Capítulo 8 Construcción de gráficos usando RStudio: funcionalidades básicas y uso del paquete ggplot2
8.1 Funciones básicas para la construcción de gráficos
De modo general R, en su versión básica, incluye funciones para crear gráficos. Sin embargo, estas herramientas son bastante limitadas en cuanto a las posibilidades de edición que incluyen. Con todo, resultan válidas para un uso de análisis exploratorio. Esto es, un uso enfocado en la visualización de información que permita - dentro del contexto de un proceso de investigación - tomar decisiones para posteriores análisis estadísticos. Luego de explorar estas alternativas se profundizará en el uso de ggplot2, paquete especializado en en el diseño de gráficos que permite una mejor visualización de resultados, sobre todo enfocados en el momento de divulgación de resultados de investigación (Field, Miles, and Field 2012, 116–17).
8.1.1 Gráficos de barras y gráficos circulares
De modo general, los gráficos de barras y circulares40 se recomiendan para visualizar los valores de frecuencias absolutas o relativas de variables nominales u ordinales. Es decir, aquellas variables cuyos valores en la base de datos representan una simple clasificación de datos, sin que sea posible aplicar todas las propiedades aritméticas para tales números (Blalock 1966, 26–37; Ritchey 2008, 42–48).
Como un paso preliminar para la demostración de la construcción de gráficos mediante R configuraremos una nueva variable en la base de datos. Para esto, la variable Sexo (CEP$sexo) será modificada en una nueva variable (sexo_factor) agregando las etiquetas “Hombre” y “Mujer” a los valores numéricos, al configurarla como un vector de tipo factor. Realizamos esta operación para contar con una variable con valores numéricos y con sus respectivas etiquetas de respuesta, con el fin de observar si tal configuración de la variable es soportada por diferentes herramientas para construir gráficos.
Ejercicio 8.1
# Transformar variable sexo a factor (contar con valores y etiquetas)
CEP <- mutate(CEP, sexo_factor = factor(CEP$sexo,
labels = c("Hombre", "Mujer")))Un primer comando básico para la construcción de gráficos en R es hist. Este comando está pensado para construir histogramas. Como se observa a continuación, no resulta apropiado para variables nominales (aunque están codificadas como numéricas); tampoco soporta los formatos character ni factor como formato de entrada de los datos a graficar.
Ejercicio 8.2
#Limitaciones de la función hist
hist(CEP$sexo)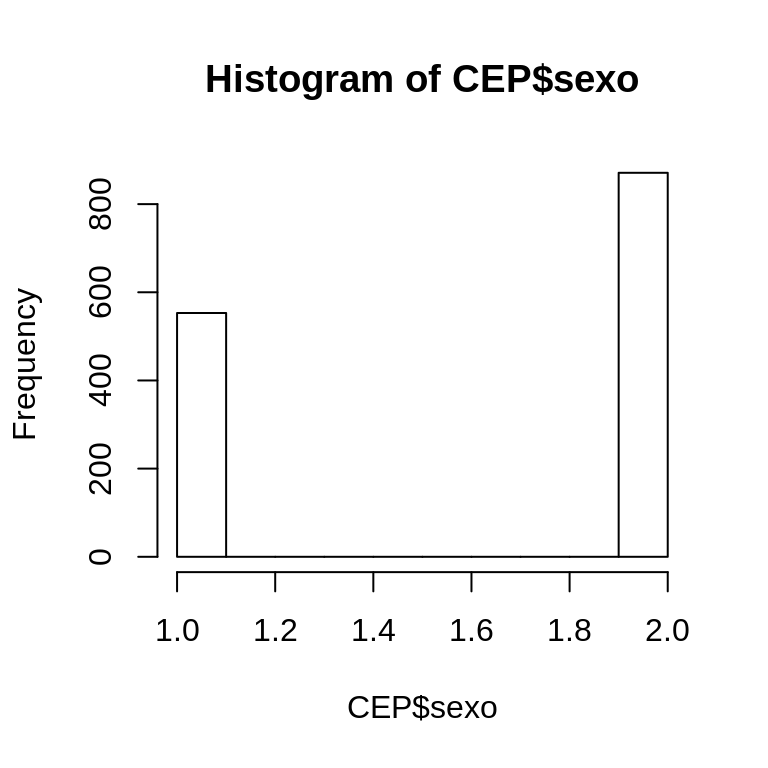
hist(CEP$sexo_chr)## Error in hist.default(CEP$sexo_chr): 'x' must be numerichist(CEP$sexo_factor)## Error in hist.default(CEP$sexo_factor): 'x' must be numericLos resultados de las líneas de código anterior muestran cómo solamente el primer gráfico es construido de manera adecuada, pero asume una continuidad de valores entre las categorías “hombre” y “mujer” (valores 1 y 2, respectivamente), lo que arroja un gráfico poco útil. Por otra parte, al indicar como variable de entrada un vector de tipo character o factor, el comando arroja error.
Por ello se sugiere el uso del comando plot para construir gráficos de barras. De manera general, este tipo de gráficos se usan para variables cualitativas (nominales u ordinales). Las categorías de una variable se sitúan en el eje X, mientras que la frecuencia absoluta o relativa (generalmente porcentajes) se sitúa en el eje Y (Ritchey 2008, 83–85)
A continuación se muestra el uso del comando plot para construir un gráfico de barras. El primer argumento es la variable a graficar. Posteriormente se usan argumentos para agregar títulos: main sirve para agregar un título general; xlab sirve para agregar un título al eje X; ylab sirve para agregar un título al eje Y. Como se observa, este resulta bastante más adecuado para la visualización exploratoria de datos.
