Chapter 14 Graphing Part II
library(tidyverse) # loading ggplot2 and dplyr
library(viridis) # The viridis color schemes
library(latex2exp) # For plotting math notation
library(plotly) # for interactive hover-text
library(maps) # package with data about country borders
library(sf) # Simple Features for GIS
library(rnaturalearth) # package with detailed information about country &
library(rnaturalearthdata) # state/province borders, and geographical features
# devtools::install_github('ropensci/rnaturalearthhires')
library(rnaturalearthhires)
library(leaflet)I have a YouTube Video Lecture for this chapter.
We have already seen how to create many basic graphs using the ggplot2 package. However we haven’t addressed many common scenarios. In this chapter we cover many graphing tasks that occur.
14.1 Multi-plots
There are several cases where it is reasonable to need to take several possibly unrelated graphs and put them together into a single larger graph. This is not possible using facet_wrap or facet_grid as they are intended to make multiple highly related graphs. Instead we have to turn to other packages that enhance the ggplot2 package.
14.1.1 cowplot package
Claus O. Wilke wrote a lovely book about data visualization and also wrote an R package to help him tweek his plots. One of the functions in his cowplot package is called plot_grid and it takes in any number of plots and lays them out on a grid.
P1 <- ggplot(iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species)) +
geom_point(size=3) + theme(legend.position='bottom')
P2 <- ggplot(trees, aes(x=Height, y=Volume, color=Girth)) +
geom_point() + theme(legend.position='bottom')
P3 <- ggplot(iris, aes(x=Sepal.Length)) +
geom_histogram(bins=30)
P4 <- ggplot(iris, aes(x=Species, y=Sepal.Length, fill=Species)) +
geom_boxplot() + theme(legend.position='bottom')
cowplot::plot_grid(P1, P2, P3, P4)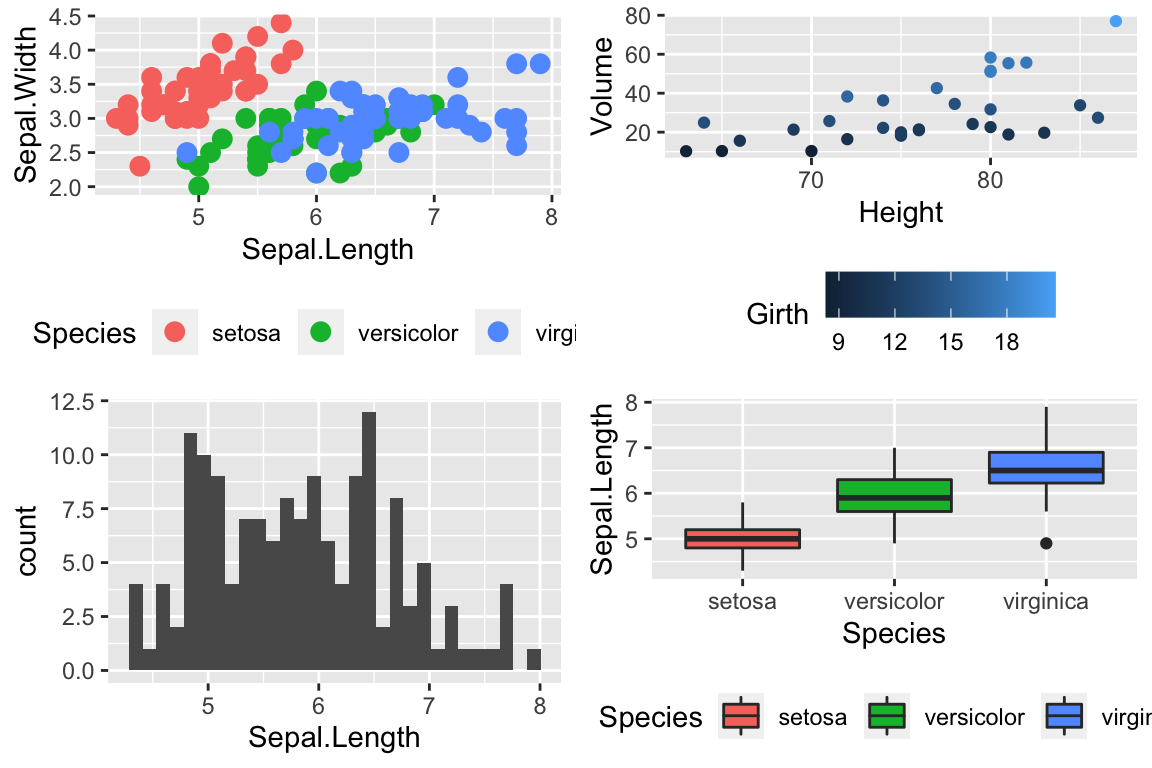
Notice that the graphs are by default are arranged in a 2x2 grid. We could adjust the number or rows/columns using the nrow and ncol arguments. Furthermore, we could add labels to each graph so that the figure caption to refer to “Panel A” or “Panel B” as appropriate using the labels option.
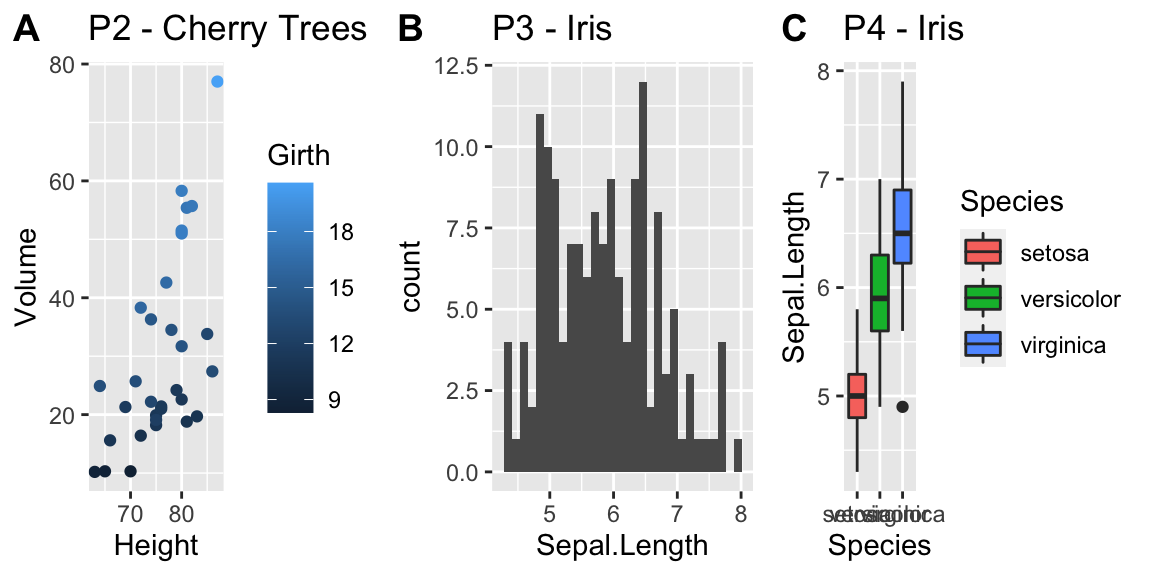
cowplot::plot_grid(P2, P3, P4, nrow=1, labels=c('A','B','C'))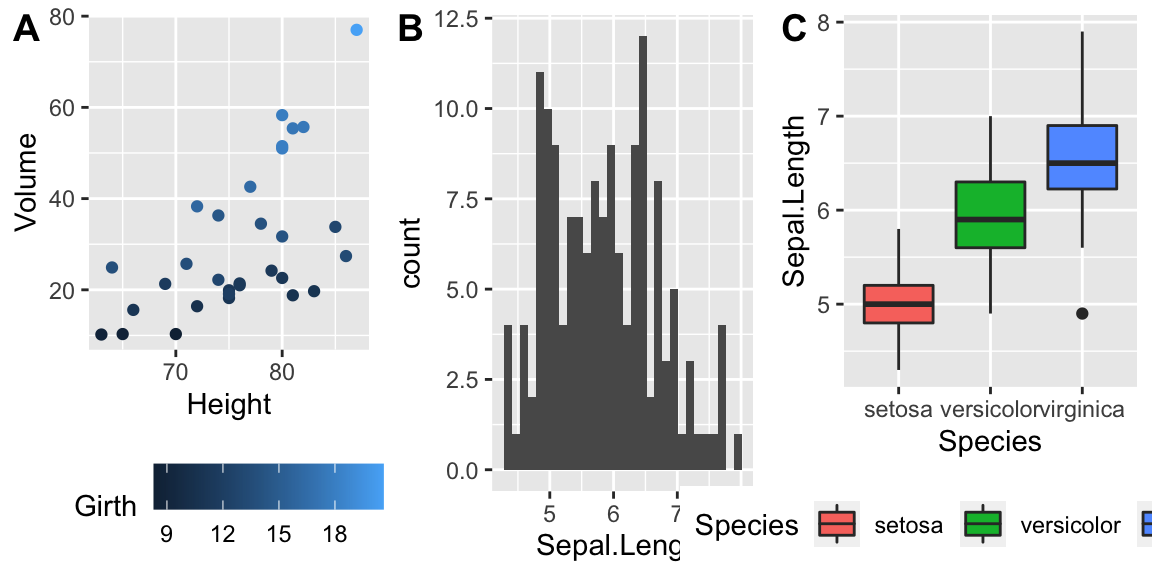
14.1.2 multiplot in Rmisc
In his book, R Graphics Cookbook Winston Chang produced a really nice function to address this issue, but just showed the code. The folks that maintain the R miscellaneous package Rmisc kindly included his function. The benefit of using this function is that you can control the layout to not be on a grid. For example we might want two graphs side by side, and then the third be short and wide underneath both. By specifying different numbers and rows and columns in my layout matrix, we can highly customize how the plot looks.
