Capítulo 6 Gestión de bases de datos
Un aspecto importante en el uso de RStudio enfocado en el análisis de datos sociales es el manejo de base de datos. Esto puede referir tanto a bases que quien efectúa el análisis haya construido como a bases de datos de estudio sociales realizados por otros.
En este manual de apoyo docente se utilizará una base de datos secundaria. Tanto para enseñar los procedimientos de importación, validación y modificación de datos, como para los posteriores aspectos de análisis estadístico descriptivo.
En los siguientes ejemplos se trabajará con la base de datos de la Encuesta Nacional de Opinión Pública del Centro de Estudios Públicos (Encuesta CEP, de aquí en más) correspondiente a su versión 81 cuyo trabajo en terreno se efectuó entre Septiembre y Octubre de 2017. Esta encuesta busca caracterizar las actitudes y opiniones, políticas, sociales y económicas de la población chilena, destacando las necesidades, principales preocupaciones y preferencias de todos los habitantes del territorio nacional. Es una de las fuentes de información más importantes para estudiar la opinión pública en Chile, respecto a temas coyunturales (CEP 2017).
Toda la información de esta encuesta se puede encontrar en el apartado Encuesta CEP de la página institucional del centro de estudios mencionado.14 Desde este sitio en línea el usuario podrá descargar las bases de datos históricas de esta encuesta, junto con sus manuales de uso metodológico.
6.1 Descarga de una base de datos de interés
Una primera acción a realizar es la descarga de la base de datos indicada al computador. Esto puede realizarse accediendo a la página web indicada del CEP. En la botonera superior de esta página se encuentra un botón de acceso a la Encuesta CEP (fecha de consulta: 10 de abril 2019).

Imagen 6.1: Página del CEP
Dentro de esa página se debe buscar el apartado Encuestas anteriores para encontrar en el repositorio la Encuesta CEP Septiembre-Octubre 2017.
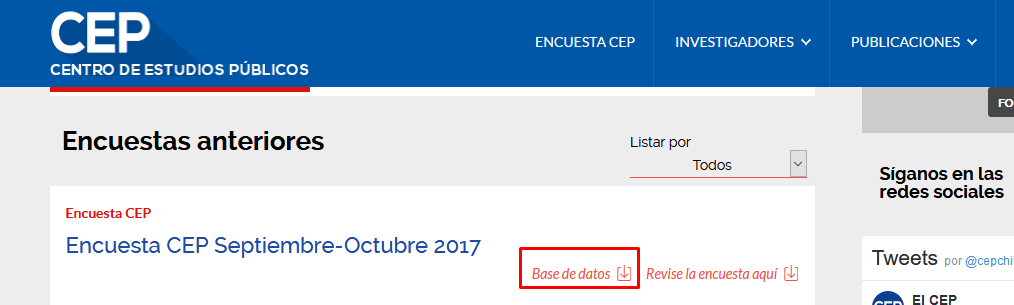
Imagen 6.2: Repositorio de bases de datos históricas de la encuesta CEP
Allí, oprimiendo el botón Base de datos se podrán descargar los archivos de interés.15
Luego de clickear el enlace de descarga se debe guardar descargar archivo comprimido como el que se ve en la siguiente imagen (con la extensión “.rar”). Para poder descomprimir el archivo original basta con tener instalado el programa WinRar (puede descargarse desde esta página). Haciendo clic derecho sobre el archivo descargado, y seleccionando la opción Extraer aquí se obtendrá el archivo original (de extensión “.sav”“)

Imagen 6.3: Archivos resultantes luego de descomprimir el archivo descargado
Como se ve en la imagen 6.3 el archivo resultante es un archivo de extensión .sav, lo que indica que se trata de un archivo para abrir y trabajar en SPSS. De aquí en más se usará este archivo para desarrollar ejemplos de análisis estadístico. Además de la base de datos, se descarga el manual de uso de la encuesta en formato PDF.16
6.2 ¿Cómo abrir bases de datos desde formato SPSS?
¿Por qué puede ser importante manejar herramientas que permitan que desde RStudio interactuemos con diferentes formatos de bases de datos? Imagine lo siguiente: durante la formación universitaria usted ha aprendido a usar RStudio como herramienta de análisis estadístico. Pero sucede que al incorporarse a un centro de estudios sociales y observa que el resto de los analistas trabaja fundamentalmente con otro software de análisis estadístico: SPSS. Si usted quiere lograr dialogar con tales especialistas - que muy probablemente no estarán dispuestos a aprender a usar RStudio - deberá lograr al menos abrir bases de datos en formato SPSS, para así poder hacer los análisis que se le encomiende.
Para ello se utiliza un paquete específico llamado haven que cuenta con funciones para abrir bases de datos desde diferentes formatos.17 Para eso primero se descarga e instala el paquete en el computador:
Ejercicio 6.1
install.packages("haven")La función específica a utilizar es read_spss cuya ejecución es muy simple. Luego de la función se indica el nombre del archivo a leer entre paréntesis y entre comillas. Como se observa a continuación, esta función sirve para leer la base de datos de la Encuesta CEP descargada en el anterior apartado. Es importante recordar que para usar una fuente de datos en análisis futuros se debe guardar como un “objeto” en el entorno de trabajo. Para eso, la ejecución de la función debe asignarse a un objeto nuevo o preexistente mediante la función de asignación. En este caso se asigna a un nuevo objeto llamado “CEP” (CEP <- lectura base de datos):18
Ejercicio 6.2
library(haven) #Debemos asegurarnos de que el paquete a ejecutar,
#está cargado en la sesión de Rtudio.
CEP <- read_spss("CEP_sep-oct_2017.sav") # Nombre del archivo entre comillas.Como se observa en la imagen a continuación, luego de tal operación ya se cuenta con un nuevo objeto (CEP) en el entorno de trabajo, que almacena la base de datos de la Encuesta CEP.19

Imagen 6.4: Base de datos CEP cargada como objeto en entorno de trabajo
Con la base de datos cargada en el entorno de trabajo podemos explorar sus principales características. Como se observa en la imagen 6.5 existe un botón (flecha azul indicando hacia abajo) que permite desplegar la estructura interna de la base de datos existente en el entorno de trabajo.
