8 Verificación, Validación Replicación
En los siete capítulos anteriores, hemos defendido la importancia y utilidad de ABM, aprendió a ampliar el ABM existente y construir otros nuevos, tomó una visión amplia de la componentes que entran en un entorno ABM y aprendieron a recopilar y analizar resultados de un ABM. En este capítulo, aprenderemos a evaluar la corrección y la utilidad. de un ABM. ¿Cómo podemos saber si nuestro ABM implementado corresponde a nuestro conceptual ¿modelo? ¿Cómo podemos evaluar la coincidencia entre nuestro ABM y el mundo real?
8.1 Corrección de un modelo
Si un modelo es útil para responder preguntas del mundo real, es importante que el modelo proporciona resultados que abordan los problemas relevantes y que los resultados son precisos: El modelo debe proporcionar resultados que sean útiles para el usuario del modelo. La precisión del modelo puede ser evaluado a través de tres procesos de modelado diferentes: validación, verificación y réplica ción La validación del modelo es el proceso de determinar si el modelo implementado corresponde a, y explica, algún fenómeno en el mundo real. Verificación del modelo es el proceso de determinar si un modelo implementado corresponde al modelo conceptual objetivo. Este proceso es equivalente a asegurarse de que el modelo ha sido corregido implementado correctamente Por último, la replicación del modelo es la implementación por un investigador o Grupo de investigadores de un modelo conceptual previamente implementado por otra persona. Al garantizar que un modelo implementado corresponde a un modelo conceptual (verificación) cuyas salidas se reflejan en el mundo real (validación), la confianza crece en el correcto ness y poder explicativo de los modelos conceptuales e implementados. Además, mientras otros científicos y constructores de modelos replican el trabajo del científico original, el científico La comunidad específica en su conjunto llega a aceptar el modelo como correcto. Verificación validación, y la replicación sustentan colectivamente la corrección y, por lo tanto, la utilidad de un modelo. Sin embargo, demostrar que un conjunto particular de resultados de un modelo corresponde a El mundo real no es suficiente. Como se discutió en capítulos anteriores, debido al estocástico naturaleza de los ABM, a menudo se necesitan múltiples ejecuciones para confirmar que un modelo es exacto. Por lo tanto, las metodologías de verificación, validación y replicación a menudo se basan en métodos de estadística. Comenzamos nuestra discusión mirando más de cerca la verificación.
8.2 Verificación
A medida que un modelo basado en agentes crece, se hace más difícil simplemente mirar su código para determinar si realmente está llevando a cabo su función prevista. El proceso de veri La notificación aborda este problema, teniendo como objetivo la eliminación de “errores” del código. Sin embargo, esto no es tan simple como puede parecer, y si los diseñadores e implementadores de modelos Si hay personas diferentes, el proceso de depuración puede volverse mucho más complejo. Una pauta general para habilitar la verificación del modelo implica construir el modelo simplemente para empezar, expandir la complejidad del modelo solo según sea necesario. Por lo tanto, adherirse Según el principio de diseño básico de ABM descrito en el capítulo 4, se obtiene un importante beneficio adicional: Si un modelo es simple para empezar, es más fácil de verificar que un modelo complejo. Igualmente, si las partes adicionales agregadas al modelo también son de naturaleza incremental - construyendo hacia su pregunta de interés en lugar de tratar de desarrollar toda la elaboración del modelo a la vez: esos componentes también serán más fáciles de verificar (y, por extensión, el modelo de de la que forman parte) Aun así, debe tenerse en cuenta que incluso si todos los componentes de un se verifican los modelos, el modelo en sí puede no serlo, ya que pueden surgir complicaciones adicionales de las interacciones entre los componentes del modelo. A lo largo de esta sección, examinamos el tema de la verificación en el contexto de un simple ABM del comportamiento de votación, utilizando la siguiente narrativa ficticia para guiar nuestra discusión: Imagine que se nos acerca un grupo de politólogos que desean desarrollar Un modelo simple de comportamiento de votación. 1 Explican que piensan que las personas son sociales Las interacciones determinan en gran medida la votación en las elecciones. Con base en sus observaciones de encuestas y resultados electorales, piensan que las personas tienen alguna forma inicial en la que quieren votar, y cuando son encuestados inicialmente, expresan esos sentimientos. Sin embargo, en el intervalo entre cuando son encuestados y cuando realmente emiten su voto, hablan con sus vecinos y colegas y discuten la forma en que planean votar; esto puede cambiar la forma en que deciden votar. De hecho, esto puede suceder varias veces durante el período previo a una elección. Los politólogos nos piden que construyamos un ABM de este fenómeno.
