Capítulo 1 Motivação e Introdução
Neste capítulo será feita uma contextualização do curso e apresentados os primeiros conceitos e nomenclaturas da literatura de Machine Learning, que em português se diz Aprendizado de Máquinas.
1.1 Inteligência Artificial, Machine Learning e Deep Learning.
O termo Deep Learning representa um subconjunto de Machine Learning, que por sua vez é um subconjunto da Inteligência Artificial (Figura 1.1) .

Figura 1.1: Inteligência Artificial, Aprendizado de Máquinas e Deep Learning.
A Inteligência Artificial é caracterizada por qualquer programa que pode sentir, raciocinar, agir ou se adaptar, habilidades estas tipicamente humanas. Veja alguns exemplos:
Internet das Coisas (Internet of Things ou IoT);
Reconhecimento de imagens;
Reconhecimento de voz;
Mineração de texto;
Sistemas de Recomendação;
Tradução de um idioma para outro.
O Aprendizado de Máquinas é uma área da Inteligência Artificial caracterizada por algoritmos que melhoram o seu desempenho quando expostos a mais dados de entrada. Por exemplo, reconhecimento de imagens; reconhecimento de voz; algoritmos de previsão; recomendação. Já Deep Learning é um subconjunto do Aprendizado de Máquinas, isto é, também são algoritmos que melhoram o seu desempenho com o aumento dos dados de entrada, criados a partir de redes neurais multicamadas. Esses tipos de algoritmos são muito usados para problemas complexos com muitas variáveis de entradas, problemas de identificação em imagens ou tradução de idiomas.
1.2 Aprendizado de Máquinas
Em Aprendizado de Máquinas existem vários tipos de problemas. Para cada um deles, diversas maneiras de solucioná-los. A Figura 1.2 apresenta uma divisão usual dos tipos de problemas em Aprendizado de Máquinas.
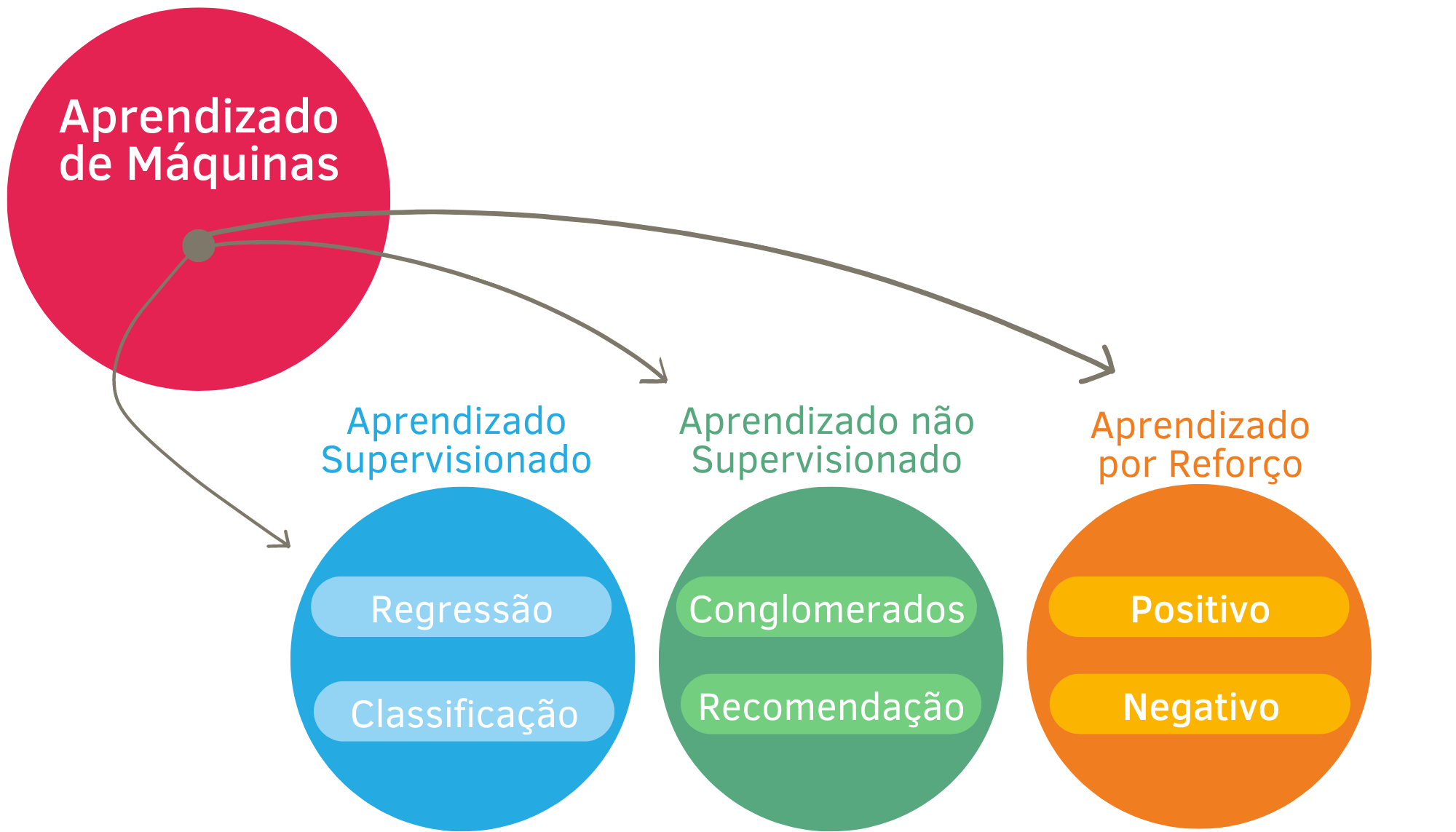
Figura 1.2: Tipos de Aprendizado de Máquinas
1.2.1 Aprendizado supervisionado
Os algoritmos de aprendizado supervisionado são aqueles que buscam prever uma variável alvo, que também pode ser chamada de desfecho, variável resposta ou variável de interesse. Nesse grupo de algoritmos um conjunto de covariáveis é usado para prever a variável alvo, que pode ser quantitativa ou qualitativa (categórica).
Quando a variável alvo for quantitativa, dizemos que o problema é de regressão. Quando a variável alvo for qualitativa, dizemos que o problema é de classificação.