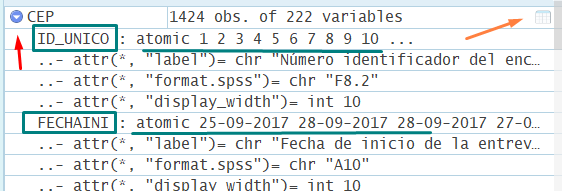
Imagen 6.5: Información de los vectores que componen la base de datos
Así se logra explorar rápidamente las principales características de la estructura interna de la base de datos cargada, es decir, los atributos de las diferentes variables en su interior. Entre estas características - a las que se puede acceder con el comando attributes - se encuentran las etiquetas, entre otros elementos de formato, que generalmente se observan en la vista de variables en SPSS. Si bien en R no se cuenta con una visualización directa de tales elementos, estos se almacenan como atributos en las variables importadas.
Como ya fue indicado en el apartado 4.5 Construcción de una base de datos aquí también es posible usar el botón con forma de planilla ubicado a la derecha del objeto en el entorno de trabajo para visualizar la base de datos como una planilla y así poder inspeccionarla visualmente. Esto permitirá explorar rápidamente su estructura y contenidos: observar los nombres de las variables, el tipo de valores que almacenan, etc.
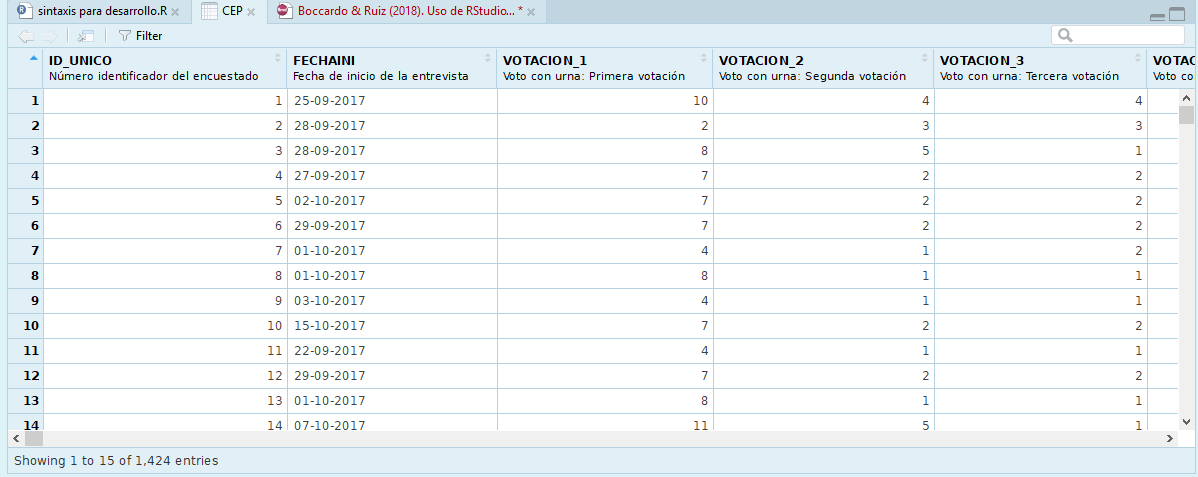
Imagen 6.6: Visualización de base CEP como planilla
6.3 ¿Cómo abrir bases de datos desde diferentes formatos de Microsoft Excel?
Otro formato relevante para el trabajo con base de datos es el ecosistema integrado por los diferentes tipos de planillas de cálculo vinculadas al software Microsoft Excel. Muchas veces la digitación de encuestas se efectúa en softwares de estas características, por lo que un formato primario para almacenar bases de datos es, sin duda, las planillas de cálculo. Es más, muchas veces diversos fenómenos sociales son registrados por la actividad humana en este tipo de archivos.20
Si bien el formato planilla de cálculo generalmente se asocia a Microsoft Excel, debido a la masividad de sus productos, refiere a un formato más general. Hoy en día, también se asocia a aplicaciones en línea como Hojas de Cálculo de Google u otros software de funcionalidad de oficina como Calc en sus versiones de Libre Office y Open Office.
A continuación se indican dos modalidades para importar bases de datos en formato de hoja de cálculo a R.
La primera opción es trabajar directamente con un archivo con formato para Microsoft Excel 2007 o superior. Se trata de archivos con una extensión .xlsx que tienen un formato de libro, es decir, pueden soportar en su interior a más de una hoja de trabajo. Para efectos caso de este manual se ha convertido la base de datos de la Encuesta CEP trabajada en el apartado anterior a tal formato. Este procedimiento es sencillo si se tiene instalado SPSS.21 Para efectos de este tutorial el archivo se puede descargar desde el siguiente enlace (indicado en la presentación de este documento), y que lleva por nombre CEP_sep-oct_2017.xlsx.
Al abrir el archivo desde el explorador de archivos se observa que tiene dos hojas. Una primera almacena el registro de las respuestas con un número de identificación por caso y la fecha de respuesta de la encuesta. La segunda hoja es la base de datos propiamente tal y es la que interesa cargar en el entorno de trabajo de R.
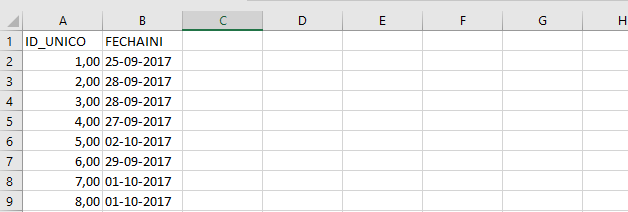
Imagen 6.7: Hoja con identificación de respondientes
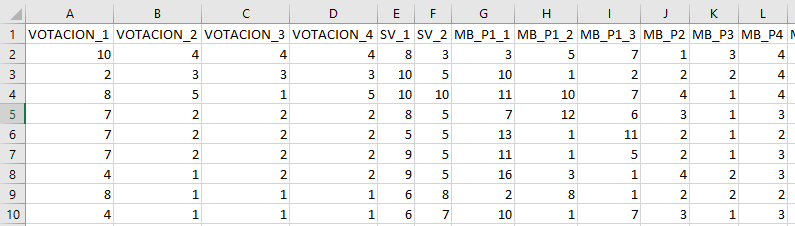
Imagen 6.8: Hoja con respuestas de encuesta
Entonces, ¿cómo cargar una base de datos desde este formato al entorno de trabajo en R? En esta instancia se usará el paquete readxl que previamente se debe descargar e instalar en el computador. Específicamente se usará la función read_excel de este paquete en su versión más simple - sin argumentos adicionales - indicando solamente el nombre del archivo a leer. Su resultado se guardará en un nuevo objeto llamado CEP_excel.
Ejercicio 6.3
install.packages("readxl") #Descarga e instalación del paquete
library(readxl) #Cargar paquete en sesión de trabajo de R
CEP_excel <- read_excel("CEP_sep-oct_2017.xlsx") #Leer libro excelAl observar la planilla cargada en el entorno de trabajo se verá que no es la que interesa para desarrollar análisis estadísticos. Por defecto la función lee la primera hoja de del libro de trabajo Excel, por lo que en este caso cargó la planilla con los datos de identificación de cada respondiente, siendo que interesa la lectura de la segunda hoja del libro de trabajo que contiene la base de datos propiamente tal.
