Capítulo 9 Introducción al uso de RMarkdown para la compilación de resultados de RStudio en diferentes formatos
9.1 ¿Qué es RMarkdown y para qué sirve?
Por su amplio y fácil uso, las y los estudiantes, y posteriormente las y los académicos e investigadores en Ciencias Sociales, generalmente utilizan Microsoft Word para construir sus reportes de investigación.46 Si bien es un software fácil de utilizar, presenta algunas limitaciones en el manejo de sus atributos estéticos y de contenido. Por una parte es difícil controlar las ediciones de su formato de presentación pues es bastante engorroso para dar formato a documentos extensos: obliga a invertir mucho tiempo haciendo clicks, indicando formatos que se pueden descalibrar al pasar a otro fomato de texto o versión de software. Por otra parte, cualquier contenido que no sea texto resulta difícil de incorporar pues se generan incompatibilidades según las versiones del programa, a la vez que no se articula de manera sencilla con otras fuentes de información: por ejemplo los resultados construidos a partir de un software de análisis estadísitico.
A estas limitaciones, que han sido señaladas por otros autores (Miller 2018) aquí se agrega otra. La interacción entre un software para análisis estadístico como R y Microsoft Word, es quizá una de las que presenta más complicaciones. Como ya fue visto en el capítulo 7 de este documento, para incorporar resultados de formato R a Microsoft Word se debe construir un tipo de datos ad hoc (matrices de datos) para poder grabarlos en un documento tipo planilla de cálculo. Recién desde allí se podrá editar el formato de tales resultados y copiarlos a Microsoft Word (por ejemplo, a un trabajo universitario, un reporte de investigación para consultoría, un borrador de un artículo académico o documento de trabajo, un libro, etc.)
¿Cuáles son, entonces, las características de RMarkdown que lo diferencian de esta forma de trabajo? En términos sencillos RMarkdown es un procesador de texto que ofrece además la posibilidad de incluir trozos de código desde R (u otros formatos). El principal beneficio de esta herramienta es que permite trabajar en un sólo documento tanto la redacción del contenido narrativo de reportes de investigación, como también la construcción y presentación formal de resultados de análisis estadísticos.47
Se distinguen entonces dos paradigmas de trabajo en los procesos de construcción de los diferentes formatos de presentación de resultados de investigación. Por un lado un paradigma no integrado en la construcción de informes de investigación: en este formato, el autor generalmente construye por separado los elementos de un reporte de resultados (texto, tablas de resultados estadísticos, gráficos, formato general del documento, referencias y listado de bibliografía utilizada). Por ejemplo, si construye una tabla de datos en cualquier software de análisis estadístico, luego la debe copiar y pegar en su reporte definitivo, editando allí su formato final. Si los datos o el sentido del análisis cambia, el autor debe repetir todo el proceso para actualizar la información su informe final. Por otro lado, en un paradigma integrado para la construcción de informes, como el que subyace a RMarkdown, existe un sólo lugar (archivo RMarkdown) donde se edita tanto el texto del reporte, como los códigos para construir los resultados a incluir, así como el formato general del documento y la gestión bibliográfica. Si el documento debe actualizarse, se efectúan en un sólo lugar todos los cambios y se re-compila el informe en el formato final deseado (sea PDF, Editor de Texto tipo Microsoft Word, diapositivas de presentación o un archivo dinámico tipo HTML) (Grolemund 2014).
Ahora bien, ¿cómo funciona esta herramienta? Crear reportes desde RMarkdown combina diferentes aplicaciones computacionales. En tal sentido, es de las operaciones de uso de R que más precisa de la correcta instalación de una serie de elementos adicionales. En una breve síntesis, la construcción de informes de resultados desde R demanda la ejecución simultánea de cuatro elementos (Grolemund 2014):
- RMarkdown. Basado en el lenguaje markdown - funcionalidad que busca convertir rápida y fácilmente texto plano tipo bloc de notas a formato HTML - RMarkdown es un tipo de documento de RStudio que permite integrar texto con código de R.
- Knitr. Este paquete integra en un sólo archivo markdown el texto ingresado en formato RMarkdown y los resultados de la ejecución de los códigos construidos mediante R.
- Conversor a formato final:
- Pandoc. Se trata de un paquete de R que convierte el formato markdown a alguno de los diferentes formatos de reporte ya señalados (HTML y editor de texto tipo Word).
- LaTex. Es una aplicación computacional en sí misma, enfocada en la preparación de documentos para su publicación con una alta calidad profesional del formato final. Está pensado para ser utilizado en procesos editoriales de alta complejidad y exigencia de calidad. Permite convertir los documentos markdown a PDF (Navarro 2014).48
Todos estos elementos se ponen en juego en un flujo de trabajo (workflow) que, luego de una corta espera, generará un documento final con una elevada calidad final en su presentación de resultados. En la imagen a continuación (Workshop 2016), se grafica tal flujo.
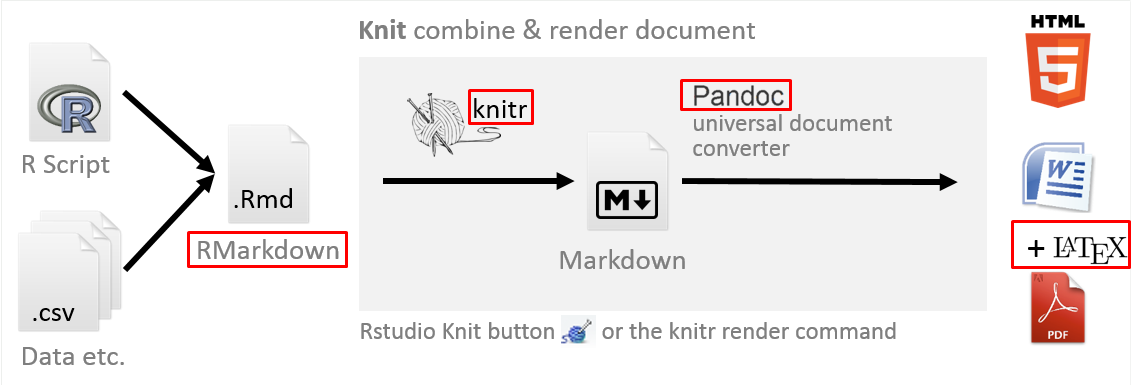
Imagen 9.1: Elementos necesarios para construir reportes con RMarkdown
Para ejecutar correctamente un documento de RMarkdown y lograr construir un reporte final en el formato deseado, es preciso asegurar que todos estos elementos estén instalados en el computador. A continuación se presenta una breve tabla que resume los elementos a instalar y cómo hacerlo.
