu=50\) remain close to zero for subgroups 1–7. These were generated from the normal distribution with mean 50. However, beginning at subgroup 8, where the process mean increased, the cumulative sums of deviations begin to increase noticeably.
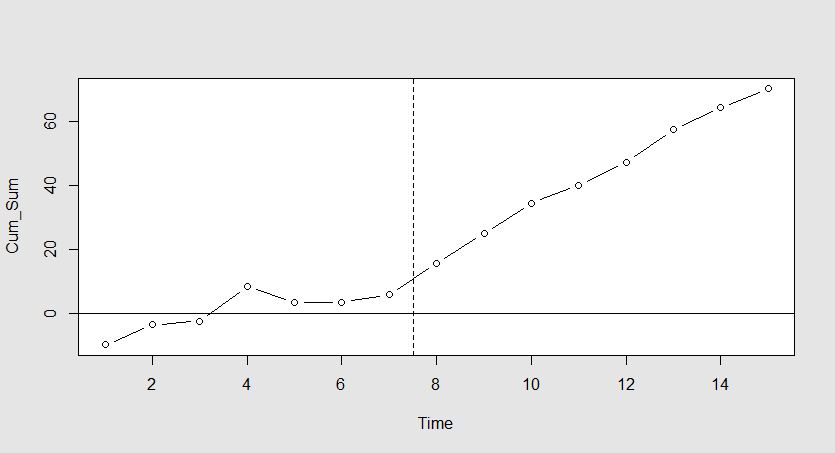
Figure 6.2 Plot of cumulative sums of deviations from Table 6.1
This illustrates a time weighted weighted chart. Although the figure appears to show an out-of-control signal, there are no formal control limits on the graph. Using the tabular Cusum control chart is one way to obtain them.
6.1.1 Cusum Charts
Standardized tabular Cusum control charts work with individual measurements rather than subgroups. Two sets of cumulative sums of the standardized individual deviations from the mean are plotted on the tabular Cusum control chart. The first are the sums of the positive deviations, \(C_i^+\) from the process mean, and the second set are the sums of the negative deviations \(C_i^-\) , from the process mean. The definition of these two cumulative sums are shown in Equation (6.2), and they are illustrated using the random data from Figure 6.1 in Table 6.2.
\[\begin{align} C_i^+=&max[0,y_i-k+C_{i-1}^+]\\ \nonumber \\ C_i^-=&max[0,-k-y_i+C_{i-1}^-], \nonumber \tag{6.2} \end{align}\]
where \(y_i=(x_i-\mu_0)/\sigma_0\) , and \(\mu_0=50\) and \(\sigma_0=5\) are the known in-control process mean and standard deviation. The constant \(k\) is generally chosen to be 1/2 the size of the mean shift in standard deviations that you would like to detect quickly. In order to detect a one standard deviation shift in the mean quickly, \(k=1/2\), and decision limits are placed on the chart at \(\pm h\). An out-of-control signal occurs if the upper Cusum \(C_i^+\) exceeds \(+h\) or the lower Cusum \(C_i^+\) falls below \(-h\) .
Using the \(\verb!cusum!\) function in the \(\verb!qcc!\) package, a Cusum chart of the random data is illustrated in the R code below and shown in Figure 6.3. The argument \(\verb!decision.interval=5!\) specifies \(h\) to be 5 and makes the ARL\(_0\) = 465; the argument \(\verb!se.shift=1!\) sets the shift in the process mean to be detected as 1, measured in standard deviations, (i.e. \(k=1/2\)); and the arguments \(\verb!center!\) and \(\verb!std.dev!\) specify the known process mean and standard deviation. The function plots \(C_i^+\) on the upper half of the graph and \(-C_i^-\) on the lower side.
# standardized Cusum chart assuming mu=50, sigma=5
library(qcc)
y1<-(x1-50)/5
y2<-(x2-50)/5
cusum(y1,center=0,std.dev=1,se.shift=1,decision.interval=5,newdata=y2)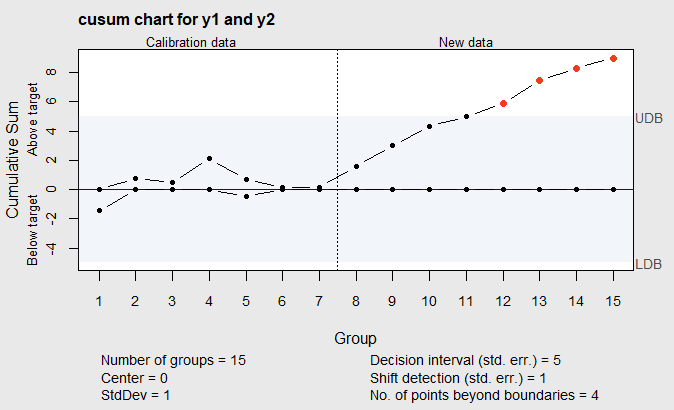
Figure 6.3 Standardized Cusum Chart of the random from Table 6.1 with \(k=1/2\) and \(h=5\)
Table 6.2 Standardized Tabular Cusums
| Individual value | \(x_i\) | \(y_i\) | \(C_i^+\) | \(-C_i^-\) |
|---|---|---|---|---|
| 1 | 40.208 | -1.958 | 0.000 | -1.458 |
| 2 | 56.211 | 1.242 | 0.742 | 0.000 |
| 3 | 51.236 | 0.247 | 0.489 | 0.000 |
| 4 | 60.686 | 2.137 | 2.126 | 0.000 |
| 5 | 45.230 | -0.954 | 0.673 | -0.453 |
| 6 | 49.849 | -0.0302 | 0.142 | 0.000 |
| 7 | 52.491 | 0.498 | 0.141 | 0.000 |
| 8 | 59.762 | 1.952 | 1.593 | 0.000 |
| 9 | 59.462 | 1.892 | 2.985 | 0.000 |
| 10 | 59.302 | 1.860 | 4.346 | 0.000 |
| 11 | 55.679 | 1.136 | 4.982 | 0.000 |
| 12 | 57.155 | 1.431 | 5.913 | 0.000 |
| 13 | 60.219 | 2.043 | 7.456 | 0.000 |
| 14 | 56.770 | 1.354 | 8.311 | 0.000 |
| 15 | 55.949 | 1.190 | 9.000 | 0.000 |
The Cusum chart shown in Figure 6.3 (and the values of \(C_i^+\) and \(-C_i^-\) in Table 6.2) shows an out-of-control signal on the 12th individual value and indicates the process mean has increased.
If the Phase I OCAP indicates that the out-of-control signal can be corrected by a change in the level of a manipulable variable, then automated manufacturing processes often use the tabular Cusums in Equation (6.2) in a feedback loop. In this loop, the manipulable variable is automatically adjusted whenever an out-of-control signal is detected.
When \(C_i^+\) exceeds \(h\) , to give an out-of-control signal, an estimate of the current value of the process mean is given by Equation (6.3) .
\[\begin{equation} \hat{\mu_c}=\mu+\sigma k+\frac{\sigma C_i^+}{N^+}, \tag{6.3} \end{equation}\]
where \(\hat{\mu_c}\) is the estimate of the current mean, \(N^+\) is the consecutive number of nonzero values of \(C_i^+\) up to and including the point where it exceeded \(h\) , and \(\mu\) , and \(\sigma\) are the known in-control values of the process mean and standard deviation.
For example, the Cusum chart in Figure 6.3 first exceeds \(h=5\) when \(C_i^+=5.913\) , and at that point there are \(N^+=11\) consecutive positive values for \(C_i^+\) . So the estimate of the process mean at that point is:
\[\begin{equation*} \hat{\mu_c}=50+5(.5)+\frac{(5)(5.913)}{11}=55.19. \end{equation*}\]
Therefore, in an automated process, the manipulable variable would be changed to reduce the process mean by \(55.19-50 = 5.19\) to get it back to the known in-control level.
When \(-C_i^-\) is less than \(-h\) , to give an out-of-control signal, an estimate of the current mean of the process is given by:
\[\begin{equation} \hat{\mu_c}=\mu-\sigma k-\frac{\sigma C_i^-}{N^-}, \tag{6.4} \end{equation}\]
and the manipulable would be changed to increase the process mean back to the known in-control level.
6.1.1.1 Head-start Feature
If an out-of-control signal is detected in Phase II monitoring with a process that is not automated, or does not contain a manipulable variable with a known relationship to the process mean, then the process is usually stopped until a change or adjustment can be made. In this situation, it might be desirable to use a more sensitive control chart immediately after restarting the process, just in case the adjustment was not effective.
(Lucas and Crosier 1982) suggested a simple adjustment to the Cusum chart called the fast initial response (FIR) or headstart feature to make it more sensitive. Instead of starting the Cusum with \(C_0^+=0.0\) and \(C_0^-=0.0\) as illustrated in Table 6.2, they suggested setting \(C_0^+=h/2\) , and \(C_0^-=-h/2\) . This is illustrated with in Table 6.3 using the first four data points in Table 6.2, as if the process were just restarted. In this case \(h=5\) so \(C_0^+=2.5\) and \(C_0^-=-2.5\) .
Table 6.3 Standardized Tabular Cusums with FIR of h/2
| Individual value | \(x_i\) | \(y_i\) | \(C_i^+\) | \(-C_i^-\) |
|---|---|---|---|---|
| 1 | 40.208 | -1.958 | 0.042 | -3.958 |
| 2 | 56.211 | 1.242 | 0.784 | -2.216 |
| 3 | 51.236 | 0.247 | 0.531 | -1.469 |
| 4 | 60.686 | 2.137 | 2.168 | 0.000 |
By using a headstart of \(h/2\) and \(h=5\) on a Cusum chart, Lucas and Crosier (Lucas and Crosier 1982) showed that the average run length (ARL) for detecting a one standard deviation change in the process mean was reduced from 10.4 to 6.35 (a 39% decrease). The ARL\(_0\), or average run length for detecting a false out-of-control signal when the mean has not changed from the known in-control value, is only decreased by 7.5% (from 465 to 430).
6.1.1.2 ARL of Shewhart and Cusum Control Charts for Phase II Monitoring.
If individual measurements are monitored rather than subgroups of data in Phase II monitoring, and a Shewhart chart is used, individual measurements would be plotted with the center line and the control limits \(\mu\) \(\pm\) 3\(\sigma\) , where \(\mu\) and \(\sigma\) are the known values of the in-control process mean and standard deviation.
The OC or operating characteristic for the Shewhart chart is the probability of falling within the control limits, and it is a function of how far the mean has shifted from the known in-control mean (as discussed in Section 4.5.1). The average run length (ARL) is the expected value of a Geometric random with ARL = 1/(1-OC) . The OC for a Shewhart when the mean has shifted \(k\) standard deviations to the left or right can be calculated with the \(\verb!pnorm()!\) function in R as \(\verb!pnorm(3-k)-pnorm(-3-k)!\).
