BLOQUE 3. TÉCNICAS DE APRENDIZAJE NO SUPERVISADO
Clase 1. “K means” y dendrograma
Muchas veces le puede interesar reducir la dimensión asociada al número de variables con el que cuenta. Es posible, por ejemplo, que le interese agrupar la información con la que cuenta para crear una nueva variable sintética. Imagine, por ejemplo, que tiene 10 variables que aluden a la clase social y la formación del individuo: quizás quiera tener una única variable que clasifique a los individuos según la información conjunta contenida en ese bloque de variables. Sin embargo, no va a poder entrenar un modelo y validarlo: usted usa la técnica sin saber, a priori, lo que va a obtener. Por eso, a estas técnicas se las conoce como no supervisadas. No puede realizar comprobaciones cuantitativas mediante test y validación. Sólo podrá usar su lógica para ver si lo que obtiene es sensato o no. Generalmente, estas técnicas son pasos intermedios para tener una base de datos más sintética que le ayude en el proceso de modelar su pregunta de interés.
Este análisis busca realizar agrupaciones de observaciones condicionadas por el valor que tomen ciertas variables disponiles. Imagine que tiene una nube de puntos asociada a dos variables: \(x_1,x_2\). Visualmente, seguro que es capaz de hacer dos grupos ¿no?
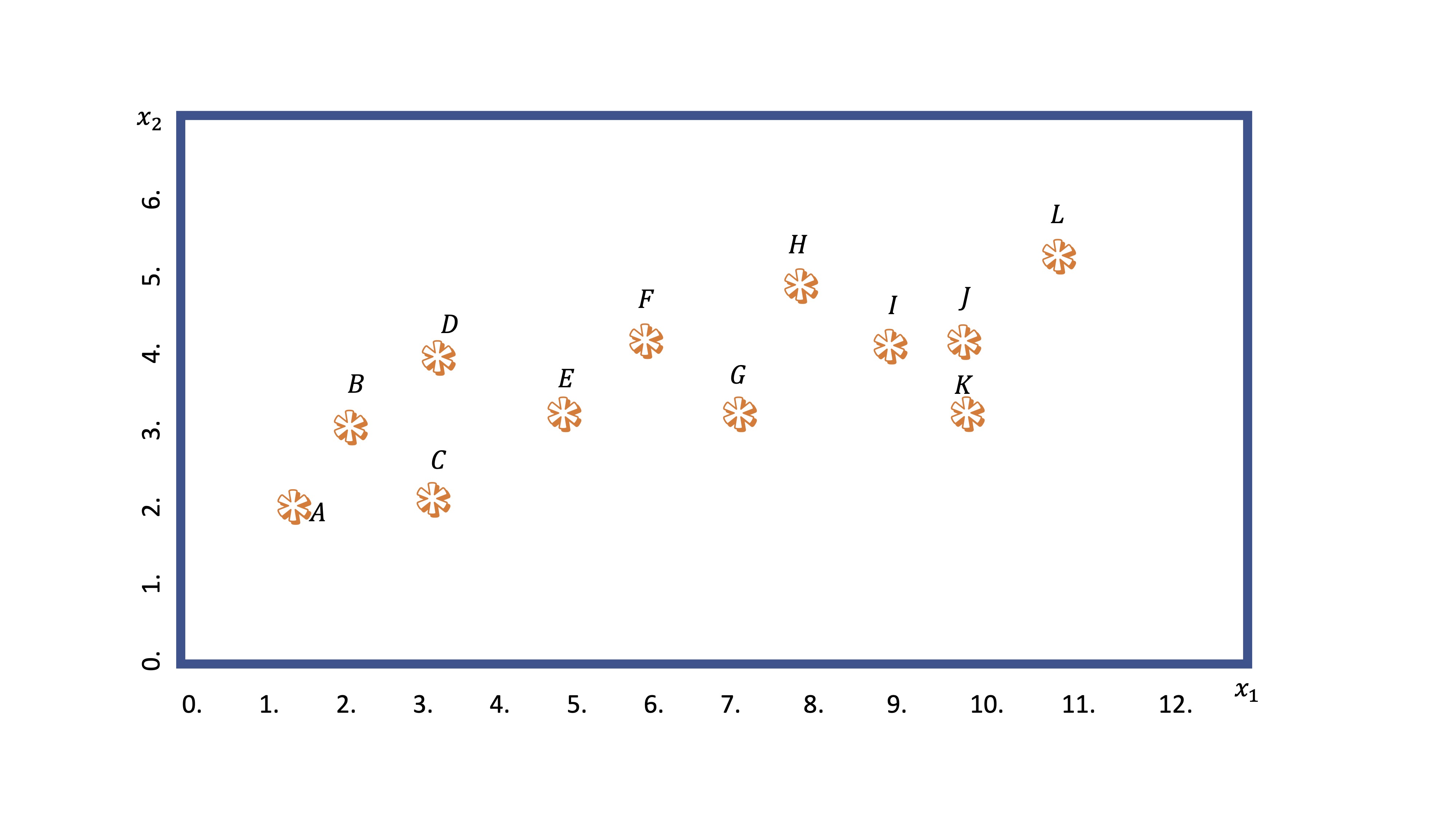
¿Cómo lo hará la máquina? Veamos el algoritmo en los diferentes pasos:
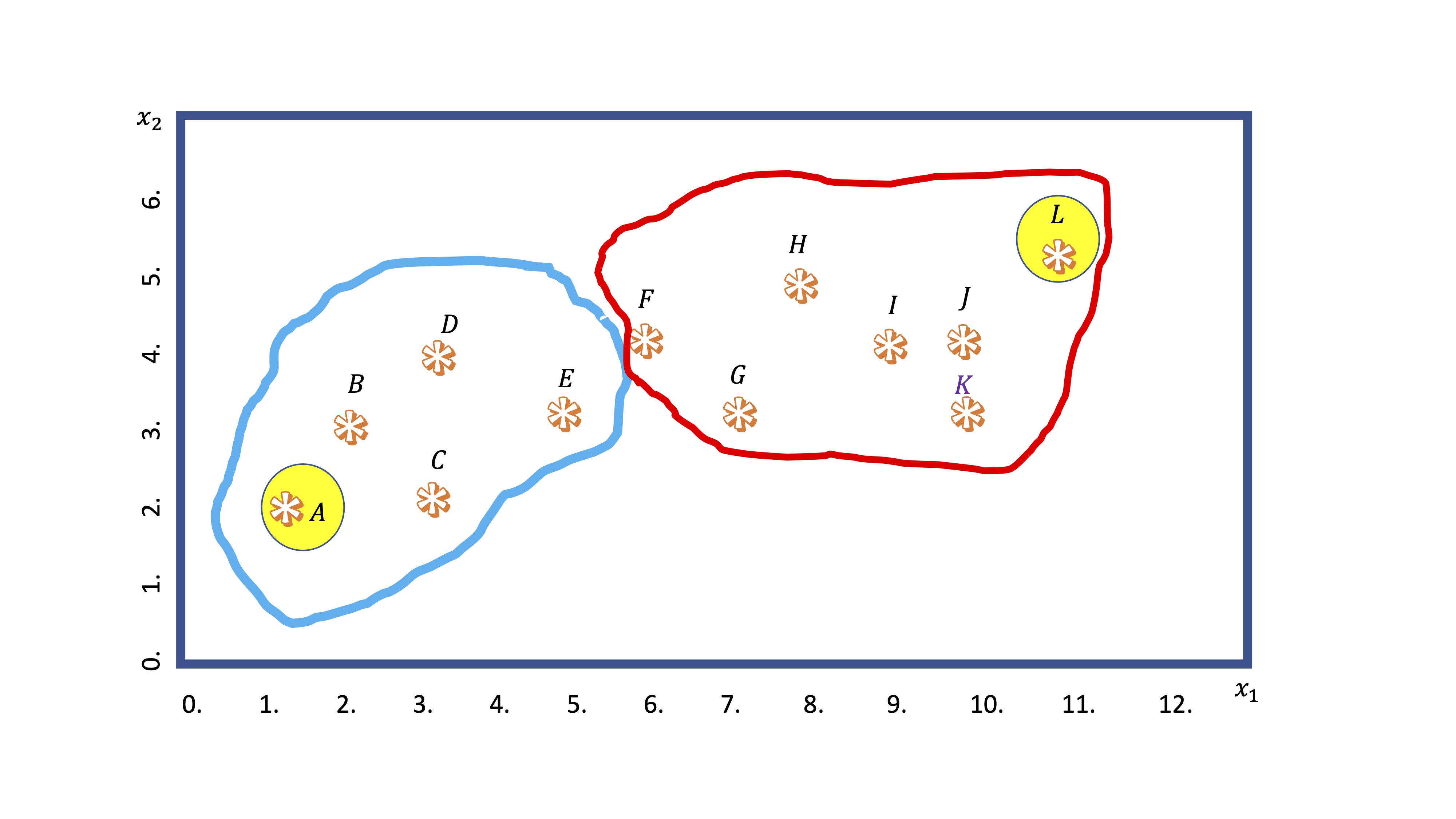
- Primero: busca dos puntos (generalmente de manera aleatoria). Nosotros elegiremos los más distantes entre sí. Esos puntos se llamarán centroides de los cluster.
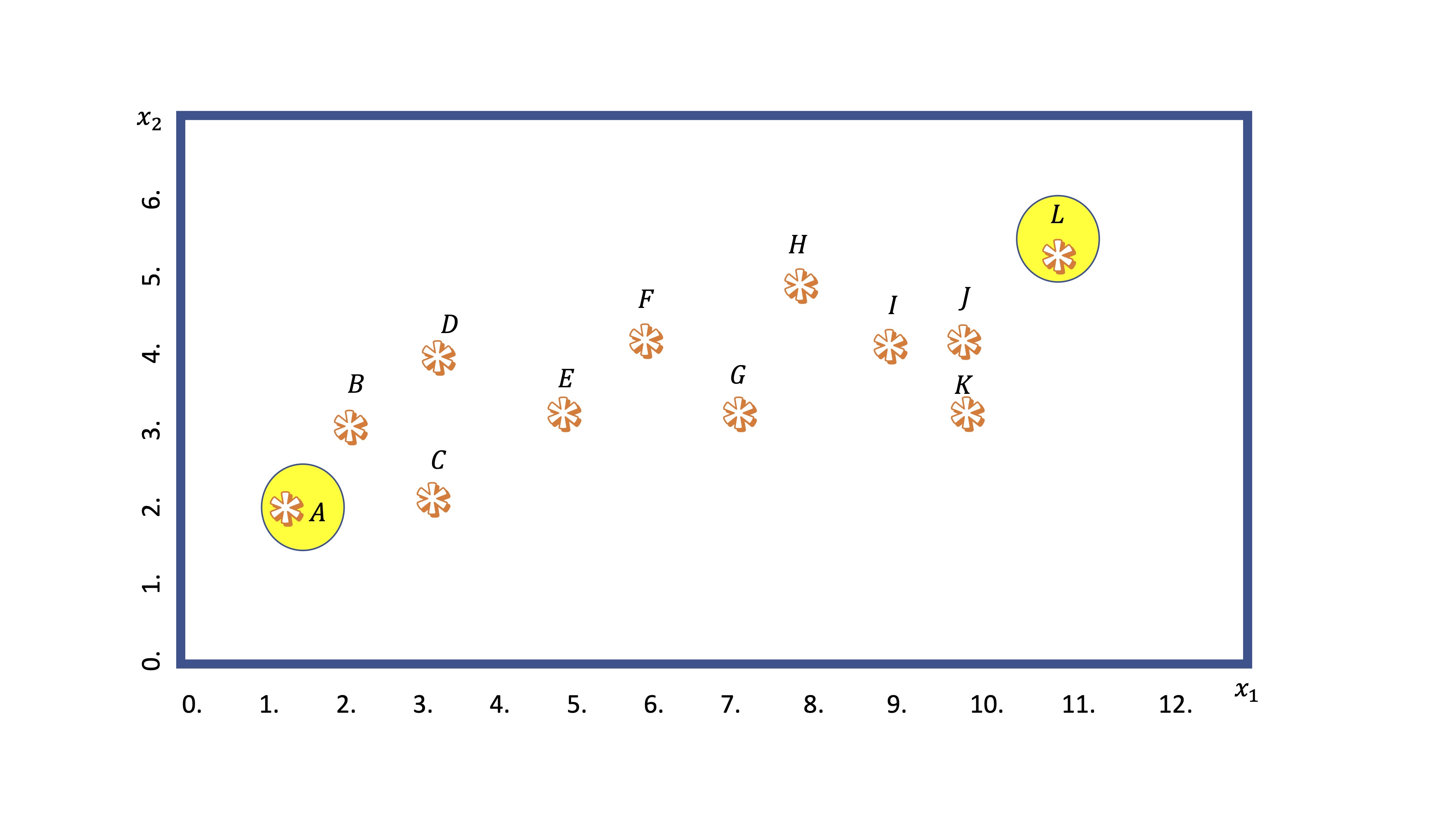
El centroide 1, el punto A, tiene coordenadas \(A(1,2)\), mientras que el centroide 2, el punto L, tiene coordenadas \(L(11,5.5)\). Esas son ahora las referencias de los grupos.
- Segundo: Calcula la distancia (mediante alguna medida general, como la norma euclídea) de cada punto a los centroides
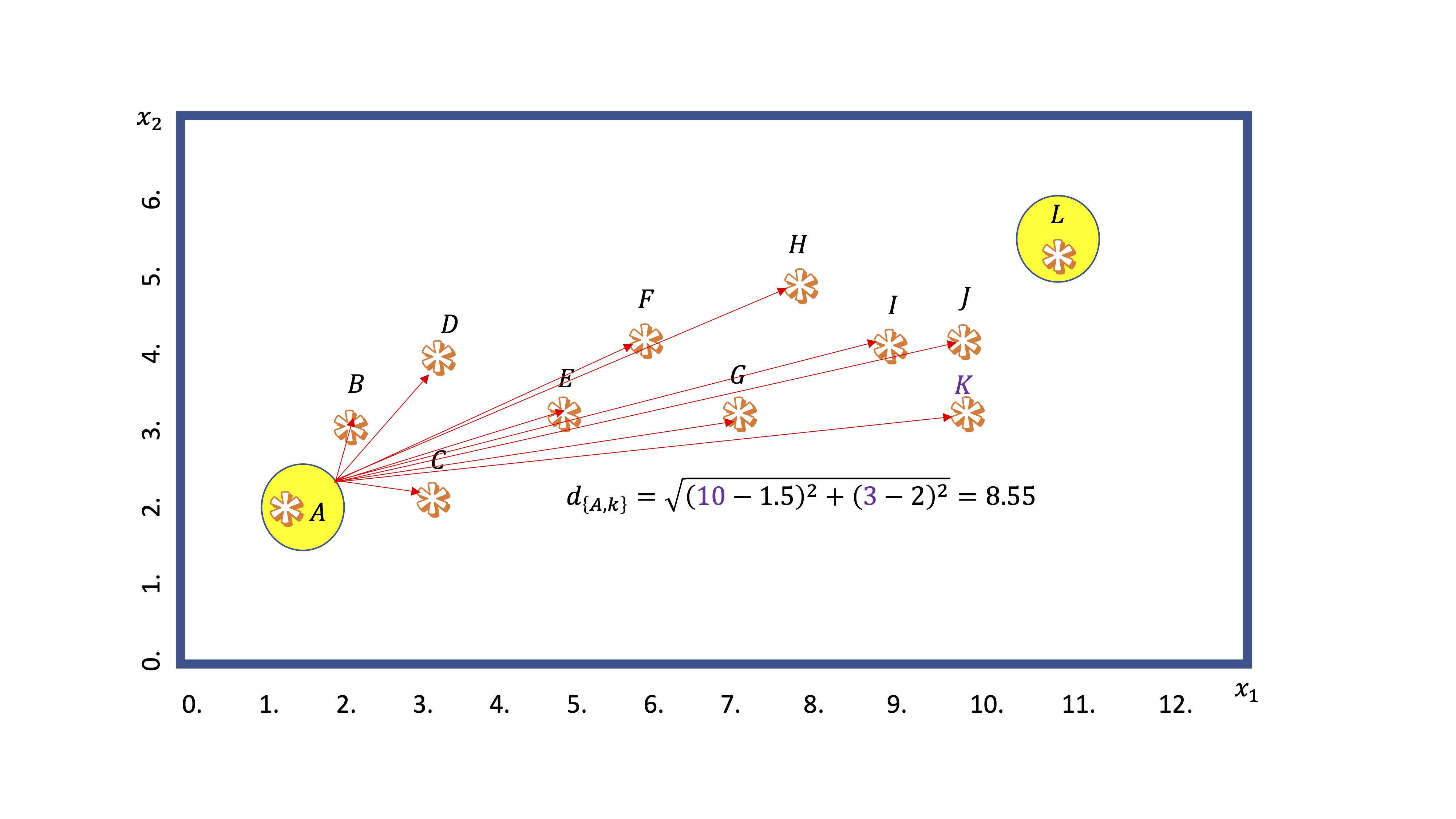
En este ejemplo, calculamos la distancia del centroide A al punto K. Obtenemos \(8.55\). Por otro lado, del centroide L al mismo punto:
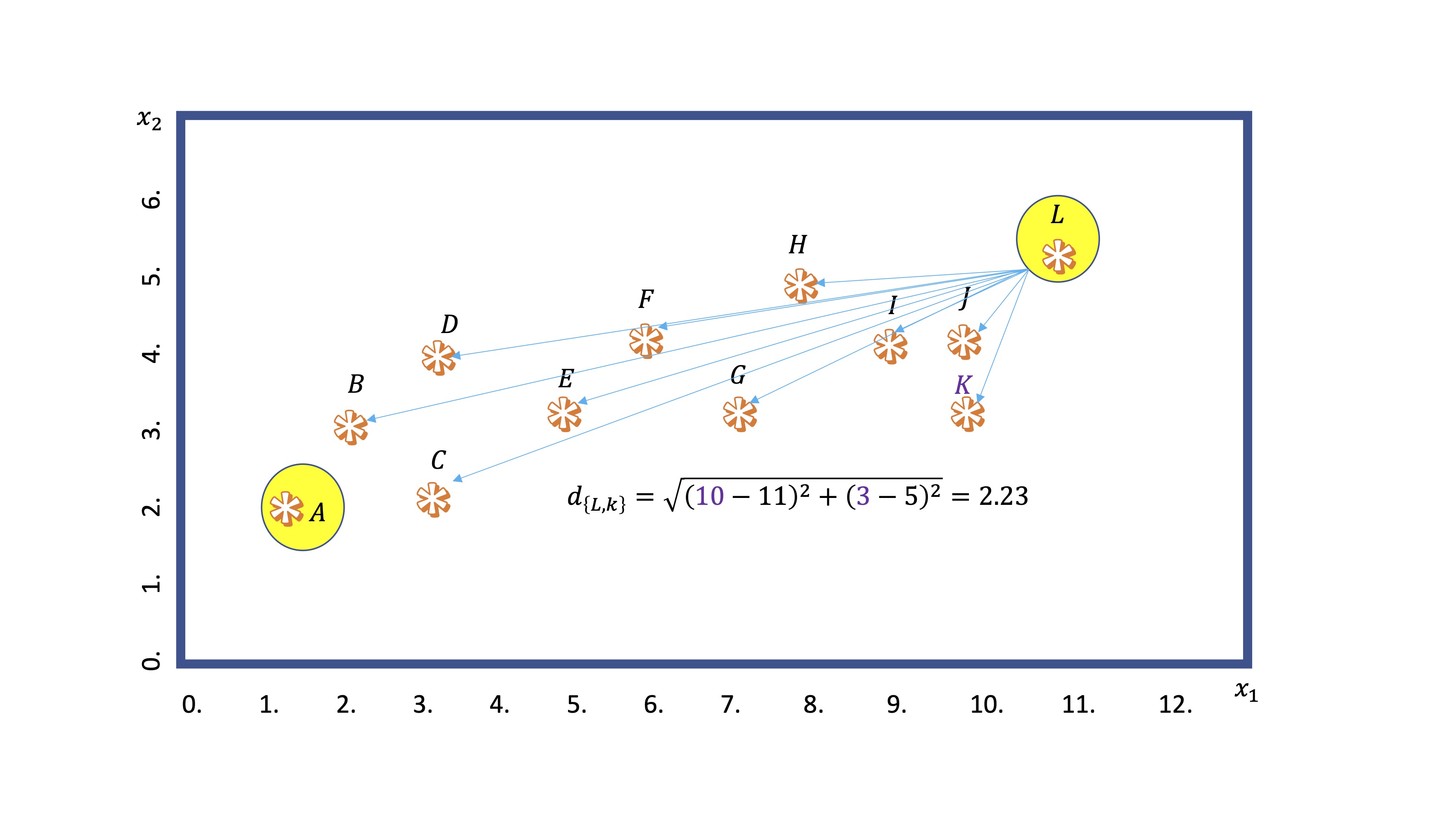
y vemos que es menor. Entonces, el algoritmo dejará al punto K dentro del nodo que “preside” L.