# Define where the first plot goes, etc.
my.layout <- matrix(c(1, 2, 2,
1, 2, 2,
3, 3, 3), byrow = TRUE, nrow=3)
matrix(c(1, 2, 2,
1, 2, 2,
3, 3, 3), nrow=3, byrow=TRUE)## [,1] [,2] [,3]
## [1,] 1 2 2
## [2,] 1 2 2
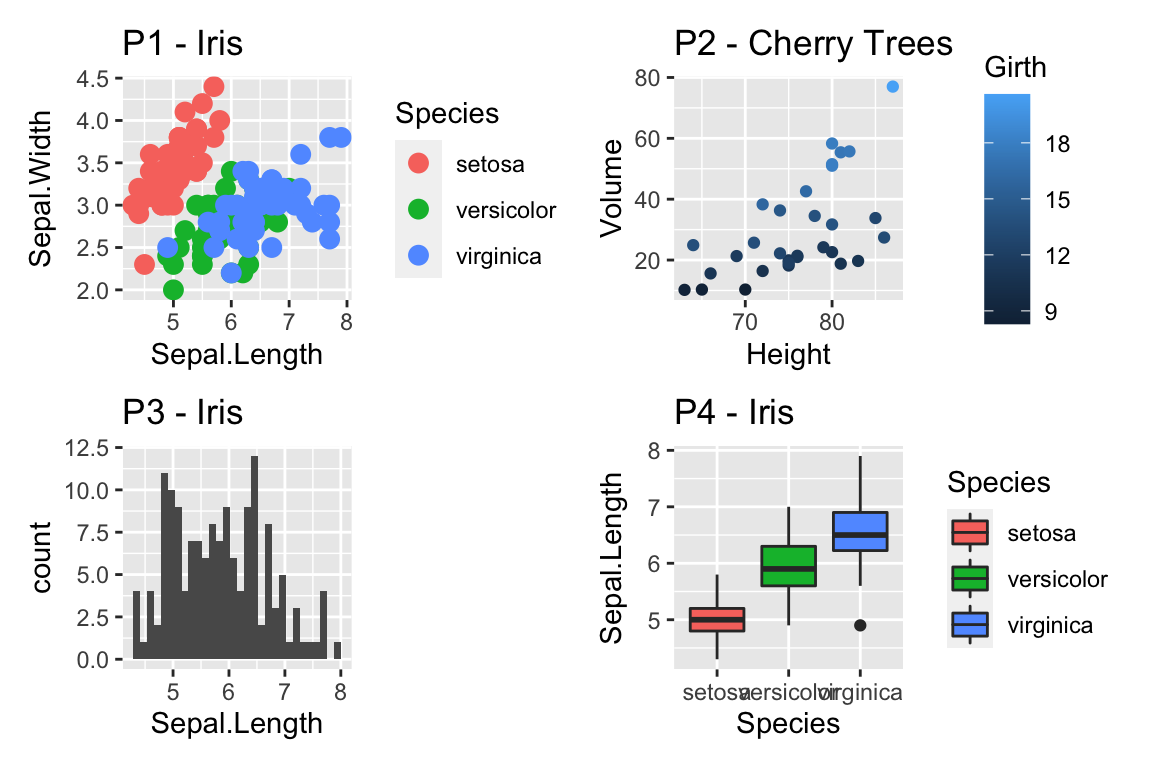
## [3,] 3 3 3Rmisc::multiplot(P2, P3, P4, layout = my.layout )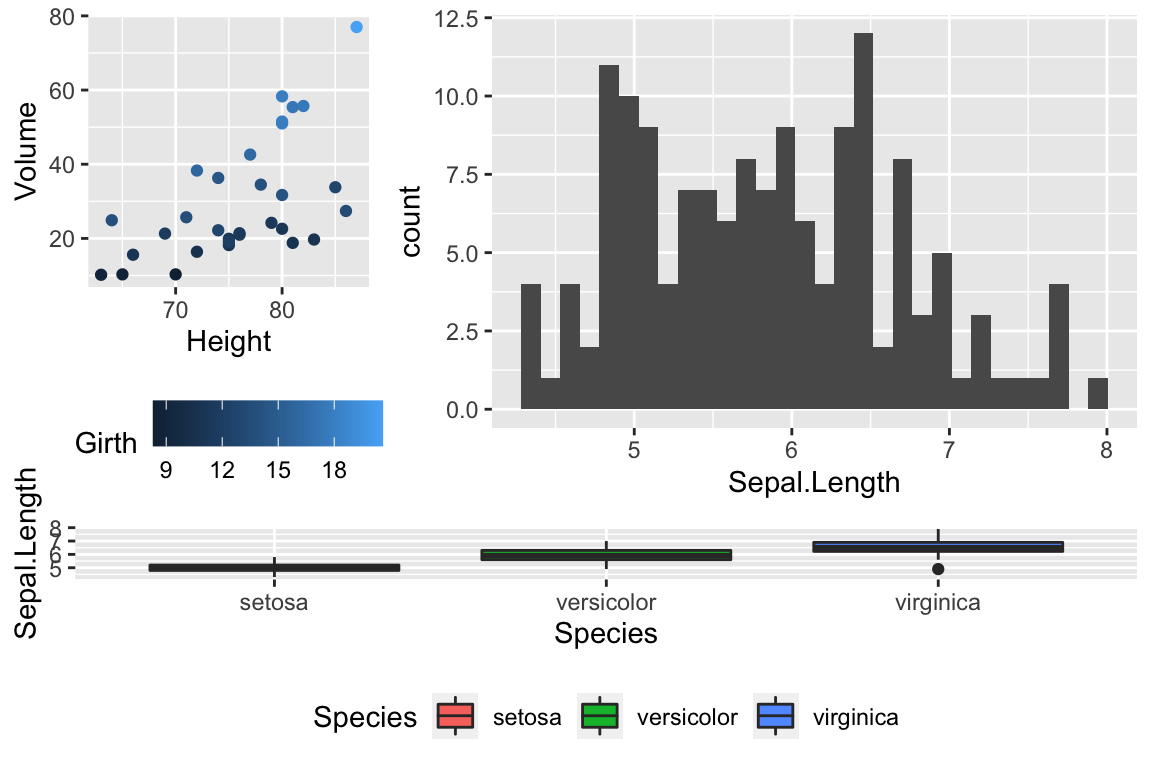
Unfortunately, Rmisc::multiplot doesn’t have a label option, so if you want to refer to “Panel A,” you need to insert the label into each plot separately.
14.2 Customized Scales
While ggplot typically produces very reasonable choices for values for the axis scales and color choices for the color and fill options, we often want to tweak them.
14.2.1 Color Scales
14.2.1.1 Manually Select Colors
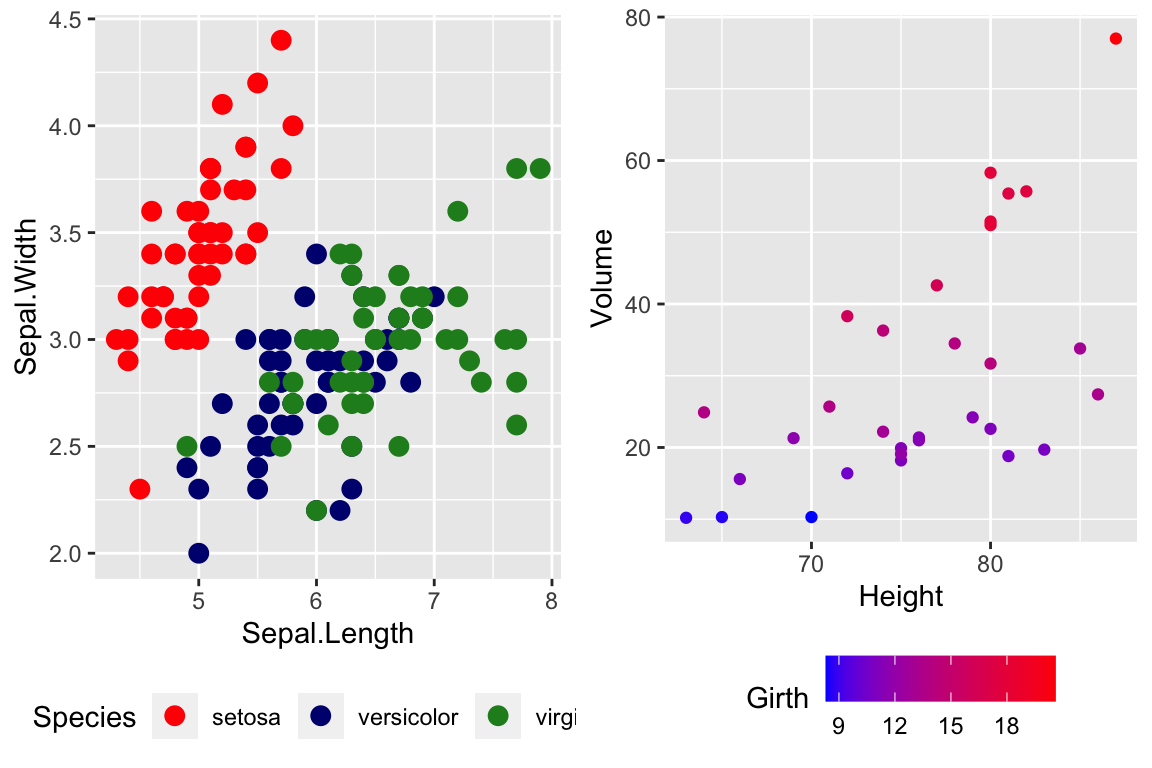
For an individual graph, we might want to set the color manually. Within ggplot there are a number of scale_XXX_ functions where the XXX is either color or fill.
cowplot::plot_grid(
P1 + scale_color_manual( values=c('red','navy','forest green') ),
P2 + scale_color_gradient(low = 'blue', high='red')
)
For continuous scales for fill and color, there is also a scale_XXX_gradient2() function which results in a divergent scale where you set the low and high values as well as the midpoint color and value. There is also a scale_XXX_grandientn() function that allows you to set as many colors as you like to move between.
