K Banos Modelos Basados en Agentes
La pregunta de investigación y el modelo que se diseñará a veces es claro desde el principio Más a menudo, uno tiene una idea del tema, pero no nada más preciso. Es esencial que el interés general en un tema se refine a una pregunta específica antes de que comience el diseño del modelo. Si esto no se hace, el la tarea de diseño puede parecer imposiblemente difícil o su modelo puede convertirse demasiado abarcador para ser útil. Es útil pensar en reducir una pregunta de investigación en términos de moverse a través de un conjunto de capas (ver Punch 2000 para un tratamiento útil). Un área de investigación, como procesos grupales, contiene muchos temas, por ejemplo, el comportamiento de multitudes de dos partes. Más específica es una pregunta de investigación general, generalmente formulada en términos de teoría conceptos y la relación entre estos. La pregunta de investigación formulada en El artículo de Jager et al. Es, ¿cuál es la relación entre las características? de una multitud de dos partidos y la aparición de peleas entre los participantes? La pregunta de investigación general generará una pequeña cantidad de preguntas de investigación, como cuál es la relación entre la proporción de miembros “incondicionales” de una multitud y las posibilidades de que haya peleas? Las preguntas de investigación específicas deben tener un nivel de detalle tal que su Los conceptos se pueden utilizar como elementos principales del modelo. Finalmente hay preguntas de datos que el modelo responderá con proporciones o porcentajes: por ejemplo, cuánta diferencia hace en la probabilidad de pelear si el porcentaje de hardcore es 1 o 5 por ciento?
1367/5000 El mundo social es muy complicado, un hecho que los modelistas están bien conscientes, especialmente cuando comienzan a definir el alcance de un modelo. Como observado en el Capítulo 2, el arte de modelar es simplificar lo más posible, pero no simplificar demasiado al punto donde las características interesantes del fenómeno se pierden (Lave y marzo de 1993). A menudo, un efectivo La estrategia es comenzar desde un modelo muy simple, que es fácil de especificar y implementar. Cuando uno comprende este modelo simple y su dinámica, se puede ampliar para abarcar más funciones y más complejidad. El modelo más simple de una multitud es probablemente un sistema en el que los agentes, todos idénticos y dispersos en una cuadrícula cuadrada, que se alejan al azar de una celda a la siguiente Tal modelo se puede construir en solo unas pocas líneas de NetLogo. El comportamiento no será interesante, si los agentes comienzan en ubicaciones aleatorias y moverse al azar, el patrón de agentes en la cuadrícula seguirá siendo aleatorio pero servirá bien como la línea de base desde la cual comportamientos más interesantes Puede ser añadido. El modelo de referencia puede diseñarse para ser el equivalente de Una hipótesis nula en el análisis estadístico: un modelo que no se espera que Muestra el fenómeno en cuestión. Entonces, si una adición al modelo de referencia está hecho, y el modelo se comporta de manera diferente, uno puede estar seguro de que es la adición la que está teniendo el efecto. l modelo de Jager et al. Incluye tres desarrollos de este modelo de referencia: un conjunto de comportamientos de agentes que varían según la cantidad de otros agentes en la localidad una división de los agentes en dos “partes” que son potencialmente en conflicto entre ellos; y una división de los agentes en tres tipos: hardcore, perchas y transeúntes. Cada uno de estos desarrollos afecta el patrones que se obtienen de la simulación de maneras interesantes. Sin embargo, Hay muchas otras extensiones que podrían hacerse al modelo (por ejemplo, agregando obstrucciones a la cuadrícula uniforme sobre la cual los agentes movimiento) y cada uno de ellos podría tener interacciones inesperadas con otros extensiones Para reducir la complejidad de todas estas posibilidades, es mejor comience de manera simple y luego agregue gradualmente características una por una. Esta estrategia también tiene la ventaja de que ayuda a centrar la atención en pregunta de investigación o preguntas que deben responderse. Un modelista debería siempre tienen a la vanguardia de su atención por qué están construyendo el modelo y lo que buscan obtener de él. Es una buena idea anote al principio una o dos preguntas que apunta el modelado contestar. Esto podría ser un objetivo resumido, junto con algunos objetivos Los autores del artículo de Jager et al. Afirman que su preocupación era con las características de grandes grupos que fomentaron la lucha entre sus miembros. Por lo tanto, su pregunta era, ¿cuáles son los efectos del tamaño del grupo, grupo simetría y composición grupal sobre la probabilidad de brotes de peleas en multitudes de dos partidos? Una declaración clara como esta de la pregunta de investigación puede Ser muy útil para guiar el desarrollo de un modelo de múltiples agentes. Si el modelo de línea base es lo suficientemente simple, la primera implementación del prototipo- a veces puede ser un modelo de “lápiz y papel”, en el que el diseñador (o el diseñador y algunos colegas) realizan la simulación “a mano” a través de algunas rondas Esta simulación de una simulación puede revelar rápidamente brechas y ambigüedades en el diseño, sin la necesidad de hacer ninguna codificación.