- Tercero: establece una agrupación por clusters en función de la distancia de cada punto a los centroides elegidos
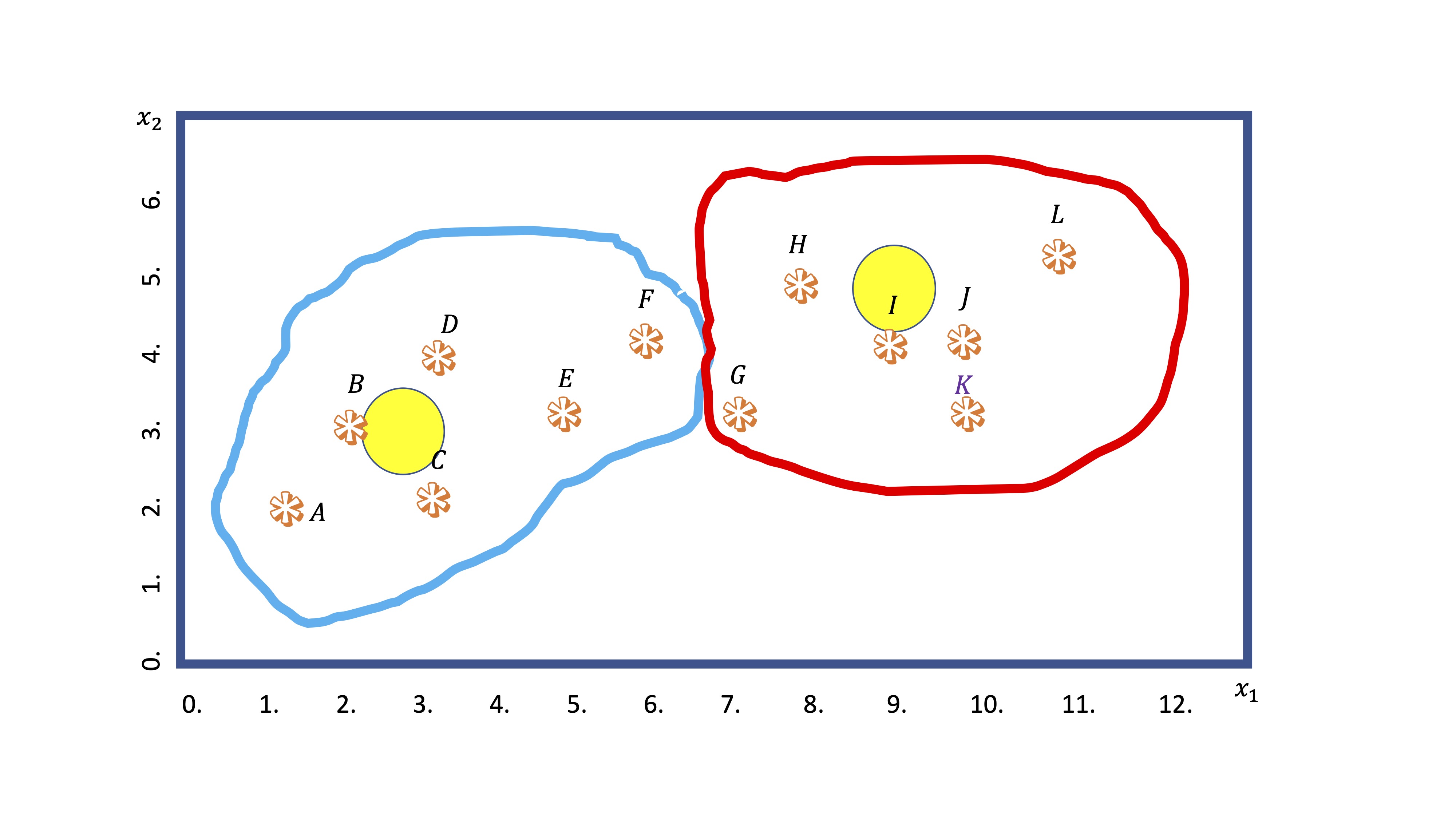
Sin embargo, con los nuevos grupos hechos, ahora recalcula los centroides (haciendo la media de las coordenadas \(x_1,x_2\) de cada punto dentro del grupo). De hecho, el nuevo centroide puede ya no ser ningún punto de los que se encuentran en el grupo.
- Cuarto: entonces, recalcula la distancia de todos los puntos a los centroides y, en base a ese dato, los grupos van a reorganizarse (observaciones en las fronteras de cada grupo irán cambiándose)
El algoritmo iterará hasta que la clasificación se estabilice. ¿Qué criterio seguiremos para decidir cuántos grupos/cluster hacer?
Elección de número de grupos “k”. Habitualmente, el algoritmo calcula la “suma de cuadrados” de cada uno de los grupos utilizando los centroides como valores de referencia. De esta manera, realiza la suma de cuadrados de las distancias de cada coordenada a su valor central en cada grupo. El objetivo es minimizar la suma total. Esa suma siempre será decreciente, por lo que se elegirá el número de grupos \(k\), donde un incremento adicional de \(k\) haga que el error caiga marginalmente. Lo veremos con un ejemplo:
Introducimos los datos que han generado las figuras anteriores
Ahora creamos un bucle que va a ir incrementando la cantidad de clusters (\(k\)) y calculando las sumas de cuadrados (whitinss, en la función empleada)
S <- vector() #inicializo mi vector de dispersiones
for(i in 1:8){
kresult<-kmeans(dataset, i, nstart=100)$withinss
S[i]<-sum(kresult)
} #calculo mediante kmeans la S para cada knote que nstart=100 quiere decir que deberá empezar 100 veces, de manera aleatoria, los centroides. Es una manera de estabilizar el algoritmo y hacer que el resultado no dependa de la selección original de centroides.
ggplot() +
geom_point(aes(x = 1:8, y = S), color = "blue") +
geom_line(aes(x = 1:8, y = S), color = "blue") +
ggtitle("Selección de clusters") +
xlab("Cantidad de Centroides k") +
ylab("S")El gráfico de la FIG7 nos sugiere, de hecho, hacer entre 4 y 5 clusters.
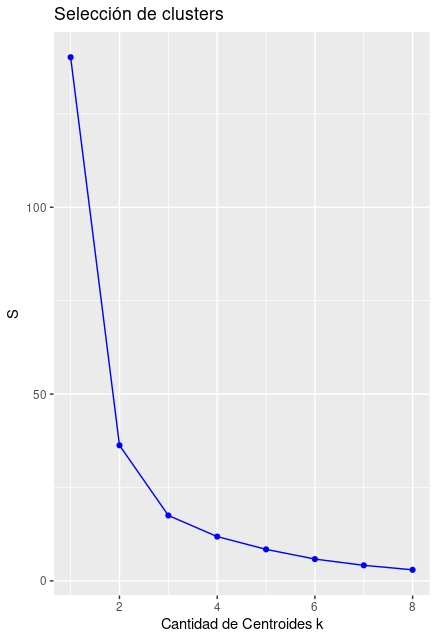
Aunque, a todas luces, parece demasiado exagerado hacer 4 clusters. Será usted, como usuario, quien deba elegir lo más conveniente (debería, por ejemplo, utilizar algún criterio extramuestral). Con este script puede dibujar los resultados:
install.packages("factoextra")
library(factoextra)
kmeans <- kmeans(dataset, 2, iter.max = 1000, nstart = 25)
fviz_cluster(kmeans, data = dataset)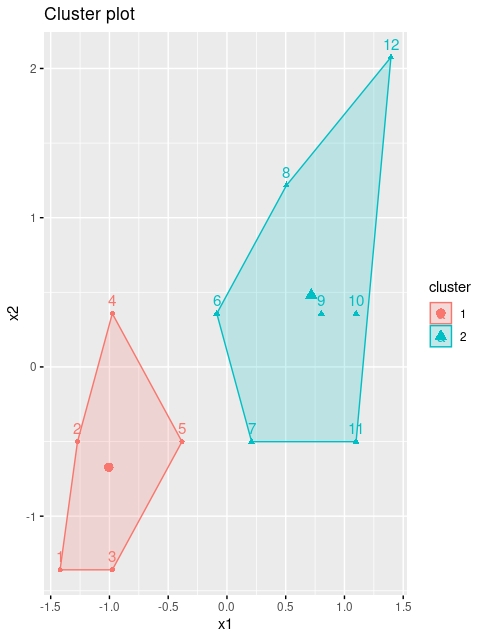
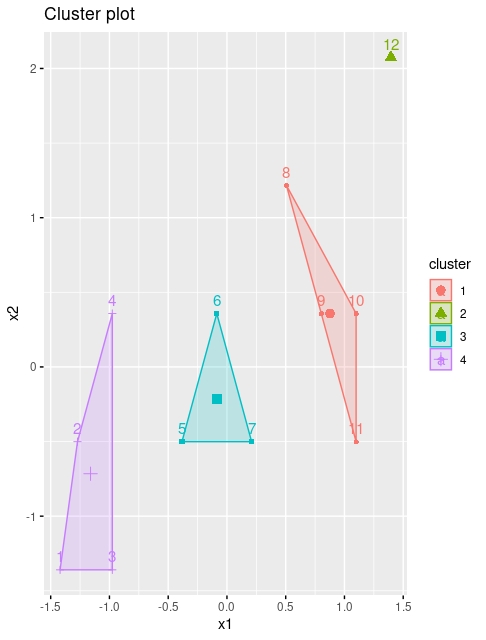 Ahora bien, lo normal es no tener acceso a estos gráficos porque usted quiera hacer los cluster con más de dos variables (no olvide que el objetivo es reducir el tamaño del conjunto de variables disponible). Entonces, le interesará acceder a la información que proporciona la función kmeans
Ahora bien, lo normal es no tener acceso a estos gráficos porque usted quiera hacer los cluster con más de dos variables (no olvide que el objetivo es reducir el tamaño del conjunto de variables disponible). Entonces, le interesará acceder a la información que proporciona la función kmeans
K-means clustering with 2 clusters of sizes 5, 7
#por un lado, le proporciona las coordenadas de los centroides. Eso le ayudará a entender el significado de estos, ya que son los promedios de cada variable en el cluster.
Cluster means:
x1 x2
1 2.90 2.80
2 8.71 4.14
#por otro lado, le proporciona la "etiqueta" del cluster al que pertenece cada observación. Esta será una nueva variable para usted que resume las anteriores. Tendrá que darle un significado, basado en los valores de los centroides
Clustering vector:
[1] 1 1 1 1 1 2 2 2 2 2 2 2
#Y estas son las sumas de cuadrados de cada cluster
Within cluster sum of squares by cluster:
[1] 10.0 26.3
(between_SS / total_SS = 74.1 %)Ejercicio Realice un ejercicio de cluster con los datos de audiencia y puntuación de los Simpson de tal forma que trate de ver si encuentra mayor capacidad predictiva de los personajes en el resultado de esa nueva variable caracterizada por los clusters que encuentre. Trate de explicar el significado de los cluster.
Algo que tiene que tener en cuenta es que, en caso de necesitar hacer “clusters”, las unidades de medida de las variables pueden influir en estos. A veces, le convendrá estandarizar las variables- en caso de que las unidades de medida de estas sean muy distintas-. Por cierto, en ese caso deberá preguntarse, antes de hacer cualquier cosa por qué merece la pena y cuál es la posible ganancia de agrupar individuos utilizando variables muy distintas. Ojo, hay veces que será necesario. Otras, parecerá un ejercicio realizado por alguien que no ha entendido muy bien qué está haciendo.
Estandarizar las variables
Una variable \(x\) con media \(\bar{x}\) y desviación típica \(\sigma_{x}\) se puede transformar a una variable con media cero y desviación típica 1 mediante la operación \(\frac{(x-\bar{x})}{\sigma_{x}}\). Sin embargo, eso no quiere decir que esté convirtiendo a la variable en Normal (error común), simplemente la está cambiando de escala.
Veamos un ejemplo que usted puede simular en su ordenador. Como ve en la FIG1, la variable \(x\) está en unidades distintas a la variable \(y\). Además, se ven claramente los dos cluster.
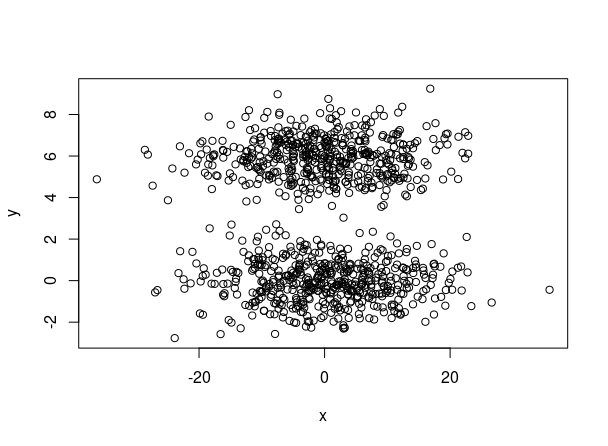
Aquí puede disponer del código para simularlos:
Se obtienen los siguientes resultados de la función “kmeans” utilizando 2 clusters
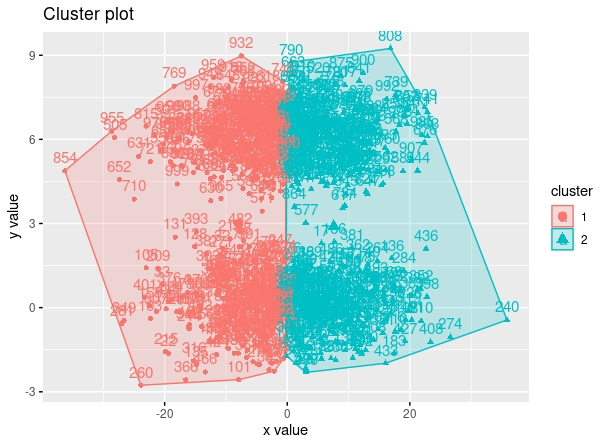
¿Qué ha ocurrido aquí? Pues que los valores de la variable \(x\) han sido los que han ejercido un mayor peso a la hora de calcular las distancias de cada punto al centroide. Las coordenadas de la variable \(y\), apenas han contribuido a ello. Sin embargo, tras estandarizarlos, obtenemos una solución más existosa
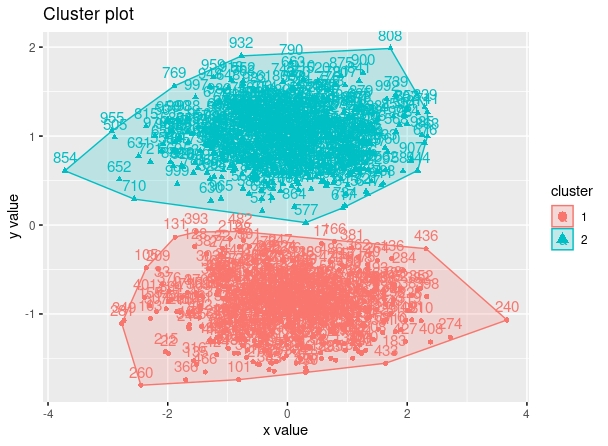
Ahora bien, ¿es siempre la solución estandarizar? En el manual FRIEDMAN, Jerome H. The elements of statistical learning: Data mining, inference, and prediction. springer open, 2017.