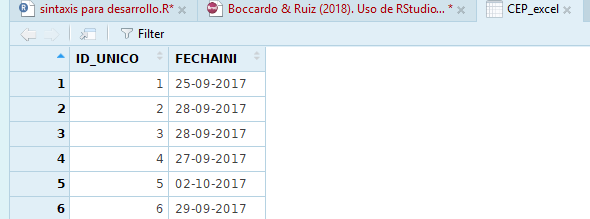
Imagen 6.9: Hoja de identificación de respondientes cargada como base de datos
Para solucionar este problema se repetirá la operación pero utilizando un argumento extra en la función. Mediante el argumento sheet = se le indica al programa la posición o nombre de la hoja que interesa leer en el interior del libro de trabajo. En este caso se indicará que interesa leer la hoja ubicada la posición “2” del libro, o la hoja de nombre “DATOS” (que es lo mismo para efectos de este manual). A continuación se sobrescribe el objeto creado en el entorno de trabajo, actualizando la función con esta información.
Ejercicio 6.3 (continuación)
CEP_excel <- read_excel("CEP_sep-oct_2017.xlsx", sheet = 2)
#indica posición de hoja en el libro de trabajo.
CEP_excel <- read_excel("CEP_sep-oct_2017.xlsx", sheet = "DATOS")
#indica nombre de hoja en libro de trabajo.Observando el entorno de trabajo se verá que el objeto CEP_excel se ha actualizado y ahora presenta 220 variables.22
Imagen 6.10: Hoja con respuestas a encuesta cargada como base de datos
Ahora bien, la función read_excel considera a la primera línea de datos como los nombres de las variables de forma automática. Hay veces en que en la primera fila no se encuentra el nombre de las variables habiendo primero otro tipo de información. Por eso resulta importante indicarle a la función desde qué fila comenzar a leer los datos. En el caso de que la información relevante comience en la fila 2, siendo tal fila la que contiene el nombre de las variables se agrega a estos argumentos la opción skip = 1 para que el software salte u omita la primera fila y comience la lectura de los datos en la fila 2.
Ejercicio 6.3 (continuación)
CEP_excel <- read_excel("CEP_sep-oct_2017.xlsx", sheet = 2, skip = 1)
#indica posición de la hoja en el libro de trabajo.Una segunda forma de importar a R archivos del tipo hoja de cálculo es trabajar con el formato CSV (comma separated values) o archivo de valores delimitados por comas. Se trata de un tipo de archivo más simple que un libro de Microsoft Excel, en la medida que puede contener sólo una - y no varias - hoja de trabajo. Si bien este tipo de archivos pueden encontrarse al descargar una base de datos secundaria, para efectos de este manual de apoyo docente se creará un archivo de este tipo a partir del archivo originalmente almacenado en formato Excel (.xlsx).
Para esto, como se observa en las imágenes 6.11 y 6.12, basta con que desde el archivo excel en cuestión, se utilice a la opción Guardar como y seleccionando el formato señalado. El programa debería advertir al usuario que el formato seleccionado no soporta múltiples hojas de trabajo (imagen 6.12), por lo que guardará sólo la hoja activa. Asegurando que la planilla que interesa guardar es la hoja que está seleccionada se hace clic sobre la opción Aceptar.
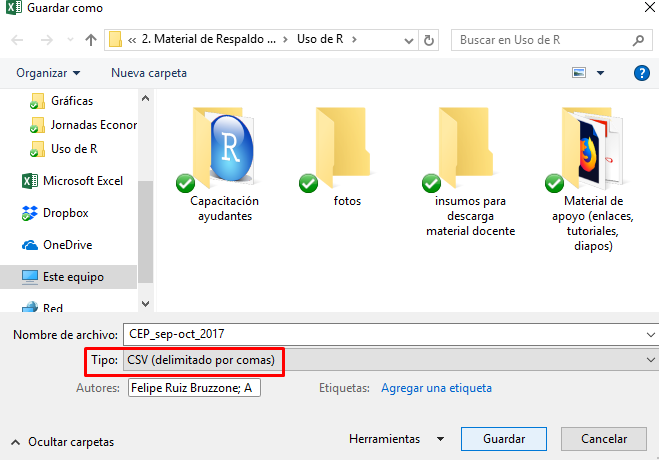
Imagen 6.11: Guardar planilla de libro de Excel en formato CSV

Imagen 6.12: Advertencia al guardar en formato CSV
El archivo resultante puede ser leído como planilla de Microsoft Excel. Sin embargo, para entender su estructura interna primero se abrirá con la aplicación Bloc de Notas mediante la opción Abrir con….

Imagen 6.13: Abrir archivo CSV con Bloc de Notas
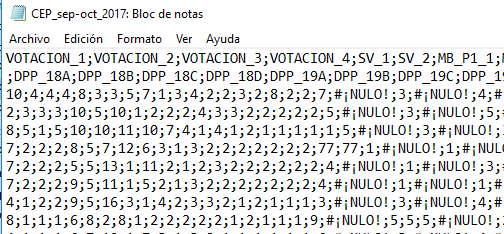
Imagen 6.14: Estructura interna del archivo CSV
Se observa en la imagen 6.14 que el archivo presenta una tabulación del tipo matriz de datos - en este caso, la base de datos que contiene las respuestas a una encuesta social - cuyos valores ( cada variable) están separados por el signo punto y coma (;). Este signo delimita cada columna de casos.
Resulta importante considerar esta estructura pues en la notación anglosajona que subyace al lenguaje original de R (el inglés) se usa la coma para separar valores y el punto para denotar valores decimales. En el caso de la notación de habla hispana se emplea la coma para denotar decimales y el punto y coma para separar las observaciones.
Este “detalle” importa pues las funciones básicas para leer archivos CSV viene configuradas por defecto para entender a las comas como separador de los casos. Esto se muestra en el siguiente ejemplo.
Ejercicio 6.4
CEP_csv <- read.csv("CEP_sep-oct_2017.csv")En este caso, la ejecución del comando implica un error de ejecución.

Imagen 6.15: Mensaje de error al leer archivo CSV
El programa avisa que la cantidad de columnas que resultan de la lectura de la planilla es mayor a la cantidad de nombres de variables, por lo que no logra leer el archivo. Esto sucede debido a que las comas presentes en los casos, que denotan valores decimales, el software las ha entendido como separador de casos.