K.1 De la teoría al modelo
Diseñar un modelo es más fácil si ya hay un cuerpo de teoría en el que basarse. En una etapa temprana, por lo tanto, uno debe buscar la teoría existente, en de la misma manera que con las metodologías de ciencias sociales más tradicionales. Teorías sobre procesos de cambio y que consideran la dinámica. de los fenómenos sociales es probable que sean más útiles que las teorías sobre equilibrios o relaciones estáticas, pero cualquier teoría es mejor que ninguna. Lo que la teoría proporciona es una entrada a la literatura de investigación existente, insinúa sobre qué factores pueden ser importantes en el modelo, y algunos indicaciones sobre fenómenos comparables. Por ejemplo, Jager et al. explique En la introducción de su artículo, las primeras teorías suponían que las personas las personalidades son diferentes en situaciones de multitudes en comparación con sus situaciones normales personalidad, pero los escritores posteriores están de acuerdo en que esto no es así. Que es diferente es que las reglas culturales normales, las normas y las formas organizativas dejan de ser aplicable en multitudes, y las personas recurren a reglas de comportamiento más simples que Todos pueden entenderlo sin instrucciones o con mucho conocimiento cultural. Esta orientación teórica informa su elección de que los participantes serán modelado utilizando un conjunto de tres reglas de comportamiento bastante simples, que llaman la regla de vista restringida, la regla de evasión de aproximación y la regla del estado de ánimo. El papel de la teoría puede ser así dirigir la atención a las características relevantes. eso necesita ser modelado (como las reglas de comportamiento de Jager et al.), pero También puede ser más fundamental para el trabajo de modelado. Malerba y col. (1999) acuñó el término “amigable con la historia” para describir un modelo destinado a encapsula una teoría existente, anteriormente formulada solo como texto. Informes En un estudio sobre la evolución a largo plazo de la industria informática, escriben: Hemos tomado un cuerpo de teorización verbal apreciativa aceleró una representación formal de esa teoría y descubrió que la versión formal de esa teoría es consistente y capaz de generando los hechos estilizados que la teoría apreciativa pretende explique. Pasar por este ejercicio analítico tiene significativamente agudizó nuestra comprensión teórica de los factores clave aspectos sobresalientes traseros de la evolución de la industria informática. (Malerba et al. 1999: 3) Otra función de la teoría puede ser identificar claramente los supuestos sobre que se construye el modelo. Estas suposiciones deben estar tan claramente articuladas como sea posible si el modelo debe ser capaz de generar información útil. por ejemplo, en el modelo de multitud, Jager et al. supongamos que hay tres tipos de participante, hardcore, perchas y transeúntes, y que las proporciones de cada uno de estos tipos es aproximadamente 1: 2: 97, es decir, la gran mayoría de la multitud está espectadores El artículo analiza el efecto de variar estas proporciones, para ejemplo, de aumentar el componente hardcore al 5 por ciento, y compara Las proporciones con evidencia de la observación de multitudes reales.
K.2 El proceso de diseño
Una vez que la investigación cuestiona, el enfoque teórico y los supuestos Si se han especificado claramente, es hora de comenzar a diseñar la simulación. Ahí es una secuencia de problemas que deben considerarse para casi todas las simulaciones, y es útil tratarlos sistemáticamente y en orden. Sin embargo, el diseño es más un arte que una ciencia y no hay “correcto” o “incorrecto” diseñar siempre que el modelo sea útil para abordar la pregunta de investigación. Aunque diseñar modelos puede parecer difícil la primera vez, se vuelve más fácil Con práctica y experiencia. El primer paso es la definición de los tipos de objetos que se incluirán en la simulación. La mayoría de estos objetos serán agentes, representando individuos o organizaciones, pero también puede haber objetos que representan características inanimadas que usan los agentes, como comida u obstáculos. Los diversos tipos de objetos. debe organizarse en una jerarquía de clases, con un objeto genérico en la parte superior, luego agentes y otros objetos como subtipos, y si es necesario, el tipo de agente dividido en otros subtipos. Estas clases se pueden organizar en una estructura de “árbol”, como en la Figura 9.2. Esta El diagrama muestra la jerarquía de clases para la simulación de multitudes. El diagrama es simple porque en esta simulación solo hay tres tipos de agente y Sin objetos inanimados. Si hubiéramos querido extender el modelo para incluirlo, por ejemplos de obstáculos por los cuales los participantes tendrían que moverse, esto sería han significado una clase adicional, como se muestra.