cowplot::plot_grid(
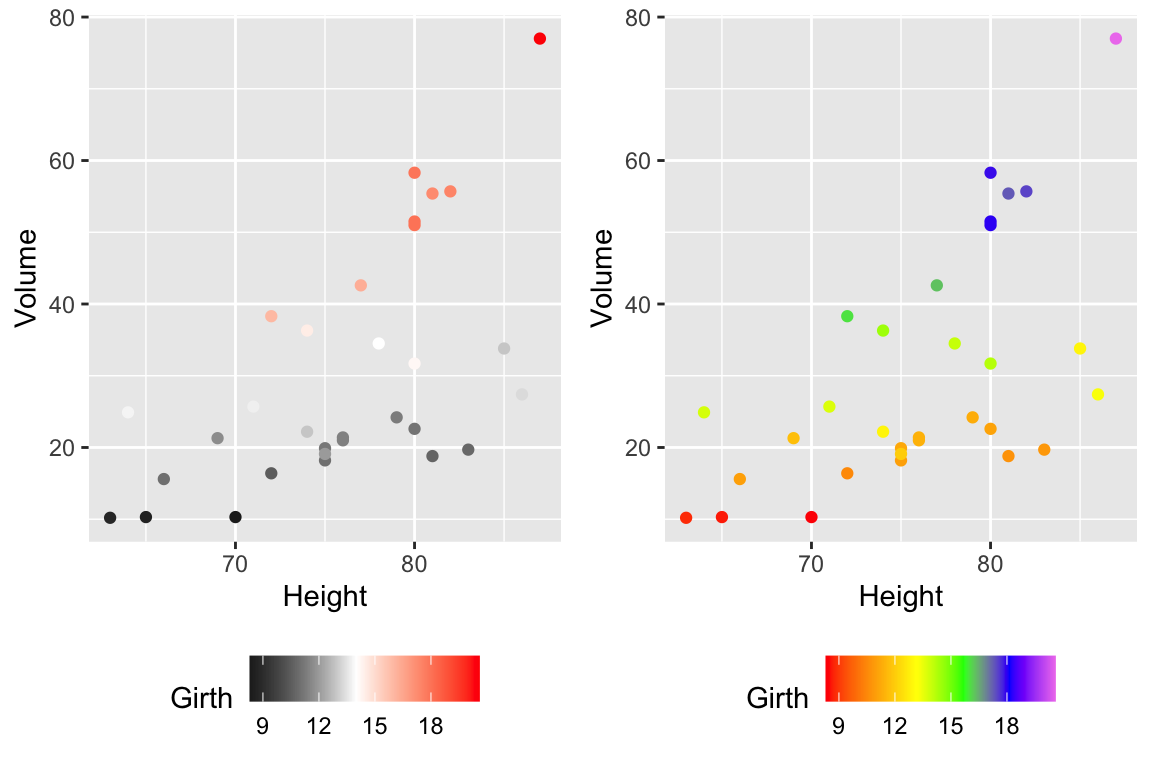
P2 + scale_color_gradient2( low = 'black', mid='white', midpoint=14, high='red' ),
P2 + scale_color_gradientn(colors = c('red','orange','yellow','green','blue','violet') )
)
Generally I find that I make poor choices when picking colors manually, but there are times that it is appropriate.
14.2.1.2 Palettes
In choosing color schemes, a good approach is to use a color palette that has already been created by folks that know about how colors are displayed and what sort of color blindness is possible. There are two palette options that we’ll discuss, but there are a variety of other palettes available by downloading a package.
14.2.1.2.1 RColorBrewer palettes
Using the ggplot::scale_XXX_brewer() functions, we can easily work with the package RColorBrewer which provides a nice set of color palettes. These palettes are separated by purpose.
Qualitative palettes employ different hues to create visual differences between classes. These palettes are suggested for nominal or categorical data sets.

Sequential palettes progress from light to dark. When used with interval data, light colors represent low data values and dark colors represent high data values.

Diverging palettes are composed of darker colors of contrasting hues on the high and low extremes and lighter colors in the middle.
To use one of these palettes, we just need to pass the palette name to scale_color_brewer or scale_fill_brewer
cowplot::plot_grid(
P1 + scale_color_brewer(palette='Dark2'),
P4 + scale_fill_brewer(palette='Dark2')
)
14.2.1.2.2 viridis palettes
The package viridis sets up a few different color palettes that have been well thought out and maintain contrast for people with a variety of color-blindess types as well as being converted to grey-scale.
cowplot::plot_grid(
P1 + scale_color_viridis_d(option='plasma'), # _d for discrete
P2 + scale_color_viridis_c( option='viridis') ) # _c for continuous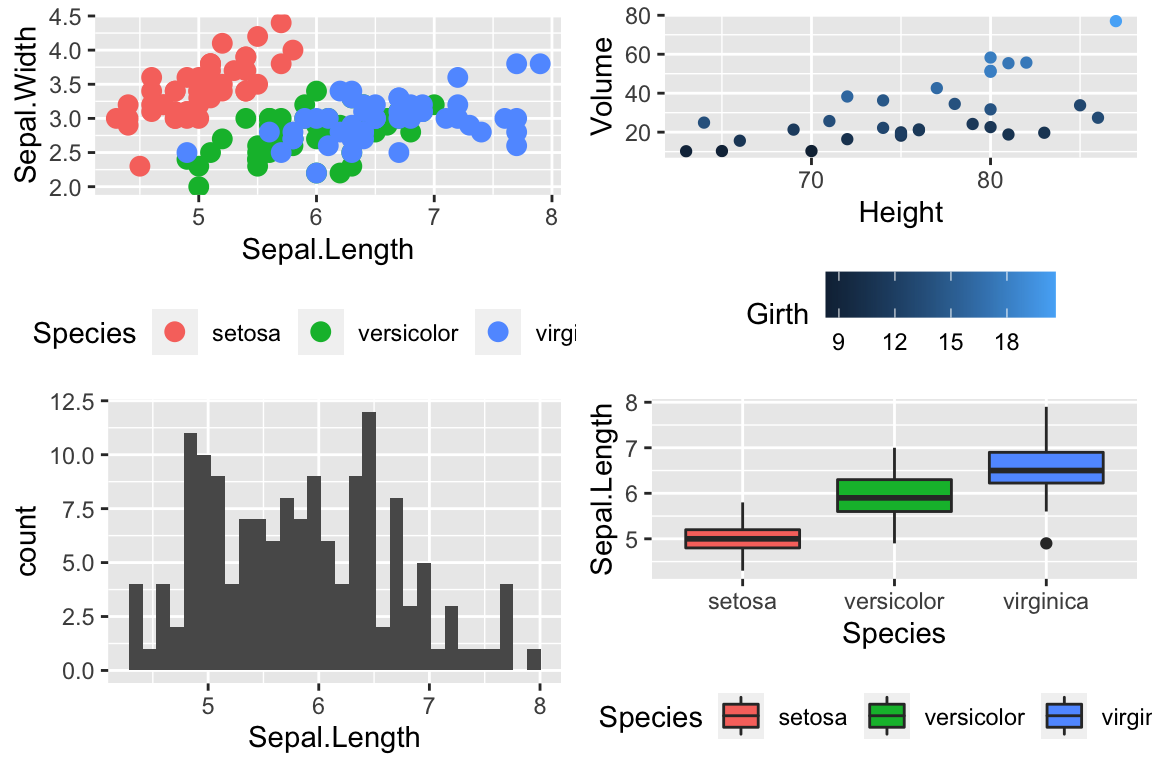
There are a bunch of other packages that manage color palettes such as paletteer, ggsci and wesanderson.