Para solucionar tal problema se indican dos opciones.
- La primera es ocupar la misma función, pero agregando un argumento
sep =mediante el cual se indica qué signo debe considerar para separar los valores. - La segunda opción es usar una variación de la función original (
read.csv2), configurada para que considere las comas como notación de decimales y el punto y coma como separador de valores.
Ejercicio 6.4 (continuación)
CEP_csv <- read.csv("CEP_sep-oct_2017.csv", sep = ";")
CEP_csv2 <- read.csv2("CEP_sep-oct_2017.csv")
Imagen 6.16: Bases de datos Excel y CSV con la misma estructura de casos y variables
El resultado muestra que se han leído tres bases de datos coincidentes en términos de estructura, por lo que se ha logrado llegar al mismo resultado usando funciones diferentes.
Para el desarrollo de todos los ejemplos posteriores de este manual se considerará una de las bases de datos leídas. Para ello se “limpiará” por primera vez el entorno de trabajo dejando solamente la base de datos nombrada como CEP_csv.
Ejercicio 6.5
remove(CEP_csv2, CEP_excel)6.4 Construir una base de datos sólo con variables de interés: exploración de bases de datos y recodificación de variables
Lograr cargar una base de datos a la sesión de R es un paso inicial que permite disponer de un conjunto de datos “en bruto” que, muy probablemente se deberán configurar para lograr efectuar los análisis de interés. Se sugiere trabajar solamente con aquellas variables a analizar y crear una nueva base de datos sólo con la información de interés, sin editar la fuente original de datos. Para los siguientes ejercicios se seleccionarán siete variables desde la base de datos de la Encuesta CEP ya mencionada. En la siguiente tabla se indica una descripción de la variable, su nombre en la base original y el nuevo nombre a asignar en la nueva base de datos.23
| Descripción de la variable | Nombre en base original | Nuevo nombre | Valores | Nivel de medición |
|---|---|---|---|---|
| Ponderador | POND | pond | Números simples para ponderación. | No aplica. |
| Género informado | SEXO | sexo | 1 = hombre, 2 = mujer. | Nominal. |
| Región de residencia | REGION | region | Número de región, del 1 al 15. | Nominal. |
| Fecha de nacimiento (edad) | DS_P2_EXACTA | edad | Edad cumplida en número entero. | Razón. |
| Satisfacción con la propia vida | SV_1 | satisfaccion | Escala del 1 al 10. | Intervalar. |
| Percepción de satisfacción de chilenos con su vida | SV_2 | satisfaccion_chilenos | Escala de 1 al 10 | Intervalar. |
| Evaluación de la situación económica nacional | MB_P2 | eval_econ | Escala del 1 al 5 | Ordinal. |
Para construir una nueva base de datos solo con las variables especificadas será preciso efectuar varias operaciones, que se detallan en este apartado. Para este tipo de manipulación de bases de datos y variables existen diferentes herramientas: algunas forman parte de las funcionalidades básicas de R, pero otras provienen del paquete dplyr.24 En la siguiente tabla se resumen las principales características de las funciones a utilizar.
| Función | Paquete | Utilidad |
|---|---|---|
| View | utils |
Visualizar un objeto tipo matriz de datos en formato planilla. |
| names | base |
Muestra los nombres de cada elemento incluido en un objeto determinado, por ejemplo, una base de datos. |
| dim | base |
Entrega la dimensionalidad del objeto. En el caso de bases de datos (formato matriz) indica el número de filas (casos) y columnas (variables), en ese orden. |
| select | dplyr |
Seleccionar variables (columnas) específicas de un objeto del tipo data.frame. |
| rename | dplyr |
Renombrar variables dentro de una misma base de datos. Usada como la función select permite seleccionar y al mismo tiempo renombrar variables. |
| mutate | dplyr |
Transformar variables en una nueva, sin alterar la original. |
| recode | dplyr |
Recodificar categorías de una variable, estableciendo una a una las equivalencias entre las categorías originales y las categorías a crear. |
| recode | car |
Recodificar categorías de una variable, permitiendo la recodificación por tramos. De especial utilidad cuando se precisa reducir las categorías de variables de nivel de medición de intervalo o razón, según tramos específicos de respuesta. |
| save | base |
Guardar objetos desde el entorno de trabajo de R al disco duro del computador. Especialmente útil para guardar nuestras bases de datos en formato .RData |
| load | base |
Cargar objetos desde el disco duro a nuestra sesión de trabajo en R. Especialmente útil para cargar bases de datos archivadas en formato .RData |
| class | base |
Informar el tipo de objeto. Permite determinar cómo R ha configurado un conjunto específico de información (una base de datos, una variable en específico, etc.) |
Así, de forma específica para la selección de las variables ya señaladas se utilizará la función select del paquete dplyr, como se observa a continuación:
Ejercicio 6.6
library(dplyr) #Cargar paquete, si no está cargado desde antes.
CEP <- select(CEP_csv, pond = POND, sexo = SEXO, region = REGION, edad = DS_P2_EXACTA,
satisfaccion_vida = SV_1, satisfaccion_chilenos = SV_2, eval_econ = MB_P2)
#Se indica base de datos, el nombre de variable a crear y los datos que la compondrán.
View(CEP) #Visualización de la baseLuego de ejecutar ese comando se habrá creado un nuevo objeto llamado CEP (del tipo base de datos) en el entorno de trabajo. Esta base de datos tiene la misma cantidad de casos (1.424) que la base de datos original (CEP_csv) pero presenta solamente las siete variables seleccionadas y renombradas mediante el comando select. Para corroborar el resultado de la construcción de esta nueva base de datos se la visualizará en formato planilla. Como se observa a continuación, esta base de datos contiene solamente las siete variables de interés.