Ejercicio 8.3
plot(CEP$sexo_factor, main = "Gráfico de barras 1",
xlab = "Género", ylab = "Frecuencia")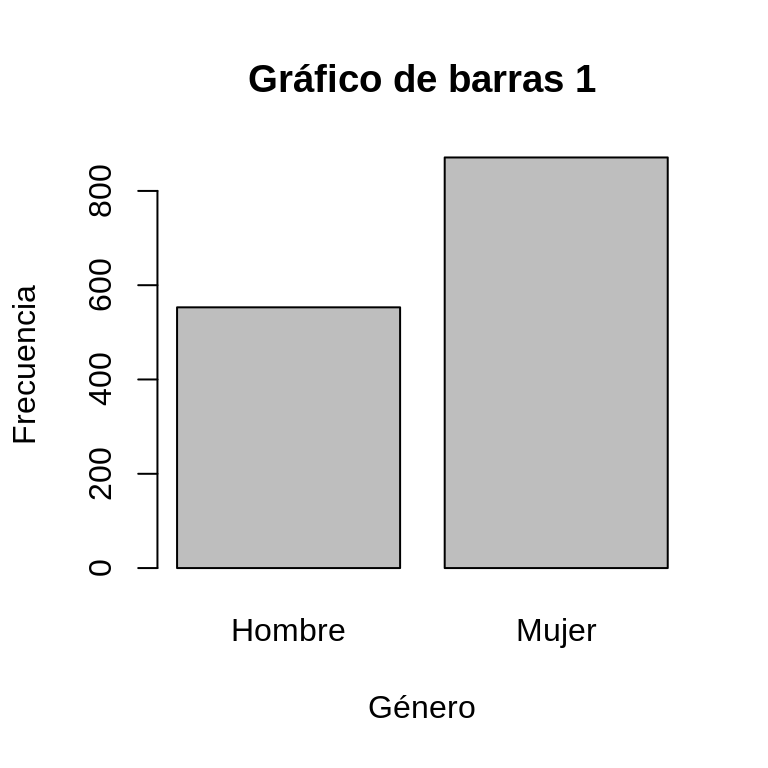
Otra forma de presentar variables nominales son los gráficos circulares (o de “torta”)“; se trata de gráficos cuya división proporcional busca representar la distribución de categorías dentro de una variable nominal u ordinal: el área del círculo representa el 100% de los casos de una variable, mientras que el área de cada división del círculo, representa el porcentaje de casos en una categoría específica de esa variable (Ritchey 2008, 80–83). Estos gráficos, a pesar de ser muy utilizados, no resultan tan recomendados pues tienden a distorsionar la percepción de la información presentada: cuando se trabajan variables con muchas opciones de respuesta la mirada tiende a distorsionar el tamaño relativo de las divisiones del círculo. No obstante pueden utilizarse cuando construimos gráficos con variables nominales de pocas categorías (entre dos y cinco), sobre todo para mostrar diferencias entre pocas categorías.
A continuación se muestra una configuración de elementos que servirán para construir el gráfico.
- Primero se usa la tabla de frecuencias relativas construida en el apartado 7.1.2. Sobre ella se aplica la función
round, que permite seleccionar la cantidad de decimales deseados para hacer la aproximación. Mediante la funciónas.numericse guardan en un nuevo vector (porcentajes) los números que configuran los resultados de tal tabla. - Luego se construye un vector de caracteres (etiquetas) con las etiquetas de cada resultado.
- A continuación se realizan dos operaciones sobre tal vector: usando el comando
pastecada etiqueta se una con los valores porcentuales que serán cada proporción del gráfico; además, al final de cada valor se incorpora un signo % que quedará expresado en las etiquetas del gráfico. En el siguiente ejemplo se muestra el vector resultante de cada parte de la operación.
Ejercicio 8.4
#Valores que dividirán el gráfico
porcentajes <- as.numeric(round(((prop.table(table(CEP$eval_econ_factor)))*100),2))
porcentajes## [1] 33.40 51.77 14.82#Etiquetas para el gráfico
etiquetas <- c("Positiva", "Neutra", "Negativa")
etiquetas## [1] "Positiva" "Neutra" "Negativa"etiquetas <- paste(etiquetas, porcentajes)
etiquetas## [1] "Positiva 33.4" "Neutra 51.77" "Negativa 14.82"etiquetas <- paste(etiquetas, "%", sep = "")
etiquetas## [1] "Positiva 33.4%" "Neutra 51.77%" "Negativa 14.82%"Considerando los dos elementos (porcentajes y etiquetas) se construye el gráfico circular. Como se observa a continuación, este se construye mediante la función pie. El primer argumento son los valores que demarcarán las divisiones del círculo que representa al 100% del área del círculo. Luego se indican los valores que determinarán la construcción de etiquetas. Posteriormente se indica mediante los argumentos main y sub, un título general para el gráfico y una descripción en su borde inferior, respectivamente. Ejecutando tal comando se obtiene el gráfico deseado.