8.3 Comunicación
2874/5000 A menudo, el implementador del modelo y el autor del modelo son la misma persona, pero esto no es siempre el caso. A veces, un equipo de personas construye un modelo, en el que una o más personas Describa el modelo conceptual mientras que otros miembros del equipo realmente implementan el modelo. Esto sucede con frecuencia cuando el experto en el dominio no tiene las habilidades técnicas para crear El modelo por su cuenta. En estas situaciones, la verificación se vuelve especialmente crítica, ya que no un individuo tiene un conocimiento completo de todas las partes del proceso de modelado. Cuando modelos están construidos de esta manera, la comunicación es crítica para asegurar que el modelo implementado refleja correctamente el modelo conceptual del experto en dominio. La mejor manera de verificar modelos construido en este tipo de equipos es para que el experto en el dominio (o expertos) se familiarice con las herramientas del modelo y, asimismo, los implementadores para aprender sobre el tema del modelo importar. Si bien uno no puede esperar que las dos partes se conviertan en expertos en los dominios del otro, Construir este terreno común es esencial para garantizar que las ideas se comuniquen de manera efectiva y el modelo refleja correctamente las intenciones de los modeladores. Por ejemplo, en nuestro modelo de votación, sería útil que los politólogos conocieran diferencia entre los barrios de Moore y von Neumann, qué red de mundo pequeño parecía, y las posibilidades de una cuadrícula hexagonal versus una cuadrícula rectangular. Este conocimiento les permitiría tomar decisiones informadas sobre cómo su modelo conceptual debería ser implementado. Además, ayudaría si el implementador tuviera una idea básica de cómo Los mecanismos de votación se conceptualizan dentro de la disciplina de la ciencia política, ya que podría ayudarlos a darse cuenta de posibles simplificaciones para el modelo o incluso potencial conceptual trampas en el modelo a medida que se implementa. Por ejemplo, ¿es razonable suponer que solo hay dos partes? ¿Es razonable suponer que el grupo de cada persona amigos no cambia durante el período de tiempo modelado en la simulación? Cuando se trata de la comunicación del modelo conceptual, a menudo hay espacio para humanos. error y malentendido En una situación ideal, el autor del modelo y el implementador son la misma persona, lo que evita el tipo de errores de comunicación que pueden resultar de diferentes vocabularios ent y supuestos diferentes. Sin embargo, el tiempo requerido para los expertos en dominios para aprender programación de computadora, o por el contrario, el tiempo requerido para el programa de computadora Mers para aprender un dominio particular, puede ser sustancial. Esto fue particularmente cierto en el pasado décadas, cuando a menudo era inviable convertirse en un implementador de modelos experto y autor modelo. Sin embargo, los nuevos lenguajes ABM de bajo umbral, como NetLogo, tienen un objetivo explícito de disminuir la cantidad de tiempo necesario para aprender a escribir ABM, por lo tanto reducir (o eliminar) la brecha entre el autor y el implementador.
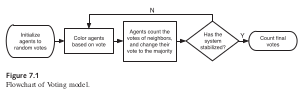
8.4 Descripción de Modelos Conceptuales
A medida que comenzamos a implementar el modelo de votación, podemos darnos cuenta de que hay algunos mecanismos nismos y propiedades de agentes que no entendimos completamente cuando hablamos con Los politólogos. Para aliviar este problema, decidimos escribir un documento que describa cómo planeamos implementar el modelo para que podamos verificar que nosotros y la ciencia política Los expertos tienen el mismo modelo conceptual en mente. Este documento servirá como un documento más formal. Descripción del modelo conceptual. Una forma de describir modelos conceptuales en términos más formales es usar un diagrama de flujo. UNA El diagrama de flujo es una descripción gráfica del modelo que describe el flujo de decisiones que ocurrir durante la operación de una pieza de código de software. Para el modelo conceptual descrito arriba, podríamos usar un diagrama de flujo como el de la figura 7.1. Los diagramas de flujo usan cuadrados redondeados para indicar los estados de inicio y detención del sistema, cuadrados para indicar procesos y diamantes para indicar puntos de decisión en el código. Estas Los símbolos proporcionan una forma clara de entender cómo fluye el control a través del software. También podemos tomar el diagrama de diagrama de flujo y reescribirlo en pseudocódigo. El objetivo de El seudocódigo sirve como punto intermedio entre el lenguaje natural y el programa formal. lenguaje ming El pseudocódigo puede ser leído por cualquier persona, independientemente de su programación conocimiento, mientras que, al mismo tiempo, contiene una estructura algorítmica que lo hace más fácil para implementar directamente en código real. Por ejemplo, al describir el modelo de votación, podríamos use un pseudocódigo como este: Los votantes tienen votos = {0, 1} Para cada votante: Establezca el voto 0 o 1, elegido con igual probabilidad Loop hasta la elección Para cada votante Si la mayoría de los votos de los vecinos = 1 y voto = 0, establezca el voto 1 De lo contrario, si la mayoría de los votos de los vecinos = 0 y voto = 1, establezca el voto 0 Si voto = 1: establece el color azul De lo contrario: color = verde Mostrar recuento de votantes con voto = 1 Mostrar recuento de votantes con voto = 0 Bucle final
882/5000 Además de los diagramas de flujo y el pseudocódigo, varios otros métodos para describir modelos ceptuales merecen mención. Por ejemplo, Booch, Rumbaugh y Jacobson idearon El lenguaje de modelado unificado (UML). UML está diseñado para que diferentes lectores tengan diferentes puntos de entrada a la descripción del modelo conceptual, por ejemplo, entrada diferente puntos para usuarios de modelos versus creadores de modelos (2005). UML usa una combinación de gráficos vistas y texto en lenguaje natural para describir modelos. También ha habido intentos recientes para integrar conceptos específicos de ABM en UML (Bauer, Muller y Odell, 2000). Otro El método implica elegir un lenguaje que sea lo suficientemente similar al pseudocódigo que pueda ser claramente entendido por un no experto. Usar un lenguaje de bajo umbral como NetLogo ayuda facilitar el proceso de verificación porque su sintaxis de código se corresponde estrechamente con la natural idioma.