Imagen 6.17: Base de datos con selección de variables
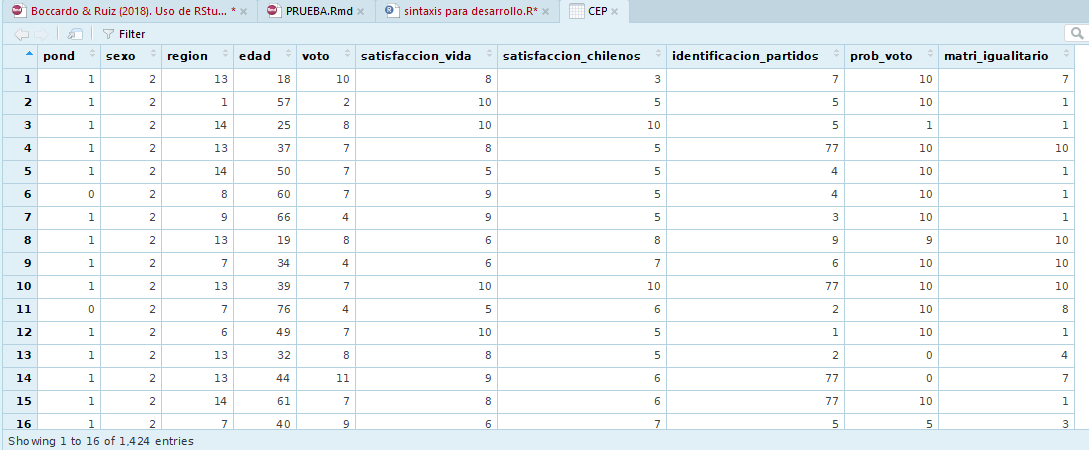
Imagen 6.18: Visualización base de datos construida
Una vez hecha esta operación de selección de variables se habrá creado una nueva base de datos que contiene solo aquellas variables que resultan de interés para los análisis. Antes de proseguir conviene guardar tal objeto como una base de datos de formato R. Para esto se usa el comando save para guardar un objeto de formato (o extensión) .RData.
Ejercicio 6.7
save(CEP, file = "seleccion_CEP.RData")Este comando creará un nuevo archivo de formato RData en la carpeta de trabajo. Este archivo puede usarse para enviar esta base de datos específica a un equipo de trabajo en el contexto de una investigación colectiva, o sencillamente contar con un archivo que ya contenga la base de datos solamente con las variables de interés.

Imagen 6.19: Nueva base de datos guardada en carpeta de trabajo
El siguiente paso es explorar las características de tales variables y configurarlas para poder ejecutar los análisis estadísticos que precisemos para nuestro proceso de investigación. Se sugiere dejar en cero el espacio de trabajo utilizando algunas de las formas ya indicadas para hacerlo.
Ejercicio 6.8
rm(list = ls())Para continuar con este manual se sugiere cargar a la sesión de R (desde la carpeta de trabajo) la base construida solo con las variables de interés y guardada en formato RData (seleccion_CEP.RData).
Ejercicio 6.9
load("seleccion_CEP.RData")Una primera opción para conocer las características de la base de datos es explorar los nombres de sus variables. Mediante el comando names aplicado sobre el objeto CEP se obtiene una lista con los nombres de cada columna de la base de datos. Esto resulta de utilidad para los procedimientos de manejo de datos pues no siempre se puede determinar con certeza el nombre de un objeto leyendo el encabezado de la columna. Al visualizarlos como se observa en el siguiente resultado se puede estar seguro del nombre exacto determinando si hay espacios en blanco antes o después de las letras que impliquen un nombre diferente al leído de manera directa.25
Ejercicio 6.10
names(CEP)## [1] "pond" "sexo" "region"
## [4] "edad" "satisfaccion_vida" "satisfaccion_chilenos"
## [7] "eval_econ"Otro comando de utilidad para conocer características generales de la base de datos es la función dim. Este comando, como se observa en el ejercicio 6.11, permite conocer la dimensión de la base de datos que se está explorando. El resultado de esta función arroja dos números: el primer número indica la cantidad de filas de la base de datos, mientras que el segundo número indica la cantidad de columnas. Las bases de datos de estudios sociales están construidas de manera que cada fila representa un caso y cada columna una variable, por lo que la dimensión de una base de datos indicará la cantidad de casos y variables (en ese orden).
Ejercicio 6.11
dim(CEP)## [1] 1424 7Finalmente, para conocer las características generales de las variables en la base de datos, y comenzar a evaluar que tipo de recodificaciones se deben realizar, se utiliza la función summary para obtener estadísticos descriptivos de cada una de las variables.
Ejercicio 6.12
summary(CEP)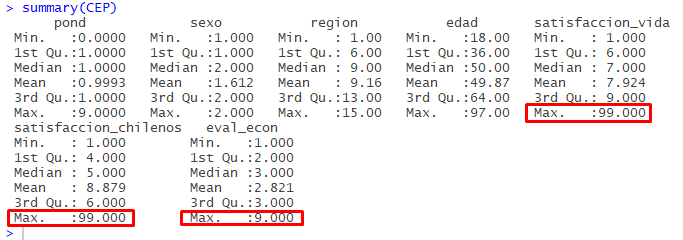
Imagen 6.20: Observación general de las variables
¿Por qué resultan de interés estos resultados? Considerando los estadísticos descriptivos construidos se observa que algunas variables contienen códigos que refieren a casos perdidos. Es el caso de las variables satisfaccion_vida, satisfaccion_chilenos y eval_econ. Como se observa en la imagen 6.20, estas variables presentan valores 9 o 99 como máximos, siendo que se trata de variables que presentan un rango menor de valores posibles: la variable satisfaccion_vida presenta valores 99 como máximos cuando es una escala de 1 a 10; lo mismo ocurre con la variable satisfaccion_chilenos; finalmente, algo similar ocurre con la variable eval_econ, que presenta valores 9 como máximos, cuando es una escala del 1 al 5.
Tal información constituye una primera alerta sobre los ajustes a hacer sobre los datos y por tanto son un valioso insumo para el proceso de recodificación de variables.
Para avanzar en los análisis se efectuarán algunas recodificaciones. Primero que todo se observan las características de cada variable a recodificar. Para eso se utiliza las funciones table para crear una tabla de frecuencias absoluta y observar los valores de la variable, y class para conocer de qué tipo de objeto se trata (en este caso, la variable sexo).
Ejercicio 6.13
table(CEP$sexo)##
## 1 2
## 553 871class(CEP$sexo)## [1] "integer"El primer resultado muestra una variable que presenta sólo valores 1 y 2, a la vez que el segundo resultado informa que se trata de un vector de tipo integer.
Luego de conocer estas características se cuenta con información suficiente para modificar la variable e incorporarla al análisis. Para recodificar se usará el comando mutate del paquete dplyr. Este comando permite transformar una variable guardando el resultado de tal operación en una nueva variable dentro de la misma base de datos. Resulta útil toda vez que permite editar variables sin perder la información (la variable) original.
Como se observa en las siguientes líneas de comando, el resultado de mutate se asigna a la base de datos. Luego de la función mutate, los argumentos son: i) el conjunto de datos del que provienen las variables (CEP, nuestra base de datos), ii) el nombre de la nueva variable a crear (sexo_chr) seguido de un igual y la operación de transformación de la variable original; en este caso, se emplea el comando recode del paquete dplyr cuyos argumentos son: la variable que se quiere transformar (CEP$sexo) y luego las equivalencias de cada categoría de respuesta. En este caso se indica que “1” se asigna a “hombre” y que “2” se asigna a “mujer”. Vale la pena enfatizar que cada categoría se expresa entre comillas y que cada equivalencia se separa de la siguiente mediante una coma.