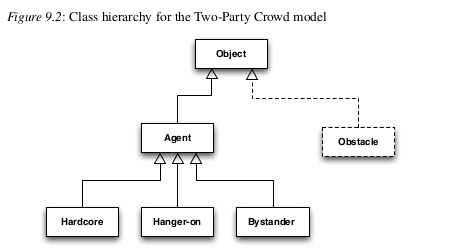

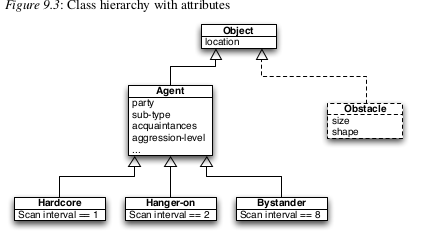
Tenga en cuenta que hemos definido una clase de Agente, como un tipo de objeto genérico, y que cada uno de los tipos de miembros de la multitud es un subtipo de este Agente. Esta significa que podremos organizar que gran parte de la codificación se ubique en la clase de agente y que cada tipo de participante es solo una pequeña modificación - una “especialización” - del tipo de agente básico. Organizarlo de esta manera hace es mucho más fácil ver qué difiere entre los miembros de la multitud y qué es lo mismo. El diagrama muestra clases o tipos de objetos. Cada objeto real en el la simulación será un ejemplo de uno de estos tipos (una “instancia” del clase). Todas las instancias de una clase son idénticas en términos del código que las crea y ejecuta, pero cada instancia puede estar en un estado diferente o tener diferentes atributos. Una vez que los objetos han sido decididos, uno puede considerar los atributos de cada objeto Un atributo es una característica o característica del objeto, y es ya sea algo que ayuda a distinguir el objeto de otros en el modelo, o es algo que varía de una vez en la simulación a otra. por ejemplo, en la simulación de multitudes, el nivel de agresión es un atributo de Los agentes que varían con el tiempo. Agentes hardcore escanean sus alrededores con más frecuencia que las suspensiones, por lo que la frecuencia de exploración es una buena opción para otro atributo de un agente. Los atributos funcionan como variables en un modelo matemático, y la mayoría de las cosas que varían deberán tratarse como atributos en la simulación. Considere cada objeto a su vez, y qué características tiene que difieren de otros objetos Las propiedades como el tamaño, el color o la velocidad pueden ser relevantes. atributos en algunos modelos. Variables de estado como riqueza, energía y número de amigos también pueden ser atributos. Un atributo puede consistir en uno solo de un conjunto de valores (por ejemplo, el atributo de color puede ser rojo, verde, azul o blanco); un número, como el nivel de energía del agente; o una lista de valores, como la lista de los nombres de todos los otros agentes que un agente ha encontrado previamente. Los subtipos heredan los atributos de sus tipos, por lo que que, por ejemplo, si todos los objetos tienen una ubicación, también lo tienen todos los subtipos de Objeto, tales como agentes y obstáculos. Cuando se han decidido los atributos para cada clase de objeto, pueden se muestra en el diagrama de clases, como en la Figura 9.3. Esta forma de representar las clases y los atributos se toman de un lenguaje de diseño llamado Unified Lenguaje de modelado (UML) (Booch et al. 2000) y se usa comúnmente en diseño de software orientado a objetos. En el ejemplo, los atributos para partici Los pantalones en la multitud se muestran en el cuadro Agente. En este ejemplo, el sub- Los tipos de agente (hardcore, perdedor y espectador) tienen un solo atributo Además de los que heredan en virtud de ser tipos de Agente, pero en otros modelos, los subtipos comúnmente tendrán atributos que solo ellos poseer, para representar características particulares de ese tipo. Habrá algunas características que pueden implementarse como atributos o como subclases. Por ejemplo, podríamos definir distintas subclases para tres tipos de participantes de la multitud, como se sugirió anteriormente, o podría haber uno tipo de agente con un atributo llamado, por ejemplo, “tipo de participante” y tomando uno de los valores, ‘hardcore’, percha ‘o’ espectador ’. Hacer cual alguna vez parece ser más natural, siempre que no haya demasiados sub clases (si bien es razonable tener tres subclases de Agente, una para para cada tipo de participante, sería incómodo si hubiera un centenar de tipos de participantes y una subclase para cada uno, mientras que no sería un problema tener un atributo con cien valores posibles). La siguiente etapa es especificar el entorno en el que se encuentran los objetos. situado. A menudo, el entorno es espacial, y cada objeto tiene un ubicación dentro de él (en ese caso, los objetos deben tener atributos que indiquen donde están en el momento actual). Pero hay otras posibilidades, como Tener a los agentes en una red unidos por relaciones de amistad o comercio con otros agentes A veces puede ser conveniente representar el medio ambiente como otro objeto, aunque sea especial, y especifique sus atributos. Uno de los Los atributos serán el tiempo simulado actual. Otro puede ser un mensaje búfer que contiene temporalmente mensajes enviados por agentes a otros agentes a través de El medio ambiente antes de ser entregados. En el curso de la definición de las clases, atributos y entorno, usted probablemente te encuentres yendo y viniendo, agregando o refinando cada uno de ellos en un proceso iterativo hasta que todo el conjunto parece consistente. Cuando esto es hecho, al menos en una primera aproximación, tiene un diseño estático para el modelo. El siguiente paso es agregar algunas dinámicas, es decir, averiguar qué sucede. cuando se ejecuta el modelo.