Alguns métodos de aprendizado supervisionado: Modelos de Regressão Linear, Modelos Lineares Generalizados, Métodos Baseados em Árvores de Decisão (Floresta Aleatória e Boosting), Redes Neurais. Neste curso serão apresentados os métodos baseados em árvores, tanto para problemas de classificação quanto para problemas de regressão.
1.3 Problemas de classificação
Os problemas de classificação são aqueles que buscam uma relação entre uma variável alvo qualitativa (categórica) e diversas covariáveis. Em geral o método retorna um vetor de números entre 0 e 1, que indica a probabilidade de pertencer a cada categoria. Seguem dois exemplos.
Identificação de transação fraudulenta em cartão de crédito
O objetivo deste problema é determinar se uma certa operação no cartão de crédito representa uma fraude ou não. Em outras palavras, queremos observar características da transação e a partir desta informação decidir entre: fraude ou legítima. Para isso precisamos de uma amostra de dados sobre diversas transações, sendo algumas fraudulentas e outras não.
As covariáveis do problema são as informações possíveis de serem observadas até o instante da compra, como por exemplo, o valor da transação, a localização do estabelecimento de compra, a hora da operação, dados do cliente, entre outras. A variável de interesse é aquela que queremos prever, que não conseguimos identificar no momento da compra, que é uma variável categórica que indica se a operação em questão é uma fraude ou é legítima.

Figura 1.3: Transação Fraudulenta no Cartão de Crédito.
Dubey et al. (Dubey, Mundhe, and Kadam 2020) comparam diferentes métodos de classificação, como Redes Neurais, Árvores de Decisão, SVM, Regressão Logística e Floresta Aleatória, para identificar se uma transação é ou não fraudulenta. Todos os métodos deste estudo apresentaram acurácia maior que 95%, com destaque para a Rede Neural e a Floresta Aleatória, com acurácia superior a 99%.
Identificação de spam
O objetivo deste problema é identificar se uma mensagem (de email ou SMS) trata-se ou não de um spam observando as características dela. As características possíveis de serem observadas são as covariáveis do problema: o texto no assunto da mensagem, o texto no corpo da mensagem, o número de remetentes, o provedor de origem da mensagem, entre outras. A variável de interesse é aquela que queremos prever, que não conseguimos identificar no momento do recebimento da mensagem, que é uma variável categórica que indica se a mensagem é ou não um spam.
Este é um problema que tem mais um complicador: boa parte da informação é fornecida em formato de texto.
