Chapter 8 Removing Data
A lot of the previous chapters have dealt with adding data or variables to your data. Sometimes though it is necessary to remove some part of our data too because it isn’t applicable to your research.
8.1 Reducing Columns
Let’s start by reducing the number of columns we have in our data. There are a few different ways you can do that, and you should probably choose the method that requires the least code. In these examples we’re going to focus on the use of the subset() command.
## YEAR SERIAL MONTH HWTFINL CPSID REGION STATEFIP METRO METAREA
## 1 2018 1 11 1703.832 2.01708e+13 32 1 2 3440
## 2 2018 1 11 1703.832 2.01708e+13 32 1 2 3440
## 3 2018 3 11 1957.313 2.01809e+13 32 1 2 5240
## 4 2018 4 11 1687.784 2.01710e+13 32 1 2 5240
## 5 2018 4 11 1687.784 2.01710e+13 32 1 2 5240
## 6 2018 4 11 1687.784 2.01710e+13 32 1 2 5240
## STATECENSUS FAMINC PERNUM WTFINL CPSIDP AGE SEX RACE EMPSTAT
## 1 63 830 1 1703.832 2.01708e+13 26 2 100 10
## 2 63 830 2 1845.094 2.01708e+13 26 1 100 10
## 3 63 100 1 1957.313 2.01809e+13 48 2 200 21
## 4 63 820 1 1687.784 2.01710e+13 53 2 200 10
## 5 63 820 2 2780.421 2.01710e+13 16 1 200 10
## 6 63 820 3 2780.421 2.01710e+13 16 1 200 10
## LABFORCE EDUC VOTED VOREG
## 1 2 111 98 98
## 2 2 123 98 98
## 3 2 73 2 99
## 4 2 81 2 99
## 5 2 50 99 99
## 6 2 50 99 99The data set dat has 22 variables. Let’s say I want to only keep 3 of them before merging it into another file. Below I extract STATEFIP, EDUC, and VOTED into a new object called dat2.
## STATEFIP EDUC VOTED
## 1 1 111 98
## 2 1 123 98
## 3 1 73 2
## 4 1 81 2
## 5 1 50 99
## 6 1 50 99The annotation below looks a little more closely at the command we used above.
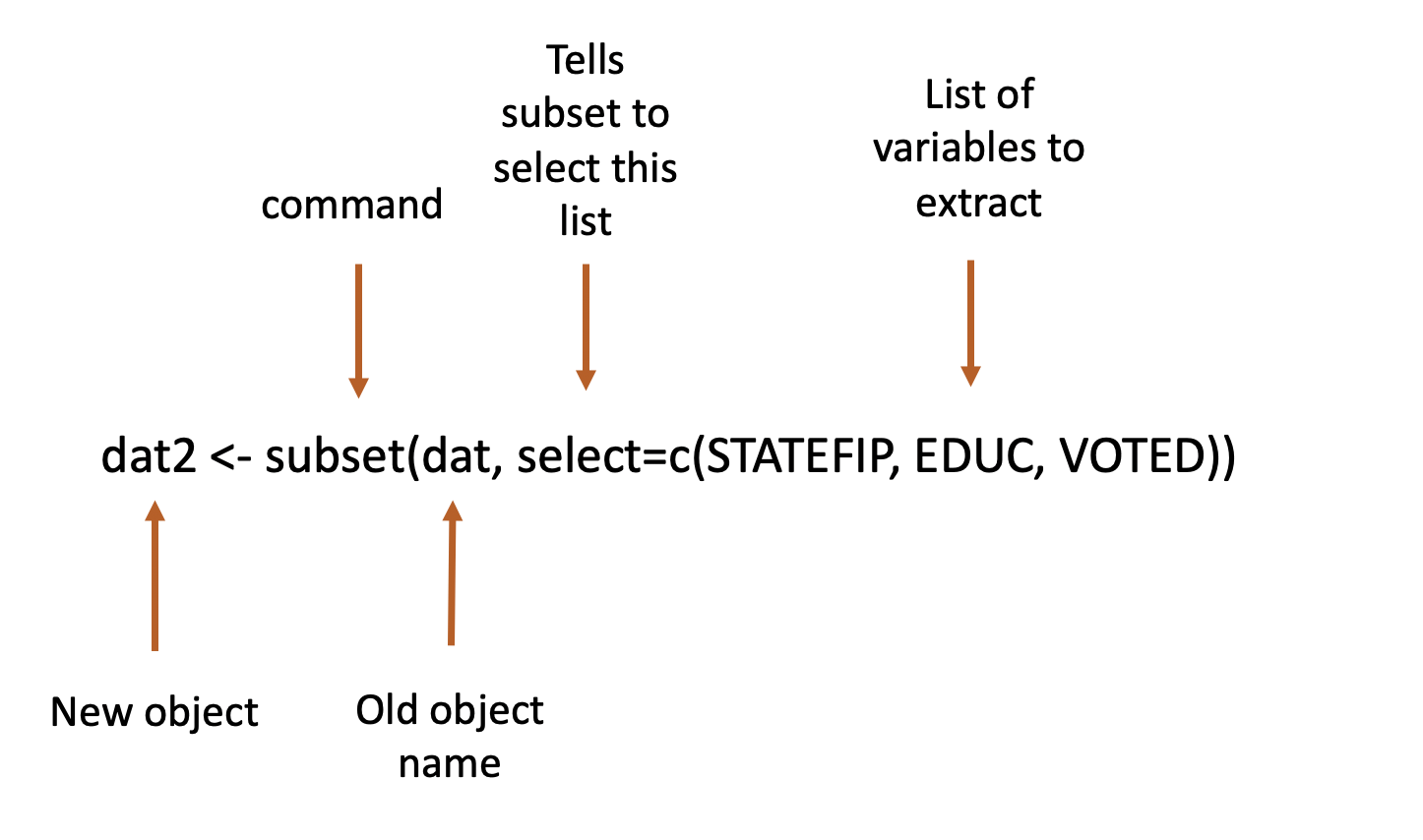
We’ll use subset a few different ways in this chapter. In that one we’re using it to “select” a list of variables that we want to keep. But, we can use that basic command to remove variables by name as well. Let’s say we have one variable that we want to get rid of for some reason.