(Vance 1986) published a computer program for finding the ARLs for Cusum control charts. The \(\verb!xcusum.arl!\) function in the R package \(\verb!spc!\) calculates ARLs for Cusum charts with or without the headstart feature by numerically approximating the integral equation used to find the expected or average run lengths. An example call of the \(\verb!xcusum.arl!\) function is \(\verb!xcusum.arl(k=.5, h=5, mu = 1.0, hs=2.5, sided="two")!\). \(\verb!k=.5!\) specifies \(k=1/2\). \(\verb!h=5!\) specifies the decision interval \(h=5\). \(\verb!mu = 1.0!\) indicates that the ARL for detecting a one \(\sigma\) shift in the mean should be calculated. \(\verb!hs=2.5!\) specifies the headstart feature to be half the decision interval, and \(\verb!sided="two"!\) indicates that the ARL for a two sided Cusum chart should be calculated.
The R code below was used to calculate the ARL for the Shewhart individuals chart for each of the mean shift values in the vector \(\verb!mu!\) using the \(\verb!pnorm!\) function; the ARL for the Cusum chart; and the ARL for the Cusum chart with the \(h/2\) headstart feature is calculated using the \(\verb!xcusum.arl!\) function.
#ARL individuals chart with 3 sigma limits
mu<-c(0.0,.5,1.0,2.0,3.0,4.0,5.0)
OC3=c(pnorm(3-mu[1])-pnorm(-3-mu[1]),pnorm(3-mu[2])-pnorm(-3-mu[2]),
pnorm(3-mu[3])-pnorm(-3-mu[3]),pnorm(3-mu[4])-pnorm(-3-mu[4]),
pnorm(3-mu[5])-pnorm(-3-mu[5]),pnorm(3-mu[6])-pnorm(-3-mu[6]),
pnorm(3-mu[7])-pnorm(-3-mu[7]))
ARL3=1/(1-OC3)
#
#ARL for Cusum with and without the headstart feature
library(spc)
ARLC<-sapply(mu,k=.5,h=5,sided="two",xcusum.arl)
ARLChs<-sapply(mu,k=.5,h=5,hs=2.5,sided="two",xcusum.arl)
round(cbind(mu,ARL3,ARLC,ARLChs),digits=2)To get a vector of Cusum ARLs corresponding to a whole vector of possible mean shift values, the R \(\verb!sapply!\) function was used in the code above. This function calculates the ARL for each value of the mean shift by repeating the call to \(\verb!xcusum.arl!\) for each value in the vector \(\verb!mu!\). The calculated ARLs form the body of Table 6.4.
Table 6.4 ARL for Shewhart and Cusum Control Charts
| Shift in Mean | Shewhart | Cusum Chart | Cusum with \(h/2\) headstart |
|---|---|---|---|
| Multiples of \(\sigma\) | Individuals Chart | \(k=1/2\), \(h=5\) | \(k=1/2\), \(h=5\) |
| 0.0 | 370.40 | 465.44 | 430.39 |
| 0.5 | 155.22 | 38.00 | 28.67 |
| 1.0 | 43.89 | 10.38 | 6.35 |
| 2.0 | 6.30 | 4.01 | 2.36 |
| 3.0 | 2.00 | 2.57 | 1.54 |
| 4.0 | 1.19 | 2.01 | 1.16 |
| 5.0 | 1.02 | 1.69 | 1.02 |
In this table we can see that the ARL for a Shewhart chart when the mean has not shifted from the known in-control mean is 370 (rounded to the nearest integer), while the ARLs for Cusum charts with or without the headstart feature are longer (i.e. 430–465). Therefore, false positive signals are reduced when using the Cusum chart.
The ARL for detecting a small shift in the mean of the order of 1\(\sigma\) is over 40 for a Shewhart chart plotting individual measurements. Recall from Section 4.5.1, that the ARL for detecting a 1\(\sigma\) shift in the mean using a Shewhart \(\overline{X}\)-chart with subgroups of size \(n=5\) was approximately 5 (exactly 4.495). That implies \(n\times ARL\approx 5\times4.49=22.45\) total measurements. Therefore, the Shewhart \(\overline{X}\)-chart can detect small shifts in the mean with fewer measurements than a Shewhart chart plotting individual measurements.
The ARL is only 2.00 for detecting a large shift in the mean of order 3\(\sigma\) using the Shewhart chart plotting individual measurements, while the ARL for detecting the same shift in the mean using a Shewhart \(\overline{X}\)-chart with subgroups of size \(n=5\) is 1.00 (or \(5 \times1.00 = 5\) total measurements). Thus, the Shewhart plotting individual measurements can detect large shifts in the mean with fewer measurements than the Shewhart \(\overline{X}\)-chart.
The total number of measurements on average for detecting a small shift in the mean (1\(\sigma\) ) with Cusum charts is even less than the Shewhart \(\overline{X}\)-chart with subgroups of size \(n=5\) (i.e., 10 for the basic Cusum and only 6 for the Cusum with the headstart). Individual measurements can be taken more frequently than subgroups, reducing the time to detect a small shift in the mean using Cusum charts. However, the ARL for detecting a large shift in the mean (3\(\sigma\)–5\(\sigma\) ) with the Cusum is greater than Shewhart individuals chart. For this reason a Cusum chart and a Shewhart individuals chart are often monitored simultaneously.
Alternatively, another type of time weighted control chart called the EWMA chart can provide a compromise. It can be constructed so that the ARL for detecting a large shift in the mean (3\(\sigma\)–5\(\sigma\)) will be almost as short as the Shewhart individual chart while the ARL for detecting a small shift in the mean (of the order of 1\(\sigma\) will be almost as short as the Cusum chart.
6.1.2 EWMA Charts
The EWMA (or exponentially weighted average control chart–sometimes called the geometric moving average control chart) can compromise between the Cusum chart that detects small shifts in the mean quickly and the Shewhart chart that detects large shifts in the mean quickly.
The EWMA control chart uses an exponentially weighted average of past observations, placing the largest weight on the most recent observation. Its value \(z_n\) is defined as:
\[\begin{align*} z_1&=\lambda x_1+(1-\lambda)\mu\\ z_2&=\lambda x_2+(1-\lambda)z_1\\ & \vdots \\ z_n&=\lambda x_n+(1-\lambda)z_{n-1}\\ \end{align*}\]
Recursively substituting for \(z_{1}\) , \(z_{2}\) etc, this can be shown to be
\[\begin{equation*} z_n=\lambda x_n+\lambda(1-\lambda)x_{n-1}+\lambda(1-\lambda)^2x_{n-2}+...+\lambda(1-\lambda)^{n-1}x_1 + (1-\lambda)^n\mu, \end{equation*}\]
which equals
\[\begin{equation} z_n=\lambda x_n+(1-\lambda)z_{n-1} = \lambda\sum_{i=0}^{n-1}(1-\lambda)^ix_{n-i} +(1-\lambda)^n\mu, \tag{6.5} \end{equation}\]
where, \(x_i\) are the individual values being monitored, \(\mu\) is the in-control process mean, and 0 < \(\lambda\) < 1 is a constant. With this definition, the weight for the most recent observation is \(\lambda\) , and the weight for the \(m\)th previous observation \(\lambda(1-\lambda)^m\) , which decreases exponentially as \(m\) increases. For a large value of \(\lambda\) , more weight is placed on the most recent observation, and the EWMA chart becomes more like a Shewhart individuals chart. For a small value of \(\lambda\) , the weights are more similar for all observations, and the EWMA becomes more like a Cusum chart.
The control limits for the EWMA chart are given by
\[\begin{equation} UCL = \mu + L\sigma\sqrt{\frac{\lambda}{2-\lambda}\left[1-(1-\lambda)^{2i}\right]} \tag{6.6} \end{equation}\]
\[\begin{equation} LCL = \mu - L\sigma\sqrt{\frac{\lambda}{2-\lambda}\left[1-(1-\lambda)^{2i}\right]},\\ \tag{6.7} \end{equation}\]
where, \(\mu\) is the known in-control process mean, \(\sigma\) is the known in-control process standard deviation, and \(L\) defines the width of the control limits. \(L\) and \(\lambda\) are chosen to control the ARL.
Table 6.5 shows an example of the EWMA calculations using the first 10 simulated observations from the Phase II data shown in Tables 6.2 and 6.1. In this example, \(\lambda=0.2\) and \(\mu=50\) is the known in-control process mean. The first value of the EWMA (\(z_1\)) is calculated as \(z_1=0.2(40.208)+(1-0.2)(50)=48.042\). The next value is calculated as \(z_2 = 0.2(56.211)+(1-0.2)(48.042)=49.675\) etc.
Although it is easy to calculate the EWMA (\(z_i\)) by hand, the control limits shown in Equations (6.6) and (6.7) are not easily calculated and change with the observation number \(i\) .
Table 6.5 EWMA Calculations =0.2 Phase II Data from Table 6.2
| Sample Number \(i\) | Observation \(x_i\) | EWMA \(z_i=(0.2)x_i + (0.8)Z_{i-1}\) |
|---|---|---|
| 1 | 40.208 | 48.042 |
| 2 | 56.211 | 49.675 |
| 3 | 51.236 | 49.988 |
| 4 | 60.686 | 52.127 |
| 5 | 45.230 | 50.748 |
| 6 | 49.849 | 50.568 |
| 7 | 59.491 | 50.953 |
| 8 | 59.762 | 52.715 |
| 9 | 59.462 | 54.064 |
| 10 | 59.302 | 55.112 |
The function \(\verb!ewma!()\) in the \(\verb!qcc!\) package will compute the EWMA and plot it along with the control limits in Figure 6.4. The R code below illustrates this.
# random data from normal N(50,5) followed by N(56.6, 5)
library(qcc)
set.seed(109)
x1<-rnorm(7,50,5)
set.seed(115)
x2<-rnorm(8,56.6,5)
x<-c(x1,x2)
# standardized ewma chart assuming mu=50, sigma=5
E1<-ewma(x[1:10],center=50,std.dev=5,lambda=.2,nsigmas=2.938)In the function call above, the argument \(\verb!center=50!\) is the known in-control mean (\(\mu\)), \(\verb!std.dev=5!\) is the known standard deviation (\(\sigma\)), \(\verb!lambda=.2!\) is the value of \(\lambda\) , and \(\verb!nsigmas=2.938!\) is the value of \(L\) . The choices of \(\lambda=0.2\) , and \(L=2.938\) were made to make the ARL for the EWMA Chart, when the mean does not change from \(\mu=50\) , equivalent to the ARL for a Cusum chart with \(k=1/2\) and \(h=5\) that was shown in Figure 6.3.
