3.5 Quantifying Results: p-Values
In addition to computing the range of likely results from the model, statisticians also typically provide a quantification of the likelihood of the observed result given the hypothesized model. This quantification is referred to as a \(p\)-value (the \(p\) stands for probability).
To compute a \(p\)-value, you count the number of results that are at least as extreme as the observed result, and divide this by the total number of results.
\[ p = \frac{\mathrm{number~of~results~at~least~as~extreme~as~observed~result}}{\mathrm{total~number~of~simulated~results}} \]
This value is then reported as a decimal value. It quantifies the probability of observing a result at least as extreme as the observed result under the hypothesized model.
To illustrate this, we will re-examine simulation results from the Sleep Deprivation study. Recall in that activity, the observed data had a difference in means of 15.9. Below is a plot of 100 differences in means simulated under the “no-effect”" model. A vertical line is shown at the observed difference of 15.9.
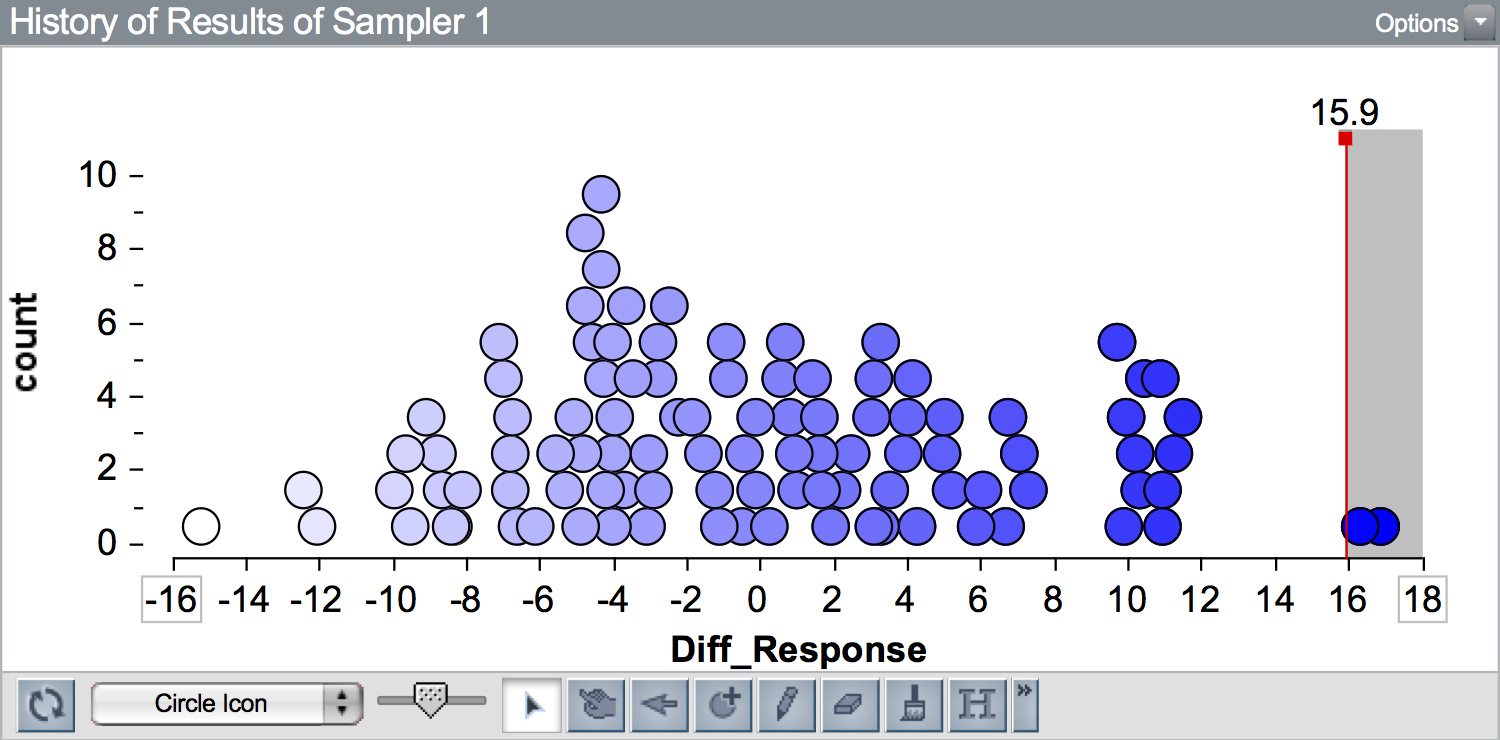
Since 15.9 is to the right of 0 (i.e., it is on the right-hand side of the plot) results that are more extreme than the observed result are to the right of 15.9. (If the observed result was to the left of 0, more extreme results would be those more negative than the observed result.) Here there are two simulated results out of 100 that are at least as extreme as 15.9 (\(\geq 15.9\)). We would report the \(p\)-value as 0.02.