## YEAR SERIAL MONTH HWTFINL CPSID REGION METRO METAREA STATECENSUS
## 1 2018 1 11 1703.832 2.01708e+13 32 2 3440 63
## 2 2018 1 11 1703.832 2.01708e+13 32 2 3440 63
## 3 2018 3 11 1957.313 2.01809e+13 32 2 5240 63
## 4 2018 4 11 1687.784 2.01710e+13 32 2 5240 63
## 5 2018 4 11 1687.784 2.01710e+13 32 2 5240 63
## 6 2018 4 11 1687.784 2.01710e+13 32 2 5240 63
## FAMINC PERNUM WTFINL CPSIDP AGE SEX RACE EMPSTAT LABFORCE EDUC
## 1 830 1 1703.832 2.01708e+13 26 2 100 10 2 111
## 2 830 2 1845.094 2.01708e+13 26 1 100 10 2 123
## 3 100 1 1957.313 2.01809e+13 48 2 200 21 2 73
## 4 820 1 1687.784 2.01710e+13 53 2 200 10 2 81
## 5 820 2 2780.421 2.01710e+13 16 1 200 10 2 50
## 6 820 3 2780.421 2.01710e+13 16 1 200 10 2 50
## VOTED VOREG
## 1 98 98
## 2 98 98
## 3 2 99
## 4 2 99
## 5 99 99
## 6 99 99Now our data has 21 columns, only losing the one we specified. The negative sign (-) in front of the list flips the meaning of select. Whereas in the first example we were selecting our list of variables to be kept or be sent to the new object, here we’re saying keep everything but these.
The subset command can also be used to find specific observations in our data and remove or keep them based on whether they meet certain criteria.
For instance, let’s say we want to remove anyone under the age of 18 from our data because we’re only interested in studying adults. We can do that by telling r we want to subset our data, and only keep those whose value in the AGE column is greater than or equal to 18.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 20.00 40.00 40.17 59.00 85.00## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 18.00 34.00 49.00 49.06 63.00 85.00Let’s think about that line of code intuitively and read it like a sentence: “Create a new object called dat4 out of the data in dat, but only keep the observations that are equal to or greater than 18 in the column AGE”.
We can do similar things with any of the mathematical operators we discussed in the section on creating variables.
| Numerical Operator | Effect |
|---|---|
| == | Equals |
| != | Doesn’t Equal |
| > | Greater than |
| >= | Greater or equal to |
| < | Less than |
| <= | Lesser or equal to |
For instance, if I only want to keep people that are exactly 18 years old, I can do that with the “equal to” operator (==).
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 18 18 18 18 18 188.2 Protect the Data
This section has loosely focused on reducing our data, either by eliminating columns or observations. Anytime you add (merge) or reduce (subset) it’s a good idea to create a new object, rather than overwrite the data set you’re already using. Why? Because often times, things will go wrong in those steps. Not irrevocably, but if there’s a bug or a typo in your code you might overwrite your data and have to start over. You can always re-load your data and do earlier steps again, but that can take time. And if your data files are large, it can take many minutes for earlier code to rerun. As such, creating a new object periodically can act to save your work. I know, I’ve harped on this elsewhere.
I’ll give you one instance of a mistake here. Let’s say I want to drop anyone under 18 from my data like I did earlier, but instead of creating a new object I use the old name dat. After all, I only want to study adults, so what’s the issue if I remove any minors? Well, maybe I’m a little tired when I write the code and I get my mathematical operator reversed.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 20.00 40.00 40.17 59.00 85.00## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 5.000 9.000 9.328 14.000 18.000Oops! Instead of keeping the observations that were over 18, I kept the ones that were under 18. And I overwrote my file dat, so I can’t just rerun that line of code with the mathematical operator switched because there aren’t any observations over 18. That’s easy enough to fix, but I’ll have to reload my data. And if I’d done anything else, merging it with different files or maybe creating new variables, I’ll have to make sure I redo all that work too. It can just be a bit annoying, so what I’d recommend is that any merge or subset be used to create a new object name.