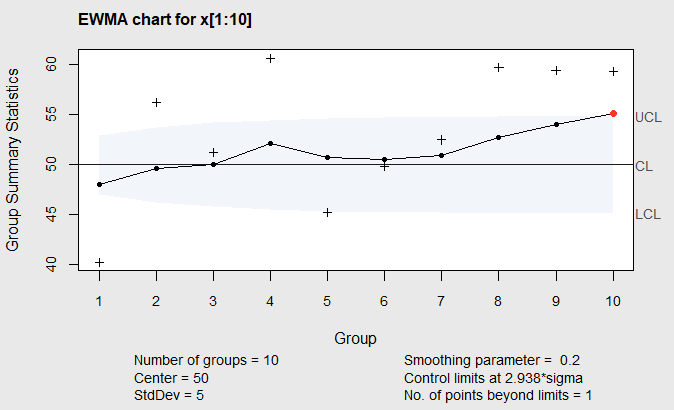
Figure 6.4 EWMA for Phase II data from Table 6.5
In this chart, the plus signs represent the individual observations \(x_i\) , and the connected dots represent the smoothed EWMA values \(z_i\) . We see that the EWMA exceeds the upper control limit at the 10th observation two observations before the Cusum chart with \(k=1/2\) and \(h=5\) . The EWMA is also used as a forecasting formula in business time series applications. So when the EWMA exceeds the control limits, the value of \(z_i\) is actually a forecast of the process mean at observation \(x_{i+1}\) . Knowing this can help in deciding how to adjust the process to get back to the target mean level \(\mu\).
The object list \(\verb!E1!\), created by the \(\verb!ewma()!\) function in the code above, contains the data in the element \(\verb!E1$statistics!\) and the calculated \(z_i\) values in the element \(\verb!E1$y!\). The control limits are in the element \(\verb!E1$limits!\). The statements \(\verb!EW1<-cbind(E1$data,E1$y)!\) and \(\verb!colnames(EW1)<-c("x","z")!\) combine the data and EWMA in a matrix and name the columns. Finally, the statement \(\verb!cbind(EW1,E1$limits)!\) creates a matrix containing a Table like Table 6.5 with the addition of the control limits.
6.1.2.1 ARL of EWMA, Shewhart and Cusum Control Charts for Phase II Monitoring
The function \(\verb!xewma.arl()!\) in the \(\verb!spc!\) package calculates the ARL for an EWMA chart. For example, to calculate the ARL for an EWMA chart with \(\lambda=0.2\) and \(L=2.938\), as shown in the chart above, use the command:
The argument \(\verb!mu=0!\) specifies the shift in the mean in units of \(\sigma\) , the argument \(\verb!c=2.938!\) specifies \(L\) , and \(\verb!sided="two"!\) specifies both upper and lower control limits will be used like those shown in Figure 6.4. The printed result \(\verb![1] 465.4878!\) shows the ARL. When there is no shift in the mean, it is equivalent to the ARL of the Cusum chart with \(k=1/2\) and \(h=5\) (as shown in Table 6.6).
Table 6.6 compares the ARL for the Cusum chart with \(k=1/2\) and \(h=5\) , the EWMA chart with \(\lambda=0.2\) and \(L=2.938\), the Shewhart individuals chart, and the EWMA chart with \(\lambda=0.4\) and \(L=2.9589\).
Table 6.6 ARL for Shewhart and Cusum Control Charts and EWMA Charts
| Shift in Mean | Cusum Chart | EWMA with | Shewhart | EWMA with |
|---|---|---|---|---|
| Multiples of \(\sigma\) | \(k=1/2\), \(h=5\) | \(\lambda=0.2\) and \(L=2.938\) | Indiv. Chart | \(\lambda=0.4\) and \(L=2.9589\) |
| 0.0 | 465.44 | 465.48 | 370.40 | 370.37 |
| 0.5 | 38.00 | 40.36 | 155.22 | 58.45 |
| 1.0 | 10.38 | 10.36 | 43.89 | 12.71 |
| 2.0 | 4.01 | 3.71 | 6.30 | 3.35 |
| 3.0 | 2.57 | 2.36 | 2.00 | 1.95 |
| 4.0 | 2.01 | 1.85 | 1.19 | 1.39 |
| 5.0 | 1.69 | 1.46 | 1.02 | 1.10 |
In this table, it can be seen that the EWMA chart with \(\lambda=0.2\) and \(L=2.938\) is nearly equivalent to the Cusum chart with \(k=1/2\) and \(h=5\). Also, the EWMA chart with a larger value of \(\lambda=0.4\) and \(L=2.9589\) will be almost as quick to detect large (4–5\(\sigma\)) shift in the mean as the Shewhart individuals chart. Yet the EWMA ARLs for smaller shifts in the mean are less that 1/3 that of the Shewhart individuals chart. Clearly, the EWMA control chart is very flexible and can detect both large and small shifts in the mean.
6.1.2.2 EWMA with FIR Feature.
To incorporate a fast initial response feature in an EWMA chart, (Steiner 1999) suggested incorporating additional constants (\(f\) and \(a\)) that narrow the time varying control limits of the EWMA for the first few observations following a process restart after a process adjustment. Using these factors the control limits are redefined as: \[\begin{equation} \pm L\sigma\left[\left( 1-(1-f)^{1+a(t-1)}\right)\sqrt{\frac{\lambda}{2-\lambda} \left( 1-(1-\lambda)^{2i} \right] } \right] \tag{6.8} \end{equation}\]
He suggests letting \(f=0.5\), because it mimics the 50% headstart feature usually used with Cusum charts, and \(a=[-2/\log(1-f)-1]/19\) so that the FIR will have little effect after \(t=20\) observations.
Although the \(\verb!ewma()!\) function in the \(\verb!qcc!\) package does not have an option to compute these revised control limits, they could be calculated with R programming statements and stored in the EWMA object element that contains the control limits (like the \(\verb!E1$limits!\) discussed above).
6.2 Time Weighted Control Charts of Individuals to Detect Changes in \(\sigma\)
When the capability index (PCR) is equal to 1.00, a 31% to 32% increase in the process standard deviation will produce as much process fallout (or nonconforming output) as a 1\(\sigma\) shift in the process mean. For that reason, it is important to monitor the process standard deviation as well as the mean during Phase II.
(Hawkins 1981) showed that the distribution of \[\begin{equation} v_i=\frac{\sqrt{\left|y_i\right|}-0.822}{0.349}, \tag{6.9} \end{equation}\]
(where \(y_i=(x_i-\mu)/\sigma\)) are standardized individual measurements) is close to a standard normal distribution, even when the distribution of the individual values \(x_i\) is a non-normal heavy-tailed distribution. Further, he showed that if the process standard deviation increases, the absolute value of \(y_i\) increases on the average, and therefore \(v_i\) increases.
If the standard deviation of the process characteristic \(x_i\) increases by a multiplicative factor \(\gamma\), then the standard deviation of the standardized value \(y_i=(x_i-\mu)/\sigma\) increases to \(\gamma\), and the expected values of \(\sqrt{|y_i|}\) and \(v_i\) will correspondingly increase.
If \(y_i\) follows a normal distribution with mean zero, and its standard deviation has increased from 1 to \(\gamma\), the expected value of \(\sqrt{|y_i|}\) can be found as shown in Equation (6.10).
\[\begin{equation} E[\sqrt{|y_i|}]=\frac{1}{\gamma\sqrt{2\pi}}\int^\infty_\infty \sqrt{|y_i|} \exp\left({\frac{-y_i^2}{2\gamma^2}}\right) dy_i. \tag{6.10} \end{equation}\]
Using numerical integration, the expected values of \(\sqrt{|y_i|}\) and \(v_i\) for four possible values of \(\gamma\) were found and are shown in Table 6.7.
Table 6.7 Expected value of \(\sqrt{|y_i|}\) and \(v_i\) as function of \(\gamma\)
| % Change in \(\sigma\) | \(\gamma\) | \(E[\sqrt{|y_i|}]\) | \(E(v_i)\) |
|---|---|---|---|
| -20% | 0.8 | 0.735379 | -0.24860 |
| 0% | 1.0 | 0.822179 | 0.00000 |
| 32% | 1.32 | 0.944612 | 0.35066 |
| 50% | 1.5 | 1.006960 | 0.52923 |
Therefore, a 32% increase in the process standard deviation will result in a 0.35066 standard deviation increase in the mean of \(v_i\), since \(v_i\) has mean zero and standard deviation one when the process mean and standard deviation have not changed.
The mean of \(\sqrt{|y_i|}\) and \(v_i\) not only change when the process standard deviation changes, but they will also change if the process mean (\(\mu\)) changes. In addition, if the process standard deviation (\(\sigma\)) increases, not only do the means of \(\sqrt{|y_i|}\) and \(v_i\) increase, but the chance of a false alarm when monitoring the process mean is also more likely.
As pointed out by (Hawkins and Olwell 1997), this is analogous to the case when using subgrouped data. When the process standard deviation increases, not only does the sample range of subgroups tend to increase, but the chance of a false positive signal being seen on an \(\overline{X}\) chart also increases. For that reason, \(\overline{X}\) and \(R\) charts are usually kept together when they are used for monitoring a process in Phase II.
As already discussed, time-weighted control charts such as the Cusum chart and EWMA chart can detect small shifts in the process mean, during Phase II monitoring, more quickly than Shewhart \(\overline{X}\)-charts when the process characteristic (\(x\)) to be monitored is normally distributed and its ``in-control’’ mean (\(\mu\)) and standard deviation (\(\sigma\)) are known.
For the same reason that \(\overline{X}\) and \(R\) charts are usually kept together when they are used for monitoring a process in Phase II, (Hawkins 1993) recommended keeping a Cusum chart of individual values \(y_i\), together with a Cusum chart of \(v_i\) when monitoring individual values in Phase II.
The Cusum chart that (Hawkins 1981) recommended for monitoring the process standard deviation is defined by Equations (6.11) and (6.12).
\[\begin{equation} C_i^+=max[0,v_i-k+C_{i-1}^+] \tag{6.11} \end{equation}\]
\[\begin{equation} C_i^-=max[0,-k-v_i+C_{i-1}^-], \tag{6.12} \end{equation}\]
where, \(k=.25\) and the decision limit \(h=6\) . He showed that if the process standard deviation increases, the Cusum chart for \(y_i\) used for monitoring the process mean (shown in column 1 of Table 6.8) may briefly cross its control or decision limit (\(h\)=5), but that the Cusum for \(v_i\), described above, will cross and stay above its control or decision limit. Therefore, keeping the two charts together will help to distinguish between changes in the process mean and changes in the process standard deviation.