| Elemento | Procedimiento de instalación | Código para instalación |
|---|---|---|
| RMarkdown | No es necesario ningún procedimiento adicional a la instalación de R y RStudio pues viene instalado con este último. | No aplica |
| Knitr | Debe instalarse como cualquier otro paquete de R, asegurando su disponiblidad para ser utilizado por RMarkdown al compilar documentos. | install.packages(“knitr”) |
| Pandoc | No es necesario ningún procedimiento adicional a la instalación de R y RStudio pues viene instalado con este último. | No aplica |
| LaTex | Debe descargarse como un paquete de R. Para asegurar su disponibilidad para ser utilizado por RMarkdown al compilar documentos, debe instalarse con un comando adicional.49 | install.packages(“tinytex”) tinytex::install_tinytex() |
En síntesis: antes de proceder a la compilación de un documento RMarkdown, debemos asegurar la instalación de estos componentes en nuestros computadores.
9.2 Los diferentes elementos de una sintaxis de RMarkdown
En este apartado se indican las nociones generales a tener en cuenta para trabajar con una sintaxis de RMarkdown.
El procedimiento básico para abrir una sintaxis de RMarkdown es similar al usado para una sintaxis de R. Es posible crear un nuevo documento de RMarkdown usando la botonera superior de RStudio. Como se observa a continuación, yendo a Archivo, Nuevo Archivo y seleccionando la opción RMarkdown.
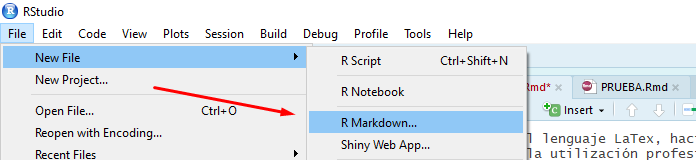
Imagen 9.2: Apertura de nuevo documento Rmarkdown vía botonera
Una vez hecho tal procedimiento aparecerá una nueva pantalla de configuración general. Aquí se establece la configuración básica del reporte de resultados, indicando un título para el documento, el nombre del autor, así como el formato de informe a construir (en este ejemplo se selecciona el formato PDF).
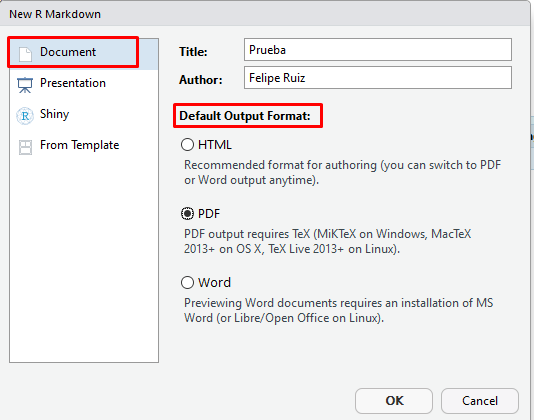
Imagen 9.3: Ventana de preconfiguración del documento de RMarkdown
Si se especifican tales condiciones, luego de apretar aceptar se desplegará una nueva pestaña en R (con extensión .Rmd) que será la sintaxis de RMarkdown en la cual se editará el reporte de investigación. Como se observa en la imagen a continuación RStudio ofrece una sintaxis de RMarkdown preconfigurada.
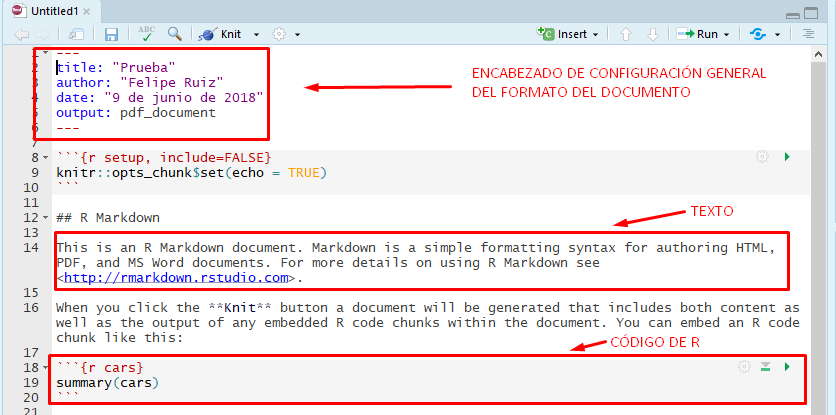
Imagen 9.4: Sintaxis Rmarkdown con preconfiguración
De esta sintaxis conviene poner atención sobre tres tipos de elementos que resultan distintivos del trabajo con RMarkdown.
- Encabezado general de formato. Al inicio del documento, y encerrado por tres guiones continuados, por arriba y por abajo de manera respectiva, se encuentra el encabezado que permite establecer los parámetros generales de formato que estructurarán el producto final (en términos técnicos se denomina como encabezado YAML). En la imágen destacada se observan los campos (en inglés): título del documento, autor del documento, fecha y formato.
- Texto. A diferencia de una sintaxis de R, RMarkdown considera como formato primario de redacción el texto plano. Todo lo que se escriba - a no ser que se indique lo contrario - será considerado como texto en el documento final.
- Trozos de código de R. Para indicar que se escribirá un código de R, las líneas de comando deben encerrarse entre tres cremillas seguidas de corchetes curvos con la letra r en su interior; luego de eso se escriben los comandos de R; al finalizar los comandos, se agrega una última línea con tres cremillas para indicar el cierre del trozo de código.