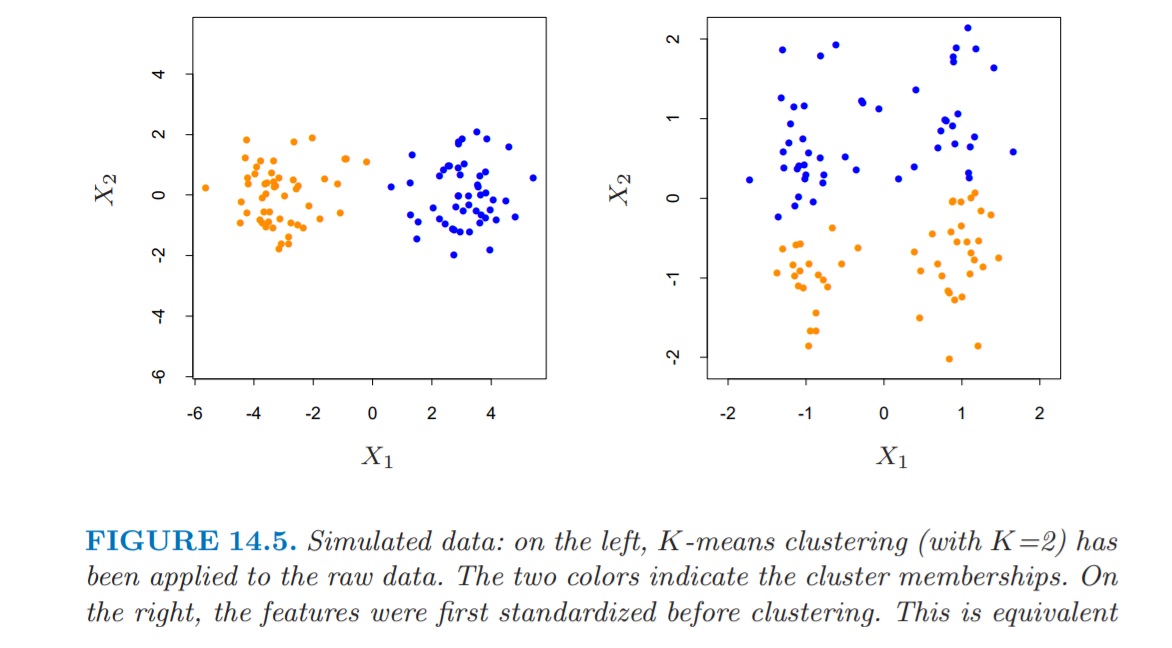
donde, como vemos, tras la estandarización, los clusters correspondientes sufren modificaciones al cambiar la dispersión respecto al eje de ordenadas.
- Es por ello que, de nuevo, hay que cuestionarse si debemos usar variables para entrenar un k-means de manera automática y con distintas unidades de medida
- En todo caso, hay que interpretar los cluster obtenidos para tratar de entender si son lógicos y satisfacen nuestras necesidades de reducir la información disponible.
Ejemplo aplicado
Seguimos tratando de averiguar si es posible predecir el resultado de un episodio de los simpson utilizando las líneas de guión de alguno de sus personajes. Una idea que puede sonar sugerente es tratar de generar una nueva variable a partir de dos de ellas: la adiencia del episodio y los espectadores que ha tenido este. De esta manera, partimos de la hipótesis de que puede haber epidodios muy bien puntuados pero con alta o baja audiencia, así como episodios mal puntuados con desigual resultado de audiencia. En el script siguiente realizamos distintos experimentos que comentamos con imágenes a continuación:
datos_S<-na.omit(data.frame(FINAL_SIMPSON$imdb_rating,FINAL_SIMPSON$us_viewers_in_millions,FINAL_SIMPSON$sumH,FINAL_SIMPSON$D))
datos_S1<-data.frame(datos_S$FINAL_SIMPSON.imdb_rating,datos_S$FINAL_SIMPSON.us_viewers_in_millions)
install.packages("factoextra")
library(factoextra)
# Primer intento#
kmeans1 <- kmeans(datos_S1, 4, iter.max = 1000, nstart = 50)
fviz_cluster(kmeans, data = datos_S1)
#segundo intento#
datos_S<-scale(datos_S1)
kmeans2 <- kmeans(datos_S1, 4, iter.max = 1000, nstart = 50)
fviz_cluster(kmeans, data = datos_S1)
#tercer intento#
kmeans3 <- kmeans(datos_S1, 3, iter.max = 1000, nstart = 50)
fviz_cluster(kmeans, data = datos_S1)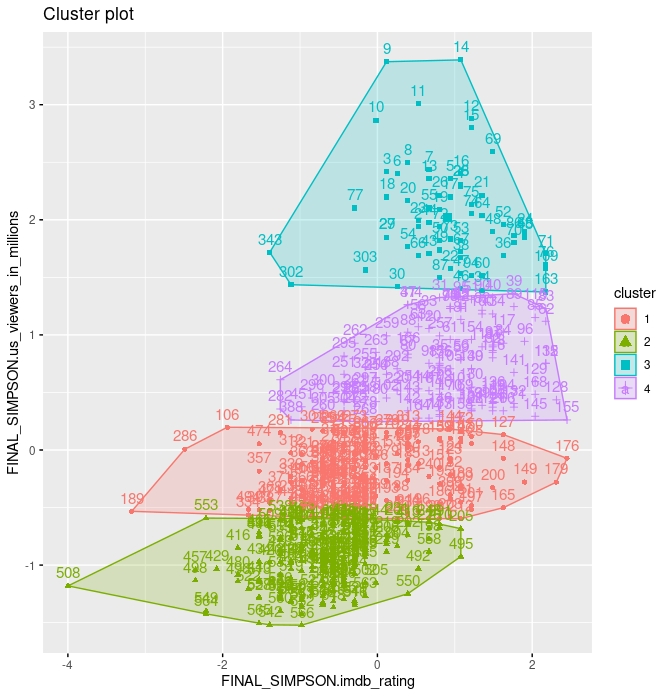
- En este primer intento, hemos pedido hacer cuatro clusters pero, como vemos es la variable de espectadores en millones la que “toma el control” a la hora de discriminar los clusters.
Los centroides, como vemos, apenas si varían para la variable de “rating” mientras que la variable de “espectadores” fluctúa en cada uno de estos clusters.
> kmeans1$centers
FINAL_SIMPSON.imdb_rating FINAL_SIMPSON.us_viewers_in_millions
1 7.275543 10.775217
2 6.925789 6.287579
3 8.074242 24.966212
4 8.012800 16.794720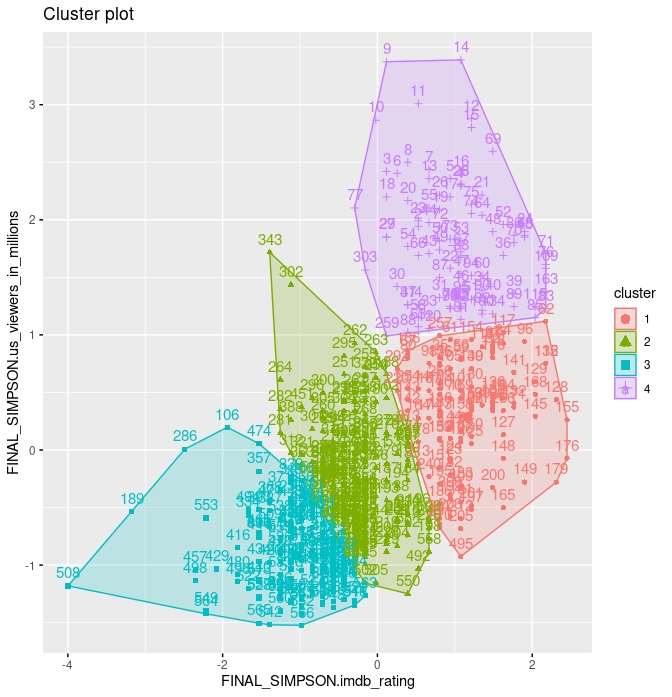 >- En este segundo intento, hemos estandarizado los datos. Ahora, generamos cuatro clusters y parece que ya hay más diferencia en los centroides (compruébelo ejecutando el código). Sin embargo, sin la necesidad de ningún criterio, podemos observar que el cluster 2 no tiene especial significancia. Creemos más sensato tener tres cluster
>- En este segundo intento, hemos estandarizado los datos. Ahora, generamos cuatro clusters y parece que ya hay más diferencia en los centroides (compruébelo ejecutando el código). Sin embargo, sin la necesidad de ningún criterio, podemos observar que el cluster 2 no tiene especial significancia. Creemos más sensato tener tres cluster
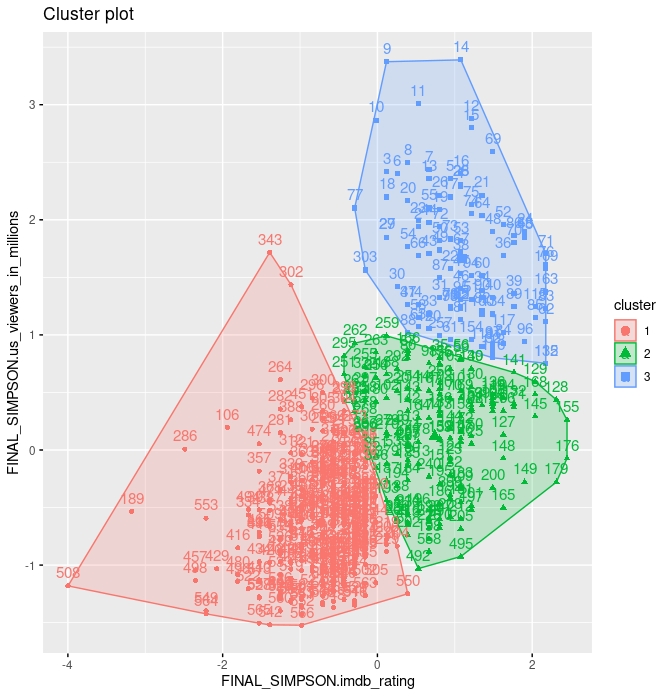
- Este parece ser más exitoso. Por un lado, es fácil ver que el cluster azul representa episodios bien calificados y con alta audiencia. El cluster verde son episodios bien calificados y con baja audiencia y el rojo son los mal calificados y con baja audiencia.
> kmeans3$centers
FINAL_SIMPSON.imdb_rating FINAL_SIMPSON.us_viewers_in_millions
1 0.7400274 0.1177825
2 -0.7350063 -0.6326758
3 1.0920830 1.6630583Los centroides (que están estandarizados) indican, las desviaciones típicas, respecto a la media de cada una de las variables de distancia en cada cluster. Por ejemplo, el cluster 3 se caracteriza por estar, en promedio 1.09 desviaciones típicas de la puntuación promedio y 1.66 desviaciones típicas de la audiencia promedio (en positivo). Lo contrario ocurre en el cluster 2, donde la puntuación está 0.73 desviaciones típicas por debajo del promedio y 0.63 desviaciones típicas por debajo del promedio de audiencia.
A continuación, vamos a generar una nueva variable, a partir de los cluster obtenidos, para tratar de predecirla con la presencia de Homer Simpson en cada episodio. Usaremos un árbol de clasificación para ello.
clasificacion<- as.factor(ifelse(kmeans3$cluster==1, 'Malo',
ifelse(kmeans3$cluster==2, 'Bueno_novisto','Bueno_visto')))
datos_S<-data.frame(datos_S,clasificacion) #añadimos esta nueva variable a la base de datos
tree.v1 <-rpart(clasificacion~FINAL_SIMPSON.sumH+FINAL_SIMPSON.D ,data=datos_S, method="class",control = rpart.control(cp = 0.05))
summary(tree.v1)
rpart.plot(tree.v1)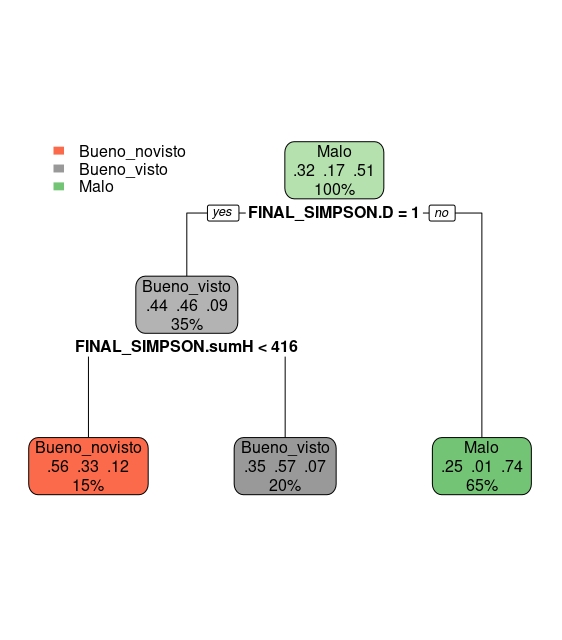 Este sencillo árbol nos permite, directamente, clasificar como episodio “malo” si la variable \(D=0\). Recuerde que, si \(D=0\) está refiriéndose directamente al “bajón” de audiencias que sufrió la serie de manera abrupta a primeros de los 2000. Da igual lo que participe “Homer”, puesto que no interviene en la clasificación del episodio como “malo”. El 65% de los episodios son malos, de acuerdo con nuestra métrica. En cambio, parece que en torno a 416 líneas de guión, en las termporadas de mayor éxito de la serie, podrían marcar la diferencia: si Homer habla más de 416 líneas, el episodio se cataloga como bueno y con audiencia alta. En caso contrario, el episodio será bueno, pero con audiencia baja. Ahora bien:
Este sencillo árbol nos permite, directamente, clasificar como episodio “malo” si la variable \(D=0\). Recuerde que, si \(D=0\) está refiriéndose directamente al “bajón” de audiencias que sufrió la serie de manera abrupta a primeros de los 2000. Da igual lo que participe “Homer”, puesto que no interviene en la clasificación del episodio como “malo”. El 65% de los episodios son malos, de acuerdo con nuestra métrica. En cambio, parece que en torno a 416 líneas de guión, en las termporadas de mayor éxito de la serie, podrían marcar la diferencia: si Homer habla más de 416 líneas, el episodio se cataloga como bueno y con audiencia alta. En caso contrario, el episodio será bueno, pero con audiencia baja. Ahora bien:
- Entrene diferentres árboles con parámetros de control variados para asegurarse de que el árbol es un buen predictor
- Piense si, de nuevo, la intervención de Homer es relevante. ¿No parece, simplemente, cuestión de la temporada, esto es, si D=0, D=1?
- Puede realizar un análisis de validación cruzada con dos árboles: uno que incluya la variable Homer y la temporada (D) y otro que excluya la variable Homer. ¿Predicen de forma muy distinta?
- Otra opción sería realizar exactamente el mismo trabajo pero partiendo la muestra en dos. Ya que asumimos que el comportamiento de la audiencia podría ser muy distinta cuando D=0 que cuando D=1, podría tratar de realizar los cluster en las dos submuestras y replicar el modelo
¡¡Hay muchas opciones posibles que explorar: no se quede en el primer intento o en un análisis superficial!!
Debería ser capaz de hacer todos estos ejercicios usando los scripts disponibles en las clases anteriores: esto puede ser muy útil para su proyecto
“El dendrograma”
Otra manera de busar clusters es, en vez de en el conjunto de observaciones, en el conjunto de variables (es decir, en vez de por filas, por columnas). Para ello, elegiremos la correlación como una medida de “similaridad” de variables. Aunque, obviamente, la correlación sólo mide similaridad de carácter lineal. Es decir: puede haber relaciones entre variables que este método no capte. Aunque lo usaremos, en general, por su sencillez y flexibilidad.
Suponga que tiene un conjunto de datos, con cinco variables (V1,V2,V3,V4,V5) del que obtiene su matriz de correlaciones, como se ve en la FIG 1, parte 1
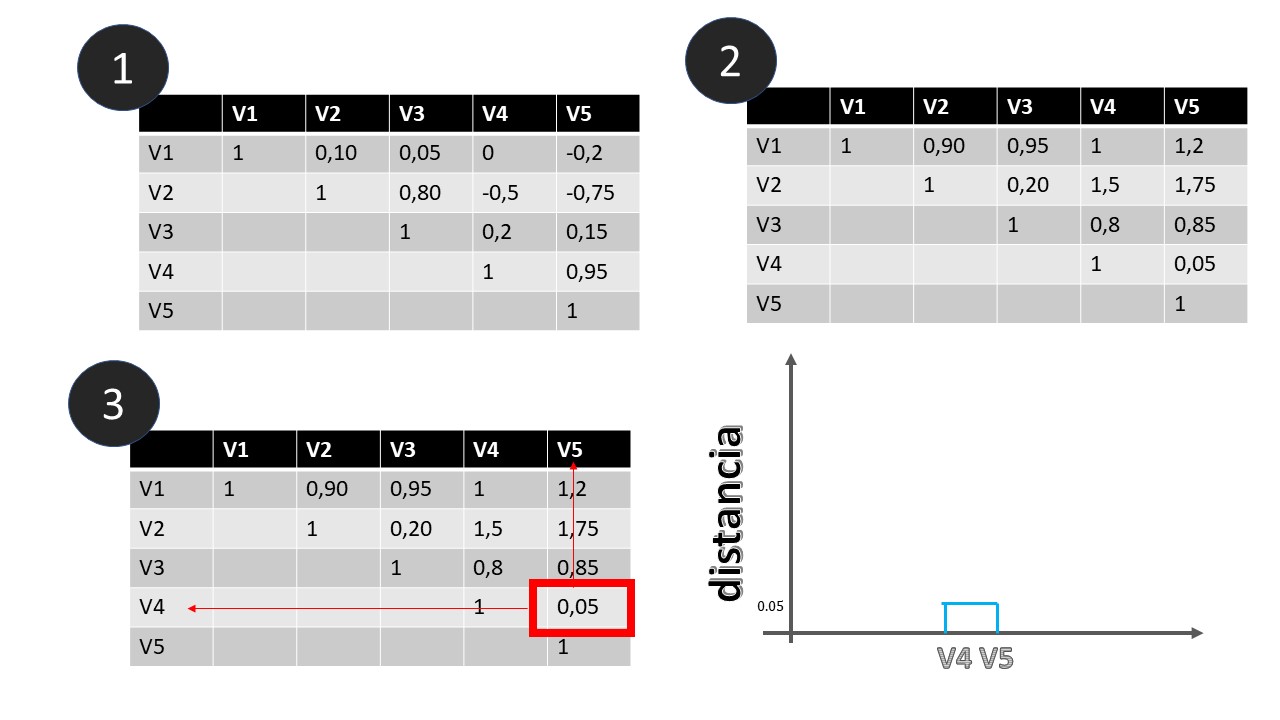
- En el punto (1), se muestra la matriz de correlaciones. En este caso, interpretaremos las correlaciones POSITIVAS y ALTAS como variables que están cerca y NEGATIVAS y ALTAS variables que están muy lejos. Como queremos una medida de distancia-positiva- que recoja esta idea, podemos utilizar \(d_{i,j}=1-\rho_{i,j}\), es decir, la distancia entre la variable \(i\) y la variable \(j\) consistirá en 1 menos la correlación.