K.3 Añadiendo la dinámica (Interacciones)
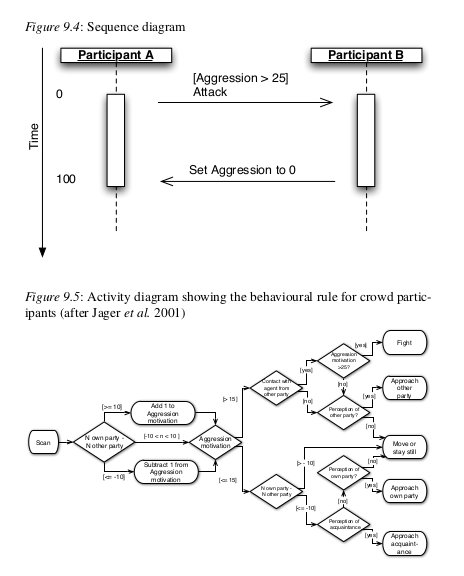
2606/5000 Por lo general, es más fácil comenzar considerando las interacciones de cada clase de agente con el medio ambiente. Un agente actuará sobre el medio ambiente en uno o Más formas. Por ejemplo, los participantes en la simulación de multitudes se mueven de ubicación a ubicación. Debe enumerar todas estas interacciones y también crear un lista de las formas en que el entorno actúa sobre el agente. Por ejemplo, el entorno evita que los miembros de la multitud se muden a un lugar ya está ocupado por otro agente. Una vez que estas listas de las acciones de los agentes y los entornos tienen creado, podemos pasar a considerar cuándo suceden las acciones. En contra la lista de acciones del agente en el entorno, indique las condiciones bajo que estas acciones deberían ocurrir. Esta tabla de condiciones y acciones conducen naturalmente a definir un conjunto de reglas de condición-acción. Cada regla debe ser asociado con un estado único del agente (un conjunto único de valores de atributo e insumos del medio ambiente). Una vez decididas las interacciones con el medio ambiente, lo mismo Se puede hacer un trabajo para las interacciones entre los agentes. En la simulación de la multitud, Hay dos tipos de interacción: los agentes pueden acercarse a otros agentes que ellos saben, y pueden luchar contra agentes de la otra parte. Como antes, estos las acciones deben estar asociadas con las condiciones bajo las cuales las acciones son tomado; por ejemplo, en la simulación de multitudes, los agentes lucharán solo cuando tienen una “motivación de agresión” superior a 25 unidades y son adyacentes a su víctima. Es probable que, al trabajar en estas listas, se dé cuenta de que Se necesitan atributos adicionales para los agentes o el entorno o ambos, por lo que el proceso de diseño deberá volver a las etapas iniciales, quizás varias veces. Cuando se ha creado un conjunto consistente de clases, atributos y reglas, puede ser útil resumir la dinámica en un diagrama de secuencia, otro tipo de diagrama UML. Un diagrama de secuencia tiene una línea vertical para cada tipo. o clase de agente, y flechas horizontales que representan mensajes o acciones que ir del objeto emisor al objeto receptor. La secuencia de mensajes se muestra por el orden vertical de las flechas, con la flecha superior que representa el primer mensaje y los mensajes posteriores que se muestran a continuación. La figura 9.4 es un ejemplo. El diagrama muestra dos tipos de agentes que tienen una pelea que dura 100 pasos de tiempo Este diagrama es bastante simple porque solo hay dos objetos y se muestran dos mensajes, pero en modelos más complejos, diagramas de secuencia puede volverse bastante elaborado (véanse las Figuras 2 y 3 de Etienne et al. 2003 para un ejemplo).