14.2.2 Setting major & minor ticks
For continuous variables, we need to be able to control what tick and grid lines are displayed. In ggplot, there are major and minor breaks and the major breaks are labeled and minor breaks are in-between the major breaks. The break point labels can also be set.
ggplot(trees, aes(x=Height, y=Volume)) + geom_point() +
scale_x_continuous( breaks=seq(65,90, by=5), minor_breaks=65:90 ) +
scale_y_continuous( breaks=c(30,50), labels=c('small','big') )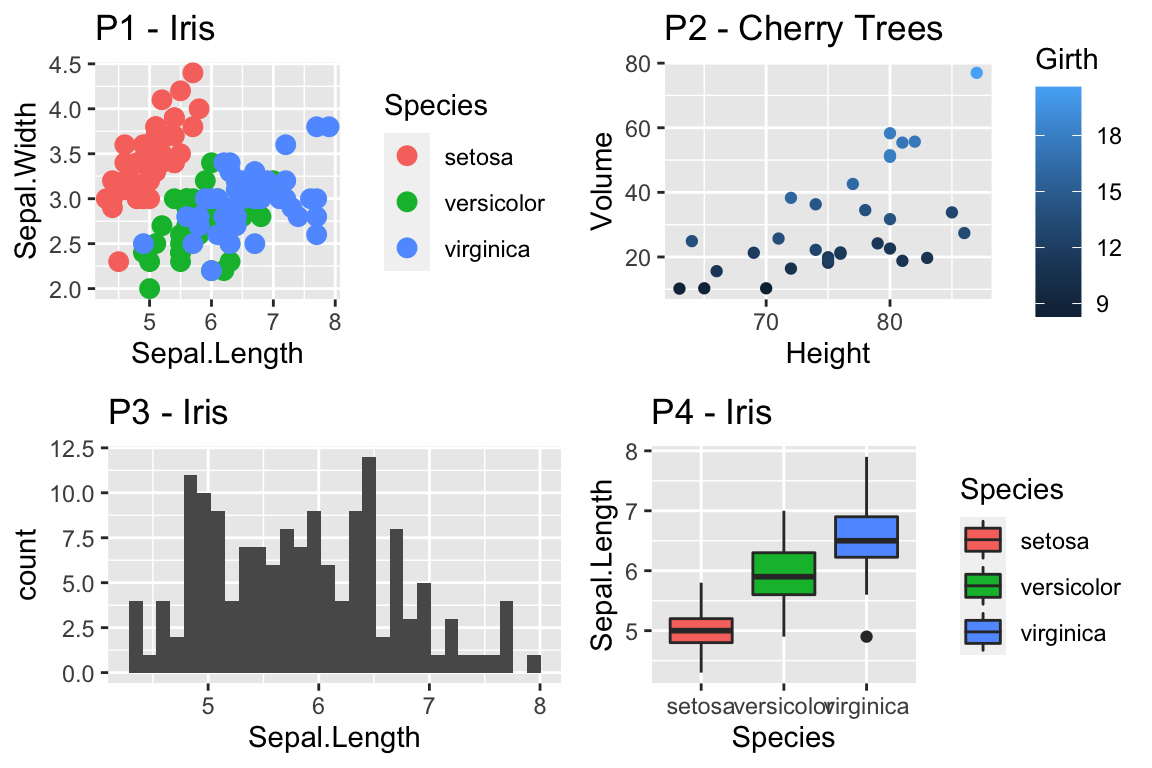
14.2.3 Log Scales
For this example, we’ll use the ACS data from the Lock5Data package that has information about Income (in thousands of dollars) and Age. Lets make a scatter plot of the data.
# Import the data and drop any zeros
data('ACS', package='Lock5Data')
ACS <- ACS %>%
drop_na() %>% filter(Income > 0)
cowplot::plot_grid(
ggplot(ACS, aes(x=Age, y=Income)) +
geom_point(),
ggplot(ACS, aes(x=Age, y=log10(Income))) +
geom_point()
)
Plotting the raw data results in an ugly graph because six observations dominate the graph and the bulk of the data (income < $100,000) is squished together. One solution is to plot income on the \(\log_{10}\) scale. The second graph does that, but the labeling is all done on the log-scale and most people have a hard time thinking in terms of logs.
This works quite well to see the trend of peak earning happening in a persons 40s and 50s, but the scale is difficult for me to understand (what does \(\log_{10}\left(X\right)=1\) mean here? Oh right, that is \(10^{1}=X\) so that is the $10,000 line). It would be really nice if we could do the transformation but have the labels on the original scale.
cowplot::plot_grid(
ggplot(ACS, aes(x=Age, y=Income)) +
geom_point() +
scale_y_log10(),
ggplot(ACS, aes(x=Age, y=Income)) +
geom_point() +
scale_y_log10(breaks=c(1,10,100),
minor=c(1:10,
seq( 10, 100,by=10 ),
seq(100,1000,by=100))) +
ylab('Income (1000s of dollars)')
)
While it is certainly possible to specify everything explicitly, I prefer to
have a little bit of code to define the minor breaks where all I have to specify
is the minimum and maximum order of magnitudes to specify. In the following code,
that is the 0:2 components. In the minor breaks, the by=1 or by=2 specifies
if we should have 9 or 4 minor breaks per major break.
cowplot::plot_grid(
ggplot(ACS, aes(x=Age, y=Income)) +
geom_point() +
scale_y_log10(
breaks = 10^(0:2),
minor = outer(seq(0,10,by=1), 10^(0:2)) %>% as.vector()
) +
ylab('Income (1000s of dollars)'),
ggplot(ACS, aes(x=Age, y=Income)) +
geom_point() +
scale_y_log10(
breaks = 10^(0:2),
minor = outer(seq(0,10,by=2), 10^(0:2)) %>% as.vector()
) +
ylab('Income (1000s of dollars)')
)
Now the y-axis is in the original units (thousands of dollars) but we’d like to customize the minor tick marks. Lets define the major break points (the white lines that have numerical labels) to be at 1,10,100 thousand dollars in salary. Likewise we will tell ggplot2 to set minor break points at 1 to 10 thousand dollars (with steps of 1 thousand dollars) and then 10 thousand to 100 thousand but with step sizes of 10 thousand, and finally minor breaks above 100 thousand being in steps of 100 thousand.
14.3 Themes
Many fine-tuning settings in ggplot2 can be manipulated using the theme() function. I’ve used it previously to move the legend position, but there are many other options.
p1 <- ggplot(ChickWeight, aes(x=Time, y=weight, colour=Diet, group=Chick)) +
geom_line() + labs(title='Chick Weight: Birth to 21 days')
# Two common examples of things to change
cowplot::plot_grid(nrow=2,
p1 + theme(plot.title = element_text(hjust = 0.5, size=25)),
p1 + theme(legend.position = 'bottom') # legend to bottom
)
There are many things to tweak using the theme() command and to get a better idea of what is possible, I recommend visiting the ggplot2 web page documentation and examples. Notably, one thing that is NOT changed using the theme command is the color scales.