EWMA charts can also be used to monitor changes in individual values like \(v_i\). The EMMA at time point \(i\) is defined as:
\[\begin{equation} z_i=\lambda v_i + (1-\lambda)z_{i-1} \tag{6.13} \end{equation}\]
where \(\lambda=0.05\), and the control limits for the EWMA chart at time point \(i\) are given by:
\[\begin{equation} LCL=-L\sqrt{\frac{\lambda}{2-\lambda}\left[1-(1-\lambda)^{2i}\right]}, \tag{6.14} \end{equation}\]
\[\begin{equation} UCL=+L\sqrt{\frac{\lambda}{2-\lambda}\left[1-(1-\lambda)^{2i}\right]}. \tag{6.15} \end{equation}\]
The \(\verb!xewma.crit()!\) function in the R package \(\verb!spc!\) can be used to determine the value of the multiplier \(L\) used in the formula for the control limits so that the ARL\(_0\) of the chart will match that of (Hawkins 1981)’s recommended Cusum chart for monitoring \(v_i\). It is illustrated in the R code shown below where it was used to find the multiplier \(L=2.31934\) needed to produce an ARL\(_0 = 250.805\) matching the Cusum chart with \(k=.25\) and \(h=6\).
Table 6.8 shows the average run lengths for detecting the positive % change in \(\sigma\) shown in Table 6.7. In this table are shown the ARLs for Hawkins recommended Cusum chart of \(v_i\) , the ARLs of the EWMA chart of \(v_i\) with similar properties, and the ARLs of a Shewhart individuals chart of \(v_i\) with control limits at \(\pm2.88\sigma\) to match the ARL\(_0\) of the other two charts in the table.
Table 6.8 ARL for Detecting Increases in \(\sigma\) by Monitoring \(v_i\)
| % Increase in | Cusum Chart | EWMA | Shewhart Individuals Chart |
|---|---|---|---|
| \(\sigma\) | \(k=.25\), \(h=6\) | \(\lambda=0.05\) and \(L=2.31934\) | \(\pm2.88\sigma\) Limits |
| 0% | 250.805 | 250.800 | 250.824 |
| 32% | 33.51 | 33.37 | 157.58 |
| 50% | 19.39 | 19.98 | 102.94 |
It can be seen that either the Cusum Chart or EWMA chart of \(v_i\) will detect a 32% to 50% increase in the process standard deviation much quicker than the Shewhart individuals chart of \(v_i\). Also, the ARL for detecting a 32% increase in the standard deviation using the standard R chart (with UCL\(=d_2(n)\times D_4(n)\times\sigma\), and LCL=0) is 17.44 when the subgroup size is 4, and 15.57 when the subgroup size is 5. This appears to be shorter than the ARL for the Cusum and EWMA charts shown in Table 6.8. However, an ARL 17.44 with a subgroup size of \(n=4\) is \(4\times 17.44=69.76\) total observations, and an ARL of 15.57 with a subgroup size of \(n=5\) is \(5\times 15.57=77.85\) total observations. This is more than twice the total number of observations required of the Cusum and EWMA charts. In addition, an increase in the process standard deviation could be detected quicker by taking one observation every 15 minutes than it could by taking one subgroup of 4 every hour.
6.3 Examples
As an example of a Cusum chart to monitor process variability with individual values, consider the data shown in the R code below. This data comes from (Summers 2000) and represents the diameter of spacer holes in surgical tables.
diameter<-c(.25,.25,.251,.25,.252,.253,.252,.255,.259,.261,.249,.250,
.250,.250,.252)
mu<-.25
sigma<-.0025
y<-(diameter-mu)/sigma
v<-(sqrt(abs(y))-.822179)/.3491508
library(qcc)
cusum(v,center=0,std.dev=1,decision.interval=6,se.shift=.5)There is no known mean or standard deviation for this data, but there are known specification limits of \(0.25 \pm 0.01\). If the mean was \(\mu=0.25\) and the standard deviation was \(\sigma=0.0025\), then \(C_p = C_{pk} = 1.33\). A shift of the mean away from \(\mu=0.25\) by more than 0.0025 in either direction would result in \(C_{pk} < 1.0\), and an increase in the standard deviation by more than 50% would also result in \(C_p < 1.0\). Therefore, although the process mean and standard deviation are unknown, Phase II monitoring of changes in the process mean and standard deviation from the values known to result in \(C_p = C_{pk} = 1.33\) could begin, and there is no need for a Phase I study to estimate \(\mu\) and \(\sigma\).
In the code above, \(\verb!mu!\) and \(\verb!sigma!\) are assigned the values that would result in \(C_p = C_{pk} = 1.33\). The standardized values \(\verb!y!\) are calculated along with the values of \(\verb!v!\). Next the \(\verb!cusum!\) function in the R package \(\verb!qcc!\) is used to create a Cusum chart of \(\verb!v!\) using value of \(k=0.25\) (i.e. \(\verb!se.shift=.5!\)), and \(h=5\) (i.e. \(\verb!decision.interval=5!\)) to result in an ARL\(_0\) = 250.805, as shown in Table 6.8.
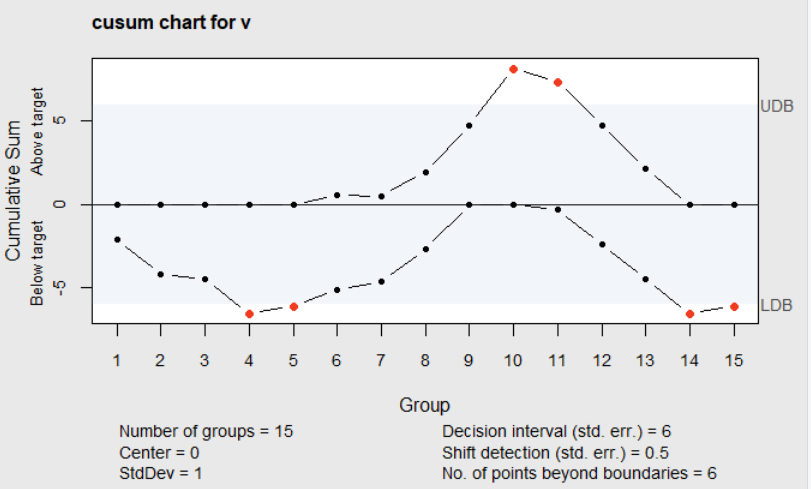
Figure 6.5 Cusum Chart of \(v_i\)
Figure 6.5 shows the resulting Cusum chart. It can be seen that the upper Cusum exceeds the upper decision interval at observation 10, but falls back within the limit at observation 12. It is unlikely that the process standard deviation would only temporarily change. To get a better understanding of what has changed in the process, the Cusum chart of the standardized values \(\verb!y!\) was also made using the \(\verb!cusum!\) function call shown in the block of code below.
Specifying \(h\)=5 or \(\verb!decision.interval=5!\) and \(k=.5\) or \(\verb!se.shift=1!\) will result an an ARL\(_0\) of 465.44 (as shown in Table 6.6), and an ARL for detecting a one standard deviation change in the mean of 10.38. The resulting Cusum chart is shown in Figure 6.6. There it can be seen that the positive cusums exceeds the upper decision limit at observation 9, and stays above it from that point on. Examination of both of these charts makes it clear that the process mean changed, and the signal on the control chart of \(v_i\) was caused by the mean change.
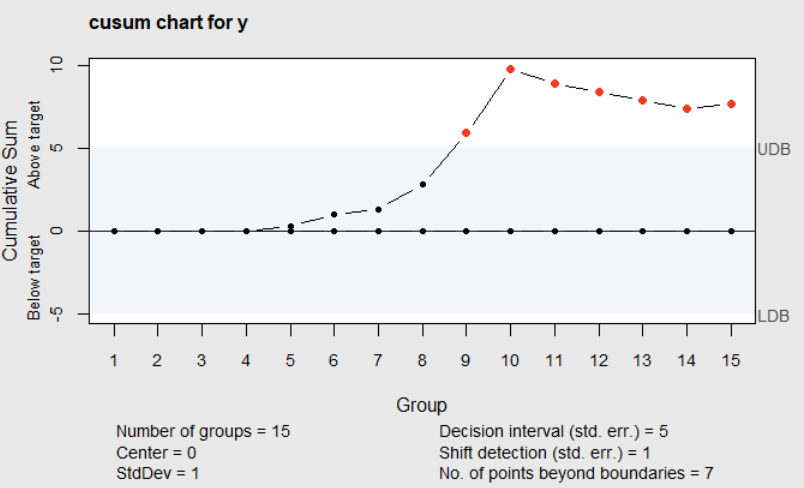
Figure 6.6 Cusum Chart of \(y_i\)
As a second example of monitoring the process mean and variability with individual observations, consider the block of R code shown below. In this code, the situation where the process standard deviation increases while the process mean remains unchanged is illustrated using randomly generated data. The data is monitored with EWMA charts. 15 observations were generated with a mean of 50 and a standard deviation of 7.5 If the in-control process standard deviation was known to be 5.0, and the in-control mean was known to be 50.0, the random data would represent a 50% increase in the standard deviation with no change in the mean. The \(\verb!emma()!\) function in the R package \(\verb!qcc!\) was used to create the two EWMA charts shown in Figure 6.7. The arguments \(\verb!center!\) and \(\verb!std.dev!\) represent the known in-control process mean and standard deviation. The EWMA parameters \(\lambda=.2\) and \(L=2.938\) are defined in the first function call with the arguments \(\verb!l=.2!\) and \(\verb!nsigmas=2.938!\). The second EWMA (with \(\lambda=.05\) and \(L=2.248\)) is defined in the second function call with \(\verb!l=.05!\) and \(\verb!nsigmas=2.248!\).
set.seed(29)
# random data from normal N(50, 7.5)
x<-rnorm(15,50,7.5)
# standardize assuming sigma=5, mu=50
y<-(x-50)/5
# calculate v
v<-(sqrt(abs(y))-.822179)/.3491508
library(qcc)
EWMA <- ewma(y, center=0, std.dev=1,
lambda=.2, nsigmas=2.938)
EWMA <- ewma(v, center=0, std.dev=1,
lambda=.05, nsigmas=2.248)In Figure 6.7 it can be seen that the EWMA chart of \(y_i\) shows no out-of-control signals, while a signal is first shown on the EWMA chart of \(v_i\) at observation number two. In this case, since there is no indication that the process mean has changed, the out-of-control signal on the EWMA chart of \(v_i\) would be an indication that the process standard deviation has increased.
