Chapter 19 Can you trust the published literature?
![]()
19.1 Publication bias
Imagine the situation of a researcher who conducts a study of the effectiveness of an intervention that she has developed to improve children’s vocabulary. She has attended to all the sources of bias that feature in earlier chapters, and run a well-powered randomized controlled trial. But at the end of the day, the results are disappointing. Mean vocabulary scores of intervention and control groups are closely similar, with no evidence that the intervention was effective. So what happens next?
A common response is that the researcher decides the study was a failure and files the results away. Another possibility is that they write up the research for publication, only to find that a series of journals reject the paper, because the null results are not very interesting. There is plentiful evidence that both of these things happen frequently, but does it matter? After all, it’s true that null results are uninteresting: we read journals in the hope we will hear about new, effective interventions.
In fact, failure to publish null results from well-designed studies is a massive problem for any field. This is because science is cumulative. We don’t judge an intervention on a single trial: the first trial might inspire us to do further studies to get a better estimate of the effect size and generalisability of the result. But those estimates will be badly skewed if the literature is biased to contain only positive results.
This problem was recognized decades ago. Social psychologist Greenwald (1975) talked about the “Consequences of prejudice against the null hypothesis”, memorably concluding that
“As it is functioning in at least some areas of behavioral science research, the research-publication system may be regarded as a device for systematically generating and propagating anecdotal information.”
A few years later, another psychologist, Rosenthal (1979), coined the term file drawer problem to describe the fate of studies that were deemed insufficiently exciting to publish.
In 1976, journal editor Michael Mahoney conducted a study which would raise eyebrows in current times (Mahoney, 1976). He sent 75 manuscripts out to review, but tweaked them so the results and discussion either agreed with the reviewer’s presumed viewpoint, or disagreed. He found that manuscripts that were identical in topic and procedure attracted favourable reviews if they found positive results, but were recommended for rejection if they found negative results. Methods that were picked apart for flaws if the findings were negative, were accepted without question when there were positive results.
Michael Mahoney: a man ahead of his time
“…after completing the study on the peer review system, I submitted it to Science. After several months, I received copies of the comments of three referees. One was extremely positive, opening his review with the statement that the ‘paper is certainly publishable in its present form.’ The other two referees were also positive - describing it as ‘bold, imaginative, and interesting’ - but requesting some minor revisions in the presentation and interpretation of the data. Notwithstanding these three positive reviews, Science editor Philip H. Abelson decided to reject the manuscript! Making the minor changes mentioned by the reviewers, I resubmitted the article along with a letter to Abelson noting the positive tone of the reviews and expressing puzzlement at his decision to reject. Abelson returned a three sentence letter saying (a) the manuscript ‘is obviously suitable for publication in a specialized journal,’ (b) if ‘it were shortened it might be published as a Research Report (in Science), and (c) that I should qualify my conclusions regarding ’the area of research and publications which are covered.’ It is not clear whether this latter remark was intended to imply that the peer review system in the physical sciences is not as flawed as that in the social sciences. In any case, I shortened the article, emphasized the study’s limitations, and noted the researchable possibility that different results might have been obtained with a different sample of referees or in a different discipline. My efforts were rewarded several months later when Assistant Editor John E. Ringle returned the manuscript with a five sentence rejection letter, recommending that I lengthen the article and submit it to a psychology journal”.
Figure 19.1 shows how publication bias can work out in practice. In this study, the authors searched a trial registry operated by the Food and Drug Administation (FDA) for studies on drug treatments for depression. Pharmaceutical companies are required to register intervention studies in advance, which makes it possible to detect unpublished as well as published research. As can be seen from the left-most bar (a), around half of the trials were deemed to have “negative” results, and the remainder found a positive effect of intervention. The second bar (b) shows the impact of publication bias: whereas nearly all the positive studies were published, only half of those with null results made it into print.
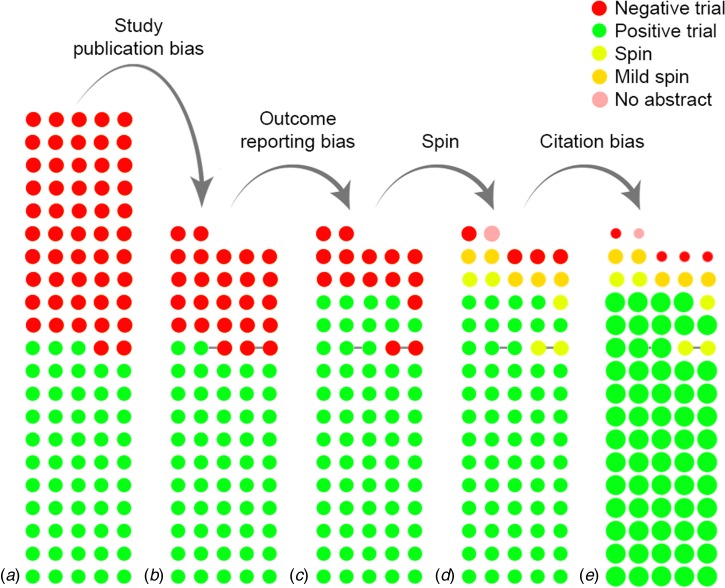
Figure 19.1: The cumulative impact of reporting and citation biases on the evidence base for antidepressants. Bar (a) displays the initial, complete cohort of trials, while (b) through (e) show the cumulative effect of biases. Each circle indicates a trial, while the color indicates the results or the presence of spin. Circles connected by a grey line indicate trials that were published together in a pooled publication. In (e), the size of the circle indicates the (relative) number of citations received by that category of studies
The next bar (c) shows yet more bias creeping in: ten negative trials switched from positive to negative, by either omitting or changing the primary study outcome. As the authors noted: “Without access to the FDA reviews, it would not have been possible to conclude that these trials, when analyzed according to protocol, were not positive.” And yet other trials reported a negative result in the body of the paper, but presented the findings with a positive spin in the Abstract, either by focusing on another result, or by ignoring statistical significance.