A great deal of thought went into the default settings of ggplot2 to maximize the visual clarity of the graphs. However some people believe the defaults for many of the tiny graphical settings are poor. You can modify each of these but it is often easier to modify them all at once by selecting a different theme. The ggplot2 package includes several, theme_bw(), and theme_minimal() being the two that I use most often. Other packages, such as cowplot and ggthemes, have a bunch of other themes that you can select from. Below are a few examples:
Rmisc::multiplot( cols = 2,
p1 + theme_bw() + labs(title='theme_bw'), # Black and white
p1 + theme_minimal() + labs(title='theme_minimal'),
p1 + theme_dark() + labs(title='theme_dark'),
p1 + theme_light() + labs(title='theme_light')
)
Rmisc::multiplot( cols = 2,
p1 + cowplot::theme_cowplot() + labs(title='cowplot::theme_cowplot()'),
p1 + cowplot::theme_minimal_grid() + labs(title='cowplot::theme_minimial_grid'),
p1 + ggthemes::theme_stata() + labs(title='ggthemes::theme_stata()'),
p1 + ggthemes::theme_tufte() + labs(title='ggthemes::theme_tufte()'),
p1 + ggthemes::theme_economist() + labs(title='ggthemes::theme_economist()'),
p1 + ggthemes::theme_fivethirtyeight() + labs(title='ggthemes::theme_fivethirtyeight()'),
p1 + ggthemes::theme_excel_new() + labs(title='ggthemes::theme_excel_new()'),
p1 + ggthemes::theme_gdocs() + labs(title='ggthemes::theme_gdocs()')
)
Finally, we might want to select a theme for all subsequent plots or modify a specific aspect of the theme.
| Command | Result |
|---|---|
theme_set( theme_bw() ) |
Set the default theme to be the theme_bw() theme. |
theme_update( ... ) |
Update the current default them. |
This will allow you to set the graphing options at the start of your Rmarkdown/R-script document. However the one thing it does not do is allow you to change the default color themes (we still have to do for each graph).
14.4 Mathematical Notation
It would be nice to be able to include mathematical formula and notation on plot axes, titles, and text annotation. R plotting has a notation scheme which it calls expressions. You can learn more about how R expressions are defined by looking at the plotmath help help page. They are similar to LaTeX but different enough that it can be frustrating to use. It is particularly difficult to mix character strings and math symbols. I recommend not bothering to learn R expressions, but instead learn LaTeX and use the R package latex2exp that converts character strings written in LaTeX to be converted into R’s expressions.
LaTeX is an extremely common typesetting program for mathematics and is widely used. The key idea is that $ will open/close the LaTeX mode and within LaTeX mode, using the backslash represents that something special should be done. For example, just typing $alpha$ produces \(alpha\), but putting a backslash in front means that we should interpret it as the greek letter alpha. So in LaTeX, $\alpha$ is rendered as \(\alpha\). We’ve already seen an introduction to LaTeX in the Rmarkdown Tricks chapter.
However, because I need to write character strings with LaTeX syntax, and R also uses the backslash to represent special characters, then to get the backslash into the character string, we actually need to do the same double backslash trick we did in the string manipulations using regular expressions section.
seed <- 7867
N <- 20
data <- data.frame(x=runif(N, 1, 10)) %>% # create a data set to work with
mutate(y = 12 - 1*x + rnorm(N, sd=1)) # with columns x, y
model <- lm( y ~ x, data=data) # Fit a regression model
data <- data %>% # save the regression line yhat points
mutate(fit=fitted(model))
ggplot(data, aes(x=x)) +
geom_point(aes(y=y)) +
geom_line(aes(y=fit), color='blue') +
annotate('text', x=9, y=9.5,
label=latex2exp::TeX('$\\hat{\\rho}$ = 0.916') ) + # always double \\
labs( x=latex2exp::TeX('X-axis $\\alpha$'),
y=latex2exp::TeX('Y: $\\log_{10}$(Income)'),
title=latex2exp::TeX('Linear Models use: $\\hat{\\beta} = (X^TX)^{-1}X^Ty$'))## Warning in is.na(x): is.na() applied to non-(list or vector) of type
## 'expression'
The warning message that is produced is coming from ggplot and I haven’t figured out how to avoid it. Because it is giving us the graph we want, I’m just going to ignore the error for now.
One issue is how to add expression to a data frame. Unfortunately, neither data.frame nor tibble will allow a column of expressions, so instead we have store it as a character string. Below, we create three character strings using standard LaTeX syntax, and then convert it to a character string that represents the R expression. Finally, in ggplot, we tell the geom_text layer to parse the label and interpret it as an R expression.
foo <- data.frame( x=c(1,2,3), y=c(2,2,2) ) %>%
mutate( label1 = paste('$\\alpha$ = ', x) ) %>% # label is a TeX character string
mutate( label2 = latex2exp::TeX(label1, output = 'character') ) # label2 is an expression character string
ggplot(foo, aes(x=x, y=y) ) +
geom_label( aes(label=label2), parse=TRUE ) # parse=TRUE forces an expression interpretation 
14.5 Interactive plots with plotly
Plotly is technical computing company that specializes in data visualization. They have created an open source JavaScript library to produce graphs, which is confusingly referred to as plotly. Because plotly is JavaScript, and RStudio’s Viewer pane is actually a web browser, it easily provides interactive abilities in RStudios Viewer pane.
A good tutorial book about using plotly was written by Carson Sievert.
The simple version is that you can take a ggplot graph and pipe it into the ggplotly and it will be rendered into an interactive version of the graph.
P1 <- trees %>%
ggplot(aes(y=Volume, x=Height)) +
geom_point()
P1 %>% plotly::ggplotly()We can use the widgets to zoom in and out of the graph. Notice that as we hover over the point, it tells us the x/y coordinates. To add information to the hover-text, we just need to add a text aesthetic mapping to the plot.
P1 <- trees %>%
mutate(Obs_ID = row_number()) %>%
ggplot(aes(y=Volume, x=Height,
text=paste('Girth: ', Girth, '\n', # add some extra text
'Obs #: ', Obs_ID, sep=''))) + # to the hover information
geom_point()
P1 %>% ggplotly() 14.6 Geographic Maps
We often need to graph countries or U.S. States. We might then fill the color of the state or countries by some variable. To do this, we need information about the shape and location of each country within some geographic coordinate system. The easiest system to work from is Latitude (how far north or south of the equator) and Longitude (how far east or west the prime meridian).
14.6.1 Package maps
The R package maps is one of the easiest way to draw a country or state map because it is built into the ggplot package. Unfortunately it is fairly US specific.
Because we might be interested in continents, countries, states/provinces, or counties, in the following discussion we’ll refer to the geographic area of interest as a region. For ggplot2 to interact with GIS type objects, we need a way to convert a GIS database of regions into a data.frame of a bunch of data points about the region’s borders, where each data point is a Lat/Long coordinate and the region and sub-region identifiers. Then, to produce a map, we just draw a path through the data points. For regions like Hawaii’s, which are composed of several non-contiguous areas, we include sub-regions so that the boundary lines don’t jump from island to island.
Once we have the data.frame of regions that we are interested in selected, all we need to do is draw polygons in ggplot2.
# ggplot2 function to create a data.frame with world level information
geo.data <- ggplot2::map_data('world') # Using maps::world database.