Ejercicio 8.4 (continuación)
pie(porcentajes, etiquetas,
main = "Gráfico de torta 1",
sub = "Evaluación de la situación económica")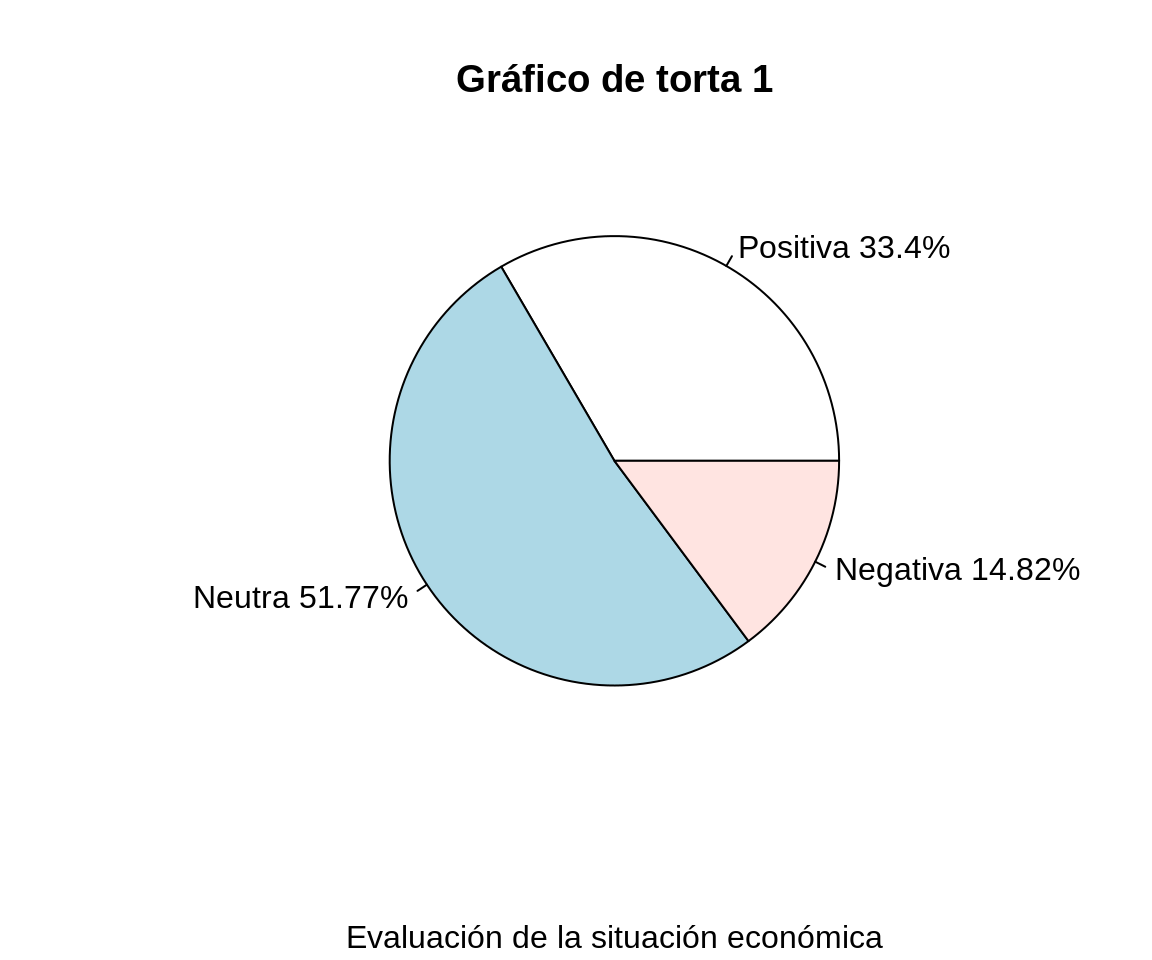
8.1.2 Histogramas
El histograma es una representación gráfica que se utiliza para observar la forma de la distribución de variables cuantitativas (intervalo o razón). De manera similar al gráfico de barras, sobre el eje X se posicionan las puntuaciones de la variable, mientras que la frecuencia (absoluta o relativa) de cada valor se posiciona en el eje Y. Así, se construye un gráfico de columnas verticales; la principal diferencia entre un gráfico de barras y un histograma es que en este último las columnas se tocan entre sí, pues representa a un continuo de valores numéricos (Ritchey 2008, 86–89).
Con el siguiente comando se ilustra la construcción de un histograma usando R. El comando utilizado es hist; sus argumentos son main, xlab e ylab para incorporar un título general y para cada eje. Además podemos indicar el color de relleno de las barras mediante el argumento color, mientras que el color de los bordes de la barra se establece con el argumento border. Adicionalmente, los argumentos xlim e ylim permiten definir manualmente la extensión de los ejes (se indica un vector numérico con los valores mínimo y máximo).41
Ejercicio 8.5
hist(CEP$edad, main = "Histograma de frecuencias 1",
xlab = "Edad (años cumplidos)",
ylab = "Frecuencia",
col = "red",
border = "black",
xlim = c(18, 97),
ylim = c(0, 150))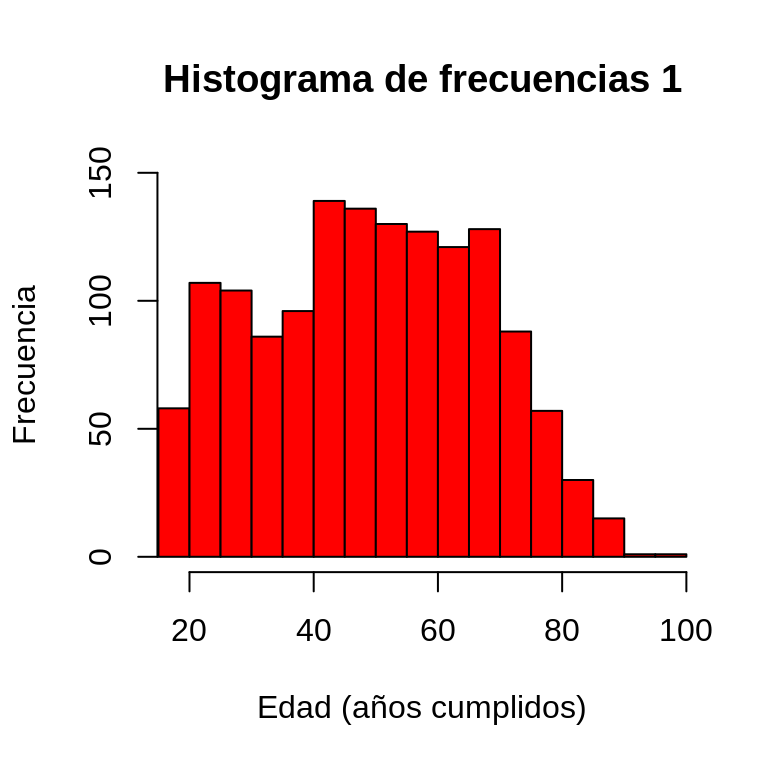
Existe otro tipo de histograma denominado de “densidad”. Este gráfico no representa las barras de frecuencias de cada alternativa de respuesta de la variable, sino que aplica una suavización sobre los valores observados con el objetivo de conseguir una representación de la forma de la distribución que no se vea alterada por la cantidad de barras que incluya el histograma. La principal utilidad de este tipo de gráficos es poder observar la forma de la distribución de una variable, de la manera más precisa posible. En el ejemplo a continuación se muestra cómo construir un histograma de este tipo: en primer lugar se calcula la información de densidad de una variable con la función density asignando su resultado al objeto densidad_edad; luego, mediante la función plot se gráfica esta información indicando título al gráfico y a los ejes de la forma que ya ha sido explicada.