Ejercicio 6.14
CEP <- mutate(CEP, sexo_chr = recode(CEP$sexo, "1" = "hombre", "2" = "mujer"))
table(CEP$sexo_chr)##
## hombre mujer
## 553 871class(CEP$sexo_chr)## [1] "character"Al ejecutar tal recodificación y solicitar una tabla de frecuencias simple así como la información sobre el tipo de variable creada, ahora la tabla contiene las categorías “hombre” y “mujer”, haciendo más fácil su lectura, mientras que la variable recodificada es del tipo “character”, al contener ahora una codificación basada en letras. Si bien es un ejemplo muy simple, permite entender una primera utilidad de la recodificación de variables, que tiene que ver con facilitar nuestro acercamiento a los datos.
Adicionalmente, se aplicará una segunda recodificación sobre esta variable para convertirla en un vector de tipo factor, aplicando etiquetas para las dos categorías de respuesta (“Hombre” y “Mujer”). ¿Para qué resulta de utilidad esto si ya contamos con resultados entendibles?: pues bien, en el ejercicio anterior al recodificar a valores de tipo character, la información numérica almacenada en la variable CEP$sexo se perdió al ser reemplazada por letras. Para determinados análisis, precisaremos contar con ambos niveles de información: los valores numéricos asociados a las respuestas, pero también las etiquetas de tales valores, que indican lo que representan los números almacenados en la base de datos en términos analíticos.
Ejercicio 6.14 (continuación)
CEP <- mutate(CEP, sexo_factor = factor(CEP$sexo,
labels = c("Hombre", "Mujer")))Como se observa en el ejercicio 6.14, el comando factor permite incorporar las etiquetas a cada código de respuesta. En este caso, al ingresar los valores Hombre y Mujer, en el argumento labels, lo que estamos haciendo es asociar las etiquetas indicadas a los valores 1 y 2 en que está codificada la variable.26
Ahora se recodificará la variable región indicando que sólo habrán dos categorías: “otras regiones” y “región Metropolitana”. Como en el caso anterior, primero conviene observar las características generales de la variable: interesa saber cuantos casos están en la categoría Región Metropolitana para así asegurar que luego de la transformación de la variable, la estructura de casos siga el mismo patrón. Primero exploraremos las características generales de la variable de interés.
Ejercicio 6.15
table(CEP$region) #Observar características de la variables##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## 24 57 24 52 150 82 94 192 98 69 5 17 501 39 20class(CEP$region)## [1] "integer"En base a estos primeros resultados se observa que se trata de una variable cuyo nivel de medición es nominal. La categoría “13”, que equivale a la región Metropolitana, presenta 501 casos. También sabemos que la variable está configurada como un vector de tipo integer. Así, usando el comando mutate se recodificará la variable en una nueva denominada region_factor; sin embargo, al interior del comando que se utilizaría por defecto, introduciremos una variante.
Si introducimos una función como argumento dentro una función determinada, R siempre aplica las funciones que corresponden al paquete de la función principal inicialmente indicada (en este caso, es el paquete dplyr). Para el caso del comando recode, el provisto por este paquete no resulta de utilidad para recodificar variables con gran cantidad de categorías, pues no permite realizar una recodificación por tramos de información. Por ello, antes de la función recode - que implicaría utilizar aquella incorporada en dplyr - incorporamos el argumento car::, lo que fuerza a que se ejecute el comando recode incluido en un paquete distinto llamado car, para así poder recodificar indicando tramos de datos.27
Para el caso de la siguiente recodificación se indica el mismo valor para los códigos del 1 al 12, y del 13 al 14, mientras que se asigna un valor diferente para el valor 13 (correspondiente a la región Metropolitana). Primero se recodifica en una nueva variable indicando los tramos de recodificación ya explicados. Posteriormente se sobrescribe la variable asignándole el resultado de la operación de convertirla en una variable de tipo factor, aplicando etiquetas para las dos categorías de respuesta ahora existentes.
Ejercicio 6.15 (continuación)
#Transformar a una variable distinta, categorías "Otras regiones" y "Región Metropolitana".
CEP <- mutate(CEP, region_factor = car::recode(CEP$region, "1:12 = 1; 13 = 2; 14:15 = 1"))
#Sobreescribir variable con resultado de convertir a factor incorporando etiquetas
CEP$region_factor <- factor(CEP$region_factor,
labels = c("Otras regiones", "Región Metropolitana"))
table(CEP$region_factor) #Se sigue manteniendo la estuctura de casos.##
## Otras regiones Región Metropolitana
## 923 501class(CEP$region_factor) #Cambia el formato del objeto.## [1] "factor"El resultado muestra que, por un lado, se mantuvo la estructura de casos, con 501 casos en la región Metropolitana y 923 casos en otras regiones. Eso indica que la recodificación se hizo de manera adecuada. Además, la tabla muestra etiquetas y al solicitar el formato de la variable indica que es un vector de tipo factor. En síntesis, la recodificación se efectuó de manera óptima.
Ahora se recodificarán las variables satisfacción con la vida propia y percepción de satisfación que los chilenos en general sienten con su propia vida. Primero se exploran ambas variables.
Ejercicio 6.16
#Explorar variable "satisfacción con la propia vida"
class(CEP$satisfaccion_vida)## [1] "integer"table(CEP$satisfaccion_vida)##
## 1 2 3 4 5 6 7 8 9 10 88 99
## 20 10 30 63 176 169 256 244 142 304 4 6summary(CEP$satisfaccion_vida)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 6.000 7.000 7.924 9.000 99.000El análisis exploratorio de esta primera variable28 permite identificar que la variable está compuesta por valores discretos entre 1 y 10, aunque se observa también valores 88 y 99 en la distribución que - debido a la lectura del cuestionario y la ficha técnica de la encuesta - se sabe que denotan las categorías “no sabe”y “no responde.”29 Es posible afirmar entonces que el nivel de medición de esta variables de tipo intervalar, pues incluye más de 7 categorías de respuesta.