Si el documento de RMarkdown construido por defecto al abrir uno nuevo se compila en formato PDF, el inicio de este documento se verá como sigue. Se observa que los campos puestos en el encabezado han pasado a ser parte del título general del documento. A la vez, se distingue el texto plano del código de R que, en este caso, integra en el documento el resultado de una función summary:

Imagen 9.5: Resultado de ejecución de plantilla básica de RMarkdown
En los siguientes apartados se explicará la configuración específica de diferentes elementos de formato básico para la edición de cualquier informe de resultados vía RMarkdown. Se ilustrará la visualización básica de los diferentes elementos indicados en RMarkdown. Todos los elementos indicados pueden ser encontrados de manera unificada en el siguiente enlace, donde nuestros lectores encontrarán una plantilla básica de RMarkdown disponible para descarga, así como el documento PDF que resulta de su ejecución.
9.3 Aspectos generales (formato de texto)
9.3.1 Formato general: encabezado YAML
Este encabezado determina los parámetros generales de formato para el reporte a compilar. En lenguaje computacional se entiende como los metadatos del documento; esto es, información que define el formato del archivo resultante, más no su contenido. En el ejemplo que aquí presentamos se observan las siguientes definiciones:
- Título (title). Texto entre comillas que servirá de título general al documento.
- Subtítulo (subtitle). Texto entre comllas que servirá de subtítulo para el título general del documento.
- Autor (author). Texto entre comillas para indicar el nombre del o los autores.
- Fecha (date). Campo para indicar la fecha. En el texto, con la expresión today, se solicita que imprima la fecha actual según el calendario del sistema operativo.
- Bibliografía (bibliography). Se indica el nombre del archivo que contiene los datos para construir el listado de referencia bibliográficas. Como será explicado más adelante, este archivo es de formato BibTex y se construye usando un gestor de referencias como Zotero.
- Formato de bibliografía (csl). Nombre de un archivo de extensión .csl para indicar el formato de referencias en el cuerpo del texto y el listado de bibliografía al final del documento. La sigla refiere a Estilo del Lenguaje de Referencias (Citation Language Style) y permite definir si se usarán citas al estilo APA, ASA, Chicago, etc. Se adecúa a los diferentes requerimientos de referencias bibliográficas.
- Color de los enlaces. Mediante las opciones linkcolor y urlcolor se define el color asignado al indicador de notas al pie y a los enlaces a páginas web, respectivamente. En este caso se sugiere el color azul (blue).
- Los argumentos dentro del apartado resultado (output) son los siguientes:
- pdf_document: indica el formato preestablecido para compilar el documento. En este caso, se trata de un PDF. Puede ser html_document o word_document. El usuario puede escoger la modalidad que desee al compilar usando las opciones del botón knit; si se compila sin escoger ninguna opción, se compilará según el formato indicado en este encabezado.
- fig_caption: indica si las figuras deben incorporar leyendas.
- latex_engine: permite definir el motor de LaTex utilizado para compilar los documentos.
- number_sections: si está definido como yes define que se numerarán los títulos y sutítulos a lo largo del documento, de manera automática y correlativa.
- toc: es la abreviación de table of contents; si está definido como yes incorporará al inicio del documento una tabla de contenidos construida a partir de los tres primeros niveles de los títulos y subtítulos de sección utilizados.
Ejercicio 9.1
---
title: "Ejemplo Uso de RMarkdown"
subtitle: "Material de apoyo docente, asignatura Estadística Descriptiva - Semestre de otoño 2018"
author: "Giorgio Boccardo Bosoni y Felipe Ruiz Bruzzone"
date: '\today'
bibliography: bibliografia.bib
csl: apa.csl
linkcolor: blue
urlcolor: blue
output:
pdf_document:
fig_caption: yes
latex_engine: xelatex
number_sections: yes
toc: yes
---En definitiva, todos estos elementos configuran una importante información para indicar el formato general del documento que se busca compilar. No se trata específicamente del contenido a utilizar pero es, por así decirlo, toda la información de “contexto” que el software necesita manejar para construir un reporte final con el formato deseado.
9.3.2 Títulos, subtítulos y saltos de página
En el caso de RMarkdown los signos “gato” (#) indican que se está señalando un título o subtítulo de sección. Mientras más signos gatos se pongan se estará indicando que se trata de un título de menor jerarquía. Por otra parte, con el comando \pagebreak se pueden indicar saltos de página. Esto último sirve, por ejemplo, para comenzar cada sección del documento en una página nueva.
Ejercicio 9.2
# Título 1 (nivel de mayor jerarquía)
## Título 2 (nivel de segunda jerarquía)
### Título 3 (nivel de tercera jerarquía)
\pagebreak #Salto de página.Si se utilizan tales instrucciones el documento final irá adquiriendo la siguiente forma:

Imagen 9.6: Compilación de Rmarkdown con índice, títulos y subtítulos
9.3.3 Énfasis de texto
Otro elemento importante son los distintas marcas que permiten introducir diferentes énfasis en el texto. A lo largo del texto se pueden introducir las clásicas configuraciones de formato que, en los procesadores de texto más utilizados, se configuran mediante la selección del texto con el cursor y la utilización de uno o más botones. A continuación se muestra cómo se indican tales configuraciones en el texto plano (sin compilar):
Ejercicio 9.3
**negrita**
*cursiva*
_subrayado_
> Texto con un tabulado mayor al párrafo normal.
Texto que está hablando de un tema y quiere poner una nota al pie [^1].
[^1]: texto de la nota al pie
Para ingresar un enlace asociado a una palabra, se debe encerrar la palabra o palabras
que [queremos sea un enlace](www.url.com)Considerando tales elementos, a continuación se presenta un texto con sus especificaciones de énfasis en formato RMarkdown y a continuación su resultado luego de la compilación.
Ejercicio 9.4
Así, si se aplica lo recién anotado, podemos configurar palabras en **negrita** y en
*cursiva*.
> Podemos incluir un párrafo con un tabulado mayor al del párrafo regular.
Asimismo, en cualquier parte del documento podemos incluir una nota al pie [^1].
[^1]: texto de la nota al pie. En cualquier parte del documento, aquí lo haremos en esta nota al pie, podemos definir enlaces que [redireccione a páginas web](https://cran.r-project.org/).
Imagen 9.7: Compilación de documento RMarkdown con énfasis de texto
9.3.4 Listas
El proceso de construcción de listas de elementos en RMarkdown es muy sencillo. Pueden ocuparse números, para listas numeradas o signos asterisco (*) o signos más (+), para definir listas no numeradas.
