Chapter 18 Single case designs
![]()
The single case design, also known as N-of-1 trial, or small N design, is a commonly used intervention design in speech and language therapy, clinical psychology, education, and neuropsychology, including aphasia therapy (Perdices & Tate, 2009). The single case design may be regarded as an extreme version of a within-subjects design, where two more more conditions are compared within a single person. This type of trial is sometimes dismissed as providing poor quality evidence, but a well-designed single case trial can be an efficient way to obtain an estimate of treatment efficacy in an individual. Very often, a set of single case trials is combined into a case series (see below). It is important to note that a single case trial is not a simple case report, but rather a study that is designed and analysed in a way that controls as far as possible for the kind of unwanted influences on results described in chapters 2-5.
18.1 Logic of single case designs
Table 18.1 compares the logic of the standard RCT and single case designs.
| Design | Participants | Time | Outcome |
|---|---|---|---|
| RCT: Multiple participants | Yes |
|
|
| Single case: Multiple time-points |
|
Yes |
|
| Single case: Multiple outcomes |
|
|
Yes |
The first row of Table 18.1 shows the design for a simple 2-arm RCT, where intervention is varied between participants who are assessed on the same occasion and on the same outcome. The second row shows a version of the single case design where the invention is varied in a single subject at different time points. The third row shows the case where intervention is assessed by comparing treated vs untreated outcomes in the same subject on the same occasion - this is referred to by Krasny-Pacini & Evans (2018) as a multiple baseline design across behaviours and by Ledford et al. (2019) as an Adapted Alternating Treatment Design.
Whatever design is used, the key requirements are analogous to those of the RCT:
- To minimize unwanted variance (noise) that may mask effects of interest.
- To ensure that the effect we observe is as unbiased as possible.
- To have sufficient data to reliably detect effects of interest
18.1.1 Minimising unwanted variance
In the RCT, this is achieved by having a large enough sample of participants to distinguish variation associated with intervention from idiosyncratic differences between individuals, and by keeping other aspects of the trial, such as timing and outcomes, as constant as possible.
With single case trials, we do not control for variation associated with individual participant characteristics - indeed we are interested in how different people respond to intervention - but we do need to control as far as possible for other sources of variation. The ABA design is a popular single-case design that involves contrasting an outcome during periods of intervention (B) versus periods of no intervention (A). For example, Armson & Stuart (1998) studied the impact of frequency-altered auditory feedback on 12 people who stuttered. They contrasted a baseline period (A), a period with auditory feedback (B), and a post-intervention period (A), taking several measures of stuttering during each period. Figure 18.1 shows data from two participants during a reading condition. Although the initial amount of stuttering differs for the two individuals, in both cases there is a precipitate drop in stuttering at the 5 minute point corresponding to the onset of the masking, which is sustained for some minutes before gradually rising back towards baseline levels. The baseline period is useful for providing a set of estimates of stuttering prior to intervention, so we can see that the drop in stuttering, at least initially, is outside the range of variation that occurs spontaneously.
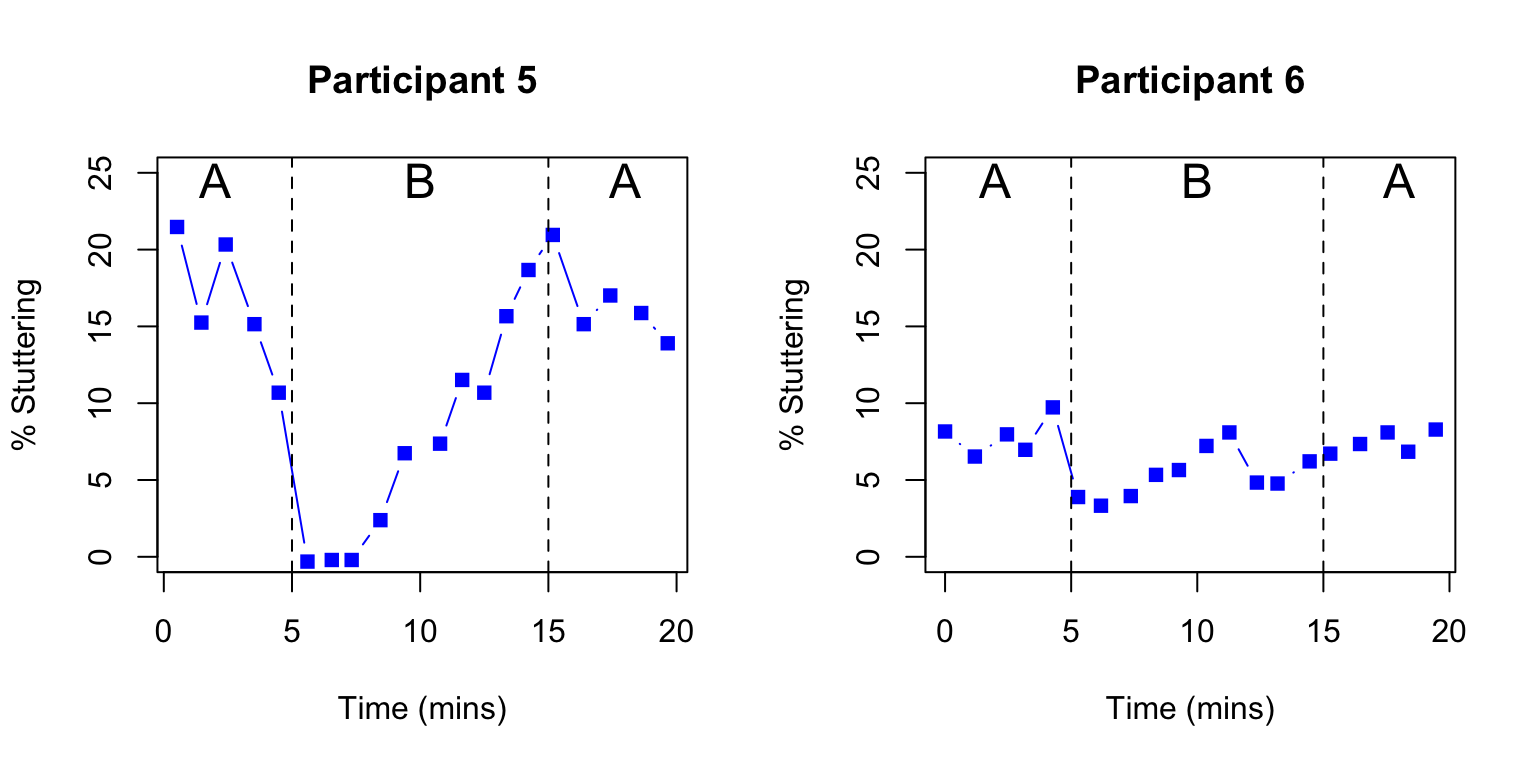
Figure 18.1: Outcome over time in a single case ABA design. Redrawn from digitized data from two participants from Figure 2 of Armson et al (1998)
In the context of neurorehabilitation and speech-and-language therapy, there would appear to be a major drawback of the ABA design. In the course of a historical review of this approach, Mirza et al. (2017) described the “N-of-1 niche” as follows:
“The design is most suited to assessing interventions that act and cease to act quickly. It is particularly useful in clinical contexts in which variability in patient responses is large, when the evidence is limited, and/or when the patient differs in important ways from the people who have participated in conventional randomized controlled trials.”