#Explorar variable "percepción de la satisfacción que los chilenos tienen con su vida"
class(CEP$satisfaccion_chilenos)## [1] "integer"table(CEP$satisfaccion_chilenos)##
## 1 2 3 4 5 6 7 8 9 10 88 99
## 33 21 97 216 469 241 160 56 24 47 52 8summary(CEP$satisfaccion_chilenos)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 4.000 5.000 8.879 6.000 99.000Algo similar ocurre con esta segunda variable. Al igual que la anterior, presenta valores 88 y 99 como casos válidos, lo que altera la distribución de casos ceñida a la escala de 1 a 10. Tal como en la variable anterior, también es posible afirmar - dado que presenta más de 7 categorías - que el nivel de medición de esta variable es de intervalo.
Por tanto, se efectuará una operación de transformación de estas variables, asignando el valor lógico NA a aquellos valores que representan casos perdidos (sin respuesta). Este valor lógico servirá pues R lo reconoce como un valor que no puede utilizarse para operaciones matemáticas, a la vez que no representa un valor alfanumérico contable, por lo que no alterará el tipo de vector (en este caso, numérico de tipo integer). Entonces se ejecutan las siguientes funciones, para cada variable:30
Ejercicio 6.16 (continuación)
CEP$satisfaccion_vida[CEP$satisfaccion_vida==88]<- NA #Asignar NA a casos con valor 88
CEP$satisfaccion_vida[CEP$satisfaccion_vida==99]<- NA #Asignar NA a casos con valor 99
CEP$satisfaccion_chilenos[CEP$satisfaccion_chilenos==88]<- NA
CEP$satisfaccion_chilenos[CEP$satisfaccion_chilenos==99]<- NAHabiendo ejecutado tales instrucciones, R habrá cambiado los valores 88 y 99 de cada variable por el valor lógico NA. Para evaluar si la transformación de datos resultó en el sentido esperado, a continuación se solicita una tabla de frecuencias y estadísticos de resumen para cada variable.
table(CEP$satisfaccion_vida) #Ver resultado de codificación##
## 1 2 3 4 5 6 7 8 9 10
## 20 10 30 63 176 169 256 244 142 304summary(CEP$satisfaccion_vida)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 6.000 7.000 7.311 9.000 10.000 10table(CEP$satisfaccion_chilenos)##
## 1 2 3 4 5 6 7 8 9 10
## 33 21 97 216 469 241 160 56 24 47summary(CEP$satisfaccion_chilenos)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 4.000 5.000 5.334 6.000 10.000 60Como se observa en los resultados, si luego de la recodificación se solicitan tablas de frecuencias para ambas variables, estas ya no mostrarán los casos perdidos (88 y 99). Y si se solicitan estadísticos descriptivos, se observará que ahora los valores mínomo y máximo de la variable en la base de datos, coinciden con los valores mínimos y máximos del rango de la variable discernible desde el cuestionario y ficha técnica del estudio, indicándose además la cantidad de casos NA que han resultado excluidos de los análisis.
Ahora se explorará la variable que mide la percepción de la persona entrevistada respecto a la situación económica del país. Como se observa en el ejercicio 6.17, se utiliza el comando class, table y summary para efectuar una aproximación exploratoria a la variable.
Ejercicio 6.17
#Explorar variable "evaluación de la economía"
class(CEP$eval_econ)## [1] "integer"table(CEP$eval_econ)##
## 1 2 3 4 5 8 9
## 74 397 730 204 5 8 6summary(CEP$eval_econ)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.000 3.000 2.821 3.000 9.000Como se observa en los resultados, la variable es una escala de acuerdo compuesta por valores del 1 al 5,31 aunque también se observan valores 88 y 99 en la distribución que gracias a la información disponible en el cuestionario y ficha técnica de este estudio, sabemos que representan a a las categorías “no sabe” y “no contesta” (casos perdidos). Así, es posible afirmar que se trata de una variable de nivel de medición ordinal.
Para efectos de simplificar las respuestas para su análisis, esta variable se recodificará en tres categorías de evaluación (negativa, neutra y positiva). Asimismo, en el ejercicio 6.17 también se indicará una segunda forma de asignar casos perdidos (valores NA) esta vez desde una recodificación vía comando mutate.
la variable está compuesta por valores discretos entre 1 y 10, aunque se observa también valores 88 y 99 en la distribución que - debido a la lectura del cuestionario y la ficha técnica de la encuesta - se sabe que denotan las categorías “no sabe”y “no responde”. Es posible afirmar entonces que el nivel de medición de esta variables de tipo intervalar, pues incluye más de 7 categorías de respuesta.
Ejercicio 6.17 (continuación)
#Recodificar variable a 3 tramos: positiva, neutra, negativa
#Valores perdidos se asignan en la misma codificación,
#con argumento else ("todos los demás valores")
CEP <- mutate(CEP, eval_econ_factor =
car::recode(CEP$eval_econ,
"1:2 = 1; 3 = 2; 4:5 = 3; else = NA"))
CEP$eval_econ_factor <- factor(CEP$eval_econ_factor,
labels = c("Positiva", "Neutra", "Negativa"))
table(CEP$eval_econ_factor)##
## Positiva Neutra Negativa
## 471 730 209summary(CEP$eval_econ_factor)## Positiva Neutra Negativa NA's
## 471 730 209 14Habiendo efectuado estas transformaciones sobre las variables originales, ya se cuenta con variables de los diferentes tipos para efectuar análisis de estadística univariada: variables cuyo nivel de medición es nominal, ordinal, intervalar y de razón. En el siguiente capítulo se verá como ejecutar análisis estadísticos univariados, en sus variantes de alcance muestral y poblacional.
Bibliografía
CEP. 2017. “Manual Del Usuario Encuesta CEP Nº 81. Estudio Nacional de Opinión Pública Nº 51 – Tercera Serie, Septiembre-Octubre 2017.” Centro de Estudios Públicos. https://www.cepchile.cl/estudio-nacional-de-opinion-publica-septiembre-octubre-2017/cep/2017-10-25/105022.html.