También puede ser útil emplear gráficos de estado y diagramas de actividad para resumir el comportamiento de los agentes (Fowler y Scott 1999). Un diagrama de estado El diagrama muestra cada estado distinto de un agente y lo que implica moverse de un estado a otro. Un diagrama de actividad muestra cómo se toman las decisiones. por un agente La Figura 9.5 muestra el modelo de comportamiento de un agente de multitudes como un diagrama de actividad (adaptado de Jager et al. 2001). Resumir el comportamiento de los agentes (Fowler y Scott 1999). Un diagrama de estado El diagrama muestra cada estado distinto de un agente y lo que implica moverse de un estado a otro. Un diagrama de actividad muestra cómo se toman las decisiones. por un agente La Figura 9.5 muestra el modelo de comportamiento de un agente de multitudes como un diagrama de actividad (adaptado de Jager et al. 2001).
K.4 Modelos Cognitivos
La figura 9.5 podría considerarse como un modelo cognitivo bastante simple de un agente. Describe cómo reacciona el agente cuando se le presentan estímulos del entorno. ronment. Sin embargo, como modelo cognitivo, sufre el divorcio de comprensión de los psicólogos de cómo funciona la cognición humana. Si la investigación la pregunta lo justifica, modelos cognitivos que están relativamente bien respaldados por los datos psicológicos se pueden usar directamente en una simulación o como espiración por las reglas del agente psicológicamente informadas. Uno de los primeros cognitivos modelos fue Soar (Laird et al. 1987), y continúa desarrollándose para esto día (para una descripción general reciente, ver Wray y Jones 2005). Soar es una producción sistema de reglas, lo que significa que incluye reglas de condición-acción, como aquellas discutido en el capítulo anterior, aunque también puede manejar más poderoso reglas que incluyen variables (usando predicado, en lugar de lógica proposicional). Soar también tiene una memoria de trabajo, pero en contraste con la regla de producción simple introducida en el Capítulo 8, esta memoria se divide en “estados”, correspondiente a los diferentes problemas que el agente ha estado resolviendo. los la condición de más de una regla de producción puede coincidir con cualquiera tiempo, y Soar tiene un sistema de procedimientos de preferencia para priorizar qué la regla es disparar entre todos aquellos cuyas condiciones coinciden. Se dispara repetidamente a través de un “ciclo de decisión” en el que primero obtiene entradas de percepción del entorno, calcula el conjunto de reglas que podrían activarse, aplica la preferencia procedimientos para seleccionar una regla para disparar, y luego dispara esa regla llevando a cabo La acción que especifica. Finalmente, se realiza cualquier salida al entorno. Este ciclo se repite indefinidamente. (Esta es una cuenta simplificada de más mecanismo complejo; para más detalles ver Rosenbloom et al. 1993.) ACT-R es otro modelo cognitivo (o “arquitectura”) con objetivos similares a Alza: para simular y comprender el comportamiento humano (Anderson y Lebiere 1998). Es un sistema modular, con distintos módulos que se ocupan de la memoria, entradas perceptivas del entorno, memorias intermedias que gestionan las interfaces entre módulos y un patrón de coincidencia que determina qué reglas son capaz de disparar Al igual que Soar, ACT-R incluye un sistema de producción, pero también tiene Un nivel sub-simbólico que controla las actividades de los módulos simbólicos. Por ejemplo, el sistema sub-simbólico se usa para ponderar las reglas en orden para decidir cuál de los varios candidatos debe despedir, tomando el lugar de Se disparan los procedimientos de preferencia simbólica. A nivel simbólico, la información en la memoria de trabajo y las reglas de producción se dividen en fragmentos y pueden ser recuperados de acuerdo con su “activación” sub-simbólica. La activación de un el fragmento está influenciado por factores como la frecuencia con la que se accede, cómo Ha pasado mucho tiempo desde la última vez que se accedió, y cuán estrechamente vinculado a otra información activa es. Esto permite que ACT-R se use para modelar el aprendizaje y olvidando La ventaja de estas arquitecturas es que se basan en décadas de Investigación en ciencias cognitivas sobre el rendimiento humano. Usando uno de ellos allí Por lo tanto, aumenta la posibilidad de que el comportamiento del agente corresponda a El comportamiento de un humano dada la misma situación, historia y percepciones. Tanto SOAR como ACT-R están disponibles como implementaciones que pueden reducirse cargado a través de Internet y utilizado como un lenguaje de programación para Construir modelos. Sin embargo, esto tiene un costo. La cantidad de conocimiento que debe integrarse en un modelo cognitivo para que funcione a todo puede estar desproporcionado con el valor obtenido al usarlo. Porque su complejidad, estos modelos cognitivos requieren mucho trabajo preliminar para aprender a operarlos, generalmente corren lentamente y son bastante difíciles para integrarse con otras herramientas de simulación (por ejemplo, SOAR es una herramienta independiente programa, mientras que ACT-R es una biblioteca escrita en el lenguaje de programación Ceceo; por lo tanto, el resto de la simulación de múltiples agentes también necesitará ser escrito o ser capaz de interactuar con Lisp). En lugar de usar el programas directamente, también es posible implementar algunos elementos de su arquitecturas cognitivas en los propios modelos, en cualquier nivel de detalle Parece apropiado para la pregunta de investigación.