3.5.1 Adjustment for Simulation Results
In simulation studies, we make one small adjustment to the \(p\)-value computation; we add 1 to both the numerator and denominator:
\[ p = \frac{\mathrm{number~of~results~at~least~as~extreme~as~observed~result} + 1}{\mathrm{total~number~of~simulated~results} + 1} \]
This adjustment assures that we never get a \(p\)-value of 0. Consider the \(p\)-value if our observed result would have been 18 (instead of 15.9). There are 0 results that are at least as extreme as 18 (\(\geq 18\)). Without making the simulation adjustment, we would report a \(p\)-value of 0. This implies that seeing a result at least as extreme as 18 under the “no-effect” model is impossible. The problem is that we only ran 100 trials of the simulation. If we had run this simulation for all possible randomizations of the data, we would have seen results \(\geq 18\). So, to report a \(p\)-value of 0 is misleading. The \(p\)-value we report should be,
\[ p = \frac{0 + 1}{100 + 1} = 0.0099 \]
After the adjustment, the \(p\)-value is still quite small, indicating that had we seen an observed result of 18, we would say that it is inconsistent with the model of “no-effect”. In fact it is in the outer 0.01 (1%) of the results simulated from the hypothesized model.
Going back to the \(p\)-value computed from the observed value of 15.9,
\[ p = \frac{2 + 1}{100 + 1} = 0.0297 \]
We can interpret the \(p\)-value of 0.030 as indicating that the observed difference of 15.9 is in the outer 0.03 (3%) of results simulated from the hypothesized model. It is quite unlikely that we would see a result as extreme as 15.9, or more extreme, under the hypothesized model of “no effect”.
3.5.2 p-Values as Evidence
Large \(p\)-values indicate that the observed data are more compatible with the results from the model, while small \(p\)-values indicate that the observed data are not very compatible with the results from the model. As researchers, our goal is often to then translate this quantitative evidence into support for the hypothesized model. For example, in the Sleep Deprivation study, we obtained a \(p\)-value of 0.03. This suggests a low degree of compatibility between the observed data (our empirical evidence) and the hypothesized model of “no effect”.
The broader scientific question about whether sleep deprivation has a harmful effect on learning, however is difficult to ascertain from a \(p\)-value. There are no hard-and-fast rules for gauging how strong the evidence is against the hypothesized model because what counts as evidence in one scientific discipline or context may not count in another scientific discipline or context. And, even if there were rules about the degree of evidence needed, you would still need to evaluate other criteria such as internal and external validity evidence, and sample size. Even then, the results from a single study are not typically convincing enough for most scientists to draw definitive conclusions. It is only through consistent findings that emerge from multiple studies (which may take decades) that we may have convincing evidence about the answer to the broader scientific question.
3.5.3 Six Principles about p-Values
Because they are so ubiquitous in the research literature for any field, and because they are often mis-interpreted (even by PhDs, researchers, and math teachers) it is important to be aware of what a \(p\)-value tells you, and more importantly, what it doesn’t tell you. To this end, the American Statistical Association released a statement on \(p\)-values in which it listed six principles:16
- Principle 1: \(P\)-values can indicate how incompatible the data are with a specified statistical model.
- Principle 2: \(P\)-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.
- Principle 3: Scientific conclusions and business or policy decisions should not be based only on whether a \(p\)-value passes a specific threshold.
- Principle 4: Proper inference requires full reporting and transparency.
- Principle 5: A \(p\)-value does not measure the size of an effect or the importance of a result.
- Principle 6: By itself, a \(p\)-value does not provide a good measure of evidence regarding a model or hypothesis.
Yaddanapudi (2016) published a paper in the Journal of Anaesthesiology, Clinical Pharmacology in which she explains each of these six principles for practicing physician-scientists using an example of treatment efficacy for a drug.↩︎