Figura 1.4: Identificação de Spam
Goswami et al (Goswami, Malviya, and Sharma 2020) e Navaney et al. (Navaney, Dubey, and Rana 2018) comparam, em duas pesquisas diferentes, o desempenho de alguns métodos de classificação para a identificação de spam em mensagens de SMS. Os dois artigos trabalham com o mesmo conjunto de dados, que foi retirado do UC Irvine Machine Learning Repository4. Goswami et al (Goswami, Malviya, and Sharma 2020) compara o desempenho dos métodos de Floresta Aleatória, Naive Bayes (NB) e Support Vector Machine (SVM); já Navaney et al. (Navaney, Dubey, and Rana 2018) compara o desempenho do NB e SVM. A medida de comparação adotada foi a acurácia. Os resultados de Goswami et al (Goswami, Malviya, and Sharma 2020) apresentam valores de acurácia de 97.11%, 99.49% e 86.35% para os métodos de Floresta Aleatória, Naive Bayes e Support Vector Machine, respectivamente. Já o estudo de Navaney et al. (Navaney, Dubey, and Rana 2018) obteve uma acurácia melhor para o SVM quando comparado com o NB.
1.3.1 Identificação de risco para Diabetes
Na área de saúde é de grande interesse identificar fatores de riscos para doenças. Dessa forma é possível identificar os indivíduos com maior chance de desenvolver a doença e realizar um acompanhamento preventivo a fim de identificar a doença em seu estágio inciail.

Figura 1.5: Identificação de risco para DIabetes
Dudkina et al. (Dudkina et al. 2021) realizaram uma pesquisa cujo objetivo é prever as chances de um indivíduo ter diabetes. Para isso foi construído um modelo de aprendizagem de máquinas com base em métodos de árvore de decisão. Os pesquisadores utilizaram a base pública The Pima Indians Diabetes DataBase, disponível pelo Kaggle*5, que contém informações sobre 768 pacientes do sexo feminino, com mais de 21 anos e de orige indígena Pima. Foram usados 9 atributos para a análise, 8 covariáveis e 1 variável alvo. As covariáveis são características das pacientes, como idade e índice de massa corporal. A variável alvo é uma variável indicadora sobre a paciente ter ou não diabetes.
1.4 Problemas de regressão
Os problemas de regressão são aqueles que buscam uma relação entre uma variável alvo quantitativa, geralmente contínua, e diversas covariáveis. O método retorna uma estimativa para a variável alvo dada uma observação das covariáveis.
Predição do consumo de energia
Prever gastos previne surpresas e permite que o provedor se prepare para as despesas futuras. A previsão do consumo de energia em edifícios, em particular, é um problema desafiador uma vez que o consumo nos edifícios tem uma relação complexa com várias covariáveis.
Figura 1.6: Previsão do Consumo de Energia em um prédio.
Ding et. al. (Ding, Fan, and Liu 2021) realizaram um estudo que comparou o desempenho de diversos métodos de aprendizado de máquinas para previsão do gasto de energia de um prédio. O banco de dados utilizado, depois de um processo de limpeza, continha informações sobre 2.370 prédios. Foram ajustados seis modelos de regressão: Regressão Linear, Ridge Regression, SVR, Árvores de Decisão, Floresta Aleatória e XGBoost. Em particular, o método XGBoost apresentou o modelo mais adequado para a previsão do consumo de energia em um prédio. Analisando as variáveis importantes para todos os modelos pode-se concluir que o tipo principal de equipamento de refrigeração e a principal atividade do prédio foram as mais representativas para a previsão do consumo de energia.
Previsão de popularidade em redes sociais
Hoje em dia muitas pessoas usam as redes sociais como forma de trabalho, são os chamados influenciadores. Em geral, boa parte da fonte de renda deles vem de anúncios ou propagandas no seu perfil. O que faz uma marca se interessar em anunciar no perfil de um influenciador, é a sua popularidade. Então este é um indicador importante para se fazer negócios neste meio.

Figura 1.7: Previsão da Popularidade de Usuários do Instagram.
No trabalho de Purba et. al. (Purba, Asirvatham, and Murugesan 2020) o objetivo principal é prever a popularidade de usuários do Instagram. A variável alvo utilizada foi um índice de popularidade que combina a taxa de engajamento e a taxa de crescimento dos seguidores. Foram consideradas 14 covariáveis, entre elas: número de postagens, tamanho da descrição do perfil, número médio de hashtags utilizadas, entre outras. Os métodos utilizados para realizar essa previsão foram a Regressão Linear, Árvores de Regressão, Redes Neurais, XGBoost, Floresta Aleatória e SVR. Para a comparação dos modelos foi realizado uma validação cruzada e comparados os valores de \(R^2\), \(MAE\), \(RSME\) e \(RAE\). O Método de Floresta Aleatória apresentou o melhor resultado: \(R^2 = 0,852\) e o número de seguidores foi a variável mais relevante para a predição.