K.5 Interfaz de usuario
En esta etapa del proceso de diseño, la mayoría de los aspectos internos del modelo habrá sido definido, aunque normalmente todavía habrá una gran cantidad de Se necesita refinamiento. El último paso es diseñar la interfaz de usuario. Dependiente en el kit de herramientas que se usa, los componentes de esta interfaz serán controles deslizantes, interruptores, botones y diales para la entrada de parámetros y varios gráficos y se muestra para la salida, para mostrar el progreso de la simulación. Inicialmente, por simplicidad, es mejor usar un mínimo de controles de entrada. Como comprensión del modelo mejora, y se identifican parámetros de control adicionales, Se pueden agregar más controles. Del mismo modo, con las pantallas de salida, es mejor comience de manera simple y agregue gradualmente más a medida que se haga evidente su necesidad. Por supuesto, cada modelo necesita un control para iniciarlo y una pantalla para mostrar que la simulación continúa como se esperaba (por ejemplo, un contador para mostrar el número de pasos completados). En las primeras etapas, también puede ser necesario para pantallas de salida que están principalmente allí para depurar y construir confianza en que el modelo se está ejecutando como se esperaba. Más tarde, si estas pantallas no están obligados a responder la pregunta de investigación, se pueden eliminar nuevamente. Para su artículo sobre la agrupación en multitudes de dos partidos, Jager et al. usó tres muestra: una vista de la cuadrícula cuadrada sobre la cual se movieron los agentes (ver Figura 9.1); una gráfica de un índice de agrupamiento contra el tiempo simulado y una gráfica de la Número de peleas iniciadas en cada paso de tiempo. Es probable, sin embargo, que en el trabajo que condujo a la redacción del artículo, varias otras tramas han sido examinados Es requisito construir parcelas rápidamente y sin mucho esfuerzo adicional que hace que el uso de herramientas para el modelado de múltiples agentes necesario. Por ejemplo, una ventaja de NetLogo, el paquete descrito en los dos capítulos anteriores, es un diagrama de línea completamente etiquetado que muestra cómo algunos los cambios de parámetros a lo largo del tiempo se pueden agregar con solo dos líneas de programa código.
K.6 Pruebas Unitarias
Incluso antes de comenzar la codificación de un modelo, vale la pena considerar cómo La simulación será probada. Una técnica que está ganando popularidad es ‘examen de la unidad’. La idea es que pequeños trozos de código que ejercitan el programa están escritos en paralelo con la implementación del modelo. Cada vez que el se modifica el programa, todas las pruebas unitarias se vuelven a ejecutar para mostrar que el cambio tiene errores no introducidos en el código existente. Además, a medida que se extiende el modelo, más las pruebas unitarias están escritas, el objetivo es tener una prueba de todo. La idea de las pruebas unitarias proviene de un enfoque de programación llamado XP (para eX- programación treme, Beck 1999), una metodología de ingeniería de software que es particularmente efectivo para el tipo de prototipos iterativos de desarrollo enfoque que es común en la mayoría de las investigaciones de simulación. Cuando hay muchos pruebas unitarias para llevar a cabo, se vuelve tedioso iniciarlas todas individualmente y Se necesita un arnés de prueba que automatice el proceso. Esto también tendrá para ser diseñado, posiblemente como parte del diseño del modelo en sí, aunque También hay paquetes de software que facilitan el trabajo (ver, por ejemplo, el conjunto de herramientas de código abierto Eclipse, http://www.eclipse.org/). Cuando el modelo funciona como se esperaba, probablemente será necesario para llevar a cabo análisis de sensibilidad (ver Capítulo 2) que involucran múltiples ejecuciones de la simulación al variar los parámetros de entrada y grabar las salidas. Hacer estas ejecuciones manualmente también es tedioso y propenso a errores, por lo que un segundo La razón para tener un arnés de prueba es automatizar el análisis. Usted debería ser capaz de establecer los puntos de inicio y finalización de un rango de entrada y luego barrer a través del intervalo, volver a ejecutar el modelo y registrar los resultados para cada valor diferente Para permitir que esto se haga, el modelo puede tener dos interfaces: una gráfica para que el investigador pueda ver lo que está sucediendo y una interfaz alternativa basada en pruebas o archivos que interactúa con las pruebas framework (por ejemplo, NetLogo tiene una instalación llamada “BehaviorSpace”).