Ejercicio 8.6
densidad_edad <- density(CEP$edad)
plot(densidad_edad,
main = "Histograma de densidad 1",
xlab = "Edad (años cumplidos)",
ylab = "Densidad")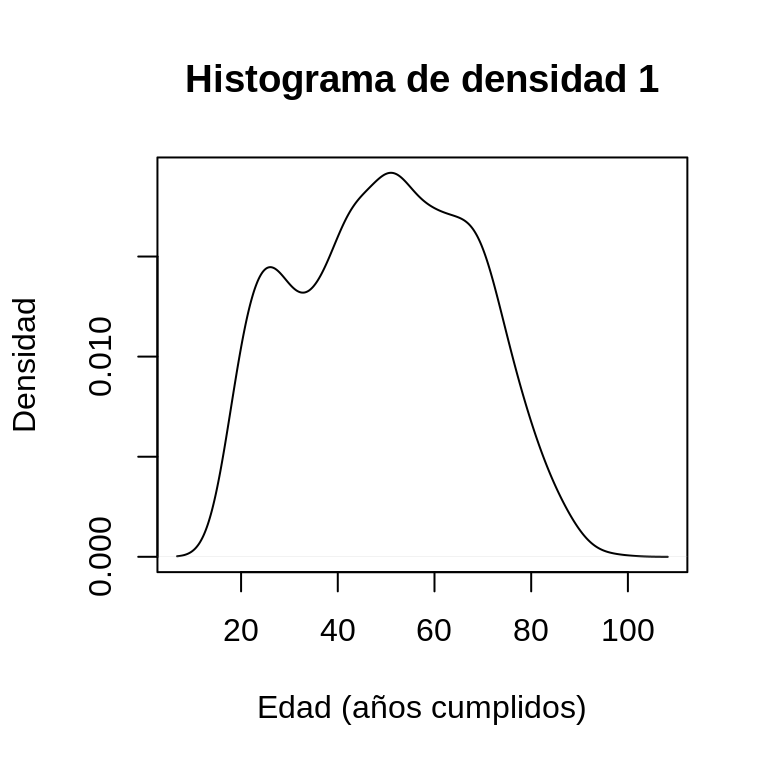
8.1.3 Diagrama de cajas
El último gráfico a construir con las funcionalidades básicas de R es el diagrama de cajas (boxplot en inglés). La línea central de este gráfico representa a la mediana, es decir al valor que señala el 50% de la distribución de la variable en estudio. La parte superior e inferior de la caja demarcan al tercer y segundo cuartil respectivamente (esto es, el 75% y 25% de los casos): así, la caja demarca al 50% central de los casos. Por otra parte, los extremos superior e inferior de la línea vertical, demarcan los valores máximo y mínimo de la distribución. Así, la distancia entre el extremo superior o inferior de tal línea y el borde superior o inferior de la caja, demarca la distribución de casos en el cuartil superior (25% de casos con puntuaciones más elevadas) y en el cuartil inferior (25% de casos con menores puntuaciones) de la distribución, respectivamente (Field, Miles, and Field 2012, 151–52).
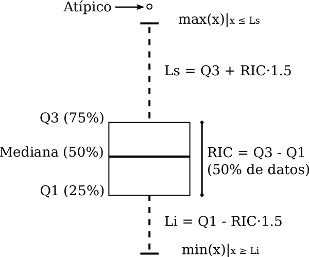
Imagen 8.1: Gráfico de caja
Para construir un gráfico de cajas el código de R es bastante simple. Basta con ejecutar la función boxplot indicando como primer argumento la variable de interés. A esto se le puede agregar un título (argumento main) y el argumento outline especificado como TRUE, para que si existen casos atípicos estos se grafiquen. A continuación se muestra un comando de este tipo y su resultado.
Ejercicio 8.7
boxplot(CEP$edad, main = "Gráfico de cajas 1",
outline = TRUE)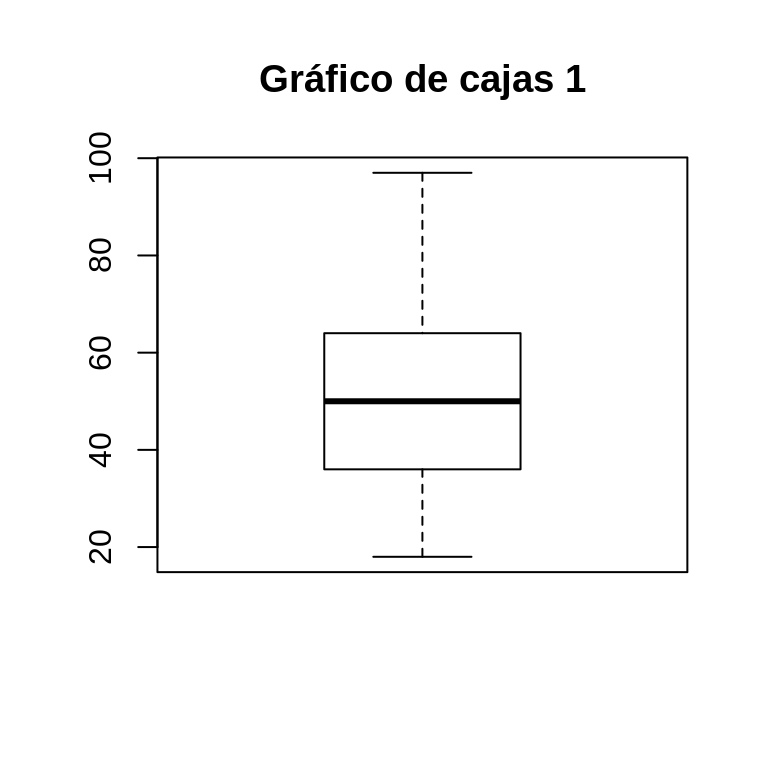
8.2 Introducción al uso del paquete ggplot2
8.2.1 Nociones generales
El paquete ggplot2 es un paquete de R especializado en la construcción y diseño para la visualización de datos. En este sentido, se trata de un paquete cuyas funcionalidades van más allá de un uso puramente “científico” o exploratorio y se orienta a las diferentes dinámicas de divulgación de resultados de procesos de investigación, esto incluye:
- Divulgación de resultados de procesos de investigación científica para público especializado. Esto puede referir a contextos académicos (publicaciones en revistas especializadas, libros, etc.) o profesionales (informes de investigación para actividades de consultoría en el ámbito público o privado, por ejemplo).