Última fecha de consulta: 15 de abril de 2019↩
Para los siguientes apartados se trabajará con esta base de datos. El CEP sólo la dispone en formato SPSS (extensión .sav).↩
Es importante respetar el nombre del archivo para leerlo desde RStudio. En este caso se ha decidido nombrar al archivo de la siguiente forma: CEP_sep-oct_2017.sav.↩
Para efectos de este documento tutorial solo se explicará cómo importar bases de datos desde el formato SPSS, que es uno de los más utilizados en ciencias sociales, como también desde archivos generalmente usados vía Microsoft Excel. No obstante, el paquete
haventambién incorpora funciones para importar datos desde el formato para el software Stata, programa más utilizado en el campo de la economía. Estas funciones son similares a los códigos utilizados para trabajar con bases de datos en formato en SPSS. Para más información, leer el siguiente enlace.↩Es importante recordar que para que el programa sepa donde buscar los archivos indicados, hay que especificar una “carpeta de trabajo” donde se encuentren los archivos a usar. En este caso, se debe definir una carpeta donde se guarde la base de datos de la Encuesta CEP y la sintaxis donde se irán diseñando los análisis. Para más detalles, repasar el apartado 4.2 Carpeta de trabajo y memoria temporal del programa.↩
Un elemento que se torna relevante al trabajar con más de una base de datos es cómo se nombran los objetos a manipular con R. Como regla general se sugiere trabajar con nombres simples que en el caso de reflejar diferentes momentos en el tiempo, expresen tal orden en los nombres asignados. Por ejemplo, si tuvieramos más de una base de datos correspondiente a diferentes versiones de la Encuesta CEP registradas en 2017, valdría la pena nombrarlas al cargarlas en R con la forma iterativa
CEP2017_1,CEP2017_2y así de forma sucesiva, donde el último número representa la posición temporal del estudio dentro del año indicado. Tal formato de nombrar los objetos facilitará enormemente el manejo de los datos al programar análisis con R↩Evidentemente con fines prácticos antes que de investigación. Por ejemplo, procesos contables o de salud, por ejemplo. Estos registros primarios que muchas instituciones realizan - por ejemplo una empresa o una clínica - muchas veces constituyen una interesante fuente de información que puede ser usada para el análisis social.↩
Basta con ir a Guardar como y seleccionar el formato compatible con Excel (.xlsx) para obtener una planilla de Excel con la base de datos originalmente guardada en formato .sav.↩
Dos variables menos que las 222 presentes en la base original. Tal diferencia se explica pues manualmente se pasaron a otra hoja las dos primeras variables de identificación de las variables.↩
Para evitar problemas de redacción en los códigos de sintaxis, así como para facilitar la redacción de instrucciones computacionales, se sugiere: i) usar nombres cortos pero descriptivos de las variable, ii) usar sólo mayúsculas o minúsculas, sin combinarlas, iii) evitar usar espacios, privilegiando guiones normales o guiones bajos, sin combinarlos y iv) asignar nombres a los archivos y objetos de forma tal que resulten coherentes para la lectura del computador; por ejemplo, combinar letras y números de forma alfabética o numérica ascendente, de forma tal que se establezca un orden lógico entre los diferentes elementos.↩
El paquete
dplyrforma parte de un conjunto más amplio de herramientas integradas en una colección de paquetes de R denominada tidyverse (Wickham 2017), donde se incluyen paquetes especializados en la manipulación y visualización de diferentes estructuras de datos. Se trata de los paquetesdplyr,ggplot2,tidyr,purrr,readr,forcats,stringrytibble. Utilizando la funcióninstall.packages("tidyverse")pueden descargarse de una vez todos los paquetes mencionados. Asimismo, ejecutando el comandolibrary(tidyverse)pueden disponerse de los paquetes señalados en la sesión de R↩Al momento de codificar una encuesta, debido a que se trata de un proceso manual, pueden producirse errores humanos. Por ejemplo, la persona que codifica puede haber introducido un espacio en blanco antes o después del nombre de la variable; tanto las planillas de cálculo como la visualización de bases de datos de R no muestran tales espacios en blanco pues sólo visualizan las letras. Es por eso que a simple vista resulta difícil ver si el nombre de una variable es “variable” o “_variable" (el guión bajo representa la existencia de un espacio en blanco, no se observa así cuando R entrega la información del nombre de la variable). Por otra parte, para prevenir errores de tipeo en la redacción de las sintaxis de análisis, es preferible copiar el nombre de variables u otros objetos directamente desde el listado que resulta al aplicar la función
names*↩Resulta importante indicar que R por lo general funciona con una lógica ascendente, y de izquierda a derecha, en relación a la lectura de información. Por tanto, como los valores de la variable
CEP$sexoson 1 y 2, al indicar las etiquetaslabels = c("Hombre", "Mujer")estamos asignando tales etiquetas a los valores, sabiendo que R respetará el orden numérico para efectuar la asignación. Ello se debe tener presente en cualquier operación de recodificación de variables para no errar en lo que buscamos realizar.↩Esto resulta de utilidad en variables de nivel de medición nominal u ordinal con muchas categorías, pero especialmente en variables de nivel de medición intervalar o de razón como ingreso o edad. Dado que presentan un rango muy amplio de valores resulta mucho más sencillo recodificar indicando tramos de valores. En el caso de que los últimos tramos sean valores perdidos, la función construida puede incorporar un último tramo indicando el argumento
elsey asignando el valor lógico usado por R para denotar casos perdidos (NA):CEP <- mutate(CEP, region_factor = car::recode(CEP$region, "1:12 = 1; 13 = 2; 14:15 = 1; else = NA"))Veremos una aplicación concreta de esto en la siguiente recodificación.↩En este caso, se indican dos maneras de explorar los valores de la variable. Una opción es el comando
tableque ya ha sido utilizado con anterioridad. Sin embargo, otra opción que sirve es el comandosummary, mediante el cual se construye un resumen de estadísticos descriptivos. No obstante, esta última opción puede resultar poco clara, ya que impide observar el valor 88 presente en la distribución, pues solamente muestra el valor máximo de la distribución de datos de la variable (99).↩En este manual no se profundizará de forma específica en los dilemas que implica el tratamiento de casos perdidos. No obstante, se debe considerar que la decisión de excluir los valores perdidos de los análisis no será siempre la primera opción de trabajo por dos razones: la primera tiene que ver con que la eliminación de tales datos puede provocar sesgos en nuestros resultados si es que las respuestas no se distribuían de forma aleatoria, mientras que la segunda tiene que ver con la potencial de reducción de casos alterando los diseños muestrales que permiten la inferencia estadística. En la actualidad existen diversas herramientas para imputar casos que deben considerarse sobre todo cuando la distribución de las no respuestas no es aleatoria, sino que responde a un patrón o sesgo presente en nuestros datos. Para profundizar en este asunto sugerimos una reciente publicación sobre el tema (Buuren 2018), disponible en línea.↩
Como se observa en el siguiente código de R, el comando para codificar valores como NA en la misma variable tiene la siguiente estructura: se indica la variable (base/variable). luego entre corchetes se indica un valor específico dentro de la misma, eso se hace escribiendo nuevamente la variable seguida de dos signos igual y el valor de interés (
[base$variable==88]). Con eso se indica qué valor se busca; luego, con el asignador se indica que a tal selección se asigna el valor NA (<- NA).↩Los valores originales son “1 = Muy mala”, “2 = Mala” “3 = Ni buena ni mala”, “4 = buena” y “5 = Muy buena”.↩