8.5 Verification Testing
Después de diseñar el modelo conceptual con nuestros colegas de ciencias políticas, podemos comenzar codificación. Seguimos el principio de diseño central de ABM y comenzamos a verificar de forma simple e incremental La alineación entre nuestro modelo conceptual y el código. Por ejemplo, podemos escribir el procedimiento de configuración, como aquí:
patches-own [ vote ;; my vote (0 or 1) total ;; sum of votes around me] to setup clear-all ask patches [ if (random [ set vote] ask patches [ if (random 2 = [ set vote] ask patches [ recolor-patch] end 2 = 0) ;; half a chance of this 1 ] 0) ;; half a chance of this 0 ] to recolor-patch ;; patch procedure ifelse vote = 0 [ set pcolor green ] [ set pcolor blue ] end
648/5000 Luego podemos escribir una pequeña prueba que examine si el código creó el número correcto de votantes verdes y azules. 2 En el estado inicial del modelo de votación, el número de votantes con voto 0 debería ser aproximadamente igual al número de votantes con voto 1. Podemos verificar esto fácilmente al configurar nuestro modelo varias veces, comparando los recuentos de cada voto. Si la diferencia en estas muchas configuraciones es más de aproximadamente el 10 por ciento, por ejemplo, nuestro código podría tener un insecto. 3 Si la diferencia es inferior al 10 por ciento del número total, podemos sentir relativamente confiamos en que las poblaciones se generan como pretendíamos. Este código se vería así:
to check-setup let diff abs ( count patches with [ vote = 0 ] - count patches with [ vote = 1 ] ) if diff > .1 * count patches [ print “Warning: Difference in initial voters is greater than 10 4 %.”] end
832/5000 Podemos insertar una llamada a CHECK-SETUP en la parte inferior del procedimiento de CONFIGURACIÓN. Esta prueba luego se ejecutará cada vez que el modelo ejecute SETUP y, si hay un problema, alertará Quien está ejecutando el modelo que hay un desequilibrio de votación. Usando este procedimiento de CONFIGURACIÓN, la advertencia aparece casi cada vez que ejecutamos el modelo, lo que nos dice que el código no está logrando lo que pretendíamos. Además, es visualmente Es evidente que este código crea muchos más parches que son verdes (voto = 0) que azules (voto = 1). Debido a que todos los errores no son aparentes visualmente, es importante escribir pruebas de verificación Tant. (Se alienta a los lectores a examinar el código de configuración anterior y determinar su falla). Después de descubrir el error, podemos reescribir el procedimiento de configuración con lo siguiente (más simple) código, que logra el equilibrio correcto de los votantes iniciales.
to setup clear-all ask patches [ set vote random 2] ask patches [ recolor-patch] check-setup end
Esta técnica de verificación es una forma de prueba unitaria. Pruebas unitarias (relacionadas con el componente prueba) es un enfoque que implica escribir pequeñas pruebas que verifican si las unidades individuales funcionan correctamente en el código (Rand & Rust, 2011). Al escribir pruebas unitarias a medida que desarrollamos nuestro código, podemos asegurarnos de que los cambios futuros en nuestro código no interrumpan el código anterior. Dado que esta prueba unitaria se ejecutará cada vez que ejecutemos este modelo, garantiza que podamos modificar el código sin temor a que nuestros cambios alteren indetectable el código anterior. De Por supuesto, esta es solo una prueba unitaria, y hay muchas más que podrían escribirse. Lo anterior es un ejemplo de prueba de unidad “en modelo”, a veces llamada unidad “en línea” prueba porque sucede mientras se ejecuta el modelo. También es posible escribir por separado conjunto de pruebas unitarias que no forman parte del modelo implementado, sino que están escritas para ejecutarse el modelo con entradas particulares y compruebe si las salidas corresponden a lo esperado resultados. Este enfoque a veces se denomina prueba de unidad “fuera de línea”. (Una cuenta más detallada de pruebas unitarias está más allá del alcance de este libro de texto, pero para obtener más información sobre el software prueba, consulte Patton, 2005.) Después de estar seguros de que se verifica el código de CONFIGURACIÓN, nosotros comenzar un proceso similar para el procedimiento GO. Traducimos el pseudocódigo en NetLogo código de la siguiente manera:
to go ask patches [ set total (sum [vote] of neighbors)] ;; this is equivalent to count neighbors with [vote = 1] ;; use two ask patches blocks so all patches compute “total” ;; before any patches change their votes ask patches [ ifelse vote = 0 and total >= 4 [ set vote 1] [if vote = 1 and total <= 4 ] [ [set vote 0] recolor-patch] tick end
389/5000 En este código, primero pedimos a los parches que calculen el número total de vecinos con voto. = 1. Si el parche está votando 0 y tiene un total mayor o igual a 4, entonces cambia a votación 1. Del mismo modo, si el parche está votando 1 y tiene un total menor o igual a 4, cambia su voto a 0. Después de verificar los procedimientos SETUP y GO, podemos comenzar a investigar los resultados del modelo
8.6 Más allá de la verificación
A pesar de los mejores esfuerzos para verificar que el modelo implementado basado en el agente corresponde a En el modelo conceptual, a veces producirá resultados que no parecen corresponder a lo que los implementadores y los autores plantearon. Con el tiempo, puede quedar claro que no hay “error” en el modelo, sino que los resultados emergentes y sorprendentes de la modelo son consecuencias no deseadas de decisiones a nivel individual que el modelador tiene codificado.