- Divulgación de resultados de procesos de investigación científica para público no especializado. Esto refiere por ejemplo a la difusión de información en contextos como medios de comunicación masivos (televisión, diarios en papel o digital) o redes sociales (twitter, facebook, instagram, etc.).
Se trata, en suma, de un conjunto de funciones altamente especializadas en la construcción de resultados visualmente atractivos para quien leerá la información. Debido a esta especialización, el nivel de configuración y trabajo de codificación para llegar a un resultado deseable, puede ser elevado.
En tal medida, para quien desempeña tareas de investigación social, se abre la tensión entre enfocar su trabajo en la construcción de productos para análisis exploratorio o enfocarse en diseñar visualizaciones de datos estéticamente atractivas para públicos amplios. Vale la pena señalar que el objetivo de este manual es enfocarse en un punto intermedio: manejar los elementos básicos de un paquete como ggplot2 para no depender de que un tercer actor configure nuestros resultados básicos, pero sin profundizar su estudio hasta el punto de que nos aleje de nuestro principal objetivo: construir análisis sociológicamente relevantes y estadísticamente rigurosos.
Es por ello que en este manual centraremos los contenidos en una introducción general al uso de este paquete. Enfatizamos en que no es necesario convertirse en un experto, sino más bien manejar a cabalidad los fundamentos de su funcionamiento. Resultará central en esta dinámica manejar elementos de apoyo para realizar cuestiones más avanzadas.42
8.2.2 Gramática del paquete ggplot2
El paquete ggplot2 presenta distintas características que lo distinguen:
- En primer lugar, los objetos resultantes de la construcción de un gráfico no son una imagen sino un objeto de tipo graphic específico. Esto permite configurar un gráfico como cualquier otro elemento de R, directamente desde la sintaxis,
- Debido a lo anterior, la editabilidad de los gráficos construidos es mayor. Definiendo el conjunto de información a visualizar, se pueden configurar diferentes tipos de gráficos.
- En tercer lugar, puede señalarse que la estructura de este paquete presenta una gramática específica en relación a sus sintaxis. Como veremos a continuación, su sintaxis guarda directa relación con tres elementos que compondrán la estructura de cualquier visualización de datos: la información (data) a utilizar, la estética (aesthetics) o la definición de los ejes donde se posicionarán los datos a visualizar, y la geometría (geometry) o los elementos visuales que se posicionarán en la gráfica para representar los datos que interesa visualizar.
Resulta importante comprender que en el paquete ggplot2 los gráficos se construyen en base a una serie de capas de información que superpuestas, configuran el resultado final. Andy Field et.al. (2012, 121–36) propone que los gráficos construidos mediante la función ggplot pueden entenderse como una serie de transparencias donde se imprime cierta información; esta información pueden ser números, títulos, barras, líneas, puntos, etc. Luego de definir tales capas de datos, lo que realiza la función ggplot es presentar el resultado de la superposición de tales capas de información como un elemento unitario.
Para estandarizar una gramática general para la construcción de gráficos mediante capas de información, el paquete se basa en un lenguaje estándar para la construcción de gráficos. Esta nomenclatura se basa en los planteamientos de un famoso libro titulado “The Grammar of Graphics (Statistics and Computing)” (Wilkinson, Wills, and Rope 2005), en el que sus autores definen una base común para la producción de gráficas basadas en información cuantitativa, aplicable a casi cualquier campo de producción de conocimiento.
| Capa | Descripción |
|---|---|
| Datos | Conjunto de información que se representará de manera gráfica. En nuestro caso se trata de una o más variables, o una base de datos. |
| Estética | Escala en la cual se posicionará la información de interés. Refiere al posicionamiento de la información a representar sobre los diferentes ejes y dimensiones del gráfico resultante. Hablamos del posicionamiento de variables en los ejes X e Y como también de la posibilidad de indicar variables que pueden ser posicionadas como color de relleno dentro de los diferentes ejes, como una función de transparencia, etc. |
| Geometría | Formas, elementos visuales, que se emplearán para representar visualmente la información ya consignada en los datos y ubicada en las diferentes posiciones del gráfico mencionadas en la estética.43 Cada especificación de geometría permite visualizar diferentes características de la(s) variable(s) y su distribución. |
Es importante entender esta clasificación de elementos que componen un gráfico. Tal diferenciación de elementos comanda la estructuración de la sintaxis específica para crear gráficos mediante la función ggplot.
Como se observa a continuación, en la primera línea de argumentos de esta función (primer paréntesis) se definen los datos a visualizar y luego la estética. Luego, agregando un signo más al final de cada línea, se agregan líneas de comando adicionales que permiten agregar diferentes capas de información al gráfico final, cuyos datos y estética ya han sido definidos.