# group: which set of points are contiguous and should be connected
# order: what order should the dots be connected
# region: The name of the region of interest
# subregion: If there are sub-regions with greater region
head(geo.data)## long lat group order region subregion
## 1 -69.89912 12.45200 1 1 Aruba <NA>
## 2 -69.89571 12.42300 1 2 Aruba <NA>
## 3 -69.94219 12.43853 1 3 Aruba <NA>
## 4 -70.00415 12.50049 1 4 Aruba <NA>
## 5 -70.06612 12.54697 1 5 Aruba <NA>
## 6 -70.05088 12.59707 1 6 Aruba <NA># Now draw a nice world map,
ggplot(geo.data, aes(x = long, y = lat, group = group)) +
geom_polygon( colour = "white", fill='grey50') 
The maps package has several data bases of geographical regions.
| Database | Description |
|---|---|
world |
Country borders across the globe |
usa |
The country boundary of the United States |
state |
The state boundaries of the United States |
county |
The county boundaries within states of the United States |
lakes |
Large fresh water lakes across the world |
italy |
Provinces in Italy |
france |
Provinces in France |
nz |
North and South Islands of New Zealand |
From within each of these databases, we can select to just return a particular region. So for example, we can get all the information we have about Ghana using the following:
ggplot2::map_data('world', regions='ghana') %>%
ggplot( aes(x=long, y=lat, group=group)) +
geom_polygon( color = 'white', fill='grey40')
The maps package also has a data.frame of major US cities.
az.cities <- maps::us.cities %>% # Lat/Long of major US cities
filter(country.etc == 'AZ') %>% # Only the Arizona Cities
mutate(name = str_remove(name, '\\sAZ') ) # remove ' AZ' from the city name
small.az.cities <- az.cities %>%
filter(name %in% c('Flagstaff','Prescott','Lake Havasu City','Yuma','Tucson',
'Sierra Vista','Phoenix','Tempe','Scottsdale'))
ggplot2::map_data('state', regions='arizona') %>%
ggplot( aes(x=long, y=lat)) +
geom_polygon( aes(group=group), color = 'white', fill='grey40') +
geom_point(data=az.cities) +
ggrepel::geom_label_repel(data=small.az.cities, aes(label=name))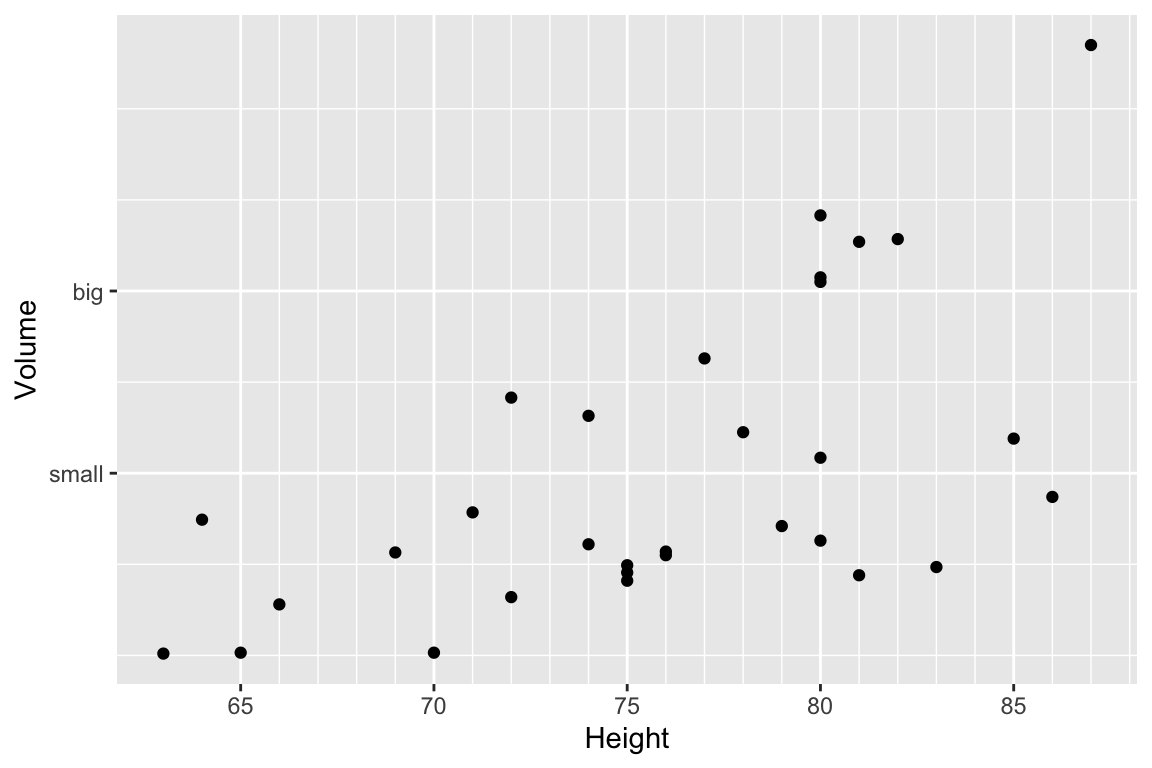
14.6.2 Packages sf and rnaturalearth
The maps package is fairly primitive in the data it has as well as the manner in which it stores the data. Another alternative is to use the spatial features package sf along with an on-line data base of GIS information from Natural Earth.
There is a nice set of tutorials for the sf package.
Part 1,
Part 2, and
Part 3.
From the Natural Earth package, we can more easily obtain information about world countries and state/provinces. There is also information about urban areas and roads as well as geographical details such as rivers and lakes.