Ejercicio 9.5
#Construcción de una lista numerada
1. Elemento 1
2. Elemento 2
#Construcción de una lista sin números
* Elemento 1
* Elemento 2
#Lista sin números, con sublista numerada (tabulado es de 4 espacios)
+ Elemento 1
+ Elemento 2
1. Sub elemento 1.
2. Sub elemento2.Al compilar los elementos recién expuestos, se obtiene el siguiente resultado:

Imagen 9.8: Compilación de documento RMarkdown con listas
9.3.5 Tablas
La construcción de tablas en RMarkdown se realiza separando los elementos de cada columna con un tabulador vertical (|). Cada fila de texto corresponderá a una fila de la tabla. Se puede definir la alineación del texto según la distribución de guiones debajo de los títulos. Si los guiones exceden hacia ambos lados del texto, este quedará centrado. Si excede hacia uno u otro lado quedará alineado hacia la izquierda o la derecha. Las reglas para destacar texto, incluir enlaces y notas al pie, también aplican las tablas. No es necesario separar cada fila con guiones, basta comenzar una nueva fila de texto.
Ejercicio 9.6
Table: Tabla simple
**Título Columna 1** | **Título columna 2** |
----------------------| ----------------------|
*Texto 1* | Texto 2
*Texto 3* | Texto 4A continuación se ve el resultado de la ejecución del comando anterior resultando una tabla simple en formato RMarkdown.
| Título Columna 1 | Título columna 2 |
|---|---|
| Texto 1 | Texto 2 |
| Texto 3 | Texto 4 |
9.3.6 Bibliografía
Este apartado asume que quien lee este documento tiene experiencia con gestores electrónicos de referencias bibliográficas como Zotero. Por lo tanto no se profundizará en explicaciones sobre cómo utilizarlo: se sugiere revisar esta documentación preparada por la unidad de Información y Bibliotecas de la Univeridad de Chile, en torno al uso del software Zotero como gestor de referencias.
Para incorporar una bibligrafía formal a un reporte, tanto en lo que respecta a referencias en el cuerpo del texto como para construir un listado de referencias bibliográficas utilizadas al final del documento, se deben manejar dos elementos:
- Zotero y Zotero connector. Mediante este software se crea un listado bibliográfico compatible con LaTex (archivo .bib) que - cargado a RMarkdown - permitirá insertar referencias y que luego se construya un listado bibliográfico. Ambos pueden descargarse desde este enlace.
- Contar con un archivo .csl para indicarle el formato de cita al documento (Citation Language Style). Se puede descargar el adecuado para formato APA 6a Edición desde esta página. También se pueden descargar otros formatos como Vancouver, Chicago o ASA (American Sociological Asociation).
El primer elemento se construye exportando un listado de bibliografía desde Zotero al formato BibTex. Como se observa en la imagen a continuación es una exportación simple. Se opera haciendo click derecho sobre el conjunto de referencias bibliográficas que interesa, seleccionando la opción exportar. En la siguiente pestaña se selecciona el formato BibTex para luego introducir el nombre del archivo de extensión (.bib) a guardar. Importa guardarlo en la misma carpeta que funcione como carpeta de trabajo para el documento RMarkdown.
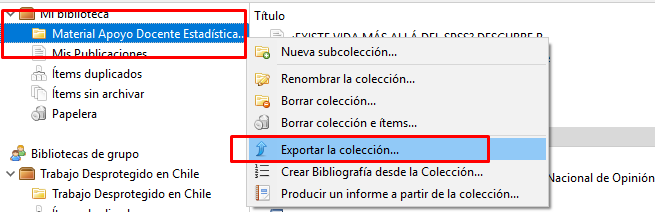
Imagen 9.9: Construcción de archivo de referencia bibligráficas usando Zotero
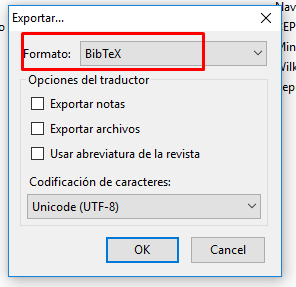
Imagen 9.10: Elección de formato “.bibtex”
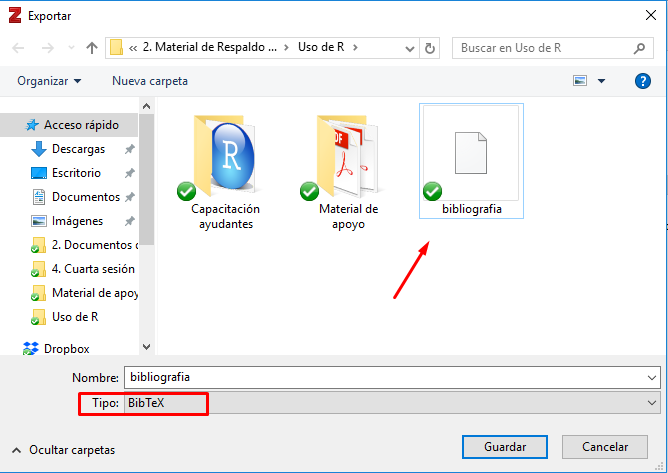
Imagen 9.11: Elección de formato “.bibtex”
El segundo elemento (archivo CSL) se puede descargar desde la página web de Zotero. Como se observa en las imágenes a continuación, mediante el buscador puede indicarse el estilo deseado (en este caso, APA). Luego se descarga la versión de formato de referencias que se adecúe al requerimiento específico. Para este material se utiliza la 6ta versión del formato APA de referencias bibliográficas, que además está recientemente actualizada. Tal archivo también debe quedar guardado en la carpeta de trabajo del documento RMarkdown.