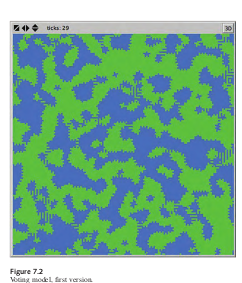
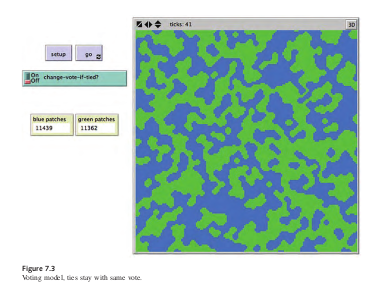
Por ejemplo, después de codificar el modelo anterior, presentamos los resultados a nuestra política colegas científicos (figura 7.2). Los resultados del modelo confunden a los politólogos, porque esperaban que el modelo se uniera con los votantes formando bloques estáticos con suavidad bordes, en lugar de los bordes irregulares que aparecen en la figura. De hecho, este modelo nunca alcanza el equilibrio; Continuamente recorre un conjunto de estados. Después de un examen más detallado, queda claro que lo que está causando el ciclo del modelo y tener bordes dentados es empatar votos. Como lo codificamos, el modelo hace que los votantes cambien su voto si el recuento de votos de sus vecinos está vinculado. Por lo tanto, los votantes al borde de la concentración Los bloques siguen yendo y viniendo entre los dos votos. Podemos cambiar el modelo para que los votantes no cambien su voto si los votos de sus vecinos están empatados. Después de hacer esto cambiar, los bloques se unen con bordes lisos (figura 7.3). Sin embargo, como lo político los científicos se han interesado en cómo un cambio aparentemente pequeño crea una gran diferencia En el resultado, deciden hacer de este un elemento del modelo que puedan controlar agregando un interruptor, llamado CAMBIAR-VOTAR-SI-TIED? Tener esta opción como elemento controlable nos permite explorar nuevos comportamientos de votación. Por ejemplo, ¿qué pasaría si los votantes decidieran ponerse del lado del partido minoritario en su ¿barrio? Es decir, imagine una comunidad donde, cuando los vecinos de un miembro están dividido estrechamente entre dos candidatos, el miembro decide votar por el desvalido (quienquiera que la mayoría de sus vecinos no voten), ya que el miembro podría ser capaz de asegurar la victoria del desvalido. Tenga en cuenta que esta perversidad hipotética de los agentes puede No refleja las prácticas de votación del mundo real. Sin embargo, esta es una cuestión de validación del modelo. (que discutiremos más adelante), en lugar de la verificación. A continuación se muestra el código para el programa go cedure con las dos opciones agregadas:
to go ask patches [ set total (sum [vote] of neighbors) ] ;; use two ask patches blocks so all patches compute “total” ;; before any patches change their votes ask patches [ if total > 5 [ set vote 1 ] if total < 3 [ set vote 0 ] if total = 4 [ if change-vote-if-tied? [ set vote (1 - vote) ] ] ;; switch vote if total = 5 [ ifelse award-close-calls-to-loser? [ set vote 0 ] [ set vote 1 ] ] if total = 3 [ ifelse award-close-calls-to-loser? [ set vote 1 ] [ set vote 0 ] ] recolor-patch ] tick end
1655/5000 La oportunidad de explorar situaciones hipotéticas intrigantes es uno de los puntos fuertes de modelado basado en agentes. Cuando la opción “votar por los desvalidos” está activada, que es controlado por nuestro PREMIO-CIERRE-LLAMADAS-A-PERDEDOR? interruptor, otro emergente resultados del patrón (figura 7.4). En este caso, bloques de azules y verdes se unen mientras son irregulares Los límites entre las zonas se desvían y distorsionan gradualmente a medida que pasa el tiempo. Si decidimos activar tanto el “CAMBIAR-VOTAR-SI-TIED?”Y el" PREMIO- ¿LLAMADAS CERCANAS AL PERDEDOR? “Opción, obtenemos un resultado diferente. Esta última opción (figura 7.5) da como resultado un patrón de colores aparentemente aleatorio, sin grandes bloques sólidos De cualquier color. Este ejemplo ilustra que, al examinar los resultados del modelo, puede ser difícil descifrar si el resultado de un modelo es el resultado de errores en el código, una falta de comunicación entre el autor del modelo y el implementador, o un resultado”correcto" pero no anticipado del Reglas de agente. Por lo tanto, es vital que el implementador del modelo y el autor del modelo discutan ambos modelar reglas y resultados con la mayor frecuencia y regularidad posible, y no simplemente cuando finalice izing el modelo. Saltarse este proceso de comunicación puede resultar en el modelo implementador creando un modelo con comportamiento de agente que el autor del modelo no tenía la intención. Sin embargo, al mantener estas comunicaciones, el autor del modelo puede descubrir que Las variantes en su modelo conceptual resultan en resultados dramáticamente diferentes. Incluso si los la misma persona es autor e implementador del modelo, es útil revisar las reglas del modelo y resultados de forma iterativa y discutirlos con personas que están familiarizadas con el fenómeno modelado
8.7 análisis de sensibilidad y robustez
2011/5000 Después de que hayamos terminado de construir un modelo y encontrado algunos resultados interesantes, es importante explorar estos resultados para determinar qué tan sensible es nuestro modelo al conjunto particular de condiciones iniciales que estamos usando. A veces, esto solo significa variar un grupo de parámetros que ya tenemos dentro de nuestro modelo, pero otras veces, esto implica agregar nuevos parámetros al modelo. Este proceso, llamado análisis de sensibilidad, crea una comprensión. de cuán sensible (o robusto) es el modelo a varias condiciones. Un tipo de análisis de sensibilidad implica alterar los valores de entrada del modelo. Por ejemplo, uno de los politólogos está preocupado por las condiciones iniciales del modelo, piensa ing que el comportamiento actual del modelo puede depender inicialmente de tener un equilibrio Número de votantes para cada partido (color). Ella se pregunta si inclinar el saldo inicial en una dirección u otra daría como resultado que un color domine el paisaje. Probar Con esta hipótesis, creamos un parámetro (un control deslizante en la interfaz del modelo) que controla El porcentaje de agentes verdes en el estado inicial del modelo. Usando BehaviorSpace (como discutido en el capítulo 6), luego ejecutamos un conjunto de experimentos donde variamos este porcentaje del 25 por ciento al 75 por ciento en incrementos del 5 por ciento. Al establecer la condición de parada para En este experimento, debemos tener en cuenta que es posible tener patrones oscilantes interminables. Por esta razón, decidimos establecer dos condiciones de parada diferentes: (1) el modelo detenerse si ningún votante cambió de votos en el último paso de tiempo, y (2) el modelo se detendrá después de uno se han ejecutado cien pasos de tiempo, ya que parece ser tiempo suficiente para llegar a una final estado del modelo. Esta investigación significará que tenemos que reevaluar nuestro componente prueba (configuración de verificación creada durante el proceso de verificación inicial, ya que ahora estamos delib- alterando completamente la distribución inicial. Por lo tanto, podemos alterar este código para que tome en cuenta el nuevo parámetro:
to check-setup let expected-green (count patches * initial-green-pct / 100) let diff-green (count patches with [ vote = 0 ] ) - expected-green if diff-green > (.1 * expected-green) [ print “Initial number of green voters is more than expected.”] if diff-green < (- .1 * expected-green) [ print “Initial number of green voters is less than expected.”] end
2035/5000 Podemos examinar la relación entre la distribución inicial de votantes y el recuento final de votos por ejecutando diez ejecuciones para cada porcentaje inicial. La medida más simple del dominio de cada partido político debe contar el porcentaje de votantes finales que son verdes o azules. Después de ejecutar nuestro experimento BehaviorSpace, podemos trazar los resultados del porcentaje final edad contra el porcentaje de entrada, obteniendo el gráfico en la figura 7.6. Estos resultados muestran que, a medida que nos alejamos de una distribución inicial de votantes medio azules y votantes medio verdes, hay un efecto no lineal en la distribución final de los votantes. los El modelo es sensible a estos parámetros, y por lo tanto, un ligero cambio en el número de inicial los votantes de un partido dan como resultado un mayor número de votantes finales para ese mismo partido. Sin embargo, La definición de “sensibilidad” depende de los resultados del modelo que esté considerando. por Por ejemplo, la sensibilidad en los resultados cuantitativos no significa necesariamente que habrá sensibilidad en los resultados cualitativos. Si el resultado de su modelo principal es el hallazgo cualitativo que se forman islas sólidas de votantes de ambos colores, dejando la segregación, entonces esta cualitativa el resultado sigue siendo cierto incluso si perturba la distribución inicial de los votantes en un 10 por ciento en cualquier dirección. Cuando están perturbadas, las islas de un color u otro pueden ser mucho más pequeño, pero aún habrá bloques sólidos. Por lo tanto, para esta medida cualitativa, podría Concluimos que este modelo es insensible a pequeños cambios en el balance inicial de votantes. El análisis de sensibilidad es un examen del impacto de diferentes parámetros del modelo en Resultados del modelo. Para determinar qué tan sensible es un modelo, examinamos el efecto que diferentes Las condiciones iniciales y los mecanismos del agente tienen en los resultados del modelo. Además, podemos examinar el entorno en el que opera el modelo. Por ejemplo, en el modelo de votación, estamos usando una cuadrícula toro bidimensional, pero estos resultados podrían cambiar drásticamente si los votantes se ubicaron en una cuadrícula hexadecimal, una red o alguna otra topología.
1056/5000 También se han realizado investigaciones anteriores sobre metodologías para automatizar el proceso de envío. análisis de sitividad. BehaviorSpace de NetLogo facilita el proceso de análisis de sensibilidad al facilitar el barrido de un gran conjunto de parámetros y examinar los resultados. Molinero (1998) desarrollaron una metodología llamada Prueba no lineal activa (ANT), que toma un conjunto de parámetros, un modelo y un criterio como sus entradas. El criterio es el aspecto de la modelo que nos gustaría probar, como la cantidad de votantes verdes al final de la carrera. ANT luego usa una técnica de optimización, como algoritmos genéticos, para encontrar un conjunto de parámetros que maximizan este criterio. Presenta al usuario un conjunto de parámetros que mejor “romper” el modelo de acuerdo con algunos criterios. Stonedahl y Wilensky (2010b, 2010c) han desarrollado técnicas y una herramienta, llamada BehaviorSearch, 6 para automatizar parámetros exploración y análisis mediante la búsqueda de comportamientos del modelo objetivo. BehaviorSearch puede ser muy útil cuando el espacio de parámetros es demasiado grande para buscar exhaustivamente.
8.8 Beneficios de la verificación
2924/5000 Existen muchos beneficios al realizar análisis de verificación, que incluyen el desarrollo de un comprensión de la causa de resultados inesperados y exploración del impacto de los pequeños cambios en las reglas El nivel básico de verificación es que el implementador del modelo compare la descripción conceptual del modelo con el código implementado para determinar si El modelo implementado corresponde al modelo conceptual. Cuanto más riguroso sea el modelo proceso de verificación, es más probable que el modelo implementado resultante corrija responder al modelo conceptual. Si los dos modelos corresponden exactamente, entonces el modelo los autores entienden las reglas de bajo nivel del modelo. Esto significa que entienden cómo El modelo genera sus resultados. Aún así, comprender los componentes de bajo nivel del modelo no garantiza una comprensión de todas las interacciones de estos componentes o de por qué el modelo genera los resultados agregados que hace. La verificación es importante porque ayuda a garantizar que el autor (o autores) entiendan los mecanismos que subyacen fenómeno que se está explorando. Sin pasar por este proceso, los autores no pueden ser confía en las conclusiones extraídas del modelo. La verificación puede ser difícil de lograr porque es difícil determinar si Un resultado sorprendente es el producto de un error en el código, una falta de comunicación entre el autor e implementador del modelo, o un resultado inesperado de una regla de bajo nivel. Pelaje- además, aún puede ser difícil aislar y eliminar un error, o corregir el error nicación Incluso si estamos seguros de que el resultado es una consecuencia inesperada pero precisa, Puede ser difícil descubrir qué causó que los resultados fueran diferentes de lo que esperado. El proceso de comprender cómo funciona un modelo también puede ayudarnos a comprender el Pregunta de “por qué”. Por ejemplo, en el modelo anterior, como examinan los politólogos En el modelo, comienzan a comprender la razón por la que el segundo modelo se une en bloques. Al pensar en las reglas del modelo desde el punto de vista del agente, queda claro que una vez que se forma un bloque de individuos permanecerá constante, mientras que si la mayoría de un los vecinos del agente votan de una manera y ninguno de ellos está cambiando, entonces el agente lo hará seguir votando de la misma manera. Por lo tanto, una vez que todos los agentes hayan alcanzado la mayoría consenso de sus vecinos, se quedarán así para siempre. Es solo cuando damos agentes la capacidad de cambiar colores según los recuentos que los rodean, como en las otras dos reglas, que vemos un cambio perpetuo en los resultados. El proceso de verificación no es binario. Un modelo no está verificado o no verificado, pero más bien existe a lo largo de un continuo de verificación. Siempre es posible escribir más comp pruebas de ponente o para realizar más análisis de sensibilidad. Por lo tanto, depende del autor del modelo. e implementador (y más tarde un replicador de modelos) para decidir cuándo la verificación