K.7 Debuggiing
2233/5000 Es muy probable que toda la salida que verá de su primera ejecución de su El modelo se debe, no al comportamiento previsto de los agentes, sino al efecto de errores en tu código! La experiencia muestra que es casi imposible crear simulaciones que inicialmente están libres de errores y, aunque hay formas de reducir errores (por ejemplo, el enfoque de prueba de unidad mencionado anteriormente), usted debería permitir al menos tanto tiempo para perseguir errores como para construir el modelo. La estrategia más importante para encontrar errores es crear casos de prueba para los cuales el resultado es conocido o predecible, y ejecutarlos después de cada cambio hasta Todos los casos de prueba arrojan los resultados esperados. Incluso esto no necesariamente eliminar todos los errores y los modeladores siempre deben ser conscientes de la posibilidad de que sus resultados son simplemente artefactos generados por sus programas. Otro tipo de prueba es comparar los resultados del modelo con los datos. desde el objetivo (es decir, desde el “mundo real” que se está modelando). Mientras tal las comparaciones son altamente deseables, no es frecuente que se puedan lograr. A menudo, el objetivo en sí mismo no se entiende bien ni es fácil de acceder (eso esta es una de las razones para construir una simulación, en lugar de observar el objetivo directamente). Además, el comportamiento tanto del objetivo como del modelo. puede ser estocástico (influenciado por eventos aleatorios) y muy sensible a la condiciones o parámetros al inicio (Goldspink 2002). Si este último es el caso, incluso se podría esperar que un modelo perfecto difiera en su comportamiento de El comportamiento del objetivo. Es posible ejecutar el modelo muchas veces para obtener una distribución estadística estable de la salida, pero normalmente no es posible “ejecutar el mundo real” muchas veces. Como resultado, lo mejor que se puede hacer es probar que existe una probabilidad razonable de que el comportamiento observado de el objetivo podría extraerse de la distribución de resultados del modelo: lo cual es más bien una prueba débil. La forma más completa de verificar un modelo (de asegurar que el resultado refleja el modelo subyacente y no es consecuencia de errores, vea El Capítulo 2) es volver a implementar el modelo usando una programación diferente lenguaje e, idealmente, un implementador diferente. Hales y col. (2003) comentario:
"" Ahora está claro que MABS [simulación basada en múltiples agentes] tiene más en común, metodológicamente, con las ciencias naturales y disciplinas de ingeniería que la lógica deductiva o las matemáticas: está más cerca de una ciencia experimental que de una formal. Con esto en mente, es importante que las simulaciones sean replicadas antes de que sean aceptados como correctos. Eso es resultado de simula- No se pueden probar las opciones, sino solo analizarlas inductivamente. Este indi- indica que los mismos tipos de métodos utilizados dentro de otros inductivos las ciencias serán aplicables. En su forma más simple, un resultado que es reproducido muchas veces por diferentes modeladores, re-implementado en varias plataformas en diferentes lugares, debería ser más confiable. Aunque nunca alcanzamos el estado de una prueba, podemos llegar a ser más confianza con el tiempo en cuanto a la veracidad de los resultados. (Hales et al. 2003: 1.4) ""
1690/5000 Se han realizado algunos experimentos para volver a implementar modelos de múltiples agentes llevado a cabo, un proceso a veces llamado “acoplamiento”, con resultados interesantes: en En algunos casos, se ha encontrado imposible replicar incluso modelos publicados (ver Axelrod 1997b y Hales et al. 2003 para ejemplos). En preparación para Al escribir este capítulo, Jager et al. modelo (que fue escrito originalmente en el lenguaje de programación C ++) se volvió a implementar en NetLogo. Porque el documento que describe la simulación estaba bien escrito, la reimplementación podría hacerse sin recurrir a los autores, a excepción de algunos asuntos requiere aclaración La reimplementación produjo los mismos patrones de agrupamiento y lucha como se informa en el artículo original. Habiendo obtenido una simulación que crees que está libre de errores y representando con precisión su diseño, solo queda comparar el simu- con el objetivo y usar el modelo para generar resultados. El proceso de la validación y el uso se han descrito en el Capítulo 2 y hay poco que Es especial para los modelos de múltiples agentes a este respecto. Para recordar, es deseable participar en un análisis de sensibilidad para examinar en qué medida la variación en Los parámetros del modelo producen diferencias en el resultado. Un resultado que puede provienen de dicho análisis, o de los antecedentes teóricos de la investigación pregunta, es el rango de aplicabilidad del modelo, es decir, las circunstancias en el que el modelo corresponde al objetivo. Por ejemplo, las dos partes el modelo de hacinamiento no se aplicaría si el número de participantes es muy bajo (no hay entonces una “multitud”). Es importante cuando se presentan resultados para indicar claramente el rango de aplicabilidad del modelo.