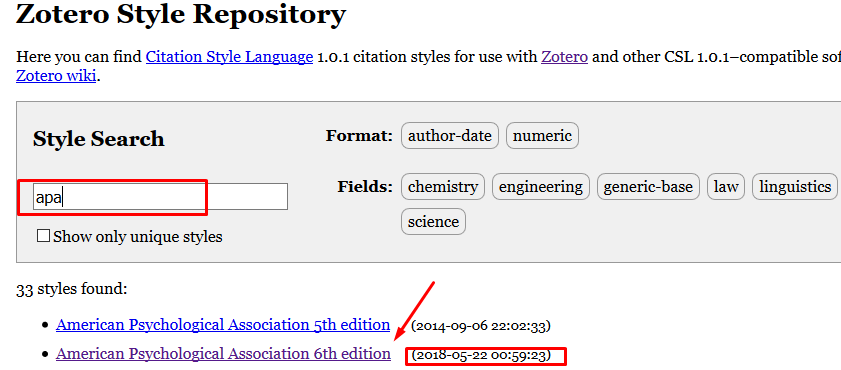
Imagen 9.12: Descarga de archivo CSL para formato de referencias
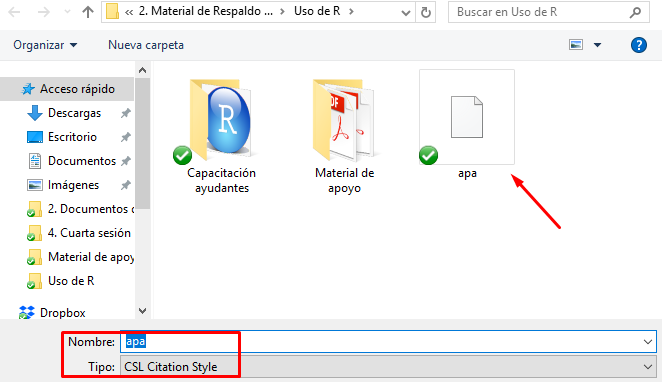
Imagen 9.13: Archivo CSL para formato APA de referencias
En el encabezado del archivo RMarkdown se deben indicar los nombres de estos dos archivos para poder construir de forma adecuada las referencias bibliográficas. Ahora bien, ¿cómo agregar las referencias en el cuerpo del texto? Para determinar cómo se recomienda abrir con el bloc de notas el archivo .bib donde está el listado bibliográfico.
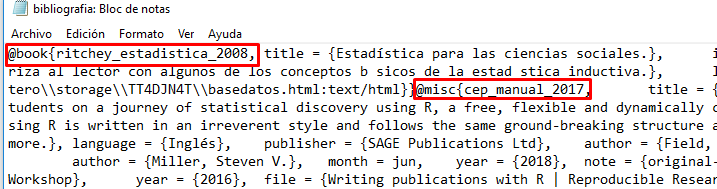
Imagen 9.14: Estructura interna del archivo CSL
Si se observa la estructura interna del archivo CSL. Se notará que a lo largo del texto se van definiendo los diferentes campos de información que tiene cada referencia bibliográfica (autor, año, título, edición, tipo de referencia, etc.). Así, hay que encontrar el identificador de la referencia, luego del signo arroba (@). Abriendo un paréntesis de corchetes en el cuerpo del documento e incluyendo tal texto luego de una arroba, se incorporá una (Elousa 2009) o más referencias bibliográficas (Elousa 2009, 22; Grolemund 2014).
A continuación se observa el texto plano que define las referencias recién escritas:
Ejercicio 9.7
Abriendo un paréntesis de corchetes en el cuerpo del documento e incluyendo tal texto luego
de una arroba, se incorporá una [@elousa_existe_2009] o más referencias bibliográficas
[@elousa_existe_2009, 22; @grolemund_introduction_2014].La bibliografía siempre se compila al final del documento. Eso significa que estará al final del último elemento escrito. El listado bibliográfico final se contruirá siempre con base a las citas realizadas en el cuerpo del texto y según todas las referencias presentes en el archivo de referencias exportado desde zotero. Podemos asegurarnos de que el último título del documento sea algo como Referencias bibliográficas, para que tal contenido tenga un encabezado apropiado.
9.4 Aspectos generales (configuración de trozos de código)
El tercer elemento de importancia (además del encabezado de configuración y del texto propiamente tal) son los trozos de código de R o code chunks (en inglés). Se trata de bloques de código delimitados por la siguiente estructura: el inicio de un código está delimitado por tres apóstrofes seguidos por un r entre corchetes curvos {r}, y su cierre por otros tres apóstrofes. Eso delimita lo que se ejecutará como código de computación, diferenciándolo respecto al texto simple. A continuación se observa un ejemplo de esto:

Imagen 9.15: Trozo de código de R en documento RMarkdown
El título del código sirve para incorporarlo a la estructura de contenidos del archivo RMarkdown de manera similar a los títulos y subtítulos de secciones de texto. Por otra parte los argumentos sirven para configurar el comportamiento del código al momento de compilar el documento. Para introducir un trozo de código en nuestra sintaxis de RMarkdown se puede utilizar el botón insert existente en la botonera de la sintaxis RMarkdown, como se observa en la siguiente imagen: debemos seleccionar la primera opción que indica el lenguaje de programación R. Las otras opciones indican una de las potencias de RMarkdown, permite integrar en una sola plataforma diferentes lenguajes de programación.
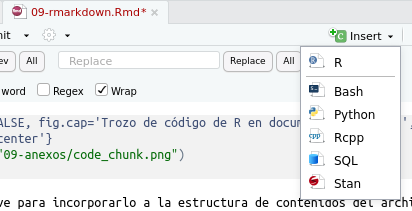
Imagen 9.16: Insertar trozos de código en RMarkdown
Como no siempre se buscará que en el reporte final se despliegue la sintaxis original, o los mensajes y/o advertencias que reporta R luego de ejecutar un comando, es posible configurar la ejecución de cada trozo de código agregando diferentes opciones.
Por ejemplo, al abrir el siguiente código de nuestra sintaxis de Markdown con las siguintes opciones {r, echo = FALSE, results = 'asis', message= FALSE} les estamos indicando lo siguiente:
echo = FALSEsignifica que no se desplegará la sintaxis en el reporte, pero sí se ejecutará la operación y mostrarán los resultados.results = 'asisindica que el resultado se exportará directamente al nuevo archivo, sin que sea configurado por RMarkdown. Esto es útil con funciones que formatean de manera inmediata los resultados al formato deseado.message = FALSEindica que no se mostrarán los mensajes de información en el informe final.