En la figura a continuación se observa una sintaxis que: i) posiciona una variable X en el eje X, configurándola como factor; que ii) posiciona una variable Y en el eje Y sin transformarla; y que iii) utiliza una tercera variable para el relleno de color de las figuras geométricas finales. En las dos líneas adicionales se establece: en primer lugar, el argumento geom_point() indica que uno de los elementos geométricos a posicionar son puntos, sin configuraciones adicionales; en segundo lugar, se posiciona - mediante el comando geom_smooth(method=lm, linetype=2) una línea de tendencia suavizada (mediante un procedimiento de regresión lineal) que mostrará la tendencia lineal de la nube de puntos.
No olvidar que luego de la primera línea, las funciones de geometría deben agregarse indicando un signo +.

Imagen 8.2: Estructura básica de una sintaxis de la función ggplot
En términos generales ésta es la estructura general para construir gráficos mediante ggplot. Puede que se introduzcan más o menos configuraciones dentro de cada elemento (data, aesthetics, geom) y que se agreguen más o menos capas de objetos geométricos sobre el gráfico a desplegar. No obstante, la lógica básica seguirá siendo siempre la misma.44
8.2.3 Construcción de gráficos usando la función ggplot: diagramas de barras, histogramas de frecuencia absoluta y relativa
En este apartado se replicarán los gráficos construidos con las funcionalidades básicas de R, pero ahora aplicando la función ggplot. Se comienza por un diagrama de barras.
Como se observa en el código a continuación, este comando sigue la lógica y estructura de sintaxis ya explicada para el paquete ggplot2. En la primera línea de la función se definen los datos (CEP), y con el argumento aes (estética) se define qué variable irá en el eje X (sexo_factor). En este caso, al no definir una variable para el eje Y, el software efectúa un conteo simple de los casos que caen en cada categoría de la variable definida para el eje X. Luego, separado por un signo +, se define la figura geométrica o geometría a utilizar: en este caso se trata de un gráfico de barras (geom_bar); se agrega como argumento de esta subfunción un argumento width que permitirá definir el ancho de las barras, así como un argumento fill para definir el color de relleno de las barras, con la función rgb.45 Finalmente los argumentos siguientes (también especificados luego de un signo +) definen diferentes elementos adicionales: título del eje X (scale_x_discrete), título del eje Y (scale_y_continuous) y título y subtitulo general para el gráfico (labs.)
Ejercicio 8.8
library(ggplot2)
#Gráfico de barras 2: sexo en frecuencias absolutas
ggplot(CEP, aes(x = sexo_factor)) +
geom_bar(width = 0.4, fill=rgb(0.1,1,0.5,0.7)) +
scale_x_discrete("Sexo") + # configuración eje X (etiqueta del eje)
scale_y_continuous("Frecuencia") +
labs(title = "Gráfico de barras 2",
subtitle = "Frecuencia absoluta de la variable sexo")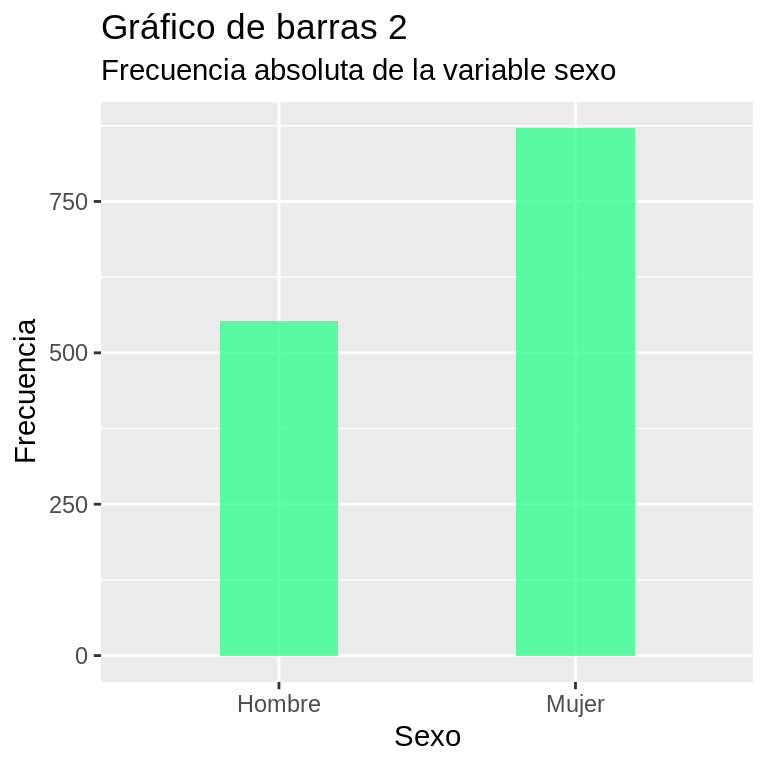 Si bien se trata de un código algo más complejo que la función básica que incluye el software, es posible afirmar que hay una mejora estética notable en comparación con los gráficos más básicos.
Si bien se trata de un código algo más complejo que la función básica que incluye el software, es posible afirmar que hay una mejora estética notable en comparación con los gráficos más básicos.
Una variante del gráfico anterior es construirlo para frecuencias relativas expresadas en porcentajes, uso muy común para la presentación de datos en contextos de divulgación de resultados.