While the characteristics in the second sentence fit well with speech-and-language therapy interventions, the first requirement - that the intervention should “act and cease to act quickly” is clearly inapplicable. As described in the previous chapter, with few exceptions, interventions offered by those working in education as well as speech and language therapists and those working in other allied health professions are intended to produce long-term change that persists long after the therapy has ended. Indeed, a therapy that worked only during the period of administration would not be regarded as a success. This means that ABA designs, which compare an outcomes for periods with (B) and without (A) intervention, anticipating that scores will go up transiently during the intervention block, will be unsuitable. In this regard, behavioural interventions are quite different from many pharmaceutical interventions, where ABA designs are increasingly being used to compare a series of active and washout periods for a drug.
Despite this limitation, it is feasible to use an approach where we compare different time periods with and without intervention in some situations, most notably when there is good evidence that the targeted behaviour is unlikely to improve spontaneously. Inclusion of a baseline period, where behaviour is repeatedly sampled before intervention has begun, may give confidence that this is the case. An example of this multiple baseline approach from a study by Swain et al. (2020) is discussed below. Where the same intervention can be applied to a group of participants, then a hybrid method known as the multiple baseline across participants design can be used, which combines both between and within-subjects comparisons. A study of this kind by Koutsoftas et al. (2009) is discussed in the Class Exercise for this chapter.
In another kind of single case approach, the multiple baseline across behaviours design, it is the outcome measure that is varied. This approach is applicable where a single intervention has potential to target several specific behaviours or skills. This gives fields such as speech and language therapy an edge that drug trials often lack: we can change the specific outcome that is targeted by the intervention and compare it with another outcome that acts as a within-person control measure. To demonstrate effectiveness, we need to show that it is the targeted behaviour that improves, while the comparison behaviour remains unaffected.
For instance, Best et al. (2013) evaluated a cueing therapy for anomia in acquired aphasia in a case series of 16 patients, with the aim of comparing naming ability for 100 words that had been trained versus 100 untrained words. By using a large number of words, carefully selected to be of similar initial difficulty, they had sufficient data to show whether or not there was selective improvement for the trained words in individual participants.
Figure 18.2 is redrawn from data of Best et al. (2013). The black points show N items correct on the two sets of items prior to intervention. They were selected to be of similar difficulty and hence they cluster around the dotted line, which shows the point where scores on both item sets are equivalent. The red points show scores after intervention. Points that fall above the dotted line correspond to cases who did better with trained than untrained words; those below the line did better with untrained than trained words. The red points tend to be placed vertically above the pre-test scores for each individual, indicating that there is improvement after intervention in the trained items (y-axis), but not on control items (x-axis).
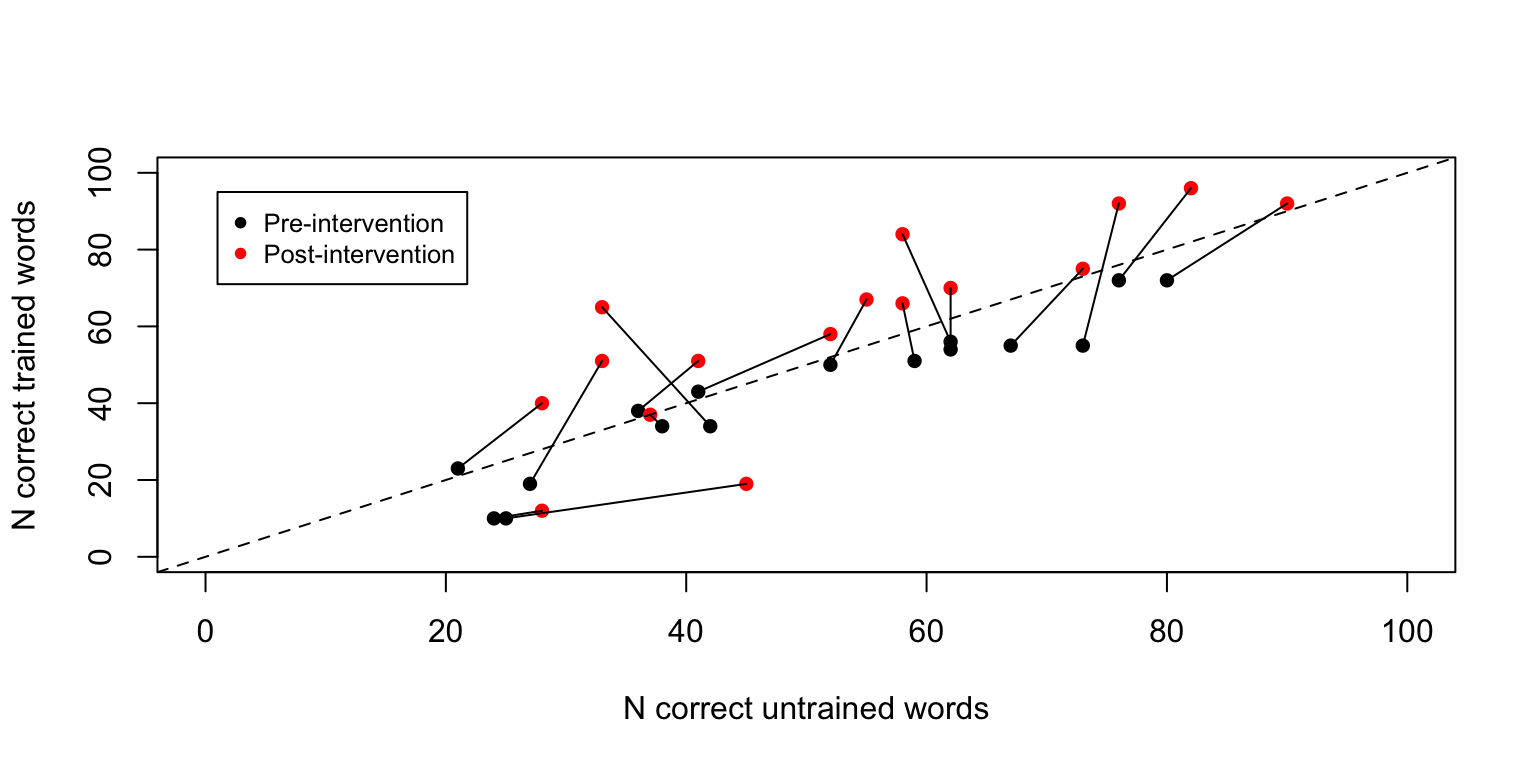
Figure 18.2: Outcome over time in multiple outcomes design. Reconstructed data from 16 participants, Best et al (2013)
Given the large number of items in each set, it is possible to do a simple comparison of proportions to see whether each person’s post-intervention score is reliably higher than their pre-intervention score for each item set. For 14 of the 16 cases, there is a statistically significant increase in scores from pre-intervention to post-intervention for target items (corresponding to those with lines that extend vertically above the dotted line), whereas this is the case for only two of the cases when control items are considered (corresponding to cases which show change in the horizontal direction from pre-intervention to post-intervention).