En la siguiente tabla se indican algunos de los argumentos de mayor utilidad para configurar trozos de código en RMarkdown.
| Argumento | Valor por defecto | Detalle |
|---|---|---|
| eval | TRUE | Si se configura como FALSE, R sólo mostrará, pero no correrá el código |
| include | TRUE | Si se configura como FALSE, R no mostrará el código, pero correrá el comando y mostrará sus resultados. |
| error | TRUE | Si se configura como FALSE, R no mostrará los mensajes de errores que resulten de la ejecución del código. |
| results | — | Si se configura como hide, R no mostrará los resultados del código aunque lo ejecutará tras bambalinas. Si se configura como delay, R mostrará sólo el último resultado del trozo de código. Si se configura como asis R no configurará con markdown la estructura de los resultados, imprimiéndolos de manera directa en el reporte final. Esto resulta útil cuando usamos funciones específicas para presentar resultados en algún formato de reporte específico (Word, PDF, etc.) |
| warning | TRUE | Si se configura como FALSE R no mostrará los mensajes de advertencia que resulten de la ejecución del código. |
| message | TRUE | Si se configura como FALSE R no mostrará ningún tipo de mensaje que resulten de la ejecución del código. |
Se indican sólo algunos de muchos argumentos posibles de utilizar. Para un listado completo de estas configuraciones posibles para los trozos de código, así como para la configuración y uso general de RMarkdown, se sugiere ver las diapositivas RMarkdown Cheat Sheet y RMarkdown Reference Guide. Estos materiales preparados por el equipo desarrollador de RStudio y RMarkdown resumen de manera muy sintética la mayor cantidad de argumentos y estructuras de código que pueden utilizarse en RMarkdown. Puede accederse a elo mediante la botonera de RStudio, como se muestra a continuación:
Imagen 9.17: Uso de material de apoyo para RMarkdown
9.5 Presentación de resultados básicos en RMarkdown
Habiendo indicado una parte importante de los elementos básicos de redacción de RMarkdown, a continuación se explica como incorporar en un reporte que contenga tablas de frecuencias y de estadísticos descriptivos univariados.
Para incorporar esos elementos se crearán funciones incorporadas en un paquete llamado summarytools. Este paquete es de alta utilidad pues simplifica el proceso de construcción de tablas de resultados para análisis estadístico univariado.
La principal característica de este paquete es que su lógica pone énfasis tanto en la selección de resultados específicos a calcular como en su formato de presentación. Por eso permite controlar qué resultados se construyen y cómo son presentados (Comtois 2018). Esto hace que las funciones de este paquete sirvan para construir resultados tanto para un uso exploratorio como para el diseño de su presentación en reportes de investigación, es decir un uso orientado a la divulgación.50
Debido a esta última característica las funciones de este paquete permiten obtener resultados en texto plano para ser visualizados en la consola de R (lo que sería el comportamiento predefinido para casi cualquier función de R), como también especificar formatos de presentación compatibles con RMarkdown para hacer posible su compilación en reportes.
9.5.1 Tablas de frecuencias
El primero comando a utilizar de este paquete será freq. Permite obtener una tabla de frecuencias absolutas y relativas para una variable de tipo nominal u ordinal. En el primer comando se utiliza el formato por defecto para la construcción de resultados en la consola de R (argumento style = simple). Con el argumento justifiy se indica la alineación del texto de la tabla, en este caso se configura un formato de texto centrado ("center"). Luego, con el argumento omit.headings = TRUE se indica que no se imprima un encabezado con la especificación de la tabla solicitada.
Ejercicio 9.8
library(summarytools)
freq(CEP$sexo_factor, style = "simple", justify = "center", omit.headings = TRUE)##
## Freq % Valid % Valid Cum. % Total % Total Cum.
## ------------ ------ --------- -------------- --------- --------------
## Hombre 553 38.83 38.83 38.83 38.83
## Mujer 871 61.17 100.00 61.17 100.00
## <NA> 0 0.00 100.00
## Total 1424 100.00 100.00 100.00 100.00En la tabla resultante se presentan las frecuencias absolutas y relativas (expresadas como porcentaje) para la variable sexo, indicando también los porcentajes acumulados válidos (es decir, sin contar los NA’s) y los porcentajes acumulados totales. Esta tabla es construida por defecto por la función, pero no aquella con un formato específico para RMarkdown.
En el siguiente trozo de código de R se configura este comando para su ejecución con RMarkdown. En primer lugar, destaca la configuración específica del trozo de código: mediante el argumento results = 'asis' se configura que el resultado sea impreso directamente al formato RMarkdown para que la tabla resultante esté construida en la lógica de construcción de tablas que ya ha sido presentada en este documento; en segundo lugar, con el argumento warning = FALSE se especifica que en el reporte no sean impresos los mensajes de alerta que pueda arrojar la ejecución del comando. También se puede incorporar el argumento echo = FALSE para evitar que el trozo de código se visualice en el reporte de resultados, dejando como resultado de esta operación sólo la compilación de la tabla de frecuencias; aquí se utiliza pues interesa mostrar el trozo de código con fines pedagógicos.
En segundo lugar, destacan las configuraciones adicionales establecidas para la ejecución del código con formato adecuado a RMarkdown. En primer lugar, el estilo definido para la tabla se ha indicado como “rmarkdown”. Esto último permite que la tabla resultante sea como se observa en la siguiente imagen: integra los resultados a un tabulado de texto plano que permitirá contar con una tabla adecuadamente configurada al compilar el documento con RMarkdown.

Imagen 9.18: Tabla de frecuencias en formato RMarkdown
Finalmente, el argumento report.nas = FALSE le indica al software que no incluya en la tabla el conteo de casos codificados como NA (perdidos), puesto que ya se sabe que esta variable no presenta casos de este tipo.
Ejercicio 9.9
library(summarytools)
freq(CEP$sexo_factor, style = "rmarkdown", justify = "center", omit.headings = TRUE,
report.nas = FALSE)| Freq | % | % Cum. | |
|---|---|---|---|
| Hombre | 553 | 38.83 | 38.83 |
| Mujer | 871 | 61.17 | 100.00 |
| Total | 1424 | 100.00 | 100.00 |
Así, luego de incorporar el comando como trozo de código en un documento RMarkdown se obtiene una tabla con un diseño estético adecuado a RMarkdown que resulta apropiada como formato final para la presentación de resultados en un reporte de investigación.