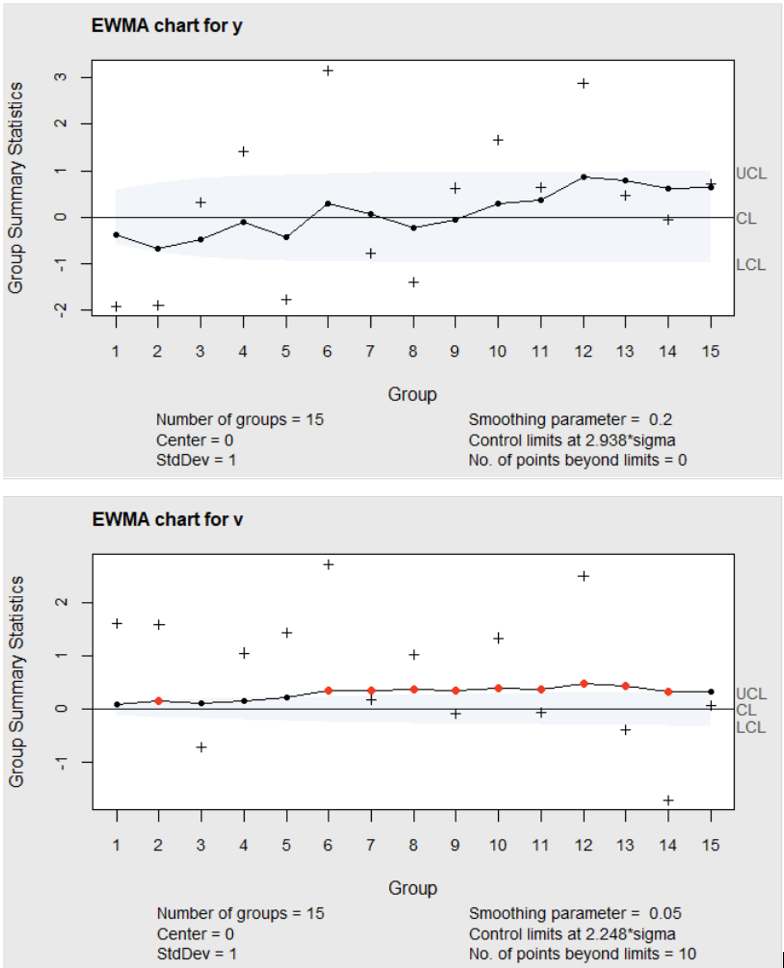
Figure 6.7 EWMA charts of \(y_i\) and \(v_i\)
It is interesting to note that if the 15 data points from these two examples were grouped in three subgroups of size 5, the R chart with UCL=\(D_4(5)\times d_2(5)\times \sigma\) would not have shown any out-of-control points. This reiterates the fact that time weighted charts of \(v_i\) are more sensitive to small changes in variability, as shown in Tables 6.7 and 6.8.
6.4 Time Weighted Control Charts using Phase I estimates of the In-control \(\mu\) and \(\sigma\)
When the the in-control process mean and standard deviation are unknown, the standard recommendation (see Section 6.3.2 of the NIST Engineering Statistics Handbook–Section 6.3.4.3 for CUSUM and 6.3.2.4 for EWMA) is to use the estimates \(\hat{\mu}=\overline{\overline{X}}\) and \(\hat{\sigma}=\overline{R}/d_2\) from a Phase I study using \(\overline{X}\)-\(R\) charts with subgroups of size \(n=4\) or \(5\), and \(m=25\) subgroups. But of course these quantities are random variables.
Figure 6.8 Shows a histogram of 10,000 simulated values of \(\overline{R}/d_2\sigma\) . Although the distribution is nearly symmetric, it shows that 50% of the time the estimate \(\overline{R}/d_2\) will be less than the actual \(\sigma\) and 10% of the time it will be less than 90% of \(\sigma\).
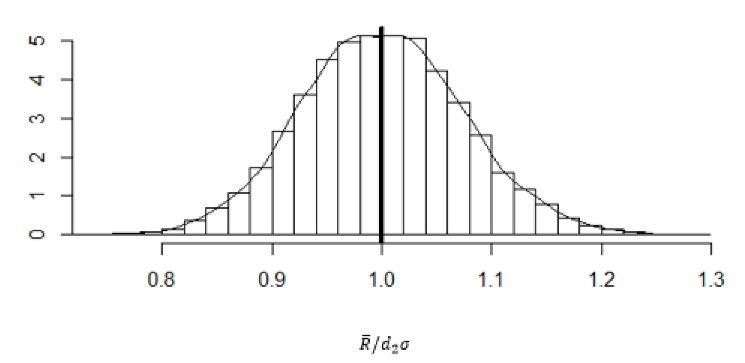
Figure 6.8 Simulated Distribution of \(\overline{R}/d_2\sigma\)
The width of the control limits for the Phase II control charts for monitoring the mean (like the \(\overline{X}\) chart or time-weighted charts such as the Cusum or EWMA) are multiples of \(\sigma\) , and when \(\overline{R}/d_2\) is used in place of the known \(\sigma\) the control limits will be too narrow at least 50% of the time.
When the control limits are too narrow, the ARL\(_0\) will be decreased and the chance of detecting a spurious out-of-control signal will be increased. This will result in wasted time trying to discover the cause (for which there is none), or if a Phase I OCAP has been established it will result in unnecessary adjustments to the process. The unnecessary adjustments to the process are what (Deming 1986) has called “Tampering” and will actually result in increased variability in the process output.
In order to prevent the chance of “Tampering” and increasing process variation, the multiplier of \(\sigma\) in the formulas for the control limits should be increased, thus making the control limits wider. If the control limits become wider, the ARL\(_0\) will increase, but the ARL\(_1\) for detecting a change in the process mean will also increase.
(Gandy and Kvaloy 2013) recommended that a control chart be designed so that the ARL\(_0\) should achieve the desired value with a specified probability. To do this they proposed a method based on bootstrap samples to find the 90th percentile of the control limit multiplier to guarantee the ARL\(_0\) be at least equal to the desired value. They found that the increase in the control limit multiplier only slightly increased the ARL\(_1\) for detecting a shift in the process mean.
The R package \(\verb!spcadjust!\) (2015) contains the function \(\verb!SPCproperty()!\) that computes the adjusted multiplier for the control limits of the two-sided EWMA chart based on Gandy and Kvaloy’s bootstrap method. It can be used to replace the \(\verb!xewma.crit()!\) function that was illustrated in in Section 6.1.3 to find the multiplier for the control limits to achieve a desired value ARL\(_0\) when the process mean and standard deviation were known. Consider the following example that is similar to that shown in Section 6.1.4. The process mean is \(\mu=50\) , and the process standard deviation is \(\sigma=5\), but unlike the example in Section 6.1.4, these values are unknown and must be estimated from a Phase I study. The R-code below simulates 100 observations from the Phase I study. In practice this simulated Phase I data (\(\verb!X!\)) would be replaced with the final “in-control” data from a Phase I study.
The \(\verb!"SPCEWMA"!\) class in the R package \(\verb!spcadjust!\) specifies the parameters of the EWMA chart. The option \(\verb!Delta=0!\) in the \(\verb!SPCModelNormal!\) call below indicates that you want to find the adjusted multiplier that will guarantee the ARL\(_0\) be greater than a desired value with a specified probability.
library(spcadjust)
chart <- new("SPCEWMA",model=SPCModelNormal(Delta=0),lambda=0.2);
xihat <- xiofdata(chart,X)
str(xihat)The \(\verb!xiofdata!\) function computes the Phase I estimated parameters from the simulated data \(\verb!X!\). In this case \(\hat{\mu}=\overline{X}=\)\(\verb!xihat$mu=49.5!\), and \(\hat{\sigma}=s =\)\(\verb!xihat$sd=4.5!\) were calculated from the simulated Phase I data.
Next, the \(\verb!SPCproperty!\) function in the \(\verb!spcadjust!\) package is called to get the adjusted multiplier \(L\) for the EWMA chart. Actually this function computes \(L \times\sqrt{\frac{\lambda}{2-\lambda}}\) where \(L\) is the adjusted multiplier. The option \(\verb!target=465.48!\) specifies the desired value of ARL\(_0\), and \(\lambda=.2\) was specified in \(\verb!"SPCEWMA"!\) class above. The function call is shown below.
library(spcadjust)
cal <- SPCproperty(data=X,nrep=1000,
property="calARL",chart=chart,params=list(target=465.48),quiet=TRUE)
cal
90 % CI: A threshold of +/- 1.128 gives an in-control ARL of at least 465.48.
Unadjusted result: 0.9795
Based on 1000 bootstrap repetitions.The argument \(\verb!nrep=1000!\) in the function call specifies 1000 bootstrap samples, which is Gandy and Kvaloy’s recommended number to get an accurate estimate of the 90th percentile of the control limit multiplier. The argument \(\verb!property!\) specifies the property to be computed (i.e., the ARL). The argument \(\verb!quiet=TRUE!\) suppresses printing of the progress bar in the R Studio Console window. After a pause to run the bootstrap samples, \(\verb!cal!\) is typed to reveal the value stored in this variable after running the code. It can be seen in the output below the code that \(L \times\sqrt{\frac{\lambda}{2-\lambda}} =1.128\) gives an in-control ARL of at least 465.48. Thus, \(L=\frac{1.128}{\sqrt{\frac{.2}{2-.2}}}=3.384\). This value will change slightly if the code is rerun due to the random nature of the bootstrap samples, but it will guarantee that ARL\(_0\) will be at least 465.48, 90% of the time. Recall from Table 6.6 that if \(\mu\) and \(\sigma\) are known, \(\lambda =.2\) and \(L=2.938\) will result in ARL\(_0=465.48\).
To illustrate the use of the adjusted multiplier in Phase II monitoring, the code below generates 15 random observations from a normal distribution with mean \(\mu=55\), and standard deviation \(\sigma=5\). This indicates a one standard deviation shift from the unknown but in-control mean. Next the \(\verb!ewma()!\) function in the \(\verb!qcc!\) package is used to make an EWMA chart of the simulated Phase II data. In the \(\verb!ewma()!\) call, the arguments \(\verb!center=xihat$mu!\) and \(\verb!std.dev=xihat$sd!\) specify the Phase I estimated values of the mean and standard deviation since the real values are unknown. The arguments \(\verb!lambda=.2!\) and \(\verb!nsigmas=3.384!\) indicate the value of \(\lambda\) and the adjusted value of \(L\).
# Simulate Phase II data with 1 sigma shift in the mean
set.seed(49)
x<-rnorm(15,55,5)
library(qcc)
ewma(x,center=xihat mu,std.dev=xihat sd,lambda=.2,nsigmas=3.384)Figure 6.9 shows the EWMA chart. There it can be seen that the EWMA first exceeds the upper control limit (indicating an upward shift in the mean) at observation 9. Table 6.6 showed that the ARL\(_1\) for detecting a one standard deviation shift in the mean was 10.36 when \(\lambda=0.2\) and the unadjusted multiplier \(L=2.938\) is used. The fact that the EWMA chart in Figure 6.9 detects the one standard deviation shift in the mean after 9–10 points (<10.36) illustrates the following statement Gandy and Kvaloy made: Adjusting the multiplier \(L\) guarantees the ARL\(_0\) will be at least 465.48, 90% of the time, but will only increase the ARL\(_1\) slightly.