8.9 Validación
1699/5000 La validación es el proceso de asegurar que haya una correspondencia entre modelo implementado y realidad. La validación, por su naturaleza, es compleja, multinivel y relativa. tive Los modelos son simplificaciones de la realidad; Es imposible que un modelo exhiba todos los mismas características y patrones que existen en la realidad. Al crear un modelo, queremos incorporar los aspectos de la realidad que sean pertinentes a nuestras preguntas. Así, cuando se emprende Al realizar el proceso de validación, es importante tener en cuenta las preguntas del modelo conceptual. y validar aspectos del modelo que se relacionan con estas preguntas. Hay dos ejes diferentes para considerar los problemas de validación (Rand & Rust, 2011). El primer eje es el nivel en el que se produce el proceso de validación. Microvalida- es asegurarse de que los comportamientos y mecanismos codificados en los agentes del modelo coincidir con sus análogos del mundo real. La macrovalidación es el proceso de asegurar que las propiedades agregadas y emergentes del modelo corresponden a las propiedades agregadas en el mundo real. El segundo eje de validación es el nivel de detalle del proceso de validación. La validación facial es el proceso de mostrar que los mecanismos y propiedades del modelo parecen mecanismos y propiedades del mundo real. La validación empírica asegura que el modelo genera datos que pueden demostrarse que corresponden a patrones similares de datos en el mundo real. Para ayudar a ilustrar el proceso de validación de un ABM, utilizaremos el modelo Flocking de la sección de Biología de la biblioteca de modelos NetLogo. Este modelo intenta recrear patrones de aves que acuden como existen en la naturaleza (ver figura 7.7). El modelo de flocado es
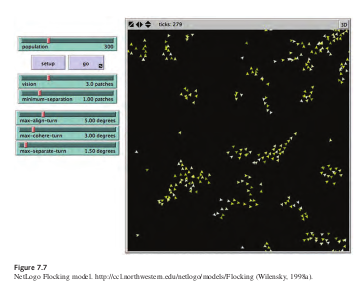
1195/5000 Un modelo clásico basado en agentes basado en los modelos originales de Boids de Reynolds (1987). El modelo demuestra que pueden surgir bandadas de pájaros sin ser guiados de ninguna manera por Aves líderes especiales. Por el contrario, cada ave sigue exactamente el mismo conjunto de reglas, desde qué bandadas emergen. Cada ave sigue tres reglas: “alineación”, “separación” y “coherencia” Sion. "" Alineación “significa que un pájaro gira para que se mueva en la misma dirección que cerca aves.”Separación" significa que un pájaro gira para evitar golpear a otro pájaro. “Cohesión” significa un pájaro se mueve hacia otras aves cercanas. La regla de “separación” anula las otras dos, lo que significa que si dos pájaros se acercan, siempre se separarán. En esto caso, las otras dos reglas se desactivan hasta que se logra la separación mínima. los tres reglas afectan solo el rumbo del ave. Cada ave siempre avanza al mismo tiempo velocidad constante. Las reglas son notablemente robustas y se pueden adaptar al enjambre de insectos, escolarización de peces y patrones de flocado, como la “V” de gansos (Stonedahl y Wilensky, 2010a). Describamos brevemente la implementación de estas tres reglas. La regla de alineación es codificado de la siguiente manera
to align ;; turtle procedure turn-towards average-flockmate-heading max-align-turn end
372/5000 Este código le dice al pájaro que gire hacia el rumbo promedio de sus compañeros de manada, pero no más que el control deslizante MAX-ALIGN-TURN, que especifica el ángulo máximo que puede girar un pájaro con el fin de alinearse con sus compañeros de rebaño. Este código requiere dos procedimientos auxiliares: uno para encontrar los compañeros de bandada de un pájaro y otro para encontrar su rumbo promedio. El primero es sencillo:
to find-flockmates ;; turtle procedure set flockmates other turtles in-radius vision end
8.10 Replicación
3044/5000 Uno de los componentes fundamentales del método científico es la idea de replicación. (Latour y Woolgar, 1979). Desde este punto de vista, para que un experimento sea considerado aceptable por la comunidad científica, los científicos que originalmente realizaron el experimento debe publicar los detalles de cómo se realizó el experimento. Esta La descripción de puede ayudar a los equipos de científicos posteriores a realizar el experimento ellos mismos para determinar si sus resultados son lo suficientemente similares como para confirmar los resultados originales. Esta el proceso confirma el hecho de que el experimento no dependía de ninguna condición local, mientras que la descripción escrita del experimento es lo suficientemente satisfactoria como para registrar el conocimiento ventaja obtenida en el registro permanente. La replicación es una parte importante del proceso científico y es tan importante dentro el ámbito de los modelos computacionales como lo es dentro del ámbito de los experimentos físicos. Reps- La reproducción de un experimento físico ayuda a demostrar que los resultados originales no se deben a errores o descuidos en la ejecución probando y comparando tanto la configuración experimental como resultados posteriores. La replicación de un modelo computacional sirve para este mismo propósito. Adicionalmente, replicar un modelo computacional aumenta nuestra confianza en la verificación del modelo ya que Una nueva implementación del modelo conceptual ha arrojado los mismos resultados que el original. La replicación también puede ayudar en la validación del modelo, ya que requiere que los replicadores del modelo intenten entender las elecciones de modelado que se hicieron y cómo los modeladores originales vieron el coincidencia entre el modelo conceptual y el mundo real. Wilensky y Rand (2007) 7 dan Una descripción detallada de la replicación de un modelo basado en agentes utilizando el modelo de etnocentrismo de Axelrod y Hammond (2002, 2006; ver figura 7.11). En este modelo, los agentes compiten por espacio limitado a través de interacciones de tipo Dilema de prisioneros. Los agentes tienen uno de cuatro posibles etnias y cada agente tiene una estrategia que incluye si coopera o si falla con agentes de su propia etnia y con otras etnias. Los agentes “etnocéntricos” tratan