9.5.2 Tabla de estadísticos univariados
Una segunda herramienta de utilidad del paquete summarytools es la función descr que permite obtener tablas de estadísticos univariados de nivel muestral, para variables continuas (de intervalo o razón). En el primer trozo de código se ejecuta la función en su configuración por defecto, indicando solamente argumentos adicionales para la alineación del texto y la presentación del encabezado (ya explicados para la función freq).
Ejercicio 9.10
descr(CEP$edad, style = "simple", justify = "center", omit.headings = T)| edad | |
|---|---|
| Mean | 49.87 |
| Std.Dev | 17.79 |
| Min | 18.00 |
| Q1 | 36.00 |
| Median | 50.00 |
| Q3 | 64.00 |
| Max | 97.00 |
| MAD | 20.76 |
| IQR | 28.00 |
| CV | 0.36 |
| Skewness | 0.01 |
| SE.Skewness | 0.06 |
| Kurtosis | -0.93 |
| N.Valid | 1424.00 |
| Pct.Valid | 100.00 |
El resultado obtenido es una tabla vertical, con trece estadísticos univariados de tipo descriptivo. Este resultado podría configurarse para su presentación mediante RMarkdown simplemente indicando que utilizaremos el estilo de tabla RMarkdown. Sin embargo, como se observa en el siguiente trozo de código, se recomienda incorporar algunas configuraciones adicionales.
- Indicar mediante el argumento
transpose = TRUEque el formato final de la tabla sea construido horizontalmente; es decir, que tanto el título de cada estadístico como su valor sean ingresados como filas y no como columnas. - Indicar mediante un vector de valores alfabéticos el detalle específico de los estadísticos univariados descriptivos a incluir (y en qué orden) en la tabla de resultados.
- Especificar una tabla construida en estilo RMarkdown con texto centrado y que omita el conteo de casos perdidos.
Ejercicio 9.11
descr(CEP$edad, transpose = TRUE,
stats = c("N.Valid", "min","q1","med","mean","sd","q3","max","iqr"),
style = "rmarkdown", justify = "center", omit.headings = T)| N.Valid | Min | Q1 | Median | Mean | Std.Dev | Q3 | Max | IQR | |
|---|---|---|---|---|---|---|---|---|---|
| edad | 1424.00 | 18.00 | 36.00 | 50.00 | 49.87 | 17.79 | 64.00 | 97.00 | 28.00 |
De tal modo se construye una tabla de resultados adecuada para un reporte de investigación, con la información específica que interesa desplegar para análisis.
9.5.3 Tablas de estimación de parámetros
En este apartado se indica como construir tablas de presentación para los resultados de estimación de parámetros poblacionales a partir de resultados que ya han sido calculados en ejemplos anteriores.
9.5.3.1 Intervalos de confianza para proporciones
Para el caso de construir una tabla para el intervalo de confianza de una proporción se considera lo ya ejecutado en el capítulo 7. Luego de contar con los resultados de tal ejercicio se procede a definir como vector simple a cada resultado. En el caso de los límites del intervalo de confianza simplemente se copia cada resultado (producto de las función exactci) y se almacena como un vector simple (linf y lsup respectivamente); lo mismo se realiza con el nivel de confianza (vector nc). Luego, mediante la función cbind, se configura una matriz (data.frame) con tales valores.
Ejercicio 9.12
library(PropCIs)
table(CEP$eval_econ_factor)##
## Positiva Neutra Negativa
## 471 730 209nrow(CEP)## [1] 1424exactci(x = 730, n = 1424, conf.level = 0.95)##
##
##
## data:
##
## 95 percent confidence interval:
## 0.4863248 0.5389039#Definición de cada valor como vector simple
linf <- (0.4863248*100)
lsup <- (0.5389039*100)
nc <- 0.95*100
#Configuración de un data.frame a partir de los vectore creados
ICP <- cbind(linf, lsup, nc)Con tales elementos se puede utilizar la función kable del paquete knitr para imprimir tal matriz de datos en formato RMarkdown. Así, se le indica el objeto a imprimir (ICP), con el argumento caption se le agrega un título a la tabla, mediante el argumento align se le indica la alineación del texto (en este caso, 'c' significa texto centrado), el argumento digits permite indicar la cantidad de decimales aceptados en el redondeo y finalmente el argumento col.names permite indicar un vector de caracteres con los títulos de cada columna. Especificar la opción asis en la configuración del trozo de código permite que los resultados se impriman sin ser editados en el formato RMarkdown.
Ejercicio 9.12 (continuación)
#Paquete necesario para imprimir tablas
library(knitr)
#Construcción de tabla de resultados con formato
kable(ICP, caption = "Tabla 1. Estimación de un intervalo de confianza para proporciones",
align = 'c', digits = round(2),
col.names = c("Límite inferior","Límite superior",
"Nivel de confianza"))| Límite inferior | Límite superior | Nivel de confianza |
|---|---|---|
| 48.63 | 53.89 | 95 |
9.5.3.2 Intervalos de confianza para medias
Algo similar a lo ya indicado se efectúa para construir una tabla de resultados de la estimación del intervalo de confianza de una media. En este caso se replica lo calculado en el capítulo 7 y los resultados de la función ci.mean se almacenan configurados como matriz de datos (usando la función as.data.frame) en un nuevo objeto denominado ic.
Ejercicio 9.13
# Intervalos de confianza
library(Publish)
#Nivel de confianza por defecto.
ci.mean(CEP$satisfaccion_vida)## mean CI-95%
## 7.31 [7.20;7.42]ic <- as.data.frame(ci.mean(CEP$satisfaccion_vida))Sobre este objeto se aplica la función kable del paquete knitr. De forma similar al ejemplo anterior, se aplica la función señalada sobre el objeto ic; en este caso, se seleccionan las columnas 1, de la 3 a la 5, y la columna 2 (en ese orden). Con el argumento caption se le agrega un título a la tabla, mediante el argumento align se le indica la alineación del texto (en este caso, 'c' significa texto centrado), el argumento digits permite indicar la cantidad de decimales aceptados en el redondeo y finalmente el argumento col.names permite indicar un vector de caracteres con los títulos de cada columna. Especificar la opción asis en la configuración del trozo de código permite que los resultados se impriman sin ser editados en el formato RMarkdown.