- En el punto (2) se obtienen dichas distancias.
- Empecemos eligiendo el par de variables que tienen menor distancia que son V4 y V5. Las unimos en un gráfico que llamaremos dendrograma (no “dendograma”) y que se construye indicando, en el eje de ordenadas, dicha distancia. El eje de abcisas es “mudo”.
Ahora, pasemos a la FIG2
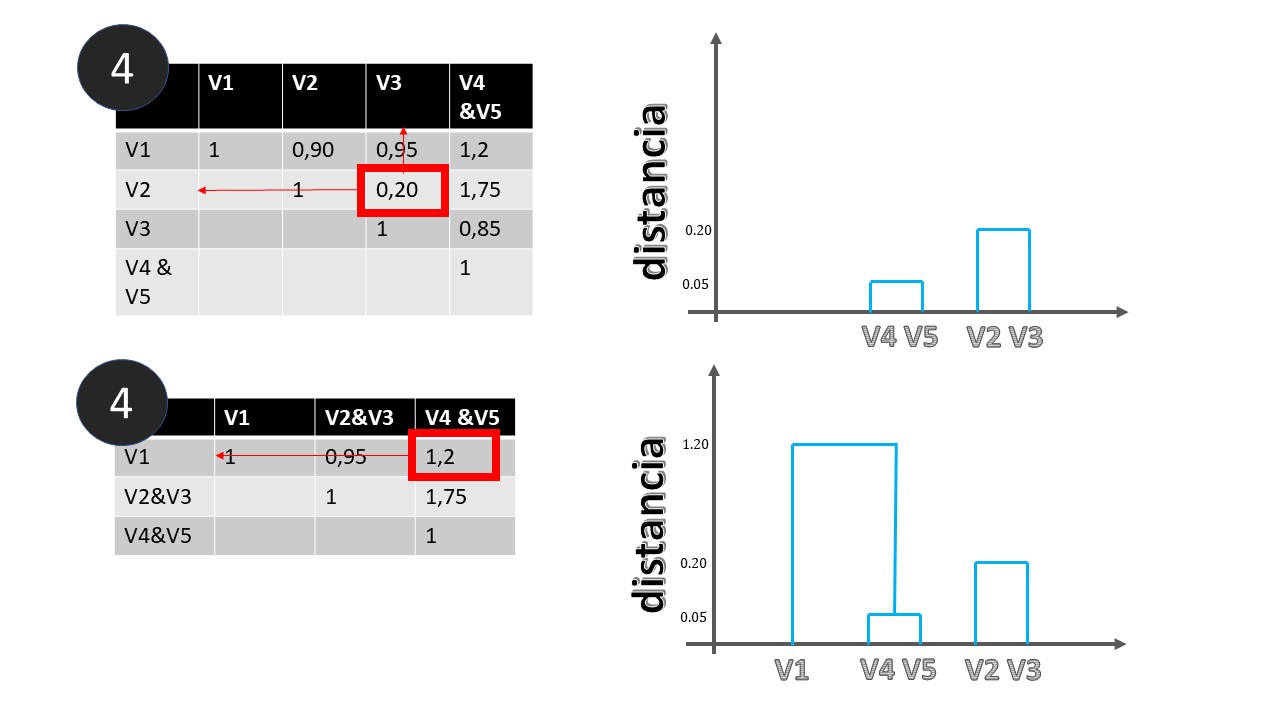
- En el punto (4) hemos creado una nueva categoría que es la unión de la variable 4 y la 5 y obtenemos las distancias del resto de variables a esta nueva categoría. Se coge la mayor de entre las dos posibles. Ahora la menor distancia es entre V2 y V3 y hacemos la correspondiente marca en el dendrograma.
- En el punto (5) hemos creado el nuevo grupo y recalculamos distancias hasta que, finalmente, llegamos al último punto
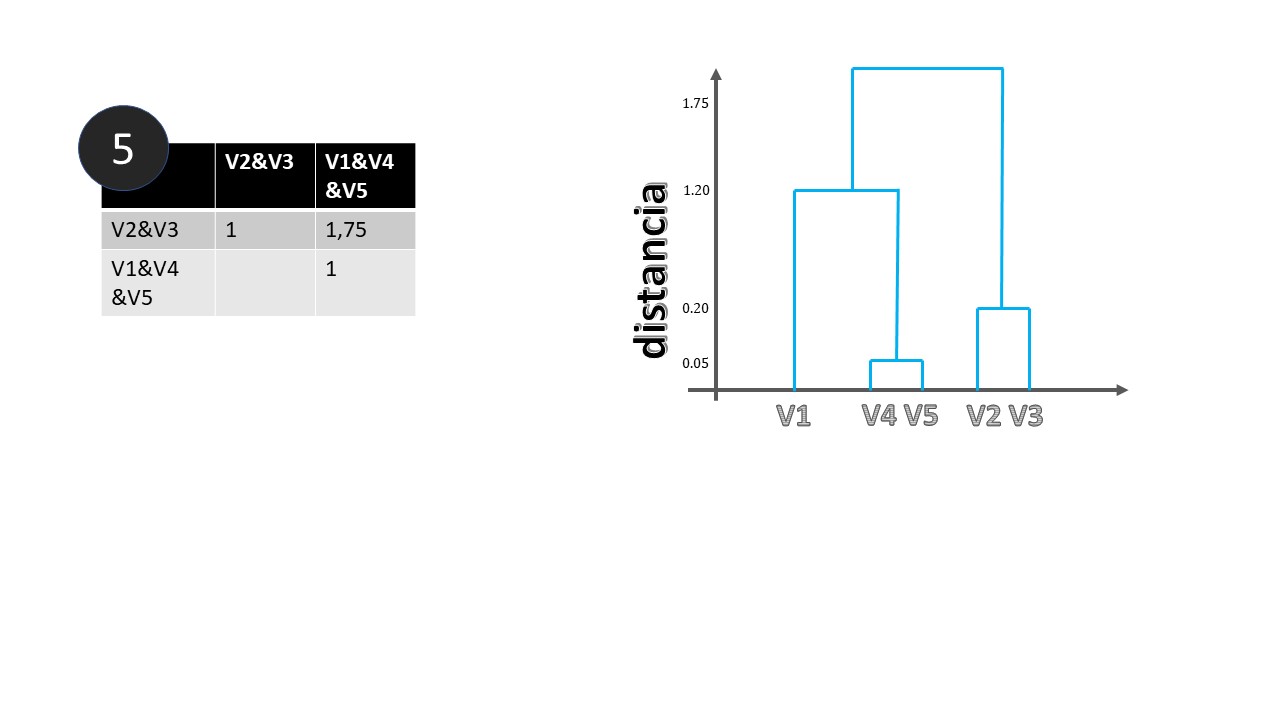
Este gráfico nos permite agrupar las variables de forma jerárquica. Por ejemplo, si queremos hacer dos grupos, el gráfico nos dice, claramente, que uno de ellos estará formado por las variables V1,V4 y V5 y el otro por V2 y V3. Si quisiéramos hacer tres grupos, entonces, uno de ellos sería el formado por V1, el otro por V4 y V5 y el último por V2 y V3. Y así sucesivamente, descendiendo de manera imaginaria en el eje de ordenadas.
Es fácil obtener el dendrograma para los datos de los Simpson. Mediante este script y la función “hclust”
Homer<-(SIMPSONS$Homer)
Bart<-(SIMPSONS$Bart)
Lisa<-(SIMPSONS$Lisa)
Marge<-(SIMPSONS$Marge)
Apu<-SIMPSONS$Apu
Flanders<-SIMPSONS$Flanders
Krusty<- SIMPSONS$Krusty
Milhause<-SIMPSONS$Milhause
SIMPSONS_char<-data.frame(Homer,Bart,Lisa,Marge,Apu,Flanders,Krusty,Milhause)
dd <- as.dist((1 - cor(SIMPSONS_char)))
round(1000 * dd)
plot(hclust(dd))llegamos a la FIG 4, donde se pueden ver distintas agrupaciones posibles:
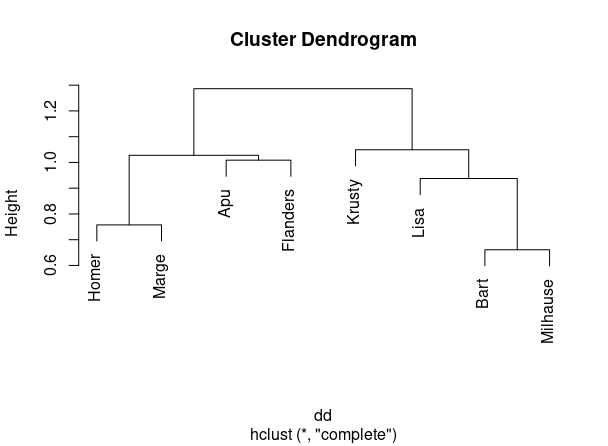 Si queremos:
Si queremos:
- Dos cluster: Homer+Marge+Apu+Flanders y Krusty+Lista+Bart+Milhause
- Tres cluster: Homer+Marge y Apu+Flanders y Krusty+Lista+Bart+Milhause
- Cuatro cluster: Homer+Marge, Apu+Flanders, Krusty, Lisa+Bart+Milhause
y así, sucesivamente.
Ejercicio de interés ¿Pueden estas asociaciones de personajes explicar los resultados de los cluster de episodios?
Clase 2: Componentes Principales
El análisis de componentes principales tiene una clara idea geométrica basada en un concepto clave: la proyección ortogonal. Primero, explicaremos visualmente la idea de proyección ortogonal para, a continuación, ir usando esas ideas con el objetivo de entender el método. La forma de desarrollarlo estará basada en intuiciones para, al final, disponer de un apéndice que le permita entender, con algo más de profundidad (si está interesado), las expresiones que se utilizan en el texto principal.
NOTA!
Aquí empieza la parte que no se verá en la explicación de clase, pero es importante interiorizar para entenderlo
Algunas ideas de álgebra y geometría
Las ideas que aquí se cuentan son, en realidad, un ejemplo gráfico y divulgativo. De esta manera, tanto los conceptos centrales de proyección ortogonal y de diagonalización de matrices, se enuncian de forma aplicada y se anima al lector/a que acuda a un texto de matemáticas (si tiene más interés en asentar esas ideas). Un buen texto es “Álgebra Lineal y sus Aplicaciones” de David C. Lay.
- Vector. La definición típica de vector es “un segmento de recta orientado”. Por ejemplo, el vector \(\overrightarrow{x}=\left[\begin{array}{c} 1\\ 2 \end{array}\right]\) nos dice que tenemos que orientarnos dado un paso en sentido el eje \(x\) (es decir, a la derecha) y dando dos pasos en sentido del eje \(y\) (es decir, hacia arriba). Sin embargo, el vector no dice nada de dónde debemos empezar, esto es, el punto de aplicación: todos estos vectores son el mismo:
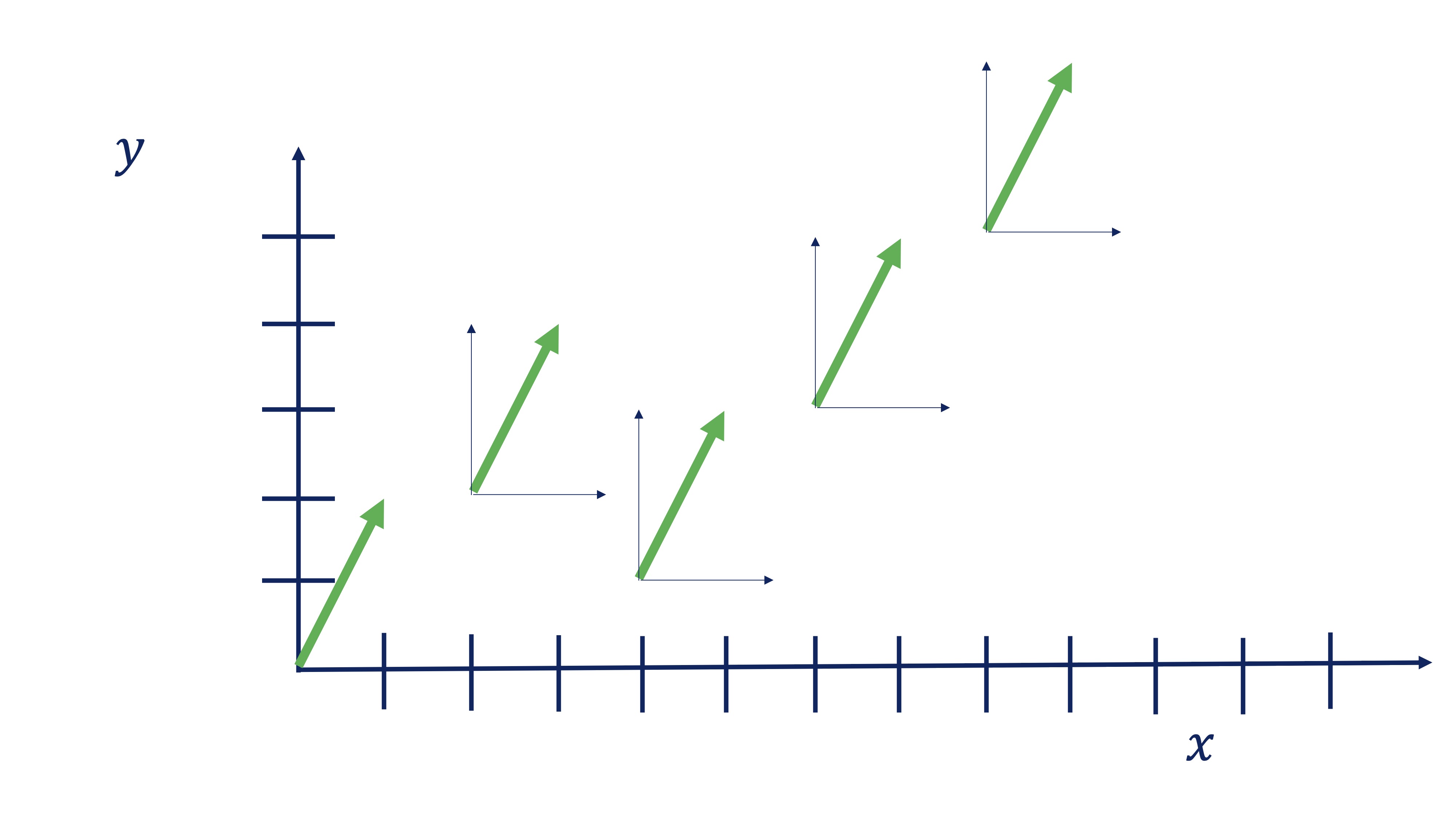
La definición de segmento de recta orientado, quizás no le permita hacerse una idea de para qué usará los vectores. En nuestro caso, un vector será un almacenador de información. De hecho, el ojo humano suele “vectorizar” el análisis de datos. Mire, si no, el precio de la acción de Coca-Cola:
Como puede ver, nuestro ojo no está preparado para procesar todas las pequeñas discrepancias de la evolución de los datos. Seguro que prefiere tener una idea más general de los movimientos de la bolsa usando esas flechitas que llamamos vectores.