a los agentes dentro de su grupo más beneficiosamente que aquellos fuera de su grupo. El modelo incluye un mecanismo de herencia (genético o cultural) de estrategias. El modelo sugiere que El comportamiento “etnocéntrico” puede evolucionar bajo una amplia variedad de condiciones, incluso cuando hay no son “etnocéntricos” nativos y no hay forma de que los agentes sepan de antemano si otro agente Cooperará con ellos. En el proceso de intentar la replicación, se descubrieron diferencias entre los Modelo Wilensky-Rand y el modelo Axelrod-Hammond; el modelo replicado tenía que ser modificado para producir los resultados originales. El esfuerzo de replicación finalmente tuvo éxito pero el proceso que se requirió para determinar que la replicación fue exitosa fue problemas imprevistos complicados e involucrados. Wilensky y Rand describieron la consideración aciones que deben examinarse cuidadosamente y extraer algunos principios para ambos modelos replicadores y autores de modelos. Revisaremos los de este documento.
4993/5000 Límite de caracteres: 5000 La replicación es la implementación por un científico o grupo de científicos de un concepto modelo (modelo replicado) descrito y ya implementado (modelo original) por una ciencia entiste o grupo de científicos en un momento anterior. La implementación del modelo replicado debe diferir de alguna manera del modelo original y también debe ser ejecutable (en lugar de otro modelo conceptual formal). Dado que la replicación se refiere a la creación de un nuevo implemento mentación de un modelo conceptual basado en los resultados previos de una implementación, el Los términos modelo original y modelo replicado siempre se refieren a modelos implementados. Un modelo original y un modelo replicado asociado pueden diferir en al menos seis dimensiones: (1) tiempo, (2) hardware, (3) idiomas, (4) juegos de herramientas, (5) algoritmos y (6) autores. Esta lista está ordenada según la probabilidad de que el esfuerzo de replicación produzca Resultados diferentes del modelo original. Por lo general, más de una de estas dimensiones son variado en el curso de un modelo único de replicación. Tiempo Un modelo puede ser replicado por el mismo individuo en el mismo hardware y en el mismo kit de herramientas y entorno de lenguaje pero reescrito en un momento diferente. Este cambio en es menos probable que la dimensión produzca resultados significativamente diferentes pero, si lo hiciera, lo haría indicar que la especificación publicada es inadecuada, ya que incluso el investigador original no se pudo volver a crear el modelo a partir del modelo conceptual original. Este es el único dimen- Sión de replicación que siempre será variada. Hardware El modelo puede ser replicado por el mismo individuo pero en diferente hardware mercancía. Como mínimo, por un cambio en el hardware queremos decir que el modelo implementado fue correr en una máquina diferente. Los cambios de hardware también se pueden obtener replicando el modelo en una plataforma de hardware diferente. Independientemente, dada la prevalencia de hardware idiomas independientes, ninguno de estos cambios debe proporcionar significativamente diferente resultados. Sin embargo, si los resultados son diferentes, las investigaciones (a menudo técnicas) están justificadas y podría, por ejemplo, señalar que el modelo es susceptible a pequeños cambios en el orden de ejecución de comportamiento. Idiomas El modelo podría replicarse en un lenguaje de computadora diferente. Por un com lenguaje informático, nos referimos al lenguaje de programación que se utilizó para codificar la instrucción iones en el modelo implementado. Java, Fortran, Objective-C y NetLogo son ejemplos de diferentes idiomas A menudo, la sintaxis y la semántica de un lenguaje (p. Ej., Procesal versus lenguajes funcionales) tienen un efecto significativo en cómo el investigador traduce el modelo conceptual en una implementación real. Por lo tanto, la replicación en un nuevo idioma puede Destacar las diferencias entre el modelo conceptual y la implementación. Incluso apareciendo detalles menores en lenguaje y especificaciones algorítmicas, como los detalles de flotante la aritmética puntual o las diferencias entre implementaciones de protocolos, pueden causar diferencias ences en modelos replicados (Izquierdo y Polhill, 2006; Polhill e Izquierdo, 2005; Polhill, Izquierdo y Gotts, 2005, 2006). Para que un modelo sea ampliamente aceptado como parte de la investigación científica conocimiento, debe ser robusto a tales cambios. Juegos de herramientas El modelo podría replicarse en un juego de herramientas de modelado diferente basado en el mismo lenguaje de ordenador. Un juego de herramientas, en este sentido, es una biblioteca de software o un conjunto de bibliotecas escritas en un idioma particular con el propósito de ayudar al desarrollo de un modelo. Por ejemplo, Repast (Collier, Howe y North, 2003), Ascape (Parker 2000) y MASON (Luke et al., 2004) son kits de herramientas claramente diferentes para construir ABM, aunque todos están escritos en Java. NetLogo es un ejemplo interesante porque, si bien el software de NetLogo está escrito en una combinación de Java y Scala, los modeladores usan otro lenguaje (también referido como NetLogo) para desarrollar modelos. Por lo tanto, clasificamos NetLogo como un kit de herramientas y un idioma. Con muchos kits de herramientas de modelado diferentes disponibles para su uso, los resultados de la replicación Inventar un modelo en un conjunto de herramientas diferente a menudo puede iluminar problemas no solo con lo conceptual modelo, pero también, con los propios kits de herramientas. Algoritmos El modelo podría replicarse usando diferentes algoritmos. Por ejemplo, hay Hay muchas formas de implementar algoritmos de búsqueda (por ejemplo, primero en amplitud, primero en profundidad) o actualizar una gran cantidad de objetos (por ejemplo, en orden de creación de objetos, en un orden aleatorio elegido en el comienzo de la carrera, en un orden aleatorio cada vez). De hecho, un modelo replicado puede simplemente realice los pasos de un modelo en un orden diferente al del modelo original. Todas estas diferencias pueden potencialmente crear disparidades en los resultados. Por otra parte, También es posible que la descripción algorítmica difiera, pero que los resultados no lo hagan. Esta podría suceder porque dos individuos describen el mismo algoritmo de manera diferente, o que el Las diferencias algorítmicas no afectan los resultados. Autores Los individuos, aparte del investigador original, pueden replicar el modelo.