Ejercicio 9.13 (continuación)
kable(ic[c(1,3:5,2)], caption = "Tabla 2. Estimación de intevalo de confianza para media",
align = 'c', digits = round(2),
col.names = c("Media", "Límite superior","Límite inferior",
"Nivel de confianza","Error estándar"))| Media | Límite superior | Límite inferior | Nivel de confianza | Error estándar |
|---|---|---|---|---|
| 7.31 | 7.2 | 7.42 | 0.05 | 0.06 |
Con tales configuraciones ya es posible contar con tablas de resultados configuradas para ser impresas vía RMarkdown, con un formato adecuado para su presentación en un reporte de resultados.
9.5.4 Gráficos
La inserción de gráficos en un reporte a compilar vía RMarkdown es simple. Sólo se precisa incorporar alguna de las sintaxis para procesar gráficos ya construidas anteriormente en este material, en un trozo de código de R. En este caso se replica el gráfico construido en el capítulo 8. Vale la pena recordar que si se busca no compilar el trozo de código de R en el reporte, hay que agregar el argumento echo = TRUE a las especificaciones del trozo de código. Con los argumentos fig.height, fig.width y fig.align es posible configurar el ancho y alto máximos de la figura así como su alineación respecto a la página.
Ejercicio 9.14
library(ggplot2)
#Gráfico de barras 2: sexo en frecuencias absolutas
ggplot(CEP, aes(x = sexo_factor)) +
geom_bar(width = 0.4, fill=rgb(0.1,1,0.5,0.7)) +
scale_x_discrete("Sexo") + # configuración eje X (etiqueta del eje)
scale_y_continuous("Frecuencia") +
labs(title = "Gráfico de barras 2",
subtitle = "Frecuencia absoluta de la variable sexo")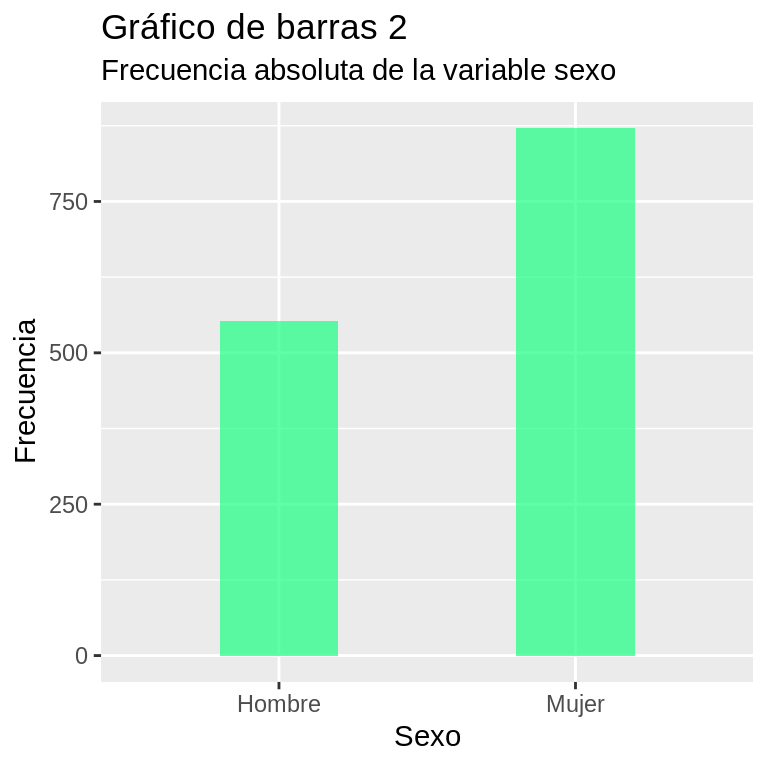
Bibliografía
Miller, Steven V. 2018. “A Pandoc Markdown Article Starter and Template.” https://github.com/svmiller/svm-r-markdown-templates.
Grolemund, Garret. 2014. “Introduction to R Markdown.” https://rmarkdown.rstudio.com/articles_intro.html.
Workshop, Reproducible Research. 2016. “Writing Publications with R.” Writing Publications with R. http://www.geo.uzh.ch/microsite/reproducible_research/post/rr-r-publication/.
Elousa, Paula. 2009. “¿EXISTE VIDA MÁS ALLÁ DEL SPSS? DESCUBRE R.” Revista Psicothema 21 (4): 652–55. http://www.psicothema.com/psicothema.asp?id=3686.
Comtois, Dominic. 2018. “Introduction to Summarytools.” https://cran.r-project.org/web/packages/summarytools/vignettes/Introduction.html.
Debido a que es ampliamente utilizado se hace referencia al procesador de texto de Microsoft Office. Estas anotaciones también resultan aplicables a otros paquetes de software de oficina ya nombrados en este documento como Open Office y Libre Office.↩
Para información de carácter general sobre RMarkdown como plataforma de trabajo (fichas técnicas, manuales, plantillas y tips de trabajo) sugerimos visitar la página oficial del proyecto.↩
Es importante señalar que RMarkdown simplifica el lenguaje LaTex, haciendo más intuitivo su uso para un usuario que no está enfocado en la utilización profesional de sus prestaciones. Desde este lenguaje viene la impronta asimilada por RMarkdown de separar el contenido del formato de un documento.↩
Existen diferentes versiones de LaTex, de descarga gratuita. Sin embargo, estas distribuciones de LaTex (por ejemplo MikTex es una de las más conocidas para sistema operativo Windows) presentan diversas limitaciones y complicaciones de configuración que hacen difícil su uso integrado con RMarkdown. Por eso se sugiere usar TinyTex, paquete diseñado para disminuir tales complicaciones y facilitar la integración de RMarkdown con las funcionalidades de LaTex. Para mayores detalles se recomienda revisar la página web de su desarrollador.↩
Para una introducción (en inglés) detallada al uso general de este paquete, se recomienda la lectura del siguiente documento elaborado Dominic Comtois para el sitio oficial de R (2018).↩