Por ejemplo, si almacenamos en un vector, \(\overrightarrow{v}\) la siguiente información sobre el precio de las acciones de Coca Cola:
\[ \overrightarrow{v}=\left[\begin{array}{cc} \#meses, & variaci\acute{o}n\:precio\end{array}\right], \]
tendremos algo así:
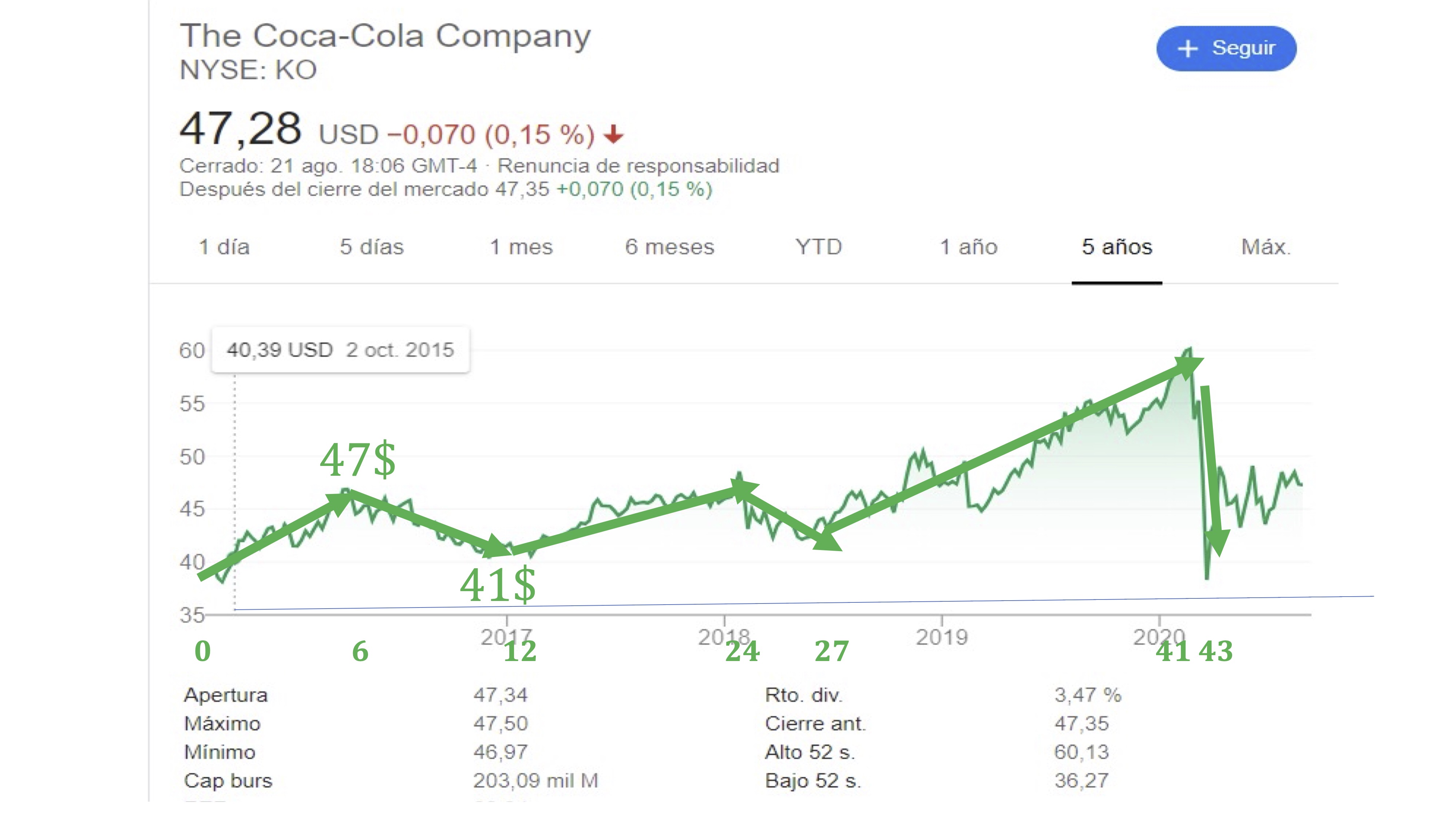
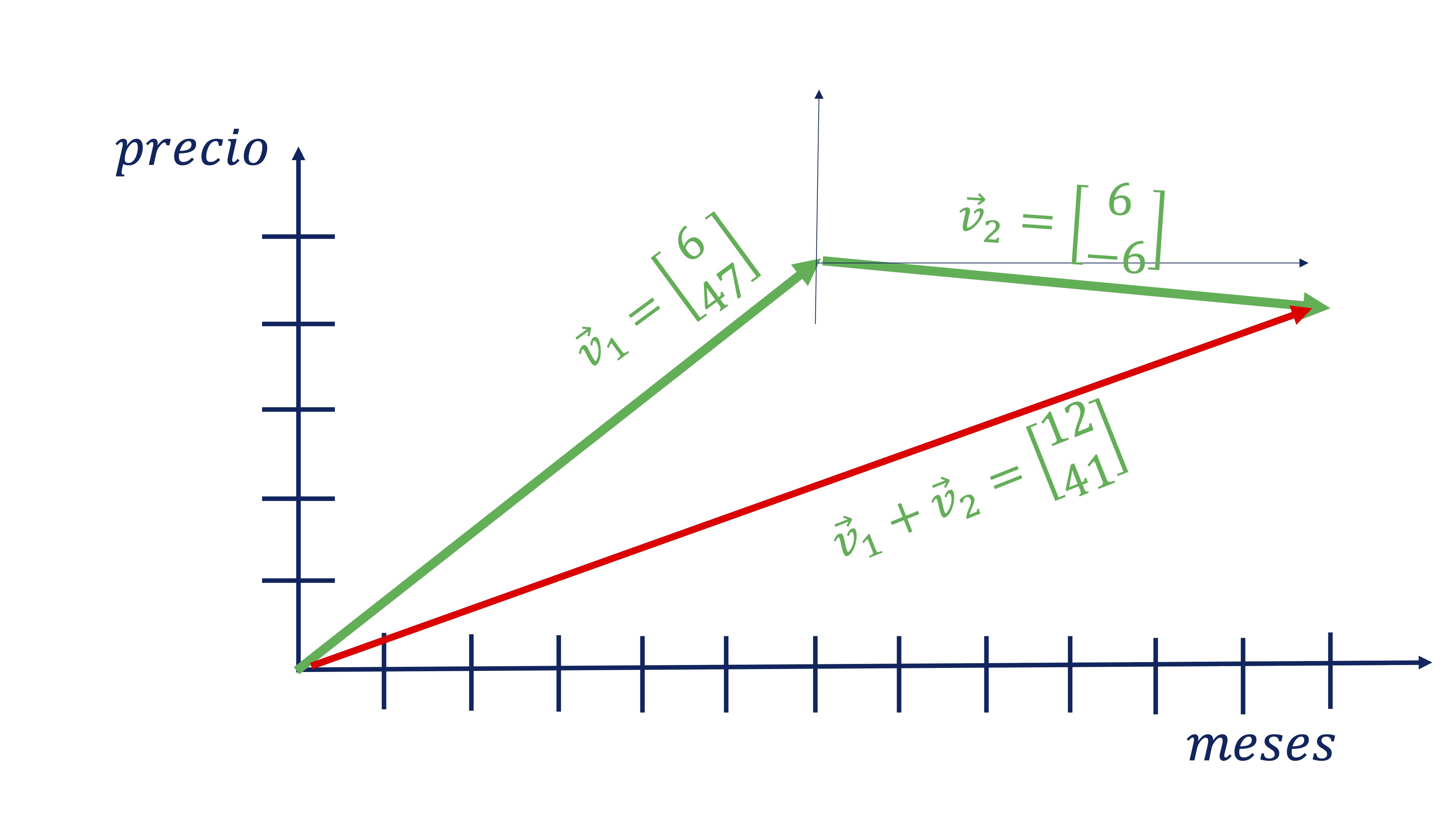 Donde, además, la suma de los dos vectores tiene sentido ya que nos
da en el primer componente el tiempo que ha pasado y en el segundo
el precio en dicho momento (vector rojo).
Donde, además, la suma de los dos vectores tiene sentido ya que nos
da en el primer componente el tiempo que ha pasado y en el segundo
el precio en dicho momento (vector rojo).
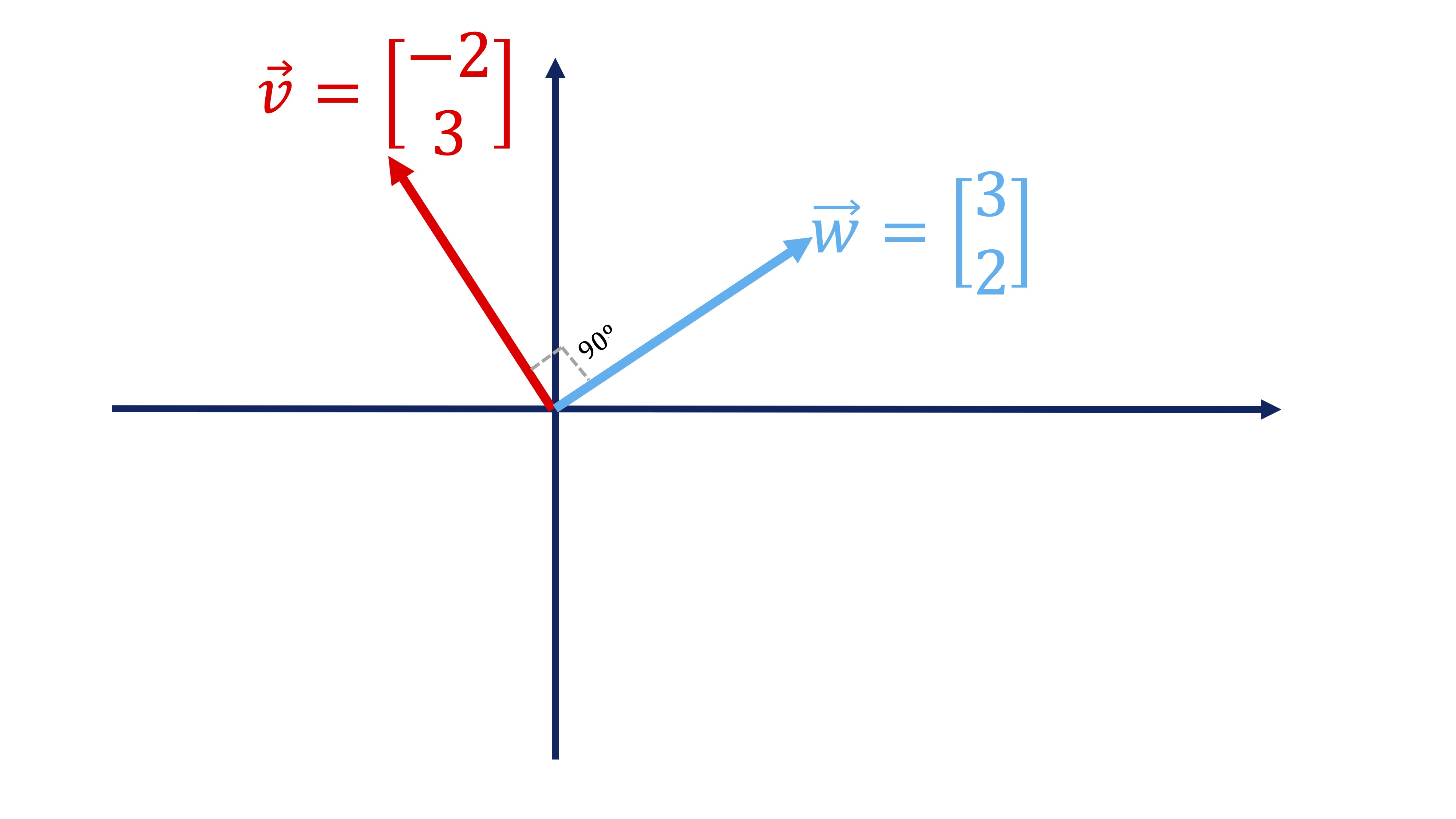
Recuerde que, en general, denotamos un vector como \(\overrightarrow{v}\) (la flecha superior indica que es un vector) y ponemos sus componentes en columna: \(\overrightarrow{v}=\left[\begin{array}{c} -2\\ 3 \end{array}\right]\). Además, recuerde que si quiere tener el vector como una fila, lo ha de trasponer: \(\overrightarrow{v}^{T}=\left[\begin{array}{cc} -2 & 3\end{array}\right]\), usando la letra \(T\) en el exponente para indicarlo. Si tenemos otro vector \(\overrightarrow{w}=\left[\begin{array}{c} 3\\ 2 \end{array}\right]\), definimos el producto escalar de ambos vectores como:
\[ \overrightarrow{v}^{t}\overrightarrow{w}=\left[\begin{array}{cc} -2 & 3\end{array}\right]\left[\begin{array}{c} 3\\ 2 \end{array}\right]=(-2\times3)+(3\times2)=0 \]
(como ve, se define “producto escalar” porque al multiplicarlos obtenemos siempre un número-un escalar). Como en nuestro caso, si el producto escalar de dos vectores es 0, eso indica que son perpendiculares (es decir, conforman un ángulo de 90º). Los dibujamos para que vea que, efectivamente, ocurre:
-Matriz Respecto a una matriz, puede verla como una generalización de la idea de vector. Sigue siendo un buen almacén de información que, en este caso, es como si estuviera formada por un montón de vectores apilados. Por ejemplo, esta matriz guarda en columnas el número de observación (id), los meses, y la variación del precio (\(\Delta precio\)):
| Id | Meses | \(\Delta precio\) |
|---|---|---|
| 1 | 6 | 47 |
| 2 | 6 | -6 |
| … | … | … |
Es decir,
\[ X=\left[\begin{array}{ccc} 1 & 6 & 47\\ 2 & 6 & -6 \end{array}\right], \]
esta matriz decimos que es de dimensión \(2\times3\), ya que tiene 2 filas y 3 columnas. De manera más formal, se puede escribir así: \(X\in\mathcal{M}_{2\times3}\), que indica que \(X\) pertenece al espacio de las matrices de dimensión \(2\times3.\)
Recuerde que para que dos matrices puedan multiplicarse se debe poder realizar el producto escalar, visto anteriormente con los vectores, para cada fila y columna. Es decir, \(X=\left[\begin{array}{cc} 1 & 0\\ 3 & 1\\ 5 & 2 \end{array}\right]\), \(Y=\left[\begin{array}{cc} 1 & 2\\ 0 & 1 \end{array}\right]\), pueden multiplicarse así \(XY\) porque el número de columnas de la primera matriz es igual al número de filas de la segunda, pero no pueden multiplicarse así: \(YX\):
\[ XY=\left[\begin{array}{cc} 1 & 0\\ 3 & 1\\ 5 & 2 \end{array}\right]\left[\begin{array}{cc} 1 & 2\\ 0 & 1 \end{array}\right]=\left[\begin{array}{cc} 1 & 2\\ 3 & 7\\ 5 & 12 \end{array}\right] \]
\[ YX=\left[\begin{array}{cc} 1 & 2\\ 0 & 1 \end{array}\right]\left[\begin{array}{cc} 1 & 0\\ 3 & 1\\ 5 & 2 \end{array}\right]=? \]
- MATRIZ DE VARIANZAS Y COVARIANZAS. Una aplicación del producto de matrices, que encontrará habitualmente, es la matriz de varianzas y covarianzas. Recuerde que la varianza de una variable es \(var(x)=\frac{\sum_{i=1}^{n}(x_{i}-\bar{x})^{2}}{n-1}\) y la covarianza entre dos variables es \(cov(x,y)=\frac{\sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{n-1}\) y podemos construir una matriz con esa información:
\[\begin{equation} C=\left[\begin{array}{cc} var(x) & cov(x,y)\\ cov(x,y) & var(y) \end{array}\right]\label{eq:matrizC} \end{equation}\]
(dese cuenta de que es una matriz simétrica). \(C\) se puede obtener con cálculos más rápidos mediante operaciones con matrices. Vamos a imaginar que la \(X\) es ahora nuestra matriz de datos, donde la columna 1 es la variable \(x\) y la columna 2 es la variable \(y\), de tal forma que las filas son las observaciones por individuos:
| Id | \(x\) | \(y\) |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 3 | 1 |
| 3 | 5 | 2 |
para poder seguir con la fórmula, vamos a transformar la matriz y le vamos a restar a cada columna su media:
| Id | \(x-\bar{x}\) | \(y-\bar{y}\) |
|---|---|---|
| 1 | -2 | -1 |
| 2 | 0 | 0 |
| 3 | 2 | 1 |
de tal forma que tenemos que \(\widetilde{X}=\left[\begin{array}{cc} -2 & -1\\ 0 & 0\\ 2 & 1 \end{array}\right]\) es la matriz \(X\) donde le hemos restado las medias (se dice que es la matriz \(X\) en desviaciones con respecto a sus medias). Si ahora hacemos esta cuenta:
\[ \frac{1}{n-1}\widetilde{X}^{t}\widetilde{X}=\frac{1}{3}\left[\begin{array}{ccc} -2 & 0 & 2\\ -1 & 0 & 1 \end{array}\right]\left[\begin{array}{cc} -2 & -1\\ 0 & 0\\ 2 & 1 \end{array}\right]=\frac{1}{2}\left[\begin{array}{cc} 8 & 4\\ 4 & 2 \end{array}\right]=\left[\begin{array}{cc} 4 & 2\\ 2 & 1 \end{array}\right] \]
donde \(N\) representa el número de elementos muestrales, nos proporciona la matriz de varianzas y covarianzas.
x1<-c(1,3,5)
x2<-c(0,1,2)
X<-data.frame(x1,x2)
C<-cov(X)
#equivalente a hacer
x1<-x1-mean(x1)
x2<-x2-mean(x2)
X<-as.matrix(data.frame(x1,x2))
C<-(1/(dim(X)[1]-1))*(t(X))%*%XPor lo tanto, concluímos que:
- Una matriz \(W\) cuyas filas son observaciones por individuo y las columnas son variables, si está expresada en desviaciones con respecto a la media, su matriz de varianzas y covarianzas resulta ser:
Ejercicio: pruebe que si las variables están estandarizadas (es decir los elementos de \(W\) no sólo están desviados con respecto a la media, sino que se los divide por su desviación típica), al hacer \(\frac{1}{N-1}W^{t}W,\) lo que obtenemos es la matriz de correlaciones.
La noción de proyección ortogonal
Otra de las preguntas de interés en álgebra son las que están relacionadas con la proyección ortogonal. Aquí vamos a ver un ejemplo sencillo, con el que trabajaremos a mano. Pero antes, necesitamos saber qué es un vector proporcional a otro. Diremos que un vector \(\overrightarrow{w}\) es proporcional a otro \(\overrightarrow{v}\) (y se escribe con esta notación \(\overrightarrow{w}\propto\overrightarrow{v},\) leyéndose \(\propto\) como “es proporcional a”) si se cumple que:
\[ \overrightarrow{w}=\lambda\overrightarrow{v}, \]
con \(\lambda\in\mathbb{R}.\) En la figura siguiente, tiene un ejemplo donde -una manera de verlo- el vector \(\overrightarrow{v}_{2}\propto\overrightarrow{v}_{1}\), con \(\lambda=2\), indicando que siguen la misma dirección y sentido, solo que \(\overrightarrow{v}_{2}\) es más grande. \(\overrightarrow{v}_{3}\propto\overrightarrow{v}_{1}\), con \(\lambda=-1/2\), indicando que siguen la misma dirección y sentido contrario (y es más pequeño). Como ve, los vectores proporcionales comparten dirección.