18.1.2 Minimising systematic bias
We have seen in previous chapters how the RCT has evolved to minimize numerous sources of unwanted systematic bias. We need to be alert to similar biases affecting results of single case trials. This is a particular concern for trial designs where we compare different time periods that do or do not include intervention. On the one hand, we may have the kinds of time-linked effects of maturation, practice or spontaneous recovery that lead to a general improvement over time, regardless of the intervention (see Chapter 4), and on the other hand there may be specific events that affect a person’s performance, such as life events or illness, which may have a prolonged beneficial or detrimental effect on performance.
The general assumption of this method is that if we use a sufficient number of time intervals, time-linked biases will average out, but while this may be true for transient environmental effects, such as noise or other distractions, it is not the case for systematic influences that continue over time. It is important to be aware of such limitations, and it may be worth considering combining this kind of design with other elements that control for time-related biases more effectively (see below).
18.1.3 The need for sufficient data
Some early single case studies in neuropsychology may have drawn over-optimistic conclusions because they had insufficient replications of outcome measures, assuming that the observed result was a valid indication of outcome without taking into account error of measurement. For instance, if someone’s score improved from 2/10 items correct prior to intervention to 5/10 correct after intervention, it can be hard to draw firm conclusions on the basis of this data alone: the change could just be part of random variability in the measure. The more measurements we have in this type of study, the more confidence we can place in results: whereas in RCTs we need sufficient participants to get a sense of how much variation there is in outcomes, in single case studies we need sufficient observations, and should never rely just a few instances.
In effect, we need to use the same kind of logic that we saw in Chapter 10, where we estimated statistical power of a study by checking how likely we would be to get a statistically significant result from a given sample size. Table 18.2 shows power to detect a true effect of a given size in a multiple baseline across behaviours design of the kind used by Best et al. (2013), where we have a set of trained vs untrained items, each of which is scored either right or wrong. The entries in this table show power, which is the probability that a study would detect a true effect of a given size on a one-tailed test. These entries were obtained by simulating 1000 datasets with each of the different combinations of sample size and effect size.
The columns show the effect size as the raw difference in proportion items correct for trained vs untrained words. It is assumed that these two sets were equated for difficulty prior to intervention, and the table shows the difference in proportion correct between the two sets after intervention. So if the initial proportion correct was .3 for both trained and untrained items, but after intervention, we expect accuracy on trained items to increase to .6 and the untrained to stay at .3, then the difference between the two sets after treatment is .3, shown in the 4th column of the table. We can then read down this column to see the point at which power reaches 80% or more. This occurs at the 4th row of the table, when there are 40 items in each set. If we anticipated a smaller increase in proportion correct for trained items of .2, then we would need 80 items per set to achieve 80% power.
| N_per_Set | .1 | .2 | .3 | .4 | .5 | .6 |
|---|---|---|---|---|---|---|
| 10 | 6 | 13 | 24 | 43 | 64 | 81 |
| 20 | 10 | 25 | 49 | 76 | 92 | 99 |
| 30 | 14 | 37 | 70 | 92 | 99 | 100 |
| 40 | 17 | 49 | 81 | 97 | 100 | 100 |
| 50 | 20 | 58 | 89 | 100 | 100 | 100 |
| 60 | 25 | 68 | 95 | 100 | 100 | 100 |
| 70 | 30 | 73 | 97 | 100 | 100 | 100 |
| 80 | 32 | 80 | 98 | 100 | 100 | 100 |
| 90 | 35 | 85 | 100 | 100 | 100 | 100 |
| 100 | 38 | 88 | 100 | 100 | 100 | 100 |
| 110 | 39 | 90 | 100 | 100 | 100 | 100 |
| 120 | 44 | 93 | 100 | 100 | 100 | 100 |
| 130 | 47 | 94 | 100 | 100 | 100 | 100 |
| 140 | 49 | 96 | 100 | 100 | 100 | 100 |
| 150 | 52 | 97 | 100 | 100 | 100 | 100 |
| 160 | 56 | 98 | 100 | 100 | 100 | 100 |
| 170 | 57 | 98 | 100 | 100 | 100 | 100 |
| 180 | 60 | 98 | 100 | 100 | 100 | 100 |
| 190 | 61 | 99 | 100 | 100 | 100 | 100 |
| 200 | 66 | 99 | 100 | 100 | 100 | 100 |
18.2 Examples of studies using different types of single case design
As noted above, single case designs cover a wide range of options, and can vary the periods of observation or the classes of observations made for each individual.
18.2.1 A multiple baseline design: Speech and language therapy for adolescents in youth justice.
The key feature of a multiple baseline design is onset of intervention is staggered across at least three different points in time. Potentially, this could be done by having three or more participants, each of whom was measured in a baseline and an intervention phase, but with the timing of the intervention phase varied across participants. Alternatively, one can have different outcomes assessed in a single participant. Figure 18.3 from Swain et al. (2020) provides an illustration of the latter approach with a single participant, where different outcomes are targeted at different points in a series of intervention sessions. Typically, the timing of the interventions is not preplanned, but rather, they are introduced in sequence, with the second intervention only started after there is a documented effect from the first intervention, and so on (Horner & Odom, 2014).