1.4.1 Previsão do aumento no custo de vida com a COVID
Durante a pandemia do coronavírus (COVID-19) vivemos um período de incertezas. Um fator relevante neste período foi a instabilidade no orçamento das famílias, muitas delas tiveram diminuição de renda com a política de isolamento social.

Figura 1.8: Previsão do aumento no custo de vida com a COVID.
Lotfy (Lotfy 2021) realizou um estudo durante o período pandêmico cujo objetivo era prever o valor médio dos custos extras nos gastos dos lares egípcios com a pandemia da COVID-19. Um questionário estruturado pré-desenhado foi criado para medir o impacto da situação da COVID-19 sobre a economia dos lares. A maioria dos entrevistados eram mulheres (81%) e tinham entre 30 e 40 anos de idade (56,3%). Cerca de 63,1% das famílias mantiveram a mesma renda mensal enquanto 35,4% tiveram diminuição na renda mensal. Um modelo de Árvore de Regressão foi ajustado e detectou que o gasto extra em mercearia foi o item dominante em comparação com outros itens. Quanto à árvore de regressão, a média máxima dos custos extras devidos à pandemia de COVID-19 foi cerca de 88,56$/mês, enquanto a média mínima dos custos extras foi de 13,86$/mês. Concluiu-se que O efeito da pandemia da COVID-19 nos gastos domésticos varia muito entre as famílias, depende do que elas fazem para prevenir a COVID-19.
1.5 Base de Dados
A base de dados a ser analisada pode ser construída pelos próprios pesquisadores ou pode ser retirada de algum repositório público de dados. Quando a base é de autoria dos pesquisadores, estes são responsáveis por realizar um plano amostral, de acordo com o seu problema, selecionar os indivíduos e recolher as características de interesse do estudo. Quando a base utilizada é de um repositório, os pesquisadores tentam ajustar o seu problema para a base já existente.
1.5.1 Alguns repositórios de dados
| Nome do Repositório | Endereço |
|---|---|
| UC Irvine Machine Learning Repository | https://archive.ics.uci.edu/ml/index.php |
| Kaggle | https://www.kaggle.com/datasets |
| Amazon Datasets | https://registry.opendata.aws/ |
| Google’s Datasets Search Engine | htt ps://datasetsearch.research.google.com |
| Microsoft Datasets | https://msropendata.com/ |
| Awesome Public Datasets Collection | https://github.com/awesomedata/awesome-public-datasets/ |
| Government Datasets |
1.6 Atividade
Para os 8 trabalhos apresentados a seguir identifique:
Se o problema é de regressão ou classificação.
Quais são as covariáveis e a variável alvo.
Descreva quem são os indivíduos que compõe a base de dados utilizada no trabalho.
Caso não esteja claro no resumo alguma das respostas acima, indique possíveis respostas baseado na situação descrita.
(J. O. D. D. SOUZA 2021) A prematuridade é um problema alarmante de saúde pública e a principal causa de óbito neonatal no Brasil. O presente trabalho teve como objetivo avaliar a associação entre as características maternas e do recém-nascido e a prevalência de prematuridade no Estado do Rio de Janeiro em 2019. Foi realizado um estudo transversal, com os dados do Sistema de Informações sobre Nascidos Vivos (SINASC 2019). A prevalência de prematuridade foi de 9,5%. Conclui-se que tanto características demográficas da mãe, como idade, situação conjugal e raça/cor, quanto características clínicas do bebê e às relativas ao parto estão associadas com a prematuridade.
(FERNANDES 2021) Neste trabalho abordaremos o uso de modelos de regressão baseados em métodos de Regressão Linear Múltipla, Árvores de Regressão e Florestas Aleatórias, para realizar a previsão de preços de imóveis situados na cidade de Ames, nos Estados Unidos. Primeiro foi feita uma análise descritiva tanto da variável resposta como das variáveis explicativas. Em seguida foram ajustados os métodos citados acima, sendo considerado como variável resposta não só o preço de venda como também seu logaritmo. Os modelos com melhor resultado foram aqueles cuja variável resposta foi o logaritmo do preço de venda. Vale destacar que tanto o modelo Linear quanto o Floresta Aleatória apresentaram bons resultados tanto nos dados de treino quanto nos de teste.