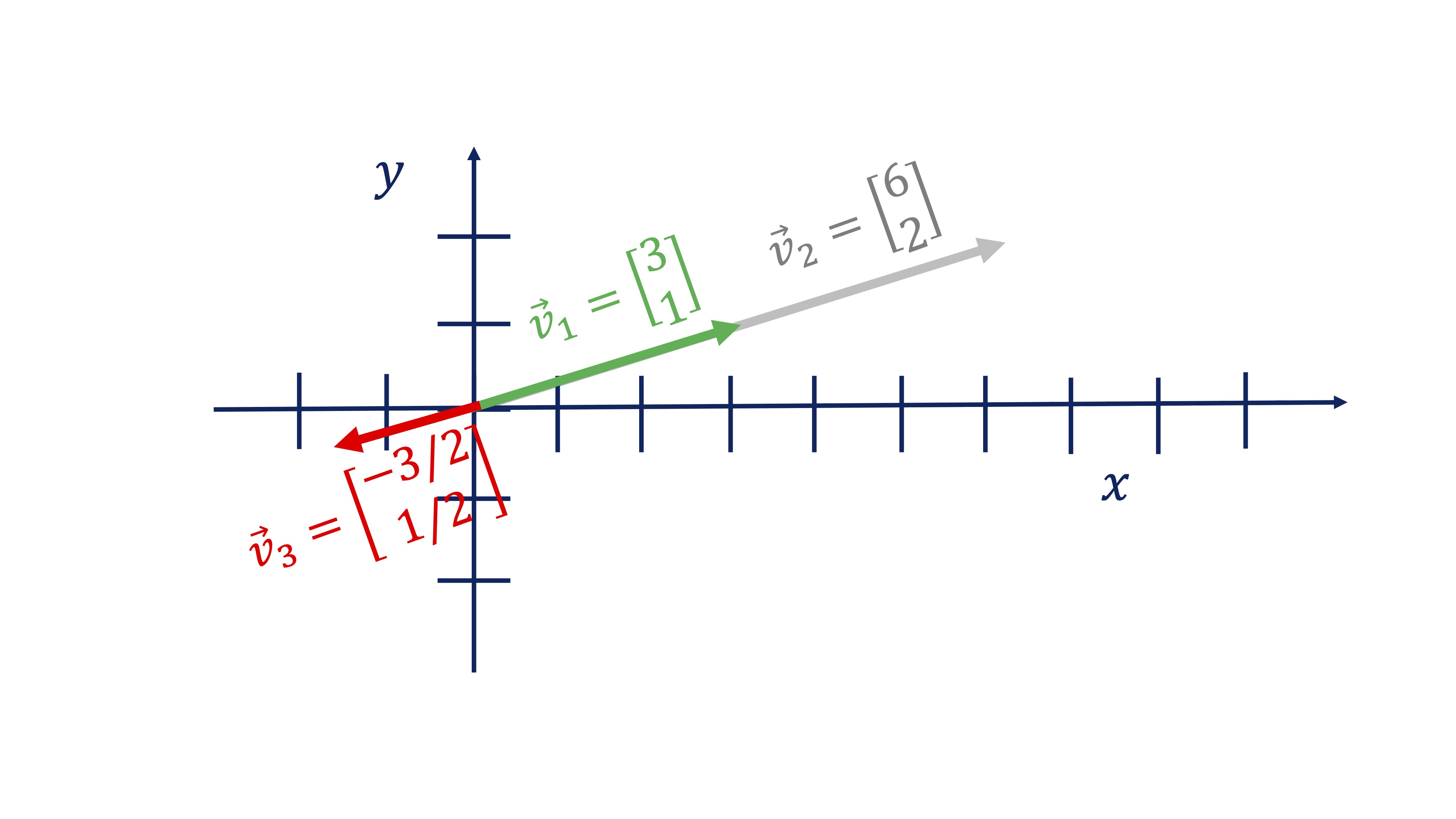
La idea de proyección ortogonal necesita tnener clara la de vector proporcional. De hecho, la idea de proyectar el vector \(\overrightarrow{w}\) sobre el vector \(\overrightarrow{v}\) consiste en lo siguiente:
**buscar un vector proporcional a \(\overrightarrow{v}\) que esté lo más cerca posible de \(\overrightarrow{w}:\)
Piense que hay infinitos vectores proporcionales a \(\overrightarrow{v}\) pero sólo uno de estos será el más cercano a \(\overrightarrow{w}.\) ¿Cuál cree que es en la figura siguiente?
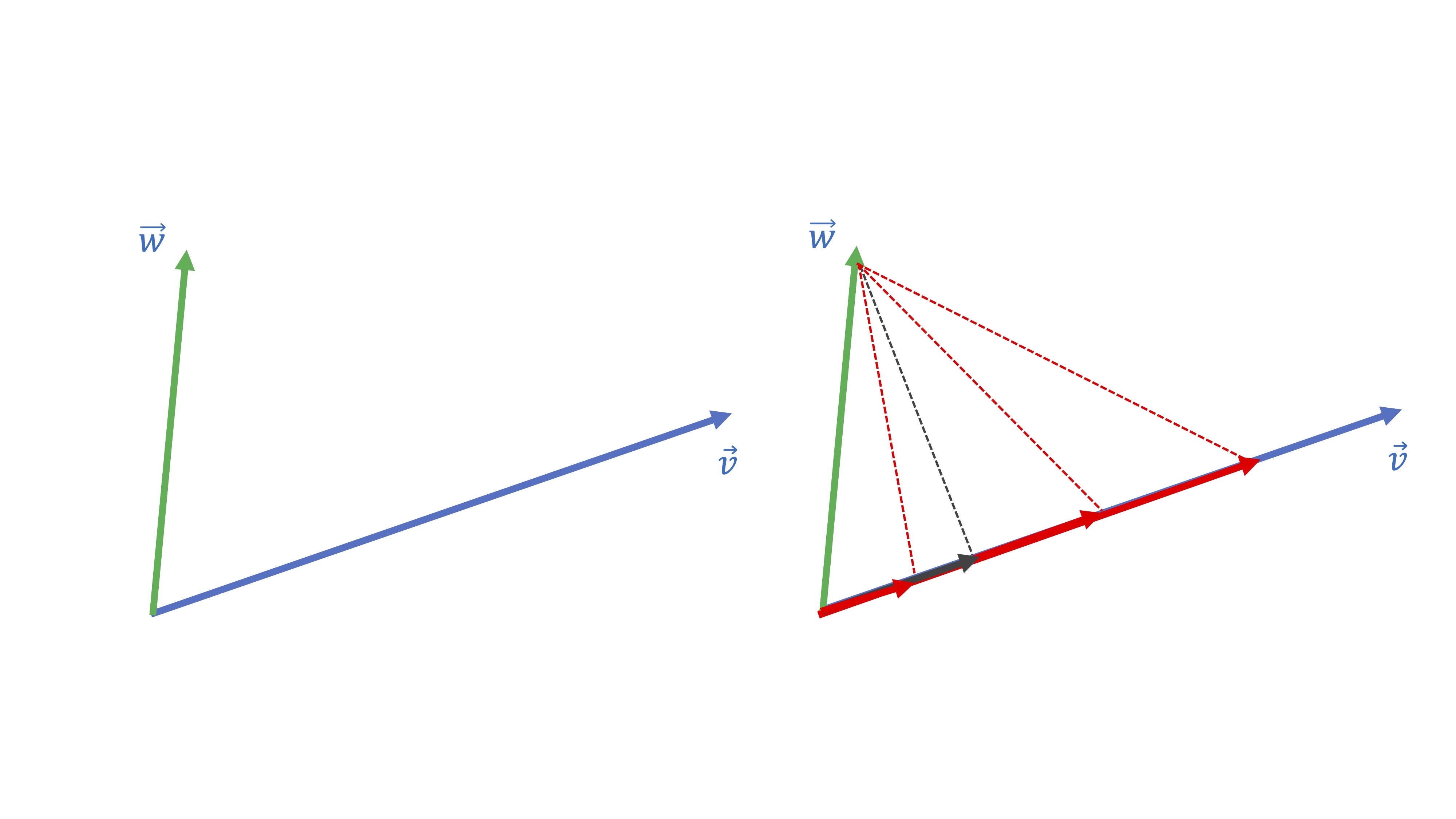
Seguramente, habrá caído en la cuenta de que el más cercano es el gris:
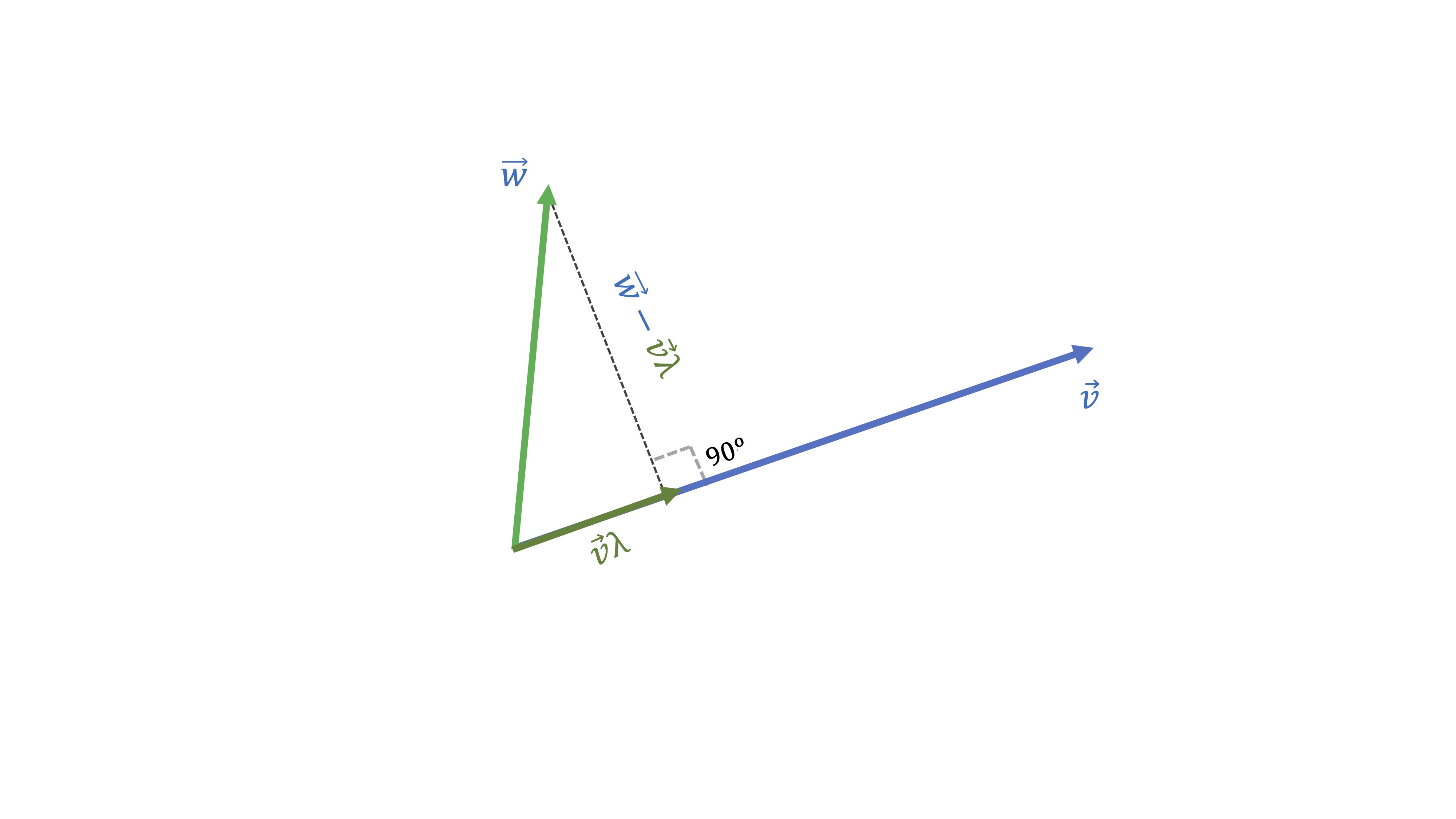
Nuestro objetivo será encontrar qué vector proporcional a \(\overrightarrow{v}\) (es decir, \(\overrightarrow{v}\lambda\), donde \(\lambda\) es un escalar) está más cerca de \(\overrightarrow{w}.\) Ese “más cerca” quiere decir que la distancia entre los dos vectores sea la mínima posible. Como puede ver, esa es la distancia que genera el segmento ortogonal al vector \(\overrightarrow{v}\). Como ya hemos dicho, han de ser ortogonales, es decir, han de cumplir:
\[ \left(\overrightarrow{w}-\overrightarrow{v}\lambda\right)^{t}\overrightarrow{v}=0\Rightarrow\lambda=\frac{\overrightarrow{w}^{t}\overrightarrow{v}}{\overrightarrow{v}^{t}\overrightarrow{v}} \]
Veamos un ejemplo “a mano”.
- Si queremos proyectar el vector \(\overrightarrow{w}=\left[\begin{array}{c} 3\\ 1 \end{array}\right]\) sobre el vector \(\overrightarrow{v}=\left[\begin{array}{c} 1\\ 0 \end{array}\right]\), tendremos que
\[ \lambda=\frac{\overrightarrow{w}\cdot\overrightarrow{v}}{\overrightarrow{v}\cdot\overrightarrow{v}}=\frac{\left[\begin{array}{cc} 3 & 1\end{array}\right]\left[\begin{array}{c} 1\\ 0 \end{array}\right]}{\left[\begin{array}{cc} 1 & 0\end{array}\right]\left[\begin{array}{c} 1\\ 0 \end{array}\right]}=\frac{3}{1}=3 \]
Por lo que el vector más parecido a \(\overrightarrow{w}=\left[\begin{array}{c} 3\\ 1 \end{array}\right]\) pero que es proporcional a \(\overrightarrow{v}=\left[\begin{array}{c} 1\\ 0 \end{array}\right]\) es \(3\overrightarrow{v}=\left[\begin{array}{c} 3\\ 0 \end{array}\right]\). Dibújelo para cercionarse.
Autovalores y autovectores
Ya estamos terminando de la parte introductoria de álgebra. Nos queda, eso sí, justo lo más necesario para poder entender la idea de los componentes principales. Ciertas matrices cuadradas tienen una propiedad muy utilizada y muy famosa en álgebra: se dice que son diagonalizables si, por ejemplo, la matriz \(X=\left(\begin{array}{ccc} 1 & 2 & 3\\ 6 & 0 & 0\\ 2 & 2 & 2 \end{array}\right)\), admite esta descomposición:
\[ \left(\begin{array}{ccc} 1 & 2 & 3\\ 6 & 0 & 0\\ 2 & 2 & 2 \end{array}\right)\left(\begin{array}{c} -0.57\\ -0.57\\ -0.57 \end{array}\right)=6\left(\begin{array}{c} -0.57\\ -0.57\\ -0.57 \end{array}\right) \]
Cuando esto ocurre, lo que tenemos es \[ X\overrightarrow{v}=\lambda\overrightarrow{v}, \]
donde \(\overrightarrow{v}\) se denomina autovector y \(\lambda\) autovalor. De hecho, esta matriz, \(X\) va a tener tres autovalores (y sus correspondientes autovectores) no necesariamente distintos. Para calcularlos, vamos a usar R.
X<-matrix(c(1,2,3,6,0,0,2,2,2),3,3,byrow=TRUE)
ev<-eigen(X)
#donde ev nos proporciona los resultados que buscamos
eigen() decomposition
$values
[1] 6 -2 -1
$vectors
[,1] [,2] [,3]
[1,] -0.5773503 -0.3015113 0.1441708
[2,] -0.5773503 0.9045340 -0.8650248
[3,] -0.5773503 -0.3015113 0.4805693Llegamos, entonces, al resultado que decíamos
\[ \left(\begin{array}{ccc} 1 & 2 & 3\\ 6 & 0 & 0\\ 2 & 2 & 2 \end{array}\right)\left(\begin{array}{c} -0.57\\ -0.57\\ -0.57 \end{array}\right)=6\left(\begin{array}{c} -0.57\\ -0.57\\ -0.57 \end{array}\right),\]
\[ \left(\begin{array}{ccc} 1 & 2 & 3\\ 6 & 0 & 0\\ 2 & 2 & 2 \end{array}\right)\left(\begin{array}{c} -0.30\\ 0.90\\ -0.30 \end{array}\right)=\left(\begin{array}{c} 0.30\\ -0.90\\ 0.30 \end{array}\right),\left(\begin{array}{ccc} 1 & 2 & 3\\ 6 & 0 & 0\\ 2 & 2 & 2 \end{array}\right)\left(\begin{array}{c} 0.14\\ 0.86\\ 0.48 \end{array}\right)=-2\left(\begin{array}{c} 0.14\\ 0.86\\ 0.48 \end{array}\right) \]
¿Cualquier matriz cuadrada admite esta descomposición?. No toda matriz cuadrada es diagonalizable: sin embargo, las que vamos a utilizar en este contexto (que, en esencia, serán matrices de varianzas y covarianzas y de correlaciones) sí admiten esta descomposición por ser simétricas. Además,
- La suma de los autovalores es igual a la suma de los elementos de la diagonal principal de la matriz
- Los autovectores son perpendiculares. Esto implica que la correlación entre ellos es cero
NOTA!
Hasta aquí acaba la parte que no se verá en la explicación
El método de los componentes principales (PCA)
Ya es momento de entender en qué consiste el método de “componentes principales”. Para ello, necesitaremos acudir a la proyección ortogonal y a la descomposición en autovalores y autovectores de una matriz simétrica.