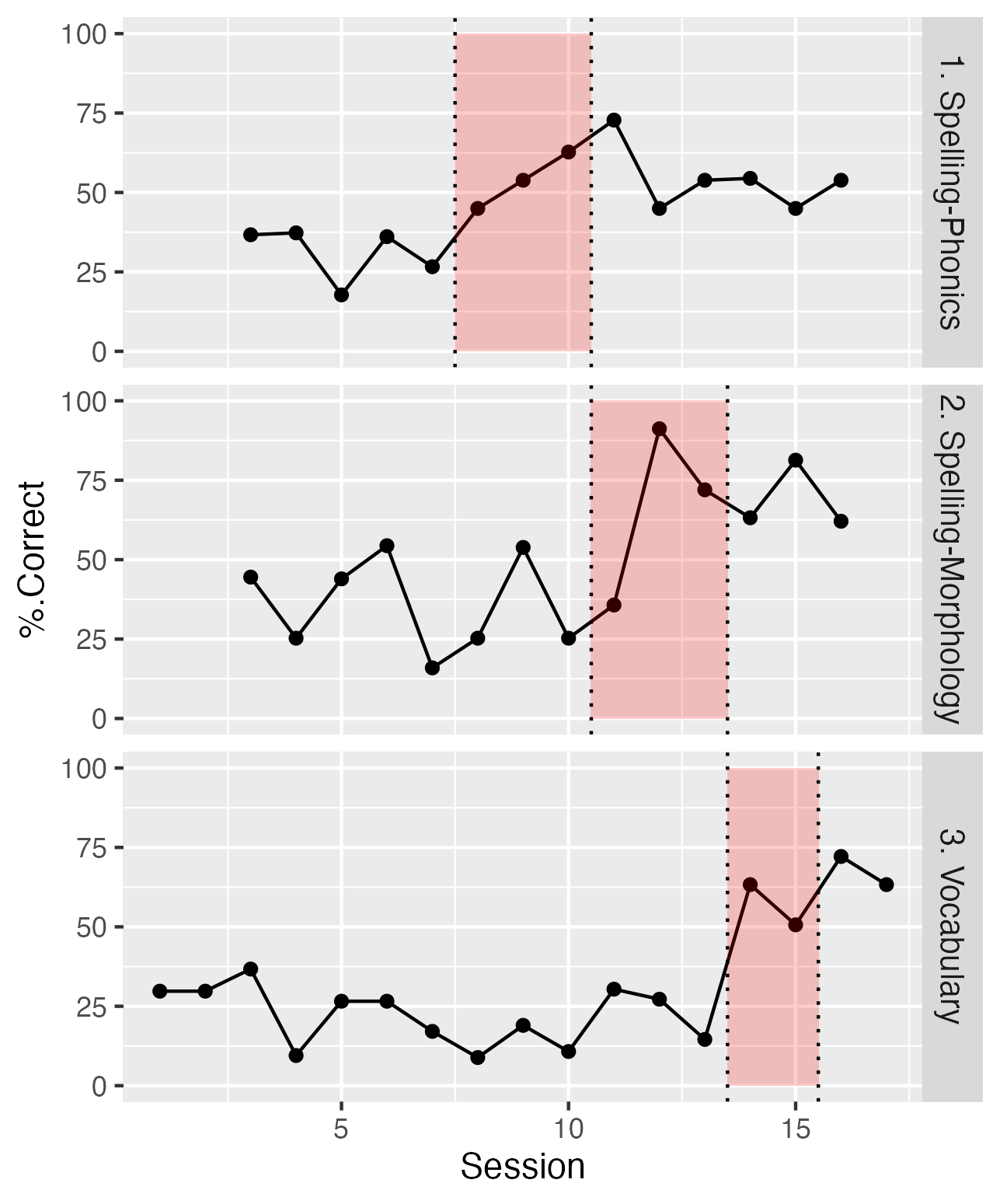
Figure 18.3: Data from one case in the Swain et al. (2020) study. The shaded region shows sessions with intervention for each of the three outcomes.
The three panels show percentages correct on outcome probes for three skills: spelling-phonics, spelling-morphology and vocabulary. These were targeted sequentially in different sessions, and evidence for intervention effectiveness is obtained when a selective increase in performance is shown for the period during and after intervention. Note that for all three tasks, there is little or no overlap for scores during baseline and those obtained during and after intervention. The baseline data establish that although targeted behaviours vary from day to day, there is no systematic upward trend in performance until the intervention is administered. Furthermore, the fact that improvement is specific to the behaviour that is targeted in that session gives confidence that this is not just down to some general placebo effect.
In the other case studies reported by Swain et al. (2020), different behaviours were targeted, according to the specific needs of the adolescents who were studied.
18.2.2 A study using multiple baseline across behaviours: Effectiveness of electropalatography
We noted in the previous chapter how, electropalatography, a biofeedback intervention that provides information about the position of articulators to help clients improve production of speech sounds, is ill-suited to evaluation in a RCT. It is potentially applicable to people with a wide variety of aetiologies, so the treated population is likely to be highly heterogenous, it requires expensive equipment including an individualized artificial palate, and the intervention is delivered over many one-to-one sessions. The goal of the intervention is to develop and consolidate new patterns of articulation that will persist after the intervention ends. It would not, therefore, make much sense to do a single case trial of electropalatography using an ABA design that involved comparing blocks of intervention vs no intervention. One can, however, run a trial that tests whether there is more improvement on targeted speech sounds than on other speech sounds that are not explicitly treated.
Leniston & Ebbels (2021) applied this approach to seven adolescents with severe speech disorders, all of whom were already familiar with electropalatography. Diagnoses included verbal dyspraxia, structural abnormalities of articulators (velopharyngeal insufficiency), mosaic Turner syndrome, and right-sided hemiplegia. At the start of each school term, two sounds were identified for each case: a target sound, which would be trained, and a control sound, which was also produced incorrectly, but which was not trained. Electropalatography training was administered twice a week in 30 minute sessions. The number of terms where intervention was given ranged from 1 to 3.