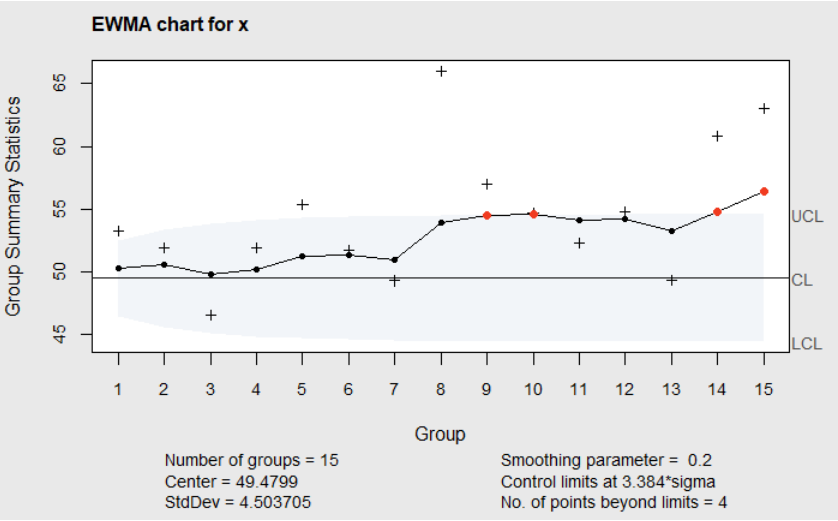
Figure 6.9 EWMA chart of Simulated Phase II Data with Adjusted L
When making an EWMA chart of \(v_i\) to monitor the process standard deviation in Phase II, (Lawson 2019) shows the same strategy can be used to find the adjusted multiplier, \(L\) , for the EWMA chart. The R code below shows an example using the same simulated data as shown in the last example. In this case the desired ARL\(_0\) is 250.805 to match the ARL\(_0\) of the Cusum chart (with \(k=.25\) , and \(h=6\) ) recommended by (Hawkins 1981) for monitoring \(v_i\). This code produces the EWMA chart in Figure 6.10.
# Simulate Phase I study with 100 observations
set.seed(99)
x1 <- rnorm(100,50,5)
# standardize using Phase I estimated mean and standard deviation
y1<-(x1-mean(x1))/sd(x1)
v1<-(sqrt(abs(y1))-.822179)/.3491508
library(spcadjust)
# chart for monitoring sigma using v with lambda=.05
chart<-new("SPCEWMA",model=SPCModelNormal(Delta=0),lambda=.05)
# use xiofdata function to get phase I estimates of vbar and sd.v
xihat<-xiofdata(chart,v1)
str(xihat)
# get the adjusted multiplier for the ewma control limits
cal<-SPCproperty(data=v1,nrep=1000,property="calARL",chart=chart,
params=list(target=250.805),quiet=TRUE)
cal
#90 % CI: A threshold of +/- 0.489 gives an in-control ARL of at least 250.805.
#Unadjusted result: 0.3716
#Based on 1000 bootstrap repetitions.
# L=.489/sqrt(.05/(2-.05))=3.0538
#Simulate Phase II data with one sigma shift in the mean and no shift in the standard deviation
set.seed(49)
x2<-rnorm(15,55,5)
#standardize these simulated values with Phase I estimated mean and standard deviation
y2<-(x2-mean(x1))/sd(x1)
v2<-(sqrt(abs(y2))-.822179)/.3491508
# make a control chart of the Phase II values of v to detect a change from Phase I mean
library(qcc)
ev<-ewma(v2,center=xihat mu,std.dev=xihat sd,lambda=.05,nsigmas=3.0538)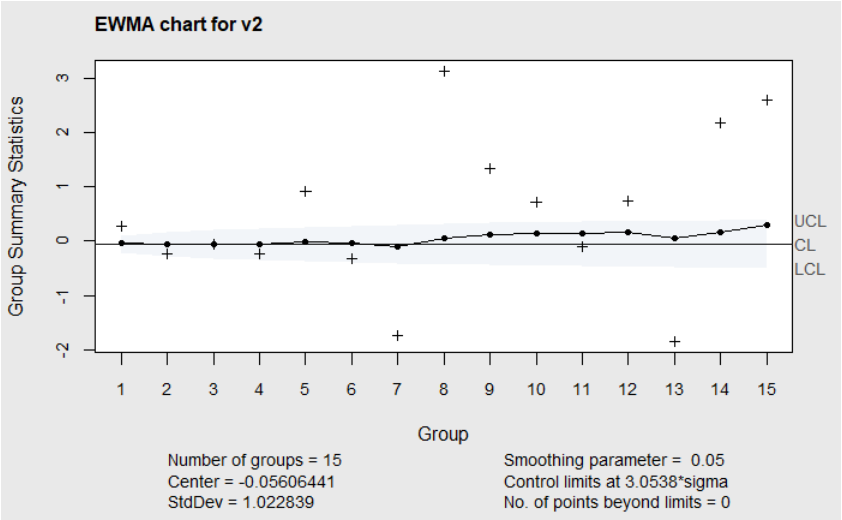
Figure 6.10 EWMA chart of \(v_i\) from Simulated Phase II Data with Adjusted \(L\)
As expected, there are no out of control points on this chart since the standard deviation (\(\sigma=5\)) did not change from the Phase I simulated data.
6.5 Time Weighted Charts for Phase II Monitoring of Attribute Data
Cusum charts can be used for counts of the number of nonconforming items per subgroup or the number of nonconformities per inspection unit in place of the Shewhart \(np\)–chart or \(c\)–chart. The Cusum charts will have a shorter ARL for detecting an increase or decrease in the average count and are more accurate. Therefore, they are very useful for processes where there are only counts rather than numerical measures to monitor.
If the target mean for the count is known, or it has been determined in a Phase I study, then Phase II monitoring is usually done using an \(np\)–chart or a \(c\)–chart. However, if the target or average count is small, the normal approximation used to calculate the control limits for an \(np\)–chart or \(c\)–chart is not accurate. For example, Figure 6.11 shows the Poisson probabilities (dark vertical lines) when \(\lambda =2\), a normal (N(\(\mu=2\),\(\sigma=\sqrt{2}\))) approximation curve, and the control limits (\(2\pm 3\sqrt{2}\) ) for a \(c\)–chart.
It can be seen from the figure that the \(c\)–chart is incapable of detecting a decrease in the count since the lower control limit is zero. In addition, there is a 0.0166 probability (i.e., false positive rate) of exceeding the upper control limit when the mean count \(\lambda=2\) has not increased. Therefore the average run length to a false positive signal is ARL\(=(1/0.0166)= 60.24\).
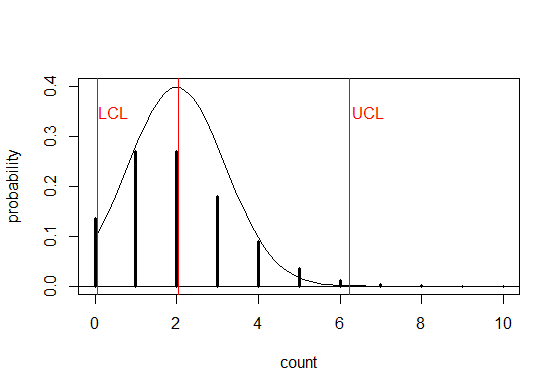
Figure 6.11 Normal Approximation to Poisson with \(\lambda=2\) and \(c\)-chart control limits
6.5.1 Cusum for Attribute Data
(Lucas 1985) developed a Cusum control scheme for counted data. Of the Cusums shown in Equation (6.16), \(C_i^+\) is used for detecting an increase in \(D_i\), the count of nonconforming items per subgroup (or the number of nonconformities per inspection unit). \(C_i^-\) is used for detecting a decrease in the count.
\[\begin{equation} C_i^+=max[0,D_i-k+C_{i-1}^+] \end{equation}\]
\[\begin{equation} C_i^-=max[0,k-D_i+C_{i-1}^-] \tag{6.16} \end{equation}\]
He recommended the reference value \(k\) be determined by Equation (6.17), rounded to the nearest integer so that the cusum calculations only require integer arithmetic.
\[\begin{equation} k=\frac{\mu_d - \mu_a}{\ln(\mu_d/\mu_a)} \tag{6.17} \end{equation}\]
In this equation, \(\mu_a\) is an acceptable mean rate (i.e., \(\lambda\), or \(np\)) that is chosen as the Phase I average or a target level, and the Cusum is designed to quickly detect an increase in the mean rate from \(\mu_a\) to \(\mu_d\). The decision interval \(h\) is then determined to give a long ARL when there is no shift in the mean and a short ARL when the mean shifts to the undesirable level \(\mu_d\).
(Lucas 1985) provided extensive tables of the ARL (indexed by \(h\) and \(k\) ) for detecting an increase or decrease in the mean count for Cusums with or without a headstart feature at \(h/2\). (White and Keats 1996) developed a computer program to calculate the ARL as a function of \(k\), and \(h\). An R function will be shown with the example below that duplicates some features of their program. (White, Keats, and Stanley 1997) showed that the ARL for this Lucas’s Cusum scheme is shorter than a comparable \(c\)–chart, and that it is robust to the distribution assumption (i.e. Poisson or Binomial).
Consider the application of the Cusum for counted data presented by (White, Keats, and Stanley 1997).“Motorola’s Sensor Products Division is responsible for the production of various lines of pressure sensors and accelerometers. Each of these devices consists of a single silicon die mounted in a plastic package with multiple electrical leads. In one of the final assembly steps in the manufacturing process, the bond pads on the silicon chip are connected to the package leads with very thin (1–2\(\mu\)) gold wire in the process known as wire bonding. During this process, the wire is subjected to an electrical charge that welds it to its connections. The amount of energy used in the bond must be carefully controlled because too little energy will produce a bond that is weak and too much energy will severely weaken the wire above the bond and cause subsequent failure of the connection. To maintain control of this process, destructive testing is conducted at regular intervals by selecting a number of units and pulling on the wires until they break. The pull strength as well as the location of the break are recorded. Statistical control of the pull strength falls within the realm of traditional SPC techniques, as these are continuous variable measurements and roughly normal independent and identically distributed. The location of the break is known to engineers as the failure mode. This qualitative variable provides additional information about the state of control for the process … Failure modes for the wire pull destructive testing procedure can take on four values (see Figure 6.12 taken from (White, Keats, and Stanley 1997)) … Failure at area 3 is known as a postbond heel break and is a cause of concern if the rate for this failure gets too large. Failure in this area is an indication of an overstressed wire caused by excessive bond energy.”