K.8 Usando las simulaciones
Muchas simulaciones basadas en agentes se crean para desarrollar y probar redes sociales. teorías, otros tienen un objetivo más práctico: ayudar a un grupo de personas entender su mundo para controlarlo y cambiarlo. Por ejemplo, social La simulación se está utilizando ahora para desarrollar políticas para la gestión del agua. recursos, sugiera consejos a las compañías en línea sobre la comercialización de productos en Internet, comprender las implicaciones de las principales políticas estratégicas bancarias, gestionar los ecosistemas rurales y aprender cómo responder mejor a las epidemias. los La conexión entre estos temas de otra manera dispares es que en cada caso hay es un grupo de “interesados” interesados en la simulación porque Esperamos aprender de los resultados y así mejorar su efectividad. En lugar de simplemente presentar los resultados de la investigación de simulación a usuarios potenciales al final de un proyecto, cada vez es más común para que las partes interesadas se involucren en todas las etapas, desde la formulación de la pregunta de investigación inicial a la síntesis de las conclusiones de la investigación. Hay varias ventajas de tener partes interesadas estrechamente involucradas. Primero, uno puede estar más seguro de que la pregunta de investigación que se aborda está en hecho uno cuya respuesta va a ser relevante para los usuarios. En lo tradicional modo, es muy fácil para los proyectos estudiar temas que son de interés para el investigador, pero de poca relevancia para la audiencia para la investigación. Trayendo en las partes interesadas en una etapa temprana ayuda a que esto sea menos probable. Segundo, las partes interesadas tienen más probabilidades de sentir alguna obligación de responder a la respuesta buscar resultados si han estado muy involucrados en el proyecto. La investigación Es menos probable que el informe sea archivado y olvidado. Tercero, las partes interesadas son a menudo un rica fuente de conocimiento sobre el fenómeno que se está modelando. Cuarto, es probable que su participación en la investigación aumente su interés en y nivel de conocimiento sobre los problemas. Estas ventajas de ‘participativo modelado “(Hare et al. 2003) puede superar las desventajas, que incluyen la complicación y el gasto adicionales de involucrar a los interesados, la necesidad de mantener la motivación de los interesados durante el proyecto y las posibilidades de sesgo resultante de los puntos de vista particulares de las partes interesadas. La simulación basada en agentes es adecuada para la investigación participativa. (Ramanath y Gilbert 2004). La idea de agentes autónomos realizando Las actividades y la comunicación entre ellos es fácil de entender para las personas que No están familiarizados con el modelado. Otra ventaja es que a veces es posible diseñar el modelo para que los propios interesados puedan actuar como agentes Por ejemplo, puede ser posible ejecutar el modelo, no como una computadora simulación, pero como un juego de mesa, con usuarios jugando roles y siguiendo el reglas que de otra forma habrían sido programadas en los agentes (ver Hare et al. 2002). Alternativamente, uno o más de los”agentes" en una computación la simulación puede ser jugada por una persona que selecciona qué acciones llevar En cada paso, la computadora ejecuta a los otros agentes de la manera habitual. El beneficio de esto es que la persona puede obtener un conocimiento profundo de lo que es involucrado en jugar el papel. Por ejemplo, este es el enfoque adoptado en un proyecto que fue diseñado para ayudar a los interesados involucrados en proporcionar agua doméstica a la ciudad de Zurich. El “Juego de agua de Zurich” (Gilbert et al. 2002) fue una simulación de múltiples agentes en la que algunos de los agentes pudieron pasar a ser controlado por los jugadores del juego. El juego corrió Internet, con un servidor central que genera el entorno y simula todos los agentes que no estaban siendo controlados directamente por los jugadores. Utilizando el juego, los jugadores podrían explorar las consecuencias de sus propias decisiones sobre las estrategias de otros jugadores y los efectos de retroalimentación de esas estrategias en sus Oportunidades y estrategias propias.
K.9 Conclusión
En este capítulo, hemos descrito un proceso para diseñar mods de múltiples agentes els. Será de gran ayuda para usted si tiene una idea del tema que están interesados pero aún no tienen una pregunta de investigación clara o un diseño de modelo. La experiencia ha demostrado que pasar de un interés de investigación a un diseño de modelo es probablemente la parte más difícil de construir modelos de múltiples agentes y, por lo tanto, es útil para establecer la tarea de manera sistemática. Por otro lado, es posible diseñar buenos modelos sin seguir ninguna de las sugerencias realizado en este capítulo, que debe tratarse solo como heurística útil. En el próximo capítulo, pasamos a examinar modelos de simulación que son capaz de adaptarse y aprender de su experiencia. Los problemas de diseño siguen siendo los mismos que con los modelos de múltiples agentes más simples que hemos tenido en este capítulo, pero tienen la complicación adicional de que los comportamientos de los agentes pueden cambiar durante el transcurso de la carrera.