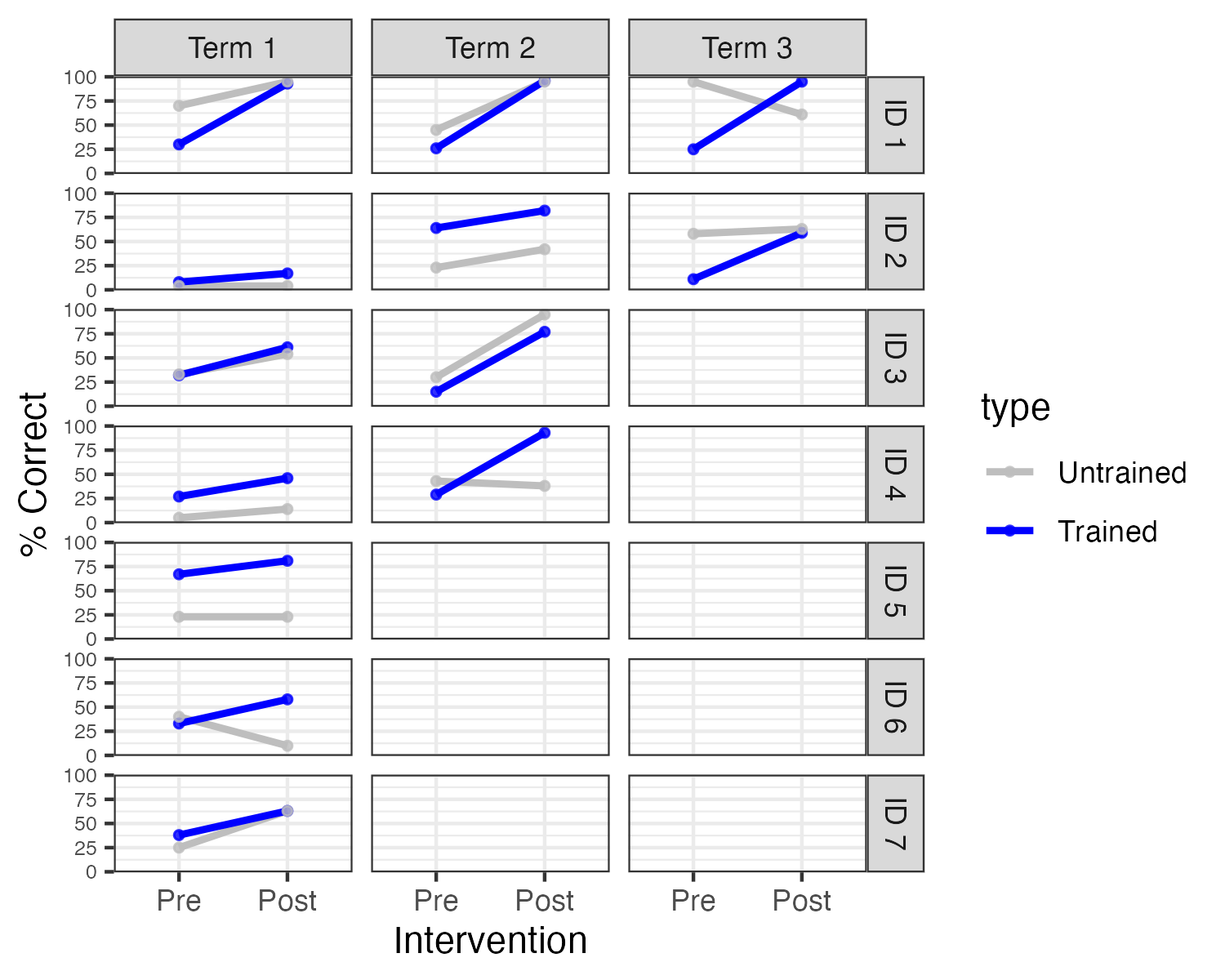
Figure 18.4: Individual results for targets and controls at each term (Redrawn Fig 3 from Leniston & Ebbels, data kindly provided by Susan Ebbels)
An analysis of group data found no main effect of target or time, but a large interaction between these, indicating greater improvement on trained speech sounds. The design of the study made it possible to look at individual cases, which gave greater insights into variation of the impact of intervention. As shown in Figure 18.4, in the first term of intervention, there was a main effect of time for three of the participants (IDs 1, 3, and 4), but no interaction with sound type. In other words, these children improved over the course of the term, but this was seen for the untrained as well as the trained sound. By term 2, one of four children showed an interaction between time and sound type (ID4), and both children who continued training into term 3 (ID 1 and 2) showed such an interaction. Three children did not show any convincing evidence of benefit - all of these stopped intervention after one term.
As the authors noted, there is a key limitation of the study: when a significant interaction is found between time and sound type, this provides evidence that the intervention was effective. But when both trained and untrained sounds improve, this is ambiguous. It could mean that the intervention was effective, and its impact generalized beyond the trained sounds. But it could also mean that the intervention was ineffective, with improvement being due to other factors, such as maturation or practice on the outcome measure. Inclusion of a series of baseline measures might have helped establish how plausible these two possibilities were.
In sum, this method can handle the (typical) situation where intervention effects are sustained, but it is most effective if we do not expect any generalization of learning beyond the targeted behaviour or skill. Unfortunately, this is often at odds with speech and language therapy methods. For instance, in phonological therapy, the therapist may focus on helping a child distinguish and/or produce a specific sound pair, such as [d] vs [g], but there are good theoretical reasons to expect that if therapy is successful, it might generalize to other sound pairs, such as [t] vs [k], which depend on the same articulatory contrast between alveolar vs velar place. Indeed, if we think of the child’s phonology as part of a general system of contrasts, it might be expected that training on one sound pair could lead the whole system to reorganize. This is exactly what we would like to see in intervention, but it can make single case studies extremely difficult to interpret. Before designing such a study, it is worthwhile anticipating different outcomes and considering how they might be interpreted.
18.2.3 Example of an analysis of case series data
The terms ‘single case’ and ‘N-of-1’ are misleading in implying that only one participant is trained. More commonly, studies assemble a series of N-of-1 cases. Where the same intervention is used for all cases, regular group statistics may be applied. But unlike in RCTs, heterogeneity of response is expected and needs to be documented. In fact, in a single case case series, the interest is less in whether an overall intervention effect is statistically significant, as in whether the data provide evidence of individual variation in response to intervention, as this is what would justify analysis of individual cases. Formally, it is possible to test whether treatment effects vary significantly across participants by comparing a model that does or does not contain a term representing this effect, using linear mixed models, but we would recommend that researchers consult a statistician, as those methods are complex and require specific types of data. In practice, it is usually possible to judge how heterogeneous responses to intervention are by inspecting plots for individual participants.
Typically the small sample sizes in N-of-1 case series preclude any strong conclusions about the characteristics of those who do and do not show intervention effects, but results may subsequently be combined across groups, and specific hypotheses formulated about the characteristics of those who show a positive response.
An example comes from the study by Best et al. (2013) evaluating rehabilitation for anomia in acquired aphasia. As described above, researchers contrasted naming ability for words that had been trained, using a cueing approach, versus a set of untrained control words, a multiple baseline across behaviours design. In general, results were consistent with prior work in showing that improvement was largely confined to trained words. As noted above, this result allows us to draw a clear conclusion that the intervention was responsible for the improvement, but from a therapeutic perspective it was disappointing, as one might hope to see generalization to novel words.