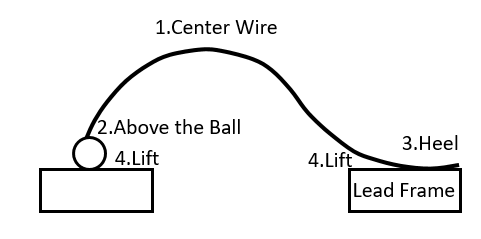
Figure 6.12 Wire Pull Failure Modes
The number of post bond heel breaks (\(D_i\)) were observed in samples of 16 destructive wire pull tests. If the probability of a the failure mode being the post bond heel break is \(p\), then the \(D_i\) follows an Binomial(16,\(p\)) distribution, and the mean or expected number would be 16\(p\). The acceptable mean rate was \(\mu_a=1.88\) (established as either a target or through a Phase I study). An unacceptably high mean rate was defined to be \(\mu_d=3.2\).
If a \(c\)–chart was used to monitor the number of post bond heel breaks in Phase II, it would have a center line \(\overline{c}\) =1.88, with the upper control limit UCL = \(\overline{c}+3\times\sqrt{\overline{c}}=5.99\), and lower control limit = 0. The average run length (ARL) when there is no change in mean count can be calculated using the \(\verb!ppois()!\) function in R as:
ARL\(_{\lambda=1.88}\) = 1/(1-\(\verb!ppois(5,1.88)!\))=79.28,
where 5 is the greatest integer less than UCL=5.99. This means a false positive signal would be generated every 80 samples of 16 on the average. The ARL for detecting a shift to \(\lambda=\mu_d=3.2\) with the \(c\)–chart would be:
ARL\(_{\lambda=3.2}\) = 1/(1-\(\verb!ppois(5,3.2)!\))=9.48.
If Lucas’s Cusum control scheme for counted data was used in Phase II instead of the \(c\)–chart, \(k\) would be calculated to be:
\[\begin{equation} k=\frac{\mu_d - \mu_a}{\ln(\mu_d/\mu_a)}=\frac{3.2-1.88}{ln(3.2)-ln(1.88)}=2.48, \tag{6.18} \end{equation}\]
which was rounded to the nearest integer \(k\)=2.0.
With \(k\)=2.0 , the next step is to choose \(h\). Larger values of \(h\) will result in longer ARLs both when \(\lambda=\mu_a=1.88\), and when \(\lambda=\mu_d=3.2\).
The function \(\verb!arl!\) in the R package \(\verb!IAcsSPCR!\) (that contains the data and functions from this book) was used to calculate ARL\(_{\lambda=1.88}\), and ARL\(_{\lambda=3.2}\) for the Cusum control scheme for counted data with \(k\) held constant at 2.0, and various values for \(h\). The values of \(h\) chosen were 6, 8, 10, and 12. By choosing even number integers for \(h\), \(h/2\) is also an integer and the cusum calculations with or without the FIR feature will only involve integer arithmetic. The function calls in the block of code below were used to calculate the entries in Table 6.9.
library(IAcsSPCR)
arl(h=6,k=2,lambda=1.88,shift=0)
arl(h=6,k=2,lambda=1.88,shift=.9627)
arl(h=8,k=2,lambda=1.88,shift=0)
arl(h=8,k=2,lambda=1.88,shift=.9627)
arl(h=10,k=2,lambda=1.88,shift=0)
arl(h=10,k=2,lambda=1.88,shift=.9627)
arl(h=12,k=2,lambda=1.88,shift=0)
arl(h=12,k=2,lambda=1.88,shift=.9627)For example, when \(h=6\) and \(k=2\), for the case where \(\lambda\) has increased to \(3.2\), the ARL is calculated with the function call \(\verb!arl(h=6,k=2,lambda=1.88,shift=.9627)!\) since \(3.2=\lambda=1.88+.9627\times \sqrt{1.88}\), or an increase in the mean by 0.9627 standard deviations. The resulting ARLs for \(h\)=6, 8, 10, and 12 are shown in Table 6.9.
Table 6.9 ARL for various values of \(h\) with \(k=2\), \(\lambda_0=1.88\)
| Value of \(h\) | ARL\(_{\lambda=1.88}\) | ARL\(_{\lambda=3.2}\) |
|---|---|---|
| 6 | 37.20 | 5.49 |
| 8 | 66.52 | 7.16 |
| 10 | 108.60 | 8.82 |
| 12 | 166.98 | 10.49 |
From this table, it can be seen that when \(h\) is 10, the ARL\(_{\lambda=1.88}=108.60\) which is 37% longer than the ARL\(_{\lambda=1.88}=79.28\) that would result if a \(c\)–chart were used. Additionally, the ARL\(_{\lambda=3.2}=8.82\) is 7% shorter than the ARL\(_{\lambda=3.2}=9.48\) that would result for the \(c\)–chart. This is the only case where both ARL\(_{\lambda=1.88}\) and ARL\(_{\lambda=3.2}\) for the Cusum scheme for counted data differ from the ARL ’s for the \(c\)–chart in the desired directions. Therefore, this is the value of \(h\) that should be used.
The calculated cusums (using \(C_i^+\) in Equation (6.16) for the number of the number of post bond heel breaks ( \(D_i\) ) on machine number two in the article by (White, Keats, and Stanley 1997) is shown in Table 6.10. Here it can be seen that the Cusum without the FIR detects a positive signal at sample number 10, where \(C_{10}^+>h=10\) . This would indicate that the number of heel breaks has increased, and that the amount of energy used in the bonding process should be reduced to bring the process back to the target level.
The Cusum including the FIR at ( \(C_0^+=h/2=5\) ) detects a positive signal even sooner at sample number 8. Use of this Cusum would be appropriate when restarting the process after a manual adjustment of the energy level. The \(c\)–chart shown in the article did not detect an increase until sample number 14. Therefore, the Cusum chart detected the increase in the mean faster and had a 37% increase in the expected average time between false positive signals. Also, with an integers for \(k\) and \(h/2\) , the arithmetic needed to calculate \(C_i^+\) is so simple it can be done in your head as you write the last three elements of each row in a table like 6.10.
Table 6.10 Calculations for counted data Cusum for detecting an increase with \(k=2\) , \(h=10\)
| Sample No. \(i\) | \(D_i\) | \(D_i-k\) | \(C_i^+\) with No FIR | \(C_i^+\) with FIR \(h/2\) |
|---|---|---|---|---|
| 1 | 3 | 1 | 1 | 6 |
| 2 | 1 | -1 | 0 | 5 |
| 3 | 4 | 2 | 2 | 7 |
| 4 | 1 | -1 | 1 | 6 |
| 5 | 3 | 1 | 2 | 7 |
| 6 | 1 | -1 | 1 | 6 |
| 7 | 5 | 3 | 4 | 9 |
| 8 | 4 | 2 | 6 | 11 |
| 9 | 5 | 3 | 9 | - |
| 10 | 5 | 3 | 12 | - |
R code can also be used to calculate the entries in Table 6.10 as shown in the example below. This block of code also illustrates how to produce the graphical representation of the Cusum chart without and with the headstart feature shown in Figure 6.13.
#Calculations to Get Table 6.10
library(qcc)
D<-c(3,1,4,1,3,1,5,4,5,5)
CUSUM<-cusum(D,center=0,std.dev=1,decision.interval=10,se.shift=4,plot=FALSE)
FIR<-cusum(D,center=0,std.dev=1,decision.interval=10,se.shift=4,head.start=5,plot=FALSE)
M<-cbind(D,(D-k),CUSUM pos,FIR pos)
colnames(M)<-c("D","D-k","C+(without(FIR))","C+(with(FIR))")
MBy specifying \(\verb!center=0!\) and \(\verb!std.dev=1!\), in the calls to the \(\verb!cusum()!\) function, the values of \(C_i^+\) shown in Equation (6.16) without the FIR feature can be found in the named element \(\verb!CUSUM$pos!\) of the object \(\verb!CUSUM!\), and the vector of values for \(C_i^+\) with the FIR feature can be found in the named element \(\verb!FIR$pos!\) of the object \(\verb!FIR!\). \(C_0^+=0.0\) for the Cusum without FIR, and \(C_0^+=5\) for the Cusum with FIR. The number of postbond heel breaks is stored in the vector \(\verb!D!\).
When monitoring to detect an improvement or reduction in the Poisson process mean, \(\mu_d\) will be less than \(\mu_a\) , and in that case the values the values of \(-C_i^-\) the negatives of \(C_i^-\) shown in Equation (6.16) can be found in the element \(\verb!CUSUM$neg!\) when the call to the \(\verb!cusum()!\) function is
and \(\verb!-6!\) in the argument \(\verb!shift=-6!\) is the negative of \(k\) found using Equation (6.18). When the objective is to detect increases in the Poisson process mean, the line plot on the negative side of the cusum chart plotted by the \(\verb!cusum!\) function should be ignored, and when the objective is to detect a decrease in the Poisson mean by assigning the \(\verb!shift!\) argument to be the negative of \(k\), the line graph graph on the positive side of the cusum chart created by the \(\verb!cusum!\) function should be ignored.
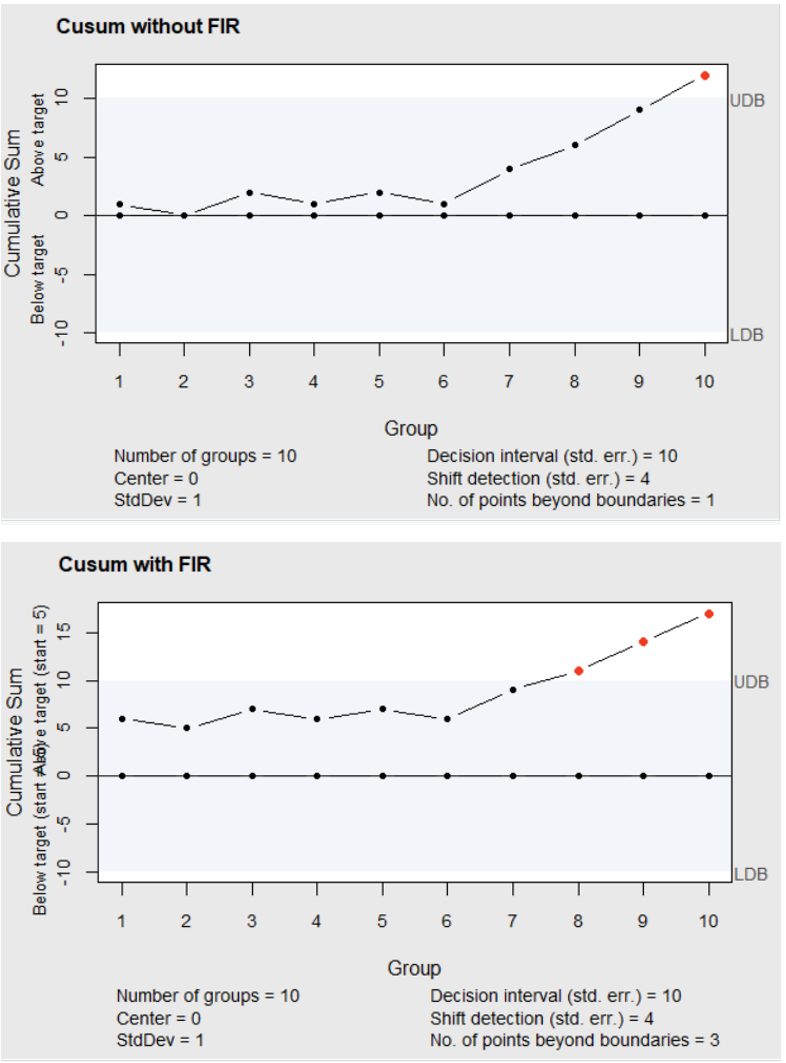
Figure 6.13 Cusum for counts without and with FIR
The advantage for using a Cusum for counted data rather than a \(c\)–chart or \(np\)–chart for Phase II monitoring is usually much greater than that shown in the last example. To illustrate, consider the case where the target or Phase I in-control average count was \(\lambda=4\). In this case, Table 6.11 compares the expected ARLs for the \(c\)–chart and the Cusum chart with and without the FIR feature.