4425/5000 Autores Los individuos, aparte del investigador original, pueden replicar el modelo. Esto es un prueba sólida de la replicabilidad de un modelo. Si otro investigador puede tomar una descripción formal del modelo y recrearlo para producir los mismos resultados, tenemos evidencia razonable de que el modelo se describe con precisión y los resultados son robustos a los cambios en las dimensiones de replicación que han sido alteradas. Una replicación exitosa es aquella en la que los replicadores pueden establecer que El modelo replicado crea salidas suficientemente similares a las salidas del original. Esta no significa necesariamente que los dos modelos tengan que generar exactamente los mismos resultados. Muchas veces es más importante que cambios similares generen efectos similares, pero disuadir la minería del estándar para el éxito queda en manos del investigador que realiza la replicación. los El criterio por el cual se juzga el éxito de la replicación se llama estándar de replicación (RS) Existen diferentes estándares de replicación para el nivel de similitud entre los resultados del modelo. Axtell y col. (1996) examinaron esta cuestión de estándares. Desarrollaron tres categorías. de estándares de replicación para un experimento de replicación. La primera categoría de replicación. estándares, “identidad numérica”, es difícil de establecer, ya que implica mostrar que el origen Los modelos finales y replicados producen exactamente los mismos resultados numéricos. Una forma de minimizar El riesgo de fracaso de la identidad numérica es mediante el uso de semillas aleatorias especificadas. 8 El segundo La categoría de los estándares de replicación es “equivalencia distributiva”. “Aquí, el objetivo es mostrar que los dos modelos implementados son suficientemente similares entre sí según las estadísticas medidas de cal. Para cumplir con este criterio, los investigadores de RS a menudo intentan mostrar indistintos estadísticos. guishability, es decir, que dados los datos actuales, no hay pruebas de que los modelos no sean distribucionalmente equivalente (Axtell et al., 1996; Edmonds y Hales, 2003). 9 La categoría final de los estándares de replicación es la”alineación relacional“.”Existe alineación relacional si los resultados de los dos modelos implementados muestran relaciones cualitativamente similares entre variables de entrada y salida. Por ejemplo, si aumenta la variable de entrada x en ambos modelos, la variable de salida y debería responder de la misma manera tanto en el primer modelo como en el El segundo modelo. Después de decidir la categoría de RS para un esfuerzo de replicación, es importante definir los detalles del RS particular que pretendes seguir más concretamente ya que hay muchos estándares de replicación más específicos que podrían definirse. Los ABM generalmente producen grandes cantidades de datos, muchos de los cuales generalmente son irrelevantes para el objetivo de modelado real. Solo los datos que son centrales para el modelo conceptual deben medirse y probarse durante replicación. Por ejemplo, la replicación de salidas como coordenadas x e y para cada agente con el tiempo, o la generación de números aleatorios particulares, puede ignorarse durante el proceso de replicación si no son parte integral del fenómeno que se está modelando. Por lo general, uno debe elegir las funciones apropiadas en un subconjunto de las variables de salida para que sean las medidas para replicación Una vez que se han elegido las medidas particulares, también es necesario elegir cómo a menudo se compararán los resultados. Un RS específico es simplemente hacer coincidir un conjunto particular de salidas al final de la ejecución. Otra RS más detallada sería hacer coincidir un conjunto de valores en varios puntos intermedios a lo largo de la carrera. Alternativamente, uno podría Intente hacer coincidir todas las salidas a lo largo de la ejecución para demostrar la equivalencia en el evolución de las salidas a lo largo del tiempo. Este último RS está quizás más en el espíritu ABM en que se preocupa menos por el equilibrio y más por la dinámica a lo largo del tiempo. Como Epstein afirma en su artículo seminal de 1999: “Si no lo cultivaste, no explicaste su emergencia gence En otras palabras, para comprender completamente un fenómeno, es importante modelar el proceso que lo crea en lugar de simplemente ajustar una curva a algunos de los números que caracterízalo Tenga en cuenta que las medidas mismas también deben reproducirse en el modelo replicado. En Para evitar un retroceso infinito de repeticiones, los replicadores de modelos a menudo proceden con la suposición de que una determinación de la replicación exitosa de las medidas puede ser logrado al comparar las medidas replicadas con su descripción conceptual (es decir,”veri ficación "de las medidas).