The authors subdivided the participants according to their language profiles, and suggested that improvement on untrained words was seen in a subset of cases with a specific profile of semantic and phonological strengths. This result, however, was not striking and would need to be replicated.
18.2.4 Combining approaches to strengthen study design
In practice, aspects of different single-case designs can be combined - e.g. the cross-over design by Varley et al. (2016) that we described in Chapter 17 compared an intervention across two time points and two groups of participants, and also compared naming performance on three sets of items: trained words, untrained words that were phonemically similar to the trained words, and untrained words that were dissimilar to the trained words. Furthermore, baseline measures were taken in both groups to check the stability of naming responses. That study was not, however, analysed as a single case design: rather the focus was on average outcomes without analysing individual differences. However, the inclusion of multiple outcomes and multiple time points meant that responses of individuals could also have been investigated.
18.3 Statistical approaches to single case designs
Early reports of single case studies often focused on simple visualization of results to determine intervention effects, and this is still a common practice (Perdices & Tate, 2009). This is perfectly acceptable provided that differences are very obvious, as in Figure 18.1 above. We can think back to our discussion of analysis methods for RCTs: the aim is always to ask whether the variation associated with differences in intervention is greater than the variation within the intervention condition. In Figure 18.1 there is very little overlap in the values for the intervention vs non-intervention periods, and statistics are unnecessary. However, results can be less clearcut than this. Figure 18.5 shows data from two other participants in the study by Armson & Stuart (1998), where people may disagree about whether or not there was an intervention effect. Indeed, one criticism of the use of visual analysis in single case designs is that it is too subjective, with poor inter-rater agreement about whether effects are seen. In addition, time series data will show dependencies: autocorrelation. This can create a spurious impression of visual separation in data for different time periods (Kratochwill et al., 2014). A more quantitative approach that adopts similar logic is to measure the degree of non-overlap between distributions for datapoints associated with intervention and those from baseline or control conditions (Parker et al., 2014). This has the advantage of simplicity, and relative ease of interpretation, but may be bedevilled by temporal trends in the data, and have relatively low statistical power unless there are large numbers of observations.
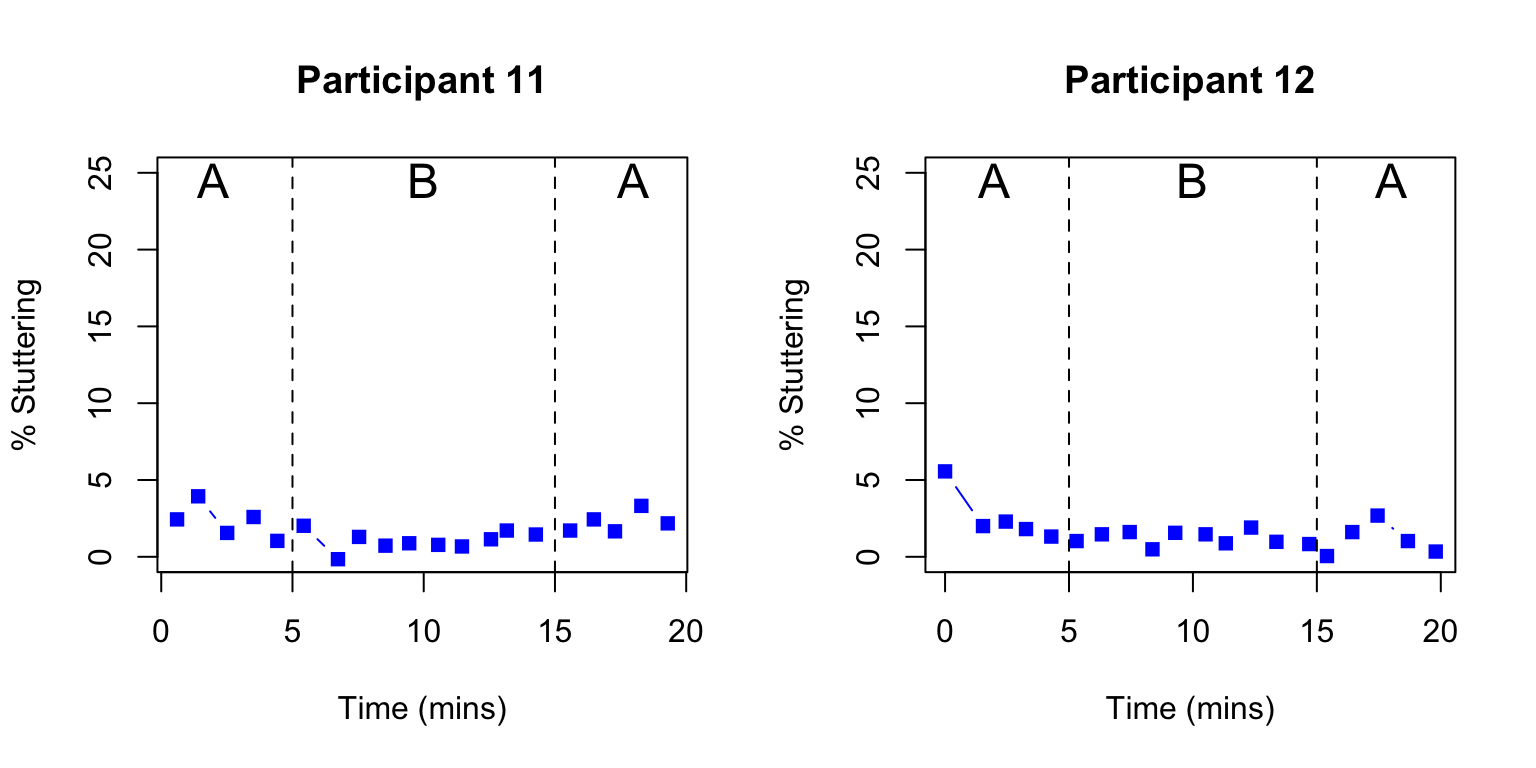
Figure 18.5: Outcome over time in a single case ABA design. Digitized data from two participants from Figure 2 of Armson et al (1998)
Unfortunately, rather than a well-worked-out set of recommendations for statistical analysis of single case trials, there is a plethora of methods in use, which can be challenging, or even overwhelming, for anyone starting out in this field to navigate (Kratochwill & Levin, 2014). Furthermore, most of the focus has been on ABA and related designs, with limited advice on how to deal with designs that use comparisons between treated and untreated outcomes.