Table 6.11 Comparison of ARL for \(c\)–chart and Cusum for counted data (\(k=5\), \(h=10\)) with target \(\lambda=4\)
| \(\lambda\) | ARL for c chart | ARL for Cusum without FIR | ARL for Cusum with FIR |
|---|---|---|---|
| 4 | 352.14 | 421.60 | 397.5 |
| 5 | 73.01 | 29.81 | 22.38 |
| 6 | 23.46 | 9.73 | 6.11 |
| 7 | 10.15 | 5.59 | 3.35 |
| 10 | 2.40 | 2.58 | 1.58 |
In this table, it can be seen that there is a 12.9% to 19.7% increase in the average time between false positive signals (depending on whether the FIR feature is used or not). Further, there is a 58% to 74% decrease in the average time to detect a one standard deviation increase in the average count (from \(\lambda=4\) to \(\lambda=6\)).
Although a Cusum control chart will detect a small shift in the mean quicker than a Shewhart control chart, it will not detect a large shift in the mean as quickly as a Shewhart chart. For example, Table 6.4 shows that the Cusum chart will detect a 0.5 to 1.0 standard deviation shift in the mean quicker than the Shewhart individuals chart, but the Shewhart chart will detect a 4.0–5.0 shift in the mean quicker than the Cusum chart. Likewise, Table 6.11 shows that a Cusum chart for counted data will detect a 0.5 to 1.5 standard deviation shift in the mean (i.e., \(\lambda=4\) to \(\lambda=5\), \(6\) or \(7\)) faster than the Shewhart \(c\)–chart, but that the \(c\)-chart will detect a 3.0 standard deviation shift (i.e. \(\lambda=4\) to \(\lambda=10\) ) faster than the Cusum chart.
This is because the Cusum chart weights all past observations leading up to the out-of-control signal equally, while the Shewhart chart ignores all but the last observation. If the mean suddenly shifted by a large amount, the Cusum value ( \(C_i^+\) or \(C_i^-\) ) de-weights the last observation by averaging it with the past. Therefore, a Shewhart individuals chart and Cusum chart are often used simultaneously in Phase II monitoring.
By using the FIR feature, the Cusum chart can be made to detect a large shift as quickly as a Shewhart chart. However, this feature is normally only used after the process has been manually reset after an out-of-control signal. Always using the FIR feature can lead to a reduction in the ARL to encountering a false positive.
6.5.2 EWMA for Attribute Data
The EWMA chart like the Cusum chart can also be used for attribute data like counts of the number of nonconforming items per subgroup or the number of nonconformities in an inspection unit. The EWMA ( \(z_i=\lambda x_i +(1-\lambda)z_{i-1}\), where \(z_0=\mu_0\)) is a weighted average of past observations or counts (\(x_i\)), and due to the Central Limit Theorem it will be approximately normally distributed.
(Borror, Champ, and Rigdon 1998) present the control limits for an EWMA chart for counts as shown in Equations (6.19) and (6.20).
\[\begin{equation} UCL = \mu_0 + A\sqrt{\frac{\lambda\mu_0}{2-\lambda}} \tag{6.19} \end{equation}\]
\[\begin{equation} LCL = \mu_0 - A\sqrt{\frac{\lambda\mu_0}{2-\lambda}} \tag{6.20} \end{equation}\]
Where, \(A\) is the control limit factor, and \(\mu_0\) is the target count (or mean established in Phase I). Once \(\mu_0\) is known and \(\lambda\) is selected, the factor \(A\) should be selected to control the ARL for various values of the shift in the mean. The paper gives graphs of the ARL as functions of \(\lambda\), and \(A\) that can be used to do this. There is an example of one of these graphs in the lecture slides for Chapter 6. The paper also shows that the EWMA control chart for counts will detect a small shift in the average count faster than the Shewhart \(c\)–chart.
6.6 Exercises
Run all the code examples in the chapter, as you read.
Assuming the target mean is 15 and the in-control standard deviation is \(\sigma\) = 2.0,
Make a cusum chart with \(h = 4\) that will quickly detect a one \(\sigma\) shift in the mean in the following Phase II data: 10.5 14.0 15.4 10.7 13.7 13.3 16.4 17.2 14.2 12.6 12.9 13.4 13.0 10.7 10.8 12.9 12.1 10.1 11.4 10.9
Calculate the ARL\(_0\) for the chart you constructed in part (a).
- If \(\lambda\) = .3, find the value of \(L\) for an EWMA chart that would match the ARL\(_0\) of the cusum chart you made in question 2.
Make the EWMA chart of the data in exercise 2 using \(\lambda=.3\) and the value of \(L\) you determined above.
Are the results the same as they were for the cusum chart in exercise 2?
- E.L. Grant(1946) showed the following data from a Chemical plant. The numbers represent the daily analyses of the percentages of unreacted lime (CaO) at an intermediate stage of a continuous process.
.24,.13,.11,.19,.16,.17,.13,.17,.10,.14,.16,.14,.17,.15,.20,.26,.16,0.0,.18,.18,.20,.11,.30,.21,.11,.17,.18,.13,.28, .16,.14,.16,.14,.10,.13,.20,.14,.10,.18,.11,.08,.12,.13,.12,.17,.10,.09
Make a Cusum chart of the data assuming the in-control mean was \(\mu=0.15\) and the in-control standard deviation \(\sigma=\).04. Use \(k=\frac{1}{2}\) and \(h=5\).
Remake the chart using the headstart feature. Is there any difference in the two charts?
When would you recommend using the headstart feature with individual data from a chemical plant?
Make a EWMA chart with the similar ARL\(_0\) and the headstart feature.
Is the result the same as the Cusum chart used in (b)
- Using Borror et. al.(1998)’s method, make an EWMA control chart of the count data data in Table 6.10 assuming \(\mu_0 = 1.88\) and using \(\lambda = 0.2\), and \(A = 2.55\).
Do you detect any out of control signal? If so at what observation number?
If \(\mu_0 = 4.0\), and \(\lambda = 0.3\), what values of \(A\) would you recomend to obtain an ARL\(_0\) = 500 for an EWMA chart made with the Borror et. al.(1998) method.
- Hawkins proposed a Cusum chart of \(v_i=\frac{\sqrt{|y_i|}-0.822}{0.349}\), where \(y_i=(x_i-\mu)/\sigma\) to detect changes in the standard deviation of \(x_i\).
Can you use an EWMA chart with individual observations to detect an increase in the standard deviation?
If so, do it with the data in the first column of Table 6.1 and assuming \(\mu_0=50\) and \(\sigma_0=5\).
- The data in the data vector \(\verb!x2!\) in the R package \(\verb!IAcsSPCR!\) is from Phase II monitoring. The in-control mean and standard deviation are unknown, but the data in the vector \(\verb!x1!\) in the R package \(\verb!IAcsSPCR!\) are from a Phase I study after eliminating out-of control data points.
Find the 90th percentile of the multiplier \(L\) for the control limits of a Phase II EWMA chart with \(\lambda=.2\) so that the ARL\(_0\) will be guaranteed to be at least 465.48 90% of the time.
Use the multiplier you found in (a) to construct the EWMA control chart of the data in the vector \(\verb!x2!\).
Has the process remained in control during Phase II?
References
Borror, C. M., C. W. Champ, and s. E. Rigdon. 1998. “Poisson Ewma Control Charts.” Journal of Quality Technology 30 (4): 352–61.
Deming, W. E. 1986. Out of the Crisis. Cambridge, Mass.: MIT Center for Advance Engineering Study.
Gandy, A., and J. T. Kvaloy. 2013. “Guarranteed Conditional Performance of Control Charts via Bootstrap Methods.” Scandinavian Journal of Statistics 40: 647–68.
Gandy, A., and J. T. Kvaloy. 2013. “Guarranteed Conditional Performance of Control Charts via Bootstrap Methods.” Scandinavian Journal of Statistics 40: 647–68.
2015. spcadjust: Functions for Calibrating Control Charts. https://CRAN.R-project.org/package=spcadjust.Hawkins, D. M. 1981. “A Cusum for a Scale Parameter.” Journal of Quality Technology 13 (4): 228–31.
Hawkins, D. 1993. “Cusum Control Charting: An Underutilized Spc Tool.” Quality Engineering 5 (3): 463–77.
Hawkins, D. M., and D. H. Olwell. 1997. Cumulative Sum Charts and Charting for Quality Improvement. New York, N.Y.: Springer.
Lawson, J. S. 2019. “Phase I I Monitoring of Variability Using Individual Observations.” Quality Engineering 31 (3): 417–29.
Lucas, J. M. 1985. “Counted Data Cusum’s.” Technometrics 27 (2): 129–43.
Lucas, J. M., and R. B. Crosier. 1982. “Fast Initial Response for Cusum Quality Control Schemes: Give Your Cusum a Head Start.” Technometrics 24 (3): 199–205.
Steiner, S. H. 1999. “EWMA Control Chart with Time Varying Control Limits and Fast Initial Response.” Journal of Quality Technology 31 (1): 75–86.
Summers, D. C. S. 2000. Quality. 2nd ed. Upper Saddle River, N.J.: Prentice Hall.
Vance, L. C. 1986. “Average Run Lengths of Cumulative Sum Control Charts for Controlling Normal Means.” Journal of Quality Technology 18: 189–93.
White, C. H., and J. B. Keats. 1996. “ARLs and Higher-Order Run-Length Moments for the Poisson Cusum.” Journal of Quality Technology 28 (3): 363–69.
White, C. H., J. B. Keats, and J. Stanley. 1997. “Poisson Cusum Versus c Chart for Defect Data.” Quality Engineering 9 (4): 673–79.