Ejercicio 8.9
ggplot(CEP, aes(x = sexo_factor)) +
geom_bar(width = 0.4, fill=rgb(0.1,0.3,0.5,0.7), aes(y = (..count..)/sum(..count..))) +
scale_x_discrete("Sexo") + # configuración eje X (etiqueta del eje)
scale_y_continuous("Porcentaje",labels=scales::percent) + #Configuración eje y
labs(title = "Gráfico de barras 3",
subtitle = "Frecuencia relativa de la variable sexo")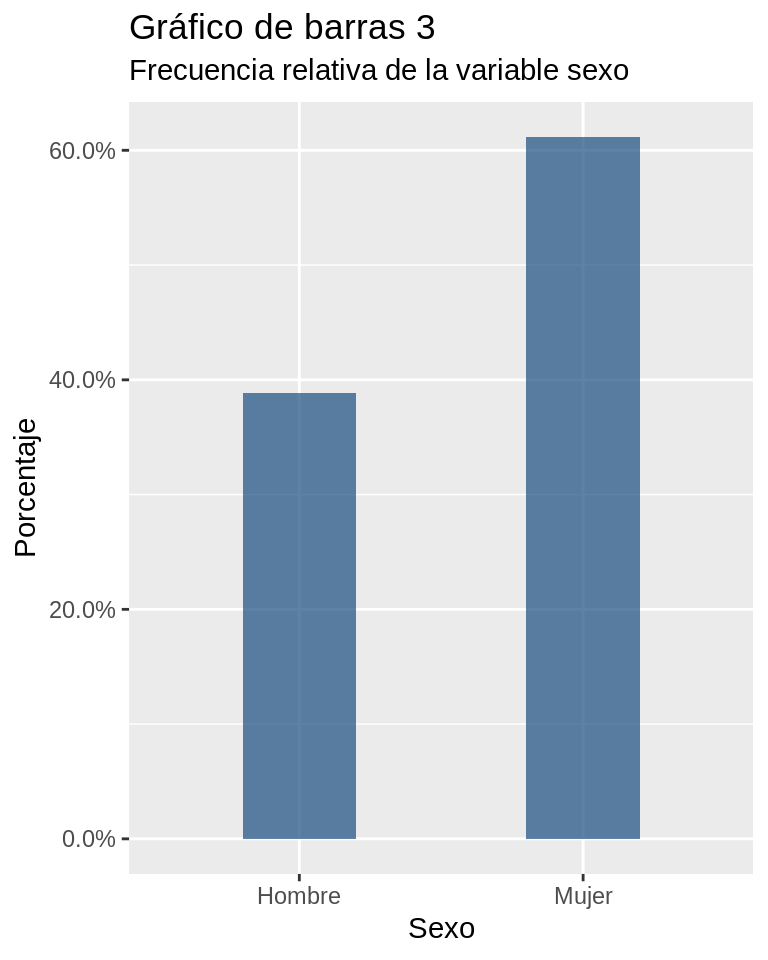 A continuación se indican las modificaciones realizadas al código anterior:
A continuación se indican las modificaciones realizadas al código anterior:
- Se modificaron algunos valores del argumento
fillde la funcióngeom_barpara alterar el color resultante de las barras. - En la función
geom_barse agregó un argumentoaespara editar el tipo de conteo ejecutado en el eje Y. Específicamente se le indica que el conteo hecho en Y es igual al conteo simple, dividido en la suma total de casos. - Luego, se agrega un
scale_y_continuouseditar los parámetreos del eje vertical. Ello permite agregar el título de porcentaje al eje Y, a la vez que definir que las etiquetas del eje (labels) respondan a una escala de tipo porcentual (label=scales::percent). - El resto de los comandos se mantuvo igual.
El siguiente comando muestra como construir un histograma de frecuencias absolutas. En este caso, luego de los datos a utilizar (CEP), se indica que en el eje X se posicione a la variable edad pero considerándola como variable numérica continua (as.numeric) pues originalmente es una variable de tipo integer, lo que impide posicionarla en el gráfico como variable continua. El resto de los comandos es similar a un gráfico de barras, sólo que ahora se le indica la función geom_histogram para construir el histograma; dentro de esta función se indica un binwidth para ajustar el ancho de la barra. Nótese que la configuración de ambos ejes indica que se trata de variables continuas (scale_x_continuous, scale_y_continuous), de lo contrario no podría configurarse el gráfico.
Ejercicio 8.10
ggplot(CEP, aes(x = as.numeric(edad))) +
geom_histogram(binwidth = 0.6) +
scale_x_continuous("Edad (años cumplidos)") +
scale_y_continuous("Frecuencia") +
labs(title = "Histograma de frecuencias 2",
subtitle = "Frecuencia absoluta de la variable edad")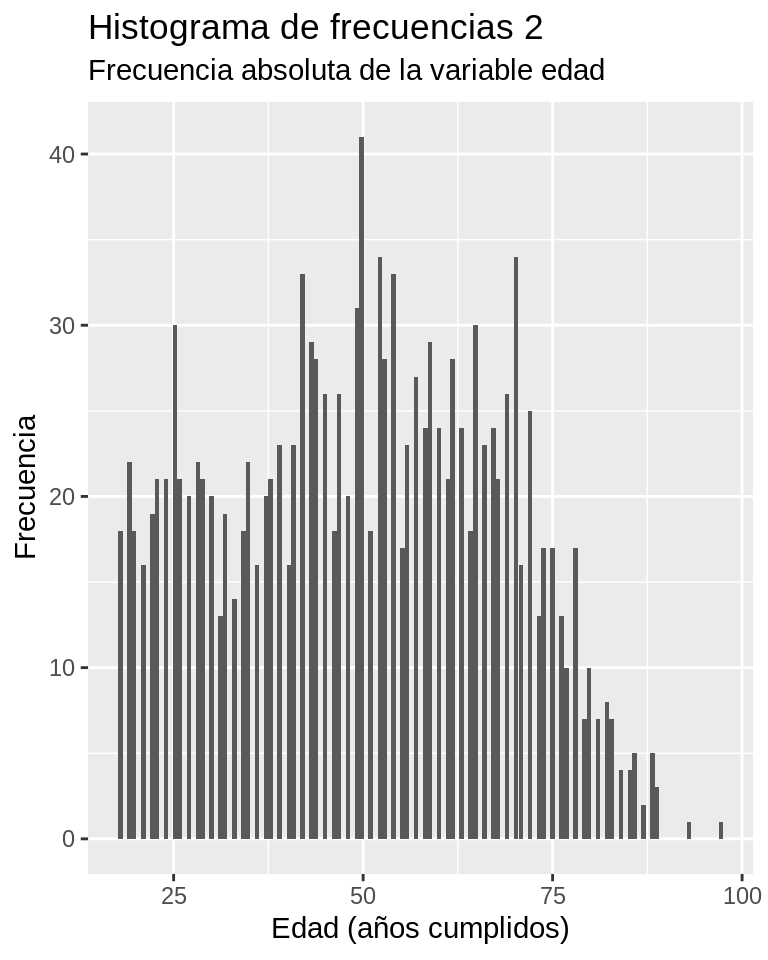
Como fue señalado en el apartado anterior la manera que resulta más óptima para observar la forma de la distribución de una variable es la construcción de un histograma de densidad. A continuación se muestra la sintaxis que permite construir un histograma de densidad de la variable Edad. La estructura de la sintaxis sigue la misma lógica que los otros gráficos construidos con el paquete ggplot2; en este caso, la especificación de la geometría es el argumento geom_density. El resultado permite observar de manera precisa la forma de la distribución de la variable Edad.