Our view is that single-case designs have considerable potential. There has been much argument about how one should analyse single case study data; multilevel models have been proposed as a useful way of answering a number of questions with a single analysis - how large the treatment effect is for individual cases, how far the effect varies across cases, and how large the average effect is. However, caution has been urged, because, as Rindskopf & Ferron (2014) noted, these more complex models make far more assumptions about the data than simpler models, and results may be misleading if they are not met. We suggest that the best way to find the optimal analysis method may be to simulate data from a single-case study design, so that one can then compare the power and efficiency of different analytic approaches, and also their robustness to aspects of the data such as departures from normality. Simulation of such data is complicated by the fact that repeated observations from a single person will show autocorrelation, but this property can be incorporated in a simulation. A start has been made on this approach: see this website by James Pustejovsky. The fact that single-case studies typically make raw data available means there is a wealth of examples that could be tested in simulations.
18.4 Overview of considerations for single case designs
In most of the examples used here, the single case design could be embedded in natural therapy sessions, include heterogeneous participants, and be adapted to fit into regular clinical practice. This makes the method attractive to clinicians, but it should be noted that while incorporating evaluation into clinical activities is highly desirable, it often creates difficulties for controlling aspects of internal validity. For instance, in the study by Swain et al. (2020), the researchers noted an element of unpredictability about data collection, because the young offenders that they worked with might either be unavailable, or unwilling to take part in intervention sessions on a given day. In the Leniston & Ebbels (2021) study the target and control probes were not always well-matched at baseline, and for some children, the amount of available data was too small to give a powerful test of the intervention effect. Our view is that it is far better to aim to evaluate interventions than not to do so, provided limitations of particular designs are understood and discussed. Table 18.3 can be used as a checklist against which to assess characteristics of a given study, to evaluate how far internal validity has been controlled.
| Biases | Remedies |
|---|---|
| Spontaneous improvement | Control outcome and/or baseline time period |
| Practice effects | Control outcome and/or baseline time period |
| Regression to the mean | Control outcome and/or baseline time period |
| Noisy data (1) | Baseline period to establish variability |
| Noisy data (2) | Outcomes with low measurement error |
| Selection bias | NA |
| Placebo effects |
|
| Experimenter bias (1) | Record sessions |
| Experimenter bias (2) | Strictly specified protocol |
| Biased drop-outs | Report on the number and characteristics of drop-outs |
| Low power | A priori power analysis; need for many observations |
| False positives due to p-hacking | Registration of trial protocol |
We are not aware of specific evidence on this point, but it seems likely that the field of single case studies, just like other fields, is likely to suffer from problems of publication bias (Chapter 19), whereby results are reported when an intervention is successful, but not when it fails. If studies are adequately powered - and they should be designed so that they are - then all results should be reported, including those which may be ambiguous or unwanted, so that we can learn from what doesn’t work, as well as from what does.
A final point, which cannot be stressed enough, is that when evaluating a given intervention, a single study is never enough. Practical constraints usually make it impossible to devise the perfect study that gives entirely unambiguous results: rather we should aim for our studies to reduce the uncertainty in our understanding of the effectiveness of intervention, with each study building on those that have gone before. With single case studies, it is common to report the raw data in the paper, in either numeric or graphical form, and this is particularly useful in allowing other researchers to combine results across studies to form stronger conclusions (see Chapter 21).
18.5 Class exercise
- Koutsoftas et al. (2009) conducted a study of effectiveness of phonemic awareness intervention with a group of children who showed poor sound awareness after receiving high quality whole-classroom teaching focused on this skill. Intervention sessions were administered by speech-language pathologists or experienced teachers to 13 groups of 2-4 children twice per week for a baseline and post-intervention period, and once per week during the 6 week intervention. Active intervention was preceded by a baseline period - one week (with two outcome measurement points) for seven groups of children, and two weeks (4 measurement points) for the other six groups. Outcome probes involved identifying the initial sound from a set of three words in each session. The researchers reported effect sizes for individual children that were calculated by comparing score on the probes in the post-intervention period with those in the baseline period, showing that most children showed significant gains on the outcome measure. Group results on the outcome measure (redrawn from Table 2 of the paper) are shown in Figure 18.6.
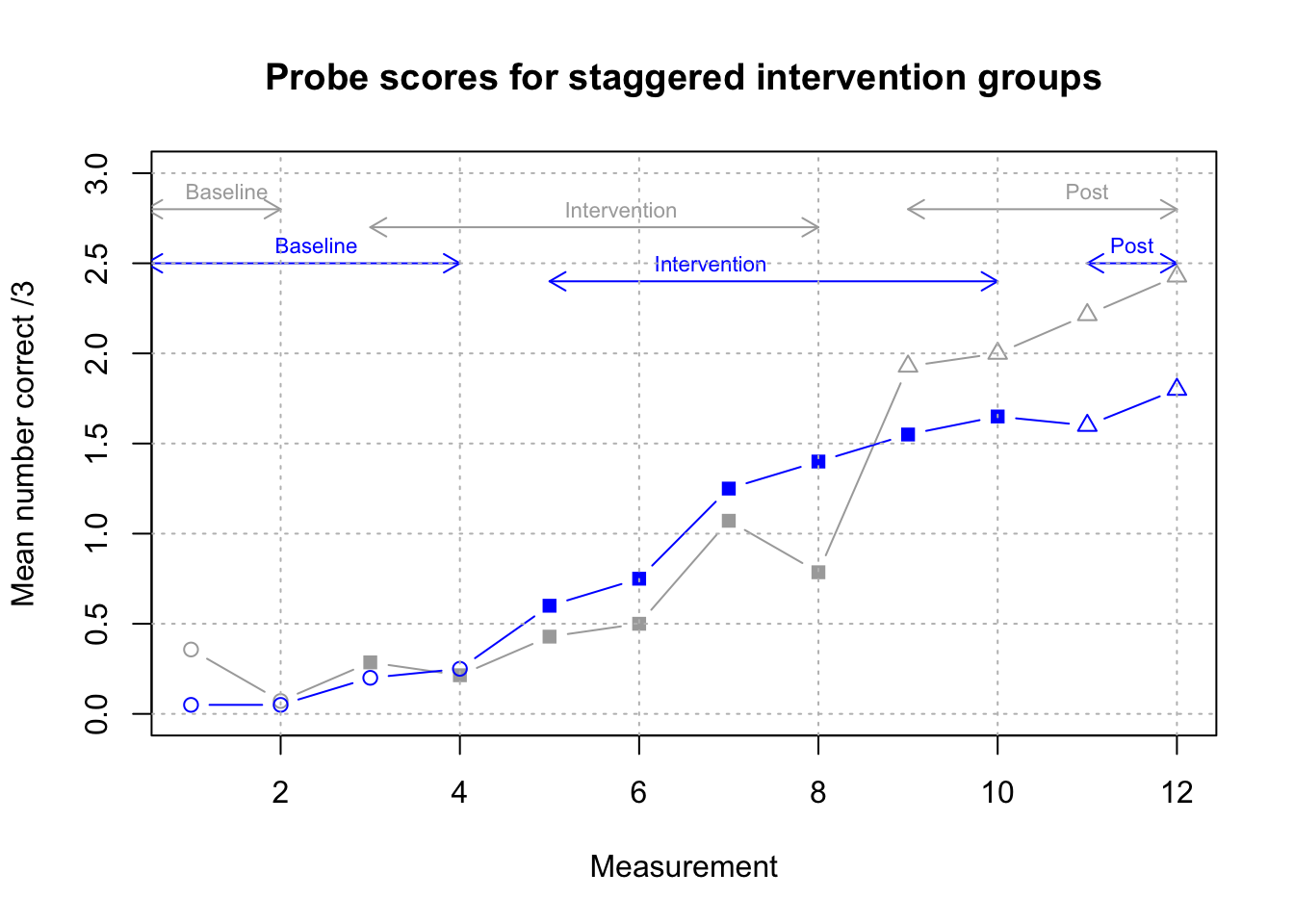
Figure 18.6: Group means from Koutsoftas et al, 2009. Filled points show intervention phase, unfilled show baseline or post-intervention
Consider the following questions about this study.