ne_countries(continent='Africa', returnclass = 'sf') %>% # grab country borders in Africa
ggplot() + geom_sf() +
labs(title='Africa')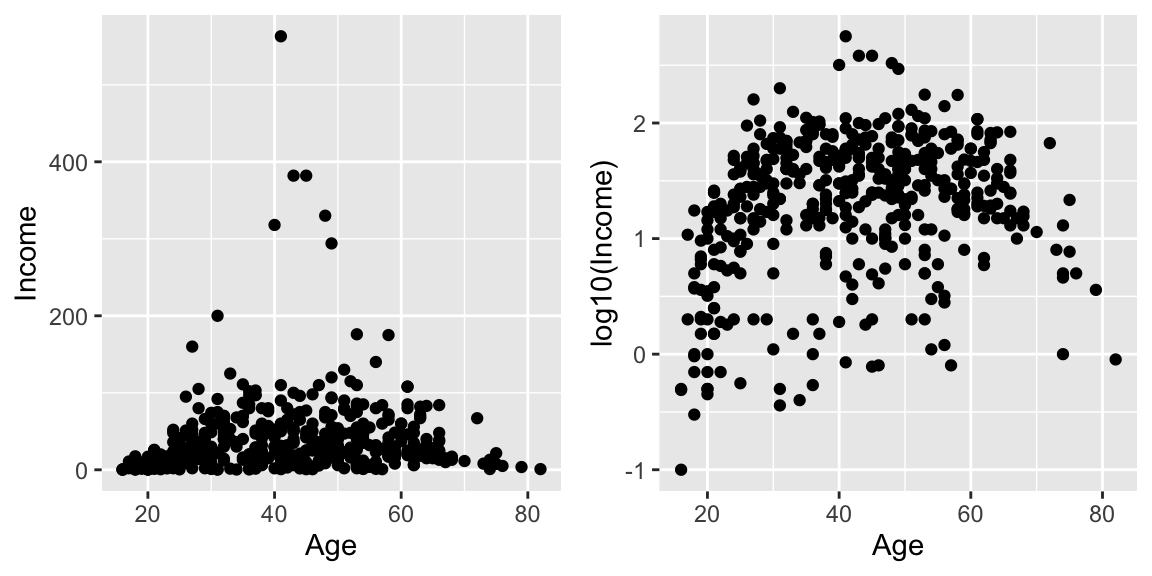
ne_states(country='Ghana', returnclass = 'sf') %>% # grab provinces within Ghana
ggplot() +
geom_sf( ) +
labs(title='Ghana')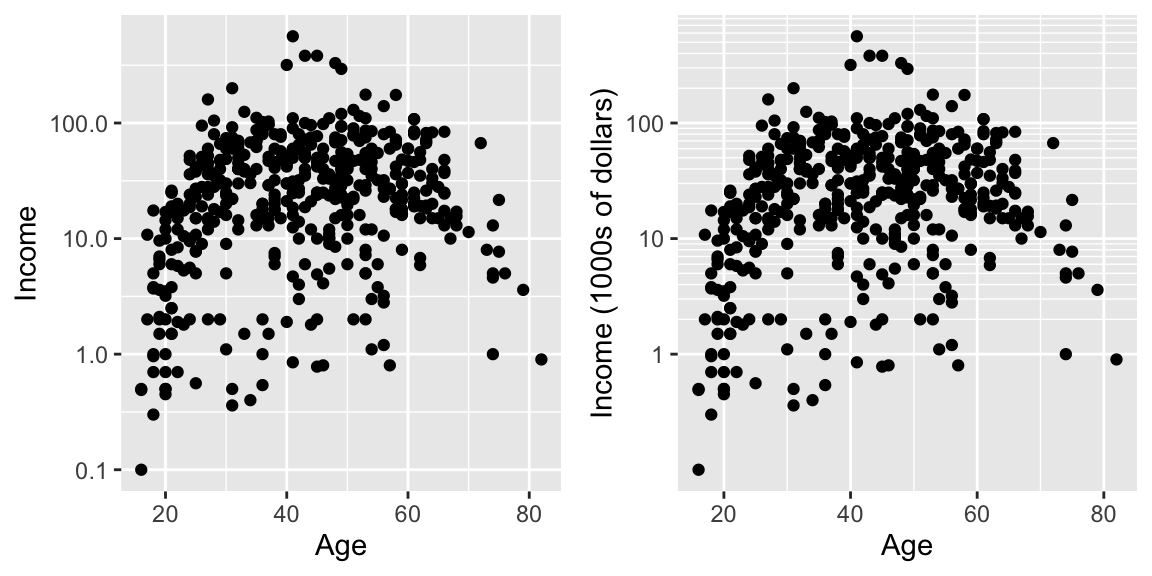
# The st_centroid function takes the sf object and returns the center of
# the polygon, again as a sf object.
Ghana <- ne_states(country='Ghana', returnclass = 'sf') # grab provinces within Ghana
Ghana %>% ggplot() +
geom_sf( ) +
geom_text( data=st_centroid(Ghana), size=2,
aes(x=longitude, y=latitude, label=woe_name)) +
labs(title='Ghana Administrative Regions')## Warning in st_centroid.sf(Ghana): st_centroid assumes attributes are constant
## over geometries of x## Warning in st_centroid.sfc(st_geometry(x), of_largest_polygon =
## of_largest_polygon): st_centroid does not give correct centroids for longitude/
## latitude data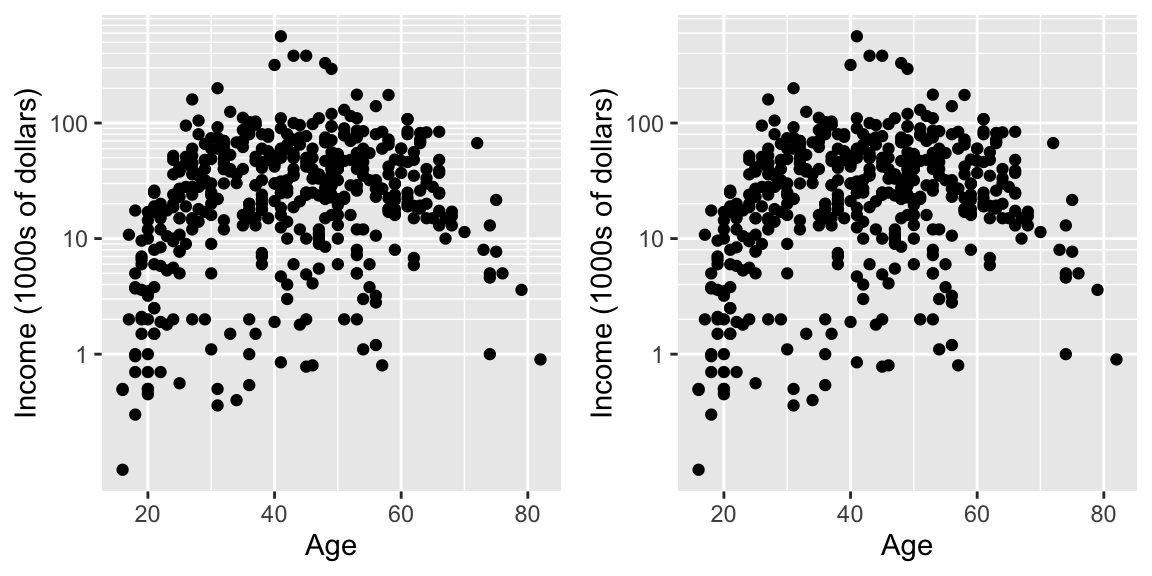
14.6.3 Package leaflet
Leaflet is a popular open-source JavaScript library for interactive maps. The package leaflet provides a nice interface to this package. The tutorial for this package is quite good.
The basic work flow is:
- Create a map widget by calling leaflet().
- Create and add layers (i.e., features) to the map by using layer functions
addTilesaddMarkersaddPolygons
- Repeat step 2 as desired.
- Print the map widget to display it.
map <- leaflet() %>% # Build a base map
addTiles() %>% # Add the default tiles
addMarkers(lng=-1*(111+37/60+52/3600), lat=35+11/60+57/3600, popup="Flagstaff, AZ")
map %>% print()Because we have added only one marker, then leaflet has decided to zoom in as much as possible. If we had multiple markers, it would have scaled the map to include all of them.
As an example of an alternative, I’ve downloaded a GIS shape file of forest service administrative area boundaries.
# The shape file that I downloaded had the CRS format messed up. I need to
# indicate the projection so that leaflet doesn't complain.
Forest_Service <-
sf::st_read('data-raw/Forest_Service_Boundaries/S_USA.AdministrativeRegion.shp') %>%
sf::st_transform('+proj=longlat +datum=WGS84')## Reading layer `S_USA.AdministrativeRegion' from data source `/Users/dls354/GitHub/444/data-raw/Forest_Service_Boundaries/S_USA.AdministrativeRegion.shp' using driver `ESRI Shapefile'
## Simple feature collection with 9 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -179.2311 ymin: 17.92523 xmax: 179.8597 ymax: 71.44106
## geographic CRS: NAD83leaflet() %>%
addTiles() %>%
addPolygons(data = Forest_Service) %>%
setView(-93, 42, zoom=3)