Given that the problems of publication bias have been recognized for decades, we may ask why they still persist - generating what Ferguson & Heene (2012) has termed “A vast graveyard of undead theories”. There appear to be two driving forces. First, traditionally journals have made their money by selling content, and publishers and editors know that people are usually far more interested in positive than in negative findings. Negative findings can be newsworthy, but only only if they challenge the effectiveness of an intervention that is widely-used and incurs costs. When reading the results of a positive intervention study, it is always worth asking yourself whether the study would have been accepted for publication if the results had turned out differently. For further discussion of this point see this blogpost.
Another force can be conflict of interest. Sometimes the developer of an intervention has the potential to gain or lose substantial amounts of income, depending on whether a trial is positive or negative. Even if there are no financial consequences, someone who has put a lot of time and effort into developing an intervention will have a strong bias towards wanting it to work. If there is a conflict of interest, it needs to be declared: of course, we should not assume that a researcher with a conflict of interest is dishonest, but there is empirical evidence that there is an association between conflict of interest and the reporting of positive results, which needs to be taken into account when reading the research literature (Friedman & Richter, 2004).
An example of spin in evaluating speech and language therapy
(a) individualized language intervention by a speech-language pathologist;
(b) computer-assisted language intervention;
(c) Fast Forword-Language (FFW-L) - a commercial intervention designed to remediate a putative auditory processing deficit thought to cause language problems;
(d) an academic enrichment program which did not target language skills.
The last of these was intended as an active control (see Chapter 6). There was no difference in outcomes between these four groups. The natural conclusion from such a result would be that none of the language-focused interventions had succeeded in boosting language skills, because a similar amount of improvement was seen in the active control condition which did not focus on language. Instead, the authors changed how they conceptualized the study, and decided to focus on the fact that all four groups showed significant improvement from baseline to post-test. This means that the study was no longer a RCT, but was rather treated as the kind of pre- vs post-intervention design whose limitations were noted in Chapter 5.
In the Discussion, the authors showed awareness of the problem of doing this: “One important finding is that the primary measures of language and auditory processing improved significantly across groups. One possible conclusion from this pattern of results is that all four arms were equally ineffective. That is, the gains in language and auditory processing that were observed across the four arms of the study may have arisen as a result of practice effects, maturation, regression to the mean, and/or spontaneous recovery.” Yet they went on to write at length about possible reasons why the active control might have boosted language (see HARKing, Chapter 11), and the Abstract reports results in a positive fashion, noting that “The children in all four arms improved significantly on a global language test”, and arguing that the improvements were of “clinical significance”. If one were to simply scan the Abstract of this paper without digging in to the Results, it would be easy to come away with the impression that a large RCT had provided support for all three language interventions.
19.2 Citation bias
In the rightmost bar of Figure 19.1, the size of the circles represents the number of citations of each paper in the literature. This illustrates another major bias that has received less attention than publication bias - citation bias. We can see that those null studies that made it through to this point, surviving with correct reporting despite publication bias, outcome reporting bias, and spin, get largely ignored, whereas studies that are reported as positive, including those which involved outcome-switching, are much more heavily cited.
Quite apart from there being bias against null results, many researchers are not particularly thorough in their citation of prior literature. In an overview of publication bias and citation bias, Leng & Leng (2020) drew attention to the neglect of prior literature in papers reporting randomized controlled trials. Based on a paper by Robinson & Goodman (2011), they noted that regardless of how many studies had been conducted, on average only two studies were cited, and concluded “seemingly, while scientists may see further by standing on the shoulders of those who have gone before, two shoulders are enough, however many are available.” (p. 206).
Citation bias is often unintentional, but is a consequence of the way humans think. Bishop (2020) described a particular cognitive process, confirmation bias, which makes it much easier to attend to and remember things that are aligned with our prior expectations. Confirmation bias is a natural tendency that in everyday life that often serves a useful purpose in reducing our cognitive load, but which is incompatible with objective scientific thinking. We need to take explicit measures to counteract this tendency in order to evaluate prior literature objectively.
19.3 Counteracting publication and citation biases
In Chapter 20 and Chapter 21, we discuss two approaches to counteracting biases: preregistration offers a solution to publication bias, and a systematic approach to literature review offers a (partial) solution to citation bias.
19.4 Class exercise
As a group exercise, you may like to try a game of Statcheck, the materials and rules for which are available here: https://sachaepskamp.github.io/StatcheckTheGame/. This should induce a sufficiently cynical approach towards the current publication system.
Find a published report of an intervention that interests you. Take a look at the introduction, and list the references that are cited as background. Next, go online and search for articles on this topic that were published two or more years before the target paper. Do you find many articles that are relevant but which were not cited? If so, did they give positive or negative results?
N.B. There are various ways you can conduct a literature search. Google Scholar is often preferred because it is free and includes a wide range of source materials, including books. Scopus and Web of Science are other commercial options that your institution may subscribe to. Both of these are more selective in coverage, which can be a positive if you want some quality control over your search (e.g. restricted to peer-reviewed journals), but a negative if you want to be comprehensive. If you compare these different ways of searching the literature, you will find they can give very different results.