a. What kind of design is this?
b. How well does this design guard against the biases shown in Table 18.3?
c. Could the fact that intervention was delivered in small groups affect study validity? (Clue: see Chapter 16).
d. If you were designing a study to follow up on this result, what changes might you make to the study design?
e. What would be the logistic challenges in implementing these changes?
The SCRIBE guidelines have been developed to improve reporting of single case studies in the literature. An article by Tate et al. (2016) describing the guidelines with explanation and elaboration is available here, with a shorter article summarising the guidelines here.
Identify a single case study in the published literature in your area and check it against the guidelines to see how much of the necessary information is provided.
This kind of exercise can be more useful than just reading the guidelines, as it forces the reader to read an article carefully and consider what the guidelines mean.In the previous chapter, we described a study by Calder et al. (2021), which used a cross-over design to evaluate the effect of an intervention designed to improve grammatical morphology. This study also included probes to test mastery of untrained morphological endings. The trained structure was past tense -ed; a ‘generalization’ probe was another verb ending, 3rd person singular -s, and a control probe was possessive -s. Before studying Figure 18.7 make a note of your predictions about what you might expect to see with these additional probes.
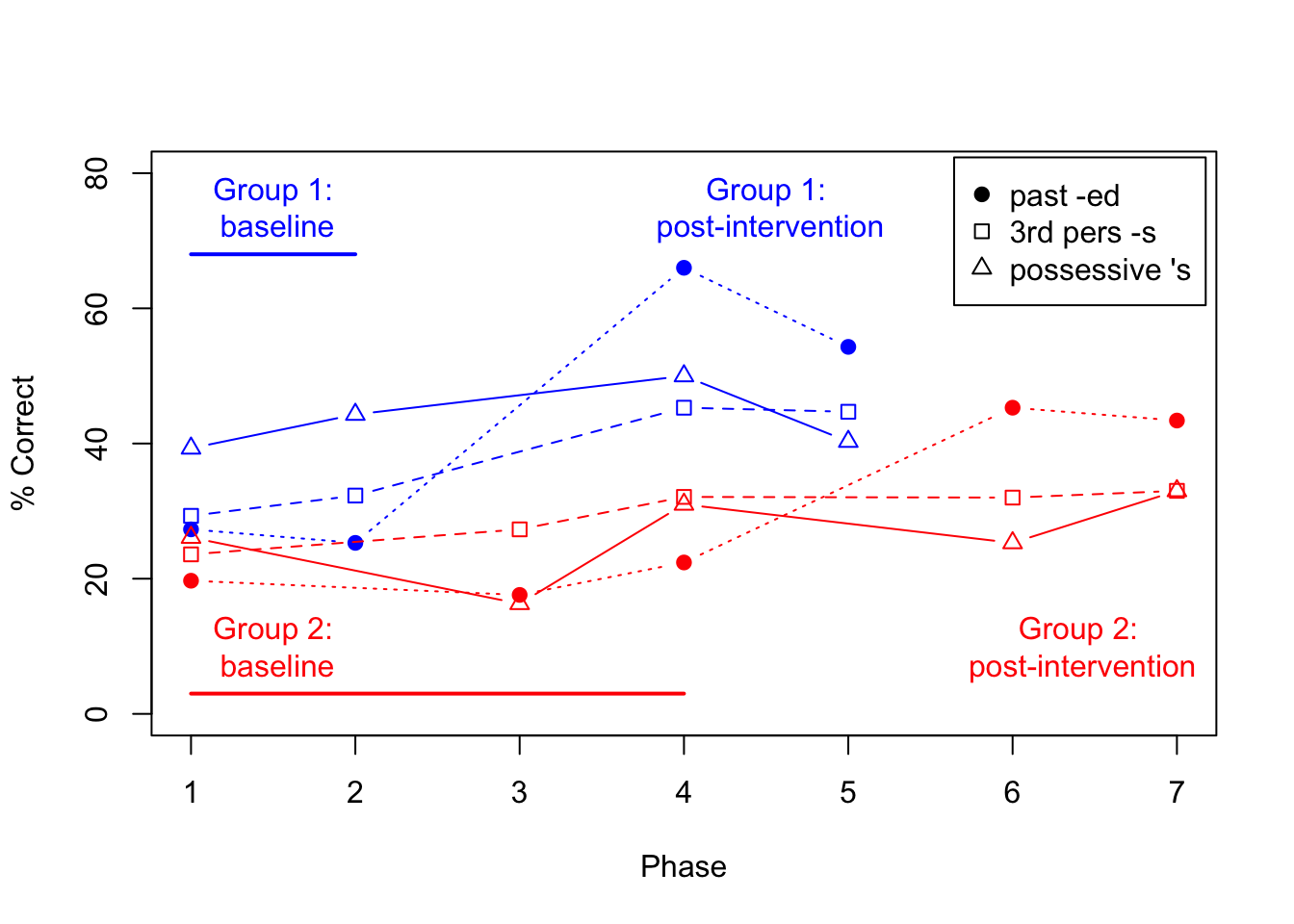
Figure 18.7: Mean % correct for all 3 probes in delayed cross-over study by Calder et al, 2021 (data plotted from Calder et al’s Table 2).
Once you have studied the Figure, consider whether you think the inclusion of the probes has strengthened your confidence in the conclusion that the intervention is effective.