(PORTO 2021) Este trabalho analisou o desempenho de 6 diferentes modelos estatísticos em um problema de identificação de tumores entre malignos e benignos a partir de informações extraídas de exames de imagem. Os métodos utilizados foram: (i) Regressão Logística, (ii) K-Nearest Neighbors, (iii) Arvores de Classificação, (iv) Florestas Aleatórias, (v) SVM Polinomial e (vi) SVM Radial. A despeito de ter sido utilizada uma base de dados didática, é importante destacar o bom desempenho dos modelos, todos com níveis de acerto na base teste acima de 90,0%, com destaque para a Regressão Logística, Florestas Aleatórias e SVM Polinomial, que obtiveram os melhores resultados. Ainda, os modelos foram capazes de identificar o raio do tumor como a covariável de maior impacto nas chances de diagnóstico de câncer de mama.
(A. A. C. D. SOUZA 2021) A colelitíase, também conhecida como pedra na vesícula, é a situação em que pequenas pedras são formadas por conta do depósito de substâncias associadas aos fluidos digestivos. Em pacientes que realizam cirurgia bariátrica, a colelitíase vem sendo notada naqueles que tiveram rápida perda de peso, mas ainda não está estabelecido na literatura médica quais seriam os fatores determinantes para a formação desses cálculos. A proposta deste estudo é fazer uma abordagem ampla, recuperando ferramentas estatísticas e acrescentando o uso de regressão logística para avaliar possíveis fatores de risco para presença de colelitíase após realizar a cirurgia bariátrica. Para isso, foram coletadas informações dos prontuários de 565 pacientes que realizaram as cirurgias Bypass gástrico em Y de Roux ou a gastrectomia vertical, conhecida como Sleeve, em uma clínica particular de gastroplastia. Deste total de pacientes, 439 (77,7%) são do sexo feminino; 309 (54,6 %) são da cor ou raça branca e 313 (55,4%) realizaram a cirurgia Bypass gástrico em Y de Roux. A idade média dos pacientes foi de 40 \(\pm\) 9,8 anos, com altura de \(1,65 \pm 0,09\) metros, peso inicial de 116 \(\pm\) 21,8 kg e peso ideal de 58 \(\pm\) 21,8 kg. O IMC teve média observada de 42,3 \(\pm\) 5,6 kg/m². A esteato-hepatite não alcoólica (NASH), esteve presente em 271 (47,9%) pacientes. Os resultados mostraram que 78 (13,8%) pacientes desenvolveram colelitíase após o procedimento cirúrgico. No grupo com colelitíase foi observada maior presença de pacientes do sexo feminino, e com presença da comorbidade esteato-hepatite não-alcoólica (NASH). Além disso, o tempo até o diagnóstico de colelitíase foi significativamente menor na cirurgia Bypass do que na cirurgia Sleeve. Ao comparar pacientes com e sem colelitíase após a cirurgia bariátrica, foi possível observar associação significativa entre a presença da esteato-hepatite não alcoólica (NASH) e a colelitíase após a cirurgia bariátrica. Inicialmente, foram ajustados 3 modelos de regressão logística que resultaram em uma acurácia menor que 50% e baixas taxas de sensibilidade. Diante dos resultados, foi aplicada a abordagem de Firth à regressão logística, que teve medidas de desempenho semelhantes às da regressão logística usual. As variáveis que foram significativas no modelo escolhido foram sexo, peso inicial, peso ideal, e NASH. Apesar dos modelos não se adequarem bem aos dados, o estudo permite concluir que ser do gênero masculino é um fator de proteção para a colelitíase e a presença de esteato-hepatite não-alcoólica (NASH) é fator de risco para desenvolvimento de colelitíase após a cirurgia bariátrica.