Ejercicio 8.11
ggplot(CEP, aes(x = edad)) +
geom_density() +
scale_y_continuous("Densidad") +
scale_x_continuous("Edad") +
labs(title = "Histograma de densidad 2",
subtitle = "Forma de la distribución de la variable edad")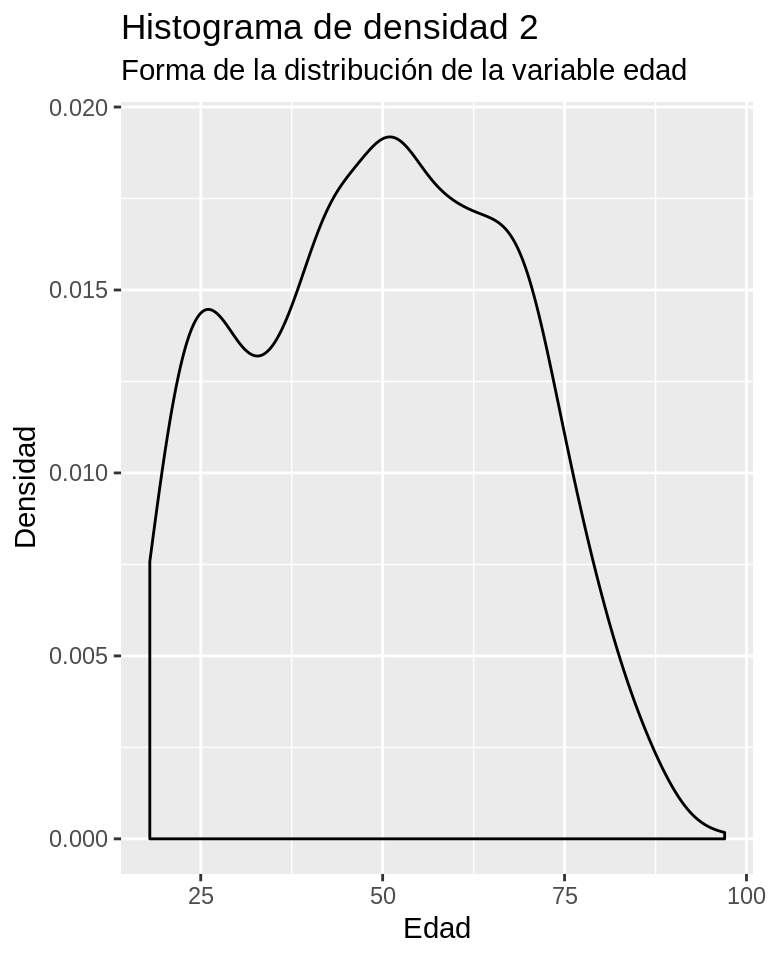
Bibliografía
Field, Andy, Jeremy Miles, and Zoe Field. 2012. Discovering Statistics Using R. Edición: 1. London ; Thousand Oaks, Calif: SAGE Publications Ltd.
Blalock, Hubert M. 1966. Estadística Social. Fondo de Cultura Económica.
Ritchey, Ferris J. 2008. Estadística Para Las Ciencias Sociales. McGraw-Hill Interamericana de España S.L.
Wilkinson, Leland, D. Wills, and D. Rope. 2005. The Grammar of Graphics. Edición: 2nd edition. 2005. New York: Springer.
Popularmente conocidos como gráficos “de torta”.↩
R incluye una paleta bastante grande de colores. Para una explicación general de cómo funcionan los colores en R se sugiere visitar este enlace o descargar la siguiente guía en inglés. Para descargar la plantilla general de colores, y asociar visualmente un color con su nombre estándar, presionar el siguiente enlace que efectúa la descarga de tal plantilla en formato PDF. Si se ejecuta el comando
colors()se obtiene el listado general de posibilidades de colores con nombre, que incluye R.↩Una buena fuente de información, que incluye ejemplos interesantes de visualización de datos junto con sus respectivas sintaxis de configuración puede encontrarse en el apartado ggplot2 de la Galería de Gráficos de R. Recomendamos explorar este tipo de recursos cuando se desee implementar una visualización cuyo código no se maneje.↩
Internamente, esta capa también puede contener propiedades estéticas, como la la transparencia, el color o tamaño de los objetos geométricos utilizados. Tal información estética interna a la geometría, no debe confundirse con la información estética general del gráfico.↩
Para contar con un listado explicativo completo de las configuraciones posibles para la función
ggplot, sugerimos revisar la Guía de Referencia para ggplot2 elaborada y puesta en línea por su equipo de desarrollo. Desde esta página se puede acceder a la guía completa en línea de la familia de paquetestidyverse, que incluye documentación de los siguientes paquetes: dplyr, tidyr, tibble, purr, readr y, por supuesto, ggplot2.↩En este caso, se trata de la función
rgb, que define concentraciones de los colores básicos rojo, verde y azul (red, green and blue).↩