Partimos de una nube de puntos
Vamos a dibujar esta matriz de datos,
| Id | \(x\) | \(y\) |
|---|---|---|
| 1 | 4.5 | 3 |
| 2 | 1 | -1 |
| 3 | -1 | -2 |
| 4 | -3 | -1.5 |
| 5 | -1.5 | 1.5 |
| 6 | 0 | 0 |
donde contamos con \(6\) observaciones y dos variables \((x,y)\), en una nube de puntos.
Como ve, estos puntos tienen una cierta relación lineal (es decir, un valor alto del coeficiente de correlación). La idea de los componentes principales consiste en pensar lo siguiente:
Si las variables son parecidas (tienen una correlación alta) quisiera intentar quedarme con una combinación de las dos y así pasar de tener dos variables a tener una
Es decir, idea lo que busca es reducir la dimensión (en columnas) de un conjunto de datos con un cierto número de variables relacionadas entre sí. En resumen, el objetivo de PCA, será el siguiente:
análisis de Componentes Principales!
Reducir el número de variables \(m\) de un conjunto de datos a un número \(k\) tal que \(k<<m\).
Para ello nació el análisis de componentes principales
Como hemos visto, sólo en casos muy concretos es sensato utilizar el promedio como un “reductor” de la dimensión de nuestra información disponible. En realidad, si seguimos trabajando en este caso con información bidimensional, nos interesará proyectar los puntos sobre una recta (como hicimos antes con el promedio) pero que tenga, en general unos “pesos” para cada variable, elegidos mediante algún criterio sensato.
Entonces nos preguntamos: ¿Cómo buscar los valores \(C1,a1\) en esta expresión?
\[ C1_{i}=a1_{1}x_{i}+a1_{2}y_{i} \]
donde \(a1_{1},a1_{2}\) son los pesos asociados a cada variable, los cuales nos permitirán resumir lo mejor posible la información conjunta de las variables \(x,y\) en una nueva variable que llamaremos \(C1\)? Lo que vamos a hacer aquí lo contaremos de una manera sencilla (pensando sobre un gráfico) aunque en el apéndice se desarrolla el álgebra necesaria para entenderlo todo. Tenemos que buscar una recta sobre la que proyectar los puntos de tal forma que esos puntos estén lo más cerca posible a la recta. Seguro que ya ha averiguado que aquí:
buscamos una proyección ortogonal.
Vamos a imaginarnos, entonces, que somos capaces de encontrar una recta que nos permita realizar la proyección ortogonal de todos los puntos a esa recta (y que nos permite, entonces, pasar de \(\mathbb{R}^{2}\rightarrow\mathbb{R}\)). Usando, por ahora, la imaginación, nos podríamos acercar a algo así:
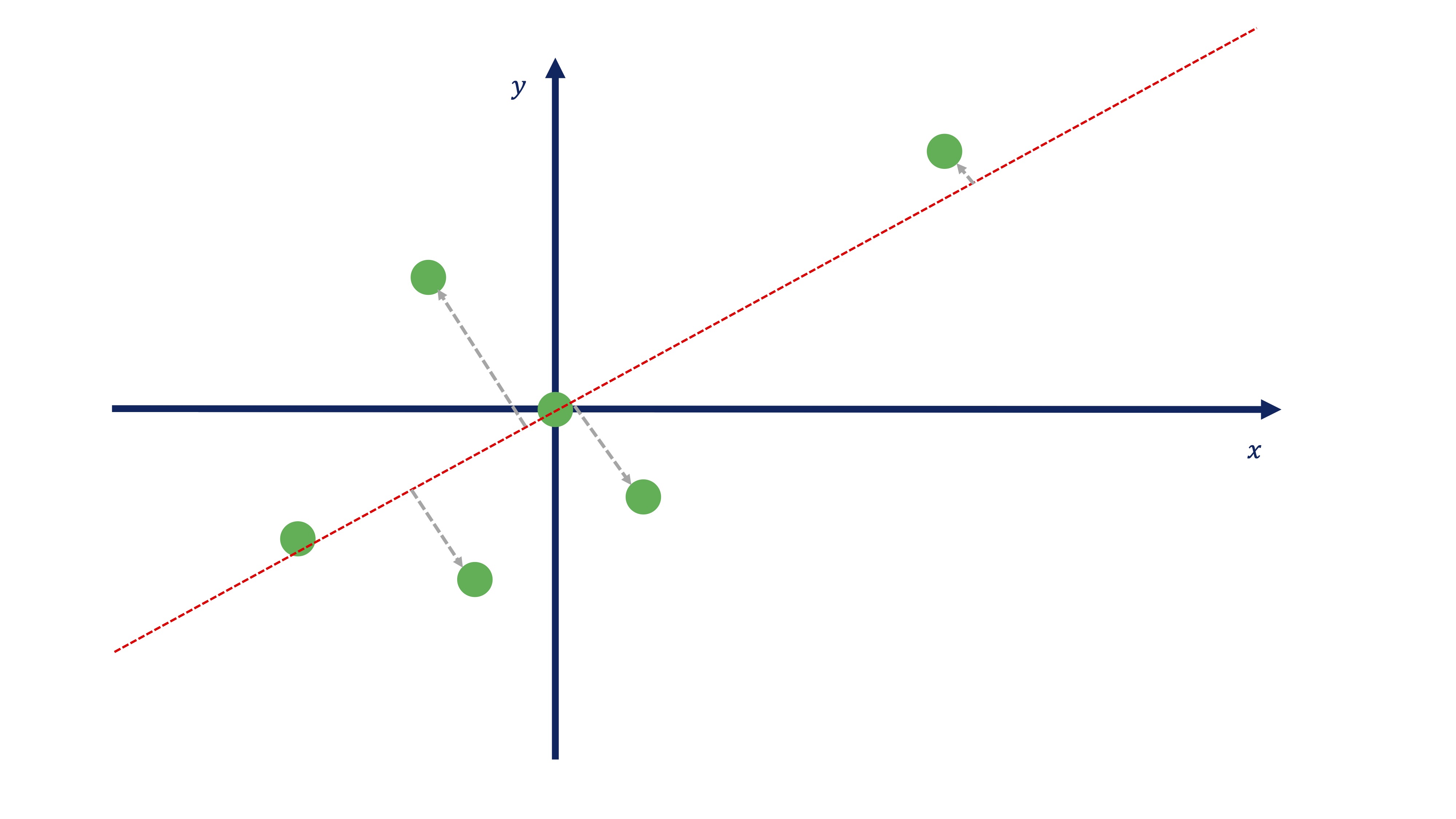
A lo mejor, alguien ha pensado esta otra recta (o similar):
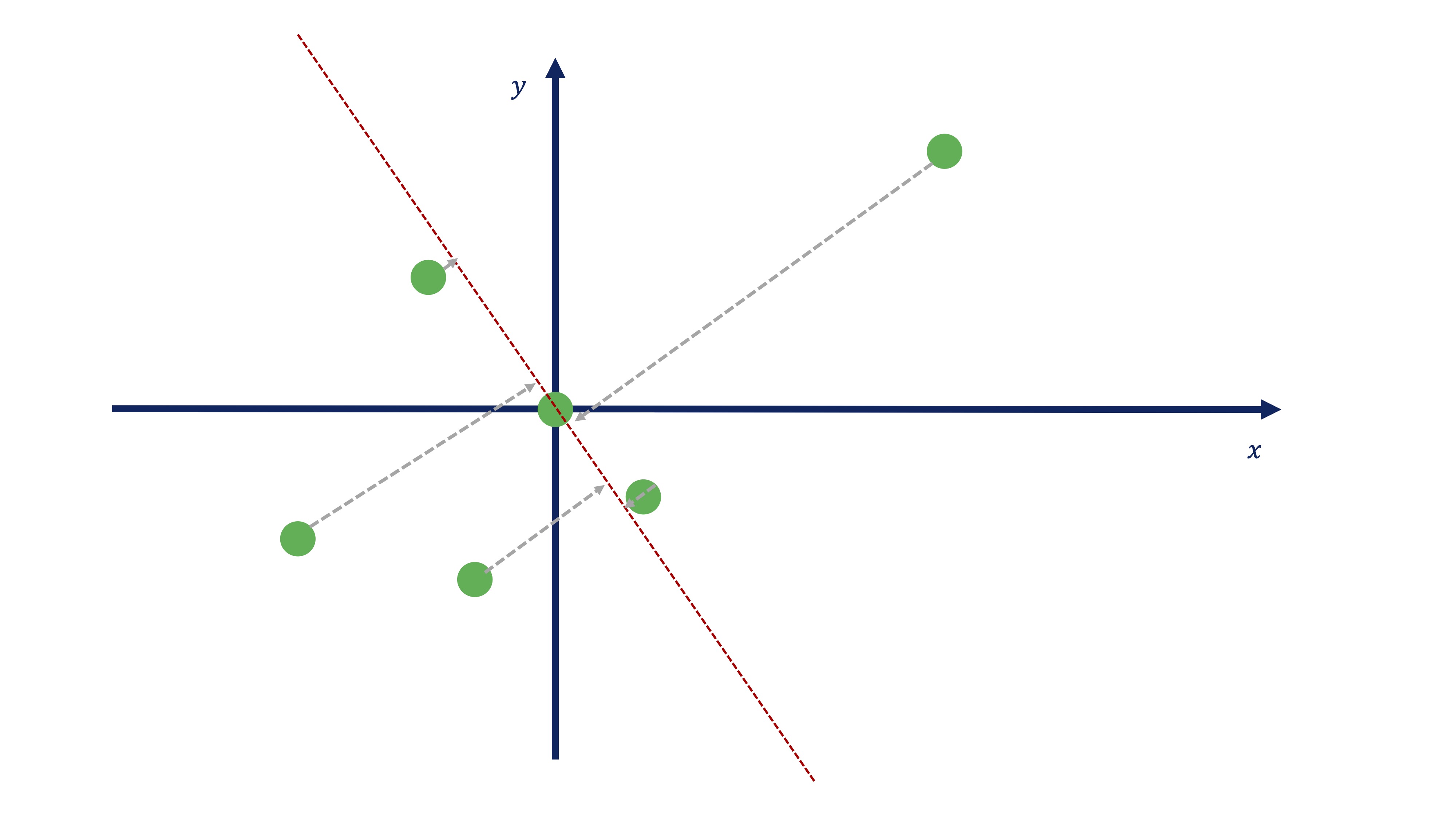
Ambas se llaman DIRECCIONES PRINCIPALES. Antes de tomar una decisión sobre qué dirección principal es más interesante, tendremos que plantearnos cómo se obtienen esos coeficientes que nos permiten parametrizar las direcciones. En el apéndice matem?tico se prueba que se obtienen mediante la diagonalización de la matriz de varianzas y covarianzas de los datos.
Es decir, tenemos que \[ X=\left[\begin{array}{cc} 4.5 & 3\\ 1 & -1\\ -1 & -2\\ -3 & -1.5\\ -1.5 & 1.5\\ 0 & 0 \end{array}\right] \]
cuya matriz de varianzas y covarianzas es:
\[ C(X)=\left(\begin{array}{cc} 6.7 & 3.35\\ 3.35 & 3.70 \end{array}\right) \]
x1<-c(4.5,1,-1,-3,-1.5,0) #Genera las dos variables
x2<-c(3,-1,-2,-1.5,1.5,0)
X<-data.frame(x1,x2) #dale estructura de datos
RES<-(princomp(X)) #usamos componentes principalesusando la función princomp podemos obtener lo que necesitmos.
RES$loadings #nos proporciona los autovectores
Loadings:
Comp.1 Comp.2
x1 0.839 0.544
x2 0.544 -0.839
RES$scores #nos proporciona cada componente (C1,C2))
Comp.1 Comp.2
[1,] 5.407863e+00 -7.084558e-02
[2,] 2.954918e-01 1.382998e+00
[3,] -1.926752e+00 1.134737e+00
[4,] -3.333365e+00 -3.723922e-01
[5,] -4.432378e-01 -2.074498e+00
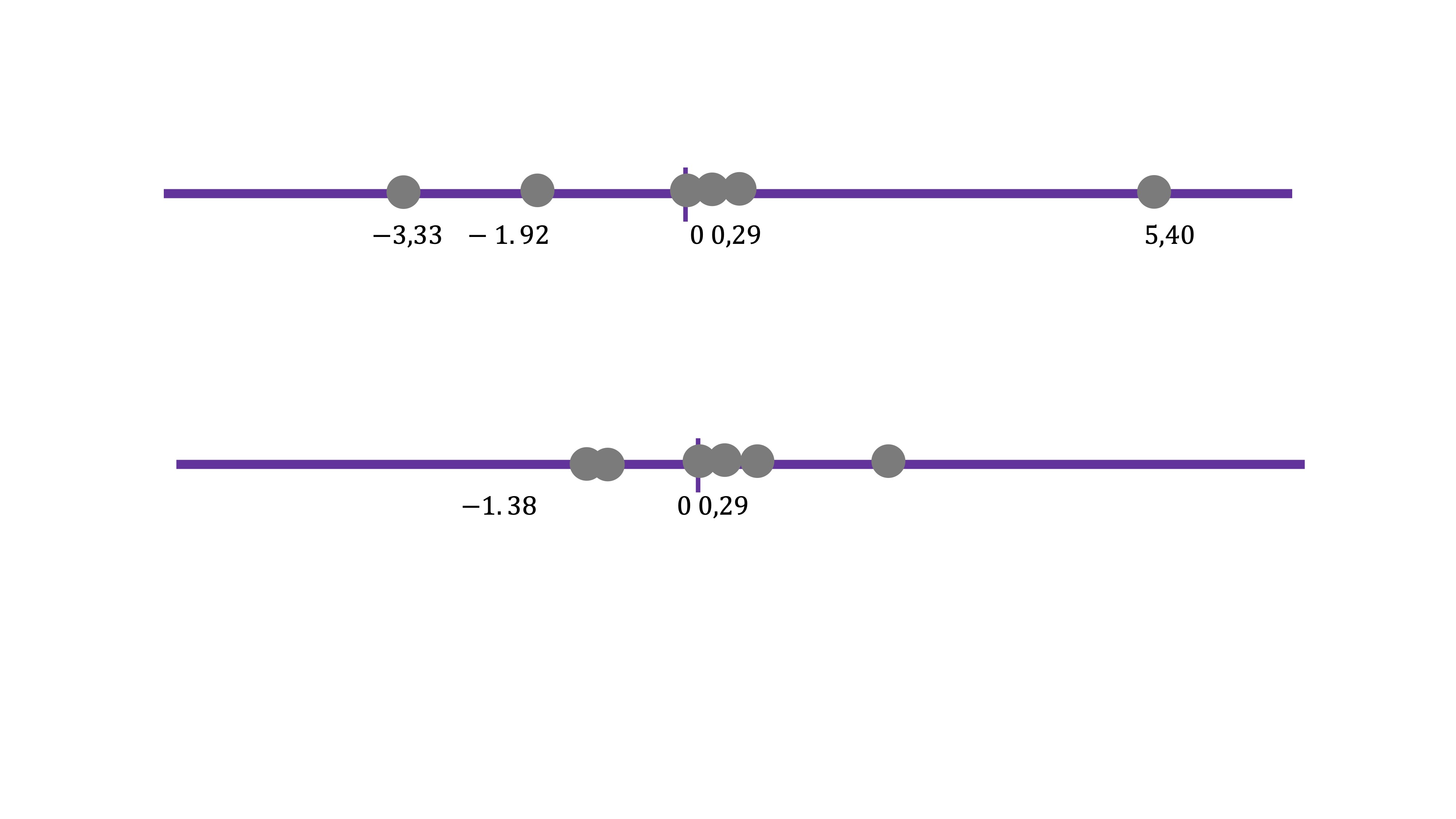
[6,] -1.509219e-17 2.329373e-17Así, el primer autovector nos dará la dirección principal primera. Fíjese, si representamos el vector \(\overrightarrow{a}_{1}=\left(\begin{array}{c} 0.8392\\ 0.5438 \end{array}\right)\), conjuntamente con los datos:
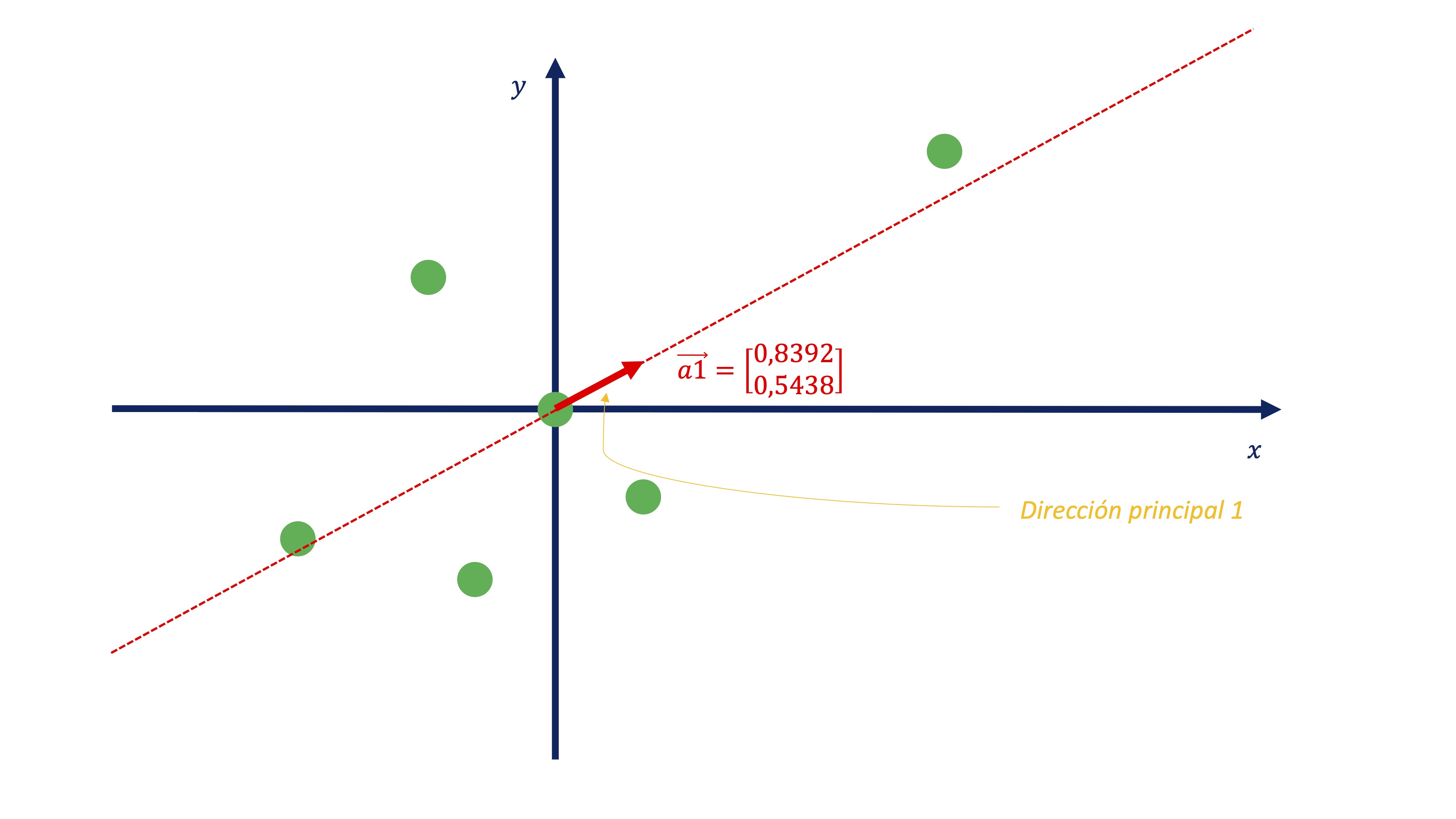
nos permite encontrar cuál es esa recta. De tal forma que usando esos coeficientes, obtenemos dicha proyección:
\[ C1_{i}=0.8392x_{i}+0.5438y_{i} \]
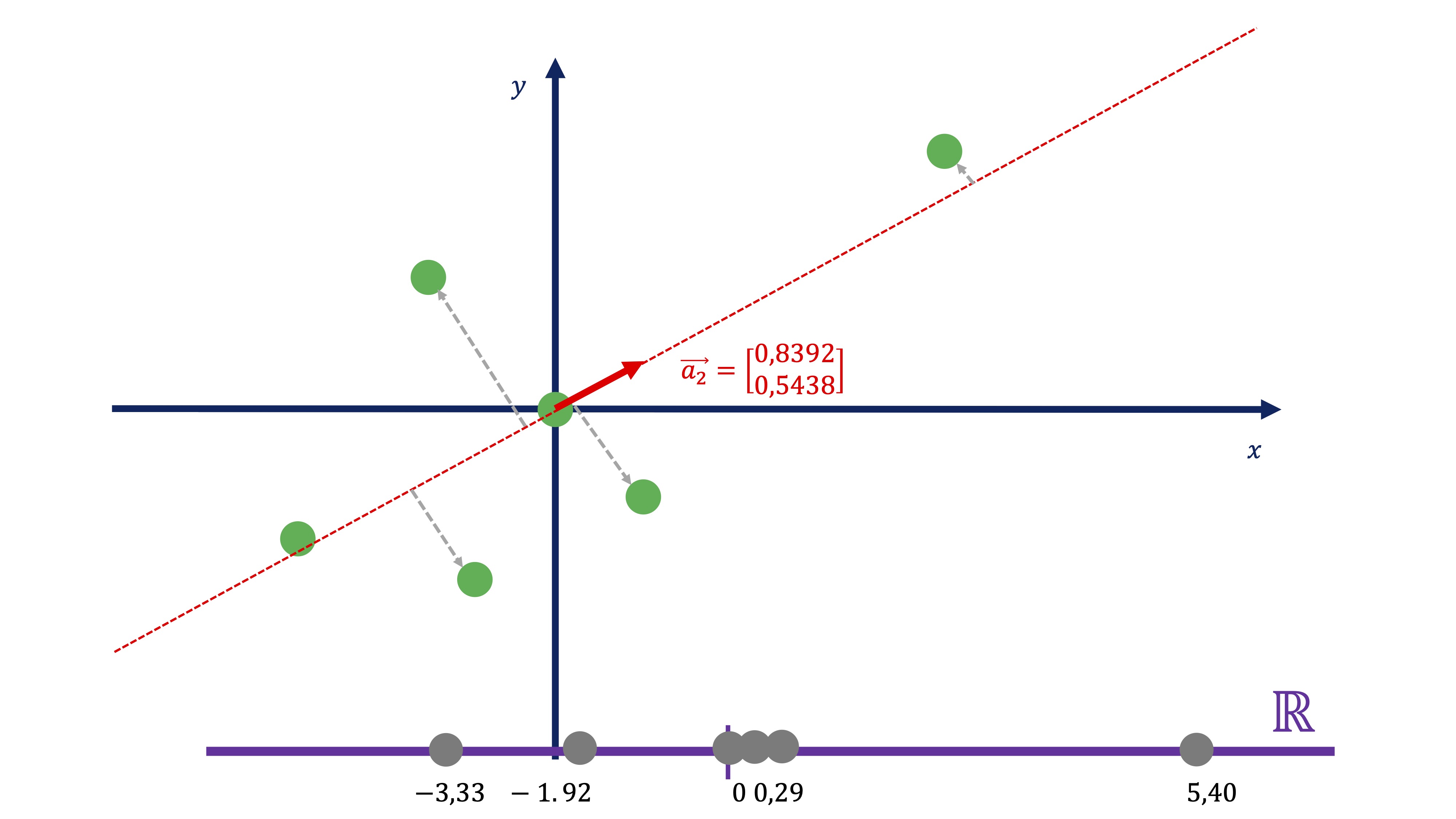
Entonces, usando la expresión de la dirección principal 1, podemos obtener el “resumen” de las dos variables en una nueva, que llamamos \(C1\). Esta nueva variable no tiene unas unidades de medida claras, pues es la combinación de dos variables que pueden no tener las mismas unidades. Podemos entenderla como un “índice” de tal forma que el valor que toma \(C1\) como tal no es importante, sino su variación a través de la muestra.
De igual manera, podemos obtener el segundo componente
\[ C2_{i}=-0.5438x_{i}+0.8392y_{i} \]
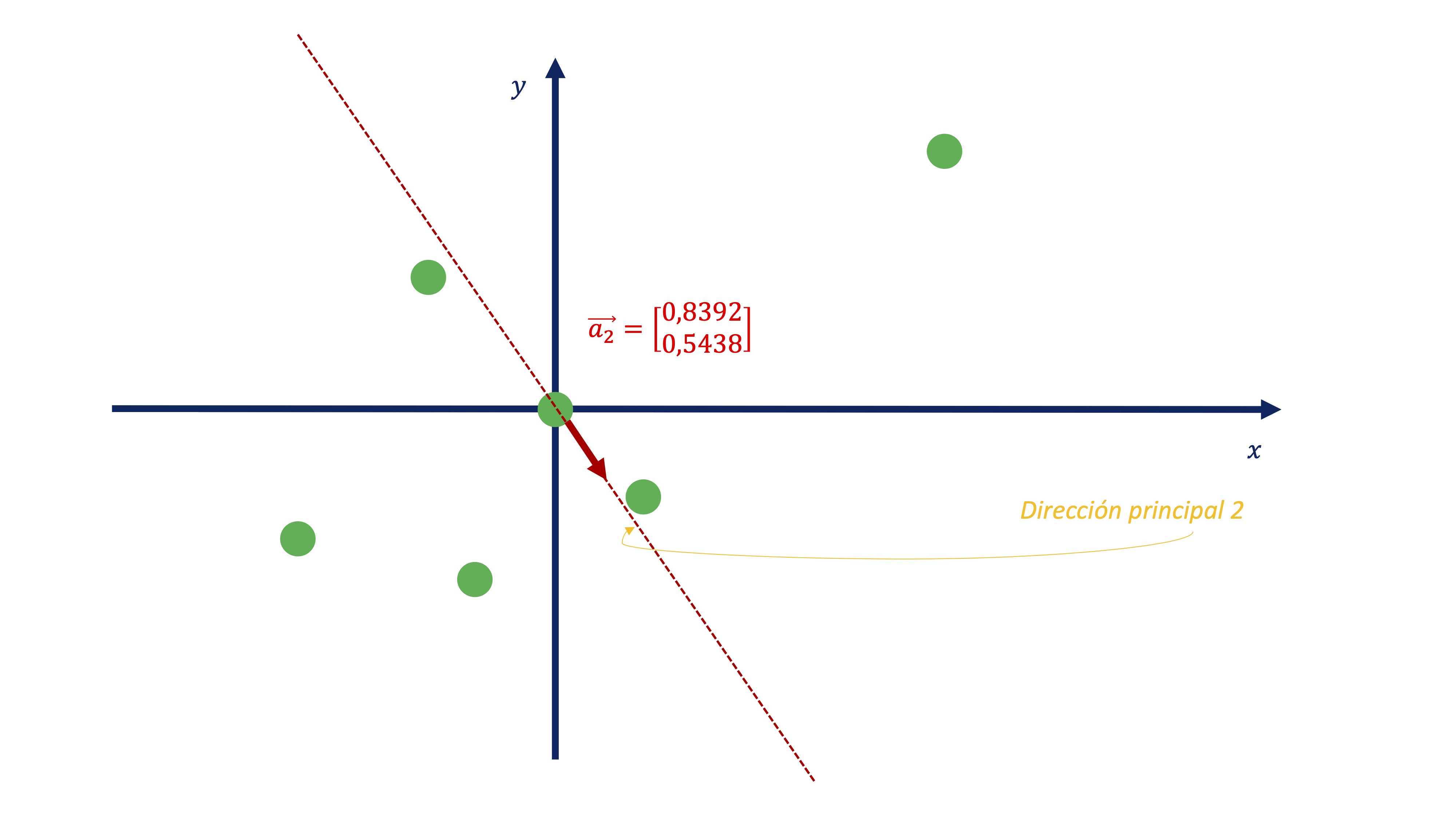
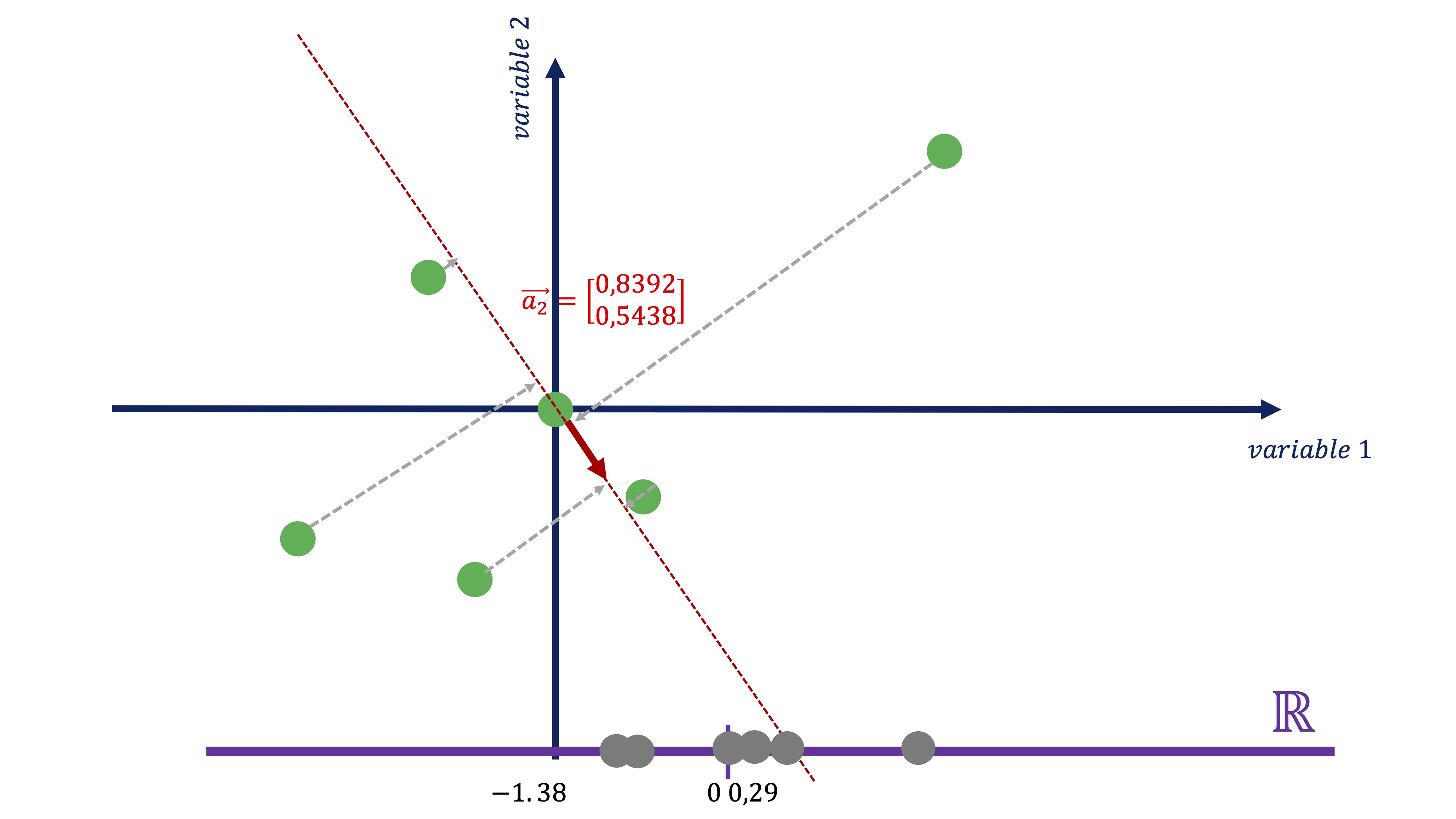
Como vemos (FIG 14, FIG 16) parece más exitoso quedarse con el primer componente antes con el segundo, puesto que el primero parece recoger de una manera más acertada la variabilidad que muestran los datos
Conclusiones hasta ahora
Tanto los autovalores como los autovectores van a tener una interpretación que nos ayudaá a entender mejor cómo se toman decisiones en el análisis PCA. >- Autovalores
princomp(covmat=cov(X))$sd^2 #obtención de los autovalores
Comp.1 Comp.2
8.87049 1.52951
C<-cov(X) #y, por otro lado, la matriz de varianzas y covarianzas de los datos
C
x1 x2
x1 6.70 3.35
x2 3.35 3.70Para empezar, la suma de los autovalores es igual a la suma de los elementos de la diagonal principal de \(C\) (propiedad 1} que vimos en el apartado de diagonalización de la matriz C). De esta manera: \(6.7+3.7=10.4\) es igual a \(8.87+1.53=10.4\). Esto es interesante, puesto que podemos considerar la suma de los elementos de la diagonal principal de \(C\) como la “varianza total” con la que contamos en los datos. Entonces, es fácil ver que, de la varianza total el primer componente ya representa \(8.87/10.4=0.85\) un 85% de la variación total. Nos parece, entonces, un buen resumen de la información disponible.
- Respecto a la interpretación de los componentes como “índices” lo verá claro en la aplicación con datos reales relacionados con el informe PISA.
- Si las variables tienen mucha diferencia en las varianzas, entonces se puede recomendar hacer la descomposición mediante la matriz de correlaciones. Esta postura es criticada, por cuanto se pierde la información de las varianzas.
0.2.2 Apéndice
¿De dónde se obtiene la expresión de componentes principales mediante la diagonalización de una matriz de varianzas y covarianzas?
Queremos minimizar la distancia entre las observaciones (\(X\)) y la proyección \(\left(XV\right)\), donde \(X\in M^{n\times k}\),\(V\in M^{k\times k}\)
\[ \min_{V}\left\Vert X-XV\right\Vert ^{2}, \]
con la restricción (para asegurarnos unicidad de solución) \(\left\Vert V\right\Vert =I.\) Asumiremos que la matriz \(X\) tiene sus observaciones en desviaciones respecto a la media. Nótese que, en este caso, nuestra incógnita es una matriz, \(V\), cuyas columnas conformarán lo que llamaremos coeficientes de la proyección para cada componente . Ahora bien, nótese también que, utilizando propiedades de vectores y matrices, la expresión anterior puede reescribirse como \[ \min_{V}\left(X-XV\right)^{T}\left(X-XV\right), \] que resulta ser
\[ \min_{V}X^{T}X-2V^{T}XX^{T}V+V^{T}XX^{T}V, \] que es equivalente (deshaciéndonos de \(X^{T}X\), porque no desempeña ningún papel, ya que no depende de \(V\))
\[ \min_{V}-V^{T}XX^{T}V, \]
donde minimizar “menos” una cantidad es equivalente a maximizarla:
\[ \max_{V}V^{T}XX^{T}V, \]
sin olvidar que \(\left\Vert V\right\Vert =I\) sigue siendo la restricción. Nótese que, las variables \(X\) están escritas en desviación a su media y que, por tanto, \(\mathbb{E}\left(XX^{T}\right)=Var-cov(X)=\Sigma\), es decir, queremos maximizar
\[ \max_{V}V^{T}\Sigma V, \]
Para resolver este problema, planteamos el lagrangiano \[ L(V,\lambda)=V^{T}\Sigma V-\overrightarrow{\lambda}^{T}\left(V^{T}V-I\right) \]
y derivando con respecto a \(V\), tenemos que la CPO es \[ 2\Sigma V-2\overrightarrow{\lambda}V=0\Rightarrow\Sigma V=\overrightarrow{\lambda}^{T}V \] y esta condición es, exactamente, el resultado de la diagonalización de matrices:\(V\) es una matriz que almacena los autovectores y \(\overrightarrow{\lambda}\) es un vector que almacena los autovalores.