(VARANDA 2021) Os acidentes de transporte são aqueles que envolvem equipamentos projetados ou utilizados para o transporte de bens ou pessoas, englobando os acidentes de trânsito e as demais ocorrências em via pública. Esses acidentes estão situados entre uma das principais causas de morte no Brasil, em especial entre as principais causas externas de mortalidade. Diante disto, este trabalho buscou modelar as taxas de óbitos por acidentes nas Unidades Federativas do Brasil, através da modelagem sob a perspectiva bayesiana, e considerando variáveis explicativas socioeconômicas tais como Índice de Gini e percentual da população com 25 anos ou mais que possuíam ao menos o ensino médio completo. Foram ajustados modelos sem e com estrutura espacial. Para estrutura espacial, utilizou-se o modelo Modelo Autorregressivo Condicional (CAR) proposto por Leroux, Lei e Breslow (2000). Para comparação dos modelos utilizou-se as medidas Erro Quadrático Médio (EQM) e Critério de Informação do Desvio (DIC). Os modelos CAR Leroux apresentaram melhor ajuste e maior precisão.
(SOARES 2021) O mercado de seguro de automóveis no Brasil é extremamente competitivo e obriga as seguradoras a realizarem uma tarifação correta e bem ajustada de acordo com o perfil do segurado. Neste trabalho, foram analisados modelos estatísticos para a precificação de seguros de automóveis na cidade do Rio de Janeiro, usando informações de uma carteira de apólices de seguros de uma determinada seguradora brasileira, no ano de 2015. Além disso, buscou-se determinar quais são os fatores relevantes para o preço pago pelo segurado, o qual denomina-se prêmio. O conhecimento destes fatores ajuda na mitigação dos riscos da seguradora. De um modo geral, o prêmio deve ser suficiente para cobrir os sinistros esperados e as demais despesas da seguradora, incluindo uma margem de lucro. Devido à natureza assimétrica dos dados de severidade, foram adotados os modelos lineares generalizados para modelar a precificação de seguros, levando em consideração as características individuais do segurado, bem como as informações disponíveis sobre sua região de residência e seu respectivo automóvel. Foi realizado um paralelo entre as abordagens frequentista e Bayesiana e, em especial, foram considerados os modelos log-normal e gama para ajustar o prêmio do seguro de automóveis. Considerando o AIC como medida de comparação entre os modelos frequentistas e, o DIC entre os modelos Bayesianos, foi observado que o modelo log-normal se ajustou melhor ao conjunto de dados analisados em ambas as abordagens. Pelo fato de terem sido adotadas distribuições a priori vagas, os resultados das estimativas dos coeficientes foram similares para os métodos frequentista e Bayesiano. Além disso, todas as covariáveis consideradas (idade, sexo, estado civil, categoria do veículo e área de planejamento) mostraram-se relevantes para a modelagem de prêmio em ambas as abordagens.
(LUZ 2021) O cenário mundial da pandemia por Corona Vírus gerou questionamentos que o comportamento das internações hospitalares decorrentes desta doença poderia ser similar às ocorridas por doenças respiratórias. O objetivo deste trabalho é avaliar o perfil das internações emergenciais hospitalares em idosos, decorrentes de problemas respiratórios, e identificar possíveis fatores associados ao óbito. Metodologia: Modelos de regressão logística em função de características dos pacientes, das internações e do hospital foram utilizados tendo como variável resposta a variável indicadora do desfecho (alta/óbito), tomando como base registros do SIHSUS/DATASUS, do Rio de Janeiro no ano de 2019. Resultados: Alguns dos principais fatores de risco para o óbito associados ao modelo que considera os diagnósticos principais classificados em apenas 4 categorias e incorpora a informação sobre utilização da UTI foram: classe etária 80 anos ou mais (RC: 1,86), uso da UTI (RC: 4,10) e diagnóstico de insuficiência respiratória (RC: 12,26).
(OLIVEIRA 2021) O presente trabalho busca observar fatores de indivíduos e de seus domicílios associados a condição de pobreza monetária na Região Metropolitana do Rio de Janeiro no último trimestre de 2012, 2016 e 2020. São observados domicílios com alguma pessoa ocupada na PNAD Contínua, realizada pelo IBGE. O principal teste do estudo está relacionado ao mercado de trabalho, que visa estimar uma redução na chance de ser considerado pobre uma vez que o domicílio conte com alguém ocupado dentro do mercado de trabalho formal. É definido um recorte monetário de pobreza, a renda do trabalho mensal domiciliar per capita de elegibilidade do Bolsa Família. Para estimar o efeito de cada fator relacionado aos indivíduos pobres ou não, é utilizada uma Regressão Logística que aproxima a distribuição a posteriori destes fatores para identificar o comportamento de cada efeito. É encontrada redução da chance de ser pobre em um domicílio com ocupados no mercado formal em relação a domicílios com informais e o efeito é maior que o da relação de escolaridade do responsável na redução da chance de ser pobre.